
The Hypertext Transport Protocol (HTTP) is the common language that web browsers and web servers use to communicate with each other on the Internet. CGI is built on top of HTTP, so to understand CGI fully, it certainly helps to understand HTTP. One of the reasons CGI is so powerful is because it allows you to manipulate the metadata exchanged between the web browser and server and thus perform many useful tricks, including:
Serve content of varying type, language, or other encoding according to the client’s needs.
Check the user’s previous location.
Check the browser type and version and adapt your response to it.
Specify how long the client can cache a page before it is considered outdated and should be reloaded.
We won’t cover all of the details of HTTP, just what is important for our understanding of CGI. Specifically, we’ll focus on the request and response process: how browsers ask for and receive web pages.
If you are interested in understanding more about HTTP than we provide here, visit the World Wide Web Consortium’s web site at http://www.w3.org/Protocols/. On the other hand, if you are eager to get started writing CGI scripts, you may be tempted to skip this chapter. We encourage you not to. Although you can certainly learn to write CGI scripts without learning HTTP, without the bigger picture you may end up memorizing what to do instead of understanding why. This is certainly the most challenging chapter, however, because we cover a lot of material without many examples. So if you find it a little dry and want to peek ahead to the fun stuff, we’ll forgive you. Just be sure to return here later.
During our discussion of HTTP and CGI, we will be often be referring to URLs , or Uniform Resource Locators. If you have used the Web at all, then you are probably familiar with URLs. In web terms, a resource represents anything available on the web, whether it be an HTML page, an image, a CGI script, etc. URLs provide a standard way to locate these resources on the Web.
Note that URLs are not actually specific to HTTP; they can refer to resources in many protocols. Our discussion here will focus strictly on HTTP URLs.
HTTP URLs consist of a scheme, a host name, a port number, a path, a query string, and a fragment identifier, any of which may be omitted under certain circumstances (see Figure 2.1).
HTTP URLs contain the following elements:
- Scheme
The scheme represents the protocol, and for our purposes will either be
httporhttps.httpsrepresents a connection to a secure web server. Refer to The Secure Sockets Layer later in this chapter.- Host
The host identifies the machine running a web server. It can be a domain name or an IP address, although it is a bad idea to use IP addresses in URLs and is strongly discouraged. The problem is that IP addresses often change for any number of reasons: a web site may move from one machine to another, or it may relocate to another network. Domain names can remain constant in these cases, allowing these changes to remain hidden from the user.
- Port number
The port number is optional and may appear in URLs only if the host is also included. The host and port are separated by a colon. If the port is not specified, port 80 is used for
httpURLs and port 443 is used forhttpsURLs.It is possible to configure a web server to answer other ports. This is often done if two different web servers need to operate on the same machine, or if a web server is operated by someone who does not have sufficient rights on the machine to start a server on these ports (e.g., only root may bind to ports below 1024 on Unix machines). However, servers using ports other than the standard 80 and 443 may be inaccessible to users behind firewalls. Some firewalls are configured to restrict access to all but a narrow set of ports representing the defaults for certain allowed protocols.
- Path information
Path information represents the location of the resource being requested, such as an HTML file or a CGI script. Depending on how your web server is configured, it may or may not map to some actual file path on your system. As we mentioned last chapter, the URL path for CGI scripts generally begin with /cgi/ or /cgi-bin/ and these paths are mapped to a similarly-named directory in the web server, such as /usr/local/apache/cgi-bin.
Note that the URL for a script may include path information beyond the location of the script itself. For example, say you have a CGI at:
http://localhost/cgi/browse_docs.cgi
You can pass extra path information to the script by appending it to the end, for example:
http://localhost/cgi/browse_docs.cgi/docs/product/description.text
Here the path /docs/product/description.text is passed to the script. We explain how to access and use this additional path information in more detail in the next chapter.
- Query string
A query string passes additional parameters to scripts. It is sometimes referred to as a search string or an index. It may contain name and value pairs, in which each pair is separated from the next pair by an ampersand (
&), and the name and value are separated from each other by an equals sign (=). We discuss how to parse and use this information in your scripts in the next chapter.Query strings can also include data that is not formatted as name-value pairs. If a query string does not contain an equals sign, it is often referred to as an index. Each argument should be separated from the next by an encoded space (encoded either as
+or%20; see Section 2.1.3 below). CGI scripts handle indexes a little differently, as we will see in the next chapter.- Fragment identifier
Fragment identifiers refer to a specific section in a resource. Fragment identifiers are not sent to web servers, so you cannot access this component of the URLs in your CGI scripts. Instead, the browser fetches a resource and then applies the fragment identifier to locate the appropriate section in the resource. For HTML documents, fragment identifiers refer to anchor tags within the document:
<a name="anchor" >Here is the content you're after...</a>
The following URL would request the full document and then scroll to the section marked by the anchor tag:
http://localhost/document.html#anchor
Web browsers generally jump to the bottom of the document if no anchor for the fragment identifier is found.
Many of the elements within a URL are optional. You may omit the scheme, host, and port number in a URL if the URL is used in a context where these elements can be assumed. For example, if you include a URL in a link on an HTML page and leave out these elements, the browser will assume the link applies to a resource on the same machine as the link. There are two classes of URLs:
- Absolute URL
URLs that include the hostname are called absolute URLs. An example of an absolute URL is http://localhost/cgi/script.cgi.
- Relative URL
URLs without a scheme, host, or port are called relative URLs. These can be further broken down into full and relative paths:
- Full paths
Relative URLs with an absolute path are sometimes referred to as full paths (even though they can also include a query string and fragment identifier). Full paths can be distinguished from URLs with relative paths because they always start with a forward slash. Note that in all these cases, the paths are virtual paths, and do not necessarily correspond to a path on the web server’s filesystem. An example of an absolute path is /index.html.
- Relative paths
Relative URLs that begin with a character other than a forward slash are relative paths. Examples of relative paths include script.cgi and ../images/photo.jpg.
Many characters must be
encoded within a URL for a
variety of reasons. For example, certain characters such as
?, #, and /
have special meaning within URLs and will be misinterpreted unless
encoded. It is possible to name a file
doc#2.html on some systems, but the URL
http://localhost/doc#2.html would not point to
this document. It points to the fragment 2.html
in a (possibly nonexistent) file named doc. We
must encode the # character so the web browser and
server recognize that it is part of the resource name instead.
Characters are encoded by representing them with a
percent sign (%)
followed by the two-digit hexadecimal value for that character based
upon the ISO Latin 1 character set or ASCII character set (these
character sets are the same for the first eight bits). For example,
the # symbol has a hexadecimal value of
0x23, so it is encoded as %23.
The following characters must be encoded:
Control characters: ASCII
0x00through0x1Fplus0x7FEight-bit characters: ASCII
0x80through0xFFCharacters given special importance within URLs:
; / ? : @ & = + $ ,Characters often used to delimit (quote) URLs:
< > # % "Characters considered unsafe because they may have special meaning for other protocols used to transmit URLs (e.g., SMTP):
{ } | ^ [ ] `
Additionally,
spaces should be encoded as
+ although %20 is also allowed.
As you can see, most characters must be encoded; the list of
allowed characters is actually much
shorter:
Letters:
a-zandA-ZDigits:
0-9The following characters:
- _ . ! ~ * ' ( )
It is actually permissible and not uncommon for any of the allowed characters to also be encoded by some software. Thus, any application that decodes a URL must decode every occurrence of a percentage sign followed by any two hexadecimal digits.
The following code encodes text for URLs:
sub url_encode {
my $text = shift;
$text =~ s/([^a-z0-9_.!~*'( ) -])/sprintf "%%%02X", ord($1)/ei;
$text =~ tr/ /+/;
return $text;
}Any character not in the allowed set is replaced by a percentage sign
and its two-digit hexadecimal equivalent. The three percentage signs
are necessary because percentage signs indicate format codes for
sprintf, and literal percentage signs must be
indicated by two percentage signs. Our format code thus includes a
percentage sign, %%, plus the format code for two
hexadecimal digits, %02X.
Code to decode URL encoded text looks like this:
sub url_decode {
my $text = shift;
$text =~ tr/+/ /;
$text =~ s/%([a-f0-9][a-f0-9])/chr( hex( $1 ) )/ei;
return $text;
}Here we first translate any plus signs to spaces. Then we scan for a
percentage sign followed by two hexadecimal digits and use
Perl’s chr
function to convert the hexadecimal value into a
character.
Neither the encoding nor the decoding operations
can be safely repeated on the same text. Text encoded twice differs
from text encoded once because the percentage signs introduced in the
first step would themselves be encoded in the second. Likewise, you
cannot encode or decode entire URLs. If you were to decode a URL, you
could no longer reliably parse it, for you may have introduced
characters that would be misinterpreted such as /
or ?. You should always parse a URL to get the
components you want before decoding them; likewise, encode components
before building them into a full URL.
Note that it’s good to understand how a wheel works but
reinventing it would be pointless. Even though you have just seen how
to encode and decode text for URLs, you shouldn’t do so
yourself. The
URI::URL module (actually it is a
collection of modules), available on CPAN (see Appendix B), provides many URL-related modules and
functions. One of the included modules, URI::Escape, provides the
url_escape
and
url_unescape functions. Use them. The
subroutines in these modules have been vigorously tested, and future
versions will reflect any changes to HTTP as it evolves.[2]
Using standard subroutines will also make your code much clearer to
those who may have to maintain your code later (this includes you).
If, despite these warnings, you still insist on writing your own decoding code yourself, at least place it in appropriately named subroutines. Granted, some of these actions take only a line or two of code, but the code is quite cryptic, and these operations should be clearly labeled.
Now that we have a clearer understanding of URLs, let’s return to the main focus of this chapter: HTTP, the protocol that clients and servers use to communicate on the Web.
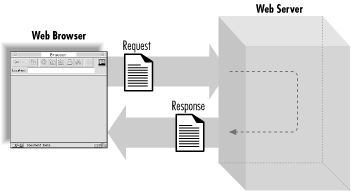
When a web browser requests a web page, it sends a request message to a web server. The message always includes a header, and sometimes it also includes a body. The web server in turn replies with a reply message. This message also always includes a header and it usually contains a body.
There are two features that are important in understanding HTTP:
It is a request/response protocol: each response is preceded by a request.
Although requests and responses each contain different information, the header/body structure is the same for both messages. The header contains meta-information —information about the message—and the body contains the content of the message.
Figure 2.2 shows an example of an HTTP transaction. Say you told your browser you wanted a document at http://localhost/index.html. The browser would connect to the machine at localhost on port 80 and send it the following message:
GET /index.html HTTP/1.1 Host: localhost Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, image/xbm, */* Accept-Language: en Connection: Keep-Alive User-Agent: Mozilla/4.0 (compatible; MSIE 4.5; Mac_PowerPC)
Assuming that a web server is running and the path maps to a valid document, the server would reply with the following message:
HTTP/1.1 200 OK Date: Sat, 18 Mar 2000 20:35:35 GMT Server: Apache/1.3.9 (Unix) Last-Modified: Wed, 20 May 1998 14:59:42 GMT ETag: "74916-656-3562efde" Content-Length: 141 Content-Type: text/html <HTML> <HEAD><TITLE>Sample Document</TITLE></HEAD> <BODY> <H1>Sample Document</H1> <P>This is a sample HTML document!</P> </BODY> </HTML>
In this example, the request includes a header but no content. The response includes both a header and HTML content, separated by a blank line (see Figure 2.3).
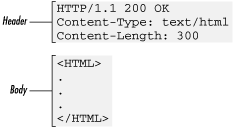
If you are familiar with the format of Internet email, this header and body syntax may look familiar to you. Historically, the format of HTTP messages is based upon many of the conventions used by Internet email, as established by MIME (Multipurpose Internet Mail Extensions). Do not be tricked into thinking that HTTP and MIME headers are the same, however. The similarity extends only to certain fields, and many early similarities have changed in later versions of HTTP.
Here are the important things to know about header syntax:
The first line of the header has a unique format and special meaning. It is called a request line in requests and a status line in replies.
The remainder of the header lines contain name-value pairs. The name and value are separated by a colon and any combination of spaces and/or tabs. These lines are called header fields .
Some header fields may have multiple values. This can be represented by having multiple header fields contain the same field name and different values or by including all the values in the header field separated by a comma.
Field names are not case-sensitive; e.g.,
Content-Typeis the same asContent-type.Header fields don’t have to appear in any special order.
Every line in the header must be terminated by a carriage return and line feed sequence, which is often abbreviated as CRLF and represented as
�15�12in Perl on ASCII systems.The header must be separated from the content by a blank line. In other words, the last header line must end with two CRLFs.
This chapter discusses HTTP 1.1, which includes several improvements to previous versions of HTTP. Although HTTP 1.1 is backward-compatible, there are many new features in HTTP 1.1 not recognized by HTTP 1.0 applications. There are even a few instances where the new protocol can cause problematic behavior with older applications, especially with caching. Most major web servers and browsers are now HTTP 1.1-compliant as this book is being written. There will continue to be HTTP 1.0 applications on the Web for some time, however. Features discussed in this chapter that differ between HTTP 1.1 and HTTP 1.0 will be noted.
Every HTTP interaction starts with a request from a client, typically a web browser. A user provides a URL to the browser by typing it in, clicking on a hyperlink, or selecting a bookmark, and the browser fetches the corresponding document. To do that, it must create an HTTP request (see Figure 2.4).
Recall that in our previous example, a web browser generated the following request when it was asked to fetch the URL http://localhost/index.html :
GET /index.html HTTP/1.1 Host: localhost Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, image/xbm, */* Accept-Language: en Connection: Keep-Alive User-Agent: Mozilla/4.0 (compatible; MSIE 4.5; Mac_PowerPC) . . .
From our discussion of URLs, you know that the URL can be broken down
into multiple elements. The browser creates a network connection by
using the hostname and the port number (80 by
default). The scheme (http) tells our web browser
that it is using the HTTP protocol, so once the connection is
established, it sends an HTTP request for the resource. The first
line of an HTTP request is the
request line, which includes a
full virtual path and query string (if present); see Figure 2.5.
The first line of an HTTP
request includes the request method, a URL
to the resource being requested, and the version string of the protocol.
Request methods are
case-sensitive and uppercase. There are several request methods
defined by HTTP although a web server may not make all of them
available for each resource (see Table 2.1). The
version string is the name and version of the protocol separated by a
slash. HTTP 1.0 and HTTP 1.1 are represented as
HTTP/1.0 and HTTP/1.1. Note
that https requests also produce one of these two
HTTP protocol strings.
Table 2-1. HTTP Request Methods
|
Method |
Description |
|---|---|
|
GET |
Asks the server for the given resource |
|
HEAD |
Used in the same cases that a GET is used but it only returns HTTP headers and no content |
|
POST |
Asks the server to modify information stored on the server |
|
PUT |
Asks the server to create or replace a resource on the server |
|
DELETE |
Asks the server to delete a resource on the server |
|
CONNECT |
Used to allow secure SSL connections to tunnel through HTTP connections |
|
OPTIONS |
Asks the server to list the request methods available for the given resource |
|
TRACE |
Asks the server to echo back the request headers as it received them |
Of the request methods listed in Table 2.1, the three you will encounter most often when writing CGI scripts are GET, HEAD, and POST. However, let’s first take a look at why the PUT and DELETE methods are not used with CGI.
The Web was originally conceived as a medium where users could both read and write content. However, the Web took off initially as a read-only medium and it is only through Web Distributed Authoring and Versioning (WebDAV) that interest is returning to the ability to write content to the Web. The PUT and DELETE methods tell the server to create, replace, or remove the resource they are directed at. Note that this means that if one of these requests is targeted at a CGI script (assuming the request is valid), the CGI script will be replaced or removed, but not executed. Thus, you do not need to worry about these request methods within your CGI scripts. While it might be possible to remap a PUT or DELETE request directed at a particular URL so that a different CGI script handles it, such a discussion of WebDAV implementation is beyond the scope of this book.
GET is the standard request method for retrieving a document via HTTP on the Web. When you click on a hyperlink, type a location into your browser, or click on a bookmark, the browser generally creates a GET request for the URL you requested. GET requests are intended only to retrieve resources and should not have side effects. They should not alter information maintained on the web server; POST is intended for that purpose. GET requests do not have a content body.
In practice, some CGI developers do not understand nor follow the policy that GET requests should not have side effects, even though it is a good idea to do so. Because web browsers assume that GET requests have no side effects, they may be carefree about making multiple requests for the same document. For instance, if the user presses the browser’s “back” button to return to a page that was originally requested via GET and is no longer in the browser’s cache, the browser may GET a new copy. If the original request was via POST, however, the user would instead receive a message that the document is no longer available in the cache. If the user then decides to reload the request, he or she will generally receive a dialog confirming that they wish to resend the POST request. These features help the user avoid mistakenly sending a request multiple times when the request would modify information stored on the server.
You may have noticed that we said that your web browser generally creates a GET request to fetch resources you have requested. If your browser has previously retrieved a resource, it may be stored within the browser’s cache. In order for the browser to know whether to display the cached copy or whether to request a fresh copy, the browser can send a HEAD request. HEAD requests are formatted exactly like GET requests, and the server responds to it exactly like a GET request with one exception: it sends only the HTTP headers, it doesn’t send the content. The browser can then check the meta-information contained in the headers, such as the modification date of the resource, to see if it has changed and whether it should replace the cached version with the newer version. HEAD requests do not have a content body either.
In practice, you can treat HEAD requests the same as GET requests in your CGI scripts, and the web server will truncate the content of your responses and return only headers. For this reason, we will rarely discuss to the HEAD request method in this book. If you are concerned about performance, you may wish to check the request method yourself and conserve resources by not generating content for HEAD requests. We will see how your script can determine the request method in the next chapter.
POST is used with HTML forms to submit information that alters data stored on the web server. POST requests always include a body containing the submitted information formatted like a query string. POST requests thus require additional headers specifying the length of the content and its format. These headers are described in the following section.
Although POST requests should only be used to modify data on the server, CGI developers commonly use POST requests for CGI scripts that simply return information, but do not modify data. This practice is more common and less dangerous than the reverse situation—using GET to modify data on the server. Developers use POST for any number of reasons:
Some developers believe that forms submitted via POST offer greater security over those submitted via GET because a user cannot modify the values within the URL in the browser as they can with GET. This reasoning is flawed. Knowledgeable users, as we will see in our security discussion in Chapter 8, can easily find ways around this.
The responses to resources received via POST cannot be bookmarked or hyperlinked (at least without using a bookmarklet; see Chapter 7). Although this is generally inconvenient for the user, sometimes this is the preferred behavior.
Note that users may encounter browser warnings about expired pages if they attempt to revisit cached pages obtained via POST.
The client generally sends several header fields with its request. As mentioned earlier, these consist of a field name, a colon, some combination of spaces or tabs (although one space is most common), and a value (see Figure 2.6). These fields are used to pass additional information about the request or about the client, or to add conditions to the request. We’ll discuss the common browser headers here; they are listed in Table 2.2. Those connected with content negotiation and caching are discussed later in this chapter.
Table 2-2. Common HTTP Request Headers
|
Header |
Description |
|---|---|
|
Host |
Specifies the target hostname |
|
Content-Length |
Specifies the length (in bytes) of the request content |
|
Content-Type |
Specifies the media type of the request |
|
Specifies the username and password of the user requesting the resource | |
|
User-Agent |
Specifies the name, version, and platform of the client |
|
Referer |
Specifies the URL that referred the user to the current resource |
|
Cookie |
Returns a name/value pair set by the server on a previous response |
The Host field is new and is required in HTTP 1.1. The client sends the host name of the web server in this field. This may sound redundant, since the host should know its own identity, right? Well, not always. A machine with one IP address may have multiple domain names mapped to it, such as www.oreilly.com and www.ora.com. When a request comes in, it looks at this header to determine what name the client is referring to it as, and thus maps the request to the correct content.
POST requests include a content body; in order for the web server to know how much data to read, it must declare the size of the body in bytes in the Content-Length field. There are a couple of circumstances where HTTP 1.1 clients may omit this field, but these cases don’t concern us because the web server will still calculate this value for us and provide it to our CGI scripts as though it had been included in the original request. POST requests that contain empty contents supply a value of in this header. Requests that do not have a content body, such as GET and HEAD, omit this field.
The Content-Type header must always be provided with requests containing a body. It specifies the media type of the message. The most common value of this data received from an HTML form via POST is application/x-www-form-urlencoded, although another option for form input (used when submitting files) is multipart/form-data . We’ll discuss how to specify the media type of requests in our discussion of HTML forms in Chapter 4, and we will look at how to parse multipart requests in Chapter 5.
Web servers can require a login for access to some resources. If you have ever attempted to access a restricted area of a web site and been prompted for a login and password, then you have encountered this form of HTTP authentication (see Figure 2.7).[3] Note that the login prompt includes text identifying what you are logging in to; this is the realm . Resources that share the same login are part of the same realm. For most web servers, you assign resources to a realm by putting them in the same directory and configuring the web server to assign the directory a name for the realm along with authorization requirements. For example, if you wanted to restrict access to URL paths that begin with /protected , then you would add the following to httpd.conf (or access.conf, if you are using it):
<Location /protected> AuthType Basic AuthName "The Secret Files" AuthUserFile /usr/local/apache/conf/secret.users require valid-user </Location>
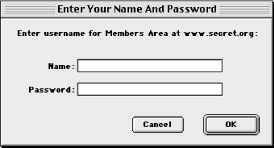
The user file contains usernames and encrypted passwords separated by a colon. You can use the htpasswd utility that comes with Apache to create and update this file; refer to its manpage or the Apache manual for usage. When the browser requests a resource in a restricted realm, the server informs the browser that it requires login information by sending a 401 status code and the name of the realm in the WWW-Authenticate header (we’ll discuss this later in the chapter). The browser then prompts the user for a username and password for this realm (if it hasn’t done so already) and resends the request with the credentials in an Authorization field. There are multiple types of HTTP authentication, but the only type that is widely supported by browsers and servers is basic authentication.
The Authorization field for basic authentication looks like this:
Authorization: Basic dXNlcjpwYXNzd29yZA==
The encoded portion is simply the username and password joined with a colon and Base64-encoded. This can be easily decoded, so basic authentication provides no security against third parties sniffing usernames and passwords unless the connection is secured via SSL.
The server handles authentication and authorization transparently for you. As we will see in the next chapter, you may access the login name from your CGI scripts but not the password.
This field indicates what client the user is using to access the Web. The value is generally comprised of a nickname of the browser, its version number, and the operating system and platform on which it’s running. Here is an example from Netscape Communicator:
User-Agent: Mozilla/4.5 (Macintosh; I; PPC)
Unfortunately, Microsoft Internet Explorer made the dubious decision when it released its browser of also claiming to be “Mozilla,” which is Netscape’s nickname. Apparently this was done because a number of web sites used this field to distinguish Netscape browsers from others in order to take advantage of the additional features Netscape offered at the time. Microsoft made their browser compatible with many of these features and wanted its users to also take advantage of these enhanced web sites. Even now, the “Mozilla” moniker remains for the sake of backward-compatibility. Here is an example from Internet Explorer:
User-Agent: Mozilla/4.0 (compatible; MSIE 4.5; Mac_PowerPC)
The Accept field and related fields that begin with Accept, such as Accept-Language, are sent by the client to tell the server the categories of responses it is capable of understanding. These categories include file formats, languages, character sets, etc. We discuss this process in more detail later in this chapter in Section 2.6.
No, this is not a typo. Unfortunately, the Referer field was misspelled in the original protocol and, due to the need to maintain backward-compatibility, we are stuck with it this way. This field provides the URL of the last page the user visited, which is generally the page that linked the user to the requested page:
Referer: http://localhost/index.html
This field is not always sent to the server; browsers provide this field only when the user generates a request by following a hyperlink, submitting a form, etc. Browsers don’t generally provide this field when the user manually enters a URL or selects a bookmark, since these may involve a significant invasion of the user’s privacy.
Web browsers or servers may provide additional headers that are not part of the HTTP standard. The receiving application should ignore any headers it does not recognize. A example of a pair of headers not specified in the HTTP protocol are Set-Cookie and Cookie, which Netscape introduced to support browser cookies. Set-Cookie is sent by the server as part of a response:
Set-Cookie: cart_id=12345; path=/; expires=Sat, 18-Mar-05 19:06:19 GMT
This header contains data for the client to echo back in the Cookie header in future requests to that server:
Cookie: cart_id=12345
By assigning different values to each user, servers (and CGI scripts) can use cookies to differentiate between users. We discuss cookies extensively in Chapter 11.
Server responses, like client requests, always contain HTTP headers and an optional body. Here is the server response from our earlier example:
HTTP/1.1 200 OK Date: Sat, 18 Mar 2000 20:35:35 GMT Server: Apache/1.3.9 (Unix) Last-Modified: Wed, 20 May 1998 14:59:42 GMT ETag: "74916-656-3562efde" Content-Length: 141 Content-Type: text/html <HTML> <HEAD><TITLE>Sample Document</TITLE></HEAD> <BODY> <H1>Sample Document</H1> <P>This is a sample HTML document!</P> </BODY> </HTML>
The structure of the headers for the response is the same as for requests. The first header line has a special meaning, and is referred to as the status line. The remaining lines are name-value header field lines. See Figure 2.8.
The first line of the header is the status line, which includes the protocol and version just as in HTTP requests, except that this information comes at the beginning instead of at the end. This string is followed by a space and the three-digit status code, as well as a text version of the status. See Figure 2.9.
Web servers can send any of dozens of status codes. For example, the server returns a status of 404 Not Found if a document doesn’t exist and 301 Moved Permanently if a document is moved. Status codes are grouped into five different classes according to their first digit:
- 1xx
These status codes were introduced for HTTP 1.1 and used at a low level during HTTP transactions. You won’t use 100-series status codes in CGI scripts.
- 2xx
200-series status codes indicate that all is well with the request.
- 3xx
300-series status codes generally indicate some form of redirection. The request was valid, but the browser should find the content of its response elsewhere.
- 4xx
400-series status codes indicate that there was an error and the server is blaming the browser for doing something wrong.
- 5xx
500-series status codes also indicate there was an error, but in this case the server is admitting that it or a CGI script running on the server is the culprit.
We’ll discuss each of the common status codes and how to use them in your CGI scripts in the next chapter.
After the status line, the server sends its HTTP headers. Some of these server headers are the same headers that browsers send with their requests. The common server headers are listed in Table 2.3.
Table 2-3. Common HTTP Server Headers
|
Header |
Description |
|---|---|
|
Content-Base |
Specifies the base URL for resolving all relative URLs within the document |
|
Content-Length |
Specifies the length (in bytes) of the body |
|
Content-Type |
Specifies the media type of the body |
|
Date |
Specifies the date and time when the response was sent |
|
ETag |
Specifies an entity tag for the requested resource |
|
Last-Modified |
Specifies the date and time when the requested resource was last modified |
|
Location |
Specifies the new location for the resource |
|
Server |
Specifies the name and version of the web server |
|
Set-Cookie |
Specifies a name-value pair that the browser should provide with future requests |
|
WWW-Authenticate |
Specifies the authorization scheme and realm |
The Content-Base field contains a URL to use as the base for relative URLs in HTML documents. Using the <BASE HREF=...> tag in the head of the document accomplishes the same thing and is more common.
As with request headers, the Content-Length field in response headers contains the length of the body of the response. Browsers use this to detect an interrupted transaction or to tell the user the percentage of the download that is complete.
You will use the Content-Type header very often in your CGI scripts. This field is provided with every response containing a body and must be included for all requests accompanied by a status code of 200. The most common value for this response is text/html, which is what is returned with HTML documents. Other examples are text/plain for text documents and application/pdf for Adobe PDF documents.
Because this field originally derived from a similar MIME field, this field is often referred to as the MIME type of the message. However, this term is not accurate because the possible values for this field differs for the Web than for Internet email. The IANA maintains a registry of registered media types for the Web, which may be viewed at http://www.isi.edu/in-notes/iana/assignments/media-types/. Although you could invent your media type values, it is a good idea to stick with these registered ones since web browsers need to know how to handle the associated documents.
HTTP 1.1 requires that servers send the Date header with all responses. It specifies the date and time the response is sent. Three different date formats are acceptable in HTTP:
Mon, 06 Aug 1999 19:01:42 GMT Monday, 06-Aug-99 19:01:42 GMT Mon Aug 6 19:01:42 1999
The HTTP specification recommends the first option, but all should be
supported by HTTP applications. The last is the format generated by
Perl’s gmtime function.[4]
The ETag header specifies an entity tag corresponding to the requested resource. Entity tags were added to HTTP 1.1 to address problems with caching. Although HTTP 1.1 does not specify any particular way for a server to generate an entity tag, they are analogous to a message digest or checksum for a file. Clients and proxies can assume that all copies of a resource with the same URL and same entity tag are identical. Thus, generating a HEAD request and checking the ETag header of the response is an effective way for a browser to determine whether a previously cached response needs to be fetched again. Web servers typically do not generate these for CGI scripts, although you can generate your own if you wish to have greater control over how HTTP 1.1 clients cache your responses.
The Last-Modified header returns the date and time that the requested resource was last updated. This was intended to support caching, but it did not always work as well as hoped in HTTP 1.0, so the ETag header now supplements it. The Last-Modified header is restrictive because it implies that HTTP resources are static files, which is obviously not always the case. For example, for CGI scripts the value of this field must reflect the last time the output changed (possibly due to a change in a data source), and not the date and time that the CGI script itself was last updated. Like the ETag header, the web server does not typically generate the Last-Modified header for your CGI scripts, although you can output it yourself if you desire.
The Location header is used to inform a client that it should look elsewhere for the requested resource. The value should contain an absolute URL to the new location. This header should be accompanied by a 3xx series status code. Browsers generally fetch the resource from the new location automatically for the user. Responses with a Location field may also contain contents with instructions for the user since very old browsers may not respond to the Location field.
The Server header provides the name and version of the application acting as the web server. The web server automatically generates this for standard responses. There are circumstances when you should generate this yourself, which we will see in the next chapter.
The Set-Cookie header asks the browser to remember a name-value pair and send this data back on subsequent requests to this server. The server can specify how long the browser should remember the cookie and to what hosts or domains the browser should provide it. We’ll discuss cookies in detail in our discussion of maintaining state in Chapter 11.
As we discussed earlier in Section 2.3.2.4, web servers can restrict certain resources to users who provide a valid username and password. The WWW-Authenticate field is used along with a status code of 401 to indicate that the requested resource requires a such a login. The value of this field should contain the form of authentication and the realm for which the authorization applies. An authorization realm generally maps to a certain directory on the web server, and a username and password pair should apply to all resources within a realm.
Quite often, web browsers do not interact directly with web servers; instead they communicate via a proxy. HTTP proxies are often used to reduce network traffic, allow access through firewalls, provide content filtering, etc. Proxies have their own functionality that is defined by the HTTP standard. We don’t need to understand these details, but we do need to recognize how they affect the HTTP request and response cycle. You can think of a proxy as a combination of a simplified client and a server (see Figure 2.10). An HTTP client connects to a proxy with a request; in this way, it acts like a server. The proxy forwards the request to a web server and retrieves the appropriate response; in this way, it acts like a client. Finally, it fulfills its server role by returning the response to the client.
Figure 2.10 shows how an HTTP proxy affects the request and response cycle. Note that although there is only one proxy represented here, it’s quite possible for a single HTTP transaction to pass through many proxies.
Proxies affect us in two ways. First, they make it impossible for web servers to reliably identify the browser. Second, proxies often cache content. When a client makes a request, proxies may return a previously cached response without contacting the target web server.
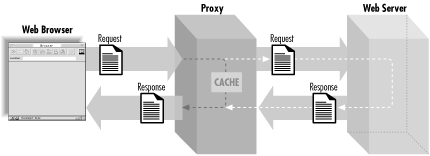
Basic HTTP requests do not contain any information that identifies the client. In a simple network transaction, this is generally not an issue, because a server knows which client is talking to it. We can see this by analogy. If someone walks up to you and hands you a note, you know who delivered the note regardless of what the note says. It’s apparent from the context.
The problem is determining who wrote the note. If the note isn’t signed, you may not know whether the person handing you the note wrote the note or is simply delivering it. The same is true in HTTP transactions. Web servers know which system is requesting information from them, but they don’t know whether this client is a web browser that originated the request (i.e., the author of the note) or if they are just a proxy (i.e., the messenger). This is not a shortcoming of proxies, because this anonymity is actually a feature of proxies integrated into firewalls. Organizations with firewalls typically prefer that the outside world not know the addresses of systems behind their firewall.
Thus, unless the browser passes identifying information in its request to the server, there is no way to differentiate among different users on different systems since they could be connecting via the same proxy. We’ll explore how to tackle this issue in Chapter 11.
One of the benefits of proxies is that they make HTTP transactions more efficient by sharing some of the work the web server typically does. Proxies accomplish this by caching requests and responses. When a proxy receives a request, it checks its cache for a similar, previous request. If it finds this, and if the response is not stale (out of date), then it returns this cached response to the client. The proxy determines whether a response is stale by looking at HTTP headers of the cached response, by sending a HEAD request to the target web server to retrieve new headers to compare against, and via its own algorithms. Regardless of how it determines this, if the proxy does not need to fetch a new, full response from the target web server, the proxy reduces the load on the server and reduces network traffic between the server and itself. This can also make the transaction much faster for the user.
Because most resources on the Internet are static HTML pages and images that do not often change, caching is very helpful. For dynamic content, however, caching can cause problems. CGI scripts allow us to generate dynamic content; a request to one CGI script can generate a variety of responses. Imagine a simple CGI script that returns the current time. The request for this CGI script looks the same each time it is called, but the response should be different each time. If a proxy caches the response from this CGI script and returns it for future requests, the user would get an old copy of the page with the wrong time.
Fortunately, there are ways to indicate that the response from a web server should not be cached. We’ll explore this in the next chapter. HTTP 1.1 also added specific guidelines for proxies that solved a number of problems with earlier proxies. Most current proxies, even if they do not fully implement HTTP 1.1, have adopted these guidelines.
Caching is not unique to proxies. You probably know that browsers do their own caching too. Some web pages have instructions telling users to clear their web browser’s cache if they are having problems receiving up-to-date information. Proxies present a challenge because users cannot clear the cache of intermediate proxies (they often may not even know they are using a proxy) as they can for their browser.
People from all over the world access the same Internet, using many different languages, many different character sets, and many different browsers. One representation of a document is not going to satisfy the requirements of all these people. This is why HTTP provides something called content negotiation, which allows clients and servers to negotiate the best possible format for each given resource.
For example, say you want to make a document available in multiple languages. You could store each translation of this document separately so that they each have a unique URL. This would be a bad idea for a number of reasons, but most importantly because you would have to advertise multiple URLs for the same resource. URLs have been designed to be easily exchanged offline as well as via hyperlinks, and there is no reason why people who speak different languages should not be able to share the same URL. By utilizing content negotiation, you can offer the appropriate translation of a requested document automatically.
There are four primary forms of content negotiation: language, character set, media type, and encoding. Each have their own corresponding headers, but the negotiation process works the same way for all of them. Negotiation can be performed by the server or by the client. In server-side negotiation, the client sends a header indicating the forms of content it accepts, and the server responds by selecting one of these options and returning the resource in the appropriate format. In client-side negotiation, the client requests a resource without special headers, the server sends a list of the available contents to the client, the client then makes an additional request to specify the format of the resource desired, and the server then returns the resource in that format. Clearly there is more overhead in client-side negotiation (although caching helps), but the client is generally better than the server at choosing the most appropriate format.
Clients may include a header with their HTTP request indicating a list of preferred formats. The header for media type looks like this:
Accept: text/html;q=1, text/plain;q=0.8,
image/jpeg, image/gif, */*;q=0.001The Accept header list contains HTTP media types in the type/subtype format used by the Content-Type header, followed by optional quality factors (asterisks serve as wildcards). Quality factors are floating-point numbers between and 1 that indicate a preference for a particular type; the default is 1. Servers are expected to examine the Accept media types and return data that is preferred by the browser. When multiple values have the same quality factor, the more specific one (i.e., where the quality factor is specified or the media type is not a wildcard) has higher priority.
In the previous example, documents would be returned with the following priority:
In reality, media type negotiation is not often used because it is unwieldy for a browser to list the media types of all documents it supports each time it makes a request. The majority of browsers today specify only new or less common image formats in addition to */*. Examples of the newer formats are image/p-jpeg (progressive JPEG) or image/png. (PNG was created as an open alternative to GIF, which has patent issues; see Chapter 13). Web servers generally do not support media type negotiation for static documents, but we will look at a CGI script that does this in the next chapter.
Although media type negotiation is becoming outdated, other forms of content negotiation are gaining much more importance. Internationalization has become a new arena where content negotiation plays an important role. Providing a document to members of other countries can mean two things: supporting other translations and possibly supporting other character sets. The Roman alphabet, the Cyrillic alphabet, and Kanji, for example, use different character sets. HTTP supports these forms of negotiation with the Accept-Language and Accept-Charset headers. Examples of these headers are:
Accept-Charset: iso-8859-5, iso-8859-1;q=0.5 Accept-Language: ru, en-gb;q=0.5, en;q=0.4
The first line indicates that the server should return the content in Cyrillic if possible or Western Roman otherwise. The language specifies Russian as the first choice, with British English as the second, and other forms of English as the third. Note that a single asterisk can be used in place of any of these values to represent a wildcard match. The default character set, unless specified, is US-ASCII or ISO-8859-1 (US-ASCII is a subset of ISO-8859-1).
Most web servers support language negotiation automatically for static documents. For example, if you perform a new installation of Apache, it will install multiple copies of the “It Worked!” welcome file in /usr/local/apache/htdocs. The files all share the index.html base name but have different extensions indicating the language code: index.html.en, index.html.fr, index.html.de, etc. If you point your browser at index.html, change the preferred language in your browser, and then reload the page, you should see it in another language.
The final form of content negotiation supports encoding. Options for encoding include gzip , compress, and identity (no encoding). Here is an example header specifying that the browser supports compress and gzip :
Accept-Encoding: compress, gzip
A server may be able to speed up the download of a large document to this client by sending an encoded version of the document. The browser should decode the document automatically for the user.
Congratulations! You just made it through HTTP, the most complicated part of learning CGI. Everything from now on builds upon what we have learned here. And everything else is a lot more fun since you actually get to write code. In fact, we start the next chapter by looking at a CGI script.
[2] Don’t think this could happen? What if we told you the
tilde character (~) was not always allowed in
URLs? This restriction was removed after it became common practice
for some web servers to accept a tilde plus username in the path to
indicate a user’s personal web directory.
[3] The distinction between authentication and authorization is subtle, but important. Authentication is the process of identifying someone. Authorization determines what that person can access.
[4] More specifically, gmtime generates a date
string like this when it is called in a
scalar context. In list context, it
returns a list of date elements instead. If this distinction seems
unclear, then you may want to refer to a good Perl book like
Programming Perl for the difference between
list and scalar context.