
8
THINKING LIKE A PROGRAMMER

It’s time for us to bring together everything we’ve experienced over the previous chapters to complete the journey from fledgling coder to problem-solving programmer.
In previous chapters, we’ve solved problems in a variety of areas. I believe these areas are the most beneficial for the developing programmer to master, but of course there are always more things to learn, and many problems will require skills not covered in this book. So in this chapter, we’re going to come full circle to general problem-solving concepts, taking the knowledge we’ve gained in our journey to develop a master plan for attacking any programming problem. Although we might call this a general plan, in one way it’s actually a very specific plan: It will be your plan, and no one else’s. We’ll also look at the many ways you can add to your knowledge and skills as a programmer.
Creating Your Own Master Plan
Way back in the first chapter, we learned the first rule of problem solving was that you should always have a plan. A more precise formulation would be to say you should always follow your plan. You should construct a master plan that maximizes your strengths and minimizes your weaknesses and then apply this master plan to each problem you must solve.
Over many years of teaching, I’ve seen students of all different abilities. By that I don’t simply mean that some programmers have more ability than others, although of course this is true. Even among programmers with the same level of ability, there is great diversity. I’ve lost track of how often I’ve been surprised by a formerly struggling student who quickly masters a particular skill or a talented student who displays a weakness in a new area. Just as no two fingerprints are the same, no two brains are the same, and lessons that are easy for one person are difficult for another.
Suppose you’re a football coach, planning your offense for the next game. Because of an injury, you’re not sure which of two quarterbacks will be able to start. Both quarterbacks are highly capable professionals, but like any individuals in any endeavor, they have their strengths and weaknesses. The game plan that creates the best opportunity for victory with one quarterback might be terrible for the other.
In creating your master plan, you are the coach and your skill set is your quarterback. To maximize your chances for success, you need a plan that recognizes both your strengths and your weaknesses.
Playing to Your Strengths and Weaknesses
The key step in making your own master plan, then, is identifying your strengths and weaknesses. This is not difficult, but it requires effort and a fair degree of honest self-appraisal. In order to benefit from your mistakes, you must not only correct them in programs in which they appear, but you must also note them, at least mentally, or better yet, in a document. In this way, you can identify patterns of behavior that you would have otherwise missed.
I’m going to describe weaknesses in two different categories: coding and design. Coding weaknesses are areas where you tend to repeat mistakes when you’re actually writing the code. For example, many programmers frequently write loops that iterate one time too many or one time too few. This is known as a fencepost error, from an old puzzle about how many fenceposts are needed to build a 50-foot fence with 10-foot-long rails between posts. The immediate response from most people is five, but if you think about it carefully, the answer is six, as shown in Figure 8-1.
Most coding weaknesses are situations in which the programmer creates semantic errors by coding too quickly or without enough preparation. Design weaknesses, in contrast, are problems you commonly have in the problem-solving or design stage. For example, you might discover you have trouble getting started or trouble integrating previously written subprograms into a complete solution.
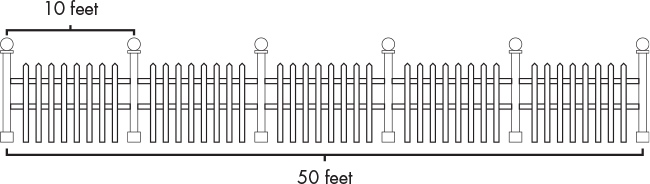
Figure 8-1: The fencepost puzzle
Although there is some overlap between these two categories, the two types of weaknesses tend to create different sorts of problems and must be defended against in different ways.
Planning Against Coding Weaknesses
Perhaps the most frustrating activity in programming is spending hours tracking down a semantic error that turns out to be a simple thing to fix once identified. Because no one is perfect, there’s no way to completely eliminate these situations, but a good programmer will do all he or she can to avoid making the same mistakes over and over again.
I knew a programmer who had tired of making what is perhaps the most common semantic error in C++ programming: the substitution of the assignment operator (=) for the equality operator (==). Because conditional expressions in C++ are integer, not strictly Boolean, a statement such as the following is syntactically legal:
if (number = 1) flag = true;
In this case, the integer value 1 is assigned to number, and then the value 1 is used as the result of the conditional statement, which C++ evaluates as true. What the programmer meant to do, of course, was:
if (number == 1) flag = true;
Frustrated at making this type of mistake over and over, the programmer taught himself to always write equality tests the other way, with the numerical literal on the left side, such as:
if (1 == number) flag = true;
By doing this, if the programmer slips up and substitutes the equality operator, the expression 1 = number would no longer be legal C++ syntax, and would produce a syntax error that would be caught at compile time. The original error is legal syntax, so it’s only a semantic error, which would be caught at compile time or not caught at all. Since I had made this mistake many times myself (and driven myself crazy trying to track the bug down), I employed this method, putting the numerical literal on the left side of the equality operator. In doing so, I discovered something curious. Because this ran counter to my usual style, putting the literal on the left forced me to pause momentarily when writing conditional statements. I would think, “I need to remember to put the literal on the left so that I’ll catch myself if I use the assignment operator.” As you might expect, by having that thought run through my head, I never actually used the assignment operator but always correctly used the equality operator. Now, I no longer put the literal on the left side of the equality operator, but I still pause and let those thoughts run through my head, which keeps me from using the wrong operator.
The lesson here is that being aware of your coding-level weaknesses is often all that is necessary to avoid them. That’s the good news. The bad news is that you still have to put in the work to be aware of your coding weaknesses in the first place. The key technique is asking yourself why you made a particular mistake, rather than just fixing the mistake and moving on. This will allow you to identify the general principle you failed to follow. For example, suppose you had written the following function to compute the average of the positive numbers in an array of integers:
double averagePositive(int array[ARRAYSIZE]) {
int total = 0;
int positiveCount = 0;
for (int i = 0; i < ARRAYSIZE; i++) {
if (array[i] > 0) {
total += array[i];
positiveCount++;
}
}
➊return total / (double) positiveCount;
}
At a glance, this function looks fine, but upon closer inspection, it has a problem. If there are no positive numbers in the array, then the value of positiveCount will be zero when the loop ends, and this will result in a division by zero at the end of the function ➊. Because this is floating-point division, the program may not actually crash but rather produce odd behavior, depending on how the value of this function is used in the overall program.
If you were quickly trying to get your code running and you discovered this problem, you might add some code to handle the case where positiveCount is zero and move on. But if you want to grow as a programmer, you should ask yourself what mistake you made. The specific problem, of course, is that you didn’t account for the possibility of dividing by zero. If that’s as deep as the analysis goes, though, it won’t help you very much in the future. Sure, you might catch another situation where a divisor might turn out to be zero, but that is not a very common situation. Instead, we should ask what general principle has been violated. The answer: that we should always look for special cases that can blow up our code.
By considering this general principle, we’ll be more likely to see patterns in our mistakes and therefore more likely to catch those mistakes in the future. Asking ourselves, “Any chance of dividing by zero here?” is not nearly as useful as asking ourselves, “What are the special cases for this data?” By asking the broader question, we’ll be reminded to check not just for division by zero but also for empty data sets, data outside the expected range, and so on.
Planning Against Design Weaknesses
Design weaknesses require a different approach to circumvent. The first step, though, is the same: You identify the weaknesses. A lot of people have trouble with this step because they don’t like to turn such a critical eye on themselves. We’re conditioned to conceal personal failings. It’s like when a job interviewer asks you what your biggest weakness is, and you are expected to answer with some nonsense about how you care too much about the quality of your work instead of providing an actual weakness. But just as Superman has his Kryptonite, even the best programmers have real weaknesses.
Here’s a sample (and certainly not exhaustive) list of programmer weaknesses. See whether you recognize yourself in any of these descriptions.
Convoluted designs
The programmer with this weakness creates programs that have too many parts or too many steps. While the programs work, they don’t inspire confidence—like worn clothing that looks as if it would fall apart at the first tug of a thread—and they are clearly inefficient.
Can’t get started
This programmer has a high degree of inertia. Whether from a lack of confidence in problem solving or plain procrastination, this programmer takes too long to make any initial progress on a problem.
Fails to test
This programmer doesn’t like to formally test the code. Often the code will work for general cases, but not for special cases. In other situations, the code will work fine but won’t “scale up” for larger problem sets that the programmer hasn’t tested.
Overconfident
Confidence is a great thing—this book is intended to increase the confidence of its readers—but too much confidence can sometimes be as much a problem as too little. Overconfidence manifests itself in various ways. The overconfident programmer might attempt a more complicated solution than necessary or allow too little time to finish a project, resulting in a rushed, bug-ridden program.
Weak area
This category is a bit of a catchall. Some programmers work smoothly enough until they hit certain concepts. Consider the topics discussed in previous chapters of this book. Most programmers, even after completing the exercises, will be more confident in some of the areas we’ve covered than others. For example, perhaps the programmer gets lost with pointer programs, or recursion turns the programmer’s head inside out. Maybe the programmer has trouble designing elaborate classes. It’s not that the programmer can’t muddle through and solve the problem, but it’s rough work, like driving through mud.
There are different ways you can confront your large-scale weaknesses, but once you recognize them, it’s easy to plan around them. If you’re the kind of programmer who often skips testing, for example, make testing an explicit part of your plan for writing each module, and don’t move onto the next module until you put a check in that box. Or consider a design paradigm called test-driven development, in which the testing code is written first, and then the code is written to fill those tests. If you have trouble getting started, use the principles of dividing or reducing problems, and start writing code as soon as you can, with the understanding that you may have to rewrite that code later. If your designs are often too complicated, add an explicit refactoring step to your master plan. The point is, no matter what weaknesses you have as a programmer, if you recognize them, you can plan around them. Then your weaknesses are no longer weaknesses—just obstacles in the road that you will steer around on the way to successful project completion.
Planning for Your Strengths
Planning for your weaknesses is largely about avoiding mistakes. Good planning, though, isn’t just about avoiding mistakes. It’s about working toward the best possible result given your current abilities and whatever restraints you may be operating under. This means you must also incorporate your strengths into your master plan.
You might think that this section isn’t for you, or at least not yet. After all, if you are reading this book, then you are still becoming a programmer. You might wonder whether you even have any strengths at this stage of your development. I’m here to tell you that you do, even if you haven’t recognized them yet. Here’s a list of common programmer strengths, by no means exhaustive, with descriptions of each and hints to help you recognize whether the term applies to you:
Eye for detail
This type of programmer can anticipate special cases, see potential performance issues before they arise, and never lets the big picture cloud over the important details that must be handled for the program to be a complete and correct solution. Programmers with this strength tend to test their plans on paper before coding, code slowly, and test frequently.
Fast learner
A fast learner picks up new skills quickly, whether that’s learning a new technique in an already-known language or working with a new application framework. This type of programmer enjoys the challenge of learning new things and may choose projects based on this preference.
Fast coder
The fast coder doesn’t need to spend a lot of time with a reference book to hammer out a function. Once it’s time to start typing, the code flows off the ends of the fast coder’s fingers without much effort and with few syntactical errors.
Never gives up
For some programmers, a pesky bug is a personal affront that can’t be ignored. It’s like the program has slapped the programmer across the mouth with a leather glove, and it’s up to the programmer to respond. This type of programmer always seems to stay levelheaded, determined but never very frustrated, and confident that with enough effort, victory is assured.
Super problem-solver
Presumably you were not a super problem-solver when you bought this book, but now that you’ve gotten some guidance, perhaps it’s all starting to come easily. The programmer with this trait is starting to envision potential solutions to a problem even as he or she is reading it.
Tinkerer
To this sort of programmer, a working program is like a wonderful toy box. The tinkerer has never lost the thrill of making the computer do his or her bidding and loves to keep finding something else for the computer to do. Maybe the tinkering means adding more and more functionality to a working program—a symptom known as creeping featurism. Maybe the program can be refactored for improved performance. Maybe the program can just be made prettier for the programmer or the user.
Few programmers will exhibit more than a couple of these strengths—in fact, some of them tend to cancel each other out. But every programmer has strengths. If you don’t recognize yourself in any of these, it just means you have yet to learn enough about yourself or your strength is something that doesn’t fit into one of my categories.
Once you’ve identified your strengths, you need to factor them into your master plan. Suppose you’re a fast coder. Obviously this will help get any project across the finish line, but how can you leverage this strength in a systematic way? In formal software engineering, there is an approach called rapid prototyping, in which a program is initially written without extensive planning and then improved through successive iterations until the results meet the problem requirements. If you’re a fast coder, you might try adopting this method, coding as soon as you have a basic idea and letting your rough prototype guide the design and development of the final program code.
If you’re a rapid learner, maybe you should start every project by hunting for new resources or techniques to solve the current problem. If you’re not a rapid learner, but you are the sort of programmer who doesn’t easily get frustrated, maybe you should start the project with the areas you think will be the most difficult to give yourself the most time to tackle them.
So whatever strengths you have, make sure you are taking advantage of them in your programming. Design your master plan so that you spend as much time as possible doing what you do best. Not only will you produce the best results this way, but you’ll also have the most fun, too.
Putting the Master Plan Together
Let’s look at constructing a sample master plan. The ingredients include all the problem-solving techniques we have developed, plus our analysis of our strengths and weaknesses. For this example, I’ll use my own strengths and weaknesses.
In terms of problem-solving techniques, I use all of the techniques I share in this book, but I’m especially fond of the “reduce the problem” technique because using that technique allows me to feel that I’m always making concrete progress toward my goal. If I’m currently unable to figure out a way to write code that meets the full specification, I just throw out part of the specification until I gain momentum.
My biggest coding weakness is excessive eagerness. I love to program because I love to see computers following my instructions. Sometimes this leads me to think, “Let’s give this thing a rip and see what happens,” when I should still be analyzing the correctness of what I just wrote. The danger here isn’t that the program will fail—it’s that the program will either appear to succeed but not cover all the special cases, or succeed but not be the best possible solution I could write.
I love elegant program designs that are easy to expand and reuse. Often when I code larger projects, I spend a lot of time developing alternative designs. On the whole, this is a good trait, but sometimes this results in me spending too much time in the design phase, not leaving enough time to actually implement the selected design. Also, this can sometimes result in a solution that is over-designed. That is, sometimes the solution is more elegant, expandable, and robust than it really needs to be. Because every project is limited in time and money, the best solution must balance the desire for high software quality with the need to conserve resources.
My best programming strength, I think, is that I pick up new concepts well, and I love to learn. While some programmers like using the same skills over and over, I love a project where I can learn something new, and I’m always exhilarated by that challenge.
With all that in mind, here is my master plan for a new project.
To fight my primary design weakness, I will strictly limit my time spent in the design phase or, alternatively, limit the number of distinct designs I will consider before moving on. This might sound like a dangerous idea to some readers. Shouldn’t we spend as much time as we can in the design phase before jumping into coding? Don’t most projects fail because not enough time was spent on the front end, leading to a cascade of compromises on the back end? These concerns are valid, but remember that I’m not creating a general guidebook for software development. I’m creating my own personal master plan for tackling programming problems. My weakness is over-designing, not under-designing, so a rule limiting design time makes sense for me. For another programmer, such a rule could be disastrous, and some programmers may need a rule to force them to spend more time on design.
After I complete my initial analysis, I’m going to consider whether the project presents opportunities to learn new techniques, libraries, and so forth. If it does, I’m going to write a small test-bed program to try out these new skills before attempting to incorporate them into my developing solution.
To fight excessive eagerness, I could incorporate a miniature code-review step when I finish coding each module. However, that will require an exercise of willpower on my part—when I complete each module, I’m going to want to go ahead and try it out. Simply hoping that I can talk myself out of it each time is like leaving an open bag of potato chips next to a hungry man and being surprised when the bag is emptied. It’s better to subvert weaknesses with a plan that doesn’t require the programmer to fight his or her instincts. So what if I create two versions of the project: a crusty, anything-goes version and a polished version for delivery? If I allow myself to play with the first version at will but prevent myself from incorporating code into the polished version until it’s been fully vetted, I’m much more likely to overcome my weakness.
Tackling Any Problem
Once we have a master plan, we’re ready for anything. That’s what this book is ultimately all about: starting with a problem, any problem, and finding a way through to the solution. In all the previous chapters, the problem descriptions pushed us in a particular initial direction, but in the real world, most problems don’t come with a requirement to use an array or recursion or to encapsulate some part of the program’s functionality into a class. Instead, the programmer makes those decisions as part of the problem-solving process.
At first, fewer requirements might seem to make problems easier. After all, a design requirement is a constraint, and don’t constraints make problems harder? While this is true, it’s also true that all problems have constraints—it’s just that in some cases they are more explicitly spelled out than in others. For example, not being told whether a particular problem requires a dynamically allocated structure doesn’t mean that the decision has no effect. The broad constraints of the problem—whether for performance, modifiability, speed of development, or something else—may be more difficult, or perhaps impossible, to meet if we make the wrong design choices.
Imagine a group of friends has asked you to select a movie for everyone to watch. If one friend definitely wants a comedy, another doesn’t like older films, and another lists five films she’s just seen and doesn’t want to see again, these constraints will make the selection difficult. However, if no one has any suggestions beyond “just pick something good,” your work is even harder, and you’re highly likely to pick something that at least one member of the group won’t like at all.
Therefore larger, broadly defined, weakly constrained problems are the most difficult of all. However, they are susceptible to the same problem-solving techniques we’ve used throughout this book; they just take more time to solve. With your knowledge of these techniques and your master plan in hand, you will be able to solve any problem.
To demonstrate what I’m talking about, I’m going to walk you through the first steps of a program that plays hangman, the classic children’s game, but with a twist.
Before we get to the problem description, let’s review the basic rules of the game. The first player selects a word and tells a second player how many letters are in the word. The second player then guesses a letter. If the letter is in the word, the first player shows where the letter appears in the word; if the letter appears more than once, all appearances are indicated. If the letter is not in the word, the first player adds a piece to a stick-figure drawing of a man being hanged. If the second player guesses all the letters in the word, the second player wins, but if the first player completes the drawing, the first player wins. Different rules exist for how many pieces make up the drawing of the hanged man, so more generally we can say that the players agree ahead of time how many “misses” will win the game for the first player.
Now that we’ve covered the basic rules, let’s look at the specific problem, including the challenging twist.
This is not a monster-sized problem by real-world standards, but it’s large enough to demonstrate the issues we face when dealing with a programming problem that specifies results but no methodology. Based on the problem description, you could fire up your development environment and begin to write code in one of dozens of different places. That, of course, would be a mistake because we always want to program with a plan, so I need to apply my master plan to this specific situation.
The first part of my master plan is limiting the amount of time I spend in the design phase. In order to make that a reality, I need to think carefully about the design before I work on the production code. However, I believe that some experimentation will be necessary in this case for me to work out a solution to the problem. My master plan also allows me to create two projects, a rough-and-ready prototype and a final, polished solution. So I’m going to allow myself to begin coding for the prototype at any time, prior to any real design work, but not allow any coding in the final solution until I believe my design is set. That won’t guarantee I’ll be entirely satisfied with the design in the second project, but it offers the best opportunity for that to be so.
Now it’s time to start picking this problem apart. In previous chapters, we would sometimes list all of the subtasks needed to complete a problem, so I’d like to make an inventory of the subtasks. At this point, though, this would be difficult because I don’t know what the program will actually do to accomplish the cheating. I need to investigate this area further.
Finding a Way to Cheat
Cheating at hangman is specific enough that I don’t expect to find any help in the normal sources of components; there is no NefariousStrategy pattern. At this point, I have a vague idea how the cheating could be accomplished. I’m thinking that I’ll choose an initial puzzle word and hang on to that as long as Player 2 chooses letters that aren’t actually in that word. Once Player 2 hits upon a letter that’s actually in the word, though, I’ll switch to another word if it’s possible to find one that has none of the letters selected thus far. In other words, I’ll deny a match to Player 2 as long as possible. That’s the idea, but I need more than an idea—I need something I can implement.
In order to firm up my ideas, I’m going to work through an example on paper, taking on the role of Player 1, working from a word list. To keep things simple, I’m going to assume that Player 2 has requested a three-letter word and that the complete list of three-letter words that I know are shown in the first column of Table 8-1. I’ll assume that my first choice “puzzle word” is the first word on the list, bat. If Player 2 guesses any letter besides b, a, or t, I’ll say “no,” and we’ll be one step closer to completing the gallows. If Player 2 guesses a letter in the word, then I’ll pick another word, one that doesn’t contain that letter.
Looking at my list, though, I’m not so sure this strategy is the best. In some situations, it probably makes sense. Suppose Player 2 guesses b. No other word in the list contains b, so I can switch the puzzle word to any of them. This also means that I’ve minimized the damage; I’ve eliminated only one possible word from my list. But what happens if Player 2 guesses a? If I just say “no,” I eliminate all words containing an a, which leaves just the three words in the second column of Table 8-1 for me to choose from. If I decided instead to admit the presence of letter a in the puzzle word, I would have five words left I could choose from, as shown in the third column. Note, though, that this extended selection exists only because all five of the words have the a in the same position. Once I declare a guess correct, I have to show exactly where the letter appears in the word. I’ll feel a lot better about my chances for the rest of the game if I have more word choices remaining to react to future guesses.
All Words |
Words Without a |
Words with a |
bat |
dot |
bat |
car |
pit |
car |
dot |
top |
eat |
eat |
|
saw |
pit |
|
tap |
saw |
|
|
tap |
|
|
top |
|
|
Also, even if I managed to avoid revealing letters early in the game, I have to expect that Player 2 will eventually make a correct guess. Player 2 could start with all of the vowels, for example. Therefore, at some point I will have to decide what to do when a letter is revealed, and from my experiment with the sample list, it looks like I will have to find the location (or locations) where the letter appears most often. From this observation, I realized that I have been thinking about cheating in the wrong way. I should never actually pick a puzzle word, even temporarily, but just keep track of all the possible words I could choose if I have to.
With this idea in mind, I can now define cheating in a different way: Keep as many words as possible in the list of candidate puzzle words. For each guess that Player 2 makes, the program has a decision to make. Do we claim that the guess was a miss or a match? If it was a match, in which positions does the guessed letter appear? I’ll have my program keep an ever-dwindling list of candidate puzzle words and, after each guess, make the decision that will leave the greatest number of words in that list.
Required Operations for Cheating at Hangman
Now I understand the problem well enough to create my list of subtasks. In a problem of this size, there’s a good chance that a list made at this early stage will leave some operations out. This is okay, because my master plan anticipates that I will not create a perfect design the first time around.
Store and maintain a list of words.
This program must have a list of valid English words. The program will therefore have to read a list of words from a file and store them internally in some format. This list will be reduced, or extracted from, during the game as the program cheats.
Create a sublist of words of a given length.
Given my intention to maintain a list of candidate puzzle words, I have to start the game with a list of words of the length specified by Player 2.
Track letters chosen.
The program will need to remember which letters have been guessed, how many of those were incorrect, and for any that were deemed correct, where they appear in the puzzle word.
Count words in which a letter does not appear.
In order to facilitate cheating, I’ll need to know how many words in the list do not contain the most recently guessed letter. Remember that the program will decide whether the most recently guessed letter appears in the puzzle word with the goal of leaving the maximum number of words in the candidate word list.
Determine the largest number of words based on letter and position.
This looks like the trickiest operation. Let’s suppose Player 2 has just guessed the letter d and the current game has a puzzle-word length of three. Perhaps the current candidate word list as a whole contains 10 words that include d, but that’s not what’s important because the program will have to state where the letter occurs in the puzzle word. Let’s call the positioning of letters in a word a pattern. So d?? is a three-letter pattern that specifies the first letter is a d and the other two letters are anything other than a d. Consider Table 8-2. Suppose that the list in the first column contains every three-letter word containing d known to the program. The other columns break this list down by pattern. The most frequently occurring pattern is ??d, with 17 words. This number, 17, would be compared with the number of words in the candidate list that do not contain a d to determine whether to call the guess a match or a miss.
Create a sublist of words matching a pattern.
When the program declares that a Player 2 guess is a match, it will create a new candidate word list with only those words that match the letter pattern chosen. In the previous example, if we declared d a match, the third column in Table 8-2 would become the new candidate word list.
Keep playing until the game is over.
After all the other operations are in place, I need to write the code that glues everything together and actually play the game. The program should repeatedly request a guess from Player 2 (the user), determine whether the candidate word list would be longer by rejecting or accepting that guess, reduce the word list accordingly, and then display the resulting puzzle word, with any correctly guessed letters revealed, along with a review of all previously guessed letters. This process would continue until the game was over, having been won by one player or the other—the conditions for which I also need to figure out.
All Words |
?dd |
??d |
d?? |
d?d |
add |
add |
aid |
day |
did |
aid |
odd |
and |
die |
|
and |
|
bad |
doe |
|
bad |
|
bed |
dog |
|
bed |
|
bid |
dry |
|
bid |
|
end |
due |
|
day |
|
fed |
|
|
did |
|
had |
|
|
die |
|
hid |
|
|
doe |
|
kid |
|
|
dog |
|
led |
|
|
dry |
|
mad |
|
|
due |
|
mod |
|
|
end |
|
old |
|
|
fed |
|
red |
|
|
had |
|
rid |
|
|
hid |
|
sad |
|
|
kid |
|
|
|
|
led |
|
|
|
|
mad |
|
|
|
|
mod |
|
|
|
|
odd |
|
|
|
|
old |
|
|
|
|
red |
|
|
|
|
rid |
|
|
|
|
sad |
|
|
|
|
Initial Design
Although it may appear that the previous list of required operations merely lists raw facts, design decisions are being made. Consider the operation “Create a sublist of words matching a pattern.” That operation is going to appear in my solution, or at least this initial version of it, but strictly speaking, it’s not a required operation at all. Neither is “Create a sublist of words of a given length.” Rather than maintaining a list of candidate puzzle words that keeps getting smaller, I could keep the original master list of words throughout the game. This would complicate most of the other operations, though. The operation to “Count words in which a letter does not appear” could not merely iterate through the candidate puzzle-word list and count all words without the specified letter. Because it would be searching through the master list, it would also have to check the length of each word and whether the word matches the letters revealed so far in the puzzle word. I think the path I have chosen is easier overall, but I have to be aware that even these early choices are affecting the final design.
Beyond the initial breakdown of the problem into subtasks, though, I have other decisions to make.
How to store the lists of words
The key data structure of the program will be the list of words, which the program will reduce throughout the game. In choosing a structure, I make the following observations. First, I don’t believe I will require random access to the words in the list but instead will always be processing the list as a whole, from front to back. Second, I don’t know the size of the initial list I require. Third, I’m going to be reducing the list frequently. Fourth and finally, the methods of the standard string class will probably come in handy in this program. Putting all of these observations together, I decide that my initial choice for this structure will be the standard template list class, with an item type of string.
How to track letters guessed
The chosen letters are conceptually a set—that is, a letter has either been chosen or it hasn’t, and no letter can be chosen more than once. Thus, it’s really a question of whether a particular letter of the alphabet is a member of the “chosen” set. I’m therefore going to represent chosen letters as an array of bool of size 26. If the array is named guessedLetters, then guessedLetters[0] is true if a has been guessed during the game so far and false otherwise; guessedLetters[1] is for b, and so on. I’ll use the range conversion techniques we’ve been employing throughout this book to convert between a lowercase alphabet letter and its corresponding position in the array. If letter is a char representing a lowercase letter, then guessedLetters[letter - 'a'] is the corresponding location.
How to store patterns
One of the operations I’ll be coding, “Create a sublist of words matching a pattern,” is going to use the pattern of a letter’s positions in a word. This pattern will be produced by another operation, “Determine the largest number of words based on letter and position.” So what format will I use for that data? The pattern is a series of numbers representing the positions in which a particular letter appears. There are a lot of ways I could store these numbers, but I’m going to keep things simple and use another list, this one with an item type of int.
Am I writing a class?
Because I am coding this program in C++, I can use object-oriented programming or not, at my discretion. My first thought is that many of the operations in my list could naturally coalesce into a class, called wordList perhaps, with methods to remove words based on specified criteria (that is, length and pattern). However, because I’m trying to avoid making design decisions now that I’ll have to revoke later, I’m going to make my first, rough-and-ready program entirely procedural. Once I’ve worked out all of the tricky aspects of the program and actually written code for all of the operations in my list, I’ll be in a great position to determine the applicability of object-oriented programming for the final version.
Initial Coding
Now the fun begins. I fire up my development environment and get to work. This program is going to use a number of classes from the standard library, so for clarity, let me set all of those up first:
#include <iostream>
using std::cin;
using std::cout;
using std::ios;
#include <fstream>
using std::ifstream;
#include <string>
using std::string;
#include <list>
using std::list;
using std::iterator;
#include <cstring>
Now I’m ready to start coding the operations on my list. To some extent, I could code the operations in any order, but I’m going to start with a function to read a plain text file of words into my chosen list<string> structure. At this point, I realize I need to find an existing master file of words—I don’t want to type it up myself. Luckily, Googling word list reveals a number of sites that have lists of English words in plain-text format, one word per line of the file. I’m already familiar with reading text files in C++, but if I weren’t, I would write a small test program just to play around with that skill first and then integrate that ability into the cheating hangman program, a practice I discuss later in this chapter.
With the file in hand, I can write the function:
list<string> readWordFile(char * filename) {
list<string> wordList;
➊ifstream wordFile(filename, ios::in);
➋if (wordFile == NULL) {
cout << "File open failed.
";
return wordList;
}
char currentWord[30];
➌while (wordFile >> currentWord) {
➍if (strchr(currentWord, ''') == 0) {
string temp(currentWord);
wordList.push_back(temp);
}
}
return wordList;
}
This function is straightforward, so I’ll make just a few brief comments. If you’ve never seen one before, an ifstream object ➊ is an input stream that works just like cin, except that it reads from a file instead of standard input. If the constructor is unable to open the file (usually this means the file wasn’t found), the object will be NULL, something I explicitly check for ➋. If the file exists, it’s processed in a loop ➌ that reads each line of the file into a character array, converts the array to a string object, and adds it to a list. The file of English words I ended up using included words with apostrophes, which aren’t legal for our game, so I explicitly exclude them ➍.
Next, I write a function to display all the words in my list<string>. This isn’t on my required list of operations, and I wouldn’t use it in the game (that would only help Player 2, whom I’m trying to cheat, after all), but it’s a good way to test whether my readWordFile function is working correctly:
void displayList(➊const list<string> & wordList) {
➋list<string>::const_iterator iter;
iter = wordList.begin();
while (iter != wordList.end()) {
cout << ➌iter->c_str() << "
";
iter++;
}
}
This is essentially the same list traversal code introduced in the previous chapter. Note that I have declared the parameter as a const reference ➊. Because the list may be quite large at the beginning, having a reference parameter reduces the overhead of the function call, while a value parameter would have to copy the entire list. Declaring that reference parameter a const signals that the function won’t change the list, which aids the readability of the code. A const list requires a const iterator ➋. The cout stream can’t output a string object, so this method produces the equivalent null-terminated char array using c_str()➌.
I use this same basic structure to write a function that counts the words in the list that do not contain a specified letter:
int countWordsWithoutLetter(const list<string> & wordList, char letter) {
list<string>::const_iterator iter;
int count = 0;
iter = wordList.begin();
while (iter != wordList.end()) {
➊if (iter->find(letter) == string::npos) {
count++;
}
iter++;
}
return count;
}
As you can see, this is the same basic traversal loop. Inside, I call the find method of the string class ➊, which returns the position of its char parameter in the string object, returning the special value npos when the character isn’t found.
I use this same basic structure to write the function that removes all the words from my word list that don’t match the specified length:
void removeWordsOfWrongLength(list<string> & wordList,
int acceptableLength)
{
list<string>::iterator iter;
iter = wordList.begin();
while (iter != wordList.end()) {
if (iter->length() != acceptableLength) {
➊iter = wordList.erase(iter);
} else {
➋iter++;
}
}
}
This function is a good example of how every program you write is an opportunity to deepen your understanding of how programs work. This function was straightforward for me to write because I understood what was happening “under the hood” from previous programs that I had written. This function employs the basic traversal code of the previous functions, but the code gets interesting inside the loop. The erase() method removes an item, specified by an iterator, from a list object. But from our experience implementing the iterator pattern for a linked list in Chapter 7, I know that the iterator is almost certainly a pointer. From our experience with pointers back in Chapter 4, I know that a pointer is useless, and often dangerous, when it’s a dangling reference to something that’s been deleted. Therefore, I know I need to assign a valid value to iter after this operation. Fortunately, the designers of erase() have anticipated this problem and have the method return a new iterator that points to the item immediately following the one we just erased, so I can assign that value back to iter ➊. Also note that I explicitly advance iter ➋ only when I have not deleted the current string from the list, because the assignment of the erase() return value effectively advances the iterator, and I don’t want to skip any items.
Now for the tough part: finding the most common pattern of a specified letter in the remaining word list. This is another opportunity to use the divide-the-problem technique. I know one of the subtasks of this operation is determining whether a particular word matches a particular pattern. Remember that a pattern is a list<int>, with each int representing a position where the letter appears in the word, and that for a word to match a pattern, not only must the letter appear in the specified positions in the word, but the letter must not appear anywhere else in the word. With that thought in mind, I’m going to test a string for a match by traversing it; for each position in the string, if the specified letter appears, I’ll make sure that position is in the pattern, and if some other letter appears, I’ll make sure that position is not in the pattern.
To make things even simpler, I’ll first write a separate function to check whether a particular position number appears in a pattern:
bool numberInPattern(const list<int> & pattern, int number) {
list<int>::const_iterator iter;
iter = pattern.begin();
while (iter != pattern.end()) {
if (*iter == number) {
return true;
}
iter++;
}
return false;
}
This code is pretty simple to write based on the previous functions. I simply traverse the list, searching for number. Either I find it and return true or I get to the end of the list and return false. Now I can implement the general pattern-matching test:
bool matchesPattern(string word, char letter, list<int> pattern) {
for (int i = 0; i < word.length(); i++) {
if (word[i] == letter) {
if (!numberInPattern(pattern, i)) {
return false;
}
} else {
if (numberInPattern(pattern, i)) {
return false;
}
}
}
return true;
}
As you can see, this function follows the plan outlined earlier. For each character in the string, if it matches letter, the code checks that the current position is in the pattern. If the character doesn’t match letter, the code checks that the position is not in the pattern. If a single position doesn’t match the pattern, the word is rejected; otherwise, the end of the word is reached, and the word is accepted.
At this point, it occurs to me that finding the most frequent pattern will be easier if every word in the list contains the specified letter. So I write a quick function to chop out the words without the letter:
void removeWordsWithoutLetter(list<string> & wordList,
char requiredLetter) {
list<string>::iterator iter;
iter = wordList.begin();
while (iter != wordList.end()) {
if (iter->find(requiredLetter) == string::npos) {
iter = wordList.erase(iter);
} else {
iter++;
}
}
}
This code is just a combination of the ideas used in the previous functions. Now that I think about it, I’m going to need the opposite function as well, one that chops out all the words that have the specified letter. I’ll use this to reduce the candidate word list when the program calls the latest guess a miss:
void removeWordsWithLetter(list<string> & wordList, char forbiddenLetter) {
list<string>::iterator iter;
iter = wordList.begin();
while (iter != wordList.end()) {
if (iter->find(forbiddenLetter) != string::npos) {
iter = wordList.erase(iter);
} else {
iter++;
}
}
}
Now I’m ready to find the most frequent pattern in the word list for the given letter. I considered a number of approaches and picked the one that I thought I could most easily implement. First, I’ll use a call to the function above to remove all the words without the specified letter. Then, I’ll take the first word in the list, determine its pattern, and count how many other words in the list have the same pattern. All of these words will be erased from the list as I count them. Then the process will repeat again with whatever word is now at the head of the list and so on until the list is empty. The result looks like this:
void mostFreqPatternByLetter(➊list<string> wordList, char letter,
➋list<int> & maxPattern,
➌int & maxPatternCount) {
➍removeWordsWithoutLetter(wordList, letter);
list<string>::iterator iter;
maxPatternCount = 0;
➎while (wordList.size() > 0) {
iter = wordList.begin();
list<int> currentPattern;
➏for (int i = 0; i < iter->length(); i++) {
if ((*iter)[i] == letter) {
currentPattern.push_back(i);
}
}
int currentPatternCount = 1;
iter = wordList.erase(iter);
➐while (iter != wordList.end()) {
if (matchesPattern(*iter, letter, currentPattern)) {
currentPatternCount++;
iter = wordList.erase(iter);
} else {
iter++;
}
}
➑if (currentPatternCount > maxPatternCount) {
maxPatternCount = currentPatternCount;
maxPattern = currentPattern;
}
currentPattern.clear();
}
}
The list arrives as a value parameter ➊ because this function is going to whittle the list down to nothing during processing, and I don’t want to affect the parameter passed by the calling code. Note that maxPattern ➋ and maxPatternCount ➌ are outgoing parameters only; these will be used to send the most regularly occurring pattern and its number of occurrences back to the calling code. I remove all of the words without letter ➍. Then I enter the main loop of the function, which continues as long as the list isn’t empty ➎. The code inside the loop has three main sections. First, a for loop constructs the pattern for the first word in the list ➏. Then, a while loop counts how many words in the list match that pattern ➐. Finally, we see whether this count is greater than the highest count seen so far, employing the “King of the Hill” strategy first seen back in Chapter 3 ➑.
The last utility function I should need will display all of the letters guessed so far. Remember that I am storing these as an array of 26 bool values:
void displayGuessedLetters(bool letters[26]) {
cout << "Letters guessed: ";
for (int i = 0; i < 26; i++) {
if (letters[i]) cout << ➊(char)('a' + i) << " ";
}
cout << "
";
}
Note that I am adding the base value of one range, in this case, the character a, to a value from another range ➊, a technique we first employed back in Chapter 2.
Now I have all the key subtasks completed, and I’m ready to try solving the whole problem, but I have a lot of functions here that haven’t been fully tested, and I would like to get them tested as soon as possible. So, rather than tackle the rest of the problem in one step, I’m going to reduce the problem. I’ll do this by making some of the variables, such as the size of the puzzle word, into constants.
Because I’m going to be throwing this version away, I’m comfortable with putting the entire game-playing logic into the main function. Because the result is lengthy, though, I’m going to present the code in stages.
int main () {
➊list<string> wordList = readWordFile("wordlist.txt");
const int wordLength = 8;
const int maxMisses = 9;
➋int misses = 0;
➌int discoveredLetterCount = 0;
➍removeWordsOfWrongLength(wordList, wordLength);
➎char revealedWord[wordLength + 1] = "********";
➏bool guessedLetters[26];
for (int i = 0; i < 26; i++) guessedLetters[i] = false;
➐char nextLetter;
cout << "Word so far: " << revealedWord << "
";
This first section of code sets up the constants and variables we’ll need to play the game. Most of this code is self-explanatory. The word list is created from a file ➊ and then pared down to the specified word length, in this case, the constant value 8 ➍. The variable misses ➋ stores the number of wrong guesses by Player 2, while discoveredLetterCount ➌ tracks the number of positions revealed in the word (so if d appears twice, guessing d increases this value by two). The revealedWord variable stores the puzzle word as currently known to Player 2, with asterisks for letters that have not yet been guessed ➎. The guessedLetters array of bool ➏ tracks the specific letters guessed so far; a loop sets all the values to false. Finally, nextLetter ➐ stores the current guess of Player 2. I output the initial revealedWord, and then I’m ready for the main game loop.
➊ while (discoveredLetterCount < wordLength && misses < maxMisses) {
cout << "Letter to guess: ";
cin >> nextLetter;
➋guessedLetters[nextLetter - 'a'] = true;
➌int missingCount = countWordsWithoutLetter(wordList, nextLetter);
list<int> nextPattern;
int nextPatternCount;
➍mostFreqPatternByLetter(wordList, nextLetter, nextPattern, nextPatternCount);
if (missingCount > nextPatternCount) {
➎removeWordsWithLetter(wordList, nextLetter);
misses++;
} else {
➏list<int>::iterator iter = nextPattern.begin();
while (iter != nextPattern.end()) {
discoveredLetterCount++;
revealedWord[*iter] = nextLetter;
iter++;
}
wordList = reduceByPattern(wordList, nextLetter, nextPattern);
}
cout << "Word so far: " << revealedWord << "
";
displayGuessedLetters(guessedLetters);
}
There are two conditions that can end the game. Either Player 2 discovers all of the characters in the word, so that discoveredLetterCount reaches wordLength, or Player 2’s bad guesses complete the hangman, in which case misses will equal maxMisses. So the loop continues as long as neither condition has occurred ➊. Inside the loop, after the next guess is read from the user, the corresponding position in guessedLetters is updated ➋. Then the cheating begins. The program determines how many candidates would be left in the word list if the guess were declared a miss using countWordsWithoutLetter ➌, and it determines the maximum that could be left if the guess were declared a hit using mostFreqPatternByLetter ➍. If the former is larger, the words with the guessed letter are culled and misses is incremented ➎. If the latter is larger, we’ll take the pattern given by mostFreqPatternByLetter and update revealedWord, while also removing all words from the list that don’t match the pattern ➏.
if (misses == maxMisses) {
cout << "Sorry. You lost. The word I was thinking of was '";
cout << ➊(wordList.cbegin())->c_str() << "'.
";
} else {
cout << "Great job. You win. Word was '" << revealedWord << "'.
";
}
return 0;
}
The remainder of the code is what I call a loop postmortem, where the post-loop action is determined by the condition that “killed” the loop. Here, either our program successfully cheated its way to a victory or Player 2, against all odds, forced the program to reveal the entire word. Note that when the program wins, at least one word must remain in the list, so I just display the first word ➊ and claim that was the one I was thinking of all along. A more devious program might randomly select one of the remaining words to reduce the chance of the opponent detecting the cheating.
Analysis of Initial Results
I’ve put all this code together and tested it, and it works, but clearly there are a lot of improvements to be made. Beyond any design considerations, the program is missing a lot of functionality. It doesn’t allow the user to specify the size of the puzzle word or the number of allowable wrong guesses. It doesn’t check to see whether the guessed letter has been guessed before. For that matter, it doesn’t even check that the input character is a lowercase letter. It’s missing a lot of interface pleasantries, like telling the user how many more misses are available. I think it would also be nice if the program could offer to play again, rather than making the user re-run the program.
As for the design, when I begin to think about the finished version of the program, I’m going to seriously consider an object-oriented design. A wordlist class now seems like a natural choice. The main function looks too large to me. I like a modular, easy-to-maintain design, and that should result in a main function that is short and merely directs traffic among the subprograms that do the real work. So my main function needs to be broken up into several functions. Some of my initial design choices might need rethinking. For example, in hindsight, storing patterns as list<int> looks cumbersome. Perhaps I could try an array of bool, in a manner analogous to guessedLetters?
Or perhaps I should look for another structure entirely. Now is also the time for me to step back to see whether there are any opportunities to learn new techniques in solving this problem. I’m wondering whether there are specialized data structures that I have not yet considered that could be helpful. Even if I end up sticking with my original choices, I could learn a lot from the investigation.
Though all of these decisions are still looming, I feel like I’m well on my way with this project. Having a working program that meets the essential requirements of the problem is a great place to be. I can easily experiment with the different design ideas in this rough version, with the confidence that comes from knowing I already have a solution, and I’m only looking for a better solution.
The Art of Problem Solving
Did you recognize all the problem-solving techniques I employed in my solution so far? I had a plan for solving the problem. As always, this is the most crucial of all problem-solving techniques. I decided to start with what I knew for the first version of my solution, employing a couple of data structures with which I was very familiar, arrays and the list class. I reduced the functionality to make it easier to write my rough-and-ready version and to allow me to test my code earlier than I could otherwise. I divided the problem into operations and made each operation a different function, allowing me to work on pieces of the program separately. When I was unsure how to cheat, I experimented, allowing me to restate “cheating” as “maximizing the size of the candidate word list,” which was a concrete concept for me to code. In the particulars of coding the operations, I employed techniques analogous to those used throughout this book.
I also successfully avoided getting frustrated, although I suppose you’ll have to take my word for that.
Before we move on, let me be clear that I have demonstrated the steps I took to get to this stage in the process of solving this problem. These are not necessarily the same steps you would take to solve this problem. The code shown above is not the best solution to the problem and is not necessarily better than what you would come up with. What I hope it demonstrates is that any problem, no matter the size, can be solved using variations of the same basic techniques used throughout this book. If you were tackling a problem twice as large as this one, or 10 times as large, it might test your patience, but you could solve it.
Learning New Programming Skills
There’s one more topic to discuss. In mastering the problem-solving techniques of this book, you are taking the key step down the road of life as a programmer. However, as with most professions, this is a road without a destination, for you must always be striving to better yourself as a programmer. As with everything else in programming, you should have a plan for how you will learn new skills and techniques, rather than just trusting that you will pick up new things here and there along the way.
In this section, we’ll discuss some of the areas in which you may want to acquire new skills and some systematic approaches for each. The common thread running through all of the areas is that you must put what you want to learn into practice. That’s why each chapter in this book ends with exercises—and you have been working through those exercises, right? To read about new ideas in programming is a vital first step in actually learning them, but it is only the first step. To reach the point where you can confidently employ a new technique in the solution for a real-world problem, you should first try out the technique in a smaller, synthetic problem. Remember that one of our basic problem-solving techniques is to break complex problems down, by either dividing the problem or temporarily reducing the problem so that each state we’re dealing with has just one nontrivial element. You don’t want to try to solve a nontrivial problem at the same time that you’re learning the skill that will be central to your solution because then your attention will be divided between two difficult problems.
New Languages
I think C++ is a great programming language for production code, and I explained in the first chapter why I think it’s also a great language to learn with. That said, no programming language is superior in all situations; therefore, good programmers must learn several.
Take the Time to Learn
Whenever possible, you should give yourself time to study a new language before attempting to write production code with one. If you attempt to solve a nontrivial problem in the language you have never used before, you are quickly going to run counter to an important problem-solving rule: Avoid frustration. Set yourself the task of learning a language, and complete the task before you assign yourself any “real” programs in that language.
Of course, in the real world, sometimes we are not completely in control of when we are assigned projects. At any moment, someone could request that we write a program in a particular language, and that request could be accompanied by a deadline that would prevent us from leisurely studying the language before tackling the actual problem. The best defense against encountering this situation is to begin studying other programming languages before you are absolutely required to know them. Investigate languages that interest you or that are used for areas in which you expect to program during your career. This is another situation in which an activity that seems like a poor use of time in the short term will pay large dividends in the long term. Even if it turns out that you don’t require the language you have studied in the near future, studying another language can improve your skills with the other languages you already know because it forces you to think in new and different ways, breaking you out of old habits and giving you fresh perspectives on your skills and techniques. Think of it as the programming equivalent of cross-training.
Start with What You Know
When you begin learning a new programming language, by definition you know nothing about it. If it’s not your first programming language, though, you do know a lot about programming. So a good first step in learning a new language is to understand how code that you already know how to write in another language can be written in the new language.
As stated before, you want to learn this by doing, not just by reading. Take programs you have written in other languages, and rewrite them in the new language. Systematically investigate individual language elements, such as control statements, classes, other data structures, and so on. The goal is to transfer as much of your previous knowledge as possible to the new language.
Investigate What’s Different
The next step is to study what is different about the new language. While two high-level programming languages may have extensive similarities, something must be different with the new language, or there would be no reason to choose this language over any other. Again, learn by doing. Just reading, for example, that a language’s multiple-selection statement allows ranges (instead of the individual values of a C++ switch statement) isn’t as helpful to your development as actually writing code that meaningfully employs the capability.
This step is obviously important for languages that are noticeably dissimilar but is equally important for languages that have a common ancestor, such as C++, C#, and Java, which are all object-oriented descendents of C. Syntax similarities can trick you into believing you know more about the new language than you really do. Consider the following code:
integerListClass numberList;
numberList.addInteger(15);
If these lines were presented to you as C++ code, you would understand that the first line constructed an object, numberList, of a class, integerListClass, and the second line invoked an addInteger method on that object. If that class actually exists and has a method of that name that takes an int parameter, this code makes perfect sense. Now suppose I told you this code had been written in Java, not C++. Syntactically, there is nothing illegal about these two lines. However, in Java, a mere variable declaration of a class object does not actually construct the object because object variables are actually references—that is, they behave in a manner analogous to pointers. To perform the equivalent steps in Java, the correct code would be:
integerListClass numberList = new integerListClass;
numberList.addInteger(15);
You would likely catch on to this particular difference between Java and C++ quickly, but many other differences could be quite subtle. If you don’t take the time to discover them, they can make debugging very difficult in the new language. As you scan your code, your internal programming language interpreter will be feeding you incorrect information about what you are reading.
Study Well-Written Code
I’ve made a point throughout this book that you shouldn’t try to learn programming by taking someone else’s code and modifying it. There are times, however, when the study of someone else’s code is vital. While you can build up your skills in a new language by writing a series of original programs, to reach a level of mastery, you will want to seek out code written by a programmer skilled in that language.
You’re not looking to “crib” this code; you’re not going to borrow this code to solve a specific problem. Instead, you’re looking at existing code to discover the “best practices” in that language. Look at an expert programmer’s code and ask yourself not just what the programmer is doing but why the programmer is doing it. If the code is accompanied by the programmer’s explanations, all the better. Differentiate between style choices and benefits to performance. By completing this step, you will avoid a common pitfall. Too often, programmers will learn just enough in a new language to survive, and the result is weak code that doesn’t use all of the features of the language. If you are a C++ programmer required to write code in Java, for example, you don’t want to settle for writing code in pidgin C++; instead, you want to learn to write actual Java code the way a Java programmer would.
As with everything else, put what you learn into practice. Take the original code and modify it to do something new. Put the code out of sight and try to reproduce it. The goal is to become comfortable enough with the code that you could answer questions about it from another programmer.
It’s important to emphasize that this step comes after the others. Before we reach the stage of studying someone else’s code in a new language, we have already learned the syntax and grammar of the new language and applied the problem-solving skills we learned in another language to the new language. If we try to shorten the process by starting the study of the new language with the study of long program samples and the modification of those samples, there’s a real risk that that’s all we’ll ever be able to do.
New Skills for a Language You Already Know
Just because you reach the point where you can say that you “know” a language, doesn’t mean you know everything about that language. Even once you have mastered the syntax of the language, there will always be new ways to combine existing language features to solve problems. Most of these new ways will fall under one of the “component” headings of the previous chapter, in which we discussed how to build component knowledge. The important factor is effort. Once you get good at solving problems in certain ways, it’s easy to rely on what you already know and cease growing as a programmer. At that point, you’re like a baseball pitcher who throws a mean fastball but doesn’t know how to throw anything else. Some pitchers have had successful professional careers with only one pitch, but the pitcher who wants to go from being a reliever to a starter needs more.
To be the best programmer you can be, you need to seek new knowledge and new techniques and put them into practice. Look for challenges and overcome them. Investigate the work of expert programmers of your chosen languages.
Remember that necessity is the mother of invention. Seek out problems that cannot satisfactorily be solved with your current skill set. Sometimes you can modify problems you have already solved to provide new challenges. For example, you may have written a program that works fine when the data set is small, but what happens when you allow the data to grow to gargantuan proportions? Or what if you have written a program that stores its data on the local hard drive, but you wanted the data to be stored remotely? What if you need multiple executions of the program that could access and update the remote data concurrently? By starting with a working program and adding new functionality, you can focus on just the new aspects of the programming.
New Libraries
Modern programming languages are inseparable from their core libraries. When you learn C++, you’ll inevitably learn something about the standard template libraries, for example, and when you study Java, you will learn about standard Java classes. Beyond the libraries bundled with the language, though, you’ll need to study third-party libraries. Sometimes these are general application frameworks, such as Microsoft’s .NET framework, that can be used with several different high-level languages. In other cases, the library is specific to a particular area, like OpenGL for graphics, or is part of a third-party proprietary software package.
As with learning a new language, you should not try to learn a new library during a major project that requires that library. Instead, learn the main components of the library separately in a test project of zero importance before employing them in a real project. Assign yourself a progression of increasingly difficult problems to solve. Remember that the goal is not necessarily to complete any of those problems, only to learn from the process, so you don’t need to polish the solutions or even complete them once you have successfully employed that part of the library in your program. These programs can then serve as references for later work. When you find yourself stuck because you’re unable to remember how to, let’s say, superimpose a 2D display over a 3D scene in OpenGL, there’s nothing better than being able to open up an old program that was created just to demonstrates that very technique and is written in your own style because it was written by you.
Also, as with learning a new language, once you are comfortable with the basics of a library, you should review the code written by experts in the use of that library. Most large libraries have idiosyncrasies and caveats that aren’t exposed by the official documentation and that, outside of long experience, can only be discovered from other programmers. In truth, to make much headway with some libraries requires the initial use of a framework provided by another programmer. The important thing is not to rely on others’ code any more than you have to and to quickly get to the stage where you re-create the code you were originally shown. You might be surprised how much you learn from the process of re-creating someone else’s existing code. You may see a call to a library function in the original code and understand that the arguments passed in this call produce a certain result. When you set that code aside, though, and try to reproduce that effect on your own, you’ll be forced to investigate the function’s documentation, all the particular values the arguments could take, and why they have to be what they are to get the desired effect.
Take a Class
As a longtime educator, I feel I have to conclude this section by talking about classes—not in the object-oriented programming sense, but in the sense of a course at a school. Whatever area of programming you want to learn about, you’ll find someone offering to teach you, whether in a traditional classroom or in some online environment. However, a class is a catalyst for learning, not the learning itself, especially in an area like programming. No matter how knowledgeable or enthusiastic a programming instructor is, when you actually learn new programming abilities, it will happen as you’re sitting in front of your computer, not as you’re sitting in a lecture hall. As I reiterate throughout this book, you have to put programming ideas into practice, and you have to make them your own to truly learn them.
This isn’t to suggest that classes have no value—because they often have tremendous value. Some concepts in programming are inherently difficult or confusing, and if you have access to an instructor with a talent for explaining difficult concepts, that may save you loads of time and frustration. Also, classes provide an evaluation of your learning. If you are again fortunate with your instructor, you may learn much from the evaluation of your code, which would streamline the learning process. Finally, the successful completion of a class provides some evidence to current or future employers that you understand the subjects taught (if you are unfortunate and have a poor instructor, you can at least take solace in that).
Just remember that your programming education is your responsibility, even when you take a class. A course will provide a framework for acquiring a grade and credit at the end of the term, but that framework doesn’t limit you in your learning. Think of your time in the class as a great opportunity to learn as much about the subject as possible, beyond any objectives listed in the course syllabus.
Conclusion
I fondly remember my first programming experience. I wrote a short, text-based simulation of a pinball machine, and no, that doesn’t make any sense to me either, but it must have at the time. I didn’t own a computer then—who did in 1976?—but at my father’s office was a teletype terminal, essentially an enormous dot-matrix printer with a click-clack keyboard, that communicated with the mainframe at the local university via acoustic modem. (You picked up the phone to dial by hand, and when you heard electronic screaming, you dropped the handset into a special cradle connected to the terminal.) As primitive and pointless as my pinball simulation was, the moment the program worked and the computer was acting under my instructions, I was hooked.
The feeling I had that day—that a computer was like an infinite pile of Legos, Erector Sets, and Lincoln Logs, all for me to build anything I could imagine—is what drives my love of programming. When my development environment announces a clean build and my fingers reach for the keystroke that will begin execution of my program, I’m always excited, in anticipation of success or failure, and anxious to see the results of my efforts, whether I am writing a simple test project or putting the finishing touches on a large solution, or whether I am creating beautiful graphics or just constructing the front end of a database application.
I hope you have similar feelings when you program. Even if you are still struggling with some of the areas covered in this book, I hope you now understand that as long as programming excites you so much that you always want to stick with it, there is no problem you can’t solve. All that is required is the willingness to put in the effort and to go about the process the right way. Time takes care of the rest.
Are you thinking like a programmer yet? If you’ve solved the exercises at the ends of these chapters, then you should be thinking like a programmer and be confident in your problem-solving ability. If you haven’t solved many of the exercises, then I have a suggestion for you, and I’ll bet you can guess what it is: Solve more exercises. If you’ve skipped some in previous chapters, don’t start with the exercises in this chapter—go back to where you left off, and work your way forward from there. If you don’t want to do more exercises because you don’t enjoy programming, then I can’t help you.
Once you are thinking like a programmer, be proud of your skills. If someone calls you a coder rather than a programmer, say that a well-trained bird could be taught to peck out code—you don’t just write code, you use code to solve problems. When you’re sitting across an interview table from a future employer or client, you’ll know that whatever the job requires, you can figure it out.
Exercises
You had to know that there would be one last set of exercises. These are, of course, tougher and more open-ended than any from previous chapters.
8-1. Write a complete implementation for the cheating hangman problem that’s better than mine.
8-2. Expand your hangman program so that the user can choose to be Player 1. The user still selects the number of letters in the word and the number of missed guesses, but the program does the guessing.
8-3. Rewrite your hangman program in another language, one that you currently know little or nothing about.
8-4. Make your hangman game graphical, actually displaying the gallows and the hangman as he is being constructed. You’re trying to think like a programmer, not like an artist, so don’t worry about the quality of the art. You must make an actual graphical program, though. Don’t draw the hangman using ASCII text—that’s too easy. You might want to investigate 2D graphics libraries for C++ or choose a different platform that’s more graphically oriented to begin with, like Flash. Having a graphical hangman might require constraining the number of wrong guesses, but there may be a way to offer at least a range of choices for this number.
8-5. Design your own exercise: Employ the skills you learned in the hangman problem to solve something completely different that involves manipulating a list of words, such as another game that uses words—like Scrabble, a spellchecker, or whatever else you can think of.
8-6. Design your own exercise: Search for a C++ programming problem of such size or difficulty that you are sure you would have once considered it impossible for you to solve with your skills, and solve it.
8-7. Design your own exercise: Find a library or API that interests you but that you have yet to use in a program. Then investigate that library or API and use it in a useful program. If you’re interested in general programming, consider the Microsoft .NET library or an open-source database library. If you like low-level graphics, consider OpenGL or DirectX. If you’d like to try making games, consider an open-source game engine like Ogre. Think about the kinds of programs you’d like to write, find a library that fits, and go at it.
8-8. Design your own exercise: Write a useful program for a new platform (one that’s new to you)—for example, mobile or web programming.