
Chapter 10. XML
10.0 Introduction
Extensible Markup Language (XML) is a simple, portable, and flexible way to represent data in a structured format. XML is used in a myriad of ways, from acting as the foundation of web-based messaging protocols such as SOAP to being one of the more popular ways to store configuration data (such as the web.config, machine.config, or security.config files in the .NET Framework). Microsoft recognized the usefulness of XML to developers and has done a nice job of giving you choices concerning the trade-offs involved. Sometimes you want to simply run through an XML document looking for a value in a read-only cursorlike fashion; other times you need to be able to randomly access various pieces of the document; and sometimes, it is handy to be able to query and work with XML declaratively. Microsoft provides classes such as XmlReader and XmlWriter for lighter access and XmlDocument for full Document Object Model (DOM) processing support. To support querying an XML document or constructing XML declaratively, C# provides LINQ to XML (also known as XLINQ) in the form of the XElement and XDocument classes.
It is likely that you will be dealing with XML in .NET to one degree or another. This chapter explores some of the uses for XML and XML-based technologies, such as XPath and XSLT, as well as showing how these technologies are used by and sometimes replaced by LINQ to XML. It also explores topics such as XML validation and transformation of XML to HTML.
10.1 Reading and Accessing XML Data in Document Order
Solution
Create an XmlReader and use its Read method to process the document as shown in Example 10-1.
Example 10-1. Reading an XML document
public static void AccessXml()
{
// New LINQ to XML syntax for constructing XML
XDocument xDoc = new XDocument(
new XDeclaration("1.0", "UTF-8", "yes"),
new XComment("My sample XML"),
new XProcessingInstruction("myProcessingInstruction",
"value"),
new XElement("Root",
new XElement("Node1",
new XAttribute("nodeId", "1"), "FirstNode"),
new XElement("Node2",
new XAttribute("nodeId", "2"), "SecondNode"),
new XElement("Node3",
new XAttribute("nodeId", "1"), "ThirdNode")
)
);
// write out the XML to the console
Console.WriteLine(xDoc.ToString());
// create an XmlReader from the XDocument
XmlReader reader = xDoc.CreateReader();
reader.Settings.CheckCharacters = true;
int level = 0;
while (reader.Read())
{
switch (reader.NodeType)
{
case XmlNodeType.CDATA:
Display(level, $"CDATA: {reader.Value}");
break;
case XmlNodeType.Comment:
Display(level, $"COMMENT: {reader.Value}");
break;
case XmlNodeType.DocumentType:
Display(level, $"DOCTYPE: {reader.Name}={reader.Value}");
break;
case XmlNodeType.Element:
Display(level, $"ELEMENT: {reader.Name}");
level++;
while (reader.MoveToNextAttribute())
{
Display(level, $"ATTRIBUTE: {reader.Name}='{reader.Value}'");
}
break;
case XmlNodeType.EndElement:
level--;
break;
case XmlNodeType.EntityReference:
Display(level, $"ENTITY: {reader.Name}", reader.Name);
break;
case XmlNodeType.ProcessingInstruction:
Display(level, $"INSTRUCTION: {reader.Name}={reader.Value}");
break;
case XmlNodeType.Text:
Display(level, $"TEXT: {reader.Value}");
break;
case XmlNodeType.XmlDeclaration:
Display(level, $"DECLARATION: {reader.Name}={reader.Value}");
break;
}
}
}
private static void Display(int indentLevel, string format, params object[] args)
{
for (int i = 0; i < indentLevel; i++)
Console.Write(" ");
Console.WriteLine(format, args);
}
This code dumps the XML document in a hierarchical format:
<!--My sample XML--> <?myProcessingInstruction value?> <Root> <Node1 nodeId="1">FirstNode</Node1> <Node2 nodeId="2">SecondNode</Node2> <Node3 nodeId="1">ThirdNode</Node3> </Root> COMMENT: My sample XML INSTRUCTION: myProcessingInstruction=value ELEMENT: Root ELEMENT: Node1 ATTRIBUTE: nodeId='1' TEXT: FirstNode ELEMENT: Node2 ATTRIBUTE: nodeId='2' TEXT: SecondNode ELEMENT: Node3 ATTRIBUTE: nodeId='1' TEXT: ThirdNode
Discussion
Reading existing XML and identifying different node types is one of the fundamental actions that you will need to perform when dealing with XML. The code in the Solution creates an XmlReader from a declaratively constructed XML document and then iterates over the nodes while re-creating the formatted XML for output to the console window.
The Solution shows you how to create an XML document by using an XDocument and composing the XML inline using various XML to LINQ classes, such as XElement, XAttribute, XComment, and so on:
XDocument xDoc = new XDocument(
new XDeclaration("1.0", "UTF-8", "yes"),
new XComment("My sample XML"),
new XProcessingInstruction("myProcessingInstruction",
"value"),
new XElement("Root",
new XElement("Node1",
new XAttribute("nodeId", "1"), "FirstNode"),
new XElement("Node2",
new XAttribute("nodeId", "2"), "SecondNode"),
new XElement("Node3",
new XAttribute("nodeId", "1"), "ThirdNode")
)
);
Once the XDocument has been established, you need to configure the settings for the XmlReader on an XmlReaderSettings object instance via the XmlReader.Settings property. These settings tell the XmlReader to check for any illegal characters in the XML fragment:
// create an XmlReader from the XDocument XmlReader reader = xDoc.CreateReader(); reader.Settings.CheckCharacters = true;
The while loop iterates over the XML by reading one node at a time and examining the NodeType property of the reader’s current node to determine what type of XML node it is:
while (reader.Read())
{
switch (reader.NodeType)
{
The NodeType property is an XmlNodeType enumeration value that specifies the types of XML nodes that can be present. The XmlNodeType enumeration values are shown in Table 10-1.
| Name | Description |
|---|---|
Attribute |
An attribute node of an element. |
CDATA |
A marker for sections of text to escape that would usually be treated as markup. |
Comment |
A comment in the XML: <!-- my comment --> |
Document |
The root of the XML document tree. |
DocumentFragment |
A document fragment node. |
DocumentType |
The document type declaration. |
Element |
An element tag: <myelement> |
EndElement |
An end element tag: </myelement> |
EndEntity |
Returned at the end of an entity after ResolveEntity is called. |
Entity |
An entity declaration. |
EntityReference |
A reference to an entity. |
None |
The node returned if Read has not yet been called on the XmlReader. |
Notation |
A notation in the DTD (document type definition). |
ProcessingInstruction |
The processing instruction:
<?pi myProcessingInstruction?> |
SignificantWhitespace |
Whitespace when a mixed-content model is used or when whitespace is being preserved. |
Text |
Text content for a node. |
Whitespace |
The whitespace between markup entries. |
XmlDeclaration |
The first node in the document that cannot have children:
<?xml version='1.0'?> |
See Also
The “XmlReader Class,” “XmlNodeType Enumeration,” and “XDocument Class” topics in the MSDN documentation.
10.2 Querying the Contents of an XML Document
Problem
You have a large and complex XML document, and you need to find various pieces of information, such as all of the contents in a specific element that have a particular attribute setting. You want to query the XML structure without having to iterate through all the nodes in the XML document and search for a particular item by hand.
Solution
Use the new Language Integrated Query (LINQ) to XML API to query the XML document for the items of interest. LINQ allows you to select elements based on element and attribute values, order the results, and return an IEnumerable-based collection of the resulting data, as shown in Example 10-2.
Example 10-2. Querying an XML document with LINQ
private static XDocument GetAClue() => new XDocument(
new XDeclaration("1.0", "UTF-8", "yes"),
new XElement("Clue",
new XElement("Participant",
new XAttribute("type", "Perpetrator"), "Professor Plum"),
new XElement("Participant",
new XAttribute("type", "Witness"), "Colonel Mustard"),
new XElement("Participant",
new XAttribute("type", "Witness"), "Mrs. White"),
new XElement("Participant",
new XAttribute("type", "Witness"), "Mrs. Peacock"),
new XElement("Participant",
new XAttribute("type", "Witness"), "Mr. Green"),
new XElement("Participant",
new XAttribute("type", "Witness"), "Miss Scarlet"),
new XElement("Participant",
new XAttribute("type", "Victim"), "Mr. Boddy")
));
Notice the similarity between the structure of the XML and the structure of the code when we use LINQ to construct this XML fragment in the GetAClue method:
public static void QueryXml()
{
XDocument xDoc = GetAClue();
// set up the query looking for the married female participants
// who were witnesses
var query = from p in xDoc.Root.Elements("Participant")
where p.Attribute("type").Value == "Witness" &&
p.Value.Contains("Mrs.")
orderby p.Value
select p.Value;
// write out the nodes found (Mrs. Peacock and Mrs. White in this instance,
// as it is sorted)
foreach (string s in query)
{
Console.WriteLine(s);
}
}
This outputs the following for the LINQ to XML example:
Mrs. Peacock Mrs. White
To query an XML document without LINQ, you could also use XPath. In .NET, this means using the System.Xml.XPath namespace and classes such as XPathDocument, XPathNavigator, and XPathNodeIterator. LINQ to XML also supports using XPath to identify items in a query through the XElement.XPathSelectElements method.
In the following example, you use these classes to select nodes from an XML document that holds members from the board game Clue (or Cluedo, as it is known outside North America) and their various roles. You want to be able to select the married female participants who were witnesses to the crime. To do this, pass an XPath expression to query the XML data set, as shown in Example 10-3.
Example 10-3. Querying an XML document with XPath
public static void QueryXML()
{
XDocument xDoc = GetAClue();
using (StringReader reader = new StringReader(xDoc.ToString()))
{
// Instantiate an XPathDocument using the StringReader.
XPathDocument xpathDoc = new XPathDocument(reader);
// Get the navigator.
XPathNavigator xpathNav = xpathDoc.CreateNavigator();
// Get up the query looking for the married female participants
// who were witnesses.
string xpathQuery =
"/Clue/Participant[attribute::type='Witness'][contains(text(),'Mrs.')]";
XPathExpression xpathExpr = xpathNav.Compile(xpathQuery);
// Get the nodeset from the compiled expression.
XPathNodeIterator xpathIter = xpathNav.Select(xpathExpr);
// Write out the nodes found (Mrs. White and Mrs.Peacock, in this instance).
while (xpathIter.MoveNext())
{
Console.WriteLine(xpathIter.Current.Value);
}
}
}
This outputs the following for the XPath example:
Mrs. White Mrs. Peacock
Discussion
Query support is a first-class citizen in C# when you are using LINQ. LINQ to XML brings a more intuitive syntax to writing queries for most developers than XPath and thus is a welcome addition to the language. XPath is a valuable tool to have in your arsenal if you are working with systems that deal with XML extensively, but in many cases, you know what you want to ask for; you just don’t know the syntax in XPath. For developers with even minimal SQL experience, querying in C# just got a lot easier:
The XML being worked on in this recipe looks like this:
<?xml version='1.0'?> <Clue> <Participant type="Perpetrator">Professor Plum</Participant> <Participant type="Witness">Colonel Mustard</Participant> <Participant type="Witness">Mrs. White</Participant> <Participant type="Witness">Mrs. Peacock</Participant> <Participant type="Witness">Mr. Green</Participant> <Participant type="Witness">Miss Scarlet</Participant> <Participant type="Victim">Mr. Boddy</Participant> </Clue>
This query says, “Select all of the Participant elements where the Participant is a witness and her title is Mrs.”:
// set up the query looking for the married female participants
// who were witnesses
var query = from p in xDoc.Root.Elements("Participant")
where p.Attribute("type").Value == "Witness" &&
p.Value.Contains("Mrs.")
orderby p.Value
select p.Value;
Contrast this with the same query syntax in XPath:
// set up the query looking for the married female participants // who were witnesses string xpathQuery = "/Clue/Participant[attribute::type='Witness'][contains(text(),'Mrs.')]";
Both ways of performing the query have merit, but the issue to consider is how easily the next developer will be able to understand what you have written. It is very easy to break code that is not well understood.
Note
Generally, more developers understand SQL than XPath, even with all of the web service work today. This may differ from your experience, especially if you do a lot of cross-platform work, but the point is to think of LINQ as not just another syntax, but as a way to make your code more readable by a broader audience of developers. Code is rarely owned by one person, even in the short term, so why not make it easy for those who come after you? After all, you may be on the other side of that coin someday. Let’s break down the two queries a bit more.
The LINQ query uses some of the keywords in C#:
-
varindicates to the compiler to expect an inferred type based on the result set. -
from, which is known as the generator, provides a data source for the query to operate on as well as a range variable to allow access to the individual element. -
whereallows for a Boolean condition to be applied to each element of the data source to determine if it should be included in the result set. -
orderbydetermines the sort order of the result set based on the number of elements and indicators ofascendingordescendingper element. Multiple criteria can be specified for multiple levels of sorting. -
selectindicates the sequence of values that will be returned after all evaluation of conditions. This is also referred to as projection of the values.
This means that our syntax can be boiled down as follows:
-
from p in xDoc.Root.Elements("Participant")says, “Get all of theParticipants under the root-level nodeClue.” -
where p.Attribute("type").Value == "Witness"says, “Select onlyParticipants with an attribute calledtypewith a value ofWitness.” -
&& p.Value.Contains("Mrs.")says, “Select onlyParticipants with a value that containsMrs.”. -
orderby (string) p.Valuesays, “Order theparticipants by name in ascending order.” -
select (string) p.Valuesays, “Select the value of theParticipantelements where all of the previous criteria have been met.”
The XPath syntax performs the same function:
-
/Clue/Participantsays, “Get all of theParticipants under the root-level nodeClue.” -
Participant[attribute::type='Witness']says, “Select onlyParticipants with an attribute calledtypewith a value ofWitness.” -
Participant[contains(text(),'Mrs.')]says, “Select onlyParticipants with a value that containsMrs.”.
Put them all together, and you get all of the married female participants who were witnesses in both cases, with the additional twist for LINQ that it sorted the results.
See Also
The “Query Expressions,” “XElement Class,” and “XPath, reading XML” topics in the MSDN documentation.
10.3 Validating XML
Solution
Use the XDocument.Validate method and XmlReader.Settings property to validate XML documents against any descriptor document, such as an XSD, a DTD, or an XDR, as shown in Example 10-4. Validating the XML that you generate from your software as part of your testing will save you from bugs later when you’re integrating with other systems (or components of your systems) and is highly encouraged!
Example 10-4. Validating XML
public static void ValidateXml()
{
// open the bookbad.xml file
XDocument book = XDocument.Load(@"....BookBad.xml");
// create XSD schema collection with book.xsd
XmlSchemaSet schemas = new XmlSchemaSet();
schemas.Add(null,@"....Book.xsd");
// wire up handler to get any validation errors
book.Validate(schemas, settings_ValidationEventHandler);
// create a reader to roll over the file so validation fires
XmlReader reader = book.CreateReader();
// report warnings as well as errors
reader.Settings.ValidationFlags =
XmlSchemaValidationFlags.ReportValidationWarnings;
// use XML Schema
reader.Settings.ValidationType = ValidationType.Schema;
// roll over the XML
while (reader.Read())
{
if (reader.NodeType == XmlNodeType.Element)
{
Console.Write($"<{reader.Name}");
while (reader.MoveToNextAttribute())
{
Console.Write($"{reader.Name}='{reader.Value}'");
}
Console.Write(">");
}
else if (reader.NodeType == XmlNodeType.Text)
{
Console.Write(reader.Value);
}
else if (reader.NodeType == XmlNodeType.EndElement)
{
Console.WriteLine($"</{reader.Name}>");
}
}
}
private static void settings_ValidationEventHandler(object sender,
ValidationEventArgs e)
{
Console.WriteLine($"Validation Error Message: {e.Message}");
Console.WriteLine($"Validation Error Severity: {e.Severity}");
Console.WriteLine($"Validation Error Line Number: {e.Exception?.LineNumber}");
Console.WriteLine(
$"Validation Error Line Position: {e.Exception?.LinePosition}");
Console.WriteLine($"Validation Error Source: {e.Exception?.Source}");
Console.WriteLine($"Validation Error Source Schema: " +
$"{{e.Exception?.SourceSchemaObject}");
Console.WriteLine($"Validation Error Source Uri: {e.Exception?.SourceUri}");
Console.WriteLine($"Validation Error thrown from: {e.Exception?.TargetSite}");
Console.WriteLine($"Validation Error callstack: {e.Exception?.StackTrace}");
}
Discussion
The Solution illustrates how to use the XDocument and XmlReader to validate the book.xml document against a book.xsd XSD definition file. DTDs were the original way to specify the structure of an XML document, but it has become more common to use XSD since it reached W3C Recommendation status in May 2001. XDR was a predecessor of XSD provided by Microsoft, and, while you might encounter it in existing systems, it should not be used for new development.
The first thing to do is create an XmlSchemaSet to hold your XSD file (book.xsd) and call the Add method to add the XSD to the XmlSchemaSet. Call the Validate method on the XDocument with the XmlSchemaSet and the handler method for validation events. Now that the validation is mostly set up, we can set a few more items on the XmlReader created from the XDocument. The ValidationFlags property on the XmlReaderSettings allows for signing up for warnings in validation, processing identity constraints during validation, and processing inline schemas, and allows for attributes that may not be defined in the schema:
// create XSD schema collection with book.xsd
XmlSchemaSet schemas = new XmlSchemaSet();
schemas.Add(null,@"....Book.xsd");
// wire up handler to get any validation errors
book.Validate(schemas, settings_ValidationEventHandler);
// create a reader to roll over the file so validation fires
XmlReader reader = book.CreateReader();
// report warnings as well as errors
reader.Settings.ValidationFlags =
XmlSchemaValidationFlags.ReportValidationWarnings;
// use XML Schema
reader.Settings.ValidationType = ValidationType.Schema;
Note
To perform DTD validation, use a DTD and ValidationType.DTD, and to perform XDR validation, use an XDR schema and ValidationType.XDR.
The settings_ValidationEventHandler function then examines the ValidationEventArgs object passed when a validation error occurs and writes the pertinent information to the console:
private static void settings_ValidationEventHandler(object sender,
ValidationEventArgs e)
{
Console.WriteLine($"Validation Error Message: {e.Message}");
Console.WriteLine($"Validation Error Severity: {e.Severity}");
Console.WriteLine(
$"Validation Error Line Number: {e.Exception?.LineNumber}");
Console.WriteLine(
$"Validation Error Line Position: {e.Exception?.LinePosition}");
Console.WriteLine($"Validation Error Source: {e.Exception?.Source}");
Console.WriteLine($"Validation Error Source Schema: " +
$"{{e.Exception?.SourceSchemaObject}");
Console.WriteLine($"Validation Error Source Uri: {e.Exception?.SourceUri}");
Console.WriteLine(
$"Validation Error thrown from: {e.Exception?.TargetSite}");
Console.WriteLine($"Validation Error callstack: {e.Exception?.StackTrace}");
}
You then proceed to roll over the XML document and write out the elements and attributes:
while (readerOld.Read())
{
if (readerOld.NodeType == XmlNodeType.Element)
{
Console.Write($"<{readerOld.Name}");
while (reader.MoveToNextAttribute())
{
Console.Write($"{readerOld.Name}='{readerOld.Value}'");
}
Console.Write(">");
}
else if (readerOld.NodeType == XmlNodeType.Text)
{
Console.Write(reader.Value);
}
else if (readerOld.NodeType == XmlNodeType.EndElement)
{
Console.WriteLine($"</{readerOld.Name}>");
}
}
The BookBad.xml file contains the following:
<?xml version="1.0" encoding="utf-8"?>
<Book xmlns="http://tempuri.org/Book.xsd" name="C# Cookbook">
<Chapter>File System IO</Chapter>
<Chapter>Security</Chapter>
<Chapter>Data Structures and Algorithms</Chapter>
<Chapter>Reflection</Chapter>
<Chapter>Threading and Synchronization</Chapter>
<Chapter>Numbers and Enumerations</Chapter>
<BadElement>I don't belong here</BadElement>
<Chapter>Strings and Characters</Chapter>
<Chapter>Classes And Structures</Chapter>
<Chapter>Collections</Chapter>
<Chapter>XML</Chapter>
<Chapter>Delegates, Events, and Anonymous Methods</Chapter>
<Chapter>Diagnostics</Chapter>
<Chapter>Toolbox</Chapter>
<Chapter>Unsafe Code</Chapter>
<Chapter>Regular Expressions</Chapter>
<Chapter>Generics</Chapter>
<Chapter>Iterators and Partial Types</Chapter>
<Chapter>Exception Handling</Chapter>
<Chapter>Web</Chapter>
<Chapter>Networking</Chapter>
</Book>
The book.xsd file contains the following:
<?xml version="1.0" ?>
<xs:schema id="NewDataSet" targetNamespace="http://tempuri.org/Book.xsd"
xmlns:mstns="http://tempuri.org/Book.xsd"
xmlns="http://tempuri.org/Book.xsd"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"
attributeFormDefault="qualified" elementFormDefault="qualified">
<xs:element name="Book">
<xs:complexType>
<xs:sequence>
<xs:element name="Chapter" nillable="true"
minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:simpleContent
msdata:ColumnName="Chapter_Text" msdata:Ordinal="0">
<xs:extension base="xs:string">
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="name" form="unqualified" type="xs:string"/>
</xs:complexType>
</xs:element>
</xs:schema>
When this is run, the following output is generated, showing the validation failure occurring on BadElement:
Validation Error Message: The element 'Book' in namespace 'http://tempuri.org/Bo ok.xsd' has invalid child element 'BadElement' in namespace 'http://tempuri.org/ Book.xsd'. List of possible elements expected: 'Chapter' in namespace 'http://te mpuri.org/Book.xsd'. Validation Error Severity: Error Validation Error Line Number: 0 Validation Error Line Position: 0 Validation Error Source: Validation Error Source Schema: Validation Error Source Uri: Validation Error thrown from: Validation Error callstack: <Book xmlns='http://tempuri.org/Book.xsd' name='C# Cookbook'><Chapter>File Syste m IO</Chapter> <Chapter>Security</Chapter> <Chapter>Data Structures and Algorithms</Chapter> <Chapter>Reflection</Chapter> <Chapter>Threading and Synchronization</Chapter> <Chapter>Numbers and Enumerations</Chapter> <BadElement>I don't belong here</BadElement> <Chapter>Strings and Characters</Chapter> <Chapter>Classes And Structures</Chapter> <Chapter>Collections</Chapter> <Chapter>XML</Chapter> <Chapter>Delegates, Events, and Anonymous Methods</Chapter> <Chapter>Diagnostics</Chapter> <Chapter>Toolbox</Chapter> <Chapter>Unsafe Code</Chapter> <Chapter>Regular Expressions</Chapter> <Chapter>Generics</Chapter> <Chapter>Iterators and Partial Types</Chapter> <Chapter>Exception Handling</Chapter> <Chapter>Web</Chapter> <Chapter>Networking</Chapter> </Book>
See Also
The “XmlReader Class,” “XmlSchemaSet Class,” “ValidationEventHandler Class,” “ValidationType Enumeration,” and “XDocument Class” topics in the MSDN documentation.
10.4 Detecting Changes to an XML Document
Solution
To track changes to an active XML document, subscribe to the events published by the XDocument class. XDocument publishes events for when a node is changing and when it has changed for both the pre- and post-conditions of a node change.
Example 10-5 shows a number of event handlers defined in the same scope as the DetectXMLChanges method, but they could just as easily be callbacks to functions on other classes that are interested in the manipulation of the live XML document.
DetectXMLChanges loads an XML fragment you define in the method; wires up the event handlers for the node events; adds, changes, and removes some nodes to trigger the events; and then writes out the resulting XML.
Example 10-5. Detecting changes to an XML document
public static void DetectXmlChanges()
{
XDocument xDoc = new XDocument(
new XDeclaration("1.0", "UTF-8", "yes"),
new XComment("My sample XML"),
new XProcessingInstruction("myProcessingInstruction",
"value"),
new XElement("Root",
new XElement("Node1",
new XAttribute("nodeId", "1"), "FirstNode"),
new XElement("Node2",
new XAttribute("nodeId", "2"), "SecondNode"),
new XElement("Node3",
new XAttribute("nodeId", "1"), "ThirdNode"),
new XElement("Node4",
new XCData(@"<>&'"))
)
);
//Create the event handlers.
xDoc.Changing += xDoc_Changing;
xDoc.Changed += xDoc_Changed;
// Add a new element node.
XElement element = new XElement("Node5", "Fifth Element");
xDoc.Root.Add(element);
// Change the first node
//doc.DocumentElement.FirstChild.InnerText = "1st Node";
if(xDoc.Root.FirstNode.NodeType == XmlNodeType.Element)
((XElement)xDoc.Root.FirstNode).Value = "1st Node";
// remove the fourth node
var query = from e in xDoc.Descendants()
where e.Name.LocalName == "Node4"
select e;
XElement[] elements = query.ToArray<XElement>();
foreach (XElement xelem in elements)
{
xelem.Remove();
}
// write out the new xml
Console.WriteLine();
Console.WriteLine(xDoc.ToString());
Console.WriteLine();
}
Example 10-6 shows the event handlers from the XDocument, along with one formatting method, WriteElementInfo. This method takes an action string and gets the name and value of the object being manipulated. Both of the event handlers invoke this formatting method, passing the corresponding action string.
Example 10-6. XDocument event handlers and WriteElementInfo method
private static void xDoc_Changed(object sender, XObjectChangeEventArgs e)
{
//Add - An XObject has been or will be added to an XContainer.
//Name - An XObject has been or will be renamed.
//Remove - An XObject has been or will be removed from an XContainer.
//Value - The value of an XObject has been or will be changed. In addition, a
//change in the serialization of an empty element (either from an empty tag to
//start/end tag pair or vice versa) raises this event.
WriteElementInfo("changed", e.ObjectChange, (XObject)sender);
}
private static void xDoc_Changing(object sender, XObjectChangeEventArgs e)
{
//Add - An XObject has been or will be added to an XContainer.
//Name - An XObject has been or will be renamed.
//Remove - An XObject has been or will be removed from an XContainer.
//Value - The value of an XObject has been or will be changed. In addition, a
//change in the serialization of an empty element (either from an empty tag to
//start/end tag pair or vice versa) raises this event.
WriteElementInfo("changing", e.ObjectChange, (XObject)sender);
}
private static void WriteElementInfo(string action, XObjectChange change,
XObject xobj)
{
if (xobj != null)
Console.WriteLine($"XObject: <{xobj.NodeType.ToString()}> "+
$"{action} {change} with value {xobj}");
else
Console.WriteLine("XObject: <{xobj.NodeType.ToString()}> " +
$"{action} {change} with null value");
}
The DetectXmlChanges method results in the following output:
XObject: <Element> changing Add with value <Node5>Fifth Element</Node5> XObject: <Element> changed Add with value <Node5>Fifth Element</Node5> XObject: <Text> changing Remove with value FirstNode XObject: <Text> changed Remove with value FirstNode XObject: <Text> changing Add with value 1st Node XObject: <Text> changed Add with value 1st Node XObject: <Element> changing Remove with value <Node4><![CDATA[<>&']]></Node4> XObject: <Element> changed Remove with value <Node4><![CDATA[<>&']]></Node4> <!--My sample XML--> <?myProcessingInstruction value?> <Root> <Node1 nodeId="1">1st Node</Node1> <Node2 nodeId="2">SecondNode</Node2> <Node3 nodeId="1">ThirdNode</Node3> <Node5>Fifth Element</Node5> </Root>
Discussion
The XDocument class is derived from the XElement class. XDocument can also contain a DTD (XDocumentType), a root element (XDocument.Root), comments (XComment), and processing instructions (XProcessingInstruction). Typically, you would use XElement for constructing most types of XML documents, but if you need to specify any of the preceding items, use XDocument.
See Also
The “XDocument Class” and “XObjectChangeEventHandler delegate” topics in the MSDN documentation.
10.5 Handling Invalid Characters in an XML String
Problem
You are creating an XML string. Before adding a tag containing a text element, you want to check it to determine whether the string contains any of the following invalid characters:
< > " ' &
If any of these characters are encountered, you want them to be replaced with their escaped form:
< (<)
> (>)
" (")
' (')
& (&)
Solution
There are different ways to accomplish this, depending on which XML-creation approach you are using. If you are using XElement, either using the XCData object or just adding the text directly as the value of the XElement will take care of the proper escaping. If you are using XmlWriter, the WriteCData, WriteString, WriteAttributeString, WriteValue, and WriteElementString methods take care of this for you. If you are using XmlDocument and XmlElements, the XmlElement.InnerText method will handle these characters.
In the first way to handle invalid characters using XElement, the XCData object will wrap the invalid character text in a CDATA section, as shown in the creation of the InvalidChars1 element in the example that follows. The second way using XElement is to assign the text as the value of the XElement, and that will automatically escape the text for you, as shown in the creation of the InvalidChars2 element:
// set up a string with our invalid chars
string invalidChars = @"<>&'";
XElement element = new XElement("Root",
new XElement("InvalidChars1",
new XCData(invalidChars)),
new XElement("InvalidChars2",invalidChars));
Console.WriteLine($"Generated XElement with Invalid Chars:
{element}");
Console.WriteLine();
The output from this is:
Generated XElement with Invalid Chars: <Root> <InvalidChars1><![CDATA[<>&']]></InvalidChars1> <InvalidChars2><>&'</InvalidChars2> </Root>
In the first way to handle invalid characters using XmlWriter, the WriteCData method will wrap the invalid character text in a CDATA section, as shown in the creation of the InvalidChars1 element in the example that follows. The second way using XmlWriter is to use the WriteElementString method to automatically escape the text for you, as shown in the creation of the InvalidChars2 element:
// Set up a string with our invalid chars.
string invalidChars = @"<>&'";
XmlWriterSettings settings = new XmlWriterSettings();
settings.Indent = true;
using (XmlWriter writer = XmlWriter.Create(Console.Out, settings))
{
writer.WriteStartElement("Root");
writer.WriteStartElement("InvalidChars1");
writer.WriteCData(invalidChars);
writer.WriteEndElement();
writer.WriteElementString("InvalidChars2", invalidChars);
writer.WriteEndElement();
}
The output from this is:
<?xml version="1.0" encoding="IBM437"?> <Root> <InvalidChars1><![CDATA[<>&']]></InvalidChars1> <InvalidChars2><>&'</InvalidChars2> </Root>
There are two ways you can handle this problem with XmlDocument and XmlElement. The first way is to surround the text you are adding to the XML element with a CDATA section and add it to the InnerXML property of the XmlElement:
// Set up a string with our invalid chars.
string invalidChars = @"<>&'";
// create the first invalid character node
XmlElement invalidElement1 = xmlDoc.CreateElement("InvalidChars1");
// wrap the invalid chars in a CDATA section and use the
// InnerXML property to assign the value, as it doesn't
// escape the values, just passes in the text provided
invalidElement1.AppendChild(xmlDoc.CreateCDataSection(invalidChars));
The second way is to let the XmlElement class escape the data for you, by assigning the text directly to the InnerText property like this:
// Set up a string with our invalid chars.
string invalidChars = @"<>&'";
// create the second invalid character node
XmlElement invalidElement2 = xmlDoc.CreateElement("InvalidChars2");
// Add the invalid chars directly using the InnerText
// property to assign the value as it will automatically
// escape the values
invalidElement2.InnerText = invalidChars;
// append the element to the root node
root.AppendChild(invalidElement2);
The whole XmlDocument is created with these XmlElements in this code:
public static void HandleInvalidChars()
{
// set up a string with our invalid chars
string invalidChars = @"<>&'";
XElement element = new XElement("Root",
new XElement("InvalidChars1",
new XCData(invalidChars)),
new XElement("InvalidChars2",invalidChars));
Console.WriteLine($"Generated XElement with Invalid Chars:
{element}");
Console.WriteLine();
XmlWriterSettings settings = new XmlWriterSettings();
settings.Indent = true;
using (XmlWriter writer = XmlWriter.Create(Console.Out, settings))
{
writer.WriteStartElement("Root");
writer.WriteStartElement("InvalidChars1");
writer.WriteCData(invalidChars);
writer.WriteEndElement();
writer.WriteElementString("InvalidChars2", invalidChars);
writer.WriteEndElement();
}
Console.WriteLine();
XmlDocument xmlDoc = new XmlDocument();
// create a root node for the document
XmlElement root = xmlDoc.CreateElement("Root");
xmlDoc.AppendChild(root);
// create the first invalid character node
XmlElement invalidElement1 = xmlDoc.CreateElement("InvalidChars1");
// wrap the invalid chars in a CDATA section and use the
// InnerXML property to assign the value as it doesn't
// escape the values, just passes in the text provided
invalidElement1.AppendChild(xmlDoc.CreateCDataSection(invalidChars));
// append the element to the root node
root.AppendChild(invalidElement1);
// create the second invalid character node
XmlElement invalidElement2 = xmlDoc.CreateElement("InvalidChars2");
// Add the invalid chars directly using the InnerText
// property to assign the value as it will automatically
// escape the values
invalidElement2.InnerText = invalidChars;
// append the element to the root node
root.AppendChild(invalidElement2);
Console.WriteLine($"Generated XML with Invalid Chars:
{xmlDoc.OuterXml}");
Console.WriteLine();
}
The XML created by this procedure (and output to the console) looks like this:
Generated XML with Invalid Chars: <Root><InvalidChars1><![CDATA[<>&']]></InvalidChars1><InvalidChars2><>&a mp;'</InvalidChars2></Root>
Discussion
The CDATA node allows you to represent the items in the text section as character data, not as escaped XML, for ease of entry. Normally, these characters would need to be in their escaped format (e.g., < for <), but the CDATA section allows you to enter them as regular text.
When you use the CDATA tag in conjunction with the InnerXml property of the XmlElement class, you can submit characters that would normally need to be escaped first. The XmlElement class also has an InnerText property that will automatically escape any markup found in the string assigned. This allows you to add these characters without having to worry about them.
See Also
The “XElement Class,” “XCData Class,” “XmlDocument Class,” “XmlWriter Class,” “XmlElement Class,” and “CDATA Sections” topics in the MSDN documentation.
10.6 Transforming XML
Problem
You have a raw XML document that you need to convert into a more readable format. For example, you have personnel data that is stored as an XML document, and you need to display it on a web page or place it in a comma-delimited text file for legacy system integration. Unfortunately, not everyone wants to sort through reams of XML all day; they would rather read the data as a formatted list or within a grid with defined columns and rows. You need a method of transforming the XML data into a more readable form as well as into the comma-delimited format.
Solution
The solution for this problem is to use LINQ to XML to perform a transformation in C#. In the example code, you transform some personnel data from a fictitious business stored in Personnel.xml. The data is first transformed into HTML, and then into comma-delimited format:
// LINQ way
XElement personnelData = XElement.Load(@"....Personnel.xml");
// Create HTML
XElement personnelHtml =
new XElement("html",
new XElement("head"),
new XElement("body",
new XAttribute("title","Personnel"),
new XElement("p",
new XElement("table",
new XAttribute("border","1"),
new XElement("thead",
new XElement("tr",
new XElement("td","Employee Name"),
new XElement("td","Employee Title"),
new XElement("td","Years with Company"),
new XElement("td","Also Known As")
)
),
new XElement("tbody",
from p in personnelData.Elements("Employee")
select new XElement("tr",
new XElement("td", p.Attribute("name").Value),
new XElement("td", p.Attribute("title").Value),
new XElement("td",
p.Attribute("companyYears").Value),
new XElement("td", p.Attribute("nickname").Value)
)
)
)
)
)
);
personnelHtml.Save(@"....Personnel_LINQ.html");
var queryCSV = from p in personnelData.Elements("Employee")
orderby p.Attribute("name").Value descending
select p;
StringBuilder sb = new StringBuilder();
foreach(XElement e in queryCSV)
{
sb.AppendFormat($"{EscapeAttributeForCSV(e, "name")}," +
$"{EscapeAttributeForCSV(e, "title")}," +
$"{EscapeAttributeForCSV(e, "companyYears")}," +
$"{EscapeAttributeForCSV(e, "nickname")}" +
$"{Environment.NewLine}");
}
using(StreamWriter writer = File.CreateText(@"....Personnel_LINQ.csv"))
{
writer.Write(sb.ToString());
}
The output from the LINQ transformation to CSV is shown here:
Rutherford,CEO,27,""BigTime"" Chas,Salesman,3,""Money"" Bob,Customer Service,1,""Happy"" Alice,Manager,12,""Business""
The Personnel.xml file contains the following items:
<?xml version="1.0" encoding="utf-8"?>
<Personnel xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<Employee name="Bob" title="Customer Service" companyYears="1"
nickname=""Happy""/>
<Employee name="Alice" title="Manager" companyYears="12"
nickname=""Business""/>
<Employee name="Chas" title="Salesman" companyYears="3"
nickname=""Money""/>
<Employee name="Rutherford" title="CEO" companyYears="27"
nickname=""BigTime""/>
</Personnel>
You might be wondering why the nickname attribute values have extra double quotes in the CSV output. This is to support RFC 4180, “Common Format and MIME Type for CSV Files,” which says, “If double-quotes are used to enclose fields, then a double-quote appearing inside a field must be escaped by preceding it with another double quote.” We do this with the EscapeAttributeForCSV method:
private static string EscapeAttributeForCSV(XElement element,
string attributeName)
{
string attributeValue = element.Attribute(attributeName).Value;
//RFC-4180, paragraph "If double-quotes are used to enclose fields, then a
//double-quote appearing inside a field must be escaped by preceding it with
//another double quote."
return attributeValue.Replace(""", """");
}
This approach is discussed more in Recipe 10.8.
We can also accomplish this solution using an XSLT stylesheet to transform the XML into another format using the XslCompiledTransform class. First, load the stylesheet for generating HTML output and then perform the transformation to HTML via XSLT using the PersonnelHTML.xsl stylesheet. After that, transform the data to comma-delimited format using the PersonnelCSV.xsl stylesheet:
// Create a resolver with default credentials. XmlUrlResolver resolver = new XmlUrlResolver(); resolver.Credentials = System.Net.CredentialCache.DefaultCredentials; // transform the personnel.xml file to html XslCompiledTransform transform = new XslCompiledTransform(); XsltSettings settings = new XsltSettings(); // disable both of these (the default) for security reasons settings.EnableDocumentFunction = false; settings.EnableScript = false; // load up the stylesheet transform.Load(@"....PersonnelHTML.xsl",settings,resolver); // perform the transformation transform.Transform(@"....Personnel.xml",@"....Personnel.html");
The PersonnelHTML.xsl stylesheet looks like this:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xsl:template match="/">
<html>
<head />
<body title="Personnel">
<xsl:for-each select="Personnel">
<p>
<xsl:for-each select="Employee">
<xsl:if test="position()=1">
<table border="1">
<thead>
<tr>
<td>Employee Name</td>
<td>Employee Title</td>
<td>Years with Company</td>
<td>Also Known As</td>
</tr>
</thead>
<tbody>
<xsl:for-each select="../Employee">
<tr>
<td>
<xsl:for-each select="@name">
<xsl:value-of select="." />
</xsl:for-each>
</td>
<td>
<xsl:for-each select="@title">
<xsl:value-of select="." />
</xsl:for-each>
</td>
<td>
<xsl:for-each select="@companyYears">
<xsl:value-of select="." />
</xsl:for-each>
</td>
<td>
<xsl:for-each select="@nickname">
<xsl:value-of select="." />
</xsl:for-each>
</td>
</tr>
</xsl:for-each>
</tbody>
</table>
</xsl:if>
</xsl:for-each>
</p>
</xsl:for-each>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
To generate the HTML screen in Figure 10-1, use the PersonnelHTML.xsl stylesheet and the Personnel.xml file.
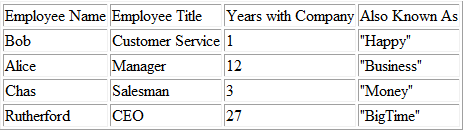
Figure 10-1. Personnel HTML table generated from Personnel.xml
Here is the HTML source for the LINQ transformation:
<?xml version="1.0" encoding="utf-8"?>
<html>
<head />
<body title="Personnel">
<p>
<table border="1">
<thead>
<tr>
<td>Employee Name</td>
<td>Employee Title</td>
<td>Years with Company</td>
<td>Also Known As</td>
</tr>
</thead>
<tbody>
<tr>
<td>Bob</td>
<td>Customer Service</td>
<td>1</td>
<td>"Happy"</td>
</tr>
<tr>
<td>Alice</td>
<td>Manager</td>
<td>12</td>
<td>"Business"</td>
</tr>
<tr>
<td>Chas</td>
<td>Salesman</td>
<td>3</td>
<td>"Money"</td>
</tr>
<tr>
<td>Rutherford</td>
<td>CEO</td>
<td>27</td>
<td>"BigTime"</td>
</tr>
</tbody>
</table>
</p>
</body>
</html>
Here is the HTML source for the XSLT transformation:
<?xml version="1.0" encoding="utf-8"?>
<html>
<head />
<body title="Personnel">
<table border="1">
<thead>
<tr>
<td>Employee Name</td>
<td>Employee Title</td>
<td>Years with Company</td>
</tr>
</thead>
<tbody>
<tr>
<td name="Bob" />
<td title="Customer Service" />
<td name="Bob" />
</tr>
<tr>
<td name="Alice" />
<td title="Manager" />
<td name="Alice" />
</tr>
<tr>
<td name="Chas" />
<td title="Salesman" />
<td name="Chas" />
</tr>
<tr>
<td name="Rutherford" />
<td title="CEO" />
<td name="Rutherford" />
</tr>
</tbody>
</table>
</body>
</html>
To generate comma-delimited output, use PersonnelCSV.xsl and Personnel.xml:
// transform the personnel.xml file to comma-delimited format
// load up the stylesheet
XslCompiledTransform transformCSV = new XslCompiledTransform();
XsltSettings settingsCSV = new XsltSettings();
// disable both of these (the default) for security reasons
settingsCSV.EnableDocumentFunction = false;
settingsCSV.EnableScript = false;
transformCSV.Load(@"....PersonnelCSV.xsl", settingsCSV, resolver);
// perform the transformation
XsltArgumentList xslArg = new XsltArgumentList();
CsvExtensionObject xslExt = new CsvExtensionObject();
xslArg.AddExtensionObject("urn:xslext", xslExt);
XPathDocument xPathDoc = new XPathDocument(@"....Personnel.xml");
XmlWriterSettings xmlWriterSettings = new XmlWriterSettings();
xmlWriterSettings.ConformanceLevel = ConformanceLevel.Fragment;
using (XmlWriter writer = XmlWriter.Create(@"....Personnel.csv",
xmlWriterSettings))
{
transformCSV.Transform(xPathDoc, xslArg, writer);
}
The PersonnelCSV.xsl stylesheet is shown here:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:xslext="urn:xslext">
<xsl:output method="text" encoding="UTF-8"/>
<xsl:template match="/">
<xsl:for-each select="Personnel">
<xsl:for-each select="Employee">
<xsl:for-each select="@name">
<xsl:value-of
select="xslext:EscapeAttributeForCSV(string(.))" />
</xsl:for-each>,<xsl:for-each select="@title">
<xsl:value-of
select="xslext:EscapeAttributeForCSV(string(.))" />
</xsl:for-each>,<xsl:for-each select="@companyYears">
<xsl:value-of
select="xslext:EscapeAttributeForCSV(string(.))" />
</xsl:for-each>,<xsl:for-each select="@nickname">
<xsl:value-of
select="xslext:EscapeAttributeForCSV(string(.))" />
</xsl:for-each>
<xsl:text> 
</xsl:text>
</xsl:for-each>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
The output from the PersonnelCSV.xsl stylesheet is shown here:
Bob,Customer Service,1,""Happy"" Alice,Manager,12,""Business"" Chas,Salesman,3,""Money"" Rutherford,CEO,27,""BigTime""
Once again we do some work to support RFC 4180, “Common Format and MIME Type for CSV Files,” with the EscapeAttributeForCSV method on the CsvExtensionObject that we passed as an Extension object to the transform, which is discussed in more detail in Recipe 10.8:
public class CsvExtensionObject
{
public string EscapeAttributeForCSV(string attributeValue) =>
attributeValue.Replace(""", """");
}
Discussion
XSLT is a very powerful way to transform XML from one format to another. That being said, the capacity that LINQ brings in C# to perform XML transformations without having to shell out to another parser or process is very compelling. This means that to perform XML transformations in your applications, you no longer have to understand XSLT syntax or maintain application code in both C# and XSLT. This also means that when reviewing code from other team members, you no longer have to go into separate files to understand what the transformation is doing; it’s all C# and all right there.
XSLT is by no means dead or inappropriate as a method for transforming XML; it is simply no longer the only realistic alternative for C# developers. XSLT can still be used with all of the existing XML API in .NET and will continue to be feasible for years to come. Our challenge to you is to try implementing a transformation in LINQ that you currently have in XSLT and see for yourself the possibilities with LINQ.
When you are performing transformations using XSLT, there are many overrides for the XslCompiledTransform.Transform method. Since XmlResolver is an abstract class, you need to use either the XmlUrlResolver or the XmlSecureResolver or pass null as the XmlResolver-typed argument. The XmlUrlResolver will resolve URLs to external resources, such as schema files, using the FILE, HTTP, and HTTPS protocols. The XmlSecureResolver restricts the resources that you can access by requiring you to pass in evidence, which helps prevent cross-domain redirection in XML.
Note
If you are accepting XML from the Internet, it could easily redirect to a site where malicious XML is waiting to be downloaded and executed if you are not using the XmlSecureResolver. If you pass null for the XmlResolver, you are saying you do not want to resolve any external resources. Microsoft has declared the null option to be obsolete, and it shouldn’t be used anyway because you should always use some type of XmlResolver.
XSLT is a very powerful technology that allows you to transform XML into just about any format you can think of, but it can be frustrating at times. The simple need of a carriage return/line feed combination in the XSLT output was such a trial that we were able to find more than 20 different message board requests for help on how to do this! After looking at the W3C spec for XSLT, we found you could do this combination using the xsl:text element like this:
<xsl:text> 
</xsl:text>
The 
 stands for a hexadecimal 13, or a carriage return, and the 
 stands for a hexadecimal 10, or a line feed. This is output at the end of each employee’s data from the XML.
See Also
The “XslCompiledTransform Class,” “XmlResolver Class,” “XmlUrlResolver Class,” “XmlSecureResolver Class,” and “xsl:text” topics in the MSDN documentation.
10.7 Validating Modified XML Documents Without Reloading
Solution
Use the XDocument.Validate method to perform the validation and apply schema defaults and type information.
Create an XmlSchemaSet with the XML Schema document (book.xsd) and an XmlReader and then load the book.xml file using XDocument.Load:
// Create the schema set
XmlSchemaSet xmlSchemaSet = new XmlSchemaSet();
// add the new schema with the target namespace
// (could add all the schema at once here if there are multiple)
xmlSchemaSet.Add("http://tempuri.org/Book.xsd",
XmlReader.Create(@"....Book.xsd"));
XDocument book = XDocument.Load(@"....Book.xml");
Set up a ValidationEventHandler to catch any errors and then call XDocument.Validate with the schema set and the event handler to validate book.xml against the book.xsd schema:
ValidationHandler validationHandler = new ValidationHandler();
ValidationEventHandler validationEventHandler =
validationHandler.HandleValidation;
// validate after load
book.Validate(xmlSchemaSet, validationEventHandler);
The ValidationHandler class holds the current validation state in a ValidXml property and the code for the ValidationEventHandler implementation method HandleValidation:
public class ValidationHandler
{
private object _syncRoot = new object();
public ValidationHandler()
{
lock(_syncRoot)
{
// set the initial check for validity to true
this.ValidXml = true;
}
}
public bool ValidXml { get; private set; }
public void HandleValidation(object sender, ValidationEventArgs e)
{
lock(_syncRoot)
{
// we got called so this isn't valid
ValidXml = false;
Console.WriteLine($"Validation Error Message: {e.Message}");
Console.WriteLine($"Validation Error Severity: {e.Severity}");
Console.WriteLine($"Validation Error Line Number: " +
$"{{e.Exception?.LineNumber}");
Console.WriteLine($"Validation Error Line Position: " +
$"{{e.Exception?.LinePosition}");
Console.WriteLine($"Validation Error Source: {e.Exception?.Source}");
Console.WriteLine($"Validation Error Source Schema: " +
"{e.Exception?.SourceSchemaObject}");
Console.WriteLine($"Validation Error Source Uri: " +
$"{{e.Exception?.SourceUri}");
Console.WriteLine($"Validation Error thrown from: " +
$"{{e.Exception?.TargetSite}");
Console.WriteLine($"Validation Error callstack: " +
$"{{e.Exception?.StackTrace}");
}
}
}
If you are wondering what the lock statement is for in the preceding code sample, check out Recipe 12.2 for a full explanation. The short version is that multiple threads can’t run in a lock statement.
Add a new element node that is not in the schema into the XDocument and then call Validate again with the schema set and event handler to revalidate the changed XDocument. If the document triggers any validation events, then the validationHandler.ValidXml property is set to false in the ValidationHandler instance:
// add in a new node that is not in the schema
// since we have already validated, no callbacks fire during the add...
book.Root.Add(new XElement("BogusElement","Totally"));
// now we will do validation of the new stuff we added
book.Validate(xmlSchemaSet, validationEventHandler);
if (validationHandler.ValidXml)
Console.WriteLine("Successfully validated modified LINQ XML");
else
Console.WriteLine("Modified LINQ XML did not validate successfully");
Console.WriteLine();
You could also use the XmlDocument.Validate method to perform the validation in a similar fashion to XDocument:
string xmlFile = @"....Book.xml";
string xsdFile = @"....Book.xsd";
// Create the schema set
XmlSchemaSet schemaSet = new XmlSchemaSet();
// add the new schema with the target namespace
// (could add all the schema at once here if there are multiple)
schemaSet.Add("http://tempuri.org/Book.xsd", XmlReader.Create(xsdFile));
// load up the xml file
XmlDocument xmlDoc = new XmlDocument();
// add the schema
xmlDoc.Schemas = schemaSet;
Load the book.xml file into the XmlDocument, set up a ValidationEventHandler to catch any errors, and then call Validate with the event handler to validate book.xml against the book.xsd schema:
// validate after load xmlDoc.Load(xmlFile); ValidationHandler handler = new ValidationHandler(); ValidationEventHandler eventHandler = handler.HandleValidation; xmlDoc.Validate(eventHandler);
Add a new element node that is not in the schema into the XmlDocument and then call Validate again with the event handler to revalidate the changed XmlDocument. If the document triggers any validation events, then the ValidationHandler.ValidXml property is set to false:
// add in a new node that is not in the schema
// since we have already validated, no callbacks fire during the add...
XmlNode newNode = xmlDoc.CreateElement("BogusElement");
newNode.InnerText = "Totally";
// add the new element
xmlDoc.DocumentElement.AppendChild(newNode);
// now we will do validation of the new stuff we added
xmlDoc.Validate(eventHandler);
if (handler.ValidXml)
Console.WriteLine("Successfully validated modified XML");
else
Console.WriteLine("Modified XML did not validate successfully");
Discussion
One advantage to using XmlDocument over XDocument is that there is an override to the XmlDocument.Validate method that allows you to pass a specific XmlNode to validate. This fine-grained control is not available on XDocument.
public void Validate(
ValidationEventHandler validationEventHandler,
XmlNode nodeToValidate
);
One other approach to this problem is to instantiate an instance of the XmlNodeReader with the XmlDocument and then create an XmlReader with validation settings, as shown in Recipe 10.3. This would allow for continual validation while the reader navigated through the underlying XML.
The output from running the code is listed here:
Validation Error Message: The element 'Book' in namespace 'http://tempuri.org/Bo ok.xsd' has invalid child element 'BogusElement'. List of possible elements expe cted: 'Chapter' in namespace 'http://tempuri.org/Book.xsd'. Validation Error Severity: Error Validation Error Line Number: 0 Validation Error Line Position: 0 Validation Error Source: Validation Error Source Schema: Validation Error Source Uri: Validation Error thrown from: Validation Error callstack: Modified LINQ XML did not validate successfully Validation Error Message: The element 'Book' in namespace 'http://tempuri.org/Bo ok.xsd' has invalid child element 'BogusElement'. List of possible elements expe cted: 'Chapter' in namespace 'http://tempuri.org/Book.xsd'. Validation Error Severity: Error Validation Error Line Number: 0 Validation Error Line Position: 0 Validation Error Source: Validation Error Source Schema: Validation Error Source Uri: file:///C:/CSCB6/CSharpRecipes/Book.xml Validation Error thrown from: Validation Error callstack: Modified XML did not validate successfully
Notice that the BogusElement element you added was not part of the schema for the Book element, so you got a validation error along with the information about where the error occurred. Finally, you got a report that the modified XML did not validate correctly.
See Also
Recipe 10.2; the “XDocument Class” and “XmlDocument.Validate” topics in the MSDN documentation.
10.8 Extending Transformations
Solution
If you are using LINQ to XML, you can call out to a function directly when transforming the result set, as shown here by the call to GetErrata:
XElement publications = XElement.Load(@"....publications.xml");
XElement transformedPublications =
new XElement("PublishedWorks",
from b in publications.Elements("Book")
select new XElement(b.Name,
new XAttribute(b.Attribute("name")),
from c in b.Elements("Chapter")
select new XElement("Chapter", GetErrata(c))));
Console.WriteLine(transformedPublications.ToString());
Console.WriteLine();
The GetErrata method used in the preceding sample is listed here:
private static XElement GetErrata(XElement chapter)
{
// In here we could go do other lookup calls (XML, database, web service)
// to get information to add back in to the transformation result
string errata = $"{chapter.Value} has {chapter.Value.Length} errata";
return new XElement("Errata", errata);
}
If you are using XSLT, you can add an extension object to the transformation that can perform the operations necessary based on the node it is passed. You accomplish this by using the XsltArgumentList.AddExtensionObject method. This object you’ve created (XslExtensionObject) can then be accessed in the XSLT and a method called on it to return the data you want included in the final transformed result:
string xmlFile = @"....publications.xml";
string xslt = @"....publications.xsl";
//Create the XslCompiledTransform and load the style sheet.
XslCompiledTransform transform = new XslCompiledTransform();
transform.Load(xslt);
// load the xml
XPathDocument xPathDoc = new XPathDocument(xmlFile);
// make up the args for the stylesheet with the extension object
XsltArgumentList xslArg = new XsltArgumentList();
XslExtensionObject xslExt = new XslExtensionObject();
xslArg.AddExtensionObject("urn:xslext", xslExt);
// send output to the console and do the transformation
using (XmlWriter writer = XmlWriter.Create(Console.Out))
{
transform.Transform(xPathDoc, xslArg, writer);
}
Note that when the extension object is added to the XsltArgumentList, it supplies a namespace of urn:xslext. This namespace is used in the XSLT stylesheet to reference the object. The XSLExtensionObject is defined here:
// Our extension object to help with functionality
public class XslExtensionObject
{
public XPathNodeIterator GetErrata(XPathNodeIterator nodeChapter)
{
// In here we could go do other lookup calls (XML, database, web service)
// to get information to add back in to the transformation result
nodeChapter.MoveNext();
string errata = $"<Errata>{nodeChapter.Current.Value} has " +
$"{nodeChapter.Current.Value.Length} errata</Errata>";
XmlDocument xDoc = new XmlDocument();
xDoc.LoadXml(errata);
XPathNavigator xPathNav = xDoc.CreateNavigator();
xPathNav.MoveToChild(XPathNodeType.Element);
XPathNodeIterator iter = xPathNav.Select(".");
return iter;
}
}
The GetErrata method is called during the execution of the XSLT stylesheet to provide data in XPathNodeIterator format to the transformation. The xmlns:xslext namespace is declared as urn:xslext, which matches the namespace value you passed as an argument to the transformation. In the processing of the Book template for each Chapter, an xsl:value-of is called with the select criteria containing a call to the xslext:GetErrata method. The stylesheet makes the call, as shown here:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xslext="urn:xslext">
<xsl:template match="/">
<xsl:element name="PublishedWorks">
<xsl:apply-templates/>
</xsl:element>
</xsl:template>
<xsl:template match="Book">
<Book>
<xsl:attribute name ="name">
<xsl:value-of select="@name"/>
</xsl:attribute>
<xsl:for-each select="Chapter">
<Chapter>
<xsl:value-of select="xslext:GetErrata(/)"/>
</Chapter>
</xsl:for-each>
</Book>
</xsl:template>
</xsl:stylesheet>
The outputs for the two approaches are the same and look like this (partial listing):
<PublishedWorks>
<Book name="Subclassing and Hooking with Visual Basic">
<Chapter>
<Errata>Introduction has 12 errata</Errata>
</Chapter>
...
</Book>
<Book name="C# Cookbook">
<Chapter>
<Errata>Numbers has 7 errata</Errata>
</Chapter>
...
</Book>
<Book name="C# Cookbook 2.0">
<Chapter>
<Errata>Numbers and Enumerations has 24 errata</Errata>
</Chapter>
...
</Book>
<Book name="C# 3.0 Cookbook">
<Chapter>
<Errata>Language Integrated Query (LINQ) has 32 errata</Errata>
</Chapter>
...
</Book>
<Book name="C# 6.0 Cookbook">
<Chapter>
<Errata>Classes and Generics has 20 errata</Errata>
</Chapter>
<Chapter>
<Errata>Collections, Enumerators, and Iterators has 39 errata</Errata>
</Chapter>
<Chapter>
<Errata>Data Types has 10 errata</Errata>
</Chapter>
<Chapter>
<Errata>LINQ and Lambda Expressions has 27 errata</Errata>
</Chapter>
<Chapter>
<Errata>Debugging and Exception Handling has 32 errata</Errata>
</Chapter>
<Chapter>
<Errata>Reflection and Dynamic Programming has 34 errata</Errata>
</Chapter>
<Chapter>
<Errata>Regular Expressions has 19 errata</Errata>
</Chapter>
<Chapter>
<Errata>Filesystem I/O has 14 errata</Errata>
</Chapter>
<Chapter>
<Errata>Networking and Web has 18 errata</Errata>
</Chapter>
<Chapter>
<Errata>XML has 3 errata</Errata>
</Chapter>
<Chapter>
<Errata>Security has 8 errata</Errata>
</Chapter>
<Chapter>
<Errata>Threading, Synchronization, and Concurrency has 43 errata</Errata>
</Chapter>
<Chapter>
<Errata>Toolbox has 7 errata</Errata>
</Chapter>
</Book>
</PublishedWorks>
Discussion
Using LINQ to XML, you can extend your transformation code to include additional logic simply by adding method calls that know how to operate and return XElements. This is simply adding another method call to the query that contributes to the result set, and no additional performance penalty is assessed just by the call. Certainly if the operation is expensive it could slow down the transformation, but this is now easily located when your code is profiled.
The ability to call custom code from inside an XSLT stylesheet is very powerful, but should be used cautiously. Adding code like this into stylesheets usually renders them less useful in other environments. If the stylesheet never has to be used to transform XML in another parser, this can be a good way to offload work that is either difficult or impossible to accomplish in regular XSLT syntax.
The sample data used in the Solution is presented here:
<?xml version="1.0" encoding="utf-8"?>
<Publications>
<Book name="Subclassing and Hooking with Visual Basic">
<Chapter>Introduction</Chapter>
<Chapter>Windows System-Specific Information</Chapter>
<Chapter>The Basics of Subclassing and Hooks</Chapter>
<Chapter>Subclassing and Superclassing</Chapter>
<Chapter>Subclassing the Windows Common Dialog Boxes</Chapter>
<Chapter>ActiveX Controls and Subclassing</Chapter>
<Chapter>Superclassing</Chapter>
<Chapter>Debugging Techniques for Subclassing</Chapter>
<Chapter>WH_CALLWNDPROC</Chapter>
<Chapter>WH_CALLWNDPROCRET</Chapter>
<Chapter>WH_GETMESSAGE</Chapter>
<Chapter>WH_KEYBOARD and WH_KEYBOARD_LL</Chapter>
<Chapter>WH_MOUSE and WH_MOUSE_LL</Chapter>
<Chapter>WH_FOREGROUNDIDLE</Chapter>
<Chapter>WH_MSGFILTER</Chapter>
<Chapter>WH_SYSMSGFILTER</Chapter>
<Chapter>WH_SHELL</Chapter>
<Chapter>WH_CBT</Chapter>
<Chapter>WH_JOURNALRECORD</Chapter>
<Chapter>WH_JOURNALPLAYBACK</Chapter>
<Chapter>WH_DEBUG</Chapter>
<Chapter>Subclassing .NET WinForms</Chapter>
<Chapter>Implementing Hooks in VB.NET</Chapter>
</Book>
<Book name="C# Cookbook">
<Chapter>Numbers</Chapter>
<Chapter>Strings and Characters</Chapter>
<Chapter>Classes And Structures</Chapter>
<Chapter>Enums</Chapter>
<Chapter>Exception Handling</Chapter>
<Chapter>Diagnostics</Chapter>
<Chapter>Delegates and Events</Chapter>
<Chapter>Regular Expressions</Chapter>
<Chapter>Collections</Chapter>
<Chapter>Data Structures and Algorithms</Chapter>
<Chapter>File System IO</Chapter>
<Chapter>Reflection</Chapter>
<Chapter>Networking</Chapter>
<Chapter>Security</Chapter>
<Chapter>Threading</Chapter>
<Chapter>Unsafe Code</Chapter>
<Chapter>XML</Chapter>
</Book>
<Book name="C# Cookbook 2.0">
<Chapter>Numbers and Enumerations</Chapter>
<Chapter>Strings and Characters</Chapter>
<Chapter>Classes And Structures</Chapter>
<Chapter>Generics</Chapter>
<Chapter>Collections</Chapter>
<Chapter>Iterators and Partial Types</Chapter>
<Chapter>Exception Handling</Chapter>
<Chapter>Diagnostics</Chapter>
<Chapter>Delegates, Events, and Anonymous Methods</Chapter>
<Chapter>Regular Expressions</Chapter>
<Chapter>Data Structures and Algorithms</Chapter>
<Chapter>File System IO</Chapter>
<Chapter>Reflection</Chapter>
<Chapter>Web</Chapter>
<Chapter>XML</Chapter>
<Chapter>Networking</Chapter>
<Chapter>Security</Chapter>
<Chapter>Threading and Synchronization</Chapter>
<Chapter>Unsafe Code</Chapter>
<Chapter>Toolbox</Chapter>
</Book>
<Book name="C# 3.0 Cookbook">
<Chapter>Language Integrated Query (LINQ)</Chapter>
<Chapter>Strings and Characters</Chapter>
<Chapter>Classes And Structures</Chapter>
<Chapter>Generics</Chapter>
<Chapter>Collections</Chapter>
<Chapter>Iterators, Partial Types, and Partial Methods </Chapter>
<Chapter>Exception Handling</Chapter>
<Chapter>Diagnostics</Chapter>
<Chapter>Delegates, Events, and Lambda Expressions</Chapter>
<Chapter>Regular Expressions</Chapter>
<Chapter>Data Structures and Algorithms</Chapter>
<Chapter>File System IO</Chapter>
<Chapter>Reflection</Chapter>
<Chapter>Web</Chapter>
<Chapter>XML</Chapter>
<Chapter>Networking</Chapter>
<Chapter>Security</Chapter>
<Chapter>Threading and Synchronization</Chapter>
<Chapter>Toolbox</Chapter>
<Chapter>Numbers and Enumerations</Chapter>
</Book>
<Book name="C# 6.0 Cookbook">
<Chapter>Classes and Generics</Chapter>
<Chapter>Collections, Enumerators, and Iterators</Chapter>
<Chapter>Data Types</Chapter>
<Chapter>LINQ and Lambda Expressions</Chapter>
<Chapter>Debugging and Exception Handling</Chapter>
<Chapter>Reflection and Dynamic Programming</Chapter>
<Chapter>Regular Expressions</Chapter>
<Chapter>Filesystem I/O</Chapter>
<Chapter>Networking and Web</Chapter>
<Chapter>XML</Chapter>
<Chapter>Security</Chapter>
<Chapter>Threading, Synchronization, and Concurrency</Chapter>
<Chapter>Toolbox</Chapter>
</Book>
</Publications>
See Also
The “LINQ, transforming data” and “XsltArgumentList Class” topics in the MSDN documentation.
10.9 Getting Your Schemas in Bulk from Existing XML Files
Solution
Use the XmlSchemaInference class to infer schema from the XML samples. The GenerateSchemasForDirectory function in Example 10-7 enumerates all of the XML files in a given directory and processes each of them using the GenerateSchemasForFile method. GenerateSchemasForFile uses the XmlSchemaInference.InferSchema method to get the schemas for the given XML file. Once the schemas have been determined, GenerateSchemasForFile rolls over the collection and saves out each schema to an XSD file using a FileStream.
Example 10-7. Generating an XML schema
public static void GenerateSchemasForFile(string file)
{
// set up a reader for the file
using (XmlReader reader = XmlReader.Create(file))
{
XmlSchemaSet schemaSet = new XmlSchemaSet();
XmlSchemaInference schemaInference =
new XmlSchemaInference();
// get the schema
schemaSet = schemaInference.InferSchema(reader);
string schemaPath = string.Empty;
foreach (XmlSchema schema in schemaSet.Schemas())
{
// make schema file path and write it out
schemaPath = $"{Path.GetDirectoryName(file)}\" +
$"{Path.GetFileNameWithoutExtension(file)}.xsd";
using (FileStream fs =
new FileStream(schemaPath, FileMode.OpenOrCreate))
{
schema.Write(fs);
fs.Flush();
}
}
}
}
public static void GenerateSchemasForDirectory(string dir)
{
// make sure the directory exists
if (Directory.Exists(dir))
{
// get the files in the directory
string[] files = Directory.GetFiles(dir, "*.xml");
foreach (string file in files)
{
GenerateSchemasForFile(file);
}
}
}
The GenerateSchemasForDirectory method can be called like this:
// Get the directory two levels up from where we are running. DirectoryInfo di = new DirectoryInfo(@"...."); string dir = di.FullName; // Generate the schema. GenerateSchemasForDirectory(dir);
Discussion
Having an XSD for the XML files in an application allows for:
-
Validation of XML presented to the system
-
Documentation of the semantics of the data
-
Programmatic discovery of the data structure through XML reading methods
Using the GenerateSchemasForFile method can jump-start the process of developing schema for your XML, but each schema should be reviewed by the team member responsible for producing the XML. This will help to ensure that the rules as stated in the schema are correct and also that additional items, such as schema default values and other relationships, are added. Any relationships that were not present in the example XML files would be missed by the schema generator.
See Also
The “XmlSchemaInference Class” and “XML Schemas (XSD) Reference” topics in the MSDN documentation.
10.10 Passing Parameters to Transformations
Solution
If you are using LINQ to XML, simply build a method to encapsulate the transformation code and pass parameters to the method just as you normally would for other code:
// transform using LINQ instead of XSLT
string storeTitle = "Hero Comics Inventory";
string pageDate = DateTime.Now.ToString("F");
XElement parameterExample = XElement.Load(@"....ParameterExample.xml");
string htmlPath = @"....ParameterExample_LINQ.htm";
TransformWithParameters(storeTitle, pageDate, parameterExample, htmlPath);
// now change the parameters
storeTitle = "Fabulous Adventures Inventory";
pageDate = DateTime.Now.ToString("D");
htmlPath = @"....ParameterExample2_LINQ.htm";
TransformWithParameters(storeTitle, pageDate, parameterExample, htmlPath);
The TransformWithParameters method looks like this:
private static void TransformWithParameters(string storeTitle, string pageDate,
XElement parameterExample, string htmlPath)
{
XElement transformedParameterExample =
new XElement("html",
new XElement("head"),
new XElement("body",
new XElement("h3", $"Brought to you by {storeTitle} " +
$"on {pageDate}{Environment.NewLine}"),
new XElement("br"),
new XElement("table",
new XAttribute("border","2"),
new XElement("thead",
new XElement("tr",
new XElement("td",
new XElement("b","Heroes")),
new XElement("td",
new XElement("b","Edition")))),
new XElement("tbody",
from cb in parameterExample.Elements("ComicBook")
orderby cb.Attribute("name").Value descending
select new XElement("tr",
new XElement("td",cb.Attribute("name").Value),
new XElement("td",
cb.Attribute("edition").Value))))));
transformedParameterExample.Save(htmlPath);
}
If you are using XSLT to perform transformations, use the XsltArgumentList class to pass arguments to the XSLT transformation. This technique allows the program to generate an object (such as a dynamic string) for the stylesheet to access and use while it transforms the given XML file. The storeTitle and pageDate arguments are passed in to the transformation in the following example. The storeTitle is for the title of the comic store, and pageDate is the date for which the report is run. You add these using the AddParam method of the XsltArgumentList object instance args:
//transform using XSLT and parameters
XsltArgumentList args = new XsltArgumentList();
args.AddParam("storeTitle", "", "Hero Comics Inventory");
args.AddParam("pageDate", "", DateTime.Now.ToString("F"));
// Create a resolver with default credentials.
XmlUrlResolver resolver = new XmlUrlResolver();
resolver.Credentials = System.Net.CredentialCache.DefaultCredentials;
The XsltSettings class allows for changing the behavior of the transformation. If you use the XsltSettings.Default instance, you can do the transformation without allowing scripting or the use of the document XSLT function, as they can be security risks. If the stylesheet is from a trusted source, you can just create an XsltSettings object and use it, but it is better to be safe. Further changes to the code could open it up to use with untrusted XSLT stylesheets:
XslCompiledTransform transform = new XslCompiledTransform();
// load up the stylesheet
transform.Load(@"....ParameterExample.xslt", XsltSettings.Default,
resolver);
// perform the transformation
FileStream fs = null;
using (fs =
new FileStream(@"....ParameterExample.htm",
FileMode.OpenOrCreate, FileAccess.Write))
{
transform.Transform(@"....ParameterExample.xml", args, fs);
} XslCompiledTransform transform = new XslCompiledTransform();
// Load up the stylesheet.
transform.Load(@"....ParameterExample.xslt", XsltSettings.Default,
resolver);
// Perform the transformation.
FileStream fs = null;
using (fs = new FileStream(@"....ParameterExample.htm",
FileMode.OpenOrCreate, FileAccess.Write))
{
transform.Transform(@"....ParameterExample.xml", args, fs);
}
To show the different parameters in action, now you change storeTitle and pageDate and run the transformation again:
// now change the parameters and reprocess
args = new XsltArgumentList();
args.AddParam("storeTitle", "", "Fabulous Adventures Inventory");
args.AddParam("pageDate", "", DateTime.Now.ToString("D"));
using (fs = new FileStream(@"....ParameterExample2.htm",
FileMode.OpenOrCreate, FileAccess.Write))
{
transform.Transform(@"....ParameterExample.xml", args, fs);
}
The ParameterExample.xml file contains the following:
<?xml version="1.0" encoding="utf-8" ?>
<?xml-stylesheet href="ParameterExample.xslt" type="text/xsl"?>
<ParameterExample>
<ComicBook name="The Amazing Spider-Man" edition="1"/>
<ComicBook name="The Uncanny X-Men" edition="2"/>
<ComicBook name="Superman" edition="3"/>
<ComicBook name="Batman" edition="4"/>
<ComicBook name="The Fantastic Four" edition="5"/>
</ParameterExample>
The ParameterExample.xslt file contains the following:
<?xml version="1.0" encoding="UTF-8" ?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" indent="yes" />
<xsl:param name="storeTitle"/>
<xsl:param name="pageDate"/>
<xsl:template match="ParameterExample">
<html>
<head/>
<body>
<h3>
<xsl:text>Brought to you by </xsl:text>
<xsl:value-of select="$storeTitle"/>
<xsl:text> on </xsl:text>
<xsl:value-of select="$pageDate"/>
<xsl:text> 
</xsl:text>
</h3>
<br/>
<table border="2">
<thead>
<tr>
<td>
<b>Heroes</b>
</td>
<td>
<b>Edition</b>
</td>
</tr>
</thead>
<tbody>
<xsl:apply-templates/>
</tbody>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="ComicBook">
<tr>
<td>
<xsl:value-of select="@name"/>
</td>
<td>
<xsl:value-of select="@edition"/>
</td>
</tr>
</xsl:template>
</xsl:stylesheet>
The output from the first transformation using XSLT to ParameterExample.htm or using LINQ to ParameterExample_LINQ.htm is shown in Figure 10-2.

Figure 10-2. Output from the first set of parameters
Output from the second transformation using XSLT to ParameterExample2.htm or using LINQ to ParameterExample2_LINQ.htm is shown in Figure 10-3.
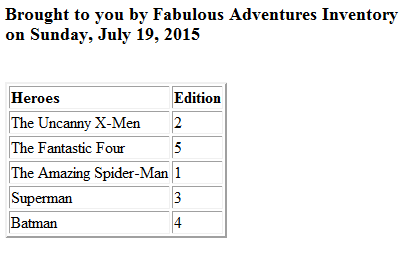
Figure 10-3. Output from the second set of parameters
Discussion
Both approaches allow you to templatize your code and provide parameters to modify the output. With the LINQ to XML method, the code is all in .NET, and .NET analysis tools can be used to measure the impact of the transformation. Using the declarative style of the code conveys the intent more clearly than having to go to the external XSLT file. If you don’t know XSLT, you don’t have to learn it, as you can do it in code now.
If you already know XSLT, you can continue to leverage it. Being able to pass information to the XSLT stylesheet allows for a much greater degree of flexibility when you are designing reports or user interfaces via XSLT transformations. This capability can help you customize the output based on just about any criteria you can think of, as the data being passed in is totally controlled by your program. Once you get the hang of using parameters with XSLT, a whole new level of customization becomes possible. As an added bonus, it is portable between environments.
See Also
The “LINQ, transforming data,” “XsltArgumentList Class,” and “XsltSettings Class” topics in the MSDN documentation.