
Software Is a Virtual Computer
Unlike many words in the vocabulary of computing, virtual has more or less retained its standard English definition: "That is so in essence or effect, although not formally or actually; admitting of being called by the name so far as the effect or result is concerned."[9] In other words, a virtual computer would be something that acts just like a computer, but really isn't one. Who would want such a thing?
[9] Oxford English Dictionary, first current definition (4).
Apparently everyone, since virtual computer is just another name for what we have been calling software. This may seem a rash statement, but it really isn't. One of the most important mathematical discoveries (inventions?) of the twentieth century was Alan Turing's demonstration in 1936 that it was possible to create a fairly simple computing device (called a Turing machine for some obscure reason) that could imitate any other computing device. This machine works in the following way: You provide it with a description of the other computer you want it to imitate and it follows those directions. Suppose we want a computer that calculates only trigonometric functions. We could theoretically write a set of instructions as to how such a computer would behave, feed it into a Turing machine and have the Turing machine imitate the behavior of this theoretical "trigonometric computer".
Susan was quite impressed by this achievement:
This is undoubtedly interesting, but you may be wondering what it has to do with programming. Well, what do we do when we write a program? In the case of our pumpkin weighing program, we're describing the actions that would be taken by a hypothetical "pumpkin weighing computer". When we run the program, the real computer simulates these actions. In other words, we have created a virtual pumpkin weighing computer.
The same analysis applies to any program. A program can most fundamentally be defined as instructions to a "universal computer", telling it how to simulate the specialized computer you actually want to use. When the universal computer executes these instructions, it behaves exactly as the hypothetical specialized computer would.
Of course, actual computers aren't really universal; they have limits in the amount of memory or disk space they contain and the speed of their execution. However, for problems that can be solved within those limits, they are truly universal computing devices that can be tailored to a particular problem by programming.
Object Files
Now let's take a look at one of these areas of software technology. We've already seen that the function of a compiler is to convert our human-readable C++ program into machine instructions that can be executed by the computer. However, the compiler doesn't actually produce an executable program that can stand by itself; instead, it translates each implementation file into a machine language file called an object code module (or object file). This file contains the instructions that correspond to the source code statements you've written, but not the "infrastructure" needed to allow them to be executed. We'll see what that infrastructure does for us shortly.
The creation of an object file rather than a complete executable program isn't a universal characteristic of compilers, dictated by nature. In fact, one of the most popular compilers in the early history of the PC, the Turbo Pascal™ compiler, did create an executable file directly from source code. This appears much simpler, so we have to ask why this approach has been abandoned with C++. As I've mentioned before, C++ was intended to be useful in writing large programs. Such programs can consist of hundreds or even thousands of modules (sections of source code) each containing hundreds or thousands of lines of code. Once all the modules are compiled, the object files resulting from the compilation are run through a program called the linker. The linker combines information from all of the object files, along with some previously prepared files called library modules (or libraries), to produce an executable program; this is called linking the program. One reason for this two-step approach is that we wouldn't want to have to recompile every module in a large program every time we made a change in one section; therefore, only those modules that have been affected are recompiled.[10] When all of the affected modules have been recompiled, the program is relinked to produce an updated executable.
[10] The alert reader may wonder why I referred to modules that have been “affected" rather than “changed". The reason is that even if we don't change a particular module, we must recompile it if a header file that it uses is changed. This is a serious maintenance problem in large systems but can be handled by special programming methods which are beyond the scope of this book.
To make such a system work, it's necessary to set up conventions as to which parts will be executed first, where data needed by more than one module will be stored, and so on. Also, a lot of operations aren't supplied as part of the language itself but are very handy in writing programs, such as the I/O functions that we've already seen. These make up the infrastructure needed to execute C++ programs.
Figure 5.6 is a picture of the process of turning source code into an executable file.

Susan found this explanation and diagram to be helpful.
Susan: This is beginning to come into focus. So you write your source code, it has a middle man called an object file and that just passes the buck over to a linker, which gathers info the program may need from the libraries, and then the program is ready to be read by the machine. Close?
Operating System Facilities
As is often the case in programming, this infrastructure is divided into several layers, the higher ones depending on the lower ones for more fundamental services. The lowest level of the infrastructure is supplied by the operating system, a program that deals with the actual hardware of your computer. By far the most common operating system for Intel® CPUs, as this is written, is some variant of Microsoft Windows, with Linux® in a distant second place. All of these provide some of the same facilities; for example, you are accustomed to dealing with files and directories when using application programs such as word processors and spreadsheets. However, the disk drive in your computer doesn't know anything about files or directories. As we have seen in Chapter 2, all it can do is store and retrieve fixed-size pieces of data called sectors, given an absolute address on the disk described by a platter, track number, and sector number. Files are a creation of the operating system, which keeps track of which parts of which files are stored where on the disk.[11]
[11] You might say that files are "virtual"; that is, they're a figment of the operating system's imagination. Nonetheless, they are quite useful. This reminds me of the story about the man who went to a doctor, complaining that his brother had thought he was a hen for many years. The doctor asked why the family hadn't tried to help the brother before and the man replied, "We needed the eggs".
A modern operating system provides many more facilities than just keeping track of file storage. For example, it arranges for code and data to be stored in separate areas of RAM with different access rights, so that code can't be accidentally overwritten by a runaway program; that is, one that writes outside the memory areas it is supposed to use. This is a valuable service, as errors of this kind are quite difficult to find and can cause havoc when they occur.
That's the good news. The bad news is that MS-DOS, which is still the basis of all versions of Windows before Windows NT® and Windows 2000®, was created before the widespread availability of reasonably priced CPUs with memory protection facilities. For this reason, when using those earlier operating systems, it's entirely possible for a runaway program to destroy anything else in memory. Theoretically, we should all be running "real" operating systems by the time you read this; so far, though, the rumors of the demise of MS-DOS have been greatly exaggerated.
This notion intrigued Susan. Here's how that conversation went:
Susan: What is a runaway program?
Steve: One that is writing in areas that it shouldn't, thus destroying data or programs outside its assigned memory areas.
Susan: How would an operating system actually separate code from data areas? Would it be a physical thing?
Steve: What makes this possible are certain hardware mechanisms built into all modern CPUs, so that certain areas of memory can be assigned to specific programs for use in predefined ways. When these mechanisms are used, a program can't write (or read, in some cases) outside its assigned area. This prevents one program from interfering with another.
Library Modules
The next level of the infrastructure is supplied by the aforementioned library modules, which contain standardized segments of code that can perform I/O, mathematical functions, and other commonly used operations. So far, we have used the iostream and string parts of the C++ standard library, which provided the keyboard input and screen output in our example programs.[12] We've also relied implicitly on the "startup" library, which sets up the conditions necessary for any C++ program to execute properly.
[12] We've also used the vector part of the library indirectly, through my Vec type.
Susan wanted to know how we were using the startup library:
Susan: I don't know what you are talking about when you say that we have also used a startup library. When did we do that? At startup? Well, is it something that you are actually using without knowing you are using it?
Steve: Yes. It initializes the I/O system and generally makes the environment safe for C++ programs; they're more fragile than assembly language programs and have to have everything set up for them before they can venture out.
To understand the necessity for the startup library, we have to take a look at the way variables are assigned to memory locations. So far, we have just assumed that a particular variable had a certain address, but how is this address determined in the real world?
There are several possible ways for this to occur; the particular one employed for any given variable is determined by the variable's storage class. The simplest of these is the static storage class; variables of this class are assigned memory addresses in the executable program when the program is linked. The most common way to put a variable in the static storage class is to define it outside any function.[13] Such a variable will be initialized only once before main starts executing. We can specify the initial value if we wish; if we don't specify it, a default value (0 for numeric variables) will be assigned.[14] An example of such a definition would be writing the line short x = 3; outside any function; this would cause x to be set to 3 before main starts executing. We can change the value of such a variable whenever we wish, just as with any other variable. The distinction I'm making here is that a static variable is always initialized before main begins executing. As you will see, this seemingly obvious characteristic of static variables is not shared with variables of other storage classes.
[13] Another way to make a variable static is to state explicitly that the variable is static. However, this only works for variables defined inside functions. The keyword static is not used to specify that variables defined outside any function variable are statically allocated; since globals are always statically allocated, the keyword static means something different when applied to a global variable or function. Even though we won't be using static for global variables or functions, it's possible that you will run into it in other programs so it might be useful for you to have some idea of its meaning in those situations. An approximate translation of static for global functions or variables is that the function or variable is available for use only in the same file where it is defined, following the point of its definition.
[14] You can count on this because it's part of the language definition, although it's nicer for the next programmer if you specify what you mean explicitly.
This idea of assigning storage at link time led to the following discussion with Susan:
Susan: If you declare a variable with only one value then it isn't a variable anymore, is it?
Steve: A static variable can have its value changed, so it's a genuine variable. I was saying that it's possible to specify what its initial value should be before main starts executing.
Susan: Are you trying to say where in memory this variable is to be stored? Isn't the compiler supposed to worry about that?
Steve: I'm not specifying a location, but rather an attribute of the variable. A static variable behaves differently from the "normal" variables that we've seen up till now. One difference is that a static variable is always initialized to a known value before main starts executing.
Why All Variables Aren't Automatically Initialized
The notion of storage classes is essential to the solution of another mystery. You may recall that I mentioned some time ago that C++ doesn't provide automatic initialization of all variables because that facility would make a program bigger and slower. I'll admit that the truth of this isn't intuitively obvious to the casual observer; after all, a variable (or more exactly, the storage location it occupies) has to have some value, so why not something reasonable? As we have just seen, this is done for static variables. However, there is another storage class for which such a facility isn't quite as easy or inexpensive to implement;[15] that's the auto (short for "automatic") storage class, which is the default class used for variables defined in functions. An auto variable does not actually exist until the function in which it is defined starts execution and even then has no known value until we specifically assign a value to it.[16]
[15] "Inexpensive", in programming parlance, means "not using up much time and/or space".
[16] I'm oversimplifying a bit here. Variables can actually be declared inside any block, not just any function. An auto variable that is declared inside a block is born when the block is entered and lives until that block is finished executing. A static variable that is declared inside a block is initialized when that block is entered for the first time. It retains its value from that point on unless it is explicitly changed, as with any other statically allocated variable.
This notion led to a fair amount of discussion with Susan.
Susan: Then so far I know about two types of variables, static and auto, is this correct?
Steve: Right, those are the two "storage classes" that we've talked about so far.
Susan: The auto variables are made up of garbage and the static variables are made up of something understandable, right?
Steve: The auto variables are uninitialized by default, and the static variables are initialized to 0 (if they're numeric, at least).
Susan: When you say that the auto class is used for functions by default does this mean you don't use static ones ever?
Steve: Default means "what you get if you don't specify otherwise". For example, these days, if you buy almost any type of car and don't specify that you want a manual transmission, you will get an automatic, so automatic transmissions are the default.
Susan: So, since we have used auto variables up to this point, then I am confused when we initialize them to a value. If we do, would that not make them static?
Steve: This is a difficult topic, so it's not surprising that you're having trouble. I didn't realize quite how difficult it was until I tried to answer your question and ended up with the essay found under the heading “Automatic vs. Static Allocation” on page 264.
Susan: How do you know what the address will be to assign to a variable? OK, I mean this makes it sound like you, the programmer, know exactly which address in memory will be used for the variable and you assign it to that location.
Steve: You don't have to know the address; however, you do have to know that the address is fixed at link time. That's what makes it possible to initialize a static variable before main starts (if outside all functions), or just once the first time its definition is encountered (if inside a function). On the other hand, an auto variable can't be initialized until the beginning of each execution of the function in which it is defined, because its address can change between executions of the function.
Susan: I am having a hard time trying to figure out what you mean by using static variables outside functions. I have meant to ask you this, is main really a function even if you don't have anything to call? For example, in the first pumpkin weighing program, we didn't have to call another function but I have been wondering if main is really a function that just has nothing to call? So in that case, the variables used in main would be auto?
Steve: You are correct that main is a function. To be precise, it's the first function executed in any C++ program.[17] If it calls other functions, that's fine, but it doesn't have to. As with any other function, the variables used in main are auto by default; in the case of the pumpkin weighing program, since we didn't make any of them static, they're all auto in fact.
[17] As I have noted before, this is actually an oversimplification. It is possible to write programs where some of our code is executed before the beginning of main. I'll explain how this can be done (and why) in the section entitled “Executing Code before the Beginning of main” on page 740, but we won't actually make use of such a facility in this book.
So far, all of our variables have been auto, and in most programs the vast majority of all variables are of this class.[18] Why should we use these variables when static ones have an initialization feature built in?
[18] You may have noticed that we haven't defined any variables as auto. That's because any variables defined within a function and not marked as static are set to the default class, auto.
The first clue to this mystery is in the name auto. When we define a variable of the auto class, its address is assigned automatically when its function is entered; the address is valid for the duration of that function.[19] Since the address of the variable isn't known until its function is entered, it can't be initialized until then, unlike the case with static variables. Therefore, if auto variables were automatically initialized, every function would have to start with some extra code to initialize every auto variable, which would make the program both slower and larger. Since Bjarne Stroustrup's design goals required that a C++ program should have the same run-time performance as a C program and as little space overhead as possible, such a feature was unacceptable. Luckily, forgetting to initialize an auto variable is something that can be detected at compile time, so it's possible for the compiler to warn us if we make this error. In general, it's a good idea to tell the compiler to warn you about dubious practices. Although not all of them may be real errors, some will be and this is by far the fastest and best way to find them.[20]
[19] This is why variables defined outside a function are static rather than auto; if they were auto, when would their addresses be assigned?
[20] There are also commercial tools that help locate errors of this type, as well as other errors, by analyzing the source code for inconsistencies.
Now we've seen why auto variables aren't initialized by default: Their addresses aren't known until entering the function in which they're defined. But that doesn't explain the advantage of assigning the addresses then. Wouldn't it be simpler (and faster) to assign them all during the linking process, as is done with static variables?
Nested Functions
To understand why auto variables aren't assigned addresses during the linking process, we have to look at the way functions relate to one another. In particular, it is very common for a statement in one function to call another function; this is called nesting functions and can continue to any number of levels.
Susan explained this in her inimitable way:
Susan: Nesting of functions—does that mean a whole bunch of functions calling each other?
Steve: Not exactly. Usually functions don't call one another.[21] Nesting of functions actually means one function calling another function, which in turn calls another function, and so on.
[21] There are cases in which functions call one another, e.g., one function calls a second function, which calls the first function. However, we won't see any examples of this recursion in this book.
Although functions can and often do call other functions, it is very unlikely that every function in a large program will be in the midst of execution at any given time. This means that reserving space in the executable program for all of the variables in all of the functions will make that executable considerably larger than it otherwise would be.
If we had only static variables, this wasteful situation would indeed occur. The alternative, of course, is to use auto variables, which as we have just noted are assigned storage at run time. But where is that storage assigned, if not in the executable program?
While all static variables are assigned storage in the executable program when it is linked, auto variables are instead stored in a data structure called a stack; the name is intended to suggest the notion of stacking clean plates on a spring-loaded holder such as you might see in a cafeteria. The last plate deposited on the stack of plates will be the first one to be removed when a customer needs a fresh plate. Back in the world of programming, a stack with one entry might look something like Figure 5.7.
Figure 5.7. A stack with one entry

If we add (or push) another value on to the stack, say 999, the result would look like Figure 5.8.
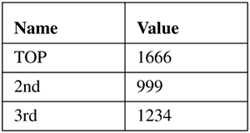
Figure 5.8. A stack with two entries

If we were to push one more item with the value 1666, the result would look like Figure 5.9. Now, if we retrieve (or pop) a value, we'll get the one on top; namely 1666. Then the stack will look like it did in Figure 5.8. The next value to be popped off the stack will be the 999, leaving us with the situation in Figure 5.7 again. If we continue for one more round we'll get the value 1234, leaving us with an empty stack.
Figure 5.9. A stack with three entries
The reason that stacks are used to store auto variables is that the way items are pushed onto or popped off a stack exactly parallels what happens when one function calls another.
Susan had a question about stacks:
Susan: How many things can you push on the stack?
Steve: That depends on what kind of compiler you have, what operating system you are using and how much memory you have in your machine. With a 32-bit compiler running on a modern operating system and a modern PC, you might be able to store several million items on the stack before you run out of space.
Let's look at this stack idea again, but this time from the point of view of keeping track of where we are in one function when it calls another one, as well as allocating storage for auto variables.[22]
[22] The actual memory locations used to hold the items in the stack are just like any other locations in RAM; what makes them part of the stack is how they are used. Of course, as always, one memory location can hold only one item at a given time, so the locations used to hold entries on the stack cannot be simultaneously used for something else like machine instructions.
Returning to the Calling Function
In Figure 5.5, there are two calls to the function Average: The first one is used to average two weights and the other to average two ages. One point I didn't stress was exactly how the Average function "knew" which call was which; that is, how did Average return to the right place after each time it was called? In principle, the answer is fairly simple: The calling function somehow notifies the called function of the address of the next instruction that should be executed after the called function is finished (the return address). There are several possible ways to solve this problem. The simplest solution is to store the return address at some standardized position in the code of the called function; at the end of the called function, that address is used to get back to the caller. While this used to be standard practice, it has a number of drawbacks that have relegated it to the history books. A major problem with this approach is that it requires changing data that are stored with the code of the called routine. As we've already seen, when running a program on a modern CPU under a modern operating system, code and data areas of memory are treated differently and changing the contents of code areas at run time is not allowed.
Luckily, there is another convenient place to store return addresses: on the stack. This is such an important mechanism that all modern CPUs have a dedicated register, usually called the stack pointer, to make it easy and efficient to store and retrieve return addresses and other data that are of interest only during the execution of a particular function. In the case of the Intel CPUs, the stack pointer's name is esp.[23] A machine instruction named call is designed to push the return address on the stack and jump to the beginning of the function being called.[24] The call instruction isn't very complex in its operation, but before going into that explanation, you'll need some background information about how the CPU executes instructions.
[23] That's the 32-bit stack pointer. As in the case of the other registers, there's a 16-bit stack pointer called sp, which consists of the 16 lower bits of the "real" stack pointer esp.
[24] That is, its name is call on Intel machines and many others; all modern CPUs have an equivalent instruction, although it may have a different name.
How does the CPU "know" what instruction is the next to be executed? By using another dedicated register that we haven't discussed before, the program counter, which holds the address of the next instruction to be executed. Normally, this is the instruction physically following the one currently being executed; however, when we want to change the sequence of execution, as in an if statement or a function call, the program counter is loaded with the address of the instruction that logically follows the present one. Whatever instruction is at the address specified in the program counter is by definition the next instruction that will be executed; therefore, changing the address in the program counter to the address of any instruction causes that instruction to be the next one to be executed.
Here are the actual steps that the call instruction performs:
1. | It saves the contents of the program counter on the stack. |
2. | Then it loads the program counter with the address of the first instruction of the called function. |
What does this sequence of events achieve? Well, since the program counter always points to the next instruction to be executed, the address stored on the stack by the first step is the address of the next instruction after the call. Therefore, the last instruction in the called function can resume execution of the calling function by loading the program counter with the stored value on the stack. This will restart execution of the calling function at the next instruction after the call, which is exactly what we want to achieve.
The effect of the second step is to continue execution of the program with the first instruction of the called function; that's because the program counter is the register that specifies the address of the next instruction to be executed.
The Layout of Data in a Stack
As we'll see, the actual way that a stack is implemented is a bit different than is suggested by the "stack of plates" analogy, although the effect is exactly the same. Rather than keeping the top of the stack where it is and moving the data (a slow operation), the data are left where they are and the address stored in the stack pointer is changed, which is a much faster operation. In other words, whatever address the stack pointer is pointing to is by definition the top of the stack.
Before we get started on this analysis, here are some tips on how to interpret the stack diagrams. First, please note that the range of addresses that the stack occupies in these diagrams (given in hexadecimal) is arbitrary. The actual address where the stack is located in your program is determined by the linker and the operating system.
Next, the "Top of Stack" address, that is, the address where the stack pointer is pointing, will be in bold type. Also note that when we push items on the stack the stack pointer will move upward in the diagram. That's because lower addresses appear first in the diagram, and new items pushed onto the stack go at lower addresses. Anything in the diagram "above" the stack pointer (i.e., at a lower address than the stack pointer's current value) is not a meaningful value, as indicated in the "meaning" column.
Now let's suppose we start with an empty stack, with the stack pointer at 20001ffe, and ???? to indicate that we don't know the contents of that memory location. Thus, the stack will look like Figure 5.10.
Figure 5.10. An empty stack

Then, the user types in the two values "2" and "4" as the values of FirstWeight and SecondWeight, and the first call to Average occurs; let's suppose that call is at location 10001000. In that case, the actual sequence of events is something like this, although it will vary according to the compiler you are using:
The address of the next instruction to be executed (say, 10001005) is pushed onto the stack, along with the values for the arguments First and Second, which are copies of the arguments FirstWeight and SecondWeight. In the process, the CPU will subtract eight (the size of one address added to the size of two shorts, in bytes) from the stack pointer (which is then 20001ff6) and store the return address at the address currently pointed to by the stack pointer. Thus, the stack looks like Figure 5.11.
Execution starts in the Average function. However, before the code we write can be executed, we have to reserve space on the stack for the auto variable(s) defined in Average (other than the arguments First and Second, which have already been allocated); in this case, there is only one, namely Result. Since this variable is a short it takes 2 bytes, so the stack pointer has to be reduced by 2.

After this operation is completed, the stack will look like Figure 5.12
Wait a minute. What are those ???? doing at location 20001ff4? They represent an uninitialized memory location. We don't know what's in that location, because that depends on what it was used for previously, which could be almost anything. The C++ compiler uses stack-based addressing for auto variables, as well as copies of arguments passed in from the calling function. That is, the addresses of such variables are relative to the stack pointer, rather than being fixed addresses. In this case, the address of Result would be [esp], or the current value of the stack pointer; Second would be referred to in the object file as [esp+6] (i.e, 6 more than the current value of the stack pointer, to leave room for the return address and Result). Similarly, the address of First would be [esp+8], or 8 more than the current value of the stack pointer.[25] Since the actual addresses occupied by these variables aren't known until the setup code at the beginning of the function is actually executed, there's no way to clear the variables out before then. That's why auto variables aren't automatically initialized.
[25] The actual mechanism used to refer to variables on the stack in a real compiler is likely to be different from this one and indeed can vary among compilers. However, this implementation is similar in principle to the mechanisms used by compiler writers.
Figure 5.12. The stack after auto variable allocation

As you might have guessed, Susan and I went over this in gory detail. Here's the play by play.
Susan: Yes, I think this is what has confused me in the past about functions. I never fully understood how the mechanism worked as how one function calls another. I still don't. But I guess it is by the position of the next address in a stack?
Steve: The stack is used to pass arguments and get return values from functions, but its most important use is to keep track of the return address where the calling function is supposed to continue after the called function is done.
Susan: This is how I am visualizing the use of the stack pointer. In one of my other books it showed how the clock worked in the CPU and it seemed to cycle by pointing in different directions as to what was to happen next in a program. So it was sort of a pointer. Is this how this pointer works? So let me get this straight. All CPUs have some kind of stack pointer, but they are used only for calling functions? Exactly where is the instruction call? It sounds to me like it is in the hardware, and I am having a very difficult time understanding how a piece of hardware can have an instruction.
Steve: All of the instructions executed in a program are executed by the hardware. The call instruction, in particular, does two things:
1.It saves the address of the next instruction (the contents of the program counter) on the stack.
2. It changes the program counter to point to the first instruction of the called function.
The return instruction is used to return to the calling function. It does this by the following steps:
[26] Note that the compiler may be required to adjust the stack pointer before retrieving the saved value of the program counter, to allow for the space used by local variables in the function. In our example, we have to add 2 to the esp register to skip over the local variable storage and point to the return address saved on the stack.
The result of this is that execution of the program continues with the next instruction in the calling function.
Susan: Are you saying that, rather than the pointer of a stack actually pointing to the top of the physical stack, wherever it points to by definition will be the top of the stack, even if it really doesn't look like it?
Susan: Now I see why we have to know what a short is. So then the pointer is pointing to 20001ff4 as the top of the stack even though it doesn't look like it?