
CHAPTER 7
The F# Libraries
Although F# can use all the classes available in the .NET BCL, it also ships with its own set of libraries.
The F# libraries are split into two, FSLib.dll, which is also referred to as the native F# library or just FSLib, and MLLib.dll, which is sometimes referred to as the ML compatibility library or MLLib. FSLib contains everything that the F# compiler really needs to work; for example, it contains the Tuple class that is used when you use a tuple. MLLib is a set of libraries for doing common programming tasks partially based on the libraries that ship with OCaml.
The objective of this chapter is not to completely document every nuance of every F# library type and function. It is to give you an overview of what the modules can do, with a particular focus on features that aren't readily available in the BCL. The F# online documentation (http://research.microsoft.com/fsharp/manual/namespaces.html) is the place to find detailed documentation about each function.
There is some crossover between the functionality provided by the F# libraries and the .NET BCL. Programmers often ask when should they use functions from the F# library and when should they use the classes and methods available in the .NET BCL. Both have their advantages and disadvantages, and a good rule of thumb is to prefer what is in FSLib over the classes available in the .NET Framework BCL and prefer what is available in the .NET Framework BCL over MLLib.
Libraries Overview
The following sections list all the modules that are contained in FSLib and MLLib; the modules covered in this chapter are highlighted in bold.
The Native F# Library FSLib.dll
These are the modules in FSLib:
Microsoft.FSharpIdioms
ReflectionMicrosoft.FSharp.CollectionsArrayArray2Array3ComparisonIdentityHashIdentityIEnumerableLazyListListMapReadonlyArrayResizeArraySeqSet
Microsoft.FSharp.Collections.TagsOptimizations
Microsoft.FSharp.CompatibilityCompatArrayCompatMatrixMATLAB
Microsoft.FSharp.ControlIEventLazyLazyStatus
Microsoft.FSharp.CoreByteCharEnumFloatFloat32Int16Int32Int64Int8LanguagePrimitivesOperatorsOptimizedClosuresOptionSByteStringUInt16UInt32UInt64UInt8
Microsoft.FSharp.MathBigIntBigNumBigRationalComplexGlobalAssociationsInstancesLinearAlgebraMatrixNotationRawMatrixOpsRowVectorVector
Microsoft.FSharp.Math.PrimitiveBigNatFFT
Microsoft.FSharp.NativeInteropNativePtrRef
Microsoft.FSharp.PrimitivesBasics
Microsoft.FSharp.QuotationsRawRawTypesTypedUtilities
Microsoft.FSharp.TextPrintfPrintfImpl
Microsoft.FSharp.Text.StructuredFormatDisplayLayoutOps
Microsoft.FSharp.Tools.FsYaccParseHelpers
The ML Compatibility Library MLLib.dll
These are the modules in MLLib:
Microsoft.FSharp.Compatibility.OCamlArgBig_intBufferBytearrayFilenameHashtblLexingNumObjParsingPervasivesPrintexcSys
The Native F# Library FSLib.dll
FSLib contains all the classes that you need to make the compiler work, such as the definition of the type into which F#'s list literal compiles. I'll cover the following modules:
Microsoft.FSharp.Core.Operators: A module containing functions similar to useful C# constructs such asusingandlock.
Microsoft.FSharp.Reflection: A module containing functions that supplement the .NET Framework's reflection classes to give a more accurate view of F# types and values.
Microsoft.FSharp.Collections.Seq: A module containing functions for any type that supports theIEnumerableinterface.
Microsoft.FSharp.Core.Enum: A module containing functions for .NET enumeration types.
Microsoft.FSharp.Text.Printf: A module for formatting strings.
Microsoft.FSharp.Control.IEvent: A module for working with events in F#.
Microsoft.FSharp.Math: A namespace that contains several modules related to mathematics. These include arbitrary precision integers and rationales, vectors, matrices, and complex numbers.
The Microsoft.FSharp.Core.Operators Module
In F#, operators are defined by libraries rather than built into the language; this module contains some of the language's operators. It also contains some useful operators such as functions, and it is these that I'll be covering here. The module is open by default, which means the user can use these functions with no prefix. Specifically, I will cover the following functions:
The
usingfunction: A function that helps you ensure that unmanaged or limited resources are disposed of in a timely mannerThe
lockfunction: A function that helps you ensure that any resources that need to be shared between threads are dealt with correctlyTuple functions: Functions on tuples
The using Function
The IDisposable interface has one member, Dispose; typically this interface is used when a class that wraps some unmanaged or limited resource, such as a database connection, calling Dispose ensures that the resource can always be reclaimed in a timely manner and you do not have to wait for garbage collection. The using function is a great way to ensure that the Dispose method of the IDisposable interface is always called when you are finished with the class, even if an exception is thrown.
The using function has the type 'a -> ('a -> 'b) -> 'b when 'a :> IDisposable. It therefore has two parameters: the first must implement the IDisposable interface, and the second is a function that must take a parameter of type IDisposable interface and that can return a parameter of any type. The parameter returned from this function is the return type of the using function. The following example illustrates this by opening a file to append to it:
#light
open System.IO
using (File.AppendText("test.txt"))
(fun streamWriter ->
streamWriter.WriteLine("A safe way to write to a file"))
The call to the BCL's method File.AppendText will return a System.IO.StreamWriter, which is a way of writing to a file. A file is managed by the operating system, so it has an "unmanaged" aspect. This is why System.IO.StreamWriter implements IDisposable. A System.IO.StreamWriter is passed to the function, which itself makes up the second parameter passed to the using function. This is a neat way of ensuring that the streamWriter is available only inside a limited scope of the function and that it is disposed of straightaway when the function ends. If you did not write your file access using the using function, you would have to explicitly call the Dispose method, or your text would not be flushed from memory into the file. Similarly, there would be a risk that an exception could occur. Although the risk is limited, there is a real risk that a file would not be closed properly and the text not written to it.
It's worth noting that using returns unit because the call to StreamWriter.WriteLine returns unit. If you were performing an operation that didn't return unit, say reading from a file or database, you could return a value from the using function. The following example illustrates this by reading from a file and then binding the contents of the first line of that file to the identifier text:
#light
open System.IO
let text =
using (File.OpenText("test.txt")) (fun streamReader ->
streamReader.ReadLine()
)
The lock Function
The lock function operates in a fashion similar to using. The purpose of the function is to lock a section of code so that only one thread can pass through it at a time. This issue arises in multithreaded programming because a thread can context switch at any time, leaving operations that should have been atomic half done. This is controlled by locking on an object; the idea is that as soon as the lock is taken, any thread attempting to enter the section of code will be blocked until the lock is released by the thread that holds it. Code protected in this way is sometimes called a critical section. This is achieved by calling System.Threading.Monitor.Enter at the start of the code that is to be protected and System.Threading.Monitor.Exit at the end; it is important to guarantee that Monitor.Exit is called, or this could lead to threads being locked forever. The lock function is a nice way to ensure that Monitor.Exit is always called if Monitor.Enter has been called. It takes two parameters; the first is the object to be locked on, and the second is a function that contains the code to be protected. This function should take unit as its parameter, and it can return any value.
The following example demonstrates the subtle issues involved in locking. It needs to be quite long and has been deliberately written to exaggerate the problem of context switching. The idea is that two threads will run at the same time, both trying to write the console. The aim of the sample is to write the string "One ... Two ... Three ... " to the console atomically; that is, one thread should be able to finish writing its message before the next one starts. The example has a function, called makeUnsafeThread, that creates a thread that will not be able to write to the console atomically and a second one, makeSafeThread, that writes to the console atomically by using a lock.
#light
open System
open System.Threading
// function to print to the console character by character
// this increases the chance of there being a context switch
// between threads.
let printSlowly (s : string) =
s.ToCharArray()
|> Array.iter print_char
// create a thread that prints to the console in an unsafe way
let makeUnsafeThread() =
new Thread(fun () ->
for x = 1 to 100 do
printSlowly "One ... Two ... Three ... "
print_newline()
done)
// the object that will be used as a lock
let lockObj = new Object()
// create a thread that prints to the console in a safe way
let makeSafeThread() =
new Thread(fun () ->
for x = 1 to 100 do
// use lock to ensure operation is atomic
lock lockObj (fun () ->
printSlowly "One ... Two ... Three ... "
print_newline()
)
done)
// helper function to run the test to
let runTest (f : unit -> Thread) message =
print_endline message;
let t1 = f() in
let t2 = f() in
t1.Start()
t2.Start()
t1.Join()
t2.Join()
// runs the demonstrations
let main() =
runTest
makeUnsafeThread
"Running test without locking ..."
runTest
makeSafeThread
"Running test with locking ..."
main ()
The part of the example that actually uses the lock is repeated next to highlight the important points. You should note a couple of important factors. First, the declaration of the lockObj will be used to create the critical section. Second, the use of the lock function is embedded in the makeSafeThread function. The most important thing to notice is how the printing functions you want to be atomic are placed inside the function that is passed to lock.
// the object that will be used as a lock
let lockObj = new Object()
// create a thread that prints to the console in a safe way
let makeSafeThread() =
new Thread(fun () ->
for x = 1 to 100 do
// use lock to ensure operation is atomic
lock lockObj (fun () ->
printSlowly "One ... Two ... Three ... "
print_newline()
)
done)
The results of the first part of the test will vary each time it is run, since it depends on when a thread context switches. It might also vary based on the number of processors, because if a machine has two or more processors, then threads can run at the same time, and therefore the messages will be more tightly interspersed. On a single-processor machine, things will look less messy, because the messages will go wrong only when a content switch takes place. The results of the first part of the sample, run on a single-processor machine, are as follows:
Running test without locking ...
...
One ... Two ... Three ...
One One ... Two ... Three ...
One ... Two ... Three ...
...
The results of the second half of the example will not vary at all, because of the lock, so it will always look like this:
Running test with locking ...
One ... Two ... Three ...
One ... Two ... Three ...
One ... Two ... Three ...
...
Locking is an important aspect of concurrency. Any resource that will be written to and shared between threads should be locked. A resource is often a variable, but it could also be a file or even the console, as shown in this example. You should not think of locks as a magical solution to concurrency. Although they work, they also can also create problems of their own since they can create a deadlock, where different threads lock resources that each other needs and neither can advance. The simplest solution to concurrency is often to simply avoid sharing a resource that can be written to between threads.
Note You can find more information about concurrency at http://www.strangelights.com/fsharp/foundations/default.aspx/FSharpFoundations.Concurrency.
Tuple Functions
The Operators module also offers two useful functions that operate on tuples. You can use the functions fst and snd to break up a tuple with two items in it. The following example demonstrates their use:
printf "(fst (1, 2)): %i
" (fst (1, 2))
printf "(snd (1, 2)): %i
" (snd (1, 2))
The results of this code are as follows:
(fst (1, 2)): 1
(snd (1, 2)): 2
The Microsoft.FSharp.Reflection Module
This module contains F#'s own version of reflection. F# contains some types that are 100 percent compatible with the CLR type system but aren't precisely understood with .NET reflection. For example, F# uses some sleight of hand to implement its union type, and this is transparent in 100 percent F# code but can look a little strange when you use the BCL to reflect over it. The F# reflection system addresses this kind of problem. But, it blends with the BCL's System.Reflection namespace, so if you are reflecting over an F# type that uses BCL types, you will get the appropriate object from the System.Reflection namespace.
In F#, you can reflect over types or over values. The difference is a bit subtle and is best explained with an example. Those of you familiar with .NET reflection might like to think of reflection over types as using the Type, EventInfo, FieldInfo, MethodInfo, and PropertyInfo types and reflections over values as calling their members such as GetProperty or InvokeMember to get values dynamically, but reflection over values offers a high-level, easy-to-use system.
- Reflection over types lets you examine the types that make up a particular value or type.
- Reflection over values lets you examine the values that make up a particular composite value.
Reflection Over Types
The following example shows a function that will print the type of any tuple:
#light
open Microsoft.FSharp.Reflection
let printTupleTypes x =
match Value.GetTypeInfo(x) with
| TupleType types ->
print_string "("
types
|> List.iteri
(fun i t ->
if i <> List.length types - 1 then
Printf.printf " %s * " t.Name
else
print_string t.Name)
print_string " )"
| _ -> print_string "not a tuple"
printTupleTypes ("hello world", 1)
First you use the function Value.GetTypeInfo() to get a TypeInfo value that represents the object passed to the function. This is similar to calling GetType() on a BCL object. If you had a System.Type object instead of a value, you could have used Type.GetTypeInfo to retrieve the same TypeInfo value. TypeInfo is a union type, so you pattern-match over it. In this case, you are interested only in tuples, so you print "not a tuple" if you receive anything else. The TupleType constructor contains a list of System.Type values that represent the members of a tuple, so by printing the Name property of System.Type, you can print the names of the types that make up the tuple. This means when compiled and run, the sample outputs the following:
( String * Int32 )
Reflection Over Values
Imagine instead of displaying the types of a tuple that you wanted to display the values that make up the tuple. To do this, you would use reflection over values, and you would need to use the function GetValueInfo to retrieve a value of type ValueInfo that is similar to TupleType, except that instead of containing information about types, it contains information about values. To print out the values within a tuple, you use the TupleValue constructor, which contains a list of values that make up the tuple. The following example implements such a function:
#light
open Microsoft.FSharp.Reflection
let printTupleValues x =
match Value.GetInfo(x) with
| TupleValue vals ->
print_string "("
vals
|> List.iteri
(fun i v ->
if i <> List.length vals - 1 then
Printf.printf " %s, " (any_to_string v)
else
print_any v)
print_string " )"
| _ -> print_string "not a tuple"
printTupleValues ("hello world", 1)
The result of this code, when compiled and executed, is as follows:
( "hello world", 1 )
Reflection is used both within the implementation of fsi, the interactive command-line tool that is part of the F# tool suite (see Chapter 11), and within the F# library functions any_to_string and print_any. If you want to learn more about the way you can use reflection, take a look at the source for any_to_string and print_any, available in the distribution in the file libmlliblayout.fs.
The Microsoft.FSharp.Collections.Seq Module
The Microsoft.FSharp.Collections.Seq module contains functions that work with any collection that supports the IEnumerable interface, which is most of the collections in the .NET Framework's BCL. The module is called Seq because F# gives the alias seq to the IEnumerable interface to shorten it and make it easier to type and read; this alias is used when type definitions are given.
Note FSLib contains several modules designed to work with various types of collections. These include Array, Array2 (two-dimensional arrays), Array3 (three-dimensional arrays), Hashtbl (a hash table implementation), IEnumerable, LazyList, List, Map, and Set. I'll cover only Seq because it should generally be favored over these collections because of its ability to work with lots of different types of collections. Also, although each module has functions that are specific to it, many functions are common to them all.
Some of these functions can be replaced by the list comprehension syntax covered in Chapters 3 and 4. For simple tasks and working with untyped collections, it's generally easier to use list comprehension, but for more complicated tasks you will want to stick to these functions. You will take a look at the following functions:
mapanditer: These two functions let you apply a given function to every item in the collection.
concat: This function lets you concatenate a collection of collections into one collection.
fold: This function lets you create a summary of a list by folding the items in the collection together.
existsandfor_all: These function let you make assertions about the contents of a collection.
filter,findandtryfind: These functions let you pick elements in the list that meet certain conditions.
choose: This function lets you perform a filter and map at the same time.
init_finiteandinit_infinite: These functions let you initialize collections.
unfold: This provides a more flexible way to initialize lists.
untyped: This gives you a look at the functions that are designed to work with the nongeneric version ofIEnumerable, rather thanIEnumerable<T>.
The map and iter Functions
You'll look at map and iter first. These apply a function to each element in a collection. The difference between them is that map is designed to create a new collection by transforming each element in the collection, while iter is designed to apply an operation that has a side effect to each item in the collection. A typical example of a side effect would be writing the element to the console. The following example shows both map and iter in action:
#light
let myArray = [|1; 2; 3|]
let myNewCollection =
myArray |>
Seq.map (fun x -> x * 2)
print_any myArray
print_newline()
myNewCollection |> Seq.iter (fun x -> printf "%i ... " x)
The results of this code, when compiled and executed, are as follows:
[|1; 2; 3|]
2 ... 4 ... 6 ...
The concat Function
The previous example used an array, because it was convenient to initialize this type of collection, but you could use any of the collection types available in the BCL. The next example uses the List type provided in the System.Collections.Generic namespace and demonstrates how to use the concat function, which has type #seq< #seq<'a> > -> seq<'a> and which collects IEnumerable values into one IEnumerable value:
#light
open System.Collections.Generic
let myList =
let temp = new List<int[]>()
temp.Add([|1; 2; 3|])
temp.Add([|4; 5; 6|])
temp.Add([|7; 8; 9|])
temp
let myCompleteList = Seq.concat myList
myCompleteList |> Seq.iter (fun x -> printf "%i ... " x)
The results of this code, when compiled and executed, are as follows:
1 ... 2 ... 3 ... 4 ... 5 ... 6 ... 7 ... 8 ... 9 ...
The next example demonstrates the fold function, which has type ('b -> 'a -> 'b) -> 'b -> #seq<'a> -> 'b. This is a function for creating a summary of a collection by threading an accumulator value through each function call. The function takes two parameters. The first of these is an accumulator, which is the result of the previous function, and the second is an element from the collection. The function body should combine these two values to form a new value of the same type as the accumulator. In the next example, the elements of myPhrase are concatenated to the accumulator so that all the strings end up combined into one string.
#light
let myPhrase = [|"How"; "do"; "you"; "do?"|]
let myCompletePhrase =
myPhrase |>
Seq.fold (fun acc x -> acc + " " + x) ""
print_endline myCompletePhrase
The result of this code, when compiled and executed, is as follows:
How do you do?
The exists and for_all Functions
The next example demonstrates two functions that you can use to determine facts about the contents of collections. These functions are exists and for_all, which both have the type ('a -> bool) -> #seq<'a> -> bool. You can use the exists function to determine whether any element in the collection exists that meets certain conditions. The conditions that must be met are determined by the function passed to exists, and if any of the elements meet this condition, then exists will return true. The function for_all is similar except that all the elements in the collection must meet the condition before it will return true. The following example first uses exists to determine whether there are any elements in the collections that are multiples of 2 and then uses for_all to determine whether all items in the collection are multiples of 2:
#light
let intArray = [|0; 1; 2; 3; 4; 5; 6; 7; 8; 9|]
let existsMultipleOfTwo =
intArray |>
Seq.exists (fun x -> x % 2 = 0)
let allMultipleOfTwo =
intArray |>
Seq.exists (fun x -> x % 2 = 0)
printfn "existsMultipleOfTwo: %b" existsMultipleOfTwo
printfn "allMultipleOfTwo: %b" allMultipleOfTwo
The results of this code, when compiled and executed, are as follows:
existsMultipleOfTwo: true
allMultipleOfTwo: false
The filter, find, and tryfind Functions
The next example looks at three functions that are similar to exists and for_all; these functions are filter of type ('a -> bool) -> #seq<'a> -> seq<'a>, find of type ('a -> bool) -> #seq<'a> -> 'a and tryfind of type ('a -> bool) -> #seq<'a> -> 'a option. They are similar to exists and for_all because they use functions to examine the contents of a collection, but instead of returning a Boolean, these functions actually return the item or items found. The function filter uses the function passed to it to check every element in the collection. The filter function then returns a list that contains all the elements that have met the condition of the function. If no elements meet the condition, then an empty list is returned. The functions find and tryfind both return the first element in the collection to meet the condition specified by the function passed to them. Their behavior is altered when no element in the collection meets the condition; find throws an exception, whereas tryfind returns an option type that will be None if no element is found. Since exceptions are relatively expensive in .NET, you should prefer tryfind over find.
In the following example, you'll look through a list of words; first you use filter to create a list containing only the words that end in at. Then you'll use find to find the first word that ends in ot. Finally, you'll use tryfind to check whether any of the words end in tt.
#light
let shortWordList = [|"hat"; "hot"; "bat"; "lot"; "mat"; "dot"; "rat";|]
let atWords =
shortWordList
|> Seq.filter (fun x -> x.EndsWith("at"))
let otWord =
shortWordList
|> Seq.find (fun x -> x.EndsWith("ot"))
let ttWord =
shortWordList
|> Seq.tryfind (fun x -> x.EndsWith("tt"))
atWords |> Seq.iter (fun x -> printf "%s ... " x)
print_newline()
print_endline otWord
print_endline (match ttWord with | Some x -> x | None -> "Not found")
The results of this code, when compiled and executed, are as follows:
hat ... bat ... mat ... rat ...
hot
Not found
The choose Function
The next Seq function you'll look at is a clever function that allows you to do a filter and a map at the same time. This function is called choose and has the type ('a -> 'b option) -> #seq<'a> -> seq<'b>. To do this, the function that is passed to choose must return an option type. If the element in the list can be transformed into something useful, the function should return Some containing the new value, and when the element is not wanted, the function returns None.
In the following example, you'll take a list of floating-point numbers and multiply them by 2. If the value is an integer, it is returned; otherwise, it is filtered out. This leaves you with just a list of integers.
#light
let floatArray = [|0.5; 0.75; 1.0; 1.25; 1.5; 1.75; 2.0 |]
let integers =
floatArray |>
Seq.choose
(fun x ->
let y = x * 2.0
let z = floor y
if y - z = 0.0 then
Some (int_of_float z)
else
None)
integers |> Seq.iter (fun x -> printf "%i ... " x)
The results of this code, when compiled and executed, are as follows:
1 ... 2 ... 3 ... 4 ...
The init_finite and init_infinite Functions
Next you'll look at two functions for initializing collections, init_finite of type int -> (int -> 'a) -> seq<'a> and init_infinite of type (int -> 'a) -> seq<'a>. You can use the function init_finite to make a collection of a finite size; it does this by calling the function passed to it the number of times specified by the number passed to it. You can use the function init_infinite to create a collection of an infinite size. It does this by calling the function passed to it each time it is asked for a new element this way; in theory, a list of unlimited size can be created, but in reality you are constrained by the limits of the machine performing the computation.
The following example shows init_finite being used to create a list of ten integers, each with the value 1. It also shows a list being created that should contain all the possible 32-bit integers and demonstrates using the function take to create a list of the first ten.
#light
let tenOnes = Seq.init_finite 10 (fun _ -> 1)
let allIntegers = Seq.init_infinite (fun x -> System.Int32.MinValue + x)
let firstTenInts = Seq.take 10 allIntegers
tenOnes |> Seq.iter (fun x -> printf "%i ... " x)
print_newline()
print_any firstTenInts
The results of this code, when compiled and executed, are as follows:
1 ... 1 ... 1 ... 1 ... 1 ... 1 ... 1 ... 1 ... 1 ... 1 ...
[−2147483648; −2147483647; −2147483646; −2147483645; −2147483644; −2147483643;
−2147483642; −2147483641; −2147483640; −2147483639]
The unfold Function
You already met unfold in Chapter 3; it is a more flexible version of the functions init_finite and init_infinite. The first advantage of unfold is that it can be used to pass an accumulator through the computation, which means you can store some state between computations and do not simply have to rely on the current position in the list to calculate the value, like you do with init_finite and init_infinite. The second advantage is that it can be used to produce a list that is either finite or infinite. Both of these advantages are achieved by using the return type of the function passed to unfold; the return type of the function is 'a * 'b option, meaning an option type that contains a tuple of values. The first value in the option type is the value that will be placed in the list, and the second is the accumulator. If you want to continue the list, you return Some with this tuple contained within it. If want to stop it, you return None.
The following example, repeated from Chapter 2, shows unfold being used to compute the Fibonacci numbers. You can see the accumulator being used to store a tuple of values representing the next two numbers in the Fibonacci sequence. Because the list of Fibonacci numbers is infinite, you never return None.
#light
let fibs =
(1,1) |> Seq.unfold
(fun (n0, n1) ->
Some(n0, (n1, n0 + n1)))
let first20 = Seq.take 20 fibs
print_any first20
The results of this code, when compiled and executed, are as follows:
[1; 1; 2; 3; 5; 8; 13; 21; 34; 55; 89; 144; 233; 377; 610; 987;
1597; 2584; 4181; 6765]
The example demonstrates using unfold to produce a list that terminates. Imagine you want to calculate a sequence of numbers where the value decreases by half its current value, such as a nuclear source decaying. Imagine beyond a certain limit the number becomes so small that you are no longer interested in it. You can model such a sequence in the following example by returning None when the value has reached its limit:
#light
let decayPattern =
Seq.unfold
(fun x ->
let limit = 0.01
let n = x - (x / 2.0)
if n > limit then
Some(x, n)
else
None)
(10.0)
decayPattern |> Seq.iter (fun x -> printf "%f ... " x)
The results of this code, when compiled and executed, are as follows:
10.000000 ... 5.000000 ... 2.500000 ... 1.250000 ...
0.625000 ... 0.312500 ... 0.156250 ... 0.078125 ... 0.039063 ...
The generate and generate_using Functions
The generate function of type (unit -> 'b) -> ('b -> 'a option) -> ('b -> unit) -> seq<'a> and the generate_using function of type (unit -> 'a) -> ('a -> 'b option) -> seq<'b> when 'a :> IDisposable are two useful functions of creating IEnumerable collections. They allow you to generate collections from some kind of cursor. The cursor can be a file stream, as shown in these examples, or perhaps more commonly a database cursor; or it can be any type that will generate a sequence of elements. The generate function takes three functions: one to open the cursor (the opener function in the following example), one to do the work of actually generating the collection (the generator function), and one to close the cursor (the closer function). The collection can then be treated as any other IEnumerable collection, but behind the scenes, the functions you have defined will be called to go to the data source and read the elements from it. The following example shows the function being used to read a comma-separated list of words from a file:
#light
open System
open System.Text
open System.IO
// test.txt: the,cat,sat,on,the,mat
let opener() = File.OpenText("test.txt")
let generator (stream : StreamReader) =
let endStream = ref false
let rec generatorInner chars =
match stream.Read() with
| −1 ->
endStream := true
chars
| x ->
match Convert.ToChar(x) with
| ',' -> chars
| c -> generatorInner (c :: chars)
let chars = generatorInner []
if List.length chars = 0 && !endStream then
None
else
Some(new string(List.to_array (List.rev chars)))
let closer (stream : StreamReader) =
stream.Dispose()
let wordList =
Seq.generate
opener
generator
closer
wordList |> Seq.iter (fun s -> print_endline s)
The results of this code, when compiled and executed, are as follows:
the
cat
sat
on
the
mat
The generate_using function is the same as the generate function, except that the type used to create the collection must support the IDisposable interface, and this will be called when the last item has been read from the collection instead of the closer function. This saves you the trouble of explicitly defining a closer function, leading to short programs. I consider the generate_using function very useful because most types you want to generate collections from will support the IDisposable interface; its usage is demonstrated here:
#light
open System
open System.Text
open System.IO
// test.txt: the,cat,sat,on,the,mat
let opener() = File.OpenText("test.txt")
let generator (stream : StreamReader) =
let endStream = ref false
let rec generatorInner chars =
match stream.Read() with
| −1 ->
endStream := true
chars
| x ->
match Convert.ToChar(x) with
| ',' -> chars
| c -> generatorInner (c :: chars)
let chars = generatorInner []
if List.length chars = 0 && !endStream then
None
else
Some(new string(List.to_array (List.rev chars)))
let closer (stream : StreamReader) =
stream.Dispose()
let wordList =
Seq.generate_using
opener
generator
wordList |> Seq.iter (fun s -> print_endline s)
read_line()
The results of this code, when compiled and executed, are as follows:
the
cat
sat
on
the
mat
The .NET Framework's BCL contains two versions of the IEnumerable interface, one defined in System.Collections.Generic and an older one defined in System.Collections. All the samples shown so far have been designed to work with the new generic version from System.
Collections.Generic. However, sometimes it might be necessary to work with collections that are not generic, so the F# IEnumerable module also provides a number of functions to work with nongeneric collections. These functions all start with the prefix untyped and then have the same name as their generic counterpart. The big disadvantage of using these functions is that they do not contain any type information; therefore, the compiler cannot type check them properly, which can mean some code might throw an invalid cast exception at runtime.
Before using these functions, I strongly recommend that you see whether you can use the list comprehension syntax covered in Chapters 3 and 4 instead. This is because the list comprehension syntax can infer the types of many untyped collections, usually by looking at the type of the Item indexer property, so there is less need for type annotations, which generally makes programming easier.
The following example looks at an array list that stores a sequence of integers and then uses untyped_map to double each of the integers in the list:
#light
open System.Collections
let arrayList =
let temp = new ArrayList()
temp.AddRange([| 1; 2; 3 |])
temp
let doubledArrayList =
arrayList |>
Seq.untyped_map (fun x -> x * 2)
doubledArrayList |> Seq.untyped_iter (fun x -> printf "%i ... " x)
The results of this code, when compiled and executed, are as follows:
2 ... 4 ... 6 ...
As you can see from the previous example, when the programmer gets the types right, using the untyped functions is pretty straightforward. However, consider the following example that tries to perform the same operation on the list, except this time it contains strings:
#light
open System.Collections
let stringArrayList =
let temp = new ArrayList()
temp.AddRange([| "one"; "two"; "three" |])
temp
let invalidCollection =
stringArrayList |>
Seq.untyped_map (fun x -> x * 2)
invalidCollection |> Seq.untyped_iter (fun x -> printf "%O ... " x)
The results of this code, when compiled and executed, are as follows:
System.InvalidCastException: Specified cast is not valid.
at [email protected]_Current()
at Microsoft.FSharp.Collections.IEnumerator.untyped_iter@12[A,U](FastFunc`2 f, U e)
at <StartupCode>.FSI_0011._main()
stopped due to error
It's easy to see that using untyped collections places an extra burden on the programmer to ensure the types in the collection are correct. So, I highly recommend that if for some reason you must use an untyped collection, then it is best to convert it to a typed collection. This is done using the function untyped_to_typed, which is demonstrated in the following example:
#light
open System.Collections
open System.Collections.Generic
let floatArrayList =
let temp = new ArrayList()
temp.AddRange([| 1.0; 2.0; 3.0 |])
temp
let (typedIntList : seq<float>) =
Seq.untyped_to_typed floatArrayList
Using untyped_to_typed always required using type annotations to tell the compiler what type of list you are producing. Here you have a list of floats, so you use the type annotation IEnumerable<float> to tell the compiler it will be an IEnumerable collection containing floating-point numbers.
The Microsoft.FSharp.Core.Enum Module
The Enum module is a simple module to help deal with enumerations in F#. I will cover the following functions:
to_intandof_int: Functions for converting to and from integers
combineandtest: Functions for combining enums with a bitwise "and" and testing whether a bit is set
The to_int and of_int Functions
The following example shows how to convert from an enumeration to an integer and then convert it back to an enumeration. Converting from an enumeration to an integer is straightforward; you just use the to_int function. Converting back is slightly more complicated; you use the of_int function, but you must provide a type annotation so that the compile knows which type of enumeration to convert it to. You can see this in the following sample where you add the annotation DayOfWeek to the identifier dayEnum:
#light
open System
let dayInt = Enum.to_int DateTime.Now.DayOfWeek
let (dayEnum : DayOfWeek) = Enum.of_int dayInt
print_int dayInt
print_newline ()
print_any dayEnum
The results of this code, when compiled and executed, are as follows:
0
Sunday
The combine and test Functions
The other common tasks that you need to perform with enumerations is to combine them using a logical "or" and then test them using a logical "and." The functions combine and test are provided to fulfill these roles. The function combine takes a list of enumerations and combines them into one enumeration. The function test tests whether a particular enumeration is part of a combined enumeration.
The following example combines two enumeration values, AnchorStyles.Left and AnchorStyles.Left, and then uses test to test the resulting enumeration:
#light
open System.Windows.Forms
let anchor = Enum.combine [AnchorStyles.Left ; AnchorStyles.Left]
printfn "(Enum.test anchor AnchorStyles.Left): %b"
(Enum.test anchor AnchorStyles.Left)
printfn "(Enum.test anchor AnchorStyles.Right): %b"
(Enum.test anchor AnchorStyles.Right)
The results of this code, when compiled and executed, are as follows:
(Enum.test anchor AnchorStyles.Left): true
(Enum.test anchor AnchorStyles.Right): false
Enum types marked with the System.Flags attribute also support the use of the &&& and ||| operators to perform these operations directly. For example, you could write the previous code as follows:
#light
open System.Windows.Forms
let anchor = AnchorStyles.Left ||| AnchorStyles.Left
printfn "test AnchorStyles.Left: %b"
(anchor &&& AnchorStyles.Left <> Enum.of_int 0)
printfn "test AnchorStyles.Right: %b"
(anchor &&& AnchorStyles.Right <> Enum.of_int 0)The Microsoft.FSharp.Text.Printf Module
The Printf module provides functions for formatting strings in a type-safe way. The functions in the Printf module take a string with placeholders for values as their first argument. This returns another function that expects values for the placeholders. You form placeholders by using a percentage sign and a letter representing the type that they expect. Table 7-1 shows the full list.
Table 7-1. Printf Placeholders and Flags
The following example shows how to use the printf function. It creates a function that expects a string and then passes a string to this function.
#light
Printf.printf "Hello %s" "Robert"
The results of this code are as follows:
Hello Robert
The significance of this might not be entirely obvious, but the following example will probably help explain it; if a parameter of the wrong type is passed to the printf function, then it will not compile:
#light
Printf.printf "Hello %s" 1
The previous code will not compile, giving the following error:
Prog.fs(4,25): error: FS0001: This expression has type
int
but is here used with type
string
This also has an effect on type inference. If you create a function that uses printf, then any arguments that are passed to printf will have their types inferred from this. For example, the function myPrintInt, shown here, has the type int -> unit because of the printf function contained within it:
#light
let myPrintInt x =
Printf.printf "An integer: %i" x
The basic placeholders in a Printf module function are %b for a Boolean; %s for a string; %d or %i for an integer; %u for an unsigned integer; and %x, %X, or %o for an integer formatted as a hexadecimal. It is also possible to specify the number of decimal places that are displayed in numeric types. The following example demonstrates this:
#light
let pi = System.Math.PI
Printf.printf "%f
" pi
Printf.printf "%1.1f
" pi
Printf.printf "%2.2f
" pi
Printf.printf "%2.8f
" pi
The results of this code are as follows:
3.141593
3.1
3.14
3.14159265
The Printf module also contains a number of other functions that allow a string to be formatted in the same ways as printf itself but allow the result to be written to a different destination. The following example shows some of the different versions available:
#light
// write to a string
let s = Printf.sprintf "Hello %s
" "string"
print_string s
// prints the string to the given channel
Printf.fprintf stdout "Hello %s
" "channel"
// prints the string to a .NET TextWriter
Printf.twprintf System.Console.Out "Hello %s
" "TextWriter"
// create a string that will be placed
// in an exception message
Printf.failwithf "Hello %s" "exception"
The results of this code are as follows:
Hello string
Hello channel
Hello TextWriter
Microsoft.FSharp.FailureException: Hello exception
at [email protected](String s)
at [email protected](A inp))
at <StartupCode>.FSI_0003._main()
stopped due to error
The Microsoft.FSharp.Control.IEvent Module
You can think of an event in F# as a collection of functions that can be triggered by a call to a function. The idea is that functions will register themselves with the event, the collection of functions, to await notification that the event has happened. The trigger function is then used to give notice that the event has happened, causing all the functions that have added themselves to the event to be executed.
I will cover the following features of the IEvent module:
Creating and handling events: The basics of creating and handling events using the create and add functions
The
filterfunction: A function to filter the data coming into eventsThe
partitionfunction: A function that splits the data coming into events into twoThe
mapfunction: A function that maps the data before it reaches the event handler
Creating and Handling Events
The first example looks at a simple event being created using the IEvent module's create function. This function returns a tuple containing the trigger function as its first item and the event itself as its second item. Often you need to add type annotations to say what type of event you want, that is, what type of parameter your event's handler functions should take. After this, you use the event's Add function to add a handler method, and finally you trigger the event using the trigger function:
#light
let trigger, event = IEvent.create<string>()
event.Add(fun x -> printfn "%s" x)
trigger "hello"The result of this code is as follows:
hello
In addition to this basic event functionality, the F# IEvent module provides a number of functions that allow you to filter and partition events to give fine-grained control over which data is passed to which event handler.
The filter Function
The following example demonstrates how you can use the IEvent module's filter function so that data being passed to the event is filtered before it reaches the event handlers. In this example, you filter the data so that only strings beginning with H are sent to the event handler:
#light
let trigger, event = IEvent.create<string>()
let newEvent = event |> IEvent.filter (fun x -> x.StartsWith("H"))
newEvent.Add(fun x -> printfn "new event: %s" x)
trigger "Harry"
trigger "Jane"
trigger "Hillary"
trigger "John"
trigger "Henry"
The results of this code, when compiled and executed, are as follows:
new event: Harry
new event: Hillary
new event: Henry
The partition Function
The IEvent module's partition function is similar to the filter function except two events are returned, one where data caused the partition function to return false and one where data caused the partition function to return true. The following example demonstrates this:
#light
let trigger, event = IEvent.create<string>()
let hData, nonHData = event |> IEvent.partition (fun x -> x.StartsWith("H"))
hData.Add(fun x -> printfn "H data: %s" x)
nonHData.Add(fun x -> printfn "None H data: %s" x)
trigger "Harry"
trigger "Jane"
trigger "Hillary"
trigger "John"
trigger "Henry"
The results of this code are as follows:
H data: Harry
None H data: Jane
H data: Hillary
None H data: John
H data: Henry
It is also possible to transform the data before it reaches the event handlers. You do this using the map function provided in the IEvent module. The following example demonstrates how to use it:
#light
let trigger, event = IEvent.create<string>()
let newEvent = event |> IEvent.map (fun x -> "Mapped data: " + x)
newEvent.Add(fun x -> print_endline x)
trigger "Harry"
trigger "Sally"
The results of this code are as follows:
Mapped data: Harry
Mapped data: Sally
This section has just provided a brief overview of events in F#. You will return to them in more detail in Chapter 8 when I discuss user interface programming, because that is where they are most useful.
The Microsoft.FSharp.Math Namespace
The Microsoft.FSharp.Math namespace is designed to enable F# to ensure that the F# libraries include definitions of some of the foundational constructs used across a wide range of graphics, mathematical, scientific, and engineering applications. First you will look briefly at the modules that make it up, and then you'll dive into a more detailed example.
It contains arbitrary precision numbers; these are numbers whose values have no upper limit and include the modules BigInt and BigNum. A typical use of these would be in a program that searches for large prime numbers, perhaps for use in cryptography.
The modules Matrix, Vector, RowVector, and Notations all contain operations related to matrices and vectors. Matrices are sets of numbers arranged in rows and columns to form a rectangular array. Vectors are a column of numbers and are like a matrix with one column but are a separate type. A vector is a quantity characterized by magnitude and direction, so a two-dimensional vector is specified by two coordinates, a three-dimensional vector by three coordinates, and so on; therefore, vectors are represented as a matrix made up of one column with the number of rows depending on the dimension of the vector.
There is a module, Complex, for working with complex numbers. The complex numbers are the base for many types of fractal images, so I will demonstrate how you can use the F# complex number library to draw the most famous fractal of all, the Mandelbrot set. The Mandelbrot set is generated by repeated iteration of the following equation:
Cn+1 = Cn2 + c
The next number in the series is formed from the current number squared plus the original number. If repeated iteration of this equation stays between the complex number C(1, 1i) and C(−1, −1i), then the original complex number is a member of the Mandelbrot set. This can be implemented in F# with the following:
#light
open Microsoft.FSharp.Math
open Microsoft.FSharp.Math.Notation
let cMax = complex 1.0 1.0
let cMin = complex -1.0 -1.0
let iterations = 18
let isInMandelbrotSet c0 =
let rec check n c =
(n = iterations)
or (cMin < c) && (c < cMax) && check (n + 1) ((c * c) + c0)
check 0 c0
The function isInMandelbrotSet tests whether a complex number is in the Mandelbrot set by recursively calling the check function with the new c value of ((c * c) + c0) until either the complex number passes one of the constants cMax or cMin or the number of iterations exceeds the constant iterations. If the number of iterations specified by iterations is reached, then number is a member of the set; otherwise, it is not.
Because the complex numbers consist of two numbers, they can be represented in a two-dimensional plane. The Mandelbrot complex numbers exist between C(1, 1i) and C(−1, −1i) so the plane that you need to draw has the origin, which is the point 0, 0, in the center, and its axis extends out in either direction until reaching a maximum of 1.0 and a minimum of −1.0, such as the plane on the right of Figure 7-1. However, when it comes to pixels on a computer screen, you must deal with a plane where the origin is in the top-right corner and it extends rightward and downward. Because this type plane is made up of pixels, which are discrete values, it is represented by integers typically somewhere in the range 0 to 1600. Such a plane appears on the left of Figure 7-1.
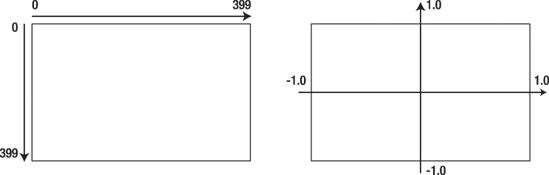
Figure 7-1. A bitmap plane vs. a complex plane
So, the application must map the points in the bitmap plane to points in the complex plane so that you can tell whether a pixel is part of the complex plane.
It is easy to perform this mapping in just a few lines of F# code:
#light
open Microsoft.FSharp.Math
open Microsoft.FSharp.Math.Notation
let scalingFactor = 1.0 / 200.0
let offset = -1.0
let mapPlane (x, y) =
let fx = ((float x) * scalingFactor) + offset
let fy = ((float y) * scalingFactor) + offset
complex fx fy
Once this is complete, you just need to cycle through all the points in your bitmap plane, mapping them to the complex plane using the mapPlane function. Then you need to test whether the complex number is in the Mandelbrot set using the function isInMandelbrotSet. Then you set the color of the pixel. The full program is as follows:
#light
open System
open System.Drawing
open System.Windows.Forms
open Microsoft.FSharp.Math
open Microsoft.FSharp.Math.Notation
let cMax = complex 1.0 1.0
let cMin = complex -1.0 -1.0
let iterations = 18
let isInMandelbrotSet c0 =
let rec check n c =
(n = iterations)
or (cMin < c) && (c < cMax) && check (n + 1) ((c * c) + c0)
check 0 c0
let scalingFactor = 1.0 / 200.0
let offset = -1.0
let mapPlane (x, y) =
let fx = ((float x) * scalingFactor) + offset
let fy = ((float y) * scalingFactor) + offset
complex fx fy
let form =
let image = new Bitmap(400, 400)
for x = 0 to image.Width - 1 do
for y = 0 to image.Height - 1 do
let isMember = isInMandelbrotSet ( mapPlane (x, y) )
if isMember then
image.SetPixel(x,y, Color.Black)
let temp = new Form() in
temp.Paint.Add(fun e -> e.Graphics.DrawImage(image, 0, 0))
temp
[<STAThread>]
do Application.Run(form)
This program produces the image of the Mandelbrot set in Figure 7-2.

Figure 7-2. The Mandelbrot set
The ML Compatibility Library MLLib.dll
The MLLib library was designed to allow cross-compilation with code written in OCaml. It contains implementations of a subset of the modules that are distributed with OCaml. This played an important role in the development of F# because the compiler was originally written in OCaml and then cross-compiled into F# to produce a .NET assembly.
It contains many functions that are really useful, even to programmers who have no intention of cross-compiling their code; the most useful of these is the Arg module. Here, I will cover the following modules:
Microsoft.FSharp.MLLib.Pervasives: A module containing some floating-point functions and some simple functions to help the programmer manage I/O
Microsoft.FSharp.MLLib.Arg: A module for processing command-line arguments
The Microsoft.FSharp.Compatibility.OCaml.Pervasives Module
The word pervasive means thoroughly penetrating or permeating, which is a good description for the Pervasives module. It is automatically opened by the compiler, and its functions permeate through most F# code, since functions that it contains can be used automatically without a qualifier. You have already met some of the functions in many examples in this book, especially the print_string, print_endline, and print_int functions that were often used to write to the console.
It's hard to categorize the type of functions found in the Pervasives module; because they are generally the sort of thing a programmer will find useful, I will cover the following topics:
Arithmetic operators: Operators for basic arithmetic operations such as addition and subtraction
Floating-point arithmetic functions: More advanced arithmetic functions including logarithms and trigonometry
Mutable integer functions: Functions on mutable integers
Streams: Functions to help the programmer mange I/O
Arithmetic Operators
As already covered in Chapter 2, in F# operators can be defined by the programmer, so all the arithmetic operators are defined in the Pervasives module rather than built into the language. Therefore, the majority of operators that you will use in your day-to-day programming in F# are defined in the Pervasives module. I imagine that operators such as + and - need little explanation, since their usage is straightforward:
let x1 = 1 + 1
let x2 = 1 - 1
However, the F# equality operator is a bit more subtle. This is because in F# equality is structural equality, meaning that the contents of the objects are compared to check whether the items that make up the object are the same. This is opposed to referential equality, which determines whether two identifiers are bound to the same object or the same physical area of memory; a referential equality check can be performed using the method obj.ReferenceEquals. The structural equality operator is =, and the structural inequality operator is <>. The next example demonstrates this. The records robert1 and robert2 are equal, because even though they are separate objects, their contents are the same. On the other hand, robert1 and robert3 are not equal because their contents are different.
#light
type person = { name : string ; favoriteColor : string }
let robert1 = { name = "Robert" ; favoriteColor = "Red" }
let robert2 = { name = "Robert" ; favoriteColor = "Red" }
let robert3 = { name = "Robert" ; favoriteColor = "Green" }
printf "(robert1 = robert2): %b
" (robert1 = robert2)
printf "(robert1 <> robert3): %b
" (robert1 <> robert3)
The results of this code, when compiled and executed, are as follows:
(robert1 = robert2): true
(robert1 <> robert3): true
Structural comparison is also used to implement the > and < operators, which means they too can be used to compare F#'s record types. This is demonstrated here:
#light
let robert2 = { name = "Robert" ; favoriteColor = "Red" }
let robert3 = { name = "Robert" ; favoriteColor = "Green" }
printf "(robert2 > robert3): %b
" (robert2 > robert3)
The results of this code, when compiled and executed, are as follows:
(robert2 > robert3): true
If you need to determine whether two objects are physically equal, then you can use the eq function available in the Obj module, as in the following example:
#light
let robert1 = { name = "Robert" ; favoriteColor = "Red" }
let robert2 = { name = "Robert" ; favoriteColor = "Red" }
printfn "(Obj.eq robert1 robert2): %b" (Obj.eq robert1 robert2)
Floating-Point Arithmetic Functions
The Pervasives module also offers a number of functions (see Table 7-2) specifically for floating-point numbers, some of which are used in the following sample:
#light
printfn "(sqrt 16.0): %f" (sqrt 16.0)
printfn "(log 160.0): %f" (log 160.0)
printfn "(cos 1.6): %f" (cos 1.6)
The results of this code, when compiled and executed, are as follows:
(sqrt 16.0): 4.000000
(log 160.0): 5.075174
(cos 1.6): −0.029200
Table 7-2. Arithmetic Functions for Floating-Point Numbers
Mutable Integer Functions
The Pervasives module also offers two useful functions that operate on mutable integers. The incr and decr functions increment and decrement a mutable integer, respectively. The use of these functions is demonstrated here:
#light
let i = ref 0
(incr i)
print_int !i
print_newline ()
(decr i)
print_int !iThe results of this code are as follows:
1
0
Streams
Finally, you've come to the last major set of functions within the Pervasives module—functions that read from and write to streams. Streams are a way of managing I/O that allows a file, a network connection, or an area of memory to be written to in a homogeneous fashion. A stream is a value that provides functions to either read from it or write to it. A stream is an abstract concept, because no matter whether it represents a file, a connection, or memory, you can use the same methods to write to it. You have already seen the functions print_endline, print_newline, print_string, print_int, and printf used throughout the examples in this book. These are all examples of functions that write to the standard output stream, typically the console. The Pervasives module also provides several functions for reading from the standard input stream, typically the keyboard:
#light
let myString = read_line ()
let myInt = read_int ()
let myFloat = read_float ()
When executed, this sample will bind the identifier myString to a string input by the user. It will also bind myInt and myFloat to the integer and float values input by the user, provided the user types a correctly formed integer and float.
The fact that these functions read from and write to streams is not entirely obvious because they don't take stream parameters. This is because they are wrapper methods that hide that they are reading from or writing to a stream. They are built on top of some more general functions for reading from and writing to a stream. The next example demonstrates how to use the stream stdout, which defaults to the console, and shows how this can be written to in the same manner as writing to a file, using the output_string function:
#light
let getStream() =
print_string "Write to a console (y/n): "
let input = read_line ()
match input with
| "y" | "Y" -> stdout
| "n" | "N" ->
print_string "Enter file name: "
let filename = read_line ()
open_out filename
| _ -> failwith "Not an option"
let main() =
let stream = getStream()
output_string stream "Hello"
close_out stream
read_line() |> ignore
main()
The function getStream allows the user to switch between writing to the console and writing to a file. If the user chooses to write to the console, the stream stdout is returned; otherwise, it asks the user to provide a filename so open_out can be used to open a file stream.
The implementation of streams is based on the classes available in System.IO namespace; the out_channel is an alias for TextWriter, and in_channel is an alias for TextReader. These aliases were included for compatibility purposes; you probably want to consider the classes available in the BCL's System.IO namespace directly, because this often gives you more flexibility.
The Microsoft.FSharp.Compatibility.OCaml.Arg Module
The Arg module allows users to quickly build a command-line argument parser. It does this by using F#'s union and list types to create a little language that is then interpreted by a number of functions provided in the Arg module.
The Arg module exposes a tuple type called argspec, which consists of two strings and a union type called spec. The first string in the tuple specifies the name of the command-line argument. The second item in the tuple is the union type spec, which specifies what the command-line argument is; for example, is it followed by a string value, or is it just a flag? It also specifies what should be done if and when the command-line token is found. The final string in the tuple is a text description of what the flag does. This will be printed to the console in the case of a mistake in the command-line arguments. It also serves as a useful note to the programmer.
The Arg module exposes two functions for parsing arguments: parse, which parses the command passed in on the command line, and parse_argv, which requires the arguments to be passed directly to it. Both should be passed a list of type argspec describing the command-line arguments expected, a function that will be passed all the command-line arguments not prefixed with -, and finally a string to describe the usage.
The module also exposes a third function usage, which can be passed a list of type argspec and will just directly write out the usage.
The following example demonstrates an argument parser built in this manner. The parameters collected from the command line are stored in identifiers for later use, in this case being written to the console.
#light
let myFlag = ref true
let myString = ref ""
let myInt = ref 0
let myFloat = ref 0.0
let (myStringList : string list ref) = ref []
let argList =
[
("-set", Arg.Set myFlag, "Sets the value myFlag");
("-clear", Arg.Clear myFlag, "Clears the value myFlag");
("-str_val", Arg.String(fun x -> myString := x), "Sets the value myString");
("-int_val", Arg.Int(fun x -> myInt := x), "Sets the value myInt");
("-float_val", Arg.Float(fun x -> myFloat := x), "Sets the value myFloat");
]
if Sys.argv.Length <> 1 then
Arg.parse
argList
(fun x -> myStringList := x :: !myStringList)
"Arg module demo"
else
Arg.usage
argList
"Arg module demo"
exit 1
printfn "myFlag: %b" !myFlag
printfn "myString: %s" !myString
printfn "myInt: %i" !myInt
printfn "myFloat: %f" !myFloat
printfn "myStringList: "
print_any !myStringListWhen run with no command-line arguments or faulty command-line arguments, the program will output this:
Arg module demo
-set: Sets the value my_flag
-clear: Clears the value my_flag
-str_val <string>: Sets the value my_string
-int_val <int>: Sets the value my_int
-float_val <float>: Sets the value my_float
--help: display this list of options
-help: display this list of options
When run with the command line args.exe -clear -str_val "hello world" -int_val 10 -float_val 3.14 "file1" "file2" "file3", the program will output the following:
myFlag: false
myString: hello world
myInt: 10
myFloat: 3.140000
myStringList: ["file3"; "file2"; "file1"]
The Arg module is an excellent example of how creating a little language can make programming tasks easier and quicker and the resulting code easier to understand and more maintainable. You'll find more details on this style of programming in Chapter 11.
Summary
I covered a lot ground in this chapter, since the F# libraries have a diverse range of functionalities. First you looked through the FSLib.dll library with its useful Collections, Reflection, and Math modules. Then you looked at MLLib.dll, which provides functions that are excellent building blocks for all applications. Its Seq module is something that any nontrivial F# program will not be able to do without.
The next three chapters will look at how you can use F# with various .NET APIs for common programming tasks. You'll start with a look at implementing user interfaces in Chapter 8, and then you'll move to data access in Chapter 9 and distributed applications in Chapter 10.