
Let's understand the RL key terms—agent, environment, state, policy, reward, and penalty—with our pet dog training analogy:
- Our pet dog, Santy, is the agent that is exposed to the environment.
- The environment is a house or play area, depending on what we want to teach to Santy.
- Each situation encountered is called the state. For example, Santy crawling under the bed or running can be interpreted as states.
- Santy, the agent, reacts by performing actions to change from one state to another.
- After changes in states, we give the agent either a reward or a penalty, depending on the action that is performed.
- The policy refers to the strategy of choosing an action for finding better outcomes.
Now that we understand each of the RL terms, let's define the terms more formally and visualize the agent's behavior in the diagram that follows:
- States: The complete description of the world is known as the states. We do not abstract any information that is present in the world. States can be a position, a constant, or a dynamic. States are generally recorded in arrays, matrices, or higher order tensors.
- Actions: The environment generally defines the possible actions; that is, different environments lead to different actions, based on the agent. The valid actions for an agent are recorded in a space called an action space. The possible valid actions in an environment are finite in number.
- Environment: This is the space where the agent lives and with which the agent interacts. For different types of environments, we use different rewards and policies.
- Reward and return: The reward function is the one that must be kept track of at all times in RL. It plays a vital role in tuning, optimizing the algorithm, and stopping the training of the algorithm. The reward is computed based on the current state of the world, the action just taken, and the next state of the world.
- Policies: A policy in RL is a rule that's used by an agent for choosing the next action; the policy is also known as the agent's brain.
Take a look at the following flowchart to understand the process better:
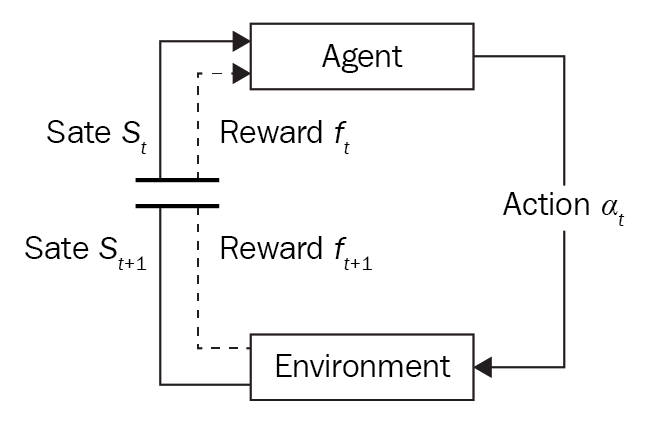
Agent behavior in RL
At each step, t, the agent performs the following tasks:
- Executes action at
- Receives observation st
- Receives scalar reward rt
The environment implements the following tasks:
- Changes upon action at
- Emits observation st+1
- Emits scalar reward rt+1
Time step t is incremented after each iteration.