
Chapter 4. Intrusion Investigation
Eoghan Casey, Christopher Daywalt and Andy Johnston
Contents
Introduction135
Methodologies139
Preparation143
Case Management and Reporting157
Common Initial Observations170
Scope Assessment174
Collection175
Analyzing Digital Evidence179
Combination/Correlation191
Feeding Analysis Back into the Detection Phase202
Conclusion206
References206
Introduction
Intrusion investigation is a specialized subset of digital forensic investigation that is focused on determining the nature and full extent of unauthorized access and usage of one or more computer systems. We treat this subject with its own chapter due to the specialized nature of investigating this type of activity, and because of the high prevalence of computer network intrusions.
If you are reading this book, then you probably already know why you need to conduct an investigation into computer network intrusions. If not, it is important to understand that the frequency and severity of security breaches has increased steadily over the past several years, impacting individuals and organizations alike. Table 4.1 shows that the number of publicly known incidents has risen dramatically since 2002.
| Year | # of Incidents Known | Change |
|---|---|---|
| 2002 | 3 | NA |
| 2003 | 11 | +266% |
| 2004 | 22 | +100% |
| 2005 | 138 | +527% |
| 2006 | 432 | +213% |
| 2007 | 365 | –15.5% |
| 2008 | 493 | +35% |
These security breaches include automated malware that collects usernames and passwords, organized theft of payment card information and personally identifiable information (PII), among others. Once intruders gain unauthorized access to a network, they can utilize system components such as Remote Desktop or customized tools to blend into normal activities on the network, making detection and investigation more difficult. Malware is using automated propagation techniques to gain access to additional systems without direct involvement of the intruder except for subsequent remote command and control. There is also a trend toward exploiting nontechnological components of an organization. Some of this exploitation takes the form of social engineering, often combined with more sophisticated attacks targeting security weaknesses in policy implementation and business processes. Even accidental security exposure can require an organization to perform a thorough digital investigation.
A service company that utilized a wide variety of outside vendors maintained a database of vendors that had presented difficulties in the past. The database was intended for internal reference only, and only by a small group of people within the company. The database was accessible only from a web server with a simple front end used to submit queries. The web server, in turn, could be accessed only through a VPN to which only authorized employees had accounts. Exposure of the database contents could lead to legal complications for the company.
During a routine upgrade to the web server software, the access controls were replaced with the default (open) access settings. This was only discovered a week later when an employee, looking up a vendor in a search engine, found a link to data culled from the supposedly secure web server.
Since the web server had been left accessible to the Internet, it was open to crawlers from any search engine provider, as well as to anyone who directed a web browser to the server's URL. In order to determine the extent of the exposure, the server's access logs had to be examined to identify the specific queries to the database and distinguish among those from the authorized employees, those from web crawlers, and any that may have been directed queries from some other source.
Adverse impacts on organizations that experienced the most high impact incidents, such as TJX and Heartland, include millions of dollars to respond to the incident, loss of revenue due to business disruption, ongoing monitoring by government and credit card companies, damage to reputation, and lawsuits from customers and shareholders. The 2008 Ponemon Institute study of 43 organizations in the United States that experienced a data breach indicates that the average cost associated with an incident of this kind has grown to $6.6 million (Ponemon, 2009a). A similar survey of 30 organizations in the United Kingdom calculated the average cost of data breaches at £1.73 million (Ponemon, 2009b).
Furthermore, these statistics include only those incidents that are publicly known. Various news sources have reported on computer network intrusions into government-related organizations sourced from foreign entities (Grow, Epstein & Tschang, 2008). The purported purpose of these intrusions tends to be reported as espionage and/or sabotage, but due to the sensitivity of these types of incidents, the full extent of them has not been revealed. However, it is safe to say that computer network intrusions are becoming an integral component to both espionage and electronic warfare.
In addition to the losses directly associated with a security breach, victim organizations may face fines for failure to comply with regulations or industry security standards. These regulations include Health Insurance Portability and Accountability Act of 1996 (HIPAA), the Sarbanes-Oxley Act of 2002 (SOX), the Gramm-Leach-Bliley Act (GLBA), and the Payment Card Industry Data Security Standard (PCI DSS).
In the light of these potential consequences, it is important for the digital forensic investigators to develop the ability to investigate a computer network intrusion. Investigating a security breach may require a combination of file system forensics, collecting evidence from various network devices, scanning hosts on a network for signs of compromise, searching and correlating network logs, combing through packet captures, and analyzing malware. The investigation may even include nondigital evidence such as sign-in books and analog security images. The complexity of incident handling is both exciting and daunting, requiring digital investigators to have strong technical, case management, and organizational skills. These capabilities are doubly important when an intruder is still active on the victim systems, and the organization needs to return to normal operations as quickly as feasible. Balancing thoroughness with haste is a demanding challenge, requiring investigators who are conversant with the technology involved, and are equipped with powerful methodologies and techniques from forensic science.
This chapter introduces basic methodologies for conducting an intrusion investigation, and describes how an organization can better prepare to facilitate future investigations. This chapter is not intended to instruct you in technical analysis procedures. For technical forensic techniques, see the later chapters in this text that are dedicated to specific types of technology. This chapter also assumes that you are familiar with basic network intrusion techniques.
A theoretical intrusion investigation scenario is used throughout this chapter to demonstrate key points. The scenario background is as follows:
Part 1: Evidence Sources
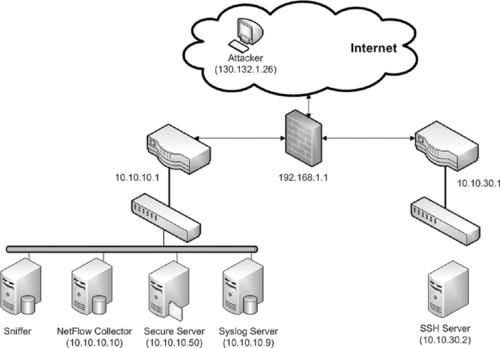
A company located in Baltimore named CorpX has learned that at least some of their corporate trade secrets have been leaked to their competitors. These secrets were stored in files on the corporate intranet server on a firewalled internal network. A former system administrator named Joe Wiley, who recently left under a cloud, is suspected of stealing the files and the theft is believed to have taken place on April 2, 2009, the day after Joe Wiley was terminated. Using the following logs, we will try to determine how the files were taken and identify any evidence indicating who may have taken them:
▪ Asavpn.log: Logs from the corporate VPN (192.168.1.1)
▪ SecEvent.evt: Authentication logs from the domain controller
▪ Netflow logs: Netflow data from the internal network router (10.10.10.1)
▪ Server logs from the SSH server on the DMZ (10.10.10.50)
Although the organization routinely captures network traffic on the internal network (10.10.10.0), the data from the time of interest is archived and is not immediately available for analysis. Once this packet capture data has been restored from backup, we can use it to augment our analysis of the immediately available logs.
In this intrusion investigation scenario, the organization had segmented high-value assets onto a secured network that was not accessible from the Internet and only accessible from certain systems within their network as shown in Figure 4.1. Specifically, their network is divided into a DMZ (10.10.30.0/24) containing employee desktops, printers, and other devices on which sensitive information isn't (or at least shouldn't be) stored. In order to simplify remote access for the sales force, a server on DMZ can be accessed from the Internet using Secure Shell (SSH) via a VPN requiring authentication for individual user accounts. The internal network (10.10.10.0/24) is apparently accessible only remotely using Remote Desktop via an authenticated VPN connection. The intranet server (10.10.10.50) provides both web (intranet) and limited drive share (SMB) services. In addition to isolating their secure systems, they monitored network activities on the secured network using both NetFlow and full packet capture as shown in Figure 4.1. However, they did not have all of their system clocks synchronized, which created added work when correlating logs as discussed in the section on combination/correlation later in this chapter.
Methodologies
The Incident Response Lifecycle
There are several different prevalent methodologies for responding to and remediating computer security incidents. One of the more common is the Incident Response Lifecycle, as defined in the NIST Special Publication 800-61, “Computer Security Incident Handling Guide.” This document, along with other NIST computer security resources, can be found at http://csrc.nist.gov. The lifecycle provided by this document is shown in Figure 4.2.
 |
| Figure 4.2 NIST Incident Response Lifecycle (Scarfone, Grance & Masone, 2008). |
The purpose of each phase is briefly described here:
▪ Preparation: Preparing to handle incidents from an organizational, technical, and individual perspective.
▪ Detection and Analysis: This phase involves the initial discovery of the incident, analysis of related data, and the usage of that data to determine the full scope of the event.
▪ Containment, Eradication and Recovery: This phase involves the remediation of the incident, and the return of the affected organization to a more trusted state.
▪ Post-Incident Activity: After remediating an incident, the organization will take steps to identify and implement any lessons learned from the event, and to pursue or fulfill any legal action or requirements.
The NIST overview of incident handling is useful and deserves recognition for its comprehensiveness and clarity. However, this chapter is not intended to provide a method for the full handling and remediating of security incidents. The lifecycle in Figure 4.2 is provided here mainly because it is sometimes confused with an intrusion investigation. The purpose of an intrusion investigation is not to contain or otherwise remediate an incident, it is only to determine what happened. As such, intrusion investigation is actually a subcomponent of incident handling, and predominantly serves as the second phase (Detection and Analysis) in the NIST lifecycle described earlier. Aspects of intrusion investigation are also a component of the Post-incident Activity including presentation of findings to decision makers (e.g., writing a report, testifying in court). This chapter will primarily cover the process of investigating an intrusion and important aspects of reporting results, as well as some of the preparatory tasks that can make an investigation easier and more effective.
Forensic investigators are generally called to deal with security breaches after the fact and must deal with the situation as it is, not as an IT security professional would have it. There is no time during an intrusion investigation to bemoan inadequate evidence sources and missed opportunities. There may be room in the final report for recommendations on improving security, but only if explicitly requested.
Intrusion Investigation Processes: Applying the Scientific Method
So if the Incident Response Lifecycle is not an intrusion investigation methodology, what should you use? It is tempting to use a specialized, technical process for intrusion investigations. This is because doing something as complex as tracking an insider or unknown number of attackers through an enterprise computer network would seem to necessitate a complex methodology. However, you will be better served by using simpler methodologies that will guide you in the right direction, but allow you to maintain the flexibility to handle diverse situations, including insider attacks and sophisticated external intrusions.
In any investigation, including an intrusion case, you can use one or more derivatives of the scientific method when trying to identify a way to proceed. This simple, logical process summarized here can guide you through almost any investigative situation, whether it involves a single compromised host, a single network link, or an entire enterprise.
1. Observation: One or more events will occur that will initiate your investigation. These events will include several observations that will represent the initial facts of the incident. You will proceed from these facts to form your investigation. For example, a user might have observed that his or her web browser crashed when they surfed to a specific web site, and that an antivirus alert was triggered shortly afterward.
2. Hypothesis: Based upon the current facts of the incident, you will form a theory of what may have occurred. For example, in the initial observation described earlier, you may hypothesize that the web site that crashed the user's web browser used a browser exploit to load a malicious executable onto the system.
3. Prediction: Based upon your hypothesis, you will then predict where you believe the artifacts of that event will be located. Using the previous example hypothesis, you may predict that there will be evidence of an executable download in the history of the web browser.
4. Experimentation/Testing: You will then analyze the available evidence to test your hypothesis, looking for the presence of the predicted artifacts. In the previous example, you might create a forensic duplicate of the target system, and from that image extract the web browser history to check for executable downloads in the known timeframe. Part of the scientific method is to also test possible alternative explanations—if your original hypothesis is correct you will be able to eliminate alternative explanations based on available evidence (this process is called falsification).
5. Conclusion: You will then form a conclusion based upon the results of your findings. You may have found that the evidence supports your hypothesis, falsifies your hypothesis, or that there were not enough findings to generate a conclusion.
This basic investigative process can be repeated as many times as necessary to come to a conclusion about what may have happened during an incident. Its simplistic nature makes it useful as a grounding methodology for more complex operations, to prevent you from going down the rabbit hole of inefficient searches through the endless volumes of data that you will be presented with as a digital forensic examiner.
The two overarching tasks in an intrusion investigation to which the scientific method can be applied are scope assessment and crime reconstruction. The process of determining the scope of an intrusion is introduced here and revisited in the section, “Scope Assessment,” later in this chapter. The analysis techniques associated with reconstructing the events relating to an intrusion, and potentially leading to the source of the attack, are covered in the section, “Analyzing Digital Evidence” at the end of this chapter.
Determining Scope
When you begin an intrusion investigation, you will not know how many host and network segments have been compromised. In order to determine this, you will need to implement the process depicted in Figure 4.3. This overall process feeds scope assessment, which specifies the number of actually and potentially compromised systems, network segments, and credentials at a given point in time during the investigation with the ultimate goal of determining the full extent of the damage.
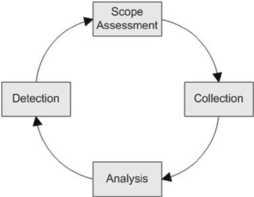
The phases in the process are described here:
1. Scope Assessment: Specify the number of actually and potentially compromised systems, network segments, and credentials at a given point in time during the investigation.
2. Collection: Obtain data from the affected systems, and surrounding network devices and transmission media.
3. Analyze: Consolidate information from disparate sources to enable searching, correlation, and event reconstruction. Analyze available data to find any observable artifacts of the security event. Correlate information from various sources to obtain a more complete view of the overall intrusion.
4. Detection: Use any of the artifacts uncovered during the analysis process to sweep the target network for any additional compromised systems (feeding back into the Scope Assessment phase).
The main purpose of the scope assessment cycle is to guide the investigator through the collection and analysis of data, and then push the results into the search for additional affected devices. You will repeat this cycle until no new compromised systems are discovered. Note that depending upon your role, you may be forced to halt the cycle when the target organization decides that it is time to begin containment and/or any other remediation tasks.
The initial investigation into a data breach of a major commercial company focused on its core credit card processing systems, and found evidence of extensive data theft. Digital investigators were dedicated to support the data breach of the credit card systems, and were not permitted to look for signs of intrusion in other areas of the company. One year later, it was discovered that the same attackers had gained unauthorized access to the primary servers in one of the company's largest divisions one year before they targeted the core credit card systems. The implications of this discovery were far-reaching. Not only did the intruders have access to sensitive data during the year prior to the discovery of the intrusion, they had continuous access during the year that digital investigators were focusing their efforts on the core credit card processing systems. If the earlier intrusion had been discovered during the initial investigation, there would have been a better chance of finding related digital evidence on the company's IT systems. However, two years after the initial intrusion, very limited information was available, making it difficult for digital investigators to determine where the intrusion originated and what other systems on the company's network were accessed. Until digital investigators learned about the earlier activities, they had no way to determine how the intruders originally gained unauthorized access to the company's network. As a result, remediation efforts were not addressing the root of the problem.
In certain cases, the evidence gathered from the victim network may lead to intermediate systems used by the attacker, thus expanding the scope of the investigation. Ultimately, the process depicted in Figure 4.3 can expand to help investigators track down the attacker.
As with any digital investigation, make sure you are authorized to perform any actions deemed necessary in response to a security breach. We have dealt with several cases in which practitioners have been accused of exceeding their authorization. Even if someone commands you to perform a task in an investigation, ask for it in writing. If it isn't written down, it didn't happen. Ideally the written authorization should provide specifics like who or what will be investigated, whether covert imaging of computers is permitted, what types of monitoring should be performed (e.g., computer activities, eavesdropping on communications via network or telephones or bugs, surveillance cameras), and who is permitted to examine the data. Also be sure that the person giving you written authorization is authorized to do so! When in doubt, get additional authorization.
Preparation
Sooner or later, almost every network will experience an information security breach. These breaches will range from simple spyware infections to a massive, intentional compromise from an unknown source. Given the increasing challenges of detecting and responding to security breaches, preparation is one of the keys to executing a timely and thorough response to any incident. Any experienced practitioner will tell you that it is more straightforward to investigate an incident when the problem is detected soon after the breach, when evidence sources are preserved properly, and when there are logs they can use to reconstruct events relating to the crime. The latest Ponemon Institute study indicates that the cost of data breaches were lower for organizations that were prepared for this type of incident (Ponemon, 2009a).
Therefore, it makes sense to design networks and equip personnel in such a way that the organization can detect and handle security events as quickly and efficiently as possible, to minimize the losses associated with downtime and data theft. Preparation for intrusion investigation involves developing policies and procedures, logging infrastructure, configuring computer systems as sources of evidence, a properly equipped and trained response team, and performing periodic incident response drills to ensure overall readiness.
Digital investigators should use their knowledge and control of the information systems to facilitate intrusion investigation as much as feasible. It is important for digital investigators to know where the most valuable information assets (a.k.a., crown jewels) are located. Since this is the information of greatest concern, it deserves the greatest attention. Furthermore, even if the full scope of a networkwide security breach cannot be fully ascertained, at least the assurance that the crown jewels have not been stolen may be enough to avoid notification obligations.
Developing an understanding of legitimate access to the crown jewels in an organization can help digital investigators discern suspicious events. Methodically eliminating legitimate events from logs leaves a smaller dataset to examine for malicious activity. For instance, connections to a secure customer database may normally originate from the subnet used by the Accounting Department, so connections from any other subnet within the organization deserve closer attention. In short, do not just instrument the Internet borders of an organization with intrusion detection systems and other monitoring systems. Some internal monitoring is also needed, especially focused monitoring of systems that contain the most valuable and sensitive data.
Beyond being able to monitor activities on hosts and networks, it is useful to establish baselines for host configuration and network activities in order to detect deviations from the norm. Added advantage can be gained through strategic network segmentation prior to an incident, placing valuable assets in more secure segments, which can make containment easier. Under the worst circumstances, secure segments can be completely isolated from the rest of the network until remediation is complete.
One of the most crucial aspects of preparation for a security breach is identifying and documenting the information assets in an organization, including the location of sensitive or valuable data, and being able to detect and investigate access to these key resources. An organization that does not understand its information assets and the associated risks cannot determine which security breaches should take the highest priority. Effective intrusion investigation is, therefore, highly dependent on good Risk Management practices. Without a Risk Management plan, and the accompanying assessment and asset inventory, incident handling can become exceedingly difficult and expensive. An intelligent approach to forensic preparedness is to identify the path these information assets take within the business processes, as well as in the supporting information systems. Data about employees, for example, will likely be maintained in offices responsible for Personnel and Payroll. Customer information may be gathered by a sales force and eventually end up in an Accounting office for billing. Such information may be stored and transmitted digitally around the clock in a large business. Security measures need to be put in place to safeguard and track this information and to insure that only appropriate parties have access to it.
Being able to gauge the relative severity of an incident, and knowing when to launch an investigation is the first step in effective handling of security breaches. The inability to prioritize among different incidents can be more harmful to a business than the incidents themselves. Imagine a bank that implemented an emergency response plan (designed for bank robberies) each time an irate customer argued with a manager over unexplained bank charges. Under these conditions, most banks would be in constant turmoil and would lose most of their customers. In information security, incidents must undergo a triage process in order to prioritize the most significant problems and not waste resources on relatively minor issues.
This section of the text enumerates some of the more important steps that can be taken to ensure that future intrusion investigations can be conducted more effectively. Note that this section is not intended to be comprehensive with respect to security recommendations; only recommendations that will assist in an investigation are listed.
When preparing an organization from a forensic perspective, it is important to look beyond expected avenues of attack, since intrusion often involve anomalous and wily activities that bypass security. Therefore, effective forensic preparation must account for the possibility that security mechanisms may not be properly maintained or that they may be partially disabled through improper maintenance. Moreover, all mechanisms may work exactly as intended, yet still leave avenues of potential exploitation. A prime example of this arises in security breach investigations when firewall logs show only denied access attempts but will not record a successful authentication that may be an intrusion. In such cases, it is more important to have details about successful malicious connections than about unsuccessful connection attempts. Therefore, logs of seemingly legitimate activity, as well as exceptional events, should be maintained.
As another example, social engineering exploits often target legitimate users and manipulate them into installing malware or providing data that can be used for later attacks. Intrusion Prevention/Detection Systems will record suspicious or clearly hostile activity, but investigation of sophisticated attacks requires examination of normal system activity as well. Social engineering attacks do not exploit technological vulnerabilities and normally do not carry any signatures to suggest hostile activity. It is important to realize that, in social engineering attacks, all technological components are behaving exactly as they were designed to. It is the design of the technology, and often the design of the business process supported by the technology, that is being exploited. Since an exploit may not involve any unusual transactions within the information systems, the forensic investigator must be able to investigate normal activity, as well as exceptional activity, within an IT infrastructure. For this reason, preparing for an incident also supports the ongoing information assurance efforts of an organization, helping practitioners maintain the confidentiality, integrity and availability of information.
Asset/Data Inventory
The rationale for this is straightforward. To protect an organization's assets, and investigate any security event that involves them, we must know where they are, and in what condition they are supposed to be. To benefit an intrusion analysis several key types of asset documentation should be kept, including:
▪ Network topology. Documents should be kept that detail how a network is constructed, and identify the logical and physical boundaries. A precisely detailed single topology document is not feasible for the enterprise, but important facets can be recorded, such as major points of ingress/egress, major internal segmentation points, and so on.
▪ Physical location of all devices. Forensic investigators will inevitably need to know this information. It is never a good situation when digital investigators trace attacker activity to a specific host name, and nobody at the victimized organization has any idea where the device actually is.
▪ Operating system versions and patch status. It is helpful to the intrusion investigator to understanding what operating systems are in use across the network, and to what level they are patched. This will help to determine the potential scope of any intrusion.
▪ Location of key data. This could be an organization's crown jewels, or any data protected by law or industry regulations. If an organization maintains data that is sufficiently important that it would be harmed by the theft of that data, then its location should be documented. This includes the storage location, as well as transit paths. For example, credit data may be sent from a POS system, through a WAN link to credit relay servers where it is temporarily stored, and then through a VPN connection to a bank to be verified. All of these locations and transit paths should be documented thoroughly for valuable or sensitive data.
Fortunately, this is a standard IT practice. It is easier to manage an enterprise environment when organizations know where all of their systems are, how the systems are connected, and their current patch status. So an organization may already be collecting this information regularly. All that a digital investigator would need to know is how to obtain the information.
Policies and Procedures
Although they might not be entertaining to read and write, policies and procedures are necessary for spelling out exactly how an organization will deal with a security event when it occurs. An organization with procedures will experience more efficient escalations from initial discovery to the initiation of a response. An organization without procedures will inevitably get bogged down in conference calls and arguments about how to handle the situation, during which the incident could continue unabated and losses could continue to mount. Examples of useful policies and procedures include:
▪ Key staff: This will define all individuals who will take part in an intrusion investigation, and what their roles will be. (See the section, “Organizational Structure” of this chapter for a description of common roles.)
▪ Incident definition and declaration thresholds: These will define what types of activity can be considered a security incident and when an organization will declare that an incident has occurred and initiate a response (and by extension an investigation).
▪ Escalation procedures: These will define the conditions under which an organization will escalate security issues, and to whom.
▪ Closure guidelines: These will define the conditions under which an incident is considered closed.
▪ Evidence handling procedures: These will define how items of evidence will be handled, transferred, stored, and otherwise safeguarded. This will include chain of custody and evidence documentation requirements, and other associated items.
▪ Containment and remediation guidelines: This will define the conditions under which an organization will attempt to contain and remediate an incident. Even if this is not your job as an investigator, it is important to understand when this will be done so that you can properly schedule your investigation to complete in time for this event.
▪ Disclosure guidelines: These will specify who can and should be notified during an investigation, and who should not.
▪ Communication procedures: These will define how the investigative team will communicate without alerting the attacker to your activity.
▪ Encryption/decryption procedures: These will define what is encrypted across an organization's systems, and how data can be decrypted if necessary. Investigative staff will need access to the victim organization's decryption procedures and key escrow in order to complete their work if the enterprise makes heavy use of on-disk encryption.
In terms of forensic preparation, an organization must identify the mechanisms for transmission and storage of important data. Beyond the data flows, policies should be established to govern not just what data is stored, but how long it is stored and how it should be disposed of. These policies will not be determined in terms of forensic issues alone, but forensic value should be considered as a factor when valuing data for retention. As with many issues involving forensic investigation and information security in general, policies must balance trade-offs among different organizational needs.
Host Preparation
Computer systems are not necessarily set up in such a way that their configuration will be friendly to forensic analysis. Take for example NTFS Standard Information Attribute Last Accessed Time date-time stamp on modern Windows systems. Vista is configured by default not to update this date-time stamp, whereas previous versions of Windows would. This configuration is not advantageous for forensic investigators, since date-time stamps are used heavily in generating event timelines and correlating events on a system.
It will benefit an organization to ensure that its systems are configured to facilitate the job of the forensic investigator. Setting up systems to leave a more thorough audit trail will enable the investigator to determine the nature and scope of an intrusion more quickly, thereby bringing the event to closure more rapidly. Some suggestions for preparing systems for forensic analysis include:
▪ Activate OS system and security logging. This should include auditing of:
▪ Account logon events and account management events
▪ Process events
▪ File/directory access for sensitive areas (both key OS directories/files as well as directories containing data important to the organization)
▪ Registry key access for sensitive areas, most especially those that involve drivers and any keys that can be used to automatically start an executable at boot (note that this is available only in newer versions of Windows, not in Windows XP)
Aren't sure which locations to audit? Use the tool autoruns from Microsoft (http://technet.microsoft.com/en-us/sysinternals/bb963902.aspx) on a baseline system. It will give you a list of locations on the subject system that can be used to automatically run a program. Any location fed to you by autoruns should be set up for object access auditing. Logs of access to these locations can be extremely valuable, and setting them up would be a great start. This same program is useful when performing a forensic examination of a potentially compromised host. For instance, instructing this utility to list all unsigned executables configured to run automatically can narrow the focus on potential malware on the system.
▪ Turn on file system journals, and increase their default size. The larger they are, the longer they can retain data. For example, you can instruct the Windows operating system to record the NTFS journal to a file of a specific size. This journal will contain date-time stamps that can be used by a forensic analyst to investigate file system events even when the primary date-time stamps for file records have been manipulated.
▪ Activate all file system date-time stamps, such as the Last Accessed time previously mentioned in Vista systems. This can be done by setting the following Registry DWORD value to 0: HKLMSYSTEMCurrentControlSetControlFileSystemNtfsDisableLastAccessUpdate
▪ Ensure that authorized applications are configured to keep a history file or log. This includes web browsers and authorized chat clients.
▪ Ensure that the operating system is not clearing the swap/page file when the system is shut down, so that it will still be available to the investigator who images after a graceful shutdown. In Windows this is done by disabling the Clear Virtual Memory Pagefile security policy setting.
▪ Ensure that the operating system has not been configured to encrypt the swap/page file. In newer versions of Windows, this setting can be found in the Registry at HKLMSYSTEMCurrentControlSetControlFileSystemNtfsEncryptPagingFile.
▪ Ensure that the log file for the system's host-based firewall is turned on, and that the log file size has been increased from the default.
Right about now, you might be saying something along the lines of “But attackers can delete the log files” or “The bad guys can modify file system date-time stamps.” Of course there are many ways to hide one's actions from a forensic analyst. However, being completely stealthy across an enterprise is not an easy task. Even if they tried to hide their traces, they may be successful in one area, but not in another. That is why maximizing the auditing increases your chances to catch an attacker. To gain more information at the host level, some organizations deploy host-based malware detection systems. For instance, one organization used McAfee ePolicy Orchestrator to gather logs about suspicious activities on their hosts, enabling investigators to quickly identify all systems that were targeted by a particular attacker based on the malware. Let us continue the list for some helpful hints in this area.
▪ Configure antivirus software to quarantine samples, not to delete them. That way if antivirus identifies any malicious code, digital investigators will have a sample to analyze rather than just a log entry to wonder about.
▪ Keep log entries for as long as possible given the hardware constraints of the system, or offload them to a remote log server.
▪ If possible, configure user rights assignments to prevent users from changing the settings identified earlier.
▪ If possible, employ user rights assignments to prevent users from activating native operating system encryption functions—unless they are purposefully utilized by the organization. If a user can encrypt data, they can hide it from you, and this includes user accounts used by an attacker.
Note that this will leave the pagefile on disk when the system is shut down, which some consider a security risk. Note that some settings represent a tradeoff between assisting the investigator and securing the system. For example, leaving the swap/page file on disk when the system is shut down is not recommended if the device is at risk for an attack involving physical access to the disk. The decision in this tradeoff will depend upon the sensitivity of the data on the device, and the risk of such an attack occurring. Such decisions will be easier if the organization in question has conducted a formal risk assessment of their enterprise.
Logging Infrastructure
The most valuable resources for investigating a security breach in an enterprise are logs. Gathering logs with accurate timestamps in central locations, and reviewing them regularly for problems will provide a foundation for security monitoring and forensic incident response.
Most operating systems and many network devices are capable of logging their own activities to some extent. As discussed in Chapter 9, “Network Analysis,” these logs include system logs (e.g., Windows Event logs, Unix syslogs), application logs (e.g., web server access logs, host-based antivirus and intrusion detection logs), authentication logs (e.g., dial-up or VPN authentication logs), and network device logs (e.g., firewall logs, NetFlow logs).
The National Institute of Standards and Technology publication SP800-92, “Guide to Computer Security Log Management” provides a good overview of the policy and implementation issues involved in managing security logs. The paper presents log management from a broad security viewpoint with attention to compliance with legally mandated standards. The publication defines a log as “a record of the events occurring within an organization's systems and networks.” A forensic definition would be broader: “any record of the events relevant to the operation of an organization's systems and networks.” In digital investigation, any record with a timestamp or other feature that allows correlation with other events is a log record. This includes file timestamps on storage media, physical sign-in logs, frames from security cameras, and even file transaction information in volatile memory.
Having each system keep detailed logs is a good start, but it isn't enough. Imagine that you have discovered that a particular rootkit is deleting the Security Event Logs on Windows systems that it infects, and that action leaves Event ID 517 in the log after the deletion. Now you know to look for that event, but how do you do that across 100,000 systems that each store their logs locally? Uh-oh. Now you've got a big problem. You know what to look for, but you don't have an efficient way to get to the data.
When a centralized source of Windows Event logs is not available, we have been able to determine the scope of an incident to some degree by gathering the local log files from every host on the network. However, this approach is less effective than using a centralized log server because individual hosts may have little or no log retention, and the intruder may have deleted logs from certain compromised hosts. In situations in which the hosts do not have synchronized clocks, the correlation of such logs can become a very daunting task.
The preceding problem is foreseeable and can be solved by setting up a remote logging infrastructure. An organization's systems and network devices can and should be configured to send their logs to central storage systems, where they will be preserved and eventually archived. Although this may not be feasible for every system in the enterprise, it should be done for devices at ingress/egress points as well as servers that contain key data that is vital to the organization, or otherwise protected by law or regulations. Now imagine that you want to look for a specific log event, and all the logs for all critical servers in the organization are kept at a single location. As a digital investigator, you can quickly and easily grab those logs, and search them for your target event. Collecting disparate logs on a central server also provides a single, correlated picture of all the organization's activity on one place that can be used for report generation without impacting the performance of the originating systems. Maintaining centralized logs will reduce the time necessary to conduct your investigation, and by extension it will bring your organization to remediation in a more timely manner.
There are various types of solutions for this, ranging from using free log aggregation software (syslog) to commercial log applications such as Splunk, which provide enhanced indexing, searching, and reporting functions. There are also log aggregation and analysis platforms dedicated to security. These are sometimes called Security Event Managers, or SEMs, and a common example is Cisco MARS. Rolling out any of these solutions in an enterprise is not a trivial task, but will significantly ease the burden of both intrusion analysts as well as a variety of other roles from compliance management to general troubleshooting. Due to the broad appeal, an organization may be able to leverage multiple IT budgets to fund a log management project.
To gain better oversight of network-level activities, it is useful to gather three kinds of information. First, statistical information is useful for monitoring general trends. For instance, a protocol pie chart can show increases in unusual traffic whereas a graph of bytes/minute can show suspicious spikes in activity. Second, session data (e.g., NetFlow or Argus logs) provide an overview of network activities, including the timing of events, end-point addresses, and amount of data. Third, traffic content enables digital investigators to drill into packet payloads for deeper analysis.
Because central log repositories can contain key information about a security breach, they are very tempting targets for malicious individuals. Furthermore, by their nature, security systems often have access to sensitive information as well as being the means through which information access is monitored. Therefore, it is important to safeguard these valuable sources of evidence against misuse by implementing strong security, access controls, and auditing. Consider using network-based storage systems (network shares, NFS/AFS servers, NAS, etc.) with strong authentication protection to store and provide access to sensitive data. Minimizing the number of copies of sensitive data and allowing access only using logged authentication will facilitate the investigation of a security breach.
Having granular access controls and auditing on central log servers has the added benefit of providing a kind of automatically generated chain of custody, showing who accessed the logs at particular times. These protective measures can also help prevent accidental deletion of original logs while they are being examined during an investigation.
Technical controls can be undermined if a robust governance process is not in place to enforce them. An oversight process must be followed to grant individuals access to logging and monitoring systems. In addition, periodic audits are needed to ensure that the oversight process is not being undermined.
A common mistake that organizations make is to configure logging and only examine the logs after a breach occurs. To make the most use of log repositories, it is necessary to review them routinely for signs of malicious activity and logging failures. The more familiar digital investigators are with available logs, the more likely they are to notice deviations from normal activity and the better prepared they will be to make use of the logs in an investigation. Logs that are not monitored routinely often contain obvious signs of malicious activities that were missed. The delay in detection allows the intruder more time to misuse the network, and investigative opportunities are lost. Furthermore, logs that are not monitored on a routine basis often present problems for digital investigators, such as incomplete records, incorrect timestamps, or unfamiliar formats that require specialized tools and knowledge to interpret.
We have encountered a variety of circumstances that have resulted in incomplete logs. In several cases, storage quotas on the log file or partition had been exceeded and new logs could not be saved. This logging failure resulted in no logs being available for the relevant time period. In another case, a Packeteer device that rate-limited network protocols was discarding the majority of NetFlow records from a primary router, preventing them from reaching the central collector. As a result, the available flow information was misleading because it did not include large portions of the network activities during the time of interest. As detailed in Chapter 9 (Network Investigations), NetFlow logs provide a condensed summary of the traffic through routers. They are designed primarily for network management, but they can be invaluable in an investigation of network activity.
Incomplete or inaccurate logs can be more harmful than helpful, diverting the attention of digital investigators without holding any relevant information. Such diversions increase the duration and raise the cost of such investigations, which is why it is important to prepare a network as a source of evidence.
A simple and effective approach to routine monitoring of logs is to generate daily, weekly, or monthly reports from the logs that relate to security metrics in the organization. For instance, automatically generating summaries of authentication (failed and successful) access activity to secure systems on a daily basis can reveal misuse and other problems. In this way, these sources of information can be used to support other information assurance functions, including security auditing. It is also advisable to maintain and preserve digital records of physical access, such as swipe cards, electronic locks, and security cameras using the same procedures as those used for system and network logs.
Log Retention
In digital investigative heaven, all events are logged, all logs are retained forever, and unlimited time and resources are available to examine all the logged information. Down on earth, however, it does not work that way. Despite the ever-decreasing cost of data storage and the existence of powerful log management systems, two cost factors are leading many organizations to review (or create) data retention policies that mandate disposal of information based on age and information type. The first factor is simply the cost of storing data indefinitely. Although data storage costs are dropping, the amount of digital information generated is increasing. Lower storage costs per unit of data do not stop the total costs from becoming a significant drain on an IT budget if all data is maintained in perpetuity (Gartner, 2008). The second factor is the cost of accessing that data once it has been stored. The task of sifting through vast amounts of stored data, such as e-mail, looking for relevant information can be overwhelming. Therefore, it is necessary to have a strategy for maintaining logs in an enterprise.
Recording more data is not necessarily better; generally, organizations should only require logging and analyzing the data that is of greatest importance, and also have non-mandatory recommendations for which other types and sources of data should be logged and analyzed if time and resources permit. (NIST SP800-92)
This strategy involves establishing log retention policies that identify what logs will be archived, how long they will be kept, and how they will be disposed of. Although the requirements within certain sectors and organizations vary, we generally recommend having one month of logs immediately accessible and then two years on backup that can be restored within 48 hours. Centralized logs should be backed up regularly and backups stored securely (off-site, if feasible).
Clearly documented and understood retention policies provide two advantages. First, they provide digital investigators with information about the logs themselves. This information is very useful in planning, scheduling, and managing an effective investigation from the start. Second, if the organization is required by a court to produce log records, the policies define the existing business practice to support the type and amount of logs that can be produced.
It is important to make a distinction between routine log retention practices and forensic preservation of logs in response to a security breach. When investigating an intrusion, there is nothing more frustrating than getting to a source of evidence just days or hours after it has been overwritten by a routine process. This means that, at the outset of an investigation, you should take steps to prevent any existing data from being overwritten. Routine log rotation and tape recycling should be halted until the necessary data has been obtained, and any auto deletion of e-mail or other data should be stopped temporarily to give investigators an opportunity to assess the relevance and importance of the various sources of information in the enterprise. An effective strategy to balance the investigative need to maximize retention with the business need for periodic destruction is to snapshot/freeze all available log sources when an incident occurs. This log freeze is one of the most critical parts of an effective incident response plan, promptly preserving available digital evidence.
Network Architecture
The difficulty in scoping a network intrusion increases dramatically with the complexity of the network architecture. The more points of ingress/egress added to an enterprise network, the more difficult it becomes to monitor intruder activities and aggregate logs. In turn, this will make it more difficult to monitor traffic entering and leaving the network. If networks are built with reactive security in mind, they can be set up to facilitate an intrusion investigation.
▪ Reduce the number of Internet gateways, and egress/ingress points to business partners. This will reduce the number of points digital investigators may need to monitor.
▪ Ensure that every point of ingress/egress is instrumented with a monitoring device.
▪ Do not allow encrypted traffic in and out of the organization's network that is not sent through a proxy that decrypts the traffic. For example, all HTTPS traffic initiated by workstations should be decrypted at a web proxy before being sent to its destination. When organizations allow encrypted traffic out of their network, they cannot monitor the contents.
▪ Remote logging. Did we mention logging yet? All network devices in an organization need to be sending their log files to log server for storage and safe keeping.
Note that the approach to network architecture issues may need to vary with the nature of the organization. In the case of a university or a hospital, for instance, there may be considerable resistance to decrypting HTTPS traffic at a proxy. As with all other aspects of preparedness, the final design must be a compromise that best serves all of the organization's goals.
Domain/Directory Preparation
Directory services, typically Microsoft's Active Directory, play a key role in how users and programs are authenticated into a network, and authorized to perform specific tasks. Therefore Active Directory will be not only a key source of information for the intrusion investigator, but will also often be directly targeted by advanced attackers. Therefore it must be prepared in such a way that intrusion investigators will be able to obtain the information they need. Methods for this include:
▪ Remote logging. Yes, we have mentioned this before, but keeping logs is important. This is especially true for servers that are hosting part of a directory service, such as Active Directory Domain Controllers. These devices not only need to be keeping records of directory-related events, but logging them to a remote system for centralized access, backup, and general safekeeping.
▪ Domain and enterprise administrative accounts should be specific to individual staff. In other words, each staff member that is responsible for some type of administrative work should have a unique account, rather than multiple staff members using the same administrative account. This will make it easier for digital investigators to trace unauthorized behavior associated with an administrative account to the responsible individual or to his or her computer.
▪ Rename administrator accounts across all systems in the domain. Then create a dummy account named “administrator” that does not actually have administrative level privilege. This account will then become a honey token, where any attempt to access the account is not legitimate. Auditing access attempts to such dummy accounts will help digital investigators in tracing unauthorized activity across a domain or forest.
▪ Ensure that it is known which servers contain the Global Catalog, and which servers fill the FSMO (Flexible Single Master Operation) roles. The compromise of these systems will have an effect on the scope of the potential damage.
▪ Ensure that all trust relationships between all domains and external entities are fully documented. This will have an impact on the scope of the intrusion.
▪ Use domain controllers to push policies down that will enforce the recommendations listed under “Host Preparation” later in this chapter.
At the core of all authentication systems, there is a fundamental weakness. The system authenticates an entity as an account and logs activity accordingly. Even with biometrics, smart cards and all the other authentication methods, the digital investigator is reconstructing activity that takes place under an account, not the activity of an individual person. The goal of good authentication is to minimize this weakness and try to support the accountability of each action to an individual person. Group accounts, like the group administrative account mentioned earlier, seriously undermine this accountability. Accountability is not (or shouldn't be) about blame. It's about constructing an accurate account of activities.
Time Synchronization
Date and time stamps are critical pieces of information for the intrusion investigator. Because an intrusion investigation may involve hundreds or thousands of devices, the time settings for these devices should be synchronized. Incorrect timestamps can create confusion, false accusations, and make it more difficult to correlate events using multiple log types. Event correlation and reconstruction can proceed much more efficiently if the investigators can be sure that multiple sources of event reports are all using the same clock. This is very difficult to establish if the event records are not recorded using synchronized clocks. If one device is five minutes behind its configured time zone, and another device is 20 minutes ahead, it will be difficult for an investigator to construct an event timeline from these two systems. This problem is magnified when dealing with much larger numbers of systems. Therefore, it is important to ensure that the time on all systems in an organization is synchronized with a single source.
▪ Windows: How Windows Time Service Works (http://technet.microsoft.com/en-us/library/cc773013.aspx)
▪ UNIX/Linux: Unix Unleashed 4th edition, Chapter 6
▪ Cisco: Network Time Protocol www.cisco.com/en/US/tech/tk648/tk362/tk461/tsd_technology_support_sub-protocol_home.html
Operational Preparedness, Training and Drills
Following the proverb, “For want of a nail the shoe was lost,” a well-developed response plan and well-designed logging infrastructure can be weakened without some basic logistical preparation. Like any complex procedure, staff will be more effective at conducting an intrusion investigation if they have been properly trained and equipped to preserve and make use of the available evidence, and have recent experience performing an investigation.
Responding to an incident without adequate equipment, tools, and training generally reduces the effectiveness of the response while increasing the overall cost. For instance, rushing out to buy additional hard drives at a local store is costly and wastes time. This situation can be avoided by having a modest stock of hard drives set aside for storing evidence. Other items that are useful to have in advance include a camera, screwdrivers, needle-nose pliers, flashlight, hardware write blockers, external USB hard drive cases, indelible ink pens, wax pencils, plastic bags of various sizes, packing tape, network switch, network cables, network tap, and a fire-resistant safe. Consider having some redundant hardware set aside (e.g., workstations, laptops, network hardware, disk drives) in order to simplify securing equipment and media as evidence without unduly impacting the routine work. If a hard drive needs to be secured, for instance, it can be replaced with a spare drive so that work isn't interrupted. Some organizations also employ tools to perform remote forensics and monitoring of desktop activities when investigating a security breach, enabling digital investigators to gather evidence from remote systems in a consistent manner without having to travel to a distant location or rely on untrained system administrators to acquire evidence (Casey, 2006).
Every effort should be made to send full-time investigators and other security staff to specialized training every year, and there is a wide variety of incident handling training available. However, it will be more difficult to train nonsecurity technical staff in the organization to assist during an incident. If the organization is a large enterprise, it may not be cost- and time-effective to constantly fly their incident handlers around the country or around the world to collect data during incidents. Instead the organization may require the help of system and network administrators at various sites to perform operations to serve the collection phase of an intrusion investigation (e.g., running a volatile data script, collecting logs, or even imaging a system). In this situation it will also not be cost-effective to send every nonsecurity administrator to specialized incident handling training, at the cost of thousands of dollars per staff member. A more effective solution is to build an internal training program, either with recorded briefings by incident handling staff or even computer-based training (CBT) modules if the organization has the capability to produce or purchase these. Coupled with explicit data gathering procedures, an organization can give nonsecurity technical staff the resources they need to help in the event of an intrusion.
In addition to training, it is advisable to host regular response drills in your organization. This is especially the case if the organization does not experience security incidents frequently, and the security staff also performs other duties that do not include intrusion investigation. As with any complex skill, one can get out of practice.
Case Management and Reporting
Effective case management is critical when investigating an intrusion, and is essentially an exercise in managing fear and frustration. Managing an intrusion investigation can be a difficult task, requiring you to manage large, dispersed teams and to maintain large amounts of data. Case management involves planning and coordinating the investigation, assessing risks, maintaining communication between those involved, and documenting each piece of media, the resulting evidence, and the overall investigative process. Continuous communication is critical to keep everyone updated on developments such as new intruder activities or recent security actions (e.g., router reconfiguration). Ideally, an incident response team should function as a unit, thinking as one. Daily debriefings and an encrypted mailing list can help with the necessary exchange of information among team members. Valuable time can be wasted when one uninformed person believes that an intruder is responsible for a planned reconfiguration of a computer or network device, and reacts incorrectly. Documenting all actions and findings related to an incident in a centralized location or on an e-mail list not only helps keep everyone on the same page, but also helps avoid confusion and misunderstanding that can waste invaluable time.
The various facets of case management with respect to computer network intrusions are described in the following sections.
Organizational Structure
There are specific roles that are typically involved in an intrusion investigation or incident response. Figure 4.4 is an example organizational chart of such individuals, followed by a description of their roles.

Who are these people?
▪ Investigative Lead: This is the individual who “owns” the investigation. This individual determines what investigative steps need to be taken, delegates them to staff as needed, and reports all results to management. The “buck” stops with this person.
▪ Designated Approval Authority: This is the nontechnical manager or executive responsible for the incident response and/or investigation. Depending on the size of the organization, it could be the CSO, or perhaps the CIO or CTO. It is also the person who you have to ask when you want to do something like take down a production server, monitor communications, or leave compromised systems online while you continue your investigation. This is the person who is going to tell you “No” the most often.
▪ Legal Counsel: This is the person who tells the DAA what he or she must or should do to comply with the law and industry regulation. This is one of the people who will tell the DAA to tell you “No” when you want to leave compromised devices online so that you can continue to investigate. This person may also dictate what types of data need to be retained, and for how long.
▪ Financial Counsel: This is the person who tells the DAA how much money the organization is losing. This is one of the people you'll have to convince that trying to contain an incident before you have finished your investigation could potentially cost the organization more money in the long run.
▪ Forensic Investigators: These are the digital forensics specialists. As the Investigative Lead, these are the people you will task with collection and analysis work. If the team is small, each person may be responsible for all digital forensic analysis tasks. If the organization or team is large, these individuals are sometimes split between operating system, malware, and log analysis specialists. These last two skills are absolutely required for intrusion investigations, but may not be present in other forms of digital investigation.
▪ IT Staff: These are the contacts who you will require to facilitate your investigation through an organization.
▪ The Desktop Engineers will help you to locate specific desktop systems both physically and logically, and to facilitate scans of desktop systems across the network.
▪ Server Engineers will help you to locate specific servers both physically and logically, and to facilitate scans of all systems across the network.
▪ Network Engineers will help you to understand the construction of the network, and any physical or logical borders in place that could either interfere with attacker operation, or could serve as sources of log data.
▪ Directory Service (Usually Active Directory) Administrators will help you to understand the access and authorization infrastructure that overlays the enterprise. They may help you to deploy scanning tools using AD, and to access log files that cover user logins and other activities across large numbers of systems.
▪ Security Staff: These individuals will assist you in gathering log files from security devices across the network, and in deploying new logging rules so that you can gather additional data that was not previously being recorded. These are also the people who may be trying to lock down the network and “fix” the problem. You will need to keep track of their activities, whether or not you are authorized to directly manage them, because their actions will affect your investigation.
It is not uncommon for some technical staff to take initiative during an incident, and to try and “help” by doing things like port scanning the IP address associated with an attack, running additional antivirus and spyware scans against in-scope systems, or even taking potentially compromised boxes offline and deleting accounts created by the intruders. Unfortunately, despite the best intentions behind these actions, they can damage your investigation by alerting the intruder to your activities. You will need to ensure that all technical staff understands that they are to take no actions during an incident without the explicit permission of the lead investigator or incident manager.
Any organization concerned about public image or publicly available information should also designate an Outside Liaison, such as a Public Relations Officer, to communicate with media. This function should report directly to the Designated Approval Authority or higher and probably should not have much direct contact with the investigators.
Task Tracking
It can be very tempting just to plunge in and start collecting and analyzing data. After all, that is the fun part. But intrusion investigations can quickly grow large and out of hand. Imagine the following scenario. You have completed analysis on a single system. You have found a backdoor program and two separate rootkits, and determined that the backdoor was beaconing to a specific DNS host name. After checking the DNS logs for the network, you find that five other hosts are beaconing to the same host name. Now all of a sudden you have five new systems from which you will need to collect and analyze data. Your workload has just increased significantly. What do you do first, and in what order do you perform those tasks?
To handle a situation like this, you will need to plan your investigation, set priorities, establish a task list, and schedule those tasks. If you are running a group of analysts, you will need to split those tasks among your staff in an efficient delegation of workload. Perhaps you will assign one person the task of collecting volatile data/memory dumps from the affected systems to begin triage analysis, while another person follows the first individual and images the hard drives from those same devices. You could then assign a third person to collect all available DNS and web proxy logs for each affected system, and analyze those logs to identify a timeline of activity between those hosts and known attacker systems. Table 4.2 provides an example of a simple task tracking chart.
Task tracking is also important in the analysis phase of an intrusion investigation. Keeping track of which systems have been examined for specific items will help reduce missed evidence and duplicate effort. For instance, as new intrusion artifacts emerge during investigations like IP addresses and malware, performing ad hoc searches will inevitably miss items and waste time. It is important to search all media for all artifacts; this can be tracked using a chart of relevant media to record the date each piece of media was searched for each artifact list as shown in Table 4.3. In this way, no source of evidence will be overlooked.
If case management sounds like project management, that's because it is. Common project management processes and tools may benefit your team. But that doesn't mean that you can use just any project manager for running an investigation, or run out immediately to buy MS Project to track your investigative milestones. A network intrusion is too complicated to be managed by someone who does not have detailed technical knowledge of computer security. It would be more effective to take an experienced investigator, who understands the technical necessities of the trade, and further train that individual in project management. If you take this approach, your integration of project management tools and techniques into incident management will go more smoothly, and your organization may see drastic improvements in efficiency, and reductions in cost.
Communication Channels
By definition, you will be working with an untrusted, compromised network during an intrusion investigation. Sending e-mails through the e-mail server on this network is not a good idea. Documenting your investigative priorities and schedules on this network is also not a good idea. You should establish out-of-band communication and off-network storage for the purposes of your investigation. Recommendations include the following:
▪ Cell network or WiMAX adapters for your investigative laptops. This way you can access the Internet for research or communication without passing your traffic or connecting to the compromised network.
▪ Do not send broadcast e-mail announcements to all staff at an organization about security issues that have arisen from a specific incident until after the incident is believed to have been resolved.
▪ Communicate using cell phones rather than desk phones, most especially if those desk phones are attached to the computing environment that could be monitored easily by intruders (i.e., IP phones).
When investigating a security breach, we always assume that the network we are on is untrustworthy. Therefore, to reduce the risk that intruders can monitor our response activities, we always establish a secure method for exchanging data and sharing updated information with those who are involved in the investigation. This can be in the form of encrypted e-mail or a secure server where data.
Containment/Remediation versus Investigative Success
There is a critical decision that needs to be made during any security event, and that decision involves choosing when to take defensive action. Defensive action in this sense could be anything from attempting to contain an incident with traffic filtering around an affected segment to removing malware from infected systems, or rebuilding them from trusted media. The affected organization will want to take these actions immediately, where “immediately” means “yesterday.” You may hear the phrase, “Stop the bleeding,” because no one in charge of a computer network wants to allow an attacker to retain access to their network. This is an understandable and intuitive response. Continued unauthorized access means continued exposure, increased risk and liability, and an increase in total damages. Unfortunately, this response can severely damage your investigation.
When an intrusion is first discovered, you will have no idea of the full extent of the unauthorized activity. It could be a single system, 100 systems, or the entire network with the Active Directory Enterprise Administrator accounts compromised. Your ability to discover the scope of the intrusion will often depend upon your ability to proceed without alerting the attacker(s) that there is an active investigation. If they discover what you are doing, and what you have discovered so far about their activity, they can take specific evasive action. Imagine that an attacker has installed two different backdoors into a network. You discover one of them, and immediately shut it down. The attacker realizes that one of the backdoors has been shut off, and decides to go quiet for a while, and not take any actions on or against the compromised network. Your ability to then observe the attacker in action, and possibly locate the second backdoor, now has been severely reduced.
Attribute Tracking
In a single case, you may collect thousands of attributes or artifacts of the intrusion. So where do you put them, and how do you check that list when you need information? If you are just starting out as a digital investigator, the easier way to track attributes is in a spreadsheet. You can keep several worksheets in a spreadsheet that are each dedicated to a type of artifact. Table 4.4 provides an example attribute tracking chart used to keep a list of files associated with an incident.
You could also keep an even more detailed spreadsheet, by adding rows that include more granular detail. For example, you could add data such as file system date-time stamps, hash value, and important file metadata to Table 4.4 to provide a more complete picture of the files of interest in the table. However, as you gradually add more data, your tables will become unwieldy and difficult to view in a spreadsheet. You will also find that you will be recording duplicate information in different tables, and this can easily become a time sink. A more elegant solution would be a relational database that maintains the same data in a series of tables that you can query using SQL statements from a web front-end rather than scrolling and sorting in Excel. However, developing such a database will require that you be familiar with the types of data that you would like to keep recorded, and how you typically choose to view and report on it.
There are third-party solutions for case management. Vendors such as i2 provide case management software that allows you to input notes and lists of data that can be viewed through their applications. The i2 Analysts Notebook application can also aid in the analysis phase of intrusion investigation by automating link and timeline analysis across multiple data sets, helping digital investigators discern relationships that may not have been immediately obvious, and to visualize those relationships for more human-friendly viewing. This type of tool can be valuable, but it is important to obtain an evaluation copy first to ensure that it will record all the data that you would like to track. A third-party solution will be far easier to maintain, but not as flexible as a custom database. Custom databases can be configured to more easily track attributes such as file metadata values than could a third-party solution. You may find that a combination of third-party tools and custom databases suits your needs most completely.
Attribute Types
An intrusion investigation can potentially take months to complete. During this time, you may be collecting very large amounts of data that are associated with the incident. Examples of common items pertinent to an intrusion investigation are described in this section, but there are a wide variety of attributes that can be recorded. As a general rule, you should record an artifact if it meets any of the following criteria:
▪ It can be used to prove that an event of interest actually occurred.
▪ It can be used to search other computers.
▪ It will help to explain to other people how an event transpired.
Specific examples of attributes include the following.
Host Identity
You will need to identify specific hosts that are either compromised or that are sources of unauthorized activity. These are often identified by:
▪ Internal host name: For example, a compromised server might be known as “app-server-42.widgets.com.” These names are also helpful to remember as internal technical staff will often refer to their systems by these names.
▪ IP address: IP addresses can be used to identify internal and external systems. However, be aware that internal systems may use DHCP, and therefore their IP may change. Record the host name as well.
▪ External host name: It is common for modern malware to beacon to a domain name rather than an IP address. This allows the attacker to maneuver these beacons around IP blocks by using dynamic DNS to quickly change the IP associated with the DNS host name.
Some intruders will frequently change the IP addresses associated with DNS host name beacon targets. In some cases, we have tracked the changes with a quick script that performs name resolution queries (e.g., using nslookup) on these domains at regular intervals, and dumps the results into a CSV file that you can either open as a spreadsheet or import into a database.
Files of Interest
You will also need to track files of interest. In an intrusion, this could be files such as malicious executables, keystroke logs, e-mail attachments, configuration files for subverted programs, and so on. The things you will need to track about them include, at a minimum:
▪ File names
▪ Full storage path
▪ Hash value
▪ File system date-time stamps
▪ Key strings
▪ Key metadata values
Operating System and Application Configuration Settings
Attackers will often use their own code with specific configuration settings or modify the configuration settings of legitimate programs and the operating system. These configuration settings should be examined for distinctive details pertaining to the intrusion.
An attacker was using the software OpenVPN to set up a tunnel from a credit relay server to an external system. This tunnel was used to steal PCI data from that system, and from others. The IP address to which the tunnel was initiated was recorded in the configuration file for the OpenVPN program.
Indicators of Execution
Another valuable type of data to track is indicators of execution. For example, as detailed in Chapter 5, “Windows Forensic Analysis,” when attackers run their own code, or use programs from the compromised system, Windows systems may record this activity in items such as:
▪ Prefetch files: Execution time is based on both file system and embedded date-time stamps.
▪ Link files: Execution time is based on file system date-time stamps.
▪ Registry “Userassist” keys: Execution is based on a date-time stamp kept inside the key.
▪ Active processes: Execution time is based on the uptime of the process subtracted from the current time of the system. This is also the potential timeframe of execution for any DLLs loaded into a given process.
▪ Log entries: There are a wide variety of log entry types that track program execution. Common examples are Windows System Log entries that show service starts and stops, and Windows Security Log entries that show general process starts and stops (as long as auditing is turned on for such an event).
Account Events
User account events may also be linked to intrusion-related activity. You will need to be able to record activity such as:
▪ Unauthorized user accounts
▪ Compromised user accounts
▪ Logon/logoff times for accounts of interest
▪ New user account creations
▪ Changes in user account permissions
Network Transmissions and Sessions
During your investigation you may identify and need to record occurrences of network transmissions, or extended network communication sessions between two hosts. From these events, you will need to record the following data if available:
▪ Date-time stamp
▪ Source and destination IP address
▪ Source and destination host name
▪ Source and destination port numbers (if TCP or UDP is in use)
▪ Transmission content (if visible)
▪ Transmission size (number of bytes transmitted in each direction)
▪ Network location where the event was observed
General Event Tracking
For case management and analysis purposes, it is necessary to maintain an event timeline. This timeline will typically consist of a collection of occurrences that somehow are established by collections of other artifacts. Maintaining a timeline document helps identify gaps in understanding that need to be addressed, and supports the analysis process of understanding how an intrusion developed. Table 4.5 shows a brief example of a short, related chain of events, and how each event has multiple sources of evidence corroborating that the event occurred.
Reporting
Intrusion investigations can be very complicated engagements, involving many distributed systems and spanning long periods of time. These investigations bring with them their own set of reporting challenges, including those described in this section.
Fact versus Speculation
You will sometimes arrive to investigate an intrusion months or even years after it has been in progress. This, combined with the fact that most modern enterprises do not rigorously collect and preserve security event data, means that many of the details of the intrusion will be lost permanently. The primary role of a forensic investigator is to report facts. However, an intrusion investigator may be required to speculate, depending upon his or her employer. For example, the results of an intrusion investigation may be used in an attempt to better secure a network, or to determine whether the organization has a notification obligation. Although the results may not have yielded a definitive answer to the point of entry or exfiltration of data, the investigator may be required to make a best guess so that the organization can take some action.
If you find yourself in the position where you are being asked to speculate, make sure that your report clearly differentiates between what is fact and what is speculation. This is common for corporate investigations. In this situation speculate only where specifically asked to do so by your customer, and make sure that you clearly indicate what evidence there is for your guess, and where there is no concrete evidence. However, if you are asked to speculate in a forensic report in a criminal investigation, you should refuse.
There is a distinction between baseless speculation and probability based on available evidence. When available evidence does not lead to a definitive answer, digital forensic practitioners may be asked to render an opinion on the likelihood of a particular aspect of the investigation. For instance, if there is no solid evidence showing that sensitive information was stolen by intruders, an organization may want some measure of the risk to help them reach a decision on the best course of action. After carefully analyzing the evidence, digital investigators can indicate the probability of exposure using the terms “possible” and “probable,” or “unlikely,” “likely,” and “most likely” depending on the level of certainty. A general approach for coming up with this type of probability is covered in (Casey, 2002 and Casey, 2004).
Reporting Audiences
Digital investigators will generally have several different audiences for their reports in an intrusion investigation. Nontechnical managers will want to know only the bottom line. That is, when you will know exactly what happened, and when they can start fixing it. If you are not close to fulfilling either one of these requests, you need to have a clear explanation as to why you are not.
Technical staff needs to be supplied with the information they require to do their job. If they are supposed to be monitoring specific IPs, they will need updated lists of those addresses. If they are supposed to retain certain types of data, they will need to know precisely which data, and for how long.
Managers who are still or formerly were technical will not want the same information as technical managers, but will often want to hear the basic event timeline in shallow technical detail. They won't be concerned with granular attributes of the attack, but will want to know some technical details of the initial attack, and how the attacker is moving throughout the network.
Law enforcement needs concrete evidence of the crime and its apparent source to obtain subpoenas and search warrants. For instance, providing the IP addresses used by attackers and the associated time periods can enable law enforcement to obtain information from Internet service providers (ISPs) that enable them to apprehend the attacker. In some cases you may also be asked to provide details about artifacts found on compromised systems that might be stored on the intruder's computer, enabling law enforcement to show linkage between the attacker and victim systems. It is critical that the information you provide law enforcement is complete and accurate, since the actions they take can have broad consequences, potentially mobilizing search and seizure teams and detaining suspected individuals. If you mistype an IP address or do not account for time-zone differences, it will be your fault when the wrong person is subjected to the attention of law enforcement.
Interim Reports
Shortly after you are asked to begin a digital investigation, it is not uncommon to be asked when you will be finished. Although intrusion investigations can easily span months, digital investigators must provide information as soon as is feasible to support important decisions, including whether to involve law enforcement, whether they should notify customers, and when it is advisable to initiate remediation measures. During this time, you will be expected to deliver regular reports, both written and oral. These reports may include anywhere from daily briefings to weekly updates. The key will be in determining how to deliver these interim reports, and what information to include.
As time goes on, your explanations will need to stay firm, as the pressure will mount on you to complete your investigation. Interim reports can easily turn into arguments as the managers of a compromised organization will want to move immediately to remediation. The longer your investigation takes, the more frustrated they will become. If you have some improvement to show, this will make your job easier.
During your interim reports, make sure that technical managers receive an ever-expanding storyline. “We now know that the attacker has done X, Y, or Z.” These individuals will also need updates on the effectiveness of your search. “We were able to scan X number of devices since our last report, and the result was Y new infections.” Nontechnical managers will simply need an estimated time to completion.
Common Initial Observations
Security incidents can start in a variety of ways. How you initially discover an incident will determine how you proceed in the beginning of the investigation. Some of the more common initial observations are described next.
Antivirus Alerts
It is not uncommon for an intrusion to begin with one or more alerts from antivirus programs. It is tempting to treat the malicious code that is detected by antivirus software as low-threat, mindless malware infection, like some random virus that happened to be accidentally copied to one of your computers. It is also tempting to assume that if antivirus found it, then your defenses did their job, and you're good to go, no further action necessary. This assumption can be a critical mistake.
Upon an antivirus alert, remember that you still do not know the following:
▪ How long the malicious files were actually on the system (unless the antivirus alert was specific to a file just copied through some medium)
▪ Whether or not they were placed there intentionally as part of a compromise or by accidental infection through unsafe web browsing or similar activity
▪ Whether or not there is additional, undetected malicious files on the system
▪ Whether or not the malicious code (if it includes backdoor functionality) has been used to remotely access the system, and possibly to use it to target other internal devices
The only way to discover the answer to these questions is to conduct analysis on the systems that received the alerts, and to determine the full extent of malicious code presence, and any other unauthorized activity that may have occurred on that system, or against other systems.
A large company discovers antivirus alerts on five systems, each for the exact same backdoor program. At this point, all the company knew was that they had five systems running the same backdoor program. They did not know how long those backdoor programs had been there, or what was done with them.
This company could have treated this event as a simple virus infection, but instead they chose to treat it as a security incident, and a possible intentional compromise. Some time later, forensic analysis of these systems, and subsequent searches through the enterprise revealed at least 80 systems that had different variations of the same backdoor as well as other rootkit and backdoor software that had not been detected by the company's antivirus software. This included the compromise of over 30 servers. Antivirus alerts were the initial window into this intrusion.
IDS Alerts
An alert from an intrusion detection system is a direct warning of attempted unauthorized activity. This is the main purpose of an IDS. However, before using IDS alerts to spur a forensic exam, ensure that your organization has properly tuned its sensors and rule set. Otherwise you will spend too much time chasing down false positives. Also, you should specify in your policy exactly what types of IDS alerts you will use to trigger further data gathering from the target device. For example, conducting a full acquisition and analysis of an Internet accessible web server because it was port scanned might easily be a waste of resources. Hosts on the Internet are randomly scanned on a frequent basis. However, if your IDS detected a reverse shell spawned from the same server, you would want to treat that alert more seriously.
E-mail with Suspicious Contents
E-mail is a common delivery vector for malicious payloads, and as an initial vector of entry into large corporations and government organizations. If someone reports that they have received an e-mail from an unknown source and that they have followed a link contained within, or opened an attachment that was delivered with the e-mail, this may constitute a security event that will require an investigation. Once a user executes a phishing or spear phishing attack payload, they may have installed malicious code onto their system. There may still be an issue even if the e-mail comes from a known source, but the attachment was unexpected, as source addresses can be spoofed. In some cases, spear phish attacks will originate from an organization that has been compromised to another organization that is a business partner. By routing the e-mail attack through a compromised organization, it will appear to be more legitimate, and will therefore be more likely to be opened.
System and Application Crashes
Malicious code, from exploits to rootkits, is typically not created through a robust software development lifecycle, with a significant testing and evaluation phase that is intended to work out bugs. Because of this, attackers may cause a target application or operating system to crash. This can be a first warning to a user or administrator that there may be a security problem. Obviously you cannot treat every OS or application error as an attack, but there are certain circumstances where such an event is more likely to be a security problem, including:
▪ The crash results from the opening of an e-mail attachment.
▪ A web browser crashes upon viewing a specific web page.
▪ An operating system continues to crash, and IT staff cannot successfully identify the problem.
▪ An otherwise stable server crashes, particularly a Domain Controller or other critical system.
A corporate user receives an e-mail message from an individual claiming to act for a government agency, soliciting a response for a Request For Proposals (RFP) that is attached to the e-mail as a Microsoft Word document. Because the user is a member of the sales staff, he opens the e-mail. After all, responding to RFPs is how he earns a living. However, when he opens the document, Microsoft Word crashes. He tries again, with the same result. He then forwards the document to a work associate, who tries to open the RFP. Word crashes on his system as well. The user then notifies the help desk. A member of the help desk staff tries to open the document, and when Word crashes on his system, he recognizes this as a security issue, and notifies security staff.
Analysis revealed that (1) the Word document contained malicious code that would download additional malware from an overseas location when the Office document was opened, and (2) The “From” line of the e-mail included an e-mail address for a nonexistent individual. Three systems were infected at this point, but this spear phish attack was detected early because a help desk worker was knowledgeable enough to understand that under certain circumstances, an application crash can be a symptom of attack.
Crashes as a result of an attack will continue to become less prevalent over time, as more malicious code is developed professionally for organized crime and state-related entities. However it can still be a common indicator of an intrusion.
Blacklist Violations
Over time, an organization may develop blacklists that contain signs of unauthorized or malicious activity in network traffic. These lists are often in the form of specific, known-bad IP addresses or DNS host names, but could also be other descriptors such as port numbers associated with specific backdoors or unauthorized chat programs. When an internal host is detected attempting to reach one of these external systems or using a disallowed port, this is a sign that a compromise may have occurred and an investigation may be required. You should set investigative thresholds that depend upon the nature of the blacklisted item. For example, some blacklisted items may require a more immediate response. An IP address associated with a previous intrusion may be treated differently from a DNS host name associated with a publicly known worm. Likewise you may observe some traffic that is more likely a sign of misuse than compromise, such as AOL Instant Messenger traffic from a user that did not realize that it was against your company policy. Some government organizations also maintain blacklists that may be available to digital investigators in certain cases.
Abnormal Patterns of Network Traffic
Although there are not necessarily any set rules for this, there are general behavior patterns that may indicate a compromise when seen in network traffic. Some common examples include:
▪ Workstations sending significantly more data outbound than they receive
▪ Devices that generate a high volume of traffic in either direction that are not intended for massive traffic volume
▪ Devices that are communicating using abnormal ports/protocols, or an unusually high variety of ports/protocols
External Notifications
The worst way to find out about a security incident is when somebody from outside your organization tells you about it. Unfortunately, this sometimes happens. These situations will vary widely depending upon the exact evidence presented to you by the outside party, and so your investigation will be crafted to match.
In 2007, a retail chain corporate office received a phone call from a major credit card vendor. It turns out that this vendor had traced the theft of thousands of credit card numbers to that retail chain. As a CISO, this is not how you want to start your day. As you may guess, a security incident was rightfully declared.
Scope Assessment
Identifying the full scope of an intrusion is one of the primary goals of the investigation. Keeping in mind that a security breach could have occurred before it was detected, it is a good practice to extend analysis to a time before the initial detection. Furthermore, it is important to look beyond a single compromised computer when considering the method of intrusion and the scope of a security breach. It is generally necessary to assume that other computers or devices on the network were involved in or impacted by the breach.
The scope of an intrusion consists of the following:
▪ Actual scope: Devices and network segments on which intruder activity is verified to have taken place.
▪ Potential scope: All devices for which the attacker has (1) network access and (2) valid credentials. For example, if the attacker can communicate with server-01 through DCE/RPC and SMB/CIFS, and the attacker has credentials for that system, then it is potentially within scope.
The answer to the question of scope will include several key pieces of data:
▪ What devices were directly compromised and where are those devices located?
▪ What host/network/domain credentials were compromised?
▪ For which hosts/networks/domains are those credentials valid, and where are those assets?
▪ What hosts/networks/domains have trust relationships with compromised assets?
To better understand the intent of these questions, consider the following example.
Suppose you discover a single potentially compromised workstation. You collect data from it, and conduct analysis on that system. Your analysis reveals that the attacker used the pwdump utility to extract the local password hashes. These hashes included the local administrator account. The same password is used for all local administrator accounts for all desktops on the entire domain. This was probably done to ease the burden of help desk staff and desktop engineers by preventing them from having to remember too many passwords. However, the fact that this credential has been stolen means that every device that utilizes the same local admin password is now in the potential scope of incident. They are not necessarily in the actual scope, as you have not verified whether or not any direct unauthorized action was taken against those devices, but they must be considered at significant risk nonetheless. This is most especially true if the system you first discovered has been compromised for any length of time. Once proper credentials have been stolen, an attacker can move between Windows systems in a matter of minutes.
In the beginning of an incident, you will have only your initial observations to guide your scope assessment, and so your scope will be mostly potential. As you collect data, analyze it, and then use your discoveries to find additional compromised systems, both your actual and potential scopes may continue to expand, and will hopefully become more concrete. All devices in the potential scope of the incident will need to be searched for known artifacts. This process is covered later in this chapter.
Collection
For the most part, the collection of evidence for network intrusions is similar to collections for any other digital investigation, as detailed in Casey (2004). In general, the data you choose to collect will be driven by the needs of the investigation. However, we would like to reinforce a few specific points here.
When dealing with a network that has not been prepared adequately from a forensic standpoint, it is generally necessary to have a meeting with select IT personnel to identify potential log sources. Explain from the outset that the goal is to identify any sources of information with timestamps that could have recorded events related to the incident, including security related devices (e.g., firewalls, IDS, intrusion prevention or antivirus agents) as well as system management systems (e.g., NetFlow logs, bandwidth monitoring, web proxy logs). Through such discussion, and review of associated documentation, it is often possible to generate a list of the most promising sources of information on the victim network. This information gathering meeting is also an opportunity to develop a coordinated preservation plan, instructing specific individuals to preserve backup tapes or provide access to systems that contain log data.
Your job as a forensic investigator involves reconstruction of events from available data. It does not involve apportioning blame for an incident. Unfortunately, many of the technical support staff upon whom you will depend for information will suspect that your findings may be used to apportion blame, anyway. Given the dynamics of most organizations, they may be right. This can place the digital investigator in a delicate situation in which some investigative activities could be taken as implied criticism. The next Practitioner's Tip: Trust but Verify, is a case in point. If the network administrator tells you that a firewall is blocking packets to TCP port 139 and you then generate such traffic to test that statement, it may seem that you don't “believe” what you have been told. Your best defense in these cases is your own professionalism. It really doesn't matter whether or not you believe anything you are told. It is your job to verify everything you can. It might help if you emphasize that you need to “illustrate” the information rather than “verify” it, however. Your final product will be a report, and the results of any tests you run will be included to illustrate the characteristics of the network and the systems under examination. This is not just a verbal trick, but a valid and useful way to approach your professional responsibilities.
In some instances it may be necessary to rely on someone who is more familiar with a given system to help collect certain data, particularly when you do not have the necessary password or expertise. Whenever feasible, guide the individual through the collection process, document the steps taken as completely and accurately as possible (e.g., taking screenshots or saving queries), and ask questions about the resulting data to ensure that all of the required information is preserved. When dealing with complex systems such as databases or security event management systems, it may be necessary to perform trial queries or samplings to determine whether the output contains the required data. During this process, digital investigators generally refine what is needed from the system and learn more about the logs and associated systems, which can be invaluable from an analysis standpoint.
When you have to rely on a system administrator's description of the network, and of how and what events are logged to interpret your evidence, do not assume that everything you are told is correct. In so far as possible, verify what you are told empirically. If for instance, you are told that certain packets are blocked on the network, try to generate them and make sure they are blocked. If you are told that certain events will generate a given pattern of log records, try to duplicate those events and examine the log records for verification. This is part of identifying and reducing the number of assumptions you are making. Similarly, if you are told that specific activities are not logged, consider asking multiple system administrators. In one case, one system administrator asserted that the domain controllers did not retain DHCP logs, making it difficult to determine which users were assigned specific IP addresses during the time of interest. However, another system administrator was posed the same question and directed investigators to a logon script he had written to record useful information each time a user logged into a Windows system in the domain, including the username, computer name, MAC address, and IP address. This recorded information was sufficient for digital investigators to complete their work.
Live Collection
In the field of digital forensics it is traditional to shut down systems, and then create a forensic duplicate of the hard drives. Once that has been done in an intrusion case, the targeted organization will typically want to clean the system and then place it back online. As mentioned previously in this chapter, early remediation of compromised systems can tip the attacker off about the investigation. On one hand, it is common for Windows workstations to go offline for long periods. People shut their computers down at night, or take their laptops home. So if you took a workstation or two down to image, the attacker might not notice, as long as the device is not re-imaged or cleaned afterward, thereby removing their persistent malware. However it is not common for high availability systems to go offline. If you took down all three domain controllers for a single domain overnight to image, this will look more suspicious to the attacker, and you will be exposing the investigation to discovery.
So it is more beneficial to leave compromised systems online until the investigation has completed. If you choose to pursue this course of action, this means that sooner or later, you will do some live forensic preservation. Live forensic preservation has been considered detrimental, largely because the data is constantly changing and you are not supposed to change evidence that will be used in court. There are several counterpoints to this:
▪ You may not be a criminal investigator. If this is the case, your first responsibility may be to protect the target organization, not to prosecute a criminal, and so it is more important for you to not tip off the attacker.
▪ Even if you are a criminal investigator, your ability to apprehend the perpetrator may still be irrevocably damaged by tipping him or her off to the investigation. You will have to decide whether or not the fact that the system is changing while you copy it is that large of a problem.
▪ The systems in question may be critical to the business operations of the organization, and taking it out of service could cause greater damage to the organization than the intrusion you are investigating.
The reality is that much digital evidence cannot be collected except while it is changing. The most obvious example of this is the contents of computer memory. When investigating an intrusion, it is usually necessary to collect volatile data including information about running processes, open files, and active network connections. Although executing any command on a live system will alter its state and overwrite portions of memory, this does not make the acquired data any less useful in an investigation. If you are to collect data from a live system, you must simply be able to indicate that the act of gathering the data did not have an impact on the actual facts that you report as evidence of the intrusion. Having said this, when extensive examination and searching of a compromised system is required, it is advisable to acquire a full forensic duplicate of data for offline examination.
One of the risks when acquiring evidence from a live system when investigating an intrusion is that the subject system could be compromised to such a degree that the operation of even trusted incident response tools is skewed. For instance, system files or the kernel may have been modified to destroy data or return incomplete information. Therefore, it is generally recommended to acquire the full contents of memory prior to executing other utilities on the live system.
Forensic Acquisition of Memory
Although we would argue that the contents of memory should be collected in almost every case, it is especially vital in an intrusion investigation for several reasons:
▪ Memory can contain artifacts of an intrusion, just as a disk can. In fact, some types of artifacts can often be found only in memory (as opposed to on disk), such as currently running processes, or currently active network connections.
▪ Moreover, these artifacts may be remotely searchable. If you have visibility into physical memory across your enterprise, then you can search for known artifacts in memory to identify additional compromised systems during your scope assessment.
▪ Some malicious code is memory-resident only. This means that there is no file on disk corresponding to the process that is active in memory on the computer. Once the contents of memory are lost, so is the malicious code. If you do not collect memory, you will miss these types of malicious programs.
▪ Some malicious code contains key data, such as passwords, or even segments of code, in an encrypted form that only decrypts in memory. Although is it usually possible in theory to decrypt the executable as stored on the disk, it is often much more convenient to examine the decrypted code in memory.
▪ Volatile data can be collected more quickly than full disk images. If you are in a triage situation, where you are just trying to determine whether a system has or has not been compromised, you can quickly gather volatile data and select pieces of data from disk to make this assessment.
▪ Volatile data takes up less storage space than full disk images. If you are trying to collect enough data remotely to make an assessment as to whether or not a system has been compromised, volatile data and select pieces of data from disk can easily be transmitted across networkwide area network links. This makes it easier for you to utilize a remote agent (person or program) to collect this data and transmit it to you at your location.
For these reasons, a full memory dump should be collected wherever possible from compromised systems. Forensic preservation and examination of memory specifically, and volatile data in general, is covered in Malware Forensics (Malin, Casey & Aquilina, 2008).
Network Packet Capture
Computer intrusions typically involve computer networks, and there is always going to be the potential for valuable evidence on the network transmission medium. Capturing network traffic can give investigators one of the most vivid forms of evidence, a live recording of a crime in progress (Casey, 2004). This compelling form of digital evidence can be correlated with other evidence to build an airtight case, demonstrating a clear and direct link between the intruder and compromised hosts. The problem is that this medium is volatile. If you are not capturing traffic on a network link when a transmission of interest is sent, then it is lost. You will never have access to that data. It is advisable that you begin capturing traffic in the beginning of an incident, at least for the devices that are exhibiting the initial symptoms of a security event.
Later during the incident, you will be able to readjust your monitoring locations based upon more detailed results of your analysis. In an ideal world, you would be able to capture all network traffic entering and leaving any network segment that is in the potential scope of the incident, as well as data to and from your network management and data “crown jewels.” But your organization most likely does not have the capacity for network traffic collection on this scale, so you will need to prioritize your captures. Your priority should be to collect network traffic to and from known compromised systems, so that you can collect enough information to be able to identify specific artifacts that can be used later to detect attacker activity across other network devices already in place, such as firewalls, proxy servers, and IDS sensors.
Whenever you encounter a source of logs on a network, preserve the entire original log for later analysis, not just portions that seem relevant at the time. The reason for this admonition is that new information is often uncovered during an investigation and the original logs need to be searched again for this information. If you do not preserve the original log, there is a risk that it will be overwritten by the time you return to search it for the new findings. When exporting logs from any system, make sure that DNS resolution is not occurring because this will slow the process and may provide incorrect information (when DNS entries have changed since the time of the log entry).
Analyzing Digital Evidence
The ultimate goal of an intrusion investigation can vary depending on the situation, and can be influenced by business concerns, cost-benefit analysis, due diligence considerations, admissibility in court, and so on. In some cases the goal may be to locate and remediate all systems that the intruder accessed. In other cases the goal may be to determine whether the attacker stole sensitive data. In still other cases the goal may be to determine whether the victim network was used as a platform for illegal activities. When an intrusion results in significant damage or loss, the goal may be to apprehend and prosecute the attackers (Casey, 2006). The fact that the goal can vary underscores the importance of defining and documenting that goal from the start.
Regardless of the ultimate goal, digital investigators need to ascertain the method through which the intruders gained access, the time (or times) that this access occurred, where the attacks came from, and what systems and data were exposed. Answering these questions requires some degree of forensic reconstruction, including a combination of temporal, functional, and relational analysis of available data.
Date and time correlation is by far one of the most effective intrusion analysis techniques. There is such an abundance of temporal information on computers and networks that the different approaches to analyzing this information are limited only by our imagination and current tools. Temporal analysis can be summed up by the following statement: Look for other events that have occurred around the same date and time as one or more events already identified as related to the intrusion. Here are some examples:
▪ Look for other malicious or unknown executables with date-time stamp values close to a known piece of malware. Many intrusions involve more than one malware file. If you can find one, there is a good chance that there are more files created, written or modified around the same time as that file.
▪ Look for log entries that show processes being started, stopped, or experiencing errors during your known timeframe. For example, some malware adds itself as a service, and Event Log entries can be generated in Windows when a service is started. Poorly coded malware and exploits also will often crash legitimate systems, leaving traces in OS logs and crash dumps.
▪ Look for authentication log entries during your known timeframe. Attackers will often move through networks using stolen credentials because this is less obvious than using exploits or fake accounts. If you can correlate the logon of legitimate accounts to known-bad events, then you may be able to discover which accounts are being used by an attacker, or even that you have an insider problem.
For the past several years, it has been common for malicious code to modify its own file system date-time stamps. For example, some programs will change their NTFS Standard Information Attribute date-time stamps to match those of legitimate Windows system DLLs. However it is not as common for malware to modify every date-time stamp. So in your searches for date-related information, remember to check all file system date-time stamps, as well as those in file metadata and other embedded values.
The key with items listed earlier is date and time. You will not have the time to manually inspect every crash dump file on your enterprise, but you should check the crash dumps on in-scope systems that occur at the same time as other known bad activity.
The goal of functional analysis is to understand what actions were possible within the environment of the offense, and how the intruder's toolkit works. Functional analysis includes reviewing network device configuration to determine what the intruder could access. For instance, if a firewall was configured to block connections from the Internet to the targeted systems, then investigators must figure out how the intruder bypassed the firewall restrictions (e.g., by connecting through an intermediate system within the network, or having insider assistance).
Relational analysis involves studying how the various systems involved in a compromise relate to each other and how they interact. For instance, trust relationships between systems need to be explored in order to determine whether the intruder used them to gain access to additional systems.
Part 2a: Forensic Analysis
We will begin our digital investigation by examining NetFlow activity for web and SMB protocols over the internal network. NetFlow is a routing management tool developed by Cisco, as detailed in Chapter 9, “Network Analysis.” Many routers can be configured to dump a stream of network activity information to designated servers. The data does not record individual packet information, but a higher-level of communication called flows. These can be seen as records of closely associated traffic for particular packet exchange sessions. As detailed in Chapter 9, analysis of NetFlow logs in this scenario reveals a significant amount of traffic from the intranet server at 10.10.10.50 to the VPN at 192.186.1.1 on April 2, 2009 around 22:40. This information enables us to start an event timeline, shown in Table 4.6.
Now, with the timeline as a guide, we look in the web server access logs on the intranet server (10.10.10.50). Note that Microsoft Internet Information Server (IIS) logs' timestamps are in UTC by default. In this scenario, the other logs use the local Eastern Daylight Savings time zone (UTC-0400). The necessary adjustment for time zone should be noted in the timeline's comments field.
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /iisstart.htm - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil1.jpg - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil2.jpg - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil3.jpg - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil4.gif - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil5.jpg - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil7.jpg - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil8.jpg - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil6.jpg - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil9.jpg - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil10.jpg - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil11.jpg - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 404 0 2
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil12.jpg - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil13.jpg - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
These web server access logs show access to a series of JPEG files in the “snakeoil” series from the VPN (192.168.1.1). The timestamps, adjusted to UTC-0400, do not quite match those on the NetFlow logs. This may be due to a small discrepancy between the clock setting on the intranet server and the clock on the router that generated the NetFlow records. Such discrepancies appear often in the infrastructure of many organizations and need to be noted and eventually accounted for as detailed in the correlation section later in this chapter.
Fortunately for the organization, its security design did not permit remote VPN access to the most secure files on the intranet server. A functional analysis of the network configuration confirms that the company secrets could not have been accessed directly via the VPN. At this point in the investigation it would seem that CorpX's most sensitive data was protected from unauthorized access (to be continued…).
The principle of Occam's Razor is frequently misconstrued to mean that the simplest answer must be the correct one. Thus, the principle could be used to justify laziness in scientific inquiry. In fact, the principle states that an explanation of any phenomenon should be based on as few assumptions as possible. In the context of intrusion investigation, we can apply this principle by employing the scientific method, conducting experiments, and relying on available evidence.
Part 2b: Employing the Scientific Method
a.k.a. Practitioner's Tip: Challenge Your Assumptions
When conducting any investigation, it is important to consider alternative possibilities and to try to disprove your own conclusions. For instance, when investigating a security breach, do not rule out the possibility that someone gained physical access to the computer rather than compromised it via the network, or vice versa. For instance, in the intrusion investigation scenario used in this chapter, the company secrets stored on the intranet server could not be accessed directly via the VPN. However, by performing a relational analysis (looking at how various systems on the network can interact) and a functional analysis (checking to see whether certain systems could access the intranet server), we found that systems on the DMZ could access corporate secrets on the intranet server.
Further analysis of NetFlow logs reveals an unusually large quantity of data being transferred from the intranet server (10.10.10.50) to a host on the DMZ (10.10.30.2) at around the time of concern as summarized in Table 4.7.
The network diagram identifies 10.10.30.2 as an SSH server, which are usually UNIX-based systems. An individual with knowledge of the CorpX network could establish a VPN connection, log onto the SSH server in the DMZ, and from there access the files containing company secrets on the intranet server. Examining these NetFlow records confirms that, starting at around 23:13 and ending at 23:28, connections were established between the SSH server and ports 139 and 445 on the intranet server. The ports 139 and 445 are generally associated with the SMB protocol, indicating that a network file share on the intranet server was accessed at this time. In the correlation section later in this chapter, we will look for correlating events in other logs to develop a more complete picture of what occurred.
Still, at this stage of the investigation, it is not safe to rule out alternate possibilities. The IP address (10.10.30.2) used to gain unauthorized access to the company secrets is assigned to a system in the DMZ. Based on what we have been told, all DMZ systems are on the premises. At this point we have a computer on the premises in use at 11 pm, and it is possible that someone on the premises was responsible for these activities. Therefore, any physical security data, such as logs or security camera records, should be checked to see if any on-premises activity has been recorded. In this scenario, the physical security systems indicated that nobody was on the premises at the time in question, making this possibility very unlikely. Nonetheless, when you can prove that an alternate hypothesis is invalid rather than assume it, the effort is not wasted (recall the role of falsification in the scientific method).
To get a clearer sense of whether files of concern were stolen, digital investigators can check whether the files on the intranet server were accessed at the time of the suspicious activity (provided last accessed times are enabled as discussed earlier in this chapter). However, when dealing with a server that is critical to the operation of CorpX, it is preferable not to shut the system down and create a full forensic duplicate. In such situations, digital investigators can use a remote forensics tool to examine the file system while the server is still running. In this way, the needed digital evidence can be obtained in a forensically sound manner while maintaining business continuity. Figure 4.5 shows ProDiscover IR being used to examine the intranet server from the intrusion investigation scenario used in this chapter. Note that the remote forensic tool must be set to the same time zone as the system being examined in order to display timestamps accurately. This remote forensic preview reveals that secret formula files were indeed last accessed during the time of concern. Specifically, five of the six secret files on the server were last accessed on April 2, 2009 at 23:26, which is during the time someone logged into the SSH server on the DMZ and accessed a network file share on the intranet server. In short, it looks very likely that someone took CorpX's trade secrets! Now the big question on everyone's mind is who stole their data (to be continued…).

Once digital investigators confirm a serious problem such as theft of valuable information, it is generally necessary to delve more deeply into available sources of evidence and combine findings to form a comprehensive reconstruction of the crime. Techniques and tools for performing forensic analysis of NetFlow and other common types of network data are covered in Chapter 9. The remainder of this chapter covers techniques and tools for pulling all available data in an investigation together to reconstruct a more complete understanding of events surrounding a security breach.
Host-based Analysis Techniques
Many analysis techniques used in network intrusion investigations are similar to those used in other types of digital investigations. Here are some of the techniques that are particularly useful when attempting to track down an intrusion.
Hash Correlation
A common method of analyzing data is to identify specific files via hash value. There are two general ways to proceed. You can identify known-good files via hash so as then to be able to focus on files that are unknown. Conversely, you can identify known-bad files by hash value that you have previously discovered. This second technique is especially useful in identifying malware used on multiple systems in an intrusion, and in network traffic. Once you discover one system on which a program has been used, you can hash that executable and search for files with that hash value on other systems.
Fuzzy Hashing and Segmentation Hashing
Classic file hashing and correlation via hash value is done by hashing entire files, and comparing those values to the hash values of other full files to identify identical files. Skilled attackers understand this, and will make small modifications to their malicious executables so that the backdoor they drop on one system will not have the same hash value as a backdoor dropped onto another system. Fortunately, there are hashing techniques that allow you to compare parts of a file to parts of other files, rather than the file as a whole. These techniques are called fuzzy hashing and segmentation hashing. Segmentation hashing is the process of collecting hash values for chunks of a file that are a specific size. For example, you could hash a file in 50 byte chunks, collecting a hash value for bytes 1–50, 51–100, and so on. Fuzzy hashing is often a more effective method. Fuzzy hashing algorithms choose sections of a file to hash based upon probable similarities. You can then compare the fuzzy hash values from a known-bad file to a set of unknown executables, to determine if they share a percentage of their instructions in common. This is especially effective in determining if two files that are not identical are nonetheless related. An example of a tool that performs this is ssdeep (http://ssdeep.sourceforge.net/).
Process Structure Correlation
Identification of a malicious process will lead you to other artifacts. In a memory dump, the name of a process and its PID (Process Identifier) number will map to other things such as:
▪ Loaded DLLs: This may include libraries supplied by the attacker that you did not previously locate, and their storage location.
▪ File handles: This may include other files supplied by the attacker.
▪ Registry handles: This will tell you what Registry keys are being accessed by the process, possibly including the Registry keys used to automatically start the executable at boot.
▪ Network sockets and connections: The PID will be linked to any related listening sockets or active connections. This can tell you one or more ports that the process uses, and possibly with what other hosts it is communicating.
▪ Execution path: The full path to the original file used to execute the program. Even if the file has been deleted since, this can lead you to a directory used by the attacker for other activities. This may also include command line options used to start the program, which can be useful when conducting malicious code analysis.
▪ Parent process: You can determine the parent process of the malicious process. This can tell you how it was started, and other related data. For example, if a malicious process was started by Internet Explorer, then it may be that it was created as the result of an Internet Explorer exploit.
▪ Structure comparison: If the process is not shown in the basic process list, but is present in another structure such as the linked list of EPROCESS blocks, then it may be that there is a rootkit attempting to hide the process.
Directory Correlation
It is common for an attacker to store multiple malicious files in the same directory. If you discover one file related to the intrusion, you can take a look at the other files in the same directory to see if any of them look suspicious. This may be unrealistic if the directory in question is something like C:windowssystem32, which is clogged with legitimate files, but for less populated directories this is worth a try.
Keyword/Regex Search
A keyword or regular expression search is the process of searching an item of evidence for specific characters or character patterns that are either considered suspicious or are direct signs of unauthorized activities. For example, an attacker may have packed his or her code with a specific packing tool that has a unique or unusual name for the packed sections of the executable. If you find one such program, you may be able to find other programs packed with this same program by searching for that executable section name.
Over time you will aggregate a generic set of keywords that you find are useful in more than one intrusion investigation. Even if you know nothing about a new case, you could use these terms for an initial keyword search for suspicious items. For example, intruders that are not skilled enough to write their own code will often use public tools such as pskill from Microsoft. This program, and some of the other pstools contain the string “Sysinternals,” referencing the former company of the author. A keyword search for this string, though it may yield false positives, may also lead you to tools used by the intruder stored alongside these common programs.
Unknown Code Assessment
In an increasing number of cases it is necessary to analyze malicious programs found on a compromised system. The results of such analysis can give digital investigators additional leads such as files placed on the system or IP addresses of remote systems. In addition, malware analysis can enable digital investigators to decode file contents or network traffic that was otherwise inaccessible. The complete process of analyzing malware in a forensic manner is beyond the scope of this chapter and is covered in detail in Malware Forensics (Malin, Casey & Aquilina, 2008). However, given the importance of this aspect of intrusion investigation, it deserves some attention here.
When you do discover unknown executable code that may be related to unauthorized activity, you will need to assess that code to determine its functionality and the artifacts of its execution. This will include attempting to determine information such as:
▪ Unique metadata signature of executable files
▪ Unique text strings found in the files
▪ Any additional files created, deleted, or modified by the malware
▪ Additional files required for the malware to operate
▪ The names of any processes that the malware attempts to hide, terminate, inject itself into, etc.
▪ Any Registry keys that are manipulated, or any other modifications of system configuration
▪ Listening ports opened by the code
▪ Target of any network communication initiated by the malware, and the protocols used
▪ Methods for interacting with the code, and signatures that can be used to identify it on the network
There are several different types of activities that can be used to determine this type of information, and they are described in the following subsections.
Automated Scanning
You can use automated tools to identify and deconstruct the code to determine its function. Tools usable for this range from typical antivirus programs to those that attempt to automatically unpack an executable, and even run it in a sandbox to determine how it functions.
Static File Inspection
You can inspect a static file with some simple techniques to determine some basic pieces of information. This includes using programs to extract readable strings from the file, examine executable file metadata, and check library dependencies.
Dynamic Analysis
Execute the code to observe its actions. This will also typically require you to interact with the code to some extent to elicit its full functionality. In some cases you will need to create programs with which the code can interact across network links in a test environment. This type of analysis may involve simple tools that log the behavior of programs on the system, or it may require that you use a debugger to run the code in a more controlled environment.
Disassembly and Decompilation
This is the process of taking a binary executable and reverting it back to either assembly code or to the higher-level language in which it was constructed. This is not an exact process, as compiler optimizations will have changed the code sufficiently that you will not be able to determine the exact original instructions, but you will be able to determine overall functionality.
Initial Processing
Most of your analysis tasks and techniques will be selected based upon the facts of the investigation. However, there are some tasks that can and should be performed regardless of the conditions. Most of these are processes you can simply kick off when you receive the evidence, and let run over night. When they are complete, the evidence will be in a better position to analyze and you will have more information to go on. The steps are as follows.
There will be times when you are in an extreme rush, and do not have the time to tie up your primary analysis system performing these processes. In this case, you will obviously have to proceed manually in an attempt to find what you need. But even if you must start manual analysis immediately, it would benefit you to have another system conducting these operations in the event that you will need their results at a later date.
Initial Processing: Host Analysis
These steps are specific to the processing of host-based data.
1. Hash verification. Verify the hash value of evidence transferred into your possession to verify its integrity.
2. Create a working copy. If you only have one copy of the image, create a working copy and store the original. Verify the hash value of your working copies.
3. Verify time settings. Check and note the time settings of the device, and check responder notes to see if the device time was accurate. You will not be able to properly correlate events from multiple sources unless you know how their time settings are configured, and whether or not the time of the device was accurate.
4. Recover deleted files. Have your forensic tool undelete/recover any deleted files that it sees, if it does not do so automatically. This is so they can be directly included in any future searches or analysis steps.
5. File signature analysis. Use your tool to automatically tag any files that either do not have a valid file signature or where the signature does not match the file extension (assuming you are analyzing an operating system where this matters).
6. Carve files. Attackers will commonly delete some malicious programs once they are finished with them. You should always carve any executable files and libraries that can be recovered from slack and unallocated space.
7. Calculate file hashes and compare to known files. This can be used to immediately identify known-bad files, and will also provide you with additional information regarding other files as you conduct your manual searches later.
When filtering files out of view because they have hashed out to be a known-good file (or for any other reason), do not forget to put them back into view when you have completed the specific search you are doing. Even activities relating to legitimate files can be valuable to an investigation, and inadvertently excluding files from analysis can result in incomplete understanding of events.
8. Antivirus scan. The attacker may be using malicious code that is already known to some antivirus vendors, or is obvious enough to trigger a generic alert. You should scan every possibly compromised system with multiple antivirus packages. This will require that you mount the evidence files as a logical drive so that an antivirus scanner can see the files.
9. Packer detection scan. It is common for intruders to pack, or obfuscate their code. Sometimes these obfuscations contain known patterns that can be identified using tools specialized for such a search. This can be a quick way to find malware that is not known to antivirus software, but does contain a known-packer signature.
10. Index files. Index the system images using a tool like PTK (www.dflabs.com) or FTK (www.accessdata.com). This will link individual files to the strings that they contain. This is a time-consuming process, but it will make your subsequent keyword searches occur much more quickly.
11. Generic keyword search. You should always kick off a search for your generic intrusion keywords in the beginning of a new analysis operation.
12. Case-specific keyword search. For the very first system you analyze in a given case, you may not yet have identified any case-specific keywords. But for every subsequent system, you will have such a list that will include attributes such as known-bad IP addresses and host names, and unique malware strings. So a keyword search for any known case keywords should be conducted for every new system found.
Initial Processing: Log Analysis
These steps are specific to the processing of log files.
1. Hash verification. Verify the hash value of evidence transferred into your possession to verify its integrity.
2. Create a working copy. If you have only one copy of the log file, create a working copy and store the original. Verify the hash value of your working copies.
3. Check the file to verify the format of the log entries. Many log analysis applications can process only certain log formats. If you attempt to import an incompatible format into a log analysis program that does not understand it properly, you may miss data and never even know.
4. Line count. Determine how many lines the log file has so that you will know if it will be possible to review it manually or if it will need to be filtered.
5. Determine time span. Always check the date-time stamps for the first and last log entries to determine if the log file even covers the timeframe of interest, and check responder notes to see if the device time was accurate. You don't want to spend an hour analyzing log files from today when you are trying to correlate events that occurred a week ago. Note that an intruder may have tampered with the system clock settings and make sure that the timestamps from a compromised system are consistent.
Initial Processing: Malicious Code
1. Hash verification. If you were given the malware rather than extracting it from a host, verify the hash value of evidence transferred into your possession to verify its integrity.
2. Create a working copy. If you have only one copy of the file, create a working copy and store the original. Verify the hash value of your working copies.
3. Antivirus scan. Scan the malware with as many antivirus packages as you can to see if the malware is already known.
4. Fuzzy hash. Create fuzzy hash values for the file and compare it to the other malware in your library to see if there is a link.
5. Automated sandbox scan. If you have access to an automated sandbox, you should have the sandbox process the malicious code to determine if it automatically reveals any artifacts.
6. Packer detection scan. As mentioned in the host-based list earlier, a packer detection scan can help you to determine if the code is obfuscated in a known way. Some such programs will also attempt to automatically unpack the executable for you.
The complete process of examining Windows and Linux systems for evidence of intrusion and traces of malware is covered in more detail in Malware Forensics (Malin, Casey & Aquilina, 2008) with examples of associated tools.
Combination/Correlation
Ideally, in an intrusion investigation, we should be able to determine the scope of an intrusion and establish the continuity of offense, connecting the virtual dots from the target systems back to the intruder. We have a better chance of obtaining a complete and accurate picture of events when we combine information from multiple independent sources to increase the completeness and accuracy of our understanding of an intrusion.
The most common approach to correlating logs is to look at particular time periods of interest in an effort to find related events recorded in multiple logs.
Part 3a: Log Correlation and Crime Reconstruction
Back to the big question of who stole CorpX's data. The timeline, based primarily on NetFlow logs, puts the start of the suspicious SMB network file share activities at 23:12:47 from IP address 10.10.30.2. Examining the Security Event logs on the intranet server around this time period, and searching for the string 10.10.30.2, yields a successful logon record timestamped 23:11:30, as shown in Figure 4.6. The user name is “ow3n3d,” which is not a user account that system administrators at CorpX recognize, suggesting that it is not a legitimate account.
Searching the Security Event logs around this time period for other occurrences of the “ow3n3d” account, we find that it was originally created and was granted Administrative access rights just a few minutes earlier at 10:56:06 by someone using the administrator account (Table 4.8).
| Date-time | Event ID | Event Details |
|---|---|---|
| 4/2/2009 22:43 | 624 | Account Management “ow3n3d|CORPX|%{S-1- 5-21-1312302602-2019440308-3395481400- 1116}|Administrator|CORPX|(0x0,0x3F9D99F)|- |ow3n3d|ow3n3d|[email protected]|-|-|-|-|-|%%1794|%%1794|513|-|0x0|0x15|” |
| 4/2/2009 22:43 | 628 | Account Management “ow3n3d|CORPX|%{S-1-5-21-1312302602-2019440308-3395481400-1116}|Administrator|CORPX|(0x0,0x3F9D99F)|-” S-1-5-21-1312302602-2019440308-3395481400-500 “User Account password set: Target Account Name: ow3n3d Target Domain: CORPX Target Account ID: %{S-1-5-21-1312302602-2019440308-3395481400-1116} Caller User Name: Administrator Caller Domain: CORPX Caller Logon ID: (0x0,0x3F9D99F)” |
| 4/2/2009 22:56 | 636 | Account Management “CN=ow3n3d,DC=CorpX,DC=local|%{S-1-5-21- 1312302602-2019440308-3395481400-1116}| Administrators|Builtin|%{S-1-5-32-544}|Administrator| CORPX|(0x0,0x3F9D99F)|-” S-1-5-21-1312302602- 2019440308-3395481400-500 “Security Enabled Local Group Member Added: Member Name: CN=ow3n3d,DC=CorpX,DC=local Member ID: %{S-1-5-21-1312302602-2019440308-3395481400-1116} Target Account Name: Administrators Target Domain: Builtin Target Account ID: %{S-1-5-32-544} Caller User Name: Administrator Caller Domain: CORPX Caller Logon ID: (0x0,0x3F9D99F) Privileges: - ” |
Further examination of the Security Event logs during this period reveal that the individual who used the administrator account to create the “ow3n3d” account connected to the intranet server via the VPN (192.168.1.1) using Remote Desktop. Pertinent details about the logon and logoff events associated with this suspicious use of the administrator account are provided in Table 4.9. As a point of interest, observe that the event log entries in Table 4.9 captured the name of the attacker's machine (EVILADMIN) even though it was a remote system on the Internet that was connected into the target CorpX network via VPN. When an intruder uses a Windows system to establish a VPN connection into the target network and access Windows servers within the network, some distinctive information like the attacker's machine name can be transferred into the Security Event logs of the target systems.
So, to learn more about the intruder, it is necessary to examine logs generated by the VPN. Unfortunately, the clock on the VPN device was incorrect, making it more difficult to correlate its logs with logs from other systems. Therefore, we must take a detour in our analysis to figure out the clock offset of the VPN device. But first, we need to update the timeline with results from our latest analysis as shown in Table 4.10.
Resolving Unsynchronized Date-time Stamps
Failure to maintain consistent, accurate time in log servers is one of the greatest stumbling blocks to log correlation. Clocks on Cisco devices are particularly prone to drift and must be maintained using NTP. If the logs are recent and the investigator has access to the logging systems, it may be possible to establish the relative time offset with some confidence. Unfortunately, the existence of the offset casts doubt on the consistency of the offset. If the clocks are 10 minutes out of synchronization now, it reduces our confidence that they were no more or less than 10 minutes out of synchronization one month ago.
The best approach to correlating two unsynchronized logs is to identify an event, or a pattern of events, that generates a record in both logs simultaneously. The timestamps for the event can be compared and the time offset computed. In the chapter scenario, for example, the timestamps in logs associated with the VPN device do not match those on other systems on the network. Since we do not yet know which, if either, system was properly calibrated, we will use the intranet server logs as our working time baseline.
Fortunately, the Cisco VPN device in use at CorpX was configured to record access attempts to resources on the intranet web server. Comparing the web access log entry for the snakeoil1.jpg file with the corresponding entry in the VPN log, we see that the date-time stamps generated by the VPN are 58 minutes and 25 seconds behind.
Web access log entry on intranet server (UTC):
2009-04-03 02:38:10 W3SVC1 10.10.10.50 GET /images/snakeoil1.jpg - 80 - 192.168.1.1 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1) 200 0 0
Corresponding VPN log entry:
Apr 02 2009 21: 39:45: %ASA-6-716003: Group <DfltGrpPolicy> User <jwiley> IP <130.132.1.26> WebVPN access GRANTED:http://10.10.10.50//images/snakeoil1.jpg
Even this approach to determining clock offsets can result in errors and confusion. Digital investigators may inadvertently select a log source that has an inaccurate timestamp as the basis for correcting time offsets, thus throwing off all the times in their analysis. This situation can be avoided by looking for more than one reference point across the various logs. In the preceding example, incorporating NetFlow logs in the calculation of clock offset reveals that the router clock was 77 seconds ahead of the intranet server. Even such a small offset can create confusion when developing an intrusion timeline. In short, the more independent sources of evidence that can be correlated and the more events that can be correlated across the logs, the more likely we are to get an accurate picture of events.
Part 3b: Putting Together Pieces of the Puzzle
Having determined that date-time stamps in the VPN logs need to be adjusted by adding one hour, we are ready to continue our analysis into who stole CorpX's trade secrets. Examining the VPN logs for the times of interest reveals that the data thief authenticated with the VPN using the jwiley user account at 22:37:49 and accessed the intranet web server. The intruder subsequently connected to the intranet server using Remote Desktop at the time the ow3n3d account was created as shown in the following VPN log entry (having added 58 minutes, 25 seconds):
Apr 02 2009 22: 55:21: %ASA-6-716003: Group <DfltGrpPolicy> User <jwiley> IP <130.132.1.26> WebVPN access GRANTED: rdp://10.10.10.50/
VPN logs also show that the ow3n3d account was later used to authenticate to the VPN at 23:08:42, and established an SSH connection with the SSH server in the DMZ (10.10.30.2). Examination of authentication logs on the SSH server for this time period show that the intruder logged in using the jwiley account between 23:12 and 23:30. This was the only account logged into the SSH server during the period when trade secrets on the intranet server were accessed.
Furthermore, the following entries in /var/secure.log on the SSH server show that the jwiley account was used at 23:30:15 to establish an sftp session, potentially to transfer the stolen trade secrets off of the system onto the intruder's computer.
Apr 2 23:30:15 Shell.CorpX.com com.apple.SecurityServer[22]: checkpw() succeeded, creating credential for user jwiley
Apr 2 23:30:15 Shell.CorpX.com com.apple.SecurityServer[22]: checkpw() succeeded, creating shared credential for user jwiley
Apr 2 23:30:15 Shell.CorpX.com com.apple.SecurityServer[22]: Succeeded authorizing right system.login.tty by client /usr/sbin/sshd for authorization created by /usr/sbin/sshd
Apr 2 23:30:15 Shell.CorpX.com sshd[4025]: Accepted keyboard-interactive/pam for jwiley from 10.10.20.1 port 1025 ssh2
Apr 2 23:30:15 Shell.CorpX.com sshd[4037]: subsystem request for sftp
In all the pertinent VPN log entries, including those relating to the jwiley and ow3n3d accounts, the thief's originating IP address was recorded 130.132.1.26. With the proper legal authorization, the Internet Service Provider (ISP) responsible for that IP address may be able to provide information about the subscriber who was using that IP address at the time. This information could lead to a search warrant of the intruder's home and seizure of his computers, which we would search for traces of the stolen data, check to see if the machine name was EVILADMIN, and look for other linkage with the intrusion and data theft.
Although digital investigators follow the trail left by an intruder, it is important to document the key findings into a logical progression of events, as discussed in the section, “Case Management,” earlier in this chapter (see Table 4.5). To demonstrate this in the context of the investigative scenario for this chapter, we have developed the timeline of events shown in Table 4.11.
Recall that this documentation process serves several purposes, and is an effective tool to reaching a clearer understanding of events relating to an intrusion. In addition to helping us keep track of our findings, this type of chronological event tracking chart provides everyone involved in an ongoing investigation with an overview of what is known about the intrusion, and where there are still gaps in knowledge. In the longer term, this documentation can be included in a final report and can be an invaluable memory aid for testimony, summarizing the most important events.
Although most tools organize and correlate logs by time, there are other systems for organizing evidence. In some cases it may make more sense to organize by file ownership, for instance, or IP of origin. Any characteristics or traces of the intrusion that you can extract from logs or compromised hosts may be useful to search various data sources.
Quite often one correlation method, such as a timeline, will point to other types of correlation. In the case scenario, we saw an access by a machine named EVILADMIN. We should check the logs for other systems accessed by EVILADMIN in the past (remember the point about looking back before the time of detection). Mind you, we ultimately strive to incorporate our findings into a bigger and better timeline, but there would be nontemporal correlations within the master sequence. We like time. Events and time go together so nicely.
During an intrusion investigation, available data sources are searched repeatedly as the investigation progresses and investigators find new information, such as IP addresses, nonstandard ports, or communication methods used by the intruders. Therefore, it is important for digital investigators to be conversant with tools and techniques for correlating and searching various sources of data.
Splunk (www.splunk.com) is one of the most flexible log correlation tools available. Although Splunk does recognize some specific log formats, it uses a flexible approach to extract features from any log data, and indexes log data to enable quicker searches. The data input screen of Splunk is shown in Figure 4.7 with the specific cisco_syslog format specified.

Unlike many other log correlation tools that require logs to be in a well-defined format, Splunk does not depend on specific log formats, and recognizes timestamps of most kinds. In practical terms, digital investigators can load every available log (defined loosely to include any record with a timestamp) into Splunk, including file system information, server logs, and network traffic, and examine these disparate sources together. This is the definition of correlation! The main caveat is that logs must generally be in plain text for Splunk to understand them. Fortunately, most binary data sources can be converted to text. The following commands were used to convert logs from the intrusion investigation scenario using this chapter into text format for input into Splunk:
▪ Windows Security Event logs: LogParser “SELECT * FROM SecEvent.Evt WHERE (TimeGenerated > ‘2009-04-02 09:00:00’) and (EventID IN (528;529;540; 624;628;636;682;683))” –q -i:EVT –o:CSV
▪ NetFlow: flow-print -f 5
▪ Network traffic: tcpdump -r 20090323-gooddryrun.pcap -tttt -vv -n
Note that conversion can introduce errors, particularly in date-time stamps. For instance, make sure that the system used to convert Windows Event logs has its clock and time zone set to the same values as the original logs.
Once all available logs have been loaded and indexed in Splunk, they can be viewed and queried with the ease of a search engine. Splunk has the ability to correlate on any feature in log files, including IP address, host name, username, and message text. Clicking on any value in a given log entry will cause Splunk to search its index for all items containing that value. In addition to searching for specific items in the logs, the timeline feature can be used to perform temporal analysis. Splunk provides a histogram of events per unit time that digital investigators can use to observe high concentrations of activity, and drill down into potentially significant time periods. In addition, results can be restricted by date range. Combining the filtering and histogram features of Splunk enables digital investigators to locate periods of suspicious activities. All these features are shown in Figure 4.8, where the digital investigator is viewing logs between the times 22:50 and 23:00 on April 2, 2009 that contain the keywords ow3n3d or eviladmin (Splunk treats an asterisk as a wildcard). Observe in Figure 4.8 that Splunk normalizes the differently formatted date-time stamps in the logs, thus enabling the correlation.
 |
| Figure 4.8 |
Because Splunk indexes log data, it shows how available strings relate to information being entered in the query field as shown in Figure 4.9.

{kind=link}
An added benefit from a forensic perspective is that Splunk retains the original logs and provides a “Show source” option, enabling digital investigators to view important events in their original context.
Among Splunk's shortcomings is the lack of a feature to adjust for time zone differences or clock offset. Digital investigators must make necessary adjustments prior to loading data into Splunk. Difficulties can arise when input data has multiple date-time stamps in each record (e.g., file system information), making it necessary to create a custom template for the specific format. In addition, the ability to recognize most timestamp formats comes with a price. Splunk can mistakenly identify nontimestamps as timestamps. Before performing analysis, digital investigators should test each type of data they are loading into Splunk to verify that it is interpreting each log source as expected.
Other tools that can be useful for log correlation but rely on specific log formats include xpolog (www.xplg.com) and Sawmill (www.sawmill.net). There are also more expensive commercial log correlation tools like CS-MARS from Cisco, nFX from NetForensics, and NetDetect or from Niksun.
When dealing with the more skilled adversary, investigators should always look at the logs for signs of subterfuge such as hardware clock tampering, missing entries, or time gaps. It is important to perform this type of examination on raw logs prior to import into a database or other tool because entries that have timestamps out of sequence with their surrounding entries can be critical from a forensic perspective. Since most analysis tools simply order entries by their timestamps, it will not be evident from these tools that there are entries out of sequence.
Feeding Analysis Back into the Detection Phase
Once you have identified specific artifacts related to an intrusion, you will then be able to search the enterprise for those artifacts, thereby identifying additional compromised systems and network segments. This involves searching several types of structures, primarily systems, network communication links, and directories.
Host-based Detection
Host-based detection sweeps involve auditing all hosts within the potential scope of the incident to determine if they possess any of the known artifacts of the incident. These artifacts exist either in memory, or in the primary nonvolatile data storage used by the operating system. The primary types of artifacts for which you will need to be able to sweep include:
▪ Filenames and file naming conventions
▪ File metadata values or specific string contents
▪ Registry keys or configuration file contents
▪ Log messages
▪ Process names and execution paths
▪ Process library load outs and file handle lists
▪ Loaded driver modules
▪ Specific discrepancies between kernel structures, or between a kernel structure and results of kernel API queries
Searching for these artifacts is not an easy task. There are several constraints that will affect your ability to sweep for these artifacts.
Enterprisewide Visibility
Your first problem will be obtaining access to all systems in the potential scope of the incident. For example, if the attacker has compromised domain-level credentials, then all systems in the domain are in the potential scope of the incident. This means you will need to search each and every system in that domain for known artifacts to determine if they had malicious code installed upon them, even if this includes thousands of systems. If you do not conduct this search, you will risk there being undetected, compromised hosts. This assumes that the devices in the domain are of an operating system capable of running the malware. For example, a Vista system may not execute malware specifically written for XP SP2, let alone Mac OS X.
From a simple enterprise management perspective, this means that you will need the ability to deploy agents to all such systems and/or remotely poll the operating system or a preexisting agent for the specific information that you require. This brings us back to the Preparation phase of the Incident Response Lifecycle. Many organizations are not set up for this, and that can be a barrier to an effective investigation.
Furthermore, in an enterprise there will invariably be staff members on travel, or people who simply have their systems turned off. You can't search a system that is at a customer site in another country, or that isn't even powered on. Your best option is to trigger searches when systems authenticate to the network, so that the next time a remote worker returns to the office, or connects via a VPN an agent is loaded or a remote search is initiated.
Finally, you will have systems that are not part of your network authentication and authorization structure, such as experimental systems that haven't been added to one of your domains, student-owned systems at a university, or wireless systems on an airport's public wireless network. These systems will not respond to searches or agents pushed out through the directory. Searches of these devices will have to be conducted separately at a greater administrative overhead, if you even know they exist and where they are. This is another reason that a proper asset inventory is essential to an intrusion investigation. You cannot search devices of which you are completely unaware.
Hardware Load
You will also have to deal with the fact that you will be taxing the remote system you are trying to search. Conducting operations such as searching the entire directory structure, and parsing every executable file to identify specific metadata is not a trivial task. At organizations that have three to five year turnover rates for their workstations, you will significantly slow down the older systems during these searches. If possible, conduct your searches during off hours. Otherwise, prepare your help desk to field complaint calls about systems “acting slow.”
Circumventing Rootkit Interference to Conduct Artifact Sweeps
Remember that if the system you are searching is compromised, malicious code already running on the system may actively attempt to hide itself from standard OS queries for file system and process data. Because of this, you will not be able to trust that a simple API query for an artifact type returned a proper result. For example, you may attempt to obtain a list of DLLs in C:windowssystem32 to determine if a specific Trojan DLL is present, but just because the result is negative does not mean that the file is not there.
There are several ways to deal with this. First, you can attempt to query for artifacts directly at the structures for which you are searching. In other words, imagine again that you are searching system32 for a specific DLL. Rather than your tool (whatever it may be) issuing a query to kernel32.dll as part of the public Windows API, you could open a handle directly to the MFT (Master File Table) of an NTFS volume and search it directly, thereby circumventing basic rootkit API hooks. This is a common technique used by remote forensic tools. Similar techniques are available for searching for other types of artifacts. However, if the target system is already running a rootkit, you cannot be absolutely sure that a way has not been found to circumvent this type of technique.
Another method is to compare structures and assess for discrepancies. Not only could you query the MFT directly, but you can also compare the contents of the MFT with the results of a directory listing via API call. This is how some rootkit detection programs work, and you should have this capability as well.
Tool Options
There are different options for software tools that will actually enable you to conduct such a search:
▪ Custom Scripts: You can utilize custom scripts to query for different artifacts. For example, WMI scripting is a robust method for querying the Windows operating system directly for artifacts.
▪ Specialized Forensic Tools: There are several forensic tools that are designed for remote forensic searches. EnCase Enterprise and ProDiscover IR are two examples. Note that there are significant differences in their feature sets and methods. Both tools offer custom scripting so that you can automate searches for artifact types, but there is also significant cost for such tools.
▪ Forensic Access Facilitators: A new remote forensic tool type has emerged that grants remote access directly to remote system memory and disks completely separate from the analysis platform being used to assess those structures. One tool that accomplishes this at this time is called F-Response. You can deploy F-Response agents, and then simply search the remote systems with lower cost forensic tools that do not inherently include remote search capabilities. Note however, that F-Response offers only agent-based access to remote systems.
Network-based Detection
Network-based Intrusion Detection, or NIDS, is a more commonly developed practice, and is essentially already covered by common intrusion detection methodologies. Devices that exist at network choke points, such as IDS sensors, firewalls, and application proxies can be used to search ingress/egress network traffic for specific artifacts that you have discovered during your analysis tasks. These artifacts will typically be one of the following:
▪ IP addresses of known victims or external hosts involved in the intrusion
▪ DNS host names involved in the intrusion
▪ TCP/UDP port numbers used in attack-related traffic
▪ Specific ASCII or hex values found in packets associated with incident-related traffic
▪ Abnormal protocol header values directly associated with incident-related traffic
▪ Volumes of traffic, either abnormal for a particular host in a compromised network segment, or abnormal for direction in a specific direction (i.e., a workstation exhibiting excessively heavy egress traffic)
For example, if during your analysis of a malicious code sample, you discover that it communicates to several specific hosts via port 80 and embeds instructions inside valid HTML, all of these things can be searched using the network devices just mentioned. You can configure your firewall to log access to the IP addresses in question, and though you may not be able to simply monitor for port 80 access, you can configure web proxies to search for specific HTML signatures that correlate to the unauthorized traffic. Searching for artifacts such as these at network borders will assist you in identifying additional hosts.
As mentioned previously in this chapter, you will probably not be able to deploy a sufficient number of sniffers to cover all points of ingress/egress on your network to monitor for unauthorized activity. However you can use the devices already in play.
Conclusion
Intrusion investigation is an exciting and dynamic process that requires strong technical skills and effective case management, often requiring a team of digital investigators and forensic examiners. In practice it sometimes seems like controlled chaos, particularly when an intruder is still active on the victim systems. Digital investigators have a better chance of navigating the challenges and complexities of intrusion investigations if they follow the scientific method and scope assessment cycle. In addition, the success of this type of investigation depends heavily on having a mechanism to keep track of the investigative and forensic subtasks.
References
Casey, E.; Stanley, A., Tool review: Remote forensic preservation and examination tools, Digital Investigation 1 (4) (2004).
Casey, E., Error, uncertainty and loss in digital evidence, International Journal of Digital Evidence 1 (2) (2002).
Casey, E., Digital evidence & computer crime. 2nd ed. (2004) Academic Press, San Diego, CA.
Casey, E., Network traffic as a source of evidence: Tool strengths, weaknesses, and future needs, Journal of Digital Investigation 1 (1) (2004).
Casey, E., Investigating sophisticated security breaches, Communications of ACM 49 (2) (2006).
Gartner Press Release, Gartner Says Companies Should Implement Information Access Technologies, Rather Than Buying More Storage, to Manage Old Corporate Data. (2008) STAMFORD, Conn.
Grow, B.; Epstein, K.; Tschang, C.C., The new e-spionage threat, Business Week (2008); Available online atwww.businessweek.com/magazine/toc/08_16/B4080magazine.htm.
Malin, C.; Casey, E.; Aquilina, J., (2008) Syngress, Malware Forensics.
Ponemon Institute, 2008 Annual study: US Cost of a Data Breach. (2009) .
Ponemon Institute, 2008 Annual study: UK Cost of a Data Breach. (2009) .
Scarfone, K.; Grance, T.; Masone, K., Computer security incident handling guide, special publication 800-61, revision 1. (2008) National Institute of Standards and Testing; Available online athttp://csrc.nist.gov/publications/nistpubs/800-61-rev1/SP800-61rev1.pdf.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.