

Security Architecture and Engineering
Domain Objectives
• 3.1 Research, implement, and manage engineering processes using secure design principles.
• 3.2 Understand the fundamental concepts of security models (e.g., Biba, Star Model, Bell-LaPadula).
• 3.3 Select controls based upon systems security requirements.
• 3.4 Understand security capabilities of Information Systems (IS) (e.g., memory protection, Trusted Platform Module (TPM), encryption/decryption).
• 3.5 Assess and mitigate the vulnerabilities of security architectures, designs, and solution elements.
• 3.6 Select and determine cryptographic solutions.
• 3.7 Understand methods of cryptanalytic attacks.
• 3.8 Apply security principles to site and facility design.
• 3.9 Design site and facility security controls.
Domain 3, “Security Architecture and Engineering,” is one of the largest and possibly most difficult domains to understand and remember for the CISSP exam. Domain 3 comprises approximately 13 percent of the exam questions. We’re going to cover its nine objectives, which address secure design principles, security models, and selection of controls based on security requirements. We will also discuss security capabilities and mechanisms in information systems and go over how to assess and mitigate vulnerabilities that come with the various security architectures, designs, and solutions. Then we will cover the objectives that focus on cryptography, examining the basic concepts of the various cryptographic methods and understanding the attacks that target them. Finally, we will look at physical security, reviewing the security principles of site and facility design and the controls that are implemented within them.
 Research, implement, and manage engineering processes using secure design principles
Research, implement, and manage engineering processes using secure design principles
In this objective we will begin our study of security architecture and engineering by looking at secure design principles that are used throughout the process of creating secure systems. The scope of security architecture and engineering encompasses the entire systems and software life cycle, but it all begins with understanding fundamental security principles before the first design is created or the first component is connected. We have already touched upon a few of these principles in the previous domains, and in this objective (as well as throughout the remainder of the book) we will explore them in more depth.
Threat Modeling
Recall that we discussed the principles and processes of threat modeling back in Objective 1.11. Here, we will discuss them in the context of secure design. In addition to threat modeling as a process that should be performed on a continual basis throughout the infrastructure, threat modeling should also be considered during the architecture and engineering design phases of a system life cycle. As a reminder, threat modeling is the process of describing detailed threats, events, and their specific impacts on organizational assets. In the context of threat modeling as a secure design principle, cybersecurity architects and engineers should consider determining specific threat actors and events and how they will exploit a range of vulnerabilities that are inherent to a system or application that is being designed.
Least Privilege
As previously introduced in Objective 1.2, the principle of least privilege states that an entity (most commonly a user) should only have the minimum level of rights, privileges, and permissions required to perform their job duties, and no more. The principle of least privilege is accomplished by strict review of an individual’s access requirements and comparing them to what that individual requires to perform their job functions. The principle of least privilege should be practiced in all aspects of information security, to include system and data access (including physical), privileged use, and assignment of roles and responsibilities. This secure design principle should be used whenever a system or its individual components are bought or built and connected together to include mechanisms that restrict privileges by default.
Defense in Depth
Defense in depth means designing and implementing a multilayer approach to securing assets. The theory is that if multiple layers of protection are applied to an asset or organization, the asset or organization will still be protected in the event one of those layers fails. An example of this defense-in-depth strategy is that of a network that is protected by multiple levels at ingress/egress points. Firewalls and other security devices may protect the perimeter from most bad traffic entering the internal network, but other access controls, such as resource permissions, strong encryption, and authentication mechanisms are used to further limit access to the inside of the network from the outside world. Layers of defenses do not all have to be technical in nature; administrative controls in the form of policies and physical controls in the form of secured processing areas are also used to add depth to these layers.
Secure Defaults
Security and functionality are often at odds with each other. Generally, the more functional a system or application is for its users, the less secure it is, and vice versa. As a result, many applications and systems are configured to favor functionality by permitting a wider range of actions that users and processes can perform. The focus on functionality led organizations to configure systems to “fail open” or have security controls disabled by default. The principle of secure defaults means that out-of-the-box security controls should be secure, rather than open. For instance, when older operating systems were initially installed, cybersecurity professionals had to “lock down” the systems to make them more secure, since by default the systems were intended to be more functional than secure. This meant changing default blank or simple passwords to more complex ones, implementing encryption and strong authentication mechanisms, and so on. A system that follows the principle of secure defaults already has these controls configured in a secure manner upon installation, hence its default state.
Fail Securely
Another application of the secure default principle is when a control in a system or application fails due to an error, disruption of service, loss of power, or other issue, the system fails in a secure manner. For example, if a system detects that it is being attacked and its resources, such as memory or CPU power, are degraded, the system will automatically secure itself, preventing access to data and critical system components. The related term for the secure default principle during a failure is “fail secure,” which contrasts with the term “fail safe.”
Although in some controls the desired behavior is to fail to a secure state, other controls must fail to a safe mode of operation in order to protect human safety, prevent equipment damage and data loss, and so on. An example of the fail-safe principle would be when a fire breaks out in a data center, the exit doors fail to an open state, rather than a secured or locked state, to allow personnel to safely evacuate the area.

EXAM TIP Secure default is associated with the term “fail closed,” which means that in the event of an emergency or crisis, security mechanisms are turned on. Contrast this to the term “fail open,” which can also be called “fail safe,” and means that in the event of a crisis, security controls are turned off. There are situations where either of those conditions could be valid responses to an emergency situation or crisis.
Separation of Duties
The principle of separation of duties (SoD) is a very basic concept in information security: one individual or entity should not be able to perform multiple sensitive tasks that could result in the compromise of systems or information. The SoD principle states that tasks or duties should be separated among different entities, which provides a system of checks and balances. For example, in a bank, tellers have duties that may allow them to access large sums of money. However, to actually transfer or withdraw money from an account requires the signature of another individual, typically a supervisor, in order for that transaction to occur. So, one individual cannot simply transfer money to their own account or make a large withdrawal for someone else without a separate approval.
The same applies in information security. A classic example is that of an individual with administrative privileges, who may perform sensitive tasks but is not allowed to also audit those tasks. Another individual assigned to access and review audit records would be able to check the actions of the administrator. The administrator would not be allowed to access the audit records since there’s a possibility that the administrator could alter or delete those records to cover up their misdeeds or errors. The use of defined roles to assign critical tasks to different groups of users is one way to practically implement the principle of separation of duties.
A related principle is that of multiperson control, also sometimes referred to as “M of N” or two-person control. This principle states two or more people are required to perform a complete task, such as accessing highly sensitive pieces of information (for example, the enterprise administrator password). This principle helps to eliminate the possibility of a single person having access to sensitive information or systems and performing a malicious act.
Keep It Simple
Keep it simple is a design principle that means that architectures and engineering designs should be kept as simple as possible. The more complex a system or mechanism, the more likely it is to have inherent weaknesses that will not be discovered or security mechanisms that may be circumvented. Additionally, the more complex a system, the more difficult it is to understand, configure, and document. Security architects and engineers must avoid the temptation to unnecessarily overcomplicate a security mechanism or process.
Zero Trust
The principle of zero trust states that no entity in the infrastructure automatically trusts any other entity; that is to say, each entity must always reestablish trust with another one. Under this principle, an entity is considered hostile until proven otherwise. For example, hosts in a network should always have to mutually authenticate with each other to verify the other host’s identity and access level, even if they have performed this action before. Additionally, the principle ensures that even when trust is established, it is kept as minimal as possible. Trust between entities is very defined and discrete—not every single action, process, or component in a trusted entity is also considered trusted. This principle mitigates the possibility that, if the host or other entity is compromised since the last time they established trust, the systems are able to communicate or exchange data.
Mutual authentication, periodic reauthentication, and replay prevention are three key security measures that can help establish and support the zero-trust principle. Since widespread use of the zero-trust principle throughout an infrastructure could hamper data communication and exchange, implementation is usually confined to only extremely sensitive assets, such as sensitive databases or servers.
Privacy by Design
Privacy by design means that considerations for individual privacy are built into the system and applications from the beginning, including as part of the initial requirements for the system and continuing into design, architecture, and implementation. Remember that privacy and security are not the same thing. Security seeks to protect information from unauthorized disclosure, modification, or denial to authorized entities. Privacy seeks to ensure that the control of certain types of information is kept by the individual subject of that information. Privacy controls built into systems and applications ensure that privacy data types are marked with the appropriate metadata and protected from unauthorized access or transfer to an unauthorized entity.
Trust But Verify
Trust but verify is the next logical extension of the zero-trust model. In the zero-trust model, no entity is automatically trusted. The trust but verify principle goes one step further by requiring that once trust is established, it is periodically reestablished and verified, in the event one entity becomes compromised. Auditing is also an important part of the verification process between two trusted entities; critical or sensitive transactions are audited and monitored closely to ensure that the trust is warranted, is within accepted baselines, and has not been broken.
Shared Responsibility
Shared responsibility is a model that applies when more than one entity is responsible and accountable for protecting systems and information. Each entity has its own prescribed tasks and activities focused on protecting systems and data. These responsibilities are formally established in an agreement or contract and appropriately documented. The best example of a shared responsibility model is that of a cloud service provider and its client, who are each responsible for certain aspects of securing systems and information as well as their access. The organization may maintain responsibilities on its end for initially provisioning user access to systems and data, while the cloud provider is responsible for physical and technical security protections for those systems and data.
REVIEW
Objective 3.1: Research, implement, and manage engineering processes using secure design principles For the first objective of Domain 3, we discussed foundational principles that are critical during security architecture and engineering design activities.
• Threat modeling should occur not only as a routine process but also before designing and implementing systems and applications, since security controls can be designed to counter those threats before the system is implemented.
• principle of least privilege states that entities should only have the required rights, permissions, and privileges to perform their job function, and no more.
• Defense in depth is a multilayer approach to designing and implementing security controls to protect assets in the organization. It is employed such that in the event that one or more security controls fail, others can continue to protect sensitive assets.
• Secure default is the principle that states that when a system is first implemented or installed, its default configuration is a secure state.
• Fail secure means that a system should also fail to a secure state when it is unexpectedly halted, interrupted, or degraded.
• Separation of duties means that critical or sensitive tasks should not all fall onto one individual; these tasks should be separated amongst different individuals to prevent one person from being able to cause serious damage to systems or information.
• Keep it simple means that the more complex the system or application, the less secure it is and more difficult to understand and document.
• Zero trust means that two or more entities in an infrastructure do not start out by trusting each other. Trust must first be established and then periodically reestablished.
• Trust but verify is a principle that means that once trust is established, it must be periodically reestablished and verified as still current and necessary, in the event one entity becomes compromised.
• Privacy by design is the principle that privacy considerations should be included in the initial requirements, design, and architecture for systems, applications, and processes, so that individual privacy can be protected.
• Shared responsibility is the principle that means that two or more entities share responsibility and accountability for securing systems and data. This shared responsibility should be formally agreed upon and documented.
3.1 QUESTIONS
1. You are a cybersecurity administrator in a large organization. IT administrators frequently perform many sensitive tasks, to include adding user accounts and granting sensitive data access to those users. To ensure that these administrators do not engage in illegal acts or policy violations, you must frequently check audit logs to make sure they are fulfilling their responsibilities and are accountable for their actions. Which of the following principles is employed here to ensure that IT administrators cannot audit their own actions?
A. Principle of least privilege
B. Trust but verify
C. Separation of duties
D. Zero trust
2. Your company has just implemented a cutting-edge data loss prevention (DLP) system, which is installed on all workstations, servers, and network devices. However, the documentation for the solution is not clear regarding how data is marked and transits throughout the infrastructure. There have been several reported instances of data still making it outside of the network during tests of the solution, due to multiple possible storage areas, transmission paths, and conflicting data categorization. Which of the following principles is likely being violated in the secure design of the solution, which is allowing sensitive data to leave the infrastructure?
A. Keep it simple
B. Shared responsibility
C. Secure defaults
D. Fail secure
3.1 ANSWERS
1. C The principle of separation of duties is employed here to ensure that critical tasks, such as auditing administrative actions, are not performed by the people whose activities are being audited, which in this case are the IT administrators. Auditors are responsible for auditing the actions of the IT administrators, and these two tasks are kept separate to ensure that unauthorized actions do not occur.
2. A In this scenario, the principle of keep it simple is likely being violated, since the solution may be configured in an overly complex manner and is allowing data to traverse multiple uncontrolled paths. A further indication that this principle is not being properly employed is the lack of clear documentation for the solution, as indicated in the scenario.
 Understand the fundamental concepts of security models (e.g., Biba, Star Model, Bell-LaPadula)
Understand the fundamental concepts of security models (e.g., Biba, Star Model, Bell-LaPadula)
A security model (sometimes also called an access control model) is a mathematical representation of how systems and data are accessed by entities, such as users, processes, and other systems. In this objective we will examine security models and explain how they allow access to data based on a variety of criteria, including security clearance, need-to-know, and job roles.
Security Models
Security models propose how to allow entities controlled access to information and systems, maintaining confidentiality and/or integrity, two key goals of security. Security levels are different sensitivity levels assigned to information systems. These levels come directly from data sensitivity policies or classification schemes. Models that approach access control from the confidentiality perspective don’t allow an entity at one security level to read or otherwise access information that resides at a different security level. Models that approach access control from the integrity perspective do not allow subjects to write to or change information at a given security level. Most of the security models we will discuss are focused on those two goals, confidentiality and integrity.
Security models are most often associated with the mandatory access control (MAC) paradigm of access control, which is used by administrators to enforce highly restrictive access controls on users and other entities (called subjects) and their interactions with systems and information, often referred to as objects.
Cross-Reference
Mandatory access control (MAC), discretionary access control (DAC), role-based access control (RBAC), and other access control models are discussed in Objective 5.4.
Terms and Concepts
Access to information in mandatory access control models is based upon the three important concepts of security clearance, management approval, and need-to-know. A security clearance verifies that an individual person is “cleared” for information at a given security level, such as the U.S. military classification levels of “Secret” and “Top Secret.” A person with a Secret security clearance is not allowed to access information at the Top Secret level due to the difference in classification level permissions. Access to a given system or set of information is denied when it has a security level higher than that of the subject desiring access. Need-to-know also restricts access even if the subject has equal or higher security clearance than the system or data.
As mentioned earlier, the type of access, for our purposes here, is the ability to read information from or write information to that security level. If a subject is not authorized to “read up” to a higher (more restrictive) security level, they cannot access information or systems at that level. If a subject is not authorized to write to a different security level (regardless of whether or not they can read it), then they cannot modify information at that level. Based on these restrictions, it would seem that if a subject has a clearance to access information at a given level, they would automatically be allowed to access information at any lower (less restrictive) level. This is not necessarily the case, however, because the additional requirements of need-to-know and management approval must be applied.
Even if a subject has the clearance to access information at a higher (or even the same) security level, if they don’t have a valid need-to-know related to their job position, then they should not be allowed access to that information, regardless of whether it resides at a lower security level or not. Additionally, management must formally approve the access; simply having the clearance and need-to-know does not automatically grant information access. Figure 3.2-1 shows how the concepts of confidentiality and integrity are implemented in these examples.

FIGURE 3.2-1 Ensuring confidentiality and integrity in mandatory access control

NOTE We often look at multilevel security as being between levels that are higher (more restrictive) or lower (less restrictive) than each other, but this is not necessarily the case. Information can also be compartmented (even at the same “level”) but still separated and restricted in terms of access controls. This is where “need-to-know” comes into play the most.
System States and Processing Modes
Before we discuss the various confidentiality and integrity models, it’s helpful to understand the different “states” and “modes” that a system operates in for information categorized at different security levels. In a single-state system, the processor and system resources may handle only one security level at a time. A single-state system should not handle multiple security levels concurrently, but could switch between them using security policy mechanisms. A multistate system, on the other hand, can handle several security levels concurrently, because it has specialized security mechanisms built in. Different processing modes are defined based on the security levels processed and the access control over the user. There are four generally recognized processing modes you should be familiar with for the exam, presented next in order of most restrictive to least restrictive.
Dedicated Security Mode
Dedicated security mode is a single-state type of system, meaning that only one security level is processed on it. However, the access requirements to interact with information are restrictive. Essentially, users that access the security level must have
• A security clearance allowing them to access all information processed on the system
• Approval from management to access all information processed by the system
• A valid need-to-know, related to their job position, for all information processed on the system
System-High Security Mode
For system-high security mode, the user does not have to possess a valid need-to-know for all of the information residing on the system but must have the need-to-know for at least some of it. Additionally, the user must have
• A security clearance allowing them to access all information processed on the system
• Approval from management and signed nondisclosure agreements (NDAs) for all information processed by the system
Compartmented Security Mode
Compartmented security mode is slightly less restrictive in terms of allowing user access to the system. For compartmented security mode, users must meet the following requirements:
• Level of security clearance allowing them to access all information processed on the system
• Approval from management to access at least some information on the system and signed NDAs for all information on the system
• Valid need-to-know for at least the information they will access
Multilevel Security Mode
Finally, multilevel security mode may have multiple levels of sensitive information processed on the system. Users are not always required to have the security clearance necessary for all of the information on the system. However, users must have
• Security clearance at least equal to the level of information they will access
• Approval from management for any information they will access and signed NDAs for all information on the system
• A valid need-to-know for at least the information they will have access to
Figure 3.2-2 illustrates the concepts associated with multilevel security.

FIGURE 3.2-2 Multilevel security states and modes
EXAM TIP Understanding the security states and processing modes is key to understanding the confidentiality and integrity models we discuss for this objective, although you may not be asked specifically about the states or processing modes on the exam.
Confidentiality Models
As mentioned, security models target either the confidentiality aspect or the integrity aspect of security. Confidentiality models, discussed here, seek to strictly control access to information, namely the ability to read information at specific security levels. Confidentiality models, however, do not consider other aspects, such as integrity, so they do not address the potential for unauthorized modification of information by a subject that may be able to “write up” to the security level, even if they cannot read information at that level.
Bell-LaPadula
The most common example of a confidentiality access control model is the Bell-LaPadula model. It only addresses confidentiality, not integrity, and uses three main rules to enforce access control:
• Simple security rule A subject at a given security level is not allowed to read data that resides at a higher or more restrictive security level. This is commonly called the “no read up” rule, since the subject cannot read information at a higher classification or sensitivity level.
• *-property rule (called the star property rule) A subject at a given security level cannot write information to a lower security level; in other words, the subject cannot “write down,” which would transfer data of a higher sensitivity to a level with lower sensitivity requirements.
• Strong star property rule Any subject that has both read and write capabilities for a given security level can only perform both of those functions at the same security level—nothing higher and nothing lower. For a subject to be able to both read and write to an object, the subject’s clearance level must be equal to that of the object’s classification or sensitivity.
Figure 3.2-1, shown earlier, demonstrates how the simple security and star property rules function in a confidentiality model.
EXAM TIP The CISSP exam objectives specifically mention the “Star Model,” but this is a reference to the star property and star integrity rules (often referred to in shorthand as “* property” and “* integrity”) found in confidentiality and integrity models.
Integrity Models
As mentioned, some mandatory access control models only address integrity, with the goals of ensuring that data is not modified by subjects who are not allowed to do so and ensuring that data is not written to different classification or security levels. Two popular integrity models are Biba and Clark-Wilson, although there are many others as well.
Biba
The Biba model uses integrity levels (instead of security levels) to prevent data at any integrity level from flowing to a different integrity level. Like Bell-LaPadula, Biba uses three primary rules that affect reading and writing to different security levels and uses them to enforce integrity protection instead of confidentiality. These levels are also illustrated in Figure 3.2-1.
• Simple integrity rule A subject cannot read data from a lower integrity level (this is also called “no read down”).
• *-integrity rule A subject cannot write data to an object residing at a higher integrity level (called “no write up”).
• Invocation rule A subject at one integrity level cannot request or invoke a service from a higher integrity level.
EXAM TIP Although Bell-LaPadula (confidentiality model) and Biba (integrity model) address different aspects of security, both are called information flow models since they control how information flows between security levels. For the exam, remember the rules that apply to each. If the word “simple” is used, the rule addresses reading information. If the rule uses the * symbol or “star” in its name, the rule applies to writing information.
Clark-Wilson
The Clark-Wilson model is also an integrity model but was developed after Biba and uses a different approach to protect information integrity. It uses a technique called well-formed transactions, along with strictly defined separation of duties. A well-formed transaction is a series of operations that transforms data from one state to another, while keeping the data consistent. The consistency factor ensures that data is not degraded and preserves its integrity. Separation of duties between processes and subjects ensures that only valid subjects can transform or change data.
Other Access Control Models
We covered two of the key security models, confidentiality and integrity, involved in mandatory access control, and there are several other models that perform some of the same functions, using different techniques. In reality, neither of these security models is very practical in the real world; each has its place in very specific contexts. For example, a classified military system or even a secure healthcare system may use different kinds of access control models to protect information at different stages of processing, so they do not rely only on one type of access control model. More often than not, you will see these security models used together under different circumstances.
Although we will not discuss them in depth here, additional models that you may need to be familiar with for the purposes of the exam include
• Noninterference model This multilevel security model requires that commands or activities performed at one security level should not be seen by or affect subjects and objects at a different security level.
• Brewer and Nash model Also called the Chinese Wall model, this model is used to protect against conflicts of interest by stating that a subject can write to an object if and only if the subject cannot read another object from a different set of data.
REVIEW
Objective 3.2: Understand the fundamental concepts of security models (e.g., Biba, Star Model, Bell-LaPadula) In this objective we examined the fundamentals of security models, which typically follow the paradigm of mandatory access control. We examined models that use two different approaches to access control: confidentiality models and integrity models. Confidentiality models are concerned with strictly controlling the ability of a subject to “read” or access information at a given security level. The main confidentiality example is the Bell-LaPadula model, which uses rules to inhibit the ability of a subject to “read up” and “write down,” to prevent unauthorized data access. Integrity models rigorously restrict the ability of subjects to write to or modify information at given security levels. We also discussed system states and processing modes, which include dedicated security mode, system-high security mode, compartmented security mode, and multilevel security mode.
3.2 QUESTIONS
1. If a user has a security clearance equal to all information processed on the system, but is only approved by management for some information and only has a need-to-know for that specific information, which of the following is the security mode for the system?
A. Compartmented security mode
B. Dedicated security mode
C. Multilevel security mode
D. System-high security mode
2. Mandatory access control security models address which of the following two goals of security?
A. Confidentiality and availability
B. Availability and integrity
C. Confidentiality and integrity
D. Confidentiality and nonrepudiation
3. Your supervisor has granted you rights to access a system that processes highly sensitive information. In order to actually access the system, you must have a security clearance equal to all information processed on the system, management approval for all information processed on the system, and need-to-know for all information processed on the system. In which of the following security modes does the system operate?
A. Multilevel security mode
B. System-high security mode
C. Dedicated security mode
D. Compartmented security mode
4. You are a cybersecurity engineer helping to design a system that uses mandatory access control. The goal of the system is to preserve information integrity. Which of the following rules would be used to prevent a subject from writing data to an object that resides at a higher integrity level?
A. Strong security rule
B. *-security rule
C. Simple integrity rule
D. *-integrity rule
3.2 ANSWERS
1. A Compartmented security mode means that the user must have a security clearance equal to all information processed on the system, regardless of management approval to access the information or need-to-know. Additionally, the user must have specific management approval and need-to-know for at least some of the information processed on the system.
2. C Mandatory access control models address the confidentiality and integrity goals of security.
3. C Since the user must meet all three requirements for all information processed on the system (security clearance, management approval, and need-to-know), the system operates in dedicated security mode. This indicates a single-state system since it is using only one security level.
4. D The *-integrity rule states that a subject cannot write data to an object at a higher integrity level (called “no write up”).
 Select controls based upon systems security requirements
Select controls based upon systems security requirements
In this objective we will discuss how to select security controls for implementation based upon systems security requirements. We discussed some of these requirements in Domain 1. In this objective we will review them in the context of the entire system’s life cycle and, more specifically, how to select security controls during the early stages of that life cycle.
Selecting Security Controls
As you may remember from Objective 1.10, we select security controls to implement based on a variety of criteria. In addition to cost, we consider the protection needs of the asset, the risk the control reduces, and how well the control complies with governance requirements. We should reconsider implementing a control if it either costs more than the asset is worth or does not provide sufficient protection, risk reduction, or compliance to balance its costs.
Controls should not be selected for implementation after the system or application is already installed and working; the control selection process actually takes place before the system is built or bought. To identify the type of security controls to implement prior to installation and operation of the system, we must review the full requirements of the system. This review takes place during the requirements phase of the software/system development life cycle (SDLC) and includes functional requirements (what it must do), performance requirements (how well it must do it), and, of course, security requirements. Also, remember that technical controls are not the only ones to consider; administrative and physical controls go hand-in-hand with technical controls and should be considered as well. While there are many variables to consider when selecting which security controls to implement, we’ll focus on several key requirements that you should understand for purposes of the exam.
Cross-Reference
We’ll discuss the SDLC in greater detail in Objective 8.1.
Performance and Functional Requirements
Security requirements state what the system, software, or even a mechanism has to do; in other words, what function it fulfills. To meet security requirements, controls have to be selected based upon their functional requirements (what they do) and their ability to perform that function (how well they do it). Functional and performance requirements for controls should be established before a system or application is acquired (built or purchased). A control may be selected because it provides a desired security functionality that supports confidentiality, integrity, and/or availability. From a practical perspective, this functionality might be encryption or authentication.
We also have to consider how well the control performs its function. Requirements should always describe acceptable performance criteria for the system the control will support. Simply selecting a control that provides authentication services is not enough; it must meet specific standards, such as encryption strength, timing, interoperability with other systems, and so on. For example, choosing an older authentication mechanism that only supports basic username and password authentication or unencrypted protocols would likely not meet expected performance standards today. Functionality and performance requirements can be traced back to data protection and governance directives as well.
Data Protection Requirements
Data protection requirements can come from different sources, including governance. However, the two key factors in data protection are data criticality and sensitivity, as discussed in depth in Objective 2.1. Remember that criticality describes the importance of the information or systems to the organization in terms of its business processes and mission. Sensitivity refers to the information’s level of confidentiality and relates to its vulnerability to unauthorized access or disclosure. These two requirements should be considered when selecting controls.
Controls must take into account the level of criticality of the system or the information that system processes and be implemented to protect that asset at that level. A business impact analysis (BIA), discussed in Objective 1.8, helps an organization determine the criticality of its business processes and identify the assets that support those processes. Using the BIA findings, an organization can choose and implement appropriate controls to protect critical processes. Controls that protect critical data provide resiliency and availability of assets. Examples of these types of controls include backups, system redundancy and failover, and business continuity and disaster recovery plans.
As mentioned, sensitivity must also be considered when selecting and implementing controls. The more sensitive the systems and information, the stronger the control should be to protect their confidentiality. Controls designed to protect confidentiality include strong encryption, authentication, and other access control mechanisms, such as rights, permissions, and defined roles, and so on.
Governance Requirements
Beyond the organization’s own determination of criticality and sensitivity, governance heavily influences control selection and implementation. Governance may levy specific mandatory requirements on the controls that must be in place to protect systems and information. For example, requirements may include a specific level of encryption strength or algorithm, or physical controls that call for inclusion of guards and video cameras in secure processing areas where sensitive data is accessed. Examples of governance that have defined control requirements include the Health Insurance Portability and Accountability Act (HIPAA), the Payment Card Industry Data Security Standard (PCI DSS), Sarbanes-Oxley (SOX), and various privacy regulations.
Interface Requirements
Interface requirements influence controls at a more detailed level and are quite important. These requirements dictate how systems and applications interact with other systems and applications, processes, and so on. Interface requirements should consider data exchange, formatting, and access control. Since sensitive data may traverse one or several different networks, it’s important to look at the controls that sit between those networks or systems to ensure that they allow only the authorized level of data to traverse them, under very specific circumstances. For example, if a sensitive system is connected to systems of a lower sensitivity level, data must not be allowed to travel between systems unless it has been appropriately sanitized or processed so that it is the same sensitivity level of the destination system. A more specific example is a system in a hospital that contains protected healthcare information; if the system is connected to financial systems, certain information should be restricted from flowing to those systems, but other information, such as the patient’s name and billing information, must be transferred to those systems. Controls at this level could be responsible for selectively redacting private health information that is not required for financial transactions.
Controls that are selected based upon interface requirements include secure protocols and services that move information between systems, strong encryption and authentication mechanisms, and network security devices, such as firewalls.
Risk Response Requirements
Risk response requirements that the controls must fulfill may be hard to nail down during the requirements phase. This is why a risk assessment and analysis must take place—before the system even exists. Risk assessments conducted during the requirements phase gather data about the threat environment and take into account existing security controls that may already be in place to protect an asset. Controls selected for implementation may be above and beyond those already in place but are necessary to bridge the gap between those controls and the potentially increased threats facing a new system.
A risk assessment and analysis should take into account all the other items we just discussed: governance, criticality and sensitivity factors, interconnection and interface requirements, as well as many other factors. Other factors that should be considered include the threat landscape (threat actors and known threats to the organization and its assets); potential vulnerabilities in the organization, its infrastructure, and in the asset (even before it is acquired); and the physical environment (facilities, location, and other environmental factors).
EXAM TIP Controls are considered and selected based upon several different factors, including functional and performance requirements, governance, the interfaces they will protect, and responses to risk analysis. However, the most important factor in selecting security controls is how well they protect systems and data.
Threat modeling contributes to the requirements phase risk assessment by developing a lot of the risk information for you; you will discover vulnerabilities and other particulars of risk as an incidental benefit to the threat modeling effort. The key to selecting controls based on risk response is weighing the existing controls against the threats that are identified for the asset and organization, and then closing the gap between the current security posture and the desired security state once the asset is in place.
Cross-Reference
Objective 1.11 provided in-depth coverage of threat modeling.
REVIEW
Objective 3.3: Select controls based upon systems security requirements In this objective we expanded our discussion of security control selection and discussed how these controls should be considered and selected even before the asset is acquired. This takes place during the requirements phase of the SDLC and includes considerations for functionality and performance of the control, data protection requirements, governance, interface requirements, and even risk response.
3.3 QUESTIONS
1. Your company is considering purchasing a new line-of-business application and integrating it with a legacy infrastructure. In considering additional controls for the new application, management has already taken into account governance, as well as how the controls must perform. However, it has not yet considered security controls affecting the interoperability of the application with other components. Which of the following requirements should management take into account when selecting security controls for the new application?
A. Functionality requirements
B. Risk response requirements
C. Interface requirements
D. Authentication requirements
2. Which of the following should be conducted during the requirements phase of the SDLC to adequately account for new threats, potential asset vulnerabilities, and other organizational factors that may affect the selection of additional security controls?
A. Business impact analysis
B. Risk assessment
C. Interface assessment
D. Controls assessment
3.3 ANSWERS
1. C Interface requirements address the interconnection of the application to other system components, as well as its interoperability with those legacy components. Security controls must consider how data is exchanged between those components in a secure manner, especially if the legacy components cannot use the same security mechanisms.
2. B During the requirements phase, a risk assessment should be conducted to ascertain the existing state of controls as well as any new or emerging threats that could present a problem for new assets. Additionally, the organizational security posture should be considered. A risk assessment will help determine new controls that would be available for risk response.
 Understand security capabilities of Information Systems (IS) (e.g., memory protection, Trusted Platform Module (TPM), encryption/decryption)
Understand security capabilities of Information Systems (IS) (e.g., memory protection, Trusted Platform Module (TPM), encryption/decryption)
In this objective we will explore some of the integrated security capabilities of information systems. These security solutions are built into the hardware and firmware, such as the Trusted Platform Module, the hardware security module, and the self-encrypting drive. We also will briefly discuss bus encryption, which is used to protect data while it is accessed and processed within the computing device. Additionally, we will examine security concepts and processes such as the trusted execution environment, processor security extensions, and atomic execution. Understanding each of these concepts is important to fully grasp how system security works at the lower hardware levels.
Information System Security Capabilities
While many types of information system security capabilities are available, we are going to limit the discussion here to the security capabilities of hardware and firmware that are specified or implied in exam objective 3.4. We will discuss other information system security capabilities throughout the book, including cryptographic capabilities in Objectives 3.6 and 3.7.
Hardware and Firmware System Security
Hardware and firmware security capabilities embedded in a system are designed to address two main issues: trust in the system’s components; and protection of data at rest (residing in storage), in transit (actively being sent across a transmission media), and in use (actively being processed by a device’s CPU and residing in volatile or temporary memory). Again, although there are several components that contribute to these processes, we’re going to talk about the specific ones that you are required to know to meet the exam objective.
Trusted Platform Module
A Trusted Platform Module (TPM) is implemented as a hardware component installed on the main board of the computing device. Most often it is implemented as a computer chip. Its purpose is to carry out several security functions, including storing cryptographic keys and digital certificates. It also performs operations such as encryption and hashing. TPMs are used in two important scenarios:
• Binding a hard disk drive This means that the hard drive is “keyed” through the use of encryption to work only on a particular system, which prevents the hard drive from being stolen and used in another system in order to gain access to its data.
• Sealing This is the process of encrypting the data for a system’s specific hardware and software configuration and storing it on the TPM. This method is used to prevent tampering with hardware and software components to circumvent security mechanisms. If the drive or system is tampered with, the drive cannot be accessed.
TPMs use two different types of memory to store cryptographic keys: persistent memory and versatile memory. The type of memory used for each key and other security information depends on the purpose of the key. Persistent memory maintains its contents even when power is removed from the system. Versatile memory is dynamic and will lose its contents when power is turned off or lost, just as normal system RAM (volatile memory) does. The types of keys and other information stored in these memory areas include the following:
• Endorsement key (EK) This is the public/private key pair installed in the TPM when it is manufactured. This key pair cannot be modified and is used to verify the authenticity of the TPM. It is stored in persistent memory.
• Storage root key (SRK) This is the “master” key used to secure keys stored in the TPM. It is also stored in persistent memory.
• Platform configuration registers (PCRs) These are used to store cryptographic hashes of data and used to “seal” the system via the TPM. These are part of the versatile memory of the TPM.
• Attestation identity keys (AIKs) These keys are used to attest to the validity and integrity of the TPM chip itself to various service providers. Since these keys are linked to the TPM’s identity when it is manufactured, they are also linked to the endorsement key. These keys are stored in the TPM’s versatile memory.
• Storage keys These keys are used to encrypt the storage media of the system and are also located in versatile memory.
Hardware Security Module
A hardware security module (HSM) is almost identical in function to a TPM, with the difference being that a TPM is implemented as a chip on the main board of the computing device, whereas an HSM is a peripheral device and can be connected externally to systems that do not possess a TPM via an add-on card or even a USB connection.
EXAM TIP A TPM and HSM are almost identical and serve the same functions; the difference is that a TPM is built into the system’s mainboard and an HSM is a peripheral device in the form of an add-on card or USB device.
Self-Encrypting Drive
A self-encrypting drive (SED), as its name suggests, is a self-contained hard disk that has encryption mechanisms built into the drive electronics; it does not require the TPM or HSM of a computing device. The key is stored within the drive itself and can be managed by a password chosen by the user. An SED can be moved between devices, provided they are compatible with the drive.
Bus Encryption
Bus encryption was developed to solve a potential issue that results when data must be decrypted from permanent storage before it is used by applications and hardware on a system. During that transition, the data is in use (active) and, if unencrypted, is vulnerable to being read by a malicious application and sent to a malicious entity. Bus encryption encrypts data before it is put on the system bus and ensures that data is encrypted even within the system while it is in use, except when being directly accessed by the CPU. However, bus encryption requires the use of a cryptoprocessor, which is a specialized chip built into the system to manage this process.
Secure Processing
There are several key characteristics of secure processing that you need to be familiar with for the CISSP exam, which include those managed by the hardware and firmware discussed in the previous section. Note that these are not the only secure processing mechanisms, but for objective 3.4, we will focus on the trusted execution environment, processor security extensions, and atomic execution.
Trusted Execution Environment
A trusted execution environment (TEE) is a secure, separated environment in the processor where applications can run and files can be open and protected from outside processes. Trusted execution environments are used widely in mobile devices (Apple refers to its implementation as a secure enclave). TEEs work by creating a trusted perimeter around the application processing space and controlling the way untrusted objects interact with the application and its data. The TEE has its own access to hardware resources, such as memory and CPU, that are unavailable to untrusted environments and applications.
You should note that a TEE protects several aspects of the processing environment; since the application runs in memory space that should not be corrupted by any other processes, this is referred to as memory protection. Memory protection is also achieved using a combination of other mechanisms as well, such as operating system and software application controls.
EXAM TIP A TEE is a protected processing environment; it is not a function of the TPM itself, but it does rely on the TPM to provide a chain of trust to the device hardware so the trusted software environment can be created.
Processor Security Extensions
Modern hardware built with security in mind can provide the needed security boundary to create a TEE. Modern CPUs come with processor security extensions, which are instructions specifically created to provide trusted environment support. Processor security extensions enable programmers to create special reserved regions in memory for sensitive processes, allowing these memory areas to contain encrypted data that is separated from all other processes. These memory areas can be dynamically decrypted by the CPU using the security extensions. This protects sensitive data from any malicious process that attempts to read it in plaintext. Processor security extensions also provide the ability to control interactions between applications and data in a TEE and untrusted applications and hardware that reside outside the secure processing perimeter.
Atomic Execution
Atomic execution is not so much a technology as it is a method of controlling how parts of applications run. It is an approach that prevents other, nonsecure processes from interfering with resources and data used by a protected process. To implement atomic execution, programmers leverage operating system libraries that invoke hardware protections during execution of specific code segments. A disadvantage of this, however, is that it can result in performance degradation for the system. An atomic operation is either fully executed or not performed at all.
Atomic execution is specifically designed to protect against timing attacks, which exploit the dependencies on sequence and timing in applications to execute multiple tasks and processes concurrently. These attacks are routinely called time-of-check to time-of-use (TOC/TOU) attacks. They attempt to interrupt the timing or sequencing of tasks that segments of code must complete. If an attacker can interrupt the sequence or timing after specific tasks, it can cause the application to fail, at best, or allow an attacker to read sensitive information, at worst. This type of attack is also referred to as an asynchronous attack.
REVIEW
Objective 3.4: Understand security capabilities of Information Systems (IS) (e.g., memory protection, Trusted Platform Module (TPM), encryption/decryption) In this objective we discussed some of the many security capabilities built into information systems. Specific to this objective, we discussed hardware and firmware system security that makes use of Trusted Platform Modules, hardware security modules, self-encrypting drives, and bus encryption. We also discussed characteristics of secure processing that rely on this hardware and firmware. We explored the concept of a trusted execution environment, which provides an enclosed, trusted environment for software to execute. We also mentioned processor security extensions, additional code built into a CPU that allows for memory reservation and encryption for sensitive processes. Finally, we talked about atomic execution, which is an approach used to secure or lock a section of code against asynchronous or timing attacks that could interfere with sequencing and task execution timing.
3.4 QUESTIONS
1. Which of the following security capabilities is able to encrypt media and can be moved from system to system, but does not rely on the internal device cryptographic mechanisms to manage device encryption?
A. Hardware security module
B. Self-encrypting drive
C. Bus encryption
D. Trusted Platform Module
2. Which of the following secure processing capabilities is used to protect against time-of-check to time-of-use attacks?
A. Trusted execution environment
B. Trusted Platform Module
C. Atomic execution
D. Processor security extensions
3.4 ANSWERS
1. B A self-encrypting drive has its own cryptographic hardware mechanisms built into the drive electronics, so it does not rely on other device security mechanisms, such as TPMs, HSMs, or bus encryption to manage its encryption capabilities. Additionally, self-encrypting drives can be moved from device to device.
2. C Atomic execution is an approach used in secure software construction that locks or isolates specific code segments and prevents outside processes or applications from interrupting their processing and taking advantage of sequencing and timing issues when processes or tasks are executed.
 Assess and mitigate the vulnerabilities of security architectures, designs, and solution elements
Assess and mitigate the vulnerabilities of security architectures, designs, and solution elements
In this objective we will take a look at various security architectures and designs, examining what they are and how they may fit into an overall organizational security picture. We will also discuss some of the vulnerabilities that affect each of these architectures.
Vulnerabilities of Security Architectures, Designs, and Solutions
There are a multitude of ways that infrastructures can be designed and architected, and each way has its own advantages and disadvantages as well as unique security issues. In this objective we will discuss several of the key architectures that you will see both on the exam and in the real world. We will also talk about some of the vulnerabilities that plague each of these solutions. Most of the vulnerabilities associated with all of these solutions involve recurring themes: weak authentication, lack of strong encryption, lack of restrictive permissions, and, in the case of specialized devices, the inability to securely configure them while still connecting them to sensitive networks or even the larger Internet.
Client-Based Systems
A client-based system is one of the simplest computer architectures. It usually does not depend on any external devices or processing power; all physical hardware and necessary software are self-contained within the system. Client-based systems use applications that are executed entirely on a single device. The device may or may not have or need any type of network connectivity to other devices.
Although client-based systems are not the norm these days, you will still see them in specific implementations. In some cases, they are simply older or legacy devices and implementations, and in many other cases they are devices that have very specialized uses and are designed intentionally to be independent and self-contained. Regardless of where you see them or why they exist, client-based systems still may require patches and updates and, due to limited storage, may require connections to external storage devices. Occasional external processing could involve connections to other applications or network-enabled devices. However, all the core processing is still performed on the client-based system.
Vulnerabilities associated with client-based systems are the same as those that are magnified to a greater extent on other types of architectures. Client-based systems often suffer from weak authentication because the designers do not feel there is a risk in using simple (or sometimes nonexistent) authentication, based on the assumption that the systems likely won’t connect to anything else. There also may be very weak encryption mechanisms, if any at all, on the device. Again, the assumption is that the device will not connect to any other devices, so data does not need to be transmitted in an encrypted form. However, this assumption does not consider data that should be encrypted while in storage on the device. Most security mechanisms on the client-based system are a single point of failure; that is, if they fail, there is no backup or redundancy.
Server-Based Systems
Server-based system architectures extend client-based system architectures (where everything occurs on a single device or application) by connecting clients to the network, enabling them to communicate with other systems and access their resources. Server-based systems, commonly called a client/server or two-tiered architecture, consist of a client (either a device or an application) that connects to a server component, sometimes on the same system or another system on the network, to access data or services. Most of the processing occurs on the server component, which then passes data to the client.
Vulnerabilities inherent to server-based systems include operating system and application vulnerabilities, weak authentication, insufficient encryption mechanisms, and, in the case of network client/server components, nonsecure communications.
Distributed Systems
Distributed systems are those that contain multiple components, such as software or data residing on multiple systems across the network or even the Internet. These are called n-tier computing architectures, since there are multiple physical or software components connected together in some fashion, usually through network connections. A single tier is usually one self-contained system, and multiple tiers means that applications and devices connect to and rely on each other to provide data or services. These architectures can range from a simple two-tiered client/server model, such as one where a client’s web browser connects to a web server to retrieve information, to more complex architectures with multiple tiers and many different components, such as application or database servers.
What characterizes distributed systems the most is that processing is shared between hosts. Some hosts in an n-tiered system provide most of the processing, some hosts provide storage capabilities, and still others provide services such as security, data transformation, and so on.
There are many different security concerns with n-tiered architectures. One is the flow of data between components. From strictly a functional perspective, data latency, integrity, and reliability are concerns since connections can be interrupted or degraded, which then affects the availability goal of security. However, other security concerns include nonsecure communications, weak authentication mechanisms, and lack of adequate encryption. Two other key considerations in n-tiered architectures are application vulnerabilities and vulnerabilities associated with the operating system on any of the components.
Database Systems
Databases come in many implementations and are often targets for malicious entities. A database can be a simple spreadsheet or desktop database that contains personal financial information, or it can be a large-scale, multitiered big data implementation. There are several models for database construction, and some of these lend themselves to security better than others.
Relational databases, which make up the large majority of database design, are based on tables of information, with rows and columns (also called records and fields, respectively). Database rows contain data about a specific subject, and columns contain specific information elements common to all subjects in the table. The key is one or more fields in the table used to uniquely identify a record and establish a relationship with a related record in a different table. The primary key is a unique combination of fields that identifies a record based upon nonrepeating data. A foreign key is used to establish a relationship with a related record in a different table or even another database. Indexes are keys that are used to facilitate data searches within the database.
In addition to relational databases (the most common type), there are other database architectures that exist and are used in different circumstances. Some of these are simple databases that use text files formatted in simple comma- or tab-separated fields and use only one table (called a flat-file database). Another type, called NoSQL, is used to aggregate databases and data sources that are disparate in nature, such as a structured database combined with unstructured (unformatted) data. NoSQL databases are used in “big data” applications that must glean usable information from multiple data sources that have no format, structure, or even data type in common. A third type of database architecture is the hierarchical database, which is an older type still used in some applications. Hierarchical databases use a hierarchical structure where a main data element has several nested hierarchies of information under it. Note that there are many more types of database architectures and variations of the ones we just mentioned.
Regardless of architecture, common vulnerabilities of databases include poor design that allows end users to view information they should not have access to, inadequate interfaces, lack of proper permissions, and vulnerabilities in the database management system itself. To combat these vulnerabilities, implement restrictive views and constrained interfaces to limit the data elements that authorized users are able to access, as well as database encryption and vulnerability/patch management for database management systems.
Cryptographic Systems
Cryptographic systems have two primary types of vulnerabilities: those that are inherent to the cryptographic algorithm or key, and those that affect how a cryptosystem is implemented. Between the two, weak algorithms and keys are more common, but there can be issues with how cryptographic systems are designed and implemented. We will go more into depth on the weaknesses of cryptographic systems in Objective 3.6.
Industrial Control Systems
Industrial control systems (ICSs) are a unique set of information technologies designed to control physical devices in mechanical and physical processes. ICSs are different from traditional IT systems in that some of their devices, programming languages, and protocols are legacy or proprietary and were meant to stand alone and not connect to traditional networks. A distributed control system (DCS) is a network of these devices that are interconnected but may be part of a closed network; typically a DCS consists of devices that are in close proximity to each other, so they do not require long-haul or wide-area connections. A DCS may be the type of control device network encountered in a manufacturing or power facility. Whereas a DCS is limited in range and has devices that are very close to each other, a supervisory control and data acquisition (SCADA) system covers a large geographic area and consists of multiple physical devices using a mixture of traditional IT and ICS.
NOTE Both DCS and SCADA systems, as well as some IoT and embedded systems, all fall under the larger category of ICS.
Concepts and technologies related to ICSs that you should be aware of for the exam include
• Programmable logic controllers (PLCs) These are devices that control electromechanical processes.
• Human–machine interfaces (HMIs) These are monitoring systems that allow operators to monitor and interact with ICS systems.
• Data historian This is the system that serves as a data repository for ICS devices and commonly stores sensor data, alerts, command history, and so on.
Because ICS devices tend to be relatively old or proprietary in nature, they often do not have authentication or encryption mechanisms built-in, and they may have weak security controls, if any. However, modern technologies and networks now connect to some of these older or legacy devices, which poses issues regarding security compatibility and the many vulnerabilities involving data loss and the ability to connect into otherwise secure networks through these legacy devices. Operational technology (OT) is the grouping together of traditional IT and ICS devices into a system and requires special attention in securing those networks.
Internet of Things
Closely related to ICS devices are the more modern, commercialized, and sometimes consumer-driven versions of those devices, popularly referred to as the Internet of Things (IoT). IoT is a more modern approach to embedding intelligent systems that can interact with and connect to other systems, including the worldwide Internet. A wide range of devices—from smart refrigerators, doorbells, and televisions to medical devices, wearables (e.g., smart watches), games, and automobiles—are considered part of the Internet of Things, as long as they have the ability to connect to other systems via wireless or wired connections. IoT devices use standardized communications protocols, such as TCP/IP, and have very specialized but sometimes limited processing power, memory, and data storage. Inadequate security when connected to the Internet is their primary weakness, as many of these IoT devices do not have advanced authentication, encryption, or other security mechanisms, which makes them an easy entryway into other traditional systems that may house sensitive data.
Embedded Systems
Embedded systems are integrated computers with all of their components self-contained within the system. They are typically designed for specific uses and may only have limited processing or storage capabilities. Examples of embedded systems are those that control engine functions in a modern automobile or those that control aircraft systems. Embedded systems are similar to ICS/SCADA and IoT systems in that they are special-function devices that are often connected to the Internet, sometimes without consideration for security mechanisms. Many embedded systems are proprietary and do not have robust, built-in security mechanisms such as strong authentication or encryption capabilities. Additionally, the software in embedded systems is often embedded into a computer chip and may not be easily updatable or patched as vulnerabilities are discovered for the system.
Cloud-Based Systems
Cloud computing is a set of relatively new technologies that facilitate the use of shared remote computing resources. A cloud service provider (CSP) offers services to clients that subscribe to the services. Normally, the cloud service provider owns the physical hardware, and sometimes the infrastructure and software, that is used by the clients to access the services. A client connects to the provider’s infrastructure remotely and uses the resources as if the client were connected on the client’s premises. Cloud computing is usually implemented as large data centers that run multiple virtual machines on robust hardware that may or may not be dedicated to the client.
Organizations subscribe to cloud services for many reasons, which include cost savings by reducing the necessity to build their own infrastructures, buy their own equipment, or hire their own network and security personnel. The cloud service provider takes care of all these things, to one degree or another, based upon what the client’s subscription offers.
There are three primary models for cloud computing subscription services:
• Software as a Service (SaaS) The client subscribes to applications offered by the CSP.
• Platform as a Service (PaaS) Virtualized computers run on the CSP’s infrastructure and are provisioned for the use of the client.
• Infrastructure as a Service (IaaS) The CSP offers networking infrastructure and virtual hosts that clients can provision and use as they see fit.
Other types of cloud services that CSPs offer include Security as a Service (SECaaS), Database as a Service (DBaas), Identity as a Service (IDaas), and many others.
In addition to the three primary subscription models, there are also four primary deployment models for cloud infrastructures:
• Private cloud The client organization owns the infrastructure, or subscribes to a dedicated portion of infrastructure located in a cloud service provider’s data center.
• Public cloud The client organization uses public cloud infrastructure providers and subscribes to specific services only; infrastructure services are not dedicated solely to the client but are shared among different clients.
• Community cloud Cloud infrastructure is shared between like organizations for the purposes of collaboration and information exchange.
• Hybrid cloud This is a combination of any or all of the other deployment models, and is likely the most common you will see.
While a cloud service provider uses a shared responsibility model that offsets some of the burden of security protection from the client, there are still vulnerabilities in cloud-based models and deployments. Some of the considerations for the shared security model include
• Delineated responsibilities Responsibilities between the cloud service provider and the client must be delineated and accountability must be maintained.
• Administrative access to devices and infrastructure The client may or may not have access to all of the devices and infrastructure they use and may have limited ability to configure or secure those devices.
• Auditing Both the client and the CSP must share responsibility for auditing actions on the part of client personnel and the CSP.
• Configuration and patching Usually the CSP is responsible for host, software, and infrastructure configuration and patching, but this must be detailed in the agreement.
• Data ownership and retention Data owned by the client, particularly sensitive data such as healthcare information and personal data, may be accessed or processed by the CSP’s personnel, but accountability for its protection remains with the client.
• Legal liability CSP agreements must address issues such as breaches in terms of legal liability, responsibility, and accountability.
• Data segmentation The client must determine if the data will be comingled with or segmented from other organizations’ data when it is processed and stored on the CSP’s equipment.
Virtualized Systems
Virtualized systems use software to emulate hardware resources; they exist in simulated environments created by software. The most popular example of a virtualized system is a virtual operating system that is created and managed by a hypervisor. A hypervisor is responsible for creating the simulated environment and managing hardware resources for the virtualized system. It acts as a layer between the virtual system and the higher-level operating system and physical hardware. A hypervisor comes in two flavors:
• Type I Also called a bare-metal hypervisor, this is a minimal, special-purpose operating system that runs directly on hardware and supports virtual machines installed on top of it.
• Type II This is implemented as a software application that runs on top of an existing operating system, such as Windows or Linux, and acts as an intermediary between the operating system and the virtualized system. The virtualized OS is sometimes referred to as a guest, and the physical system it runs on is referred to as a host.
Containerization
A virtualized system can be an entire computer, including its operating system, applications, and user data. However, sometimes a full virtualized system is not needed. Virtualized systems can be scaled to a much smaller level than guest operating systems. A smaller simulated environment, called a container, can be created that simply runs an application in its entirety so there’s no need for a full virtual operating system. The container interacts with the hypervisor to get all the necessary resources, such as CPU processing time, RAM, and so on. This allows for minimal resource use and eliminates the necessity to build an entire virtual computer. Popular containerization software includes Kubernetes and Docker.
Microservices
Microservices are a minimalized form of containerization that doesn’t require building a large application. Application functionality and services that an application might otherwise provide are divided up into much smaller components, called microservices. Microservices run in a containerized environment and are essentially small, decentralized individual services designed and built to support business capabilities. Microservices are also independent; they tend to be loosely coupled, meaning they do not have a lot of required dependencies between individual services. Microservices can be a quick and efficient way to rapidly develop, test, and provision a variety of functions and services.
Serverless
An even more minimalized form of virtualization are serverless functions. In a serverless implementation, services such as compute, storage, messaging, and so on, along with their configuration parameters, are deployed as microservices. They are called serverless functions because a dedicated hosting service or server is not required. Serverless architectures work at the individual function level.
High-Performance Computing Systems
High-performance computing (HPC) systems are far more powerful than traditional general-purpose computing systems, and they are designed to solve large problems, such as in mathematics, economics, and advanced physics. In addition to having extremely high-end hardware in every step of the processing chain, HPC systems also aggregate computing power by using multiple processors (sometimes hundreds of thousands), faster buses, and specialized operating systems designed for speed and accuracy.
Edge Computing Systems
In the age of real-time financial transactions, video streaming, high-end gaming, and the need to have massive processing power and storage with lightning-fast network speeds readily available, edge computing has become a more important piece of distributed computing. Edge computing is the natural evolution of content distribution networks (CDNs; also sometimes referred to as content delivery networks), which were originally invented to deliver web content (think gaming and video streaming services) to users. As large data centers hosting these services became more powerful, and then distributed throughout large regions, slow, cross-country wide area network (WAN) links often became the bottleneck. It became a necessity to bring speed and efficiency closer to the user.
EXAM TIP CDNs provide redundance and more reliable delivery of services by locating content across several data centers. Edge computing is designed to bring that content geographically closer to the user to overcome slow WAN links. Both, however, use similar methods and are almost part of the same infrastructures.
Rather than a user connecting through a network of potentially slow links across an entire country or even overseas, edge computing allows for intermediate distribution points for data and services to be established physically and logically closer to the user to help reduce the dependency on overtaxed long-haul connections. This way, a user doesn’t necessarily have to maintain a constant connection to a centralized data center for video streaming; the content can also be replicated to edge computing points so that the user can simply access those points without having to contend with slower links over large distances. Edge computing also uses the fastest available equipment and links to help minimize latency.
REVIEW
Objective 3.5: Assess and mitigate the vulnerabilities of security architectures, designs, and solution elements In this objective we discussed different types of computing architectures and designs, as well as their vulnerabilities. Client-based systems do not depend on any external devices or processing power and are not necessarily connected to a network. Server-based systems have client and server-based components to them. N-tier architectures are distributed systems that use multiple components. We looked at the basics of database systems, including relational and hierarchical systems. Nontraditional IT systems include industrial control systems, SCADA systems, and Internet of Things devices which may or may not have secure authentication or encryption mechanisms built in. We also reviewed cloud subscription services and cloud deployment architectures, to include Software as a Service, Infrastructure as a Service, and Platform as a Service, as well as public, private, community, and hybrid cloud models. Virtualized systems are made up of various components including hypervisors, virtualized guests, physical hosts, containers, microservices, and serverless architectures. These components emulate not only for operating systems, but also applications and lower-level constructs to minimize hardware requirements and provide specific functions. We also briefly discussed embedded systems which are essentially systems embedded into computer chips, as well as computing platforms on the opposite end of the scale which deal with massive amounts of processing power, or high-performance computing. Finally, we briefly discussed edge computing systems, which deliver services closer to the user to help eliminate latency issues over wide area networks.
3.5 QUESTIONS
1. A large system in a company has many components, including an application server, a web server, and a backend database server. Clients access the system through a web browser. Which of the following best describes this type of architecture?
A. N-tier architecture
B. Client/server architecture
C. Client-based system
D. Serverless architecture
2. Your company needs to provide some functionality for users that perform only very minimal services but will connect to another, larger line of business applications. You don’t need to program another large enterprise-level application. Which of the following is the best solution that will fit your needs?
A. Microservices
B. Virtualized operating systems
C. Embedded systems
D. Industrial control systems
3.5 ANSWERS
1. A An n-tier architecture is characterized by multiple distributed components. In this case, the n-tier architecture is composed of an application server, web server, and database server, along with its client-based web browsing connection.
2. A Microservices provide low-level functionality that can be accessed by other applications, without the need to build an entire enterprise-level application.
 Select and determine cryptographic solutions
Select and determine cryptographic solutions
Objectives 3.6 and 3.7 cover cryptography. You should understand the basic terms and concepts associated with cryptography, but you don’t have to understand the math behind it for the exam. We will go over basic terms and concepts in this objective, and in Objective 3.7 we will discuss some of the attacks that can be perpetrated on cryptography.
In this objective we will look at various aspects of cryptology and cryptography, including the cryptographic life cycle, which explains how keys and algorithms are selected and managed, and cryptographic methods that are used, such as symmetric, asymmetric, and quantum cryptography. We’ll also look at the application of cryptography, in the form of the public key infrastructure (PKI).
Cryptography
Cryptography is the science of storing and transmitting information that can only be read or accessed by specific entities through the use of mathematical algorithms and keys. While cryptography is the most popular term we use in association with the science, cryptology is the overarching term that applies to both cryptography and cryptanalysis. Cryptanalysis refers to analyzing and reversing cryptographic processes in order to break encryption. Encryption is the process of converting plaintext information, which can be read by humans and computers easily, into what is called ciphertext, which cannot be read or accessed by humans or machines without the proper cryptographic mechanisms in place. Decryption reverses that process and allows authorized entities to view information hidden by encryption. Cryptology supports the confidentiality and integrity goals of security, and also helps to ensure that supporting tenets, such as authentication, nonrepudiation, and accountability, are met.
Most cryptography in use today involves the use of ciphers, which convert individual characters (or the binary bits that make up the characters) into ciphertext. By contrast, the term code refers to using symbols, rather than characters or numbers, to represent entire words or phrases. Earlier ciphers used simple transposition to rearrange the characters in a message, so that they were merely scrambled among themselves, or substitution, in which the cipher replaced characters with different characters in the alphabet.
NOTE The term cipher can also be interchanged with the term algorithm, which refers to the mathematical rules that a given encryption/decryption process must follow. We’ll discuss algorithms in the next two sections as well.
Cryptographic Life Cycle
There are many different components to cryptography, each of which is controlled according to a carefully planned life cycle. The cryptographic life cycle is the continuing process of identifying cryptography requirements, choosing the algorithms that meet your needs, managing keys, and implementing the cryptosystems that will facilitate the entire encryption/decryption process. Regardless of the method used for cryptography, there are three important components: algorithms, keys, and cryptosystems.
Algorithms
Algorithms are complex mathematical formulas or functions that facilitate the cryptographic processes of encryption and decryption. They dictate how plaintext is manipulated to produce ciphertext. Algorithms are normally standardized and publicly available for examination. If it were just a matter of putting plaintext through an algorithm and producing ciphertext, this process could be repeated over and over to produce the same resulting ciphertext. However, this predictability eventually would be a vulnerability in that, given enough samples of plaintext and ciphertext, someone may figure out how the algorithm works. That’s why another piece of the puzzle, the key, is introduced to add variability and unpredictability to the encryption process.
Keys
The key, sometimes called a cryptovariable, is introduced into the encryption process along with the algorithm to add to the complexity of encryption and decryption. Keys are similar to passwords in that they must be changed often and are usually known only to the authorized entities that have access and authorization to encrypt and decrypt information. In 1883, Auguste Kerckhoffs published a paper stating that only the key should be kept secret in a cryptographic system. Known as Kerckhoffs’ principle, it further states that the algorithm in a cryptographic system should be publicly known so that its vulnerabilities can be discovered and mitigated.
There have been some exceptions to this principle; of note are the U.S. government’s Clipper Chip and Skipjack algorithms, whose inner workings were kept secret under the theory that if no one outside the government circles knew how they worked, then no one would be able to discover vulnerabilities. Industry and professional security communities disagree with this approach, as it tends to follow the faulty principle of security through obscurity, meaning that simply not being aware of a security control makes it stronger. As such, most commonly used algorithms today are open for inspection and review.
Keys should be created to be strong, meaning that the following guidance should be considered when creating keys:
• Longer key lengths contribute to stronger keys.
• A larger key space (number of available character sets and possibilities for each in a key) creates stronger keys.
• Keys that are more random and not based on common terms, such as dictionary words, are stronger.
• Keys should be protected for confidentiality the same as passwords—not written down in publicly accessible places or shared.
• Keys should be changed frequently to mitigate against attacks that could compromise them.
• No two keys should generate the same ciphertext from the same plaintext, which is called clustering.
Cryptosystems
A cryptosystem is the device or mechanism that implements cryptography. It is responsible for the encryption and decryption processes. A cryptosystem does not have to be a piece of hardware; it can be software, such as an application that generates keys or encrypts e-mail. Cryptosystems are built in a secure fashion, but also use complex keys and algorithms. The strength of a cryptosystem is called its work function. The higher the work function, the stronger the cryptographic system. As we will see in Objective 3.7, attacks against cryptosystems and any weaknesses in their implementation are commonplace.
Cryptographic Methods
Using the common cryptographic components of algorithms, keys, and cryptosystems, cryptography is implemented using many different methods and means. Cryptographic methods are designed to increase strength and resiliency of cryptographic processes while at the same time reducing their complexity when possible.
Two basic operations are used to convert plaintext into ciphertext:
• Confusion The relationship between any plaintext and the key is so complex that an attacker cannot encrypt plaintext into ciphertext and figure out the key from those relationships.
• Diffusion A very small change in the plaintext, even a single character in a sentence, causes much larger changes to ripple through the resulting ciphertext. So, changing a single character in the plaintext does not necessarily result in just changing a single character in the ciphertext; the resulting change would likely change a large part of the resulting ciphertext.
Another cryptographic process you should be aware of involves the use of Boolean math, which is binary. Cryptography uses logical operators, such as AND, NAND, OR, NOR, and XOR, to change binary bits of plaintext into ciphertext. The exact combination of logical operations used, and their order, depends largely on the algorithm in use. These processes also use one-way functions. A one-way function is a mathematical operation that cannot be easily reversed, so plaintext that processes through one of these functions into ciphertext cannot be reversed to its original state from ciphertext using the same function, without knowing the algorithm and key. Some algorithms also add random numbers or seeds (called a nonce) to make the encryption process more complex, random, and difficult to reverse engineer.
Various cryptographic methods exist, but for purposes of preparing for the CISSP exam, you should be familiar with four in particular: symmetric encryption, asymmetric encryption, quantum cryptography, and elliptic curve cryptography.
Symmetric Encryption
Symmetric encryption (also called secret key or session key cryptography) uses one key for its encryption and decryption operations. The key is selected by all parties to the communications process, and everyone has the same key. The key can be generated on-the-fly by the cryptographic system or application, such as when a person accesses a secure website and negotiates a secure connection with the remote server. The main characteristics of symmetric encryption include the following:
• It is not easily scalable, since complete confidential communications between all parties involved requires many more keys that have to be managed.
• It is relatively fast and suitable for encrypting bulk data.
• Key exchange is problematic, since symmetric keys must be given to all parties securely to prevent unauthorized entities from getting access to the key.
One of the main vulnerabilities in symmetric encryption is that it is not scalable, since the number of keys required between multiple parties increases as the size of the group requiring encryption among themselves increases. For example, if two people want to use symmetric encryption to send encrypted messages between each other, they need only one symmetric key. However, if three people are involved, and they each need to send encrypted messages between each other that only the other person can decrypt, each person needs two symmetric keys to connect to the other two. For larger groups, this number can become unwieldy; the formula for determining the number of keys needed between multiple parties is N(N – 1)/2, where N is the number of parties involved.
As an example, if 100 people need to be able to exchange secure messages with each other, and all 100 people are authorized to read all messages, then only one symmetric key is needed. However, if certain messages have to be encrypted and only decrypted by certain persons within that group, then more keys are needed. In this example, to ensure that each individual can exchange secure messages with every other single individual only, according to the formula 100(100 – 1)/2, then 4,950 individual keys would be required. As you will see in the next section, asymmetric encryption methods can solve the scalability problem.
Symmetric encryption methods use either of two primary types of cipher: block or stream. A block cipher encrypts data in huge chunks, called blocks. Block sizes are measured in bits. Common block sizes are 64-bit, 128-bit, and 256-bit blocks. Typical block ciphers include Blowfish, Twofish, DES, and the Advanced Encryption Standard, or AES, which are detailed in Table 3.6-1.
TABLE 3.6-1 Common Symmetric Algorithms

Stream ciphers, on the other hand, encrypt data one bit at a time. Stream ciphers are much faster than block ciphers. The most common example of a widely used stream cipher is RC4. Initialization vectors (IVs) are random seed values that are used to begin the encryption process with a stream cipher.
Asymmetric Encryption
Asymmetric encryption, unlike its symmetric counterpart, uses two keys. One of these keys is arbitrarily referred to as the public key, and the other is the private key. The keys are mathematically related but not identical. Having access to or knowledge of one key does not allow someone to derive the other key in the pair. An important thing to understand about asymmetric encryption is that whatever data one key encrypts, only the other key can decrypt, and vice versa. You cannot decrypt ciphertext using the same key that was used to encrypt it. This is an important distinction to make since it is the foundation of asymmetric encryption, also referred to as public key cryptography.
Other key characteristics of asymmetric encryption include the following:
• It uses mathematically complex algorithms to generate keys, such as prime factorization of extremely large numbers.
• It is much slower than symmetric encryption.
• It is very inefficient at encrypting large amounts of data.
• It is very scalable, since even a large group of people exchanging encrypted messages only each need their own key pair, not multiple keys from other people.
Asymmetric encryption allows the user to retain one key, referred to as the user’s private key, and give the public key out to anyone. Since anything encrypted with the public key can only be decrypted with the user’s private key, this ensures confidentiality. Conversely, anything encrypted with a user’s private key can only be decrypted with the public key. While this definitely does not guarantee confidentiality, it does assist in ensuring authentication, since only the user with the private key could have encrypted data that anyone else with the public key can decrypt. Common asymmetric algorithms include those listed in Table 3.6-2.
TABLE 3.6-2 Common Asymmetric Algorithms
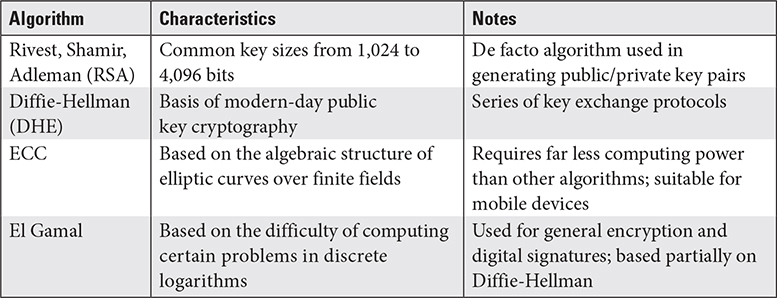
Quantum Cryptography
Quantum cryptography is a cutting-edge technology that uses quantum mechanics to provide for cryptographic functions that are essentially impossible to eavesdrop on or reverse engineer. Although much of quantum cryptography is still theoretical and years away from practical implementation, quantum key distribution (QKD) is one aspect of quantum cryptography that is becoming more useful in the near term. QKD can help with secure key distribution issues associated with symmetric cryptography. It uses orientation of polarized photons, assigned to binary values, to pass keys from one entity to another. Note that observing or attempting to measure the orientation of these photons actually changes them and disrupts communication, rendering the process moot. This is why it would be very easy to detect any unauthorized eavesdropping or modification of the communication stream.
Elliptic Curve Cryptography
Elliptic curve cryptography (ECC) is an example of an asymmetric algorithm and uses points along an elliptic curve to generate public and private keys. The keys are mathematically related, as are all asymmetric keys, but cannot be used to derive each other. ECC is used in many different functionalities, including digital signatures (discussed in an upcoming section), secure key exchange and distribution, and, of course, encryption. The main characteristics of ECC you need to remember are that it is highly efficient, much more so than other asymmetric algorithms, is far less resource intensive, and requires much less processing capability. This makes ECC highly suitable for mobile devices that are limited in processing power, storage, electrical power, and bandwidth.
Integrity
Along with confidentiality and availability, integrity is one of the three primary goals of security, as described in Objective 1.2. Integrity ensures that data and systems are not tampered with, and that no unauthorized modifications are made to them. Integrity can be assured in a number of ways, one of which is via cryptography, which establishes that data has not been altered by computing a one-way hash (also called a message digest) of the piece of data. For example, a message that is hashed using a one-way hashing function produces a unique fingerprint, or message digest. Later, after the message has been transmitted, received, or stored, if the integrity of the message is questioned or required, the same hashing algorithm is applied to the message. If the message has been unaltered, the hash should be identical. If it has been changed in any way, either intentionally or unintentionally, the resulting hash will be different.
Hashing can be used in a number of circumstances, including data transmission and receipt, e-mail, password storage, and so on. Remember that hashing is not the same thing as encryption; the goal of hashing is not to encrypt something that must be decrypted. Hashes are generated using a one-way function that cannot be reversed and then the hashes are compared, not decrypted.
Hash values should be unique to a piece of data and not duplicated by any other different piece of data using the same algorithm. If this occurs, it is called a collision, and represents a vulnerability in the hashing algorithm. Popular hashing algorithms include MD5 and the Secure Hash Algorithm (SHA) family of algorithms.
EXAM TIP Although it is a cryptographic process, hashing is not the same thing as encryption. Encrypted text can be decrypted; that is, reversed back to its plaintext state. Hashed text is not decrypted, the text is merely hashed again so the hashes can be compared to verify integrity.
Hybrid Cryptography
Hybrid cryptography, as you might guess from its name, is the combination of multiple methods of cryptography, primarily symmetric and asymmetric. On one hand, symmetric encryption is not easily scalable but is quick and well suited for encrypting bulk amounts of information; it’s not suitable for use among large groups of people. On the other hand, asymmetric encryption only uses two keys per person, and the public key can be given to anyone, which makes it very scalable. But it is slower and not suitable for bulk data encryption, which is more appropriate for symmetric encryption. It’s easy to see that each of these algorithms makes up for the disadvantages of the other, so it makes sense to use them together.
In order to use asymmetric and symmetric encryption together two people who wanted to share encrypted data between them could do the following:
1. The first user (the sender) would give their public key to the second user (the recipient).
2. The recipient would generate a symmetric key, and then encrypt that symmetric key with the sender’s public key.
3. The sender would then decrypt the encrypted key using their own private key.
Once the sender has the key, then neither party needs to worry about public and private key pairs; they can simply use the symmetric key to exchange large amounts of data quickly. In this particular example, the symmetric key is called a session key, since it is used only for that particular session of exchanging encrypted data.
The asymmetric encryption method allows for secure key exchange, which also happens in the practical world when a user establishes an HTTPS connection to a secure server using a web browser. In this example, one party (usually the client side) creates a session key for both parties to use. Since it’s not secure to send that key to the second party (in this case, the server) in an unencrypted form, the sender can use the recipient’s public key to encrypt the session key. The recipient then uses their private key to decrypt the message, allowing them to access the session key. Now that both parties have the session key, they can use it to exchange large amounts of data in a fast and efficient manner.
Digital Certificates
Digital certificates are electronic files that contain public and/or private keys. The digital certificate file is a way of securely distributing public and private keys and serves to prove they are solidly connected to an individual entity, such as a person or organization. The certificates are generated through a server that issues them, called a certificate authority server. Digital certificates can be installed in any number of software applications or even hardware devices. Once installed, they reside in the system’s secure certificate store. This enables them to be used automatically and transparently when users need them to encrypt e-mail, connect to a secure financial website, or encrypt a file before transmitting it.
Digital certificates contain attributes such as the user’s name, organization, the certificate issuance date, its expiration date, and its purpose. Digital certificates can be used for a variety of purposes, and a digital certificate can be issued for a single purpose or multiple purposes, depending upon the desires of the issuing organization. For example, a digital certificate could be used to encrypt e-mail and files, provide for identity authentication, and so on, or a digital certificate could be generated only for a specific purpose and used only by a software development company to digitally sign software. Most digital certificates use the popular X.509 standard, which dictates their format and structure. Common file formats for digital certificates include DER, PEM, and the Public Key Cryptography Standards (PKCS) #7 and #12.
NOTE PKCS was developed by RSA Security and is a proprietary set of standards.
Public Key Infrastructure
Public key infrastructure, or PKI, is the name given to the set of technologies, processes, and procedures, along with associated infrastructure, that implements hybrid cryptography (using both asymmetric and symmetric methods and algorithms) to provide a trusted infrastructure for encryption, file integrity, and authentication. PKI follows a formalized hierarchical structure, as shown in Figure 3.6-1.
FIGURE 3.6-1 A typical PKI
The typical PKI consists of a trusted entity, called a certificate authority (CA), that provides the certificates and keys. This may be a commercial company that specializes in this business (such as Verisign, Thawte, Entrust, etc.) or even a department within your own company that is charged with issuing keys and certificates. Trusted entities can also be third parties, just as long as they can validate the identities of subjects. Trust in a CA is based on the assumption that it verifies the identity and validity of entities to which it issues keys and certificates (called subjects).
Generally, if a certificate is to be used or trusted only within your organization, it should come from an internal CA; if you need organizations external to yours to trust the certificate (e.g., customers, business partners, suppliers, etc.), then you should use an external or third-party CA.
NOTE The term certificate authority can refer to either the trusted entity itself or to the server that actually generates the keys and certificates, depending on the context.
In larger organizations, the workload of validating identities is often offloaded to a different department or organization; this is known as the registration authority (RA). The RA collects proof of identity, such as an individual’s driver’s license, passport, birth certificate, and so on, and validates that the user is actually who they say they are. The RA then passes this information on to the CA, which performs the actual key generation and issues the digital certificates.
In organizations where the root (top-level) CA performs all the key-generation and certificate-issuance functions, it might be prudent to add subordinate (sometimes referred to as intermediate) CAs, which are additional servers tasked with issuing specific types of certificates to offload the root CA’s work. The subordinate servers could issue specific certificates, such as user certificates or code signing certificates, or they could simply share the load of issuing all the same certificates as the root CA. Implementing subordinate CAs is also a good security practice. By having subordinate CAs issue all certificates, the root CA can be taken offline to protect it, since an attack on that server would compromise the entire trust chain of the certificates issued by the organization.
While PKI is the most common implementation of asymmetric cryptography, it is not the only one. As just described, PKI relies on a hierarchy of trust, which begins with a centralized root CA, and is constructed similar to a tree. Other models implement digital identities, including peer-to-peer models, such as the web-of-trust model used by the Pretty Good Privacy (PGP) encryption program.
Nonrepudiation and Digital Signatures
Nonrepudiation means that someone cannot deny that they took an action, such as sending a message or accessing a resource. Nonrepudiation is vital to accountability and auditing, since accountability is used to ensure that any individual’s actions can be traced back to them and they can be held responsible for those actions. Auditing assists in establishing nonrepudiation for a variety of actions, including those relating to accessing resources, exercising privileges, and so on.
Cryptography can assist with nonrepudiation through the use of digital signatures. Digital signatures are completely tied to an individual, so their use guarantees (provided the digital certificate has not been compromised in any way) that an individual cannot deny that they took an action, such as sending an e-mail that has been digitally signed.
Digital signatures support the authenticity process to prove that a message sent by the user is authentic and that the user is the one who sent it. This is a perfect example of hybrid cryptography; the message to be sent is hashed, which provides integrity since the message cannot be altered without changing its hash. The sender’s private key encrypts the message hash, and this is sent as part of the transmission to the recipient. When the recipient receives the message (which could also be encrypted in addition to being digitally signed), they can use the sender’s public key to decrypt the hash of the message, and then compare the hashes to ensure integrity. Hashing ensures message integrity, and encrypting the hash with the user’s private key ensures authenticity, since the message could have come only from the private key holder.
Key Management Practices
Key management consists of the procedures and processes used to manage and protect cryptographic keys throughout their life cycle. Note that keys could be those used by hardware mechanisms or software applications, as well as individual keys issued to users. Management of keys includes setting policies and implementing the key management infrastructure. The practical portion of key management includes
• Verifying user identities
• Issuing keys and certificates
• Secure key storage
• Key escrow (securely maintaining copies of users’ keys in the event a user leaves and encrypted data needs to be recovered)
• Key recovery (in the event a user loses a key, or its digital copy becomes corrupt)
• Managing key expiration (renewing or reissuing keys and certificates prior to their expiration)
• Suspending keys (for temporary reasons, such as an investigation or extended vacation)
• Key revocation (permanent action based on circumstances such as key compromise or security policy violations by user)
Among the listed items, one of the most important responsibilities of key management is to ensure that certificates and their associated keys are renewed before they expire. If they are allowed to lapse, it may prove difficult to reuse them, and the organization would have to re-issue new keys and certificates.
Certificate revocation is an important security issue as well. Organizations typically use several means to revoke certificates that are suspected of compromise or misuse. First, an organization publishes a formal certificate revocation list (CRL), which identifies revoked certificates. This process can be manual and produce an actual downloadable list, but most modern organizations use the Online Certificate Status Protocol (OCSP), which automates the process of publishing certificate status, including revocations. The CRL is published periodically or as needed and is also copied electronically to a centralized repository for the organization. This allows for certificates to be checked prior to their use or trust by another organization.
While certificate revocation is normally a permanent action taken in the event of a policy violation or compromise, organizations also have the option to temporarily suspend keys and certificates and then reactivate and reuse them once certain conditions are met. For example, an organization might suspend keys and certificates so that an individual cannot use them during an investigation or during an extended vacation. The organization should always consider carefully whether it needs to revoke a certificate or simply suspend it temporarily, since revoking a certificate effectively renders it permanently void.
Another important consideration is certificate compromise. If this occurs, the organization should revoke the certificate immediately so that it can no longer be used. The details of the revocation should be published to the CRL and sent with the next OCSP update. Additionally, the organization should decrypt all data encrypted with that key pair and issue new keys and certificates to replace the compromised ones.
REVIEW
Objective 3.6: Select and determine cryptographic solutions In this first of two objectives that cover cryptography in depth, we discussed the basic elements of cryptography, including terms and definitions related to cryptography, cryptology, and cryptanalysis, as well as the basic components of cryptography, which include algorithms, keys, and cryptosystems.
We also examined various cryptographic methods, including symmetric cryptography (using a single key for both encryption and decryption), asymmetric cryptography (using a public/private key pair), quantum cryptography, and elliptic curve cryptography.
We briefly discussed the role cryptography plays in ensuring data integrity, in the form of hashing or message digests. Hybrid cryptography is a solution that applies different methods of cryptography, usually symmetric, asymmetric, and hashing, in order to make up for the disadvantages in each of these methods when used individually. With hybrid cryptography, we can ensure confidentiality, integrity, authentication, authenticity, and nonrepudiation. Hybrid cryptography is implemented through the use of digital certificates, which are generated by a public key infrastructure.
Digital certificates are used to ensure authenticity of a message and validate its sender. Public key infrastructure consists of several components, including certificate authorities, registration authorities, and subordinate certificate servers. Key management practices involve managing keys and certificates throughout their life cycle, and include setting policies, issuing keys and certificates, renewing them before they expire, and suspending or revoking them when necessary.
3.6 QUESTIONS
1. You are teaching a CISSP exam preparation class and are explaining the basics of cryptography to the students in the class. Which of the following is the key characteristic of Kerckhoffs’ principle?
A. Both keys and algorithms should be publicly reviewed.
B. Algorithms should be publicly reviewed, and keys must be kept secret.
C. Keys should be publicly reviewed, and algorithms must be kept secret.
D. Neither keys nor algorithms must be publicly reviewed; they should both be kept secret.
2. Evie is a cybersecurity analyst who works at a major research facility. She is reviewing different cryptosystems for the research facility to potentially purchase and she wants to be able to compare them. Which of the following is a measure of a cryptosystem’s strength, which would enable her to compare different systems?
A. Work function
B. Key space
C. Key length
D. Algorithm block size
3. Which of the following types of algorithms uses only a single key, which can both encrypt and decrypt information?
A. Elliptic curve
B. Hashing
C. Asymmetric cryptography
D. Symmetric cryptography
4. Which of the following algorithms has the disadvantage of not being very effective at encrypting large amounts of data, as it is much slower than other encryption methods?
A. Quantum cryptography
B. Hashing
C. Asymmetric cryptography
D. Symmetric cryptography
3.6 ANSWERS
1. B Kerckhoffs’ principle states that algorithms should be open for inspection and review, in order to find and mitigate vulnerabilities, while keys should remain secret.
2. A Work function is a measure that indicates the strength of a cryptosystem. It considers several factors, including the variety of algorithms available for the cryptosystem to use, key sizes, key space, and so on.
3. D Symmetric cryptographic algorithms only require the use of one key to both encrypt and decrypt information.
4. C Asymmetric cryptography does not handle large amounts of data very well when encrypting, and it can be quite slow, as opposed to symmetric encryption, which is much faster and can easily handle bulk data encryption/decryption.
 Understand methods of cryptanalytic attacks
Understand methods of cryptanalytic attacks
In this objective we will continue our discussion of cryptography from Objective 3.6 by looking at the many different ways cryptographic systems can be vulnerable to attack, as well as discussing some of those attack methods. This won’t make you an expert on cryptographic attacks, but you will become familiar with some of the basic attack methods used against cryptography that are within the scope of the CISSP exam.
Cryptanalytic Attacks
Cryptographic systems are vulnerable to a variety of attacks. Cryptanalysis is the process of breaking into cryptosystems. The goal of cryptanalysis, and cryptographic attacks, is to circumvent encryption by discovering the key involved, breaking the algorithm, or otherwise defeating the cryptographic system’s implementation such that the system is ineffective.
There are many different attack vectors used in cryptanalysis, but they all target one or more of three primary areas: the key itself, the algorithm used to create the encryption process, and the implementation of the cryptosystem. Secondary areas that are targeted are the data itself, whether ciphertext or plaintext, and people, through the use of social engineering techniques. Some of these attack methods are specific to particular types of cryptographic algorithms or systems, while other attack methods are very general in nature. We will discuss many of these attack methods throughout this objective.
Brute Force
A brute-force attack is one in which the attacker has little to no knowledge of the key, the algorithm, or the cryptosystem. Essentially, the attacker is trying every possible combination of ciphertext to derive the correct key (or password), until the correct plaintext is discovered. Most brute-force attacks are offline attacks against password hashes captured from systems through other attack methods, since online attacks are easily thwarted by account lockout mechanisms. Theoretically, given enough computational power, almost all offline brute-force attacks would succeed eventually, but the extraordinary length of time required to break some of the more complex algorithms and keys makes most such attacks infeasible.
It’s also important to distinguish a dictionary attack from a brute-force attack. In a dictionary attack, the attacker uses a much smaller range of characters, often compiled into word lists that are hashed and tried against a targeted password hash. If the password hashes match, then the attacker has discovered the password. If they don’t match, then the attack progresses to the next word in the word list. Dictionary attacks are often accelerated by using precomputed hashes (called rainbow tables). Note that a dictionary attack is less random than a brute-force attack. In a brute-force attack, the attacker uses all possible combinations of allowable characters to attempt to guess a correct password or key.
EXAM TIP Both dictionary and brute-force attacks are typically automated and can attempt hundreds of thousands of password combinations per minute. Whereas a brute-force attack will theoretically eventually succeed, given enough time and computing power, dictionary attacks are limited to the word lists used and may exhaust all possibilities in the list while never discovering the targeted password.
Ciphertext Only
A ciphertext-only attack is one in which the attacker only has samples of ciphertext to analyze. This type of attack is one of the most common types of attacks since it’s very easy to get ciphertext by intercepting network traffic. There are different methods that can be used for a ciphertext-only attack, including frequency analysis, discussed in the upcoming sections.
Known Plaintext
In this type of attack, an attacker has not only ciphertext but also known plaintext that corresponds with it, enabling the attacker to compare the known plaintext with its ciphertext results to determine any relationships between the two. The attacker looks for patterns that may indicate how the plaintext was converted to ciphertext, including any algorithms used, as well as the key. The purpose of this type of attack is not necessarily to decrypt the ciphertext that the attacker has, but to be able to gather information that the attacker can use to collect additional ciphertext and then have the ability to decrypt it.
Chosen Ciphertext and Chosen Plaintext
In a chosen-ciphertext attack, the attacker generally has access to the cryptographic system and can choose ciphertext to be decrypted into plaintext. This type of attack isn’t necessarily used to gain access to a particular piece of encrypted plaintext, but to be able to decrypt future ciphertext. The attacker may also want to discover how the system works, including deriving the keys and algorithms, if the attacker doesn’t already have that information.
The chosen-plaintext attack, on the other hand, enables the attacker to choose the plaintext that gets encrypted and view the resulting ciphertext. This also allows the attacker to compare each plaintext input with its corresponding ciphertext output to determine how the cryptosystem works. Again, both of these types of attack assume that the attacker has some sort of access to the cryptographic system in question and can feed in plaintext and obtain ciphertext from the system at will.
Frequency Analysis
Frequency analysis is a technique used when an attacker has access to ciphertext and looks for statistically common patterns, such as individual characters, words, or phrases in that ciphertext. Think of the popular “cryptogram” puzzles you may see in supermarket magazines. This technique typically only works if the ciphertext is not further scrambled or organized into a more puzzling pattern; grouping the ciphertext into distinct groups of ten characters, for example, regardless of how they are spaced apart in the plaintext message, will help defeat this technique.
Implementation
Implementation attacks target not just the key or algorithm but how the cryptosystem in general is constructed and implemented. For example, there may be flaws in how the system stores plaintext in memory before it is encrypted, and this might enable an attacker to access that memory before the encryption process even occurs. Other systems may store decrypted text or even keys in memory. There are a variety of different attacks that can be used against cryptosystems, a few of which we will discuss in the next few sections.
Side Channel
A side-channel attack is any type of attack that does not directly attack the key or the algorithm but rather attacks the characteristics of the cryptosystem itself. A side-channel attack may attack different aspects of how the cryptographic system is implemented indirectly. The goal of a side-channel attack is to attempt to gain information on how the cryptosystem works, such as by recording power fluctuations, CPU processing time, and other characteristics of the cryptosystem, and deriving information about the sensitive inner workings of the cryptographic processes, possibly including narrowing down which algorithms and key sizes are used. There are many different methods of executing a side-channel attack; often the attacker’s choice of method depends on the type of cryptosystem involved. Among these methods are fault injection and timing attacks.
Fault Injection
A fault injection attack attempts to disrupt a cryptosystem sufficiently to cause it to repeat sensitive processes, such as authentication, giving the attacker an opportunity to gain information about those processes or, at the extreme, intercept credentials or insert themselves into the process. A classic example of a fault injection attack is when an attacker broadcasts deauthentication traffic over a wireless network and disrupts communications between a wireless client and a wireless access point. This causes both the client and the access point to have to reauthenticate to each other, leaving the door wide open for the attacker to intercept the four-way authentication handshake that the wireless access point uses.
Timing
Timing attacks take advantage of faulty sequences of events during sensitive operations. In Objective 3.4, we discussed how timing attacks exploit the dependencies on sequence and timing in applications that execute multiple tasks and processes concurrently, which includes cryptographic applications and processes. Remember that these attacks are called time-of-check to time-of-use (TOC/TOU) attacks. They attempt to interrupt the timing or sequencing of tasks cryptographic systems must execute in sequence. If an attacker can interrupt the sequence or timing, the interruption may allow an attacker to intercept credentials or inject themselves into the cryptographic process. This type of attack is also referred to as an asynchronous attack.
Man-in-the-Middle (On-Path)
An on-path attack, formerly known widely as a man-in-the-middle (MITM) attack, can be executed using a couple of different methods. The first method is to intercept the communications channel itself and attempt to use captured keys, certificates, or other authenticator information to insert the attacker into the conversation. Then the attacker can intercept what is being sent and received and has the ability to send false messages or replies. This is related to a similar attack, called a replay attack, where the attacker initially intercepts and then “replays” credentials, such as session keys. The second method is to attempt to discover and reverse the encryption and decryption functions to a point that the remaining functions can be determined. This variation is known as a meet-in-the-middle attack.
Pass the Hash
In certain circumstances, Windows will use what is known as pass-through authentication to authenticate a user to an additional resource. This may happen without the user explicitly having to authenticate, since password hashes are stored in the Windows system even after authentication is complete. In this attack, the perpetrator intercepts the Windows password hash used during pass-through authentication and attempts to reuse the hash on the network to authenticate to other hosts by simply passing the hash to them. Note that the attacker doesn’t have the actual password itself, only the password hash. The resource assumes that the password hash comes from a valid user’s pass-through authentication attempt.
Pass-the-hash attacks are most often seen in systems that still use older authentication protocols, such as NTLM, but even modern Windows systems can default to using NTLM during certain conditions while communicating with peer systems on a Windows Active Directory network. This makes the pass-the-hash attack still a serious problem even with modern Windows networks.
Kerberos Exploitation
Kerberos, described in detail in Objective 5.6, is highly dependent on consistent time sources throughout the infrastructure, since it timestamps tickets and requests and only allows a very minimal span of time that they can be used. Disrupting or attacking the Kerberos realm’s authoritative time source can help an attacker engage in replay attacks. Additional attacks on Kerberos include attempting to intercept tickets for reuse, as well as the aforementioned pass-the-hash attacks. Note that the Kerberos Key Distribution Center (KDC) can also be a single point of failure if compromised.
Ransomware
Ransomware attacks are a twist on traditional cryptographic attacks. Instead of the attacker attempting to steal credentials, discover keys, attack cryptosystems, and decrypt ciphertext, the attacker uses cryptography to hold an organization’s data hostage by encrypting it and demanding a ransom in exchange for the decryption key. The attacker frequently threatens the organization by encrypting sensitive and critical data, which the organization cannot get back, and sometimes even threatens to release encrypted data, along with the key, to the public Internet.
Almost all ransomware attacks occur after a malicious entity has invaded an organization’s infrastructure through attack vectors, very often phishing attacks. Ransomware has recently been used to attack hospitals, school districts, manufacturing companies, and other critical infrastructure. One of the most recent examples was the Colonial Pipeline attack, showing that ransomware is rapidly becoming the most impactful cyberthreat that organizations face.
REVIEW
Objective 3.7: Understand methods of cryptanalytic attacks In this objective we discussed the various attack methods that can be attempted against cryptographic systems. Cryptanalytic attacks typically target keys, algorithms, and implementation of the cryptosystem itself.
Attacks that target keys include common brute-force and dictionary attacks. Algorithm attacks include more sophisticated attacks that target both pieces of ciphertext and plaintext to gain insight into how the encryption/decryption process works. We also examined frequency analysis and chosen ciphertext attacks. Implementation attacks include side-channel attacks, fault injection attacks, and timing attacks. We also discussed on-path (formally known as man-in-the-middle or MITM) attacks that attempt to interrupt communications or cryptographic processes. Other advanced techniques include pass-the-hash and Kerberos exploitation attacks. We concluded our discussion with how ransomware attacks use cryptography in a different way to deny people the use of their data.
3.7 QUESTIONS
1. Your company has recently endured a cyberattack, and researchers have discovered that many different users’ encryption keys were compromised. The post-attack analysis indicates that the attacker was able to hack the application that generates keys, discovering that keys are temporarily stored in memory until the application is rebooted, and was therefore able to steal the keys directly from the application. Which of the following best describes this type of attack?
A. Fault injection attack
B. Timing attack
C. Ransomware attack
D. Implementation attack
2. You are a security researcher, and you have discovered that a web-based cryptographic application is vulnerable. If it receives carefully crafted input, it can be made to issue valid encryption keys to anyone, including an attacker. Which of the following best describes this type of attack?
A. Timing attack
B. Fault injection
C. Frequency analysis
D. Pass-the-hash
3.7 ANSWERS
1. D Since this type of attack took advantage of a flaw in the application that generates keys, this would be an implementation attack.
2. B In this type of attack, a web application could receive faulty input, which creates an error condition and causes valid encryption keys to be issued to an attacker. This would be considered a fault injection attack.
 Apply security principles to site and facility design
Apply security principles to site and facility design
In this objective and the next one, Objective 3.9, we’ll discuss physical security elements. First, in this objective, we will explore how the secure design principles outlined in Objective 3.1 apply to the physical and environmental security controls, particularly site and facility design.
Site and Facility Design
Although much of the CISSP exam relates to technical and administrative controls, it also covers physical controls, which are also critically important to protect assets. Site and facility design are advanced concepts that many cybersecurity professionals don’t have knowledge of or experience with. We’re going to discuss how to secure an organization’s site and its facilities and how to design and implement controls to protect people, equipment, and facilities.
Site Planning
If an organization is developing a new site, it has the opportunity to design the premises and facilities to address a wide variety of threats. If the organization is taking over an existing facility, particularly an old one, it may have to make some adjustments in the form of remodeling, retrofitting, landscaping, and so on, to ensure that fundamental security controls are in place to meet threats.
Site planning focuses on several key areas:
• Crime prevention and disruption Placement of fences, security guards, and warning signage, as well as implementation of physical security and intrusion detection alarms, motion detectors, and security cameras. Crime disruption (delay) mechanisms are layers of defenses that slow down an adversary, such as an intruder, and include controls of locks, security personnel, and other physical barriers.
• Reduction of damage Minimization of damage resulting from incidents, by implementing stronger interior walls and doors, adding external barriers, and hardening structures.
• Incident prevention, assessment, and response Assessment and response controls include the same physical intrusion detection mechanisms and security guards. Response procedures include fire suppression mechanisms, emergency response and contingency procedures, law enforcement notification, as well as external medical and security entities.
Common site planning steps to help ensure that physical and environmental security controls are in place include the following:
1. Identifying governance (regulatory and legal) requirements that the organization must meet
2. Defining risk for the physical and environmental security program, which includes assessment, analysis, and risk response
3. Developing controls and countermeasures in response to a risk assessment, as well as their performance metrics
4. Focusing on deterrence, delaying, detection, assessment, and response processes and controls
Cross-Reference
Objective 1.10 covered risk management concepts in depth.
Secure Design Principles
In Objective 3.1, we discussed several key principles that are critical in security architecture and engineering. Security design is important so that systems, processes, and even the security controls involved don’t have to be redesigned, reengineered, or replaced at a later date. Although we discussed secure design principles in the context of administrative and technical controls, these same principles apply to physical and environmental design.
Threat Modeling
You already know that threat modeling goes beyond simply listing generic threats and threat actors. For threat modeling to be effective, you must go into a deeper context and relate probable threats with the inherent vulnerabilities in assets unique to your organization. Threat modeling in the physical and environmental context works the same way and requires that you do the following:
• Determine generic threat actors and threats
• Relate those threat actors and threats to the specifics of the organization, its facilities, site design, and weaknesses that are inherent to those characteristics
• Take into account the organization’s schedules and traffic flows, as well as its natural and artificial barriers
• Examine the assets that someone would want to physically interact with, to include disrupting them, destroying them, or stealing them
Using threat modeling for your physical environment will help you to design very specific physical and environmental controls to counter those threats.
Least Privilege
As with technical assets and processes, personnel should only have the least amount of physical access privileges assigned to them that are necessary to perform their job functions. Not all personnel should have the same access to every physical area or piece of equipment. While all employees have access to common areas, fewer have access to sensitive processing areas. Least privilege is a physical control when implemented as a facility or sensitive area access control list.
Defense in Depth
The principle of defense in depth (aka layered security) applies to physical and environmental security just as it applies to technical security. Physical security controls are also layered to provide strong protection even when one or more layers fail or are compromised. Layers of physical control include security and safety signage, access control badges, video surveillance and recording systems, physical perimeter barriers, security guards, and the arrangement of centralized entry/exit points.
Secure Defaults
The principle of secure defaults means that security controls are initially locked down and then relaxed only as needed. This includes default physical access to sensitive areas, entrance and exit points, parking lots, emergency exits, nonemergency doors, and storage facility exits and entrances. As an administrative control, the default is to grant access to sensitive areas only to people who need that access to perform their job functions. By default, access is not granted to everyone.
Fail Securely
The term “fail secure” means that in the event of an emergency, security controls default to a secure mode. For example, this can include doors to sensitive areas that lock in the event of a theft or intrusion by unauthorized personnel. Contrast this to the term “fail safe,” which means that when a contingency or emergency happens, certain controls fail to an open or safe mode. A classic example is that the doors to a data center should fail to a safe mode and remain unlocked during a fire to allow personnel to escape safely.
Whether to use fail secure controls or fail safe controls is a design choice that management must carefully consider, since the safety and the preservation of human life are the most important aspects of physical security. However, at the same time, assets must be protected from theft, destruction, and damage. A balance may be to implement controls that are complex and advanced enough to be programmed for certain scenarios and fail appropriately. For example, in the event of an intrusion alarm, either automatic systems or security guards could manually ensure that all doors fail secure, but the same doors, in the event of a fire alarm, may unlock and remain open.
EXAM TIP Note that in the event of an incident, fail secure means that controls will fail to a more secure state; however other controls may fail safe to a less secure or open state. Fail safe is used to protect lives and ensure safety, while fail secure is used to protect equipment, facilities, systems and information.
Separation of Duties
Just as technical and administrative controls often require a separation of duties, physical controls often necessitate this same principle. Physical security duties are normally separated to mitigate unauthorized physical access, intrusion, destruction of equipment, criminal acts, and other unauthorized activities. For example, separation of duties applied to physical controls could be a policy that requires a person in management to sign in guests but requires another employee to escort the visitors. This demonstrates a two-person control, in that the person who authorizes the visitor is not the same person who escorts them, and adds the assurance that someone else knows they are in the vicinity.
Keep It Simple
The design principle of keep it simple can be applied to physical and environmental security design as well. Simpler physical security design makes the physical layout more conducive to the work environment, reducing traffic and unnecessary movement, and makes maintaining controlled access throughout the facility easier. The simpler facility or workplace design can also help eliminate hiding spots for intruders and help with the positioning of security cameras and guards.
Along with a simpler layout, straightforward procedures to allow access in and throughout the facility are a necessary part of simpler physical design. Overly complicated procedures will almost certainly ensure that those procedures fail at some point, for a variety of reasons:
• Employees don’t understand them.
• Employees become too complacent to follow them.
• The procedures interrupt business processes to an unacceptable level.
• The procedures don’t meet the functional needs of the organization.
Additionally, simpler procedures for access control within a facility can greatly enhance both security and safety.
Zero Trust
Recall from Objective 3.1 that the zero trust principle means that no entity trusts another entity until that trust has been conclusively authenticated each time there is an interaction between those entities. All entities start out as untrusted until proven otherwise. Physical and procedural controls must be implemented to initially establish trust with entities in the facility and to subsequently verify that trust. These controls include both physical and personnel security measures, such as:
• Positive physical and logical identification of the individual
• Nondisclosure agreements
• Security clearances
• Need-to-know for specific areas
• Supervisor approval for sensitive area access
• Relevant security training
Trust But Verify
As we discussed earlier in the domain, trust is not always automatically maintained after it has been established. Entities can become untrusted, or even compromised. Following the same lines as the zero trust principle, trust must be periodically reverified and the organization must ensure that trust is still valid. There are several ways to validate ongoing trust, and most of these relate to auditing and accountability measures, which may include verifying physical logs, reviewing video surveillance footage, conducting periodic reacknowledgement of the rules of behavior in recurrent security training, and revalidating need-to-know and security clearances from time to time.
Privacy by Design
Privacy by design as a design principle ensures that privacy is considered even before a security control is implemented. In physical environment security planning, facilities and workspaces are designed so that individual privacy is considered as much as possible. Some obvious work areas that must be considered include those where an employee has a reasonable expectation of privacy, like a restroom or locker room. But these also include work areas where sensitive processing of personal data occurs, as well as supervisory work areas where employees are expected to be able to discuss personal or sensitive information with their supervisors. Other spaces that should be considered for privacy include healthcare areas, such as company clinics, and human resources offices.
Shared Responsibility
As discussed in Objective 3.1, the shared responsibility principle of security design means that an organization, such as a service provider, often shares responsibility with its clients. The classic example is the cloud service provider and a client that receives services from that provider. In the physical and environmental context, however, there is also a paradigm of shared responsibility. Take, for example, a large facility that houses several different companies. Each company may have a small set of offices or work areas that are assigned to them. However, overall responsibility for the facility security may fall to the host organization and could include providing a security guard staff, surveillance cameras, a centralized reception desk with a controlled entry point into the facility, and so on. The tenant organizations in the facility may be responsible for other physical security controls, such as access to their own specific area, and assistance in identifying potential intruders or unauthorized personnel.
REVIEW
Objective 3.8: Apply security principles to site and facility design In this objective we discussed site and facility design, focusing on the secure design principles we discussed first in Objective 3.1. These principles apply to physical and environmental security design in much the same way as they apply to administrative and technical controls. We discussed the need for threat modeling in the physical environment, so physical threats can be understood and mitigated. The principle of least privilege applies to physical space in environments that need to restrict access. Defense-in-depth principles ensure that the physical environment has multiple levels of controls to protect it. We talked about secure defaults for controls that may be configured as more functional than secure, as well as the definitions of fail secure and fail safe. Remember that fail secure means that if a control fails, it will do so in a secure manner. Fail safe applies to those controls that must fail in an open or safe manner to preserve lives and safety. We also discussed separation of duties, and how it applies to the physical environment. The keep it simple principle applied in site and facility design helps to ensure security while not over complicating controls that may interfere with security or safety. Zero-trust people are not trusted by default with access to physical facilities; they must establish that trust and maintain it throughout their time in the facility. Additionally, we discussed the trust but verify principle, meaning that trust must be occasionally reestablished and verified as well. Privacy by design ensures that private spaces are included in site and facility planning. Finally, shared responsibility addresses facilities where there may be multiple organizations that share the facility and security functions must be shared amongst them.
3.8 QUESTIONS
1. Which of the following principles states that personnel should have access only to the physical areas they need to enter to do their job, and no more than that?
A. Separation of duties
B. Least privilege
C. Zero trust
D. Trust but verify
2. In your company, when personnel first enter the facility, they not only must swipe their electronic access badge in a reader, which verifies who they are, but also must pass through a security checkpoint where a guard visually verifies their identification by viewing the picture on their badges. Periodically throughout the day, they must swipe their access badges in additional readers and may be subject to additional physical verification. Which of the following principles is at work here?
A. Trust but verify
B. Separation of duties
C. Privacy by design
D. Secure defaults
3.8 ANSWERS
1. B The principle of least privilege provides that personnel in an organization should have access only to the physical areas that they need to enter to perform their job functions, and no more than that. This ensures that people do not have more access to the facility and secure work areas than they need.
2. A Since personnel must initially verify their identity when entering the facility and then periodically reverify it throughout the day, these actions conform to the principle of trust but verify.
 Design site and facility security controls
Design site and facility security controls
In this objective we’re continuing our discussion of physical and environmental security control design. We’re moving beyond the basic principles of site and facilities security that were introduced in Objective 3.8 to cover key areas and factors you must address during the building and floorplan design processes.
Designing Facility Security Controls
Designing security controls for the physical environment requires that you understand not only the design principles we discussed in Objectives 3.1 and 3.8, but also how they may apply to different situations, site layouts, and facility characteristics. You also need to understand the security requirements of your organization. As mentioned in the previous objectives, site and facility design require that you consider key goals, such as preventing crime, detecting events, protecting personnel and assets, and delaying the progress of intruders or other malicious actors until security controls can be invoked, all while assessing the situation. Achieving these key goals requires you to consider some key areas of focus you should take into consideration, which we will discuss in the upcoming sections, as well as specifically how to prevent criminal or malicious acts through purposeful environmental design.
Crime Prevention Through Environmental Design
Preventing crime or other malicious acts is the focus of a discipline called Crime Prevention Through Environmental Design (CPTED). The theory behind CPTED is that the environment that human beings interact with can be manipulated, designed, and architected to discourage and reduce malicious acts. CPTED addresses characteristics of a site or facility such as barrier placement, lighting, personnel and vehicle traffic patterns, landscaping, and so on. The idea is to influence how people interact with their immediate environment to deter malicious acts or make them more difficult. For example, increasing the coverage of lighting around a facility may discourage an intruder from breaking into the building at night; the placement of physical barriers, such as bollards, helps to prevent vehicles from charging an entryway of a building.
CPTED addresses the following four primary areas:
• Natural access control This entails naturally guiding the entrance and exit processes of a site or facility by controlling spaces and the placement of doors, fences, lighting, landscaping, sidewalks, and other barriers.
• Natural surveillance Natural surveillance is intended to make malicious actors feel uncomfortable or deterred by designing environmental features such as sidewalks and common areas to be highly visible so that observers (other than guards or electronic means) can watch or surveil them.
• Territorial reinforcement This is intentional physical site design emphasizing or extending an organization’s physical sphere of influence. Examples include walls or fencing, signage, driveways, or other barriers that might show the property ownership or boundary limits of an organization.
• Maintenance This refers to keeping up with physical maintenance to ensure that the site or facility presents a clean, uncluttered, and functional appearance. Repairing broken windows or fences, as well as maintaining paint and exterior details, demonstrate that the facility is cared for and well kept, and shows potential intruders that security is taken seriously.
Key Facility Areas of Concern
In every site or facility, several areas warrant special attention when designing and implementing security controls. These include restricted work areas, server rooms, and large data centers. Storage facilities, such as those used to store sensitive media or investigative evidence, also must be carefully controlled. Designing site and facility security controls encompasses not only protecting data and assets, but also ensuring personnel safety. Safety features that must be carefully planned and implemented include appropriate utilities and environmental controls as well as fire safety and electrical power management.
Wiring Closets/Intermediate Distribution Facilities
Any organization that relies on an Internet service provider (ISP) to deliver high-bandwidth communications services has specific sensitive areas and equipment on its premises that are devoted to receiving those services. These communications areas are called distribution facilities and are the physical points where external data lines come into the building and are broken out from higher bandwidth lines into several lower bandwidth lines. In larger facilities, these are called main distribution facilities, or MDFs. Smaller distribution areas and equipment are referred to as intermediate distribution facilities, or IDFs. IDFs break out high-bandwidth connections into individual lines or network cabling drops for several endpoints, either directly to hosts or to centralized network switches. MDFs are usually present in data centers and server rooms of large facilities, whereas IDFs commonly are located in small wiring closets.
Usually, MDFs are secured because they are located in large data centers or server rooms that are almost always protected. IDFs may sometimes be less secure and located in unprotected common areas or even in janitors’ closets. Ideally, both MDFs and IDFs should be in locked or restricted areas with limited access. They should also be elevated in the event of floods or other types of damage, so they obviously should not be implemented in basement areas or below ground level. They should also be located away from risks presented by faulty overhead sprinklers, broken water pipes, and even heating, ventilation, or air conditioning (HVAC) equipment.
Server Rooms/Data Centers
Since server rooms and large data centers contain sensitive data and processing equipment, these areas must be restricted only to personnel that have a need to be there to perform their job function. In terms of facility design, it’s better to locate data centers, server rooms, and other sensitive areas in the core or center of a facility, to leverage the protection afforded by areas of differing sensitivity, such as thick walls. Additionally, server rooms and data centers should be located in the lower floors of a building so that emergency personnel will have easier access.
There are specific safety regulations that must be implemented for critical server rooms or data centers. Most fire regulations require at least two entry and exit doors in controlled areas for emergencies. Server room and data center doors should also be equipped with alarms and fail to safe mode (fail safe) in the event of an emergency.
Cross-Reference
The use of “fail safe” mechanisms to preserve human health and safety was discussed in Objective 3.1.
Additional security characteristics of server rooms and data centers include
• Positive air pressure to ensure smoke and other contaminants are not allowed into sensitive processing areas
• Fire detection and suppression mechanisms
• Water sensors placed strategically below raised floors in order to detect flooding
• Separate power circuits from other equipment or areas in the facilities, as well as backup power supplies
Media Storage Facilities
Media should be stored with both security and environmental considerations in mind. Due to the sensitive nature of data stored on media, the media should be stored in areas with restricted access and environmental controls. Media with differing sensitivity or classification levels should be separated. Note that depending upon what type of backup media are present, such as tape or optical media, the facility operators must carefully control temperature and humidity in media storage locations. All types of media, regardless of sensitivity or backup type, should be under inventory control so that missing sensitive media can easily be identified and located.
Evidence Storage
Evidence storage has its own security considerations, but sensitive areas within facilities that are designated as evidence storage should also have at least the following considerations:
• Highly restrictive access control
• Secured with locks and only one entrance/exit
• Strict chain of custody required to bring evidence in or out of storage area
• Segregated areas within evidence storage that apply to evidence of differing sensitivity levels
Restricted and Work Area Security
All sensitive areas, whether designated for processing sensitive data or storage, must be designed with security and safety in mind. Sensitive work areas should have restrictive access controls and only allow personnel in the area who have a valid need to be there to perform their job functions. Sensitive work areas need to be closely monitored using intrusion detection systems, video surveillance, and so on. Strong barriers, as well as locking mechanisms and wall construction, should be implemented whenever possible. Work areas containing data of different sensitivity levels should be designed so that they are segmented by need-to-know. Both dropped ceilings and raised floors, when implemented, should be equipped with alarms and carefully monitored to prevent intruders.
Utilities and Heating, Ventilation, and Air Conditioning
Facility utilities include electric power, water, communications, and heating, ventilation, and air conditioning (HVAC) services. HVAC is required to ensure proper temperature and humidity control in the processing environment, and requires redundant power to ensure this environment is properly maintained. Sensitive areas need positive drains (meaning content flows out) built into floors to protect against flooding. Additionally, water, steam, and gas lines should have built-in safety mechanisms such as monitors and shut-off valves. Spaces should be designed so that equipment can be positioned within processing areas with no risk that a burst or leaking pipe will adversely affect processing, damage equipment, or create unsafe conditions.
Environmental Issues
Depending upon the geographical location of the facility, wet/dry or hot/cold climates can create issues by having more or less moisture in the air. Areas with high humidity and hotter seasons may have more moisture in the air that can cause rust issues and short-circuits. Static electricity is an issue in dry or colder climates due to less moisture in the air. Static electricity can cause shorts, seriously damage equipment, and create unsafe conditions. In addition to monitoring humidity and temperature controls, use of thermometers/thermostats to monitor and modify temperature and hygrometers to control humidity necessary. A hygrothermograph can be used to measure and control both temperature and humidity concurrently.
Fire Prevention, Detection, and Suppression
Addressing fires involves three critical efforts: preventing them, detecting them, and suppressing or extinguishing them. Of these three areas, fire prevention is the most important. Fire prevention is accomplished in several ways, including training personnel on how to prevent fires and, most importantly, how to react when fires do occur.
Another critical part of fire prevention is having a clean, uncluttered, and organized work environment to reduce the risk of fire. Construction and design of the facility can contribute to preventing fires; walls, doors, floors, equipment cabinets, and so on should have the proper fire resistance rating, which is typically required by building or facility codes. Fire resistance ratings for building materials are published by ASTM International.
Fires can be detected through both manual and automatic detection means. Obviously, people can sense fires through sight or smell and report them, but often this might be slower than other detection mechanisms. Smoke-activated sensors can sound an alarm before the fire suppression system activates. These sensors are typically photoelectric devices that detect variations in light intensity caused by smoke. There are also heat-activated sensors that can sound a fire alarm when a predefined temperature threshold is reached or when temperature increases rapidly over a specific time period (called the rate of rise). Fire detection sensors should be placed uniformly throughout the facility in key areas and tested often.
NOTE Rate-of-rise sensors provide faster warnings than fixed-temperature sensors but can be prone to false alarms.
Fire requires three things: a fuel source, oxygen, and an ignition source. Reducing or taking away any one of these three elements can prevent and stop fires. Suppressing a fire means removing its fuel source, denying it of oxygen, or reducing its temperature. Table 3.9-1 lists the elements of fires and how they may be extinguished or suppressed.
TABLE 3.9-1 Combustion Elements and Fire Suppression Methods

Fire suppression also includes having the right equipment on hand close by to extinguish fires by targeting each one of these elements. Fire suppression methods should be matched to the type of fire, as well as its fuel and other characteristics. Table 3.9-2 identifies the U.S. classification of fires, including their class, type, fuel, and the suppression agents used to control them.
TABLE 3.9-2 Characteristics of Common Fires and Their Suppression Methods


CAUTION Using the incorrect fire suppression method not only will be ineffective in suppressing the fire, but may also cause the opposite effect and spread the fire or cause other serious safety concerns. An example would be throwing water on an electrical fire, which could create a serious electric shock hazard.
EXAM TIP You should be familiar with the types and characteristics of common fire extinguishers for the exam.
There are some key considerations in fire suppression that you should be aware of; most of these relate to the use of water suppression systems, since water is not the best option for use around electrical equipment, particularly in data centers. However, water pipe systems are still used throughout other areas of facilities. Water pipe or sprinkler systems are usually much simpler and cost less to implement. However, they can cause severe water damage, such as flooding, and contribute to electric shock hazard.
There are four main types of water sprinkler systems:
• Wet pipe This is the basic type of system; it always contains water in the pipes and is released by temperature control sensors. A disadvantage is that it may freeze in colder climates.
• Dry pipe In this type of system there is no water kept in the system; the water is held in a tank and released only when fire is detected.
• Preaction This is similar to a dry pipe system, but the water is not immediately released. There is a delay that allows personnel to evacuate or the fire to be extinguished using other means.
• Deluge As its name would suggest, this allows for a large volume of water to be released in a very short period, once a fire is detected.
EXAM TIP You should be familiar with the four main types of water sprinkler systems: wet pipe, dry pipe, preaction, and deluge.
There are some other key items you should remember for the CISSP exam, and in the real world, when dealing with fire prevention, detection, and suppression. First, you should ensure that personnel are trained on detecting and suppressing fires and, more importantly, that there is an emergency evacuation system in place in the event personnel cannot control the fire. This evacuation plan should be practiced frequently. Second, HVAC systems should be connected to the alarm and suppression system so that they shut down if a fire is detected. The HVAC system could actually spread the fire by supplying air to it as well as conveying smoke throughout the facility. Third, since cabling is often run in the spaces above dropped ceilings, you should ensure that only plenum-rated cabling is used. This means that the cabling should not be made of polyvinyl chloride (PVC), since burning those types of cables can release toxic gases harmful to humans.
Power
All work areas in the facility, especially data centers and server rooms, require a constant supply of clean electricity. There are several considerations when dealing with electrical power, including backup power and power fluctuations. Note that redundant power is applied to systems at the same time as main power; there is no delay if the main power fails, and redundant power takes over. Backup power, on the other hand only comes on after a main power failure. Backup power strategies include
• Uninterruptible power supplies Used to supply battery backup power to an electrical device, such as a server, for only a brief period of time so that the server may be gracefully powered down.
• Generators Self-contained engine that runs to provide power to a facility for a short-term (typically hours or days), which must be fueled on a frequent basis. Note that generators can quickly produce large volumes of dangerous exhaust gases and should only be operated by trained personnel.
Power issues within a facility can be short or long term. Even momentary power issues can cause damage to equipment, so it’s vitally important that power be carefully controlled and conditioned as it is supplied to the facility and the equipment. Power issues can include a momentary interruption or even a momentary increase in power, either of which can damage equipment.
Power loss conditions include faults, which are momentary power outages, and blackouts, which are prolonged and usually complete losses of power. Power can also be degraded without being completely lost. A sag or dip is a momentary low-voltage condition usually only lasting a few seconds. A brownout is a prolonged dip that is below the normal voltage required to run equipment. Momentary increases of power include an inrush current condition, which is an initial surge of current required to start a load, which usually happens during the switchover to a generator, and also a surge or spike, which is a momentary increase in power that may burn out or otherwise damage equipment. Voltage regulators and line conditioners are electrical devices connected inline between a power supply and equipment to ensure clean and smooth distribution of power throughout the facility, data center, or perhaps just a rack of equipment.
REVIEW
Objective 3.9: Design site and facility security controls In this objective we completed our discussion of designing site and facility security controls using the security principles we covered in Objectives 3.1 and 3.8. This discussion applied those principles to security control design and focused on crime prevention through the purposeful design of environmental factors, such as lighting, barrier placement, natural access control, surveillance, territorial reinforcement, and maintenance. We also discussed protection of key facility areas, such as the main and intermediate distribution facilities, which provide the connection to external communications providers and distribute communication service throughout the facility. We considered the safety and security of server rooms and data centers, as well as media storage facilities, evidence storage, and sensitive work areas. We talked about security controls related to utilities such as electricity, communications, and HVAC. We touched upon the need to monitor critical environmental issues such as humidity and temperature to ensure that they are within the ranges necessary to avoid equipment damage. We also covered the importance of fire prevention, detection, and suppression, and how those three critical processes work. Finally, we assessed power conditions that may affect equipment and some solutions to minimize impact.
3.9 QUESTIONS
1. You are working with the facility security officer to help design physical access to a new data center for your company. Using the principles of CPTED, you wish to ensure that anyone coming within a specific distance of the entrance to the facility will be easily observable by employees. Which of the following CPTED principles are you using?
A. Natural surveillance
B. Natural access control
C. Maintenance
D. Territorial reinforcement
2. Which of the following types of fire suppression methods would be appropriate for an electrical fire that may break out in a server room?
A. This is a Class A fire, so water or foam would be appropriate.
B. This is a Class B fire, so wet chemicals would be appropriate.
C. This is a Class K fire, so wet chemicals would be appropriate.
D. This is a Class C fire, so CO2 would be appropriate.
3.9 ANSWERS
1. A In addition to electronic surveillance measures, you want to design the physical environment to facilitate observation of potential intruders or other malicious actors by normal personnel, such as employees. This is referred to as natural surveillance.
2. D An electrical fire is a Class C fire, which is normally suppressed by using fire extinguishers using CO2 or dry powders. Water, foam, or other wet chemicals would be inappropriate and may create an electrical shock hazard.