
Chapter 2 A Taxonomy of Kernel Vulnerabilities
Information in this Chapter
-
Uninitialized/Nonvalidated/Corrupted Pointer Dereference
-
Memory Corruption Vulnerabilities
-
Integer Issues
-
Race Conditions
-
Logic Bugs (a.k.a. the Bug Grab Bag)
Introduction
Software has bugs. A bug is a malfunction in a program that makes the program produce incorrect results, behave in an undesired way, or simply crash/terminate unexpectedly. In most cases, bugs are the result of programming errors, as is the case in the following snippet of code taken from the 2.6.9 version of the Linux Kernel:
static int bluez_sock_create(struct socket *sock, int proto)
{
if (proto >= BLUEZ_MAX_PROTO)
return –EINVAL;
[…]
return bluez_proto[proto]->create(sock,proto);
}
In this code, the parameter proto is checked against a maximum value, BLUEZ_MAX_PROTO, to avoid reading past the size of the bluez_proto array later, when proto is used as an index inside the array. The problem here is that proto is a signed integer, and as such it can have a negative value. Therefore, if proto is less than 0, any memory before the bluez_proto array will be accessed. Since this memory is used as a function pointer, this bug likely will result in a crash when either attempting to dereference an unmapped address or wrongly accessing some other memory location as a consequence of executing a random sequence of bytes. The obvious way to fix this bug is to simply check if proto is less than 0 at the start of the function, and to error out if it is. (This is exactly what Linux kernel developers did in 2005 after they were notified of the issue.1 )
When they are not a consequence of a programming error, bugs almost always are a consequence of design flaws (especially when it comes to large projects, as the kernel indeed is). A design flaw, as the name suggests, is a weakness in a software program's architecture, and is fundamentally language-independent (i.e., regardless of the language used to implement the software, the security issue will still be present). A classic example of a design flaw is to rely on a weak encryption scheme or to implicitly trust some component of the architecture that an attacker could impersonate or manipulate without the need for certain privileges. We provide a detailed example of a design flaw in the “Kernel-Generated User-Land Vulnerabilities” subsection later in this chapter.
Of course, not all bugs are security bugs. In fact, bugs usually have nothing to do with security. Simply put, a bug becomes a security issue as soon as someone figures out how to gain privileges from it. Sometimes the approach used to exploit a specific bug can be generalized and reused on similar bugs. In these cases, we are referring to bug classes and exploiting techniques. The more precisely you can define and characterize these classes, the more accurate and reliable your exploiting techniques will be. This is the goal of the taxonomy we present in this chapter.
Uninitialized/Nonvalidated/Corrupted Pointer Dereference
Perhaps the most famous kernel bug class is the NULL pointer dereference. As every C manual states, a pointer is a variable that holds the address of another variable in memory. Each time the pointer is dereferenced, the value contained at the memory address it holds is retrieved. The ISO C standard2 dictates that a static, uninitialized pointer has a NULL (0x0) value, and NULL is the usual return value that indicates failure in a memory allocation function. If a kernel path attempts to dereference a NULL pointer, it will simply try to use the memory address 0x0, which likely will result in a panic condition, since usually nothing is mapped there. The number of NULL pointer dereference bugs that have been discovered in the various kernels is impressive, as a quick search on your favorite search engine will prove.
NULL pointer dereference vulnerabilities are a subset of a larger class of bug known as the uninitialized/nonvalidated/corrupted pointer dereference. This category covers all situations in which a pointer is used while its content has been corrupted, was never properly set, or was not validated enough. We know a static declared pointer is initialized to NULL, but what happens to a pointer declared as a local variable in a function? And what is the content of a pointer contained in a structure freshly allocated in memory? Until these pointers are explicitly assigned a value, they are uninitialized and their value is unspecified. Let's look at this in a little more detail.
We said that a pointer is a variable and, as with any variable, it has a size and needs to be stored in memory to be used. The size of the pointer depends on the data model the system uses and is usually directly influenced by the system architecture. The data model is usually expressed using the int, long, and pointer size notation; for example, ILP32 refers to a system in which all ints, longs, and pointers are 32 bits wide, whereas LP64 refers to a system in which longs and pointers are 64 bits wide but integers are not (in fact, integers will be 32 bits, but that's not explicitly stated). Table 2.1 provides a recap of data type sizes for each model (sizes are expressed in number of bits).
Table 2.1 Data type sizes in the different data models
| Data type | LP32 | ILP32 | LP64 | ILP64 | LLP64 |
| Char | 8 | 8 | 8 | 8 | 8 |
| Short | 16 | 16 | 16 | 16 | 16 |
| Int | 16 | 32 | 32 | 64 | 32 |
| Long | 32 | 32 | 64 | 64 | 32 |
| Long long | 64 | 64 | 64 | 64 | 64 |
| Pointer | 32 | 32 | 64 | 64 | 64 |
Now, let's say the ILP32 model is in place. In this case, the pointer occupies four bytes in memory. While the pointer is uninitialized, its value is whatever value resides in the memory assigned to hold the pointer variable. People already familiar with writing exploits (or who have an exploit-oriented mindset) might be wondering if it is possible to predict the value of that memory and use it to their advantage. The answer is yes, in many cases it is (or, at least, it is possible to have an idea of the range). For instance, consider a pointer declared as a local variable, as shown in the following code. This pointer will be stored on the stack, and its value will be the previous function left on the stack:
#include <stdio.h>
#include <strings.h>
void big_stack_usage() {
char big[200];
memset(big,'A', 200);
}
void ptr_un_initialized() {
char *p;
printf("Pointer value: %p ", p);
}
int main()
{
big_stack_usage();
ptr_un_initialized();
}
By compiling and executing the preceding code (remember that the hexadecimal code of A is 0x41), we get the following:
macosxbox$ gcc -o p pointer.c
macosxbox$ ./p
Pointer value: 0x41414141
macosxbox$
As you can see, the pointer allocated inside ptr_un_initialized() has, as we predicted, the value the previous function left on the stack. A range of memory that has some leftover data is usually referred to as dead memory (or a dead stack). Granted, we crafted that example, and you might think such a thing is unlikely to happen. It is indeed rare, but what about the following FreeBSD 8.0 path?3
struct ucred ucred, *ucp; [1]
[…]
refcount_init(&ucred.cr_ref, 1);
ucred.cr_uid = ip->i_uid;
ucred.cr_ngroups = 1;
ucred.cr_groups[0] = dp->i_gid; [2]
ucp = &ucred;
At [1] ucred is declared on the stack. Later, the cr_groups[0] member is assigned the value dp->i_gid. Unfortunately, struct ucred is defined as follows:
struct ucred {
u_int cr_ref; /* reference count */
[…]
gid_t *cr_groups; /* groups */
int cr_agroups; /* Available groups */
};
As you can see, cr_groups is a pointer and it has not been initialized (but it is used directly) by the previous snippet of code. That means the dp->i_gid value is written to whatever address is on the stack at the time ucred is allocated.
Moving on, a corrupted pointer is usually the consequence of some other bug, such as a buffer overflow (which we describe in the following section, “Memory Corruption Vulnerabilities”), which trashes one or more of the bytes where the pointer is stored. This situation is more common than using an uninitialized variable (with the notable exception of NULL dereferences) and usually gives the attacker some degree of control over the contents of the variable, which directly translates into a more reliable exploit.
A nonvalidated pointer issue makes the most sense in a combined user and kernel address space. As we said in Chapter 1 in such an architecture the kernel sits on top of user land and its page tables are replicated inside the page tables of all processes. Some virtual address is chosen as the limit address: this means virtual addresses above (or below) it belong to the kernel, and virtual addresses below (or above) it belong to the user process. Internal kernel functions use this address to decide if a specific pointer points to kernel land or user land. In the former case usually fewer checks are necessary, whereas in the latter case more caution must be taken before accessing it. If this check is missing (or is incorrectly applied) a user-land address might be dereferenced without the necessary amount of control.
As an example, take a look at the following Linux path:4
error = get_user(base, &iov->iov_base); [1]
[…]
if (unlikely(!base)) {
error = -EFAULT;
break;
}
[…]
sd.u.userptr = base; [2]
[…]
size = __splice_from_pipe(pipe, &sd, pipe_to_user);
[…]
static int pipe_to_user(struct pipe_inode_info *pipe, struct pipe_buffer *buf,
struct splice_desc *sd)
{
if (!fault_in_pages_writeable(sd->u.userptr, sd->len)) {
src = buf->ops->map(pipe, buf, 1);
ret = __copy_to_user_inatomic(sd->u.userptr, src + buf->offset, sd->len); [3]
buf->ops->unmap(pipe, buf, src);
[…]
}
The first part of the snippet comes from the vmsplice_to_user() function and gets the destination pointer at [1] using get_user(). That destination pointer is never validated and is passed, through [2], to __splice_from_pipe(), along with pipe_to_user() as the helper function. This function also does not perform any checks and ends up calling __copy_to_user_inatomic() at [3]. We will discuss in the rest of the book the various ways to copy, from inside kernel land, to and from user space; for now, it's enough to know that Linux functions starting with a “__” (such as __copy_to_user_inatomic()) don't perform any checks on the supplied destination (or source) user pointer. This vulnerability allows a user to pass a kernel address to the kernel, and therefore directly access (modify) kernel memory.
Thus far we have discussed dereferencing pointers, but we have not discussed the type of access performed by the kernel path that uses them. An arbitrary read occurs when the kernel attempts to read from the trashed pointer, and an arbitrary write occurs when the kernel attempts to store a value on the memory address referenced by the pointer (as was the case in the preceding example). Moreover, a controlled or partially controlled read/write occurs when the attacker has full or partial control over the address that the pointer will point to, and an uncontrolled read/write occurs when the attacker has no control over the value of the trashed pointer. Note that an attacker might be able to predict to some extent the source/destination of an uncontrolled read/write, and therefore successfully and, more importantly, reliably exploit this scenario too.
Memory Corruption Vulnerabilities
The next major bug class we will analyze covers all cases in which kernel memory is corrupted as a consequence of some misbehaving code that overwrites the kernel's contents. There are two basic types of kernel memory: the kernel stack, which is associated to each thread/process whenever it runs at the kernel level, and the kernel heap, which is used each time a kernel path needs to allocate some small object or some temporary space.
As we did for pointer corruption vulnerabilities (and as we will do throughout this chapter), we leave the details regarding exploitation of such issues for Chapter 3, (for generic approaches) and to the chapters in Part II of this book.
Kernel Stack Vulnerabilities
The first memory class we will examine is the kernel stack. Each user-land process running on a system has at least two stacks: a user-land stack and a kernel-land stack. The kernel stack enters the game each time the process traps to kernel land (i.e., each time the process requests a service from the kernel; for example, as a consequence of issuing a system call).
The generic functioning of the kernel stack is not different from the generic functioning of a typical user-land stack, and the kernel stack implements the same architectural conventions that are in place in the user-land stack. These conventions comprise the growth direction (either downward, from higher addresses to lower addresses, or vice versa), what register keeps track of its top address (generally referred to as the stack pointer), and how procedures interact with it (how local variables are saved, how parameters are passed, how nested calls are linked together, etc.).
Although the kernel- and user-land stacks are the same in terms of how they function, there are some slight differences between the two that you should be aware of. For instance, the kernel stack is usually limited in size (4KB or 8KB is a common choice on x86 architectures), hence the paradigm of using as few local variables as possible when doing kernel programming. Also, all processes' kernel stacks are part of the same virtual address space (the kernel address space), and so they start and span over different virtual addresses.
Note
Some operating systems, such as Linux, use so-called interrupt stacks. These are per-CPU stacks that get used each time the kernel has to handle some kind of interrupt (in the Linux kernel case, external hardware-generated interrupts). This particular stack is used to avoid putting too much pressure on the kernel stack size in case small (4KB for Linux) kernel stacks are used.
As you can see from this introduction, kernel stack vulnerabilities are not much different from their user-land counterparts and are usually the consequence of writing past the boundaries of a stack allocated buffer. This situation can occur as a result of:
-
Using one of the unsafe C functions, such as strcpy() or sprintf(). These functions keep writing to their destination buffer, regardless of its size, until a � terminating character is found in the source string.
-
An incorrect termination condition in a loop that populates an array. For example:
#define ARRAY_SIZE 10
void func() {
int array[ARRAY_SIZE];
for (j = 0; j <= ARRAY_SIZE; j++) {
array[j] = some_value;
[…]
}
}
Since array elements go from 0 to ARRAY_SIZE, when we copy some_value inside array[j] with j == 10 we are actually writing past the buffer limits and potentially overwriting sensitive memory (e.g., a pointer variable saved right after our array).
-
Using one of the safe C functions, such as strncpy(), memcpy(), or snprintf(), and incorrectly calculating the size of the destination buffer. This is usually the consequence of particular bug classes that affect integer operations, generally referred to as integer overflows, which we will describe in more detail in the “Integer Issues” section later in this chapter.
Since the stack plays a critical role in the application binary interface of a specific architecture, exploiting kernel stack vulnerabilities can be heavily architecture-dependent, as you will see in Chapter 3.
Kernel Heap Vulnerabilities
In Chapter 1 we saw that the kernel implements a virtual memory abstraction, creating the illusion of a large and independent virtual address space for all the user-land processes (and, indeed, for itself). The basic unit of memory that the kernel manages is the physical page frame, which can vary in size but is never smaller than 4KB. At the same time, the kernel needs to continuously allocate space for a large variety of small objects and temporary buffers. Using the physical page allocator for such a task would be extremely inefficient, and would lead to a lot of fragmentation and wasted space. Moreover, such objects are likely to have a short lifetime, which would put an extra burden on the physical page allocator (and the demand paging on disk), sensibly hitting the overall system performance.
The general approach that most modern operating systems take to solve this problem is to have a separated kernel-level memory allocator that communicates with the physical page allocator and is optimized for fast and continuous allocation and relinquishing of small objects. Different operating systems have different variations of this type of allocator, and we will discuss the various implementations in Part II of this book. For now, it's important to understand the general ideas behind this kind of object allocator so that you know what kinds of vulnerabilities might affect it.
We said that this allocator is a consumer of the physical page allocator; it asks for pages, and eventually it returns them. Each page is then divided into a number of fixed-size chunks (commonly called slabs, from the Slab Allocator designed by Jeff Bonwick for Sun OS 5.45 ), and pages containing objects of the same size are grouped together. This group of pages is usually referred to as a cache.
Although objects can be of virtually any size, power-of-two sizes are generally used, for efficiency reasons. When some kernel subsystem asks for an object, the allocator returns a pointer to one of those chunks. The allocator also needs to keep track of which objects are free (to be able to satisfy the subsequent allocation/free correctly). It can keep this information as metadata inside the page, or it can keep the data in some external data structure (e.g., a linked list). Again, for performance reasons the object memory is usually not cleared at free or allocation time, but specific functions that do clear the object memory at these times are provided. Recalling our discussion about dead memory, it's also possible to talk about a dead heap.
Size can be the only discriminator in the creation of different caches; however, object-specific caches can be created too. In the latter case, frequently used objects receive a specific cache, and size-based general-purpose caches are available for all other allocations (e.g., temporary buffers). An example of a frequently used object is the structure for holding information about each directory entry on the file system or each socket connection created. Searching for a file on the file system will quickly consume a lot of directory entry objects and a big Web site will likely have thousands of open connections.
Whenever such objects receive a specific cache, the size of the chunks will likely reflect the specific object size; as a result, non-power-of-two sizes will be used to optimize space. In this case, as well as in the case of in-cache metadata information, the free space available for chunks might not be divisible by the chunk size. This “empty” space is used, in some implementations, to color the cache, making the objects in different pages start at different offsets and, thus, end on different hardware cache lines (again improving overall performance).
The vulnerabilities that can affect the kernel heap are usually a consequence of buffer overflows, with the same triggering modalities we described earlier in the “Kernel Stack Vulnerabilities” section (use of unsafe functions, incorrectly terminated loops, incorrect use of safe functions, etc.). The likely outcome of such an overflow is to overwrite either the contents of the chunk following the overflowed chunk, or some cache-related metadata (if present), or some random kernel memory (if the overflow is big enough to span past the boundary of the page the chunks reside in, or if the chunk is at the end of the cache page).
Tip
Nearly all the object allocators present in the operating systems we will evaluate provide a way to detect this kind of overflow, via a technique that is usually referred to as redzoning, which consists of placing an arbitrary value at the end of each chunk and checking if that value was overwritten at the time the object was freed. Similar techniques are also implemented to detect access to uninitialized or freed memory. All of these debugging options have an impact on operating system performance and are thus turned off by default. They can usually be enabled either at runtime (by setting a boot flag or modifying a value via a kernel debugger) or at compile time (via compile options). We can take advantage of them to see how our heap exploit is behaving (is it overwriting a chunk?) or employ them along with fuzzing to have a better understanding of the kinds of bugs we hit.
Integer Issues
Integer issues affect the way integers are manipulated and used. The two most common classes for integer-related bugs are (arithmetic) integer overflows and sign conversion issues.
In our earlier discussion about data models, we mentioned that integers, like other variables, have a specific size which determines the range of values that can be expressed by and stored in them. Integers can also be signed, representing both positive and negative numbers, or unsigned, representing only positive numbers.
With n representing the size of an integer in bits, logically up to 2 n values can be represented. An unsigned integer can store all the values from 0 to 2 n – 1, whereas a signed integer, using the common two's complement approach, can represent ranges from –(2 n – 1) to (2 n – 1 – 1).
Before we move on to a more detailed description of various integer issues, we want to stress a point. This kind of vulnerability is usually not exploitable per se, but it does lead to other vulnerabilities—in most cases, memory overflows. A lot of integer issues have been detected in basically all the modern kernels, and that makes them a pretty interesting (and, indeed, rewarding) bug class.
(Arithmetic) Integer Overflows
An integer overflow occurs when you attempt to store inside an integer variable a value that is larger than the maximum value the variable can hold. The C standard defines this situation as undefined behavior (meaning that anything might happen). In practice, this usually translates to a wrap of the value if an unsigned integer was used and a change of the sign and value if a signed integer was used.
Integer overflows are the consequence of “wild” increments/multiplications, generally due to a lack of validation of the variables involved. As an example, take a look at the following code (taken from a vulnerable path that affected the OpenSolaris kernel;6 the code is condensed here to improve readability):
static int64_t
kaioc(long a0, long a1, long a2, long a3, long a4, long a5)
{
[…]
switch ((int)a0 & ~AIO_POLL_BIT) {
[…]
case AIOSUSPEND:
error = aiosuspend((void *)a1, (int)a2, (timespec_t *)a3, [1]
(int)a4, &rval, AIO_64);
break;
[…]
/*ARGSUSED*/
static int
aiosuspend(void *aiocb, int nent, struct timespec *timout, int flag, long *rval, int run_mode)
{
[…]
size_t ssize;
[…]
aiop = curproc->p_aio;
if (aiop == NULL || nent <= 0) [2]
return (EINVAL);
if (model == DATAMODEL_NATIVE)
ssize = (sizeof (aiocb_t *) * nent);
else
ssize = (sizeof (caddr32_t) * nent); [3]
[…]
cbplist = kmem_alloc(ssize, KM_NOSLEEP) [4]
if (cbplist == NULL)
return (ENOMEM);
if (copyin(aiocb, cbplist, ssize)) {
error = EFAULT;
goto done;
}
[…]
if (aiop->aio_doneq) {
if (model == DATAMODEL_NATIVE)
ucbp = (aiocb_t **)cbplist;
else
ucbp32 = (caddr32_t *)cbplist;
[…]
for (i = 0; i < nent; i++) { [5]
if (model == DATAMODEL_NATIVE) {
if ((cbp = *ucbp++) == NULL)
In the preceding code, kaioc() is a system call of the OpenSolaris kernel that a user can call without any specific privileges to manage asynchronous I/O. If the command passed to the system call (as the first parameter, a0) is AIOSUSPEND [1], the aiosuspend() function is called, passing as parameters the other parameters passed to kaioc(). At [2] the nent variable is not sanitized enough; in fact, any value above 0x3FFFFFFF (which is still a positive value that passes the check at [2]), once used in the multiplication at [3], will make ssize (declared as a size_t, so either 32 bits or 64 bits wide, depending on the model) overflow and, therefore, wrap. Note that this will happen only on 32-bit systems since nent is explicitly a 32-bit value (it is obviously impossible to overflow a 64-bit positive integer by multiplying a small number, as, for example, at [3], by the highest positive 32-bit integer). Seeing this in code form might be helpful; the following is a 32-bit scenario:
![]()
In the preceding code, the integer value is cropped, which translates to a loss of information (the discarded bits). ssize is then used at [4] as a parameter to kmem_alloc(). As a result, much less space is allocated than what the nent variable initially dictated.
This is a typical scenario in integer overflow issues and it usually leads to other vulnerabilities, such as heap overflows, if later in the code the original value is used as a loop guard to populate the (now too small) allocated space. An example of this can be seen at [5], even if in this snippet of code nothing is written to the buffer and “only” memory outside it is referenced. Notwithstanding this, this is a very good example of the type of code path you should hunt for in case of an integer overflow.
Sign Conversion Issues
Sign conversion issues occur when the same value is erroneously evaluated first as an unsigned integer and then as a signed one (or vice versa). In fact, the same value at the bit level can mean different things depending on whether it is of a signed or unsigned type. For example, take the value 0xFFFFFFFF. If you consider this value to be unsigned, it actually represents the number 232 − 1 (4,294,967,295), whereas if you consider it to be signed, it represents the number −1.
The typical scenario for a sign conversion issue is a signed integer variable that is evaluated against some maximum legal value and then is used as a parameter of a function that expects an unsigned value. The following code is an example of this, taken from a vulnerable path in the FreeBSD kernel7 up to the 6.0 release:
int fw_ioctl (struct cdev *dev, u_long cmd, caddr_t data, int flag, fw_proc *td)
{
[…]
int s, i, len, err = 0; [1]
[…]
struct fw_crom_buf *crom_buf = (struct fw_crom_buf *)data; [2]
[…]
if (fwdev == NULL) {
[…]
len = CROMSIZE;
[…]
} else {
[…]
if (fwdev->rommax < CSRROMOFF)
len = 0;
else
len = fwdev->rommax - CSRROMOFF + 4;
}
if (crom_buf->len < len) [3]
len = crom_buf->len;
else
crom_buf->len = len;
err = copyout(ptr, crom_buf->ptr, len); [4]
Both len [1] and crom_buf->len are of the signed integer type, and we can control the value of crom_buf->len since it is taken directly from the parameter passed through the ioctl call [2]. Regardless of what specific value len is initialized to, either 0 or some small positive value, the condition check at [3] can be satisfied by setting crom_buf->len to a negative value. At [4] copyout() is called with len as one of its parameters. The copyout() prototype is as follows:
int copyout(const void * __restrict kaddr, void * __restrict udaddr, size_t len) __nonnull(1) __nonnull(2);
As you can see, the third parameter is of type size_t, which is a typedef (a “synonymous of” in C) to an unsigned integer; this means the negative value will be interpreted as a large positive value. Since crom_buf->ptr is a destination in user land, this issue translates to an arbitrary read of kernel memory.
With the release in 2009 of Mac OS X Snow Leopard, all the operating systems we will cover in this book now support a 64-bit kernel on x86 64-bit-capable machines. This is a direct indication of wider adoption of the x86 64-bit architecture (introduced by AMD in 2003), in both the server and user/consumer markets. We will discuss the x86-64 architecture in more detail in Chapter 3.
Of course, change is never easy, especially when it pertains to maintaining backward compatibility with applications built for previous data models. To increase the “fun” most compilers use the ILP32 model for 32-bit code and the LP64 model for 64-bit code (we discussed the meaning of these data models earlier, in the section “Uninitialized/Nonvalidated/Corrupted Pointer Dereference”). This refers to all the major UNIX systems (Linux, Solaris, the *BSDs, etc.) and to Mac OS X “using” the LP64 model. The only notable exception is Windows, which uses the LLP64 data model, where long and int are 32 bits wide and long longs and pointers are 64 bits wide.
This change exposes (sometimes with security implications) a bad habit among some C programmers, which is to assume pointers, integers, and longs all of the same size, since that has been true for a long time on 32-bit architectures. This is another pretty common source of integer issues and is particularly subtle because it affects code that has been working correctly for a long time (up until the port to 64 bits). It is also worth mentioning that the compiler usually raises a warning for the most common misuse of integer data types (e.g., attempting to save a 64-bit pointer address inside a 32-bit integer variable).
In general, it's easier to understand integer issues in C/C++ if you are familiar with the standard promotion and usual arithmetic rules. Such rules specify what happens when data types of different sizes are used in the same arithmetic expression and how the conversion among them occurs. Aside from the C99 standard, a very good reference for helping you to understand these rules and related issues is the CERT Secure Coding Standard.8
Race Conditions
Nearly every academic concurrent programming course at some point mentions the term race condition. Simply put, a race condition is a generic situation in which two or more actors are about to perform a move and the result of their actions will be different depending on the order in which they will occur. When it comes to an operating system, in most cases you really do not want to be in this situation: determinism is indeed a good property, especially for paths that are critical to the correct functioning of a system.
For a race condition to occur, the (two or more) actors need to execute their action concurrently or, at least, be interleaved one with the other(s). The first case is typical on symmetric multiprocessing (SMP) systems. Since there is more than one CPU (core), multiple different kernel paths can be executing at the same time. The second case is the only possible situation for race conditions on uniprocessor (UP) systems. The first task needs to be interrupted somehow for the second one to run. Nowadays, this is not a remote possibility: a lot of the parts of modern kernels can be preempted, which means they can be scheduled off the CPU in favor of some other process. Moreover, kernel paths can sleep—for example, waiting for the outcome of a memory allocation. In this case, so as not to waste CPU cycles, they are again simply scheduled off and another task is brought in. We will see in Chapter 3 how much we can influence the behavior of the scheduler and how we can increase the likelihood of “winning” the race.
To prevent race conditions from occurring, you must guarantee some sort of synchronization among the various actors—for example, to prevent one of the actors from performing its task until the other one is finished. In fact, in operating systems, coordination among different kernel tasks/paths is achieved using various synchronization primitives (e.g., locks, semaphores, conditional variables, etc.). However, these synchronization primitives do not come without a cost. For example, a kernel task that holds a specific exclusive lock prevents all the other kernel tasks from going down through the same path. If the first task spends a lot of time with the lock that is being held and there is a lot of contention on the lock (i.e., a lot of other tasks want to grab it), this can noticeably slow the performance of the operating system. We provide a detailed analysis of this situation in Chapter 3 and in the chapters in Part II of this book. In addition, you can refer to the “Related Reading” section at the end of Chapter 1 for further reading on this topic.
Now that you understand the basics of race conditions, let's discuss what a race condition looks like. As you may already know, race conditions can come in multiple different forms (the generic concept of each kernel exploit being a story unto itself is especially true with race conditions and logical bugs), and can arguably be among the nastiest bugs to track down (and reproduce). In recent years, race conditions have led to some of the most fascinating bugs and exploits at the kernel level, among them sys_uselib 9 and the page fault handler 10 issues on the Linux kernel.
We will discuss page fault handler issues on the Linux kernel at the end of this section; here, we will discuss yet another typical scenario for a race condition that concerns another of our favorite bugs, also from the Linux kernel.11 This bug is an example of the interaction between the kernel and some user-land buffer that has to be accessed (and therefore copied in kernel memory). This classic situation has occurred frequently (and likely will continue to occur) inside different kernels. Here is the code:
int cmsghdr_from_user_compat_to_kern(struct msghdr *kmsg,
unsigned char *stackbuf, int stackbuf_size)
{
struct compat_cmsghdr __user *ucmsg;
struct cmsghdr *kcmsg, *kcmsg_base;
compat_size_t ucmlen;
__kernel_size_t kcmlen, tmp;
kcmlen = 0;
kcmsg_base = kcmsg = (struct cmsghdr *)stackbuf; [1]
[…]
while(ucmsg != NULL) {
if(get_user(ucmlen, &ucmsg->cmsg_len)) [2]
return -EFAULT;
/* Catch bogons. */
if(CMSG_COMPAT_ALIGN(ucmlen) <
CMSG_COMPAT_ALIGN(sizeof(struct compat_cmsghdr)))
return -EINVAL;
if((unsigned long)(((char __user *)ucmsg - (char __user *)kmsg->msg_control) + ucmlen) > kmsg->msg_controllen) [3]
return -EINVAL;
tmp = ((ucmlen - CMSG_COMPAT_ALIGN(sizeof(*ucmsg))) +
CMSG_ALIGN(sizeof(struct cmsghdr)));
kcmlen += tmp; [4]
ucmsg = cmsg_compat_nxthdr(kmsg, ucmsg, ucmlen);
}
[…]
if(kcmlen > stackbuf_size) [5]
kcmsg_base = kcmsg = kmalloc(kcmlen, GFP_KERNEL);
[…]
while(ucmsg != NULL) {
__get_user(ucmlen, &ucmsg->cmsg_len); [6]
tmp = ((ucmlen - CMSG_COMPAT_ALIGN(sizeof(*ucmsg))) +
CMSG_ALIGN(sizeof(struct cmsghdr)));
kcmsg->cmsg_len = tmp;
__get_user(kcmsg->cmsg_level, &ucmsg->cmsg_level);
__get_user(kcmsg->cmsg_type, &ucmsg->cmsg_type);
/* Copy over the data. */
if(copy_from_user(CMSG_DATA(kcmsg), [7]
CMSG_COMPAT_DATA(ucmsg),
(ucmlen -
CMSG_COMPAT_ALIGN(sizeof(*ucmsg)))))
goto out_free_efault;
As you can see from the preceding code, the length (ucmsg->cmsg_len) of a user-land buffer is copied in the kernel address space at [2], and again at [6] by the get_user() function. This value is then used to calculate the exact size [4] of the kernel-land buffer kcmsg, originally saved on the stack [1] (stackbuf is just a pointer to some allocated stack space of size stackbuf_size). To prevent an overflow, checks are performed at [3]. Later, however, after the exact space has been allocated at [5] (either the preallocated stack is used or some space on the heap is reserved), the length value is copied in again [6] and is used, with fewer sanitizing checks, to perform the final copy of the user-land buffer at [7].
In a normal situation, this code would work just fine, but what happens if, between the first [2] and second [6] instances of get_user(), another thread is scheduled on the CPU and the user-land value is modified? Of course, the value could be increased just enough to lead to a memory overflow. This is an example of a race condition in which the first actor (the kernel path) attempts to perform an action (copy the user-land buffer) while the second actor tries to change the length of the buffer between the two times the value containing the size of the buffer is evaluated. We said this bug is among our favorites, and here is another reason why: It not only shows a typical race condition situation, but it also can be turned into a heap overflow or a stack overflow at will. In fact, the way the buffer will be allocated depends on the first value of the user-controlled ucmsg->cmsg_len variable. Without dwelling on the details of exploitation, it is important to point out that this bug is exploitable on UP systems as well, and that all you need is a way to make the preceding path sleep (and, thus, relinquish the CPU). Obviously, not all kernel functions/paths can be forced into such a situation, but as you will learn in the rest of this book (and in Chapter 3 in particular), functions that deal with memory (and thus can trigger demand paging) generally can be (e.g., by waiting for the disk I/O if the requested page had been swapped out).
The second vulnerability we will discuss is a beauty that affected the Linux page fault handler. You can find a detailed discussion of the issue and the exploitation approach on the iSEC Web site (www.isec.pl); as is the case with the iSEC's other kernel advisories (especially the ones on issues regarding virtual memory), it is a very interesting read. Here is the code:
down_read(&mm->mmap_sem);
vma = find_vma(mm, address);
if (!vma) [1]
goto bad_area;
if (vma->vm_start <= address) [2]
goto good_area;
if (!(vma->vm_flags & VM_GROWSDOWN)) [3]
goto bad_area;
if (error_code & 4) {
/*
* accessing the stack below %esp is always a bug.
* The "+ 32" is there due to some instructions (like
* pusha) doing post-decrement on the stack and that
* doesn't show up until later..
*/
if (address + 32 < regs->esp)
goto bad_area;
}
if (expand_stack(vma, address)) [4]
goto bad_area;
At first, you might think this code looks a bit cryptic, especially because it requires some knowledge of Linux virtual memory internals, but don't worry: in Chapter 4 we will go into all the gory details. For now, consider vma [1] as a representation, from a kernel perspective, of a range of consecutive virtual memory addresses owned by a user-land process and delimited by vm_start and vm_end. VM_GROWSDOWN [3] is a flag that can be assigned to a virtual memory range to specify that it is or behaves like a stack, which means it grows downward, from higher addresses to lower ones. Anytime a user attempts to access a page below the virtual memory area limit [2], the kernel tries to expand the area via expand_stack(). Now, let's consider two threads that share a common VM_GROWSDOWN area that is limited, for example, at 0x104000, and that enter into this path at the same time. Also, assume that the first thread attempts to access an address between 0x104000 and 0x104000 – PAGE_SIZE (0x1000), as is common for an area that grows downward (that accesses the next address after the limit), while the second thread attempts to access an address in the next page, that is, between 0x103000 (0x104000 – PAGE_SIZE) and 0x103000 – PAGE_SIZE, as shown in Figure 2.1.

Figure 2.1 Two threads racing to expand a common VM_GROWSDOWN area.
Now, let's say the first thread gets up past the check at [2] and is scheduled off the CPU before expand_stack(), and the second thread manages to get all the way down to a successful expand_stack(). As a result, this function will be called twice, and in both cases it extends the vma->vm_start address accordingly. As you can see in Figures 2.2 and 2.3, as soon as the second call to expand_stack() completes, it decreases the vma->vm_start to end at 0x103000. Since page tables have been allocated to cover the fault, a set of pages are allocated inside the process page tables that are not covered by any vma; in other words, the kernel has lost track of them.

Figure 2.2 Intermediate memory layout when thread B succeeds.
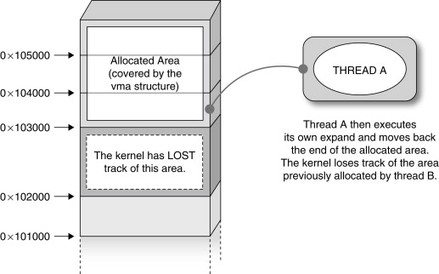
Figure 2.3 Final memory layout once thread A is also complete.
This is enough of a condition to successfully exploit the bug, but we will not go into more detail here, since our purpose was to show where the race was occurring. It is worth pointing out, however, that the race window is very small and that the two threads (from our earlier explanation) need to be executing concurrently, which, as we stated, is a condition that can occur only on SMP systems.
Tools & Traps…
You Think You Found a Race Condition…
…but you are not managing to trigger it. Race conditions can be pretty nasty to trigger, especially when the window is very small. Moreover, if many subsystems and locks are involved, it is easy to misjudge a path as potentially racy or vice versa. This can lead to some wasted time and frustration. It would be very useful to be able to test if the race condition really exists. If you are lucky enough to be on a system that provides the DTrace dynamic tracing framework12 (OpenSolaris/Solaris and Mac OS X at the time of this writing), you may find an ally in the chill() function, which is designed to stop for the specified number of nanoseconds the targeted kernel function (which, thanks to the fbt provider, basically means almost anywhere in the kernel). That will allow you to expand the window to trigger race for testing (with some caveats, as explained in the DTrace manual).
Logic Bugs (a.k.a. the Bug Grab Bag)
Logic bugs are a pretty large class of bugs and they are complicated to model. In fact, some people would argue that, typos excluded, all bugs can be defined logically. A less extreme point of view would at least include race conditions as a subtype of logic bugs. We agree with that point of view, but due to the importance of race conditions, we gave them their own section. In this section, we provide an overview of bug types that are too specific for a generic class, but are nonetheless particularly interesting. Get ready for a bit of variety.
Reference Counter Overflow
The obvious goal of a kernel subsystem is to have consumers. Each consumer will have a demand for resources that need to be allocated and freed. Sometimes the same resource will be allocated, with a larger or smaller number of constraints, to different consumers, thereby becoming a shared resource. Examples of shared resources are everywhere on the system: shared memory, shared libraries (.so in the UNIX world and .dll in the Windows world), open directory handles, file descriptors, and so on.
Allocating a resource occupies space in the kernel memory to store a description (a struct in C) of it, and this space must be freed correctly when the consumer is finished with it. Just imagine what would happen if the system could keep allocating a new structure for each file that is opened and forgets to free/release it each time it is closed. The whole operating system would quickly be brought to its knees. Therefore, resources must be freed, but in the case of shared resources, this has to be done when the last reference is closed. Reference counters solve this problem, by keeping track of the number of users that own the specific resource.
Operating systems usually provide get and put/drop functions to transparently deal with reference counters: a get will increment a reference of an already allocated resource (or it will allocate one if it's the first occurrence), and a put/drop will just decrement the reference and release the resource if the counter drops to 0. With that in mind, take a look at the following path,13 taken from the FreeBSD 5.0 kernel:
int fpathconf(td, uap)
struct thread *td;
register struct fpathconf_args *uap;
{
struct file *fp;
struct vnode *vp;
int error;
if ((error = fget(td, uap->fd, &fp)) != 0) [1]
return (error);
[…]
switch (fp->f_type) {
case DTYPE_PIPE:
case DTYPE_SOCKET:
if (uap->name != _PC_PIPE_BUF)
return (EINVAL); [2]
p->p_retval[0] = PIPE_BUF;
error = 0;
break;
[…]
out:
fdrop(fp, td); [3]
return (error);
}
The fpathconf() system call is used to retrieve information about a specific open file descriptor. Obviously, during the lifetime of the call, the kernel must ensure that the associated file structure is not cleared. This is achieved by getting a reference to the file descriptor structure via fget() at [1]. A subsequent fdrop() will be executed at [3] on exit (or on some error condition). Unfortunately, the code at [2] returns directly, without releasing the associated reference counter. This means that on that specific error condition, the reference counter associated to the fd will not be decremented. By continuously calling the fpathconf() system call on the same fd and generating the error condition at [2] (note that both uap->name and the type of the file descriptor, decided at open() time, are user-controlled), it is possible to overflow the reference counter (which, in this case, was an unsigned integer). This logic bug thus leads to an integer overflow, which in turn can lead to a variety of situations.
A good thing about operating systems (and computers in general) is that they tend to do exactly what you tell them to do. By overflowing the counter and making it go back to 0, and by making a successful fget()/fdrop() pair of calls, the file descriptor structure will be freed, but we will still have many pointers to the now-empty structure under our control. This can lead to NULL/trashed pointer dereference (if, for example, we attempt to close one of the other descriptors). Alternatively, it can be logically exploited thanks to the fact that kernel structures, once freed, will be reallocated in a future call and it is generally possible, depending on the subsystem, to control where this occurs. This is usually another common (and probably more logical in style) path for this kind of vulnerability.
Physical Device Input Validation
Another mandatory operating system task is management of physical devices. This is usually achieved through device drivers. Supporting a large number of devices is a goal for an operating system that aims to be successful. Moreover, if the operating system's target is the desktop user, a lot of effort has to be made to support the large number of external, portable, and pluggable devices that are available today. One technology that has greatly simplified the life of desktop users is Plug and Play or hotplug technology (which means a device can be attached at any time during the lifetime of the machine and it will be activated), accompanied by auto-detection (the device will be recognized, the proper driver will be loaded, and it will be “automagically” usable immediately).
Of course, hardware devices can be hacked or modified. If a specific driver is not ready for some unexpected behavior, this could result in a successful compromise by the attacker. Hardware hacking is well beyond the scope of this book, and obviously it requires physical access to the machine (which is not an entirely unlikely scenario, if you consider libraries or universities), but we thought it would be interesting to mention it. Moreover, there have already been examples of command execution based on hardware properties and device interaction. A very simple and widespread example is the ability, on Windows, to run user-controlled commands after attaching a USB device to the machine.
Kernel-Generated User-Land Vulnerabilities
The next bug type that we have placed in our imaginary grab bag embraces all the vulnerabilities that arise from the interaction between the kernel and some user-mode helper program. In fact, in modern kernels, it is not uncommon (we could actually say it is a growing trend) to offload some tasks to a user-land application.
Note
To some extent, we could consider the aforementioned USB-related vulnerability as part of this category too, but we want to focus our attention here on software-related issues, emphasizing those involving some protocol used to communicate between the kernel and the user-land application.
This approach has a couple of advantages:
-
Code running in user land is subject to fewer constraints than code running in kernel land (the code has its own address space, can sleep freely, can rely on user-land memory allocators, can use the stack as much as it wants, etc.).
-
Code in user land runs at a lower privilege from an architecture point of view, and can drop its privileges (from an operating system point of view).
-
Errors in user-land code are not fatal for the system.
-
Code under a specific license running in user land can (with caveats) be ported or incorporated into another operating system without tainting the license under which the kernel is released.
To simplify the communication between user land and kernel land, many operating systems implement some sort of dedicated protocol for the communication. This is the case, for example, with Linux netlink sockets and OpenSolaris kernel/user-land doors. The communication is usually event-based: the user-land program acts as a dispatcher to one or more consumers of the events the kernel pushes down. Examples of this are udevd on Linux and syseventd on OpenSolaris. Both of these interprocess communications (IPC) mechanisms—netlink sockets and doors—are not limited to kernel-to-user (and vice versa) communication; they can also be used for user-to-user communication.
Since these user-land daemons interact directly with the kernel, it is important to protect them correctly (in terms of privileges), and at the same time it is important to guarantee that no one can get in between the communication, impersonating one of the two parties. This last requirement was originally improperly designed in the Linux udevd implementation, as shown in the following code:14
struct udev_monitor {
struct udev *udev;
int refcount;
int sock;
struct sockaddr_nl snl; [1]
struct sockaddr_un sun;
socklen_t addrlen;
};
[…]
int udev_monitor_enable_receiving(struct udev_monitor *udev_monitor)
{
int err;
[…]
if (udev_monitor->snl.nl_family != 0) { [2]
err = bind(udev_monitor->sock, (struct sockaddr *)
&udev_monitor->snl, sizeof(struct sockaddr_nl));
if (err < 0) {
err(udev_monitor->udev, "bind failed: %m ");
return err;
}
} else if (udev_monitor->sun.sun_family != 0) { [3]
[…]
/* enable receiving of the sender credentials */
setsockopt(udev_monitor->sock, SOL_SOCKET, [4]
SO_PASSCRED, &on, sizeof(on));
[…]
}
[…]
struct udev_device *udev_monitor_receive_device(struct udev_monitor *udev_monitor)
{
[…]
if (udev_monitor->sun.sun_family != 0) { [5]
struct cmsghdr *cmsg = CMSG_FIRSTHDR(&smsg);
struct ucred *cred = (struct ucred *)CMSG_DATA (cmsg);
if (cmsg == NULL || cmsg->cmsg_type != SCM_CREDENTIALS) {
info(udev_monitor->udev, "no sender credentials received, message ignored");
return NULL;
}
if (cred->uid != 0) {
info(udev_monitor->udev, "sender uid=%d, message ignored", cred->uid);
return NULL;
}
}
[…]
udev_device = device_new(udev_monitor->udev); [6]
if (udev_device == NULL) {
return NULL;
}
Actually, more than one issue was found with the udevd code, but we will focus on the most interesting one: a faulty architectural design. As shown at [1], [2], and [3] in the preceding code, the udevd daemon can receive sockets of type AF_NETLINK and AF_UNIX (the local UNIX socket, also used for IPC but only at the user-to-user level). The function udev_monitor_enable_receiving() sets up the receiving end of the socket. As you can see at [4], for the AF_UNIX type of socket [3], the code enables the receipt of sender credentials, to later check, in [5], if root is sending a message. On the other hand, for AF_NETLINK sockets [3], no such credential-checking system is put in place. In other words, whatever message arrives on that socket would be implicitly trusted by the application, and whatever command is inside that message will be parsed and executed (as we show, for example, at [6]).
Unfortunately, it turned out that it was not very complicated to send a message, as a regular user, to the udevd netlink socket. Whereas multicast (one-to-many) sockets are reserved for root only, unicast (one-to-one) sockets are not. The only thing that is required is the correct destination, which, for this type of socket, is the pid of the process. Although ps might have been enough to find it, that pid is actually stored in /proc/net/netlink, making the job of the exploit developer even easier. This vulnerability was exploited in a variety of ways and allowed an immediate root on nearly all the major Linux distributions, almost bypassing all kernel security patches that were in place.
This vulnerability is a classic example of the design flaws we mentioned at the beginning of this chapter. It does not (and would not) matter if the daemon is (was) written in C++, Python, or Java instead of plain C. The vulnerability would still be there. In other words, the flaw stays at a higher level; it is incidental to the architecture.
Summary
In this chapter, we discussed various different vulnerability classes that may affect an operating system. We took a bottom-up approach, starting with vulnerabilities related to the dereferencing of an uninitialized, trashed, or improperly sanitized pointer. This kind of issue can, and usually does, lead directly to a successful exploitation, as you will see in Chapter 3. We also discussed memory corruption vulnerabilities, which we divided into two major categories: stack corruption and heap corruption. In most cases, a memory corruption will lead to a corrupted pointer that will then be dereferenced.
Next, we discussed integer issues, a group of vulnerabilities that depend on incorrect use of or operations on numbers. This kind of vulnerability can be pretty subtle and has extensively plagued nearly all versions of modern operating systems today. Integer issues are not exploitable per se, but integers are generally used in memory operations. Again, our issue will generate another issue (memory corruption, most likely) and yet again we are down to a wrong dereference or memory usage.
Integer issues are the last vulnerability class that is relatively easy to model. After we discussed integer issues, we talked about logic bugs and race conditions. The basic idea behind race conditions is that a correct kernel path can lead to incorrect/exploitable results whenever more than one thread gets to execute it at the same time. In other words, race conditions expose a flaw in the locking/synchronization design of specific code. The key point in race conditions is the size of the raceable window, which puts a constraint on how easily the race condition can be triggered. For that reason, some race conditions can be exploited only on SMP systems.
Despite the fact that they are widespread, race conditions are not the only example of logic bugs. Nearly any other bug that we were not able to successfully include in any of the presented classes ends up being part of the logic bug category. In this chapter, we discussed three examples: reference counter overflows, physical-device-generated bugs, and the particularly interesting category of kernel-generated user-land helper vulnerabilities which, given today's trend of offloading increasingly more duties from kernel-land to user-land applications, might be particularly hot in the coming years.
Endnotes
1. Van Sprundel I, 2005. Bluetooth, http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2005-0750.
2. ISO/IEC 9899:TC2. 2005. Committee draft, www.open-std.org/JTC1/SC22/wg14/www/docs/n1124.pdf [accessed 06.05.05].
3. FreeBSD uninitialized pointer usage, 2009. www.jp.freebsd.org/cgi/query-pr.cgi?pr=kern/138657.
4. Purczynski W, 2008. Linux vmsplice vulnerability, www.isec.pl/vulnerabilities/isec-0026-vmsplice_to_kernel.txt.
5. Bonwick J, 1994. The slab allocator: an object-caching kernel memory allocator, www.usenix.org/publications/library/proceedings/bos94/full_papers/bonwick.a.
6. Klein T, 2009. Sun Solaris aio_suspend() kernel integer overflow vulnerability, www.trapkit.de/advisories/TKADV2009-001.txt.
7. Balestra F, Branco RR, 2009. FreeBSD/NetBSD/TrustedBSD*/DragonFlyBSD/MidnightBSD all versions FireWire IOCTL kernel integer overflow information disclousure, www.kernelhacking.com/bsdadv1.txt [accessed 15.11.06].
8. Seacord RC, 2008. The CERT C secure coding standard. Addison-Wesley.
9. Starzetz P, 2005. Linux kernel uselib() privilege elevation, www.isec.pl/vulnerabilities/isec-0021-uselib.txt [accessed 07.01.05].
10. Starzetz P, 2005. Linux kernel i386 SMP page fault handler privilege escalation, www.isec.pl/vulnerabilities/isec-0022-pagefault.txt [accessed 12.01.05].
11. Alexander V, 2005. Linux kernel sendmsg local buffer overflow, www.securityfocus.com/bid/14785.
12. Sun Microsystems. Solaris dynamic tracing guide, http://docs.sun.com/app/docs/doc/817-6223.
13. Pol J, 2003. File descriptor leak in fpathconf, http://security.freebsd.org/advisories/FreeBSD-SA-02:44.filedesc.asc [accessed 07.01.03].
14. Krahmer S, 2009. Linux udev trickery, http://c-skills.blogspot.com/2009/04/udev-trickery-cve-2009-1185-and-cve.html.