
2
Approaches for Prognosis and Health Management/Monitoring (PHM)
2.1 Introduction to Approaches for Prognosis and Health Management/Monitoring (PHM)
You learned in Chapter 1 that the purpose of prognostics is to be able to accurately detect and report a future failure in systems – to predict failure progression. Prognostic approaches in prognostics and health management/monitoring (PHM) to accomplish that purpose can be grouped into broad categories: classical, usage‐based, and condition‐based (Hofmeister et al. 2017; Pecht 2008; Kumar and Pecht 2010; O'Connor and Kleyner 2012; Sheppard and Wilmering 2009). Classical prognostic approaches can be categorized as model‐based, data‐driven, or hybrid‐driven, as shown in Figure 2.1.

Figure 2.1 Block diagram showing three approaches to PHM.
Source: based on Pecht ( 2008 ).
2.1.1 Model‐Based Prognostic Approaches
Model‐based prognostic approaches include the modeling and use of expressions related to reliability, probability, and physics of failure (PoF) models. Such models are used to study and compare, for example, the relationships of materials, manufacturing, and utilization of the reliability, robustness, and strength of a product, often in structured, designed, controlled experiments and life tests. Such modeling offers potentially good accuracy, but it is difficult to apply and use in complex, fielded systems (Speaks 2005). Those models include distributions and probability models; fundamentals of reliability theory; and models based on reliability testing, such as acceleration factors (AFs), presented in Chapter 1. Other methods will be discussed later.
2.1.2 Data‐Driven Prognostic Approaches
Data‐driven prognostic approaches include statistical and machine learning (ML) methods; are generally simpler to apply, compared to model‐based prognostic approaches; but can produce less precision and less accuracy in prognostic estimations. Statistical methods include both parametric and nonparametric models, such as those shown in (Ross 1987) and (Hollander et al. 2014); and K‐nearest neighbor (KNN), a nonparametric method for classification or regression of an object with respect to its neighbors (Medjaher and Zerhouni 2013). Machine learning includes examples such as linear discriminant analysis (LDA) to characterize or separate multiple objects, hidden Markov modeling (HMM) to model a system having hidden states, and principal component analysis (PCA) to convert observations into linearly uncorrelated variables.
2.1.3 Hybrid Prognostic Approaches
Hybrid approaches employ both model‐driven and data‐driven approaches to further improve the accuracy of and/or to better understand the relationships of parameters and objects (Medjaher and Zerhouni 2013 ). Drawbacks are increased computational processing and complexity (see Figure 2.2). We will return to these and other methods later in this chapter.

Figure 2.2 Precision and complexity: relative comparison of classical PHM approaches.
2.1.4 Chapter Objectives
The objectives of this chapter are to present classical methodologies to support prognostics for PHM and then to present an approach to condition‐based maintenance (CBM) for PHM: an approach based on CBD signatures that lays the foundation for Chapter 3.
2.1.5 Chapter Organization
The remainder of this chapter is organized to present and discuss classical approaches to modeling to support prognostics for PHM and to introduce our approach to CBM:
- 2.2 Model‐Based Prognostics
This section presents approaches to model‐based prognostics, including topics on analytical modeling, distribution modeling, PoF and reliability modeling, acceleration factors, complexity related to reliability modeling, failure distribution, failure rate and failures in time, and advantages and disadvantages of model‐based prognostics.
- 2.3 Data‐Driven Prognostics
This section presents approaches to data‐driven prognostics including topics on statistical methods and machine learning – classification and clustering.
- 2.4 Hybrid‐Driven Prognostics
This section presents approaches to hybrid‐driven prognostics: model‐based combined with data‐driven prognostics.
- 2.5 An Approach to Condition‐Based Maintenance (CBM)
This section presents an approach to CBM, including topics on modeling CBD signatures, comparing life consumption and PoF, and CBD signature methodologies. An illustration of CBD‐signature modeling is included.
- 2.6 Approaches to PHM: Summary
This section summarizes the material presented in this chapter.

Figure 2.3 Model‐based approach to development and use.
2.2 Model‐Based Prognostics
Model‐based approaches use analytical and PoF models. Analytical models include usage, statistical, and probabilistic models; and they may be validated by other models, such as PoF models and/or reliability‐based models. Reliability‐based models are associated with testing, such as accelerated life tests (ALTs) and regression analysis: Pecht favors PoF, in which life‐cycle loading and failure mechanisms are modeled and applied to assess reliability and evaluate new materials, structures, and technologies (Pecht 2008 ). It should be noted that, in general, PoF modeling tends to be computationally prohibitive when applied to systems (Sheppard and Wilmering 2009 ). A simplified approach to model‐based prognostics, shown in Figure 2.3, includes model development and model use.
Model development includes the following: (i) identification, selection, and/or development of a model; (ii) simulation and/or experimentation to produce data to evaluate and verify the model; and (iii) characterization of the data for subsequent data measurement, collection, and inputting into the model to produce prognostic information when the model is used. Model use includes the following (see Figure 2.4): (i) acquire data, (ii) process data, (iii) detect fault(s), (iv) perform diagnostics, (v) perform prognostics, (vi) make decisions, and (vii) issue maintenance and logistic directives (Medjaher and Zerhouni 2013 ).

Figure 2.4 Model‐use diagram.
Source: based on Medjaher and Zerhouni ( 2013 ).
Referring to Figures 2.4 and 2.5, the functionality of the blocks labeled Data Acquisition, Data Processing, Fault Detection, Diagnostic Processing, and Prognostic Processing are embodied in the Sensor Framework, the Feature Vector Framework, the Prediction Framework, and the Performance Validation Framework. Prognostic information is passed to a Fault Management (FM) Framework and/or written to output files for deferred decisions and actions related to maintenance, logistics, and graphical‐user interfaces (CAVE3 2015; Hofmeister et al. 2017 ).

Figure 2.5 A framework for CBM for PHM (CAVE3 2015 ).
2.2.1 Analytical Modeling
Analytical models, also referred to as physical models, employ load parameters such as those shown in Table 2.1 to estimate how a particular prognostic target in a system changes from a state of 100% healthy (not damaged) to zero health (failed) as damage accumulates (Pecht 2008 ; Hofmeister et al. 2016, 2017 ; Vichare 2006; Vichare et al. 2007). The PHM system performs health monitoring, detects an unhealthy condition, and uses, for example, fault‐tree or state‐diagram analysis to identify and determine the location(s) of the most likely prognostic target(s) causing the fault. Analytical approaches can be divided into two major groups: inductive and deductive approach.
Table 2.1 Load types and examples.
| Load | Examples of load type |
| Electrical | Current, voltage, power, energy |
| Thermal | Ambient temperature, temperature cycles, gradients, ramp rates |
| Mechanical | Pressure, vibration, shock load, stress/strain, vibration rate |
| Chemical | Humidity, reactivity – inert, active, acid, base – reaction rate |
| Physical | Radiation, magnetic and electrical fields, altitude |
Analytical Modeling: Inductive Approach
The inductive approach is based on reasoning, using qualitative data, from individual case to general conclusions. For example, such an approach might be used to determine how the elimination or reordering of components in a design affects the overall operation, or how the elimination of a sensor affects the possible observation of a failure. There are many different methods for conducting inductive analysis, such as preliminary hazard analysis (PHA), failure mode and effect analysis (FMEA), and failure mode effect and criticality analysis (FMECA) and event tree analysis (Thomas 2006; Czichos 2013).
PHA is an initial study used in the early stages of designing systems to avoid costly redesign if a hazard is discovered later. It is a broad approach, and its main focus consists of the following elements:
- Identify apparent hazards.
- Assess the potential accidents (and their severity) that might occur as the consequence of a hazard.
- Identify preventive measures to be used to reduce the risk.
FMEA first focuses on identifying potential failure modes, based on either PoF or earlier experience with the same or similar products. This information is used in the design and life‐cycle phases of equipment, especially in support of diagnostics, maintenance, and prognostics. Effective FMEA is useful in identifying candidate signals and nodes to measure and capture leading indicators of failure that, when conditioned and collected, form signatures that are valuable for producing prognostic information (Hofmeister et al. 2017 ).
FMECA is an extension of FMEA that adds a criticality analysis to find the probabilities of different failure modes and the consequent severity of those failures. It is usually combined with event tree analysis, which is a forward, causal analytical technique. It gives the failure results (responses) and consequences of a single failure event on related or higher‐level system components. Following the path from the initial event, it helps to assess the probability of the outcomes; as a result, overall system analysis can be performed (ETA 2017).
Analytical Modeling: Deductive Approach
The deductive approach is based on reasoning, using quantitative data, from general to specific events. For example, if a system failed, we wish to find out which component's behavior was the cause of the problem. A typical example of the deductive approach is the well‐known fault tree analysis (FTA). It is similar to an event tree, where the direction of the analysis starts at the highest level and proceeds to lower levels. Any fault tree is based on primary events that are not further developed. A directed graph is constructed, where the primary events are the nodes; then an arc or line is placed from an event to another event, if failure of the initial node might generate failure in the terminal node. Therefore, if a failure occurs in any element of the system, we can move along the graph's tree, backward and forward, and find possible immediate reasons for the failing element and the failure mode. Thus we have the information required to know what to fix and how to fix it, to eliminate the problem (Thomas 2006 ; Czichos 2013 ).
Fault trees are closely related to Bayesian networks, if at each node failures are characterized by probability distributions determined by Bayesian rules from those of lower levels (Zhang and Poole 1996). A similar approach is offered by using Markov chains, when the degradation has several levels and the transition probabilities between the different levels are given, or shown from past observations (Ahmed and Wu 2013).
2.2.2 Distribution Modeling
When many physical causes and/or complex reactions result in failure, a distribution model is often used instead of a physical model. Engineering experience can relate special distribution types to given failure types. Examples of distribution models and associated applications include those shown in Table 2.2 (Medjaher and Zerhouni 2013 ; Viswanadham and Singh 1998 ; Hofmeister et al. 2006, 2013; Hofmeister and Vohnout 2011; Silverman and Hofmeister 2012).
Table 2.2 Failure distributions and example applications.
| Distribution | Example applications |
| Exponential | Fatigue, wear caused by constant stress: resistors |
| Gamma | Failures caused by shock and vibration: boards, package connections |
| Lognormal | Failures caused by failure of insulation resistance, crack growth, and rate‐dependent processes: encapsulation failures |
| Gumbel | Failures caused by corrosion, shear breaks (strength), dielectric breakdown: conductor connections, interconnects |
| Weibull | Life (use) and breakdown failures: capacitors, cables |
The following distributions form characteristic curves that are useful for modeling complex failure mechanisms (a more complete list can be found in Chapter 1):

In engineering applications, the Weibull, an extreme‐value type of distribution, and the lognormal distribution are frequently used for modeling because they can be fitted to data from a large number of applications: especially lifetime distributions where failures are bounded below zero (Xu et al. 2015). The versatility of the Weibull distribution is evidenced by the following example life‐time applications and by the example Weibull plots in Figure 2.8:
- Maximum flood levels of rivers; maximum wind gusts; steam boiler pressure
- Fatigue life of bearings; blending time of powder coating materials
- Tensile strength of wires; yield strength of beams
- Lifetimes of passive electronic components, such as resistors and capacitors
- Time‐dependent dielectric breakdown (TDDB) phenomena; count of detectable high‐resistance events in solder joints

Figure 2.8 Example plots of Weibull distributions.
2.2.3 Physics of Failure (PoF) and Reliability Modeling
PoF used in reliability modeling and simulation is significantly different from the constant‐failure rate (CFR) modeling (based on exponential distribution) used as the basis for the Military Handbook 217 series (MIL‐HDBK‐217C). The PoF approach has dominated since the 1980s: root causes of failure, such as fatigue, fracture, wear, and corrosion, are studied and corrected to achieve lifetime design requirements by designing out causes of wear‐out failures in components. Such modeling is used to study system performance and reduce failures. The following is a summary of a PoF approach (Weisstein 2015):
- Identify potential failure modes.
- Design and perform highly accelerated life tests (HALTs) or highly accelerated stress tests (HASTs) to verify and select dominant failure modes leading to failure.
- Model the failure mode, and fit data to the model using statistical distributions.
- Develop an equation for a PoF model to calculate mean time to failure (MTTF) and/or mean time before failure (MTBF).
- Develop design, materials, and manufacturing improvements to increase MTTF to meet requirements.
The benefits of a PoF approach include the following:
- Reliability is designed in.
- Failures are reduced or eliminated prior to testing.
- Reliability of fielded systems is increased.
- Operational costs are decreased.
The reliability of a system can be obtained from the reliability of its building blocks.
- Assume first that the blocks have a series combination, meaning the system works if all blocks are in working condition. Let n be the number of blocks, and let R1(t), …, Rn(t) be the reliability functions of the blocks. Then that of the entire system can be obtained as

where X1, …, Xn denote the failure times of the blocks. Assuming that the blocks are independent, then
2.3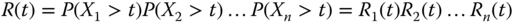
showing that the reliability functions are multiplied. If a new block is added to the system, then a new factor is added to the product, which is less than one, so the system reliability decreases.
- Assume next that the connection is parallel, meaning the system works if at least one of the blocks works. In this case

If a new block is added to the system, then the second term decreases, so R(t) increases.
In many systems, the connection of the blocks is a combination of series and parallel combinations. Then Eqs. (2.3) and (2.4) are used repeatedly, as shown in the following example.
2.2.4 Acceleration Factor (AF)
Chapter 1 discussed how TTF distributions change when an item is subject to extreme stresses. These formulas can be used backward, when observations are made under extreme conditions, to estimate failure times: based on the data, distributions of TTFs can be estimated under normal conditions. This idea is known as accelerated testing (AT), ALT, and so on.
Reliability projections, such as MTTF based on accelerated testing (such as a HALT) when the object is subject to extreme stress, are projected estimates from test results to a future, slower rate of failure at lower levels of stress under normal use conditions. Such projections assume the use of a correct model for life distribution and the use of a correct acceleration model (Tobias 2003; Nelson 2004). In an acceleration model, the TTF (or tF) at a stress level (s) is given by the following (Kentved and Schmidt 2012):
where A = constant, G(s) = stress function.
The acceleration factor (AF) is the ratio of the TFFs at two different levels of stress:
AFs used in reliability estimations (or usage modeling) include the following (White and Bernstein 2008).
Arrhenius Law for Temperature
AFs used in reliability estimations (or usage modeling) include the following (White and Bernstein 2008 ):

where
| Tuse = | Product temperature in service use |
| Ttest = | Product temperature in laboratory test |
| Ea = | Activation energy for damage mechanism and material |
| k = | Bolzman's constant = 8.617 * 10−5eV/°K |
Kemeny Law for Voltage

where in addition
| Material constants | |
| Tj = | Junction temperature |
| Vcb = | Collector‐base voltage |
| Vcbmax = | Maximum collector‐base voltage before breakdown |
Peck's Law for Temperature and Humidity

where in addition
| Muse = | Moisture level in service use |
| Mtest = | Moisture level in test |
This formula can be derived from the temperature‐humidity relationship discussed in Chapter 1.
Coffin‐Manson Law of Fatigue

where
| ΔT = | Difference between the high and low temperatures for the product in service use and in the laboratory test. |
Notice that (2.10) is derived from the inverse power law.
Eyring Formula

Similar formulas can be derived from any other known rules dealing with extreme stress levels such as the generalized Eyring, temperature non‐thermal relations, or the general log‐linear law discussed in Chapter 1.
2.2.5 Complexity Related to Reliability Modeling
In addition to requiring the use of a correct distribution model and a correct acceleration model, reliability modeling is further complicated by an almost infinite number of methods, like those in Table 2.3. Each has advantages and disadvantages in comparison to the others for a given application.
Table 2.3 Examples of reliability procedures and applications (White and Bernstein 2008 ).
| Reliability procedure/method | Example applications |
| MIL‐HDBK‐217 | Military |
| Telecordia SR‐332 | Telecom |
| CNET | Ground military |
| RDF‐93 and 2000 | Civil equipment |
| SAE Reliability Prediction Method | Automotive |
| BT‐HRD‐5 | Telecom |
| Siemens SN29500 | Siemens products |
| NTT Procedure | Commercial and military |
| PRISM | Aeronautical and military |
| FIDES | Aeronautical and military |
Reliability modeling is even more complicated because of the variability in the fitting of values used within the models of each version of a procedure. This variance is evidenced by the modeling examples of the AFs for temperature as shown in Table 2.4.
Table 2.4 Examples of temperature acceleration models (White and Bernstein 2008 ).
| Procedure | Acceleration factor for temperature |
| MIL‐HDBK‐217F | AFT = 0.1 exp [−A(1/Tj − 1/298)] |
| HRD4 | AFT = 2. 6*104 exp[−3500/Tj)] + 1. 8*1013 exp[−11600/Tj)] for Tj ≥ 70°C |
| NTT | AFT = exp[3480(l/339 − 1/Tj)] + exp[8120(l/356 − 1/Tj)] |
| CNET | AFT = Al exp[−3500/Tj] + A2 exp[11600/Tj] |
| Siemens | AFT = A exp[Ea*11605(1/Tji − l/Tj2)] + (1 − A) exp[−Ea*11605(l/Tj1 − l/Tj2)] |
In addition to differences in acceleration factors and parameter values used in modeling, there are differing versions of distribution models. Examples include three different Coffin‐Manson models for calculating a probable test cycle (Nf) that a solder joint fails when subjected to cyclic loading of temperature during accelerated testing (Viswanadham and Singh 1998 ):
where subscript u refers to a use value, subscript t refers to a test value, parameter T is in °K, and fu is a model parameter.
Now, suppose a prognostic target, such as an FPGA attached to a fiber‐resin (FR‐4) printed wire board (PWB), which is formerly and sometimes still referred to as printed circuit board (PCB), is operated such that the temperature varies in any given 24‐hour period of time from less than −40 °C to over 100 °C, with different temperature ramp‐up rates, different dwell times at high temperature, different ramp‐down rates, and different dwell times at low temperature. Also suppose that during any given 24‐hour period of time, the PWB is subjected to different rates of different magnitudes of vibration and shock (such as might be experienced from being mounted in an engine compartment of a vehicle). Further, suppose that the PWB comprises over a dozen different FPGAs, some of which use standard PbSn solder, some of which use lead‐free solder balls, some of which use plastic grid array (PGA) die packages with and without staking, and some of which use ceramic‐column grid array (CCGA); all are mounted at different distances from centers of maximum stress‐strain. Estimating with a high degree of accuracy when the primary clock‐input pin of a specific FPGA will fail and thereby cause the PWB to fail becomes a daunting task (Javed 2014).
2.2.6 Failure Distribution
As the independent variables change in distribution models, the rate of change of a given curve varies, which creates a family of failure curves having a failure distribution with a TTF as illustrated in Figure 2.11. The failure distribution is a probability density function (PDF), and the TTF is the expectation or the 0.50 value of the cumulative distribution function (CDF) of that PDF: note that TTF is not the same entity as MTTF – more on this topic is presented in Chapter 7.

Figure 2.11 Family of failure curves, failure distribution, and TTF.
2.2.7 Multiple Modes of Failure: Failure Rate and FIT
When prognostic targets are prone to more than one dominant failure mode, multiple distribution models and/or multiple‐parameter models must be used in a PoF approach. For example, a transistor device could fail because of temperature cycling and also because of failure related to high levels of voltage. Two distribution models might then apply: Arrhenius temperature, Eq. (2.7); and Kemeny distribution, Eq. (2.8). A simplifying approach is to assume that all failures are random and all failure modes are equally dominant. Overall MTTF and failure in time (FIT) values can be calculated by applying a sum‐of‐failure‐rate model and an improved AF to account for two different temperatures, use and test, as shown in Eq. (2.9). One FIT is equal to one failure in 1 billion part hours (White and Bernstein 2008 ):

2.2.8 Advantages and Disadvantages of Model‐Based Prognostics
Advantages of model‐based prognostics are many and include the following: (i) such modeling leads to a better understanding of how prognostic targets, especially devices, fail because of defects and weaknesses in manufacturing processes and materials, and how and why they fail because of loading and environmental stresses and strain; (ii) manufacturing processes, materials, electrical and physical designs, and control of operational loading and environmental conditions can be improved to increase reliability; and (iii) simple estimates of state of health (SoH) and remaining useful life (RUL) are possible.
Disadvantages of model‐based prognostics are also many and include the following: (i) modeling for other than single‐mode failures is complex; (ii) simple models for non‐steady state and multiple and variable environment loading generally do not exist; (iii) modeling of large, complex systems of hundreds or thousands of different parts becomes extremely difficult, if not computationally intractable; and, perhaps most important, (iv) model‐based approaches are not applicable to a specific prognostic target in a system, as exemplified by Figure 2.11 : MTTF, for example, applies to a population of like prognostic targets rather than a fielded, specific prognostic target in a specific system in an operational, non‐test environment.

Figure 2.12 Diagram of data‐driven approaches.
Table 2.5 Parametric and nonparametric methods.
| Parametric technique |
| Maximum likelihood (MLE) |
| Likelihood ratio test (LRT) |
| Minimum mean square error (MSE) |
| Maximum a posteriori estimation (MAP) |
| Nonparametric technique |
| K‐nearest neighbor classifier (kNN) |
| Kernel density estimation (KDE) |
| Chi square test (CST) |
2.3 Data‐Driven Prognostics
Data‐driven (DD) prognostics (Figure 2.12) comprises two major approaches, statistical and machine learning (ML), that use acquired data to statistically and probabilistically produce prognostic information such as decisions, estimates, and predictions. Statistical approaches include parametric and nonparametric methods; ML approaches include supervised and unsupervised classification and clustering, and regression and ranking (Pecht 2008 ). This book will not discuss regression and ranking.
2.3.1 Statistical Methods
Statistical methods can be divided into parametric and nonparametric methods (Pecht 2008 ), including those shown in Table 2.5.
Maximum Likelihood Method
The maximum likelihood method (Ross 1987 ) is a common procedure to estimate unknown parameters of probability distributions. As in Section 1.4, let f(t|θ) denote the PDF where θ is unknown. Assume we have a random sample t1, t2, …, tN from this distribution. The likelihood function is defined as
which represents the probability of the sampling event that actually occurred. Since the logarithmic function strictly increases, instead of L(θ), its logarithm is maximized:
and the optional θ value is accepted as the estimate of the unknown parameter.
Likelihood Ratio Test
The likelihood ratio test (Casella and Berger 2002) is usually used to determine the validity of an estimate. For example, let θ0 be an estimate of an unknown parameter of a PDF f(t|θ). The likelihood ratio test is based on the likelihood ratio

where the likelihood function is denoted by L(θ) and the denominator is the maximal value of L(θ). In other cases, two estimates are compared. Let θ1 and θ2 be two estimates for θ; then

If the value of r is small, then in the first case θ0 is unacceptable, and in the second case θ2 is a much better estimate.
Minimum Mean Square Error
Minimum mean square error is mainly used in fitting function forms with unknown parameters. For example, a density histogram is obtained from a sample with points (t1, f1), (t2, f2), …, (tN, fN), and it is known that the corresponding PDF is f(t|θ). The least square estimate of θ is obtained by minimizing the overall squared error:

Maximum a Posteriori Estimation
The maximum a posteriori estimation (Stein et al. 2002) is based on Bayesian principles. Consider again a PDF f(t|θ) depending on the unknown parameter θ. The likelihood function is given as L(θ), which is maximized in order to get the best estimate for θ. In practical cases, usually its logarithm is maximized. Assume now that a prior distribution is known for θ, with PDF g(θ). By the Theorem of Bayes

where the integration domain is the domain of all possible values of θ. Since the denominator is independent of θ, we need to optimize only L(θ)g(θ).
K‐Nearest Neighbor Classifier
The KNN classifier (Cover and Hart 1967) is based on the following simple procedure. Assume we have N vectors; each of them is attached with a class label. We need to put a given vector into the most appropriate class. We select a positive integer k ≧ 1 and determine the k closest vectors from the given N vectors by using any distance measure, such as the Euclidean distance. Then the selected k closest vectors “vote” about the class by selecting the class that appears the most times among the k closest vectors. In this way, we can order any set of vectors into given classes based on a given sample.
In a two‐dimensional case, the Euclidean distance of vectors (xc, yc) and (xi, yi) is the following:
The Euclidean distance is based on the Pythagorean theorem. If the dimension is larger than two, say n, then similarly

where the components of vector xc are ![]() and those of vector xi are
and those of vector xi are ![]() .
.
Kernel Density Estimation
This method is based on the following equation:

which can be interpreted as follows (Wand and Jones 1995). Let x1, x2, …, xN be the sample elements. A kernel function K(x) is selected that is nonnegative and that has an integral of one (like the properties of any PDF). A parameter h > 0 is also chosen, which is called the bandwith. Then Eq. (2.28) gives an estimate of the PDF, from which the sample is generated, at point x. Table 2.6 gives a collection of commonly used kernel functions.
Table 2.6 Kernel functions.
| Kernel | K(x) | Domain |
| Uniform | (−1, 1) | |
| Triangle | 1 − ∣x∣ | (−1, 1) |
| Epanechnikov | (−1, 1) | |
| Quartic | (−1, 1) | |
| Twiweight | (−1, 1) | |
| Gaussian |  |
(−∞, ∞) |
| Cosinus | (−1, 1) |
Chi‐Square Test
The chi‐square test (Ross 1987 ) is used to test whether a given sample comes from a population with a specific distribution, and therefore it does not provide the distribution; it can only be used to check whether a user‐selected distribution is appropriate. The data is divided into K bins, with yk and yk + 1 being the lower and upper limits of class k. It is assumed that the bins are defined by subintervals between the consecutive nodes y0 < y1 < … < yK. Let Ok be the observed frequency for bin k, and Ek; then the expected frequency is defined as
where N is the total number of sample elements and F(y) is a CDF. The chi‐square test computes the value of χ2 as

and the distribution F(y) is rejected if
where α is a user‐selected significance level, and c is the number of the unknown parameters. The threshold ![]() can be found in the chi‐square test tables.
can be found in the chi‐square test tables.
2.3.2 Machine Learning (ML): Classification and Clustering
Machine learning (ML), a form of artificial intelligence, predicts future behavior by learning from the past: classification and clustering are forms of ML divided into supervised and unsupervised techniques, which are further divided into discriminative and generative approaches. Certain ML approaches, such as regression and ranking, are less useful compared to classification and clustering, which use computational and statistical methods to extract information from data (Pecht 2008 ). Table 2.7 is a summary list of some of the ML techniques.
Table 2.7 Supervised and unsupervised classification and clustering.
| Technique | |
| Supervised | |
| Discriminative |
Linear discriminant analysis (LDA) Neural networks (NNs) Support vector machine (SVM) Decision tree classifier |
| Generative |
Naive Bayesian classifier (NBC) Hidden Markov model (HMM) |
| Unsupervised | |
| Discriminative |
Principal component analysis (PCA) Independent component analysis (ICA) HMM‐based approach SVM‐based approach Particle filtering (PF) |
| Generative |
Hierarchical classifier k nearest neighbor classifier (kNN) Fuzzy C‐means classifier |
These techniques are well presented in the literature; therefore we do not discuss them in detail. Instead, we will select one method from each category. The other methods are briefly described as examples.
Discriminant Analysis
The objective of discriminant analysis (Fukunaga 1990) is to classify objects (usually given as multidimensional vectors) into two or more groups based on certain features that describe the objects by minimizing the total error of classification. This is done by assigning each object to the group with the highest conditional probability. The mathematical solution requires sophisticated techniques of matrix analysis.
Neural Networks
Neural networks are database input‐output relations (Faussett 1994). They are “connectionist” computer systems. Let the input vector be denoted as x = (x1, x2, …, xm) and the output vector as y = (y1, y2, …, xn). The transformation x → y is performed in several stages. The initial nodes of the network are the input variables, the final (terminal) nodes are the output variables, and the different stages of the transformation are represented by hidden layers including the hidden nodes. Figure 2.13 shows a neural network structure with three input, three output, and two hidden nodes.

Figure 2.13 A special neural network.
The first step is to transform the input and output variables into the same order of magnitude. The hidden variables are linear combinations of the transformed inputs as
where f() represents the transform function of the variables x. In many applications
is selected, since it is strictly increasing, f(−∞) = 0, and f(∞) = 1; that is, the input values are transformed into the unit interval (0, 1). The transformed output variables are also linear combinations of the hidden variables:
In Eqs. (2.30) and (2.32) the coefficients wij and ![]() are the unknowns, and their values are determined so that the resulting input/output relation
are the unknowns, and their values are determined so that the resulting input/output relation

has the best fit to the measured input and output data.
Assume that we have N input‐output data sets:
then similar to the least squares method, the overall fit is minimal as measured by

where the unknowns are the wij and ![]() values. The optimization can be done by using software packages or by using special neural network algorithms like back propagation.
values. The optimization can be done by using software packages or by using special neural network algorithms like back propagation.
In practical cases, the structure (number of hidden layers and number of nodes on them) of the neural network is selected, and the weights wij and ![]() are determined.
are determined.
For the optimization, usually only half of the data set is used; the other half is then used for validation, when Q is computed based on data that was not used in determining the weights. If Q is sufficiently small, then the structure and weights of the network are accepted; otherwise, a new structure (with new added hidden layers and/or added nodes) is chosen, and the procedure is repeated. The optimal choice of the weights is usually called the training of the network.
Support Vector Machines
Support vector machines (Cortes and Vapnik 1995) can be described for the case of two groups of vectors. Assume there are N training data points (x1, y1), …, (xN, yN), where yi = + 1 or −1, indicating the class the vectors xi belong to. The objective is to find a maximum‐margin hyperplane that divides the set of data points (xi, yi) into two groups. In one, yi = + 1; and in the other, yi = − 1. The hyperplane is selected so the distance between the hyperplane and the closest point from either group is maximized. If the training vectors are heavily separable, then there is a vector w such that the hyperplane wTx + b = 0 satisfies the following property:
These relations can be summarized as
In order to maximize the distance between the hyperplanes
we have to minimize the length of w = (wi):
subject to the constraints yi(wTxi + b) ≥ 1. The vector w and scale b define the classifier as
The vectors closest to the separating hyperplane are called support vectors.
Decision Tree Classifier
The decision tree classifier technique (Rokach and Maimon 2008) is based on a logically based tree containing the test questions and conditions. The process uses a series of carefully selected questions about the test records of the attributes. Depending on the answer to a question, a well‐selected follow‐up question is asked; based on the answer, either a new question follows, or the process terminates with a decision about the category the object belongs to. A typical everyday example is the series of questions a doctor asks a patient to make the right diagnosis.
Naive Bayesian Classifier
The naive Bayesian classifier technique (Webb et al. 2005) is also based on m classes C1, …, Cm. An attribute vector x belongs to class Ci if and only if for the conditional probabilities,
for all j ≠ i. By the Bayesian theorem
And since P(x) is independent of the classes, optimal class Ci is selected by maximizing
The value of P(Ci) is usually taken as the relative frequency of the sample vectors belonging to class Ci. The naive Bayesian classifier assumes the class conditional independence as
where the components of vector x are the xk values.
Hidden Markov Chains
Hidden Markov chains (Ghahramani 2001) are probabilistic extensions of finite Markov chains illustrated earlier in Example 2.1. The states are not known, but certain probability values are assigned to them in addition to the state transition matrix. The states cannot be directly observed, but observations are made for outputs each state can produce with certain probabilities. This type of Markovian model is called hidden: since the states are hidden, only their outputs can be observed.
Principal Component Analysis
PCA (Jolliffe 2002) is a statistical method. Assume there are N vectors, which are usually closely related to each other. This technique uses a linear transformation to convert the observation set into a collection of linearly uncorrected variables called the principal components. The method is mathematically based on ideas of matrix analysis.
Independent Component Analysis
Independent component analysis (Stone 2004) is a procedure that finds underlying factors or components from multivariate or multidimensional data. Let the observation of random variables be denoted by x1(t), x2(t), …, xN(t). The method finds a matrix M and variables yj(t) such that
where the components of y and x are yj and xi, respectively.
The objective is to find the minimal number of independent components yj.
HMM‐Based and SVN‐Based Approaches
The HMM‐based approach (Ghahramani 2001 ) and the support‐vector network SVN based approach (Cortes and Vapnik 1995 ) are both often used in unsupervised ML.
Particle Filtering
Particle filtering (Andrieu and Doucet 2002) is a sequential Monte Carlo method based on a large sample. The estimate of the PDF converges to the true value as the number of sample elements tends to infinity.
Hierarchical Classifier
The KNN process is very close to a well‐known clustering algorithm sometimes called the hierarchical classifier (Alpaydin 2004). Assume that we have N vectors and want to organize them into k clusters where the distances between the vectors of the same cluster need to be as small as possible. At the initial step, each vector is a one‐element cluster. At each subsequent step, the number of clusters decreases by one until the required number of clusters is reached. Each cluster is represented by the algebraic average of its elements, and then the distances of these average vectors are determined. The two closest averages are selected, and their clusters are merged. In this way, we will have one less cluster in each step.
Fuzzy C‐Means Classifier
The fuzzy C‐means classifier approach (Bezdek et al. 1999) allows each piece of data to belong to two or more clusters. Let x1, …, xN be the data set, and let uij denote the degree of membership of data vector xi in cluster j (j = 1, 2, …, K). The membership values are determined by using an iterative procedure as follows:
- Step 1: Select an initial set of uij values, uij(0).
- Step 2: At each later step k, compute the center vectors for each cluster as

where m > 1 is a real number selected by the user and uij(k) is the current degree of membership of x.
- Step 3: Update the uij values as

- Step 4: Stop if for all i and j,

where ε is a threshold.

Figure 2.14 Comparison of model‐based (PoF) and data‐driven prognostic approaches.
The final uij values are accepted as degrees of membership of the data vectors in the clusters. In this approach, the number of clusters is assumed to be given. If some of the resulting cluster centers become close to each other, then we can reduce the number of clusters by merging and repeating the process.
2.4 Hybrid‐Driven Prognostics
A model‐based approach, especially PoF, is generally chosen as a prognostic health monitoring (PHM) approach when highly accurate prognostics are desirable. However, this approach is often difficult to design and develop and not very accurate for applying to a specific prognostic target. A data‐driven approach is much easier to design and develop, compared to a model‐based approach, but is often evaluated as producing less accurate prognostic information, as illustrated by Figure 2.14. Some advantages and disadvantages of the two approaches are listed in Table 2.8 (Medjaher and Zerhouni 2013 ; Javed 2014 ; Lebold and Thurston 2001).
Table 2.8 Some advantages and disadvantages of model‐based and data‐driven prognostics.
| Model‐based prognostics | Data‐driven prognostics |
| Advantages | |
|
High precision compared to data‐driven Deterministic Thresholds can be defined and related to performance measures such as stability Useful for evaluating performance of materials and electrical properties |
Less dependence on material and electrical properties Low cost of design and development Easier to apply to complex systems |
| Disadvantages | |
|
Difficult to apply to complex systems High cost of design and development Complexity and variability of model parameters related to material and electrical properties of materials |
Lower precision compared to model‐based non‐deterministic Not useful for evaluating performance of material and electrical properties of prognostic targets |
One hybrid approach combines model‐based and data‐driven prognostics in two phases: offline and online. The first phase comprises the construction of the nominal and degradation models, and the definition of the faults and performance thresholds needed to calculate the RUL of the system. The second phase comprises the use of models and thresholds to detect the onset of faults, assess the state of SoH of the system, and predict future SoH and RUL. The models are verified and fitted to data from life‐based and stress‐based experiments and tests intended to mimic real‐use conditions. Sensors are then developed and used to collect data from fielded systems to monitor and manage the health of those systems (Medjaher and Zerhouni 2013 ).
An advantage of the hybrid approach is a relative precision that is higher than that achieved by using only a model‐based approach and higher than that achieved by using only a data‐driven approach (Figure 2.15). This is especially true when a PoF‐based model is adapted to sensor data and the adapted model is used to produce prognostic information. A disadvantage is the added complexity of adapting the model to sensor data.

Figure 2.15 Relative comparison of PHM approaches – PoF, data‐driven, and hybrid.
2.5 An Approach to Condition‐Based Maintenance (CBM)
Modern prognostic‐enabled systems comprise (i) prognostic methods to support prognosis and (ii) health management. In such systems, prognostic‐enabling services sense, collect, and process condition‐based data (CBD) to provide prognostic information; and health management services use that prognostic information for prognosis to make decisions and issue imperatives related to maintenance and service: CBM. The major capabilities are the following: advanced diagnostics to detect leading indicators of failure, advanced prognostics to predict RUL, and advanced maintenance and logistics to manage the health of the system (Hofmeister et al. 2013 ; IEEE 2017).
One approach to CBM is to use CBD as input to traditional models, such as PoF and reliability, to produce prognostic information more closely related to a specific prognostic target. Difficulties with such an approach remain, especially the following: the complexity of the modeling; the time and cost required to develop, verify, and qualify a model; and the tendency of the model to be sensitive to a specific set of environment and use conditions.
An alternative approach to CBM is to use modeling of CBD signatures instead of, for example, PoF or reliability modeling of a prognostic target. It should be noted that traditional modeling, such as PoF, is still an important tool for analyzing CBD: understanding and selecting which features and leading indicators to use for prognostic enabling.
2.5.1 Modeling of Condition‐Based Data (CBD) Signatures
An example of an alternative approach to CBM based on CBD signatures is shown in Figure 2.16. A sensor framework senses, collects, and transmits sensor output data to a feature‐vector framework that performs data processing such as data conditioning, data fusing, and data transforming to transform CBD into failure‐progression signatures: fault‐to‐failure progression (FFP) signature data, degradation progression signature (DPS) data, and functional failure signature (FFS) data.

Figure 2.16 Example diagram of a heuristic‐based CBM system using CBD‐based modeling.
Any of these signatures can be used as input to a prediction framework to produce prognostic information such as estimates of RUL, prognostic horizon (PH), and SoH for processing by a health‐management framework to make intelligent decisions about the health of the system and initiate, manage, and complete service, maintenance, and logistics activities to maintain health and ensure the system operates within functional specifications.
2.5.2 Comparison of Methodologies: Life Consumption and CBD Signature
A common model‐based approach to PHM is a life‐consumption methodology defined by the Center for Advanced Life Cycle Engineering (CALCE), University of Maryland at College Park, Maryland. As seen in the simplified diagrams in Figure 2.17, that model‐based approach (Pecht 2008 ) is similar to, but different from, using CBD signature models (Hofmeister et al. 2013 ). The primary differences (see Table 2.9) are related to the difference in modeling and data: modeling using (i) physical, reliability, and/or statistical modeling or (ii) modeling based on empirical data – CBD signatures; and data using (i) environmental, usage, and operational data such as voltage, current, and temperature or (ii) CBD signatures at nodes with environmental, usage, and operational data used to condition signature data.

Figure 2.17 Diagram comparison of model‐based and CBD‐signature approaches to PHM.
Table 2.9 Differences in focus of model‐based and heuristic‐based approaches to PHM.
| Step | Model‐based focus | Heuristic‐based focus |
| l | Identify failure mode, effects analysis. | Identify failure mode, effects analysis; identify nodes and signatures comprising leading indicators of failure. |
| 2 | Identify failure modes having the earliest time‐to‐failures. | Characterize the basic curve of the signature(s) related to a failure mode. |
| 3 | Develop the model to use for predicting time of failure. | Develop the algorithms to transform CBD signatures into fault to failure (FFP) degradation progression signature (DPS) data and then further transform into functional failure signature (FFS) data. |
| 4 | Monitor environmental, usage, and operational loads: the model inputs. | Monitor signals: the model inputs; monitor selected environmental, usage, and operational loads as required for conditioning signals. |
| 5 | Simplify and condition data for model input. | Condition and transform data. Use environmental, usage, and operational data to condition data rather than as model inputs. |
| 6 | Assess the state and level of accumulated damage. | Use FFS to detect damage and as input to prediction algorithms. |
| 7 | Produce prognostic information. | Same |
| 8 | Perform fault management. | Same |
2.5.3 CBD‐Signature Modeling: An Illustration
A switch mode power supply (SMPS) such as that shown in Figure 2.18 is used to illustrate modeling of CBD signatures with an analysis of a circuit or assembly, which in this case is the output filter of the SMPS. The output filter has also been simplified: for example, to exclude such components and subcircuits as a feedback loop, diodes, and high‐frequency noise filters. Additionally, the filter has been further simplified to lump inductance, capacitance, and resistance into three passive components (L1, C1, and RL).
Example Backup and Setup
Suppose you are asked to prognostic enable a SMPS, and it is known that the supply has a high failure rate caused by failure of tantalum oxide capacitors used in the output filter. Failure and repair information reveals that the capacitors fail short and then burn open. The fail‐short condition causes high current, resulting in an overload condition that turns off the SMPS – but, at the same time, damage continues and the capacitor burns open. Subsequently, maintenance personnel declare a no fault found (NFF)/cannot duplicate (CND) repair condition. The SMPS tests okay – the DC output voltage, ripple voltage, noise levels, and regulation of the supply under loading conditions are all within specifications. Upon further inspection after disassembling the circuit card assembly (CCA) – an enclosed metal frame – physical evidence in the form of color and smell reveals 1 of 22 parallel‐connected capacitors has failed. Removal (desoldering) and testing of the capacitor confirms the capacitor has burned open, which reduces the effective total capacitance in the output filter.
Also suppose the customer specifications for prognostic enabling of the SMPS includes the following requirements: (i) the prognostic system shall detect degradation at least 200 operational days prior to functional failure; and (ii) the prognostic system shall provide estimates of RUL that shall converge to within 5% accuracy at least 72 operational days, ±2 days, before functional failure occurs. Functional failure is defined as a level of damage at which an object, such as a power supply, no longer operates within specifications.

Figure 2.18 Simplified diagram of a switch‐mode power supply (SMPS) with an output filter.
Evaluation of a Reliability‐Modeling Approach
You happen to know that tantalum oxide capacitors are a high‐failure‐rate component in a SMPS. PoF analysis reveals the following as dominant failure modes caused by the aging effects of voltage and temperature: changes in (i) capacitance (C), (ii) dissipation factor (DF), and (iii) insulation resistance (IR) (Alan et al. 2011). Loss of IR includes abrupt, avalanche failures that, for example, occur when IR drops sufficiently low to cause a high enough increase in leakage current to generate sufficient heat to melt the solder connecting the capacitor to the external leads of a package.
Mahalanobis Distance Modeling of Failure of Capacitors
One data‐driven approach to modeling the failure of capacitors uses the Mahalanobis distance (MD) method, which reduces multiple parameters to a single parameter using correlation techniques after normalizing data. MD values are calculated between incoming data and a baseline representative of a healthy state to detect anomalies in the following way (Alan et al. 2011 ).
Assume we have n vectors with m components, and each component represents a parameter. Let (xi1, xi2, …, xim) denote the ith vector. The mean of the kth parameter is given as

The standard deviation of the ![]() parameter is similarly
parameter is similarly

And so the standardized value of xik becomes

Define
Then the correlation matrix of the standardized values is given as

And finally, the MD value can be obtained as
where T denotes the transpose.
MD values are not normally distributed and need to be further transformed by using a Box Cox transformation and maximizing the logarithm of the likelihood function. However, in a highly accelerated test experiment, the MD method only predicted failure in 14 out of 26 samples (Alan et al. 2011 ). Even if the degree of accuracy were acceptable, that still leaves, for example, the problem of predicting when the power supply will fail because of the loss of sufficient capacitance for any specific failure mode. To address those kinds of problems, heuristic‐based modeling of CBD can be used rather than traditional models. We conclude that neither model‐based nor data‐driven approaches is likely to meet the requirements for resolution, precision, and prognostic accuracy.
There are other techniques as well, to reduce multiple measurements into a single health indicator. One example, for instance, is the multivariate state estimation technique (Cheng and Pecht 2007), which is based on the best healthy estimates of the sample vectors obtained by the use of least squares. However, other metrics can be also selected for the distance of the sample vectors and their estimates. These distances are indicative of SoH, since smaller distances indicate better health. Other examples include autoassociative kernel regression (Guo and Bai 2011), a method based on kernel smoothing (Wand and Jones 1995 ) discussed in Section 2.3.1. After the sequence of single health indicators is determined, the resulting time series can be used as input data for all procedures being discussed in this book.
CBD: Noise and Features
The output of an SMPS, as seen at the top of Figure 2.20, is very noisy. It consists of DC voltage (the desired output) plus all manner of noise in the form of signal variations that include the following: thermal noise; ripple‐voltage variations; switching noise; harmonic distortion; and responses to load variations such as damped‐ringing responses, an example of which is shown at the bottom of Figure 2.20 (Hofmeister et al. 2017 ).

Figure 2.20 Example of the output of a SMPS.
Noise contains information, and when noise in CBD is appropriately isolated and conditioned, leading indicators of failure can be extracted as feature data (FD). Useful FD at the output node of an SMPS includes, but is not limited to, ripple voltage (amplitude and frequency), switching amplitude and frequency, and other features found in a damped‐ringing response. An important first step in prognostic‐enabling an object such as a component, circuit, or assembly in an electrical system is to perform analyses, such as PoF and FMEA, to identify FD of interest associated with failure modes of interest.
CBD: Prognostic Requirements
It is not cost‐justifiable to select all applicable features of CBD for use as FD in signatures: you need to select one or more FD that lets you meet prognostic requirements. Important requirements include the following:
- Sensor cost to isolate, condition, and extract one or more features. Cost includes weight, footprint, power, and reliability of the sensor.
- Cost of signal conditioning by the sensor and by the PHM framework.
- Prognostic distance (PD): the time between detection of damage leading to failure and the time of functional failure. Functional failure is defined as a level of damage at which an object, such as an SMPS, no longer operates within specifications.
- Prognostic resolution and precision of estimates of a future point in time at which functional failure is likely to occur.
- Prognostic accuracy (α) and α‐distance (PDα) within which estimates of RUL and SoH must converge with respect to functional end of life (EoL).
CBD: Test Bed Experimentation and Effects Analysis
When you are pretty sure you understand the failure mode (the problem) and the effects of that failure on measurable signals, in all likelihood you will conclude that you need to experiment and perform further effects analysis. So, you design and build a test bed that allows you to inject faults (loss of filtering capacitance) in an exemplary SMPS. Such a test bed lets you perform experiments to verify your understanding of the problem, measurable effects of that problem, and how well (or not) various solutions are likely to meet prognostic requirements.
CBD: Feature Data and Degradation Function
From the results of deriving Eq. ( 2.49 ), we use the inductive approach to analytical modeling to state the following:
- Given a feature, FD, that has a nominal value FD0 in the absence of degradation, then
- Given a degradation of a parameter that has a value of P0 in the absence of degradation, and
- Let dP represent the amount of change in the value of P0 caused by degradation,
- Then the value of a given feature is the non‐degraded value of the feature times a degradation function of a parameter that changes.
In Eq. ( 2.49 ), if we let FD = ω, FD0 = ω0, P0 = C0 and dP = ΔC we have
and, in general,
The model for a given degradation function, f(dP, P0), depends on, for example, the component that is degrading, the failure mode, and the PoF. This is an important result, and more information is presented in following chapters of this book.
2.6 Approaches to PHM: Summary
This chapter presented an overview of traditional approaches to PHM including model‐based prognostics, data‐driven prognostics, and hybrid‐driven prognostics. Model‐based prognostics is potentially the most accurate, but it is the most difficult to apply to complex systems; data‐driven prognostics is the least difficult to apply, but also is the least accurate; and hybrid‐driven prognostics provides the greatest accuracy and is the most difficult to apply, especially to complex systems. A brief presentation of a CBD approach to CBM concluded the chapter: the output of an SMPS; identification and selection of a useful FD (resonant frequency) extracted from a damped‐ringing response from CBD; the effect of prognostic requirements on operational requirements and accuracy of prognostic information; and a test bed and simulation to assist in and verify modeling of a CBD signature. An important result is Eq. (2.50), which relates changes in signatures to a degradation function:
The next chapter develops and describes in more detail the approach and introduces the methods used to transform CBD signatures into signatures that are more amenable to be processed by prediction algorithms.
References
- Ahmed, W. and Wu, Y.W. (2013). Reliability prediction model of SOA using hidden Markov model. 8th China Grid Annual Conference, Changchun, China, 22–23 August.
- Alan, M., Azarian, M., Osterman, M., and Pecht, M. (2011). Prognostics of failures in embedded planar capacitors using model‐based and data‐driven approaches. Journal of Intelligent Material Systems and Structures 22: 1293–1304.
- Alpaydin, E. (2004). Introduction to Machine Learning. Cambridge, MA: MIT Press.
- Andrieu, C. and Doucet, A. (2002). Particle filtering for partially observed Gaussian state space models. Journal of the Royal Statistical Society B 64 (4): 827–836.
- Bezdek, J., Keller, J., Krishnapuram, R., and Pal, N. (1999). Fuzzy Models and Algorithms for Pattern Recognition and Image Processing. New York: Springer.
- Casella, G. and Berger, R.L. (2002). Statistical Inference, 2e. Pacific Grove, CA: Duxbury.
- Cheng, S. and Pecht, M. (2007). Multivariate state estimation technique for remaining useful life prediction of electronic products. Association for the Advancement of Artificial Intelligence. www.aaai.org.
- Cortes, C. and Vapnik, V. (1995). Support‐vector networks. Machine Learning 20 (3): 273–297.
- Cover, T. and Hart, P. (1967). Nearest neighbor pattern classification. IEEE Transactions on Information Theory 13 (1): 21–27.
- Czichos, H. (ed.) (2013). Handbook of Technical Diagnostics: Fundamentals and Application to Structures and Systems. Heidelberg/New York: Springer.
- Faussett, L.V. (1994). Fundamentals of Neural Networks: Architecture, Algorithms and Applications. Upper Saddle River, NJ: Prentice Hall.
- Fukunaga, K. (1990). Introduction to Statistical Pattern Recognition. San Diego, CA: Academic Press.
- Ghahramani, Z. (2001). An introduction to hidden Markov models and Bayesian networks. Journal of Pattern Recognition and Artificial Intelligence 15 (1): 9–42.
- Guo, P. and Bai, N. (2011). Wind turbine gearbox condition monitoring with AAKR and moving window statistic methods. Energies 4: 2077–2093.
- Hofmeister, J., Goodman, D., and Wagoner, R. (2016). Advanced anomaly detection method for condition monitoring of complex equipment and systems. 2016 Machine Failure Prevention Technology, Dayton, Ohio, US, 24–26 May.
- Hofmeister, J., Lall, P. and Graves, R. (2006). In‐situ, real‐time detector for faults in solder joint networks belonging to operational, fully programmed field programmable gate arrays (FPGAs). 2006 IEEE Autotest Conference, Anaheim, California, US, 18–21 September.
- Hofmeister, J., Szidarovszky, F., and Goodman, D. (2017). An approach to processing condition‐based data for use in prognostic algorithms. 2017 Machine Failure Prevention Technology, Virginia Beach, Virginia, US, 15–18 May.
- Hofmeister, J. and Vohnout, S. (2011). Innovative cable failure and PHM toolset. MFPT: Applied Systems Health Management Conference, Virginia Beach, Virginia, US, 10–12 May.
- Hofmeister, J., Vohnout, S., Mitchell, C. et al. (2010). HALT evaluation of SJ BIST technology for electronic prognostics. 2010 IEEE Autotest Conference, Orlando, Florida, US, 13–16 September.
- Hofmeister, J., Wagoner, R., and Goodman, D. (2013). Prognostic health management (PHM) of electrical systems using conditioned‐based data for anomaly and prognostic reasoning. Chemical Engineering Transactions 33: 992–996.
- Hollander, M., Wolfe, D.A., and Chicken, E. (2014). Nonparametric Statistical Methods, 3e. Hoboken, NJ: Wiley.
- IEEE. (2017). Draft standard framework for prognosis and health management (PHM) of electronic systems. IEEE 1856/D33.
- Javed, K. (2014). A robust & reliable data‐driven prognostics approach based on extreme learning machine and fuzzy clustering. Université de Franche‐Comté, English, 21 July.
- Jolliffe, I.T. (2002). Principal Component Analysis. New York: Springer.
- Kentved, A. and Schmidt, K. (2012). Reliability – acceleration factors and accelerated life testing. Input to SEES meeting 2012‐05‐14. www.sees.se/$‐1/file/delta‐alt‐sees‐may‐2012‐ver‐0.PDF.
- Kumar, S. and Pecht, M. (2010). Modeling approaches for prognostics and health management of electronics. International Journal of Performability Engineering 6 (5): 467–476.
- Lebold, M. and Thurston, M. (2001) Open standards for condition‐based maintenance and prognostic systems. 5th Annual Maintenance and Reliability Conference (MARCON 2001), Gatlinburg, Tennessee, US, 6–9 May.
- ManagementMania. (2017). ETA (event tree analysis) https://managementmania.com/en/eta‐event‐tree‐analysis.
- Medjaher, K. and Zerhouni, N. (2013). Framework for a hybrid prognostics. Chemical Engineering Transactions 33: 91–96. https://doi.org/10.3303/CET1333016.
- National Science Foundation Center for Advanced Vehicle and Extreme Environment Electronics at Auburn University (CAVE3). (2015). Prognostics health management for electronics. http://cave.auburn.edu/rsrch‐thrusts/prognostic‐health‐management‐for‐electronics.html (accessed November 2015).
- Nelson, W. (2004). Accelerated Testing: Statistical Models, Test Plans, and Data Analysis. New York: Wiley.
- O'Connor, P. and Kleyner, A. (2012). Practical Reliability Engineering. Chichester, UK: Wiley.
- Papoulis, A. (1984). Probability, Random Variables, and Stochastic Processes, 2e. New York: McGraw‐Hill.
- Pecht, M. (2008). Prognostics and Health Management of Electronics. Hoboken, NJ: Wiley.
- Prokpowicz, T.I. and Vaskas, A.R. (1969). Research and development, intrinsic reliability subminiature ceramic capacitors. Final Report, ECOM‐90705‐F, 1969 NTIS AD‐864068.
- Rokach, L. and Maimon, O. (2008). Data Mining with Decision Trees: Theory and Applications. Singapore: World Scientific.
- Ross, M.S. (1987). Introduction to Probability and Statistics for Engineers and Scientists. New York: Wiley.
- Sheppard, J.W. and Wilmering, T.J. (2009). IEEE standards for prognostics and health management. IEEE A&E Systems Magazine (September 2009): 34‐41.
- Silverman, M. and Hofmeister, J. (2012). The useful synergies between prognostics and HALT and HASS. IEEE Reliability and Maintainability Symposium (RAMS), Reno, Nevada, US, 23–26 January.
- Speaks, S. (2005). Reliability and MTBF overview. Vicor Reliability Engineering. http://www.vicorpower.com/documents/quality/Rel_MTBF.pdf (accessed August 2015).
- Stein, D., Beaver, S., Hoff, L. et al. (2002). Anomaly detection from hyperspectral imagery. IEEE Signal Processing Magazine 19 (1): 58–69.
- Stone, J.V. (2004). Independent Component Analysis: A Tutorial Introduction. Cambridge, MA: MIT Press.
- Thomas, D.R. (2006). A general inductive approach for analyzing qualitative evaluation data. American Journal of Evaluation 27 (2): 237–246.
- Tobias, P. (2003). How do you project reliability at use conditions? In: Engineering Statistics Handbook. National Institute of Standards and Technology https://www.itl.nist.gov/div898/handbook/apr/section4/apr43.htm.
- Vichare, N. (2006). Prognostics and health management of electrics by utilization of environmental and usage loads. Doctoral thesis. Department of Mechanical Engineering, University of Maryland.
- Vichare, N., Rodgers, P., Eveloy, V., and Pecht, M. (2007). Environment and usage monitoring of electronic products for health assessment and product design. Quality Technology and Quantitative Management 4 (2): 235–250.
- Viswanadham, P. and Singh, P. (1998). Failure Modes and Mechanisms in Electronic Packages. New York: Chapman and Hall.
- Wand, M.P. and Jones, M.C. (1995). Kernel Smoothing. London: Chapman & Hall/CRC.
- Webb, G.I., Boughton, J., and Wang, Z. (2005). Not so Naive Bayes: aggregating one‐dependence estimations. Machine Learning 58 (1): 5–24.
- Weisstein, E. (2015). Extreme value distribution. MathWorld, a Wolfram web resource. http://mathworld.wolfram.com/ExtremeValueDistribution.html.
- White, M. and Bernstein, J. (2008). Microelectronics reliability: physics‐of‐failure based modeling and lifetime evaluation. NASA Electronic Parts and Packaging (NEPP) Program, Office of Safety and Mission Assurance, NASA WBS: 939904.01.11.10, JPL Project Number: 102197, Task Number: 1.18.15, JPL Publication 08‐5.
- Xilinx. (2003). The reliability report. xgoogle.xilinx.com, 225–229.
- Xu, Z., Hong, Y., and Meeker, W. (2015). Assessing risk of a serious failure mode based on limited field data. IEEE Transactions on Reliability 64 (1): 51–62.
- Yakowitz, S. and Szidarovszky, F. (1989). An Introduction to Numerical Computations. New York: Macmillan.
- Zhang, N.L. and Poole, D. (1996). Exploiting causal independence in Bayesian network inference. Journal of Artificial Intelligence Research 5: 301–328.
Further Reading
- Filliben, J. and Heckert, A. (2003). Probability distributions. In: Engineering Statistics Handbook. National Institute of Standards and Technology http://www.itl.nist.gov/div898/handbook/eda/section3/eda36.htm.
- Saxena, A., Celaya, J., Saha, B. et al. (2009). On applying the prognostic performance metrics. Annual Conference of the Prognostics and Health Management Society (PHM09), San Diego, California, US, 27 Sep.–1 Oct.
- Tobias, P. (2003). Extreme value distributions. In: Engineering Statistics Handbook. National Institute of Standards and Technology https://www.itl.nist.gov/div898/handbook/apr/section1/apr163.htm.