
Chapter 2: Incident Response – A Key Capability in Security Operations
It is quite common during incident response to find that the indicators of an attack were there long before an incident was declared. It is also a fact that the dwell time of attackers in a victim environment can be in the order of months. Organizations are attempting to keep attackers out, but they don't seem to be succeeding.
In this chapter, I will argue that this is because organizations are not adapting to an assumption of compromise. An assumption of compromise is the result of the realization that adversaries can stay undetected for a long time, and hence it is likely that at any point in time, a part of the network is compromised or under an attack that has not yet been detected. Even in cases where an assumed compromise philosophy is adopted, the necessary lessons are not always learned: assumed compromise involves developing a continuous and advanced process of incident response, where a normal state of no incident is becoming ever rarer.
The key lesson of an assumed compromise state is that organizations are also finding themselves in a state of continuous incident response. That is the key reason why incident response is the key capability of security operations.
In the previous chapter, we discussed the four key objectives of security operations:
- Minimize attacker dwell time to the point where attackers are incapable of achieving their objectives.
- Limit lateral movement of attackers in the network.
- Prevent re-entry into the network after the closure of an incident.
- Understand attacker motivation and capabilities.
The philosophy of assumed compromise takes these objectives to the rest of security operations.
This is not how organizations usually do incident response. The best practice recommendation is that incident response should follow the incident response cycle, a structured way to resolve large-scale breaches and incidents. In this chapter, I will extend the incident response cycle to illustrate how incident response practices can and must evolve to meet the conditions of assumed compromise.
Predictable and repeatable execution of the four capabilities that make up incident response is the key to robust and predictable security operations. Beyond this point, all other elements that make up security operations are in support of this goal.
In this chapter, we will discuss what an incident response capability based on an assumed compromise philosophy looks like.
Specifically, in this chapter we will focus on the following:
- The incident response cycle and the attack kill chain
- Why agile is a good model for incident response
- How to extend to incident response cycle to include agile security operations
- How to learn from incidents and drive continuous improvement
The chapter is structured in the following way:
- Facing up to breaches
- Knowing an incident – detection and analysis
- Branches and pivots – how incidents change
- Agile incident response
- Learning from incidents – from resolution to tactics to strategy
Facing up to breaches
Organizations should have a plan for dealing with security incidents. The incident response cycle is a structured template for developing and maintaining such a plan, and it is also a good place to start our discussion of agile security operations.
The incident response cycle, which will form an important aspect of agile security operations, is depicted in the following figure:

Figure 2.1 – The incident response cycle with the identification stage split into detection and analysis steps
The incident response cycle describes a process for handling incidents in several separate steps. Somewhat dependent on the organization, the incident response cycle can take several forms and may involve a somewhat different set of steps.
We will first discuss the background to the incident response cycle. In the following sections, we will briefly discuss the NIST incident response cycle and the SANS incident response cycle.
The incident response cycle
Incident handling follows the structured processes of the incident response cycle. Incident response cycles are particularly suited to dealing with large-scale, one-off incidents. Notable varieties of the incident response cycle have been developed by SANS and NIST.
The NIST incident response cycle
The National Institute for Standards and Technology (NIST) has published a 4-step incident response process that is like SANS, but has the containment, eradication, and recovery steps as a single step. The process is available as the NIST 800-61 standard. It is available here: https://www.nist.gov/privacy-framework/nist-sp-800-61.
The following diagram is a representation of the NIST cycle:

Figure 2.2 – The NIST incident response cycle
The NIST incident response cycle consists of the following steps:
- Preparation: The preparation stage involves getting ready to handle an incident, as well as taking the necessary steps to prevent attacks on the system from becoming successful.
- Detection and analysis: The SANS model for incident response recommends that organizations understand their attack vectors and develop playbooks for handling these types of incidents.
- Containment, eradication, and recovery: This set of activities focuses first on making sure that an incident does not overwhelm the capability of defenders through containment of the incident. Eradication and recovery focus on how organizations evict the attackers and recover their systems. In the SANS model, there is a mini cycle that flows back from this stage to the detection and analysis stage to indicate that during containment and eradication, further analysis and detection may be required. This stage also contains a focus on forensic data preservation.
- Post-incident activity: This step contains a review process that allows an organization to document an incident, do no-blame reviews, and document lessons that were learned. Incidents can also be evaluated using the metrics discussed in the following section.
The documentation of the NIST incident response cycle is comprehensive and contains a large amount of documented best practices in handling computer incidents.
An important feature of the NIST incident response cycle is the inner loop between the detect and analyze step and the contain, eradicate, and recover phase. The activities that teams perform in this inner loop will be discussed in more detail in Chapter 6, Active Defense.
Metrics for incident response
The NIST guide also develops a set of metrics to measure the effectiveness of the incident response process. In Chapter 7, How Secure Are You? – Measuring Security Posture, we will focus on the topic of security metrics.
The SANS incident response cycle
As a brief alternative, we'll look at the SANS incident response cycle. The SANS institute provides a large amount of information security research, training, and online resources to practitioners. The SANS incident response cycle forms part of their course on hacker techniques and training (SANS 504) and is available in the Incident Handlers Handbook: https://www.sans.org/reading-room/whitepapers/incident/incident-handlers-handbook-33901. There is a cheat sheet here: https://www.sans.org/cyber-security-courses/hacker-techniques-exploits-incident-handling/.
The SANS incident response cycle consists of six steps:
- Preparation: In the preparation stage, organizations ensure that they have an incident response plan and the necessary policies, develop the team structure for incident response, and define the triage system for security incidents, as well as the processes for each category of incident. This stage also includes the introduction of tooling and training.
- Identification: In the identification phase, an incident is identified and triaged, and the processes defined in the previous step are started.
- Containment: In the containment phase, defenders ensure that an attacker cannot do more damage by isolating the incident in the affected systems and preventing further spread.
- Eradication: This stage focuses on the removal of the attacker from the network by removing malicious artifacts, rebuilding systems where this is necessary, and ensuring that the access routes of the attacker into the infrastructure are blocked.
- Recovery: This stage focuses on the activities that will bring the organization back to its pre-incident state.
- Lessons learned: The focus here is on what the organization can do to prevent a reoccurrence of the attack, points of improvement in the process of handling incidents, and documenting the incident for future reference.
The SANS process maps closely to the NIST process, and organizations can equally well use either of the two. In some cases, requirements may be determined by compliance regimes or the cyber insurer.
How to use the incident response cycle
At each stage of the incident response cycle, a security team must have developed and deployed a set of practices that will allow it to function at its best. As an example, in the preparation stage, it is important that a team defines and documents the policies that will allow it to operate during an incident – the systems they will have to access to allow them to collect data on an incident, under what conditions the team can get that access, any necessary change controls, business owners, and the monitoring that is already in place.
Similarly, for the collection of data, a team should know what tooling to use and how to use that tooling. If necessary, prepare a jump bag.
The value of the incident response cycle to the business is that it allows you to think through an incident in advance, define what is required, and then ensure that the necessary components are developed, implemented, and maintained. It also assists with planning the phases and ensuring that organizations do not move to remediation too quickly, destroying evidence and information about the attack in the process.
Knowing an incident – detection and analysis
In this section, I will work primarily from the SANS incident response process but will divide the identification step into two separate steps – detection and analysis. This is because detection and analysis are two different engineering activities that are better separated once we center incident response as the core security practice and assume a state of perpetual compromise.
In a state of assumed compromise, it is vital that you know when to call an incident and how to analyze and respond to it. Detection and analysis are the two key activities:
- Detection focuses on how security teams detect that an incident may be occurring.
- Analysis focuses on whether an incident is occurring and what the severity of it is.
Detection engineering
Detecting incidents can happen in several ways. As an example, teams may monitor logs, antivirus, and network events, and the combination of these events determines that a security event is occurring. A Security Information and Event Management (SIEM) system may be used to automate collecting events from different sources and collate them to determine if an event has occurred through a detection engine.
SIEM
The definition of the SIEM in the Gartner IT Glossary reads, in part, "SIEM technology aggregates event data produced by security devices, network infrastructure, systems and applications. The primary data source is log data, but SIEM technology can also process other forms of data, such as network telemetry. Event data is combined with contextual information about users, assets, threats and vulnerabilities."
https://www.gartner.com/en/information-technology/glossary/security-information-event-management
A SIEM will generally use correlation rules to determine whether an incident has occurred, and the quality and review of such correlation rules is a key determinant of the value of the SIEM to organizations.
Detection engineering takes this a step further and deploys detections as code, taking the context of the business into account.
The problem with many logging tools, standard SIEMs, and security tools is that they generate a firehose of data, events, and alerts that need to be triaged, analyzed, put in a ticketing system, and reported, leading to analyst burnout, and increasing the chances that important alerts are missed. The firehose of data has poor quality control.
It is worth spending a small amount of time considering what quality control of an alert stream is. The following table summarizes the possible outcomes of an alert system in a four-by-four matrix, determined by whether an alert was generated or not, and whether the alert was true or false.

Figure 2.3 – The four-by-four matrix of detection possibilities and consequences
Many teams generate a lot of data through their tools but struggle to make sense of it—they are overwhelmed by false positives and lack of context. Attackers take advantage of this situation by aiming to develop techniques that evade simple detection mechanisms.
Detection engineering focuses on remediating this problem. It consists of the following high-level activities:
- Develop and maintain custom code that merges known and observed security intrusions with business and data context to be able to detect attacks on the organization.
- Work with analysts and engineers from the security team to turn data from past investigations into actionable detections.
- Work with architects, process, and data owners to develop new opportunities for detection of malicious activity, such as process abuse or specific threats to infrastructure (this is discussed in more detail in Chapter 5, Defensible Architecture).
- Develop and categorize proactive and reactive controls.
- Quality monitoring of detections: focus on the number of false positives, false negatives, true positives, and true negatives. Generally, the purpose is to decrease the number of false positives and false negatives and increase the number of true positives.
- Reduce the number of low-level alerts to fewer high-fidelity ones.
Enterprise detection
Enterprise detection relies on the practice of detection engineering as a systematic discipline that follows a structured process to use the data generated by monitoring and logging systems. See https://www.sans.org/reading-room/whitepapers/analyst/detecting-malicious-activity-large-enterprises-39795.
The detection engineering process, which will be discussed in more detail at various places in this book, is depicted in Figure 2.2. The analysis that is performed by the analyst can be based on a past incident, potential threats to an existing business process, or a quality improvement in an existing detection (which is then versioned in the repository).
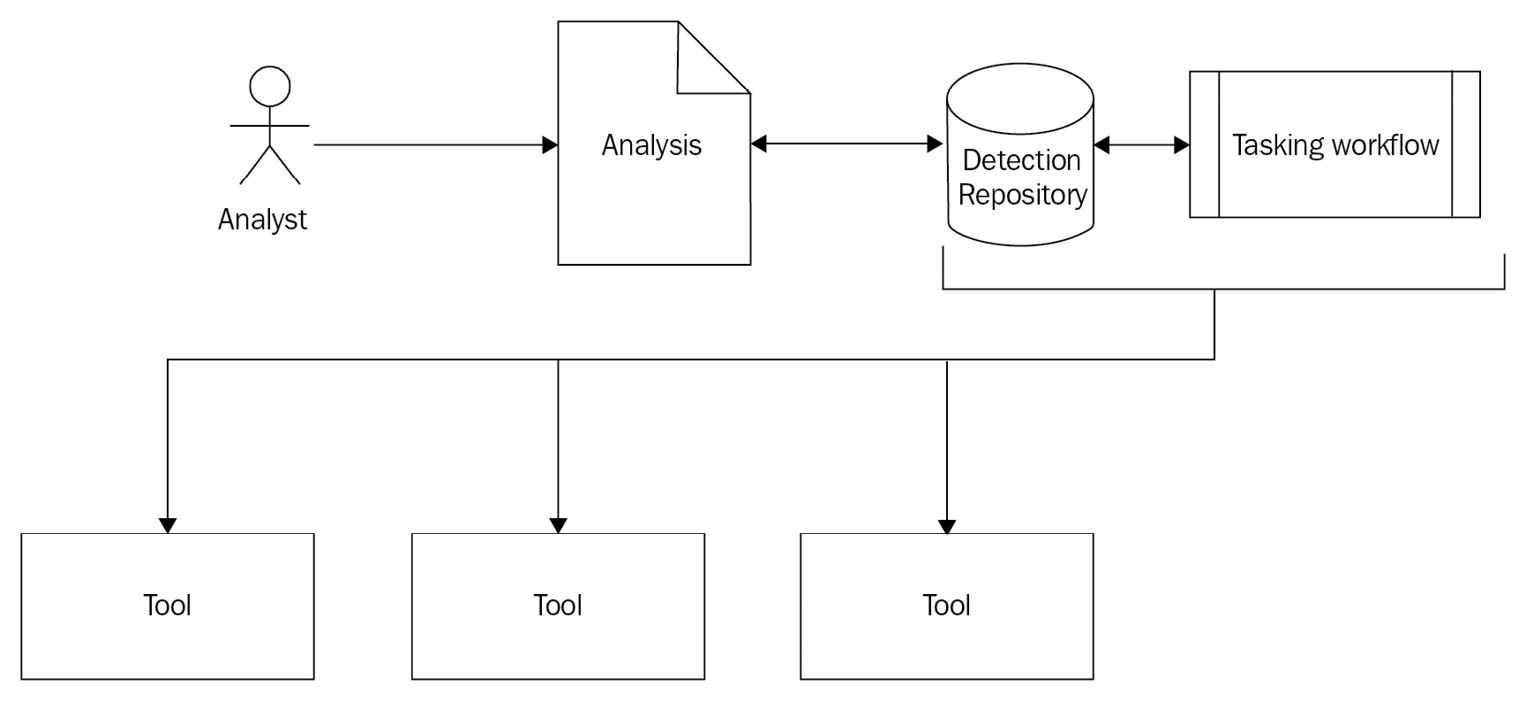
Figure 2.4 – The detection engineering process
Contributions to the detection engineering process can come from a variety of sources, such as the following:
- Subscriptions from commercial or open source feeds such as signatures and SIEM rulesets
- Previous or current incidents, especially if these have been captured in the form of tactics, techniques, and procedures (TTPs)
- External sources such as security news sites or blog posts with details of currently ongoing attacks
- Cyber threat intelligence sources (see Chapter 10, Implementing Agile Threat Intelligence)
Not all information about breaches needs to come from security infrastructure. Sometimes it is possible to re-purpose other logs in a security context.
Repurposing
Sometimes, already existing infrastructure tells you about breaches, even if it was not intended to do so. An example is, for instance, web server logs, which are sometimes used by developers to troubleshoot websites, but also contain a wealth of information that is useful in a security context. It is important that teams do not overlook the value that this data can bring.
Analyzing threats
After a threat is detected, it must be analyzed. Analysis, in the context of continuous compromise, uses forensic techniques to collect, collate, and contextualize data, and report on the findings.
Analysis consists of the following high-level activities:
- Collection of data is the process of using tools to collect the data that is necessary for the analysis from the affected system. Examples include memory collection, log file analysis, querying the system with tools such as OSQuery or Velociraptor, and disk imaging. Care must be taken that collection tools are forensically sound.
- Collation of data is combining the collected data into a single repository so that it can be searched and systematically analyzed. For log data, it is preferable to use a NoSQL platform, such as Splunk or ELK, to do this.
- Contextualizing refers to adding the necessary business and IT context to the data.
- Reporting is the process of capturing the findings. This does not need to be an official report, but it is important that teams capture the activities, assumptions, findings, and anything else worth noting down about an incident.
Analysis is not a linear process, but it may involve moving back from context to detection.
Branches and pivots – how incidents change
The incident response cycle is not necessarily linear. Even as we are handling an incident, the incident itself may change because the attacker moves from one system to another, or because the defenders discover additional areas of compromise related to the same attacker.
The evolution of cyber incidents is described in the kill chain, a model for how a cyber-attack develops.
The kill chain is a model for the evolution of a cyber-attack, not a prescriptive recipe for how an attacker should attack. Hence, attackers do not necessarily follow the kill chain. An especially important part of attacker movement is lateral movement, which is discussed toward the end of this section.
The kill chain model
The kill chain model was originally developed by Lockheed Martin to describe the development of a cyber-attack, especially by an advanced persistent threat actor using multi-stage attacks with targeted malware and remote-control components. The kill chain is a model for how cyber-attacks evolve; its purpose is to help defenders define and execute defensive actions at each stage of the chain.
Note
The term Cyber kill chain™ is trademarked by Lockheed Martin. In the following sections, we'll use the term kill chain model to denote the kill chain model in a computer security context to avoid the use of a narrowly defined trademarked term.
The kill chain model consists of seven steps:
- In the reconnaissance phase, the attackers gather information on their victim's network, such as IP address ranges, exposed vulnerabilities, DNS names, websites, email servers, and anything else that can be used as an initial vector of compromise.
- Weaponization is the development of the cyber-weapon that will be used in the attack. Weaponization has to involve development of both a delivery mechanism and a payload. For malware or phishing, it may also involve setting up external websites or command and control infrastructure that will be used during the attack.
- Delivery is the delivery of the cyber-weapon to the victim, for instance via email or another mechanism.
- Exploitation consists of achieving a form of code execution on the victim's system, or getting a victim to enter their details in a phishing page..
- Installation covers the installing of the command-and-control and actions-on-objectives pieces of the malware.
- Command and control focuses on remote control of the malware by the attacker, usually through some sort of communication channel.
- Actions on objectives focuses on how the attacker achieves their objectives.
Development of the kill chain model
The kill chain model for cyber-attacks was originally developed by Hutchins, Cloppert, and Amin from Lockheed Martin (https://www.lockheedmartin.com/content/dam/lockheed-martin/rms/documents/cyber/LM-White-Paper-Intel-Driven-Defense.pdf). The purpose of the kill chain is to develop a model that decomposes the actions of adversaries during cyber incidents and then guides defenders to a set of defensive actions at each step of the chain. The aim of defense in the kill chain model is to ensure that attackers do not achieve their objectives.
The kill chain model has developed into several varieties, such as the universal kill chain (Pols) or the ICS kill chain developed by SANS. The universal kill chain model by Pols takes the effects of lateral movement into account and acts as a model of models that aggregates different kill chain models. The universal kill chain takes lateral movement into account by creating loops in the kill chain. A copy of the universal kill chain can be downloaded from here: https://www.csacademy.nl/images/scripties/2018/Paul_Pols_-_The_Unified_Kill_Chain_1.pdf.
The ICS kill chain focuses on an adaptation of the kill chain model. The ICS kill chain whitepaper can be downloaded from here: https://www.sans.org/reading-room/whitepapers/ICS/industrial-control-system-cyber-kill-chain-36297.
There has been a lot of discussion about the exact number of steps in the kill chain, or whether the kill chain model can be used in different types of attack. Ultimately, the aim of the kill chain model is to guide defenders in how to thwart attackers, and while extensive discussion about all the steps is possible, it is not very useful.
The kill chain model was developed to illustrate that defenders have several stages at which they can prevent an attacker from achieving their objectives, and to guide defensive actions for each stage in an attack.
The current trend is that the kill chain model is gradually replaced by the more comprehensive MITRE ATT&CK model, which is based on a model of Tactics, Techniques, and Procedures (TTPs). The tactics in the ATT&CK model roughly match the stages in the kill chain model. This book is based more on the ATT&CK model than on the kill chain. The ATT&CK model will reappear at various stages in later chapters.
Expanding the options for defense
The understanding of cyber incidents is enriched by the kill chain. An awareness of the kill chain changes both the detection and analysis steps in incident response. As we have seen, the kill chain model was developed primarily to allow defenders to determine what defensive options are available to them once they understand the stage to which an attack has progressed. In terms of the incident response cycle, this means that a few things need to be considered in terms of the kill chain, especially detection, analysis, containment, and eradication:
- Detection: Coverage should include all aspects of the kill chain, rather than a single detection. Detection engineering needs to increase the chance that an attack can be picked up at any stage.
- Analysis: In addition to doing the forensic analysis of malicious artifacts, analysis also must consider the stage of the attack on the kill chain.
- One of the ways to determine the available options in the containment and eradication stage is to use one of the many Ds: Detect, Deny, Disrupt, Degrade, Deceive, and Destroy. The eradication stage effectively evicts the attacker from our network.
Considering attacks in the context of kill chain models, together with the variety of defensive options available, leaves a lot of room for defenders. Making the most of those options is the core of active defense, which we will discuss in more detail in Chapter 6, Active Defense.
Lateral movement
The initial point of compromise is rarely the objective of an attacker. Attackers do not necessarily adhere to the linear models for cyber-attacks that are suggested by the kill chain model. In many cases, attackers perform lateral movement in a victim's network, moving from an initial exploit to, for instance, reconnaissance of the infrastructure behind the firewall.
Lateral movement involves attackers moving from point to point in the network, often involving living off the land, or using the toolset that's already available on a compromised endpoint to move laterally. Lateral movement often involves tools such as PowerShell, Command Prompt, or other native administration tooling that is already present on the compromised infrastructure, and their usage is unlikely to trigger signature-driven detection systems.
One of the four objectives of incident response is to limit lateral movement on the network so that attackers will not be able to move between environments. Given that a large proportion of lateral movement involves living off the land, this involves managing permissions and accounts on the network. In Chapter 3, Engineering for Incident Response, we will discuss lateral movement in more detail.
For the purposes of this chapter, the existence and prevalence of lateral movement has important consequences:
- Architecture: Defensible architecture does not rely on hard outer shells, but instead uses, in addition to perimeter controls, detection and analysis capabilities deeper in the network.
- Detection: The techniques used in lateral movement widen the scope of what needs to be detected and need to be explicitly added to the detection framework. A problem is that the volume of traffic inside the network is usually larger than outside the network, meaning that significant capability needs to be deployed inside the network to build the necessary detections.
- Analysis: Living off the land techniques need to be recognized in the analysis step.
- Response: During incident response, an organization needs to slow the lateral movement of attackers. Conversely, the need to move laterally also slows attackers down and may give a (small and temporary) advantage to the defender.
Lateral movement is an important addition to the kill chain that adds new detection and analysis opportunities.
Agile incident response
In the previous chapter, we have argued that security operations are best done in an agile framework. This is even more true for incident response.
Even though cyber incident response is a technical capability, there are some non-technical considerations that are influential in how well organizations respond to and recover from incidents. These considerations also translate into aspects of agile security operations once we come to realize that the consequence of lateral movement is that multiple detection and analysis phases might be carried out to discover and analyze an event in its entirety.
Compromise is eternal
Once incident response becomes the key security capability and the core of security operations, incident response becomes not only a core process, but also a continuous process. The boundary between an incident and a normal situation dissolves, and the organization will manage multiple incidents in a continuous fashion. In this situation, an assumed compromise approach to cybersecurity becomes the norm.
A new philosophy for cybersecurity
The accounting firm PWC published a whitepaper entitled Are you compromised but don't know it in 2011, which outlines some of the key ideas of agile security operations, although they have evolved since then. Among others, this paper introduces the idea of the centrality of incident response because of assumed compromise. The original whitepaper has, to my knowledge, disappeared from the PWC website (although it is available through a search). A slide deck that outlines some of the key points may be found here: https://www.imf-conference.org/imf2014/docs/IMF2014-Assuming%20a%20state%20of%20compromise.pdf.
Many organizations do not define their security posture. By not doing so, they adopt an implicit default posture that somehow assumes that adversaries will never get in.
A posture of assumed compromise changes this assumption and with it changes the security conversation for the better. In this way, it helps security teams focus on the business they are there to protect.
The move from a default posture to assumed compromise quickly leads to a process of explication, clarifying the role of security to the business. This process introduces the somewhat confusing notion of security posture, which we will take up in more detail in Chapter 7, How Secure Are You? – Measuring Security Posture.
The question of acceptable security posture inherently revolves around business questions that cannot be outsourced to third parties, because the answers rely on a deep understanding of the business that outsourcers or consultants usually cannot provide.
To clarify the security posture, organizations must develop and consider the security context around the key business processes rather than systems. Three questions are useful to tease out what the business consequences of a security compromise look like:
- Which processes are key to the survivability of the business? What can we not do without?
- Which components in our system enable these processes?
- What is the business context to threats that the business currently faces in light of the answers to the previous two questions?
Good security leaders have ongoing conversations with the business around what is key now and into the future. Assumed compromise refocuses the security conversation from a fear-based mission impossible to a conversation about the already available security capability, as well as basic environment and system hygiene and visibility. This takes security from mission impossible to doable.
Incidents and compromises
It is useful to sharply distinguish between incidents and compromise.
An incident occurs when the business is down. Generally, in terms of the kill chain, having an incident means that the attackers have managed to achieve their objectives and the defenders have failed in their first objective: ensuring that attackers cannot achieve their objectives.
In comparison to incidents, a compromise is more benign. A compromise generally means that an attacker has managed to gain an initial foothold and is using tactics such as privilege escalation and discovery to try and escape that initial foothold, or move laterally. When we say compromise is eternal, what we are really advocating is eternal vigilance. The activities of attackers trying to escape their initial foothold can be detected and mitigated.
This is also the reason behind the second defender objective: to limit the lateral movement of attackers.
Why incident response needs to be agile
In the previous chapter, we discussed how security operations work better under an agile framework. This is even more so for incident response. Incident response gets the best results when it is approached in an iterative model that can quickly react to changes and anticipates the next step of the intruder in our systems and networks.
Figure 2.3 gives a high-level overview of how the incident response cycle—once lateral movement and iterations in detection, analysis, and containment are considered—maps to an agile framework. This figure is very similar to the inner loop in the NIST framework, with the exception that we are not considering the eradication and recovery part of the inner loop while the NIST framework, which has containment, eradication, and recovery as a single phase, does. This is debatable.
The incident declaration, the start of the process, leads to a series of iterative detect, analyze, and containment steps, which may, due to the lateral movement of an attacker, feed further detections, analysis, and containment.
As we will see in Chapter 6, Active Defense, the inner loop is in operation even in cases where no incident is declared. The main reason for this is that active defense is operative under conditions of incidents as well as compromises.

Figure 2.5 – Agile loops in the incident response process
Incident response does not immediately translate to agile, and the details of an agile incident response process will form the core of the next chapter.
Kanban or Scrum
As we will see in Chapter 3, Engineering for Incident Response, the agile methodology can be based on several underlying frameworks, the main ones being Kanban and Scrum. Scrum tends to be quite prescriptive, and any Scrum-based incident response framework would not be called Scrum but something else. The Kanban principles fit quite well with the process of incident response.
In the next chapter, Chapter 3, Engineering for Incident Response, we will develop a specific framework to manage and engineer for security incidents in an agile fashion.
Team structure for incident response
Incidents are confusing and volatile. This section introduces the key elements.
The team structure for incident response consists of three separate capabilities:
- Operations focuses on the activities of detection, analysis, forensics, and containment, and works together with planning to develop plans for eviction and recovery. Operations teams typically consist of members of the security team working alongside people from operations, development, and subject matter experts from the business.
- Communication focuses on both internal and external communication.
- Planning focuses on developing the plans and steps to best recover from an incident and considers the changes that are necessary to permanently evict attackers before systems are brought back online.
A diagram of the team structure is represented in the following figure:
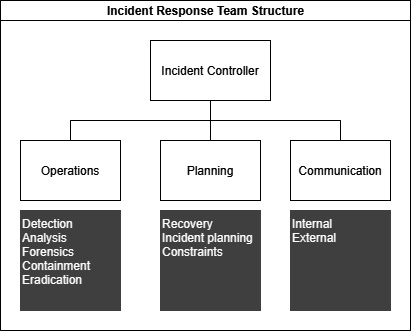
Figure 2.6 – Team structure for incident response teams
The operations team needs detection and forensics capability, while the planning team needs a robust understanding of the business context of an incident. In practice, the operations team is often constructed on the fly, whereas the communication and planning team can be determined beforehand.
Learning from incidents – from resolution to tactics to strategy
A final point we need to consider in this chapter is how organizations may learn from incidents.
Assuming an assumed compromise stance to cyber defense entails that current detected and resolved incidents are the best guide to the threats and risks facing the organization and what to do about them. This is in stark contrast to a model where a cyber defense strategy is prior to capability, and it represents a bottom-up model for strategy, one in which measurable defense activities take precedence over risk assessments and static defense.
The idea is that past incidents will be a guide to the likely future. Once the lessons of a past incident are identified, organizations must develop a strategy to ensure that the lesson is learned, and that tactics and operations change to align with the areas of known most likely threats.
There are, of course, dangers with this approach, the main one being that lack of visibility will lead to incidents going undetected and hence not being considered as a cyber risk to the organization. The bottom-up strategy approach should be accompanied by high-quality detection and analysis to mitigate this risk. What high-quality is in this context is determined by how well the visibility measures of an organization cover the kill chain of cyber-attacks.
Summary
In this chapter, we have laid the groundwork for understanding why incident response is the key security capability under an assumption of continuous compromise. We have adapted the incident response cycle to deal with conditions where security teams are responding to incidents in a continuous manner.
Specifically, this chapter has covered why a philosophy of assumed compromise requires changes to the incident response practice. In the assumed compromise model, incidents are constant and hence incident response becomes a continuous process.
We have discussed the kill chain model for cyber-attacks and argued that the reality of lateral movement implies that the kill chain model must be extended to include lateral movement. Moreover, the reality of lateral movement drives a preference for an agile incident response process.
We have also introduced a model for detection engineering, which we will return to in Chapter 3, Engineering for Incident Response.
We concluded this chapter with a discussion on how to drive a more effective security strategy from the bottom up by specifically developing the business context around our incident stream and translating this into a security posture. We will return to this topic in Chapter 7, How Secure Are You? – Measuring Security Posture.
In the next chapter, we will focus on engineering for incident response, specifically on how all the things we discussed in the previous chapters combine into an overall cyber defense.