
While many people will tell you to get data out of Excel as quickly as you can, Pandas provides a function to import data directly from Excel files. This saves you the time of converting the file.
- To create a Pandas DataFrame from an Excel file, first import the Python libraries that you need:
import pandas as pd
- Next, define a variable for the accidents data file and enter the full path to the data file:
customer_data_file = 'customer_data.xlsx'
- After that, create a DataFrame from the Excel file using the
read_excelmethod provided by Pandas, as follows:customers = pd.read_excel(customer_data_file, sheetname=0, header=0, index_col=False, keep_default_na=True )
- Finally, use the
head()command on the DataFrame to see the top five rows of data:customers.head()
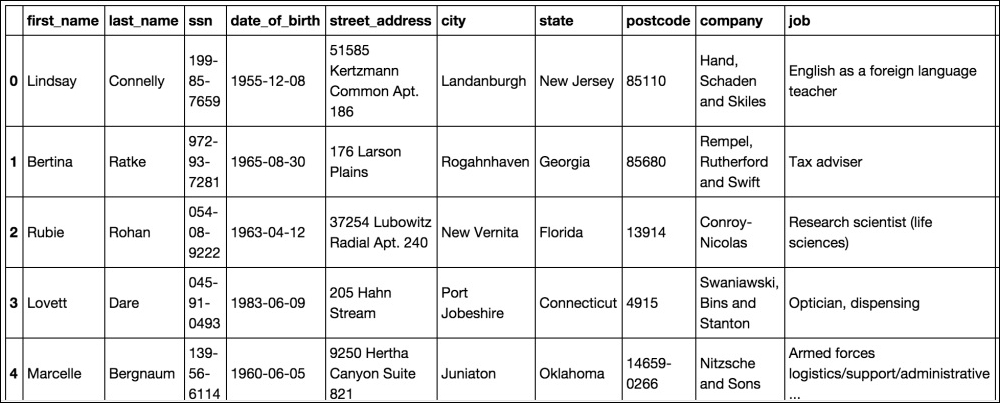
After importing Pandas and creating a variable from the path to our Excel file, we use the read_excel() function to create a DataFrame from the spreadsheet. The first argument that we pass is the path to the file. The other arguments are:
sheetname: This can either be the name of the sheet or the zero-indexed (count starting at 0) position of the sheet.header: This is the row to use for the column labels.index_col: This is for the column to use for the index value. When set toFalse, Pandas will add a zero-based index number.keep_default_na: Ifna_valuesare specified, (which they are not in this case) andkeep_default_nais set toFalse, the defaultNaN(missing) values are overridden or they are appended to.
Tip
Excel in the real world
This spreadsheet is very clean. My experience shows this is rarely the case. Some common things that I've seen people do to spreadsheets include adding titles (for reports), skip one or more lines between rows, and shift data for a few rows over a column or two. Additional arguments to read_excel() such as skiprows helps handle these issues. See the official Pandas documentation (http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_excel.html) for more configuration options.