

Security Operations
Domain Objectives
• 7.1 Understand and comply with investigations.
• 7.2 Conduct logging and monitoring activities.
• 7.3 Perform Configuration Management (CM) (e.g., provisioning, baselining, automation).
• 7.4 Apply foundational security operations concepts.
• 7.5 Apply resource protection.
• 7.6 Conduct incident management.
• 7.7 Operate and maintain detective and preventative measures.
• 7.8 Implement and support patch and vulnerability management.
• 7.9 Understand and participate in change management processes.
• 7.10 Implement recovery strategies.
• 7.11 Implement Disaster Recovery (DR) processes.
• 7.12 Test Disaster Recovery Plans (DRP).
• 7.13 Participate in Business Continuity (BC) planning and exercises.
• 7.14 Implement and manage physical security.
• 7.15 Address personnel safety and security concerns.
Domain 7 is unique in that it has the most objectives of any of the CISSP domains, and it accounts for approximately 13 percent of the exam questions. You’ll find that many of the objectives covered in this domain, Security Operations, have also been briefly discussed throughout the entire book. This is because security operations are diverse and overarching activities that span multiple areas within security.
In this domain we will examine a wide range of subjects, including those that are reactive in nature, such as investigations, logging and monitoring, vulnerability management, and incident management. We will also look at the details of how to ensure a secure change and configuration management process that is supported by patch management.
We will review some of the foundational security operations concepts that we also discussed in Domain 1 and apply some of those concepts to resource protection. We will also look at some of the more technical details of detective and preventive measures, such as firewalls and intrusion detection systems. Four of the objectives address business continuity planning and disaster recovery, and we will discuss the strategies involved with each topic as well as how to implement and test the plans associated with these processes. Finally, we will review physical and personnel safety and security concerns.
 Understand and comply with investigations
Understand and comply with investigations
In Objective 1.6 we briefly touched on the types of investigations you may encounter in security, and we also reviewed the related topics of legal and regulatory issues in Objective 1.5. These two objectives go hand-in-hand with Objective 7.1, which carries our discussion a bit further by focusing on how investigations are conducted.
Investigations
Recall from Objective 1.6 that the four primary types of investigations are administrative, regulatory, civil, and criminal investigations. Regardless of the type of investigation, however, most of the activities, processes, and techniques that are used are common across all of them. This includes how to collect and handle evidence; reporting and documenting the investigation; the investigative techniques that are used; the digital forensics tools, tactics, and procedures that are implemented; and the artifacts that are discovered on computing devices using those tools, tactics, and procedures. These common activities are the focus of this objective.
Cross-Reference
The types of investigations you may encounter in cybersecurity were discussed at length in Objective 1.6.
Forensic Investigations
Computers, mobile devices, network devices, applications, and data files all contain potential evidence. In the event of an incident involving any of them, they must all be investigated. Computing devices can be part of an incident in three different ways:
• As the target of the incident (e.g., as an attack on a system)
• As the tool of the incident (used to directly perpetrate a crime, such as a hacking attack)
• Incidental to the event (part of the event but not the direct target or tool used, such as researching how to commit a murder, for instance)
Computer forensics is the science of the identification, preservation, acquisition, analysis, discovery, documentation, and presentation of evidence to a court of law (either civil or criminal), corporate management, or even to a routine customer. Computer forensic investigations are carried out by personnel who are uniquely qualified to perform them. E-discovery is another term with which you should be familiar; it is the process of discovering digital evidence and preparing that information to be presented in court. The most important part of the computer forensics process is how evidence is collected and handled, discussed next.
Evidence Collection and Handling
Evidence preservation is the most crucial part of an investigation. Even if an unskilled investigator is not properly trained to analyze evidence, the investigation can be saved by ensuring that the evidence is preserved and protected at all stages of the investigation. Evidence preservation involves proper collection and handling, including chain of custody, physical protection, and logical protection. We will discuss proper collection and handling procedures in the next few sections. However, chain of custody is an important one to discuss first.
Chain of custody refers to the consistent, formalized documentation of who is in possession of evidence at all stages of the investigation, up to and including when the evidence is presented in court or another proceeding. Chain of custody starts at the time evidence is obtained. The individual collecting the evidence initiates a chain of custody form that describes the evidence and documents the time and location it was collected, who collected it, and its transfer. From then on, every individual who takes possession of the evidence, relocates it, or pulls it out of storage for analysis must document those actions on the chain of custody form. This ensures that an uninterrupted sequence of events, timelines, and locations for the evidence is maintained throughout the entire investigation. Chain of custody assures evidence integrity and protects against tampering. This is one of the most crucial pieces of documentation you must initiate and maintain throughout the entire investigative cycle.
Evidence Life Cycle
Evidence has a defined life cycle. This means that the moment evidence is identified during the initial response to the investigation, it is collected and handled carefully, according to strict procedures. Chain of custody begins this critical process, but it doesn’t end with that event. Evidence must be protected throughout the investigation against tampering; even the appearance of intentional or inadvertent changes to evidence may call its investigative value and admissibility into court into question.
The evidence life cycle consists of four major phases, summarized as follows:
• Initial response Evidence is identified and protected; a chain of custody is initiated.
• Collection Evidence is acquired through forensically sound processes; evidence integrity is preserved.
• Analysis All evidence is analyzed at the technical level to determine the timeline and chain of events. Determining innocence or guilt of a suspect is the goal as well as identifying the root cause of the incident.
• Presentation Evidence is summarized in the correct format for presentation and reporting for corporate management, a customer, or to a court of law.

NOTE This life cycle, as with all other life cycles, may be different depending upon the methodology or standard used, since there are many different life cycles that exist in the investigative world. However, all of them agree on fundamental evidence collection and handling processes, which are standardized all over the world.
Obviously, there are more in-depth processes and procedures that must take place at each of these phases, and we will discuss those at length in the next section. Figure 7.1-1 summarizes the evidence life cycle.
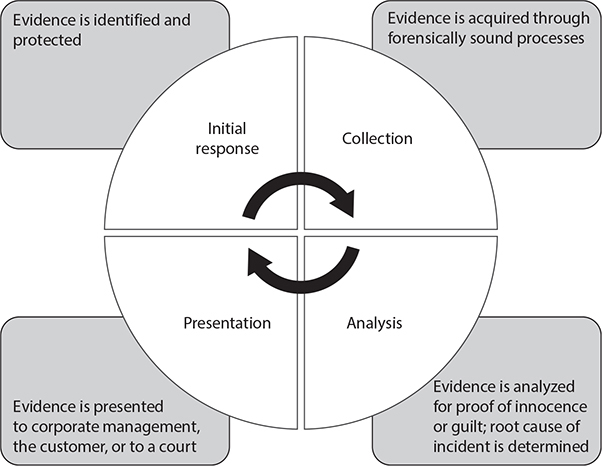
FIGURE 7.1-1 The evidence life cycle
Evidence Collection and Handling Procedures
There are standardized evidence collection and handling procedures used throughout the world, regardless of the type of investigation. These have all been adopted as formal standards by different law enforcement agencies, security firms, and professional organizations. They are summarized as follows:
• Secure the scene of the crime or incident against unauthorized personnel.
• Photograph the scene before it is disturbed in any way.
• Don’t arbitrarily power off devices until any available live evidence has been gathered from them.
• Obtain legal authorization from law enforcement or an asset owner before removing items from the scene.
• Inventory all items removed from the scene.
• Transport and store all evidence items in protected containers and store them in secure areas.
• Maintain a strong chain of custody at all times.
• Don’t perform a forensic analysis on original evidence items; forensically duplicate the evidence item and perform an analysis on the duplicate to avoid destroying or compromising the original.

EXAM TIP Once evidence is obtained from the source, such as a device, logs, and so on, that source may be placed on what is known as legal hold. Legal hold ensures that any devices or media that contain the original evidence must be kept in secure storage, and access must be controlled. These items cannot be reused, destroyed, or released to anyone outside the chain of custody until cleared by a legal department or court.
Artifacts
Artifacts are any items of potential evidentiary value obtained from a system. They are usually discrete pieces of information in the form of files, such as documents, pictures, executables, e-mails, text messages, and so on that are found on computers, mobile devices, or networks. However, they can also be information such as screenshots, the contents of RAM, and storage media images.
Artifacts are used as evidence of activities in investigations and can serve to support audit trails. For example, the Internet history files from a computer can support an audit log that indicates an individual visited a prohibited website. Files such as pictures or documents can indicate whether individuals are performing illegal activities on their system.
Note that artifacts by themselves are not indicative of an individual’s guilt or innocence; the presence of artifacts on a system mutually corroborates audit trails and other sources of information during an investigation. Artifacts must be investigated on their own merit before they are determined to meet the requirements of evidence. As discussed earlier in the objective, digital artifacts, as potential evidence, must be collected and handled with care.
Digital Forensics Tools, Tactics, and Procedures
While knowledge and experience with evidence collection and handling procedures are among the most crucial skills forensic investigators can have, they should also have core technical analysis skills and knowledge of a variety of subjects, including how storage media is constructed and operates, operating system architecture, networking, programming or scripting, and security. If you are conducting a forensic investigation, these skill sets will assist you greatly when performing some of the following forensic tasks:
• Data acquisition from volatile memory or hard drives using forensic techniques
• Establishing and maintaining evidence integrity through hashing tools to ensure artifacts are not intentionally or inadvertently changed
• Data carving (the process used to “carve” discrete data or files from raw data on a system using forensics processes) to locate and preserve artifacts that have been deleted or hidden
We are long past the days when computer forensics was performed mostly on simply end-user desktop computers or servers. In today’s environment, devices and data are integrated all the way from end-user mobile devices, into the cloud, and back to the organization’s infrastructure. While core forensics knowledge and skills are still necessary, so too are knowledge and skills related to specific procedures that are tied to more narrowly focused areas within forensics. These areas often require specialized knowledge and tools in addition to generalized forensics skills. These areas of expertise include
• Cloud forensics
• Mobile device forensics
• Virtual machine forensics
The choice of tools that a forensic investigator uses is important. There are specific tools that are used for specific actions, including data acquisition, log aggregation review, and so on. Each investigator or organization typically has favorite tools they use to perform all of these tasks. Some tools are proprietary, commercial-off-the-shelf enterprise-level software suites sold specifically for forensics processes, but many are simply individual tools that come with the operating system itself, such as utilities or built-in applications. Many forensics tools may also be internally developed utilities, to include scripts, for instance, or even open-source software utilities or applications.
Regardless of which digital forensics tools an organization uses, the following are some key things to remember about a forensics tool set:
• The tools should be standardized and thoroughly documented. An organization should have established procedures for the investigator to follow when using a tool.
• Forensics tools are often validated by professional organizations or national standards agencies; these tools should be preferred over tools developed in-house or tools whose origins and effectiveness can’t be easily verified.
• Tools that can offer repeatable and verifiable results should be used; if a tool does not image the same hard drive consistently every single time, for example, then its usefulness may be limited since its integrity cannot be trusted.
While this objective can’t possibly cover every single tool available to you during your forensic investigation, you can generally categorize tools in the following areas:
• Network tools (protocol analyzers or sniffers such as Wireshark and tcpdump)
• System tools (used to obtain technical configuration information for a system)
• File analysis tools
• Storage media imaging tools (both hardware and software tools)
• Log aggregation and analysis tools
• Memory acquisition and analysis tools
• Mobile device forensics tools
Investigative Techniques
Investigations attempt to discover what happened before, during, and after an incident. The goal of investigators is to identify the root cause of an incident and help ensure someone is held accountable for illegal acts or those that violate policy. Investigators also want to answer questions such as the who, what, where, when, and how of an incident. Investigators have the primary tasks of
• Collecting and preserving all evidence
• Determining the timeline and sequence of events
• Determining the root cause of and methods used during an incident
• Performing a technical analysis of evidence
• Submitting a complete, comprehensive, unbiased report
Investigators should always treat all investigations as if the results will eventually be presented in a court of law. This is because many investigations, even ones that seemingly start out as innocuous policy violations, may go to court if the evidence indicates that a violation of the law has occurred.
During an investigation, there are key points to keep in mind:
• Remain unbiased; don’t go into an investigation automatically presuming guilt or innocence.
• Always have another investigator validate work you have performed.
• Maintain documented, verifiable forensic procedures.
• Keep all investigation information confidential to the extent possible; it should only be shared with key personnel such as senior corporate managers or law enforcement.
• Only perform procedures on evidence that you are trained and qualified to perform; don’t undertake any actions for which you are not qualified.
• Ensure you have the proper tools to perform forensic activities on evidence; using the wrong tool could inadvertently destroy or compromise the integrity of evidence.
Reporting and Documentation
Documentation is one of the most critical aspects of investigations. An investigator should document every action they take during an investigation. The documentation for investigations should meet legal requirements and be thorough and complete. The content of documentation includes
• All actions involving evidence and witnesses (chain of custody, artifacts collected, witness interviews, etc.)
• Dates, times, and relevant events
• All forensic analysis of evidence
Reports and relevant documentation are usually delivered formally to the corporate legal department, human resources, or lawyers for all parties, as well as law enforcement investigators. Reports and investigation documentation should be clear and concise and present only the facts regarding an incident.
A good report includes investigative events, timelines, and evidence. The analysis portion of the report includes determination of the root cause(s), attack methods used during the incident, and the assertion of proof of guilt or innocence of the accused.
Investigative reports usually are formatted according to the desires of the corporate management or the court or agency that maintains jurisdiction over the investigation. In general, however, the investigation report should consist of an executive summary, the details of the events of the investigation, any findings and supporting evidence, and conclusions regarding the root cause of the case. Characteristics of a well-written investigative report include
• Clear, concise, and nontechnical
• Well written and well researched
• Answers to critical investigative questions of who, what, where, when, why, and how
• Conclusions supported by evidence
• Unbiased analysis
In addition to documentation and reporting, investigations also may make use of witness depositions or testimony. Witnesses are often asked to testify if they have direct knowledge of the facts of the case. Investigators can also be required to testify in court to detail the facts of the investigation.
REVIEW
Objective 7.1: Understand and comply with investigations This objective provided an opportunity to discuss details of investigations in more depth. Whereas Objective 1.6 covered the different types of investigations, in this objective we discussed the details of how investigations are conducted. We examined in particular forensic investigations, which involve gathering evidentiary data from computing systems.
Evidence collection and handling is the most crucial part of an investigation, since once evidence has been destroyed or compromised, it may not be recovered or trusted. The evidence life cycle consists of four general phases: initial response, collection, analysis, and presentation. The most critical part of evidence collection and handling is to establish a chain of custody that follows the evidence over its entire life cycle. Chain of custody assures that the evidence is always accounted for during transfer, storage, and analysis, and helps to rebut claims that the evidence has been tampered with or is unreliable. Other critical evidence handling activities include securing the scene of the incident or crime, photographing all evidence before it is removed, securely transporting and storing the evidence, and conducting analysis using only verifiable forensic procedures.
Artifacts are any items of potential evidentiary value obtained from a system, including files, logs, screen images, media, network traffic, and the contents of volatile memory. Artifacts are used to support a legal case and corroborate with other sources of information.
Digital forensics consists of a wide variety of tools, techniques, and procedures. The forensic investigator should be well-versed in a variety of disciplines, including networking, operating systems, programming, and other specific areas such as cloud computing, mobile device forensics, and virtual machine technology. Digital forensics tools can be categorized in terms of network tools, system tools, file analysis tools, storage media imaging tools, log aggregation analysis tools, memory acquisition and analysis tools, and mobile device tools.
Investigative techniques include solid knowledge of legal and forensic procedures with regard to evidence collection and handling, as well as technical areas of expertise. Investigators should also understand how to present an analysis of evidence in a court of law and should conduct all investigations as if they will proceed in that direction. Investigators should also approach every incident with an open mind with no bias as to the guilt or innocence of a suspect.
Forensic reports and documentation must be thorough and complete; they must follow the format prescribed by the corporate entity, customer, or the court of jurisdiction. They should include an executive summary, technical findings, and analysis of the evidence that supports those findings. They should also propose a conclusion and list any relevant facts pertinent to the case. Reports should also be clear and understandable to nontechnical personnel.
7.1 QUESTIONS
1. You have been called to investigate an incident of an employee who has violated corporate security policies by downloading copyrighted materials from the Internet. You must collect all evidence relating to the incident for the investigation, including the employee’s workstation. Which one of the following is the most critical aspect of the response?
A. Establishing a chain of custody
B. Analyzing the workstation’s hard drive
C. Creating a forensic duplicate of the workstation’s hard drive
D. Creating a formal report for management
2. Which of the following best describes one of the primary tasks a forensic investigator must complete?
A. Ensuring that the evidence proves a suspect is guilty
B. Determining a timeline and sequence of events
C. Performing the investigation alone to ensure confidentiality
D. Manually analyzing device logs
7.1 ANSWERS
1. A During the initial response, creating a solid chain of custody is critical for evidence integrity and preservation. The other choices refer to processes that normally take place after the initial response.
2. B One of the primary tasks of the investigator is to determine a timeline and sequence of events that occurred during an incident. The other choices indicate things an investigator should not do, such as only looking for evidence that proves guilt, performing an investigation alone, or manually analyzing logs.
 Conduct logging and monitoring activities
Conduct logging and monitoring activities
This objective covers the more technical aspects of logging and monitoring the network infrastructure and traffic. Although we have touched on these topics throughout the book, this objective addresses the need for and the process of collecting data from different sources all over the network, aggregating that data, and then performing analysis and correlation to determine the overall security picture for the network.
Logging and Monitoring
Remember that in Objective 6.1 you learned about security audits; auditing is directly enabled by logging network activity and monitoring the infrastructure for negative events and anomalous behavior. However, there’s more to these critical activities than that. Logging and monitoring are necessary to maintain understanding and visibility of what’s going on in the network infrastructure, which includes network devices, traffic, hosts, their applications, and user activity. You need to understand not only what’s going on in the network at any given moment, but also what’s happening over time, so that you can perform historical analysis and predict potentially negative trends.
Monitoring includes not only security monitoring but also performance monitoring, function monitoring, and user behavior monitoring. The purpose for all of this logging and monitoring is to collect small pieces of data that, when put together and given context, generate information that enables you to take proactive measures to defend the network. Some key elements of the infrastructure that you must monitor include
• Network devices and their performance
• Servers
• Endpoint security
• Bandwidth utilization and network traffic
• User behavior
• Infrastructure changes or departures from normal baselines
Much of this information is generated by logs, particularly from network and host devices. Logs that cybersecurity analysts review on almost a daily basis include firewall logs, proxy logs, and intrusion detection and prevention system logs. In this objective we will discuss many of the technologies that enable logging and monitoring, as well as how they are implemented.
Cross-Reference
Objective 7.7 provides a broader overview of firewalls and intrusion detection and prevention systems.
Continuous Monitoring
Continuous monitoring requires a resilient infrastructure that is able to collect, adjust, and analyze data on multiple levels, including both network-based data (e.g., traffic characteristics and patterns) and host-based data (such as host communications, processes, applications, and user activity). Continuous monitoring involves the use of IDS/IPSs and security information and event management systems (SIEMs).
We discuss continuous monitoring here in two different contexts. The first is more relevant to logging and monitoring the infrastructure and involves proactive monitoring of both the network infrastructure and its connected hosts to detect anomalies in configured baselines, as well as potentially malicious activities. The second context is not as technical but equally as important: monitoring overall system and organizational risk. Risk is monitored and measured on a continual basis so that any changes in the organization’s risk posture can be quickly identified and adjusted if needed. Risk changes frequently due to several factors, which include the threat landscape, the organization’s operating environment, technologies, the industry or market segment, and even the organization itself. All of these risk factors must be monitored to ensure risk does not exceed appetite or tolerance levels for the organization.
Intrusion Detection and Prevention
Historically, network and security personnel focused on simple intrusion detection capabilities. Modern security devices function as both intrusion detection and prevention systems (IDS/IPSs). They not only can detect and categorize a potential attack, but can also take actions to halt traffic that may be malicious in nature. An IDS/IPS may perform this function by dynamically rerouting network traffic, shunting connections, or even isolating hosts.
Intrusion detection typically relies on a combination of one or more of three models to detect problems in the infrastructure:
• Signature- or pattern-based (rule-based) detection Uses well-known signatures or patterns of behavior that match attack characteristics (e.g., traffic inbound on a particular port from a specific domain or IP address)
• Anomaly- or behavior-based analysis Detects deviations in normal behavior baselines
• Heuristic analysis Also detects deviations in normal behavior baselines, but matches those deviations to potential attack characteristics
EXAM TIP There is a difference between behavior-based analysis and heuristic analysis, although they are very similar. With behavior-based analysis, any deviations in the normal behavior baseline will be flagged and security personnel will be alerted. However, even deviations can be explained under certain circumstances. Heuristic analysis takes it a step further by looking to see what those abnormal behaviors might do, such as accessing protected memory areas, changing operating system files, or writing data to a hard drive.
Security Information and Event Management
With properly configured monitoring and logging, a large network, or even a medium-sized network, likely collects millions of pieces of data daily from a variety of network sources. These pieces of data come from hosts, network devices, user activity, network traffic, and so on. It would be impossible for a single person or even several people to sift through the data to make sense out of it and gain meaningful information from it. A good amount of data that comes from logging and monitoring may be insignificant; it’s up to a security analyst to determine which of the millions of pieces of data are important and what they mean to the overall security of the network.
Fortunately, the daunting process of collecting, aggregating, correlating, and analyzing this data is not simply left up to human beings to perform. This is where automation significantly contributes to the security process. We have already discussed how security tool automation is critical to the security process, but here we are talking specifically about security information and event management (SIEM) systems.
A SIEM system is a multifunctional security device whose purpose is to collect data from various sources, aggregate it, and assist security analysts in analyzing it to produce actionable information regarding what is happening on the network. SIEM systems are often the central data collection point for all log files, traffic captures, and other forms of data, sometimes disparate. A SIEM system ingests all of this data and correlates seemingly unrelated data to connect data points and show how they actually do relate to each other. This device helps you to make intelligent, risk-based decisions in almost real time about the security of the network.
SIEM systems use a concept known as a dashboard to display information to security analysts and allow them to run extensive queries on information to get very detailed analysis from all of these different sources of information.
Egress Monitoring
Egress monitoring specifically examines traffic that is leaving the network. Egress monitoring is typically performed by firewall, proxy, intrusion detection, or data loss prevention systems. For the most part this will be routine traffic, but egress monitoring looks for specific security issues. Obviously, a major issue is malware. Often an attack may come in the form of a distributed denial-of-service (DDoS) attack carried out by a botnet that uses the network against itself by infecting different hosts, which then attack other hosts on the network or even hosts on an external network. Egress monitoring looks for signs that internal hosts have been compromised and are being controlled by an external malicious entity and are communicating with it.
In addition to malware, another issue egress monitoring is useful for detecting is data exfiltration. This usually involves sensitive data that is being illegally sent outside the network, in an uncontrolled manner, to unauthorized entities. Egress monitoring uses several different technologies to detect this issue; in addition to data loss prevention (DLP) technologies deployed on both network devices and user endpoints, security devices such as firewalls implement rule sets that look for large volumes of data as well as files with particular extensions, sizes, and other characteristics.
Cross-Reference
Data loss prevention was discussed in Objective 2.6.
Log Management
If an organization does not monitor its logs and react to them properly, the logs serve no useful function. Given that there may be thousands of devices writing logs, managing logs can seem like a daunting task. Again, this is where automation comes into play. Logs are usually automatically sent to central collection points, such as the aforementioned SIEM system, or even a syslog server, for examination. Often, manual log review must occur to solve a particular problem, research a specific event, or gain more details about what is going on with the network. However, these are usually the exceptions, and most of the log management process can be automated, as mentioned previously.
Most devices generate what are known generically as event logs. An event log records an occurrence of an activity or happening. An event is usually something that is considered on a singular basis and has definable characteristics. Basic information for an event in a log includes
• Event definition
• System or resource the event effects
• Identifying information for a host, such as hostname, IP address, or MAC address
• The user or other entity that initiated or caused the event
• Date, time, and duration of the event
• Event action (e.g., file deletion, privilege use, etc.)
EXAM TIP You should be familiar with the general contents of an event log entry, which typically includes an event definition, the system affected, host information, user information, the action that was taken, and the date and time of the event.
Log analysis, also primarily an automated task performed by SIEM systems, has the goal of looking through various logs to connect data points and ascertain any patterns between those aggregated data points.
Threat Intelligence
Threat intelligence is the process of collecting and analyzing raw threat data in an effort to identify potential or actual threats to the organization. This may involve determining threat trends to predict what a threat will do, historical analysis of threat data to recognize what happened during a particular event, or behavioral analysis to understand how a threat reacted under certain circumstances to the environment.
Note that the terms threat data and threat intelligence are similar but not the same thing. Threat data refers to raw pieces of information, typically without context, which may or may not be related to each other. An example is an IP address or a log entry that shows a connection between two hosts. Threat data only becomes threat intelligence when it is analyzed and correlated to gain useful insight into how the data relates to the organization’s assets. Threat intelligence can come from various sources, called threat feeds, which include open-source, proprietary, and closed-source information.
Characteristics of Threat Intelligence
The effectiveness of threat intelligence can be evaluated based on the following three different characteristics, which will determine the quality or usefulness of the intelligence to the organization:
• Timeliness The intelligence must be obtained as soon as it is needed to be of any value in countering a threat.
• Accuracy The intelligence must be factually correct, accurate, and not contribute to false negatives or positives.
• Relevance The intelligence must be related to the given threat problem at hand and considered in the correct context when viewed with other factors.
Two other characteristics of threat intelligence are
• Threat rating Indicates the threat’s potential danger level. Typically, the higher the rating, the more dangerous the threat.
• Confidence level The trust placed in the source of the threat intelligence and the belief that the threat rating is accurate.
Both threat ratings and confidence levels can be expressed on qualitative scales, from least dangerous to most dangerous, for example, or least level of confidence to highest level of confidence, respectively. Often threat ratings and threat confidence levels directly relate to the sources from which we gain intelligence, as some are more dependable than others. Threat intelligence sources are discussed next.
EXAM TIP Make sure you are familiar with the characteristics of threat intelligence timeliness, accuracy, and relevance, and that you understand the concepts of threat rating and confidence level.
Open-Source Intelligence
Open-source intelligence (OSINT) comes from sources that are available to the general public. Examples include public databases, websites, and general news. While open-source intelligence is very useful, it is typically broader and describes very general characteristics of threats, which may not apply to your particular assets, vulnerabilities, or overall organization. Open-source intelligence comes in great volumes, which must be reduced, sorted, prioritized, and analyzed to determine its relevance to the organization. (Threat modeling, discussed a bit later, is useful for distilling OSINT.)
Closed-Source Intelligence
Closed-source intelligence comes from threat feeds that may be restricted in their availability. Consider classified government intelligence feeds, for example. These are not readily available to the general public due to data sensitivity or the sensitivity of their source, such as from an agent operating covertly in a foreign country or obtained with secret technology. Another key differentiator for closed-source intelligence versus OSINT is that typically closed-source intelligence is more accurate, more thoroughly authenticated, and holds a higher confidence level. Closed-source intelligence also often provides greater detail and fidelity about the threat, particularly as the intel is often focused on specific organizations, assets, and vulnerabilities that are targeted.
Proprietary Intelligence
Proprietary intelligence can be thought of as a closed-source intelligence feed, but it is usually developed by a private organization and sold, via subscription, to any organization that wishes to purchase it. This makes it more of an intelligence commodity as opposed to being restricted from the general public based on sensitivity. Many organizations purchase proprietary threat intelligence feeds from other companies, sometimes tailored to their specific market or circumstances.
Threat Hunting
Threat hunting is the active effort to determine whether various threats exist in an infrastructure. In some cases, an analyst may be looking to determine if specific threats or threat actors have already infiltrated the infrastructure and continue to maintain a presence. In other cases, threat hunting is more geared toward looking for a variety of threats on a continual basis to ensure that they don’t ever get into the infrastructure in the first place. Threat hunting uses both threat intelligence feeds and threat modeling to determine more precisely which threats are more likely to target which assets in the infrastructure, rather than looking for generic threats. Then the threat hunters make a concerted effort to look for those specific threats or threat actors in the network.
Threat Modeling Methodologies
Several formalized methodologies have been developed to address the different characteristics and components of threats. Some address threat indicators, some address attack methods that threat sources can use against organizations (called threat vectors), and some allow for in-depth threat modeling and analysis. All these methodologies allow the organization to formally manage threats and are critical components of the threat modeling process. A few examples are listed and described in Table 7.2-1.
TABLE 7.2-1 Various Threat Modeling Methodologies

While an in-depth discussion on any of these threat methodologies is beyond the scope of this book, you should have basic knowledge about them for the CISSP exam.
Cross-Reference
We also discussed threat modeling in Objective 1.11.
User and Entity Behavior Analytics
User and entity behavior analytics (UEBA) focuses on patterns of behavior from users and other entities (e.g., service accounts or processes). UEBA goes beyond simply reviewing a log of user actions; it looks at user behavioral patterns over time to detect when those patterns of behavior change. These behavioral patterns include when a user normally logs on or off of a system, which resources they access, and how they interact with the system as a whole.
When a pattern of behavior deviates from the normal baseline, it may be an indicator of compromise (IoC). It may indicate one of several possibilities that merit further investigation, such as:
• The user is violating a policy or doing something illegal
• The system itself is functioning but performing in a less than optimal manner
• The system is under attack from a malicious entity
As with all the other types of data in the infrastructure, user behavior data must be initially collected, aggregated, and analyzed to determine normal baselines of behavior.
REVIEW
Objective 7.2: Conduct logging and monitoring activities In this objective we discussed details of technical logging and monitoring. Logging and monitoring contribute to the auditing function by providing data to connect events to entities. Logs can come from various sources, including network devices, hosts, applications, and so on. Event log entries normally include details regarding the user that initiated the event, the identifying host information, a description or definition of the event, the date and time of the event, and what actually happened.
Continuous monitoring is a proactive way of ensuring that you not only have continuous visibility into what is happening in the network but also are able to perform historical analysis and trend prediction. Continuous monitoring also means the organization is continually monitoring its risk posture.
Intrusion detection and prevention systems use three methods of detection, sometimes in combination with each other: signature or pattern-based detection, behavioral-based detection, and heuristic detection.
Logs and other data from across the infrastructure can be fed into an automated system that aggregates and correlates all of this information, known as a SIEM system. SIEM systems allow instant visibility into the security posture of the network through dashboards and complex queries.
Egress monitoring allows security personnel to detect malware attacks that may make use of botnets and cause hosts to attack each other or, worse, attack external networks not owned by the organization. Egress monitoring also allows the organization to detect data exfiltration through secure device rule sets and data loss prevention systems.
Log management means that administrators actually review logs to detect malicious events, poor network performance, or negative trends. Most modern log management is automated through SIEM systems.
We also revisited and expanded upon the basic concepts of threat modeling. Threat modeling goes beyond simply listing generic threats that could be applicable to any organization; threat modeling takes a more in-depth, detailed look at how specific threats may affect an organization’s assets and vulnerabilities. Threat modeling uses threat intelligence that is timely, relevant, and accurate, and that intelligence may come from a variety of threat feeds, such as open-source, closed-source, or proprietary sources. Various threat management and modeling methodologies exist, including STRIDE, VAST, PASTA, and many others.
Finally, we examined user and entity behavior analytics (UEBA), which looks for abnormal behavioral patterns from users, system accounts, and processes. These deviations of normal behavior patterns could indicate an issue with a user, the system, or an attack.
7.2 QUESTIONS
1. You are designing a new intrusion detection and prevention system for your company. You want to ensure that it has the capability to accept security feeds from the system’s vendor to allow you to detect intrusions based on known attack patterns. Which one of the following detection models must you include in the system design?
A. Behavior-based detection
B. Heuristic detection
C. Signature-based detection
D. Intelligence-based detection
2. You are a cybersecurity analyst who works at a major research facility. As part of the organization’s effort to perform threat modeling for its systems, you need to look at various proprietary intelligence feeds and determine which ones would be most likely to help in this effort. Which of the following is not an important characteristic of threat intelligence you should consider when selecting threat feeds?
A. Timeliness
B. Methodology
C. Accuracy
D. Relevance
3. Nichole is a cybersecurity analyst who works for O’Brien Enterprises, a small cybersecurity firm. She is recommending various threat methodologies to one of her customers, who wants to develop customized applications for Microsoft Windows. Her customer would like to incorporate a threat modeling methodology to help them with secure code development. Which of the following should Nichole recommend to her customer?
A. PASTA
B. TRIKE
C. VAST
D. STRIDE
7.2 ANSWERS
1. C Signature-based detection allows the system to detect attacks based on known patterns or signatures.
2. B Methodology is not a consideration in evaluating intelligence feeds. To be useful to the organization, threat intelligence should be timely, relevant, and accurate.
3. D STRIDE (Spoofing, Tampering, Repudiation, Information disclosure, Denial of service, and Elevation of privilege) is a threat modeling methodology created by Microsoft for incorporating security into application development. None of the other methodologies listed are specific to application development, except for VAST (Visual, Agile, and Simple Threat Modeling), but it is not specific to Windows application development.
 Perform Configuration Management (CM) (e.g., provisioning, baselining, automation)
Perform Configuration Management (CM) (e.g., provisioning, baselining, automation)
Configuration management (CM) is a set of activities and processes performed by the change management program of an organization to ensure system configurations are consistent and secure. In this objective we will discuss topics directly related to CM, including provisioning initial configuration, maintaining baseline configurations, and automating the CM process.
Configuration Management Activities
Configuration management is part of the larger change management process. Change management is concerned with overarching strategic changes to the planning and design of the infrastructure, as well as the operational level of managing the infrastructure, while configuration management is more focused at the system level and is usually part of the tactical or day-to-day activities. Configuration management covers initial provisioning and ongoing baseline configurations of systems, applications, and other components, especially through automated processes whenever possible.
Cross-Reference
Configuration management is very closely related to patch and vulnerability management, covered in Objective 7.8, and change management, discussed in detail in Objective 7.9.
Provisioning
Just as user accounts are provisioned, as discussed in Objective 5.5, systems are also provisioned. In this context, however, provisioning is the initial installation and configuration of a system. Provisioning may require manual installation of operating systems and applications, as well as changing configuration settings to make sure that the system is both functional and secure. However, as discussed a bit later in this objective, automation can make provisioning a system far more efficient and ensure that the configuration meets its initial required baseline (discussed next).
Provisioning often uses baseline images, which are preapproved configurations that meet the organization’s requirements for hardware and software settings, to quickly deploy operating systems and software, cutting down the time and margin for error required to install a system.
Baselining
The default settings for most systems are unsecure and often do not meet the functional needs of the organization. Therefore, the initial default configuration and settings need to be changed to better suit the organization’s functional and security requirements. Baselining means ensuring that the configuration of a system is set according to established organizational standards and remains that way even throughout configuration and change processes. This doesn’t mean that the baseline for a system won’t sometimes change; baselines often change in an organization as system functions are changed, systems are upgraded, patches are applied, and the operating environment for the organization changes. Changing baselines is part of the entire change management process and must be approached with careful planning, testing, and implementation.
An organization could have several established baselines that apply to specific hosts. For example, an organization may have a workstation baseline that applies to all end-user workstations and a separate server baseline that applies to servers. It may also have baselines for network devices, and even mobile devices. The point here is that for a given device, the organization should have a baseline design that details the versions of operating systems and applications installed on the device, as well as carefully controlled configuration settings that should be standardized across all like devices.
All baseline configurations should be documented and checked periodically. There are automated software solutions, some of which are part of an operating system, that can alert an administrator if a system deviates from the baseline. Legitimate changes to baselines could be a new piece of software or even a patch that is applied to the host; these valid changes, once tested and accepted, then become part of the updated baseline configuration. It’s the nonstandard or unknown changes to the baseline that must be paid attention to, however, as these may come in the form of unauthorized changes or even malware.
Baseline configuration settings often include
• Standardized versions of operating systems and applications
• Secure configuration settings, including only allowed ports, protocols, and services
• Removal or change of default account and password settings
• Removal of unused applications and services
• Operating system and application patching
EXAM TIP You should keep in mind for the exam that baselines are critical in maintaining secure configuration of all systems in the infrastructure. Secure baselines include controlled versions of operating systems and applications, as well as their security settings. An organization may have multiple baselines, depending on the type of device in question.
Automating the Configuration Management Process
Most systems in the infrastructure are complex and have a myriad of configuration settings that must be carefully set in order to maintain their security and functionality. It would be impractical for administrators to manually set all of these configuration settings and expect to have time for any other of their daily tasks. Additionally, misconfigurations occur due to human error, and many of these configuration settings may render a system nonfunctional or not secure if not set correctly. This is where automation is fundamental in maintaining configuration baselines.
Hundreds of automated tools are available to assist with configuration management. Some of them are built into the operating system itself, and many others are free or third-party utilities that come with management software. For example, Windows Server includes Active Directory (AD), which has group policy settings that enable change management administrators to manage configuration baselines in an AD domain. Linux has its own built-in configuration management utilities as well. Additionally, organizations can use powerful customized scripts, such as those written in PowerShell or Python, as well as enterprise-level management systems. We will discuss many of the tools used to configure and maintain security settings in Objective 8.2. Using automated tools to perform configuration management can help reduce issues caused by human error, ensure standardization of configuration settings across the enterprise, and make configuration changes much more efficient.
Cross-Reference
Tool sets, software configuration management, and security orchestration, automation, and response (SOAR) are related to automating the configuration management process and are discussed in depth in Objective 8.2.
REVIEW
Objective 7.3: Perform Configuration Management (CM) (e.g., provisioning, baselining, automation) This objective reviewed configuration management processes. Configuration management is a subset of change management and is closely related to both vulnerability management and patch management. The provisioning process is where the initial installation and configuration of systems and applications occur. It’s important to establish a standardized baseline to use for devices across the organization, and there may be multiple baselines to address different types of devices. Baselines also change occasionally, as the environment changes or systems and applications change. Configuration management is made much more efficient and easier by using automated tools that can help reduce human error and ensure configuration baselines are maintained.
7.3 QUESTIONS
1. Your company is creating a secure baseline for its end-user workstations. The workstations should only be able to communicate with specific applications and hosts on the network. Which of the following should be included in the secure baseline for the workstations to ensure enforcement of these restrictive communications requirements?
A. Operating system version
B. Application version
C. Limited open ports, protocols, and services
D. Default passwords
2. Riley has been manually provisioning several hosts for a secure subnet that will process sensitive data in the company. These systems are scanned before being taken out of the test environment and connected to the production network. The scans indicate a wide variety of differences in configuration settings for the hosts that have been manually provisioned. Which of the following should Riley do so that the configuration settings will be consistent and follow the secure baseline?
A. Provision the systems using automated means, such as baseline images
B. Manually configure the systems using vendor-supplied recommendations
C. Back up a generic system on a network and restore the backup to the new systems so they will be configured identically
D. Manually configure the systems using a secure baseline checklist
7.3 ANSWERS
1. C Any open ports, protocols, and services affect how the workstation communicates with other applications on the network or other hosts. These should be carefully considered and controlled for the secure baseline. The other choices are also considerations for the secure baseline, but do not necessarily affect communicating with only specific applications or hosts on the network.
2. A Riley should use an automated means to provision the secure hosts; an OS image with a secure baseline could be deployed to make the job much easier and more efficient and ensure that the configuration settings are standardized.
 Apply foundational security operations concepts
Apply foundational security operations concepts
In this objective we reexamine some foundational security concepts that we covered in previous domains, albeit in this objective from an operations context. These concepts include need-to-know, least privilege, separation of duties, privileged account management, job rotation, and service level agreements.
Security Operations
Security operations describes the day-to-day running of the security functions and programs. When you first learned about security theories, models, definitions, and terms, it may not have been clear as to how these things apply in the course of a security professional’s normal day. Now you are going to apply the fundamental knowledge and concepts you learned earlier in the book to the operational world.
Need-to-Know/Least Privilege
Two of the important fundamental concepts introduced in Domain 1, and emphasized throughout the book, are need-to-know and the principle of least privilege. These concepts ensure that entities do not have unnecessary access to information or systems.
Need-to-Know
Recall from previous discussions that need-to-know means that an individual should have access only to information or systems required to perform their job functions. In other words, if their job does not require access, then they don’t have the need-to-know for information, and by extension, the systems that process it. This limitation helps support and enforce the security goal of confidentiality. The need-to-know concept is applied operationally throughout security activities. Examples include restrictive permissions, rights, and privileges; the requirement for need-to-know in mandatory access control models; and the need to keep privacy information confidential.
A new employee’s need-to-know should be assumed to be the minimum required to fulfill the functions of their job. As time progresses, an individual may require more access, depending on changing job requirements and the operating environment. Only then should additional access be granted. Need-to-know should be carefully considered and approved by someone with the authority to do so; normally that might mean the individual’s supervisor, a data or system owner, or a senior manager. Need-to-know should also be periodically reviewed to see if the individual still has validated requirements to access systems and information. If the job requirements change or the operating environment no longer requires the individual to have the need-to-know, then access should be revoked or reduced.
Principle of Least Privilege
The principle of least privilege, as we have discussed in other objectives, essentially means that an individual should only have the rights, permissions, privileges, and access to systems and information that they need to perform their job. This may sound similar to the concept of need-to-know, but there is a subtle difference that you must be aware of for the exam. With need-to-know, an individual may or may not have access at all to a system or information. The principle of least privilege states that if an individual does have access to system or information, they can only perform certain actions. So, it becomes a matter of no access at all (need-to-know) or minimal access necessary (least privilege).
EXAM TIP Need-to-know determines what you can access. Least privilege regulates what you can do when you have access.
The principle of least privilege is applied at the operational level by only allowing individuals, ranging from normal users to administrators and executives, to perform tasks at the minimal level of permissions necessary. For example, an ordinary user should not be able to perform privileged administrative tasks on a workstation. Even a senior executive should not be able to perform those tasks since they do not relate to their duties.
Separation of Duties and Responsibilities
The concept of separation of duties (SoD) prevents a single individual from performing a critical function that may cause damage to the organization. In practice, this means that an individual should perform only certain activities, but not others that may involve a conflict of interest or allow one person to have too much power. For example, an administrator should not be able to audit their own activities, since they could conceivably delete any audit trails that record any evidence of wrongdoing. A separate auditor should be checking the activities of administrators.
Related to the concept of separation of duties are the concepts of multiperson control and m-of-n control, which require more than one person to work in concert to perform a critical task.
Multiperson Control
Multiperson control means that performing an action or task requires more than one person acting jointly. It doesn’t necessarily imply that the individuals have the same or different privileges, just that the action or task requires multiple people to perform it, for the sake of checks and balances.
A classic example of multiperson control is when an individual bank teller signs a check for over a certain amount of money, and then a manager or supervisor must countersign the check authorizing the transaction. In this manner, no single individual can use this method to steal a large amount of funds. A bank teller and bank manager could secretly agree to commit the crime, known as collusion, but it may be less likely because the odds of getting caught increase. Another example would be a situation that requires three people to witness and sign off on the destruction of sensitive media. One person alone can’t be empowered to do this, since assigning only one person to be responsible for destroying the media could allow that person to steal the media and claim that they destroyed it. But assigning three people to witness the destruction of sensitive media would reduce the possibility of collusion and reduce the risk that the media was destroyed improperly or accessed by unauthorized individuals.
M-of-N Control
M-of-n control is the same as multiperson control, except it doesn’t require all designated individuals to be present to perform a task. There may be a given number of people, “n,” that have the ability to perform a task, but only so many of them (the “m”) are required out of that number. For example, a secure piece of software may designate that five people are allowed to override a critical financial transaction, but only three of the five are necessary for the override to take place. This means that any three of the five people could input their credentials signifying that they agree to an override for it to take place. This doesn’t necessarily imply that they all have different rights, privileges, or permissions (although in the practical world, that is often the case); it could simply mean that a single person alone can’t make that decision.
Note that separation of duties does not require multiperson control or m-of-n control. An individual can have separate duties and perform those tasks daily without having to work with anyone. Multiperson or m-of-n control only comes into play when a task must be completed by multiple people working together at that moment or in a defined sequence to make a decision or complete a sensitive or critical task.
Privileged Account Management
Privileged accounts require special care and attention. In addition to carefully vetting individuals before assigning them higher-level accounts with special privileges, those accounts should be approved by the management chain. The individual should have the proper need-to-know and security clearance for a privileged account, as well as additional training that emphasizes the special procedures for safeguarding the account and the potential dire security consequences of failing to do so. Note that it’s not only administrators who receive accounts with higher-level privileges; sometimes users receive accounts with additional privileges for legitimate business reasons.
Once a privileged account has been granted to an individual, they should also be carefully scrutinized for the correct authorizations. Even with a privileged account, the principles of separation of duties and least privilege still apply. Having a privileged account is not an all-or-nothing prospect; the account should still have only the privileges necessary to perform the functions related to the individual’s job description, and no more. Having a privileged account also does not mean that the individual has access to all resources and objects. There still may be sensitive data that they do not need to access, which falls under the principle of need-to-know, as mentioned earlier.
EXAM TIP Even privileged accounts are still subject to the principle of least privilege; not every privileged account requires full administrator privileges over the system or application. Privileged accounts can still be assigned only the limited rights, privileges, and permissions required to perform specific functions.
Individuals with privileged accounts should only use those accounts for specific privileged functions, and for only a limited amount of time. They should not be constantly logged into the privileged account, since that increases the attack surface for the account and the resources they are accessing. Privileged account holders should also maintain a routine user account and use it for the majority of their duties, especially for mundane tasks such as e-mail, Internet access, and so on. Using the methods described in Objective 5.2, the organization should employ just-in-time authorization; that is to say, the privileged account should only be used when and if necessary, and then the individual should revert to their basic account.
Cross-Reference
Just-in-time identification and authorization was discussed in Objective 5.2 and described the use of utilities such as sudo and runas to affect temporary privileged account access.
Privileged account management also lends itself to role-based authorization. Rather than granting additional privileges to a user account, security administrators can place the user in a role that allows additional privileges. Their membership in that role group should require that their account be audited more frequently and to a greater level of detail. This approach might be a better alternative than granting a user a separate privileged account if the majority of that user’s daily job requirements necessitate use of the additional privileges. Again, the key here is frequent reviews and management approval for any additional privileges and system or information access.
Job Rotation
An organization with a job rotation policy rotates employees periodically through various positions so that a single individual is not in a position sufficiently long to conduct fraud or other malicious acts to a degree that could substantially impair the organization’s ability to continue operations. Job rotation serves not only as a detective control but also as a deterrent control, because employees know that someone else will be filling their job role after a certain period of time and will be able to discover any wrongdoing. Implementing a job rotation policy in larger organizations usually is easier than in smaller organizations, which may lack multiple people with the necessary qualifications to perform the job. Even when there is no suspicion of malicious acts or policy violations, it can be difficult to rotate someone out of a job position for normal professional growth and development since they may be so ingrained in that role that no one else can do their job. This is why planned, periodic cross-training and leveraging multiple people to understand exactly what is involved with a particular job requirement is necessary. The organization should never depend on one person only to perform a job function; this would make it very difficult to rotate a person out of that position in the event they were suspected of fraud, theft, complacency, incompetency, or other negative behaviors, let alone the critical need for having someone trained in a position for business continuity in the event an individual came to harm or departed the organization for some reason.
Mandatory Vacations
Somewhat related to job rotation is the principle of mandatory vacations—forcing an individual to take leave from a job position or even the organization for a short period of time. Frequently, if an individual simply has been performing the job function for a long period of time without a break, company policy may require that they take vacation time for rest and rehabilitation. Usually, this part of the policy allows an individual to be away from the organization for an allotted number of vacation days annually, whenever they choose. This is likely one of the more positive aspects of a mandatory vacation policy.
However, a mandatory vacation policy can also be used to force someone who is suspected of malicious acts to step away from the job position temporarily so an investigation can occur. You will often see this type of action in the news if someone in a position of public trust, for example, is suspected of wrongdoing. People are often placed on “administrative leave,” with or without pay, pending an investigation. This is the same thing as a mandatory vacation. The individual may be allowed to return to their duties after the investigation completes, or they may be reassigned or even terminated from the organization.

CAUTION Organizations that actively use a mandatory vacation policy should also have, by necessity, some level of cross-training or job rotation as part of their policy and procedures.
Service Level Agreements
A service level agreement (SLA) exists between a third-party service provider and the organization. Third parties offer services, such as infrastructure, data management, maintenance, and a variety of other services, that can be provided to the organization under a contract. Note that third-party services can also include those offered by cloud providers. Service level agreements impact the security posture of an organization by affecting the security goal of availability, more often than not, but can also affect data confidentiality if a third-party has access to sensitive information. Poor performance of services can impact the organization’s efficient operations, performance, and security, so it’s important to have agreements in place that ensure consistent levels of function and performance for those third-party provided services.
In addition to the legal contract documentation that will likely be included in a contract with a third-party service provider, the SLA is critical in specifying the responsibilities of both parties. This document is used to protect both the organization and the third-party service provider. The SLA can be used to guarantee specific levels of performance and function on the part of the third-party service provider, as well as delineate the security responsibilities between the customer and the provider with regard to protecting systems and data. Failing to meet SLA requirements often incurs a financial penalty.
REVIEW
Objective 7.4: Apply foundational security operations concepts In this objective we reviewed several foundational security operations concepts, including need-to-know, least privilege, separation of duties, privileged account management, job rotation, and service level agreements. Each of these concepts has been discussed in at least one previous objective, but here we framed them in the context of security operations.
Need-to-know means that an individual does not have any access to systems or information unless their job requires that access. Contrast this to the principle of least privilege, which means that once granted access to a system or information, an individual should only be allowed to perform the minimal tasks necessary to fulfill their job responsibilities. Separation of duties means that one individual should not be able to perform all the duties required to complete a critical task, thereby preventing fraudulent or malicious activity absent the collusion of two more people. This is also further demonstrated by the concepts of multiperson control and m-of-n control, which require at least a minimum number of designated, authorized individuals present to approve or perform a critical task.
Privileged account management requires that any individual having privileges above a normal user level should be vetted and approved by management for those privileges. Privileged accounts granted to these individuals should not be used for routine user functions, but only for the privileged functions they were created to perform. Privileged accounts should also be reviewed periodically to ensure they are still valid.
Job rotation is used to replace an individual in a job function periodically so that the person’s activities can be audited for any malicious or wrongful acts. This is similar to mandatory vacations, which is only temporary and usually implemented while an individual is under investigation.
Service level agreements are used to protect both a third-party service provider and the organization by specifying the required performance and function levels in the contract, including security, for each party.
7.4 QUESTIONS
1. Which of the following is the best example of implementing need-to-know in an organization?
A. Denying an individual access to a shared folder of sensitive information because the individual does not have job duties that require the access
B. Allowing an individual to have read permissions, but not write permissions, to a shared folder containing sensitive information
C. Requiring the concurrence of three people out of four who are authorized to approve a deletion of audit logs
D. Routinely reassigning personnel to different security positions that each require access to different sensitive information
2. Audit trails for a sensitive system have been deleted. Only a few people in the company have the level of training and privileged access required to perform that action. Although a particular person is suspected of performing the malicious act, all people who have access must be removed from their position, at least on a temporary basis, during the investigation. Which of the following does this action describe?
A. Separation of duties
B. Job rotation
C. Mandatory vacation
D. M-of-n control
7.4 ANSWERS
1. A Need-to-know is typically a deny or allow situation; denying access to a shared folder containing sensitive information that the user does not require for their job duties is based on need-to-know.
2. C Since only a few people have that level of access, they must all be temporarily removed from their positions during the investigation and placed on administrative leave, a form of mandatory vacation. Job rotation is not an option if there are only a few people who can perform the job function and they are all under investigation.
 Apply resource protection
Apply resource protection
We have discussed protecting resources throughout this entire book, but in this objective we’re going to focus specifically on one area we have not previously addressed—media management and protection. Media is often associated with backup tapes, but it also includes hard drive arrays, CD-ROM and Blu-ray discs, storage area networks (SANs), network-attached storage (NAS), and portable media such as USB thumb drives, regardless of whether they are local or remote storage. This objective focuses on managing the wide variety of media and the specific security measures used to protect it.
Media Management and Protection
Regardless of the type of media your organization is using, you should carefully consider several key protection activities related to media management. These include administrative, technical, and physical security controls. Each type of control is applied to protect media from unauthorized access, theft, damage, and destruction. We’ll discuss some of these controls in the upcoming sections.
Media Management
Media management primarily uses administrative controls, such as policies and procedures, associated with dictating how media will be used in the organization. Management should create a media protection and use policy that outlines the requirements for proper care and use of storage media in the organization. This policy could also be closely tied to the organization’s data sensitivity policy, in that the data residing on media should be protected at the highest level of sensitivity dictated by the policy.
Media management requirements detailed in the policy should include
• All media must be maintained under inventory control procedures and secured during storage, transportation, and use.
• Proper access controls, such as object permissions, must be assigned to media.
• Only authorized portable media should be used in organizational systems, and portable media must be encrypted.
• Media should only be reused if sensitive data can be adequately wiped from it.
• Media should be considered for destruction if it cannot be reused due to the sensitivity of data stored on it.
Media Protection Techniques
Media management sets administrative policy controls for the use, storage, transport, and disposal of various types of media in the organization. It also dictates the practical controls expected for those activities. Protection techniques for media include technical and physical controls implemented during access, transport, storage, and disposal.
Media Access Controls
Media should be treated with care and handling commensurate with the level of sensitivity of data stored on the media. This again should be in accordance with the data sensitivity policies determined by management. These controls include
• Sensitive data stored on media should be encrypted.
• Access control permissions granted to authorized users should be based upon their job duties and need-to-know; the principles of least privilege and separation of duties should also be included in these access controls.
• Strong authentication mechanisms required to access media must be used even for authorized users.
Media Storage and Transportation
Physical controls are the primary type of control used to secure media while it is stored and during transport to prevent access by unauthorized personnel. Physical controls for media storage and transport must include
• Secure media storage areas (e.g., locked closets and rooms)
• Physical access control lists of personnel authorized to enter media storage areas
• Proper temperature and humidity controls for media storage locations
• Media inventory and accountability systems
• Proper labeling of all media, including point-of-contact information (i.e., data or system owner), sensitivity level, archival or backup date, and any special handling instructions
• Two-person integrity for transporting media containing highly sensitive information (requiring two people to witness/control the transportation of highly sensitive media for security)
EXAM TIP Key media protection controls include media usage policies, data encryption, strong authentication methods, and physical protection.
Media Sanitization and Destruction
Media should be kept only as long as it is needed. Recall that Objective 2.4 explained why data should not be retained longer than the organization requires it for legitimate business reasons or due to regulatory requirements. Once information is not needed for either reason, the organization should dispose of it in accordance with policy. This includes any media that contains the data. Often media can be sanitized or cleared for reuse within the organization, but in certain circumstances it must be destroyed to prevent any chance that sensitive information may inadvertently fall into the wrong hands.
Sanitization methods should be more thorough than simply formatting or repartitioning media; data can easily be recovered through forensic processes or by using common file recovery tools. Wiping is a much better way to clear media that is intended for reuse. Wiping involves writing set patterns of ones and zeros to the media to overwrite any remnant data that may still exist on the media even after file deletion or media formatting.
Media destruction should be used when media is worn out, obsolete, or otherwise not intended to be reused. In cases where highly sensitive data resides on the media, wiping techniques may not be enough to give management the confidence that data may not be recovered by someone using advanced forensic tools and techniques. In these cases, media should simply be destroyed. Media destruction methods include degaussing, burning, pulverizing, and even physical destruction using hammers or other methods to break the media, rendering it completely unusable. For highly sensitive media, the organization should consider implementing two-person integrity; that is to say that it requires two people to participate in and witness the destruction of sensitive media so that management can be assured it will not fall into the wrong hands.
Cross-Reference
Data retention, remanence, and destruction were also discussed in Objective 2.4.
REVIEW
Objective 7.5: Apply resource protection This objective examined resource protection, specifically focusing on media management and the controls used to protect the variety of media types. Media management begins with policies, which should include inventory control, access control, and physical protections. Media protection controls include those implemented to protect media during use, storage, transportation, and disposal. Specific controls include the need for encryption, strong authentication, and object access. Media must be sanitized to erase any sensitive data remnants if it will be reused. If reusing media is not practical, it must be destroyed.
7.5 QUESTIONS
1. Which of the following must media management and protection begin with?
A. Media policies
B. Strong encryption
C. Strong authentication
D. Physical protections
2. Management has made the decision to destroy media that contains sensitive data, rather than reuse it. Because this media might fetch a good price from the organization’s competitors, management wants to put in place additional controls to make sure that the media is destroyed properly. Which one of the following would be an effective control during media destruction?
A. Destruction documentation
B. Burning or degaussing media
C. Two-person integrity
D. Strong encryption mechanisms
7.5 ANSWERS
1. A Media protection begins with a comprehensive media use policy, established by organizational management, which dictates the requirements for media use, storage, transportation, and disposal.
2. C In this scenario, one of the most effective security controls to ensure that media has been destroyed properly is the use of a two-person integrity system, which requires two people to participate in and witness the destruction of sensitive media so that management can be assured it will not fall into the wrong hands.
 Conduct incident management
Conduct incident management
In this objective we will cover the phases of the incident management process that you need to know for the CISSP exam, which include detection, response, mitigation, reporting, recovery, remediation, and lessons learned. We’ll also look at another phase, preparation, that is commonly identified as the first phase in many other incident management life cycles. Keep in mind as you read this objective that incident management differs from disaster recovery planning and processes (covered in Objectives 7.11 and 7.12) and business continuity planning (covered in Objective 7.13), though they sometimes overlap depending on the nature of the incident.
Security Incident Management
An incident is any type of event with negative consequences for the organization. As cybersecurity professionals, we often categorize incidents as some form of infrastructure attack, but even a temporary power outage, server failure, or human error technically falls into the category of incidents if it negatively impacts the organization. Any incident which affects the security of the organization or its assets, whether it stems from a malicious hacker, a natural disaster, or simply the action of a complacent employee, is of concern to cybersecurity professionals. Any event that affects the three security goals of confidentiality, integrity, and availability could be considered a security incident. Incident management is much more than simply responding to an incident. The entire incident management process includes a management program and process used by the organization to plan and execute preparations for an incident, respond during the incident, and conduct post-incident activities.
EXAM TIP A security incident doesn’t necessarily involve a malicious act; it can also be the result of a natural disaster such as a flood or tornado, or from an accident such as a fire. It can also be the result of a negligent employee.
Incident Management Life Cycle
As a formalized process, incident management has a defined life cycle. A variety of incident management life cycles are promulgated by different books, standards, and professional organizations. Although their titles and specific phases usually differ, they all promote the phases of incident detection, response, and post-incident activities. As one example, the National Institute of Standards and Technology (NIST) offers an incident response life cycle model in its Special Publication (SP) 800-61, Revision 2, Computer Security Incident Handling Guide, which discusses the life cycle phases of preparation; detection and analysis; containment, eradication, and recovery; and post-incident activity. Figure 7.6-1 illustrates the NIST life cycle.

FIGURE 7.6-1 The NIST incident response life cycle (adapted from NIST SP 800-61 Rev. 2, Figure 3-1)
CISSP exam objective 7.6 outlines similar phases that could easily be mapped to the NIST life cycle model or any one of several other incident management life cycle models. The point here is that incident management is a formalized process that should not be left to chance. Every organization should have formal incident management policies and procedures, an adopted standard for incident response, and a formal incident management life cycle that the organization adheres to.
Preparation
Oddly enough, the preparation phase is not part of the formal CISSP exam objectives for incident management; however, it is still an important concept you should be familiar with since the other steps of the incident management process rely so much on adequate preparation. The NIST life cycle model discusses this phase as being critical in overall incident management and describes preparation as having all the correct processes in place, as well as the supporting procedures, equipment, personnel, information, and other needed resources.
The preparation phase of incident management includes
• Development of the incident management strategy, policy, plan, and procedures
• Staffing and training a qualified incident response team
• Providing facilities, equipment, and supplies for the incident response capability
The procedures that an organization must develop for incident management come from incident response policy requirements and must take into account the potential need for different processes during an incident than the organization normally follows day to day. These processes should be tailored around incident management and include
• Incident definition and classification
• Incident communications procedures, including notification and alerting, escalation, reporting, and communications with both internal stakeholders and external agencies
• Incident triage, prioritization, and escalation
• Preservation of evidence and other forensic procedures
• Incident analysis
• Attack containment
• Recovery procedures
• Damage mitigation and remediation
Detection
Most detection capabilities are not focused on incident response, but rather on incident prevention. Detection capabilities should be included as a normal part of the infrastructure architecture and design. These capabilities include intrusion detection and prevention systems (IDS/IPSs), alarms, auditing mechanisms, and so on.
Early detection is one of the most important factors in responding to an incident. Detection mechanisms must be tuned appropriately so that they catch seemingly unimportant singular events that may indicate an attack (called indicators of compromise, or IoCs) but are not prone to reporting false positives. This is a very delicate balance, and one that will never be completely perfect. As the organization matures its incident management capability, the number of false positives will decrease, allowing the organization to identify patterns that indicate an actual incident.
Detection is based on data that comes from a variety of sources, including anti-malware applications, device and application logs, intrusion detection alerts, and even situational awareness of end users who may report anomalies in using the network.
Response
Once an incident is detected, there are several things that must occur quickly. First, the incident must be triaged to determine if it is a false positive and, if not, determine its scope and potential critical impact. Organizations often develop checklists that IT, security, and even end-user personnel can use to determine if an incident exists and, if so, how serious it is and what to do next. For end users, this list is usually very basic and ends up with the correct action being to report the incident to security personnel. For IT and cybersecurity employees, this checklist will be much more involved, with multiple possible decision points.
When the incident is appropriately triaged, the incident response team is notified, and, if necessary, the incident is escalated to upper management or outside agencies. If the incident is considered any type of disaster, particularly one which could threaten human safety or cause serious damage to facilities or equipment, the disaster response team is also notified. Usually the decision to notify outside agencies must come from a senior manager with authority to make that decision. The response phase is also when the incident response team is activated. Very often this notification comes from a 24/7 security operations center (SOC), on-call person, or an incident response team member. A call tree is often activated to ensure that team members get notified quickly and effectively. In some cases, the incident response command center, if it is not already part of the SOC, is activated. Each team member has a job to do and transitions from their normal day-to-day position to their incident-handling jobs.
The incident response (IR) team has several key tasks it must perform quickly. Almost simultaneously, the IR team must gather data and analyze the cause of the incident, the scope, what parts of the infrastructure the incident is affecting, and which systems and data are affected. The IR team must also work quickly to contain the incident as soon as possible, to prevent its spread, and find the source of the incident and stop or eradicate it. All these simultaneous actions make for a very complex response, especially in large environments.
In addition to analysis, containment, and eradication, the IR team must also make every attempt to gather and preserve forensic evidence necessary to determine what happened and trace the incident back to its root cause. Evidence is also necessary to ensure that the responsible parties are discovered and held accountable.
Cross-Reference
Investigations and forensic procedures were discussed in Objective 7.1.
The initial response is not considered complete until the incident is contained and halted. For instance, a malware spread must be stopped from further damaging systems and data, a hacking attack must be blocked, and even a non-malicious incident, such as a server room flood, must be stopped. Once the incident has been contained and the source prevented from doing any further harm, the organization must now turn its attention to restoring system function and data so the business processes can resume.
Mitigation
Mitigating damage during the response has many facets. First, the incident must be contained and the spread of any damage must be limited as much as possible. Sometimes this requires implementing temporary measures. These can range from temporarily shutting down systems, rerouting networks, and halting processing to more drastic steps. But these are only temporary mitigations necessary to contain the incident; permanent mitigations may also have to be considered, sometimes even while the incident is still occurring. Temporary corrective controls like emergency patches, configuration changes, or restoring data from backups will often be put in place until more permanent solutions can be implemented. Permanent or long-term mitigations are covered later during the discussion on remediation.
EXAM TIP Remember that corrective controls are temporary in nature and are put in place to immediately mitigate a serious security issue, such as those that occur during an incident. Compensating controls are longer-term in nature and are put in place when a preferred control cannot be implemented for some reason. The difference between corrective and compensating controls was also discussed in Objective 1.10.
Reporting
There are many aspects to reporting, both during and after an incident. Effective reporting is highly dependent on the communications procedures established in the incident response plan. During the incident, reports of the status of the response, especially efforts to contain and eradicate the incident, are communicated up and down the chain of command, as well as laterally within the organization to other departments affected by the incident. During and after more serious incidents, reporting to external third parties may occur, such as law enforcement, customers, business partners, and other stakeholders. Reporting during the incident may occur several times a day and may be informal or formal communications such as status e-mails, phone calls, press conferences, or even summary reports at the end of the response day.
The other facet of reporting is post-incident reporting, which requires more formal and comprehensive reports. Note that post-incident reporting normally takes place after the remediation step is completed, as discussed later on in this objective. Reports must be delivered to key stakeholders both within the organization and outside it. Senior management must decide which sensitive information should be reported to various stakeholders, since some of the information may be proprietary or confidential. In any event, the incident response team develops a report that summarizes the incident for nontechnical people, but it may have technical appendices. The report includes the root cause analysis of the incident, the responses actions, the timeframe of the incident, and what mitigations were put in place to contain and eradicate the cause. The report also usually includes recommendations to prevent further incidents.
Recovery
Recovery efforts take place after an incident has been contained and the cause mitigated. During this phase of the incident management process, systems and data are restored and the business operations are brought back online. The goal is to bring the business back to a fully operational state as soon as possible, but that does not always happen if the damage is too extensive. If systems have been damaged or data is lost, the organization may operate in a degraded state for some time.
This phase of incident management tests the effectiveness of the organization’s business continuity planning, if the incident is serious enough to disrupt business operations. This is one point where incident response is directly related to business continuity. During the business continuity planning process, the business impact analysis defines the critical business processes and the systems and information that support them, so they can be prioritized for restoration after an incident.
Cross-Reference
Business impact analysis and business continuity were both discussed in Objective 1.8, and business continuity will be discussed in depth in Objective 7.13.
Remediation
Remediation addresses the long-term mitigations that repair the damage to the infrastructure, including replacement of lost systems and recovery of data, as well as implementation of solutions to prevent future incidents of the same type. The organization must develop a plan to remediate issues that caused the incident, including any vulnerabilities, lack of resources, deficiencies in the security program, management issues, and so on. At this point, the organization should perform an updated risk assessment and analysis. This allows the organization to reassess its risk and see if it failed to implement sufficient risk reduction measures, as well as identify new risks or update the severity rating of previously known ones.
This phase of the incident management life cycle is just as much managerial as it is technical. Vulnerabilities can be patched and systems can be rebuilt, but management failures are often found to be the root causes of incidents. Management must recommit to providing needed resources, such as money, people, equipment, facilities, and so on. This is all part of the remediation process.
Lessons Learned
The final piece of incident management is understanding and implementing lessons learned from the incident response. The organization must perform in-depth analysis to determine why the incident occurred, what could have prevented it, and what must be done in the future to prevent a similar incident from occurring again. Lessons learned should be included in the final report, but they must also be ingrained in the organization’s culture so that these lessons can be used to protect organizational assets from further incident.
Lessons learned don’t have to be limited to looking at the organization’s failures that may have led up to the incident; they can also look at how the organization planned, implemented, and executed its incident response. Some of these lessons learned may include ways to improve the following:
• Response time, including incident detection, notification, escalation, and response
• Deployment of resources during an incident, including people, equipment, and time
• Personnel staffing and training
• The incident response policy, plan, and procedures
In any event, examining the entire incident management life cycle for the organization after a response will glean many lessons that the organization can use in the future, provided it is willing to do so.
REVIEW
Objective 7.6: Conduct incident management In this objective we examined the incident management program within an organization. We reviewed the need to adopt an incident management life cycle, of which there are many, and briefly examined one in particular promulgated by NIST. We then discussed the various phases of the incident management process that you will need to understand for the CISSP exam.
• Preparation is the most important phase of the incident management process, since the remainder of the response depends on how well the organization has prepared itself for incidents.
• Early detection of an incident is extremely critical so that the organization can execute its response rapidly and efficiently.
• The response itself has many pieces to it, including incident containment, analysis, and eradication of the cause of the incident.
• The mitigation phase consists of implementing temporary measures, in the form of corrective controls that can preserve systems, data, and equipment and keep the business functioning at some level; but corrective controls need to be replaced with more permanent and carefully considered mitigations during the remediation phase.
• Reporting includes all the communications that are necessary both during and after the incident. Reporting can include communications up and down the chain of command, as well as laterally across the organization. An effective communications process should be included in the incident response plan. It may also require reporting to parties outside the organization, such as law enforcement, regulatory agencies, or partners and customers. A formal report should be generated after the incident that includes a comprehensive analysis of the root cause and recommendations for preventing further incidents.
• The incident recovery phase involves bringing the business back to a fully operational state after an incident, which may take time and happen in phases depending upon how serious the impact of the incident has been. Recovery operations include the prioritized restoration of systems and data based on a thorough business impact analysis, which is performed during the business continuity planning process.
• Remediation after an incident consists of the more permanent controls that must be implemented to repair damage to systems and prevent the incident from recurring.
• Understanding lessons learned requires examining the entire incident management process to determine deficiencies in the organization’s security posture, as well as its incident response processes. These lessons must be understood and used to protect the infrastructure from further incidents.
7.6 QUESTIONS
1. During which phase of the incident management life cycle is the incident response plan developed and the incident response team staffed and trained?
A. Preparation
B. Response
C. Lessons learned
D. Recovery
2. Your organization is in the early stages of responding to an incident in which malware has infiltrated the infrastructure and is rapidly spreading across the network, systematically rendering systems unusable and deleting data. Which of the following actions is one of the most critical in stopping the spread of the malware to prevent further damage?
A. Analysis
B. Triage
C. Escalation
D. Containment
7.6 ANSWERS
1. A All planning for incident response, including developing the actual incident response plan and fielding the response team, is conducted during the preparation phase of the incident management life cycle. Performing these activities during any of the other phases of the incident management life cycle would be too late and largely ineffective.
2. D Containment is likely the most critical activity an incident response team should engage in since this prevents further damage to systems and data. The other answers are also important but may not directly contribute to stopping the spread of the malware.
 Operate and maintain detective and preventative measures
Operate and maintain detective and preventative measures
In this objective we focus on technical controls that are considered preventive and detective in nature. Prevention is preferred so that negative activity can be stopped before it even begins; however, absent prevention, rapid detection is critical to quickly stopping an incident to contain and minimize its damage to the infrastructure. We will discuss firewalls and intrusion detection/prevention systems and how they work. We will also briefly explore third-party services and their role in security. In addition, we will examine various other preventive and detective controls used, such as sandboxing, honeypots and honeynets, and the all-important and ubiquitous anti-malware controls. Finally, we will discuss the roles that machine learning and artificial intelligence play in cybersecurity.
Cross-Reference
Control types and functions were discussed in Objective 1.10.
Detective and Preventive Controls
Of all the control functions we have discussed throughout the book, prevention is arguably the most important. Preventing an incident from occurring is very desirable in that it saves time, money, and other resources, as well as prevents loss of or damage to information assets. We have available a multitude of different administrative, technical, and physical controls that are focused on preventing illegal acts, violations of policy, emergency or disaster situations, data loss, and so on. However, preventive controls are not always enough. Despite having a well-designed and architected security infrastructure that uses defense in depth as a secure design principle, incidents still happen. Even before incidents occur, detective controls must be in place since early detection of an incident can help to reduce the level of damage done to systems, data, facilities, equipment, the organization, and most importantly, people.
Allow-Listing and Deny-Listing
Allow-listing and deny-listing (formally known as whitelisting and blacklisting, respectively) are techniques that can allow or deny (block) items in a list. These listings are essentially rule sets. A rule set is a collection of rules that stipulate allow and deny actions based on specific content items, such as types of network traffic, file types, and access control list entries. These rule sets are used to control what is processed, transmitted or received, or accessed in an infrastructure.
Most rule sets depend on context, since they can be used in different ways in security. For example, a rule set that lists allowed applications or denied applications can be used, respectively, to allow the corresponding executables to run on a system or deny them from running on a system. Another use is allowing or denying certain types of network traffic based on characteristics of that traffic, such as port, protocol, service, source or destination host IP address, domains, and so on. Still another implementation of rule sets might allow or deny access to a resource, such as a shared folder, by individuals or groups of users.
EXAM TIP As with everything in technology, concepts and terms change from time to time, based on newer technologies, the environment we live and work in, and even social change. And so it goes for the terms whitelist and blacklist, which have been deprecated and are decreasing in use within our professional security community. In fact, (ISC)2 indicates in their own blog post (https://blog.isc2.org/isc2_blog/2021/05/isc2-supports-nist.html) that they intend to follow NIST’s lead to discontinue the terms “blacklisting” and “whitelisting.” In anticipation of their changes in terminology, I will use the inclusive terms allow list and deny list, respectively. However, be aware that because the CISSP exam objectives may not have caught up with this change at the time of this writing, you may still see the terms “whitelist” and “blacklist” on the exam.
Often these rule sets are implemented in access control lists (ACLs), a term normally associated with network devices and traffic. While modern allow/deny lists may be combined into a single monolithic rule set that has both allow and deny entries in it, you may still see lists that exclusively allow or exclusively deny the items in the rule set. By way of explanation, here’s how those exclusive lists work:
• An allow list is used to allow only the items in that rule set to be processed, transmitted, received, or accessed. Since the items in this list are the exceptions that are allowed to process, anything not on the list is, by default, denied. Although called an allow list, this is also what implements a default-deny method of controlling access, since by default everything is denied unless it is in the list.
• A deny list works the exact opposite of an allow list. All the elements of the rule set are denied. Anything not in the rule set is allowed. This is called a default-allow method of controlling access, since anything not in the list is, by default, allowed to process through the rule set.
EXAM TIP The terminology can be somewhat confusing, but an allow list enables a default-deny method of controlling access, since anything that is not in the list is not processed, and a deny list enables a default-allow method of controlling access, since anything that is not in the list is processed.
Note that, as mentioned a bit earlier, modern rule sets have entries that simply have both allow and deny rules in them, so access is carefully controlled. However, whether the organization uses as the access control method a list with both allow and deny entries in it, or a default-deny or a default-allow paradigm is often based on the organization’s network resource policies regarding openness, transparency, and permissiveness. This is a good example of how an organization’s appetite and tolerance for risk is connected to how it implements technical controls; an organization that has a high tolerance for risk might implement a default-allow method of access control, which is far less restrictive than a default-deny mentality.
Allow- and deny-listing is a very important fundamental concept to understand for both the real world and the CISSP exam since this technique is used throughout security. Allow and deny lists can be used separately and together on network security devices such as firewalls, intrusion detection and prevention systems, border routers, proxies, and so on. These techniques are also used to restrict software that is allowed to run on the network, as well as control which subjects can access which objects in the infrastructure.
You’ll also encounter the following terms in the context of allow- and deny-listing:
• Explicit Refers to actual entries in an allow list or deny list. The entries in a deny list are items that are explicitly denied and the entries in an allow list are items that are explicitly allowed.
• Implicit Refers to anything that is not listed but, by implication, is allowed (in the case of a deny list) or denied (in the case of an allow list).
Firewalls
For better or for worse, firewalls have traditionally been considered by both security professionals and laypeople to be the ubiquitous be-all and end-all of security protection. However, firewalls do not take care of every security issue in the infrastructure. Firewalls are simply devices that are used to filter traffic from one point to another. Firewalls use rule sets as well as other advanced methods of inspecting network traffic to make decisions about whether to allow or deny that traffic to specific parts of the infrastructure. Most firewalls are either network based or host based, but other, more recent types of firewalls also are available, including web application firewalls and cloud-based firewalls.
Network- and Host-Based Firewalls
Traditional network-based firewalls provide separation and segmentation for different parts of the network. In a traditional firewall deployment, a firewall sits on the network perimeter of an organization, separating the public Internet from the internal organizational network. Network-based firewalls may also be deployed in a demilitarized zone (DMZ) or screened subnet architecture, which makes use of other security devices, such as border routers, in combination with one or more firewalls so that traffic is not only segmented but also routed to other network segments. In a DMZ architecture, traffic enters an external firewall, is appropriately examined and filtered (allowed or blocked), and then may be redirected to another piece of the network that is not part of the internal network. Traffic inbound for the internal network may proceed through an internal firewall before it gets to its destination. This enables multiple layers of traffic filtering.
Host-based firewalls are far less complex in nature and only protect a particular host. They may be integrated with other host-based security services, such as anti-malware or intrusion detection and prevention systems (discussed in an upcoming section). Host-based firewalls are normally not dedicated security appliances; they are simply software installed as an application on the host or, in some cases, come as part of the operating system, such as Windows Defender Firewall.
Firewall Types
Although we discussed firewalls in Objective 4.2, it’s helpful for CISSP exam preparation purposes to review them in the context of security operations and to introduce a few more firewall types used in security operations, such as web application and cloud-based firewalls. Network-based firewalls have more than one network interface, allowing them to span multiple physical and logical network segments, which enables them to perform traffic filtering and control functions between networks. Firewalls also use a variety of criteria to perform filtering, including traffic characteristics and patterns, such as port, protocol, service, source or destination addresses, and domain. Advanced firewalls can even filter based on the content of network traffic.
As a review of Objective 4.2, the primary types and generations of firewalls are as follows:
• Packet-filtering or static firewalls filter based on very basic traffic characteristics, such as IP address, port, or protocol. These firewalls operate primarily at the network layer of the OSI model (TCP/IP Internet layer) and are also known as screening routers; these are considered first generation firewalls.
• Circuit-level firewalls filter session layer traffic based on the end-to-end communication sessions rather than traffic content.
• Application-layer firewalls, also called proxy firewalls, filter traffic based on characteristics of applications, such as e-mail, web traffic, and so on. These firewalls are considered second-generation firewalls, which work at the application layer of the OSI model.
• Stateful inspection firewalls, considered third-generation firewalls, are dynamic in nature; they filter based on the connection state of the inbound and outbound network traffic. They are based on determining the state of established connections. Remember that stateful inspection firewalls work at layers 3 and 4 of the OSI model (network and transport, respectively)
• Next-generation firewalls (NGFWs) are typically multifunction devices that incorporate firewall, proxy, and intrusion detection/prevention services. They filter traffic based on any combination of all the techniques of other firewalls, including deep packet inspection (DPI), connection state, and basic TCP/IP characteristics. NGFWs can work at multiple layers of the OSI model, but primarily function at layer 7, the application layer.
Web Application Firewalls
A web application firewall (WAF) is a newer, special-purpose firewall type. It’s used specifically to protect web application servers from web-based attacks, such as SQL and command injection, buffer overflow attacks, and cross-site scripting. WAFs can also perform a variety of other functions, including authentication and authorization services through on-premises IdM services, including Active Directory, and third-party IdM providers.
Cross-Reference
Identify management (IdM) was introduced in Objective 5.2.
Cloud-Based Firewalls
Another recent development in firewall technology involves the use of cloud-based firewalls offered by cloud service providers. As we will discuss in an upcoming section on third-party security services, many organizations do not have the qualified staff available to manage security functions within the organization, so they outsource these functions to a third-party service provider. In the case of cloud-based firewalls, a third party provides Firewall as a Service (FWaaS), which consists of managing and maintaining firewall services, normally for organizations that also use other cloud-based subscriptions, such as Platform as a Service or Infrastructure as a Service. Note that while deploying a cloud-based firewall alone can greatly simplify management of the security infrastructure for the organization, using a cloud-based firewall when a larger portion of the organization’s infrastructure has migrated into the cloud makes it all the more effective.
Intrusion Detection Systems and Intrusion Prevention Systems
Historically, intrusion detection systems (IDSs) were focused on simply detecting potentially harmful events and alerting security administrators. Then, more advanced intrusion prevention systems (IPSs) were developed that could actually prevent intrusions by dynamically rerouting traffic or by making advanced filtering (allow and deny) decisions during an attack. Over the course of a few generations of technology changes, IDSs and IPSs have merged and essentially become integrated. Although an IDS/IPS could be a standalone system, typically IDS/IPS functions are part of an advanced or next-generation security system that integrates those functions, as well as firewall and proxy functions, into a single system, typically a dedicated hardware appliance or software suite.
Traditional IDS/IPSs collect and analyze traffic by forcing traffic to flow into one interface and out another, which requires the IDS/IPSs to be placed inline within the network infrastructure. The problem with this approach is that it introduces latency into the network, since the IDS/IPS’s rule set must examine every packet that comes through the system. Advances in technology, however, allow an IDS/IPS to be placed at strategic points in the infrastructure, with sensors deployed across the network in a distributed environment, so that traffic is not forced to go through a single chokepoint. This reduces latency and allows the IDS/IPS to have visibility into more network segments.
IDS/IPSs are also categorized in terms of whether they are network-based or host-based:
• Network-based IDS/IPS (NIDS/NIPS) Looks primarily at network traffic entering into an infrastructure, exiting from the infrastructure, and traveling between internal hosts. A NIDS/NIPS does not screen traffic exiting or entering a host’s network interface.
• Host-based IDS/IPS (HIDS/HIPS) Looks at traffic entering and exiting a specific host, and is typically implemented as software installed on the host as a separate application or as part of the operating system itself.
In addition to monitoring traffic for the host, the HIDS/HIPS may be integrated with other security software functions and may perform traffic filtering for the host, anti-malware functions, and even advanced endpoint monitoring and protection. Although not required, most modern HIDSs/HIPSs in large enterprises are agent-based, centrally managed systems. They use software endpoint agents installed on the host so security information can be reported back to a centralized collection point and analyzed individually or in aggregate by a SIEM, as discussed in Objective 7.2.
Objective 7.2 also discussed the methods by which an IDS/IPS detects anomalous network traffic and potential attacks. To recap, there are three primary methods that can be used alone or in combination to detect potential issues in the network:
• Signature- or pattern-based (rule-based) detection (also called knowledge-based detection) uses preconfigured attack signatures that may be included as part of a subscription service from the IDS/IPS vendor.
• Anomaly- or behavior-based analysis involves allowing the IDS/IPS to “learn” the normal network traffic patterns in the infrastructure; when the IDS/IPS detects a deviance from these normal patterns, the system alerts an administrator.
• Heuristic analysis takes behavior analysis one step further; in addition to catching changes in normal behavior patterns, a heuristic analysis engine looks at those abnormal behaviors to determine what types of malicious activities they could lead to on the network.
EXAM TIP You should understand the methods by which IDS/IPSs detect anomalies and potential intrusions, as well as how they are classified as either network-based or host-based systems.
Note that IDS/IPSs can look at a multitude of traffic characteristics to detect anomalies and potentially malicious activities, including port, protocol, service, source and destination addresses, domains, and so on. These characteristics could also include particular patterns like abnormally high bandwidth usage or network usage during a particular time of day or night when traffic usually is light. Advanced systems can also do in-depth content inspection of specific protocols, such as HTTP, and even intercept and break secure connections using protocols such as TLS, so that the systems can detect potentially malicious traffic that is encrypted within secure protocols.
Cross-Reference
Intrusion detection and prevention were also discussed in Objective 7.2.
Third-Party Provided Security Services
Organizations, particularly smaller ones, may not always be staffed sufficiently to take care of their own security services and infrastructure. With the mounting security challenges that organizations now face, there is an increasing trend in the use of managed security services (MSSs), also known as Security as a Service, third-party providers to which organizations can outsource some or all of their security functions. An MSS can manage various aspects of an organization’s security, such as security device configuration, maintenance, and monitoring, security operations center (SOC) services, and even user and resource management or control.
Contracting services out to a reputable third-party service provider has the following advantages, among others:
• Cost savings The organization does not have to hire and train its own security personnel, nor maintain a security infrastructure.
• Risk sharing Since the organization does not maintain its own security infrastructure, some of the risk involved with this endeavor is shared with another party.
However, there are also distinct disadvantages to contracting with a third-party service provider:
• Less control over the infrastructure The organization does not always have the ability to immediately control how the infrastructure is configured or react to both customer needs and events. It relies on the third party to be dependable in its responsiveness, as well as have a sense of urgency.
• Legal liability In the event of a breach, the organization still retains ultimate responsibility and accountability for sensitive information (although the third-party service provider may also have some degree of liability).
• Lack of visibility into the service provider’s infrastructure The organization may not even be able to look at its own audit logs or security device performance. The organization may also not have the ability to audit the third-party security provider’s processes, legal or regulatory compliance, or infrastructure.
Regardless of the security functions an organization chooses to outsource, the key to a successful relationship with a third-party security service provider is the service level agreement (SLA). An MSS usually offers a standard SLA, which the organization should carefully review and, if necessary, seek modification of before entering into the contract with the provider. The SLA should clearly define both distinct and shared responsibilities the organization and the third-party provider have in securing systems and information. The SLA should also address critical topics such as availability, resiliency, data information ownership, and legal liability in the event that an incident such as a breach occurs.
Cross-Reference
Third-party providers and some of the services they offer, as well as service level agreements, are discussed in detail throughout Objectives 1.12, 4.3, 5.3, and 8.4.
Honeypots and Honeynets
In their ongoing effort to prevent attackers from getting to sensitive hosts, administrators often deploy a honeypot on the network as part of their defense-in-depth strategy. A honeypot is an intentionally vulnerable host, segregated from the live network, that appears to attackers as a prime target to exploit. The honeypot distracts the attacker from sensitive hosts, and at the same time gives the administrator an opportunity to record and review the attack methods used by the attacker.
Honeypots are often deployed as virtual machines and are segmented from sensitive hosts by both physical and virtual means. They may be on their own physical subnet off of a router, as well as use VLANs that are tightly controlled. They may have dedicated IDS/IPSs monitoring them, as well as other security devices. Administrators often have the option of dynamically changing the honeypot’s configuration or disabling it altogether if needed in response to an attacker’s actions.
A sophisticated attacker may recognize a lone honeypot, so a more advanced technique network defenders may deploy is a honeynet. A honeynet is a network of honeypots that can simulate an entire network, including infrastructure devices, servers, end-user workstations, and even security devices. The attacker may be so busy trying to navigate around and attack the honeynet that they do not have time to attack actual sensitive hosts before a security administrator detects and halts the attack.
Note that an organization should carefully consider the use of honeypots and honeynets before deciding to deploy them. If implemented improperly, a honeypot/honeynet can cause legal issues for an organization, since attackers have been known to use a honeypot to further attack a different network outside the organization’s control. This could subject the organization to potential legal liability. Additionally, it can be a legal gray area if an organization tries to press charges against an attacker, as the attacker might be able to claim they were entrapped, particularly if the honeypot was set up by a law enforcement or government agency. The organization should definitely consult with its legal department before deploying honeypot technologies.
Anti-malware
Malware is a common and prevalent threat in today’s world. Most organizations take malware seriously and install anti-malware products on both hosts and the enterprise infrastructure. Much of the malware that we see today is referred to as commodity malware (aka commercial-off-the-shelf malware). This is common malware that malicious entities obtain online (often free or cheap) to use to attack organizations. It normally targets and attacks organizations that don’t do a good job of managing vulnerabilities and patches in their system, and it looks for easy targets that may not update their anti-malware software on a continual basis. This type of malware is reasonably easy to detect and eliminate, since its signatures and attack patterns are widely known and incorporated into anti-malware software. Even as it mutates in the wild (as polymorphic malware does), most anti-malware companies quickly notice these variations and add those signatures to their security suites.
Commodity malware is fairly common, unlike advanced malware that may be the product of advanced criminals or even nation-states. This type of malware specifically targets complex vulnerabilities or those that don’t yet have mitigations, such as zero-day vulnerabilities, or advanced defenses. As such, advanced malware can be very difficult to detect and contain.
Anti-malware uses some of the same methods of detection that other security services and functions use. These methods include the following:
• Signature- or pattern-based detection for common malware.
• Behavior analysis and heuristic detection. Even if an executable is not identified as a piece of malware based on its signature, how it behaves and interacts with the system, other applications, and data may demonstrate that it is malicious in nature. Anti-malware solutions that use behavior and heuristic analysis can often detect otherwise unknown malicious code.
• Reputation-based services, where the anti-malware software communicates with vendors and security sites to exchange data about the characteristics of code. Based on what others have seen the code do, a reputation score is assigned to the code, enabling the anti-malware software to classify it as “good” or “bad.”
The most important thing to remember about anti-malware solutions is that they must be updated on a consistent and continual basis with the latest signatures and updates. If an anti-malware solution is not updated frequently, it will not be able to detect new malware signatures or patterns. Most anti-malware solutions in an enterprise network are centrally managed, so updating signatures is relatively easy for the entire organization. However, administrators who are responsible for standalone hosts that use individually installed and managed anti-malware solutions must be vigilant about maintaining automatic updates or manually updating the anti-malware signatures often.
Unknown and potentially malicious code that is not detected by anti-malware solutions is a good candidate for reverse engineering. Reverse engineering is part of malware analysis, which means that an analyst obtains a copy of the potentially malicious code and analyzes its characteristics. These include its processes, memory locations, registry entries, file and resource access, and other actions it performs. This analysis also looks closely at any network traffic the unknown executable generates. Based upon this analysis, a cybersecurity analyst experienced in both programming and malware analysis may be able to determine the nature of the code.
Sandboxing
A sandbox is a protected environment within which an administrator can execute unknown and potentially malicious software so that those potentially harmful applications do not affect the network. A sandbox can be a protected area of memory and disk space on a host, a virtual machine, an application container, or even a full physical host that is completely separated from the rest of the network. Sandboxes have also been known over the years as detonation chambers, where media containing unknown executables were inserted and executed to study their actions and effects.
While anti-malware applications may be very effective at detecting malicious executables, attackers are also equally clever in obfuscating the malicious nature of those executables, simply by what is known as bit-flipping or changing the signature of the malware. A sandbox helps determine whether or not the application is malicious or harmless by allowing it to execute in a protected environment that cannot affect other hosts, applications, or the network. Note that some anti-malware applications can automatically sandbox unknown or suspicious executables as part of their ordinary actions.
Machine Learning and Artificial Intelligence
Machine learning (ML) and artificial intelligence (AI) are advanced disciplines of computer science. While not specifically focused on cybersecurity, ML and AI tools, concepts, and processes can assist in analyzing very large heterogenous datasets. These technologies give analysts far more capabilities beyond simple pattern searching or correlation. These capabilities combine behavior analysis with complex mathematical algorithms and actually “learn” from the data ML- or AI-enabled systems ingest and the analysis those systems perform.
ML and AI, when integrated into a system such as a security orchestration, automation, and response (SOAR) implementation or a SIEM system, can be very helpful for looking at large volumes of data produced from sources all over the infrastructure. They can help determine if there are potentially malicious activities occurring, by enabling data correlation between seemingly unrelated data points, as well as keying in on obscure pieces of data that may be indicators of an otherwise difficult-to-detect compromise. This type of technology is very useful in threat hunting and looking for advanced persistent threat (ATP) presence in the infrastructure.
Both ML and AI can also be used for historical data analysis to determine exactly what occurred with a given set of data over a period of time. In addition, they can be used as predictive methods to determine future trends or potential threats.
Cross-Reference
Security orchestration, automation, and response (SOAR) is discussed at length in Objective 8.2, and security information and event management (SIEM) systems were discussed in Objective 7.2.
REVIEW
Objective 7.7: Operate and maintain detective and preventative measures In this objective we looked at various detective and preventive measures used in security operations. Most of these are technical controls designed to help detect anomalous or malicious activities in the network and prevent those activities from seriously impacting the organization. Preventive controls are critical in halting malicious activities before they even begin, but if preventive controls are not effective, detection is critical in stopping a malicious event.
Allow-listing and deny-listing are techniques used to permit or block network traffic, content, and access to resources based on rules contained in lists or rule sets. Items in an allow list are explicitly allowed, and any items not in the list are implicitly, or by default, denied. Items contained in a deny list are explicitly denied, and any items not in the list are implicitly, or by default, allowed. Most modern lists, however, contain both allow and deny rules.
Firewalls are traffic-filtering devices that can use various criteria (such as port, protocol and service) and deep content inspection to make decisions on whether to allow or deny traffic into, out of, or between networks. Network-based firewalls focus on network traffic, whereas host-based firewalls primarily focus on protecting individual hosts. Firewall types include packet-filtering, circuit-level, stateful inspection, and advanced next-generation firewalls. Newer firewall types include web application firewalls, whose purpose is to protect web application servers from specific attacks, and cloud-based firewalls, which function as a service offering from cloud providers and are more effective when most of the organization’s infrastructure has been relocated to the cloud provider’s data center.
Intrusion detection/prevention systems can detect and prevent attacks against an entire network (NIDS/NIPS) or individual hosts (HIDS/NIPS). IDS/IPSs can detect traffic using a number of methods, including signature- or pattern-based detection, behavior- or anomaly-based detection, and heuristic-based detection.
Third-party security services, also known as managed security services and Security as a Service, are often contracted to perform security functions that the organization is not staffed or qualified to perform. These services may include security device configuration, maintenance, and monitoring, log review, and SOC services. As long as the third-party service provider is trusted and a strong SLA is in place between the organization and the provider, this may be a preferred way of sharing risk. However, the risks of a third-party security service provider include unclear responsibilities, lack of reliability, undefined data ownership, and legal liability in the event of a breach.
A honeypot is a decoy host set up on a network to attract the attention of an attacker so that their actions can be recorded and studied, as well as to distract them from sensitive targets. A honeynet is a network of honeypot hosts.
Anti-malware applications can be deployed across the network or on individual hosts and are usually centrally managed. Anti-malware applications can detect malicious code using some of the same methods used for intrusion detection, such as signatures or patterns, changes in behavior, or even heuristic detection methods. Anti-malware can also use reputation-based scoring to determine if an unknown application may be a piece of malware. The most critical thing to remember about anti-malware solutions is that they are constantly being updated by vendors, so administrators must ensure that either automatic or manual updates occur on a frequent basis.
Sandboxing is a method of executing potentially unknown or malicious executables in a protected environment that is isolated from the rest of the network. This helps to determine whether the software is malicious or harmless without the potential of danger or damage to the infrastructure. Sandboxes can be virtual or physical machines.
Finally, we also examined the benefits of machine learning and artificial intelligence, which can allow analysts a much wider and deeper capability of analyzing massive amounts of disparate data to determine relationships and patterns.
7.7 QUESTIONS
1. You are a cybersecurity analyst in your company and are tasked with configuring a security device’s rule set. You are instructed to take a strong approach to filtering, so you want to disallow almost all traffic that comes through the security device, except for a few select protocols. Which of the following best describes the approach you are taking?
A. Default allow
B. Default deny
C. Implicit allow
D. Explicit deny
2. You must deploy a new firewall to protect an online Internet-based resource that users access using their browsers. You want to protect this resource from injection attacks and cross-site scripting. Which of the following is the best type of firewall to implement to meet your requirements?
A. Packet-filtering firewall
B. Circuit-level firewall
C. Web application firewall
D. Host-based firewall
7.7 ANSWERS
1. B If you are only allowing a few select protocols and denying everything else, that is a condition where, by default, everything else is denied. The protocols that are allowed are explicitly listed in the rule set.
2. C A web application firewall is specifically designed to protect Internet-based web application servers, and can prevent various web-based attacks, including injection and cross-site scripting attacks.
 Implement and support patch and vulnerability management
Implement and support patch and vulnerability management
This objective addresses the necessity to update and patch systems and manage their vulnerabilities. This objective is also closely related to the configuration management (CM) discussion in Objective 7.3, as patches and configuration changes required to address vulnerabilities must be carefully controlled through the CM process.
Patch and Vulnerability Management
We discussed the necessity for secure, standardized baseline system configurations in Objective 7.3. Barring any intentional changes that we make to systems, they should, in theory, remain in those baselines indefinitely. However, this isn’t possible in practice, since vulnerabilities to operating systems, applications, and even hardware are discovered on a weekly basis. Therefore, we must apply patches or updates to the systems, which means their baselines must change, sometimes frequently. Patch management can be a race against malicious actors who exploit vulnerabilities as soon as they are released. In some cases, vulnerabilities are exploited before there is a patch; these are called zero-day vulnerabilities and are among the most urgent vulnerabilities to mitigate.
Every organization must have a comprehensive patch and vulnerability management program in place. Obviously, policy is where it all begins. An organization’s policies must address vulnerability management based on system criticality and vulnerability severity, include a patch management schedule, and address how to test patches before applying to hosts to mitigate any unexpected issues that may occur on production systems.
Managing Vulnerabilities
As mentioned, vulnerability bulletins are released on a weekly and even sometimes daily basis. Although the term “vulnerabilities” typically brings to mind technical vulnerabilities, such as those associated with operating systems, applications, encryption algorithms, source code, and so on, there are also nontechnical vulnerabilities to consider. Each vulnerability requires its own method of determining vulnerability severity and subsequent mitigation strategy.
Technical Vulnerabilities
Technical vulnerabilities are a frequent topic in this book. They apply to systems in general, but specifically can show up in operating systems, applications, code, network protocols, and even hardware, regardless of whether it is traditional IT devices or specialized devices such as those in the realm of IoT. Most technical vulnerabilities fall into one of a few categories, including, but not limited to
• Authentication vulnerabilities
• Encryption or cryptographic vulnerabilities
• Software code vulnerabilities
• Resource access and contention vulnerabilities
Technical vulnerabilities are often remediated with patches, updates, or configuration changes to the system, and in some cases completely new software or hardware is necessary to mitigate vulnerabilities if they cannot otherwise be eliminated. Technical vulnerabilities are usually detected during vulnerability scanning, which involves using a host- or network-based scanner to search a system for known vulnerabilities. We will discuss vulnerability scanning later in this objective.
Nontechnical Vulnerabilities
Nontechnical vulnerabilities can be more difficult to detect, and even harder to mitigate, than technical vulnerabilities, but they are equally serious. Nontechnical vulnerabilities include weaknesses that are inherent to administrative controls, such as policies and procedures, and physical controls. A policy addressing the mandated use of encryption is a serious weakness, for example, if no one is required to encrypt sensitive data. Physical vulnerabilities, such as lack of fencing, alarms, guards, and so on, can create serious security and safety concerns in terms of protecting facilities, people, and equipment.
Nontechnical vulnerabilities are also discovered during a vulnerability assessment, but this type of assessment looks more closely at processes and procedures, as well as administrative and physical controls. These vulnerabilities can’t, however, be addressed by simply patching; more often than not, mitigating these vulnerabilities requires more resources, additional personnel training, or additional policies.
Managing Patches and Updates
Along with vulnerability management comes patching and update management. Technical vulnerabilities are most often addressed with patches or updates to operating systems and applications. However, patches and updates shouldn’t simply be applied sporadically or only when an administrator has time. They should be carefully considered for both positive and potentially negative security and functional issues they may introduce into the infrastructure. Managing patches and updates includes considering the criticality of both the patch and the system, a solid patch update schedule, and formal patch testing and configuration management, all discussed next.
NOTE Although some professionals tend to use the terms “patches” and “updates” interchangeably in ordinary conversation, a patch is specifically used to mitigate a single vulnerability or fix a specific functional or performance problem. An update is a group of patches, released by a vendor on a less frequent basis (often scheduled periodically) and may add functionality to a system, or “roll up” several patches.
Patch and System Criticality
Criticality is a key concern in patch and update management, from two different perspectives:
• System criticality When installing patches and updates, critical assets, such as servers and networking equipment, may be offline for an indeterminate amount of time while the patch or update is applied and tested. Often this downtime is minimal, but for critical assets, the installation should be scheduled to meet the needs of the user base and the organization.
• Patch and update criticality The critical nature of the patch or update itself may be a factor. The patch may, for example, mitigate a zero-day vulnerability that creates high risk in the organization. The patch must be applied as soon as possible but should be balanced with the criticality of the systems that it must be applied to.
An organization must be prepared to make decisions that require balancing system criticality with patch criticality; this is often a subject that has to be addressed quickly by the entire change management board, so an organization must plan appropriately.
EXAM TIP Criticality of both patches and systems must be balanced when making the determination to install patches that mitigate serious vulnerabilities, especially those that have not been tested or may take systems down for an unknown period of time. You must balance the need to maintain system uptime and availability with the risk of not implementing the patch quickly.
Patch Update Schedule
Criticality aside, patches should be applied as soon as possible but should be prioritized according to the urgency of the patch and the criticality of the assets. An organization should have a regular schedule and routine for deploying patches, which should include the ability to test patches in a development environment before applying them to production systems. Administrators should have the opportunity to review patches based on the system criticality and the risk that leaving an unpatched system introduces, so they can appropriately schedule the patch for installation.
Routine patches may be applied only once a week or once a month but should at least be scheduled so that there is minimal disruption to the user base. This is where policy comes into play—the patch and vulnerability management policy should indicate a schedule based on criticality of patches and systems. A typical schedule may require critical patches to be applied within one business day and routine patches to be applied within seven calendar days. In any event, a regular patching schedule is absolutely necessary to make sure that new vulnerabilities are mitigated.
Patch Testing and Configuration Management
Simply downloading a patch and applying it to a production system is not a safe practice; patches and updates sometimes have adverse effects on systems, including affecting their functionality and performance, or even opening up further security vulnerabilities. Sometimes patching one vulnerability can lead to another, so patches should be tested on development or test systems prior to being implemented in the production environment. Unfortunately, sometimes the patch schedule makes this difficult, particularly when the patch or system is critical. In the event of an urgent patch, an organization might decide to apply it directly to production systems, after thorough research and ensuring the patch or update can be rolled back quickly if needed.
As mentioned previously, patches and updates are closely related to configuration management; sometimes applying a major patch or update changes the security baseline significantly. Once the patch has been tested and approved, it is implemented on production systems. For future systems, the patch may need to be considered for the initial build and included in the system master images. This requires configuration management and documenting changes to the official standardized baseline.
Patches and updates should be documented to the greatest extent possible; sometimes this may not be practical in the event of many patches that may come all at once, but at least maintaining a list of patches or a snapshot of the system state before and after patching can help later documentation. This is important because if a patch or update changes system functionality or lowers the security level of a system, documentation can provide valuable information when researching the root cause of the issue and can support potential rollback.
Cross-Reference
Configuration management was discussed at length in Objective 7.3.
REVIEW
Objective 7.8: Implement and support patch and vulnerability management In this objective we looked at patch and vulnerability management, which are closely related to system configuration and change management. We discussed the necessity to apply patches and updates to systems and applications on a scheduled basis and to consider both patch and system criticality when devising a patch management strategy. We also emphasized the importance of testing patches before implementing them on production systems, since even patches can cause systems to be less functional or less secure. We also examined vulnerability management, including the necessity to scan for and mitigate technical vulnerabilities. Nontechnical vulnerabilities may be more difficult to detect and mitigate than technical vulnerabilities, but addressing them is equally important. A proactive vulnerability and patch management program is critical to the security of the infrastructure.
7.8 QUESTIONS
1. Your company has ten servers running an important database application, some of which are backups for the others, with a significant vulnerability in a line-of-business application that could lead to unauthorized data access. A patch has just been released for this vulnerability and must be applied as soon as possible. You test the patch on development servers, and there are no detrimental effects. Which of the following is the best course of action to take in implementing the patch on all production servers?
A. Install the patch on all production servers at once.
B. Install the patch on only some of the production servers, while maintaining uptime of the ones that serve as backups.
C. Install the patch only on one server at a time.
D. Do not install the patch on any of the critical systems until users do not need to be in the database.
2. You install a critical patch on several production servers without testing it. Over the next few hours, users report failures in the line-of-business applications that run on those servers. After investigating the problem, you determine that the patch is the cause of the issues. Which one of the following would be the best course of action to take to quickly restore full operational capability to the servers as well as patch the vulnerabilities?
A. Rebuild each of the servers from scratch with the patch already installed.
B. Reinstall the patch on all the systems until they start functioning properly.
C. Roll back the changes and accept the risk of the patch not being installed on the systems.
D. Roll back the changes, determine why the patch causes issues, make corrections to the configuration as needed, test the patch, and install it on only some of the production servers.
7.8 ANSWERS
1. B Because the patch is critical, it must be installed as soon as possible and on as many servers at a time as practical. Since some servers are backups, those servers can remain online while the other servers are patched, and then the process can be repeated with the backups. Installing the patch on all servers at once would take down the production capability for an indeterminate amount of time and is not necessary. Installing the patch on only one server at a time would increase the window of time that the vulnerability could be exploited.
2. D The changes must be rolled back so that the servers are restored to an operational state, then research must be performed to determine why the patch caused issues. Any configuration changes should be investigated to determine if the issues can be corrected, and only then should the patches be tested and then reinstalled. You should install them only on some of the production servers so that some processing capability is maintained. If issues are still present, then you should repeat the process until the problem is solved. The servers should not need to be rebuilt from scratch, as this can take too long and is no guarantee that it will fix the problem. Reinstalling the patch over and over until the systems start functioning properly is not realistic. The risk of an unpatched system may be unacceptable to the organization if the vulnerability is critical.
 Understand and participate in change management processes
Understand and participate in change management processes
As discussed in Objective 7.3, configuration management is a subset of the overall change management process. In this objective we turn to the change management program itself and discuss the change management processes that an organization must implement both to effectively manage changes that occur in the infrastructure and to deal with the security ramifications of those changes.
Change Management
Change management is an overall management process. It refers to how an organization manages strategic and operational changes to the infrastructure. This is a formalized process, intentionally so, to prevent unauthorized changes that may inconvenience the organization, at best, or, at worst, cripple the entire organization. Change management encompasses how changes are introduced into the infrastructure, the testing and approval process, and how security is considered during those changes.
Examples of the types of change the organization should pay particular attention to include
• Software and hardware changes and upgrades
• Significant architecture or design changes to the network
• Security or risk issues requiring changes (e.g., new threats or vulnerabilities)
Cross-Reference
Change management for software development is also discussed in Objective 8.1.
Change Management Processes
As a formalized management program, change management must necessarily have documented processes, activities, tasks, and so on. The change management program begins with policy (as does every other management program in the organization) that specifies individual roles and responsibilities for managing change in the organization. Change management processes also consider change as a life cycle and address both functional and security ramifications in that life cycle.
Change Management Policy
As mentioned, the change management program starts with policy. The organization must develop and implement policy that formalizes the change management program in the organization by assigning roles and responsibilities, creating a change management cycle, and defining change levels. Roles and responsibilities are usually established and delineated by creating a change control board, discussed in the next section.
Change Management Board
The group of individuals tasked with overseeing infrastructure changes is called the change management board (CMB), change control board (CCB), or change advisory board (CAB). The individual members of the board are appointed by the organization’s senior management and come from management, IT, security, and various functional areas to ensure that changes are formally requested, tested, approved, and implemented with the concurrence of all organizational stakeholders. Each identified stakeholder group normally appoints a member and an alternate to the board to ensure that group’s interests are represented.
The CMB/CCB/CAB is often created by a document known as a charter, which establishes the various roles and their duties. The charter may also dictate the process for submitting and approving changes, the process for voting on changes, and how the board generally operates. The board usually meets on a regular basis, as dictated by the charter, to discuss and vote on an approved agenda of changes. These changes may come from the strategic plan for the organization, from changes in the operating environment and risk posture, or from changes necessitated by the industry or regulations.
Change Management Life Cycle
An organization should define a formal change management life cycle in policy. This life cycle should meet the requirements of the organization based on several criteria, including its appetite and tolerance for risk, the business and IT strategies for the organization, and urgency of changes that must take place. A generic life cycle for change management process in the organization includes these steps:
1. Identify the need for change. This can stem from planned infrastructure changes, results of risk or security assessments, environmental and technology changes, and even industry or market changes.
2. Request the change. The change must be formally requested (and championed) by someone in the organization—whether it is a representative of IT, security, or a business or functional area—who submits a formal business case justifying the change.
3. Testing approval. The CCB votes to approve or disapprove testing the change based on the request justification. The proposed change is tested to see how it may affect the existing infrastructure, including interoperability, function, performance, and security.
4. Implement the change. Based on testing results, the CCB may vote to approve the change for final implementation or send the change back to the requester until certain conditions are met. If the change is approved for implementation, the new baseline is formally adopted.
5. Post-change activities. These are unique to the organization and involve documenting the change, monitoring the change, updating risk assessments or analysis, and rolling back the change if needed due to unforeseen issues.
CAUTION Understand that these are only generic change management steps; each organization will develop its own change management life cycle based on its unique needs.
All changes aren’t considered equal; some changes are more critical than others and may require the full consideration of the change board. Other changes are less critical and the decision to implement them may be routine and delegated down to a few members of the board or even IT or security if the changes do not present significant risk to the organization. All of these options and decision trees must be determined by policy. In this regard, an organization should develop change levels that are prioritized for consideration and implementation. While each organization must develop its own change levels, generally these might be considered as follows:
• Emergency or urgent changes These are changes that must be made immediately to ensure the continued functionality and security of the system.
• Critical changes These are changes that must be made as soon as possible to prevent system or information damage or compromise.
• Important changes These are changes that must be performed as soon as practical but can be part of a planned change.
• Routine changes These are minor changes that could be made on a daily or monthly basis; most noncritical patching or updates generally fall into this category.
EXAM TIP The priority of changes is critical for an organization to develop and adhere to, since changes with some urgency must be quickly considered and implemented, especially those that impact the security of the infrastructure.
Note that some organizations, in addition to prioritizing changes based on urgency, also categorize changes in terms of the effort required to implement the change or the scope of the change. Examples may include categories such as major changes and minor changes.
Security Considerations in Change Management
Security is a critical factor in proper change management. Any changes to the infrastructure introduce a degree of risk, so these changes must undergo an assessment to determine the extent of security impact or risk they will introduce to the organization’s assets. Both before and after a change is implemented, the organization should perform vulnerability testing on the affected systems to see what deltas in vulnerabilities the changes will produce; this way any new vulnerabilities can be properly attributed to the change itself rather than other factors. The affected systems should be “frozen” or locked in configuration before this occurs, so as to not introduce any unexpected or random factors into the testing and subsequent changes. Once a security impact of the change is determined, this information is considered along with other factors, such as downtime, scope of the change, and urgency, before finalizing a change.
REVIEW
Objective 7.9: Understand and participate in change management processes This objective introduced the concept of change management as a formal program in the organization. Change management means the organization must have a formalized, documented program in place to effectively deal with strategic and operational changes to the infrastructure. Change management begins with a comprehensive policy that outlines roles, responsibilities, the change management life cycle, and categorization of changes. The change management board is responsible for overseeing the change process, including accepting change requests, approving them, and ensuring that the process follows standardized procedures. The change life cycle includes requesting the change, testing the change, approval, implementation, and documenting the change. Security impact considerations must be included in the change management process since change may introduce new vulnerabilities into the infrastructure.
7.9 QUESTIONS
1. Which of the following formally creates the change management board and establishes the change management procedures?
A. Security impact assessment
B. Charter
C. Policy
D. Change request
2. Your company’s change management board is evaluating a request to add a new line-of-business application to the network. Which step of the change management life cycle should be performed before final approval of this request?
A. Document the application and its supporting systems.
B. Test the changes to the infrastructure in a development environment.
C. Perform a rollback to the original infrastructure configuration.
D. Submit a formal business case to the board from the responsible business area.
7.9 ANSWERS
1. B A change management board charter is often used as the source document to create the change board and establish its processes.
2. B Before final approval of the change to the infrastructure, all changes should be tested in a development environment.
 Implement recovery strategies
Implement recovery strategies
In this objective we begin our discussion of disaster recovery and business continuity. We will discuss various recovery strategies, including those associated with backups, recovery sites, resilience, and high availability. Although the recovery strategies we will cover are often associated with disasters in particular, these same strategies can also be used during a variety of incidents, as we discussed in Objective 7.6. Because of this, Objective 7.10 serves as an important link between our previous discussion on incident management and Objective 7.11 that addresses disaster recovery planning, which we will discuss later on during this domain.
Recovery Strategies
Recovery strategies are designed to keep the business up and functioning during a disaster or incident and to expedite a return to normal operations. The key to recovery strategies are resiliency, redundancy, high availability, and fault tolerance. We will discuss each of these in this objective, as the different strategies that can be implemented by an organization usually target one of these key areas.
Backup Storage Strategies
To recover an organization’s processing capabilities, the organization must ensure that its data is backed up prior to any adverse event that requires data restoration. There are several backup storage strategies an organization can use; the decision regarding which one (or combination of several) to use depends on a few factors, including
• How much data the organization can afford to lose in the event of a disaster
• How much data the organization requires to restore its processing capability to an acceptable level
• How fast the organization requires the data to be restored
• How much the backup method or system and media cost
• How efficient the organization’s network and Internet connections are in terms of speed and bandwidth
In the next few sections we will discuss various backup strategies that vary in cost, speed, recoverability, and efficiency.
Traditional Backup Strategies
Traditional backup strategies involve backing up individual servers to a tape array or even to separate disk arrays. Because these backup methods are often expensive and time consuming, a system of using backup strategies such as full, incremental, and differential backups was developed to deal with these issues. Briefly, the strategies are executed as follows:
• Full backup The entire hard disk of a system is backed up, including its operating systems, applications, and data files. This type of backup typically takes a much longer amount of time and requires a great deal of storage space.
• Incremental backup This strategy backs up only the amount of data that has changed since the last full backup. It requires less storage space and is somewhat faster, but the data restore time can take much longer. The last full backup and each incremental backup since the last full backup have to be restored one at a time, in the order in which they occurred. Incremental backups reset the archive bit on a backup file, showing that the data has been backed up. If the archive bit is set to “on,” as happens when a file changes, this means it has not been backed up.
• Differential backup This backup strategy involves backing up only data that has changed since the last full or incremental backup; the difference between this type of backup and an incremental backup is that the archive bit for the backup files is not turned off. In the event of a restore, only the last full backup and the last differential backup have to be restored, since each subsequent differential backup includes all the previous changed data. However, as differential backups are run, they became larger and larger, since they include all data that has changed since the last full backup.
Again, these strategies were devised during the days when backup solutions were highly expensive, backup media was slow and unreliable, and backups were very time-consuming and tedious. Although there are still some valid uses of these strategies today, they have largely become obsolete due to the much lower cost of other backup media, high-speed networking, and both the availability and inexpensive nature of technologies such as cloud storage, all of which are discussed in the following sections.
Direct-Attached Storage
Direct-attached storage is the simplest form of backup. It also may be the least dependable, since it is an external storage media, such as a large-capacity USB drive, directly attached to the computing system. While direct-attached storage may be fast enough for the organization’s current requirements, it is unreliable in that a physical disaster that damages a system may also damage the attached storage. This type of storage is also susceptible to accidents, intentional damage, and theft. Direct-attached storage should never be used as the only form of backup for critical or sensitive data, but it may be effective as a secondary means of backup for individual user workstations or small datasets.
Network-Attached Storage
A network-attached storage (NAS) system is the next step up from direct-attached storage. It is simply a network-enabled storage device that is accessible to network hosts. It may be managed by a dedicated backup server running enterprise-level backup software. It may also double as a file server. Over a high-speed network, NAS can be quite efficient, but suffers from some of the same reliability issues as direct-attached storage. Any disaster that occurs causing damage to the infrastructure may also damage the NAS system. NAS may be sufficient for small to medium-sized businesses and may or may not offer any redundancy capabilities.
Storage Area Network
A storage area network (SAN) is larger and more robust than a simple network-attached storage device. A SAN is designed to be a significant component of a mature data center supporting large organizations. It may have its own cluster of management servers and even security devices to protect it. A SAN is often built for redundancy by having multiple storage devices that fail over to each other. Components are connected to each other and to the rest of the network with high-speed fiber connections. While designed for high availability and efficiency, a SAN still suffers from the possibility that a catastrophic event damaging the facility can also damage the SAN.
Cloud Storage
Cloud-based storage is becoming more of the norm than on-premises storage. While on-premises storage is still necessary for short-term or smaller-level data recovery, the remote storage capabilities of the cloud support large-scale data recovery that is fast and reliable. Even if a facility is entirely destroyed, data that is backed up over high-speed Internet connections to the cloud is easily available for restoration. The only limiting factors an organization may face when using cloud-based storage as a disaster recovery solution are the associated costs of cloud storage space, which may increase if the amount of data increases over time, as well as the availability of high-speed bandwidth from the organization to the cloud provider.
Offline Storage
Offline storage simply means that data is backed up and stored off of the network and/or at a remote location away from the physical facility. The methods for creating and using offline storage may be manual or electronic; even cloud-based storage is considered offline since it is not part of the same organizational infrastructure and is not housed in the same physical facility. Traditionally, organizations manually transported backup media, such as tapes, optical discs, and hard drive arrays, to a geographically separated site so that if a disaster damaged or destroyed the primary processing facility, the backup media would still be available. Another benefit of offline storage is that a malware infection, ransomware, or other malicious attack that impacts the primary processing facility is far less likely to impact the offline storage.
Electronic Vaulting and Remote Journaling
Contrary to traditional thinking, backups don’t always have to be on a full, incremental, or differential basis. Backups can also be performed on individual files and even individual transactions. They can also be captured electronically either on a very frequent basis or in real time. Electronic vaulting is a backup method where entire data files are transmitted in batch mode (possibly several at a time). This may happen two or three times a day or only during off-peak hours, for instance. Contrast this to remote journaling, which only sends changes to files, sometimes in the form of individual transactions, in either near or actual real time.
Both methods require a stable, consistent, and sometimes high-bandwidth network or Internet connection, depending on if the backup mechanism is local within the network or located at a geographically separated site.
EXAM TIP Keep in mind the differences between electronic vaulting and remote journaling. Electronic vaulting occurs on a batch basis and moves entire files on a frequent basis. Remote journaling is a real-time process that transmits only changes in files to the backup method or facility used.
Recovery Site Strategies
A recovery site, sometimes referred to as an alternate processing site, is used to bring an organization’s operations back online after an incident or disaster. A recovery site is usually needed if an organization’s primary data processing facility or work centers are destroyed or are otherwise unavailable after a disaster due to damage, lack of utilities, and so on. Many considerations go into selecting and standing up a recovery site. First, an organization must evaluate how much resources, such as money and equipment, to invest based on the likelihood that it will need to use an alternate recovery site. For example, if your organization has performed risk assessments and adequately considered the likelihood and impact of catastrophic events, and determined that the odds of such an event are very low, it very well may decide that maintaining a recovery site that is staffed 24/7 and has fully redundant equipment is unnecessary and a waste of money. Another consideration is how long your organization can afford to be down or operating at minimal capacity. If it can survive a week without being operational, then having a recovery site available that can be activated over a few days likely will be more cost-effective than having one that’s ready to go at a moment’s notice. In regard to both of these considerations, recovery site strategies depend very much on how well your organization has performed a risk analysis.
Cross-Reference
Risk analysis was covered in depth in Objective 1.10.
Another consideration in creating a strategy for a recovery site is the ease with which the organization can activate the recovery site and relocate its operations there. If the site is a considerable distance away, relocation might be too difficult if a natural disaster disrupts roads, transportation, employee family situations, and so on. Those are the types of issues that might prevent an organization from efficiently relocating to another site and adequately recovering its operations.
Other issues that your organization should consider when formulating a recovery site strategy include
• Potential level of damage or destruction caused by a catastrophic event
• Possible size of the area affected by a disaster
• Nature of the disaster (e.g., tornado, flood, hurricane, terrorist attack, war, etc.)
• Availability of public infrastructure (e.g., widespread power outages, damage to highways and transportation modes, hospital overcrowding, food shortages, etc.)
• Government-imposed requirements, such as martial law, protections against price gouging, quarantine zones, etc.
• Catastrophes that negatively affect employee families, since this will definitely impact the workforce
• Likelihood of multiple organizations competing for the same or similar resources
In addition to these considerations, recovery sites must have sufficient resources to support the organization; this includes utilities such as power, water, heat, and communications. There must be enough space in the facility to house the employees needed for recovery actions, as well as the equipment that may be relocated. These are constraints an organization will need to take into account when selecting recovery sites, discussed next.
Multiple Processing Sites
An organization must carefully consider several questions when selecting the right type of alternate processing site for its needs:
• How soon after operations are interrupted will the organization need to access the site?
• Will the site have to be fully equipped and have all the proper utilities within a few hours, or can the business afford to wait a few days or weeks before relocating?
• How much time, money, and other resources can the organization afford to invest in an alternate processing site before the cost outweighs the risk that the site will be needed?
These are all questions that can be answered with careful disaster recovery and business continuity planning.
Traditional alternate processing sites include cold, warm, and hot sites; these are used when an organization must physically relocate its operations due to damage to its facilities and physical equipment. This damage may mean that the facility is unusable because it lacks structure, lacks utilities, or even presents safety issues. The other types of sites we will examine, including reciprocal, cloud-based, and mobile sites, don’t necessarily require an organization to relocate its physical presence, instead providing “virtual” relocations or simply alternate processing capabilities.
Cold Site
A cold site is not much more than empty space in a facility. It doesn’t house any equipment, data, or creature comforts for employees. It may have very limited utilities turned on, such as power, water, and heat. It likely will not have high-bandwidth Internet connections or phone systems the organization can immediately use. This type of site is used when an organization either has the luxury of time before it is required to relocate its physical presence or simply cannot afford anything else. As the least expensive alternate processing site option, a cold site is not ready to go at a moment’s notice and must be furnished, staffed, and configured after the disaster has already taken place. All of its equipment and furniture will have to be moved in before the site is ready to take over processing operations.
Warm Site
A warm site is further along the spectrum of both expense and recoverability speed. It is more expensive than a cold site but can be activated sooner in the event of a disaster to restart an organization’s processing operations. In addition to space for employees and equipment, a warm site may have additional utilities, such as Internet and phone access, already turned on. There may be a limited amount of furniture and processing equipment in place—typically spares or redundant equipment that has already been staged at the facility. A warm site usually requires systems to be turned on, patched, securely configured, and have current data restored in order for them to be effective in taking over operations.
Hot Site
A hot site is the most expensive option for traditional physical alternate processing sites. A hot site is ready for transition to become the primary operating site quickly, often within a matter of minutes or hours. It already has all of the utilities needed, such as power, heat, water, Internet access, and so on. It usually has all of the equipment needed to resume the organization’s critical business processes at a moment’s notice. In a hot site scenario, the organization also likely transfers data quickly or even in real time to the alternate site without the risk of losing any data, especially if it uses high-speed data backup connections. Because data can be transferred in large volumes quickly with a high-speed Internet connection, many organizations use their hot site as their off-site data backup solution, which makes spending the money on a physical hot site much more efficient and cost-effective.
EXAM TIP Traditional alternate processing sites should be used when the organization needs to physically relocate its operations. A cold site is least expensive but requires the most time to be operational; a warm site is more expensive but can be ready faster; and a hot site is the most expensive and can be ready to take over processing operations within hours. The decision regarding which of these three types of sites to use is based on how much the organization can afford and how fast it needs to be operational.
Reciprocal Sites
Many organizations have a reciprocal site agreement with another organization that specifies each organization can share the other’s resources in the event of a disaster that affects only one of the organizations. This type of agreement gives the affected organization an opportunity to recover its operations without having to move to a traditional cold, warm, or hot recovery site.
A reciprocal site agreement may be an effective strategy, but there are a few key considerations:
• Are the organizations direct competitors, in a similar business market, or offering similar products or services? On one hand, being in a similar market means the two organizations probably serve well as reciprocal sites since each organization likely uses comparable equipment, applications, and processing capabilities. On the other hand, if they are direct competitors, it might not be a suitable long-term solution for maintaining confidentiality of proprietary or sensitive information.
• Are the organizations in the same geographic area? If so and a natural disaster strikes, neither organization may be able to support the other.
Cloud Sites
Cloud service providers offer a new opportunity for organizational resilience. Traditionally, if an organization suffered physical facility damage, it had to find a new place to set up operations. Depending on the level of damage to the operations, recovery could require long hours provisioning new servers, restoring data from backups (still possibly losing a couple of days’ worth of data in the process), reloading applications, and so on. Cloud computing changes this entire paradigm. If an organization suffers serious physical harm to its facilities or equipment, it’s possible to have complete redundancy for its systems and data built into the cloud. Cloud-based redundancy means that the only reasons an organization would have to find an alternate processing location would be to preserve the health, safety, and comfort of its personnel. With the surge in remote working necessary to maintain operations during the global COVID-19 pandemic, use of cloud solutions has greatly accelerated.
Even during normal processing times, with no risk of disaster or catastrophe, organizations were already slowly moving a great deal of their processing power to the cloud. Organizations have increasingly moved to Software as a Service (SaaS), Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and other, “Anything as a Service (XaaS)” cloud offerings. So if a disaster strikes, the organization may not even have to expend much effort toward disaster recovery or business continuity activities. If the majority of your organization’s systems are already functioning in the cloud, the only ones that need to be recovered are likely lower-priority systems or legacy systems that have not transitioned to the cloud.
Cross-Reference
Cloud-based systems were covered in depth in Objective 3.5.
Mobile Sites
Mobile sites add another dimension to alternate processing capabilities. While cloud-based services can certainly support information processing operations, an organization still may require a physical alternate processing site. If an organization determines, for example, that a cold or warm site is insufficient for bringing operations online quickly enough and that a hot site is too expensive, a mobile site may offer a convenient, economical alternative. A mobile site can be built into a large van, a bus, or even an 18-wheeled transfer truck. While this type of alternate site won’t hold many employees, it gives organizational leadership and key personnel the ability to still work together from a physical “command post.” The mobility advantages are clear; the mobile site can travel away from the major disaster area, where there may be plentiful power, fuel, and other resources, and where the infrastructure may be more supportive for recovery. Larger organizations may own their own vehicle specially outfitted as a mobile site; smaller businesses may be required to lease such a specialized vehicle.
Mobile sites are considered miniature hot sites; while a mobile site may not have the capacity of a large building or other facility, it can certainly hold enough physical equipment to maintain a small data center, particularly if many of its hosts are virtualized or actually present in the cloud and accessible through a strong Internet connection.
Resiliency
Resiliency is the capability of a system (or even an entire organization) to continue to function even after a catastrophic event, although it may only function at a somewhat degraded level. For example, a system with 32GB of RAM that suffers an electrical problem and loses half of that RAM is still functional, although it may be limited in its processing capability and run slower than normal. The same can be said of a server that has dual power supplies and loses one of them or experiences a failure of a disk in a hardware raid array. These components may not necessarily fail, but they may operate at a marginal level of capability.
In the case of an entire organization, resiliency means it may lose some of its overall capabilities (people, equipment, facilities, etc.) but still be able to function at an acceptable, albeit degraded, level. High resiliency is one of the goals of business continuity; it is enabled by having redundant (and often duplicate) system components, alternative means of processing, and fault-tolerant systems.
High Availability
An organization that has implemented high availability (HA) can expect its infrastructure and services to be available on a near constant basis. Traditionally, high availability means that any downtime experienced by the processing capability or a component in the infrastructure is limited to only a few hours or a few days a year. In the early days of e-commerce, most businesses could afford that level of downtime. Only critical services required higher availability rates. For example, if the infrastructure had an availability rate of 99.999 percent (commonly referred to as “five nines uptime”), it would only be down, theoretically, just five minutes and 15 seconds per year. Typically, only very large organizations with critical services could afford this level of availability.
With the advent of high-speed Internet, cloud technologies, virtualization, and other technologies, high availability is a far less expensive prospect, affordable by even small businesses. Additionally, in the ultra-connected global age we live in, even a five-minute period of downtime per year may be too much. Consider the millions of transactions that may occur in a single minute that could be lost with even a small amount of downtime. Fortunately, the technologies available for resiliency and redundancy almost guarantee, if properly implemented, that even a small level of downtime can be almost eliminated.
Quality of Service
Quality of service (QoS) is a somewhat subjective term. Essentially, QoS is the minimum level of service performance that an organization’s applications and systems require. For example, the organization could establish a minimum level of bandwidth required to move its data in and out of, as well as within, the organizational infrastructure. Different types of data and the context in which they move throughout the organization affect the level of service quality required. For example, high-resolution video typically requires a higher level of bandwidth than simple text; any degradation of bandwidth or network speeds reduces the quality of the video or prevents it from being sent or viewed.
In a situation such as a disaster that results in the loss of bandwidth, the organization may have to accept that it cannot move those large, high-resolution video files across the network and may have to settle for smaller files with lower resolution that still get the job done. For instance, Voice over IP (VoIP) traffic usually gets top priority in a network, as it can’t tolerate low bandwidth that causes interruptions (called jitter), unlike e-mail services. Users may not notice a 50ms+ delay in e-mail traffic, but voice and video traffic will experience jitter and quality degradation, so there is a minimum bandwidth needed for those services and applications. So, often QoS is a determination of what the minimum service levels the organization needs for different services versus what it normally has. QoS is also improved by redundant or alternative capabilities, fault tolerance, and service availability.
Fault Tolerance
Fault tolerance means that the infrastructure or one of its systems is resistant to failure. The expectation is that if a network has high fault tolerance, it can resist complete failure of one or more components and still function. The following are a few ways to assure fault tolerance:
• Invest in higher-quality components that have lower failure rates. Cheaply made components often break more often even under lighter loads.
• Invest in redundant components, such as servers with dual power supplies, mirrored RAID arrays, or multiple processors. A stronger example is server clustering using virtual machine capabilities.
The decision to invest in fault-tolerant components and designs can help ensure higher overall availability.
REVIEW
Objective 7.10: Implement recovery strategies In this objective we discussed various recovery strategies. All of these strategies address key concepts such as resiliency, redundancy, high availability, fault tolerance, and quality of service.
Backup storage strategies are chosen based on a number of factors, including cost, speed at which the organization needs to restore data, bandwidth and speed available for network and Internet connections, how much data the organization needs to restore and how quickly it must be restored, as well as how much data the organization can afford to lose during a disaster.
• Backup solutions include traditional backup methods that use tape or hard disk arrays and are performed using full, incremental, or differential strategies.
• Direct-attached storage is a device physically attached to a system, such as a USB hard disk.
• Network-attached storage is a storage appliance connected to the network and accessible by various systems.
• Storage area networks (SANs) are typically larger, more robust storage arrays consisting of multiple devices and connected by a high-speed backbone.
• Direct-attached storage, network-attached storage, and SANs all have the vulnerability that if the entire facility is damaged or destroyed, they will also be affected.
• Cloud-based storage is not impacted by damage to an organization’s facility, although it may be temporarily inaccessible due to network outages in the facility. However, cloud-based storage provides almost a perfect backup solution if the organization does not have to physically relocate.
• Offline storage means that data is stored at a remote site or in the cloud, using manual or electronic means.
• Electronic vaulting involves batch processing of entire files on a frequent basis.
• Remote journaling is performed in real time and only requires piecemeal backups of files, usually by transactions.
• Recovery site strategies center on how much an organization can afford, its risk of needing an alternate processing site, and how fast it needs to reach operational status after a disaster.
• A cold site is essentially empty space with minimal utilities; it does not offer the capability to recover quickly after a disaster, but it is the least expensive alternate processing site option.
• Warm sites offer a midway point along the spectrum of expense and recoverability; they are more expensive than cold sites, but include additional utilities, some equipment on standby, and the ability to get an organization up and running somewhat faster than a cold site.
• A hot site is the most expensive type of physical alternate processing site since it offers a fully functional physical processing space with redundant equipment and data, enabling an organization to return to operational capacity within minutes or hours.
• Cloud sites are a great option for organizations that have already migrated some of their processing capability to cloud-based services; they offer a fairly complete recovery solution for organizations that do not need to physically relocate to an alternate processing site.
• An organization can use a mobile site if it needs to maintain a minimal physical presence after a disaster but requires the alternative space more quickly than a cold or warm site affords and more cheaply than a hot site costs. The mobile nature allows the organization to move its command post or base of operations out of the danger zone or other disaster area to an area where there is better utility and infrastructure support. However, a mobile site does not supply adequate space for large numbers of people.
• Recovery strategies center on key concepts such as resiliency, high availability, quality of service, and fault tolerance.
• Resiliency means that a component, system, or the entire infrastructure of the organization will not fail completely or easily; the processing capability may be reduced to a lower level but will still be functional.
• High availability means that systems and data must be available on a near constant basis. With today’s need for massive amounts of data processed almost in real time, even downtime of a few seconds can be catastrophic for an organization. Fortunately, modern technology such as cloud services, high-speed networking, virtualization, and quality components can help assure high availability even for small businesses.
• Quality of service prioritizes bandwidth for selected systems or data.
• Fault tolerance is the resistance to failure by components in the infrastructure. Fault tolerance is made possible through equipment and component redundancy, duplicate capabilities, and the use of quality equipment.
7.10 QUESTIONS
1. Which of the following traditional backup methods only backs up data that has changed since the last full backup, which also resets the archive bit for the data?
A. Incremental
B. Full
C. Differential
D. Transactional
2. Which of the following traditional backup sites should be used for physically relocating an organization’s processing capability and personnel in the fastest manner possible, with all needed equipment and data already prepositioned?
A. Cold site
B. Warm site
C. Hot site
D. Mobile site
7.10 ANSWERS
1. A An incremental strategy backs up data that has changed since the last full backup only. After the data is backed up, it resets the archive bit, showing that data has been backed up. During a data restore situation, first the full backup is restored, and then each sequential incremental backup must be restored.
2. C A hot site is the most appropriate type of alternate processing site for this scenario, since the organization must be up and running quickly, and the site must contain all necessary equipment and data needed to restore full operations.