
Bayesian Networks: One Solution for Specific Challenges in Building ML Systems in Cybersecurity
Rob Mealey, Director of Data Science, Resilience Insurance
There are two concepts that help in understanding the specific data challenges faced—and constraints on—machine learning systems developed to forecast and quantify cybersecurity risk. These are applicable to systems that can be classified as tactical or defensive in some way—such as an intrusion detection prevention solution—as well as to those, such as in the domain of cybersecurity insurance, that can be thought of as more strategic, more concerned with cybersecurity risk in the context of the larger picture. These are the concepts of:
- Data scarcity, where the challenge for modeling some system is that for any number of reasons, there do not exist easily gathered, reliable datasets from which to model the relationships within the system and forecast future behavior of it;
- Interpretability, where the constraint is that the model's conclusions and forecasts must be interpretable and explainable to a human subject‐matter expert, whether for business or regulatory or any number of other reasons.
Data scarcity issues can take many forms. In some scientific and research domains, such as research around deep‐sea marine biology or other environmental research, the issue truly is a lack of data of any kind. Whether the cost of data collection is prohibitive or the events being studied are sufficiently rare or difficult to observe, researchers just don't have datasets of adequate size to use traditional supervised statistical or machine learning techniques to investigate. In cybersecurity, however, the peculiarity of the data scarcity issues faced is that on the surface, there is abundant data. A security professional engaging in a direct assessment of the cyber health of an organization can access all manner of logs and configurations. They can, either independently or through some third‐party service, get a pretty reliable understanding of the scope of the organization's public‐facing assets, the technology stacks powering those assets, and even surface critically important vulnerabilities exposed via those assets.
The challenge is not that it is difficult to gather an authoritative security profile of an organization. Nor is it even a challenge to compile a large dataset of such profiles of lots of organizations. The difficulty is in actually linking those profiles at a point in time to a specific incident, in linking those observable factors to actual outcomes. This linkage is the key requirement for building a traditional supervised machine learning system. Building a dataset of this type is difficult to impossible in cybersecurity. Privacy concerns, business interests, and regulatory challenges make even publicly reported datasets difficult to utilize, and the bad actors actually driving the key cybersecurity risks faced by modern organizations react directly to attempts to reliably forecast their behavior. In both the former case of genuine lack of data and in our case of lack of easily utilized data, alternative approaches to forecasting and quantifying risk are required.
The constraint of model interpretability is often a legal and a privacy constraint, especially in regulatory and insurance contexts. Regulators and business stakeholders need to be able to assess the performance of a system. They need to be able to interrogate what factors drive it to make which predictions or forecasts, for legitimate fairness and equity concerns, beyond any business or legal requirements. This constraint, coupled with the data scarcity issues, often push organizations to rely on subject‐matter experts to assess and forecast their risk. This reliance can be either implicit or explicit, admitted or covert, but it is difficult to escape in the domain of cybersecurity. Much of the tools and techniques in this book are concerned with making those experts more reliable and their predictions more systematic and useful.
In the design of machine learning systems built to forecast cybersecurity risk, it is essential to be explicit and deliberate about the reliance upon subject‐matter experts and their forecasting ability. One must look for tools that enable the utilization of disparate datasets, elicited expert assessments of risk factors, and other types of data that also facilitate direct interrogation of the behavior of the system and the factors driving that behavior. One answer to these challenges is to combine the output of experts calibrated as described in these pages within a system using a class of models called probabilistic graphical models (PGM), of which the Bayesian network is the most widely known. This class of model was invented by Judea Pearl, a theoretical computer scientist and philosopher who used them to develop “a theory of causal and counterfactual inference based on structural models,” so they are purpose‐built, in many ways, for use in an interpretable machine learning system.
The overall category of probabilistic graphical models are those that represent some complex probability distribution as a graph of factorized conditionally independent relationships that models the behavior of a system as a whole. These relationships and the overall structure of the model can be established by training such a model over a dataset of reasonable size, surveying and incorporating the knowledge of experts, incorporating aggregate data, or combinations of the above. This flexibility, combined with the inherent strengths in interpretability and explanatory power described previously, makes these powerful tools for the task of reliably modeling cyber risk.
The key advantages that the PGM approach has are of course that they can incorporate expert assessments, at various levels of the model construction process, with real‐world data from different sources, into a powerful, flexible, and useful tool to accurately forecast cyber risk. Bayesian networks have been or are currently being used in a wide array of cybersecurity applications, from flagging potential internal threats3 to predicting data breaches generally,4 and in specific industries.5 These systems are usually built using a combination of subject‐matter expert knowledge and real‐world datasets. The 2017 survey of applications of Bayesian Networks in cybersecurity by Sabarathinam Chockalingam et al.6 is a very useful overview detailing a number of published approaches, along with how they're constructed and the conditional probability relationships populated.
An example from Lisa De Wilde's 2016 publication “A Bayesian Network Model for Predicting Data Breaches”7 illustrates the power and flexibility of these models. De Wilde builds an initial model structure that forecasts the risk of a data breach in a health care organization:
The basis variables are the forecast nodes, where the model would produce probabilities indicating the likelihood of a malicious action, an accidental action, and the resulting probability of an overall data breach. This general framework can then be extended and filled in with detail to model the likelihood of specific types of data breach, such as insider data breach, where the motivation and capability assessments are functions of measure variables that relate to job satisfaction, etc. And the capabilities and opportunities are derived from measures of security controls implementation, training and awareness, and other steps organizations take to protect their data. This model can then be used to assess the risk of individual organizations, given their attributes. In this case, the initial structure is built from expert knowledge, and the relationships are learned from both expert knowledge and real‐world datasets from internal sources at health care organizations.
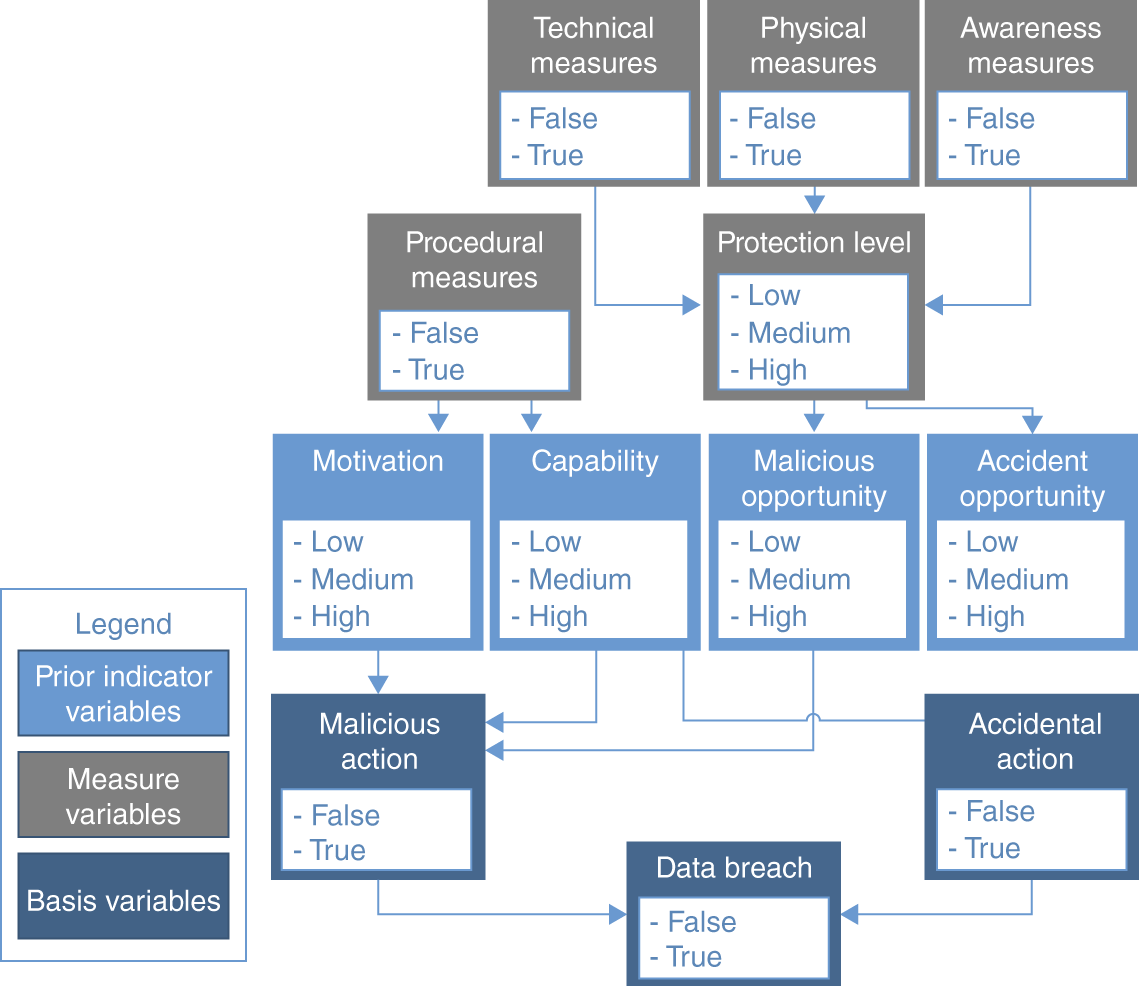
FIGURE B.8 General Bayesian network model
The domain of cybersecurity, both as an industry and as an area of research, is of course broad and diverse and the risk assessment needs and specific data scarcity issues vary widely in different subdomains. This is the distinction between tactical and strategic use cases for risk forecasting in cybersecurity referenced earlier. A cybersecurity insurance carrier is most concerned with forecasting the risk of incidents in their overall portfolio, to forecast and maintain their capital requirements, and to make pricing and other business decisions. In contrast, an intrusion detection prevention vendor is most concerned with how accurately and quickly their system can classify activity as malicious and flag such activity up for some action. Both are concerned with predicting or forecasting risk, just at very different levels. Another key advantage of the composable nature of graphical models is that it enables us to combine qualitative tactical assessments learned from real data, e.g., the quality of an organization's network security, with overall strategic forecasting gleaned from the output of calibrated experts.
Systems built with Bayesian Network models or other classes of probabilistic graphical models, such as Influence Diagrams, do come with their own set of unique challenges. The construction of a new model is no longer the work of a single data scientist working with a single dataset. It is now rather a labor‐intensive process with data collection from various sources and at various levels of granularity, with lots of potential failure points. So in the design of those systems, it is crucial to have lots of introspection and feedback loops with key stakeholders, if the system is to have any credibility or utility at all. This can have silver linings, if a team is diligent, as all machine learning systems decay, and often such decay is overlooked. But human‐in‐the‐loop systems, if they are to be of any quality, must have diligence against such decay baked into their foundations.
Other challenges are quantifying and assessing the quality of the subject‐matter experts the system relies on. The techniques in this very book are a wonderful foundation for addressing that challenge. Well‐calibrated subject‐matter experts and well‐designed tools to elicit their expert assessments and incorporate them with those of a large pool of experts are the key to building cybersecurity risk assessment systems that are truly interpretable, accurate, and useful. In data‐scarce domains, whether those issues are straightforward or complex, a combination of a flexible, interpretable machine learning approach such as probabilistic graphical models, combined with a well‐calibrated, validated team of subject‐matter experts is a powerful choice for designing and building systems to forecast risk and support better business decisions.
Notes
- 3 A Bayesian Network Model for Predicting Insider Threats (2013).
- 4 A Bayesian Network Model for Predicting Data Breaches (2016).
- 5 Bayesian Network Modelling for Analysis of Data Breach in a Bank (2011).
- 6 Bayesian Network Models in Cyber Security: A Systematic Review (2017).
- 7 A Bayesian Network Model for Predicting Data Breaches.