
C String Literals vs. strings
Susan had some questions about these objectives. Here's the discussion.
Susan: What is the difference between C string literals and variables of the string class?
Steve: A variable of the standard string class is what you've been using to store variable-length alphanumeric data. You can copy them, input them from the keyboard, assign values to them, and the like. By contrast, a C string literal is just a bunch of characters in a row; all you can do with it is display it or assign it to a string variable.
Susan: OK, then you are saying that variables of the string class are what I am used to working with. On the other hand, a C string literal is just some nonsense that you want me to learn to assign to something that might make sense? OK, this is great; sure, this is logical. Hey, a C string literal must be a part of the native language?
Steve: Right all the way along.
Susan: Yes, but why would something so basic as string not be part of the native language? This is what I don't understand. And Vecs too; even though they are difficult, I can see that they are a very necessary evil. So tell me why those basic things would not be part of the native language?
Steve: That's a very good question. That decision was made to keep the C++ language itself as simple as possible.[1] So rather than include those data types directly in the language, they were added as part of the standard library.
[1] Which, unfortunately for compiler writers, isn't very simple.
Before we get into how to create a string class like the one we've been using in this book, I should expand on the answer I gave Susan as to why string isn't a native type in the first place. One of the design goals of C++, as of C, was to allow the language to be moved, or ported, from one machine type to another as easily as possible. Since strings, vectors, and so on can be written in C++ (i.e., created out of the more elementary parts of the language), they don't have to be built in. This reduces the amount of effort needed to port C++ to a new machine or operating system. In addition, some applications don't need and can't afford anything but the barest essentials; "embedded" CPUs such as those in cameras, VCRs, elevators, or microwave ovens, are probably the most important examples of such applications, and such devices are much more common than "real" computers.
Even though the standard library strings aren't native, we've been using them for some time already without having to concern ourselves with that fact, so it should be fairly obvious that such a class provides the facilities of a concrete data type; that is, one whose objects can be created, copied, assigned, and destroyed as though they were native variables. You may recall from the discussion starting in the section entitled “Concrete Data Types” on page 305 that such data types need a default constructor, a copy constructor, an assignment operator, and a destructor. To refresh your memory, here's the description of each of these member functions:
A default constructor creates an object when there is no initial value specified for the object.
A copy constructor makes a new object with the same contents as an existing object of the same type.
An assignment operator sets an existing object to the value of another object of the same type.
A destructor cleans up when an object expires; for a local object, this occurs at the end of the block where it was created.
In the StockItem and Inventory class definitions that we've created up to this point, the compiler-generated versions of these functions were fine for all but the default constructor. In the case of our string class, though, we're going to have to create our own versions of all four of these functions, for reasons that will become apparent as we examine their implementations in this chapter and the next one.
Before we can implement these member functions for our string class, though, we have to define exactly what a string is. A string class is a data type that gives us the following capabilities in addition to those facilities that every concrete data type provides:
We can set a string to a literal value like "abc".
We can display a string on the screen with the << operator.
We can read a string in from the keyboard with the >> operator.
We can compare two strings to find out whether they are equal.
We can compare two strings to find out which is "less than" the other; that is, which one would come first in the dictionary.
We'll see how all of these capabilities work sometime in this chapter or the next one. But for now, let's start with Figure 7.1, a simplified version of the interface specification for our string class that includes the specification of the four member functions needed for a concrete data type, as well as a special constructor that is specific to the string class. I strongly recommend that you print out the files that contain this interface and its implementation, as well as the test program, for reference as you are going through this part of the chapter. Those files are string1.h, string1.cpp, and strtst1.cpp, respectively.
Figure 7.1. Our string class interface, initial version (codestring1.h)
class string
{
public:
string();
string(const string& Str);
string& operator = (const string& Str);
~string();
string(char* p);
private:
short m_Length;
char* m_Data;
};
|
The first four member functions in that interface are the standard concrete data type functions. In order, they are
The default constructor
The copy constructor
The assignment operator, operator =
The destructor
I've been instructed by Susan to let you see all of the code that implements this initial version of our string class at once before we start to analyze it. Of course I've done so, and Figure 7.2 is the result.
Figure 7.2. The initial implementation for the string class (codestring1.cpp)
#include <cstring>
using std::memcpy;
using std::strlen;
#include "string1.h"
string::string()
: m_Length(1),
m_Data(new char [m_Length])
{
memcpy(m_Data,"",m_Length);
}
string::string(const string& Str)
: m_Length(Str.m_Length),
m_Data(new char [m_Length])
{
memcpy(m_Data,Str.m_Data,m_Length);
}
string::string(char* p)
: m_Length(strlen(p) + 1),
m_Data(new char [m_Length])
{
memcpy(m_Data,p,m_Length);
}
string& string::operator = (const string& Str)
{
char* temp = new char[Str.m_Length];
m_Length = Str.m_Length;
memcpy(temp,Str.m_Data,m_Length);
delete [ ] m_Data;
m_Data = temp;
return *this;
}
string::~string()
{
delete [ ] m_Data;
}
|
The first odd thing about that implementation file is the #include <cstring>. So far, we've been using #include <string> to tell the compiler that we want to use the standard C++ library string class. So what is <cstring>?
It's a leftover from C that defines a number of functions that we will need to implement our own string class, primarily having to do with memory allocation and copying of data from one place to another. It used to be called <string.h>, and in fact you can still refer to it by that name, but all of the C standard library header files have now been renamed to follow the new C++ standard of no extension. For your reference, the new name for every C standard library header file consists of the old name with the “.h” removed and a “c” added to the beginning.
As for #include "string1.h", as you can tell from the “” around the name, that's one of our own header files; in this case, it's the header file where we declare the interface for the first version of our string class.
There's one more thing I should explain about the programs in this chapter and the next: they don't include the usual line using namespace std;. This is because we're not using the standard library string class in these programs. If we were to include that line, the compiler would complain that it couldn't tell which string class we were referring to, the one from the standard library or the one that we are defining ourselves.
Now that I hope I've cleared up any possible confusion about those topics, let's start our examination of our version of string by looking at the default constructor. Figure 7.3 shows its implementation.
Figure 7.3. The default constructor for our string class (from codestring1.cpp)
string::string()
: m_Length(1),
m_Data(new char [m_Length])
{
memcpy(m_Data,"",m_Length);
}
|
The member initialization list in this constructor contains two expressions. The first of them, m_Length(1), isn't very complicated at all. It simply sets the length of our new string to 1. However, this may seem a bit odd; why do we need any characters at all for a string that has no value? The answer to this riddle is quite simple, but to understand it you'll need to know something about a data type we haven't really discussed fully as yet: the C string.
We've been using one specific variety of that type, the C string literal, for quite awhile now. A C string literal is just a literal sequence of characters terminated by a null byte. A C string is exactly the same, except that it isn't necessarily defined literally. That is, a C string is a sequence of characters, whether or not literally specified, terminated by a null byte.
Why do we need to worry about this now when we have been able to ignore it up to this point? Because many pre-existing C functions that we may want to use in our programs use C strings rather than C++ strings. So, to make our strings as compatible as possible with those pre-existing C functions, we need to include the null byte that terminates all C strings. This means that when we calculate the number of bytes needed to hold the data for a string, we need to reserve one extra byte of memory beyond the number needed to hold the actual contents of the string. In the current case of a zero-character string, this means that we need one byte of storage for the null byte.
Next, it's important to note that this is an example where the order of execution of member initializer expressions is important: we definitely want m_Length to be initialized before m_Data, because the amount of data being assigned to m_Data depends on the value of m_Length. As you may remember from Chapter 6, the order in which the initialization expressions are executed is dependent not on the order in which they are written in the list, but on the order in which the member variables being initialized are declared in the class interface definition. Therefore, it's important to make sure that the order in which those member variables are declared is correct. In this case, it is, because m_Length is declared before m_Data in string1.h.
Susan had a very good question at this point.
Susan: If the program might not work right if we mess up the order of initialization, why isn't it an error to do that? Can't the compiler tell?
Steve: Very good point. It seems to me that the compiler should be able to tell and perhaps some of them do. But the one on the CD in the back of the book doesn't seem to mind if I write the initialization expressions in a different order than the way they will actually be executed.
Before proceeding to the next member initialization expression, let's take a look at the characteristics of the variables that we're using here. The scope of these variables, as we know from our previous discussion of the StockItem class, is class scope; therefore, each object of the string class has its own set of these variables, and they are accessible from any member functions of the class as though they were global variables.
However, an equally important characteristic of each of these variables is its data type. The type of m_Length is short, which is a type we've encountered before (a 16-bit integer variable that can hold a number between -32768 and 32767). But what about the type of the other member variable, m_Data, which is listed in Figure 7.1 as char*? We know what a char is, but what does that * mean?
Pointers
The star means pointer, which is just another term for a memory address. In particular, char* (pronounced "char star") means "pointer to a char".[2] The pointer is considered one of the most difficult concepts for beginning programmers to grasp, but you shouldn't have any trouble understanding its definition if you've been following the discussion so far. A pointer is the address of some data item in memory. That is, to say "a variable points to a memory location" is almost exactly the same as saying "a variable's value is the address of a memory location". In the specific case of a variable x of type char*, for example, to say "x points to a C string" is exactly the same as saying "x contains the address of the first byte of the C string."[3] The m_Data variable is used to hold the address of the first char of the data that a string contains; the rest of the characters follow the first character at consecutively higher locations in memory.
[2] By the way, char* can also be written as char *, but I find it clearer to attach the * to the data type being pointed to.
[3] C programmers are likely to object that a pointer has some properties that differ from those of a memory address. Technically, they're right, but in the specific case of char* the differences between a pointer and a memory address will never matter to us.
If this sounds familiar, it should. A C string literal like "hello" consists of a number of chars in consecutive memory locations; it should come as no surprise, then, when I tell you that a C string literal has the type char*.[4]
[4] Actually, this isn't quite correct. The type of a C string literal is slightly different from char*, but that type is close enough for our purposes here. We'll see on page 442 what the exact type is and why it doesn't matter for our purposes.
As you might infer from these cases, our use of one char* to refer to multiple chars isn't an isolated example. Actually, it's quite a widespread practice in C++, which brings up an important point: a char*, or any other type of pointer for that matter, has two different possible meanings in C++.[5] One of these meanings is the obvious one of signifying the address of a single item of the type the pointer points to. In the case of a char*, that means the address of a char. However, in the case of a C string literal, as well as in the case of our m_Data member variable, we use a char* to indicate the address of the first char of an indeterminate number of chars; any chars after the first one occupy consecutively higher addresses in memory. Most of the time, this distinction has little effect on the way we write programs, but sometimes we have to be sensitive to this "multiple personality" of pointers. We'll run across one of these cases later in this chapter.
[5] As this implies, it's possible to have a pointer to any type of variable, not just to a char. For example, a pointer to a short would have the type short*, and similarly for pointers to any other data type, including user-defined types. As we will see in Chapter 10, pointers to user-defined types are very important in some circumstances, but we don't need to worry about them right now.
Susan had some questions (and I had some answers) on this topic of the true meaning of a char*:
Susan: What I get from this is that char* points to a char address either singularly or as the beginning of a string of multiple addresses. Is that right?
Steve: Yes, except that it's a string of several characters, not addresses.
Susan: Oh, here we go again; this is so confusing. So if I use a string "my name is" then a char* points to the address that holds the string of all those letters. But if the number of letters exceeds what the address can hold, won't it take up the next available address in memory and the char* point to it after it points to the first address?
Steve: Each memory address can hold 1 byte; in the case of a string, that byte is the value of one char of the string's data. So a char*, as we use it, will always point to the first char of the chars that hold our string's value; the other chars follow that one immediately in memory.
Susan: Let me ask this: When you show an example of a string with the value "Test" (Figure 7.8 on page 431), the pointer at address 12340002 containing the address 1234febc is really pointing at the T as that would be the first char and the rest of the letters will actually be in the other immediately following bytes of memory?
Figure 7.8. string n in memory
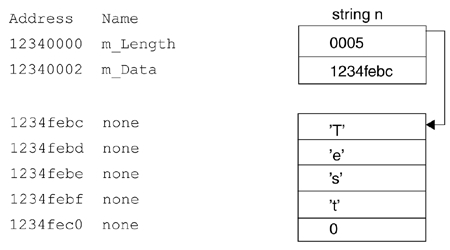
While we're on the subject of that earlier discussion of C string literals, you may recall that I bemoaned the fact that such C string literals use a 0 byte to mark the end of the literal value, rather than keeping track of the length separately. Nothing can be done about that decision now, at least as it applies to C string literals. In the case of our string class, however, the implementation is under our control rather than the language designer's; therefore, I've decided to use a length variable (m_Length) along with the variable that holds the address of the first char of the data (m_Data).
To recap, what we're doing in this chapter and the next one is synthesizing a data type called string. A string needs a length and a set of characters to represent the actual data in the string. The short named m_Length is used in the string class to keep track of the number of characters in the data part of the string; the char* named m_Data is used to hold the address of the first character of the data part of the string.
The next member initialization expression, m_Data(new char [m_Length]), takes us on another of our side trips. This one has to do with the (dreaded) topic of dynamic memory allocation.