
|
|

This chapter will cover the core set of data modeling concepts along with their MongoDB counterparts. We will start off with a comparison of data model, relational database, and MongoDB terminology. We will then dive into the core set of MongoDB objects, each explained within its data modeling context. Objects include documents, collections, fields, datatypes, and indexes. We will also show how to handle relationships, hierarchies, and recursion in MongoDB. This table compares terms used for each object across the data model, RDBMS, and MongoDB. We will discuss each of these terms within this chapter.
|
Data Model |
RDBMS |
MongoDB |
|
Entity instance |
Record or Row |
Document |
|
Entity |
Table |
Collection |
|
Attribute or Data element |
Data element, Field or Column |
Field |
|
Attribute value or Data element value |
Data element value, Field value, or Column value |
Field value |
|
Format domain |
Datatype |
Datatype |
|
Relationship |
Constraint |
Captured but not enforced either through a reference, which is similar to a foreign key, or through embedded documents. |
|
Candidate key (Primary or Alternate key) |
Unique index |
Unique index |
|
Surrogate key |
Globally Unique Id (GUID) |
ObjectId |
|
Foreign key |
Foreign key |
Reference |
|
Secondary key, Inversion entry |
Secondary key |
Non-unique index |
|
Subtype |
Rolldown, Rollup, Identity |
Rolldown, Rollup, Identity |
Entities
An entity represents a collection of information about something that the business deems important and worthy of capture. A noun or noun phrase identifies a specific entity. An entity fits into one of six categories: who, what, when, where, why, or how. Here is a definition of each of these entity categories along with examples.
|
Category |
Definition |
Examples |
|
Who |
Person or organization of interest to the enterprise. That is, “Who is important to the business?” Often a Who is associated with a role such as Customer or Vendor. |
Employee, Patient, Player, Suspect, Customer, Vendor, Student, Passenger, Competitor, Author |
|
What |
Product or service of interest to the enterprise. It often refers to what the organization makes that keeps it in business. That is, “What is important to the business?” |
Product, Service, Raw Material, Finished Good, Course, Song, Photograph, Title |
|
When |
Calendar or time interval of interest to the enterprise. That is, “When is the business in operation?” |
Time, Date, Month, Quarter, Year, Semester, Fiscal Period, Minute |
|
Where |
Location of interest to the enterprise. Location can refer to actual places as well as electronic places. That is, “Where is business conducted?” |
Mailing Address, Distribution Point, Website URL, IP Address |
|
Why |
Event or transaction of interest to the enterprise. These events keep the business afloat. That is, “Why is the business in business?” |
Order, Return, Complaint, Withdrawal, Deposit, Compliment, Inquiry, Trade, Claim |
|
How |
Documentation of the event of interest to the enterprise. Documents record the events such as a Purchase Order recording an Order event. That is, “How does the business keep track of events?” |
Invoice, Contract, Agreement, Purchase Order, Speeding Ticket, Packing Slip, Trade Confirmation |
Entity instances are the occurrences or values of a particular entity. Think of a spreadsheet as being an entity where the column headings represent the pieces of information about the entity. Each spreadsheet row containing the actual values represents an entity instance. The entity Customer may have multiple customer instances with the names Bob, Joe, Jane, and so forth. The entity Account can have instances of Bob’s checking account, Bob’s savings account, Joe’s brokerage account, and so on.
Entities can exist at conceptual, logical, and physical levels of detail. We will go into detail into conceptual, logical, and physical modeling in Section II of this book. A short definition, however, of each level will be needed for you to benefit from the following discussion. The conceptual means the high level business solution to a problem frequently defining scope and important terminology, the logical means the detailed business solution to a problem, and the physical means the detailed technical solution to a problem. “Problem” usually refers to an application development effort.
For an entity to exist at a conceptual level, it must be both basic and critical to the business. What is basic and critical depends very much on the scope of the effort we are modeling. At a universal level, there are certain concepts common to all companies such as Customer, Product, and Employee.
Making the scope slightly narrower, a given industry may have certain unique concepts. Phone Number, for example, will be a valid concept for a telecommunications company but perhaps not for other industries such as manufacturing. In the publishing world, Author, Title, and Order are conceptual entities, shown as names within rectangles:
![]()
Entities at the logical level represent the business in more detail than at the conceptual level. Frequently, a conceptual entity may represent many logical entities. Logical entities contain properties, also called “data elements” or “attributes,” which we will discuss shortly. Entities are connected through relationships, which we will discuss shortly as well. The figure on the next page shows the Order logical entities (along with their properties and relationships) based upon the Order conceptual entity from above.

At a physical level, the entities correspond to technology-specific objects, often database tables in a relational database or collections in MongoDB, which we will discuss shortly. The physical level is the same as the logical level, compromised for a specific technology. This model shows the two corresponding physical entities representing relational database tables, based upon the prior logical order entities:

The physical entities also contain database-specific information, such as the format and length of an attribute (orderStatusDescription is 50 characters), and whether the data element is required to have a value (orderNumber is not null and is therefore required to have a value, but orderActualDeliveryDate is null and therefore not required to have a value).
An entity instance is an example of an entity. So Order 4839-02 is an instance of Order, for example. An entity instance at the RDBMS level is called a record.
MongoDB Document = RDBMS Record (Entity Instance at Physical Level)
A RDBMS record is comparable to a MongoDB document. A MongoDB document is a perfect name for what it is – a document. Think of all of the documents you come into contact with during a typical day: invoices, packing slips, menus, blog postings, receipts, etc. All of these are documents in the same sense as a MongoDB document. They are all a set of somewhat related data often viewed together. Documents are composed of fields, which will be discussed shortly. For example, here is a MongoDB document based upon our Order example (Order is one document containing three lines):
Order:
{ orderNumber : “4839-02”,
orderShortDescription : “Professor review copies of several titles”,
orderScheduledDeliveryDate : ISODate(“2014-05-15”),
orderActualDeliveryDate : ISODate(“2014-05-17”),
orderWeight : 8.5,
orderTotalAmount : 19.85,
orderTypeCode : “02”,
orderTypeDescription : “Universities Sales”,
orderStatusCode : “D”,
orderStatusDescription : “Delivered”,
orderLine :
[ { productID : “9781935504375”,
orderLineQuantity : 1
},
{ productID : “9781935504511”,
orderLineQuantity : 3
},
{ productID : “9781935504535”,
orderLineQuantity : 2
} ] }
In this example the Order document contains one order with three order lines. A document begins and ends with the squiggly braces { }, and the fields within the document are separated by commas. The square brackets [ ] contain arrays. Arrays can contain individual values or sub-documents, themselves surrounded by squiggly braces. Storing dates such as orderScheduledDeliveryDate in ISO format allows you to use standard date functionality such as performing range queries, sorting dates, and even determining the day of the week.3 Notice that in OrderLine, there is a reference back to the three products. More on references shortly!
MongoDB Collection = RDBMS Table (Entity at Physical Level)
An entity at the physical level is a table in an RDBMS or a collection in MongoDB. A collection is a set of one or more documents. So imagine if we had a million orders, with an example being the one from the prior section. We can store all of these orders in one Order collection:
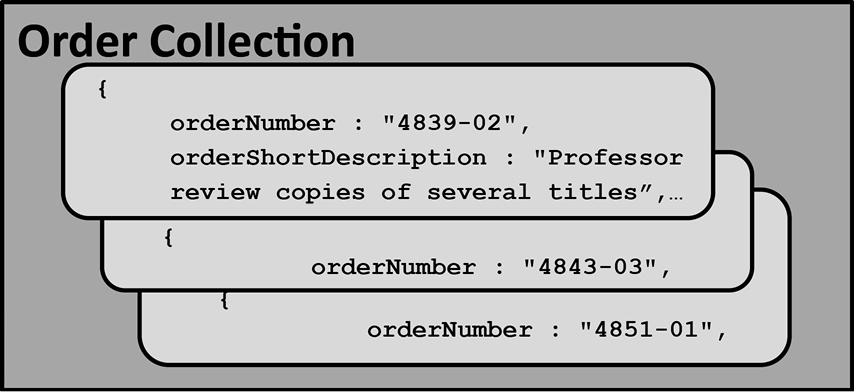
From my relational experience, I am used to defining what the structure would look like first before populating it. For example, I would define the order attributes like orderNumber and orderShortDescription before loading any orders. In MongoDB however, you can define the structure and data at the same time. Having a “flexible schema” (also known as a “dynamic schema”) means incremental changes can be made to the database structure as easily as adding new data. Having such a flexible schema is a big advantage because it lets us add things we might have forgotten or not known about earlier and also because we can test different structures very easily and pick the best one.
Attributes
An attribute is an elementary piece of information of importance to the business that identifies, describes, or measures instances of an entity. The attribute Claim Number identifies each claim. The attribute Student Last Name describes the last name of each student. The attribute Gross Sales Amount measures the monetary value of a transaction.
As with entities, attributes can exist at conceptual, logical, and physical levels. An attribute at the conceptual level must be a concept both basic and critical to the business. We do not usually think of attributes as concepts, but depending on the business need, they can be. When I worked for a telecommunications company, Telephone Number was an attribute that was so important to the business that it was represented on a number of conceptual data models.
An attribute on a logical data model represents a business property. Each attribute shown contributes to the business solution and is independent of any technology including software and hardware. For example, Author Last Name is an attribute because it has business significance regardless of whether records are kept in a paper file, within Oracle, or within MongoDB.
An attribute on a physical data model represents a database column or MongoDB field. The attribute Author Last Name might be represented as the column AUTH_LAST_NM within the relational table AUTH or the MongoDB field authorLastName within the Author collection.
MongoDB Field = RDBMS Field (Attribute at Physical Level)
The concept of a physical attribute (also called a column or field) in relational databases is equivalent to the concept of a field in MongoDB. MongoDB fields contain two parts, a field name and a field value. This is the order collection we discussed earlier, with the field names shown in bold and the field values shown in italics:
Order:
{ orderNumber : “4839-02”,
orderShortDescription : “Professor review copies of several titles”,
orderScheduledDeliveryDate : ISODate(“2014-05-15”),
orderActualDeliveryDate : ISODate(“2014-05-17”),
orderWeight : 8.5,
orderTotalAmount : 19.85,
orderTypeCode : “02”,
orderTypeDescription : “Universities Sales”,
orderStatusCode : “D”,
orderStatusDescription : “Delivered”,
orderLine :
[ { productID : “9781935504375”,
orderLineQuantity : 1
},
{ productID : “9781935504511”,
orderLineQuantity : 3
},
{ productID : “9781935504535”,
orderLineQuantity : 2
} ] }
Notice that a field value is not limited to just a simple value such as 4839-02, but can also include arrays that can contain many other fields and even documents, as we see in this example with orderLine. MongoDB provides robust capability for querying within arrays.
Every database has certain restrictions on naming fields, and MongoDB is no exception. Here are several tips in naming MongoDB fields:
- Avoid special characters. Characters such as a period, dollar sign, or null (�) should be avoided in field names.
- MongoDB is case sensitive. CustomerLastName and customerLastName are distinct fields. Make sure your organization has a naming standard so you use case consistently.
- Duplicate names are not allowed. The same document cannot contain two or more of the same field names at the same level of depth. Just like a relational database table cannot contain the element customerLastName twice, a MongoDB document cannot contain the same field twice at the same level of depth. You can, however, have the same field name at a different level of depth. For example, although { customerLastName : “Smith”, customerLastName : “Jones” } is not allowed, { customerLastName : { customerLastName : “Jones” } } is allowed.
Domains
The complete set of all possible values that an attribute contains is called a domain. An attribute can never contain values outside of its assigned domain, which is defined by specifying the actual list of values or a set of rules. Employee Gender Code, for example, can be limited to the domain of (female, male).
In relational databases, there are three main types of domains:
- Format. A format domain restricts the length and type of the data element such as a Character(15) format domain limiting the possible values of a data element to at most 15 characters. A date format limits the values of a data element to valid dates, and an integer format limits the values to any possible integer.
- List. A list domain is more restrictive than a format domain and limits the values to a specified defined set such as male or female or (A,B,C,D).
- Range. A range domain restricts the data element values to any value between two other values such as a start and end dates.
MongoDB Datatype = RDBMS Datatype (Format Domain at Physical Level)
A format domain is called a datatype in an RDBMS and also in MongoDB. In MongoDB, there are only datatype domains (no list or range domains). Here are the main datatype domains:
|
Format |
Description |
Example |
|
Boolean |
Only the values 1 (also known as True) or 0 (also known as False) |
{ studentAlumniIndicator : Boolean } |
|
Number |
MongoDB does not distinguish all of the different number varieties present in a RDBMS. The MongoDB shell defaults to 64-bit floating point numbers. |
{ meaningOfLife : 42.153 } or { meaningOfLife : 42 } |
|
String |
Any string of UTF-8 characters. |
{ meaningOfLife : "forty two" } |
|
Date |
Dates are captured as milliseconds since the epoch. |
{ orderEntryDate : new Date( ) } |
|
Array |
Arrays can be ordered (such as for queues or lists) or unordered (such as for sets). Also, arrays can contain different data types as values and even contain other arrays. |
{ author : [ “Bill Jones”, “Tom Hanks”, “Edward Scissorhands1” ] } |
|
Globally Unique Id |
Can be used as the primary key value for records and documents. An object id is a 12-byte surrogate key for documents. |
{ orderId : ObjectId( ) } |
Relationships
Many such rules can be visually captured on our data model through relationships. A relationship is displayed as a line connecting two entities that captures the rule or navigation path between them. If the two entities are Employee and Department, the relationship can capture the rules “Each Employee must work for one Department” and “Each Department may contain one or many Employees.”
In a relationship between two entities, cardinality captures how many instances from one entity participate in the relationship with instances of the other entity. It is represented by the symbols that appear on both ends of a relationship line. It is through cardinality that the data rules are specified and enforced. Without cardinality, the most we can say about a relationship is that two entities are connected in some way through a rule. For example, Employee and Department have some kind of relationship, but we don’t know more than this.
For cardinality, we can choose any combination of zero, one, or many. Many (some people read it as more) means any number greater than zero. Specifying zero or one allows us to capture whether or not an entity instance is required in a relationship. Specifying one or many allows us to capture how many of a particular instance participates in a given relationship.
Because we have only three cardinality symbols, we can’t specify an exact number4 (other than through documentation), as in “A Car contains four Tires.” We can only say, “A Car contains many Tires.” Each of the cardinality symbols is illustrated here with Author and Title:
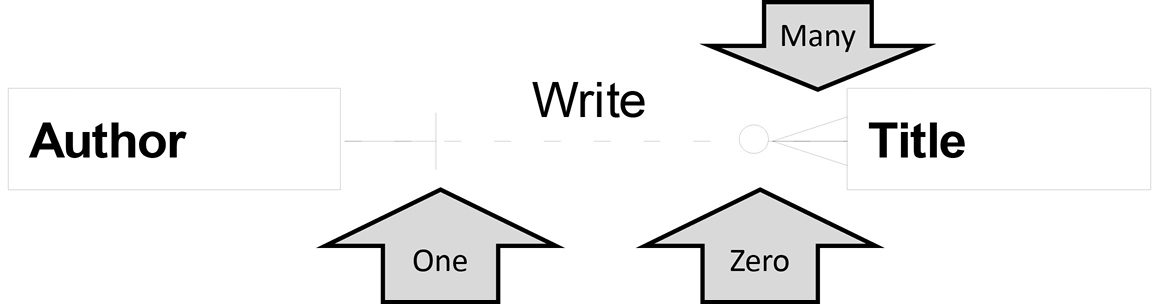
The business rules in this example are:
- Each Author may write one or many Titles.
- Each Title must be written by one Author.
The small vertical line means one. (Looks like a 1, doesn’t it?) The circle means zero. (Looks like a zero too!) The zero implies optionality and does not exclude the value one, so in the above example an author can write just one title, too.
The triangle with a line through the middle means many. Some people call the many symbol a crow’s foot. Relationship lines are frequently labeled to clarify the relationship and express the rule that the relationship represents. A data model is a communication tool, and if you think of the entities as nouns, the relationship label is a present tense verb, so we are just reading a sentence:
- Each Author may write one or many Titles.
Having a zero in the cardinality makes us use optional-sounding words such as may or can when reading the relationship. Without the zero, we use mandatory-sounding terms such as must or have to. So instead of being redundant and saying:
- Each Author may write zero, one or many Titles.
We take out the word zero because it is expressed using the word may, which implies the zero:
- Each Author may write one or many Titles.
Every relationship has a parent and a child. The parent entity appears on the one side of the relationship, and the child appears on the many side of the relationship. In this example, the parent entity is Author and the child entity is Title. When I read a relationship, I start with the entity on the one side of the relationship (the parent entity) first. “Each Author may write one or many Titles.” It’s then followed by reading the relationship from the many side: “Each Title must be written by one Author.”
I also always use the word each in reading a relationship, starting with the parent side. The reason for the word each is that you want to specify, on average, how many instances of one entity relate to an entity instance from the other entity.
Let’s change the cardinality and now allow a Title to be written by more than one Author:

This is an example of a many-to-many relationship, in contrast to the previous example, which was a one-to-many relationship. The business rules here read as follows:
- Each Author may write one or many Titles.
- Each Title must be written by one or many Authors.
Write, in both of our examples, is an example of a relationship label.
The three levels of granularity (conceptual, logical, and physical) that apply to entities and attributes also apply to the relationships that connect entities. Conceptual relationships are high level rules that connect key concepts. Logical relationships are detailed business rules that enforce the rules between the logical entities. Physical relationships are detailed technology-dependent rules between the physical structures that the relationship connects. These physical relationships eventually become database constraints, which ensure that data adheres to the rules. A “constraint” is a physical term for a relationship in an RDBMS, similar to an entity becoming a table and an attribute becoming a column. MongoDB can capture but not enforce relationships through referencing, or can combine entities together (similar to denormalizing) through embedding. Referencing and embedding will be discussed shortly.
Recursion
A recursive relationship is a relationship that starts and ends on the same entity. A one-to-many recursive relationship describes a hierarchy, whereas a many-to-many relationship describes a network. In a hierarchy, an entity instance has, at most, one parent. In a network, an entity instance can have more than one parent.
Let’s illustrate both types of recursive relationships using Employee. Here is a one-to-many recursive example:

- Each Employee may manage one or many Employees.
- Each Employee may be managed by one Employee.
And here is a many-to-many recursive example:

- Each Employee may manage one or many Employees.
- Each Employee may be managed by one or many Employees.
Using sample values such as Bob and Jill and sketching a hierarchy or network can really help you to understand, and therefore validate, cardinality. The one-to-many captures a hierarchy where each employee has at most one manager. The many-to-many captures a network in which each employee may have one or many managers such as Jane working for Bob, Ken, and Sven. (I would definitely update my resume if I were Jane.)
It is interesting to note that in both figures, there is optionality on both sides of the relationship. In these examples, it implies we can have an Employee who has no boss (such as Mary) and an Employee who is not a manager (such as Jane).
Data modelers have a love-hate relationship with recursion. On the one hand, recursion makes modeling a complex business idea very easy and leads to a very flexible modeling structure. We can have any number of levels in an organization hierarchy on both of these models, for example. On the other hand, some consider using recursion to be taking the easy way out of a difficult modeling situation. There are many rules that can be obscured by recursion. For example, where is the Regional Management Level on these models? It is hidden somewhere in the recursive relationship. Those in favor of recursion argue that you may not be aware of all the rules and that recursion protects you from having an incomplete model. The recursion adds a level of flexibility that ensures that any rules not previously considered are also handled by the model. It is therefore wise to consider recursion on a case-by-case basis, weighing obscurity against flexibility.
MongoDB Parent Reference = RDBMS Self Referencing (Recursion at Physical Level)
Using the same sample employee data as above, let’s look at MongoDB collections for each of these hierarchies and networks. Note that we used the employeeFirstName as the unique index and we are only storing the employee’s first name (and sometimes manager references), but it will illustrate how MongoDB handles recursion. Here is a collection showing the hierarchy example using parent references:
|
|
Employee : { _id : "Mary", employeeFirstName : "Mary" }, { _id : "Bob", employeeFirstName : "Bob", managerID : "Mary" }, { _id : "Jill", employeeFirstName : "Jill", managerID : "Mary" }, { _id : "Ken", employeeFirstName : "Ken", managerID : "Bob" }, { _id : "Jane", employeeFirstName : "Jane", managerID : "Bob" }, { _id : "Sven", employeeFirstName : "Sven", managerID : "Jill" } |

Depending on the business requirements, we may decide to store the full management chain with each employee as an array:
Employee :
{ _id : “Mary”, employeeFirstName : “Mary” },
{ _id : “Bob”, employeeFirstName : “Bob”, managerID : “Mary”, managerPath : [ “Mary” ] },
{ _id : “Jill”, employeeFirstName : “Jill”, managerID : “Mary”, managerPath : [ “Mary” ] },
{ _id : “Ken”, employeeFirstName : “Ken”, managerID : “Bob”, managerPath : [ “Mary”, “Bob” ] },
{ _id : “Jane”, employeeFirstName : “Jane”, managerID : “Bob”, managerPath : [ “Mary”, “Bob” ] },
{ _id : “Sven”, employeeFirstName : “Sven”, managerID : “Jill”, managerPath : [ “Mary”, “Jill” ] }
I would choose capturing the full manager path using arrays over just storing the immediate manager when the requirements state the need to do analysis across an employee’s complete management chain, such as answering the question, “What is the complete chain of command for Sven?” This trade-off is typical of the modeling choices the MongoDB modeler faces: run-time processing versus data redundancy.
Here is a collection showing the network example using parent references:
|
|
Employee : { _id : "Mary", employeeFirstName : "Mary" }, { _id : "Bob", employeeFirstName : "Bob", managerID : [ "Mary", "Jill" ] }, { _id : "Jill", employeeFirstName : "Jill", managerID : [ "Mary" ] }, { _id : "Ken", employeeFirstName : "Ken", managerID : [ "Bob" ] }, { _id : "Jane", employeeFirstName : "Jane", managerID : [ "Bob", "Ken", "Sven" ] }, { _id : "Sven", employeeFirstName : "Sven", managerID : [ "Jill" ] } |

Note that in these examples we are illustrating references, but if we would like to illustrate embedding the manager information with each employee, these collections would look very similar because we just have the two fields, _id and employeeFirstName. Also note that there are other embed and reference design options available in addition to what is shown in this example.
Keys
There is a lot of data out there, but how do you sift through it all to find what you’re looking for? That’s where keys come in. A key is one or more attributes whose purposes include enforcing rules, efficiently retrieving data and allowing navigation from one entity to another. This section explains candidate (primary and alternate), surrogate, foreign, and secondary keys.
Candidate Key (Primary and Alternate Keys)
A candidate key is one or more data elements that uniquely identify an entity instance. The Library of Congress assigns an ISBN (International Standard Book Number) to every title. The ISBN uniquely identifies each title and is, therefore, the title’s candidate key. When the ISBN for this title, 9781935504702, is entered into many search engines and database systems, the book entity instance Data Modeling for MongoDB will be returned (try it!). Tax ID can be a candidate key for an organization. Account Code can be a candidate key for an account.
Sometimes a single attribute identifies an entity instance such as an ISBN for a title. Sometimes it takes more than one attribute to uniquely identify an entity instance. For example, both a Promotion Type Code and Promotion Start Date may be necessary to identify a promotion. When more than one attribute makes up a key, we use the term composite key. Therefore, Promotion Type Code and Promotion Start Date together are a composite candidate key for a promotion. A candidate key has three main characteristics:
- Unique. There cannot be duplicate values in the data in a candidate key, and it cannot be empty (also known as nullable). Therefore, the number of distinct values of a candidate key must be equal to the number of distinct entity instances. When the entity Title has ISBN as its candidate key, if there are 500 title instances, there will also be 500 unique ISBNs.
- Stable. A candidate key value on an entity instance should never change. If a candidate key value changes, it creates data quality issues because there is no way to determine whether a change is an update to an existing instance or a new instance.
- Minimal. A candidate key should contain only those attributes that are needed to uniquely identify an entity instance. If four data elements are listed as the composite candidate key for an entity but only three are needed for uniqueness, then only those three should be in the key.
For example, each Student may attend one or many Classes, and each Class may contain one or many Students. Here are some sample instances for each of these entities:
Student
|
Student Number |
First Name |
Last Name |
Birth Date |
|
SM385932 |
Steve |
Martin |
1/25/1958 |
|
EM584926 |
Eddie |
Murphy |
3/15/1971 |
|
HW742615 |
Henry |
Winkler |
2/14/1984 |
|
MM481526 |
Mickey |
Mouse |
5/10/1982 |
|
DD857111 |
Donald |
Duck |
5/10/1982 |
|
MM573483 |
Minnie |
Mouse |
4/1/1986 |
|
LR731511 |
Lone |
Ranger |
10/21/1949 |
|
EM876253 |
Eddie |
Murphy |
7/1/1992 |
Attendance
|
Attendance Date |
|
5/10/2013 |
|
6/10/2013 |
|
7/10/2013 |
Class
|
Class Full Name |
Class Short Name |
Class Description Text |
|
Data Modeling Fundamentals |
Data Modeling 101 |
An introductory class covering basic data modeling concepts and principles. |
|
Advanced Data Modeling |
Data Modeling 301 |
A fast-paced class covering techniques such as advanced normalization and ragged hierarchies. |
|
Tennis Basics |
Tennis One |
For those new to the game of tennis; learn the key aspects of the game. |
|
Juggling |
Learn how to keep three balls in the air at once! |
Based on our definition of a candidate key (and a candidate key’s characteristics of being unique, stable, and minimal) what would you choose as the candidate keys for each of these entities?
For Student, Student Number appears to be a valid candidate key. There are eight students and eight distinct values for Student Number. So unlike Student First Name and Student Last Name, which can contain duplicates like Eddie Murphy, Student Number appears to be unique. Student Birth Date can also contain duplicates, such as 5/10/1982, which is the Student Birth Date for both Mickey Mouse and Donald Duck. However, the combination of Student First Name, Student Last Name, and Student Birth Date may make a valid candidate key.
For Attendance, we are currently missing a candidate key. Although the Attendance Date is unique in our sample data, we will probably need to know which student attended which class on this particular date.
For Class, on first glance it appears that all of its attributes are unique and any of them would therefore qualify as a candidate key. However, Juggling does not have a Class Short Name. Therefore, because Class Short Name can be empty, we cannot consider it a candidate key. In addition, one of the characteristics of a candidate key is that it is stable. I know, based on my teaching experience, that class descriptions can change. Therefore, Class Description Text also needs to be ruled out as a candidate key, leaving Class Full Name as the best option for a candidate key.
Even though an entity may contain more than one candidate key, we can only select one candidate key to be the primary key for an entity. A primary key is the candidate key that has been chosen to be the unique identifier for an entity. An alternate key is a candidate key that, although it has the properties of being unique, stable, and minimal, was not chosen as the primary key but still can be used to find specific entity instances.
We have only one candidate key in the Class entity, so Class Full Name becomes our primary key. We have to make a choice in Student, however, because we have two candidate keys. Which Student candidate key would you choose as the primary key?
In selecting one candidate key over another as the primary key, consider succinctness and security. Succinctness means if there are several candidate keys, choose the one with the fewest attributes or shortest in length. In terms of privacy, it is possible that one or more attributes within a candidate key will contain sensitive data whose viewing should be restricted. We want to avoid having sensitive data in our entity’s primary key because the primary key can propagate as a foreign key and therefore spread this sensitive data throughout our database. Foreign keys will be discussed shortly.
Considering succinctness and security in our example, I would choose Student Number over the composite Student First Name, Student Last Name, and Student Birth Date. It is more succinct and contains less sensitive data. Here is our data model with primary and alternate keys:

Primary key attributes are shown above the line in the rectangles. You will notice two numbers following the key abbreviation “AK.” The first number is the grouping number for an alternate key, and the second number is the ordering of the attribute within the alternate key. So there are three attributes required for the Student alternate key: Student First Name, Student Last Name, and Student Birth Date. This is also the order in which the alternate key index will be created because Student First Name has a “1” after the colon, Student Last Name a “2,” and Student Birth Date a “3.”
Attendance now has as its primary key Student Number and Class Full Name, which appear to make a valid primary key. Note that the two primary key attributes of Attendance are followed by “FK”. These are foreign keys, to be discussed shortly.
So to summarize, a candidate key consists of one or more attributes that uniquely identify an entity instance. The candidate key that is determined to be the best way to identify each record in the entity becomes the primary key. The other candidate keys become alternate keys. Keys containing more than one attribute are known as composite keys.
At the physical level, a candidate key is often translated into a unique index.
MongoDB Unique Index = RDBMS Unique Index (Candidate Key at Physical Level)
The concept of a candidate key in relational databases is equivalent to the concept of a unique index in MongoDB. If you want to make sure no two documents can have the same value in an ISBN, you can create a unique index:
db.title.ensureIndex( { ISBN : 1 }, { “unique” : true } )
The 1 indicates that ISBN will be indexed in ascending order (as opposed to -1, which means descending order). The true means that ISBN must be unique. Note that to create a non-unique index, which will be discussed shortly, we would set the value to false. So if the above statement is executed and we try to create three documents that have the same ISBN, only the first occurrence would be stored and the next two occurrences would be skipped.
Surrogate Key
A surrogate key is a unique identifier for a row in a table, often a counter, that is always system-generated without intelligence, meaning a surrogate key contains values whose meanings are unrelated to the entities they identify. (In other words, you can’t look at a month identifier of 1 and assume that it represents the Month entity instance value of January.) Surrogate keys should not be exposed to the business on user interfaces. They remain behind the scenes to help maintain uniqueness, to allow for more efficient navigation across structures, and to facilitate integration across applications.
You’ve seen that a primary key may be composed of one or more attributes of the entity. A single-attribute surrogate key is more efficient to use than having to specify three or four (or five or six) attributes to locate the single record you’re looking for. Surrogate keys are useful for data integration, which is an effort to create a single, consistent version of the data. Applications such as data warehouses often house data from more than one application or system. Surrogate keys enable us to bring together information about the same entity instance that is identified differently in each source system.
When using a surrogate key, always make an effort to determine the natural key, which is what the business would consider to be the way to uniquely identify the entity, and then define an alternate key on this natural key. For example, assuming a surrogate key is a more efficient primary key than Class Full Name, we can create the surrogate key Class ID for Class and define an alternate key on Class Full Name. Note that the primary key column in Attendance also changes when we change the primary key of the related entity Class.

|
Class ID |
Class Full Name |
Class Short Name |
Class Description Text |
|
1 |
Data Modeling Fundamentals |
Data Modeling 101 |
An introductory class covering basic data modeling concepts and principles. |
|
2 |
Advanced Data Modeling |
Data Modeling 301 |
A fast-paced class covering techniques such as advanced normalization and ragged hierarchies. |
|
3 |
Tennis Basics |
Tennis One |
For those new to the game of tennis; learn the key aspects of the game. |
|
4 |
Juggling |
Learn how to keep three balls in the air at once! |
Surrogate keys are frequently counters – that is, the first instance created is assigned the unique value of 1, the second 2, etc. However, some surrogate keys are Globally Unique Identifiers, or GUIDs for short. A GUID is a long and frequently randomly assigned unique value, an example being 21EC2020-3AEA-1069-A2DD-08002B30309D.
MongoDB ObjectId = RDBMS GUID (Surrogate Key at Physical Level)
Every MongoDB document is identified by a unique _id field. Although the _id defaults to an ObjectId type, you may use another data type if you need to as long as it is unique within a collection. For example, you can have Collection A contain a document with an _id key of 12345 and Collection B contain a document with an _id key of 12345, but Collection A cannot contain two documents with the _id key 12345.
The ObjectId type is similar to a Globally Unique Identifier (GUID) in how values are often assigned, and therefore the chance of getting a duplicate value is very rare. The ObjectId is 12 bytes long. The first four bytes capture the timestamp down to the second, the next three bytes represent the host machine (whose value is usually hashed), and the next two bytes come from the process identifier of the ObjectId-generating process. These first nine bytes of an ObjectId guarantee its uniqueness within a single second. The last three bytes are an incrementing counter that is responsible for uniqueness within a second in a single process. This allows for up to 16,777,216 unique ObjectIds to be generated per process per second!
Here are some sample ObjectIds:
- ObjectId(“5280bd3711b3c2b87b4f555d”)
- ObjectId(“5280bd3711b3c2b87b4f555e”)
- ObjectId(“5280bd3711b3c2b87b4f555f”)
Foreign Key
The entity on the “one” side of the relationship is called the parent entity, and the entity on the “many” side of the relationship is called the child entity. When we create a relationship from a parent entity to a child entity, the primary key of the parent is copied as a foreign key to the child.
A foreign key is one or more attributes that provide a link to another entity. A foreign key allows a relational database management system to navigate from one table to another. For example, if we need to know the customer who owns an account, we would want to include the Customer ID in the Account entity. The Customer ID in Account is the primary key for Customer.
Using this foreign key back to Customer enables the database management system to navigate from a particular account or accounts to the customer or customers that own each account. Likewise, the database can navigate from a particular customer or customers to find all of their accounts. Our data modeling tools automatically create a foreign key when a relationship is defined between two entities.
In our Student/Class model, there are two foreign keys in Attendance. The Student Number foreign key points back to a particular student in the Student entity, and the Class ID foreign key points back to a particular Class in the Class entity:
|
Student Number |
Class ID |
Attendance Date |
|
SM385932 |
1 |
5/10/2013 |
|
EM584926 |
1 |
5/10/2013 |
|
EM584926 |
2 |
6/10/2013 |
|
MM481526 |
2 |
6/10/2013 |
|
MM573483 |
2 |
6/10/2013 |
|
LR731511 |
3 |
7/10/2013 |
By looking at these values and recalling the students referenced by the Student Number and classes reference by Class ID, we learn that Steve Martin and Eddie Murphy both attended the Data Modeling Fundamentals class on 5/10/2013. Eddie Murphy also attended the Advanced Data Modeling Class with Mickey and Minnie Mouse on 6/10/2013. Lone Ranger took Tennis Basics (by himself, as usual) on 7/10/2013.
MongoDB Reference = RDBMS Foreign Key
The concept of a foreign key in relational databases is similar to the concept of a reference in MongoDB. Both a foreign key and a reference provide a way to navigate to another structure. The difference, though, is that the relational database automatically ensures each foreign key value also exists as a value in the originating primary key. That is, if there is a Product ID foreign key in Order Line originating from Product, every Product ID value in Order Line must also exist in Product. This check of valid values from foreign keys back to their primary keys is called “referential integrity” (or RI for short). In MongoDB, the reference is simply a way to navigate to another structure (without the RI).
For example, recall our data model:

Student Number and Class ID in Attendance translate into foreign keys on the Attendance RDBMS table because of the constraints from Student to Attendance and from Class to Attendance. This means that a Student Number cannot exist in Attendance without having this Student Number first exist in Student. A Class ID cannot exist in Attendance without having this Class ID exist in Class.
However, in MongoDB, if Attendance is a collection with a Student Number reference to Student and a Class reference to Class, there are no checks to ensure the Attendance Student Numbers and Class IDs point back to valid values in the Student and Class collections.
Secondary Key
Sometimes there is a need to retrieve data rapidly from a table to answer a business query or meet a certain response time. A secondary key is one or more data elements (if there is more than one data element, it is called a composite secondary key) that are accessed frequently and need to be retrieved quickly. A secondary key is also known as a non-unique index or inversion entry (IE for short). A secondary key does not have to be unique, stable, nor always contain a value. For example, we can add an IE to Student Last Name in Student to allow for quick retrieval whenever any queries require Student Last Name:

Student Last Name is not unique, as there can be two Jones; it is not stable and can change over time; and sometimes we may not know someone’s last name, so it can be empty.
MongoDB Non-Unique Index = RDBMS Secondary Key
The concept of a secondary key in relational databases is equivalent to the concept of a non-unique index in MongoDB. Indexes are added to improve retrieval performance. There are always tradeoffs with indexes, though. Balance retrieval speed with space (each index requires at least 8 kilobytes) and volatility (if the underlying data changes, the index has to change, too).
A query that does not use an index is called a “table scan” in an RDBMS and a “collection scan” in MongoDB. This means that the server has to look through all of the data, starting at the beginning, until all of the query results are found. This process is basically what you’d do if you were looking for information in a book without an index: you’d start at page one and read through the whole thing. In general, you want to avoid making the server do table scans because they is very slow for large collections.
Subtype
Subtyping groups the common attributes and relationships of entities, while retaining what is special within each entity. Subtyping is an excellent way of communicating that certain concepts are very similar and of showing examples.
In our publishing data model, an Author may write many PrintVersions and many eBooks:

- Each Author may write one or many PrintVersions.
- Each PrintVersion must be written by one Author.
- Each Author may write one or many eBooks.
- Each eBook must be written by one Author.
Rather than repeat the relationship to Author, as well as the common attributes, we can introduce subtyping:

- Each Author may write one or many Titles.
- Each Title must be written by one Author.
- Each Title may be either a PrintVersion or eBook.
- Each PrintVersion is a Title.
- Each eBook is a Title.
The subtyping relationship implies that all of the relationships and attributes from the supertype are inherited by each subtype. Therefore, there is an implied relationship from Author to eBook as well as from Author to PrintVersion. Also, the titleName, subtitleName, and titleRetailPrice belong to PrintVersion and belong to eBook. Note that each subtype must have the same attributes in their primary key as the supertype; in this case, titleISBN, which is the identifier for a particular title.
Not only does subtyping reduce redundancy on a data model, but it makes it easier to communicate similarities across what otherwise would appear to be distinct and separate concepts.
MongoDB Identity, Rolldown, Rollup = RDBMS Identity, Rolldown, Rollup (Subtype at Physical Level)
The subtyping symbol cannot exist on a physical data model, and the three ways to resolve are Identity, Rolldown, and Rollup:
|
Original Logical
|
Identity
|


|
Rolldown
|
Rollup
|
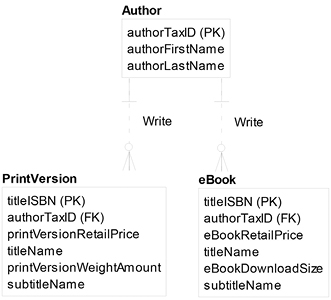

Identity, rolldown, and rollup are the same techniques for both an RDBMS and in MongoDB:
- Identity. Identity is the closest to subtyping, because the subtyping symbol is replaced with a one-to-one relationship for each supertype/subtype combination. The main advantage of identity is that all of the business rules at the supertype level and at the subtype level remain the same as in the logical data model. That is, we can continue to enforce relationships at the supertype or subtype levels as well as enforce that certain fields be required at the supertype or subtype levels. Identity allows us to still require the printVersionWeightAmount for print versions and the eBookDownloadSize for eBooks, for example. The main disadvantage of identity is that it can take more time to retrieve data as it requires navigating multiple tables to access both the supertype and subtype information.
- Rolldown. Rolldown means we are moving the attributes and relationships of the supertype down to each of the subtypes. Rolling down can produce a more user-friendly structure than identity or rolling up because subtypes are often more concrete concepts than supertypes, making it easier for the users of the data model to relate to the subtypes. However, we are repeating relationships and fields, which could reduce any user-friendliness gained from removing the supertype. In addition, the rolling down technique enforces only those rules present in the subtypes. This could lead to a less flexible data model as we can no longer easily accommodate new subtypes without modifying the data model. If a new type of Title is required in addition to PrintVersion and eBook, this would require effort to accommodate.
- Rollup. Rollup means rolling up the subtypes up into the supertype. The subtypes disappear, and all attributes and relationships only exist at the supertype level. Rolling up adds flexibility to the data model because new types of the supertype can be added, often with no model changes. However, rolling up can also produce a more obscure model as the audience for the model may not relate to the supertype as well as they would to the subtypes. In addition, we can only enforce business rules at the supertype level and not at the subtype level. For example, now printVersionWeightAmount and the eBookDownloadSize are optional instead of required. When we roll up, we often need a way to distinguish the original subtypes from each other, so we frequently add a type column such as titleTypeCode.
EXERCISE 2: Subtyping in MongoDB
Translate the Author / Title subtyping example we just reviewed into three MongoDB documents (rolldown, rollup, and identity) using the sample data on the facing page. Refer to Appendix A for the answer.
Author
|
authorTaxID |
authorFirstName |
authorLastName |
|
22-5555555 |
Steve |
Hoberman |
Title
|
titleISBN |
authorTaxID |
titleName |
subtitleName |
titleRetailPrice |
|
9780977140060 |
22-5555555 |
Data Modeling Made Simple |
A Practical Guide for Business and IT Professionals |
$44.95 |
|
9781935504702 |
22-5555555 |
Data Modeling for MongoDB |
Building Well-Designed and Supportable MongoDB Databases |
$39.95 |
|
9781935504719 |
22-5555555 |
Data Modeling for MongoDB |
Building Well-Designed and Supportable MongoDB Databases |
$34.95 |
|
9781935504726 |
22-5555555 |
The Best Data Modeling Jokes |
$9.95 |
Print Version
|
titleISBN |
printVersionWeightAmount |
|
9780977140060 |
1.5 |
|
9781935504702 |
1 |
eBook
|
titleISBN |
eBookDownloadSize |
|
9781935504719 |
3 |
|
9781935504726 |
2 |
|
Key Points
|
||
|
Data Model |
RDBMS |
MongoDB |
|
Entity instance |
Record or Row |
Document |
|
Entity |
Table |
Collection |
|
Attribute or Data element |
Data element, Field or Column |
Field |
|
Attribute value or Data element value |
Data element value, Field value, or Column value |
Field value |
|
Format domain |
Datatype |
Datatype |
|
Relationship |
Constraint |
Captured but not enforced either through a reference, which is similar to a foreign key, or through embedded documents. |
|
Candidate key (Primary or Alternate key) |
Unique index |
Unique index |
|
Surrogate key |
Globally Unique Id (GUID) |
ObjectId |
|
Foreign key |
Foreign key |
Reference |
|
Secondary key, Inversion entry |
Secondary key |
Non-unique index |
|
Subtype |
Rolldown, Rollup, Identity |
Rolldown, Rollup, Identity |