
C H A P T E R 15
Dependencies and Invalidations
Dependencies between PL/SQL packages can a perplexing source of application errors. Database administrators and developers unacquainted with how dependencies work can find themselves scratching their heads over sporadic and unrepeatable errors that are seemingly without cause. For example, while executing a procedure in a package you are responsible for, an application throws the following error:
ORA-04068: existing state of package has been discarded
This particular procedure has been executed a million times before. You can swear on your great grandmother's grave that you haven't changed the package in a long time, definitely not in the last few seconds and yet the application gets this error, the customer orders fail, and the organization loses money.
Not finding an obvious explanation, you blame a coworker for messing with this package, resulting in a heated argument which you regret instantly. Your manager intervenes and calmly asks you to show her the error. You manually re-execute the procedure in the package and (surprise, surprise) it executes without any error! Amidst that glaring from your accused coworker and the oh-you-need-help look from your manager, you are now thoroughly perplexed as to what happened. Sabotage, Oracle bug, bad karma, or none of the above?
What is this error? And why did it get resolved immediately afterwards without your intervention? The problem is not voodoo, but how PL/SQL code dependencies work. Some object referenced in the package was altered, which caused the package to be invalidated. Then the package revalidated (or, recompiled) later and had to be reinitialized.
Understanding the dependency chain and causes of invalidation is very important when you develop an application. The preceding scenario is an example of how poorly designed application code can cause an outage. This chapter explains dependencies and how you can code to reduce invalidations, thus reducing and possibly eliminating interruptions to the application during runtime.
Dependency Chains
First, you must understand dependency chains and their impact upon PL/SQL code. Suppose you have a table ORDERS and a procedure UPD_QTY that updates the column QUANTITY. Their definitions are as follows (note the dependency of the procedure upon the table; the two objects form a dependency chain):
SQL> desc orders
Name Null? Type
----------------------------------------- -------- ----------------------------
ORDER_ID NOT NULL NUMBER(5)
CUST_ID NOT NULL NUMBER(10)
QUANTITY NUMBER(10,2)
create or replace procedure upd_qty (
p_order_id in orders.order_id%type,
p_quantity in orders.quantity%type
) as
begin
update orders
set quantity = p_quantity
where order_id = p_order_id;
end;
What happens if you drop the column QUANTITY? The procedure will become meaningless, of course, so Oracle rightfully makes it invalid. Later you make another modification, either by adding the column back to the table or by removing that column from the procedure and replacing it with another in such a way that the procedure is now syntactically valid. If you added the column back into the table, you can recompile the procedure by executing:
SQL> alter procedure upd_qty compile reuse settings;
![]() Tip The RESUSE SETTINGS clause in the recompilation is a handy and powerful tool. Any special compile time parameter such as plsql_optimize_level or warning_level set earlier for the procedure will remain the same after the recompilation. If you didn't use that clause, the settings for the current sessions would have taken effect. So, unless you want to change those settings, it's a good idea to use that clause every time.
Tip The RESUSE SETTINGS clause in the recompilation is a handy and powerful tool. Any special compile time parameter such as plsql_optimize_level or warning_level set earlier for the procedure will remain the same after the recompilation. If you didn't use that clause, the settings for the current sessions would have taken effect. So, unless you want to change those settings, it's a good idea to use that clause every time.
The compilation will check the existence of all the components referenced in the procedure. This establishment of validity occurs only when the procedure is compiled—not at runtime. Why? Imagine the contents of a typical stored code base: thousands of lines long with hundreds of tables, columns, and synonyms, views, sequences, and other stored code trying to validate every object at every execution. The performance will be terrible, making the process infeasible. Therefore, the validation is done at compilation time, which is likely a one-time act. When an object (such as this table) changes, Oracle can't immediately determine whether the changes will affect the dependent objects (such as this procedure), so it reacts by marking it as invalid. The dependency among objects is clearly shown in the data dictionary view DBA_DEPENDENCIES (or, its counterpart – USER_DEPENDENCIES).
SQL> desc dba_dependencies
Name Null? Type
----------------------------------------- -------- ----------------------------
OWNER NOT NULL VARCHAR2(30)
NAME NOT NULL VARCHAR2(30)
TYPE VARCHAR2(18)
REFERENCED_OWNER VARCHAR2(30)
REFERENCED_NAME VARCHAR2(64)
REFERENCED_TYPE VARCHAR2(18)
REFERENCED_LINK_NAME VARCHAR2(128)
DEPENDENCY_TYPE VARCHAR2(4)
The REFERENCED_NAME shows the object being referenced—the other object that the current object is dependent on. The following query against the table lists dependencies for UPD_QTY. Each such dependency represents an object upon which UPD_QTY is dependent.
select referenced_owner, referenced_name, referenced_type
from dba_dependencies
where owner = 'ARUP'
and name = 'UPD_QTY'
/
REFERENCED_OWNER REFERENCED_NAME REFERENCED_TYPE
------------------------------ ------------------------------ ------------------
SYS SYS_STUB_FOR_PURITY_ANALYSIS PACKAGE
ARUP ORDERS TABLE
This output shows that the procedure UPD_QTY depends on the table ORDERS, as we expected. Had there been another object in the procedure's code, it would have been listed here as well.
![]() Note See the upcoming sidebar “What About SYS_STUB_FOR_PARITY_ANALYSIS?” for an explanation of this particular dependency.
Note See the upcoming sidebar “What About SYS_STUB_FOR_PARITY_ANALYSIS?” for an explanation of this particular dependency.
Whenever the structure of the table ORDERS is changed, the procedure's validity becomes questionable and Oracle makes it invalid. However, being questionable does not necessarily mean invalid. For instance, when you add a column to the table, it is technically a change to the table. Will it make the procedure invalid?
SQL> alter table orders add (store_id number(10));
Table altered.
If you examine the status of the UPD_QTY procedure, yes.
SQL> select status from user_objects where object_name = 'UPD_QTY';
STATUS
-------
INVALID
But the procedure does not actually reference the new column, so it shouldn't have been affected. However, Oracle does not necessarily know that. It preemptively marks the procedure invalid just to be safe. You can, at this point, recompile the procedure; it will compile fine. Otherwise, Oracle will recompile the procedure automatically when it is invoked next time.
Let's see the new procedure, including the automatic recompilation, in action.
SQL> exec upd_qty (1,1)
PL/SQL procedure successfully completed.
The procedure executed just fine, even though it was marked invalid. How was that possible? It was executed successfully because the execution forced a recompile (and re-validation) of the procedure. The recompile succeeded because the procedure does not actually have any referenced to the component in the underlying table that changed—the new column STORE_ID. The procedure compiled fine and was marked valid. You can confirm that by checking the status once again.
SQL> select status from user_objects
2 where object_name = 'UPD_QTY';
STATUS
-------
VALID
So far the events seem pretty benign; these forced recompilations take care of any changes that do not affect the validity of the program and the world just goes on as usual. Why should you care? You should care a lot.
EXECUTED IMMEDIATE IS A SPECIAL CASE
The compilation of stored code (and for that matter other dependent objects such as views on a table) forces another process in the database called parsing. Parsing is akin to compilation of source code. When you execute an SQL statement such as select order_id from orders, Oracle can't just execute the statement as is. It must ask a lot of questions, some which are:
- What is
orders? Is it a table, a view, a synonym? - Is there indeed a column in the table called
order_id? - Is there a function called
order_id? - Do you have privileges to select from this table (or the function, as is the case)?
After making sure you have all the necessary pre-conditions, Oracle makes an executable version of that SQL statement and puts it in the library cache. This process is known as parsing. Subsequent execution of the SQL will use the parsed version only and not go through the process of parsing. During the execution phase, Oracle must ensure that the components (the table ORDERS, the procedure UPD_QTY, etc.) are not changed. It does that by placing a parse lock on those objects and other structures such as cursors.
Parsing is very CPU intensive. Frequent parsing and recompilation rob the server of CPU cycles, starving other useful processes from getting their share of CPU power. You can examine the effect by checking the statistics related to parsing in a view called v$mystat which shows statistics for your current session. The view shows the stats as statistic# only; their names are available in another view called v$statname. The following is a query that joins both views and shows stats on parsing. Save the query as ps.sql to examine the effect of reparsing and recompilation.
select name, value
from v$mystat s, v$statname n
where s.statistic# = n.statistic#
and n.name like '%parse%';
The view v$mystat is a cumulative view, so the values in there do not show the current data; they are incremented. To know the stats for a period of time, you have to select from the view twice and get the difference. To find out the parse-related stats, collect the stats first by running ps.sql, execute the procedure upd_qty(), and collect the stats once again by running ps.sql, like so:
SQL> @ps
NAME VALUE
------------------------------ ----------
parse time cpu 20
parse time elapsed 54
parse count (total) 206
parse count (hard) 16
parse count (failures) 1
SQL> exec upd_qty(1,1)
PL/SQL procedure successfully completed.
SQL> @ps
NAME VALUE
------------------------------ ----------
parse time cpu 20
parse time elapsed 54
parse count (total) 208
parse count (hard) 16
parse count (failures) 1
Note the values. Nothing has increased; in other words, there was no parsing as a result of executing the procedure upd_qty. On a different session, alter the table by adding a column, like so:
SQL> alter table orders add (amount number(10,2));
Table altered.
Now, in the first session execute the procedure and collect the statistics.
SQL> exec upd_qty(1,1)
PL/SQL procedure successfully completed.
SQL> @ps
NAME VALUE
------------------------------ ----------
parse time cpu 26
parse time elapsed 60
parse count (total) 279
parse count (hard) 19
parse count (failures) 1
Notice how the parse-related statistics have increased. Hard parsing, which means the SQL statement was either not found in the library cache or whatever version was found was not usable and therefore had to be parsed fresh, jumped from 16 to 19—indicating 3 hard parses. Total parse count jumped from 208 to 279, a jump of 71. Since there are 3 hard parses, the other 68 are soft parses, which means the structures were found in the library cache and were revalidated rather than being parsed from scratch. The CPU time for parsing jumped from 20 to 26, indicating that the parsing consumed 6 centi-seconds of CPU. These CPU cycles could have been used for doing some otherwise useful work had there been not a need for parsing. It may not sound like much, but consider situations where thousands of such cases occur in a normal database system causing significant CPU consumption.
![]() Note In a RAC database, this parsing effect is even more pronounced. Since there are multiple instances, each with a library cache of its own, the parsing and invalidation must be carefully coordinated. For instance, when a table ORDERS is modified in instance INST1, the UPD_QTY procedure must be invalidated not only in the instance INST1; but in INST2 as well (assuming a two-node RAC database). The instance INST1 sends a message to INST2 to immediately mark the loaded versions of UPD_QTY invalid. Since there is a possibility someone may access the UPD_QTY procedure incorrectly, this message is sent with the high priority as a type of message known as a Direct Message. Since direct messages supersede the other types of messages, such as request for a block (which is called an Indirect Message), the other messages may not get their chance to be transmitted. That results in a lag in getting the blocks; the session that requested the blocks must wait, adding to the performance problems.
Note In a RAC database, this parsing effect is even more pronounced. Since there are multiple instances, each with a library cache of its own, the parsing and invalidation must be carefully coordinated. For instance, when a table ORDERS is modified in instance INST1, the UPD_QTY procedure must be invalidated not only in the instance INST1; but in INST2 as well (assuming a two-node RAC database). The instance INST1 sends a message to INST2 to immediately mark the loaded versions of UPD_QTY invalid. Since there is a possibility someone may access the UPD_QTY procedure incorrectly, this message is sent with the high priority as a type of message known as a Direct Message. Since direct messages supersede the other types of messages, such as request for a block (which is called an Indirect Message), the other messages may not get their chance to be transmitted. That results in a lag in getting the blocks; the session that requested the blocks must wait, adding to the performance problems.
The problem does not stop there. As you saw, the procedure is recompiled automatically when executed. It's validated, and that message is transmitted to INST2 immediately. The RAC interconnect is flooded with the messages like this, affecting the flow of other messages and blocks, and thus causing performance problems. The problem is exacerbated when the number of instances goes up since the amount of coordination goes up exponentially. Unlike blocks, there is no “master instance” of an object (cursor, table, package, etc.) in a library cache, so RAC must notify all the instances in the cluster to invalidate (and validate) the object.
In a typical application, you probably have a lot of procedures, which call a lot of other procedures. Suppose procedure P1 calls procedure P2, which in turn calls P3, which accesses the table T1. Diagrammatically, we can represent this situation as follows, with ![]() signifying “depends on,” like so:
signifying “depends on,” like so:
P1 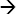 P2 P3 T1
P2 P3 T1
This is known as a dependency chain. If T1 is modified, all the dependent objects in the chain left of it (the ones that depend on it) could be invalidated and must be recompiled before being used. The recompilation must be in the order of dependency, e.g. first P3, then P2 followed by P1.This recompilation could be automatic, but it consumes CPU cycles in parsing and needs parse locks in any case. The longer the dependency chain, the more the demand for parsing, and the more the CPU consumption and need for parse locks. In a RAC database, it becomes extremely important that this cost be controlled; otherwise, the effects will spiral out of control. Therefore, your objective should be to reduce the cycle of revalidations and shorten the dependency chains.
WHAT ABOUT SYS_STUB_FOR_PURITY_ANALYSIS?
Shortening Dependency Chains
How can you reduce this vicious cycle of parsing-invalidation-parsing events? One bit of good news is that Oracle development has taken notice and the normal dependency model has been changed in Oracle Database11g. Instead of relying on modification of a table or view to invalidate dependent objects, Oracle Database 11g adopts a fine-grained dependency mechanism that looks at the column changes as well. The dependent objects are invalidated only if the columns referenced in them are modified; otherwise, they are left valid.
What about the cases where you do have to modify a column? In Oracle Database 11g, that could trigger invalidations. It may not be possible to avoid it completely, but you can reduce the impact if you shorten the dependency chain. For instance, if the above dependency chain had been just two levels instead of four, there would be fewer recompilations, resulting in lesser CPU consumption and parse locks. How can you accomplish this objective?
The answer lies in another type of stored code: packages. Packages handle invalidation differently and are much less susceptible than procedures and functions to this ripple effect of invalidations in case of a change in an upstream object. Let's see this with an example. First, you create a series of tables, packages, and procedures.
-- Create two tables
create table test1 (
col1 number;
col2 number
)
/
create table test2 (
col1 number;
col2 number
)
/
-- Create a package to manipulate these tables
create or replace package pack1
is
g_var1 number;
l_var1 number;
procedure p1 (p1_in test1.col1%TYPE);
procedure p2 (p1_in number);
end;
/
create or replace package body pack1
as
procedure p1 (p1_in test1.col1%type) is
begin
update test1
set col2 = col2 + 1
where col1 = p1_in;
end;
procedure p2 (p1_in number) is
begin
update test2
set col2 = col2 + 1
where col1 = p1_in;
end;
end;
/
create or replace package pack2
is
procedure p1 (p1_in number);
procedure p2 (p1_in number);
end;
/
create or replace package body pack2
as
procedure p1 (p1_in number) is
begin
pack1.p1(p1_in);
end;
procedure p2 (p1_in number) is
begin
pack1.p2(p1_in);
end;
end;
/
-- Create two procedures calling these packages.
create or replace procedure p1
(
p1_in in number
)
is
begin
pack2.p1 (p1_in);
end;
/
create or replace procedure p2
(
p1_in in number
)
is
begin
p1(p1_in);
end;
You've created two tables, then two packages that reference those tables (which then become dependents of the tables), a procedure that calls one of the packages, and finally another procedure that calls this procedure. From the definition the dependency chain appears to be like this:
P2 P1 PACK1,PACK2 TEST1,TEST2
Now to modify a column of the table TEST2:
SQL> alter table test2 modify (col2 number(9));
Table altered.
As per the dependency rules, all objects (PACK1, PACK2, P1, and P2) should have been invalidated and remain so until they are recompiled either manually or automatically. Confirm it by checking the status of all the objects in question.
select object_type, object_name, status
from user_objects;
OBJECT_TYPE OBJECT_NAME STATUS
------------------- ------------------------------ -------
PROCEDURE P1 VALID
PROCEDURE P2 VALID
PACKAGE PACK1 VALID
PACKAGE BODY PACK1 INVALID
PACKAGE PACK2 VALID
PACKAGE BODY PACK2 VALID
TABLE TEST1 VALID
TABLE TEST2 VALID
Interestingly, the only invalid object is package body PACK1; all others are still valid. How did that happen? Why were all the objects dependent on table TEST2 not invalidated?
The answer lies in the way the dependencies work for packages. Let's check these dependencies by running a SQL statement. Since you have to run it multiple times, save the following as dep.sql:
select referenced_type, referenced_owner, referenced_name
from dba_dependencies
where owner = '&1'
and name = '&2'
and type = '&3'
Now you can call this script several times with appropriate arguments to get the dependency information.
SQL> @dep ARUP P2 PROCEDURE
REFERENCED_TYPE REFERENCED_OWNER REFERENCED_NAME
----------------- ------------------------------ ------------------------------
PACKAGE SYS SYS_STUB_FOR_PURITY_ANALYSIS
PACKAGE SYS STANDARD
PROCEDURE ARUP P1
SQL> @dep ARUP P1 PROCEDURE
REFERENCED_TYPE REFERENCED_OWNER REFERENCED_NAME
----------------- ------------------------------ ------------------------------
PACKAGE SYS SYS_STUB_FOR_PURITY_ANALYSIS
PACKAGE SYS STANDARD
PACKAGE ARUP PACK2
SQL> @dep ARUP PACK2 PACKAGE
REFERENCED_TYPE REFERENCED_OWNER REFERENCED_NAME
----------------- ------------------------------ ------------------------------
PACKAGE SYS STANDARD
SQL> @dep ARUP PACK2 'PACKAGE BODY'
REFERENCED_TYPE REFERENCED_OWNER REFERENCED_NAME
----------------- ------------------------------ ------------------------------
PACKAGE SYS STANDARD
PACKAGE ARUP PACK1
PACKAGE ARUP PACK2
SQL> @dep ARUP PACK1 PACKAGE
REFERENCED_TYPE REFERENCED_OWNER REFERENCED_NAME
----------------- ------------------------------ ------------------------------
PACKAGE SYS STANDARD
SQL> @dep ARUP PACK1 'PACKAGE BODY'
REFERENCED_TYPE REFERENCED_OWNER REFERENCED_NAME
----------------- ------------------------------ ------------------------------
PACKAGE SYS STANDARD
TABLE ARUP TEST1
PACKAGE ARUP PACK1
TABLE ARUP TEST2
If you put this dependency information, which is really a dependency chain, into a diagram, it would look like Figure 15-1. The arrows point from dependent to referenced. I prefer those terms instead of child and parent simply because parent/child connotes a foreign key relationship. Not all dependencies are about referential integrity constraints (which are on data). Dependencies are about the references to actual objects, even if the objects may contain no data at all.
Studying Figure 15-1 carefully, you may notice an interesting fact: the package bodies depend on the packages; not on other package bodies. This is a very important property of packages and plays a beneficial role in invalidation of the objects in the dependency chain. Since the package bodies are dependent, and not the packages, they get invalidated, not the packages themselves. Objects that depend on the packages are also left valid since their referenced object is valid. In this example, no other object depends on PACK1 package body, so nothing else was invalidated.

Figure 15-1. A complex dependency chain
When does the PACK1 body get revalidated (or recompiled)? Since the modification of the table column does not fundamentally change anything, the objects can be recompiled automatically when they are called. Let's execute procedure P2, which is at the top of the dependency chain (i.e. it's the last, so nothing else depends on it).
SQL> exec p2 (1)
PL/SQL procedure successfully completed.
After execution, check the status of the objects.
OBJECT_TYPE OBJECT_NAME STATUS
------------------- ------------------------------ -------
PROCEDURE P1 VALID
PROCEDURE P2 VALID
PACKAGE PACK1 VALID
PACKAGE BODY PACK1 VALID
PACKAGE PACK2 VALID
PACKAGE BODY PACK2 VALID
TABLE TEST1 VALID
TABLE TEST2 VALID
Note how the package body was automatically recompiled. Execution of P2 executed procedure P1, which executed PACK2.P1, which in turn executed PACK1.P1. Since PACK1 was invalid, this execution forced the compilation and revalidated it. Only one package body was compiled here, not an entire chain of objects, which reduced the CPU consumption and parse locks. Consider the same case if the packages were procedures. It would have invalidated all the dependent procedures. The forced recompilation would have resulted in significantly more CPU consumption and need for parse locks.
Datatype Reference
Sometimes two best practices are desirable on their own but fail when they are used together. Such is the case with dependency tracking and some datatypes used in PL/SQL code. To illustrate the issue, I want to demonstrate a slightly different scenario. Instead of modifying table TEST2, let's modify TEST1 to add a column, like so:
SQL> alter table test1 modify (col2 number(8,3));
Table altered.
If you check for the status of the objects, you will see the following:
OBJECT_TYPE OBJECT_NAME STATUS
------------------- ------------------------------ -------
PROCEDURE P1 VALID
PROCEDURE P2 VALID
PACKAGE PACK1 INVALID
PACKAGE BODY PACK1 INVALID
PACKAGE PACK2 VALID
PACKAGE BODY PACK2 INVALID
TABLE TEST1 VALID
TABLE TEST2 VALID
Note the objects invalidated as a result of this modification—many more this time. Both the package and package body PACK1 are invalidated in this case, while only the package body was invalidated in the previous case. Why?
To answer, look at the declaration of P1 in the package specification.
procedure p1 (p1_in test1.col1%type) is
The datatype is a not a primitive such as NUMBER; it is referenced with the datatype of COL1 in the table TEST1. Defining parameters this way instead of a primitive is a good idea for performant code since the compilation ties it to the object components and makes the code faster. However, it also makes it dependent on table TEST1 more intimately than TEST2. Modifying TEST2 does not impact the datatype inside the package PACK1, but modifying datatype of COL1 in TEST1 changes the datatype of one of the parameters. Therefore, when TEST1 was modified, Oracle sensed that the package specification also changed and hence marked the package invalid. In case of the alteration of the table TEST2, the parameters passed to the procedures were not altered, the package specifications were not affected, and the package specification remained valid.
This invalidation should be automatically recompiled next time the topmost object is executed, right? No; this time the automatic recompilation will actually fail.
SQL> exec p2 (1)
BEGIN p1(1); END;
*
ERROR at line 1:
ORA-04068: existing state of packages has been discarded
ORA-04061: existing state of package "ARUP.PACK1" has been invalidated
ORA-04065: not executed, altered or dropped package "ARUP.PACK1"
ORA-06508: PL/SQL: could not find program unit being called: "ARUP.PACK1"
ORA-06512: at "ARUP.PACK2", line 5
ORA-06512: at "ARUP.P1", line 7
ORA-06512: at line 1
At this point, if you check for the validity of objects, you get the following:
OBJECT_TYPE OBJECT_NAME STATUS
------------------- ------------------------------ -------
PROCEDURE P1 VALID
PROCEDURE P2 VALID
PACKAGE PACK1 VALID
PACKAGE BODY PACK1 INVALID
PACKAGE PACK2 VALID
PACKAGE BODY PACK2 VALID
TABLE TEST1 VALID
TABLE TEST2 VALID
The two invalid objects were re-validated as a result of this attempted execution. Only one object remained invalid: the body of the package PACK1. How do you explain this and the error earlier?
The problem lies in a concept called package state. When a package is called for the very first time, it initializes its state in the memory. For instance, the global variables are one of the components in the package that are initialized. When the package specification becomes invalidated, the state is invalidated as well. The state is reinitialized, but right after the error, so the error occurs anyway. If you re-execute this procedure, you will not get the same error because the state has already been initialized this time. When the package was not recompiled the first time, its body was not recompiled either. Later, when the package state was initialized and the package recompiled fine, Oracle didn't go back and attempt another recompilation of the body and the body was left with invalid status.
At this point, if you re-execute procedure P2, package body PACK2 will be recompile and become valid, too. The application getting this error should do nothing other than simply re-executing the procedure it executed earlier. However, the application may not be able to handle it properly, throwing an exception and eventually causing an application outage—not a very desirable outcome. Therefore you should try to avoid this type of invalidation. You can easily avoid it by using primitives (such as NUMBER, DATE, etc.) for datatypes of parameters in the declaration section rather than the %type declaration. Unfortunately, doing so will result in less performing code. This brings up an interesting conundrum: would you code for performance or for more uptime?
Is there a way to accomplish both goals: writing performant code that does not invalidate easily? Fortunately, there is and it's described in the next section.
View for Table Alterations
One of the tricks to avoid or lessen the chances of cascading invalidations as a result of table modifications as you saw earlier is to use a view inside your stored code in place of a table. The view adds another layer of abstraction and will insulate the changes on the table from the dependent code. Let's see this benefit in action with an example. Let's assume there is a table called TRANS, which you can create as follows:
create table trans
(
trans_id number(10),
trans_amt number(12,2),
store_id number(2),
trans_type varchar2(1)
);
Now build the following package to manipulate the data in this table:
create or replace package pkg_trans
is
procedure upd_trans_amt
(
p_trans_id trans.trans_id%type,
p_trans_amt trans.trans_amt%type
);
end;
/
create or replace package body pkg_trans
is
procedure upd_trans_amt
(
p_trans_id trans.trans_id%type,
p_trans_amt trans.trans_amt%type
) is
begin
update trans
set trans_amt = p_trans_amt
where trans_id = p_trans_id;
end;
end;
/
You now want to write several other business code units using this package. One such unit is a function called ADJUST that updates the transaction amounts by a certain amount. Here is the code to create this function:
create or replace function adjust
(
p_trans_id trans.trans_id%type,
p_percentage number
)
return boolean
is
l_new_trans_amt number(12);
begin
select trans_amt * (1 + p_percentage/100)
into l_new_trans_amt
from trans
where trans_id = p_trans_id;
pkg_trans.upd_trans_amt (
p_trans_id,
l_new_trans_amt
);
return TRUE;
exception
when OTHERS then
return FALSE;
end;
/
![]() Note Proponents of a school of a certain coding practices will argue to place all the code to manipulate a specific table in a single package instead of spreading that code among many stored code segments, while others will argue that such a practice would have made the package long and unmanageable. I think the right answer is situation specific and therefore best left as a decision made at design time. In this example, I am not endorsing either approach but resorting to a separate procedure merely for illustration purposes.
Note Proponents of a school of a certain coding practices will argue to place all the code to manipulate a specific table in a single package instead of spreading that code among many stored code segments, while others will argue that such a practice would have made the package long and unmanageable. I think the right answer is situation specific and therefore best left as a decision made at design time. In this example, I am not endorsing either approach but resorting to a separate procedure merely for illustration purposes.
With the new objects in place, let's add a column in the view.
SQL> alter table trans add (vendor_id number);
Table altered.
Now check the status of the objects.
OBJECT_NAME OBJECT_TYPE STATUS
--------------- ------------------- -------
PKG_TRANS PACKAGE BODY INVALID
PKG_TRANS PACKAGE INVALID
ADJUST FUNCTION INVALID
It shouldn't be a surprise that the function got invalidated. It was invalidated because the components it depends on (the package specification and body of PKG_TRANS) were invalidated. Those invalidations were caused by the modification of the table TRANS. The next time these invalid components are executed, they will be automatically recompiled, but that will result in parsing, leading to increased CPU consumption and the placing of parse locks.
To avoid this scenario, you can build a view on the table.
create or replace view vw_trans
as
select trans_id, trans_amt, store_id, trans_type
from trans
/
Use this view in the package and function instead:
create or replace package pkg_trans
is
procedure upd_trans_amt
(
p_trans_id vw_trans.trans_id%type,
p_trans_amt vw_trans.trans_amt%type
);
end;
/
create or replace package body pkg_trans
is
procedure upd_trans_amt
(
p_trans_id vw_trans.trans_id%type,
p_trans_amt vw_trans.trans_amt%type
) is
begin
update vw_trans
set trans_amt = p_trans_amt
where trans_id = p_trans_id;
end;
end;
/
create or replace function adjust
(
p_trans_id vw_trans.trans_id%type,
p_percentage number
)
return boolean
is
l_new_trans_amt number(12);
begin
select trans_amt * (1 + p_percentage/100)
into l_new_trans_amt
from vw_trans
where trans_id = p_trans_id;
pkg_trans.upd_trans_amt (
p_trans_id,
l_new_trans_amt
);
return TRUE;
exception
when OTHERS then
return FALSE;
end;
/
Now add a column and then check the status of the objects.
SQL> alter table trans add (vendor_id number);
Table altered.
OBJECT_NAME OBJECT_TYPE STATUS
--------------- ------------------- -------
PKG_TRANS PACKAGE BODY VALID
PKG_TRANS PACKAGE VALID
ADJUST FUNCTION VALID
VW_TRANS VIEW VALID
All the objects are valid. This is because the package body depends on the view, not the table. The new column was not referenced in the view, so the view itself was not affected by the change in the table and was not invalidated, thanks to the fine grained dependency implemented in Oracle 11g.
![]() Note The view will be invalidated in Oracle 10g because in that version the fine-grained dependency control was not implemented. In 10g, the dependency is of the view on the table and any change in the table, even if it is a column addition that is not even referenced in the view, will invalidate the view.
Note The view will be invalidated in Oracle 10g because in that version the fine-grained dependency control was not implemented. In 10g, the dependency is of the view on the table and any change in the table, even if it is a column addition that is not even referenced in the view, will invalidate the view.
The power of fine-grained dependency is such that it not only looks at named columns, it applies to implicit columns as well. For instance, had you defined the view as create or replace view vw_trans as select * from trans (note the *; it means all columns instead of named columns earlier), the dependency wouldn't have mattered and view would not have been invalidated. However, if you recreate the view, the new column will be added to the view and makes the dependent object (the function) invalid. However, had you used a packaged function instead of a standalone function, it would not have been invalidated, as you observed earlier.
Adding Components into Packages
Now that you understand how packages are extremely valuable in shortening the dependency chain and reducing the cascading invalidations, you should always use packages, not standalone code segments in your applications. You should create packages as logical groups around functionalities. When you enhance the functionality of the applications, you may need to add new functions and procedures to the existing packages instead of creating new ones. That leads to a question. Since you altered existing packages, will doing so affect the dependent objects?
Let's examine the issue using the earlier example involving the table TRANS, the view VW_TRANS, the package PKG_TRANS, and the function ADJUST. Suppose with the revised requirements you need to add a new procedure to the package (upd_trans_type) to update the transaction type. Here is the package altering script that you would need to execute:
create or replace package pkg_trans
is
procedure upd_trans_amt
(
p_trans_id vw_trans.trans_id%type,
p_trans_amt vw_trans.trans_amt%type
);
procedure upd_trans_type
(
p_trans_id vw_trans.trans_id%type,
p_trans_type vw_trans.trans_type%type
);
end;
/
create or replace package body pkg_trans
as
procedure upd_trans_amt
(
p_trans_id vw_trans.trans_id%type,
p_trans_amt vw_trans.trans_amt%type
) is
begin
update vw_trans
set trans_amt = p_trans_amt
where trans_id = p_trans_id;
end;
procedure upd_trans_type
(
p_trans_id vw_trans.trans_id%type,
p_trans_type vw_trans.trans_type%type
) is
begin
update vw_trans
set trans_type = p_trans_type
where trans_id = p_trans_id;
end;
end;
/
After altering the package, take time to examine the status of the objects.
OBJECT_TYPE OBJECT_NAME STATUS
------------------- ------------------------------ -------
VIEW VW_TRANS VALID
TABLE TRANS VALID
PACKAGE BODY PKG_TRANS VALID
PACKAGE PKG_TRANS VALID
FUNCTION ADJUST VALID
Everything is valid. (Please note, in pre-11g versions, you will find some objects invalidated, due to the absence of fine-grained dependency tracking). Even though the package was altered by adding a new procedure, the function ADJUST itself does not call that procedure and therefore doesn't need to be invalidated—a fact recognized by fine-grained dependency checking in 11g. As you can see, the fine-grained dependency model not only tracks the column references but components in the stored code as well.
Although Oracle 11g and above seems to take care of the invalidation issue automatically, be aware that it is not always so. Consider another case where you want to have a new procedure to update the store_id.
create or replace package pkg_trans
is
procedure upd_store_id
(
p_trans_id vw_trans.trans_id%type,
p_store_id vw_trans.store_id%type
);
procedure upd_trans_amt
(
p_trans_id vw_trans.trans_id%type,
p_trans_amt vw_trans.trans_amt%type
);
end;
/
create or replace package body pkg_trans
is
procedure upd_store_id
(
p_trans_id vw_trans.trans_id%type,
p_store_id vw_trans.store_id%type
) is
begin
update vw_trans
set store_id = p_store_id
where trans_id = p_trans_id;
end;
procedure upd_trans_amt
(
p_trans_id vw_trans.trans_id%type,
p_trans_amt vw_trans.trans_amt%type
) is
begin
update vw_trans
set trans_amt = p_trans_amt
where trans_id = p_trans_id;
end;
end;
/
Notice that the new procedure is inserted at the beginning of the package instead of at the end. If you check for the validity, you get the following:
Why was the function invalidated? Interestingly, had you placed that procedure at the end, you wouldn't have invalidated the function. The reason for this seemingly odd behavior is the placement of stubs in the parsed version of the package. Each function is represented in the package as a stub and the stubs are ordered in the way they are defined in the package. The dependent components reference the stub by their stub number. When you add a function or procedure at the end, the new component is given a new stub number; the stubs of the existing components are not disturbed, so the dependent objects are not invalidated. When you add the component at the top, the order of components inside the package changes, which affects the stub numbers of the existing components. Since the dependent components refer to the stub numbers, they need to be reparsed and are therefore invalidated immediately.
![]() Tip To avoid invalidations in dependent objects when new code segments are added to the package, add new components such as functions and procedures to the end of a package specification and body—not in the middle. This will retain the stub numbering of existing components inside the package and will not invalidate its dependents.
Tip To avoid invalidations in dependent objects when new code segments are added to the package, add new components such as functions and procedures to the end of a package specification and body—not in the middle. This will retain the stub numbering of existing components inside the package and will not invalidate its dependents.
I'll close the discussion on the dependency model with another very important property that should affect your coding. Dependency tracking checks for changes in columns. If a newly added column is not used, the dependent is not invalidated. For instance, consider the cases where the following constructs are used inside a stored code.
select * into ... from test where ...;
insert into test1 values (...);
Note that there are no column names. In the first case, the * implicitly selects all the columns. When you alter the table to add a column, the * implicitly refers to that new column, even if you do not use it in the code, and so it invalidates the stored code. In the second case, the insert does not specify a column list, so all the columns are assumed and addition of a new column in test1 will force the statement to check for the value for the new column, forcing the invalidation of the stored code. Therefore, you must avoid constructs like this. You should use named columns in the stored code.
Another cause of invalidation in this scenario is all-inclusive implicitly defined column lists. In their quest to write agile code, some developers use a declaration like this:
declare l_test1_rec test1%rowtype;
Since the column list is not named, all the columns of test1 are assumed. So when you add a column, it invalidates the variable l_test1_rec, which invalidates the stored code. Do not use declarations like this. Instead, use explicitly named columns such as the following:
l_trans_id test1.trans_id%type;
l_trans_amt test1.trans_amt%type;
In this way, if a new column is added, it will not affect any of the declared variables and will not invalidate that stored code. However, please understand a very important point before you make that leap: using %rowtype may make the maintenance of the code easier since you do not have to explicitly name the variables. On the other hand, doing so makes the code more vulnerable to invalidations. You should make the decision to go either way using your best judgment.
Synonyms in Dependency Chains
Most databases use synonyms, for good reasons. Instead of using a fully qualified name like <SchemaName>.<TableName>, it's always easier to create a synonym and use it instead. However, bear in mind that a synonym is yet another object in the dependency chain and affects the cascading invalidation. Suppose that synonym S1 is in the dependency chain, as shown here:
P2 P1 PACK1 PACK2 S1 VW1 T1
In almost all cases, synonyms do not break the chain; they simply pass on the invalidations from their referenced objects downstream, with one important exception. When you alter a synonym, you have two choices.
- Drop and recreate: You would issue
drop synonym s1; create synonym s1 as … - Replace: You would issue
create or replace synonym s1 as …
The difference may seem trivial, but the first approach is a killer. When you drop a synonym, the downstream objects reference an invalid object. In the dependency chain, all the objects starting with PACK2 all the way to P2 will be invalidated. When you recreate the synonym, these objects will be automatically recompiled at their next invocation, but not without consuming some valuable CPU cycles and obtaining parse locks. The second approach does not invalidate any of the dependents. When you change a synonym, never drop and recreate it—replace it.
![]() Note The OR REPLACE syntax was introduced in recent versions of Oracle. Some of your application scripts may still implement the older approach. You should actively seek and change such scripts, modifying them to use the newer CREATE OR REPLACE syntax.
Note The OR REPLACE syntax was introduced in recent versions of Oracle. Some of your application scripts may still implement the older approach. You should actively seek and change such scripts, modifying them to use the newer CREATE OR REPLACE syntax.
Resource Locking
Changes are a fact of life. Applications do change in requirement and scope, forcing changes in stored code. The alteration of the stored code needs an exclusive lock. If any session is currently executing that object or another object that the changed object references, this exclusive lock will not be available. Let's examine this with an example table and a procedure that accesses this table:
create table test1 (col1 number, col2 number);
create or replace procedure p1
(
p1_in in number,
p2_in in number
) as
begin
update test1 set col2 = p2_in where col1 = p1_in;
end;
/
Once created, execute the procedure. Do not exit from the session.
SQL> exec p1 (1,1)
PL/SQL procedure successfully completed.
On a different session, try to add a new column to the table.
SQL> alter table test1 add (col3 number);
The earlier update statement will have put a transactional lock on the row of the table. The lock would be present even if there is not a single row in the table test1. This lock will prevent the alteration of the table. In Oracle 10g, this will error immediately with:
alter table test1 add (col3 number)
*
ERROR at line 1:
ORA-00054: resource busy and acquire with NOWAIT specified
On Oracle 11g, the ALTER TABLE statement will not error out immediately; it will likely wait for a specified time. If you check what the session is waiting on, you should get results like the following:
SQL> select event from v$session where sid = <Sid>;
EVENT
-----------------------
blocking txn id for DDL
This parameter ddl_lock_timeout is very handy in busy databases where the tables are being accessed by applications constantly so there is little or no downtime for the altering command to complete. Rather than just exiting immediately with the ORA-54 message, an ALTER TABLE statement will wait until it gets the lock. In the first session, if you issue a rollback or commit, which will end the transaction and effectively release the locks, the second session will get the lock on the table and will be able to alter the table. In the 10g case, the statement will have to be reissued.
Forcing Dependency in Triggers
Triggers are an integral part of any application code. Since they are in the domain of database, they are often considered outside of the application. Nothing can be farther from truth; triggers that support business functionality are application code and must be evaluated in the context of the overall application. Triggers are automatically executed and associated with certain events such as before insert or after alteration of table. When used properly, they offer an excellent extension to the functionality of the application not controlled by the user's action.
Best practices in code design suggests that you modularize your code (build small chunks of code that can be called multiple times instead of creating a monolithic code). This accomplishes a lot of things, such as readability, reusability of the code, ability to unit test, and much more. However, in the case of triggers, this strategy poses a unique problem. You can define multiple triggers on the table, but Oracle does not guarantee the execution order of the triggers. The triggers of the same type can be fired at any order. If they are truly independent of each other, it may not be a problem, but what if they do depend on the data and one trigger may update the data used by the other trigger? In that case, the order of execution is extremely important. If the data-changing trigger fires after the trigger that consumes that data, then the execution will not be as expected, resulting in potentially incorrect results. Let's examine that scenario with an example. Consider the following table named PAYMENTS:
Name Null? Type
-------------- -------- --------------
PAY_ID NUMBER(10)
CREDIT_CARD_NO VARCHAR2(16)
AMOUNT NUMBER(13,2)
PAY_MODE VARCHAR2(1)
RISK_RATING VARCHAR2(6)
FOLLOW_UP VARCHAR2(1)
Assume there is only one row.
SQL> select * from payments;
PAY_ID CREDIT_CARD_NO AMOUNT P RISK_R F
------ ---------------- ------ - ------ -
1
The columns are all empty at first. The column RISK_RATING is self explanatory; it shows the type of risk of that particular payment being processed with valid values being LOW (payment amount less than 1,000), MEDIUM (between 1,001 and 10,000) and HIGH (more than 10,000). Payments with higher risks are meant to be followed up later by a manager. The company uses a standard logic in defining the risk. Since this risk rating is meant to be assigned automatically, a before update row trigger does the job well, as shown:
create or replace trigger tr_pay_risk_rating
before update
on payments
for each row
begin
dbms_output.put_line ('This is tr_pay_risk_rating'),
if (:new.amount) < 1000 then
:new.risk_rating := 'LOW';
elsif (:new.amount < 10000) then
if (:new.pay_mode ='K') then
:new.risk_rating := 'MEDIUM';
else
:new.risk_rating := 'HIGH';
end if;
else
:new.risk_rating := 'HIGH';
end if;
end;
/
The high risk payments were meant to be followed up, but with high workload of managers, the company decides to follow up only certain types of high risk. The follow-up should occur for HIGH risk payments to be paid with a credit card or MEDIUM risk payments to be paid with cash. Also, credit cards from a specific bank (which is showed by the second to sixth digit of the number) are also to be followed up. A trigger is set up that automatically sets FOLLOW_UP column to Y under those conditions, as shown:
create or replace trigger tr_pay_follow_up
before update
on payments
for each row
begin
dbms_output.put_line ('This is tr_pay_follow_up'),
if (
(:new.risk_rating = 'HIGH' and :new.pay_mode = 'C')
or (:new.risk_rating = 'MEDIUM' and :new.pay_mode = 'K')
or (substr(:new.credit_card_no,2,5) = '23456')
) then
:new.follow_up := 'Y';
else
:new.follow_up := 'N';
end if;
end;
/
I have deliberately placed the dbms_output lines to show the execution of the triggers. After these two triggers are created, perform an update on the table.
update payments
set credit_card_no = '1234567890123456',
amount = 100000,
pay_mode = 'K';
This is tr_pay_follow_up
This is tr_pay_risk_rating
1 row updated.
After this, select from the table.
SQL> select * from payments;
PAY_ID CREDIT_CARD_NO AMOUNT P RISK_R F
------ ---------------- ------ - ------ -
1 1234567890123456 100000 K HIGH N
If you examine the above output, you will notice that the payment amount is more than 10,000—a condition for RISK_RATING to be HIGH. The trigger computed that condition and set the value correctly. The mode of payment is cash (PAY_MODE is set to “K”) and the amount is 100,000 and the credit card number matches the pattern “23456”—all the conditions for the FOLLOW_UP to be “Y”; but instead it is “N”. Did the trigger not fire? No, it did, as you saw in the output after the update statement “This is tr_pay_follow_up”. If the trigger fired, why didn't it set the value properly?
The answer lies in the order in which trigger executed. Note the output after the update statement was issued. The first trigger to fire was tr_pay_follow_up; not tr_pay_risk_rating. When the trigger fired, the values of all the columns satisfied the condition for follow-up, but not the RISK_RATING, which was NULL. Therefore, the trigger didn't find the row to satisfy the condition for follow-up. After the other trigger fired, it properly set the RISK_RATING column, but by that time the previous trigger had already executed and would not have executed again. However, if the order of execution of triggers were reversed (the risk rating trigger followed by the follow-up trigger), the situation would have been as you would have expected.
This is a great example of how the order of trigger execution is vital to application logic. Clearly the present example would be considered a bug in the application code. What's worse, the scenario is not reproducible at will; sometimes the order will be as expected and other times will be reverse. If you have a large number of such triggers, the potential for bugs will be even higher.
You can address this issue with putting all the code inside a single pre-update row trigger to control the execution code. You can create separate procedures for each trigger logic and call them inside a single pre-update row trigger. This may work but is not advisable because you have one trigger. What if you want to suppress functionality of one of the triggers? If you had multiple triggers, you could just disable that trigger and enable when needed again.
In Oracle Database 11g Release 1, there is an elegant solution. You can specify the order of execution of triggers.
create or replace trigger tr_pay_follow_up
before update
on payments
for each row
follows tr_pay_risk_rating
begin
dbms_output.put_line ('This is tr_pay_follow_up'),
if (
(:new.risk_rating = 'HIGH' and :new.pay_mode = 'C')
or (:new.risk_rating = 'MEDIUM' and :new.pay_mode = 'K')
or (substr(:new.credit_card_no,2,5) = '23456')
) then
:new.follow_up := 'Y';
else
:new.follow_up := 'N';
end if;
end;
/
Note the clause “follows tr_pay_risk_rating,” which specifies that the trigger should be executed after the risk rating trigger. Now you can guarantee the execution of the triggers: the risk rating trigger will fire first and then the follow-up trigger. With this new setup, if you re-execute the previous example, you will see the following:
… perform the same update as before …
This is tr_pay_risk_rating
This is tr_pay_follow_up
1 row updated.
SQL> select * from payments;
PAY_ID CREDIT_CARD_NO AMOUNT P RISK_R F
------ ---------------- ------ - ------ -
1 1234567890123456 100000 C HIGH Y
1 row selected.
The order of execution is now tr_pay_risk_rating and then tr_pay_follow_up— guaranteed. The first trigger set up the column values properly, which allowed the second trigger to compute the follow-up flag correctly. This functionality now allows you to build modular code that you can just turn on and off at will.
Creating Triggers Disabled Initially
Speaking of triggers, there is another issue that bites even the most experienced and careful developers. In many organizations, application changes such as new trigger code are deployed within a planned and approved “change window,” which is usually a time considered to be least impacting for the application and all the dependent components are deployed together. Suppose you are creating a new trigger (not a change to an existing trigger) on a table. The application change is perfectly coordinated and you create the new trigger, like so:
create or replace trigger tr_u_r_test1
before update on test1
for each row
declare
l_col1 number;
begin
select col1 into l_col1 from test3 where col1 = :new.col1;
if (l_col1 > 10000) then
:new.col2 := :new.col2 * 2;
end if;
end;
/
And it fails with this message:
Warning: Trigger created with compilation errors.
SQL> show error
Errors for TRIGGER TR_U_R_TEST1:
LINE/COL ERROR
-------- -----------------------------------------------------------------
4/2 PL/SQL: SQL Statement ignored
6/7 PL/SQL: ORA-00942: table or view does not exist
To your consternation, you find that there was a little pre-requisite missed—the user was not granted the select privileges on the table TEST3, so the trigger body was invalid. However, the trigger will fire for update statements since it is enabled. You can confirm that by checking the status of the trigger.
select status from user_triggers where trigger_name = 'TR_U_R_TEST1';
STATUS
--------
ENABLED
The fact that the trigger is enabled creates a very serious condition. Since this is an update trigger, and it is enabled, the update statements will fail on the table. Here is an example:
SQL> update test1 set col2 = 2;
update test1 set col2 = 2
*
ERROR at line 1:
ORA-04098: trigger 'ARUP.TR_U_R_TEST1' is invalid and failed re-validation
Since the trigger is enabled it will be fired for each row updated but all the executions will fail since the code is invalid. This failure of execution causes an application outage. You can fix the outage immediately by either dropping the trigger or disabling it.
drop trigger tr_u_r_test1;
alter trigger tr_u_r_test1 disable;
However, in a busy system, you may not get the locks to so implement either solution, causing the outage to extend for a longer time. To address this issue, Oracle 11g has a better option; you can create the trigger initially disabled as shown below. Note the disable clause shown in bold.
create or replace trigger tr_u_r_test1
before update on test1
for each row
disable
declare
l_col1 number;
begin
select col1 into l_col1 from test3 where col1 = :new.col1;
if (l_col1 > 10000) then
:new.col2 := :new.col2 * 2;
end if;
end;
After this trigger is created, if you check the status, it will be disabled. If the trigger does not compile due to missing objects or grants, it will cause any application issue since it will not be enabled. If the trigger didn't compile, you will know it immediately and be able to correct the problem by adding the referenced objects or granting necessary privileges. This way you will have all the necessary prerequisites before enabling the trigger. You can also use this functionality in a slightly different manner; you can create the trigger prior to the change window and enable it during the window using alter trigger … enable command.
Summary
Validation of dependent objects as a result of the change in the parent object is inevitable. In this chapter, you learned different techniques to reduce the number of invalidations. Let's summarize the key points to know to develop applications that have fewer chances of invalidations and create shortened dependency chains.
- Dependency chains show how others reference objects. The alteration of an object may render the validity of the dependent objects questionable. To resolve that potential, Oracle may mark them invalid, forcing a reparse later.
- When objects become invalidated, they may be manually recompiled to be valid. Objects will be forced into recompiling during runtime when some session invokes them.
- Compilation requires parse locks and CPU cycles, so it affects performance.
- In a RAC database, the invalidation and revalidation must occur in all instances. This causes increased inter-instance messaging and locking exacerbating the performance issue.
- Packages offer different types of dependency. Package bodies, not specifications, depend on the objects referenced within the code. Therefore, the specification does not get invalidated when the referenced objects are altered (unless the specification refers to the altered objects as well). The dependents of the package display the specification as the reference, not the body. Therefore, while changes to a referenced object may invalidate the body, the package specification may remain valid, causing no downstream invalidation.
- Use packages instead of standalone procedures and functions to shorten the dependency chains and reduce invalidations.
- When adding new procedures and functions to packages, always add to the end instead of in the middle or the top.
- Consider using views, not tables, inside the package, which will insulate the changes to the tables from the package and reduce invalidations.
- When altering synonyms, use CREATE OR REPLACE synonym syntax, not drop/create.
- Don't use constructs like select * or insert into <Table> values (…). Use column names explicitly to reduce implicit use of columns and increasing the possibility of invalidation.
- Avoid declarations referencing entire row, such as TableName%rowtype. Instead, use TableName.ColumnName%type.
- Use multiple triggers for different types of code. Establish the dependency and execution order by FOLLOWS clause.
- Always create a trigger as disabled and enable it only after it compiles fine.
- When altering an object that might be in use, instead of shutting down the application to get the lock, use the ddl_lock_timeout parameter to let the alter statement and wait for a suitable time.
All these recommendations are exactly that: recommendations, not gospel to be followed blindly. You must consider them carefully in the context of your specific scenario and weigh the pros and cons before actually implementing them. In this chapter, you learned how dependencies work, how invalidations occur, and how you can avoid them, thereby making your application highly available and increasing the performance of your application by reducing unnecessary work such as forced parsing.