
What to do if what you need to fix is in the published part of the history? As described in Perils of rewriting published history section, changing the parts of the history that were made public (which is actually creating a changed copy and replacing references) can cause problems for downstream developers. You better not to touch this part of the graph of revisions.
There are a few solutions to this problem. The most commonly used is to put a new fixup commit with appropriate changes (for example, a typo fix in a documentation). If you need to remove changes, deciding that they turned out to be bad to have, you can create a commit to revert the changes.
If you fix a commit or revert one, it would be nice to annotate that commit with the information that it was buggy, and which commit fixed (or reverted) it. Even though you cannot (should not) edit the fixed commit to add this information if the commit is public, Git provides a notes mechanism to append extra information to existing commits, which is a bit like publishing an addendum, errata, or amendment. You need however to remember that notes are not published by default, nonetheless it is easy to publish them too (you just need to remember to do it).
If you need to back-out an existing commit, undoing the changes it brought, you can use git revert. As described in Chapter 7, Merging Changes Together (see, for example, Fig 4 ), the revert operation creates a commit with reverse of changes. For example, where original commit adds a line, reversion removes it, where original commit removes a line, reversion adds it.
It is best shown on an example. Let's take for example of the last commit on branch multiple, and check the summary of its changes:
$ git show --stat multiple commit bb71a804f9686c4bada861b3fcd3cfb5600d2a47 Author: Alice Developer <[email protected]> Date: Sun Jun 1 03:02:09 2014 +0200 Support optional <count> parameter src/rand.c | 26 +++++++++++++++++++++----- 1 file changed, 21 insertions(+), 5 deletions(-)
Reverting this commit (which requires a clean working directory) would create a new revision. This revision undoes the changes that the reverted commit brought:
$ git revert bb71a80 [master 76d9e25] Revert "Support optional <count> parameter" 1 file changed, 5 insertions(+), 21 deletions(-)
Git would ask for a commit message, which should explain why you reverted a revision, how it was faulty, and why it needed to be reverted rather than fixed. The default is to give the SHA-1 of the reverted commit:
$ git show --stat commit 76d9e259db23d67982c50ec3e6f371db3ec9efc2 Author: Alice Developer <[email protected]> Date: Tue Jun 16 02:33:54 2015 +0200 Revert "Support optional <count> parameter" This reverts commit bb71a804f9686c4bada861b3fcd3cfb5600d2a47. src/rand.c | 26 +++++--------------------- 1 file changed, 5 insertions(+), 21 deletions(-)
An often found practice is to leave alone the subject (which allows to easily find reverts), but replace the content with a description of the reasoning behind the revert.
Sometimes, you might need to undo an effect of a merge. Suppose that you have merged changes, but it turned out that they were merged prematurely, and that the merge brings regressions.
Let's say that the branch that got merged is a topic branch and that you were merging it into the master branch. This situation is shown in Fig 5:

Fig 5: An accidental or premature merge commit, a starting point to reverting merges and redoing reverted merges
If you didn't publish this merge commit before you noticed the mistake and the unwanted merge exists only in your local repository, the easiest solution is to drop this commit with git reset --hard HEAD^ (see Chapter 4, Managing Your Worktree for an explanation of the hard mode of git reset).
What do you do if you realize only later that the merge was incorrect, for example, after one more commit was created on the master branch and published? One possibility is to revert the merge.
However, a merge commit has more than one parent, which means more than one delta (more than one changeset). To run revert on a merge commit, you need to specify which patch you are reverting or, in other words, which parent is the mainline. In this particular scenario, assuming that there was one more commit after the merge (and that the merge was two commits back), the command would look as follows:
$ git revert -m 1 HEAD^^ [master b2d820c] Revert "Merge branch 'topic'"
The situation after reverting a merge is shown in Fig 6:

Fig 6: The history from the previous figure after git revert -m 1 <merge commit>. The square boxes attached to the selected commits symbolize their changesets in a diff-like format (combined diff format for the merged commit)
Starting with the new !M1 commit (the symbol !M1 was used to symbolize negation or reversal of commit M1), it's as if the merge never happened, at least, with respect to the changes.
Let's assume that you continued work on a branch whose merge was reverted. Perhaps it was prematurely merged, but it doesn't mean that the development on it stopped. If you continue to work on the same branch, perhaps by creating commits with fixes, they will get ready in some time and then you will need to be able to merge them correctly into the mainline, again. Or perhaps, the mainline would mature enough to be able to accept a merge. Trouble lies ahead if you simply try to merge your branch again, the same way as the last time.

Fig 7: The unexpectedly erroneous result of trying to simply redo reverted merges in a history with a bad merge. The text beside the commits represents a list of features present in or absent from a commit. The three commits with a thick outline are merged commits ("ours" and "theirs" version) and the merge base: the common ancestor ("base")
The unexpected result is that Git has brought only the changes since the reverted merge. The changes brought by the commits on a side branch whose merge got reverted are not here. In other words, you would get a strange result: the new merge would not include the changes that were created on your branch (on side branch) before the merge that got reverted.
This is caused by the fact that revert undoes changes (the data), but does not undo the history (the DAG of revisions). This means that a new merge sees C4, the commit on the side branch just before the reverted merge, as a common ancestor. Because the default three-way merge strategy looks only at the state of the ours, theirs, and base snapshot, it doesn't search through the history to find that there was a revert there. It sees that both the common ancestor C4 and the merged branch (that is, theirs) C6 do include features brought by the commits C3 and C4, namely f3 and f4, while the branch that we merged into (that is, ours) doesn't have them because of the revert.
For the merge strategy, it looks exactly like the case where one branch deleted something, which means that this change (this removal) is the result of the merge (looks like the case when there was change only in one side). Particularly, it looks like the base has a feature, the side branch has a feature, but the current branch doesn't (because of the revert), so the result doesn't have it. You can find the explanation of the merging mechanism in Chapter 7, Merging Changes Together.
There is more than one option to fix this issue and make Git re-merge the topic branch correctly, which means including features f3 and f4 in the result. Which option you should choose depends on the exact circumstances, for example, whether the branch being merged is published or not. You don't usually publish topic branches, and if you do, perhaps in the form of the proposed-updates branch with all the topic branches merged in, it is with the understanding that they can and probably will be rewritten.

Fig 8: The history after remerging (as M2) a reverted merge M1 by reverting the revert !!M1. Notation used like in Fig 7
One option is to bring back deleted changes by reverting the revert. The result is shown in Fig 8. In this case, you have brought changes to match the recorded history.
Another option would be to change the view of the history (perhaps temporarily), for example amending it with git replace, by changing the merge !M1 to a nonmerge commit. Both these options are suitable in the situation where at least the parts of the branch being merged, namely topic, were published.
If the problem was some bugs in the commits being merged (on the branch topic) and the branch being merged was not published, you can fix these commits with the interactive rebase, as described earlier. Rebasing changes the history anyway, so if you additionally ensure that the new history you are creating with the rebase does not have any revision in common with the old history that includes the said failed and reverted merge, re-merging the topic branch would pose no challenges.
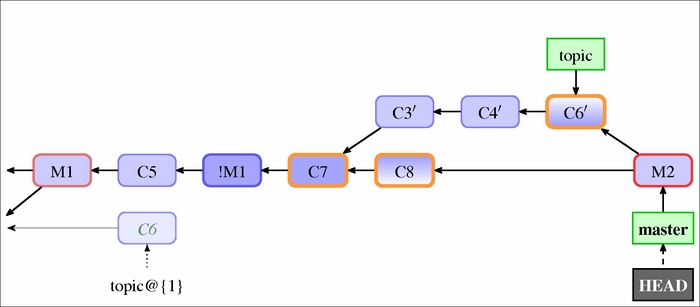
Fig 9: The history after remerging the rebased branch, which had its merge reverted. The rest of the history that is not visible here is like in Fig 6. The three commits with a thick outline are merged commits (the "ours" and "theirs" version) and the new merge base is the common ancestor ("base")
Usually, you would rebase a topic branch, topic here, on top of the current state of the branch it was forked from, which here is the master branch. This way, your changes are kept up to date with the current work, which makes a later merge easier. Now that the topic branch has new history, merging it again into master, like in Fig 9, is easy and it doesn't give any surprises or troubles.
A more difficult case would be if the topic branch is for some reason (like being able to merge it into the maint branch too) required to keep its base. Not more difficult in the sense that there would be problems with re-merging the topic branch after rebase, but that we need to ensure that the branch after rebase doesn't share history with the reverted merge arc. The goal is to have history in a shape as shown in Fig 10. By default, rebase tries to fast-forward revisions if they didn't change (for example, leaving C3 in place if the rebase didn't modify it), so we need to use -f / --force-rebase to force rebasing also of unchanged skippable commits. (or --no-ff, which is equivalent).

Fig 10: The history after remerging an "in place" rebased topic branch, where a pre-rebase merge was reverted. The notations used to mark the commits are the same as in Fig 7
So, you should not be blindly reverting the revert of a merge. What to do with the problem of re-merging after reverted merge depends on how you want to handle the branch being merged. If the branch is being rewritten (for example, using interactive rebase), then reverting the revert would be actively a wrong thing to do, because you could bring back errors fixed in the rewrite.
The notes mechanism is a way to store additional information for an object, usually a commit, without touching the objects themselves. You can think of it as an attachment, or an appendix, "stapled" to an object. Each note belongs to some category of notes, so that notes used for different purposes can be kept separate.
Sometimes, you want to add extra information to a commit— an information that is available only after its creation. It might be, for example, a note that there was a bug found in the said commit, and perhaps, even that it got fixed in some specified future commit (in case of regression). Perhaps, we realized, after the commit got published, that we forgot to add some important information to the commit message, for example, explain why it was done. Or maybe, we realized that there is another way of doing it and we want to note it to not forget about it, and for other developers to share the idea.
Because in Git history is immutable; you cannot do this without rewriting the history (creating a modified copy and forgetting the old version of the history). Immutability of history is important: it allows people to sign revisions and trust that, once inspected, history cannot change. What you can do instead is to add the extra message as a note.
Let's assume that codevelopers have switched from atoi() to strtol(), because the former is deprecated. The change was since then made public. But the commit message didn't include an explanation of why it was deprecated and why it is worth it to switch, even if the code after the change is longer. Let's add the information as a note:
$ git notes add -m 'atoi() invokes undefined behaviour upon error' v0.2~3
We have added the note directly from the command line without invoking the editor by using the -m flag (the same as for git commit) to simplify the explanation of this example. The note will be visible while running git log or git show:
$ git show --no-patch v0.2~3 commit 8c4ceca59d7402fb24a672c624b7ad816cf04e08 Author: Bob Hacker <[email protected]> Date: Sun Jun 1 01:46:19 2014 +0200 Use strtol(), atoi() is deprecated Notes: atoi() invokes undefined behaviour upon error
As you can see from the preceding output, our note is shown after the commit message in the Notes: section. Displaying notes can be disabled with the --no-notes option and (re)enabled with --show-notes.
In Git, notes are stored using extra references in the refs/notes/ namespace. By default, commit notes are stored using the refs/notes/commits ref; this can be changed using the core.notesRef configuration variable, which in turn can be overridden with the GIT_NOTES_REF environment variable.
The value of either variable must be fully qualified (that is, it must include the refs/notes/prefix, though this requirement got relaxed in newest Git). If the given ref does not exist, it is not an error, but it means that no notes should be printed. These variables decide both which type of notes are displayed with the commit after the Notes: line, and where to write the note created with git notes add.
You can see that the new type of reference has appeared in the repository:
$ git show-ref --abbrev 2b953b4 refs/heads/bar 5d25848 refs/heads/master bb71a80 refs/heads/multiple fcac4a6 refs/notes/commits 5d25848 refs/remotes/origin/HEAD 5d25848 refs/remotes/origin/master b35871a refs/stash 995a30b refs/tags/v0.1 ee2d7a2 refs/tags/v0.2
If you examine the new reference, you will see that each note is stored in a file named after the SHA-1 identifier of the annotated object. This means that you can have only one note of the given type for one object. You can always edit the note, append to it (with git notes append), or replace its content (with git notes add --force). In the interactive mode, Git opens the editor with the contents of the note, so edit/append/replace is the same here. As opposed to commits, notes are mutable:
$ git show refs/notes/commits commit fcac4a649d2458ba8417a6bbb845da4000bbfa10 Author: Alice Developer <[email protected]> Date: Tue Jun 16 19:48:37 2015 +0200 Notes added by 'git notes add' diff --git a/8c4ceca59d7402fb24a672c624b7ad816cf04e08 b/8c4ceca59d7402fb24a672c624b7ad816cf04e08 new file mode 100644 index 0000000..a033550 --- /dev/null +++ b/8c4ceca59d7402fb24a672c624b7ad816cf04e08 @@ -0,0 +1 @@ +atoi() invokes undefined behaviour upon error $ git log -1 --oneline 8c4ceca59d7402fb24a672c624b7ad816cf04e08 8c4ceca Use strtol(), atoi() is deprecated
Notes for commits are stored in a separate line of (meta-)history, but this need not be the case for the other categories of notes: the notes reference can point directly to the tree object instead of to the commit object such as for refs/notes/commits.
One important issue that is often overlooked in books and articles is that it is the full path to file with notes contents, not the base name of the file, that identifies the object the note is attached to. If there are many notes, Git can and would use a fan-out directory hierarchy, for example storing the preceding note at the 8c/4c/eca59d7402fb24a672c624b7ad816cf04e08 path (notice the slashes).
Notes are usually added to commits. But even for those notes that are attached to commits it makes sense, at least in some cases, to store different pieces of information using different categories of notes. This makes it possible to decide on an individual basis which parts of information to display, and which parts to push to the public repository, and it allows to query for specific parts of information individually.
To create a note in a namespace (category) different from the default one (where the default means notes/commits, or core.notesRef if set), you need to specify the category of notes while adding it:
$ git notes --ref=issues add -m '#2' v0.2~3
Now, by default, Git would display only the core.notesRef category of notes after the commit message. To include other types of notes, you must either select the category to display with git log --notes=<category> (where <category> is either the unqualified or qualified reference name, or a glob; you can use --notes=* to show all the categories), or configure which notes to display in addition to the default with the display.notesRef configuration variable (or the GIT_NOTES_DISPLAY_REF environment variable). You can either specify the the configuration variable value multiple times, just like for remote.<remote-name>.push (or specify a colon-separated list of pathnames in the case of using an environment variable), or you can specify a globing pattern:
$ git config notes.displayRef 'refs/notes/*' $ git log -1 v0.2~3 commit 8c4ceca59d7402fb24a672c624b7ad816cf04e08 Author: Bob Hacker <[email protected]> Date: Sun Jun 1 01:46:19 2014 +0200 Use strtol(), atoi() is deprecated Notes: atoi() invokes undefined behaviour upon error Notes (issues): #2
There are many possible uses of notes. You can, for example, use notes to reliably mark which patches (which commits) were upstreamed (forward-ported to the development branch) or downstreamed (back-ported to the more stable branch or to the stable repository), even if the upstreamed/downstreamed version is not identical, and mark a patch as being deferred if it is not ready for either upstream or downstream.
This is a bit more reliable, if requiring manual input, than relying on the mechanism of git patch-id to detect when changeset is already present (which you can use by rebasing, using git cherry, or with the --cherry / --cherry-pick / --cherry-mark option to git log). This is, of course, in case we are not using topic branches from the start, but rather we are cherry-picking commits.
Notes can be used to store results of the post-commit (but pre-merge) code audit, and to notify other developers why this version of the patch was used.
Notes can also be used to handle marking bugs and bug fixes, and verifying fixes. You often find bugs in commits long after they got published, that's why you need notes for this; if you find a bug before publishing, you would rewrite the commit instead.
In this case, first, when the bug gets reported, and if it was regression, you find which revision introduced the bug (for example with git bisect, as described in Chapter 2, Exploring Project History). Then you would want to mark this commit, putting the identifier of a bug entry in an issue tracker for the project (usually, a number or number preceded by some specific prefix such as Bug:1385) in the bugs, or defects, or issues category of notes; perhaps you would want to also include the description of a bug. If the bug affects security, it might be assigned a vulnerability identifier, for example, a Common Vulnerabilities and Exposures (CVE) number; this information could be put into the note in the CVE-IDs category.
Then, after some time, hopefully, the bug will get fixed. Just like we marked the commit that it contains the bug, we can annotate it additionally with the information on which commit fixes it, for example, in note under refs/notes/fixes. Unfortunately, it might happen that the first attempt at fixing it didn't handle the bug entirely correct, and you have to amend a fix, or perhaps even create a fix for a fix. If you are using bugfix or hotfix branches (topic branches for bugfixes), as described in Chapter 6, Advanced Branching Techniques, it will be easy to find them together and to apply them together–by merging said bugfix branch. If you are not well, then it would be a good idea to use notes to annotate fixes that should be cherry-picked together with a supplementary commit, for example by adding note in alsoCherryPick, or seeAlso, or whatever you want to name this category of notes. Perhaps also an original submitter, or a Q&A group, would get to the fix and test that it works correctly; it would be better if the commit was tested before publishing, but it is not always possible, so refs/notes/tests it is.
Third-party tools use (or could use) notes to store additional per-commit tool-specific information. For example, Gerrit, which is a free, web-based team code collaboration tool, stores information about code reviews in refs/notes/reviews: including the name and e-mail address of the Gerrit user that submitted the change, the time the commit was submitted, the URL to the change review in the Gerrit instance, review labels and scores (including the identity of the reviewer), the name of project and branch, and so on:
Notes (review):
Code-Review+2: John Reviewer <[email protected]>
Verified+1: Jenkins
Submitted-by: Bob Developer <[email protected]>
Submitted-at: Thu, 20 Oct 2014 20:11:16 +0100
Reviewed-on: http://localhost:9080/7
Project: common/random
Branch: refs/heads/masterSimilarly, git svn, a tool for bidirectional operation between the Subversion repository and Git working as a fat client for Subversion (svn), could have stored the original Subversion identifiers in notes, rather than appending this information to a commit message (or dropping it altogether).
Going to a more exotic example, you can use the notes mechanism to store the result of a build (either the archive, the installation package, or just the executable), attaching it to a commit or a tag. Theoretically, you could store a build result in a tag, but you usually expect for a tag to contain Pretty Good Privacy (PGP) signature and perhaps also the release highlights. Also, you would in almost all the cases want to fetch all the tags, while not everyone wants to pay the cost of disk space for the convenience of pre-build executables. You can select from case to case whether you want or not to fetch the given category of notes (for example, to skip pre-built binaries), while you autofollow tags. That's why notes are better than tags for this purpose.
Here the trouble is to correctly generate a binary note. You can binary-safely create a note with the following trick:
# store binary note as a blob object in the repository $ blob=$(git hash-object -w ./a.out) # take the given blob object as the note message $ git notes --ref=built add --allow-empty –C "$blob" HEAD
You cannot simply use -F ./a.out, as this is not binary safe—comments (or rather what was misdetected as comment, that is lines starting with #) would be stripped.
The notes mechanism is also used as a mechanism to enable storing cache for the textconv filter (see the section on gitattributes in Chapter 4, Managing Your Worktree). All you need to do is configure the filter, setting its cachetextconv to true:
[diff "jpeg"] textconv = exif cachetextconv = true
Here, notes in the refs/notes/texconv/jpeg category (named after the filter) are used to attach the text of the conversion to a blob object.
Notes are attached to the objects they annotate, usually commits, by their SHA-1 identifier. What happens then with notes when we are rewriting history? In the new, rewritten history, SHA-1 identifiers of objects in most cases are different.
It turns out that you can configure this quite extensively. First, you can select which categories of notes should be copied along with the annotated object during rewrite with the notes.rewriteRef multi-value configuration variable. This setting can be overridden with the GIT_NOTES_REWRITE_REF (see the naming convention) environment variable with a colon-separated list (like for the well-known PATH environment variable) of fully qualified note references, and globs denoting reference patterns to match. There is no default value for this setting; you must configure this variable to enable rewriting.
Second, you can also configure whether to copy a note during rewriting depending on the exact type of the command doing the rewriting (currently supported are rebase and amend as the value of the command) . This can be done with the Boolean-valued configuration variable notes.rewrite.<command>.
In addition, you can decide what to do if the target commit already has a note while copying notes during a rewrite, for example while squashing commits using an interactive rebase. You have to decide between overwrite (take the note from the appended commit), concatenate (which is the default value), and ignore (use the note from the original commit being appended to) for the notes.rewriteMode configuration variable, or the GIT_NOTES_REWRITE_MODE environment variable.
So, we have notes in our own local repository. What to do if we want to share these notes? How do we make them public? How can we and other developers get notes from other public repositories?
We can employ our knowledge of Git here. Section How notes are stored explained that notes are stored in an object database of the repository using special references in the refs/notes/ namespace. The contents of note are stored as a blob object, referenced through this special ref. Commit notes (notes in refs/notes/commits) store the history of notes, though Git allows you to store notes without history as well. So, what you need to do is to get notes references, and the contents of notes will follow. This is the usual mechanism of repository synchronization (of object transfer).
This means that to publish your notes, you need to configure appropriate push lines in the appropriate remote repository configuration (see Chapter 5, Collaborative Development with Git). Assuming that you are using a separate public remote (if you are the maintainer, you will probably use simply origin), which is perhaps set as remote.pushDefault, and that you would like to publish notes in any category, you can run:
$ git config --add remote.public.push '+refs/notes/*:refs/notes/*'
In the case when push.default is set to matching (or Git is old enough to have this as the default behavior), or the "push" lines use special refspec ":" or "+:", then it is enough to push notes refs the first time, and they would be pushed automatically each time after:
$ git push origin 'refs/notes/*'
Fetching notes is only slightly more involved. If you don't produce specified types of notes yourself, you can fetch notes in the mirror-like mode to the ref with the same name:
$ git config --add remote.origin.fetch '+refs/notes/*:refs/notes/*'
However, if there is a possibility of conflict, you would need to fetch notes from the remote into the remote-tracking notes reference, and then use git notes merge to join them into your notes; see the documentation for details.
There is no standard naming convention for remote-tracking notes references, but you can use either refs/notes/origin/* (so that the shortened notes category commits from the remote origin is origin/commits and so on), or go whole works and fetch refs/* from the remote origin into refs/remotes/origin/refs/* (so the commits category would land in refs/remotes/origin/refs/notes/commits).
The original idea for the replace-like/replacement-like mechanism was to make it possible to join the history of two different repositories.
The original impulse was to be able to switch from the other version control system to Git by creating two repositories: one for the current work, starting with the most recent version in the empty repository, and the second one for the historical data, storing the conversion from the original system. That way, it would be possible to take time doing the faithful conversion of historical data, and even fix it if the conversion were incorrect, without affecting the current work.
What was needed is some mechanism to connect histories of those two repositories, to have full history for inspection going back to the creation of a project (for example, for git blame, that is, the line-history annotation).
The modern incarnation of such tools is a replace (or replacements) mechanism. With it, you can replace any object, with any object or rather create a virtual history (virtual object database of a repository) by creating an overlay so that most Git commands return a replacement in place of the original object.
But the original object is still there, and Git's behavior with respect to the replacement mechanism was done in such a way as to eliminate the possibility of losing data. You can get the original view with the --no-replace-objects option to the git wrapper before the command, or the GIT_NO_REPLACE_OBJECTS environment variable. For example, to view the original history, you can use git --no-replace-objects log.
The information about replacement is saved in the repository by storing the ref named after SHA-1 of the replaced object in the refs/replace/ namespace, with the SHA-1 of replacement as its sole content. However, there is no need to edit it by hand or with the low-level plumbing commands; you can use the git replace command.
Almost all the commands use replacements, unless told not to, as explained previously. The exception are the reachability analysis commands; this means that Git would not remove the replaced objects because there are no longer reachable if we take replacement into account. Of course, replacement objects are reachable from the replaced refs.
You can replace any object with any object, though changing the type of an object requires telling Git that you know what you are doing with git replace -f <object> <replacement>. This is because such a change might lead to troubles with Git, because it was expecting one type of object and getting another.
With git replace --edit <object>, you can edit its contents interactively. What really happens is that Git opens the editor with the object contents and, after editing, Git creates a new object and a replacement ref. The object format (in particular, the commit object format, as one would almost always edit commits) was described at beginning of this chapter. You can change the commit message, commit parents, authorship, and so on.
Let's assume that you want to split the repository into two, perhaps for performance reasons. But you want to be able to treat joined history as if it were one. Or perhaps, there was a history split after the SCM change, with the fresh repository with the current work (started after switching from the current state of a project with an empty history) and the converted historical repository kept separate.
How to split history was described in the examples of using git filter-branch here in this chapter. One of solutions shown here was to run git replace --graft <to be root> on a commit where you want to split and then use git filter-branch -- --all without filters to make the split permanent.

Fig 11: The view of a split history with the replacements turned off (git --no-replace-objects). The SHA-1 in the left upper corner of a commit denotes its identifier. Note that SHA-1 identifiers were all shortened to 5 hex-digits in this figure
In many cases, you might want to create a kind of informational commit on top of the historical repository, for example, adding to the README file the notification where one can find the current work repository. Such commits for simplicity are not shown in Fig 11.
How to join history depends a bit on whether the history was originally split or was originally joined. If it was originally joined, then split; just tell Git to replace post-split with the pre-split version with git replace <post-split> <pre-split>. If the repository was split from beginning, use the --edit or --graft option to git replace.

Fig 12: The view of a split history joined using replacements. The notations are the same as in the previous figure, but with the replace ref shown in a different way—as the result of the replacement
The split history is there, just hidden from the view. For all the Git commands, the history looks like Fig 12. You can, as described earlier, turn off using replacements; in this case, you would see the history as in Fig 11.
The first attempt to create a mechanism to make it possible to join lines of history was grafts. It is a simple .git/info/grafts file with the SHA-1 of the affected commit and its replacement parents in line separated by spaces.
This mechanism was only for commits and allowed only to change the parentage. There was no support for transport, that is, for propagating this information from inside of Git. You could not turn grafts mechanism off temporarily, at least not easily. Moreover, it was inherently unsafe, because there were no exceptions for the reachability-checking commands, making it possible for Git to remove needed objects by accident during pruning (garbage collecting).
However, you can find its use in examples. Nowadays, it is obsolete, especially with the existence of the git replace --graft option. If you use grafts, consider replacing them with the replacements objects; there is the contrib/convert-grafts-to-replace-refs.sh script that can help with this in the Git sources.
How to publish replacements and how to get them from the remote repository? Because replacements use references, this is quite simple.
Each replacement is a separate reference in the refs/replaces/ namespace. Therefore, you can get all the replacements with the globing fetch or push line:
+refs/replace/*:refs/replace/*
There can be only one replacement for an object, so there are no problems with merging replacements. You can only choose between one replacement or the other.
Theoretically, you could also request individual replacements by fetching (and pushing) individual replacement references instead of using glob.