
|
|


Logical data modeling is the process of capturing the detailed business solution. The logical data model looks the same regardless of whether we are implementing in MongoDB or Oracle.
During conceptual data modeling we might learn, for example, what the terms, business rules, and scope would be for a new order entry system. Logical data modeling is taking these findings down to the next level and understanding all of the data requirements for the order entry system. For example, conceptual data modeling will reveal that a Customer may place many Orders. Logical data modeling will uncover all of the details behind Customer and Order, such as the customer’s name, their address, the order number, and what is being ordered. During logical data modeling, questions or issues may arise having to do with specific hardware or software such as:
- What should the collections look like?
- What is the optimal way to do sharding?
- How can we make this information secure?
- How should we store history?
- How can we answer this business question in less than 300 milliseconds?
These questions focus on technology concerns such as performance, data structure, and how to implement security and history. These are all physical considerations, and therefore are important to address during the physical data modeling stage, and not during logical data modeling. It is OK to document questions like these if they come up during logical data modeling, just make sure no time is spent addressing these questions until after the logical data modeling process is complete. Once the logical data modeling phase is complete, you will have more knowledge about what is needed, and will be able to make intelligent physical data modeling decisions including answering questions like these correctly.
The logical data model is also a great mapping point when multiple technologies exist. The logical data model will show one technology-independent perspective, and then we can map this business perspective to each of the various technology perspectives, similar to a hub in a bicycle tire:
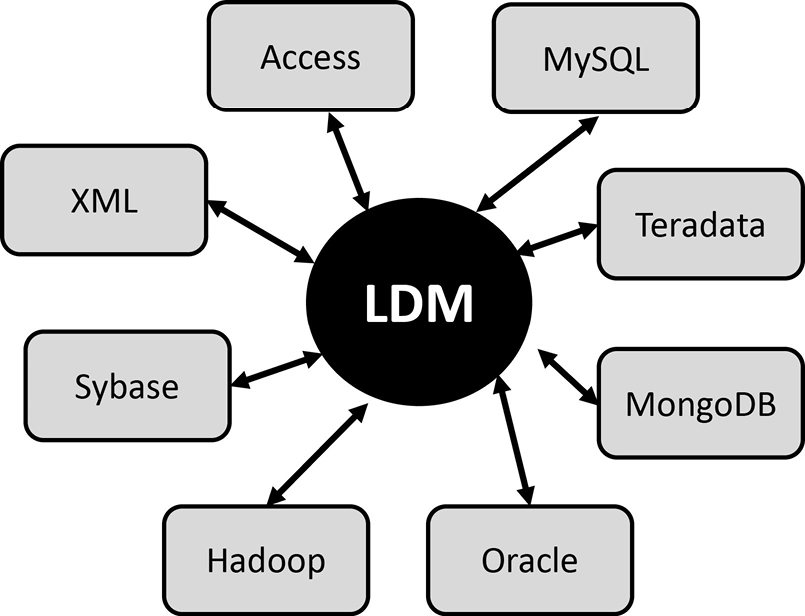
When new technologies come along, we can use the logical data model as a starting point and therefore save an incredible amount of time in building the application, as well as improving consistency within the organization.
Logical Data Modeling Approach
Logical data modeling involves completing the following four steps:

We can build upon the work done in conceptual data modeling by filling in the entities on the conceptual data model. This means identifying and defining the properties for each concept (Step 1). For relational only, we normalize and optionally abstract (Step 2). For dimensional, skip Step 2. Then similar to conceptual data modeling, we determine the most useful form (Step 3). As a final step, review your work to confirm we have the data requirements modeled correctly (Step 4). Frequently action items come out of the review and confirm step where we need go back to Step 1 and refine our concepts. Expect iteration through these steps, until the logical data model is confirmed and then we can start the physical. Let’s talk more about each of these four steps.
Step 1: Fill in the CDM
We fill in the CDM by identifying and defining the properties of each concept. The two templates we complete at this step, the Properties Template and Property Characteristics Template, are useful for both relational and dimensional efforts.
The Properties Template captures the properties (also known as attributes or data elements) of each conceptual entity:
Properties Template
|
Entity A |
Entity B |
Entity C |
|
|
Name |
|||
|
Text |
|||
|
Amount |
|||
|
Date |
|||
|
Code |
|||
|
Quantity |
|||
|
Number |
|||
|
Identifier |
|||
|
Indicator |
|||
|
Rate |
|||
|
Percent |
|||
|
Complex |
Each column heading represents one of the conceptual entities, and each row represents a grouping of properties by classword. Recall that a classword is the last part of the data element name, which represents a high level domain or category. Within each cell, you can list the properties for the conceptual entity that have that classword in common. For example, for the conceptual entity Order you can list the two properties Order Gross Amount and Order Net Amount next to the Amount cell, Order Entry Date and Order Delivery Date next to the Date cell, etc. Realize the initial names we use for each property may change as we learn more about each property.
To identify the properties for each conceptual entity, ask the question, “What [Classword] do I need to know about [Conceptual Entity]?” For example, “What Dates do I need to know about Order?”
Here are examples for each of the classwords, along with a brief description:
- Name. A textual value by which a thing, person, or concept is known. Examples: Company Name, Customer Last Name, Product Last Name
- Text. An unconstrained string of characters or any freeform comment or notes field. Examples: Email Body Text, Tweet Text, Order Comments Text
- Amount. A numeric measurement of monetary value in a particular currency such as dollars or Euros. Examples: Order Total Amount, Employee Salary Amount, Produce Retail Price Amount
- Date. A calendar date. Examples: Order Entry Date, Consumer Birth Date, Course Start Date
- Code. A shortened form representing a descriptive piece of business information. Examples: Company Code, Employee Gender Code, Currency Code
- Quantity. A measure of something in units. Quantity is a broad category containing any property that can be mathematically manipulated with the exception of currencies, which are Amounts. Quantity includes counts, weights, volumes, etc. Examples: Order Quantity, Elevator Maximum Gross Weight, Claim Count
- Number. Number can be misleading as it is usually a business key (that is, a business user’s way of identifying a concept). Number cannot be mathematically manipulated and often contains letters and special characters such as the hyphen in the case of a telephone number. Examples: Social Security Number, Credit Card Number, Employee Access Number
- Identifier. A mandatory, stable, and unique property of an entity that is used to identify instances of that entity. Examples: Case Identifier, Transaction Identifier, Product Identifier
- Indicator. When there are only two values such as Yes or No, 1 or 0, True or False, On or Off. Sometimes called a “flag.” Examples: Student Graduation Indicator, Order Taxable Indicator, Current Record Indicator
- Rate. A fraction indicating a proportion between two dissimilar things. Examples: Employee Hourly Rate, State Tax Rate, Unemployment Rate
- Percent. A ratio where 100 is understood as the denominator. Examples: Ownership Percent, Gross Sales Change Percent, Net Return Percent
- Complex. Anything that is not one of the above categories. This can include music, video, photographs, scanned images, documents, etc. Examples: Employee Photo JPEG, Contract Signed PDF, Employee Phone Conversation MPP
The second template, the Property Characteristics Template, captures important metadata on each property:
Property Characteristics Template
|
Property |
Definition |
Sample Values |
Format |
Length |
Source |
Transformations |
To complete the Property Characteristics Template, enter the name for each property in the Property column (you can copy and paste from the Property Template). Then add the definition. I usually like to see a definition that is at least a few sentences long. I know the template doesn’t leave much room for text, but in a landscape format you will have more room. If you think it would be beneficial to show some sample values, you can add those too. I often find with codes, such as Country Code, that it makes sense to add a few sample values. Format can be date, character, integer, etc., and the Length is how long the data element is. Optionally, you can include where the property comes from (the Source column) and any Transformations that might be required to bring data from the source into this property. Transformations are useful to capture for derived properties such as for Gross Sales Amount.
For Relational
Recall our relational CDM from Chapter 5:
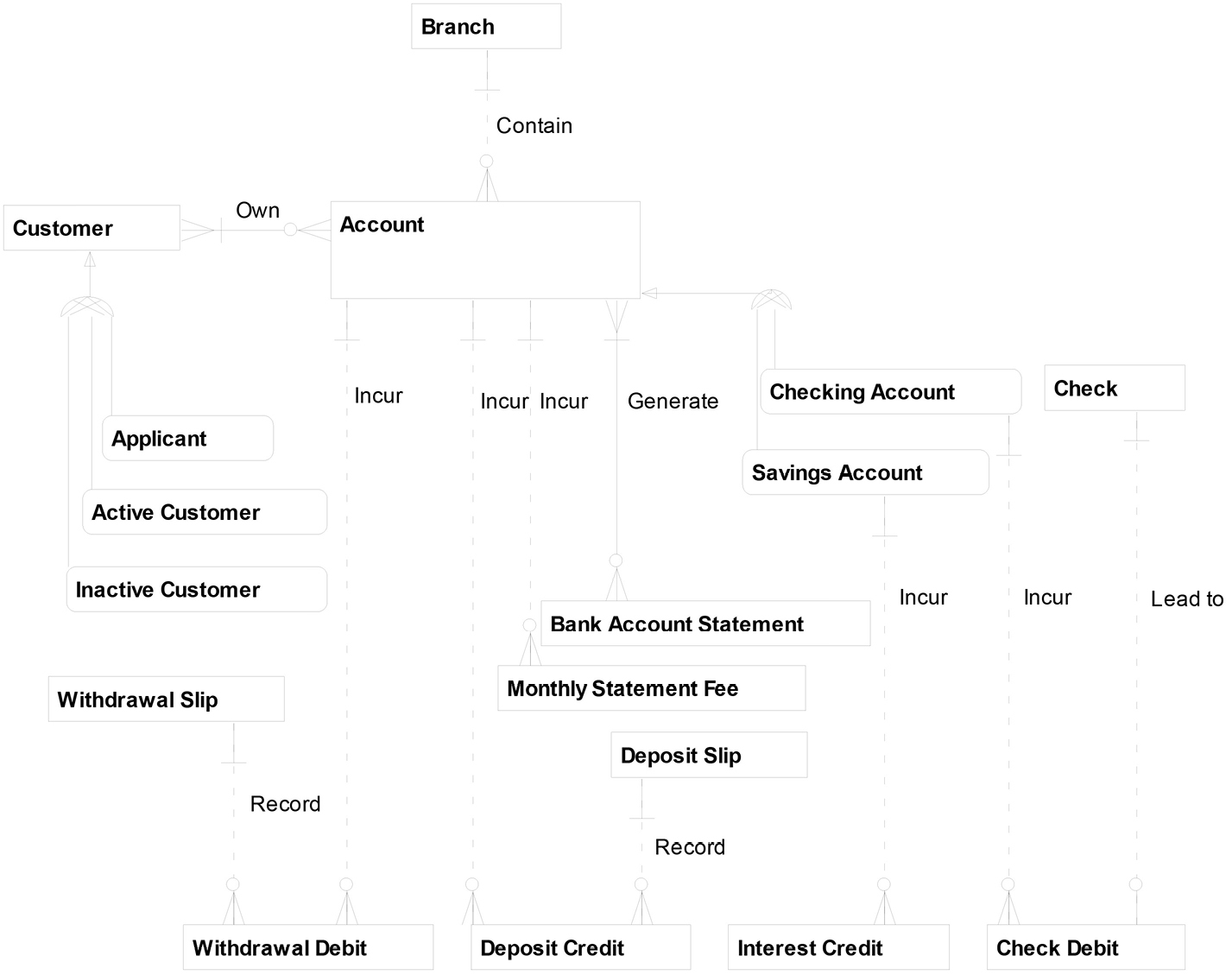
After meeting with the business experts and studying existing documentation, we completed the following Properties Template for this CDM. (Note that to save column space, I grouped all of the credits and debits under Transaction and all of the documents, such as slips and statements, under Document. To save row space, I removed those classword rows where there were no properties identified. Note also that I am showing only a handful of the actual attributes that would come out of this process.)
Account Project Properties
|
Account |
Customer |
Branch |
Transaction |
Document |
|
|
Name |
Account Name |
Customer Name, Favorite Sports Team |
|||
|
Text |
Branch Address Text |
||||
|
Amount |
Minimum Balance Amount |
Monthly Fee Amount, Deposit Amount, Withdrawal Amount |
Check Amount |
||
|
Date |
Account Open Date |
Customer Birth Date, Applicant Date, Inactive Date |
Interest Credit Amount, Interest Credit Date |
Check Date, Deposit Date, Withdrawal Date |
|
|
Code |
Branch Code, Branch Size Code |
||||
|
Quantity |
Free Checks Per Month |
||||
|
Number |
Account Number |
Social Security Number |
Check Number, Deposit Number, Withdrawal Number |
||
|
Rate |
Credit Rating |
And now we will fill in the Property Characteristics Template for each of these properties. To save space, I am only going to fill this in for five of the attributes from the Property Template above, but on an actual project you would complete this for all attributes:
Account Project Property Characteristics
|
Property |
Definition |
Sample Values |
Format |
Length |
Source |
Transformations |
|
Account Number |
The unique number assigned to each account. This number is unique across branches. Our bank employees and our customers have knowledge of this number. |
17382-112 |
Char |
8 |
New AccountSystem |
Not applicable |
|
Favorite Sports Team |
The favorite sports team of the customer, which is captured to allow the bank employees to have casual conversations with the customer. |
Mets Giants Flyers |
Char |
100 |
CRM |
Not applicable |
|
Inactive Date |
The date captured for the point where a customer has not had any transactions for a ten-year period. |
03-12-2014 |
Date |
Not applicable |
Look at today’s date and the customer’s last transaction date. If the difference is greater than ten years, insert today’s date. |
|
|
Check Number |
The unique number assigned to each check within a checking account. This is the number pre-printed on the upper right hand corner of the check. |
123 134 |
Num |
3 |
Acct Txn App |
Not applicable |
|
With-drawal Amount |
The amount taken out of an account as initiated by completing a withdrawal slip. |
$50.29 |
Dec |
15,2 |
Acct Txn App |
Not applicable |
For Dimensional
The same two templates we just described for relational also apply to dimensional. Recall our dimensional CDM from the last chapter:

On the facing page is the completed Properties Template for this CDM. To save row space, I removed those classword rows where there were no properties identified. Note also that I am showing only a handful of the actual attributes that would come out of this process. I also combined all of the characteristics for viewing student attrition under the column Criteria instead of showing each indicator in a separate column.
Student Attrition Application Properties
|
Department |
Calendar |
Criteria |
Attrition |
|
|
Name |
Department Name |
|||
|
Text |
Year Full Name, Semester Name |
|||
|
Code |
Department Code |
Year Code, Semester Code |
||
|
Number |
Semester Sequence Number |
Student Count |
||
|
Indicator |
Scholarship Indicator, Graduation Indicator, University Application Indicator, High School Application Indicator, Financial Aid Indicator |
And now we will fill in the Property Characteristics Template for each of these properties. To save space, I am only going to fill this in for the measure Student Count from the Property Template above, but on an actual project, you would complete this for all attributes:
Student Attrition Application Property Characteristics
|
Property |
Definition |
Sample Values |
Format |
Length |
Source |
Transformations |
|
Student Count |
The number of people currently enrolled in a program (both degree and non-degree). |
50 |
Num |
8 |
Student Reg App |
Derived when loading data from the data warehouse. |
Step 2: Normalize and Abstract (Relational Only)
Normalization and abstraction are techniques for properly assigning data elements to entities on the relational data model. Normalization is a mandatory technique, and abstraction is an optional technique.
Normalization
When I turned 12, I received a trunk full of baseball cards as a birthday present from my parents. I was delighted, not just because there might have been a Hank Aaron or Pete Rose buried somewhere in that trunk, but because I loved to organize the cards. I categorized each card according to year and team. Organizing the cards in this way gave me a deep understanding of the players and their teams. To this day, I can answer many baseball trivia questions.
Normalization, in general, is the process of applying a set of rules with the goal of organizing something. I was normalizing the baseball cards according to year and team. We can also apply a set of rules and normalize the attributes within our organizations. The rules are based on how the business works, and the relational data model captures the business rules, which is why normalization is the primary technique used in building the relational logical data model.
Just as those baseball cards initially lay unsorted in that trunk, our companies have huge numbers of attributes spread throughout departments and applications. The rules applied to normalizing the baseball cards entailed first sorting by year and then by team within a year. The rules for normalizing our attributes can be boiled down to a single sentence: Make sure every attribute is single-valued and provides a fact completely and only about its primary key. Single-valued means an attribute must contain only one piece of information. If Consumer Name contains Consumer First Name and Consumer Last Name, for example, we must split Consumer Name into two attributes – Consumer First Name and Consumer Last Name. Provides a fact means that a given primary key value will always return no more than one of every attribute that is in the same entity with this key. If a Customer Identifier value of 123, for example, returns three customer last names (Smith, Jones, and Roberts), Customer Last Name violates this part of the normalization definition. Completely means that the minimal set of attributes that uniquely identify an instance of the entity is present in the primary key. Only means that each attribute must provide a fact about the primary key and nothing else. That is, there can be no hidden dependencies, so we would need to remove derived attributes.
We cannot determine if every attribute is single-valued and provides a fact completely and only about its primary key unless we understand the data. To understand the data, we usually need to ask lots of questions. Therefore a second definition for normalization is: A formal process of asking business questions. Even for an apparently simple attribute such as Phone Number, for example, we can ask many questions:
- Whose phone number is this?
- Do you always have to have a phone number?
- Can you have more than one phone number?
- Do you ever recognize the area code as separate from the rest of the phone number?
- Do you ever need to see phone numbers outside a given country?
- What type of phone number is this? That is, is it a fax number, mobile number, etc.?
- Does the time of day matter? For example, do we need to distinguish between the phone number to use during working hours and outside working hours? Of course, that would lead to a discussion on what we mean by “working hours.”
To ensure that every attribute is single-valued and provides a fact completely and only about its primary key, we apply a series of rules in small steps, where each step (or level of normalization) checks something that moves us towards our goal. Most data professionals would agree that the full set of normalization levels is the following:
- first normal form (1NF)
- second normal form (2NF)
- third normal form (3NF)
- Boyce/Codd normal form (BCNF)
- fourth normal form (4NF)
- fifth normal form (5NF)
1NF is the lowest level and 5NF the highest. Each level of normalization includes the lower levels of rules that precede it. If a model is in 5NF, it is also in 4NF, BCNF, and so on. Even though there are higher levels of normalization than 3NF, many interpret the term normalized to mean 3NF. This is because the higher levels of normalization (that is, BCNF, 4NF, and 5NF) cover specific situations that occur much less frequently than the first three levels. Therefore, to keep things simple, let’s focus on only first through third normal forms.
Initial Chaos
I would describe the trunk of baseball cards I received as being in a chaotic state as there was no order to the cards—just a bunch of cards thrown in a large box. I removed the chaos by organizing the cards. The term chaos can be applied to any unorganized pile including attributes. We may have a strong understanding of each of the attributes, such as their name and definition, but we don’t know to which entity the attribute should be assigned. When I picked out a 1978 Pete Rose from the baseball card box and put this card in the 1978 pile, I started bringing order were there was chaos – similar to assigning Customer Last Name to the customer pile (called the Customer entity).
Let’s walk through an example. Here’s a bunch of what appears to be employee attributes:

Often definitions are of poor quality or missing completely, so let’s assume that this is the case with this Employee entity. We are told, however, that Employee Vested Indicator captures whether an Employee is eligible for retirement benefits – a value of Y for “yes” means the employee is eligible, and a value of N for “no” means the employee is not eligible. This indicator is derived from the employee’s start date. For example, if an employee has worked for the company for at least five years, then this indicator contains the value Y, which means this employee is eligible for retirement benefits.
What is lacking at this point, and what will be solved though normalization, is assigning these attributes to the right entities.
It is very helpful to have some sample values for each of these attributes, so let’s assume this spreadsheet is a representative set of employee values:
|
Emp Id |
Dept Cd |
Phone 1 |
Phone 2 |
Phone 3 |
Emp Name |
Dept Name |
Emp Start Date |
Emp Vested Ind |
|
123 |
A |
973-555-1212 |
678-333-3333 |
343-222-1111 |
Henry Winkler |
Data Admin |
4/1/2012 |
N |
|
789 |
A |
732-555-3333 |
678-333-3333 |
343-222-1111 |
Steve Martin |
Data Admin |
3/5/2007 |
Y |
|
565 |
B |
333-444-1111 |
516-555-1212 |
343-222-1111 |
Mary Smith |
Data Warehouse |
2/25/2006 |
Y |
|
744 |
A |
232-222-2222 |
678-333-3333 |
343-222-1111 |
Bob Jones |
Data Admin |
5/5/2011 |
N |
First Normal Form (1NF)
Recall that the series of rules can be summarized as: Every attribute is single-valued and provides a fact completely and only about its primary key. First Normal Form (1NF) is the “single-valued” part. It means that for a given primary key value, we can find, at most, one of every attribute that depends on that primary key.
Ensuring each attribute provides a fact about its primary key includes addressing repeating groups and multi-valued attributes. Specifically, the modeler needs to:
- Move repeating attributes to a new entity. When there are two or more of the same attribute in the same entity, they are called repeating attributes. The reason repeating attributes violate 1NF is that for a given primary key value, we are getting more than one value back for the same attribute. Repeating attributes often take a sequence number as part of their name, such as phone number in this employee example. We can find ourselves asking many questions just to determine if there are any repeating attributes we need to address. We can have a question template such as “Can a [[insert entity name here]] have more than one [[insert attribute name here]]?” So these are all valid questions in our employee example:
- Can an Employee have more than one Employee Identifier?
- Can an Employee have more than one Department Code?
- Can an Employee have more than one Phone Number?
- Can an Employee have more than one Employee Name?
- Can an Employee have more than one Department Name?
- Can an Employee have more than one Employee Start Date?
- Can an Employee have more than one Employee Vested Indicator?
- Separate multi-valued attributes. Multi-valued means that within the same attribute we are storing at least two distinct values. There are at least two different business concepts hiding in one attribute. For example, Employee Name may contain both a first name and last name. Employee First Name and Employee Last Name can be considered distinct attributes, and therefore Henry Winkler, stored in Name, is multi-valued, because it contains both Henry and Winkler. We may find ourselves asking many questions just to determine if there are any multi-valued attributes we need to identify. We can have another question template, such as “Does a [[insert attribute name here]] contain more than one piece of business information?” So these are all valid questions in our employee example:
- Does an Employee Identifier contain more than one piece of business information?
- Does a Department Code contain more than one piece of business information?
- Does a Phone Number contain more than one piece of business information?
- Does an Employee Name contain more than one piece of business information?
- Does a Department Name contain more than one piece of business information?
- Does an Employee Start Date contain more than one piece of business information?
- Does an Employee Vested Indicator contain more than one piece of business information?
After answering these questions based on the earlier set of sample data, and by talking with a business expert, we can update the model:
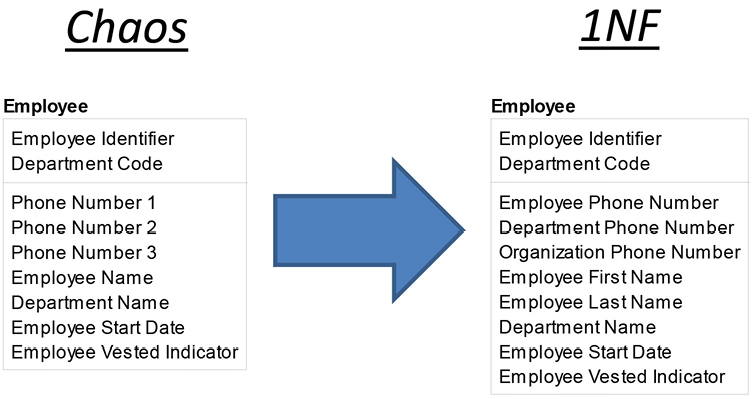
We learned that although Phone Number 1, Phone Number 2, and Phone Number 3 appear as repeating attributes, they are really three different pieces of information based upon the sample values we were given. Phone Number 3 contained the same value for all four employees, and after validating with the business expert we learned that this is the organization’s phone number. Phone Number 2 varied by department, so this attribute was renamed to Department Phone Number. Phone Number 1 is different for each employee, and we learned that this is the Employee Phone Number. We also were told that Employee Name does contain more than one piece of information, and therefore it should be split into Employee First Name and Employee Last Name.
Second Normal Form (2NF)
Recall that the series of rules can be summarized as: Every attribute is single-valued and provides a fact completely and only about its primary key. First Normal Form (1NF) is the “single-valued” part. Second Normal Form (2NF) is the “completely” part. This means each entity must have the minimal set of attributes that uniquely identifies each entity instance.
As with 1NF, we will find ourselves asking many questions to determine if we have the minimal primary key. We can have another question template such as: “Are all of the attributes in the primary key needed to retrieve a single instance of [[insert attribute name here]]?” In our Employee data model, the minimal set of primary key instances are Employee Identifier and Department Code. So these are all valid questions for our employee example:
- Are both Employee Identifier and Department Code needed to retrieve a single instance of Employee Phone Number?
- Are both Employee Identifier and Department Code needed to retrieve a single instance of Department Phone Number?
- Are both Employee Identifier and Department Code needed to retrieve a single instance of Organization Phone Number?
- Are both Employee Identifier and Department Code needed to retrieve a single instance of Employee First Name?
- Are both Employee Identifier and Department Code needed to retrieve a single instance of Employee Last Name?
- Are both Employee Identifier and Department Code needed to retrieve a single instance of Department Name?
- Are both Employee Identifier and Department Code needed to retrieve a single instance of Employee Start Date?
- Are both Employee Identifier and Department Code needed to retrieve a single instance of Employee Vested Indicator?
We learned from asking these questions that Employee Identifier is needed to retrieve a single instance of Employee Phone Number, Employee First Name, Employee Last Name, Employee Start Date, and Employee Vested Indicator. We learned also that Department Code is needed to retrieve a single instance of Department Name, Department Phone Number, and Organization Phone Number.
Normalization is a process of asking business questions. In this example, we could not complete 2NF without asking the business “Can an Employee work for more than one Department at the same time?” If the answer is “Yes” or “Sometimes,” then the first model under 2NF on the facing page is accurate. If the answer is “No,” then the second model prevails.
Third Normal Form (3NF)
Recall that the series of rules can be summarized as: Every attribute is single-valued and provides a fact completely and only about its primary key. First Normal Form (1NF) is the “single-valued” part. Second Normal Form (2NF) is the “completely” part. Third Normal Form (3NF) is the “only” part.
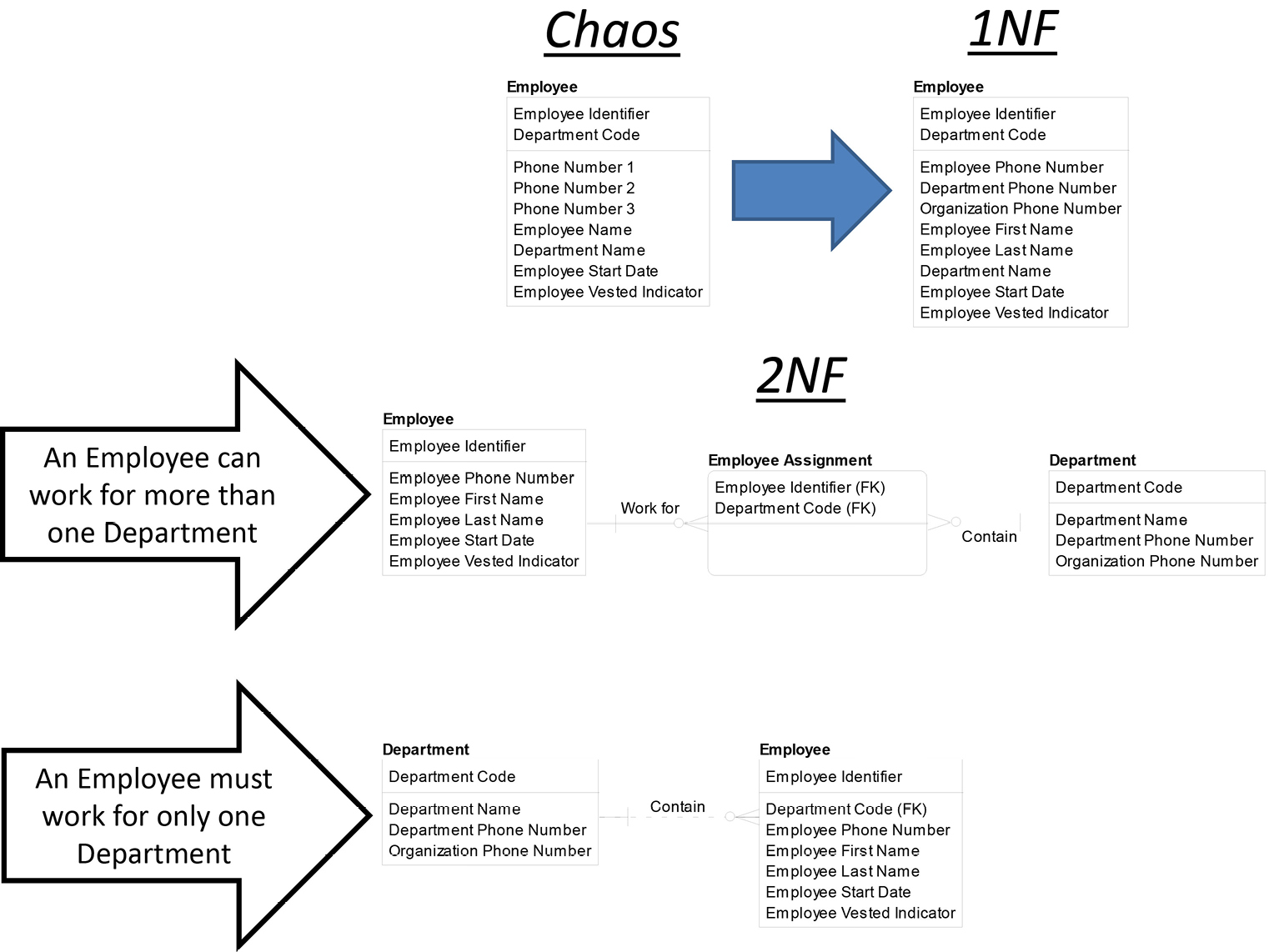
3NF requires the removal of hidden dependencies. A hidden dependency is when a property of an entity depends upon one or more other properties in that same entity instead of directly on that entity’s primary key. Each attribute must be directly dependent on only the primary key and not directly dependent on any other attributes within the same entity.
For example, assume an Order is identified by an Order Number. Within Order, there are many attributes, including Order Scheduled Delivery Date, Order Actual Delivery Date, and Order On Time Indicator. Order On Time Indicator contains either a Yes or a No, providing a fact about whether the Order Actual Delivery Date is less than or equal to the Order Scheduled Delivery Date. Order On Time Indicator, therefore, provides a fact about Order Actual Delivery Date and Order Scheduled Delivery Date, not directly about Order Number. Order Delivered On Time Indicator has a hidden dependency therefore, that must be addressed to put the model into 3NF.
The data model is a communication tool. The relational logical data model communicates which attributes are facts about the primary key and only the primary key. Hidden dependencies complicate the model and make it difficult to determine how to retrieve values for each attribute.
To resolve a hidden dependency, you will either need to remove the attribute that is a fact about non-primary key attribute(s) from the model, or you will need to create a new entity with a different primary key for the attribute that is dependent on the non-primary key attribute(s).
As with 1NF and 2NF, we will find ourselves asking many questions to uncover hidden dependencies. We can have another question template such as:
“Is [[insert attribute name here]] a fact about any other attribute in this same entity?”
So these are all valid questions for our employee example:
- Is Employee Phone Number a fact about any other attribute in Employee?
- Is Organization Phone Number a fact about any other attribute in Department?
- Is Department Phone Number a fact about any other attribute in Department?
- Is Employee First Name a fact about any other attribute in Employee?
- Is Employee Last Name a fact about any other attribute in Employee?
- Is Department Name a fact about any other attribute in Department?
- Is Employee Start Date a fact about any other attribute in Employee?
- Is Employee Vested Indicator a fact about any other attribute in Employee?
Note that Employee Vested Indicator may be a fact about Employee Start Date as Employee Vested Indicator can be calculated Y or N based upon the employee’s start date. The following figure shows the model in 3NF after removing the derived attribute Employee Vested Indicator.

You will find that the more you normalize, the more you go from applying rules sequentially to applying them in parallel. For example, instead of first applying 1NF to your model everywhere and then, when you are done, applying 2NF and so on, you will find yourself looking to apply all levels at once. This can be done by looking at each entity and making sure the primary key is correct and that it contains a minimal set of attributes and that all attributes are facts about only the primary key.
Abstraction (Relational Only)
Normalization is a mandatory technique on the relational logical data model. Abstraction is an optional technique. Abstraction brings flexibility to your data models by redefining and combining some of the attributes, entities, and relationships within the model into more generic terms.
The general question that needs to be asked is:
“Are there any entities, relationships, or data elements that should be made more generic to accommodate future requirements?”
For example, we can take our normalized data model from the prior section and abstract Employee into Party and Role to get this model:
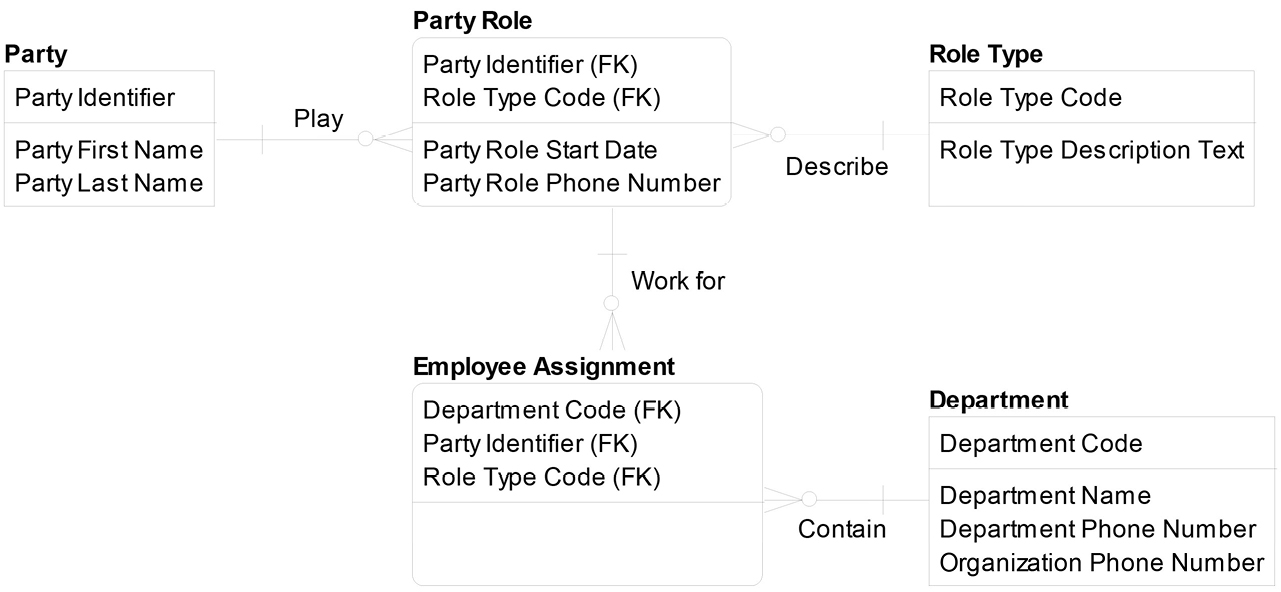
Where did our employees go? They are now a particular role that a Party can play. Party can be any person (and usually also any organization, but in this example, only person), and a person can play many roles such as employee, tennis player, or student. Which model do you like better, the 3NF model we built or this abstract model? Most of us like the 3NF model better because the abstract model has several disadvantages:
- Loss of communication. The concepts we abstract are no longer represented explicitly on the model. That is, when we abstract, we often convert column names to entity instances. For example, Employee is no longer an explicit entity, but is, instead, an entity instance of Party Role, with a Role Type Code value of 03 for Employee. One of the main reasons we model is for communication, and abstracting can definitely hinder communication.
- Loss of business rules. When we abstract, we can also lose business rules. To be more specific, the rules we enforced on the data model before abstraction now need to be enforced through other means such as through programming code. If we wanted to enforce that an Employee must have a Start Date, for example, we could no longer enforce this rule through our abstracted data model.
- Additional development complexity. Abstracting requires sophisticated development techniques to turn attributes into values when loading an abstract structure, or to turn values back into attributes when populating a structure from an abstract source. Imagine the work to populate Party Role from the source Employee. It would be much easier for a developer to load data from an entity called Employee into an entity called Employee. The code would be simpler, and it would be very fast to load.
So, although abstraction provides flexibility to an application, it does come with a cost. It makes the most sense to use abstraction when the modeler or analyst anticipates additional types of something coming in the near future. For example, in our abstract data model, additional types of people might become important in the future such as Contractor and Consumer. Roles such as Contractor and Consumer can be added gracefully without updates to our model. Abstraction might also be used when there is an integration requirement such as the requirement to recognize that Bob the employee is also Bob the student.
To minimize the cost of abstraction, some modelers prefer to wait until the physical relational data model before abstracting. This way the logical data model still reflects the business language, and then flexibility and integration can be performed in the application through abstraction in the physical data model.
If we are building a MongoDB database, abstraction can be even less desirable because MongoDB does not require us to define our physical schema in advance; therefore, we lose the flexibility benefit of abstraction because MongoDB is already flexible by design. Therefore, the only benefit of abstraction in a MongoDB world is when there is a requirement for integration and the abstract concepts such as Party serve as integration points in our application.
Step 3: Determine the Most Useful Form
Recall during conceptual data modeling how we needed to identify the validator (the person or group responsible for ensuring our modeling results are correct) and the users (the person or group who is going to use the data model). We need to perform the same activity at the logical level. Determine who the validators and users will be at the logical level, and that will determine the most useful form.
At the conceptual level, it is very possible for the validators and users to have different technical levels and experiences; therefore, there could be more than one form for communicating the conceptual data model. At the logical level, however, you will find a majority of the time that the same form will work well for both the validators and users.
Let’s see the different forms we can choose from for both relational and dimensional perspectives.
For Relational
At the relational logical level, we do have the option of multiple forms. However, it would be very difficult (but possible) to represent the LDM using business assertions or a business sketch, both of which work well on the CDM. Variations on the relational LDM have more to do with notation, such as using Information Engineering (IE for short), which is the notation in this book, versus using the UML Class Diagram, for example.
In our Account example, here is our relational LDM after normalizing, using the IE notation:

Note that often during the process of building the logical data model, we refine (and sometimes correct) rules we identified during the conceptual data modeling stage. For example, upon examining the primary key to MonthlyStatementFee, we learned that it shared the same primary key as BankAccountStatement. After further analysis, we moved the fee amount to BankAccountStatement and removed MonthlyStatementFee. We also learned that there is a one-to-many relationship between Account and BankAccountStatement, not a many-to-many relationship. We also uncovered the new property, monthlyStatementDate, which is needed to distinguish BankAccountStatements belonging to the same Account.
For Dimensional
Similar to relational, there are multiple notations we can choose for the dimensional logical. Here is our University dimensional LDM using the traditional information engineering notation:

Recall from our conceptual data modeling discussion that Student Attrition is an example of a fact table (on a conceptual and logical data model often called a “meter”). A meter is an entity containing a related set of measures. The measures on this model determine how the student attrition business process is doing—in this case, studentCount. Often the meter contains many measures. Also, often the dimensions contain many attributes, sometimes hundreds of them. On this model we have a number of dimensions, such as University, that only contain a single attribute.
Step 4: Review and Confirm
Previously we identified the person or group responsible for validating the model. Now we need to show them the model and make sure it is correct. Often at this stage after reviewing the model we go back to Step 1 and make some changes and then show the model again. This iterative cycle continues until the model is agreed upon by the validator and deemed correct so that we can move on to the physical modeling phase.
EXERCISE 6: Logical Data Modeling Mindset
Recall the MongoDB document below, which we discussed in our last chapter. Think of at least ten questions that you would ask during the logical data modeling phase based upon the data you see in this collection. See Appendix A for some of the questions I would ask.
Order:
{ orderNumber : “4839-02”,
orderShortDescription : “Professor review copies of several titles”,
orderScheduledDeliveryDate : ISODate(“2014-05-15”),
orderActualDeliveryDate : ISODate(“2014-05-17”),
orderWeight : 8.5,
orderTotalAmount : 19.85,
orderTypeCode : “02”,
orderTypeDescription : “Universities Sales”,
orderStatusCode : “D”,
orderStatusDescription : “Delivered”,
orderLine :
[ { productID : “9781935504375”,
orderLineQuantity : 1
},
{ productID : “9781935504511”,
orderLineQuantity : 3
},
{ productID : “9781935504535”,
orderLineQuantity : 2
} ] }
|
Key Points
|