
The risk treatment requirements obtained during an information risk management programme should never be actioned without having the full approval and support of senior management (often at board level), so that the correct levels of funding and people resources can be allocated without causing problems for the organisation.
One of the main avenues for establishing the support of senior management is the preparation and presentation of business cases, which will set out the risks in terms the business will understand and make clear the costs of remediation.
Following the approvals to proceed, the process of detailed decision-making, planning and implementation may begin. There may also be a spin-off in the form of a business continuity exercise, which might include DR planning.
The process of communicating within the information risk management programme is extremely important, and serves a number of purposes. It allows the information risk management programme manager to:
- Maintain a two-way flow of information between the programme manager and those stakeholders who are closely involved in the process of impact, threat and vulnerability assessments.
- Keep the organisation’s senior management and other stakeholders informed both of general progress and of specific actions regarding the highest risks encountered or those that are particularly costly to treat.
- Flag up any new risks deemed to be very severe and requiring immediate attention.
- Present business cases requesting approval of recommendations and funding.
- Report on those risks that have been successfully treated and those that remain untreated.
It is often said that senior executives will never understand information risk, but this is not entirely correct. They may not understand the technicalities of information security, but business risk is something they will definitely understand, so the streetwise information risk management programme manager will ensure that all reporting is couched in terms of risk to the organisation and the business benefits to be gained by avoiding, transferring, reducing or accepting it.
Business cases are a standard vehicle for demonstrating a genuine need to carry out some form of activity that will require senior management approval. They are generally used in those circumstances in which a significant financial spend is proposed (beyond that of day-to-day budgets), and in the case of an information risk management programme will most frequently be brought into play in gaining approval to carry out risk reduction or modification, although some aspects of risk transfer or sharing will also require board-level agreement.
In some situations, the business case might present senior management with a clear and simple ‘yes or no’ decision, while others might involve a number of options with a recommendation for a specific approach that, in the view of the information risk manager, represents the most appropriate solution combined with good value for money. In the case of the latter, the senior management team will be required to choose their favourite option, and the contents of the business case will heavily influence this choice.
It follows, therefore, that the business case should be as comprehensive and compelling as possible, so that senior management’s decision-making process is made completely straightforward and that they make a fully informed choice.
There is no generic set format for a business case. Some organisations have their own template, whereas others allow a free format of presentation. In this section, we suggest some of the essential components of the business case and describe how best to present it.
Many people will be familiar with the name of Robert Maxwell, who ran a vast publishing business empire that included newspapers such as The New York Times, The Daily Mirror, The Scottish Daily Record and The European. Whatever his faults, he adopted a very simple approach to business cases: he relied on his senior management team to pull together the best advice and to present this to him in as short a time as possible.
When it came to receiving his formal approval, a single sheet of A4 was all he needed to read, written in a 14-point Courier typeface, with 1.5 line spacing, and a signature line near the bottom of the page followed by the words ‘Approved. R Maxwell, Chairman’. Supporting information was always stapled behind this, but he rarely studied it.
Most senior executives do not have the time to read large amounts of detail and, since information security is not usually their strongest point, might find it difficult to follow. What they do need are clear, concise facts: the issue, the proposed solution, the costs, the benefits to be gained and, if necessary, the downsides of not choosing the recommended option.
It is suggested that a business case document should contain the following sections:
- An introductory executive summary – preferably on a single page.
- The benefits to the organisation of undertaking the work.
- A synopsis of the goals and objectives and the main risks threatening the information assets, together with the likely impacts or consequences faced by the organisation if the threats were to materialise.
- A synopsis of the proposed solution, together with reasoning as to how and why this would eliminate the risk or reduce it to a level acceptable to the organisation, together with the timescales for doing so.
- A financial breakdown, showing both capital and operating expenditure required over a three to five year period, with resources for premises, equipment and people clearly identified.
- A high-level project overview, including critical success factors.
- An implementation plan, including resources required, a timeline and key milestones.
Many organisations prefer a personal briefing as well as a business case document, in which case a slide presentation – probably no more than 10 slides – should be prepared and delivered by a programme representative who feels comfortable presenting to very senior managers and who can also answer penetrating questions without the need to refer to detailed notes.
Whichever approach is taken, the person presenting the business case would be well advised to socialise the business case beforehand with as many members of the approving committee as possible, so that it is approved ‘on the nod’. This approach has another advantage, in that many of the questions that might be asked during a presentation will either be known or answered beforehand, and any last-minute changes to the business case that will assist in gaining approval can be included.
RISK TREATMENT DECISION-MAKING
The decision-making process for risk treatment follows a logical path. It begins by identifying the strategic option or options that the organisation should take – risk avoidance or termination; risk transfer or sharing; risk reduction or modification; and risk acceptance or tolerance – and this part of the process will have been taken care of during the final stage of risk assessment, risk evaluation.
The next step for each of the chosen strategic approaches is to identify the tactical options. These will depend completely on the strategic approaches, but will be as follows:
- Risk avoidance or termination presents both preventative and detective options, but these are invariably used together, since the preventative course of action will require ongoing (detective) monitoring to ensure that further action is taken if something changes.
- Risk transfer or sharing has both directive and detective options and, again, these are used together, since any shared risk also requires ongoing monitoring to ensure that it is working as expected.
- Risk reduction or modification is the most complex, as it can involve directive, detective, preventative and corrective actions, again with ongoing monitoring.
- Finally, risk acceptance or tolerance follows the detective approach with ongoing monitoring, and it is very important to repeat that no risk, no matter how trivial it might appear, should ever be ignored.
Having identified the tactical risk treatment options, the final stage is to identify the operational options:
- Risk avoidance utilises both detective and preventative controls. The preventative controls will almost always be physical or technical, and the detective controls will always be procedural.
- Risk transfer’s detective controls will usually be procedural (in the case of insurance, for example), or may be both technical and procedural in the example of outsourcing operations to a cloud service provider.
- Risk reduction uses all three types of operational control. Preventative controls can be either physical (e.g. security barriers) or technical (e.g. firewalls). Corrective controls can be physical or technical (e.g. ensuring that bug fixes are applied to software), or procedural. Directive controls are instructive, and therefore always procedural, and include policies, processes and works instructions. Detective controls can be physical (e.g. CCTV systems), technical (e.g. intrusion detection software) or procedural (e.g. system activity monitoring).
- Finally, risk acceptance requires just detective procedural controls to provide ongoing monitoring of threats to ensure that the level of risk has not changed.
RISK TREATMENT PLANNING AND IMPLEMENTATION
It is quite conceivable that many of the risks requiring treatment as part of the information risk management programme can undergo treatment as an integral part of the programme. However, some risks might require extensive (or expensive) treatment, and as such may need to be treated as a project or programme of work in their own right.
However, although the implementation may be carried out under a separate project or programme, progress reporting of the implementation should remain part of the original information risk management programme so that the audit trail is complete.
Such a project requires the setting of goals, objectives, scope and milestones, which, given the controls recommended and agreed earlier in the information risk management programme, should be relatively straightforward to define.
The risk treatment plan should commence with the production of a prioritised list of risks for treatment, which includes realistic estimates of the length of time these might take to achieve, the approximate cost of the treatment and the resources required (including the name of the responsible person) for doing so. By totalling the number of completed risk treatments and the running costs, additional information can be reported to senior management.
Regardless of whether the project is to be managed from within or outside the main information risk management programme, resources, especially people and funding, must have been agreed and committed by the organisation. This will include a suitably qualified alified project manager, who may be a different entity from the information risk management programme manager, particularly if the project is significant in its scope; for example, if the agreed control is for the provision of an entire backup data centre with high-availability standby systems, this would be a major project in its own right, and would certainly require at least one dedicated project manager, if not several.
However, even if the remedial work to implement the agreed controls is relatively minor, each individual control should be considered as a task within an overall project, so that it can have resources assigned to it and be tracked to completion and sign-off.
BUSINESS CONTINUITY AND DISASTER RECOVERY
Occasionally, the controls recommended may be very wide-ranging, such as the need for business continuity management (BCM) and DR arrangements, which are specialist subject areas in their own right. However, it is worth providing a brief description of both approaches.
Business continuity
The concept of BC became better known in 2006 with the introduction of the first full standard, BS 25999-1, the Code of Practice, and then its Specification, BS 25999-2, in 2007. Prior to that, there had only ever been a publicly available specification, PAS 56, published in 2003 and developed from an early Business Continuity Institute (BCI) Good Practice Guidelines document.
The two BS 25999 standards were superseded in 2012, and the international standard ISO 22301:2019 – Societal security – Business continuity management systems – Requirements now applies instead.
BC is defined as ‘The capability of the organisation to continue delivery of products and services at acceptable predefined levels following a disruptive incident’ (ISO 22301:2019).
BC applies to a number of key areas within an organisation, and so is considered to be a holistic approach to risk management. It includes:
- The people employed by the organisation, together with its contractors.
- The organisation’s premises, whether these are offices, factories, warehouses or other types of building.
- The organisation’s processes and procedures.
- The technology that underpins the organisation’s activities.
- The organisation’s information in both physical and electronic forms.
- The organisation’s supply chain.
- The organisation’s delivery chain.
- Any other stakeholders that have an interest in the organisation.
- The organisation’s responsibilities (if any) in the event of civil emergencies.
At first sight, it would appear that information is just one of these areas, but it actually cuts across all of the remainder, and hence the principles explored in information risk management are fundamental to the discipline of BCM.
The Business Continuity Institute Good Practice Guidelines 2018
Founded in 1994, the BCI has always been at the forefront of business continuity standards development, and was instrumental in the first UK specification PAS 56, published in 2003. Its members have subsequently taken a leading role in the later development of BS 25999 in 2006/7 and ISO 22301 in 2012 and beyond.
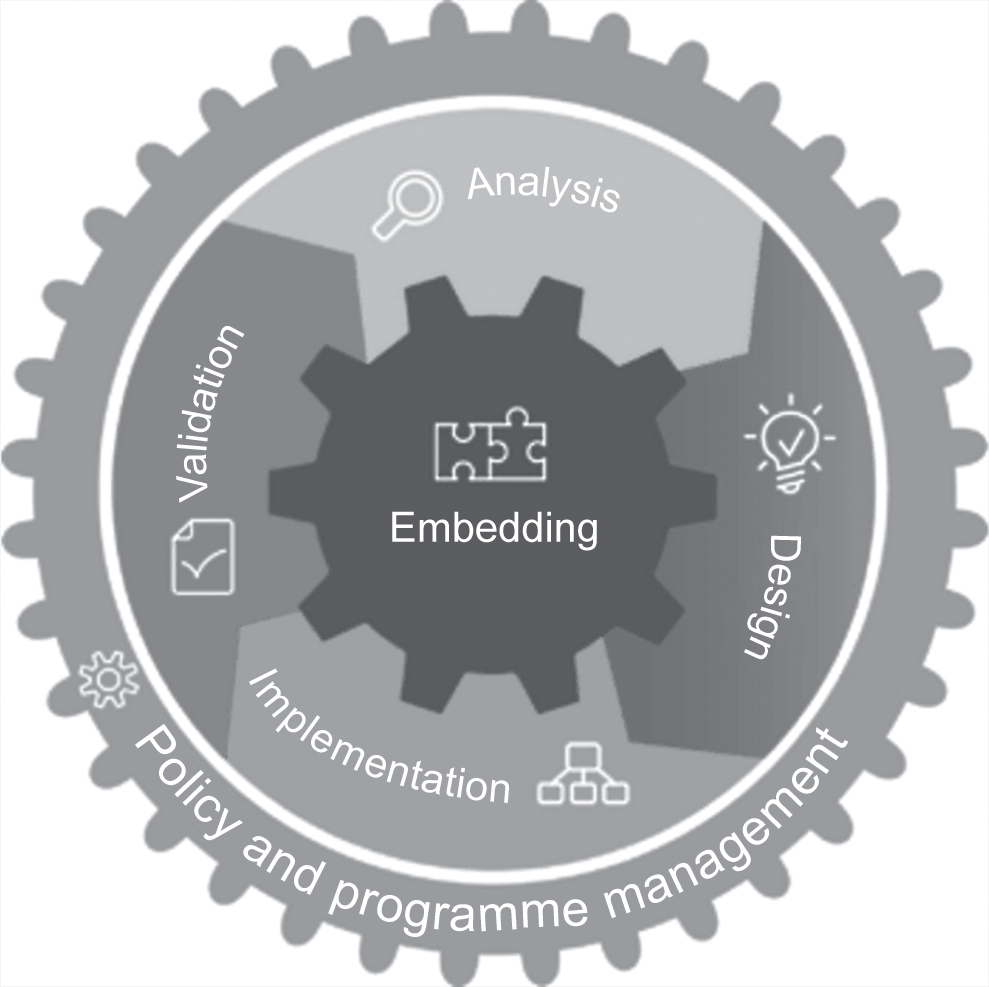
Over the years, the Institute has developed a set of good practice guidelines (GPGs) that define the generic approach to BCM in six distinct stages, or so-called Professional Practices (PPs):
PP1 Policy and Programme Management – this is the beginning of the overall BCM life cycle, and defines the organisation’s policy for BC: how it will be implemented, managed and tested.
PP2 Embedding – it is important that the culture of BCM is embedded into day-to-day operations within an organisation.
PP3 Analysis – in earlier versions of the Good Practice Guide, this was known as Understanding the Organisation, and assesses the organisation’s overall objectives, how it functions and the internal and external context within which it operates. It includes the risk assessment process of risk management.
PP4 Design – formerly known as Determining Business Continuity Strategy, this area recommends suitable approaches (both strategic and tactical) to recover from disruptive events and to provide continuity of operations.
PP5 Implementation – this area was previously known as Determining and Implementing a BCM Response, and carries out the recommended and agreed approaches through the development of business continuity plans (BCPs). Together with Design, this area aligns with the risk treatment portion of risk management.
PP6 Validation – validation was originally referred to as Exercising, Maintaining and Reviewing, and deals with the validation of BC plans through tests and exercises to ensure that they are fit for purpose and would be effective in disruptive situations.
Professional Practices 1 and 2 are described as management practices, whereas Professional Practices 3 to 6 are described as technical practices. The BCI’s life cycle diagram illustrates this graphically in Figure 8.1.1
These are by no means mandatory requirements, but most BC practitioners – and not only in the UK – will follow them, since they provide considerable assistance when an organisation wishes to become compliant with the standard and to achieve accreditation against it.
Business continuity plans
BCPs produced will normally include:
- IM plans, which deal with the immediate aftermath of business-disrupting incidents and which can include information security incidents as well as civil emergencies, strikes and pandemics.
- BC plans, which take the process following incident management through recovery to a normal, near-normal or new normal state.
- DR plans, which deal mainly with restoring the capability of IT systems.
- Business resumption (BR) plans, which are the final stage of recovery from incidents and which take operations back as closely as possible to the same state as they were in prior to the incident.
Although BC itself is generally thought of as being a form of risk reduction or modification, a BC programme of work may well make use of all forms of strategic, tactical and operational controls in order to achieve its objectives. Figure 8.2 illustrates the generic BC incident timeline.
Once IM, BCM, DR and BR plans have been developed, they must be tested in order to prove their fitness for purpose.
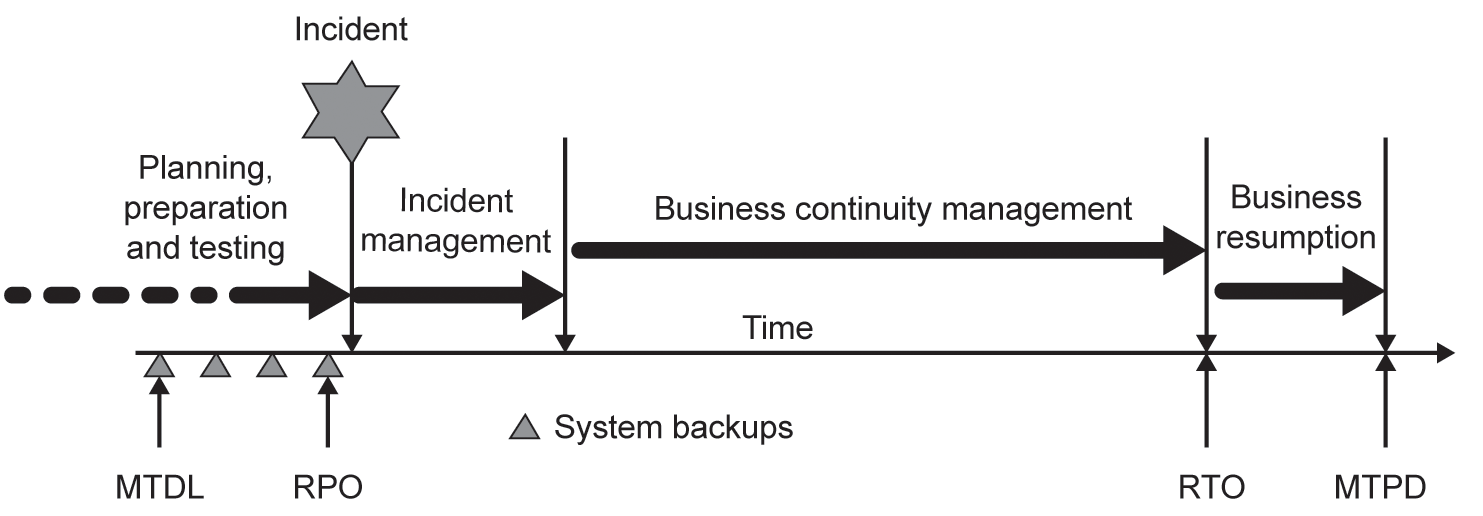
BC introduces some terminology that is not generally used in information risk management. However, when implementing a BC strategy as part of the treatment process for an information risk management programme, it is worthwhile being aware of these terms:
Recovery point objective (RPO). The point to which information used by an activity must be restored to enable the activity to operate on resumption.
Recovery time objective (RTO). The period of time following an incident within which products, services or activities must be resumed or resources must be recovered.
Maximum acceptable outage (MAO). The time it would take for adverse impacts, which might arise as a result of not providing a product/service or performing an activity, to become unacceptable.
Maximum tolerable data loss (MTDL). The maximum loss of information (electronic and other data) that an organisation can tolerate. The age of the data could make operational recovery impossible, or the value of the lost data is so substantial as to put business viability at risk.
Maximum tolerable period of disruption (MTPD). The time it would take for adverse impacts, which might arise as a result of not providing a product/service or performing an activity, to become unacceptable.
Minimum business continuity objective (MBCO). The minimum level of services and/or products that is acceptable to the organisation to achieve its business objectives during a disruption.
Various types of test may be undertaken:
- Communications tests, in which the contact procedures are invoked to ensure that members of the various teams responsible for managing the situation can be contacted and instructed either to attend the crisis management centre or to join an audio or video conference call.
- Desktop read-throughs, in which the plans are scrutinised by all members of the various response and recovery teams in order to verify that all necessary activities have been identified, that they are in the correct order and that all interdependencies have been considered.
- Scenario-based exercises, in which the BC manager develops an imaginary or real-world event-based scenario for the response and recovery teams to work through as if it were an actual event. Lessons learnt from this type of exercise will often refine the plans as gaps and overlaps are identified.
- Full-scale exercises, again usually scenario-based, in which many or all of the organisation’s staff are involved to some extent in order to verify that the plans do actually work in situations as close as possible to real-world events. Such exercises will disrupt the organisation’s business activities, and will often only be performed under exceptional circumstances.
BC is invariably conducted as a separate programme of work from that of information risk management, since it may have much wider implications for the organisation, especially in terms of the resources required to operate the programme and to exercise the plans.
Disaster recovery
DR is a specialised subset of BC, and is generally used to refer to the arrangements put in place to provide backup or recovery computing facilities, although it can refer to other forms of technical processing. In our Glossary of Terms, we describe disaster recovery as ‘A coordinated activity to enable the recovery of ICT [information, communications and technology] systems and networks due to a disruption’.
Some organisations make use of system hardware normally used for software application testing purposes to provide DR: sometimes on a one-for-one basis, so that the standby hardware is identical to the system being replicated, sometimes on a one-to-many basis, where one backup system can be used to provide DR for a number of live systems. Figure 8.3 illustrates the overall structure of DR operations:
Figure 8.3 Overall structure for disaster recovery
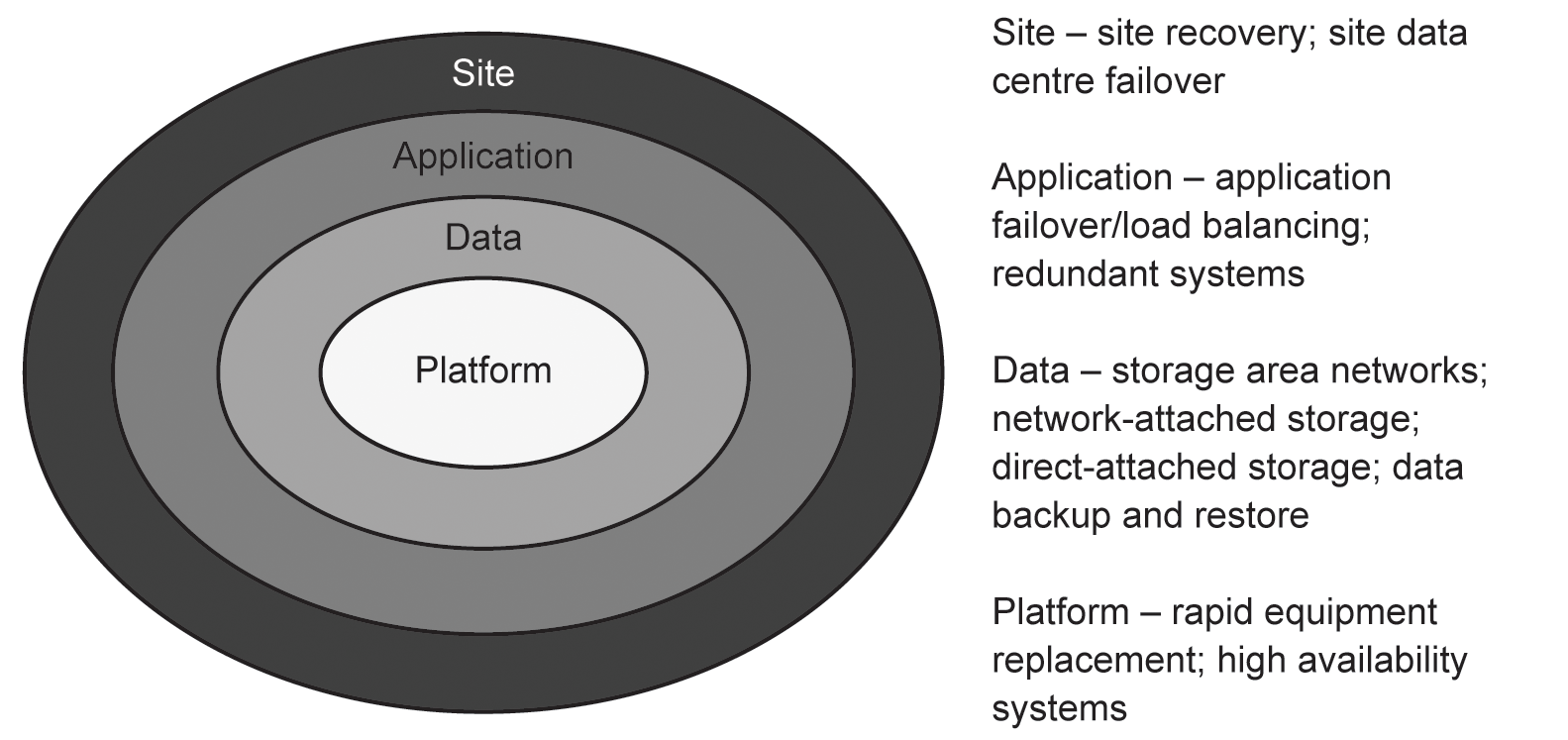
Platform DR generally involves the use of one or more of the three following types of facility.
Cold standby platforms These consist of bare computer systems and associated communications equipment. They may have an operating system loaded, but little else. The organisation or its outsourced DR partner will be responsible for loading any additional operating systems and applications software required in order to operate the system in the same way as the one it is replicating. In addition, all data must be restored from backup media, and the organisation will need to take into account any patches or software updates that have been issued.
Because these systems are very basic, they represent the lowest cost to an organisation, and take the longest amount of time to bring up to full operation.
Warm standby platforms Warm standby systems invariably have their full operating system and key applications loaded, and may have some backed-up data loaded as well. However, unless the system has been maintained in a fully ‘ready’ state, the organisation will need to take into account any patches or software updates that have been issued since the system was originally configured. Data will have to be brought fully up to date by restoring from the most recent backups.
Warm standby systems are more expensive to provide than cold standby systems, and can normally be brought into service much more quickly.
Hot standby/high-availability platforms At the top end of the DR range, there are hot standby or high-availability platforms, which are always maintained in a fully ready state from the point of view of operating systems and application software. Data will also be fully up to date, since the system being replicated will copy across all data onto the standby system.
These vary in type and cost, as can be seen from Figure 8.4. Availability is measured in ‘nines’, with five nines, that is, 99.999%, general availability being the highest, which allows for five minutes’ downtime in any 12-month period. Unsurprisingly, higher availability comes with a greatly increased cost, and each ‘nine’ added would probably increase the cost tenfold.
In cases where two systems operate jointly to deliver the service, data are copied between the live and the standby system in one of two ways:
- Asynchronous replication, in which each block of data is sent from the live system to the standby system, receipt is confirmed, but the live system continues to process data in the meantime.
- Synchronous replication, in which each block of data is sent from the live system to the standby system, but the live system waits before continuing to process data until receipt is confirmed.
Synchronous replication is slightly slower than asynchronous replication, but has greater reliability, since no data can be lost at the point of switchover. The distance between the live and standby locations cannot currently be greater than around 200 km (125 miles), and typically uses a direct fibre-optic link, which guarantees capacity as well as reliability.
Figure 8.4 Cost versus availability

High-availability systems are by far the most costly to operate, but for organisations such as banks, large online retail organisations, airlines and the like, failure of service and possible loss of information is simply not an option.
In conjunction with platform DR, organisations should take into account four key areas:
- Resilient power, in which uninterruptible power supplies (UPS) ensure that power is always available to the platforms. UPS systems feed power directly from the incoming mains supply during normal operation, and if and when the incoming supply fails, batteries take over and generate the appropriate levels of power through static inverters. In order to make the power supplies completely resilient, standby generation can also be used, but resilience of fuel supplies for these must then be taken into account.
- Cooling systems are also highly necessary to take away excess heat and allow the systems to operate at a comfortable temperature. It is common practice to allow more cooling systems than are necessary to maintain a constant temperature to allow for failures, and this is referred to as N+1, N+2, and so on.
- Since system hardware can run at temperatures higher than staff would find a comfortable environment, some organisations run the equipment rooms of their data centres slightly warmer, which can reduce cooling costs without a detrimental effect on the systems.
Systems and service monitoring is always required, so that remedial action can be taken as soon as there is a failure in any part of the service being provided. In larger organisations, the internal and external data networks are usually monitored in addition to platforms and services.
- Vendor support is the final key requirement for all operations of this kind, simply because the systems vendor organisations can often supply additional or replacement platforms either at the data centre itself or, increasingly, through cloud services.
Data resilience
Although data storage has moved on considerably in recent years, magnetic media of one kind or another remains the most cost-effective technology, although it is rarely the fastest. There are several commonly used methods of providing resilient data storage:
- Redundant Array of Inexpensive Disks (RAID), which uses several different technologies to achieve various levels of resilience, including error correction, striping and mirroring, some of which will permit a faulty disk drive to be exchanged without loss of any data whatsoever. There are currently around 12 different levels of RAID, and different operating systems (for example, Unix, Linux, MacOS and Microsoft Windows) support slightly different combinations of RAID level. In general, the RAID systems that use more disk drives provide greater resilience, but there are advantages and disadvantages of all types in terms of ease of implementation, cost, resilience and performance.
- Direct Attached Storage (DAS), in which RAID arrays are connected directly to a system using a standard RAID controller. DAS is less resilient than other methods, in that access must always be via the system and controller to which it is connected, which presents a potential single point of failure.
- Network Attached Storage (NAS). Unlike DAS storage, NAS storage does not rely on a separate system for connection but instead uses its own proprietary operating system and connects directly to a network. This means that it can be accessed in a more flexible manner, making deployment much more straightforward. With the ongoing increase of local area network (LAN) speeds, this makes NAS a very attractive option. NAS storage also has the advantage of being able to operate at block level as well as at file level, making it independent of the host operating system.
- Storage Area Networks (SANs) make use of highly resilient fibre-optic links between the host systems and their storage arrays, which are also designed to be highly resilient. Operating completely at the block level, they are entirely independent of the host operating system.
- Cloud-based data storage is increasingly popular, providing a fully managed storage service in which the supplier will take responsibility not only for storage capacity, but also for the (hopefully redundant) links into the customer’s network.
Cloud-based storage has become so low in cost for a given volume of data stored that it is now very popular at the individual consumer level as well as that of larger organisations.
Application resilience
We are all used to experiencing applications on a home or office computer, and these occasionally fail but usually impact only the computer user. At a corporate level, application failures will affect many users, and those that provide a service for online use (for example online banking applications) can affect very large numbers of people if they fail. For this reason, application resilience is key to such services, and can be delivered in one of three ways:
- Clustered file systems distribute the file system across multiple systems or nodes, each of which holds part of the overall file system, but appears to the end-user as a single entity. They provide a very high throughput, but at high cost of deployment and management.
- Application clusters, which are similar to clustered file systems but distribute just the application software across multiple systems, provide increased performance and availability. The host computer sees the application as a single resource, which requires the use of a so-called ‘heartbeat’ between all the systems in the cluster so that a node that has failed can be flagged as such and its resources transferred across the remaining online nodes. Application clusters are quite complex to deploy.
- Computer cluster services include two key options. The first is load balancing, in which the network traffic is distributed as evenly as possible across multiple servers that all share a single Internet Protocol (IP) address, and the load balancing software uses a rule set to decide which server should receive the next request. The second is failover cluster services, which has two options. In the first option, all nodes in a cluster have access to shared resources (such as DAS, NAS, SAN or cloud), and a heartbeat similar to that used in application clusters is used to assist in the control of access to nodes. This is sometimes referred to as the ‘share everything’ approach. In the second option, known as ‘share nothing’, only one node in a cluster has access to the resources at any one time.
Site recovery
Organisations may choose to replicate a complete equipment site in a physically separated location, usually around 30 miles (48 km) apart. This option is invariably expensive, both to provision and to maintain, but offers organisations the opportunity to provide a fully resilient service, not only to the organisation itself but also to its customers and suppliers.
In practice, organisations that make use of site recovery either do so through the agencies of a third party or will make use of space in other offices, warehouses, factories and the like. This is frequently the case for those organisations that operate a large data centre or telecommunications hub, in which site recovery for one location can be relatively straightforward to provide in another site having similar infrastructure and environmental facilities.
DISASTER RECOVERY FAILOVER TESTING
The testing of DR plans generally follows one of two paths:
- ‘Fire drills’, which normally refer to the testing of DR plans in which the process of bringing the standby systems into full readiness is tested but stops short of an actual switchover from live to standby systems, since, depending on the type of standby system implemented, it might be disruptive to the organisation’s business.
- Full switchover tests, in which not only are the standby systems brought into a state of full readiness, but also a switchover from live to standby systems is performed and the performance of the new system status is verified as being at an acceptable level.
Again, depending on the type of standby system implemented, a full switchover test might be disruptive, but it is the only way in which the organisation can be completely certain that its DR arrangements are fully working. However, if the standby system has been correctly implemented, everything should failover without interruption.
SUMMARY
In this chapter, we have examined the need for and the importance of business cases in gaining support from senior management for the information risk management programme, together with the processes of risk treatment decision-making, planning and implementation. Finally, we have looked at the requirements for business continuity planning, based on the BCI’s approach, and, where applicable, various types of solution to disaster recovery planning and testing.
We will look next at communicating, monitoring and reviewing activities.
1 The BCI life cycle diagram is included courtesy of the BCI.