
Chapter 2 – Kognitio Table Structures
“Let me once again explain the rules.
The Kognitio Data Warehouse Rules!”
- Tera-Tom Coffing
Kognitio has Three Table Distribution Options
1)Random - Round Robin Distribution (Default)
2)Hash Distributed
3)Replicated
Most Kognitio tables will use a Round robin distribution. This is the default when no distribution key is defined. The data is spread evenly across the nodes to maximize parallel processing.
Hash distribution. A column(s) are chosen as the distribution key. This column(s) is run through the Kognitio hashing algorithm to divide data among all of the nodes. Like values will hash to the same node. This is often done when two tables are joined together. When the join key is also the distribution key for both tables, the join works fast and efficient.
Replicated: A table can be replicated in its entirety on all nodes. This is often done when a smaller table, such as a dimension table(s) will be joined to a larger table.
Kognitio makes creating tables and distribution easy. Check out the fundamentals above.
A Table that is distributed via a Round Robin Technique

Most Kognitio tables will use a Round Robin distribution. This is defined by the keyword RANDOM. The data is spread evenly across the nodes to maximize parallel processing.
Round Robin Technique is the Default

Most Kognitio tables will use a Round robin distribution. This is the default when no distribution key is defined. The data is spread evenly across the nodes to maximize parallel processing.
Random Distribution

Kognitio tables default to Random Distribution. This means that the rows of a table are distributed randomly, but evenly across all of the nodes. Each node is responsible for an equal amount of the rows of a table. Each node can parallel process their portion of the table to maximize parallelism and the in-memory speeds that Kognitio has pioneered.
A Table that is distributed by Hash

A table that is HASHED has a distribution key that is distributed across the nodes using a Hash algorithm. Like values will go to the same node. This is important if two tables are joined together because the matching rows will be in the same memory pool, thus making the join faster.
Tables that join are excellent candidates for Hashed Tables

A table that is HASHED has a distribution key that is distributed across the nodes using a Hash algorithm. Like values will go to the same node. This is important if two tables are joined together because the matching rows will be in the same memory pool, thus making the join faster.
Hash Distribution
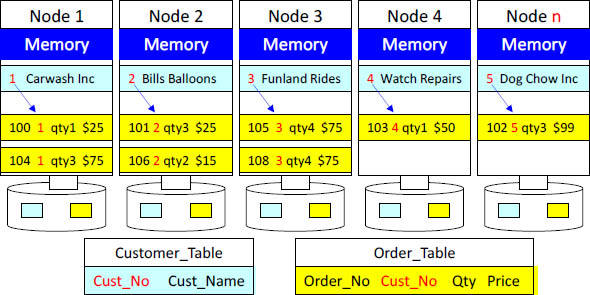
These tables join based on the column Cust_No. Both tables were distributed
by Hash on Cust_No. All joining rows are on the same node, but the data is not
necessarily distributed evenly. This does however make for extremely fast
joining between two tables. This is why you use a hash distribution.
If you join two tables a lot you will want to distribute them by Hash on the join condition. When the joining rows are already on the same node the join is said to be "Node Local". This makes for extremely fast joins.
A Table that is distributed by Hash by Multiple Columns

A table that is HASHED has a distribution key that is distributed across the nodes using a Hash algorithm. Like values will go to the same node. A table can have multiple columns as the HASHED key. Above, both Subscriber_No and Member_No are concatenated and then hashed to form a single distribution key.
The Reasons for a Multi-Column HASHED Distribution Key

A table that is HASHED has a distribution key that is distributed across the nodes using a Hash algorithm. Like values will go to the same node. This is important if two tables are joined together because the matching rows will be in the same memory pool, thus making the join faster. The other reasons to do this is for better distribution or because your application uses multiple columns within each query.
Creating a Table that is replicated across all Nodes

A replicated table is copied to every node. If a State_Table has 50 rows, then all 50 rows would be copied to each and every node. This is done to make joining smaller tables that are replicated to join efficiently to larger tables that are either Hashed or Random distributed. A replicated table always has its matching rows on the same node because they are on every node.
Replicated Distribution

The Department_Table has been Replicated across all nodes.
There are only four rows in the table. Each node holds all four rows.
A big key to improving join performance is to setup joining tables so the joining rows are naturally on the same node. When you have a small table you can replicate it across all of the nodes, thus ensuring the matching rows will be on the same node.
The Concept is all about the Joins

If tables are replicated, then they are always on the same node as the rows they join. That is why a large Fact table will often be distributed by random or by hash and the smaller tables it joins to will be replicated. The setup of tables that join are all about ensuring that the matching rows are in the same memory pool. This is how the pros design their tables.
Kognitio allows you to create Images

Kognitio give you three options for your data:
1)Store a table in memory only
2)Store a table on disk only
3)Store a table on both memory and disk
Kognitio allows you to create images of data and these images are stored in memory. Images can take all of the columns and rows of a table, but images can also be built that only take some of the columns or some of the rows. When you create an image it means you are requesting that the image be placed into memory for the fastest querying possible.
Creating a Table Image to place a Table in Memory

When you create the table, by default a RAM image is created at the same time, so this image needs to be dropped before you create another one. The CREATE TABLE IMAGE statement is how you place a table into memory, which is what Kognitio has been built to do. You can set up a RAM image of an entire table or choose only some of the columns and/or rows from a table. Any changes to the table through inserts, updates or deletes are reflected in RAM as well as on disk. Because the image is in RAM, queries run significantly faster on a table image.
Partitioning an Image

Kognitio has implemented partitioning with the latest release. See the example above. Partitioning of images is beneficial when queries involve equality predicates, in lists or if the image joins to small derived tables. Partition with multiple columns will benefit predicates using all or any of partition columns.
Partitioning an Image View

Kognitio has implemented partitioning with the latest release. See the example above. Partitioning of images is beneficial when queries involve equality predicates, in lists or if the image joins to small derived tables. Partition with multiple columns will benefit predicates using all or any of partition columns.
CREATE OR REPLACE TABLE IMAGE

You can use the CREATE OR REPLACE TABLE IMAGE statement to set up or replace an existing RAM image of a table. You can also set it up to only choose selected columns or even rows.
DEFRAG TABLE IMAGE

The DEFRAG command allows historic rows held in RAM for a table to be discarded, freeing up memory. The way this used to be done was to drop and recreate the image, but the DEFRAG command will do it if more than 10% of the rows will actually be discarded. The keyword FORCE performs the DEFRAG no matter what percentage will be discarded.