
CHAPTER 11
Language-Oriented
Programming
In this chapter, you will first take a look at what I mean by language-oriented programming, a term that has been used by many people to mean different things. I'll also briefly discuss its advantages and disadvantages. You'll then look at several different approaches to language-oriented programming in F#. These techniques include using F# literals to create "little languages," using F# quotations, and creating a parser using fslex.exe and fsyacc.exe, which are themselves little languages.
What Is Language-Oriented Programming?
Although people use the term language-oriented programming to describe many different programming techniques, the techniques they refer to generally share a common theme. It's quite common for programmers to have to implement a predefined language; often this is because of a need to extract structured data from information stored or received as string or XML data that conforms to this predefined language. The techniques introduced in this chapter will help you do this more reliably. Related to this is the idea of little languages, or domain-specific languages (DSLs); you can create a DSL when the best way to solve a problem is to create a specialist language to describe the problem and then use this language to solve the problem. Functional programming has always had a strong relationship with language-oriented programming, because functional programming languages generally have features that are well suited to creating parsers and compilers.
Data Structures As Little Languages
Language-oriented development doesn't necessarily mean you need to write your own parser or compiler, although you'll examine this possibility later in this chapter. You can accomplish a lot by creating data structures that describe what you want to do and then creating functions or modules that define how the structure should be interpreted.
You can create data structures that represent a program in just about any language, but F# lends itself well to this approach. F#'s literal lists and arrays are easy to define and require no bulky type annotations. Its union types allow the programmer to create structures that express related concepts yet do not necessarily contain the same types of data, something that is useful when creating languages. Finally, since functions can be treated as values, you can easily embed functions within data structures so F# expressions can become part of your language, usually as an action in response to some particular condition of the language.
You've already seen a great example of this style of programming in Chapter 7. There you looked at a module that provides a simple way to create a command-line argument processor. It is simple because it allows the user to specify a data structure, such as the one shown here, that describes what the arguments should be without really having to think about how they will be parsed:
let argList =
[ ("-set", Arg.Set myFlag, "Sets the value myFlag");
("-clear", Arg.Clear myFlag, "Clears the value myFlag");
("-str_val", Arg.String(fun x -> myString := x), "Sets the value myString");
("-int_val", Arg.Int(fun x -> myInt := x), "Sets the value myInt");
("-float_val", Arg.Float(fun x -> myFloat := x), "Sets the value myFloat") ]
I am particularly fond of this kind of DSL because I think it makes it really clear what arguments the program is expecting and what processing should take place if that argument is received. The fact that the help text is also stored in the structure serves a double purpose; it allows the function processing command-line arguments to automatically print out a help message if anything goes wrong, and it also reminds the programmer what the argument is in case they forget. I also like this method of creating a command-line interpreter because I have written several command-line interpreters in imperative languages, and it is not a satisfying experience—you end up having to write lots of code to detail how your command line should be broken up. If you are writing it in .NET, then you usually spend way too much time calling the string type's IndexOf and Substring methods.
A Data Structure−Based Language Implementation
Creating any DSL should start with defining what problem you need to solve; in this case, you will design a language to describe lines to be drawn on a graph. This is something of an obvious choice for F#, because its lambda functions lend themselves well to describing equations to produce lines on graphs. I'll walk you through the various elements for implementing this language. (Listing 11-1 later in this chapter lists the full program.)
The first step is to design the types to describe the graph. The first type you need to create is LineDefinition, which you use to describe the path of a line that will be plotted on the graph. You want to allow three types of line: one defined by a list of x and y coordinates, one defined by a function, and one defined by a combination of functions and a list of points. Languages are usually described formally by listing the valid constructs of the language, that is, the valid syntactic ways of constructing phrases in the language. F#-discriminated unions provide a perfect way to model the list of different possibilities, and thus a direct transcription from the formal definition of the language into code is often possible. In this case, you define a type LineDefinition that consists of three possibilities—the three possible phrases in the language. The first phrase is Points, an array of type Point. The second is Function, which consists of a function that takes a float and returns a float. The third is Combination, which consists of a list of tuples made up of float and LineDefinitions; remember, type definitions can be recursive. float gives a weight to the line, allowing the programmer to specify how much of this section should appear. LineDefinitions allows the user to specify sections that consist of a list of points or sections that consist of functions. The definition of the type is as follows:
type LineDefinition =
| Points of Point array
| Function of (float -> float)
| Combination of (float * LineDefinition) list
Simply knowing the path of a line doesn't give you enough information to be able to draw it. You also need to know the color, the width, and other attributes. Fortunately, a simple way to provide this sort of information is the System.Drawing.Pen class, which lets you specify the color, specify the width, and add effects such as making the line a dashed one.
To group this information, you create the LineDetail record type. This has two fields: one field of Pen type and one of LineDefinition type.
type LineDetails =
{ pen : Pen
definition : LineDefinition }
Of course, you could add more fields to this record, perhaps for a description to be added to the graph's legend, but I'll leave it at these two fields to keep the example simple. You'll then group instances of this LineDetail type together in a list that is used to describe all the lines that should be drawn on the graph. An example of such a list is as follows:
let wiggle = PointList [ (0.1,0.6); (0.3,−0.3); (0.5,0.8); (0.7,−0.2) ]
let straight = Function (fun x -> x + 0.1)
let square = Function (fun x -> x * x)
let strange = Combination [ (0.2, square); (0.4, wiggle); (0.4, straight) ]
let lines =
[{ pen = new Pen(Color.Blue) ;
definition = wiggle };
{ pen = new Pen(Color.Orange) ;
definition = straight };
{ pen = new Pen(Color.Red) ;
definition = square };
{ pen = new Pen(Color.Green) ;
definition = strange } ]
The last function that is critical to this example is the sample function. This allows you to specify a range of x values for a line definition and then calculate a list of points consisting of x, y values. This function actually does the work of turning the definition in your language into points that you can use to draw a graph.
The sample function definition is shown next. The first two cases are fairly straightforward. If you have a list of points for each x value, you use an interpolate function you have defined to calculate the appropriate y value. The interpolate function uses some straightforward geometry to calculate the intermediate points between the points that the user of the language has defined as a line definition and therefore work out the most appropriate y value. The case for a function is even simpler for each x value: you simply use the function that the user has defined to calculate the y value. The final case, where you have a combination, is a little more complicated mainly because you have to weigh the value of each section of the combination. You do this by creating a vector of all the weights and binding this to the identifier weights; then you create a list of points that lists all the line definitions that have been defined using the language by recursive function calls to the sample function. The resulting list from the recursive sample function call is bound to the identifier ptsl. Then you do the work of calculating the real y values; you extract all the y values from the list of points within the list ptsl and create a vector of these lists of y values using the combinel function you have defined and the Vector.of_list function. Then you use the Vectors module's dot function to scale each of the resulting vectors by the vector weights. After this, it is just a matter of combining the resulting y values with the original x values to create a list of points.
// Sample the line at the given sequence of X values
let rec sample xs line =
match line with
| Points(pts) ->
{ for x in xs -> interpolate pts x }
| Function(f) ->
{ for x in xs -> {X=x;Y=f x} }
| Combination wlines ->
let weights = wlines |> List.map fst |> Vector.of_list
// Sample each of the lines
let ptsl = wlines |> List.map snd |> List.map (sample xs)
// Extract the vector for each sample and combine by weight
let ys = ptsl |> List.map (Seq.map (fun p -> p.Y))
|> combinel
|> Seq.map Vector.of_list
|> Seq.map (Vector.dot weights)
// Make the results
Seq.map2 (fun x y -> { X=x;Y=y }) xs ys
Listing 11-1 shows the full program.
Listing 11-1. A Graph Control, Based on Language-Oriented Programming Techniques
#light
open System
open System.Drawing
open System.Windows.Forms
open Microsoft.FSharp.Math
type Point = { X : float; Y : float }
type LineDefinition =
| Points of Point array
| Function of (float -> float)
| Combination of (float * LineDefinition) list
// Derived construction function
let PointList pts =
Points(pts |> Array.of_list |> Array.map (fun (x,y) -> {X=x;Y=y}))
module LineFunctions = begin
// Helper function to take a list of sequences and return a sequence of lists
// where the sequences are iterated in lockstep.
let combinel (seqs : list< #seq<'a> >) : seq< list<'a> > =
Seq.generate
(fun () -> seqs |> List.map (fun s -> s.GetEnumerator()) )
(fun ies ->
let more = ies |> List.for_all (fun ie -> ie.MoveNext())
if more then Some(ies |> List.map (fun ie -> ie.Current))
else None)
(fun ies -> ies |> List.iter (fun ie -> ie.Dispose()))
// Interoplate the given points to find a Y value for the given X
let interpolate pts x =
let best p z = Array.fold_right (fun x y -> if p x y then x else y) pts z
let l = best (fun p1 p2 -> p1.X > p2.X && p1.X <= x) pts.[0]
let r = best (fun p1 p2 -> p1.X < p2.X && p1.X >= x) pts.[pts.Length-1]
let y = (if l.X = r.X then (l.Y+r.Y)/2.0
else l.Y + (r.Y-l.Y)*(x-l.X)/(r.X-l.X))
{ X=x; Y=y }
// Sample the line at the given sequence of X values
let rec sample xs line =
match line with
| Points(pts) ->
{ for x in xs -> interpolate pts x }
| Function(f) ->
{ for x in xs -> {X=x;Y=f x} }
| Combination wlines ->
let weights = wlines |> List.map fst |> Vector.of_list
// Sample each of the lines
let ptsl = wlines |> List.map snd |> List.map (sample xs)
// Extract the vector for each sample and combine by weight
let ys = ptsl |> List.map (Seq.map (fun p -> p.Y))
|> combinel
|> Seq.map Vector.of_list
|> Seq.map (Vector.dot weights)
// Make the results
Seq.map2 (fun x y -> { X=x;Y=y }) xs ys
end
type LineDetails =
{ pen : Pen
definition : LineDefinition }
let f32 x = Float32.of_float x
let f64 x = Float.of_float32 x
type Graph = class
inherit Control
val mutable maxX : float
val mutable maxY : float
val mutable minX : float
val mutable minY : float
val mutable lines : LineDetails list
new () as x =
{ maxX = 1.0;
maxY = 1.0;
minX = −1.0;
minY = −1.0;
lines = [] }
then
x.Paint.Add(fun e -> x.DrawGraph(e.Graphics))
x.Resize.Add(fun _ -> x.Invalidate())
member f.DrawGraph(graphics : Graphics) =
let height = Convert.ToSingle(f.Height)
let width = Convert.ToSingle(f.Width)
let widthF = f32 f.maxY - f32 f.minY
let heightF = f32 f.maxX - f32 f.minX
let stepY = height / heightF
let stepX = width / widthF
let orginY = (0.0f - f32 f.minY) * stepY
let orginX = (0.0f - f32 f.minX) * stepX
let black = new Pen(Color.Black)
graphics.DrawLine(black, 0.0f, orginY, width, orginY)
graphics.DrawLine(black, orginX, 0.0f, orginX, height)
let mapPoint pt =
new PointF(orginX + (f32 pt.X * stepX),
height - (orginY + (f32 pt.Y * stepY)))
let xs = { f.minX .. (1.0 / f64 stepX) .. f.maxX }
f.lines
|> List.iter
(fun line -> LineFunctions.sample xs line.definition
|> Seq.map mapPoint
|> Seq.to_array
|> (fun pts -> graphics.DrawLines(line.pen, pts)))
end
module GraphTest = begin
let wiggle = PointList [ (0.1,0.6); (0.3,-0.3); (0.5,0.8); (0.7,-0.2) ]
let straight = Function (fun x -> x + 0.1)
let square = Function (fun x -> x * x)
let strange = Combination [ (0.2, square); (0.4, wiggle); (0.4, straight) ]
let lines =
[{ pen = new Pen(Color.Blue) ;
definition = wiggle };
{ pen = new Pen(Color.Orange,
DashStyle = DashStyle.Dot,
Width = 2.0f) ;
definition = straight };
{ pen = new Pen(Color.Red,
DashStyle = DashStyle.Dash,
Width = 2.0f) ;
definition = square };
{ pen = new Pen(Color.Green, Width = 2.0f) ;
definition = strange } ]
let form =
let temp = new Form(Visible=true,TopMost=true)
let g = new Graph(Dock = DockStyle.Fill)
g.lines <- lines
temp.Controls.Add(g)
temp
[<STAThread>]
do Application.Run(form)
end
This example produces the graph in Figure 11-1.
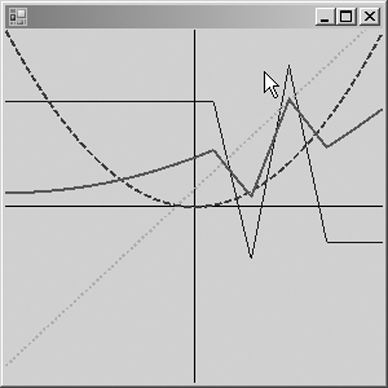
Figure 11-1. Drawing lines with a DSL
Metaprogramming with Quotations
In Chapter 6 you used quotations; these are quoted sections of F# code where the quote operator instructs the compiler to generate data structures representing the code rather than IL representing the code. This means instead of code that can be executed, you have a data structure that represents the code that was coded, and you're free to do what you want with it. You can either interpret it, performing the actions you require as you go along, or compile it into another language. Or you can simply ignore it if you want. You could, for example, take a section of quoted code and compile it for another runtime, such as the Java virtual machine (JVM). Or, like the LINQ example in Chapter 9, you could turn it into SQL and execute it against a database.
In the next example, you'll write an interpreter for integer-based arithmetic expressions in F#. This might be useful for learning how stack-based calculations work. Here, your language is already designed for you; it is the syntax available in F#. You'll work exclusively with arithmetic expressions of the form « (2 * (2 - 1)) / 2 ». This means you need to generate an error whenever you come across syntax that is neither an integer nor an operation. When working with quotations, you have to query the expression that you receive to see whether it is a specific type of expression. For example, here you query an expression to see whether it is an integer, and if it is, you push it onto the stack:
match uexp with
| Raw.Int32(x) ->
printf "Push: %i
" x
operandsStack.Push(x)
| _ ->
If it isn't an integer, you check whether it is of several other types. Listing 11-2 shows the full example.
Listing 11-2. Stack-Based Evaluation of F# Quoted Arithmetic Expressions
#light
open System.Collections.Generic
open Microsoft.FSharp.Quotations
open Microsoft.FSharp.Quotations.Typed
let interpret exp =
let uexp = to_raw exp
let operandsStack = new Stack<int>()
let rec interpretInner uexp =
match uexp with
| Raw.Apps(op, args) when args.Length > 0 ->
args |> List.iter (fun x -> interpretInner x)
interpretInner op
| _ ->
match uexp with
| Raw.Int32 x ->
printf "Push: %i
" x
operandsStack.Push(x)
| Raw.AnyTopDefnUse(def, types) ->
let preformOp f name =
let x, y = operandsStack.Pop(), operandsStack.Pop()
printf "%s %i, %i
" name x y
let result = f x y
operandsStack.Push(result)
let _,name = def.Path
match name with
| "op_Addition" ->
let f x y = x + y
preformOp f "Add"
| "op_Subtraction" ->
let f x y = y - x
preformOp f "Sub"
| "op_Multiply" ->
let f x y = y * x
preformOp f "Multi"
| "op_Division" ->
let f x y = y / x
preformOp f "Div"
| _ -> failwith "not a valid op"
| _ -> failwith "not a valid op"
interpretInner uexp
printfn "Result: %i" (operandsStack.Pop())
interpret « (2 * (2 - 1)) / 2 »
read_line()
The results of this example are as follows:
Push: 2
Push: 2
Push: 1
Sub 1, 2
Multi 1, 2
Push: 2
Div 2, 2
Result: 1
When you use quotations, you are always working with F# syntax, which is both an advantage and a disadvantage. The advantage is that you can produce powerful libraries based on this technique that integrate very well with F# code, without having to create a parser. The disadvantage is that it is difficult to produce tools suitable for end users based on this technique; however, libraries that consume or transform F# quotations can still be used from other .NET languages because the F# libraries include functions and samples to convert between F# quotations and other common metaprogramming formats such as LINQ quotations.
You'll code a parser for a small arithmetic language in the next section. Although the results are much more flexible, more design work is potentially involved if you are creating a new language rather than implementing an existing one; in addition, there is always more programming work because you need to create a parser—although the tools F# provides help simplify the creation of a parser.
An Arithmetic-Language Implementation
Another approach to language-oriented programming is to create your own language represented in a textual format. This doesn't necessarily have to be a complicated process—if your language is quite simple, then you will find it straightforward to implement. Whether creating a simple language to be embedded into an application or full-fledged DSLs, the approach is similar. It's just that the more constructs you add to your language, the more work it will be to implement it.
You'll spend the remainder of this chapter looking at how to implement a really simple arithmetic language consisting of floating-point literals; floating-point identifiers; the operators +, -, *, and /; and parentheses for the disambiguation of expressions. Although this language is probably too simple to be of much benefit, it's easy to see how with a few simple extensions it could be a useful tool to embed into many financial or mathematical applications.
Creating the language can be broken down into two steps: parsing the user input and then acting on the input.
Parsing the language can itself be broken down into three steps: defining the abstract syntax tree (AST), creating the grammar, and tokenizing the text. When creating the parser, you can implement these steps in any order, and in fact you would probably design your grammar in small, repeated iterations of all three steps. You will look at the steps separately, in the sections "The Abstract Syntax Tree," "Tokenizing the Text: Fslex," and "Generating a Parser: Fsyacc."
There are two distinct modes of acting on the results of the parser: compiling the results and interpreting them. Compiling simply means changing the AST into some other format that is faster or easier for a machine to execute. Originally this nearly always meant native code, but these days it's more likely to be something a little more abstract, such as IL, F#, or even C#. Interpreting the results means acting on the results straightaway without any transformation of the AST. You'll look briefly at both topics in the sections "Interpreting the AST" and "Compiling the AST"; then you'll compare the two approaches to get some idea of when to use each one in the section "Compilation vs. Interpretation."
The Abstract Syntax Tree
An AST is a representation of the construct that makes up the program that is meant to be easy for the programmer to use. One reason F# is good for this kind of development is its union type. Because you can use this type to represent items that are related yet do not share the same structure, it is great for representing languages. The following example shows the abstract syntax tree:
type Expr =
| Ident of string
| Val of System.Double
| Multi of Expr * Expr
| Div of Expr * Expr
| Plus of Expr * Expr
| Minus of Expr * Expr
The tree consists of just one type because it is quite simple. A complicated tree would contain many more types, but all will be generally based around this pattern. Here you can see that the tree, the type Expr, will consist of either identifiers (the Ident type), the names of the identifiers represented by a string, or values (the Val type), with their values represented by a System.Double. The type Expr consists of four more types (Multi, Div, Plus, and Minus), which represent the arithmetic operations and use recursion so are composed of other expressions.
Tokenizing the Text: Fslex
Tokenizing the text (sometimes called lexical analysis or lexing) basically means breaking up the text into manageable lumps, or tokens. To do this, you use the tool fslex.exe, which is itself a DSL for creating lexers (sometimes called scanners), programs, or modules for tokenizing text. The program fslex.exe is a command-line application that takes a text file representing the lexer and turns into an F# file that implements the lexer.
An fslex.exe file has the extension .fsl. The file can have an optional header, which is placed between braces ({}) and is pure F# code, generally used to open modules or possibly to define helper functions. The rest is used to define the regular expressions that make up the lexer. You can bind a regular expression to an identifier using the let keyword, like this:
let digit = ['0'-'9']
or you can define a regular expression as part of a rule. A rule is a collection of regular expressions that are in competition to match sections of the text. A rule is defined with the keyword rule and followed by a name for the rule and then an equals sign and the keyword parse. Next come the definitions of the regular expressions, which should be followed by an action, which is an F# expression surrounded by braces. Each rule is separated by a vertical bar (|). Each rule will become a function that is capable of matching against a stream of text. If a match is found, then the rule fires, and the F# expression is executed. If several regular expressions match the rule, then the longest match is used. The value returned by the function is the value returned by the action. This means that each action must be of the same type. If no match is found, then an exception is raised.
Note The regular expressions used in the lexer are not the same as the ones used with the .NET BCL Regex class. You can find more details about the syntax at http://strangelights.com/FSharp/Foundations/default.aspx/FSharpFoundations.FSLexRegEx.
Although the actions can be any valid F# expressions, it's normal to return the token declarations that you will make in the fsyacc file. See the next section, "Generating a Parser: Fsyacc," for more information about this. If you want to use the lexer on its own, you will place whatever logic you want to happen here, such as writing the token to the console or storing the token found in a list.
The following example shows a file that is capable of tokenizing your little language. You usually do one of two things in the actions. If you're interested in the match, you return a token that has been defined in the parser file. These are the identifiers in block capitals like RPAREN or MULTI. If you're not interested, you call token with the special lexbuf value function to start the parsing again. The lexbuf value is automatically placed in your parser definition and represents the text stream being processed. It is of type Microsoft.FSharp.Tools.FsLex.LexBuffer. Also notice how, in places where you're actually interested in the value found rather than just the fact a value was found, you use a function lexeme from the module Microsoft.FSharp.Compatibility.OCaml.Lexing to get the string representing the match from the lexbuf. Table 11-1 summarizes other useful functions from this module.
{
open System
open Pars
open Lexing
}
let digit = ['0'-'9']
let whitespace = [' ' ' ' ]
let newline = ('
' | '
' '
')
rule token = parse
| whitespace { token lexbuf }
| newline { token lexbuf }
| "(" { LPAREN }
| ")" { RPAREN }
| "*" { MULTI }
| "/" { DIV }
| "+" { PLUS }
| "-" { MINUS }
| '['[^']']+']' { ID(lexeme lexbuf) }
| ['-']?digit+('.'digit+)?(['e''E']digit+)?
{ FLOAT (Double.Parse(lexeme lexbuf)) }
| eof { EOF }
Table 11-1. Useful Functions from the Lexing Module
| Function | Description |
lexeme |
Gets the current lexeme from the lexbuf as a string |
lexeme_bytes |
Gets the current lexeme from the lexbuf as a byte array |
lexeme_char |
Takes an integer and returns the character at this index from the current lexeme in the lexbuf as a char from the lexbuf as a string |
lexeme_end |
Gets the absolute position of the lexeme, which is useful when trying to provide error information to the user |
from_text_reader |
Creates a lexbuf from a text reader, which is useful when using the lexer from F# code |
from_string |
Creates a lexbuf from a string, which is useful when using the lexer from F# code |
A lexer can contain several rules; any further rules are separated from each other by the keyword and, then a name for the rule, then an equals sign, and then the keyword parse. After this come the definitions of the regular expressions that make up this rule. This is often useful if you want to implement comments in your language. Comments often produce false positives in lexers, since they can contain any text. To deal with this, when a start-comment token is detected, it is customary to switch to another rule that looks only for an end-comment token and ignores all other input.
The following example shows a simple parser that either finds strings that are like F# identifiers or discards C#-style multiline comments. Notice how when you find the start of a comment, you call the comment function to hop into the comment rule, and to find the end of it, you return unit to hop out of it.
{
open Lexing
}
rule token = parse
| "/*" { comment lexbuf; token lexbuf }
| ['_''a'-'z''A'-'Z']['_''a'-'z''A'-'Z''0'-'9']*
{ lexeme lexbuf }
and comment = parse
| "*/" | eof { () }
| _ { comment lexbuf }
This has been quite a rapid overview of fslex.exe; you can find more information about it at http://strangelights.com/FSharp/Foundations/default.aspx/FSharpFoundations.FSLex.
Generating a Parser: Fsyacc
A scanner is a program or module that breaks a text stream into pieces. You can think of a parser as the thing that reorganizes the text into something more meaningful. The aim of the parser is usually to produce an AST, and this is done by defining rules that determine the order in which the tokens should appear. The tool fsyacc.exe can generate parsers that are look-ahead left-to-right parsers, more commonly called LALR(1). This is an algorithm for parsing grammars. Not all grammars can be parsed by this algorithm, but grammars that can't are quite rare. For more information about how the LALR(1) algorithm works, please see http://strangelights.com/FSharp/Foundations/default.aspx/FSharpFoundations.LALR.
Note The YACC part of the name fsyacc.exe is an acronym for Yet Another Compiler Compiler.
The tool fsyacc.exe works with text files with the extension .fsy. These files have three distinct parts. First is the header, which is a section of pure F# code surrounded by percentage signs and braces (%{ for opening and %} for closing). This section is typically used to open your AST module and to define short helper functions for creating the AST. Next comes the declarations, defining the terminals of your language. A terminal is something concrete in your grammar such as an identifier name or a symbol. Typically these are found by the lexer. Declarations have several different forms that are summarized in Table 11-2. The third section contains the rules that make up the grammar; these are described in the next paragraph.
Table 11-2. Declarations of Terminals in an fsyacc.exe File
| Declaration | Description |
%token |
This declares the given symbol as the token in the language. |
%token<type> |
This declares the given symbol as a token, like %token, but with arguments of the given type; this is useful for things such as identifiers and literals when you need to store information about them. |
%start |
This declares the rule at which the parser should start parsing. |
%type<type> |
This declares the type of a particular rule; it is mandatory for the start rule but optional for all other rules. |
%left |
This declares a token as left-associative, which can help resolve ambiguity in the grammar. |
%right |
This declares a token as right-associative, which can help resolve ambiguity in the grammar. |
%nonassoc |
This declares a token as nonassociative, which can help resolve ambiguity in the grammar. |
The declarations are separated from the rules by two percentage signs, which make up the last section of the file. Rules are the nonterminals of the grammar. A nonterminal defines something that can be made up of several terminals. So, each rule must have a name, which is followed by a colon and then the definition of all the items that make up the rule, which are separated by vertical bar. The items that make up rule are either the names of tokens you have defined or the names of rules; this must always be followed by an action that is F# code surrounded by braces. Here is a snippet of a rule:
Expression: ID { Ident($1) }
| FLOAT { Val($1) }
Expession is the rule name, and ID and FLOAT are two rules made up of just terminals. The sections { Ident($1) } and { Ident($1) } are the rule actions. Within these actions, you can grab the data associated with the terminal or nonterminal using a dollar sign and then the number representing the position of the item in which you are interested. The result of the action will itself become associated with the rule. All the actions of a rule must be of the same type, since a rule will be implemented as an F# function with the actions making up the items that it returns. Any comments within the rules should use the C-style comment markers, /* */.
The following example shows a simple parser definition for your language. Note how all the actions associated with rules are simple, just creating instances of types from the AST, and that all the languages terminals are in block capitals.
%{
open Strangelights.ExpressionParser.Ast
%}
%start Expression
%token <string> ID
%token <System.Double> FLOAT
%token LPAREN RPAREN EOF MULTI DIV PLUS MINUS
%type < Strangelights.ExpressionParser.Ast.Expr > Expression
%left MULTI
%left DIV
%left PLUS
%left MINUS
%%
Expression: ID { Ident($1) }
| FLOAT { Val($1) }
| LPAREN Expression RPAREN { $2 }
| Expression MULTI Expression { Multi($1, $3) }
| Expression DIV Expression { Div($1, $3) }
| Expression PLUS Expression { Plus($1, $3) }
| Expression MINUS Expression { Minus($1, $3) }
Let's take a closer look at the items that make up your rule. The simplest rule item you have consists of one terminal, ID, in this case an identifier:
ID { Ident($1) }
In the rule item's action, the string that represents the identifier is used to create an instance of the Ident constructor from the AST. A slightly more complex rule is one that involves both terminals and nonterminals:
| Expression MULTI Expression { Multi($1, $3) }
This rule item recognizes the case where you have a valid expression followed by a multiplication sign and then a valid expression. These expressions are then loaded into the constructor Multi from your AST. These expressions could be terminals in your language, such as an identifier or a literal, or they might be an expression composed of several terminals, such as a multiplication operation.
The hardest thing about creating a grammar is making sure it is not ambiguous. A grammar is ambiguous when two or more rules could be matched by the same input. Fortunately, fsyacc.exe can spot this automatically and warns you when this has occurred. It is only a warning, because the parser can still function; it just has some rules that will not be matched so is probably incorrect in some way.
Note For more information about debugging grammars, see http://strangelights.com/FSharp/Foundations/default.aspx/FSharpFoundations.FsYaccAmbigous. This has been quite a rapid overview of fsyacc.exe. You can find more information about it at http://strangelights.com/FSharp/Foundations/default.aspx/FSharpFoundations.FsYacc.
Using the Parser
Using the parser is very straightforward. You can use a lexer on its own, but a parser generated with fsyacc.exe always requires a lexer to work. You'll look at how to use your lexer on its own and combined with a parser in this section.
Caution Remember, .fsl and .fsy files cannot be used directly by the F# compiler. You need to compile them using fslex.exe and fsyacc.exe and then use the generated .fs files.
To use your lexer, you first need to create a LexBuffer that represents the text to be processed. The easiest way to do this is to create the LexBuffer from a string using the function Lexing.from_string, although it is not difficult to create one from a file using the Lexing.from_text_reader function. You can then pass this buffer to a function created by a rule in your lexer, and it will pull off the first token.
The following example shows your lexer in action. You've compiled the lexer into a module, Lex, and you use the token function to find the first, and in this case the only, token in the string.
#light
let lexbuf = Lexing.from_string "1"
let token = Lex.token lexbuf
print_any token
The result of this example is as follows:
FLOAT 1.0
Just grabbing the first token from the buffer is rarely of much value, so if you use the lexer in stand-alone mode, it is much more common to create a loop that repeatedly grabs all tokens from the buffer. The next example demonstrates how to do this, printing the tokens found as you go:
#light
let lexbuf2 = Lexing.from_string "(1 * 1) + 2"
while not lexbuf2.IsPastEndOfStream do
let token = Lex.token lexbuf2
printf "%s
" (any_to_string token)
The results of this example are as follows:
LPAREN
FLOAT 1.0
MULTI
FLOAT 1.0
RPAREN
PLUS
FLOAT 2.0
EOF
It is much more common for a lexer to be used in conjunction with a parser module. The functions generated by the parser expect their first parameter to be a function that takes a LexBuffer and transforms it into a token (LexBuffer<'a,'cty> -> Pars.token in this case). Fortunately, this is the signature that your lexer's token function has. The next example shows how you would implement this:
#light
let lexbuf3 = Lexing.from_string "(1 * 1) + 2"
let e = Pars.Expression Lex.token lexbuf3
print_any e
The result of this example is as follows:
Plus (Multi (Val 1.0,Val 1.0),Val 2.0)
And that's it! Once you have your AST, you have a nice abstract form of your grammar, so now it is up to you to create a program that acts on this tree.
Interpreting the AST
When you have created your AST, you have two choices; you can either interpret it or compile it. Interpreting it simply means walking the tree and performing actions as you go. Compiling it means changing it into some other form that is easier, or more typically faster, for the machine to execute. This section will examine interpreting the results, and the next will look at the options for compiling them; finally, you will look at when you should use interpretation and when you should use compilation.
The following example shows a short interpreter for your program. The main work of interpreting the AST is done by the function interpret, which walks the tree performing the necessary action as it goes. The logic is quite simple. If you find a literal value or an identifier, you simply return the appropriate value.
| Ident (s) -> variableDict.[s]
| Val (v) -> v
If you find an operand, you recursively evaluate the expressions it contains to obtain their values and then perform the operation:
| Multi (e1, e2) -> (interpretInner e1) * (interpretInner e2)
Listing 11-3 gives the full interpreter.
Listing 11-3. Interpreting an AST Generated from Command-Line Input
#light
open System.Collections.Generic
open Strangelights.ExpressionParser.Ast
// requesting a value for variable from the user
let getVariableValues e =
let rec getVariableValuesInner input (variables : Map<string, float>) =
match input with
| Ident (s) ->
match variables.TryFind(s) with
| Some _ -> variables
| None ->
printf "%s: " s
let v = read_float()
variables.Add(s,v)
| Multi (e1, e2) ->
variables
|> getVariableValuesInner e1
|> getVariableValuesInner e2
| Div (e1, e2) ->
variables
|> getVariableValuesInner e1
|> getVariableValuesInner e2
| Plus (e1, e2) ->
variables
|> getVariableValuesInner e1
|> getVariableValuesInner e2
| Minus (e1, e2) ->
variables
|> getVariableValuesInner e1
|> getVariableValuesInner e2
| _ -> variables
getVariableValuesInner e (Map.Empty())
// function to handle the interpretation
let interpret input (variableDict : Map<string,float>) =
let rec interpretInner input =
match input with
| Ident (s) -> variableDict.[s]
| Val (v) -> v
| Multi (e1, e2) -> (interpretInner e1) * (interpretInner e2)
| Div (e1, e2) -> (interpretInner e1) / (interpretInner e2)
| Plus (e1, e2) -> (interpretInner e1) + (interpretInner e2)
| Minus (e1, e2) -> (interpretInner e1) - (interpretInner e2)
interpretInner input
// request input from user and interpret it
printf "input expression: "
let lexbuf = Lexing.from_string (read_line())
let e = Pars.Expression Lex.token lexbuf
let args = getVariableValues e
let v = interpret e args
printf "result: %f" v
read_line()
The results of this example, when compiled and executed, are as follows:
input expression: (1 + 3) * [my var]
[my var]: 12
result: 48.000000
Compiling the AST
To many, compilation means generating native code, so it has a reputation for being difficult. But it doesn't have to mean generating native code, and for a DSL you typically generate some other more general-purpose programming language. The .NET Framework provides several features for compiling an AST into a program.
Your choice of technology depends on several factors. For example, if you're targeting your language at developers, it might be enough to generate a text file containing F#, some other language, or a compiled assembly that can then used within an application. However, if you're targeting end users, you will almost certainly have to compile and then execute it on the fly. Table 11-3 summarizes the various options available.
Table 11-3. .NET Code-Generation Technologies
| Technology | Description |
Microsoft.CSharp. CSharpCodeProvider |
This class supports compilation of a C# file that has been created on the fly, either by using simple string concatenation or by using the System.CodeDom namespace. Once the code has been compiled into an assembly, it can be loaded dynamically into memory and executed via reflection. This operation is relatively expensive, because it requires writing to the disk and using reflection to execute methods. |
System.CodeDom |
This is a set of classes aimed at abstracting between operations available in different languages. The idea is that you describe your operations using the classes available in this namespace and then use a provider to compile them into the language of your choice. .NET ships with a provider for both C# and Visual Basic. Providers for other languages are available for download. They are often the results of community projects. |
System.Reflection.Emit |
This namespace allows you to build up assemblies using IL. Since IL offers more features than either F#, C#, or System.CodeDom, it provides more flexibility; however, it is lower level so requires more patience and will probably take more time to get right. |
AbstractIL |
This is a library written in F# for manipulating IL. It provides roughly the same functionality as System.Reflection.Emit, but F# programmers might find it is more suited to their style of programming than the options available in System.Reflection.Emit. |
Note If you want to use System.CodeDom, you could consider compiling these into F# code rather than C# code using the code DOM provider written by Tomas Petricek, which is available from http://www.codeplex.com/fscodedom.
You'll use the System.Reflection.Emit.DynamicMethod class, not particularly because you need the flexibility of IL, but since IL has built-in instructions for floating-point arithmetic, it's well suited to implement the little language. The DynamicMethod also provides a fast and easy way to let you call into the resulting program.
The method createDynamicMethod actually compiles the AST by walking the AST and generating code. First, it creates an instance of the DynamicMethod class to hold the IL you define to represent the method:
let temp = new DynamicMethod("", (type float), paramsTypes, meth.Module)
Then createDynamicMethod starts walking the tree. When you encounter an identifier, you emit some code to load an argument of your dynamic method:
| Ident name ->
il.Emit(OpCodes.Ldarg, paramNames.IndexOf(name))
When you encounter a literal, you emit the IL code to load the literal value:
| Val x -> il.Emit(OpCodes.Ldc_R8, x)
When you encounter an operation, you must recursively evaluate both expressions and then emit the instruction that represents the required operation:
| Multi (e1, e2) ->
generateIlInner e1
generateIlInner e2
il.Emit(OpCodes.Mul)
Note how the operation is emitted last, after both expressions have been recursively evaluated. This is because IL is stack based, so data from the other operations must have been pushed onto the stack before the operator is evaluated.
Note It is beyond the scope of this book to give you a full overview of IL; however, you can find more details at http://strangelights.com/FSharp/Foundations/default.aspx/FSharpFoundations.IL.
Listing 11-4 gives the full compiler.
Listing 11-4. Compiling an AST Generated from Command-Line Input
#light
open System.Collections.Generic
open System.Reflection
open System.Reflection.Emit
open Strangelights.ExpressionParser.Ast
// get a list of all the parameter names
let rec getParamList e =
let rec getParamListInner e names =
match e with
| Ident name ->
if not (List.exists (fun s -> s = name) names) then
name :: names
else
names
| Multi (e1 , e2) ->
names
|> getParamListInner e1
|> getParamListInner e2
| Div (e1 , e2) ->
names
|> getParamListInner e1
|> getParamListInner e2
| Plus (e1 , e2) ->
names
|> getParamListInner e1
|> getParamListInner e2
| Minus (e1 , e2) ->
names
|> getParamListInner e1
|> getParamListInner e2
| _ -> names
getParamListInner e []
// create the dynamic method
let createDynamicMethod e (paramNames: string list) =
let generateIl e (il : ILGenerator) =
let rec generateIlInner e =
match e with
| Ident name ->
let index = List.find_index (fun s -> s = name) paramNames
il.Emit(OpCodes.Ldarg, index)
| Val x -> il.Emit(OpCodes.Ldc_R8, x)
| Multi (e1 , e2) ->
generateIlInner e1
generateIlInner e2
il.Emit(OpCodes.Mul)
| Div (e1 , e2) ->
generateIlInner e1
generateIlInner e2
il.Emit(OpCodes.Div)
| Plus (e1 , e2) ->
generateIlInner e1
generateIlInner e2
il.Emit(OpCodes.Add)
| Minus (e1 , e2) ->
generateIlInner e1
generateIlInner e2
il.Emit(OpCodes.Sub)
generateIlInner e
il.Emit(OpCodes.Ret)
let paramsTypes = Array.create paramNames.Length (type float)
let meth = MethodInfo.GetCurrentMethod()
let temp = new DynamicMethod("", (type float), paramsTypes, meth.Module)
let il = temp.GetILGenerator()
generateIl e il
temp
let collectArgs (paramNames : string list) =
paramNames
|> IEnumerable.map
(fun n ->
printf "%s: " n
box (read_float()))
|> Array.of_seq
printf "input expression: "
let lexbuf = Lexing.from_string (read_line())
let e = Pars.Expression Lex.token lexbuf
let paramNames = getParamList e
let dm = createDynamicMethod e paramNames
let args = collectArgs paramNames
printf "result: %O" (dm.Invoke(null, args))
read_line()
The results of this example are as follows:
input expression: 5 * ([my var] + 2)
[my var]: 4
result: 30
This has been a brief overview of code generation and compilation. You can find more information at http://strangelights.com/FSharp/Foundations/default.aspx/FSharpFoundations.Compilation.
Compilation vs. Interpretation
So, when should you use compilation, and when should you use interpretation? Because the final result is pretty much the same, the answer generally comes down to the raw speed of the final generated code, though memory usage and start-up times are also key concerns. If you need your code to execute more quickly, then compilation will generally give you better results, with some activities.
The test harness in Listing 11-5 enables you to execute the interpret function results of createDynamicMethod repeatedly and time how long this takes. It also tests an important variation on dynamic methods; that is where you also generate a new .NET delegate value to act as the handle by which you invoke the generated code. As you will see, it turns out that this is by far the fastest technique. Remember, you're timing how long it takes to evaluate the AST either directly or in a compiled form; you're not measuring the parse time or compilation time.
Listing 11-5. A Test Harness for Comparing
#light
open System.Diagnostics
printf "input expression: "
let input = read_line()
printf "Interpret/Compile/Compile Through Delegate [i/c/cd]: "
let interpertFlag = read_line()
printf "reps: "
let reps = read_int()
type Df0 = delegate of unit -> float
type Df1 = delegate of float -> float
type Df2 = delegate of float * float -> float
type Df3 = delegate of float * float * float -> float
type Df4 = delegate of float * float * float * float -> float
match interpertFlag with
| "i" ->
let lexbuf = Lexing.from_string input
let e = Pars.Expression Lex.token lexbuf
let args = Interpret.getVariableValues e
let clock = new Stopwatch()
clock.Start()
for i = 1 to reps do
Interpret.interpret e args |> ignore
clock.Stop()
printf "%Li" clock.ElapsedTicks
| "c" ->
let lexbuf = Lexing.from_string input
let e = Pars.Expression Lex.token lexbuf
let paramNames = Compile.getParamList e
let dm = Compile.createDynamicMethod e paramNames
let args = Compile.collectArgs paramNames
let clock = new Stopwatch()
clock.Start()
for i = 1 to reps do
dm.Invoke(null, args) |> ignore
clock.Stop()
printf "%Li" clock.ElapsedTicks
| "cd" ->
let lexbuf = Lexing.from_string input
let e = Pars.Expression Lex.token lexbuf
let paramNames = Compile.getParamList e
let dm = Compile.createDynamicMethod e paramNames
let args = Compile.collectArgs paramNames
let args = args |> Array.map (fun f -> f :?> float)
let d =
match args.Length with
| 0 -> dm.CreateDelegate(type Df0)
| 1 -> dm.CreateDelegate(type Df1)
| 2 -> dm.CreateDelegate(type Df2)
| 3 -> dm.CreateDelegate(type Df3)
| 4 -> dm.CreateDelegate(type Df4)
| _ -> failwith "too many parameters"
let clock = new Stopwatch()
clock.Start()
for i = 1 to reps do
match d with
| :? Df0 as d -> d.Invoke() |> ignore
| :? Df1 as d -> d.Invoke(args.(0)) |> ignore
| :? Df2 as d -> d.Invoke(args.(0), args.(1)) |> ignore
| :? Df3 as d -> d.Invoke(args.(0), args.(1), args.(2)) |> ignore
| :? Df4 as d -> d.Invoke(args.(0), args.(1), args.(2), args.(4)) |> ignore
| _ -> failwith "too many parameters"
clock.Stop()
printf "%Li" clock.ElapsedTicks
| _ -> failwith "not an option"
Table 11-4 summarizes the results of this program, when executed on the expression 1 + 1.
Table 11-4. Summary of Processing the Expression 1 + 1 for Various Numbers of Repetitions
| Repetitions | 1 | 10 | 100 | 1,000 | 10,000 | 100,000 | 1,000,000 |
| Interpreted | 6,890 | 6,979 | 6,932 | 7,608 | 14,835 | 84,823 | 799,788 |
| Compiled via delegate | 8,65 | 856 | 854 | 1,007 | 2,369 | 15,871 | 151,602 |
| Compiled | 1,112 | 1,409 | 2,463 | 16,895 | 151,135 | 1,500,437 | 14,869,692 |
From Table 11-4 and Figure 11-2, you can see that "Compiled" and "Compiled via delegate" are much faster over a small number of repetitions. But notice that over 1, 10, and 100 repetitions, the amount of time required grows negligibly. This is because over these small numbers of repetitions, the time taken for each repetition is insignificant. It is the time that the JIT compiler takes to compile the IL code into native code that is significant. This is why the "Compiled" and "Compiled via delegate" times are so close. They both have a similar amount of code to JIT compile. The "Interpreted" time takes longer because you must JIT compile more code, specifically the interpreter. But JIT is a one-off cost because you need to JIT each method only once; therefore, as the number of repetitions go up, this one-off cost is paid for, and you begin to see a truer picture of the relative performance cost.
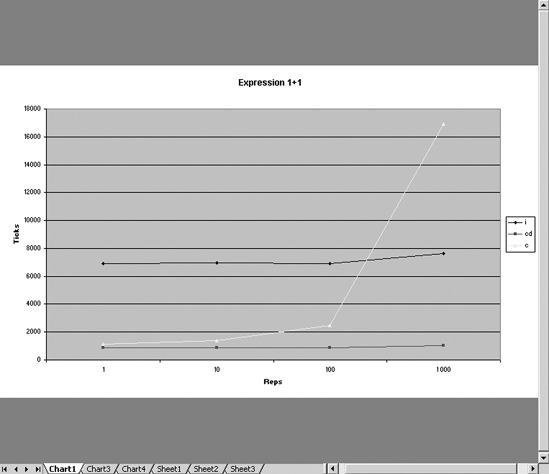
Figure 11-2. The evaluation time in machine ticks of the expression 1 + 1 against the number of evaluations of the express
You can see clearly from Figure 11-2 that as the number of repetitions goes up, the cost of "Compiled" goes up steeply. This is because accessing the compiled DynamicMethod through its Invoke method is expensive, and you incur this cost on every repetition, so the time taken for a "Compiled" method increases at the same rate as the number of repetitions. However, the problem lies not with compilation but with how you are invoking the compiled code. It turns out that calling a DynamicMethod through a delegate rather than the Invoke member on the dynamic delegate allows you to pay only once for the cost of binding to the method, so executing a DynamicMethod this way is much more efficient if you intend to evaluate the expression multiple times. So from the results, compilation with invocation via a delegate is the best option in terms of speed.
This analysis shows the importance of measurement: don't assume that compilation has given you the expected performance gains until you actually see the benefits on realistic data sets and have used all the available techniques to ensure no unnecessary overhead is lurking. However, in reality, many other factors can affect this. For example, if your expressions change often, your interpreter will need to be JIT compiled only once, but each compiled expression will need to be to JIT compiled, so you'll need to run your compiled code many times if you want to see any performance gains. Given that interpretation is usually easier to implement and that compiled code provides only significant performance gains in certain situations, interpretation is often a better choice.
When dealing with situations that require code to perform as quickly as possible, it's generally best to try a few different approaches and then profile your application to see which one gives better results. You can find more information about performance profiling in Chapter 12.
Summary
In this chapter, you looked at the main features and techniques for language-oriented programming in F#. You have seen various techniques; some use data structures as little languages or work with quotations, which involve working with the existing F# syntax to change or extend it. Others, such as implementing a parser, enable you to work with just about any language that is text based, whether this language is of your own design or perhaps more commonly a preexisting language. All these techniques when used correctly can lead to big productivity gains.
The next chapter will look at the tools available to help you to program in F#, not only the tools that are distributed with F# but also the various tools available for .NET that are useful for F# programming.