
Chapter 11. Refactoring data access
- Isolating data access components
- Understanding data access layers
- Using options for data access
In chapter 8, we talked about the logical layers that are found in most applications. In chapter 10, we discussed one of them: the user interface. In this chapter, we’ll move to the other end of the application: the data access layer (DAL).
The majority of applications need to persist data to a storage medium of some type. As a result, developers continue to spend a large portion of their project budgets writing code to store, retrieve, and manipulate data. The results are the many and varied implementations affectionately known as data access layers.
Most developers have seen almost as many ways to implement a DAL as they’ve seen projects. It seems that everyone has his or her own idea of how to best handle the problem of data persistence. We’ve seen implementations from the simple and naive to the robust and complex. Although each has its own benefits for a project, they all seem to have pitfalls that must be dealt with.
This chapter will explore the data access layer patterns and antipatterns that we (and very likely you) have seen implemented on real-world projects. We’ll stop short of claiming to have a silver bullet solution that you’ll be able to take to work tomorrow and implement with ease and success. Instead, we’ll identify problem areas with data access that you should be aware of and explore techniques that can help you avoid those pitfalls.
11.1. Pain points
Huey stared at the method in a sort of trance. He’d received word from his DBAs that a column name from one of the database tables had to be renamed due to an integration issue with another application. He’d just spent the entire morning looking through various web pages in the application, all of which contained a method similar to listing 11.1.
Listing 11.1. Brownfield sample (read at your own risk)

For a few more minutes, Huey looked at this method, almost willing it to fix itself. He was getting weary making the same
change over and over again. “Whose bright idea was it to embed hardcoded SQL directly in an ASPX page’s code-behind?” ![]() he thought. As it was, he’d already caught himself making a typo in the new column name on one page, a problem he discovered
only by accident after running the application for a spot-check. (“I wish I had time to read chapter 4 in this brownfield book,” he muttered to himself.)
he thought. As it was, he’d already caught himself making a typo in the new column name on one page, a problem he discovered
only by accident after running the application for a spot-check. (“I wish I had time to read chapter 4 in this brownfield book,” he muttered to himself.)
Meanwhile, Lewis was having issues of his own. He’d spent the better part of yesterday afternoon chasing down a bug—the user profile page would no longer update the user’s email address.
Lewis had looked for the logic for several hours in the code before finally going off on a rant to his co-worker, Jackson. After Lewis raged on for about 30 seconds, Jackson interrupted him: “Why are you looking in the code for this? All that’s handled in a stored procedure.”
Lewis calmly returned to his desk and opened the database. After looking through the stored procedures, he finally found the one he needed (listing 11.2).
Listing 11.2. Sample stored procedure

Lewis scanned the stored procedure until he found a commented line ![]() that effectively ignored any updates to the email address. After removing his fist from the monitor, he started asking around
to see who had made the change (because sadly, the stored procedures weren’t included in source control). Apparently, another
team member, Michael, had commented it out temporarily due to another issue (users were providing incorrectly formatted email
addresses).
that effectively ignored any updates to the email address. After removing his fist from the monitor, he started asking around
to see who had made the change (because sadly, the stored procedures weren’t included in source control). Apparently, another
team member, Michael, had commented it out temporarily due to another issue (users were providing incorrectly formatted email
addresses).
These are two of the most infuriating pain points you’ll see in your data access code. In the first case, a seemingly simple change in the backend has had far-reaching effects throughout the UI.
In the second case, the physical and logical separation of business logic adds an enormous amount of friction to the ongoing development and maintenance efforts. Although the argument has been made that more business logic in a stored procedure allows for easier patching of the application, in our experience brownfield applications will regularly feel pain from this approach.
One of the reasons for this pain is the prevalent attitude that changing code in stored procedures won’t break anything. The problem with this sentiment is that very often, you do break something. You just don’t know it until someone runs the application and exercises the stored procedure.
Even more dangerous is the situation where a stored procedure has branching or conditional logic in it that executes different SQL depending on parameters provided to it. The impact of a change—in either the conditional logic or the execution path within one condition—is much harder to determine.
Having confidence in both of these types of changes is difficult at best; yet developers firmly assert that the application will be just fine after making such changes. All it takes is one updated stored procedure without comprehensive prerelease testing, and a system of any size will come crashing to the ground in a fiery heap of finger pointing, accusations, and lost confidence.
Note
A situation like this is not hyperbole. We’ve seen it. If you’re lucky, you won’t. But forgive us for not putting any money on it.
Through the remainder of the chapter, we’ll work to provide you with tools and techniques that can be used to help bring these pains under control. The first step is to make sure your data access is all in one place.
11.2. Isolating your data access
Chapter 8 discussed the concept of logical layers within an application. One of the layers that almost every developer can relate to is the data access layer. The rationale behind creating any logical layer is to separate it so that changes to it will have the smallest impact on other parts of the application. Unfortunately, data access is one area where the impact of change can quickly ripple through an entire application.
Note
By impact of change, we mean the extent to which changes in one area of the application require changes in other areas. If a fundamental change to a feature is required, there’s not much you can do to minimize this risk. But as you gain experience, you’ll learn to recognize when the changes you’re making are because of fundamental feature changes versus badly layered code. To reiterate one of our overarching mantras from part 2 of this book: get rid of any code that causes ripple effects.
If you’ve jumped straight to this chapter, shame on you! Go back to chapter 8 and read about refactoring to logical layers. Before you do anything with your DAL, you must ensure that it’s encapsulated into its own isolated area of the application. The primary reason for encapsulation of the DAL is that you want to effect change without worrying about ripple effects.
For some brownfield applications, getting to a point where there’s an isolated data access layer is going to take some time and effort. But as described in chapter 8, it can be done incrementally one function at a time. Figure 11.1 is adapted from figure 8.9 in that chapter.
Figure 11.1. Initial approach to layering your data access code. As in chapter 8, we refactor in increments.

If you have a highly coupled data access scheme in your brownfield application, the key is to relayer incrementally in small chunks. If you try to isolate and encapsulate the entire DAL at once, you’ll run out of time before your client or manager asks you to deliver another piece of functionality. In a worst-case scenario, refactoring to a cleaner DAL could mean pulling code from places as far off as the user interface and everything in between.
Another scenario is multiple occurrences of what should be the same code. Brownfield applications can be rife with duplicate code. If data access logic and components are spread from top to bottom in the application, we guarantee you’ll find duplicate code. It might be code that manages the life cycle of a database connection, or it could be similar SQL statements that were unknowingly written in two or more places. Infrastructure and CRUD functionality (create, read, update, and delete; the four operations performed on data) will be the two areas where you spend most of your time refactoring.
Although not directly related to infrastructure, there’s one other area of a data access refactoring that you’ll most likely encounter: DataSets. DataSets have served a purpose in the .NET Framework, but they’re one of the leakiest abstractions that you’ll find in a brownfield codebase. DataSets that are used from the DAL all the way up to the UI are automatically imposing a tight coupling between your user interface and the datastore’s structure. Controls that are bound to a DataSet must work directly with table and column names as they exist in a datastore.
DataSets
We’ve emphasized this point in chapters 8 and 10, but just to make our opinion clear, DataSets are evil. Their data-centric view of an application runs contrary to the complexity of the business logic, the diversity of the user interface, and the ability for a developer to reuse code. DataSets are, essentially, a method to expose the tables in a database to the user for them to be able to add, modify, and remove individual records.
Our recommendation is that you avoid using DataSets. Period. We understand that it’s likely you’ll be inheriting brownfield applications that are deeply rooted in DataSet–driven design. With the proliferation of code-generation tools and object-relational mappers (discussed later in this chapter), it’s easier than ever to use a rich domain model rather than default to DataSets.
With many applications containing DataSets throughout the entirety of the codebase, it’s not going to be an easy task to refactor them out of the way. Later in this section we’ll talk about refactoring CRUD. At that point, we’ll begin to discuss how to realistically and reliably remove DataSets from your codebase.
Before getting to that, let’s take a look at the infrastructure.
11.2.1. Refactoring infrastructure
From the perspective of data access, infrastructure consists of any code that’s required for the application to work with the external datastore. Examples include creating and managing connections and commands, handling return values and types, and handling database errors. Essentially, infrastructure will be anything except the actual SQL used to interact with the datastore and the entry points for the application to access the data.
Initially, when refactoring a vertical slice of the application to nicely encapsulate its data access components, you’ll spend a lot of time on infrastructure. That very first piece of infrastructure you attack could encompass many facets: connection/session management, command management, transaction management, integrating with an object-relational mapper, and possibly others.
Once you’ve created the first portion of your layer, you’ll find it’s much easier the next time around. You recognize areas of duplication easier and see areas of isolation much more clearly. That’s because when you refactor the first piece of functionality, it’s not as easy to see which pieces will need to be reused. Beginning with the second piece of functionality, it becomes clearer where you can make your code more efficient and reduce duplication.
Related to noticing duplication is the mentality trap that you must build out all the connection management functionality in the first pass regardless of whether it’s needed. It’s easy to say to yourself, “Well, we’ll need support for relationships between multiple tables eventually so I’ll just add in the code for it now.” Attempting to build in all possible future required functionality is inefficient. Instead, only do the refactorings that are needed for the piece of code you’re working on at that time.
Challenge your assumptions: Premature optimization
Chapter 7 introduced the concept of premature optimization. To recap: deciding, in advance of ever executing the application in its whole, that the code needs to be optimized is referred to as premature optimization. The desire to optimize is premature since the system’s bottlenecks have yet to be identified.
There’s nothing wrong with “fast enough” when discussing performance of your application. If you attempt to optimize your code before checking to see if a performance problem exists, you’ll almost certainly spend time increasing the efficiency of the wrong piece of code. Until you can run the application and accurately profile its execution, you won’t fully understand the areas that require attention.
In one project we were on, well-formed arguments were made for the addition of a complex caching system to ensure processing performance. Luckily the team chose not to do the work in advance of the profiling effort. Once profiled, the results clearly pointed us to a different portion of the application as the largest bottleneck that we had. The change required to alleviate the bottleneck was an easy fix, quick to deploy, and very effective. Waiting for the profiling to occur before making the decision on where to invest resources and effort in performance saved our client money and maintained the simplest codebase possible.
Performance shouldn’t be ignored. Nor should it be addressed haphazardly. Your primary goal should be a working application. Once that’s been achieved, it can be tuned based on actual performance testing. And remember, perceived performance is more important than actual performance.
If you create only the minimum functionality required at any given time, it’s entirely possible that you won’t create support for something like transaction management in your first pass at refactoring. And that’s fine. If it’s not needed, there’s no sense in guessing at how it should work for code you’ve not looked at yet. (Recall “You ain’t gonna need it” from chapter 7.)
Putting off writing this code doesn’t mean that you won’t ever implement transaction management. Rather, it means that you’ll do it when the need arises. There’s a good chance the application will have the need for transaction management. But when you’re doing these refactorings, the need may not arise right away. Avoid the temptation to implement for future use; it’s a pitfall that will create rework or, worse yet, code that’s never used and thus hasn’t been verified.
Taking an incremental approach will allow your infrastructure code to grow organically. The nature of anything organic is that it will morph and adapt to its environment. Expect these changes to happen with your data access infrastructure code. Not only will you add new functionality, like transaction management, but you’ll also be refactoring code that you’ve already modified during previous work on the DAL. Don’t worry about this. In fact, embrace it. A codebase that has evolved naturally will be much easier to maintain and work with in the future.
In the end, what you’re looking to achieve is data access infrastructure that adheres to the DRY principle (“Don’t repeat yourself”; see chapter 7), functions as desired, and lives in isolation from the rest of the logical layers and concerns within the codebase. None of these are insurmountable goals. It can take time to achieve them, though.
The other area of your data access that will require attention is the part that does the actual work: the CRUD operations.
11.2.2. Refactoring CRUD
Between refactoring infrastructure and refactoring CRUD, the former can be considered the easier of the two. Creating a connection to a database usually happens only one way for an application. CRUD code, however, has subtle nuances in what it’s attempting to achieve. Two queries to retrieve data may look very different on the surface. If you take the time to look at the goals of both, you may find that they’re working toward similar end points. Listing 11.3 shows an example of two different SQL statements doing the same thing.
Listing 11.3. Similar SQL code

As you can see, the two statements in listing 11.3 are essentially identical in intent. Both retrieve the same data for a customer. But the first returns two result sets ![]() and the second only one
and the second only one ![]() . So they don’t quite do the same thing. If you wanted to refactor your application from one approach to the other, you’d have some work to do.
. So they don’t quite do the same thing. If you wanted to refactor your application from one approach to the other, you’d have some work to do.
Because of issues like this one, as well as the fact that refactoring tools for SQL are relatively sparse and underutilized, refactoring CRUD code so that it follows the DRY principle can be an arduous and time-consuming task. Much time can be spent consolidating queries so that there are fewer of them to manage. Consolidation isn’t a bad goal, but your initial refactoring of CRUD code should be done without this goal in mind.
Rather than trying to minimize the number of queries, focus more on encapsulation and coupling. If you’re able to encapsulate CRUD code into the DAL in such a way that it’s loosely coupled, you’re in a better position to make further changes later: you’ve reduced the impact of changes to this code.
Consolidating CRUD code will almost certainly require the use of automated integration tests (see chapter 4). These tests are the insurance that you need when changing column names, rolling two SQL statements into one, or performing other changes to the CRUD code. They’ll be the only way that you can confidently, and efficiently, ensure that nothing has been broken with the changes you’ve made.
Too often developers implement what they believe to be innocent changes to a SQL statement only to have unforeseen impacts on other parts of the application. If you’re not using automated integration tests when making these types of changes, you’ll run a high risk of releasing an application that’s broken. Without tests, the only way to ensure that no regression errors are introduced is to manually test all the functionality in the application. If your projects are anything like ours, your project manager will, to put it mildly, not be impressed with this prospect. Having automated integration tests in place will mitigate a lot, but not all, of those risks.
Tales from the trenches: Working with a net
On a recent project, we were required to implement lazy loading (more on this later in the chapter) capabilities to the application. We were lucky that the application had a nice suite of automated integration tests that could be run against the entire data access layer.
When implementing the lazy loading, a small bug was introduced where one field wasn’t being properly loaded with data. One of our integration tests caught the error and reported the failure prior to the developer even checking in the code, long before it was ever released to a testing environment. That single failing test saved our team from the embarrassment of breaking already working code as well as many hours of searching through the code to find the problem.
Although that wasn’t a refactoring of CRUD, the practice and benefits are the same. Automated tests when changing code functionality are insurance for developers. You don’t want to have to ever use it, but you’re happy you have it when the need arises.
Another technique that we’ve used with success is to refactor code into a single data access entry point. For example, instead of having one call to retrieve a customer address, another to retrieve phone/fax information, and another for office location, consider having one entry point to retrieve customer information: a call to retrieve all the data that was previously accessed through three separate calls. Listing 11.3 can be considered an example of this, as the second example was essentially a consolidation of the first.
More on premature optimization
When consolidating CRUD calls, you may worry about possible performance issues. After all, why retrieve all the customer information if all you need is the phone number?
Worrying about performance optimizations before implementing the code is judging a book by its cover. The first goal in your codebase is to make it maintainable. Build it so that it’s easy to understand (and performance optimization code usually doesn’t qualify). If you do this and performance does become an issue, then you deal with it. Again, this all falls back to the idea of letting your codebase naturally evolve.
Premature optimization plagues our industry. As developers, we look at code and immediately see some little thing that we think can help to optimize the performance of the code. We rarely take into account that the microsecond that we’re optimizing may go unnoticed by business users. Instead, developers spend time working out the nuances of increased performance at the cost of our project’s budget and often the readability and future maintainability of the code.
Instead of prematurely optimizing, write the code so that it works and then profile the application against the requirements set out by the business. As developers, we find that the optimizations we often see when reviewing code aren’t the real problems that the business encounters when using the application under load.
Remember, there are very few things (in code and in life) that you’ll want to do prematurely.
Regardless of the approach you take to refactoring the data access portion of your application, strive toward working in isolation. As we’ve explained, your data access code should evolve naturally like any layer in your application. Make sure changes made to the DAL have the least possible impact on the rest of the application. So before moving on, let’s do a quick review of the concept of an anticorruption layer from chapter 8 as it relates to data access.
11.2.3. Anticorruption layer
Recall from section 8.4 that an anticorruption layer is a means of implementing a contract over your layer to isolate the calling code from changes to it. In the case of data access layers, the anticorruption layer provides you with the ability to refactor the data access components at will while limiting the effects on the application.
One technique for creating an anticorruption layer is to have the layer implement interfaces, and then have the calling code work with those interfaces. Let’s take a look at an example that demonstrates an anticorruption layer over your data access.
The data access layer must implement an interface that sets the contract with the rest of the application. Listing 11.4 shows such an interface for a generic data access class.
Listing 11.4. Sample generic data access interface

The technique in listing 11.4 seems like a good way to promote code reuse in the application (remember DRY?). By making the interface generic ![]() , it should work in many situations with any class you throw at it. This interface will do a good many of your basic CRUD
operations.
, it should work in many situations with any class you throw at it. This interface will do a good many of your basic CRUD
operations.
A notable exception is searching based on some criteria. For example, finding a customer based on their city isn’t something that the interface in listing 11.4 should support, because the functionality is specific to a particular class. For such cases, you can add a new, more specific interface:
public interface ICustomerRepository : IRepository<Customer>
{
IEnumerable<Customer> FetchByCityMatching( string cityToMatch );
}
Notice the reuse of the generic interface, IRepository<T>, and that we’ve added a new method to it. The DAL class that implements this interface will be capable of all the CRUD operations as well as finding customers in a given city. In the meantime, you have two usable interfaces that you can start using in your code.
The creation of this anticorruption layer provides a couple of benefits. First, you can mock out the data access layer (see chapter 4), isolating its behavior and dependencies from the tests being written. This increase in testability is a kind of proof that you’ve implemented the anticorruption layer correctly.
Although testability is a huge benefit for the developers (both current and future) working on the application, it isn’t the primary reason to implement the anticorruption layer. Rather, it allows you to later refactor the code at will without fear of having to change code outside of the anticorruption layer. As long as the contract’s interface is adhered to, any changes in the data access layer are effectively being done in isolation. And it’s this isolation that allows you to continue down the refactoring path.
For completeness, figure 11.2 shows a class diagram for the interfaces described in listing 11.4 and the previous snippet, as well as the classes that implement them.
Figure 11.2. Interfaces and implementations for a generic data access scheme. The IRepository interface and BaseRepository implementation provide most of the basic operations.

Related to the idea of isolating the data layer is that of centralizing your business logic. We’ll tackle that topic next.
11.3. Centralizing business logic
In the “Pain points” section of this chapter, we mentioned applications that have business logic strewn throughout the codebase. In the previous chapter, we also discussed how to isolate the concerns of the user interface and to remove business logic-and data access-related code from it. The data access layer of the application requires the same attention to isolate it from business logic.
A data access layer that contains business logic has at least two concerns: managing persistence and performing business logic. Separation of concerns, as you learned in chapter 7, is a vital practice in making your code more understandable, changeable, reversible, and ultimately more maintainable. The pain point that we outlined earlier, where a developer spends time trying to find a piece of logic only to be told that it exists in a place more suited for data storage, is poor maintainability. Pushing business logic into irregular locations is poor asset management.
There’s a reason you want to isolate your business logic, as you would your other components. Simply put, it changes. Business logic in particular is far from static. It changes as the business changes, as management changes, and as the customers change. It even “changes” in an application as the development team learns more about it. It behooves you to ensure that it’s centrally located so that you can easily respond when the inevitable change happens.
When refactoring business logic out of a DAL, you’ll usually find it in one of two places (and often both): in stored procedures, and nestled in the existing data access code. Both situations will provide challenges when refactoring, but they can be solved.
11.3.1. Refactoring away from stored procedures
Let’s assume you have some stored procedures with logic in them that’s clearly business logic. Refactoring business logic out of them can be a touchy situation. In the simplest scenarios, the business logic stands out: the stored procedures have clearly defined controlling logic in them. They contain if...else statements or logic that throws business-specific errors. And you’ll find other nuggets of information that are obviously business related, such as statements to calculate the shipping costs of an order. These are the easy items to refactor.
Where you’ll run into difficulty is when you encounter stored procedures that contain complex joins, aggregation, groupings, or WHERE clauses. In these cases, it’s often hard to determine how to break out the logic into manageable chunks or even to determine what’s business logic and what’s CRUD.
Our path of choice is to leave these procedures alone. The effort required to untangle and replicate SQL statements that are making significant use of vendor-specific language capabilities is not well rewarded. Besides, many complex SQL statements will be related to the retrieval of data, often for reporting. Rarely do people go to such lengths when performing updates, inserts, or deletes. As a result, leaving complex and convoluted SQL SELECT statements in stored procedures is a valid choice when refactoring a data access layer.
Command/query separation
A not-so-new but increasingly popular idea to consider is command/query separation. The basic idea is that each method can be either a command or a query, but never both. A command performs some action, like updating a row in a database, whereas a query returns data to the caller.
The concept is becoming more and more important as a means to build scalable applications using a publish/subscribe model. For example, we could have some data in a cache for a quick response time. When the data changes in the database, it publishes a message to indicate so. The cache subscribes to that message and updates itself accordingly. In this case, the publisher publishes messages about changes (commands) and the subscriber queries for those changes.
Another way of thinking about the two is that commands are for creating, updating, and deleting data, and queries are for reading data.
We won’t claim any sort of expertise on the subject, but it’s an idea worth considering for a great many scenarios.
Although it’s acceptable that some stored procedures are too difficult to refactor business logic out of, it’s important to try to remove all logic from stored procedures that are altering data. Inserts, updates, and deletes should be free from logic if you expect maintenance developers to be able to easily work within your application.
The challenges aren’t all technical
Unfortunately, not all refactoring problems can be solved through code. In many cases, you’ll encounter resistance to the idea of moving logic out of stored procedures in the form of overprotective DBAs. Typically in these situations, developers aren’t allowed direct access to the database and changes to existing stored procedures must be approved through a process we call “Death by 1,000 Quick Questions.”
Joking aside, this reluctance to “give up” business logic is often a reaction to a bad experience in the past. Regardless, you’ll have a challenge ahead of you wrestling it back into your code. How you approach that is more an exercise in team dynamics than in code refactoring—which is our way of saying we don’t have any hard-and-fast answers.
Most of the arguments in favor of logic in stored procedures are based on good intentions but are impractical. In our experience, a well-designed business layer in code is far clearer and less fragile than having it in the database. It’s easier to verify and, in the end, more maintainable. In our humble opinion, your mileage may vary, opinions expressed are solely those of the authors and not their employers, and so on and so forth.
You must tread a fine line when refactoring business logic out of procedures, and it’s centered on the WHERE clause. Specifically, what’s business logic and what’s simply a data filter? In some cases, we obviously need to do the bare minimum, like so:
UPDATE TBL_CUSTOMER SET STATUS = @STATUS WHERE ID = @ID
In other cases the WHERE clause is less clear. Take this example:
UPDATE TBL_CUSTOMER SET STATUS = @STATUS WHERE CITY = @CITY
AND (PROVINCE = 'BC' OR PROVINCE = ' ' OR PROVINCE IS NULL)
The existence of the AND and OR clauses could be construed as business logic or could be the bare minimum required to do the job. In other words, it could be a filter or it could be a business rule.
You’ll see this dilemma often if you’re working to refactor business logic out of the stored procedures in your brownfield application. The only way to clarify this situation is to dig deeper into the intended use of the stored procedure. In the end, it will be a judgment call.
The next area where you’ll see business logic is in the data access code itself. Let’s see how you can get it out of there.
11.3.2. Refactoring out of the data access layer
Once you have refactored business logic out of stored procedures (or if you’ve been so lucky as to avoid this problem), there’s still the chance that you’ll find business logic buried in your DAL. Indeed, we’ve been guilty of creating code in this manner ourselves.
Although having business logic in your DAL may not seem as big a problem as having it in stored procedures, it still should cause concern. As with business logic in stored procedures, locating it in the DAL makes it more difficult for developers to find it when they’re working with the code. As we’ve mentioned a number of times, your application will spend more time in maintenance than any other part of the application’s life cycle. If a practice such as locating business logic in the DAL increases the difficulty of working with the application during that long portion of its life, you’re increasing the overall cost of the application.
Business logic should be kept where it makes the most sense: in the business layer. But, as with stored procedures, maintaining this separation can be fraught with difficulty at times.
Your primary concern when starting these refactorings should be to relocate any obvious business logic. In some cases you’ll perform a simple refactoring that only requires you to move code from one part of the application to another. Other times you’ll be facing a daunting task that requires the skills of a surgeon to slowly whittle out pieces of offending code and patch it back together in a better location.
Warning
At the risk of sounding like a broken record, before making such changes, you need to have confidence that the changes you’re making don’t break the application. Create unit and integration tests before you start.
On top of having the confidence provided by automated tests, consider working in isolation during this time. Two ways to achieve isolation are by branching the version code repository or, if you’ve created an anticorruption layer, creating new concrete classes based on the contract/interface you’ve defined. Both options allow you to reverse your changes easily if your refactoring goes awry.
As with stored procedures, removing business logic entirely from a DAL can be a lofty goal in some brownfield codebases. Be aware of the cost-benefit ratio involved while you work. Watch for situations where your efforts to refactor would be too great because you could sink into a pit of refactoring quicksand (the more you refactor, the more you need to refactor). As always, external factors play a role in your refactorings and you should ensure that you’re not biting off too much at one time.
In the next section, we’ll spend some time talking about features of a DAL you should consider during your refactoring.
11.4. Features of a DAL
Moving business logic to a centralized location is an important separation of concerns that makes a good starting point in refactoring your data access. But you should take into account other issues as you define your DAL. This section will talk about concepts that will improve your data access code for future work.
If you’re working with a hand-rolled data access layer (which isn’t unusual in brownfield applications), some of these will seem like a lot of work to implement. We won’t disagree with you. Luckily, there are alternatives in the form of third-party tools for object-relational mapping or code generation. Both will be discussed later in the chapter, but first, figure 11.3 outlines the features we think are important in a good DAL.
Figure 11.3. Features of an effective data access layer. Some are easier to implement than others.

There are many places to start this discussion, but the one that makes the most sense is encapsulation.
11.4.1. Encapsulation
To begin our discussion on encapsulation in a data access layer, let’s look at an example of bad encapsulation. Here’s a common brownfield scenario:
// ...
var customerRepository = new
CustomerRepository( );
customerRepository.OpenConnection( );
var customerList = customerRepository.GetCustomers( );
customerRepository.LoadOrdersFor( customerList );
customerRepository.CloseConnection( );
// ...
Notice how the service layer has intimate knowledge about how to open and close the connection used by the data access component. We have bad encapsulation at the DAL. There’s no reason for the service layer to know why or how this is occurring. Yes, we’ve encapsulated how the connection is opened and closed, but a good DAL shouldn’t require knowledge of connections.
Other common “mis-encapsulations” include passing around a connection string or connection object, the handling of data access return values as checks for errors, and checking for specific database types throughout your code (and this includes System.DBNull). Although the existence of these issues is by no means a sign that the application won’t work (we’ve seen dozens of applications with these encapsulation flaws that are fully functional in production), they are signs of problems to come.
Poor encapsulation will lead to code changes requiring what’s known as the shotgun effect. Instead of being able to make one change, the code will require you to make changes in a number of scattered places, similar to how the pellets of a shotgun hit a target. The cost of performing this type of change quickly becomes prohibitive, and you’ll see developers resisting having to make changes where this will occur.
Good encapsulation and good separation of concerns are closely related. Working to get your brownfield DAL to have both of these will put you in a better position to work with the remaining items that we’ll explore in this section.
11.4.2. Transactions/Unit of Work
You’ve likely dealt with database transactions at some point. They’re one of the cornerstones of data integrity and reliability.
The question with transactioning is how it’s implemented. If you’re working with a raw data access tool, such as ADO.NET, transactions are probably maintained at the database connection level (though the System.Transaction namespace, introduced in .NET 2.0, has helped alleviate this need). This means your DAL must reuse the same connection on any call, leading to the code snippet shown earlier in section 11.4.1, where calling code is responsible for managing the connection. Another scenario is when connection objects are passed into the DAL between calls, as in listing 11.5.
Listing 11.5. Managing connections through business code
// ...
var connection = DataAccessHelper.GetConnection( );
var transaction = connection.BeginTransaction();
var customerRepository = new CustomerRepository( );
var orderRepository = new OrderRepository( );
customerRepository.SaveCustomer( connection, transaction, customer );
foreach ( var order in customer.Orders )
{
orderRepository.SaveOrder( connection, transaction, order );
}
transaction.commit();
Instead of a leaky abstraction that forces the connection object management out to another layer, you should be striving for data access layers that intrinsically know how to use a transactional approach. You can achieve this with a standard ADO.NET connection object in a number of ways, but you can make it easier.
Enter the Unit of Work pattern. In this pattern, instead of making numerous separate calls to the database you’ll bundle a number of calls together and push them through at the same time. The pattern allows the code to open a transaction immediately before the first call is executed, keep it open (and thus the transaction alive) during the remaining calls, and commit or roll back the transaction when the final transaction has been completed. Figure 11.4 depicts one way it could work.
Figure 11.4. Database calls are queued in the Unit of Work and executed in a single transaction.
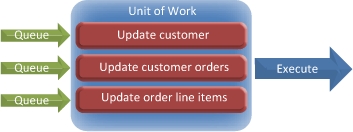
Implementing the Unit of Work pattern stops you from having to move a connection object through your code but still gives you the power of a transactional system. Unit of Work can be implemented in various degrees of complexity. At its simplest, it will manage transactions and mass execution of data calls. In more complex implementations, the calls to the database will be reconciled in the correct order so that no relational constraint errors occur.
As you can imagine, Unit of Work isn’t a commonly implemented pattern in hand-rolled data access layers. It’s not widely known and can be difficult to implement fully. But if your application is suffering from poor encapsulation due to failed attempts at transactional support, implementing a simple Unit of Work pattern is a good option. Note that we said simple—again, invoke YAGNI and implement only the functionality required to support your code’s current needs. Any more is wasteful.
11.4.3. Persistence ignorance
As with many concepts in this chapter, we’re going to reach back to the concept of separation of concerns when we discuss persistence ignorance. Persistence ignorance is the concept whereby your business entity objects (Customer, Order, Invoice, etc.) have no knowledge about the infrastructure required to perform data access (CRUD) operations against them.
So how does persistence ignorance tie back to separation of concerns?
Without persistence ignorance, entity classes will start to see other concerns creep into them. Take the class definition in listing 11.6, which shows a simple Customer entity.
Listing 11.6. Class with no persistence ignorance
[TableMap("tbl_customers")]
public class Customer {
[PropertyMap("customer_id")]
public property long Id { get; set; }
[PropertyMap("name")]
public property string Name { get; set; }
[PropertyMap("mailing_address")]
public property string Address { get; set; }
[PropertyMap("is_active")]
public property bool Active { get; set; }
}
Immediately you’ll notice extra information along with the properties: the TableMap and PropertyMap attributes. Without knowing anything about their implementation, you can guess from their names and values that they’re probably used to map the Customer class to a database table named tbl_customers and the properties to columns, like customer_id or name.
Having the mapping information directly in the class constitutes a poor separation of concerns. The DAL has crept into the domain model via the attributes. If, for whatever reason, changes were required to data access (such as renaming a column), the separated DAL wouldn’t stop changes from rippling to code in other layers.
As with many things that don’t have a good separation of concerns, the Customer class in listing 11.6 also violates the single responsibility principle. There are two scenarios that would require changing it:
- When you change the way that a customer is modeled within the application
- When the datastore storing a customer changes
As mentioned in chapter 7, poor adherence to the single responsibility principle makes code more difficult to change, verify, and maintain—hardly traits you want to incorporate into your application.
Instead, you’d rather see something like this:
public class Customer {
public property long Id { get; set; }
public property string Name { get; set; }
public property string Address { get; set; }
public property bool Active { get; set; }
}
The entity itself is devoid of any knowledge of the datastore or the methods used to perform data access. All of that knowledge is contained elsewhere, presumably within the data access layer.
Persistence ignorance doesn’t obviate the need to map your business classes to database tables. But you want to do it in a place where you can maintain good separation of concerns and single responsibility. You could use something as simple as a CustomerMapper class that takes a DataReader and converts it into a Customer object.
Or you could achieve your goal using an object-relational mapper. Listing 11.7 shows an example of how this mapping could be achieved.
Listing 11.7. Sample mapping file using an object-relational mapper

There’s no need to get into the details of the syntax, but the intent should be intuitive. The database table that the Customer class maps to ![]() is described. Next
is described. Next ![]() , the Id property is mapped to an appropriate column and a description of how it’s generated is provided. Finally
, the Id property is mapped to an appropriate column and a description of how it’s generated is provided. Finally ![]() , individual properties are mapped to corresponding columns.
, individual properties are mapped to corresponding columns.
Note that you have not eliminated the need to change your code if the name of a column changes. But you’ve separated it from the Customer class itself so that if this situation arises, you know exactly where the change should be made because that’s this class’s single responsibility.
Note
Listing 11.7 isn’t theoretical. It uses an open source library called Fluent NHibernate that builds on yet another open source library, NHibernate. For more information on Fluent NHibernate, visit http://fluentnhibernate.org.
When you’re rolling your own DAL, or if you’ve inherited one in a brownfield project, you rarely find that it has this level of separation. The result is that changes to the data structure, or to the entity model, will ripple through the codebase. As soon as that happens, there’s a significant increase in the risk that you’ve made changes that have unknown or unintended consequences. Usually that results in errors that aren’t caught until the application is in front of testers or, worse, the end users.
Although persistence ignorance has huge benefits when it comes to code maintenance and development, it isn’t something that’s supported in its purest form in many DALs, be they hand-rolled or otherwise. When you’re refactoring your brownfield DAL, take stock of the situation you’re in. If your domain model and database are stable, perhaps the need for persistence ignorance isn’t a priority.
But if your datastore and/or domain model are changing often, or if you have no control over the datastore, take a hard look at incorporating persistence ignorance during your refactoring. Having to review the ripple effects of datastore changes will only slow down your efforts if you have poor separation of concerns.
11.4.4. Persistence by reachability
Persistence by reachability builds on persistence ignorance. Consider the code in listing 11.8.
Listing 11.8. Walking an object graph to persist all the data
public void Save(Invoice invoiceToSave) {
_invoiceRepository.Save(invoiceToSave);
_customerRepository.Save(invoiceToSave.Customer);
foreach(var lineItem in invoiceToSave.Items)
{
_invoiceRepository.SaveItem(lineItem);
}
}
Most of us have written code along these lines in our career. To update a group of related entities, you walk along the object graph in the appropriate order, saving each as you go.
Of course, this example is trivial. In real life, walking the depths of an object graph, especially one with multiple nesting levels, quickly creates a call stack that can go several levels deep.
Instead, wouldn’t it be nice if you were able to run the following code and have it take care of that complexity for you?
public void Save (Invoice invoiceToSave) {
_invoiceRepository.Save(invoiceToSave);
}
You may say, “Well, that’s all well and good, but you just moved the saving of the Customer and the LineItems into the _invoiceRepository.Save(...) call.” And indeed, if you were rolling your own DAL, that may be exactly how to achieve persistence by reachability. But the end result is the same: saving an invoice should, by nature of the business rules, also entail saving the customer and line items implicitly.
In the end, regardless of how you get there, you’ve achieved a state of persistence by reachability. You’ve created a data access layer entry point (in this case the _invoiceRepository.Save(...) method) that will navigate the object graph without the calling code having to coordinate the effort.
Note
Those of you familiar with domain-driven design will recognize this concept as one of the properties of an aggregate root in a repository.
The definition of persistence by reachability is that the DAL will traverse and save any entity and entity data that it can find by navigating the properties on the entities. If the data is publicly available on an entity, the DAL will persist it. Not only that, but it will do it to the full depth of the object graph.
Implementing persistence by reachability in a hand-rolled DAL isn’t easy. Usually, half-hearted attempts contain a lot of duplicate code and a less-than-palatable level of brittleness. Because this tends to happen, many people will forego taking a DAL to this level and instead will use a variation on listing 11.8.
With some care and attention, it’s possible to make code that has pieces of persistence by reachability in it. However, the time and effort required to do so usually isn’t trivial, and with typical time pressures, incorporating it into a DAL is often not a realistic option.
Having said that, most third-party object-relational mapper (ORM) implementations do implement persistence by reachability to some degree. If you have extremely complex object graphs that you’re constantly traversing to save or update data in the datastore, consider refactoring your DAL to use an ORM. Although doing so does introduce other potential issues (which will be addressed later in this chapter), the benefits typically outweigh the costs.
11.4.5. Dirty tracking
Imagine a scenario where you have 1,000 line items in an Invoice object and you save the Invoice. The code could make up to 1,001 database calls, saving each line item as well as the invoice itself.
For brand-new invoices, you’d expect this to happen. But what if it was an existing invoice? Say you had loaded an invoice with 990 line items from the datastore, modified 2 of them, and appended 10 more line items? When you save that invoice, should the code save all 1,000 line items again? Or just the 10 new and 2 updated ones?
Hopefully you chose the latter. And accomplishing parsimonious updates isn’t all that complicated. The DAL needs to be smart enough to identify objects and data that have been modified, added, or deleted. Once these items can be identified, you’re able to perform data persistence much more parsimoniously.
One of the most common, and primitive, ways to implement this is the most intuitive: an IsDirty flag. Listing 11.9 shows this on the Customer entity.
Listing 11.9. Primitive IsDirty implementation
public class Customer {
public property long Id { get; set; }
public property string Name { get; set; }
public property string Address { get; set; }
public property bool Active { get; set; }
public property bool IsDirty { get; set; }
}
The key to listing 11.9 is that each of the first four property setters would change the state of the IsDirty flag. Although listing 11.9 is a viable solution, there are some issues with it. First, this example is capable of monitoring only a Boolean state, which can make it difficult for you to distinguish between an entity that has been added versus one that has been altered. Second, you need quite a bit of code to ensure that the IsDirty property is set when any value is changed. Single responsibility starts to break down when you have code internal to the entity performing these tasks. At the very least, it usually means you can no longer use automatic setters for the other properties because you’ll need to pepper the code with calls to IsDirty = false.
Note
Setting an IsDirty flag is a good candidate for aspect-oriented programming, as described in chapter 8. We don’t explicitly need to mark the entity as dirty; instead, we add a dirty-tracking aspect that would weave this into the code itself.
Moving these responsibilities out into their own cohesive areas of the codebase isn’t overly difficult to do, but it can be time consuming. As a result—and as with so many of these important data access features—you’re not likely to see anything more complicated than the naive IsDirty implementation in brownfield codebases, if they have any dirty tracking at all.
As with any of these features, dirty tracking may or may not be important in your application. Indeed, there’s an element of premature optimization to implementing it. If your application relies heavily on a robust and well-defined domain model (such as one developed with domain-driven design), you’ll likely benefit from having dirty tracking as a core component in your DAL. Otherwise, it may well be within your performance guidelines not to deal with it at all.
Another feature shown in figure 11.3 is lazy loading, which is discussed next.
11.4.6. Lazy loading
Consider again the Invoice with 1,000 line items. What if you wanted to display only the customer information of the invoice? It wouldn’t be efficient to load its data as well as the information for each of the 1,000 line items, each of which could require a lookup from the Product table as well as possibly the Category table.
One naive way around the abundance of data retrieval is to have one data access call that retrieves only the invoice data and another that retrieves the full object graph. A cleaner solution is to use a single call that retrieves only the basic invoice details initially and that loads the line items only when they’re requested. This is where lazy loading comes in.
When implemented properly, lazy loading will defer the execution of reads from the datastore until the last possible moment prior to the information being required for processing by the application. Take, for instance, listing 11.10.
Listing 11.10. Manual version of lazy loading
public void DoSomeStuff(Customer customer) {
var invoiceRepository = new InvoiceRepository();
var invoice = invoiceRepository.FindByCustomer(customer);
// Do some stuff with the invoice
invoiceToProcess.Items.Load();
foreach(var item in invoiceToProcess.Items) {
// do work with the items
}
}
Here, you’re using one form of lazy loading called lazy initialization. When you retrieve the invoice, the Items collection hasn’t been populated. Later, when you want to work with the Items, you make an explicit call to load them into the Invoice. In this way, you reduce the burden of making database calls when they’re not needed.
Although the code in listing 11.10 is more efficient, it’s a bit of a leaky abstraction. It requires the calling code to know that the Items aren’t loaded when the invoice is retrieved. You’ve allowed some of our DAL to creep into the business layer where it doesn’t belong.
A better implementation is one where the calling code has absolutely no knowledge of the state of the data access call. Instead, it assumes the object graph is always preloaded. Listing 11.11 shows how that code would look.
Listing 11.11. Virtual proxy version of lazy loading

The first thing that you’ll notice is...well...nothing. There’s no way to look at the code in listing 11.11 and tell whether the Items collection is preloaded or if it’s being lazy loaded. As in listing 11.10, the basic invoice information ![]() is loaded, but there’s no explicit call to load the Items collection. For all you know, the Items are all there. But behind the scenes, they don’t exist until the first call to the Items collection. At that point, the lazy loading mechanism kicks in and a call is made to the database to retrieve the items.
is loaded, but there’s no explicit call to load the Items collection. For all you know, the Items are all there. But behind the scenes, they don’t exist until the first call to the Items collection. At that point, the lazy loading mechanism kicks in and a call is made to the database to retrieve the items.
Here we have an example of the virtual proxy version of lazy loading. You always assume the Items collection is loaded. But in fact, the Invoice will contain a proxy object, which is an object that only appears to be an object of the same type as Items. When the first request is made to the Items collection, it’s loaded from the database.
Note
For completeness, we’ll mention that lazy loading can also be implemented using either a ghost or a value holder. A ghost is similar to a virtual proxy except that it’s an actual instance of the object being loaded. But it’s only partially loaded, likely with just the ID. Likewise, a value holder is also a substitute like the virtual proxy, except that it’s a generic object that must be cast to its actual type after retrieving it from the database.
Using virtual proxies may seem like voodoo, but it’s very much possible. And because of it, you can achieve what you want: code that’s clear and decoupled from infrastructure concerns in the business logic. You can now work with your Invoice object without worrying about whether you’re affecting performance with extraneous database calls.
Of the different implementations of lazy loading, lazy initialization is the easiest to implement. It’s intuitive to grasp and straightforward to implement. But it places a burden on the caller to ensure it makes the appropriate call to load the properties.
The remaining implementations also vary in complexity. Each has its strengths and weaknesses, but none of them is trivial. Again, the traits of your particular application will best guide you. For a brownfield application, lazy loading could be a case of premature optimization. There’s no reason to implement it if users aren’t experiencing performance problems. Perhaps none of your objects have very deep graphs. If you’re lucky enough that that applies to you, you’ve dodged a lazily loaded bullet.
11.4.7. Caching
No discussion of data access is complete without considering caching. Yet retrieving data from a datastore can be a costly operation. If you’re retrieving the same data over and over again and it’s not changing, why not keep a copy locally and use that instead of constantly going back to the datastore?
If the DAL is hand-rolled, many teams will neglect to add any caching to their systems. Sometimes a lack of caching is just an oversight, but in other cases, it’s because caching isn’t always as simple as it seems on the surface. For example, how long do you keep data in the cache? If it’s a list of U.S. states, it could be indefinitely. But what about a shopping cart for an online purchase? Ten minutes? An hour? A day? Or maybe based on an event, like the user logging out or the session ending? The correct answer, of course, is “It depends,” which is what makes the question of invalidating the cache so complex.
Another reason that caching is often absent from a brownfield application is that infrastructure concerns can start to enter the design conversation. For instance, how should you implement efficient caching for an application that will be residing in a web farm? What about caching data so that it’s available across sessions? Both of these are problems that commonly need to be solved when dealing with caching. There may not be simple solutions for them, though.
Tales from the trenches: Caching woes
On one project we had the chance to see a hand-rolled implementation of caching go horribly awry. The idea was simple: implement a caching scheme so that we wouldn’t have to make large numbers of calls, through a horrifically slow connection, to the datastore.
It all seemed so idyllic at the start. The code was written and it existed for quite some time while the team continued to develop around it. When the time came to do performance testing on the application server components, a disaster occurred. Making only two data requests to the middle tier from the client caused the application to stop responding. After some panicked performance profiling, we found that the caching scheme was bringing a high-powered middle-tier server to a grinding halt, so much so that it required a hard reboot of the machine.
The culprit was the mechanism by which we determined when data should have been cleared from the cache. Fortunately, we were able to change the caching to perform better in relatively short order, and the application’s performance was greatly improved and deemed adequate when compared against our goal metrics.
The lesson for our team was twofold. First, caching, when implemented incorrectly, can be as much of a problem as it can be a solution. Second, profiling and performance metrics should be incorporated into any test plan. With them in place, we can make informed decisions on where to get the largest gains for the smallest effort.
Caching is a valuable component to a fully featured data access layer. But like the other topics described here, it’s a performance optimization technique. As mentioned before, prematurely optimizing your code isn’t a practice you should have. With caching, you must understand where you’re seeing bottlenecks caused by repetitive data access. You must also have a strong understanding of the volatility of the data that’s being accessed. The combination of those two things will help you determine where caching can be of benefit to your brownfield application.
11.4.8. Tips on updating your DAL
Now that all the features from figure 11.3 have been covered and you have a sense of which ones you’d like to implement, how can you upgrade your existing DAL?
There are two issues with your current brownfield DAL (if we may be so bold). First, it’s probably functionally incomplete: it does some, or even most, of what you want, but not everything. Second, your DAL might be unmanageable. Any time a bug arises in the DAL, it requires a search party complete with Sherpa to determine where the issue is and, more importantly, how to fix it.
Beware the hidden gem
The unmanageable code problem isn’t native to the DAL by any stretch. But it’s usually a nice example of one of the major pitfalls of brownfield development: the hidden “gem” (other words come to mind, but let’s use this one for now).
A hidden gem is a piece of code that does a specific, focused task, but when you review it, you think it’s useless and your first instinct is to delete it. But removing it will introduce defects that are hard to trace and even harder to understand.
In our experience, if you encounter code like this, your best bet is to leave it alone and find a way to do what you want some other way if possible.
These scenarios aren’t mutually exclusive. It’s possible that your existing DAL is an incomplete mess. Regardless, once you’ve decided you want to add new data access functionality, you have two choices:
- Add the new functionality to the existing code.
- Create a new DAL side by side with the existing one and add new functionality to it. Over time, you can (and should) migrate the existing functionality to it.
The first option will depend on how extensible your existing DAL is. If you can easily add new functionality without duplicating a lot of code (or by refactoring the duplication into a separate location), then by all means that should be your choice. But brownfield applications aren’t generally known for being extensible, and you’ll often find that a task that at first seems easy will turn into a multiday ordeal.
That said, you should consider carefully before creating a new DAL alongside the existing one. It’s easy to make plans to migrate the existing DAL into the new one over time, but that task is often given a priority only slightly above “review TODO comments.” The reality is that you’ll likely have two DALs to maintain for some time, so be sure to balance that against the heinousness/incapability of your existing one.
Final warning
We’ve beaten both points to death, so this will be the last reminder. Before you start messing with your DAL, you should have two things in place:
- Integration tests to ensure your code still works after you’ve changed it
- An anticorruption layer to make it easier to back out your changes should things go horribly awry.
That’s it for the discussion on features of a DAL. If you do decide you want to build a DAL, you’re in luck. You have a number of options available other than building it yourself. In the next section, we’ll review them.
11.5. Options for creating a DAL
You have three main options when creating a new DAL. Although we’re only covering three, and doing so at a very high level, you’ll find that other options are available. On top of that, each of these options has different flavors, each with its own benefits and pitfalls. Remember that the solution you choose has to work for your project, its developers, and the maintenance team, and it must also support the end goal of the business. Your current DAL will play a role in your decision as well.
11.5.1. Hand-rolled
Hand-rolled DALs have been the cornerstone of .NET applications since the framework was introduced. As the name implies, this style of DAL requires that developers create all the required functionality from scratch, using only classes from the .NET base class library (such as ADO.NET).
The capabilities of hand-rolled DALs are usually basic. For example, there may be no implementation of the Unit of Work pattern in the DAL, or the caching will be a simple hash table with no concept of expiration. As a result, the DAL might either have no support for transactioning or support with poor separation of concerns.
Although support for edge case scenarios can be added to a hand-rolled DAL, the biggest concern is the amount of effort that can be required to build it. Not only that, but you have to be concerned with the correctness of each feature added. Some of these problems can be alleviated through good unit and integration testing (see chapter 4), but there will still need to be a concerted manual testing effort to ensure that the features are working correctly.
Another concern is that a hand-rolled DAL will probably be application specific. Consequently, the support and maintenance developers will need to learn, and understand, the intricacies of a particular DAL on an application-by-application basis. In many environments, these developers are responsible for more than one application, and if each has a different DAL implementation, they’ll potentially need a deep understanding of more than one data access codebase.
Note
Application-specific DALs aren’t always a bad thing. Theoretically, an application-specific DAL contains only those features needed for the current application and nothing more. An application-specific DAL is atestament to YAGNI...assuming it’s feature complete and implemented properly.
This effort can be alleviated in two ways. The first is to have common patterns used on several applications’ DALs across the organization. However, because each application may have different technical needs in its DAL, this plan can quickly break down as features are added in one application but not in others. Once that starts to happen, it’s as if each DAL was designed and written independently of the other. At this point you have all the pitfalls of a fully hand-rolled DAL with the added consequence that it now contains features you don’t need.
The second option is to completely separate the data access layer and reuse it through many applications, the so-called corporate DAL.
Designing a cross-application, corporate DAL introduces a number of issues that won’t have entered your application development practices before. Here’s a list of some of those issues:
- Functionality support
- DAL defect and resolution management
- Release and version management
- Integration with other applications
Each of these items introduces tasks, processes, and techniques that will drive your teams toward managing a fully fledged project that’s internally specific to the institution. Although this result isn’t necessarily a bad thing, there has to be a solid understanding of the task that’s being taken on as well as the overhead that it will create. Considering the number of good alternatives, tread carefully before taking on your own internal company DAL. Some of the high-level considerations you must take into account when deciding between these two DAL strategies are shown in figure 11.5.
Figure 11.5. Hand-rolled DALs can be application specific or corporate wide. Each has advantages and disadvantages.

The second option when building a DAL is to generate it automatically.
11.5.2. Code generation
In an effort to reduce the tedious, and error-prone, nature of writing DALs by hand, people sometimes turn to code generation. A code generator is able to look at your database and generate an object model based on it. Typically, the developer uses templates to further refine how the classes are generated.
Like hand-rolled DALs, the results of code generation are completely dependent on the skills of the developers who design the templates. We’ve seen instances of generated code that range from horrific to elegant.
Although generating code is perceived as a technique that greatly reduces the effort required to create a DAL, don’t underestimate the amount of effort required for the initial design and creation of the templates. It’s certainly easier to design and write a generation template than it is to hand-roll an entire DAL, but you need to factor in overhead.
Tooling for template creation, maintenance, and execution is available in a number of products. Some code-generation systems come with prebundled templates that create code in commonly known patterns. If your project environment allows for it and you’ve chosen to use code generation, we suggest you look into using one of these tools. Third-party tooling will preclude your team, and the future support and maintenance teams, from having to maintain an in-house, custom generation engine.
Creating your own code-generation engine
Creating your own generation engine is a great academic exercise in software development. But when you look at the larger picture, the generation engine is another project and codebase that needs to be maintained and supported through the life of the application that’s consuming the code it generates.
As we’re trying to simplify the brownfield application we’re working on, introducing another project is often counterproductive to that goal. If you’re considering creating your own generation engine, it’s best to treat it like a separate project, using the existing brownfield application as the testing ground.
Another maintainability concern is the learning curve for the tooling and templates. As with any tools, developers must learn to work efficiently and effectively with the code-generation engine and templating language. Granted, some tools are better than others, but you still have to consider the impact of this learning curve.
The nature of code generation is that it creates code that you include in your application. Code that exists in the application is code that your team must understand and maintain. It may be generated automatically, but that doesn’t mean that the development or maintenance team doesn’t have to be able to navigate and understand it. Like any other code in your application, generated code is a maintenance burden that you must be willing to take on.
Like with hand-rolled DALs, you should be concerned about edge cases and oneoff needs when implementing code generation. You can handle these scenarios in a number of ways, but the one constraint that you have to constantly work around is the fact that a certain portion of your codebase is completely volatile. If you manually modify generated code, be fully aware that those changes will be eliminated the next time the generation engine is run. Partial classes and inheritance are two of the most common techniques used to overcome this issue, but both introduce complexity and readability concerns into the codebase.
When contemplating the use of code generation in your brownfield application, be aware of the maintenance, extensibility, and quality issues they can introduce to the codebase. In an ideal world all of these concerns can be mitigated, but we have yet to see an ideal world. In reality we find that code generation is used for an initial period on a project (usually greenfield), and then as the project matures it’s abandoned in favor of maintaining and extending the previously generated code by hand.
Some popular code generators include SubSonic, MyGeneration, and CodeSmith.
The final option for creating a DAL, and our personal favorite, is to use an object-relational mapper.
11.5.3. Object-relational mappers
The final option to discuss in this section is object-relational mappers (ORMs). Like generated solutions, ORMs are an implementation of a DAL that helps minimize effort in the development phase of the project. With an ORM, the developer typically defines the object model independent of the database and provides a way of mapping the object model to the database. The ORM then takes care of generating the SQL statements required to perform CRUD operations on the object model. In most cases, the SQL generation happens within the ORM itself; all your application needs to do is reference the appropriate assembly.
Note
Although some ORMs generate code as well as use precompiled assemblies to provide functionality, we’ll limit our discussion to those that don’t generate code. The previous section covers many of the pertinent details for ORMs that generate code.
The major benefits and drawbacks of ORMS are shown in figure 11.6.
Figure 11.6. ORMs can provide a lot of benefit, but be prepared for possible resistance and a learning curve.

The first advantage is that third-party ORMs are usually very feature complete. Many incorporate most, if not all, of the features discussed in section 11.4.
A good example of feature completeness is lazy loading. In brownfield applications, hand-rolled and generated implementations often don’t have lazy loading implemented at all. In many third-party ORMs, lazy loading is just a matter of configuration. When talking about performance-related DAL techniques, such as lazy loading and caching, the ability to turn the features on and off is beneficial when avoiding the pitfalls of premature optimization.
Another benefit of using an ORM is that there will be much less code to maintain in your application’s codebase. You won’t have to write any code to map your object to a database table, and in many cases, you won’t even need to write SQL statements. All of that’s provided by the ORM.
It’s not all sunshine and daisies, of course. We’ve glossed over the major feature of ORMs: the mapping. At some point, you need to tell the ORM how to map your objects to one or more tables. In the worst-case scenario, the mapping process will require you to create a class or file that says something like “Map the Customer class to the Customers table, the ID property to the CustomerID column, the FirstName property to the FirstName column, etc., etc.” And that’s not to mention the intricacies of one-to-many and many-to-many collections. Although there have been inroads in making mappings easier to manage, the fact is that with an ORM, you’ll spend a lot of time dealing with configuration on some level.
Furthermore, an ORM, like any third-party library, requires ramp-up time. To be sure, any DAL will require developers to spend time learning about it, but one of the drawbacks of ORMs is that when you run into problems, most of the time you can’t solve the problem by throwing more code at it like you can with hand-rolled or generated solutions.
That said, a few ORMs are popular enough that you could reduce ramp-up time by finding a developer who is already well versed in the one you’ve chosen.
A final note on ORMs in general. Because the SQL is “magically” generated outside your control, you’ll often hit resistance to the ORMs from overprotective DBAs who believe autogenerated code (or indeed, any SQL outside a stored procedure) is inefficient or, worse, a security risk.
With most database engines, you won’t run into the same resistance. Nearly all the time, the SQL generated by ORMs is either just as efficient as you’d generate yourself, or efficient enough to the point where the difference is negligible. Furthermore, all SQL generated by ORMs is parameterized and thus isn’t susceptible to SQL injection attacks. Given that, we have yet to convince any sufficiently paranoid DBA of these facts.
Three popular object-relational mappers for .NET are NHibernate, iBATIS, and LLBLGen Pro.
An emphasis on ORMs
Although we’ve tried to remain objective throughout the book, we’re going to take a departure here and express our strong opinion in favor of ORMs.
Quite simply, we feel the benefits of an ORM far outweigh the costs and that once you’re familiar with them, they’ll save you a tremendous amount of time and money over the life of your projects. The time savings come from development time; developers won’t need to create as much code. The other savings is because there isn’t as much code to maintain.
There are plenty of arguments against ORMs. The learning curve can be higher, particularly because when you run into issues, it will usually be with the configuration of the mapping, which isn’t always intuitive. The mappings can be fragile; they may not be strongly tied to your database or your object model. So if you change the name of a column in your database, the application will still compile. The SQL is dynamically generated and thus is not as fast as it could be if you take advantage of database-specific features or stored procedures.
By the same token, there are counterarguments to each of these. “Learning curve” is one of the prerequisites to surviving in our industry. Integration tests will catch any mismatches between your mapping and your database or object model. And with the performance of today’s databases, dynamic SQL is on a par with stored procedures. In any case, we have yet to work on a project where the ORM was the source of performance problems.
If all of this sounds like a long-standing and well-rehearsed argument, you’re right. You’ll see these points/counterpoints along with many others when you start diving into the concept.
We revert back to our experience: ORMs have saved our clients money, plain and simple. And lots of it. Not just in development time but in maintenance, which we’ve said many times is much more important. Although we’ve encountered brownfield projects where implementing an ORM wasn’t the right solution, it wasn’t because of the limitations of the ORM tool or lack of experience of the team. Rather, it was due to project constraints such as time to delivery or scope of the rework.
Thus ends our discussion on creating (or configuring) a data access layer. Each of these three options—hand-rolled, code-generated, or object-relational mapper—has its place. Often the options are limited (at least at first) by corporate policy and your team’s ability and schedule. Rolling your own DAL is a good trial-by-fire exercise because most people have done it themselves at some point, and if you’re like us, you’ve likely done it without giving it much thought early in your career.
Before wrapping up our journey into data access, we’d be remiss to neglect the deployment aspect of the subject.
11.6. Improving the deployment story
Regardless of the solution that you choose, or are moving to, for your data access layer, one of the primary friction points on brownfield projects is the consistent and correct deployment of data access components. We’ve regularly worked on projects where releases to testing, and even production, have sent incorrect versions of vital assemblies or stored procedures, or sometimes were never even sent at all. These release failures are unacceptable. Nothing sours relationships between clients and testers and the development team faster than poor releases or regression errors (errors that were fixed in a previous release but that have recurred).
The first topic is a comparison of stored procedures versus inline SQL statements with respect to application deployment.
11.6.1. Stored procedures versus inline SQL statements
Each data access technique from section 11.5 offers costs and benefits to the deployment story. Some say that stored procedures are easier to manage because they can be deployed separately from the main application. This deployment benefit is achieved only if joint deployments (both the application and the stored procedures) are well managed and performed correctly all the time. Independent deployments are only as good as your ability to test the production configuration with the stored procedure to be released. If you can’t perform that integration testing with confidence, you can’t be sure that the deployment will be effective and trouble free. Brownfield applications in particular are susceptible to deployments without the means to properly test.
At the other end of the spectrum, inline SQL statements in your application eliminate the need for the integration concerns that were pointed out for stored procedures. They also provide an easier application deployment because all the data access artifacts are contained within the assemblies to be deployed. Deployment of hot fixes will, however, require you to deploy application components instead of just a database-level component.
A system that uses an ORM is similar to one that uses inline SQL statements. Deployment is simpler because you need only release the required third-party assemblies correctly. But by the same token, changes to the database typically require a redeployment of the application as you need to update the mapping between the database and the object model.
Another aspect of deployment is how you manage different versions of your database.
11.6.2. Versioning the database
Changes to your database (such as new tables or modified columns) are common during the life of an application. When they occur, they’re often a source of frustration during deployment. You must remember to execute update scripts in a certain order, and if anything goes wrong, the database can be left in an unknown state. Having a deployment process in place that will support schema changes with minimal effort is essential for the long-term maintenance and multirelease requirements of many applications.
Luckily, there are tools out there, both open source and commercial, that will help solve this deployment problem. Some will automate a good portion of the database versioning by comparing an existing production database with the development database and generating the change scripts. Others require you to create the scripts but will automate their execution and may offer the ability to roll back if any one of them fails. Almost all of these tools are useful in some way, and we encourage you to investigate them. Some examples include Red Gate’s SQL Compare, Ruby on Rails Migrations, the Tarantino project, and Migrator.NET.
The best way we’ve found to use these tools is to integrate them into the release portion of your automated build script (see section 3.7 in chapter 3 for more on using automated builds for releases). If your release process automatically creates all the required scripts for the next release and you’re continually applying these scripts through the automated build process, the pain of datastore changes will be greatly mitigated on your project.
Finally, let’s talk about a common issue with brownfield application deployments: connection strings.
11.6.3. Managing connection strings
One of the most common data-related failures is an incorrect connection string. For example, you deploy the application to the test environment with a connection string that points to the development database.
No matter how much you abstract away your connection string management, somehow your application needs to know which database to communicate with. Short of hard-coding a map of deployment servers to database names, addressing this problem involves updating a configuration file or two. And we’re willing to bet that you have, at some point in your career, deployed an application without remembering to update a configuration file.
The deployment of connection information isn’t necessarily a data access concern; it’s related to release management. Any time a configuration differs from one environment to another, it’s ripe for automation during the deployment process.
For example, say you store your connection string in the <connectionstrings> section of your app.config. A basic way to handle connection strings in a multi-environment scenario is to create three app.config files (one for dev, one for test, and one for prod) somewhere in your folder structure. Each one would contain the appropriate connection string in the <connectionstrings> section. Then you could create a “deploy to test” task in your automated build that would copy the appropriate app.config file to the appropriate folder before compiling the application for deployment to test.
Although somewhat of a brute-force method, this technique is still an effective way of ensuring the application is properly configured for the target environment. At the very least, it removes “update the app.config file” from the list of deployment steps.
When looking at data access techniques for your brownfield application, don’t forget to evaluate the current deployment story as well as how that story will change if you decide to use a different DAL technique. Deployments are often the forgotten part of the application development process. Data access deployment seems to be the most forgotten and, as a result, the most problematic. Paying close attention to this area on your project will pay dividends in developer and client happiness.
11.7. Summary
This chapter explored one of the most commonly written components of projects. Data access is also one of the most complex components that you write for your applications. As a result, it’s the bane of many a brownfield project’s existence.
This chapter pulled together quite a few techniques from previous chapters. Using these methods, along with performing a thorough examination of the needs of the application, will go a long way to reworking flawed or failed code. In this chapter we talked extensively about the fundamentals of a good data access layer. These fundamentals will guide you toward the best possible solution for your project. Applying those fundamental concepts to the three main types of data access techniques (hand-rolled, code-generated, and ORM) is a major step in determining both if your current solution is sound and if another solution is viable.
With all the data access-specific content you learned in this chapter, don’t forget about the fundamental practices that we outlined in the rest of the book. Understand that you’ll have to release the data access components to one or more environments and what that will entail. Remember that working in isolation, both behind an interface and in an isolated area of your version control system, will allow you to work through issues without severely impacting the current development effort.
Finally, don’t forget that doing anything with confidence is of the utmost importance. The developers working on any new data access code must be confident that what they’re building is working. Your project team, and the client as well, need to be confident that the changes you make won’t result in regression issues. The best way to build this confidence is through the use of well-written automated tests, which is another one of the fundamental techniques we covered at the start of the book.
Reworking, rewriting, or replacing a data access layer can be an intimidating task. The ideas and information we presented in this chapter will reduce any apprehension that you may have when working in this area of your brownfield project.
In the next chapter, we’ll move to an area that often causes problems in brownfield applications: how to handle external dependencies.