
5
Feature Engineering for Flow-Based IDS
Rahul B. Adhao* and Vinod K. Pachghare
Department of Computer Engineering, College of Engineering Pune (COEP) India
Abstract
During the last decennium, computer network security has undergone an incredible revolution with the rapid development of high-speed networking technologies. A good example is NetFlow, which has experienced a drastic advance since the arrival of flow-enabled networking devices. According to a study, 70% of the network operators have devices with flow-exporting capabilities. Netflow export technology aggregates network packets into the flow. This NetFlow format advancement in the number of IP packet features has a huge advantage. In other words, if the latest version of NetFlow is enabled on your network device, a lot of network information becomes available to you; for example, Netflow v9 traffic has 280 features. Serving many network issues, these entire features may be necessary. However, in the case of network Intrusion Detection System (IDS) not all these features may be needed. Some may be redundant and not relevant. Such features can affect the performance of the IDS. Simultaneously, the time required for identifying the attack and resource consumption for IDS is increasing. An ID detects malicious traffic based on the extracted features from network flow. This article reviews the use of feature selection for the flow-based network IDS.
Keywords: Network security, intrusion detection system, feature engineering, feature selection, net flow, flow-based intrusion detection system, IP flow
5.1 Introduction
The ever-evolving research in the computer networking field made it possible to get Internet (that is, nothing but computer network) access everywhere. Also, there is tremendous growth in network speed compared to ten years ago (which was in just KBs). Along with the increase in speed, the number of internet (computer network) users is also increasing. This rapid proliferation in technology has caused ever-increasing network traffic, which is burdening the network security analysis tools. The network security tools also need to cope with the increasing network speed and the increasing number of users or network traffic. Unfortunately, these tools are not coping. An Intrusion Detection System (IDS) is such a network analysis tool that can classify network traffic into normal and malicious traffic. However, the old packet-based approach used in such IDS looks insufficient with increased speed and traffic. This issue has motivated researchers to come up with a flow-based IDS approach. Some research uses a feature selection approach before classifying the traffic using a machine learning-based classifier. The application of feature selection before classifiers improves its performance and saves resources in memory and time.
The need for feature selections in the Flow-Based IDS approach is motivated by the following:
- Today, all high devices are equipped with a flow capturing facility, making readily available flow records, making the approach cost-effective.
- The IPFIX protocol standard defines how IP Flow information can be exported to the devices.
- Suiting today’s high speed and increased volume of network data.
- It can deal with newer protocols due to the absence of payload.
- Increasing the number of IP flow features with each flow-based (Netflow) version.
- Irrelevant and redundant features present in flow-based data
- Less storage is required for flow-based data.
The chapter’s objective is to present current futuristic feature selection methods in flow-based IDS.
5.1.1 Intrusion Detection System
There exist multiple ways for IDS classifications. In the literature detection-based model, audit source locations based or sort of study based are common, as depicted in Figure 5.1. In this chapter, IDS is classified as signature-based versus anomaly-based and host-based versus network-based.
5.1.2 IDS Classification
An IDS may be classified in various ways that supported various parameters like sorts of processing (detection model), the sort of study, or the supply of the information (audit source locations), as shown in Figure 5.1. However, we will classify IDS into two widely best-known classifications, signature versus anomaly-based and host versus network-based.
Signature-based intrusion detection is used to detect known attacks whose pattern or certain rules are stored in some database. Incoming information (data packets) are analyzed, and if their pattern is matched with stored in database then such packets are termed as malicious, and the system is alerted about such attacks. But this approach fails to detect attacks whose signatures are not stored in the database. This problem is solved with the anomaly detection approach. Here a normal profile of the system is created by training the IDS time to time. This is a dynamic approach for partially known and unseen attacks. When the IDS encounters any deviations in the normal profile, it alerts system administration about the events. But this suffers from a number of false positives [2].
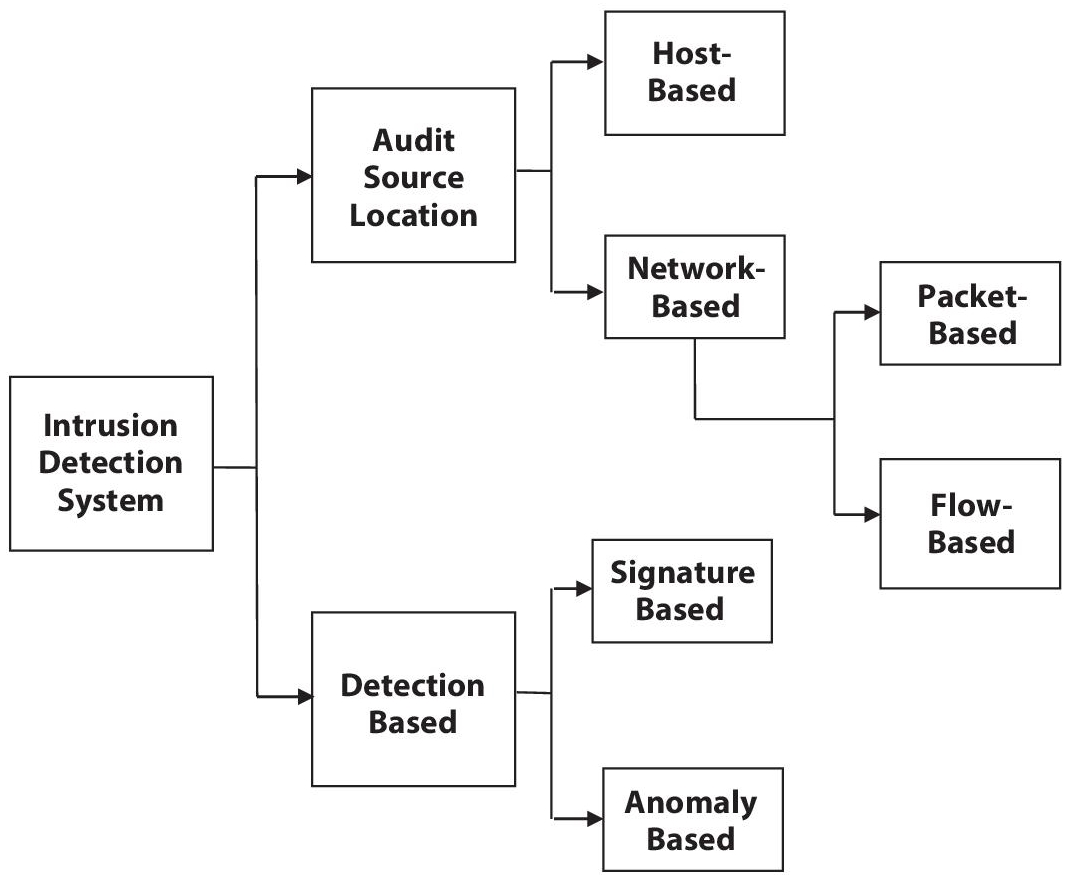
Figure 5.1 Intrusion detection system classification [1].
The Host-based IDS needs to be installed on every system on the network, similar to antivirus software. Thus it can protect only that installed system, not the complete network. There is a need to install network-based IDS (NIDS) on the network to protect the complete network. It is situated in the network so that all network traffic has to pass through this NIDS. This NIDS can be based on the packet-based approach or the flow-based approach. In the packet-based approach, each packet flowing the network will be analyzed at NIDS. However, the increase in network traffic with high network speed can result in dropping packets at NIDS, and this can affect the performance of NIDS. A flow-based approach gives the solution to this problem. In this approach, packets with similar information are grouped in terms of flow buckets. Then later, NIDS analyzes specific fields of these flow buckets. This approach suits high-speed network having extensive size network traffics [3]. This approach is the new one and has attracted researchers for the past few years. The two desirable features of IDS are Speed and Accuracy [4].
5.2 IP Flows
The capturing of IP flows has many significant benefits; hence, all vendors provide their routers with flow monitoring measuring facilities. An IP flow is captured and stored in flow records, used for traffic characterization [5]. Netflow is Cisco’s propriety technology.
The definition of IP flow given by IPFIX (IP Flow Information Export) is “a set of IP packets passing through an observation point in the network during a particular interval of time. Moreover, all packet clusters to a particular flow have a set of common properties”.
According to IPFIX (Internet Protocol Flow Information Export) documentation, a flow is identified by parameters like source address, destination addresses, source port number, destination port numbers, and IP protocols:
These elements are called flow keys or common properties. These flow keys are essential for getting behavior of network [6].
5.2.1 The Architecture of Flow-Based IDS
A Metering Process is in charge of collecting packets at Observation Points, filtering them out (if necessary), and aggregating data about them. Using the IPFIX protocol and Exporter this data is sent to a Collector, as shown in Figure 5.2 [6].
The flow inspects a group of packets flowing through the network. This gives IDS the aggregated view of network traffic. As a result, the amount of data required for comparison get substantially reduced [7]. Flow exporting and flow collection are the two phases in the flow monitoring process. A packet is provided to the flow collector after it is captured by the flow exporter, usually called flow records [8]. The flow collector must obtain flow records from the flow exporter and store them in an analytically valuable format. By aggregating packets from the same flow, we may look for unusual traffic patterns that may indicate an attack [9].
5.2.2 Wireless IDS Designed Using Flow-Based Approach
The wireless network is more complicated than the wired one. Both technologies face different situations while dealing with security. That’s why wired IDS could not be used in wireless environments. To support the 802.11 environment, the industry has been working for several years on hardware and software used in the wireless network. The Wired Equivalent Policy (WEP) was one attempt with a number of flaws in its security mechanism, and industry works very hard to solve the issue associated with WEP. This results in the introduction of WPA (Wi-Fi Protected Access) 128-bit encryption security mechanism. One of the major problems associated with a wireless network is detecting a rough access point in the network. Figure 5.3 depicts the working of a flow-based wireless intrusion detection system. Here, Sniffer is connected with the WIDS central administration system, which captures packets from wireless environments and sends them to WIDS. This system stores network packets in flow record format using five-tuple information, i.e., source and destination IP address, source port number, and destination port number, and protocol used. Later, these flow records are analyzed to detect malicious activity in the wireless environment [10].
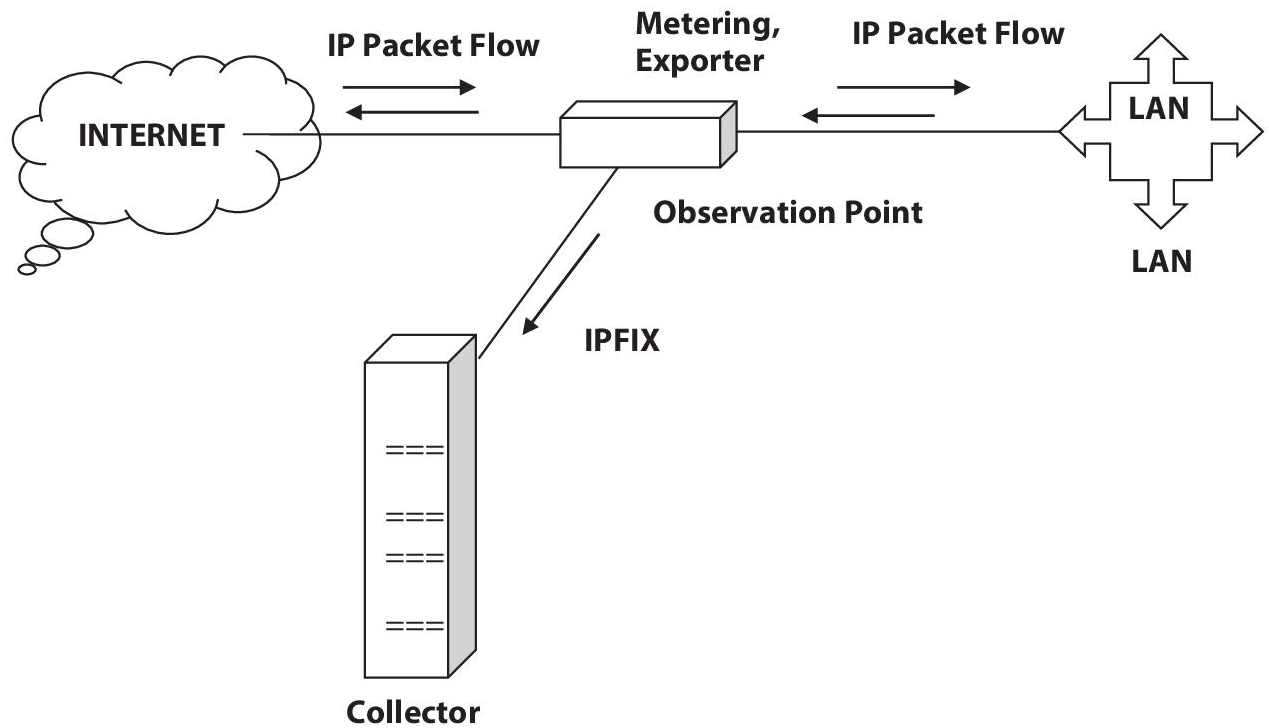
Figure 5.2 Architecture of IP flow flow-based IDS [6].
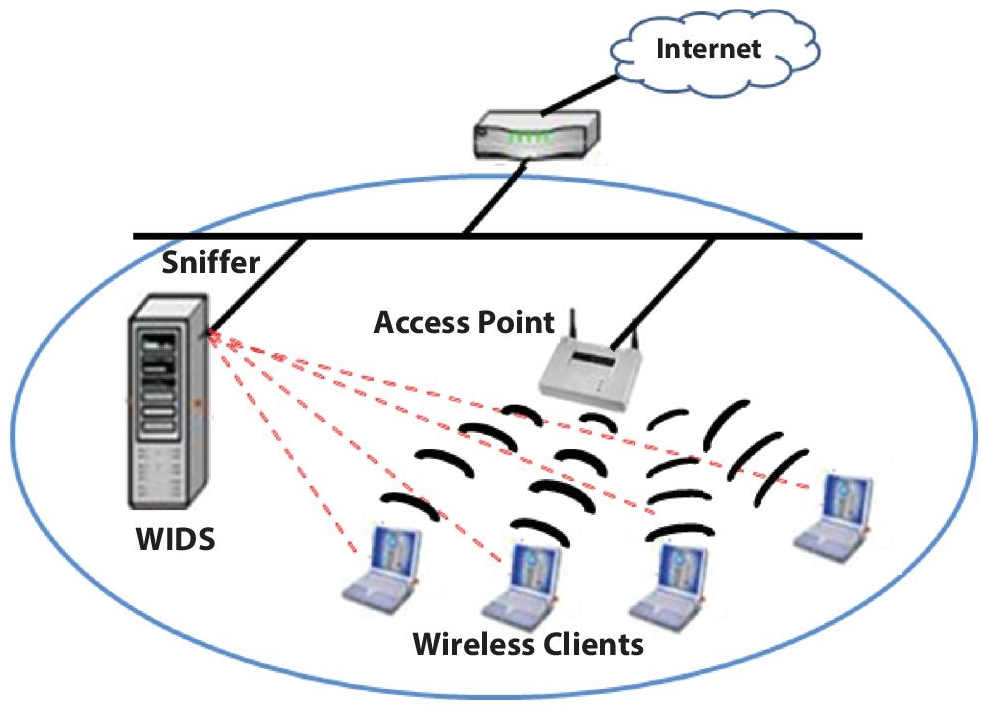
Figure 5.3 Flow-based wireless intrusion detection systems [10].
In order to protect the wireless network, one should know:
- Locations of all Access Point Planted in your network
- Set of action to be taken for an unauthorized access point (rough access point) detected within your network
- Total users accessing your wireless network
- Unencrypted information read or exchanged by such users.
5.2.3 Comparison of Flow- and Packet-Based IDS
Packet-based IDS or Traditional IDS are no longer helpful for today’s high-speed network; flow-based IDS can substitute for packet-based ones. However, they lack accuracy. The main advantage of a flow-based IDS is that it works on fewer amounts of data than the packet-based approach. So, flow-based IDS require fewer resources. However, the scarcity of data affects the accuracy of the flow-based IDS. The flow-based IDS gives reduced alert confidence and more false alarms. The encryption technology has no impact on flow-based IDS, which is generally found with packet-based IDS. The flow-based approach does not deal with payload, so there is no privacy issue as with the packet-based approach [11].
5.3 Feature Engineering
Feature engineering exploits domain knowledge of the data to create features that make machine learning algorithm work efficiently. In other words, it is the method of formulating the only acceptable options given the information, the model, and also the task. Automated feature learning will obviate the need for manual feature engineering. The next buzzword after big data is feature engineering, and it involves both selection and extraction of features. Feature selection is a method by which a subset of specific features is selected for model constructions. It is an optimization problem. Nowadays, we can get high-dimensional data everywhere, e.g., document, text, brain MRI, images, microarray data, time-series data, videos, security logs, etc. Generally, feature selection is required in classification, clustering, and regression tasks [12].
A feature is nothing but a piece of the numeric representation of raw data potentially helpful for prediction. A simple model can beat a complex model if good features are provided. Features and model sit between raw data and the desired insights, as shown in Figure 5.4. Not only does model building play an essential role in a machine learning workflow, but so do feature choices. This is a two-jointed lever, and which one you choose affects the other. The preceding modeling steps are made easier by valuable features, and the resulting model is more capable of achieving the desired task. The perfect and straightforward features are essential to the job for the model to interpret. The number of features is also essential for the machine learning model’s efficiency. If there are not enough insightful features, the model will not complete the final mission. The model would be more costly and difficult to train if there are too many features or insignificant ones. Anything may go wrong during the training phase, causing the model’s performance to suffer [13]. Feature selection is used to select valuable features, data mining to generate rules using these features, and ML classifier to detect the various attack. The main principle of feature selection is to select the feature to the point (selecting only relevant features as per the purpose).
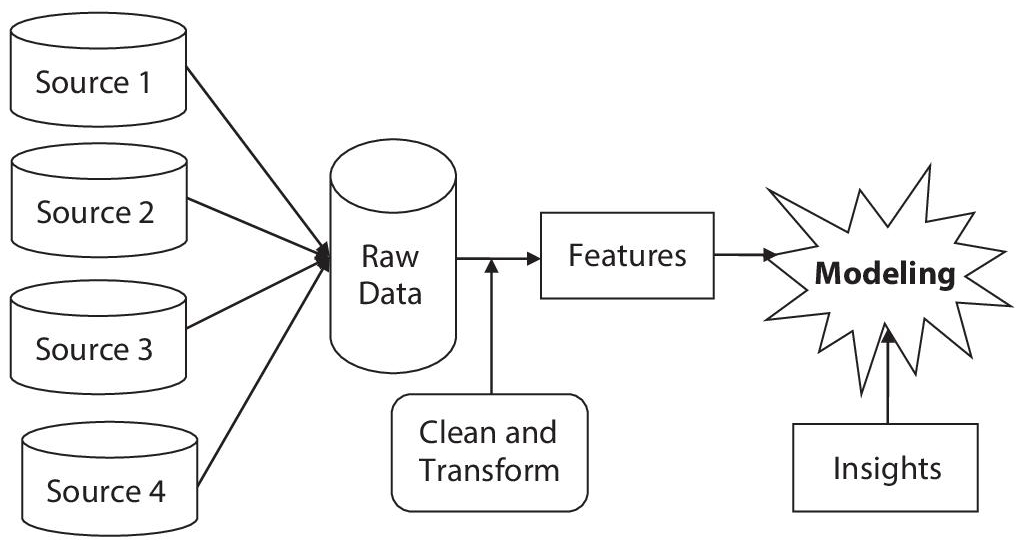
Figure 5.4 Feature engineering in machine learning workflow [13].
5.3.1 Curse of Dimensionality
The concept of the curse of dimensionality problem can be understood with the help of Figure 5.5. Initially the feature set contains zero attributes with no classification power. As we started adding the number of features in the features set for any model under observations, the model’s classification power also increases to a limit. However, after reaching an optimal number of features, adding further features starts dropping its classification power. The reason behind this is that the feature set may contain many irrelevant and redundant features. The feature space increases exponentially as the number of features increases. In the space it occupies, information becomes increasingly sparse. Sparsity makes it hard for any approach to achieve statistical significance [14]. For the sake of understanding, let’s say you lost your 10 Rs coin on a 150-meter line. How do you search for it? Just walking on that line. However, what if your coin is lost on 150*150 square meter cricket ground? Now it is tough to roam around the ground searching for the coin. The next level, (assume) what if the ground is 150*150*150 cube meters, equivalent to a thirty-story-high building. How will you find the coin? As the dimension increases, the search problem gets worse. In machine learning, more features may give more information but might not lead to better classification power.
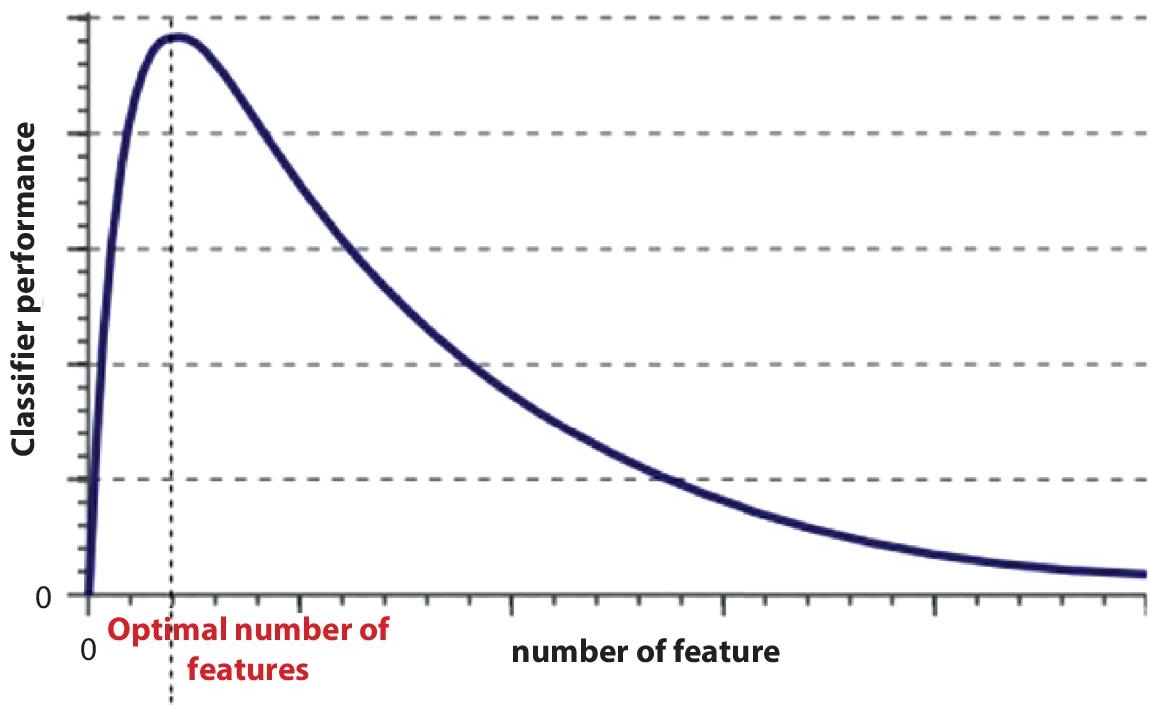
Figure 5.5 Curse of dimensionality [14].
When you have a large number of features, a large search space is required, and searching may take a long time depending upon the algorithm you choose. With limited training examples, you cannot work with many features because it leads to overfitting. When you have too many features, this will lead to the learning algorithm’s degradation and more computational time. This phenomenon is called a curse of dimensionality. Feature engineering is the solution to overcome the curse of dimensionality problem. Feature Engineering constitutes:
- Feature Selection: The procedure for selecting a small set of set features from the initially available feature set.
- Feature Extraction: In the case of feature extraction, you may get some new features that may not be a part of the initially available feature set. For example, a feature set may contain the length and breadth of a particular unit; these two features can be reduced with the area as the new feature.
Feature Engineering has the following advantages [15]:
- Redundant and irrelevant features degrade the ML algorithm’s performance; feature selection improves the data quality and increases the resulting model’s accuracy.
- Difficulty in interpretation and visualization.
- The computation may become infeasible.
- Curse of dimensionality.
- Reduces time complexity: less computation increasing algorithm speed.
- Reduces space complexity: fewer parameters at the end require less storage.
- Save the cost of observing the feature.
5.3.2 Feature Selection
Feature selection is a method by which a subset of specific features is selected for model constructions. It is an optimization problem. Feature selection is useful in a variety of situations, including data mining, classification, and object recognition. It has been effective in eliminating unnecessary and redundant features from the original dataset [16].
5.3.3 Feature Categorization
The feature set’s reduction is based on the usefulness and redundancy of the feature concerning the objective. A feature can belong to any one of the following categories [17]:
- Strongly Important: For an optimal feature subset, a strongly important (relevant) feature is always required; it cannot be excluded without affecting the original conditional target distribution.
- Weakly Important, but not redundant: For an optimum subset, a feature may not always be essential and may be based on some conditions.
- Unimportant: It is not necessary to include the unimportant (irrelevant) features at all.
- Duplicate/Redundant: Duplicate or redundant features are those that are poorly related but can be replaced entirely by a group of other features so that the target distribution is not disturbed.
5.4 Classification of Feature Selection Technique
There are various approaches for feature selection, some of which are depicted in the following Figure 5.6. All approaches covered in this chapter are mutually inclusive; one feature selection technique can come under two categories.
5.4.1 The Wrapper, Filter, and Embedded Feature Selection
Filter Methods: A filter feature selection method assigns a score to each feature using the statistical measure. The feature ranked by the score is either accepted or declined to be included from the dataset. The methods regarding the dependent variable are often univariate and consider the feature independently. Information Gain, Chi-Squared test, Correlation coefficient scores, LDA, and PCA, are examples of filter-based feature selection methods. As the filter method evaluates individual features, a feature that is not useful cannot provide a significant performance improvement when taken with others.
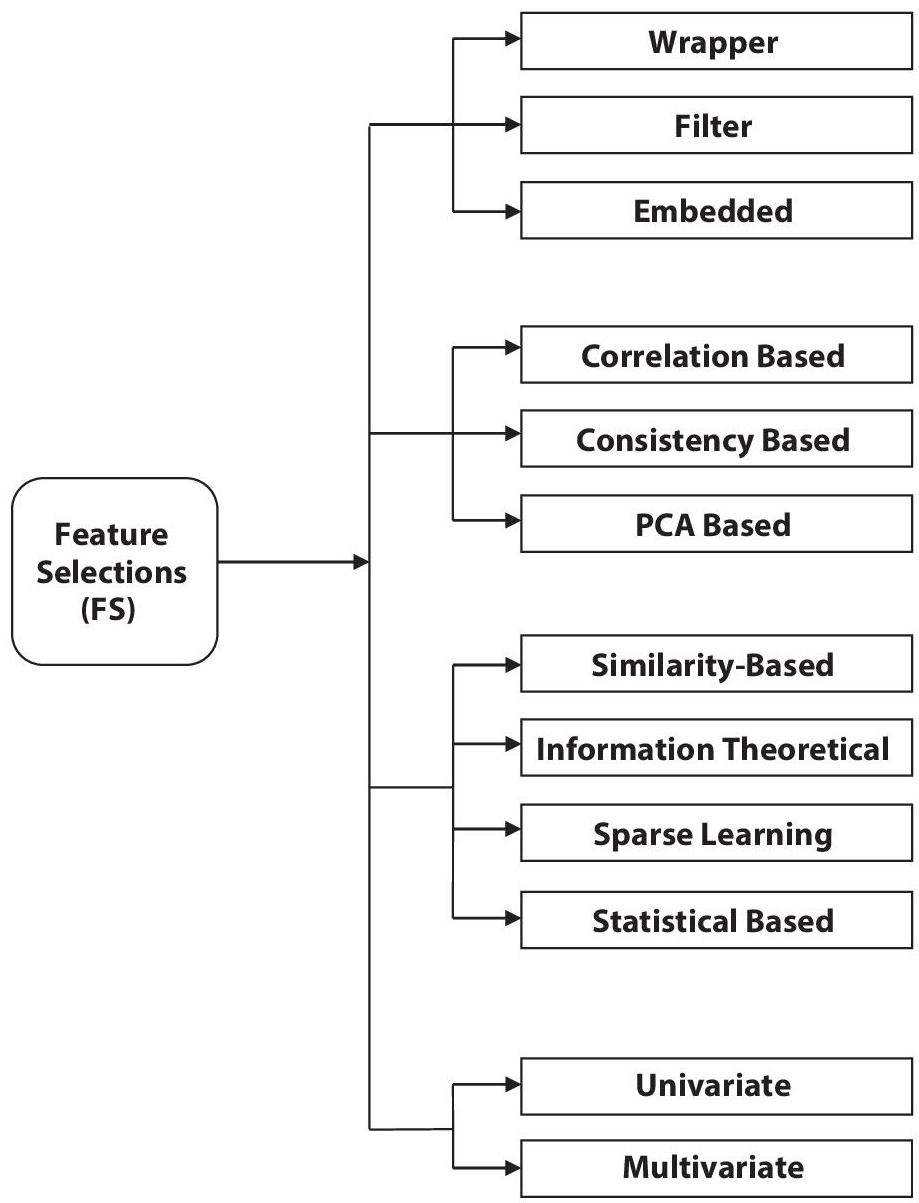
Figure 5.6 Classification of feature selection.
Wrapper Methods: A wrapper technique selects a set of features, where different combinations are prepared, evaluated, and compared to other combinations. A set of functions is evaluated, and scores are assigned based on accuracy using predictive models. Forward selection, backward elimination, recursive feature elimination, and genetic algorithm are examples of the wrapper method. The wrapper method’s limitation is that this method is computationally expensive compared to the filter method. A subset of features selected through the wrapper method makes the model more prone to overfitting. Embedded Methods: An embedded method predicts which features significantly improve the model’s accuracy while the model is being built. Decision tree, LASSO, Elastic Net, and Ridge Regression are some examples of embedded methods. This method combines the filter and wrapper method.
5.4.2 Correlation, Consistency, and PCA-Based Feature Selection
Correlation-Based Feature Selection (CFS): In CFS, features positively correlated are expected to be relevant for classification. Otherwise, they are not. As already mentioned, features are redundant if they are closely correlated and contain similar information. CFS is based on the idea that a vital feature subset contains features positively associated with the class but not with each other. As a result, CFS calculates the degree of association between features while also assessing predictive ability. It includes linear correlation-based models, e.g., PCA, IPA, ICA, and nonlinear correlation-based models, e.g., ISOMAP, LLI, etc.
Consistency-Based Feature Selection: Full consistency means zero inconsistency. The inconsistency rate over the data given set of features is the criterion for consistency-based feature selection. If two sets of values match all attributes but have different class labels, they are inconsistent. Principal Component Analysis: PCA treats instances of specific data sets as vectors of p-dimensional space, with P denoting the number of attributes per instance. PCA’s basic idea is to transform the given data set into a Q-dimensional space, with Q<P, i.e., into a set of linearly uncorrelated variables named principal components, maintaining roughly the same information in the original space.
The working principle of correlation-based feature selection (CFS) is that features within a class are highly correlated. Features are redundant if they are closely related. It calculates the degree of correlations. It includes linear correlation-based models, e.g., PCA, IPA, ICA, and nonlinear correlation-based models, e.g., ISOMAP.
5.4.3 Similarity, Information Theoretical, Sparse Learning, and Statistical-Based Feature Selection
The similarity-based feature selection method evaluates the importance of features by their capacity to preserve data similarity. A good feature should not randomly assign values to data instances. A good feature should assign similar values to each other. The closeness is calculated with the help of the data similarity matrix. It uses Laplacian score, Fisher Score, Trace ration criterion for finding closeness of feature.
Informational theoretical exploits different heuristic filter criteria to measure the importance of the feature. It divides features as strongly relevant, weakly relevant non-redundant, weakly relevant redundant, and irrelevant. Entropy, conditional entropy, information gain, etc., are some of the measures are used to divides features into four groups.
The selected features of the method, as mentioned earlier, may not be optimal for a particular learning task. The sparse learning-based process is an embedded method with several advantages like empirical success in many real-world applications, strong theoretical guarantee, and a flexible model for complex feature structure. Lassoes, an extension to the multiclass or multivariate problem, multi-cluster feature selection are examples.
Algorithms use the different statistical measures under this category for calculating feature importance. Most of them are filter-based methods. Most of the algorithm evaluates features individually, so the features redundancy is inescapable. Some algorithms can handle only discrete data. T-score, chi-square measures are used in this category. In a computer network, it is assumed that internet traffic at the network layer has statistical properties peculiar to some groups of applications, allowing users to differentiate them from one another using a statistical-based recognition method. The statistical characteristics include the minimum and maximum packet inter-arrival times and the standard deviation of packet length. The qualitative analysis of different features helps researchers choose one or more features to classify network traffic flows. A weight value could be assigned to each feature to represent its importance. Many features are used to classify network traffic, but using unrelated or redundant features often negatively impacts most ML algorithms’ accuracy. It can make the system computationally expensive since the amount of information stored and processes also improve. Therefore it is suggested to select only an important set of features [18].
5.4.4 Univariate and Multivariate Feature Selection
Univariate feature selection looks for each feature independently of others. Examples of univariate feature selection are the Pearson Correlation Coefficient, Chi-square, F-score, Signal to noise ratio, Mutual information, etc. It ranks feature by importance, and users determine ranking cut-off. The univariate method measures some correlation between two random variables, e.g., the Pearson Correlation Coefficient. Multivariate Feature Selection considers all features simultaneously.
5.5 Tools and Library for Feature Selection
We have some readily available software tools for feature selections with machine learning algorithms; libraries integrated within the tools. Some of the widely used tools include WEKA, MATLAB, ROSE2, and ROSETTA [19]. The researchers have also used the library like SCIKIT, CARET [20], and DEAP [21].
5.6 Literature Review on Feature Selection in Flow-Based IDS
Current internet connections to high-speed networks produce traffic in the gigabits per second range, necessitating rigorous analysis to understand network traffic activity at the packet level. To minimize packet analysis, aggregated network traffic information is currently interpreted in the form of flows. Hence the flows supply information and pattern about the traffic instead of packet analysis. A flow-based approach seems to be more promising since it is more scalable in increasing network speed [22]. Improving the intrusion detection system’s performance has been considered difficult due to the volatility, incompleteness, and redundancy in the voluminous network traffic pattern in a flow-based dataset. These underline the necessity of feature selection in IDS to identify the informative features and overlook the irrelevant or redundant features that degrade the IDS’s performance in computational complexity and detection rate [23]. Accuracy, reducing computation time, and false alarm rate are the key issue to be addressed properly for classifying the data.
It is not always sufficient for all features in a dataset to lead to improved IDS performance. Hence, preprocessing on the dataset before going to the detection phase plays an important role. In the preprocessing phase, feature selection is an important stage. Feature selection is the process of selecting the most important features applicable to a specific attack or malicious conduct. In machine learning, redundant or noisy data make it difficult to discover meaningful patterns from the dataset. Feature selection, also known as attribute selection, helps in many ways to improve performance and generate better results [24].
Gayatri et al. [17] used a feature reduction approach for the flow-based IDS using the J-Rip classification algorithm on CICIDS2017 datasets. The actual dataset has 86 features, which were reduced to 18 features for application-layer DDoS attacks. This reduced 18 feature set provides good accuracy (99.93%) compared with all 86 features (99.91%). These reductions in feature size also reduced the model built-up time from 4.17 seconds to 0.38 seconds.
Ammar Alazab et al. [25] mentioned that many researchers do not understand the importance of feature selection before applying the classifier. However, now it has been proved through many researches that use of feature selection before classifiers improves classifier performance reducing resources required. For a multi-classification approach, feature selection plays an important role. Abuadlla Yousef et al. [26] presented two-stage neural network-based flow IDS. The first stage gives important features for malicious traffic classification (feature preparation module). These reduced features play a key role in attack classification into normal and abnormal traffic. The conclusion of this work is the feature selection assists in improving IDS performance.
Mahendra Prasad et al. [27] presented a novel intelligent system of feature selection by combining a rough set with Bayes Theorem to build an intrusion detection system. In this system, core features are identified and ranked based on estimated probabilities. These estimated probabilities help to remove redundant features in the training phase to reduce the training complexity. Here the rough set theory is helpful to distinguish uncertain information. Here records are divided into three categories, namely normal, intermediatory and abnormal. Bayes theorem is applied to intermediary or unseen samples to make a firm decision. The CICIDS2017 dataset was used to evaluate the system. The proposed system feature count is reduced to 40, providing an accuracy of 97.95% with precision and recall of 96.37%. The system’s main drawback was that manual intervention was needed to decide the range of estimated probabilities of relevant and irrelevant features. The preprocessing work was also done manually. Tanya Garg et al. [28] attempted to reduce the number of the features using ten different classification algorithms to get the features and then ranking features according to its importance. After this, 15 top features are selected to get better performance. These features are extracted using Boolean AND operator of top six classification algorithms. In [29] proved that system performance also gets reduced by considering redundant features, e.g., attack detection accuracy is decreased with increase in overload.
Chaouki and Saoussen [30] proposed a wrapper approach-based feature selection method. Genetic algorithm (GA) and logistic regression (LR) are used in the wrapper approach for the most relevant feature selection. A genetic algorithm is used as a search strategy for representing the possible feature subset. Moreover, logistic regression is used as a predictor in the wrapper. The authors used the KDD99 dataset and the UNSW-NB15 dataset for experimentation. The most relevant feature set accuracy is tested using three decision tree classifiers, C4.5, RandomForest, and NBTree. The proposed approach provides high classification accuracy and lowers the false alarm rate. The proposed approach showed a good detection rate for Denial of Service attack with 99.98%.
Sumaiya et al. [31] suggested an IDS model for classification based on chi-square feature selection and multi-class SVM. The authors suggest a chi-square feature selection method based on rank. The NSL-KDD dataset was used to test the proposed method. A mixture of discrete and continuous features is selected using the proposed feature selection process. The proposed model achieves high detection rates and low false alarm rates with selected features due to the parameter tuning technique, optimizing gamma, and over-fitting SVM parameters. The proposed model also decreased training and testing time significantly.
Akashdeep et al. [32] proposed a feature reduction method for IDS to improve performance. The proposed system used information gain and correlation methods for ranking features. The proposed system combined features obtained from information gain and correlation to differentiate useful and useless features. The KDD99 dataset is used for training and testing the proposed system. The intrusion detection system is implemented using a neural network. The proposed Intrusion Detection System with a reduced feature set showed better performance, increased detection rate, and reduced false alarm rate than the system without feature reduction. The proposed model showed a 99.93% detection rate for DoS attacks.
Madbouly et al. [33] proposed lightweight IDS with a feature selection method. The proposed system used the KDD99 dataset. The proposed system used a correlation-based feature subset selection (CFS) evaluator with seven different search methods Best first, Evolutionary search, Rank search (gain ratio), Rank search (info gain), PSO search, Greedy stepwise, and Tabu search. The proposed method selected the 12 most relevant features from 41 features. The proposed model’s performance with 12 features reported the same performance 99.95% as with 41 features. The proposed system achieved the same detection accuracy with a higher True Positive Rate, lower False Positive Rate, and lower False Negative Rate.
ZHANG Xue-qin et al. [34] demonstrated an IDS dependent on highlight determination and SVM in which an element choice is made on the premise Fisher Score. They utilized the SVM as a classifier. The Fisher Score is joined with the SVM to choose the significant features. They brought three parameters into the record, such as Precision, Detection Rate, and False Positive Rate. They selected features for system blended attack and single attack mode for feature selection, and out of 41 features, 29 features are significant. For the assessment, they utilized KDD Cup 99 dataset for intrusion detection. In this dataset, the attack like DoS, Probe, U2R, R2L, and so forth are available.
Shang Lei [35] introduced a component choice strategy dependent on Information Gain and Genetic Algorithm in which content classification includes choice technique dependent on data gain with the recurrence of things. The author demonstrated that this element choice strategy could understand the issue of content classification.
Preeti Aggarwala and Sudhir Kumar Sharma [36] performed a detailed study on the NSL KDD data set concerning four classes: Basic, Traffic, Content, and Host data attributes categorized. They analyzed the result for Detection Rate and False Alarm Rate for IDS. NSL KDD having 42 attributes classified under four classes. Basic has nine attributes: content having 13 attributes, traffic having nine attributes, and Host having ten attributes. The KDD data set was classified, and 15 variants were created by combining all four classes. Random Tree classification algorithm and WEKA tool used for analyzing. The result showed a basic class with a high Detection Rate (81%), whereas the Host class had a Low False Rate (8.5%).
Vandna and Anurag [37] proposed the implementation of the decision tree algorithm with K-means on IDS. The authors evaluated the performance of two decision tree algorithms J48 and ID3. The attribute reduction was performed on the NSL-KDD dataset. Out of 41 original attributes, only nine attributes were selected in preprocessing, and classification algorithms are implemented. Dimension reduction played an important role in the performance evaluation of J48 and ID3 algorithms. The result showed J48 performed better for reduced dimensionalities.
The value of using feature selection methods in IDS was suggested by Krishan et al. [38]. One of the most challenging aspects of developing effective IDSs is dealing with large amounts of data with numerous features. The authors proposed several feature selection methods and graded them using InfoGain, GainRatio, RELIEF, OneR, etc. The authors used the J48 classifier to assess the performance of the best algorithms by combining features from the best algorithms. KDDCup99 data set was examined to evaluate proposed techniques. OneR and RELIEF, two newly proposed feature selection algorithms, are compared to existing feature selection algorithms such as SVM, OneR, Chi-square, Relief, GainRatio, Information Gain, and others in order to choose the best features. Their findings revealed that the proposed FS approach decreases training time while increasing accuracy. The proposed FS algorithm reduced 70.73% of the feature dimension space and roughly 60% of the training time, increasing classification accuracy from 61.39% to 66.80%.
The author of this article used Genetic Algorithms (GA) with Principal Component Analysis (PCA) for feature selections [39]. Here PCA is used only for feature transformation purposes. After this, normalized features are fed to GA for feature selection. The Decision Tree (DST) is used as a classifier for this experimentation. This hybrid model of PCA-GA-DST reduced the CICIDS2017 dataset’s features to 40 features with an accuracy of 99.53%. In another work [24], a feature of the CICIDS2017 dataset is selected based on their classifications’ performance. Here one feature from the dataset is deleted at a time, and accuracy, model build-up time, and test time is recorded. If deletion of the feature causes the reduction in accuracy and increase in the build time and test time, that feature is considered important. Using this approach, 15 features are identified as important, which gives good accuracy compared to all feature accuracy.
5.7 Challenges and Future Scope
The issue with IDS is that it must cope with ever-faster network speeds. It is difficult for packet-based IDS to keep up with such fast network traffic. The flow-based IDS can solve this problem of packet-based IDS. Increasing alert confidence, reducing false alarms, and reducing resource consumption are still open issues for the IDS researchers.
Only some portion of the current research work has focused on flow-based IDS, and still, many researchers are working on packet-based IDS despite understanding the need for flow-based IDS. Hence significantly less information is available about meaningful flow features and their capacity to classify network traffics. In the case of flow-based IDS, some researchers do not understand the importance of data cleaning. If we correctly understand our data, we can reduce some of the features before actual feature selections start. In CICIDS2017 [40], dataset features like source IP address, SourcePortNumber, DestinitionIP, FlowID are network-specific features to remove such features beforehand in the data cleaning process. While working with feature selection in IDS, each researcher has used a different portion of different datasets. However, while comparing the results, datasets need to be the same across all the works. The choosing of feature selection algorithms must consider simplicity, feature reduction capacity, stability, scalability, accuracy, storage requirement, and algorithm’s computational efficiency. The tradeoff between feature selections and feature extractions also needs to be taken care of. With the feature selection, we select the only subset of features. Hence it may be possible that some of the information may be lost.
Nevertheless, feature extractions take care of this. The choice between feature selection and feature extraction depends on the domain of the application under consideration. The use of bio-inspired algorithms for feature selections has increased a lot in the last few years. These algorithms are categorized under three groups, viz. evolutionary, ecology-based, and swarm-based. With a bio-inspired algorithm, one may be good at accuracy, but the computational time required is more. Also, setting up algorithmic parameters like the number of generations and the number of iterations takes time. The referred literature shows that anticipating an ideal number of features to enhance IDS accuracy and decrease training time complexity continues to be an open issue. Data correlation is the future of IDS. The future IDS will deliver results by analyzing input from various traces.
5.8 Conclusions
There is a rapid advancement in network technology, which is manifested in higher-speed networks. There is also a rise in the number of internet users. All this results in a huge amount of data flowing through a network (it can be considered big data), which burdens the IDS. The packet-based approach compares each and every packet so packet-based IDS cannot be used in high-speed networks. In this scenario, flow-based IDS is the prominent solution to this problem. The use of the feature selection technique with flow-based IDS helps reduce resource optimization with improved accuracy. In this study, the authors have also gone through various feature selection approaches used for flow-based IDS. This study showed how the reduced number of features could significantly save computational time and storage of a system with better accuracy than earlier.
Acknowledgement
The authors wish to acknowledge the Information Security Education and Awareness (ISEA) Project, Department of Electronics and Information Technology, Ministry of Communications and Information Technology, Government of India, which has made it possible to undertake this research.
References
- 1. Pachghare, V. K. Cryptography, and Information Security. pp. 317-335, PHI Learning Pvt. Ltd., 2019.
- 2. Hubballi, N., Suryanarayanan, V., False alarm minimization techniques in signature-based intrusion detection systems: A survey, Computer Communications, 49, pp. 1-17, 2014.
- 3. Uday Banerjee, Wireless Security: Considerations, Intrusion Detection System, Tools and More, SANS Conference, Virginia Beach, 2004.
- 4. Adhao, R. B., Kshirsagar, A. R., Pachghare, V. K., NIDS Designed Using Two Stages Monitoring, International Journal of Computer Science and Information Technologies, 5, 1, pp. 256-259, 2014.
- 5. Cisco, Introduction to Cisco IOS NetFlow - A Technical Overview, https://www.cisco.com/c/en/us/products/collateral/ios-nx-os-software/ios-net-flow/prod_white_paper0900aecd80406232.html, 2012.
- 6. Sperotto, A., Schaffrath, G., Sadre, R., Morariu, C., Pras, A., Stiller, B., An overview of IP flow-based intrusion detection. IEEE Communications Surveys & Tutorials, 12, 3, pp. 343-356, 2010.
- 7. De Vito, Luca, Rapuano, Sergio, Tomaciello, L., One-Way Delay Measurement: State of the Art, IEEE T. Instrumentation and Measurement, 57, pp. 2742-2750, 2008.
- 8. Sperotto, A., Pras, A., Flow-based intrusion detection, IEEE International Symposium on Integrated Network Management and Workshops, pp. 958-963, May 2011.
- 9. Michel, Oliver., Packet-Level Network Telemetry and Analytics, Diss. University of Colorado at Boulder, 2019.
- 10. Adhao Rahul B., Pachghare Vinod K., WIDS Using Flow Based Approach, PG Dissertation, College of Engineering, Pune, 2014.
- 11. Alaidaros, H. M., Mahmuddin, M., Al Mazari, A., From Packet-based towards Hybrid Packet-based and Flow-based Monitoring for Efficient Intrusion Detection: An Overview, International Conference on Communication and Information Technology, 2012.
- 12. Heaton, J., An empirical analysis of feature engineering for predictive modeling, IEEE SoutheastCon, pp. 1-6, March 2016.
- 13. Alice, Zheng, and Amanda, Casari, Feature Engineering for Machine Learning, pp. 1-4, O Reilly Book, 2018.
- 14. Vincent Spruyt, Computer vision for dummies - The curse of dimensionality in classification, https://www.visiondummy.com/2014/04/curse-dimensionality-affect-classification/, 2014.
- 15. Sinan, Ozdemir and Divya, Susarla, Feature Engineering Made Easy: Identify unique features from your dataset in order to build powerful machine learning systems, pp. 1-32, Packt Publishing, 2018.
- 16. Jason Brownlee, An Introduction to Feature Selection, https://machinelearningmastery.com/an-introduction-to-feature-selection, 2020.
- 17. Patil, G. V., Pachghare, K. V., Kshirsagar, D. D., Feature Reduction in Flow Based Intrusion Detection System, IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), pp. 1356-1362, May-2018.
- 18. Dhote, Y., Agrawal, S., Deen, A. J., A survey on feature selection techniques for internet traffic classification, IEEE International Conference on Computational Intelligence and Communication Networks (CICN), pp. 1375-1380, December 2015.
- 19. Pieta Piotr, Szmuc Tomasz, Kluza Krzysztof, Comparative Overview of Rough Set Toolkit Systems for Data Analysis, 2019.
- 20. Kevin Vu, Exxact Corp, Scikit-Learn vs mlr for Machine Learning, https://www.kdnuggets.com/2019/09/scikit-learn-mlr-machine-learning.html, 2019.
- 21. Fortin, Felix-Antoine, et al., DEAP: Evolutionary algorithms made easy, Journal of Machine Learning Research 13.1, pp. 2171-2175, 2012.
- 22. Umer, M. F., Sher, M., Bi, Y., Flow-based intrusion detection: Techniques and challenges, Computers & Security, 70, pp. 238-254, 2017.
- 23. Ramakrishnan, S., Devaraju, S., Attack’s feature selection-based network intrusion detection system using fuzzy control language, International Journal of Fuzzy Systems, 19, 2, pp. 316-328, 2017.
- 24. Adhao, R. B., Pachghare, V. K., Performance-Based Feature Selection Using Decision Tree, IEEE International Conference on Innovative Trends and Advances in Engineering and Technology (ICITAET), pp. 135-138, December 2019.
- 25. Alazab, A., Hobbs, M., Abawajy, J., Alazab, M., Using feature selection for intrusion detection system, IEEE International Symposium on Communications and Information Technologies (ISCIT), pp. 296-301, 2012.
- 26. Abuadlla, Y., Kvascev, G., Gajin, S., Jovanovic, Z., Flow-based anomaly intrusion detection system using two neural network stages, Computer Science and Information Systems, 11, 2, pp. 601-622, 2014.
- 27. Prasad Mahendra, Sachin Tripathi, and Keshav Dahal, An efficient feature selection based Bayesian and Rough set approach for intrusion detection, Applied Soft Computing, 87, 2020.
- 28. T. Garg and Y. Kumar, Combinational feature selection approach for network intrusion detection system, International Conference on Parallel, Distributed and Grid Computing, pp. 82-87, 2014.
- 29. Mukkamala, Srinivas, and Andrew H. Sung, Feature ranking and selection for intrusion detection systems using support vector machines, Proceedings of the Second Digital Forensic Research Workshop, pp. 1-10, 2002.
- 30. Khammassi, C., Krichen, S., A GA-LR wrapper approach for feature selection in network intrusion detection, Computers & Security, 70, pp. 255-277, 2017.
- 31. Thaseen, I. S., Kumar, C. A., Intrusion detection model using fusion of chi-square feature selection and multi class SVM, Journal of King Saud University-Computer and Information Sciences, 29, 4, pp. 462-472, 2017.
- 32. Akashdeep Sharma, Manzoor, I., Kumar, N., A feature reduced intrusion detection system using ANN classifier, Expert Systems with Applications, 88, pp. 249-257, 2017.
- 33. Madbouly, A. I., Barakat, T. M., Enhanced relevant feature selection model for intrusion detection systems, International Journal of Intelligent Engineering Informatics, 4, 1, pp. 21-45, 2016.
- 34. Xue-qin, Z., Chun-hua, G., Jia-jun, L., Intrusion detection system based on feature selection and support vector machine, IEEE International Conference on Communications and Networking in China, pp. 1-5, October 2006.
- 35. Lei, S., A feature selection method based on information gain and genetic algorithm, IEEE International Conference on Computer Science and Electronics Engineering, 2, pp. 355-358, March 2012.
- 36. Aggarwal, P., Sharma, S. K., Analysis of KDD dataset attributes-class wise for intrusion detection, Procedia Computer Science, 57, pp. 842-851, 2015.
- 37. Malviya, V., Jain, A., An Efficient Network Intrusion Detection Based on Decision Tree Classifier & Simple K-Mean Clustering using Dimensionality Reduction - A Review, International Journal on Recent and Innovation Trends in Computing and Communication, 3, 2, pp. 789-791, 2015.
- 38. Kumar, G., Kumar, K., Design of an evolutionary approach for intrusion detection, Scientific World Journal, 2013.
- 39. Adhao, R., Pachghare, V., Feature selection using principal component analysis and genetic algorithm, Journal of Discrete Mathematical Sciences and Cryptography, 23, 2, pp. 595-602, 2020.
- 40. Iman Sharafaldin, Arash Habibi Lashkari, and Ali A. Ghorbani, Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization, International Conference on Information Systems Security and Privacy (ICISSP), Portugal, January 2018.
Note
- *Corresponding author: [email protected]