
The projects of this chapter explore pipes, forks and redirection in the context of a ring of processes. Such a ring allows simple and interesting simulations of ring network topologies. The chapter also introduces fundamental ideas of distributed processing, including processor models, pipelining and parallel computation. Distributed algorithms such as leader election illustrate important implementation issues.
The ring topology is one of the simplest and least expensive configurations for connecting communicating entities. Figure 7.1 illustrates a unidirectional ring structure. Each entity has one connection for input and one connection for output. Information circulates around the ring in a clockwise direction. Rings are attractive because interconnection costs on the ring scale linearly—in fact, only one additional connection is needed for each additional node. The latency increases as the number of nodes increases because the time it takes for a message to circulate is longer. In most hardware implementations, the rate at which nodes can read information from the ring or write information to the ring does not change with increasing ring size, so the bandwidth is independent of the size of the ring. Several network standards, including token ring (IEEE 802.5), token bus (IEEE 802.4) and FDDI (ANSI X3T9.5) are based on ring connectivity.
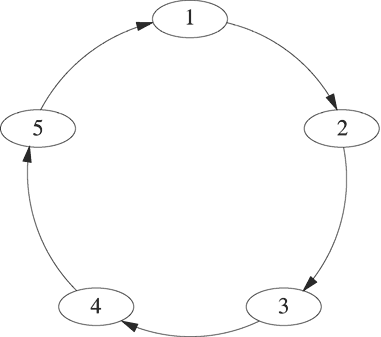
This chapter develops several projects based on the ring topology of Figure 7.1. The nodes represent processes and the links represent pipes. Each process is a filter that reads from standard input and writes to standard output. Process n-1 redirects its standard output to the standard input of process n through a pipe. Once the ring structure is set up, the project can be extended to simulate network standards or to implement algorithms for mutual exclusion and leader election based on the ring architecture.
Section 7.2 presents a step-by-step development of a simple ring of processes connected by pipes. Section 7.3 provides several exploratory exercises that build on the basic ring structure. The figures of Section 7.2 trace the code through the creation of two processes on the ring, but the basic ring is too complicated to trace manually much beyond that.
We suggest that before working through Section 7.3, you use the fork-pipe simulator to try some of the examples. The book web page has a link to this simulator, which shows a diagram of the processes and pipes as it traces the code. The simulator also allows experimentation with process chains, fans and trees as well as more complicated structures such as a bidirectional ring. The simulator allows you to experiment with the effects of using different CPU scheduling algorithms, or you can single-step through the code, determining which process runs at each step. The simulator also can produce a log of the output generated and a trace of the instructions executed.
Once you have a thorough understanding of the ring and its behavior, you can go on to the other projects in this chapter. Section 7.4 tests the ring connectivity and operation by having the ring generate a Fibonacci sequence. Section 7.5 and Section 7.6 present two alternative approaches for protecting critical sections on the ring. Once the ring structure is set up, the basic project of Section 7.2 can be extended to simulate network standards or to implement algorithms for mutual exclusion and leader election based on the ring architecture. The remaining sections of the chapter describe extensions exploring different aspects of network communication, distributed processing and parallel algorithms. The extensions described in each of the later sections are independent of those in other sections.
This section develops a ring of processes starting with a ring containing a single process. You should review Section 4.6 if you are not clear on file descriptors and redirection.
Example 7.1.
The following code segment connects the standard output of a process to its standard input through a pipe. We omit the error checking for clarity.
int fd[2]; pipe(fd); dup2(fd[0], STDIN_FILENO); dup2(fd[1], STDOUT_FILENO); close(fd[0]); close(fd[1]);
Figures 7.2–7.4 illustrate the status of the process at various stages in the execution of Example 7.1. The figures use [0] to designate standard input and [1] to designate standard output. Be sure to use STDIN_FILENO and STDOUT_FILENO when referring to these file descriptors in program code. The entries of the file descriptor table are pointers to entries in the system file table. For example, pipe write in entry [4] means “a pointer to the write entry in the system file table for pipe,” and standard input in entry [0] means “a pointer to the entry in the system file table corresponding to the default device for standard input”—usually the keyboard.
Figure 7.2 depicts the file descriptor table after the pipe has been created. File descriptor entries [3] and [4] point to system file table entries that were created by the pipe call. The program can now write to the pipe by using a file descriptor value of 4 in a write call.

Figure 7.3 shows the status of the file descriptor table after the execution of the dup2 functions. At this point the program can write to the pipe using either 1 or 4 as the file descriptor value. Figure 7.4 shows the configuration after descriptors [3] and [4] are closed.


Example 7.2.
What happens if, after connecting standard output to standard input through a pipe, the process of Example 7.1 executes the following code segment?
int i, myint;
for (i = 0; i < 10; i++) {
write(STDOUT_FILENO, &i, sizeof(i));
read(STDIN_FILENO, &myint, sizeof(myint));
fprintf(stderr, "%d
", myint);
}
Answer:
The code segment outputs the integers from 0 to 9 to the screen (assuming that standard error displays on the screen).
Example 7.3.
What happens if you replace the code in Exercise 7.2 by the following code?
int i, myint;
for (i = 0; i < 10; i++) {
read(STDIN_FILENO, &myint, sizeof(myint));
write(STDOUT_FILENO, &i, sizeof(i));
fprintf(stderr, "%d
", myint);
}
Answer:
The program hangs on the first read because nothing had yet been written to the pipe.
Example 7.4.
What happens if you replace the code in Exercise 7.2 by the following?
int i, myint;
for (i = 0; i < 10; i++) {
printf("%d ", i);
scanf("%d", &myint);
fprintf(stderr, "%d
", myint);
}
Answer:
The program may hang on the scanf if the printf buffers its output. Put an fflush(stdout) after the printf to get output.
Example 7.5.
The following code segment creates a ring of two processes. Again, we omit error checking for clarity.
int fd[2]; pid_t haschild; pipe(fd); /* pipe a */ dup2(fd[0], STDIN_FILENO); dup2(fd[1], STDOUT_FILENO); close(fd[0]); close(fd[1]); pipe(fd); /* pipe b */ haschild = fork(); if (haschild > 0) dup2(fd[1], STDOUT_FILENO); /* parent(A) redirects std output */ else if (!haschild) dup2(fd[0], STDIN_FILENO); /* child(B) redirects std input */ close(fd[0]); close(fd[1]);
The parent process in Example 7.5 redirects standard output to the second pipe. (It was coming from the first pipe.) The child redirects standard input to come from the second pipe instead of the first pipe. Figures 7.5–7.8 illustrate the connection mechanism.
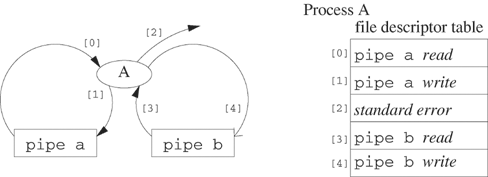
Figure 7.5. Connections to the parent process of Example 7.5 after the second pipe(fd) call executes.
Figure 7.5 shows the file descriptor table after the parent process A creates a second pipe. Figure 7.6 shows the situation after process A forks child process B. At this point, neither of the dup2 functions after the second pipe call has executed.

Figure 7.6. Connections of the processes of Example 7.5 after the fork. Process A is the parent and process B is the child.
Figure 7.7 shows the situation after the parent and child have each executed their last dup2. Process A has redirected its standard output to write to pipe b, and process B has redirected its standard input to read from pipe b. Finally, Figure 7.8 shows the status of the file descriptors after all unneeded descriptors have been closed and a ring of two processes has been formed.

Figure 7.7. Connections of the processes of Example 7.5 after the if statement executes. Process A is the parent and process B is the child.

Figure 7.8. Connections of the processes of Example 7.5 after the entire code segment executes. Process A is the parent and process B is the child.
Example 7.6.
What would happen if the code of Exercise 7.2 is inserted after the ring of two processes of Example 7.5?
Answer:
The new code is executed by two processes. Each process writes 10 integers to the pipe and reads the integers written by the other process. The processes cannot get too far out of step, since each process needs to read from the other before writing the next value. You should see two lines of 0 followed by two lines of 1, etc.
The code of Example 7.5 for forming a ring of two processes easily extends to rings of arbitrary size. Program 7.1 sets up a ring of n processes. The value of n is passed on the command line (and converted to the variable nprocs). A total of n pipes is needed. Notice, however, that the program needs an array only of size 2 rather than 2n to hold the file descriptors. After the ring of two processes is created, the parent drops out and the child forks again. (Try to write your own code before looking at the ring program.)
Example 7.1. ring.c
A program to create a ring of processes.
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main(int argc, char *argv[ ]) {
pid_t childpid; /* indicates process should spawn another */
int error; /* return value from dup2 call */
int fd[2]; /* file descriptors returned by pipe */
int i; /* number of this process (starting with 1) */
int nprocs; /* total number of processes in ring */
/* check command line for a valid number of processes to generate */
if ( (argc != 2) || ((nprocs = atoi (argv[1])) <= 0) ) {
fprintf (stderr, "Usage: %s nprocs
", argv[0]);
return 1;
}
if (pipe (fd) == -1) { /* connect std input to std output via a pipe */
perror("Failed to create starting pipe");
return 1;
}
if ((dup2(fd[0], STDIN_FILENO) == -1) ||
(dup2(fd[1], STDOUT_FILENO) == -1)) {
perror("Failed to connect pipe");
return 1;
}
if ((close(fd[0]) == -1) || (close(fd[1]) == -1)) {
perror("Failed to close extra descriptors");
return 1;
}
for (i = 1; i < nprocs; i++) { /* create the remaining processes */
if (pipe (fd) == -1) {
fprintf(stderr, "[%ld]:failed to create pipe %d: %s
",
(long)getpid(), i, strerror(errno));
return 1;
}
if ((childpid = fork()) == -1) {
fprintf(stderr, "[%ld]:failed to create child %d: %s
",
(long)getpid(), i, strerror(errno));
return 1;
}
if (childpid > 0) /* for parent process, reassign stdout */
error = dup2(fd[1], STDOUT_FILENO);
else /* for child process, reassign stdin */
error = dup2(fd[0], STDIN_FILENO);
if (error == -1) {
fprintf(stderr, "[%ld]:failed to dup pipes for iteration %d: %s
",
(long)getpid(), i, strerror(errno));
return 1;
}
if ((close(fd[0]) == -1) || (close(fd[1]) == -1)) {
fprintf(stderr, "[%ld]:failed to close extra descriptors %d: %s
",
(long)getpid(), i, strerror(errno));
return 1;
}
if (childpid)
break;
} /* say hello to the world */
fprintf(stderr, "This is process %d with ID %ld and parent id %ld
",
i, (long)getpid(), (long)getppid());
return 0;
}
The following exercises test and modify Program 7.1. You can try these either by compiling the ring code or by using the fork-pipe simulator. A link to the simulator appears on the book web page. For each modification, make a new copy of the program. Suggested names for the executables are shown in parentheses.
Run the program shown in Program 7.1 (
ring).Create a makefile with descriptions for compiling and linting the program. Use
maketo compile the program. Add targets for additional parts of this project. (Refer to Section A.3 if you are unfamiliar with themakeutility.)Make any corrections required to eliminate all lint errors and warning messages that reflect problems with the program. (Refer to Section A.4 if you are unfamiliar with the
lintutility.)Run
ringfor several values of the command-line argument and observe what happens as the number of processes in the ring varies from 1 to 20.Modify the original
ringprogram by putting awaitcall before the finalfprintfstatement (ring1). How does this affect the output of the program?Modify the original
ringprogram by putting awaitcall after the finalfprintfstatement (ring2). How does this affect the output of the program?Replace the
fprintfstatement in the originalringprogram with calls tosprintfandprtastr(ring3). Write aprtastrfunction with the following prototype.void prtastr(const char *s, int fd, int n);
The
prtastrfunction prints thesstring one character at a time to the file specified by descriptorfdusingwrite. After outputting each character,prtastrcalls the following function.wastesometime.cvoid wastesometime(int n) { static volatile int dummy = 0; int i; for (i=0; i < n; i++) dummy++; }This just wastes some CPU time. The variable
dummyis declared to be volatile so that the action of theforloop is not optimized away. Useprtastrto output the string to standard error. Pass the value ofnused byprtastras an optional command-line argument toring3. Use 0 as the default value for this parameter. (The single character at a time gives the ring processes more opportunity to interleave their output.) Run the program with a value ofnthat causes a small, but barely noticeable, delay between the output of characters.Compare the results of running the modified
ring3if you do the following.Insert
waitbefore the call toprtastr(ring4).Insert
waitafter the call toprtastr(ring5).
Modify
ring1as follows (ringtopology).Before the
wait, each process allocates an array ofnprocselements to hold the IDs of all the processes on the ring. The process puts its own process ID in element zero of the array and sets its variablenext_IDto its process ID.Do the following for
kgoing from1tonprocs-1.Write
next_IDto standard output.Read
next_IDfrom standard input.Insert
next_IDinto positionkof the ID array.
Replace the
fprintfafter thewaitwith a loop that outputs the contents of the ID array to standard error in a readable single-line format. This output tests the ring connectivity, since the ID array contains the processes in the order in which they appear upstream from a given process.
Modify
ringtopologyby having the child rather than the parent break out of the loop (ringchildbreak). We are now creating a process fan instead of a chain. Determine how this affects the topology. Do we still have a ring? If using the simulator, you can just modifyringsince you do not need to send anything around to ring to determine the topology.Modify
ringtopologyby having neither process break out of the loop (ringnobreak). We are now creating a process tree instead of a chain. Determine how this affects the topology. Do we still have a ring? The number of processes is now greater thannprocs. How does the number of processes depend onnprocs? You will need to adjust the loop that sends the process IDs around the ring.Modify
ring1to be a bidirectional ring (information can flow in either direction between neighbors on the ring). Standard input and output are used for the flow in one direction. File descriptors 3 and 4 are used for the flow in the other direction. Test the connections by accumulating ID arrays for each direction (biring).Modify
ring1to create a bidirectional torus of processes. Accumulate ID arrays to test connectivity. A torus has a two-dimensional structure. It is like a mesh except that the processes at the ends are connected together. Then2processes are arranged innrings in each dimension (torus). Each process has four connections (North, South, East, and West).
Use the ring simulator that is linked on the book web site to explore various aspects of this problem. Modify the ring simulator example to illustrate the effects of items 4 through 6. Make printing nonatomic to illustrate items 7 and 8. Pass data around the ring as in item 9, and construct a bidirectional ring for item 10.
Section 7.2 established the connections for a ring of processes. This section develops a simple application in which processes generate a sequence of Fibonacci numbers on the ring. The next number in a Fibonacci sequence is the sum of the previous two numbers in the sequence.
In this project, the processes pass information in character string format. The original parent outputs the string "1 1" representing the first two Fibonacci numbers to standard output, sending the string to the next process. The other processes read a string from standard input, decode the string, calculate the next Fibonacci number, and write to standard output a string representing the previous Fibonacci number and the one just calculated. Each process then writes the result of its calculation to standard error and exits. The original parent exits after receiving a string and displaying the numbers received.
Start with the original ring function of Program 7.1 and replace the fprintf with code to read two integers from standard input in the string format described below, calculate the next integer in a Fibonacci sequence, and write the result to standard output.
Each string is the ASCII representation of two integers separated by a single blank.
The original parent writes out the string
"1 1", representing two ones and then reads a string. Be sure to send the string terminator.All other processes first read a string and then write a string.
Fibonacci numbers satisfy the formula xn+1 = xn + xn- . Each process receives two numbers (e.g.,
afollowed byb), calculatesc = a + band writesbfollowed bycas a null-terminated string. (Thebandcvalues should be written as strings separated by a single blank.)After sending the string to standard output, the process writes a single-line message to standard error in the following form.
Process i with PID x and parent PID y received a b and sent b c.
After sending the message to standard error, the process exits. Try to write the program in such a way that it handles the largest possible number of processes and still calculates the Fibonacci numbers correctly. The execution either runs out of processes or some process generates a numeric overflow when calculating the next number. Attempt to detect this overflow and send the string
"0 0".
Notes: The program should be able to calculate Fib(46)=1,836,311,903, using 45 processes or Fib(47)=2,971,215,073, using 46 processes. It may even be able to calculate Fib(78)=8,944,394,323,791,464, using 77 processes. With a little extra work, the program can compute higher values. A possible approach for detecting overflow is to check whether the result is less than the first integer in the string.
This program puts a heavy load on the CPU of a machine. Don’t try this project with more than a few processes unless it is running on a dedicated computer. Also, on some systems, a limit on the number of processes for a user may interfere with running the program for a large number of processes.
All the processes on the ring share the standard error device, and the call to prtastr described in Section 7.3 is a critical section for these processes. This section describes a simple token-based strategy for granting exclusive access to a shared device. The token can be a single character that is passed around the ring. When a given process acquires the token (reads the character from standard input), it has exclusive access to the shared device. When that process completes its use of the shared device, it writes the character to standard output so that the next process in the ring can acquire the token. The token algorithm for mutual exclusion is similar to the speaking stick (or a conch [42]) used in some cultures to enforce order at meetings. Only the person who holds the stick can speak.
The acquisition of mutual exclusion starts when the first process writes a token (just a single character) to its standard output. From then on, the processes use the following strategy.
If a process does not wish to access the shared device, it merely passes the token on.
What happens to the preceding algorithm at the end? After a process has completed writing its messages to standard error, it must continue passing the token until all other processes on the ring are done. One strategy for detecting termination is to replace the character token by an integer. The initial token has a zero value. If a process finishes its critical section but will still access the shared device at a later time, it just passes the token unchanged. When a process no longer needs to access the shared device, it performs the following shutdown procedure.
Read the token.
Increment the token.
Write the token.
Repeat until the token has a value equal to the number of processes in the ring.
Read the token.
Write the token.
Exit.
The repeat section of the shutdown procedure has the effect of forcing the process to wait until everyone is finished. This strategy requires that the number of processes on the ring be known.
Implement and test mutual exclusion with tokens as follows.
Start with version
ring3of the ring program from Section 7.3.Implement mutual exclusion for standard error by using the integer token method just described but without the shutdown procedure. The critical section should include the call to
prtastr.Test the program with different values of the command-line arguments. In what order do the messages come out and why?
Vary the tests by having each process repeat the critical section a random number of times between 0 and
r. Passras a command-line argument. Before each call toprtastr, read the token. After callingprtastr, write the token. When done with all output, execute a loop that just passes the token. (Hint: Read the man page ondrand48and its related functions. Thedrand48function generates a pseudorandom double in the range [0, 1). Ifdrand48generates a value ofx, theny = (int)(x*n)is an integer satisfying0 ≤ = y < n.) Use the process ID for a seed so that the processes use independent pseudorandom numbers.The messages that each process writes to standard error should include the process ID and the time the operation began. Use the
timefunction to obtain a time in seconds. Print the time in a nice format as in Example 5.8. (Page 302 in Chapter 9 has a more detailed description oftime.)
One problem with the token method is that it generates continuous traffic (a form of busy waiting) even when no process enters its critical section. If all the processes need to enter their critical sections, access is granted by relative position as the token travels around the ring. An alternative approach uses an algorithm of Chang and Roberts for extrema finding [22]. Processes that need to enter their critical sections vote to see which process obtains access. This method generates traffic only when a process requires exclusive access. The approach can be modified to accommodate a variety of priority schemes in the determination of which process goes next.
Each process that is contending for mutual exclusion generates a voting message with a unique two-part ID. The first part of the ID, the sequence number, is based on a priority. The second part of the ID, the process ID, breaks ties if two processes have the same priority. Examples of priority include sequence numbers based on the current clock time or on the number of times that the process has acquired mutual exclusion in the past. In each of these strategies, the lower value corresponds to a higher priority. Use the latter strategy.
To vote, the process writes its ID message on the ring. Each process that is not participating in the vote merely passes the incoming ID messages to the next process on the ring. When a process that is voting receives an ID message, it bases its actions on the following paradigm.
If the incoming message has a higher ID (lower priority) than its own vote, the process throws away the incoming message.
If the incoming message has a lower ID (higher priority) than its own vote, the process forwards the message.
If the incoming message is its own message, the process has acquired mutual exclusion and can begin the critical section.
Convince yourself that the winner of the vote is the process whose ID message is the lowest for that ballot.
A process relinquishes mutual exclusion by sending a release message around the ring. Once a process detects that the vote has started either because it initiated the request or because it received a message, the process cannot initiate another vote until it detects a release message. Thus, of the processes that decided earliest to participate, the process that received access the fewest times in the past wins the election.
Implement the voting algorithm for exclusive access to standard error. Incorporate random values of the delay value, which is the last parameter of the prtastr function defined in Section 7.3. Devise a strategy for graceful exit after all of the processes have completed their output.
Specifications of distributed algorithms refer to the entities that execute the algorithm as processes or processors. Such algorithms often specify an underlying processor model in terms of a finite-state machine. The processor models are classified by how the state transitions are driven (synchrony) and whether the processors are labeled.
In the synchronous processor model, the processors proceed in lock step and state transitions are clock-driven. In the asynchronous processor model, state transitions are message-driven. The receipt of a message on a communication link triggers a change in processor state. The processor may send messages to its neighbors, perform some computation, or halt as a result of the incoming message. On any given link between processors, the messages arrive in the order they were sent. The messages incur a finite, but unpredictable, transmission delay.
A system of communicating UNIX processes connected by pipes, such as the ring of Program 7.1, is an example of an asynchronous system. A massively parallel SIMD (single-instruction, multiple-data) machine such as the CM-2 is an example of a synchronous system.
A processor model must also specify whether the individual processors are labeled or whether they are indistinguishable. In an anonymous system, the processors have no distinguishing characteristic. In general, algorithms involving systems of anonymous processors or processes are more complex than the corresponding algorithms for systems of labeled ones.
The UNIX fork function creates a copy of the calling process. If the parent and child were completely identical, fork would not accomplish anything beyond the activities of a single process. In fact, UNIX distinguishes the parent and child by their process IDs, and fork returns different values to the parent and child so that each is aware of the other’s identity. In other words, fork breaks the symmetry between parent and child by assigning different process IDs. Systems of UNIX processors are not anonymous because the processes can be labeled by their process IDs.
Symmetry-breaking is a general problem in distributed computing in which identical processes (or processors) must be distinguished to accomplish useful work. Assignment of exclusive access is an example of symmetry-breaking. One possible way of assigning mutual exclusion is to give preference to the process with the largest process ID. Usually, a more equitable method would be better. The voting algorithm of Section 7.6 assigns mutual exclusion to the process that has acquired it the fewest times in the past. The algorithm uses the process ID only in the case of ties.
Leader election is another example of a symmetry-breaking algorithm. Leader election algorithms are used in some networks to designate a particular processor to partition the network, regenerate tokens, or perform other operations. For example, what happens in a token-ring network if the processor holding the token crashes? When the crashed processor comes back up, it does not have a token and activity on the network comes to a standstill. One of the nonfaulty processors must take the initiative to generate another token. Who should decide which processor is in charge?
There are no deterministic algorithms for electing a leader on an anonymous ring. This section discusses the implementation of a probabilistic leader-election algorithm for an anonymous ring. The algorithm is an asynchronous version of the synchronous algorithm proposed by Itai and Roteh [58]. This is a probabilistic algorithm for leader election on an anonymous synchronous ring of size n. The synchronous version of the algorithm proceeds in phases. Each process keeps track of the number of active processes, m. These are the processes still competing for being chosen as the leader.
Phase zero
Set local variable
mton.Set
activetoTRUE.
Phase
kIf
activeisTRUE,Choose a random number,
x, between 1 andm.If the number chosen was 1, send a one-bit message around the ring.
Count the number of one-bit messages received in the next
n-1clock pulses as follows.If only one active process chose 1, the election is completed.
If no active processes chose 1, go to the next phase with no change.
If
pprocesses chose 1, setmtop.If the process is active and it did not choose 1, set its local
activetoFALSE.
In summary, on each phase the active processes pick a random number between 1 and the number of active processes. Any process that picks a 1 is active on the next round. If no process picks a 1 on a given round, the active processes try again. The probability of a particular process picking a 1 increases as the number of active processes decreases. On average, the algorithm eliminates processes from contention at a rapid rate. Itai and Roteh showed that the expected number of phases needed to choose a leader on a ring of size n is less than e ≈ 2.718, independently of n.
Using the ring of Program 7.1, implement a simulation of this leader-election algorithm to estimate the probability distribution J(n,k), which is the probability that it takes k phases to elect a leader on a ring of size n.
The implementation has to address two problems. The first problem is that the algorithm is specified for a synchronous ring, but the implementation is on an asynchronous ring. Asynchronous rings clock on the messages received (i.e., each time a process reads a message, it updates its clock). The processes must read messages at the correct point in the algorithm or they lose synchronization. Inactive processes must still write clock messages.
A second difficulty arises because the theoretical convergence of the algorithm relies on the processes having independent streams of random numbers. In practice, the processes use a pseudorandom-number generator with an appropriate seed. The processes are supposedly identical, but if they start with the same seed, the algorithm will not work. The implementation can cheat by using the process ID to generate a seed, but ultimately it should include a method of generating numbers based on the system clock or other system hardware. (The first few sections of Chapter 10 discuss library functions for accessing the system clock and timers.)
This section develops a simulation of communication on a token-ring network. Each process on the ring now represents an Interface Message Processor (IMP) of a node on the network. The IMP handles message passing and network control for the host of the node. Each IMP process creates a pair of pipes to communicate with its host process, as shown in Figure 7.9. The host is represented by a child process forked from the IMP.

Each IMP waits for messages from its host and from the ring. For simplicity, a message consists of five integers—a message type, the ID of the source IMP, the ID of the destination IMP, a status, and a message number. The possible message types are defined by the enumerated type msg_type_t.
typedef enum msg_type{TOKEN, HOST2HOST, IMP2HOST, HOST2IMP, IMP2IMP} msg_type_t;
The IMP must read a TOKEN message from the ring before it writes any message it originates to the ring. When it receives an acknowledgment of its message, it writes a new TOKEN message on the ring. The acknowledgments are indicated in the status member that is of type msg_status_t defined by the following.
typedef enum msg_status{NONE, NEW, ACK} msg_status_t;
The IMP waits for a message from either its host or the ring. When an IMP detects that the host wants to send a message, it reads the message into a temporary buffer and sets the got_msg flag. Once the got_msg flag is set, the IMP cannot read any additional messages from the host until the got_msg flag is clear.
When the IMP detects a message from the network, its actions depend on the type of message. If the IMP reads a TOKEN message and it has a host message to forward (got_msg is set), the IMP writes the host message to the network. If the IMP has no message to send (got_msg is clear), it writes the TOKEN message on the network.
If the IMP reads a message other than a TOKEN message from the ring, its actions depend on the source and destination IDs in the message.
If the source ID of the message matches the IMP’s ID, the message was its own. The IMP prints a message to standard error reporting whether the message was received by the destination. In any case, the IMP writes a
TOKENmessage to the ring and clearsgot_msg.If the destination ID of the message matches the IMP’s ID, the message is for the IMP or the IMP’s host. The IMP prints a status message to standard error reporting the type of message. The IMP changes the status of the message to
ACKand writes the message to the ring. If the message is for the host, also send the message to the host through the pipe.Otherwise, the IMP writes the message to the ring unchanged.
The actual IEEE 802.5 token-ring protocol is more complicated than this. Instead of fixed-length messages, the IMPs use a token-holding timer set to a prespecified value when transmission starts. An IMP can transmit until the timer expires, so messages can be quite long. There can also be a priority scheme [111]. In the actual token-ring protocol, one IMP is designated as the active monitor for the ring. It periodically issues control frames to tell the other stations that the active monitor is present. The active monitor detects whether a token has been lost and is responsible for regenerating tokens. All the stations periodically send standby-monitor-present control frames downstream to detect breaks in the ring.
Start with Program 7.1. Modify it so that after the ring is created, each IMP process creates two pipes and a child host process, as shown in Figure 7.9. Redirect standard output and standard input of the child host as shown in Figure 7.9, and have the child execute the hostgen program with the appropriate command-line arguments. The IMP enters an infinite loop to monitor its possible inputs, using select. When input is available, the IMP performs the simple token-ring protocol described above.
Write and test a separate program, hostgen, that takes two command-line arguments: an integer process number n and an integer sleep time s. The hostgen program monitors standard input and logs any input it receives to standard error. Use the read_timed of Program 4.16 on page 115 with a random timeout between 0 and s seconds. If a timeout occurs, write a random integer between 0 and n to standard output. Test the hostgen program separately.
The C preprocessor, cpp, preprocesses C source code so that the C compiler itself does not have to worry about certain things. For example, say a C program has a line such as the following.
#define BUFSIZE 250
In this case, cpp replaces all instances of the token BUFSIZE by 250. The C preprocessor deals with tokens, so it does not replace an occurrence of BUFSIZE1 with 2501. This behavior is clearly needed for C source code. It should not be possible to get cpp into a loop with something like the following.
#define BUFSIZE (BUFSIZE + 1)
Various versions of cpp handle this difficulty in different ways.
In other situations, the program may not be dealing with tokens and might replace any occurrence of a string, even if that string is part of a token or consists of several tokens. One method of handling the loops that may be generated by recursion is not to perform any additional test on a string that has already been replaced. This method fails on something as simple as the following statements.
#define BUFSIZE 250 #define BIGGERBUFSIZE (BUFSIZE + 1)
Another way to handle this situation is to make several passes through the input file, one for each #define and to make the replacements sequentially. The processing can be done more efficiently (and possibly in parallel) with a pipeline. Figure 7.10 shows a four-stage pipeline. Each stage in the pipeline applies a transformation to its input and then outputs the result for input to the next stage. A pipeline resembles an assembly line in manufacturing.
This section develops a pipeline of preprocessors based on the ring of Program 7.1. To simplify the programming, the preprocessors just convert single characters to strings of characters.
Write a
processcharfunction that has the following prototype.int processchar(int fdin, int fdout, char inchar, char *outstr);
The
processcharfunction reads from file descriptorfdinuntil end-of-file and writes to file descriptorfdout, translating any occurrence of the characterincharinto the stringoutstr. If successful,processcharreturns 0. If unsuccessful,processcharreturns–1 and setserrno. Write a driver to test this function before using it with the ring.Modify Program 7.1 so that it now takes four command-line arguments (
ringpp). Run the program by executing the following command.ringpp n conf.in file.in file.out
The value of the command-line argument
nspecifies the number of stages in the pipeline. It corresponds tonprocs-2in Program 7.1. The original parent is responsible for generating pipeline input by readingfile.in, and the last child is responsible for removing output from the pipeline and writing it tofile.out. Beforeringppcreates the ring, the original parent opens the fileconf.in, reads innlines, each containing a character and a string. It stores this information in an array. Theringppprogram reads theconf.infile before any forking, so the information in the array is available to all children.The original parent is responsible for copying the contents of the
file.ininput file to its standard output. When it encounters end-of-file onfile.in, the process exits. The original parent generates the input for the pipeline and does not perform any pipeline processing.The last child is responsible for removing output from the pipeline. The process copies data from its standard input to
file.out, but it does not perform any pipeline processing. The process exits when it encounters an end-of-file on its standard input.For
ibetween2andn+1, child processiuses the information in the(i-1)-th entry of the translation array to translate a character to a string. Each child process acts like a filter, reading the input from standard input, making the substitution and writing the result to standard output. Call theprocesscharfunction to process the input. Whenprocesscharencounters an end-of-file on input, each process closes its standard input and standard output, then exits.After making sure that the program is working correctly, try it with a big file (many megabytes) and a moderate number (10 to 20) of processes.
If possible, try the program on a multiprocessor machine to measure the speedup. (See Section 7.10 for a definition of speedup.)
Each stage of the pipeline reads from its standard input and writes to its standard output. You can generalize the problem by having each stage run execvp on an arbitrary process instead of calling the same function. The conf.in file could contain the command lines to execvp instead of the table of string replacements specific to this problem.
It is also possible to have the original parent handle both the generation of pipeline input and the removal of its output. In this case, the parent opens file.in and file.out after forking its child. The process must now handle input from two sources: file.in and its standard input. It is possible to use select to handle this, but the problem is more complicated than might first appear. The process must also monitor its standard output with select because a pipe can fill up and block additional writes. If the process blocks while writing to standard output, it is not able to remove output from the final stage of the pipeline. The pipeline might deadlock in this case. The original parent is a perfect candidate for threading. Threads are discussed in Chapters 12 and 13.
Parallel processing refers to the partitioning of a problem so that pieces of the problem can be solved in parallel, thereby reducing the overall execution time. One measure of the effectiveness of the partitioning is the speedup, S(n), which is defined as follows.

Ideally, the execution time is inversely proportional to the number of processors, implying that the speedup S(n) is just n. Unfortunately, linear speedup is a rare achievement in practical settings for a number of reasons. There is always a portion of the work that cannot be done in parallel, and the parallel version of the algorithm incurs overhead when the processors synchronize or communicate to exchange information.
The problems that are most amenable to parallelization have a regular structure and involve exchange of information following well-defined patterns. This section looks at two parallel algorithms for the ring: image filtering and matrix multiplication. The image filtering belongs to a class of problems in which each processor performs its calculation independently or by exchanging information with its two neighbors. In matrix multiplication, a processor must obtain information from all the other processors to complete the calculation. However, the information can be propagated by a simple shift. Other parallel algorithms can also be adapted for efficient execution on the ring, but the communication patterns are more complicated than those of the examples done here.
A filter is a transformation applied to an image. Filtering may remove noise, enhance detail or blur image features, depending on the type of transformation. This discussion considers a greyscale digital image represented by an n × n array of bytes. Common spatial filters replace each pixel value in such an image by a function of the original pixel and its neighbors. The filter algorithm uses a mask to specify the neighborhood that contributes to the calculation. Figure 7.11 shows a 3 × 3 mask of nearest neighbors. This particular mask represents a linear filter because the function is a weighted sum of the pixels in the mask. In contrast, a nonlinear filter cannot be written as a linear combination of pixels under the mask. Taking the median of the neighboring pixels is an example of a nonlinear filter.

The values in the mask are the weights applied to each pixel in the sum when the mask is centered on the pixel being transformed. In Figure 7.11, all weights are 1/9. If ai,j is the pixel at position (i, j) of the original image and bi,j is the pixel at the corresponding position in the filtered image, the mask in Figure 7.11 represents the pixel transformation
This transformation blurs sharp edges and eliminates contrast in an image. In filtering terminology, the mask represents a low-pass filter because it keeps slowly varying (low-frequency) components and eliminates high-frequency components. The mask in Figure 7.12 is a high-pass filter that enhances edges and darkens the background.

The ring of processes is a natural architecture for parallelizing the types of filters described by masks such as those of Figures 7.11 and 7.12. Suppose a ring of n processes is to filter an n × n image. Each process can be responsible for computing the filter for one row or one column of the image. Since ISO C stores arrays in row-major format (i.e., the elements of a two-dimensional array are stored linearly in memory by first storing all elements of row zero followed by all elements of row one, and so on), it is more convenient to have each process handle one row.
To perform the filtering operation in process p, do the following.
Obtain rows
p-1, p, andp+1of the original image. Represent the pixel values of three rows of the original image by the following array.unsigned char a[3][n+2];
Put the image pixels of row
p-1ina[0][1], . . .,a[0][n]. Seta[0][0]anda[0][n+1]to 0 to compute the result for border pixels without worrying about array bounds. Handle rowspandp+1similarly. Ifpis 1, seta[0][0], . . . ,a[0][n+1]to 0 corresponding to the row above the image. Ifpisn, seta[2][0], . . . ,a[2][n+1]to 0 corresponding to the row of pixels below the bottom of the image.Compute the new values for the pixels in row
pand store the new values in an array.unsigned char b[n+2];
To compute the value of
b[i], use the following program segment.int sum; int i; int j; int m; sum = 0; for (j = 0; j < 3; j++) for (m = i - 1; m < i + 2; m++) sum += a[j][m]; b[i] = (unsigned char) (sum/9);The value of
b[i]is the pixel value bp,i in the new image.Insert
bin rowpof the new image.
The preceding description is purposely vague about where the original image comes from and where it goes. This I/O is the heart of the problem. The simplest approach is to have each process read the part of the input image it needs from a file and write the resulting row to another file. In this approach, the processes are completely independent of each other. Assume that the original image is stored as a binary file of bytes in row-major order. Use lseek to position the file offset at the appropriate place in the file, and use read to input the three needed rows. After computing the new image, use lseek and write to write the row in the appropriate place in the image. Be sure to open the input and output image files after the fork so that each process on the ring has its own file offsets.
An alternative approach uses nearest-neighbor communication. Process p on the ring reads in only row p. It then writes row p to its neighbors on either side and reads rows p-1 and p+1 from its neighbors. This exchange of information requires the ring to be bidirectional, that is, a process node can read or write from the links in each direction. (Alternatively, replace each link in the ring by two unidirectional links, one in each direction.) It is probably overkill to implement the linear filter with nearest-neighbor communication, but several related problems require it.
For example, the explicit method of solving the heat equation on an n × n grid uses a nearest-neighbor update of the form
The constant D is related to the rate that heat diffuses on the grid. The array bi,j is the new heat distribution on the grid after one unit of time has lapsed. It becomes the initial array ai,j for the next time step. Clearly, the program should not write the grid to disk between each time step, so here a nearest-neighbor exchange is needed.
Another important issue in parallel processing is the granularity of the problem and how it maps to the number of processes. The ring is typically under 100 processes, while the images of interest may be 1024 × 1024 pixels. In this case, each process computes the filter for a block of rows.
Suppose the ring has m processes and the image has n × n pixels, where n = qm+r. The first r processes are responsible for q+1 rows, and the remaining processes are responsible for q rows. Each process computes from q and r the range of rows that it is responsible for. Pass m and n as command-line arguments to the original process in the ring.
Another problem that lends itself to parallel execution on a ring is matrix multiplication. To multiply two n × n matrices, A and B, form a third matrix C that has an entry in position (i, j) given by the following.

In other words, element (i, j) of the result is the product of row i of the first matrix with column j of the second matrix. Start by assuming that there are n processes on the ring. Each input array is stored as a binary file in row-major form. The elements of the array are of type int.
One approach to matrix multiplication is for process p to read row p of the input file for matrix A and column p of the input file for matrix B. Process p accumulates row p of matrix C. It multiplies row p of A by column p of B and sets c[p,p] to the resulting value. It then writes column p of matrix B to the ring and reads column p-1 from its neighbor. Process p then computes element c[p,p-1], and so on.
The row-column is very efficient once the processes have read the columns of B, but since B is stored in row-major form, the file accesses are inefficient if the process is accessing a column of B, since the read must seek for each element. In addition it is likely that matrix multiplication is an intermediate step in a larger calculation that might have the A and B distributed to processes in row-major form. The following algorithm performs matrix multiplication when process p starts with row p of A and row p of B.
Process p is going to compute row p of the result. On each iteration, a row of B contributes one term to the sum needed to calculate each element of row p of the product matrix. Each process eventually needs all the entries of B, and it receives the rows of B one at a time from its neighbors. Use the following arrays.
int a[n+1]; /* holds the pth row of A */ int b[n+1]; /* starts with the pth row of B */ int c[n+1]; /* holds the pth row of C */
Initialize the elements of a[] and b[] from their respective files. Initialize c[], using
for (k = 1; k < n+1; k++) c[k] = a[p] * b[k];
In process p, this approach accounts for the contribution of row p of B to row p of the output C. In other words, c[p,k] = a[p,p]*b[p,k]. Process p does the following.
m = p;
write(STDOUT_FILENO, &b[1], n*sizeof(int));
read(STDIN_FILENO, &b[1], n*sizeof(int));
for (k = 1; k < n+1; k++) {
if (m-- == 0)
m = n;
c[k] += a[m]*b[k];
}
The read function fills the b[] array with the values of the row of B held initially by the process immediately before it on the ring. One execution of the for loop adds the contribution of row p-1 of B to row p of the result corresponding to c[p,k]= c[p,k] +a[p,p-1]* b[p-1,k]. Execute this code n-1 times to multiply the entire array. Write the resulting c[] as row p of the output file. Note: The proposed strategy may cause a deadlock if n is so large that the write exceeds the size of PIPE_BUF. A more robust strategy might use select to process the reading and writing simultaneously.
A flexible ring is a ring in which nodes can be added and deleted. The flexibility is useful for fault recovery and for network maintenance.
Modify
ringof Program 7.1 to use named pipes or FIFOs instead of unnamed pipes. Devise an appropriate naming scheme for the pipes.Devise and implement a scheme for adding a node after node i in the ring. Pass i on the command line.
Devise and implement a scheme for deleting a node i in the ring. Pass i on the command line.
After testing the strategies for inserting and deleting nodes, convert the token-ring implementation of Section 7.8 to one using named pipes. Develop a protocol so that any node can initiate a request to add or delete a node. Implement the protocol.
This project leaves most of the specification open. Figure out what it means to insert or delete a node.
Early versions of the ring project described in this chapter can be found in [95]. A simulator that explores the interaction between pipes and forks is discussed in [97]. This simulator can be run either locally or from the Web and is available on the book web site. Local and Metropolitan Area Networks, 6th ed. by Stallings [111] has a good discussion of the token ring, token bus and FDDI network standards. Each of these networks is based on a ring architecture. Stallings also discusses the election methods used by these architectures for token regeneration and reconfiguration. The paper “A resilient mutual exclusion algorithm for computer networks” by Nishio et al. [88] analyzes the general problem of regenerating lost tokens in computer networks.
The theoretical literature on distributed algorithms for rings is large. The algorithms of Section 7.6 are based on a paper by Chang and Roberts [22], and the algorithms of Section 7.7 are discussed in Itai and Roteh [58]. A nice theoretical article on anonymous rings is “Computing on an anonymous ring” by Attiya et al. [7]. Introduction to Parallel Computing : Design and Analysis of Algorithms by Kumar et al. [67] presents a good overview of parallel algorithms and a discussion of how to map these algorithms onto particular machine architectures.