
5
SOLVING PROBLEMS WITH CLASSES

In this chapter, we’re going to discuss classes and object-oriented programming. As before, the assumption is that you’ve seen the class declaration in C++ and understand the basic syntax of creating a class, invoking the methods of a class, and so on. We’ll have a quick review in the next section, but we’ll mostly discuss the problem-solving aspects of classes.
This is another situation in which I think C++ has an advantage over other languages. Because C++ is a hybrid language, the C++ programmer can create classes where appropriate but never has to. By contrast, in a language like Java or C#, all code must appear within the confines of a class declaration. In the hands of expert programmers, this causes no undue harm, but in the hands of novices, it can lead to bad habits. To a Java or C# programmer, everything is an object. While all the code written in these languages must be encapsulated into objects, the result doesn’t always reflect sensible object-oriented design. An object should be a meaningful, closely knit collection of data and code that operates on that data. It shouldn’t be an arbitrary grab bag of leftovers.
Because we are programming in C++ and therefore have the choice between procedural and object-oriented programming, we’ll talk about good class design, as well as when classes should and should not be used. Recognizing a situation in which a class would be useful is essential to reaching the higher levels of programming style, but it’s equally important to recognize situations in which a class is going to make things worse.
Review of Class Fundamentals
As always, this book assumes you have previous contact with fundamentals and references for C++ syntax, but let’s review the fundamentals of class syntax so we are on the same page with terminology. A class is a blueprint for constructing a particular package of code and data; each variable created according to a class’s blueprint is known as an object of that class. Code outside of a class that creates and uses an object of that class is known as a client of the class. A class declaration names the class and lists all of the members, or items inside that class. Each item is either a data member—a variable declared within the class—or a method (also known as a member function), which is a function declared within the class. Member functions can include a special type called a constructor, which has the same name as the class and is invoked implicitly when an object of the class is declared. In addition to the normal attributes of a variable or function declaration (such as type, and for functions, the parameter list), each member also has an access specifier, which indicates what functions can access the member. A public member can be accessed by any code using the object: code inside the class, a client of the class, or code in a subclass, which is a class that “inherits” all the code and data of an existing class. A private member can be accessed only by the code inside the class. Protected members, which we’ll see briefly in this chapter, are similar to private members, except that methods in subclasses can also reference them. Both private and protected members, though, are inaccessible from client code.
Unlike attributes such as the return type, the access specifier inside the class declaration holds until replaced by a different specifier. Thus, each specifier usually appears only once, with the members grouped together by access. This leads programmers to refer to “the public section” or “the private section” of a class, as in, “We should put this method in the private section.”
Let’s look at a tiny example class declaration:
class ➊sample {
➋ public:
➌sample();
➍sample(int num);
➎int doesSomething(double param);
private:
➏int intData;
}➐;
This declaration starts by naming the class ➊, so afterward sample becomes a type name. The declaration begins with a public access specifier ➋, so until we reach the private specifier ➏, everything that follows is public. Many programmers include the public declarations first, expecting the public interface to be of most interest to other readers. The public declarations here are two constructors (➌ and ➍) named sample and another method, doesSomething ➎. The constructors are implicitly invoked when objects of this class are declared.
sample object1;
sample object2(15);
Here, object1 would invoke the first constructor ➌, known as the default constructor, which has no parameters, while object2 would invoke the second constructor ➍ because it specifies a single integer value and thus matches the parameter signature of the second constructor.
The declaration concludes with a private data member, intData ➏. Remember that a class declaration ends with a closing brace and a semicolon ➐. This semicolon may look a little mysterious because we don’t conclude functions, if statement blocks, or any other closing braces with semicolons. The semi-colon’s presence actually indicates that class declarations are also, optionally, object declarations; we could put identifiers in between the closing brace and semicolon and make objects as we make our classes. This isn’t too common in C++, though, especially considering that many programmers put their class definitions in separate files from the programs that use them. The mysterious semicolon appears after the closing brace of a struct, as well.
Speaking of struct, you should know that in C++, struct and class denote nearly the same thing. The only difference between the two involves members (data or methods) declared before the first access specifier. In a struct, these members would be public, while in a class, they would be private. Good programmers, though, use the two structures in different ways. This is analogous to how any for loop could be written as a while loop, but a good programmer can make code more readable by using for loops in more straightforward counting loops. Most programmers reserve struct for simpler structures, either those with no data members beyond constructors or those intended for use as parameters to methods of a larger class.
Goals of Class Use
In order to recognize the right and wrong situations for class use and the right and wrong way to build a class, we have to decide what our goals are for using classes in the first place. In considering this, we should remember that classes are always optional. That is, classes do not give us new capabilities in the way that an array or a pointer-based structure does. If you take a program that uses an array to sort 10,000 records, it won’t be possible to write that same program without the array. If you have a program that depends on a linked list’s ability to grow and shrink over time, you won’t be able to create the same effects with the same efficiency without using a linked list or similar pointer-based structure. If you take away the classes from an object-oriented program, though, and rewrite it, the program will look different, but the capabilities and efficiency of the program will not be diminished. Indeed, early C++ compilers worked as preprocessors. The C++ compiler would read C++ source code and output new source on the fly that was legal C syntax. This modified source code would then be sent to a C compiler. What this tells us is that the major additions that C++ made to the C language were not about the functional capabilities of the language but about how the source code reads to the programmer.
Therefore, in choosing our general class design goals, we are choosing goals to help us, as programmers, accomplish our tasks. In particular, because this book is about problem solving, we should think about how classes help us solve problems.
Encapsulation
The word encapsulation is a fancy way of saying that classes put multiple pieces of data and code together into a single package. If you’ve ever seen a gelatin medicine capsule filled with little spheres, that’s a good analogy: The patient takes one capsule and swallows all the individual ingredient spheres inside.
Encapsulation is the mechanism that allows many of the other goals we list below to succeed, but it is also a benefit in itself because it organizes our code. In a long program listing of purely procedural code (in C++, this would mean code with functions but no classes), it can be difficult to find a good order for our functions and compiler directives that allows us to easily remember their locations. Instead, we’re forced to rely on our development environment to find our functions for us. Encapsulation keeps stuff together that goes together. If you’re working on a class method and you realize you need to look at or modify other code, it’s likely that other code appears in another method of the same class and is therefore nearby.
Code Reuse
From a problem-solving standpoint, encapsulation allows us to more easily reuse the code from previous problems to solve current problems. Often, even though we have worked on a problem similar to our current project, reusing what we learned before still takes a lot of work. A fully encapsulated class can work like an external USB drive; you just plug it in and it works. For this to happen, though, we must design the class correctly to make sure that the code and data is truly encapsulated and as independent as possible from anything outside of the class. For example, a class that references a global variable can’t be copied into a new project without copying the global variable, as well.
Beyond reusing classes from one program to the next, classes offer the potential for a more immediate form of code reuse: inheritance. Recall that, back in Chapter 4, we talked about using helper functions to “factor out” the code common to two or more functions. Inheritance takes this idea to a larger scale. Using inheritance, we create parent classes with methods common to two or more child classes, thereby “factoring out” not just a few lines of code but whole methods. Inheritance is a large subject unto itself, and we’ll explore this form of code reuse later in the chapter.
Dividing the Problem
One technique we’ve returned to again and again is dividing a complex problem into smaller, more manageable pieces. Classes are great at dividing programs up into functional units. Encapsulation not only holds data and code together in a reusable package; it also cordons off that data and code from the rest of the program, allowing us to work on that class, and everything else separately. The more classes we make in a program, the greater the problem-dividing effect.
So, where possible, we should let the class be our method of dividing complex problems. If the classes are well designed, this will enforce functional separation, and the problem will be easier to solve. As a secondary effect, we may find that classes we created for one problem are reusable in other problems, even if we didn’t fully consider that possibility when we created them.
Information Hiding
Some people use the terms information hiding and encapsulation interchangeably, but we’ll separate the ideas here. As described previously in this chapter, encapsulation is packaging data and code together. Information hiding means separating the interface of a data structure—the definition of the operations and their parameters—from the implementation of a data structure, or the code inside the functions. If a class has been written with information hiding as a goal, then it’s possible to change the implementation of the methods without requiring any changes in the client code (the code that uses the class). Again, we have to be clear on the term interface; this means not only the name of the methods and their parameter list but also the explanation (perhaps expressed in code documentation) of what the different methods do. When we talk about changing the implementation without changing the interface, we mean that we change how the class methods work but not what they do. Some programming authors have referred to this as a kind of implicit contract between the class and the client: The class agrees never to change the effects of existing operations, and the client agrees to use the class strictly on the basis of its interface and to ignore any implementation details. Think of having a universal remote that can control any television, whether that’s an old tube model or one that uses an LCD or plasma screen. You press 2, then 5, then Enter, and any of the screens will display channel 25, even though the mechanism to make that happen is vastly different depending on the underlying technology.
There is no way to have information hiding without encapsulation, but as we have defined the terms, it’s possible to have encapsulation without information hiding. The most obvious way this can happen is if a class’s data members are declared public. In such a case, the class is still an encapsulation, in that it’s a package of code and data that belong together. However, the client code now has access to an important class implementation detail: the variables and types the class uses to store its data. Even if the client code doesn’t modify the class data directly and only inspects it, the client code then requires that particular class implementation. Any change to the class that changes the name or type of any of the variables accessed by the client code requires changes to the client code, as well.
Your first thought might be that information hiding is assured so long as all data is made private and we spend enough time designing the list of member functions and their parameter lists so that they never need to change. While all of that is required for information hiding, it’s not sufficient because information-hiding problems can be more subtle. Remember that the class is agreeing not to change what any of the methods do, regardless of the situation. In previous chapters, we’ve had to decide the smallest case a function will handle or what to do with an anomalous case, like finding the average of an array when the parameter that stores the size of the array is zero. Changing the result of a method even for an oddball case represents a change of the interface and should be avoided. This is another reason why explicitly considering special cases is so important in programming. Many a program has blown up when its underlying technology or application programming interface (API) has been updated, and some system call that used to reliably return a –1 when one of the parameters was erroneous now returns a seemingly random, but still negative, number. One of the best ways to avoid this problem is to state special case results in the class or method documentation. If your own documentation says that you return a –1 error code when a certain situation occurs, you’ll think twice about having your method return anything else.
So how does information hiding affect problem solving? The principle of information hiding tells the programmer to put aside class implementation details when working on the client code, or more broadly, to be concerned about a particular class’s implementation only when working inside that class. When you can put implementation details out of your mind, you can eliminate distracting thoughts and concentrate on solving the problem at hand.
We should be aware, however, of the limitations of information hiding as it relates to problem solving. Sometimes implementation details do matter to the client. In previous chapters, we’ve seen the strengths and weaknesses of some array-based and pointer-based data structures. Array-based structures allow random access but cannot easily grow or shrink, while pointer-based structures offer only sequential access but can have pieces added or removed without having to re-create the entire structure. Therefore, a class built with an array-based structure as a foundation will have qualities different from one based on a pointer-based structure.
In computer science, we often talk about the concept of an abstract data type, which is information hiding in its purest form: a data type defined only by its operations. In Chapter 4, we discussed the concept of a stack and described how a program’s stack is a contiguous block of memory. But as an abstract data type, a stack is any data type where you can add and remove individual items, and the items are removed in the opposite order that they were added. This is known as last-in first-out ordering, or LIFO. Nothing requires a stack to be a contiguous block of memory, and we could make a stack using a linked list. Because a contiguous block of memory and a linked list have different properties, a stack that uses one implementation or the other will also have different properties, and these may make a big difference to the client using the stack.
The point of all this is that information hiding will be a useful goal for us as problem solvers, to the extent it allows us to divide problems and work on different parts of a program separately. We cannot, however, allow ourselves to ignore implementation details entirely.
Readability
A good class enhances the readability of the program in which it appears. Objects can correspond to how we look at the real world, and therefore method calls often have an English-like readability. Also, the relationship between objects is often clearer than the relationship between simple variables. Enhancing readability enhances our ability to solve problems, because we can understand our own code more easily while it is in development and because reuse is enhanced when old code is easy to follow.
To maximize the readability benefit of classes, we need to think about how the methods of our class will be used in practice. Method names should be chosen with care to reflect the most specific meaning of the method’s effects. For example, consider a class representing a financial investment that contains a method for computing the future value. The name compute doesn’t convey nearly as much information as computeFutureValue. Even choosing the right part of speech for the name can be helpful. The name computeFutureValue is a verb, while futureValue is a noun. Look at how the names are used in the code samples that follow:
double FV;
➊ investment.computeFutureValue(FV, 2050);
➋ if (investment.futureValue(2050) > 10000) { ...
If you think about it, the former makes more sense for a call that would stand alone, that is, a void function in which the future value is sent back to the caller via a reference parameter ➊. The latter makes better sense for a call that would be used in an expression, that is, the future value comes back as the value of the function ➋.
We’ll see specific examples later in the chapter, but the guiding principle for maximizing readability is to always think about the client code when you are writing any part of the class interface.
Expressiveness
A final goal of a well-designed class is expressiveness, or what might be broadly called writability—the ease with which code can be written. A good class, once written, makes the rest of the code simpler to write in the same way that a good function makes code simpler to write. Classes effectively extend the language, becoming high-level counterparts to basic low-level features such as loops, if statements, and so forth. In C++, even central functionality like input and output is not an inherent part of the language syntax but is provided as a set of classes that must be explicitly included in the program that uses it. With classes, programming actions that previously took many steps can be done in just a few steps or just one. As problem solvers, we should make this goal a special priority. We should always be thinking, “How is this class going to make the rest of this program, and future programs that may use this class, easier to write?”
Building a Simple Class
Now that we know what goals our classes should aim for, it’s time to put theory into practice and build some classes. First, we’ll develop our class in stages for use in the following problem.
Score Range |
Letter Grade |
93–100 |
A |
90–92 |
A– |
87–89 |
B+ |
83–86 |
B |
80–82 |
B– |
77–79 |
C+ |
73–76 |
C |
70–72 |
C– |
67–69 |
D+ |
60–66 |
D |
0–59 |
F |
We’ll start by looking at a basic class framework that forms the foundation of the majority of classes. Then we’ll look at ways in which the basic framework is expanded.
The Basic Class Framework
The best way to explore the basic class framework is through a sample class. For this example, we’re going to start from the student struct from Chapter 3 and build it into a full class. For ease of reference, here’s the original struct:
struct student {
int grade;
int studentID;
string name;
};
Even with a simple struct in this form, we at least get encapsulation. Remember that in Chapter 3 we built an array of student data with this struct, and without using the struct, we would have had to build three parallel arrays, one each for the grades, IDs, and names—ugly! What we definitely don’t get with this struct, though, is information hiding. The basic class framework gives us information hiding by declaring all the data as private and then adding public methods to allow client code to indirectly access, or change, this data.
class studentRecord {
➊ public:
➋studentRecord();
studentRecord(int newGrade, int newID, string newName);
➌int grade();
➍void setGrade(int newGrade);
int studentID();
void setStudentID(int newID);
string name();
void setName(string newName);
➎ private:
➏int _grade;
int _studentID;
string _name;
};
As promised, this class declaration is separated into a public section with member functions ➊ and a private section ➎, which contains the same data as the original struct ➏. There are eight member functions: two constructors ➋ and then a pair of member functions for each data member. For example, the _grade data member has two associated member functions, grade ➌ and setGrade ➍. The first of these methods will be used by client code to retrieve the grade of a particular studentRecord, while the second of these methods is used to store a new grade for this particular studentRecord.
Retrieval and store methods associated with a data member are so common that they are typically referred to by the shorthand terms get and set. As you can see, I incorporated the word set into the methods that store new values into the data members. Many programmers would have also incorporated get into the other names, for example, getGrade instead of grade. Why didn’t I do this? Because then I would have been using a verb name for a function that is used as a noun. Some would argue, though, that the get term is so universally understood, and its meaning therefore so clear, that its use overrides the other concern. Ultimately, that’s a matter of personal style.
Although I’ve been quick in this book to point out the advantages C++ has over other languages, I must admit that more recent languages, like C#, have C++ beat when it comes to get and set methods. C# has a built-in mechanism called a property that acts as both a get and set method. Once defined, the client code can access the property as though it were a data member rather than a function call. This is a great enhancement to readability and expressiveness. In C++, without a built-in mechanism, it’s important that we decide on some naming convention for our methods and use it consistently.
Note that my naming convention extends to the data members, which, unlike the original struct, all begin with underscores. This allows me to name the get functions with (almost) the same name as the data members they retrieve. This also allows easy recognition of data member references in code, enhancing readability. Some programmers use the keyword this for all data member references instead of using an underscore prefix. So instead of a statement such as:
return _grade;
they would have:
return this.grade;
If you haven’t seen the keyword this before, it’s a reference to the object in which it appears. So if the statement above appeared in a class method and that method also declared a local variable with the name grade, the expression this.grade would refer to the data member grade, not the local variable with the same name. Employing the keyword in this way has an advantage in a development environment with automatic syntax completion: The programmer can just type this, press the period key, and select the data member from a list, avoiding extra typing and potential misspellings. Either technique highlights data member references, though, which is what’s important.
Now that we’ve seen the class declaration, let’s look at the implementation of the methods. We’ll start with the first get/set pair.
int studentRecord::grade() {
➊return _grade;
}
void studentRecord::setGrade(int newGrade) {
➋_grade = newGrade;
}
This is the most basic form of the get/set pair. The first method, grade, returns the current value of the associated data member, _grade ➊. The second method, setGrade, assigns the value of the parameter newGrade to the data member _grade ➋. If this were all we did with our class, however, we wouldn’t have accomplished anything. Although this code provides information hiding because it passes data in both directions without any consideration or modification, it’s only better than having _grade declared public because it reserves us the right to change the data member’s name or type. The setGrade method should at least perform some rudimentary validation; it should prevent values of newGrade that don’t make sense as a grade from being assigned to the _grade data member. We have to be careful to follow problem specifications, though, and not to make assumptions about data based on our own experiences, without consideration of the user. It might be reasonable to limit grades to the range 0–100, but it might not, for example, if a school allows extra credit to push a score above 100 or uses a grade of –1 as a code for a class withdrawal. In this case, because we are given some guidance by the problem description, we can incorporate that knowledge into validation.
void studentRecord::setGrade(int newGrade) {
if ((newGrade >= 0) && (newGrade <= 100))
_grade = newGrade;
}
Here, the validation is just a gatekeeper. Depending upon the definition of the problem, however, it might make sense for the method to produce an error message, write to an error log, or otherwise handle the error.
The other get/set pairs would work exactly the same way. There are undoubtedly rules about the construction of student ID numbers at a particular school that could be used for validation. With a student name, however, the best we can do is reject strings with oddball characters, like % or @, and these days perhaps even that wouldn’t be possible.
The last step in completing our class is writing the constructors. In the basic framework, we include two constructors: a default constructor, which has no parameters and sets the data members to reasonable default values, and a constructor with parameters for every data member. The second constructor form is important for our expressiveness goal, as it allows us to create an object of our class and initialize the values inside in one step. Once you have written the code for the other methods, this second constructor almost writes itself.
studentRecord::studentRecord(int newGrade, int newID, string newName) {
setGrade(newGrade);
setStudentID(newID);
setName(newName);
}
As you can see, the constructor merely calls the appropriate set methods for each of the parameters. In most cases, this is the correct approach because it avoids duplicating code and ensures that the constructor will take advantage of any validation code in the set methods.
The default constructor is sometimes a little tricky, not because the code is complicated but because there is not always an obvious default value. When choosing default values for data members, keep in mind the situations in which an object created with the default constructor would be used and, in particular, whether there is a legitimate default object for that class. This will tell you whether you should fill the data members with useful default values or with values that signal that the object is not properly initialized. For example, consider a class representing a collection of values that encapsulates a linked list. There is a meaningful default linked list, and that’s an empty linked list, so we would set our data members to create a legitimate, but conceptually empty, list. But with our sample basic class, there’s no meaningful definition of a default student; we wouldn’t want to give a valid ID number to a default studentRecord object because that could potentially cause confusion with a legitimate studentRecord. Therefore, we should choose a default value for the _studentID field that is obviously illegitimate, such as –1:
studentRecord::studentRecord() {
setGrade(0);
setStudentID(-1);
setName("");
}
We assign the grade with setGrade, which validates its parameter. This means we have to assign a valid grade, in this case, 0. Because the ID is set to an invalid value, the record as a whole can be easily identified as illegitimate. Therefore, the valid grade shouldn’t be an issue. If that were a concern, we could assign an invalid value directly to the _grade data member.
This completes the basic class framework. We have a group of private data members that reference attributes of the same logical object, in this case, a student’s class record; we have member functions to retrieve or alter the object’s data, with validation as appropriate; and we have a useful set of constructors. We have a good class foundation. The question is, do we need to do more?
Support Methods
A support method is a method in a class that does not merely retrieve or store data. Some programmers may refer to these as helper methods, auxiliary methods, or something else, but whatever they are called, they are what take a class beyond the basic class framework. A well-designed set of support methods is often what makes a class truly useful.
To determine possible support methods, consider how the class will be used. Are there common activities we would expect client code to perform on our class’s data? In this case, we’re told that the program for which we are initially designing our class will display students’ grades not only as numerical scores but also as letters. So let’s create a support method that returns a student’s grade as a letter. First, we’ll add the method declaration to the public section of our class declaration.
string letterGrade();
Now we need to implement this method. The function will convert the numerical value stored in _grade to the appropriate string based on the grade table shown in the problem. We could accomplish this with a series of if statements, but is there a cleaner, more elegant way? If you just thought, “Hey, this sounds a lot like how we converted incomes into business license categories back in Chapter 3,” congratulations—you’ve spotted an apt programming analogy. We can adapt that code, with parallel const arrays to store the letter grades and the lowest numerical scores associated with those grades, to convert the numerical score with a loop.
string studentRecord::letterGrade() {
const int NUMBER_CATEGORIES = 11;
const string GRADE_LETTER[] = {"F", "D", "D+", "C-", "C", "C+", "B-", "B", "B+", "A-", "A"};
const int LOWEST_GRADE_SCORE[] = {0, 60, 67, 70, 73, 77, 80, 83, 87, 90, 93};
int category = 0;
while (category < NUMBER_CATEGORIES && LOWEST_GRADE_SCORE[category] <= _grade)
category++;
return GRADE_LETTER[category - 1];
}
This method is a direct adaptation of the function from Chapter 3, so there’s nothing new to explain about how the code works. However, its adaptation for a class method does introduce some design decisions. The first thing to note is that we have not created a new data member to store the letter grade but instead to compute the appropriate letter grade on the fly for every request. The alternative approach would be to have a _letterGrade data member and rewrite the setGrade method to update _letterGrade alongside _grade. Then this letterGrade method would become a simple get method, returning the value of the already-computed data member.
The issue with this approach is data redundancy, a term describing a situation in which data is stored that is either a literal duplicate of other data or can be directly determined from other data. This issue is most commonly seen with databases, and database designers follow elaborate processes to avoid creating redundant data in their tables. Data redundancy can occur in any program, however, if we are unwary. To see the danger, consider a medical records program that stores age and date of birth for each of a set of patients. The date of birth gives us information the age does not. The two data items are therefore not equal, but the age does not tell us anything we can’t already tell from the birth date. And what if the two values are not in agreement (which will happen eventually, unless the age is automatically updated)? Which value do we trust? I’m reminded of the famous (though possibly apocryphal) proclamation of the Caliph Omar when he ordered the burning of the Library of Alexandria. He proclaimed that if the books in the library agreed with the Koran, they were redundant and need not be preserved, but if they disagreed with the Koran, they were pernicious and should be destroyed. Redundant data is trouble waiting to happen. The only justification would be performance, if we thought updates to _grade would be seldom and calls to letterGrade would be frequent, but it’s hard to imagine a significant overall performance boost to the program.
However, this method could be improved. In testing this method, I noticed a problem. Although the method produces correct results for valid values of _grade, the method crashes when _grade is a negative value. When the while loop is reached, the negative value of _grade causes the loop test to immediately fail; therefore, category remains zero and the return statement attempts to reference GRADE_LETTER[-1]. We could avoid this problem by initializing category to one instead of zero, but that would mean that a negative grade would be assigned “F” when it really shouldn’t be assigned any string at all because, as an invalid grade value, it doesn’t fit into any category.
Instead, we could validate _grade before converting it to a letter grade. We’re already validating grade values in the setGrade method, so instead of adding new validation code to the letterGrade method, we should “factor out” what would be the common code in these methods to make a third method. (You might wonder how, if we’re validating grades as they are assigned, we could ever have an invalid grade, but we might decide to assign an invalid grade in the constructor to signal that no legitimate grade has been assigned yet.) This is another kind of support method, which is the class equivalent of the general helper function concept introduced in previous chapters. Let’s implement this method and modify our other methods to use it:
➊ bool studentRecord::➋isValidGrade(➌int grade) {
if ((grade >= 0) && (grade <= 100))
return true;
else
return false;
}
void studentRecord::setGrade(int newGrade) {
if (➍isValidGrade(newGrade))
_grade = newGrade;
}
string studentRecord::letterGrade() {
if (➎!isValidGrade(_grade)) return "ERROR";
const int NUMBER_CATEGORIES = 11;
const string GRADE_LETTER[] = {"F", "D", "D+", "C-", "C", "C+", "B-", "B", "B+", "A-", "A"};
const int LOWEST_GRADE_SCORE[] = {0, 60, 67, 70, 73, 77, 80, 83, 87, 90, 93};
int category = 0;
while (category < NUMBER_CATEGORIES && LOWEST_GRADE_SCORE[category] <= _grade)
category++;
return GRADE_LETTER[category - 1];
}
The new grade validation method is of type bool ➊, and since this is a yes-or-no issue I’ve chosen the name isValidGrade ➋. This gives the most English-like reading to calls to this method, such as those in the setGrade ➍ and letterGrade ➎ methods. Also, note that the method takes the grade to validate as a parameter ➌. Although letterGrade is validating the value already in the _grade data member, setGrade is validating the value that we may or may not assign the data member. So isValidGrade needs to take the grade as a parameter to be useful to both of the other methods.
Although the isValidGrade method is implemented, one decision regarding it remains: What access level should we assign to it? That is, should we place it in the public section of the class or the private section? Unlike the get and set methods of the basic class framework, which always go in the public section, support methods may be public or private depending on their use. What are the effects of making isValidGrade public? Most obviously, client code can access the method. Because having more public methods appears to make a class more useful, many novice programmers make every method public that could possibly be used by the client. This, however, ignores the other effect of the public access designation. Remember that the public section defines the interface of our class, and we should be reluctant to change the method once our class is integrated into one or more programs because such a change is likely to cascade and require changes in all the client code. Placing a method in the public section, therefore, locks the method’s interface and its effects. In this case, suppose that some client code, based on the original formulation of isValidGrade, relies upon it as a 0–100 range checker, but later, the rules for acceptable grades get more complicated. The client code could fail. To avoid that, we might have to instead create a second grade validation method inside the class and leave the first one alone.
Let’s suppose that we expect isValidGrade to be of limited use to the client and have decided not to make it public. We could make the method private, but that’s not the only choice. Because the function does not directly reference any data member or any other method of the class, we could declare the function outside of the class altogether. This, however, not only creates the same problem public access has on modifiability but also lowers encapsulation because now this function, which is required by the class, is no longer part of it. We could also leave the method in the class but make it protected instead of private. The difference would be seen in any subclasses. If isValidGrade is protected, the method can be called by methods in subclasses; if isValidGrade is private, it can be used only by other methods in the studentRecord class. This is the same quandary as public versus private on a smaller scale. Do we expect methods in subclasses to get much use from our method, and do we expect that the method’s effect or its interface could change in the future? In many cases, the safest thing to do is make all helper methods private and make public only those support methods that were written to benefit the client.
Classes with Dynamic Data
One of the best reasons to create a class is to encapsulate dynamic data structures. As we discussed back in Chapter 4, programmers face a real chore keeping track of dynamic allocations, pointer assignments, and deallocations so that we avoid memory leaks, dangling references, and illegal memory references. Putting all of the pointer references into a class doesn’t eliminate the difficult work, but it does mean that once we’ve got it right, we can safely drop that code into other projects. It also means that any problems with our dynamic data structure are isolated to the code within the class itself, simplifying debugging.
Let’s build a class with dynamic data to see how this works. For our sample problem, we’re going to use a modified version of the major problem from Chapter 4.
The main differences between this description and the original version are that we’ve added a new operation, recordWithNumber, and also that none of the operations make any reference to a pointer parameter. This is the key benefit of using a class to encapsulate a linked list. The client may be aware that the class implements the student record collection as a linked list and may even be counting on that (remember our prior discussion about the limitations of information hiding). The client code, however, will have no direct interaction with the linked list or any pointer in the class.
Because this problem is storing the same information per student as the previous problem, we have an opportunity for class reuse here. In our linked list node type, instead of separate fields for each of the three pieces of student data, we’ll have one studentRecord object. Using an object of one class as a data type in a second class is known as composition.
We have enough information now to make a preliminary class declaration:
class studentCollection {
private:
➊struct studentNode {
➋studentRecord studentData;
studentNode * next;
};
➌ public:
studentCollection();
void addRecord(studentRecord newStudent);
studentRecord recordWithNumber(int idNum);
void removeRecord(int idNum);
private:
➍typedef studentNode * studentList;
➎studentList _listHead;
};
Previously, I said programmers tend to start classes with public declarations, but here we have to make an exception. We begin with a private declaration of the node struct, studentNode ➊, which we’ll use to make our linked list. This declaration has to come before the public section because several of our public member functions reference this type. Unlike our node type in Chapter 4, this node doesn’t have individual fields for the payload data but rather includes a member of the studentRecord class➋. The public member functions ➌ follow directly from the problem description; plus, as always, we have a constructor. In the second private section, we declare a typedef ➍ for a pointer to our node type for clarity, just as we did in Chapter 4. Then we declare our list head pointer, cleverly called _listHead ➎.
This class declares two private types. Classes can declare types as well as member functions and data members. As with other members, types appearing in the class can be declared with any access specifier. As with data members, though, you should think of type definitions as private by default, and only make them less restrictive if you have a clear reason to do so. Type declarations are typically at the heart of how a class operates behind the scenes, and as such, they are critical to information hiding. Furthermore, in most cases, client code has no use for the types you will declare in your class. An exception occurs when a type defined in the class is used as the return type of a public method or as the type of a parameter to a public method. In this case, the type has to be public or the public method can’t be used by client code. Class studentCollection assumes that the struct type studentRecord will be separately declared, but we could make it part of the class as well. If we did, we would have to declare it in the public section.
Now we are ready to implement our class methods, starting with the constructor. Unlike our previous example, we have only the default constructor here, not a constructor that takes a parameter to initialize our data member. The whole point of our class is to hide the details of our linked list, so we don’t want the client even thinking about our _listHead, let alone manipulating it. All we need to do in our default constructor is set the head pointer to NULL:
studentCollection::studentCollection() {
_listHead = NULL;
}
Adding a Node
We move on to addRecord. Because nothing in the problem description requires us to keep student records in any particular order, we can directly adapt the addRecord function from Chapter 4 for use here.
void studentCollection::addRecord(➊studentRecord newStudent) {
➋studentNode * newNode = new studentNode;
➌newNode->studentData = newStudent;
➍newNode->next = _listHead;
➎_listHead = newNode;
}
There are only two differences between this code and our blueprint function. Here, we need only one parameter in our parameter list ➊, which is the studentRecord object we’re going to add to our collection. This encapsulates all of the data for a student, which reduces the number of parameters needed. We also don’t need to pass a list head pointer because that is already stored in our class as _listHead and is referenced directly when needed. As with the addRecord function from Chapter 4, we create a new node ➋, copy the new student data into the new node ➌, point the next field of the new node at the previous first node in the list ➍, and finally point _listHead at the new node ➎. Normally I recommend drawing a diagram for all pointer manipulations, but since this is the same manipulation we were already doing, we can reference our previously drawn diagram.
Now we can turn our attention to the second member function in the list, recordWithNumber. That name is a bit of a mouthful, and some programmers might have chosen retrieveRecord or something similar. Following my previously stated naming rules, however, I decided to use a noun because this method returns a value. This method will be similar to averageRecord in that it needs to traverse the list; the difference in this case is that we can stop once we find the matching student record.
studentRecord studentCollection::recordWithNumber(int idNum) {
➊studentNode * loopPtr = _listHead;
➋while (loopPtr->studentData.studentID() != idNum) {
loopPtr = loopPtr->next;
}
➌return loopPtr->studentData;
}
In this function, we initialize our loop pointer to the head of the list ➊ and traverse the list as long as we haven’t seen the desired ID number ➋. Finally, arriving at the desired node, we return the entire matching record as the value of the function ➌. This code looks good, but as always, we have to consider potential special cases. The case we always consider when dealing with linked lists is an initially NULL head pointer. Here, that definitely causes a problem, as we are not checking for that and the code will blow up when we try to dereference loopPtr upon first entering the loop. More generally, though, we have to consider the possibility that the ID number provided by the client code doesn’t actually match any of the records in our collection. In that case, even if _listHead is not NULL, loopPtr will eventually become NULL when we reach the end of the list.
So the general issue is that we need to stop the loop if loopPtr becomes NULL. That’s not difficult, but then, what do we return in this situation? We certainly can’t return loopPtr->studentData because loopPtr will be NULL. Instead, we can build and return a dummy studentRecord with obvious invalid values inside.
studentRecord studentCollection::recordWithNumber(int idNum) {
studentNode * loopPtr = _listHead;
while (➊loopPtr != NULL && loopPtr->studentData.studentID() != idNum) {
loopPtr = loopPtr->next;
}
if (➋loopPtr == NULL) {
➌studentRecord dummyRecord(-1, -1, "");
return dummyRecord;
} else {
return loopPtr->studentData;
}
}
In this version of the method, if our loop pointer is NULL when the loop is over ➋, we create a dummy record with a null string for a name and –1 values for the grade and student ID ➌ and return that. Back in the loop, we are checking for that NULL loopPtr condition, which again can happen either because there is no list to traverse or because we have traversed it with no success. One key point here is that the loop’s conditional expression ➊ is a compound expression with loopPtr != NULL first. This is absolutely required. C++ uses a mechanism for evaluating compound Boolean expressions known as short-circuit evaluation; put simply, it doesn’t evaluate the right half of a compound Boolean expression when the overall value of the expression is already known. Because && represents a logical Boolean and, if the left side of an && expression evaluates to false, the overall expression must also be false, regardless of the right-side evaluation. For efficiency, C++ takes advantage of this fact, skipping the evaluation of the right side of an && expression when the left side is false (for an ||, logical or, the right side is not evaluated when the left side is true, for the same reason). Therefore, when loopPtr is NULL, the expression loopPtr != NULL evaluates to false, and the right side of the && is never evaluated. Without short-circuit evaluation, the right side would be evaluated, and we would be dereferencing a NULL pointer, crashing the program.
The implementation avoids the potential crash of the first version, but we need to be aware that it places a good deal of trust in the client code. That is, the function that calls this method is responsible for checking the studentRecord that comes back and making sure it’s not the dummy record before further processing. If you’re like me, this makes you a little uneasy.
Rearranging the List
The removeRecord method is similar to recordWithNumber in that we must traverse the list to find the node we’re going to remove from the list, but there’s a lot more to it. Removing a node from a list requires care to keep the remaining nodes in the list linked. The simplest way to sew up the hole we will have created is to link the node that came before the removed node to the node that came after. We don’t need a function outline because we already have a function prototype in the class declaration, so we just need a test case:
studentCollection s;
studentRecord stu3(84, 1152, "Sue");
studentRecord stu2(75, 4875, "Ed");
studentRecord stu1(98, 2938, "Todd");
s.addRecord(stu3);
s.addRecord(stu2);
s.addRecord(stu1);
➊ s.removeRecord(4875);
Here we’ve created a studentCollection object s, as well as three studentRecord objects, each of which is added to our collection. Note that we could reuse the same record, changing the values between the calls to addRecord, but doing it this way simplifies our test code. The last line in the test is the call to removeRecord ➊, which in this case is going to remove the second record, the one for the student named “Ed.” Using the same style of pointer diagrams used in Chapter 4, Figure 5-1 shows the state of memory before and after this call.
In Figure 5-1 (a), we see the linked list that was created by our test code. Note that because we’re using a class, our diagram conventions are a little skewed. On the left side of our stack/heap division, we have _listHead, which is the private data member inside our studentCollection object s, and idNum, which is the parameter to removeRecord. On the right side is the list itself, out in the heap. Remember that addRecord puts the new record at the beginning of the list, so the records are in the opposite order from how they were added in the test code. The middle node, "Ed", has the ID number that matches the parameter, 4875, so it will be removed from the list. Figure 5-1 (b) shows the result of the call. The first node in the list, that of "Todd", now points to what was the third node in the list, that of "Sue". The "Ed" node is no longer linked into the larger list and has been deleted.
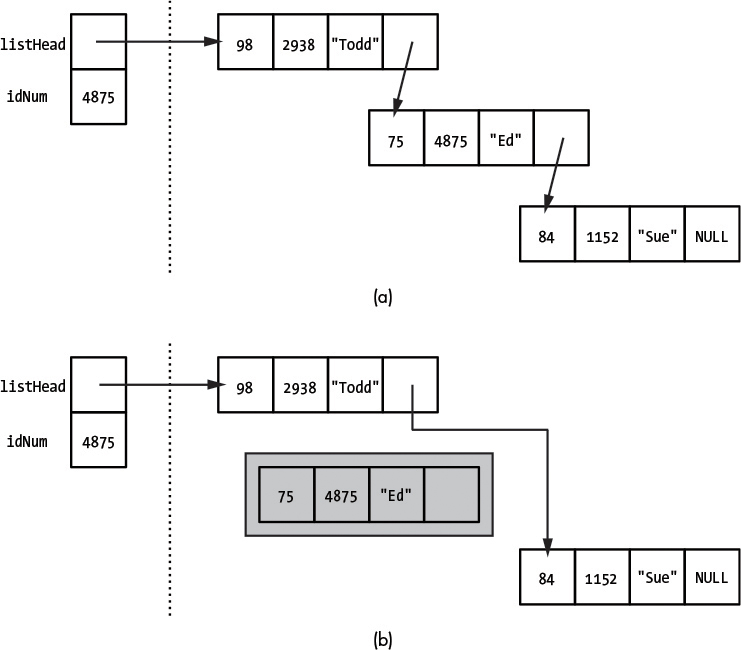
Figure 5-1: “Before” and “after” states for the removeRecord test case
Now that we know what effect the code should have, we can start to write it. Since we know we need to find the node with the matching ID number, we could start with the while loop from recordWithNumber. When that loop is complete, we would have a pointer to the node we needed to remove. Unfortunately, we need more than that to complete the removal. Look at Figure 5-1; in order to close the hole and maintain the linked list, we need to change the next field of the "Todd" node. If all we have is a pointer to the "Ed" node, there is no way to reference the "Todd" node because each node in the linked list references its successor, not its predecessor. (Because of situations like this, some linked lists link in both directions; these are known as doubly linked lists, but they are rarely needed.) So in addition to a pointer to the node to be removed (which will be called loopPtr if we adapt the code from the previous function), we need a pointer to the node immediately previous: Let’s call this pointer trailing. Figure 5-2 shows this concept applied to our sample case.

Figure 5-2: The pointers required to remove the node specified by idNum
With loopPtr referencing the node we’re removing and trailing referencing the previous node, we can remove the desired node and keep the list together.
void studentCollection::removeRecord(int idNum) {
studentNode * loopPtr = _listHead;
➊studentNode * trailing = NULL;
while (loopPtr != NULL && loopPtr->studentData.studentID() != idNum) {
➋trailing = loopPtr;
loopPtr = loopPtr->next;
}
➌if (loopPtr == NULL) return;
➍trailing->next = loopPtr->next;
➎delete loopPtr;
}
The first part of this function is like that of recordWithNumber, except that we declare our trailing pointer ➊ and, inside the loop, we assign the old value of loopPtr to trailing ➋ before advancing loopPtr to the next node. In this way, trailing is always one node behind loopPtr. Because of our work with the previous function, we are already on guard against one special case. Therefore, when the loop is over, we check to see whether loopPtr is NULL. If so, it means we never found a node with the desired ID number, and we immediately return ➌. I call a return statement that appears in the middle of a function “getting out of Dodge.” Some programmers object to this because functions with multiple exit points can be more difficult to read. The alternative in this case, though, is another level of nesting for the if statements that follow, and I would rather just get out of Dodge.
Having determined that there is a node to remove, it’s time to remove it. From our diagram, we see that we need to set the next field of the trailing node to point to the node currently pointed to by the next field of the loopPtr node ➍. Then we can safely delete the node pointed to by loopPtr ➎.
That works for our test case, but as always, we need to check for potential special cases. We’ve already handled the possibility that idNum doesn’t appear in any of the records in our collection, but is there another possible issue? Looking at our test case, would anything change if we tried to delete the first or third node rather than the middle node? Testing and hand-checking shows no issues with the third (last) node. The first node, however, does cause trouble because in this situation, there is no previous node for trailing to point to. Instead, we must manipulate _listHead itself. Figure 5-3 shows the situation after the while loop ends.

Figure 5-3: The situation prior to removing the first node in the list
In this situation, we need to repoint _listHead to the former second node in the list, the one for "Ed". Let’s rewrite our method to handle the special case.
void studentCollection::removeRecord(int idNum) {
studentNode * loopPtr = _listHead;
studentNode * trailing = NULL;
while (loopPtr != NULL && loopPtr->studentData.studentID() != idNum) {
trailing = loopPtr;
loopPtr = loopPtr->next;
}
if (loopPtr == NULL) return;
➊if (trailing == NULL) {
➋_listHead = _listHead->next;
} else {
trailing->next = loopPtr->next;
}
delete loopPtr;
}
As you can see, both the conditional test ➊ and the code to handle the special case ➋ are straightforward because we have carefully analyzed the situation before writing the code.
Destructor
With the three methods specified by the problem implemented, we might think that our studentCollection class is complete. However, as it stands, it has serious problems. The first is that the class lacks a destructor. This is a special method that is called when the object goes out of scope (when the function that declared the object completes). When a class has no dynamic data, it typically doesn’t need a destructor, but if you have the former, you definitely need the latter. Remember that we have to delete everything we have allocated with new to avoid memory leaks. If an object of our studentCollection class has three nodes, each of those nodes needs to be deallocated. Fortunately, this is not too difficult. We just need to traverse our linked list, deleting as we go. Instead of doing this directly, though, let’s write a helper method that deletes all the nodes in a studentList. In the private section of our class, we add the declaration:
void deleteList(studentList &listPtr);
The code for the method itself would be:
void studentCollection::deleteList(studentList &listPtr) {
while (listPtr != NULL) {
➊studentNode * temp = listPtr;
➋listPtr = listPtr->next;
➌delete temp;
}
}
The traversal copies the pointer to the current node to a temporary variable ➊, advances the current node pointer ➋, and then deletes the node pointed to by the temporary variable ➌. With this code in place, we can code the destructor very simply. First, we add the destructor to the public section of our class declaration:
~studentCollection();
Note that like a constructor, the destructor is specified using the name of the class, and there is no return type. The tilde before the name distinguishes the destructor from the constructors. The implementation is as follows:
studentCollection::~studentCollection() {
deleteList(_listHead);
}
The code in these methods is straightforward, but it’s important to test the destructor. Although a poorly written destructor could crash your program, many destructor problems don’t result in crashes, only memory leaks, or worse, inexplicable program behavior. Therefore, it’s important to test the destructor using your development environment’s debugger so that you can see that the destructor is actually calling delete on each node.
Deep Copy
Another serious problem remains. Back in Chapter 4, we briefly discussed the concept of cross-linking, where two pointer variables had the same value. Even though the variables themselves were distinct, they pointed to the same data structure; therefore, modifying the structure of one variable modified them both. This problem can easily occur with classes that incorporate dynamically allocated memory. To see why this can be such a problem, consider the following elementary C++ code sequence:
int x = 10;
int y = 15;
x = y;
➊ x = 5;
Suppose I asked you what effect the last statement ➊ had on the value of the variable y. You would probably wonder whether I had misspoken. The last statement wouldn’t have any effect on y at all, only x. But now consider this:
studentCollection s1;
studentCollection s2;
studentRecord r1(85, 99837, "John");
s2.addRecord(r1);
studentRecord r2(77, 4765, "Elsie");
s2.addRecord(r2);
➊ s1 = s2;
➋ s2.removeRecord(99837);
Suppose I ask you what effect the last statement ➋ had on s1. Unfortunately, it does have an effect. Although s1 and s2 are two different objects, they are no longer entirely separate objects. By default, when one object is assigned to another, as we assign s2 to s1 here ➊, C++ performs what is known as a shallow copy. In a shallow copy, each data member of one object is directly assigned to the other. So if _listHead, our only data member, were public, s1 = s2 would be the same as s1._listHead = s2._listHead. This leaves the _listHead data member of both objects pointing at the same place in memory: the node for "Elsie", which points at the other node, the one for "John". Therefore, when the node for "John" is removed, it’s apparently removed from two lists because there is actually only one list. Figure 5-4 shows the situation at the end of the code.

Figure 5-4: Shallow copy results in cross-linking; deleting "John" node from one list deletes from both.
As quirky as that is, though, it could actually have been much worse. What if the last line of the code had removed the first record, the "Elsie" node? In that case, the _listHead inside s2 would have been updated to point to "John", and the "Elsie" node would have been deleted. The _listHead inside s1, however, would still point to the deleted "Elsie" node, a dangerous dangling reference, as shown in Figure 5-5.

Figure 5-5: Removal from s2 causing a dangling reference in s1
The solution to this issue is a deep copy, which means we don’t just copy the pointer to the structure but rather make copies of everything in the structure. In this case, it means copying all of the nodes in the list to make a true list copy. As before, let’s start by making a private helper method, in this case, one that copies a studentList. The declaration in the class’s private section looks like this:
studentList copiedList(const studentList original);
As before, I’ve chosen a noun for a method that returns a value. The implementation for the method is as follows:
➊ studentCollection::studentList studentCollection::copiedList(const studentList original) {
➋if (original == NULL) {
return NULL;
}
studentList newList = new studentNode;
➌newList->studentData = original->studentData;
➍studentNode * oldLoopPtr = original->next;
➎studentNode * newLoopPtr = newList;
while (oldLoopPtr != NULL) {
➏newLoopPtr->next = new studentNode;
newLoopPtr = newLoopPtr->next;
newLoopPtr->studentData = oldLoopPtr->studentData;
oldLoopPtr = oldLoopPtr->next;
}
➐newLoopPtr->next = NULL;
➑return newList;
}
There’s a lot going on in this method, so let’s take it step by step. On a syntax note, when specifying the return type in the implementation, we have to prefix the name of the class ➊. Otherwise, the compiler won’t know what type we are talking about. (Inside the method, that’s not necessary because the compiler already knows what class the method is a part of—a bit confusing!) We check to see whether the incoming list is empty. If so, we get out of Dodge ➋. Once we know there is a list to be copied, we copy the first node’s data prior to the loop ➌ because for that node we have to modify our new list’s head pointer.
We then set up two pointers for tracking through the two lists. The oldLoopPtr ➍ traverses the incoming list; it’s always going to point to the node we are about to copy. The newLoopPtr ➎ traverses the new, copied list, and it always points to the last node we created, which is the node prior to where we’ll add the next node. Just as in the removeRecord method, we need a kind of trailing pointer here. Inside the loop ➏, we create a new node, advance newLoopPtr to point to it, copy the data from the old node to the new, and advance oldLoopPtr. After the loop, we terminate the new list by assigning NULL to the next field of the last node ➐ and return the pointer to the new list ➑.
So how does this helper method solve the issue we saw previously? By itself, it doesn’t. But with this code in place, we can now overload the assignment operator. Operator overloading is a feature of C++ that allows us to change what the built-in operators do with certain types. In this case, we want to overload the assignment operator (=), so that instead of the default shallow copy, it calls our copiedList method to perform a deep copy. In the public section of our class, we add:
➊ studentCollection& ➋operator=(➌const studentCollection & ➍rhs);
The operator we are overloading is specified by naming the method using the keyword operator followed by the operator we want to overload ➋. The name I’ve chosen for the parameter (rhs ➍) is a common choice for operator overloads because it stands for right-hand side. This helps the programmer keep things straight. So in the assignment statement that started this discussion, s2 = s1, the object s1 would be the right-hand side of the assignment operation, and s2 would be the left-hand side. We reference the right-hand side through the parameter, and we reference the left-hand side by directly accessing class members, the way we would with any other method of the class. So our task in this case is to create a list pointed to by _listHead that is a copy of the list pointed to by the _listHead of rhs. This will have the effect in the call s2 = s1 of making s2 a true copy of s1.
The type of the parameter is always a constant reference to the class in question ➌; the return type is always a reference to the class ➊. You’ll see why the parameter is a reference shortly. You might wonder why the method returns anything, since we are manipulating the data member directly in the method. It’s because C++ allows chained assignments, like s3 = s2 = s1, in which the return value of one assignment becomes the parameter of the next.
Once all of the syntax is understood, the code for the assignment operator is quite direct:
studentCollection& studentCollection::operator=(const studentCollection &rhs) {
➊if (this != &rhs) {
➋deleteList(_listHead);
➌_listHead = copiedList(rhs._listHead);
}
➍return *this;
}
To avoid a memory leak, we must first remove all of the nodes from the left-hand side list ➋. (It is for this purpose that we write deleteList as a helper method rather than including its code directly in the destructor.) With the previous left-hand list deleted, we copy the right-hand list using our other helper method ➌. Before performing either of these steps, though, we check that the object on the right-hand side is different from the object on the left-hand side (that is, it’s not something like s1 = s1) by checking whether the pointers are different ➊. If the pointers are identical, there’s no need to do anything, but this is not just a matter of efficiency. If we performed the deep copy on identical pointers, when we delete the nodes currently in the left-hand side list, we would also be deleting the nodes in the right-hand side list. Finally, we return a pointer to the left-hand side object ➍; this happens whether we actually copied anything or not because although a statement like s2 = s1 = s1 is screwy, we still would like it to work if someone tries it.
As long as we have our list-copying helper method, we should also create a copy constructor. This is a constructor that takes another object of the same class as an object. The copy constructor can be invoked explicitly whenever we need to create a duplicate of an existing studentCollection, but copy constructors are also invoked implicitly whenever an object of that class is passed as a value parameter to a function. Because of this, you should consider passing object parameters as const references instead of value parameters unless the function receiving the object needs to modify the copy. Otherwise, your code could be doing a lot of work unnecessarily. Consider a student collection of 10,000 records, for example. The collection could be passed as a reference, a single pointer. Alternatively, it could invoke the copy constructor for a long traversal and 10,000 memory allocations, and this local copy would then invoke the destructor at the end of the function with another long traversal and 10,000 deallocations. This is why the right-hand side parameter to the assignment operator overload uses a const reference parameter.
To add the copy constructor to our class, first we add its declaration to our class declaration in the public section.
studentCollection(const studentCollection &original);
As with all constructors, there is no return type, and as with the overloaded assignment operator, the parameter is a const reference to our class. The implementation is easy because we already have the helper method.
studentCollection::studentCollection(const studentCollection &original) {
_listHead = copiedList(original._listHead);
}
Now we can make a declaration like this:
studentCollection s2(s1);
This declaration has the effect of declaring s2 and copying the nodes of s1 into it.
The Big Picture for Classes with Dynamic Memory
We’ve really done a lot to this class since completing the methods specified by the problem description, so let’s take a moment to review. Here’s what our class declaration looks like now.
class studentCollection {
private:
struct studentNode {
studentRecord studentData;
studentNode * next;
};
public:
studentCollection();
~studentCollection();
studentCollection(const studentCollection &original);
studentCollection& operator=(const studentCollection &rhs);
void addRecord(studentRecord newStudent);
studentRecord recordWithNumber(int idNum);
void removeRecord(int idNum);
private:
typedef studentNode * studentList;
studentList _listHead;
void deleteList(studentList &listPtr);
studentList copiedList(const studentList original);
};
The lesson here is that new pieces are required when creating a class with dynamic memory. In addition to the features of our basic class frame-work—private data, a default constructor, and methods to send data in and out of the object—we have to add additional methods to handle the allocation and cleanup of dynamic memory. At a minimum, we should add a copy constructor and a destructor and also overload the assignment operator if there’s any chance someone would use it. The creation of these additional methods can often be facilitated by creating helper methods to copy or delete the underlying dynamic data structure.
This may seem like a lot of work, and it can be, but it’s important to note that everything you are adding to the class is something you need to deal with anyway. In other words, if we didn’t have a class for our linked-list collection of student records, we’re still responsible for deleting the nodes in the list when we’re through with them. We would still have to be wary of cross-linking, still have to traverse through a list and copy node by node if we wanted a true copy of the original list, and so on. Putting everything into the class structure is only a little more work up front, and once everything works, the client code can ignore all the memory allocation details. In the end, encapsulation and information hiding make dynamic data structures much easier to work with.
Mistakes to Avoid
We’ve talked about how to create a good class in C++, so let’s round off the discussion by talking about a couple of common pitfalls you should avoid.
The Fake Class
As I mentioned at the beginning of this chapter, I think that C++, as a hybrid language that includes both the procedural and the object-oriented paradigms, is a great language for learning object-oriented programming because the creation of a class is always a positive choice on the part of the programmer. In a language like Java, the question is never, “Should I make a class?” but rather, “How am I going to put this into a class?” The requirement to put everything into a class structure results in what I call a fake class, a class without a coherent design that is correct syntactically but has no real meaning. The word class as it is used in programming is derived from the sense of the English word meaning a group of things with common attributes, and a good C++ class meets this definition.
Fake classes can happen for several reasons. One type occurs because the programmer really wants to use global variables, not for any defensible reason (such reasons are rare, though they do exist) but out of laziness—just to avoid passing parameters from function to function. While the programmer knows that widespread use of global variables is considered terrible style, he or she thinks the loophole has been found. All or most of the functions of the program are shoveled into a class, and the variables that would have been global are now data members of the class. The main function of the program simply creates one object of the fake class and invokes some “master” method in the class. Technically, the program uses no global variables, but the fake class means that the program has all of the same defects as one that does.
Another type of fake class occurs because the programmer just assumes that object-oriented programming is always “better” and forces it into situations where it doesn’t apply. In these cases, the programmer often creates a class that encapsulates very specific functionality that only makes sense in the context of the original program for which it is written. There are two ways to test whether you are writing this type of fake class. The first is by asking, “Can I give the class a specific and reasonably short name?” If you find yourself with a name like PayrollReportManagerAndPrintSpooler, you might have a problem. The other test asks, “If I were to write another program with similar functionality, can I imagine how the class could be reused, with only small modifications? Or would it have to be dramatically rewritten?”
Even in C++, a certain number of fake classes are inevitable, for example, because we have to encapsulate data for use in collection classes. Such classes, however, are usually small and basic. If we can avoid elaborate fake classes, our code will improve.
Single-Taskers
If you’ve ever seen the television show Good Eats, you know that host Alton Brown spends a lot of time discussing how you should outfit your kitchen for maximum efficiency. He often rails against kitchen gadgets he calls single-taskers, by which he means tools that do one task well but don’t do anything else. In writing our classes, we should strive to make them as general as possible, consistent with including all the specific functionality required for our program.
One way of doing this is with template classes. This is an advanced subject with a somewhat arcane syntax, but it allows us to make classes where one or more of the data members has a type that is specified when an object of the class is created. Template classes allow us to “factor out” general functionality. For example, our studentCollection class contains a lot of code that is common to any class that encapsulates a linked list. We could instead make a template class for a general linked list, such that the type of data within the list nodes is specified when the object of the template class is created, rather than being hardwired as a studentRecord. Then our studentCollection class would have an object of the template linked list class as a data member, rather than a list head pointer, and would no longer manipulate the linked list directly.
Template classes are beyond the scope of this book, but as you develop your abilities as a class designer, you should always strive to make classes that are multitaskers. It’s a great feeling when you discover a current problem can be solved using a class you wrote previously, long before you knew the current problem existed.
Exercises
You know what I’m about to say, don’t you? Go ahead and try some!
5-1. Let’s try implementing a class using the basic framework. Consider a class to store the data for an automobile. We’ll have three pieces of data: a manufacturer name and model name, both strings, and a model year, an integer. Create a class with get/set methods for each data member. Make sure you make good decisions concerning details like member names. It’s not important that you follow my particular naming convention. What’s important is that you think about the choices you make and are consistent in your decisions.
5-2. For our automobile class from the previous exercise, add a support method that returns a complete description of the automobile object as a formatted string, such as, "1957 Chevrolet Impala". Add a second support method that returns the age of the automobile in years.
5-3. Take the variable-length string functions from Chapter 4 (append, concatenate, and characterAt) and use them to create a class for variable-length strings, making sure to implement all necessary constructors, a destructor, and an overloaded assignment operator.
5-4. For the variable-length string class of the previous exercise, replace the characterAt method with an overloaded [] operator. For example, if myString is an object of our class, then myString[1] should return the same result as myString.characterAt(1).
5-5. For the variable-length string class of the previous exercises, add a remove method that takes a starting position and a number of characters and removes that many characters from the middle of the string. So myString.remove(5,3) would remove three characters starting at the fifth position. Make sure your method behaves when the value of either of the parameters is invalid.
5-6. Review your variable-length string class for possible refactoring. For example, is there any common functionality that can be separated into a private support method?
5-7. Take the student record functions from Chapter 4 (addRecord and averageRecord) and use them to create a class representing a collection of student records, as before, making sure to implement all necessary constructors, a destructor, and an overloaded assignment operator.
5-8. For the student record collection class of the previous exercise, add a method RecordsWithinRange that takes a low grade and a high grade as parameters and returns a new collection consisting of the records in that range (the original collection is unaffected). For example, myCollection.RecordsWithinRange(75, 80) would return a collection of all records with grades in the range 75–80 inclusive.