
Chapter 8. Knowledge and Information
There is a saying that if you have one clock you know what time it is, but if you have two you are not sure. The joke is about a fundamental issue with autonomous agencies. When everyone lives in a private world, how would they come to agree about anything—in fact, would they ever need to? Whom should we trust? Who has the right answer? Do facts have any meaning? What can we say, at all, about who knows what about whom, and where?
Relativity leads to all manner of trouble and intrigue in the world of agents, human or otherwise. This is certainly one of the issues that Promise Theory attempts to get to the bottom of by decomposing the world into autonomous pieces, and then documenting their probable behaviours, even in the face of incomplete information.
How Information Becomes Knowledge
As we’ve already discussed, knowledge is a body of information that’s familiar (i.e., that you know like a friend). We sample information from the world through observation, hopefully adding the context in which the observations were made, until we’ve rehearsed that relationship. Our level of confidence about what we see only grows through this repetition. That’s why experimentalists repeat experiments many times, and why data samples need to be repeated. It is about whether we promise to accept information as fact or reject it as conjecture. This status emerges over time as we repeatedly revisit the same measurements and ask the same questions.
Knowledge: The Mystery Cat
We seek it here, we seek it there. The agency of knowledge is nowhere and everywhere! Agents can promise to give and accept information, but we cannot tell whether that information will be absorbed and understood by every agent in the same way. So how do we arrange for agents within some system or organization to become knowledgeable according to a measurable or approved standard?
Knowledge must be individual because it is based on promises to accept information (-). Knowledge is accepted in the eye of the beholder, by each individual agent. That means that each agent has its knowledge as a private world or branch of reality. If an agent wants to claim knowledge of something, it must promise (+): “I promise that fact X means (insert explanation) to me.”
Suppose then that someone asks the agent the question: “Is fact X known to be true?” The agent can answer for itself. If the question were asked open-endedly to many agents, we would really be asking: “Is there a consensus among you agents; i.e., is there some regularity to the promises all you agents make about X?”
For example, two clocks are two agents. Do they make the same promise about the time? Two humans are two agents. Do they both promise to know the name of the President of the United States? Do they agree? If they agree, do they agree by accident, or by cooperation?
If we want to engineer the knowledge of agents, to try to induce a consensus, we need to solicit the acceptance of all parts of the system. This is just as much of a problem in technology, where data has to be distributed over many computers, as it is for humans.
Passing Information Around
Let’s put it another way. We could call a sample of data a passerby. Then information might be called an acquaintance, and knowledge a real friend. If we want to promise to turn data into knowledge, a chance encounter into friendship, we need to engage with it, promise to accept it, assimilate it, and revisit it regularly.
As we know from Dunbar, the number of relationships we can really know is limited by our need for detail. If we can reduce the detail to a minimum, we have a strategy for coping. Labelling things in categories, to reduce the number of knowledge relationships, is how we do this. Here, I’m talking, of course, about human categories, not the mathematical variety of category theory, which makes up an altogether different kind of cat. Generalization is a simple example of identifying a promise role amongst a number of agencies of knowledge (facts, exemplars, and relationships).
If I say that I am an expert on subject X, it is a kind of promise that I know a lot about what happens inside the category of X.
Once we are comfortable in our own trusted knowledge, passing it on to others is a whole new story, in which the recipient is always the one calling the shots. Others don’t choose our friends for us. You cannot make a promise on behalf of anyone else.
Agents can’t promise trust on behalf of one another, so each agent needs to form its own trusted relationship with data to perform the alchemy of turning data into knowledge.
Transmitted information becomes knowledge when it is known (i.e., when it is familiar enough to be trusted and contextualized). Agents experience the world from the viewpoint of the information available to them. Each can form its own independent conclusions and categorize it with its own roles.
Categories Are Roles Made into Many World Branches
We discussed branching in connection with the coexistence of versions, where different promises could live in different agent worlds to avoid conflicting. In the same way, knowledge can avoid having conflicting meanings and interpretations by placing it into different agents. As usual, there is a (+) way and a (-) way:
-
The (-) is what we’ve already discussed. The eye of the individual agent immediately places knowledge in its own world.
-
An agent promising its own knowledge (+) can also separate concepts into different branches within itself. This is called a taxonomy or ontology. These branches are called categories or classes.
Categories are an attempt to use the many-worlds branching concept to hide information (Figure 8-1). We can understand this easily by appealing to the idea of roles. A collection of agents or things that is assessed by a user as making the same kind of promise (or collection of promises) forms a role. A role can thus label a category.

Figure 8-1. Cat(egorie)s are in the eye of the beholder. Cat(ch) them if you can!
Patterns like this tie in with the use of repetition to emphasize learning, as mentioned before, and thus patterns are related to our notion of learning by rote. They don’t really exist, except in the eye of the beholder: “You may seek him in the basement, you may look up in the air, but I tell you once and once again the category’s not there!” (apologies to T.S. Eliot).
A knowledge category is a label that applies to individual bits of knowledge. Each agency might promise a role by association. We can define such roles simply in terms of the promises they make:
-
The knowledge itself brands itself with some category label (+).
-
Or the user of information files it under some category of their own (-).
-
Or knowledge items self-organize into a collaborative role.
Superagent Aggregation (Expialidocious)
Bringing a number of concepts (or agencies of knowledge) together under a common umbrella is what we mean by categorization. We see this as an important part of knowledge management, and it’s not hard to see why. It is much cheaper to form a relationship with a container that doesn’t reveal more than its name. If we had to have a deep relationship with every internal organ in our friends and relatives, it would quite likely change our perception of them!
A superagent is just a collection of agents that form a collaborative role because of underlying promises to work together. In the extreme case of knowing nothing of what happens to the individual components inside, it is like a black box.
The attachment of a concept such as radio to a set of collaborating relationships is nothing like the naming that happens in a standard taxonomy: it is an interpretation, based on a likely incomplete understanding of the structure of the internal properties, based on an evaluation of its behaviour. In a hierarchical decomposition, one would separate the components into rigid categories like “resistor,” capacitor,” “transistor,” or “plastic” and “metal,” none of which say anything about what these parts contribute to.
A radio is thus a collection of subagents with an emergent property (i.e., a collaborative network of properties whose collective promise has no place in a taxonomic categorization related to its parts). The function “radio” is a cooperative role. Emergence is the opposite of categorization.
There might be different categories of radio, of course, at this higher level, such as a two-way radio (walkie-talkie), or a broken radio, which fails to keep its emergent promise. A user would only guess the latter if the radio had packaging that signalled the promise.
A radio is not really more than the sum of its parts, as we sometimes like to say, but its function seems to be, as it forms a collaboration that comes alive and takes on a new interpretation at a different level. Cooperation simply and unmysteriously allows new promises to be made at each cooperative scale. These are not to be found within any single component: they are irreducible, and hence the promises of the whole may be accounted for as a simple sum of the cooperative promises, together with the component promises.
Typical taxonomic decompositions are reductionistic, leaving no room for the understanding of this as a collective phenomenon. This defect can really only be repaired if we understand that it is the observer or recipient, not the designer, that ultimately makes the decision whether to accept that the assessment of a set of component promises is a radio or not.
The concept of a radio is clearly much cheaper to maintain as a new and separate entity than as a detailed understanding of how the components collaborate to produce the effect. We frequently use this kind of information hiding to reduce the cost of knowledge, but it is clear that knowledge gets lost in this process. Black boxes allow us to purposefully forget or discard knowledge in order to reduce the cost of accepting a collective role.
The ability to replace a lot of complexity with a simple label brings great economic efficiency for end users of knowledge, which one could measure in concepts per role. It is not the size of a group or role that is the best indicator for providing a reduction in perceived complexity, but rather the affinity that a receiver who promises to use this role’s defining pattern feels for the concept. In other words, how well does a user identify or feel resonance with the pattern?
The important point here, as we see repeatedly, is that it is how these terms are perceived by the user (i.e., the usage, not the definition) of these terms that is the crucial element here. What is offered is only a prerequisite. It is what is accepted by agents that is important.
Thinking in Straight Lines
Promises come from autonomous, standalone agents. Facts and events are such agents. But humans don’t think in terms of standalone facts; we are creatures of association. We love to string together facts into story lines, especially when we communicate in speech or writing. Conditional promises allow us to do this in the framework of promise theory, too.
The concept of a story or narrative is large in human culture, but as far as I can tell, very little attention has been given to its importance to the way we think and reason. A table of contents in a book promises a rough outline of the story told by the book at a very high level. It promises a different perspective on a book’s content than the index does (which is designed for random access). A story is thus a collection of topics connected together by associations in a causative thread.
Causality (i.e., starting point “cause” followed by subsequent “effect”) promises associative relationships such as “affects” or “always happens before,” “is a part of,” and so on. These relationships have a transitivity that most promised associations do not have, and this property allows a kind of automated reasoning that is not possible with arbitrary associations.
Understanding more about the principles of automated story or narrative identification as sequences of promises could also have more far-reaching consequences for knowledge than just automated reasoning. In school, not all students find it easy to make their own stories from bare facts, and this could be why some students do better than others in their understanding. We tend to feel we understand something when we can tell a convincing story about it. With more formal principles behind an effort to understand stories, technology could help struggling students grasp connections better, and one could imagine a training program to help basic literacy skills.
Knowledge Engineering
Knowledge engineering includes teaching, storytelling, indoctrination, and even propaganda. From a promise perspective, it has to be based on autonomous cooperation. In the past, this has been done by imposition. Standard stories, official taxonomies of species, or subject categories have been imposed on us from Victorian times. In today’s Internet culture, this is all changing.
In the pre-Internet world, we used directory services to navigate information with which we were only loosely acquainted. Directory services, such as tables of contents, tried to organize information within categorized branches such as chapters and sections. This is a good way of arranging a narrative structure when we need to parse information from start to finish. But once search engines, which work like indices, became common, the usefulness of directories and tables of contents was greatly reduced.
The reason is very easy to understand. A directory promises information, as long as you promise to know where to look for it. The cost of being able to find information in the right category is not trivial. The user of a taxonomy or ontology, or list of chapters, has to know a fair amount about that model before it can be used in a helpful way. An index, while offering less narrative context, requires no foreknowledge of a commonly agreed model, and it can offer all of the possible interpretations to scan through. Search engines have made this experience very consumable, and they allow agencies of knowledge to stand alone without narrative constraints, so that users can assess their own narratives as they use the data.
By stripping away unnecessary structure, a promise approach to knowledge grants knowledge the freedom to evolve in a direction dictated by common, collaborative culture.
The Victorian vision of divide-and-conquer taxonomy was naive. The likelihood that we would ever classify meaning into a single, standard, crystalline tree of life is about the same as the likelihood of unifying all the world’s cultures into one. The cultural evidence suggests that human social interaction evens out our ideas about categories through mixing and creating “norms.” Concepts swarm through the crowd, and we adjust them to follow the influences of others, out of a promise to cooperate. This brings about a condensation from noise to clarity.
The eye of the beholder is fickle and evolving. The final answers about knowledge management probably lie with social anthropology. It will be a challenge for more empirical studies to come up with evidence for the success or failure of the suggestions contained here. In the meantime, there seems to be little to lose by trying a promise approach, so I leave it to the reader to explore these simple guidelines in practice.
Equilibrium and Common Knowledge
Let’s return to the bread and butter of moving information around a collection of autonomous agents to achieve a common view. When all agents have consistent knowledge they reach an equilibrium of exchanging values and agreeing with one another. To say that they know says more than that they have accepted the information; it is a more significant promise.
There are two extremes for doing this (see Figure 8-2). The simplest way to achieve common knowledge is to have all agents assimilate the knowledge directly from a single (centralized) source agent. This minimizes the potential uncertainties, and the source itself can be the judge of whether the appropriate promises have been given by all agents mediating in the interaction. The single source becomes an appointed role. This is the common understanding of how a directory or lookup service works.

Figure 8-2. Two routes to equilibration again, for knowledge promises.
Although simplest, the centralized source model is not better than one in which data is passed on epidemically from peer to peer. Agents may still have consistent knowledge from an authoritative source, either with or without centralization of communication, but it takes time for agents to settle on their final answer for the common view.
If two agents promise to share one another’s knowledge and can both verify that they agree based on some criteria, then it is fair to say that they have consistent knowledge. We should note that, because promises include semantics, and assessment is an integral part of this, consistency requires them to interpret the mutual information in a compatible way, too.
We can express this with the following promises. Suppose agent A knows fact a, and agent B knows fact b; to say that a and b are consistent requires what’s shown in Figure 8-3.

Figure 8-3. Passing on a value received on trust.
A bit more precisely, we can say it like this:
-
A promises the information a to B (+).
-
B promises to accept the information a from A (-).
-
B promises the information b to A.
-
A promises to accept the information b from B.
-
A promises that a = b to B.
-
B promises that b = a to A.
Consistency of knowledge is a strong concept. An agent does not know the data unless it is either the source of the knowledge, or it has promised to accept and assimilate the knowledge from the source.
Integrity of Information Through Intermediaries
Knowledge can be passed on from agent to agent with integrity, but we’ve all seen the game of Chinese whispers. Because information received is in the eye of the beholder, agents can very easily end up with a different picture of the information as a result of their local capabilities and policies for receiving and relaying information.
Take a look at the following three scenarios for passing on information.
-
Accepted from a source, ignored, and passed on to a third party intact, but with no assurance (see Figure 8-4).

Figure 8-4. Passing on a value received on trust.
Note that agent 2 does not assimilate the knowledge here by making its own version equal to the one it accepted; it merely passes on the value as hearsay.
-
Accepted from a source, ignored, and local knowledge is then passed on to a third party instead. Here agent 1 accepts the information, but instead of passing it on, passes on its own version. The source does not know that agent 2 has not relayed its data with integrity (see Figure 8-5).

Figure 8-5. Passing on a different value than the received value—distorted.
-
Accepted and assimilated by an agent before being passed on to a third party with assurances of integrity (see Figure 8-6).

Figure 8-6. Passing on a different value than the received value—distorted.
Agent 2 now uses the data (value X) from Agent 1, and assimilates it as its own (X=Y). Agent 2 promises to pass on (conditionally upon receiving Y if X). It promises both involved parties to assimilate the knowledge. Only in this case does the knowledge of X become common knowledge if one continues to propagate this chain.
The first two situations are indistinguishable by the receiving agents. In the final case, the promises to make X=Y provide the information that guarantees consistency of knowledge throughout the scope of this pattern.
If we follow the approach promising integrity, we can begin to talk about engineering consensus of information, but not of knowledge. There remains nothing at all we can do to ensure that other agents will engage with information and become experts, other than forming a regular relationship with them to test their knowledge. This is Dunbar’s price for knowledge.
Relativity of Information
Wrapping our heads around behaviours that happen in parallel, at multiple locations, and from different available views, is hard. In science, the analysis of this is called relativity theory, and many of the great minds of philosophy have struggled with versions of it, including Galileo, Einstein, and Kripke. The problem is no easier in information technology, but in the increasingly distributed modern world systems we have to do it all the time.
In database science, the so-called CAP (consistency, availability, and partitions) conjecture was a trigger that unleashed a public discussion about consistency of viewpoint in distributed systems—what Einstein called simultaneity, and what databasers call distributed consistency.
Most stories about simultaneity generally end up with the same answer: that simultaneity is not a helpful concept because multiple agents, players, and actors are doomed and sometimes encouraged to see the world from unique perspectives. Promise Theory helps to remind us that, ultimately, it is the responsibility of each observer of the world to find his own sense of consistency from his own perspective.
Promising Consistency Across Multiple Agents and CAP
Agents are caches for their own knowledge and for information that comes from outside. We’ve discussed how information propagates, but there is the question of who knows, and when.
Because there is value in consistency and expectation—for example, for reputation—many businesses and goods and service providers would like to be able to promise consistency across all of their service points, but it should be clear by now that this does not make sense. To begin with, we have made it a rule that one should not try to make a promise on behalf of any agent other than oneself, so promising for all agents is a stretch. Now let’s see why.
A conjecture, commonly known as the CAP conjecture, was made at the end of the 1990s about how certain trade-offs must be made about a user’s expectations of consistency and availability of information in databases. Although it was only about databases, it applies to any case where information is disseminated to multiple locations, which means always. Understanding the details goes beyond the scope of this book, but we can get an idea of the challenges.
The simple observation was that hoping for a perfect world with global and consistent viewpoints on knowledge was subject to certain limitations, especially if the parts of that world were distributed in a network with potentially unreliable connectivity or cooperation. This much is indisputable. The letters CAP stand for:
-
C: Consistency means freshness and uniformity of data at all locations (no one lags behind updates once they have been made somewhere within the system; there is only one value for each key globally).
-
A: Availability of the data service (we can access data in a reasonable time).
-
P: Partition tolerance, a slightly odd name meaning that if we break up the system into pieces that can’t communicate, it should continue to work “correctly.”
Without getting too technical, let’s try to see if we can define C, A, and P somewhat better, taking into account time and space, and using promises.
To make a Promise Theory model of data availability, we need to include all the agents that play a role in accessing data. Recall the discussion of the client-server model:
-
C: A client who will make a request for data/state and give up waiting for a response after a maximum time interval. This limit is the policy that distinguishes available from unavailable.
-
S: A server that will answer that request at a time of its choosing.
-
N: The network that promises to transport the data in between, at a time and rate of its choosing.
-
O: An observer to whom the answer would be reported by the client (as a final arbiter).
Each of these agents can only make promises about its own behaviour. A server agent can be said to be available to a client agent if the client receives a reply to its request from the server within a finite amount of time.
A Is for Availability
In accordance with Promise Theory, the definition of availability to the client is purely from the observable viewpoint of the client agent, and makes no assumptions about what happens anywhere else. The client takes the promises made by other agents under advisement and makes its own promises to obtain data conditionally on the assumption that they will try to keep their promises.
A definition of availability has to refer to time, as a time-out is the only way to resolve whether a reply has been received or not, without waiting forever. At what point do we stop waiting to know the answer? The client must have some kind of internal clock to make this assessment, else we have no way of measuring availability.
I added an observer as a separate agent to a client aggregator in Figure 8-7 to show the possibility of caching information from the server locally at any client. The observer might perceive cached data as live data and consider it (the cached data) to be available, because it receives a response quickly. Of course, now we have to worry about whether the cache is consistent with the value of the remote data.
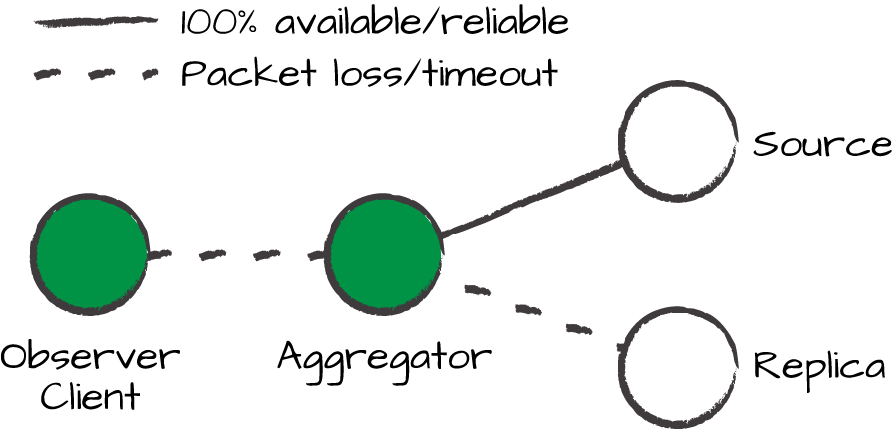
Figure 8-7. Availability of all or part of the data, or agents. Can we get the answers we need from some agent? What goes missing affects what we can say about consistency.
We see easily that availability and consistency need each other in different ways at different places and times — it does not makes sense to talk about the availability of the whole system, but only of the agents individually.
Availability of the server is needed to establish consistency of data at the client, and availability of the client has to be voluntarily curtailed to guarantee that the observer cannot see inconsistent values between the cache and data retrieved from the server (but how would an agent know?). See Figure 8-8.
According to the rules of Promise Theory, we would model the smallest part of the system that can change independently as a separate agent that makes individual promises (see Figure 8-8). Thus, for a database, this tells us that the availability promise applies to each data value represented here by the server independently, not the whole database interface, represented by the client. Promise Theory tells us to lock, or limit, availability to data individually. We just rediscovered database transaction locking.

Figure 8-8. A partition between different sources means they can’t equilibrate, back up, or secure data redundancy. An observer can still reach data, but if some systems suddenly failed, the versions might be out of sync. The user might even be able to see two different versions of the data. How would it choose?
C Is for Consistency
Consistency means that if information is recorded as having some value at some global time T, by any agent in a distributed system, then at any time following this, all agents should see that value (see Figure 8-9).

Figure 8-9. Partition on external availability (can’t get complete access to data), but the part we see can still be self-consistent.
Notice that for keeping this promise, any agent needs to agree about the global time at which changes occur on another agent (i.e., they need to be able to agree about arbitrary points in time, or effectively have a common clock). This adds a difficulty, as global clocks don’t really exist, for the same reason we can’t have consistency of anything else.
If there is a single server, as in the availability discussion above, this seems easy. The server promises to provide the latest value. Then consistency is trivially achieved. But now, suppose that we have several users looking at the same information, but with different transit latencies. Suddenly, information is propagated to different locations at different rates, and the global view is lost. No agent can promise how quickly another can obtain it.
Global time does not help us at all because the finite speed of information transfer leads to inevitable delays. We cannot make promises once data has left an agent. In other words, no one can compare their results at any theoretical same time. At best, they could agree to compare results averaged over a coarse grain of time, or a time interval “bucket.” That time interval would need enough slack for information to equilibrate around the system (i.e., travel from one end of the system to the other and back).
Banks use this approach deliberately when they cease trading at the end of each day and force customers to wait, say, three working days for transaction verification, in spite of modern communications. In some circumstances, one might place this determinism ahead of accuracy of timing, but there is a trade-off here, too. However we choose to define consistency, we have to deal with distortion of the history of data, an artificial slowdown in capture performance, or both.
To regain a global view, we can, of course, wait again until all the parts catch up. This is equilibration. To reach equilibrium, all agents in a system may promise to coordinate and agree on the same data values. In other words, the best promise we can make is: if you wait a number of seconds, I promise the data can be uniform, assuming that all agents honoured their promises to block further changes. In this sense, all consistency has to be eventual in the sense that a delay must be introduced somewhere.
To summarize:
-
Consistency does not happen by itself, because the finite speed of information makes different values current at different times and places.
-
Data values must come to equilibrium by cross-checking the values at different locations.
-
We have to deny access to the entire system until all values are trusted or verified to be the same. This requires users to choose an arbitrary boundary at which we stop caring.
-
What is the entire system? Does it include the end users?
Once again, all of the responsibility of choice lies with the observer or consumer of promises.
P Is for Partition Tolerance
“P” is the vaguest of the properties in the CAP literature. The meaning of a partition is clear enough, but what is partition tolerance? What semantics shall we imbue to the term? Well, it refers to what agents promise to do in the event that they need to rely on information that is located in a different partition (i.e., someone they can’t talk to). An agent may be said to be partition tolerant if it promises to deliver a correct response to a query within a maximum time limit, even if its response depends on information from another agent in a different partition.
Although this sounds very ad hoc, it is theoretically possible to define a correct response for chosen regions of a distributed system, for every conceivable scenario, as a piecewise function, and get agents to keep such promises. However, these are, of course, dependent on the definitions of C and A, and the work required to do this is not useful. Then the only useful thing we can say is that partition tolerance cannot be defined for push-based systems at all because there is no way to know whether equilibration happened.
The World Is My Database, I Shall Not Want
At first glance, everything is a database. The entire world around us is something that we read from and write to—we use and we alter. Even if we restrict attention to IT infrastructure, our networks, PCs, and mobile devices, we are all living users of a massively distributed data system. From the point of view of CAP, this is abstract enough to be true, but how do we draw insight from it?
We need predictable platforms on which to build society. Users of services and information have to know what they can expect. This means we need certain standards of conformity to be able to make use of the services that infrastructure provides. Infrastructure should also be ever present for the same reasons. This is two of the three CAP properties: Consistency, or standards of expectation, and Availability, or ready for use. For the third property, P, we need to talk about all possible system partitions, not just client-server interruptions.
Some partitions are intended, such as access controls, firewalls, user accounts, privacy barriers, government institutions, differentiation of organs in the body, and so on. Some are born of unreliability: faults, outages, crashes, cracks, earthquakes, and so on. How services continue to keep their promises to users, while dealing with each of these, gives us the P for partition tolerance.
Any system can be discussed in terms of the three axes of CAP, as long as we are careful not to think too literally. By working through these ideas and the promises they make, we can design systems that meet our expectations. This brings us to the final topic: how to understand systems.
We need to get used to the idea of many worlds and only local consistency as we head into the future of information systems. As distances become greater and timescales get shorter, the ability to promise consensus between agents loses its meaning, and we’re better off dealing with the inconsistencies rather than trying to make them disappear.
Some Exercises
-
If a chain of supermarkets promised a completely consistent inventory in all their stores, would you trust this promise? Why or why not? If a bank promises that your account balance will be known to all its branches around the world, would you trust this promise? If a restaurant promises that all members of a dinner party will receive the same meal, would you trust this?
-
Imagine arranging books, LPs, CDs, DVDs, and so on, on shelves in your home, so that they will be easy to find. Describe some possible ways of reducing this promise to specific properties of the books and the shelves.
Is it possible to promise that it will be easy to find an item on the shelves? Suppose you group the books into categories. What promise can you associate with the pattern of placement? Consider whether the person searching for an item is a one-time visitor, or has a repeated relationship with the items.
-
A report about the crash of a passenger aircraft presents a narrative about a sequence of events, some of which happen in sequence, and some of which happen in parallel. The narrative discusses the promises made by technology, people, and incidental factors, such as the weather. What promises, or sequence of promises, can such a narrative keep?