
3
Fundamentals of Software Engineering for Games
In this chapter, we’ll discuss the foundational knowledge needed by any professional game programmer. We’ll explore numeric bases and representations, the components and architecture of a typical computer and its CPU, machine and assembly language, and the C++ programming language. We’ll review some key concepts in object-oriented programming (OOP), and then delve into some advanced topics that should prove invaluable in any software engineering endeavor (and especially when creating games). As with Chapter 2, some of this material may already be familiar to some readers. However, I highly recommend that all readers at least skim this chapter, so that we all embark on our journey with the same set of tools and supplies.
3.1 C++ Review and Best Practices
Because C++ is arguably the most commonly used language in the game industry, we will focus primarily on C++ in this book. However, most of the concepts we’ll cover apply equally well to any object-oriented programming language. Certainly a great many other languages are used in the game industry—imperative languages like C; object-oriented languages like C# and Java; scripting languages like Python, Lua and Perl; functional languages like Lisp, Scheme and F#, and the list goes on. I highly recommend that every programmer learn at least two high-level languages (the more the merrier), as well as learning at least some assembly language programming (see Section 3.4.7.3). Every new language that you learn further expands your horizons and allows you to think in a more profound and proficient way about programming overall. That being said, let’s turn our attention now to object-oriented programming concepts in general, and C++ in particular.
3.1.1 Brief Review of Object-Oriented Programming
Much of what we’ll discuss in this book assumes you have a solid understanding of the principles of object-oriented design. If you’re a bit rusty, the following section should serve as a pleasant and quick review. If you have no idea what I’m talking about in this section, I recommend you pick up a book or two on object-oriented programming (e.g., [7]) and C++ in particular (e.g., [46] and [36]) before continuing.
3.1.1.1 Classes and Objects
A class is a collection of attributes (data) and behaviors (code) that together form a useful, meaningful whole. A class is a specification describing how individual instances of the class, known as objects, should be constructed. For example, your pet Rover is an instance of the class “dog.” Thus, there is a one-to-many relationship between a class and its instances.
3.1.1.2 Encapsulation
Encapsulation means that an object presents only a limited interface to the outside world; the object’s internal state and implementation details are kept hidden. Encapsulation simplifies life for the user of the class, because he or she need only understand the class’ limited interface, not the potentially intricate details of its implementation. It also allows the programmer who wrote the class to ensure that its instances are always in a logically consistent state.
3.1.1.3 Inheritance
Inheritance allows new classes to be defined as extensions to preexisting classes. The new class modifies or extends the data, interface and/or behavior of the existing class. If class Child extends class Parent, we say that Child inherits from or is derived from Parent. In this relationship, the class Parent is known as the base class or superclass, and the class Child is the derived class or subclass. Clearly, inheritance leads to hierarchical (tree-structured) relationships between classes.
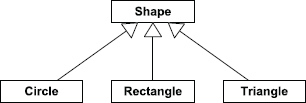
Inheritance creates an “is-a” relationship between classes. For example, a circle is a type of shape. So, if we were writing a 2D drawing application, it would probably make sense to derive our Circle class from a base class called Shape.
We can draw diagrams of class hierarchies using the conventions defined by the Unified Modeling Language (UML). In this notation, a rectangle represents a class, and an arrow with a hollow triangular head represents inheritance. The inheritance arrow points from child class to parent. See Figure 3.1 for an example of a simple class hierarchy represented as a UML static class diagram.
Multiple Inheritance
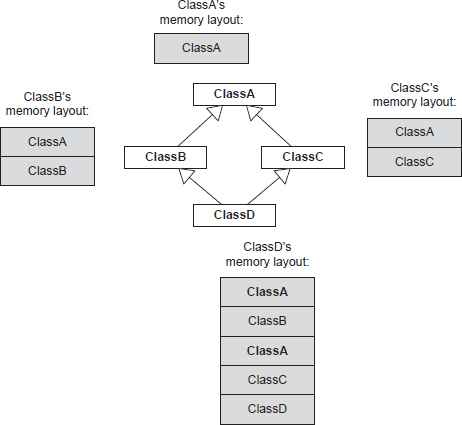
Some languages support multiple inheritance (MI), meaning that a class can have more than one parent class. In theory MI can be quite elegant, but in practice this kind of design usually gives rise to a lot of confusion and technical difficulties (see http://en.wikipedia.org/wiki/Multiple_inheritance). This is because multiple inheritance transforms a simple tree of classes into a potentially complex graph. A class graph can have all sorts of problems that never plague a simple tree—for example, the deadly diamond (http://en.wikipedia.org/wiki/Diamond_problem), in which a derived class ends up containing two copies of a grandparent base class (see Figure 3.2). (In C++, virtual inheritance allows one to avoid this doubling of the grandparent’s data.) Multiple inheritance also complicates casting, because the actual address of a pointer may change depending on which base class it is cast to. This happens because of the presence of multiple vtable pointers within the object.
Most C++ software developers avoid multiple inheritance completely or only permit it in a limited form. A common rule of thumb is to allow only simple, parentless classes to be multiply inherited into an otherwise strictly single-inheritance hierarchy. Such classes are sometimes called mix-in classes because they can be used to introduce new functionality at arbitrary points in a class tree. See Figure 3.3 for a somewhat contrived example of a mix-in class.

3.1.1.4 Polymorphism
Polymorphism is a language feature that allows a collection of objects of different types to be manipulated through a single common interface. The common interface makes a heterogeneous collection of objects appear to be homogeneous, from the point of view of the code using the interface.
For example, a 2D painting program might be given a list of various shapes to draw on-screen. One way to draw this heterogeneous collection of shapes is to use a switch statement to perform different drawing commands for each distinct type of shape.
void drawShapes(std::list<Shape*>& shapes)
{
std::list<Shape*>::iterator pShape = shapes.begin();
std::list<Shape*>::iterator pEnd = shapes.end();
for (; pShape != pEnd; pShape++)
{
switch (pShape->mType)
{
case CIRCLE:
// draw shape as a circle
break;
case RECTANGLE:
// draw shape as a rectangle
break;
case TRIANGLE:
// draw shape as a triangle
break;
//…
}
}
}
The problem with this approach is that the drawShapes() function needs to “know” about all of the kinds of shapes that can be drawn. This is fine in a simple example, but as our code grows in size and complexity, it can become difficult to add new types of shapes to the system. Whenever a new shape type is added, one must find every place in the code base where knowledge of the set of shape types is embedded—like this switch statement—and add a case to handle the new type.
The solution is to insulate the majority of our code from any knowledge of the types of objects with which it might be dealing. To accomplish this, we can define classes for each of the types of shapes we wish to support. All of these classes would inherit from the common base class Shape. A virtual function—the C++ language’s primary polymorphism mechanism—would be defined called Draw(), and each distinct shape class would implement this function in a different way. Without “knowing” what specific types of shapes it has been given, the drawing function can now simply call each shape’s Draw() function in turn.
struct Shape
{
virtual void Draw() = 0; // pure virtual function
virtual ∼Shape() {} // ensure derived dtors are virtual
};
struct Circle : public Shape
{
virtual void Draw()
{
// draw shape as a circle
}
};
struct Rectangle : public Shape
{
virtual void Draw()
{
// draw shape as a rectangle
}
};
struct Triangle : public Shape
{
virtual void Draw()
{
// draw shape as a triangle
}
};
void drawShapes(std::list<Shape*>& shapes)
{
std::list<Shape*>::iterator pShape = shapes.begin();
std::list<Shape*>::iterator pEnd = shapes.end();
for (; pShape != pEnd; pShape++)
{
pShape->Draw(); // call virtual function
}
}
3.1.1.5 Composition and Aggregation
Composition is the practice of using a group of interacting objects to accomplish a high-level task. Composition creates a “has-a” or “uses-a” relationship between classes. (Technically speaking, the “has-a” relationship is called composition, while the “uses-a” relationship is called aggregation.) For example, a spaceship has an engine, which in turn has a fuel tank. Composition/aggregation usually results in the individual classes being simpler and more focused. Inexperienced object-oriented programmers often rely too heavily on inheritance and tend to underutilize aggregation and composition.
As an example, imagine that we are designing a graphical user interface for our game’s front end. We have a class Window that represents any rectangular GUI element. We also have a class called Rectangle that encapsulates the mathematical concept of a rectangle. A naïve programmer might derive the Window class from the Rectangle class (using an “is-a” relationship). But in a more flexible and well-encapsulated design, the Window class would refer to or contain a Rectangle (employing a “has-a” or “uses-a” relationship). This makes both classes simpler and more focused and allows the classes to be more easily tested, debugged and reused.
3.1.1.6 Design Patterns
When the same type of problem arises over and over, and many different programmers employ a very similar solution to that problem, we say that a design pattern has arisen. In object-oriented programming, a number of common design patterns have been identified and described by various authors. The most well-known book on this topic is probably the “Gang of Four” book [19].
Here are a few examples of common general-purpose design patterns.
The game industry has its own set of design patterns for addressing problems in every realm from rendering to collision to animation to audio. In a sense, this book is all about the high-level design patterns prevalent in modern 3D game engine design.
Janitors and RAII
As one very useful example of a design pattern, let’s have a brief look at the “resource acquisition is initialization” pattern (RAII). In this pattern, the acquisition and release of a resource (such as a file, a block of dynamically allocated memory, or a mutex lock) are bound to the constructor and destructor of a class, respectively. This prevents programmers from accidentally forgetting to release the resource—you simply construct a local instance of the class to acquire the resource, and let it fall out of scope to release it automatically. At Naughty Dog, we call such classes janitors because they “clean up” after you.
For example, whenever we need to allocate memory from a particular type of allocator, we push that allocator onto a global allocator stack, and when we’re done allocating we must always remember to pop the allocator off the stack. To make this more convenient and less error-prone, we use an allocation janitor. This tiny class’s constructor pushes the allocator, and its destructor pops the allocator:
class AllocJanitor
{
public:
explicit AllocJanitor(mem::Context context)
{
mem::PushAllocator(context);
}
∼AllocJanitor()
{
mem::PopAllocator();
}
};
To use the janitor class, we simply construct a local instance of it. When this instance drops out of scope, the allocator will be popped automatically:
void f()
{
// do some work…
// allocate temp buffers from single-frame allocator
{
AllocJanitor janitor(mem::Context::kSingleFrame);
U8* pByteBuffer = new U8[SIZE];
float* pFloatBuffer = new float[SIZE];
// use buffers…
// (NOTE: no need to free the memory because we // used a single-frame allocator)
} // janitor pops allocator when it drops out of scope
// do more work…
}
See http://en.cppreference.com/w/cpp/language/raii for more information on the highly useful RAII pattern.
3.1.2 C++ Language Standardization
Since its inception in 1979, the C++ language has been continually evolving. Bjarne Stroustrup, its inventor, originally named the language “C with Classes”, but it was renamed “C++” in 1983. The International Organization for Standardization (ISO, www.iso.org) first standardized the language in 1998—this version is known today as C++98. Since then, the ISO has been periodically publishing updated standards for the C++ language, with the goals of making the language more powerful, easier to use, and less ambiguous. These goals are achieved by refining the semantics and rules of the language, by adding new, more-powerful language features, and by deprecating, or removing entirely, those aspects of the language which have proven problematic or unpopular.
The most-recent variant of the C++ programming language standard is called C++17, which was published on July 31, 2017. The next iteration of the standard, C++2a, was in development at the time of this publication. The various versions of the C++ standard are summarized in chronological order below.
nullptr literal, to replace the bug-prone NULL macro that had been inherited from the C language;auto and decltype keywords for type inference;decltype of a function’s input arguments to be used to describe the return type of that function;override and final keywords for improved expressiveness when defining and overriding virtual functions;constexpr keyword for defining compile-time constant values by evaluating expressions at compile time;__attribute__((…)) and __declspec().C++11 also introduced an improved and expanded standard library, including support for threading (concurrent programming), improved smart pointer facilities and an expanded set of generic algorithms.
auto keyword, without the need for the verbose trailing decltype expression required by C++11;auto to declare its input arguments;0b (e.g., 0b10110110);1’000’000 instead of 1000000);constexpr, including the ability to use if, switch and loops within constant expressions.register keyword, and the already-deprecated auto_ptr smart pointer class;void f() noexcept(true); and void f() noexcept(false); are now distinct types;u8‘x’), and floating-point literals with a hexadecimal base and decimal exponent (e.g., 0xC.68p+2);auto [a, b] = func_that_returns_a_pair();)—a syntax that is strikingly similar to that of returning multiple values from a function via a tuple in Python;[[fallthrough]] which allows you to explicitly document the fact that a missing break statement in a switch is intentional, thereby suppressing the warning that would otherwise be generated.3.1.2.1 Further Reading
There are plenty of great online resources and books that describe the features of C++11, C++14 and C++17 in detail, so we won’t attempt to cover them here. Here are a few useful references:
auto and decltype.3.1.2.2 Which Language Features to Use?
As you read about all the cool new features being added to C++, it’s tempting to think that you need to use all of these features in your engine or game. However, just because a feature exists doesn’t mean your team needs to immediately start making use of it.
At Naughty Dog, we tend to take a conservative approach to adopting new language features into our codebase. As part of our studio’s coding standards, we have a list of those C++ language features that are approved for use in our runtime code, and another somewhat more liberal list of language features that are allowed in our offline tools code. There are a number of reasons for this cautious approach, which I’ll outline in the following sections.
Lack of Full Feature Support
The “bleeding edge” features may not be fully supported by your compiler. For example, LLVM/Clang, the C++ compiler used on the Sony Playstation 4, currently supports the entire C++11 standard in versions 3.3 and later, and all of C++14 in versions 3.4 and later. But its support for C++17 is spread across Clang versions 3.5 through 4.0, and it currently has no support for the draft C++2a standard. Also, Clang compiles code in C++98 mode by default—support for some of the more-advanced standards are accepted as extensions, but in order to enable full support one must pass specific command-line arguments to the compiler. See https://clang.llvm.org/cxx_status.html for details.
Cost of Switching between Standards
There’s a non-zero cost to switching your codebase from one standard to another. Because of this, it’s important for a game studio to decide on the most-advanced C++ standard to support, and then stick with it for a reasonable length of time (e.g., for the duration of one project). At Naughty Dog, we adopted the C++11 standard only relatively recently, and we only allowed its use in the code branch in which The Last of Us Part II is being developed. The code in the branch used for Uncharted 4: A Thief’s End and Uncharted: The Lost Legacy had been written originally using the C++98 standard, and we decided that the relatively minor benefits of adopting C++11 features in that codebase did not outweigh the cost and risks of doing so.
Risk versus Reward
Not every C++ language feature is created equal. Some features are useful and pretty much universally acceptable, like nullptr. Others may have benefits, but also associated negatives. Still other language features may be deemed inappropriate for use in runtime engine code altogether.
As an example of a language feature with both benefits and downsides, consider the new C++11 interpretation of the auto keyword. This keyword certainly makes variables and functions more convenient to write. But the Naughty Dog programmers recognized that over-use of auto can lead to obfuscated code: As an extreme example, imagine trying to read a .cpp file written by somebody else, in which virtually every variable, function argument and return value is declared auto. It would be like reading a typeless language such as Python or Lisp. One of the benefits of a strongly-typed language like C++ is the programmer’s ability to quickly and easily determine the types of all variables. As such, we decided to adopt a simple rule: auto may only be used when declaring iterators, in situations where no other approach works (such as within template definitions), or in special cases when code clarity, readability and maintainability is significantly improved by its use. In all other cases, we require the use of explicit type declarations.
As an example of a language feature that could be deemed inappropriate for use in a commercial product like a game, consider template metaprogramming. Andrei Alexandrescu’s Loki library [3] makes heavy use of template metaprogramming to do some pretty interesting and amazing things. However, the resulting code is tough to read, is sometimes non-portable, and presents programmers with an extremely high barrier to understanding. The programming leads at Naughty Dog believe that any programmer should be able to jump in and debug a problem on short notice, even in code with which he or she may not be very familiar. As such, Naughty Dog prohibits complex template metaprogramming in runtime engine code, with exceptions made only on a case-by-case basis where the benefits are deemed to outweigh the costs.
In summary, remember that when you have a hammer, everything can tend to look like a nail. Don’t be tempted to use features of your language just because they’re there (or because they’re new). A judicious and carefully considered approach will result in a stable codebase that’s as easy as possible to understand, reason about, debug and maintain.
3.1.3 Coding Standards: Why and How Much?
Discussions of coding conventions among engineers can often lead to heated “religious” debates. I do not wish to spark any such debate here, but I will go so far as to suggest that following at least a minimal set of coding standards is a good idea. Coding standards exist for two primary reasons.
In my opinion, the most important things to achieve in your coding conventions are the following.
#defined symbols with extra care; remember that C++ preprocessor macros are really just text substitutions, so they cut across all C/C++ scope and namespace boundaries.3.2 Catching and Handling Errors
There are a number of ways to catch and handle error conditions in a game engine. As a game programmer, it’s important to understand these different mechanisms, their pros and cons and when to use each one.
3.2.1 Types of Errors
In any software project there are two basic kinds of error conditions: user errors and programmer errors. A user error occurs when the user of the program does something incorrect, such as typing an invalid input, attempting to open a file that does not exist, etc. A programmer error is the result of a bug in the code itself. Although it may be triggered by something the user has done, the essence of a programmer error is that the problem could have been avoided if the programmer had not made a mistake, and the user has a reasonable expectation that the program should have handled the situation gracefully.
Of course, the definition of “user” changes depending on context. In the context of a game project, user errors can be roughly divided into two categories: errors caused by the person playing the game and errors caused by the people who are making the game during development. It is important to keep track of which type of user is affected by a particular error and handle the error appropriately.
There’s actually a third kind of user—the other programmers on your team. (And if you are writing a piece of game middleware software, like Havok or OpenGL, this third category extends to other programmers all over the world who are using your library.) This is where the line between user errors and programmer errors gets blurry. Let’s imagine that programmer A writes a function f(), and programmer B tries to call it. If B calls f() with invalid arguments (e.g., a null pointer, or an out-of-range array index), then this could be seen as a user error by programmer A, but it would be a programmer error from B’s point of view. (Of course, one can also argue that programmer A should have anticipated the passing of invalid arguments and should have handled them gracefully, so the problem really is a programmer error, on A’s part.) The key thing to remember here is that the line between user and programmer can shift depending on context—it is rarely a black-and-white distinction.
3.2.2 Handling Errors
When handling errors, the requirements differ significantly between the two types. It is best to handle user errors as gracefully as possible, displaying some helpful information to the user and then allowing him or her to continue working—or in the case of a game, to continue playing. Programmer errors, on the other hand, should not be handled with a graceful “inform and continue” policy. Instead, it is usually best to halt the program and provide detailed low-level debugging information, so that a programmer can quickly identify and fix the problem. In an ideal world, all programmer errors would be caught and fixed before the software ships to the public.
3.2.2.1 Handling Player Errors
When the “user” is the person playing your game, errors should obviously be handled within the context of gameplay. For example, if the player attempts to reload a weapon when no ammo is available, an audio cue and/or an animation can indicate this problem to the player without taking him or her “out of the game.”
3.2.2.2 Handling Developer Errors
When the “user” is someone who is making the game, such as an artist, animator or game designer, errors may be caused by an invalid asset of some sort. For example, an animation might be associated with the wrong skeleton, or a texture might be the wrong size, or an audio file might have been sampled at an unsupported sample rate. For these kinds of developer errors, there are two competing camps of thought.
On the one hand, it seems important to prevent bad game assets from persisting for too long. A game typically contains literally thousands of assets, and a problem asset might get “lost,” in which case one risks the possibility of the bad asset surviving all the way into the final shipping game. If one takes this point of view to an extreme, then the best way to handle bad game assets is to prevent the entire game from running whenever even a single problematic asset is encountered. This is certainly a strong incentive for the developer who created the invalid asset to remove or fix it immediately.
On the other hand, game development is a messy and iterative process, and generating “perfect” assets the first time around is rare indeed. By this line of thought, a game engine should be robust to almost any kind of problem imaginable, so that work can continue even in the face of totally invalid game asset data. But this too is not ideal, because the game engine would become bloated with error-catching and error-handling code that won’t be needed once the development pace settles down and the game ships. And the probability of shipping the product with “bad” assets becomes too high.
In my experience, the best approach is to find a middle ground between these two extremes. When a developer error occurs, I like to make the error obvious and then allow the team to continue to work in the presence of the problem. It is extremely costly to prevent all the other developers on the team from working, just because one developer tried to add an invalid asset to the game. A game studio pays its employees well, and when multiple team members experience downtime, the costs are multiplied by the number of people who are prevented from working. Of course, we should only handle errors in this way when it is practical to do so, without spending inordinate amounts of engineering time, or bloating the code.
As an example, let’s suppose that a particular mesh cannot be loaded. In my view, it’s best to draw a big red box in the game world at the places that mesh would have been located, perhaps with a text string hovering over each one that reads, “Mesh blah-dee-blah failed to load.” This is superior to printing an easy-to-miss message to an error log. And it’s far better than just crashing the game, because then no one will be able to work until that one mesh reference has been repaired. Of course, for particularly egregious problems it’s fine to just spew an error message and crash. There’s no silver bullet for all kinds of problems, and your judgment about what type of error handling approach to apply to a given situation will improve with experience.
3.2.2.3 Handling Programmer Errors
The best way to detect and handle programmer errors (a.k.a. bugs) is often to embed error-checking code into your source code and arrange for failed error checks to halt the program. Such a mechanism is known as an assertion system; we’ll investigate assertions in detail in Section 3.2.3.3. Of course, as we said above, one programmer’s user error is another programmer’s bug; hence, assertions are not always the right way to handle every programmer error. Making a judicious choice between an assertion and a more graceful error-handling technique is a skill that one develops over time.
3.2.3 Implementation of Error Detection and Handling
We’ve looked at some philosophical approaches to handling errors. Now let’s turn our attention to the choices we have as programmers when it comes to implementing error detection and handling code.
3.2.3.1 Error Return Codes
A common approach to handling errors is to return some kind of failure code from the function in which the problem is first detected. This could be a Boolean value indicating success or failure, or it could be an “impossible” value, one that is outside the range of normally returned results. For example, a function that returns a positive integer or floating-point value could return a negative value to indicate that an error occurred. Even better than a Boolean or an “impossible” return value, the function could be designed to return an enumerated value to indicate success or failure. This clearly separates the error code from the output(s) of the function, and the exact nature of the problem can be indicated on failure (e.g., enum Error {kSuccess, kAssetNotFound, kInvalidRange, …}).
The calling function should intercept error return codes and act appropriately. It might handle the error immediately. Or, it might work around the problem, complete its own execution and then pass the error code on to whatever function called it.
3.2.3.2 Exceptions
Error return codes are a simple and reliable way to communicate and respond to error conditions. However, error return codes have their drawbacks. Perhaps the biggest problem with error return codes is that the function that detects an error may be totally unrelated to the function that is capable of handling the problem. In the worst-case scenario, a function that is 40 calls deep in the call stack might detect a problem that can only be handled by the top-level game loop, or by main(). In this scenario, every one of the 40 functions on the call stack would need to be written so that it can pass an appropriate error code all the way back up to the top-level error-handling function.
One way to solve this problem is to throw an exception. Exception handling is a very powerful feature of C++. It allows the function that detects a problem to communicate the error to the rest of the code without knowing anything about which function might handle the error. When an exception is thrown, relevant information about the error is placed into a data object of the programmer’s choice known as an exception object. The call stack is then automatically unwound, in search of a calling function that has wrapped its call in a try-catch block. If a try-catch block is found, the exception object is matched against all possible catch clauses, and if a match is found, the corresponding catch’s code block is executed. The destructors of any automatic variables are called as needed during the stack unwinding process.
The ability to separate error detection from error handling in such a clean way is certainly attractive, and exception handling is an excellent choice for some software projects. However, exception handling does add some overhead to the program. The stack frame of any function that contains a try-catch block must be augmented to contain additional information required by the stack unwinding process. Also, if even one function in your program (or a library that your program links with) uses exception handling, your entire program must use exception handling—the compiler can’t know which functions might be above you on the call stack when you throw an exception.
That said, it is possible to “sandbox” a library or libraries that make use of exception handling, in order to avoid your entire game engine having to be written with exceptions enabled. To do this, you would wrap all the API calls into the libraries in question in functions that are implemented in a translation unit that has exception handling enabled. Each of these functions would catch all possible exceptions in a try/catch block and convert them into error return codes. Any code that links with your wrapper library can therefore safely disable exception handling.
Arguably more important than the overhead issue is the fact that exceptions are in some ways no better than goto statements. Joel Spolsky of Microsoft and Fog Creek Software fame argues that exceptions are in fact worse than gotos because they aren’t easily seen in the source code. A function that neither throws nor catches exceptions may nevertheless become involved in the stack-unwinding process, if it finds itself sandwiched between such functions in the call stack. And the unwinding process is itself imperfect: Your software can easily be left in an invalid state unless the programmer considers every possible way that an exception can be thrown, and handles it appropriately. This can make writing robust software difficult. When the possibility for exception throwing exists, pretty much every function in your codebase needs to be robust to the carpet being pulled out from under it and all its local objects destroyed whenever it makes a function call.
Another issue with exception handling is its cost. Although in theory modern exception handling frameworks don’t introduce additional runtime overhead in the error-free case, this is not necessarily true in practice. For example, the code that the compiler adds to your functions for unwinding the call stack when an exception occurs tends to produce an overall increase in code size. This might degrade I-cache performance, or cause the compiler to decide not to inline a function that it otherwise would have.
Clearly there are some pretty strong arguments for turning off exception handling in your game engine altogether. This is the approach employed at Naughty Dog and also on most of the projects I’ve worked on at Electronic Arts and Midway. In his capacity as Engine Director at Insomniac Games, Mike Acton has clearly stated his objection to the use of exception handling in runtime game code on numerous occasions. JPL and NASA also disallow exception handling in their mission-critical embedded software, presumably for the same reasons we tend to avoid it in the game industry. That said, your mileage certainly may vary. There is no perfect tool and no one right way to do anything. When used judiciously, exceptions can make your code easier to write and work with; just be careful out there!
There are many interesting articles on this topic on the web. Here’s one good thread that covers most of the key issues on both sides of the debate:
Exceptions and RAII
The “resource acquisition is initialization” pattern (RAII, see Section 3.1.1.6) is often used in conjuction with exception handling: The constructor attempts to acquire the desired resource, and throws an exception if it fails to do so. This is done to avoid the need for an if check to test the status of the object after it has been created—if the constructor returns without throwing an exception, we know for certain that the resource was successfully acquired.
However, the RAII pattern can be used even without exceptions. All it requires is a little discipline to check the status of each new resource object when it is first created. After that, all of the other benefits of RAII can be reaped. (Exceptions can also be replaced by assertion failures to signal the failure of some kinds of resource acquisitions.)
3.2.3.3 Assertions
An assertion is a line of code that checks an expression. If the expression evaluates to true, nothing happens. But if the expression evaluates to false, the program is stopped, a message is printed and the debugger is invoked if possible.
Assertions check a programmer’s assumptions. They act like land mines for bugs. They check the code when it is first written to ensure that it is functioning properly. They also ensure that the original assumptions continue to hold for long periods of time, even when the code around them is constantly changing and evolving. For example, if a programmer changes code that used to work, but accidentally violates its original assumptions, they’ll hit the land mine. This immediately informs the programmer of the problem and permits him or her to rectify the situation with minimum fuss. Without assertions, bugs have a tendency to “hide out” and manifest themselves later in ways that are difficult and time-consuming to track down. But with assertions embedded in the code, bugs announce themselves the moment they are introduced—which is usually the best moment to fix the problem, while the code changes that caused the problem are fresh in the programmer’s mind. Steve Maguire provides an in-depth discussion of assertions in his must-read book, Writing Solid Code [35].
The cost of the assertion checks can usually be tolerated during development, but stripping out the assertions prior to shipping the game can buy back that little bit of crucial performance if necessary. For this reason assertions are generally implemented in such a way as to allow the checks to be stripped out of the executable in non-debug build configurations. In C, an assert() macro is provided by the standard library header file <assert.h>; in C++, it’s provided by the <cassert> header.
The standard library’s definition of assert() causes it to be defined in debug builds (builds with the DEBUG preprocessor symbol defined) and stripped in non-debug builds (builds with the NDEBUG preprocessor symbol defined). In a game engine, you may want finer-grained control over which build configurations retain assertions, and which configurations strip them out. For example, your game might support more than just a debug and development build configuration—you might also have a shipping build with global optimizations enabled, and perhaps even a PGO build for use by profile-guided optimization tools (see Section 2.2.4). Or you might also want to define different “flavors” of assertions—some that are always retained even in the shipping version of your game, and others that are stripped out of the non-shipping build. For these reasons, let’s take a look at how you can implement your own ASSERT() macro using the C/C++ preprocessor.
Assertion Implementation
Assertions are usually implemented via a combination of a #defined macro that evaluates to an if/else clause, a function that is called when the assertion fails (the expression evaluates to false), and a bit of assembly code that halts the program and breaks into the debugger when one is attached. Here’s a typical implementation:
#if ASSERTIONS_ENABLED
// define some inline assembly that causes a break
// into the debugger -- this will be different on each
// target CPU
#define debugBreak() asm {int 3}
// check the expression and fail if it is false #define ASSERT(expr)
if (expr) {}
else
{
reportAssertionFailure(#expr,
__FILE__, __LINE__);
debugBreak();
}
#else
#define ASSERT(expr) // evaluates to nothing
#endif
Let’s break down this definition so we can see how it works:
#if/#else/#endif is used to strip assertions from the code base. When ASSERTIONS_ENABLED is nonzero, the ASSERT() macro is defined in its full glory, and all assertion checks in the code will be included in the program. But when assertions are turned off, ASSERT(expr) evaluates to nothing, and all instances of it in the code are effectively removed.debugBreak() macro evaluates to whatever assembly-language instructions are required in order to cause the program to halt and the debugger to take charge (if one is connected). This differs from CPU to CPU, but it is usually a single assembly instruction.ASSERT() macro itself is defined using a full if/else statement (as opposed to a lone if). This is done so that the macro can be used in any context, even within other unbracketed if/else statements.Here’s an example of what would happen if ASSERT() were defined using a solitary if:
// WARNING: NOT A GOOD IDEA!
#define ASSERT(expr) if (!(expr)) debugBreak()
void f()
{
if (a < 5)
ASSERT(a >= 0);
else
doSomething(a);
}
This expands to the following incorrect code:
void f()
{
if (a < 5)
if (!(a >= 0))
debugBreak();
else // oops! bound to the wrong if()!
doSomething(a);
}
ASSERT() macro does two things. It displays some kind of message to the programmer indicating what went wrong, and then it breaks into the debugger. Notice the use of #expr as the first argument to the message display function. The pound (#) preprocessor operator causes the expression expr to be turned into a string, thereby allowing it to be printed out as part of the assertion failure message.__FILE__ and __LINE__. These compiler-defined macros magically contain the .cpp file name and line number of the line of code on which they appear. By passing them into our message display function, we can print the exact location of the problem.I highly recommend the use of assertions in your code. However, it’s important to be aware of their performance cost. You may want to consider defining two kinds of assertion macros. The regular ASSERT() macro can be left active in all builds, so that errors are easily caught even when not running in debug mode. A second assertion macro, perhaps called SLOW_ASSERT(), could be activated only in debug builds. This macro could then be used in places where the cost of assertion checking is too high to permit inclusion in release builds. Obviously SLOW_ASSERT() is of lower utility, because it is stripped out of the version of the game that your testers play every day. But at least these assertions become active when programmers are debugging their code.
It’s also extremely important to use assertions properly. They should be used to catch bugs in the program itself—never to catch user errors. Also, assertions should always cause the entire game to halt when they fail. It’s usually a bad idea to allow assertions to be skipped by testers, artists, designers and other non-engineers. (This is a bit like the boy who cried wolf: if assertions can be skipped, then they cease to have any significance, rendering them ineffective.) In other words, assertions should only be used to catch fatal errors. If it’s OK to continue past an assertion, then it’s probably better to notify the user of the error in some other way, such as with an on-screen message, or some ugly bright-orange 3D graphics.
Compile-Time Assertions
One weakness of assertions, as we’ve discussed them thus far, is that the conditions encoded within them are only checked at runtime. We have to run the program, and the code path in question must actually execute, in order for an assertion’s condition to be checked.
Sometimes the condition we’re checking within an assertion involves information that is entirely known at compile time. For example, let’s say we’re defining a struct that for some reason needs to be exactly 128 bytes in size. We want to add an assertion so that if another programmer (or a future version of yourself) decides to change the size of the struct, the compiler will give us an error message. In other words, we’d like to write something like this:
struct NeedsToBe128Bytes
{
U32 m_a;
F32 m_b;
// etc.
};
// sadly this doesn’t work…
ASSERT(sizeof(NeedsToBe128Bytes) == 128);
The problem of course is that the ASSERT() (or assert()) macro needs to be executable at runtime, and one can’t even put executable code at global scope in a .cpp file outside of a function definition. The solution to this problem is a compile-time assertion, also known as a static assertion.
Starting with C++11, the standard library defines a macro named static_assert() for us. So we can re-write the example above as follows:
struct NeedsToBe128Bytes
{
U32 m_a;
F32 m_b;
// etc.
};
static_assert(sizeof(NeedsToBe128Bytes) == 128,
“wrong size”);
If you’re not using C++11, you can always roll your own STATIC_ASSERT() macro. It can be implemented in a number of different ways, but the basic idea is always the same: The macro places a declaration into your code that (a) is legal at file scope, (b) evaluates the desired expression at compile time rather than runtime, and (c) produces a compile error if and only if the expression is false. Some methods of defining STATIC_ASSERT() rely on compiler-specific details, but here’s one reasonably portable way to define it:
#define _ASSERT_GLUE(a, b) a ## b
#define ASSERT_GLUE(a, b) _ASSERT_GLUE(a, b)
#define STATIC_ASSERT(expr)
enum
{
ASSERT_GLUE(g_assert_fail_, __LINE__)
= 1 / (int)dl(expr))
}
STATIC_ASSERT(sizeof(int) == 4); // should pass
STATIC_ASSERT(sizeof(float) == 1); // should fail
This works by defining an anonymous enumeration containing a single enumerator. The name of the enumerator is made unique (within the translation unit) by “gluing” a fixed prefix such as g_assert_fail_ to a unique suffix—in this case, the line number on which the STATIC_ASSERT() macro is invoked. The value of the enumerator is set to 1 / (!!(expr)). The double negation !! ensures that expr has a Boolean value. This value is then cast to an int, yielding either 1 or 0 depending on whether the expression is true or false, respectively. If the expression is true, the enumerator will be set to the value 1/1 which is one. But if the expression is false, we’ll be asking the compiler to set the enumerator to the value 1/0 which is illegal, and will trigger a compile error.
When our STATIC_ASSERT() macro as defined above fails, Visual Studio 2015 produces a compile-time error message like this:
1>test.cpp(48): error C2131: expression did not evaluate to a constant 1> test.cpp(48): note: failure was caused by an undefined arithmetic operation
Here’s another way to define STATIC_ASSERT() using template specialization. In this example, we first check to see if we’re using C++11 or beyond. If so, we use the standard library’s implementation of static_assert() for maximum portability. Otherwise we fall back to our custom implementation.
#ifdef __cplusplus
#if __cplusplus >= 201103L
#define STATIC_ASSERT(expr)
static_assert(expr,
“static assert failed:”
#expr)
#else
// declare a template but only define the
// true case (via specialization)
template<bool> class TStaticAssert;
template<> class TStaticAssert<true> {};
#define STATIC_ASSERT(expr)
enum
{
ASSERT_GLUE(g_assert_fail_, __LINE__)
= sizeof(TStaticAssert<!!(expr)>)
}
#endif
#endif
This implementation, using template specialization, may be preferable to the previous one using division by zero, because it produces a slightly better error message in Visual Studio 2015:
1>test.cpp(4 8): error C2027: use of undefined type ’TStaticAssert<false>’ 1>test.cpp(4 8): note: see declaration of ’TStaticAssert<false>’
However, each compiler handles error reporting differently, so your mileage may vary. For more implementation ideas for compile-time assertions, one good reference is http://www.pixelbeat.org/programming/gcc/static_assert.html.
3.3 Data, Code and Memory Layout
3.3.1 Numeric Representations
Numbers are at the heart of everything that we do in game engine development (and software development in general). Every software engineer should understand how numbers are represented and stored by a computer. This section will provide you with the basics you’ll need throughout the rest of the book.
3.3.1.1 Numeric Bases
People think most naturally in base ten, also known as decimal notation. In this notation, ten distinct digits are used (0 through 9), and each digit from right to left represents the next highest power of 10. For example, the number 7803 = (7 × 103) + (8 × 102) + (0 × 101) + (3 × 100) = 7000 + 800 + 0 + 3.
In computer science, mathematical quantities such as integers and real-valued numbers need to be stored in the computer’s memory. And as we know, computers store numbers in binary format, meaning that only the two digits 0 and 1 are available. We call this a base-two representation, because each digit from right to left represents the next highest power of 2. Computer scientists sometimes use a prefix of “0b” to represent binary numbers. For example, the binary number 0b1101 is equivalent to decimal 13, because 0b1101 = (1 × 23) + (1 × 22) + (0 × 21) + (1 × 20) = 8 + 4 + 0 + 1 = 13.
Another common notation popular in computing circles is hexadecimal, or base 16. In this notation, the 10 digits 0 through 9 and the six letters A through F are used; the letters A through F replace the decimal values 10 through 15, respectively. A prefix of “0x” is used to denote hex numbers in the C and C++ programming languages. This notation is popular because computers generally store data in groups of 8 bits known as bytes, and since a single hexadecimal digit represents 4 bits exactly, a pair of hex digits represents a byte. For example, the value 0xFF = 0b11111111 = 255 is the largest number that can be stored in 8 bits (1 byte). Each digit in a hexadecimal number, from right to left, represents the next power of 16. So, for example, 0xB052 = (11 × 163) + (0 × 162) + (5 × 161) + (2 × 160) = (11 × 4096) + (0 × 256) + (5 × 16) + (2 × 1) = 45,138.
3.3.1.2 Signed and Unsigned Integers
In computer science, we use both signed and unsigned integers. Of course, the term “unsigned integer” is actually a bit of a misnomer—in mathematics, the whole numbers or natural numbers range from 0 (or 1) up to positive infinity, while the integers range from negative infinity to positive infinity. Nevertheless, we’ll use computer science lingo in this book and stick with the terms “signed integer” and “unsigned integer.”
Most modern personal computers and game consoles work most easily with integers that are 32 bits or 64 bits wide (although 8- and 16-bit integers are also used a great deal in game programming as well). To represent a 32-bit unsigned integer, we simply encode the value using binary notation (see above). The range of possible values for a 32-bit unsigned integer is 0x00000000 (0) to 0xFFFFFFFF (4,294,967,295).
To represent a signed integer in 32 bits, we need a way to differentiate between positive and negative vales. One simple approach called the sign and magnitude encoding reserves the most significant bit as a sign bit. When this bit is zero, the value is positive, and when it is one, the value is negative. This leaves us 31 bits to represent the magnitude of the value, effectively cutting the range of possible magnitudes in half (but allowing both positive and negative forms of every distinct magnitude, including zero).
Most microprocessors use a slightly more efficient technique for encoding negative integers, called two’s complement notation. This notation has only one representation for the value zero, as opposed to the two representations possible with simple sign bit (positive zero and negative zero). In 32-bit two’s complement notation, the value 0xFFFFFFFF is interpreted to mean −1, and negative values count down from there. Any value with the most significant bit set is considered negative. So values from 0x00000000 (0) to 0x7FFFFFFF (2,147,483,647) represent positive integers, and 0x80000000 (−2,147,483,648) to 0xFFFFFFFF (−1) represent negative integers.

3.3.1.3 Fixed-Point Notation
Integers are great for representing whole numbers, but to represent fractions and irrational numbers we need a different format that expresses the concept of a decimal point.
One early approach taken by computer scientists was to use fixed-point notation. In this notation, one arbitrarily chooses how many bits will be used to represent the whole part of the number, and the rest of the bits are used to represent the fractional part. As we move from left to right (i.e., from the most significant bit to the least significant bit), the magnitude bits represent decreasing powers of two (…, 16, 8, 4, 2, 1), while the fractional bits represent decreasing inverse powers of two (½, ¼, ⅛, , …). For example, to store the number −173.25 in 32-bit fixed-point notation with one sign bit, 16 bits for the magnitude and 15 bits for the fraction, we first convert the sign, the whole part and the fractional part into their binary equivalents individually (negative = 0b1, 173 = 0b0000000010101101 and 0.25 = ¼ = 0b010000000000000). Then we pack those values together into a 32-bit integer. The final result is 0x8056A000. This is illustrated in Figure 3.4.
The problem with fixed-point notation is that it constrains both the range of magnitudes that can be represented and the amount of precision we can achieve in the fractional part. Consider a 32-bit fixed-point value with 16 bits for the magnitude, 15 bits for the fraction and a sign bit. This format can only represent magnitudes up to ±65,535, which isn’t particularly large. To overcome this problem, we employ a floating-point representation.
3.3.1.4 Floating-Point Notation
In floating-point notation, the position of the decimal place is arbitrary and is specified with the help of an exponent. A floating-point number is broken into three parts: the mantissa, which contains the relevant digits of the number on both sides of the decimal point, the exponent, which indicates where in that string of digits the decimal point lies, and a sign bit, which of course indicates whether the value is positive or negative. There are all sorts of different ways to lay out these three components in memory, but the most common standard is IEEE-754. It states that a 32-bit floating-point number will be represented with the sign in the most significant bit, followed by 8 bits of exponent and finally 23 bits of mantissa.

The value v represented by a sign bit s, an exponent e and a mantissa m is v = s × 2(e−127) × (1 + m).
The sign bit s has the value +1 or −1. The exponent e is biased by 127 so that negative exponents can be easily represented. The mantissa begins with an implicit 1 that is not actually stored in memory, and the rest of the bits are interpreted as inverse powers of two. Hence the value represented is really 1 + m, where m is the fractional value stored in the mantissa.
For example, the bit pattern shown in Figure 3.5 represents the value 0.15625, because s = 0 (indicating a positive number), e = 0b01111100 = 124 and m = 0b0100… = 0 × 2−1 + 1 × 2−2 = ¼. Therefore,
The Trade-Off between Magnitude and Precision
The precision of a floating-point number increases as the magnitude decreases, and vice versa. This is because there are a fixed number of bits in the mantissa, and these bits must be shared between the whole part and the fractional part of the number. If a large percentage of the bits are spent representing a large magnitude, then a small percentage of bits are available to provide fractional precision. In physics the term significant digits is typically used to describe this concept (http://en.wikipedia.org/wiki/Significant_digits).
To understand the trade-off between magnitude and precision, let’s look at the largest possible floating-point value, FLT_MAX ≈ 3.403 × 1038, whose representation in 32-bit IEEE floating-point format is 0x7F7FFFFF. Let’s break this down:
So FLT_MAX is 0x00FFFFFF × 2127 = 0xFFFFFF00000000000000000000000000. In other words, our 24 binary ones were shifted up by 127 bit positions, leaving 127 − 23 = 104 binary zeros (or 104/4 = 26 hexadecimal zeros) after the least significant digit of the mantissa. Those trailing zeros don’t correspond to any actual bits in our 32-bit floating-point value—they just appear out of thin air because of the exponent. If we were to subtract a small number (where “small” means any number composed of fewer than 26 hexadecimal digits) from FLT_MAX, the result would still be FLT_MAX, because those 26 least significant hexadecimal digits don’t really exist!
The opposite effect occurs for floating-point values whose magnitudes are much less than one. In this case, the exponent is large but negative, and the significant digits are shifted in the opposite direction. We trade the ability to represent large magnitudes for high precision. In summary, we always have the same number of significant digits (or really significant bits) in our floatingpoint numbers, and the exponent can be used to shift those significant bits into higher or lower ranges of magnitude.
Subnormal Values
Another subtlety to notice is that there is a finite gap between zero and the smallest nonzero value we can represent with floating-point notation (as it has been described thus far). The smallest nonzero magnitude we can represent is FLT_MIN = 2−126 ≈ 1.175 × 10−38, which has a binary representation of 0x00800000 (i.e., the exponent is 0x01, or −126 after subtracting the bias, and the mantissa is all zeros except for the implicit leading one). The next smallest valid value is zero, so there is a finite gap between the values −FLT_MIN and +FLT_MIN. This underscores the fact that the real number line is quantized when using a floating-point representation. (Note that the C++ standard library exposes FLT_MIN as the rather more verbose std::numeric_limits <float>::min(). We’ll stick to FLT_MIN in this book for brevity.)
The gap around zero can be filled by employing an extension to the floating-point representation known as denormalized values, also known as subnormal values. With this extension, any floating-point value with a biased exponent of 0 is interpreted as a subnormal number. The exponent is treated as if it had been a 1 instead of a 0, and the implicit leading 1 that normally sits in front of the bits of the mantissa is changed to a 0. This has the effect of filling the gap between −FLT_MIN and +FLT_MIN with a linear sequence of evenly-spaced subnormal values. The positive subnormal float that is closest to zero is represented by the constant FLT_TRUE_MIN.
The benefit of using subnormal values is that it provides greater precision near zero. For example, it ensures that the following two expressions are equivalent, even for values of a and b that are very close to FLT_MIN:
if (a == b) {…}
if (a - b == 0.0f) {…}
Without subnormal values, the expression a − b could evaluate to zero even when a != b.
Machine Epsilon
For a particular floating-point representation, the machine epsilon is defined to be the smallest floating-point value ε that satisfies the equation, 1 + ε ≠ 1. For an IEEE-754 floating-point number, with its 23 bits of precision, the value of ε is 2−23, which is approximately 1.192 × 10−7. The most significant digit of ε falls just inside the range of significant digits in the value 1.0, so adding any value smaller than ε to 1.0 has no effect. In other words, any new bits contributed adding a value smaller than ε will get “chopped off” when we try to fit the sum into a mantissa with only 23 bits.
Units in the Last Place (ULP)
Consider two floating-point numbers which are identical in all respects except for the value of the least-significant bit in their mantissas. These two values are said to differ by one unit in the last place (1 ULP). The actual value of 1 ULP changes depending on the exponent. For example, the floating-point value 1.0f has an unbiased exponent of zero, and a mantissa in which all bits are zero (except for the implicit leading 1). At this exponent, 1 ULP is equal to the machine epsilon (2−23). If we change the exponent to a 1, yielding the value 2.0f, the value of 1 ULP becomes equal to two times the machine epsilon. And if the exponent is 2, yielding the value 4.0f, the value of 1 ULP is four times the machine epsilon. In general, if a floating-point value’s unbiased exponent is x, then 1 ULP = 2x · ε.
The concept of units in the last place illustrates the idea that the precision of a floating-point number depends on its exponent, and is useful for quantifying the error inherent in any floating-point calculation. It can also be useful for finding the floating-point value that is the next largest representable value relative to a known value, or conversely the next smallest representable value relative to that value. This in turn can be useful for converting a greater-than-or-equal comparison into a greater-than comparison. Mathematically, the condition a ≥ b is equivalent to the condition a + 1 ULP > b. We use this little “trick” in the Naughty Dog engine to simplify some logic in our character dialog system. In this system, simple comparisons can be used to select different lines of dialog for the characters to say. Rather than supporting all possible comparison operators, we only support greater-than and less-than checks, and we handle greater-than-or-equal-to and less-than-or-equal-to by adding or subtracting 1 ULP to or from the value being compared.
Impact of Floating-Point Precision on Software
The concepts of limited precision and the machine epsilon have real impacts on game software. For example, let’s say we use a floating-point variable to track absolute game time in seconds. How long can we run our game before the magnitude of our clock variable gets so large that adding 1/30th of a second to it no longer changes its value? The answer is 12.14 days or 220 seconds. That’s longer than most games will be left running, so we can probably get away with using a 32-bit floating-point clock measured in seconds in a game. But clearly it’s important to understand the limitations of the floating-point format so that we can predict potential problems and take steps to avoid them when necessary.
IEEE Floating-Point Bit Tricks
See [9, Section 2.1] for a few really useful IEEE floating-point “bit tricks” that can make certain floating-point calculations lightning fast.
3.3.2 Primitive Data Types
C and C++ provide a number of primitive data types. The C and C++ standards provide guidelines on the relative sizes and signedness of these data types, but each compiler is free to define the types slightly differently in order to provide maximum performance on the target hardware.
char. A char is usually 8 bits and is generally large enough to hold an ASCII or UTF-8 character (see Section 6.4.4.1). Some compilers define char to be signed, while others use unsigned chars by default.int, short, long. An int is supposed to hold a signed integer value that is the most efficient size for the target platform; it is usually defined to be 32 bits wide on a 32-bit CPU architecture, such as Pentium 4 or Xeon, and 64 bits wide on a 64-bit architecture, such as Intel Core i7, although the size of an int is also dependent upon other factors such as compiler options and the target operating system. A short is intended to be smaller than an int and is 16 bits on many machines. A long is as large as or larger than an int and may be 32 or 64 bits wide, or even wider, again depending on CPU architecture, compiler options and the target OS.float. On most modern compilers, a float is a 32-bit IEEE-754 floating-point value.double. A double is a double-precision (i.e., 64-bit) IEEE-754 floatingpoint value.bool. A bool is a true/false value. The size of a bool varies widely across different compilers and hardware architectures. It is never implemented as a single bit, but some compilers define it to be 8 bits while others use a full 32 bits.Portable Sized Types
The built-in primitive data types in C and C++ were designed to be portable and therefore nonspecific. However, in many software engineering endeavors, including game engine programming, it is often important to know exactly how wide a particular variable is.
Before C++11, programmers had to rely on non-portable sized types provided by their compiler. For example, the Visual Studio C/C++ compiler defined the following extended keywords for declaring variables that are an explicit number of bits wide: __int8, __int16, __int32 and __int64. Most other compilers have their own “sized” data types, with similar semantics but slightly different syntax.
Because of these differences between compilers, most game engines achieved source code portability by defining their own custom sized types. For example, at Naughty Dog we use the following sized types:
F32 is a 32-bit IEEE-754 floating-point value.U8, I8, U16, I16, U32, I32, U64 and I64 are unsigned and signed 8-, 16-, 32- and 64-bit integers, respectively.U32F and I32F are “fast” unsigned and signed 32-bit values, respectively. Each of these data types contains a value that is at least 32 bits wide, but may be wider if that would result in faster code on the target CPU.<cstdint>
The C++11 standard library introduces a set of standardized sized integer types. They are declared in the <cstdint> header, and they include the signed types std::int8_t, std::int16_t, std::int32_t and std::int64_t and the unsigned types std::uint8_t, std::uint16_t, std::uint32_t and std::uint64_t, along with “fast” variants (like the I32F and U32F types we defined at Naughty Dog). These types free the programmer from having to “wrap” compiler-specific types in order to achieve portability. For a complete list of these sized types, see http://en.cppreference.com/w/cpp/types/integer.
OGRE’s Primitive Data Types
OGRE defines a number of sized types of its own. Ogre::uint8, Ogre::uint16 and Ogre::uint32 are the basic unsigned sized integral types.
Ogre::Real defines a real floating-point value. It is usually defined to be 32 bits wide (equivalent to a float), but it can be redefined globally to be 64 bits wide (like a double) by defining the preprocessor macro OGRE_DOUBLE_PRECISION to 1. This ability to change the meaning of Ogre::Real is generally only used if one’s game has a particular requirement for double-precision math, which is rare. Graphics chips (GPUs) always perform their math with 32-bit or 16-bit floats, the CPU/FPU is also usually faster when working in single-precision, and SIMD vector instructions operate on 128-bit registers that contain four 32-bit floats each. Hence, most games tend to stick to single-precision floating-point math.
The data types Ogre::uchar, Ogre::ushort, Ogre::uint and Ogre::ulong are just shorthand notations for C/C++’s unsigned char, unsigned short and unsigned long, respectively. As such, they are no more or less useful than their native C/C++ counterparts.
The types Ogre::Radian and Ogre::Degree are particularly interesting. These classes are wrappers around a simple Ogre::Real value. The primary role of these types is to permit the angular units of hard-coded literal constants to be documented and to provide automatic conversion between the two unit systems. In addition, the type Ogre::Angle represents an angle in the current “default” angle unit. The programmer can define whether the default will be radians or degrees when the OGRE application first starts up.
Perhaps surprisingly, OGRE does not provide a number of sized primitive data types that are commonplace in other game engines. For example, it defines no signed 8-, 16- or 64-bit integral types. If you are writing a game engine on top of OGRE, you will probably find yourself defining these types manually at some point.
3.3.2.1 Multibyte Values and Endianness
Values that are larger than eight bits (one byte) wide are called multibyte quantities. They’re commonplace on any software project that makes use of integers and floating-point values that are 16 bits or wider. For example, the integer value 4660 = 0x1234 is represented by the two bytes 0x12 and 0x34. We call 0x12 the most significant byte and 0x34 the least significant byte. In a 32-bit value, such as 0xABCD1234, the most-significant byte is 0xAB and the least-significant is 0x34. The same concepts apply to 64-bit integers and to 32- and 64-bit floating-point values as well.
Multibyte integers can be stored into memory in one of two ways, and different microprocessors may differ in their choice of storage method (see Figure 3.6).
U32 value = 0xABCD1234; U8* pBytes = (U8*)&value;

Figure 3.6. Big- and little-endian representations of the value 0xABCD1234.
Most programmers don’t need to think much about endianness. However, when you’re a game programmer, endianness can become a bit of a thorn in your side. This is because games are usually developed on a Windows or Linux machine running an Intel Pentium processor (which is little-endian), but run on a console such as the Wii, Xbox 360 or PlayStation 3—all three of which utilize a variant of the PowerPC processor (which can be configured to use either endianness, but is big-endian by default). Now imagine what happens when you generate a data file for consumption by your game engine on an Intel processor and then try to load that data file into your engine running on a PowerPC processor. Any multibyte value that you wrote out into that data file will be stored in little-endian format. But when the game engine reads the file, it expects all of its data to be in big-endian format. The result? You’ll write 0xABCD1234, but you’ll read 0x3412CDAB, and that’s clearly not what you intended!
There are at least two solutions to this problem.
Integer Endian-Swapping
Endian-swapping an integer is not conceptually difficult. You simply start at the most significant byte of the value and swap it with the least significant byte; you continue this process until you reach the halfway point in the value. For example, 0xA7891023 would become 0x231089A7.
The only tricky part is knowing which bytes to swap. Let’s say you’re writing the contents of a C struct or C++ class from memory out to a file. To properly endian-swap this data, you need to keep track of the locations and sizes of each data member in the struct and swap each one appropriately based on its size. For example, the structure
struct Example
{
U32 m_a;
U16 m_b;
U3 m_c;
};
might be written out to a data file as follows:
void writeExampleStruct(Example& ex, Stream& stream)
{
stream.writeU32(swapU32(ex.m_a));
stream.writeU16(swapU16(ex.m_b));
stream.writeU32(swapU32(ex.m_c));
}
and the swap functions might be defined like this:
inline U16 swapU16(U16 value)
{
return ((value & 0x00FF) << 8)
| ((value & 0xFF00) >> 8);
}
inline U32 swapU32(U32 value)
{
return ((value & 0x000000FF) << 24)
| ((value & 0x0000FF00) << 8)
| ((value & 0x00FF0000) >> 8)
| ((value & 0xFF000000) >> 24);
}
You cannot simply cast the Example object into an array of bytes and blindly swap the bytes using a single general-purpose function. We need to know both which data members to swap and how wide each member is, and each data member must be swapped individually.
Some compilers provide built-in endian-swapping macros, freeing you from having to write your own. For example, gcc offers a family of macros named __builtin_bswapXX() for performing 16-, 32- and 64-bit endian swaps. However, such compiler-specific facilities are of course non-portable.
Floating-Point Endian-Swapping
As we’ve seen, an IEEE-754 floating-point value has a detailed internal structure involving some bits for the mantissa, some bits for the exponent and a sign bit. However, you can endian-swap it just as if it were an integer, because bytes are bytes. You merely reinterpret the bit pattern of your float as if it were a std::int32_t, perform the endian swapping operation, and then reinterpret the result as a float again.
You can reinterpret floats as integers by using C++’s reinterpret_cast operator on a pointer to the float, and then dereferencing the type-cast pointer; this is known as type punning. But punning can lead to optimization bugs when strict aliasing is enabled. (See http://www.cocoawithlove.com/2008/04/using-pointers-to-recast-in-c-is-bad.html for an excellent description of this problem.) One alternative that’s guaranteed to be portable is to use a union, as follows:
union U32F32
{
U32 m_asU32;
F32 m_asF32;
};
inline F32 swapF32(F32 value)
{
U32F32 u;
u.m_asF32 = value;
// endian-swap as integer
u.m_asU32 = swapU32(u.m_asU32);
return u.m_asF32;
}
3.3.3 Kilobytes versus Kibibytes
You’ve probably used metric (SI) units like kilobytes (kB) and megabytes (MB) to describe quantities of memory. However, the use of these units to describe quantities of memory that are measured in powers of two isn’t strictly correct. When a computer programmer speaks of a “kilobyte,” she or he usually means 1024 bytes. But SI units define the prefix “kilo” to mean 103 or 1000, not 1024.
To resolve this ambiguity, the International Electrotechnical Commission (IEC) in 1998 established a new set of SI-like prefixes for use in computer science. These prefixes are defined in terms of powers of two rather than powers of ten, so that computer engineers can precisely and conveniently specify quantities that are powers of two. In this new system, instead of kilobyte (1000 bytes), we say kibibyte (1024 bytes, abbreviated KiB). And instead of megabyte (1,000,000 bytes), we say mebibyte (1024 × 1024 = 1,048,576 bytes, abbreviated MiB). Table 3.1 summarizes the sizes, prefixes and names of the most commonly used byte quantity units in both the SI and IEC systems. We’ll use IEC units throughout this book.

Table 3.1. Comparison of metric (SI) units and IEC units for describing quantities of bytes.
3.3.4 Declarations, Definitions and Linkage
3.3.4.1 Translation Units Revisited
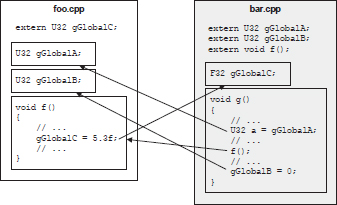
As we saw in Chapter 2, a C or C++ program is comprised of translation units. The compiler translates one .cpp file at a time, and for each one it generates an output file called an object file (.o or .obj). A .cpp file is the smallest unit of translation operated on by the compiler; hence, the name “translation unit.” An object file contains not only the compiled machine code for all of the functions defined in the .cpp file, but also all of its global and static variables. In addition, an object file may contain unresolved references to functions and global variables defined in other .cpp files.
The compiler only operates on one translation unit at a time, so whenever it encounters a reference to an external global variable or function, it must “go on faith” and assume that the entity in question really exists, as shown in Figure 3.7. It is the linker’s job to combine all of the object files into a final executable image. In doing so, the linker reads all of the object files and attempts to resolve all of the unresolved cross-references between them. If it is successful, an executable image is generated containing all of the functions, global variables and static variables, with all cross-translation-unit references properly resolved. This is depicted in Figure 3.8.
The linker’s primary job is to resolve external references, and in this capacity it can generate only two kinds of errors:
extern reference might not be found, in which case the linker generates an “unresolved symbol” error.
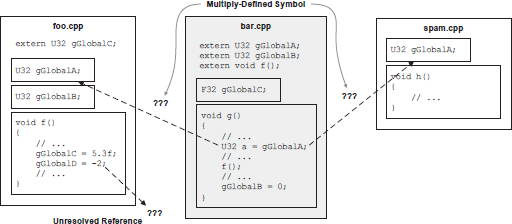
These two situations are shown in Figure 3.9.
3.3.4.2 Declaration versus Definition
In the C and C++ languages, variables and functions must be declared and defined before they can be used. It is important to understand the difference between a declaration and a definition in C and C++.
In other words, a declaration is a reference to an entity, while a definition is the entity itself. A definition is always a declaration, but the reverse is not always the case—it is possible to write a pure declaration in C and C++ that is not a definition.
Functions are defined by writing the body of the function immediately after the signature, enclosed in curly braces:
foo.cpp
// definition of the max() function
int max(int a, int b)
{
return (a > b)? a : b;
}
// definition of the min() function
int min(int a, int b)
{
return (a <= b)? a : b;
}
A pure declaration can be provided for a function so that it can be used in other translation units (or later in the same translation unit). This is done by writing a function signature followed by a semicolon, with an optional prefix of extern:
foo.h extern int max(int a, int b); // a function declaration int min(int a, int b); // also a declaration (the extern // is optional/assumed)
Variables and instances of classes and structs are defined by writing the data type followed by the name of the variable or instance and an optional array specifier in square brackets:
foo.cpp // All of these are variable definitions: U32 gGlobalInteger = 5; F32 gGlobalFloatArray[16]; MyClass gGlobalInstance;
A global variable defined in one translation unit can optionally be declared for use in other translation units by using the extern keyword:
foo.h // These are all pure declarations: extern U32 gGlobalInteger; extern F32 gGlobalFloatArray[16]; extern MyClass gGlobalInstance;
Multiplicity of Declarations and Definitions
Not surprisingly, any particular data object or function in a C/C++ program can have multiple identical declarations, but each can have only one definition. If two or more identical definitions exist in a single translation unit, the compiler will notice that multiple entities have the same name and flag an error. If two or more identical definitions exist in different translation units, the compiler will not be able to identify the problem, because it operates on one translation unit at a time. But in this case, the linker will give us a “multiply defined symbol” error when it tries to resolve the cross-references.
Definitions in Header Files and Inlining
It is usually dangerous to place definitions in header files. The reason for this should be pretty obvious: if a header file containing a definition is #included into more than one .cpp file, it’s a sure-fire way of generating a “multiply defined symbol” linker error.
Inline function definitions are an exception to this rule, because each invocation of an inline function gives rise to a brand new copy of that function’s machine code, embedded directly into the calling function. In fact, inline function definitions must be placed in header files if they are to be used in more than one translation unit. Note that it is not sufficient to tag a function declaration with the inline keyword in a .h file and then place the body of that function in a .cpp file. The compiler must be able to “see” the body of the function in order to inline it. For example:
foo.h
// This function definition will be inlined properly.
inline int max(int a, int b)
{
return (a > b)? a : b;
}
// This declaration cannot be inlined because the
// compiler cannot “see” the body of the function.
inline int min(int a, int b);
foo.cpp
// The body of min() is effectively “hidden” from the
// compiler, so it can ONLY be inlined within foo.cpp.
int min(int a, int b)
{
return (a <= b)? a : b;
}
The inline keyword is really just a hint to the compiler. It does a cost/benefit analysis of each inline function, weighing the size of the function’s code versus the potential performance benefits of inling it, and the compiler gets the final say as to whether the function will really be inlined or not. Some compilers provide syntax like __forceinline, allowing the programmer to bypass the compiler’s cost/benefit analysis and control function inlining directly.
Templates and Header Files
The definition of a templated class or function must be visible to the compiler across all translation units in which it is used. As such, if you want a template to be usable in more than one translation unit, the template must be placed into a header file (just as inline function definitions must be). The declaration and definition of a template are therefore inseparable: You cannot declare templated functions or classes in a header but “hide” their definitions inside a .cpp file, because doing so would render those definitions invisible within any other .cpp file that includes that header.
3.3.4.3 Linkage
Every definition in C and C++ has a property known as linkage. A definition with external linkage is visible to and can be referenced by translation units other than the one in which it appears. A definition with internal linkage can only be “seen” inside the translation unit in which it appears and thus cannot be referenced by other translation units. We call this property linkage because it dictates whether or not the linker is permitted to cross-reference the entity in question. So, in a sense, linkage is the translation unit’s equivalent of the public: and private: keywords in C++ class definitions.
By default, definitions have external linkage. The static keyword is used to change a definition’s linkage to internal. Note that two or more identical static definitions in two or more different .cpp files are considered to be distinct entities by the linker (just as if they had been given different names), so they will not generate a “multiply defined symbol” error. Here are some examples:
foo.cpp
// This variable can be used by other .cpp files
// (external linkage).
U32 gExternalVariable;
// This variable is only usable within foo.cpp (internal
// linkage).
static U32 gInternalVariable;
// This function can be called from other .cpp files
// (external linkage).
void externalFunction()
{
// …
}
// This function can only be called from within foo.cpp
// (internal linkage).
static void internalFunction()
{
// …
}
bar.cpp
// This declaration grants access to foo.cpp’s variable.
extern U32 gExternalVariable;
// This ‘gInternalVariable’ is distinct from the one
// defined in foo.cpp -- no error. We could just as
// well have named it gInternalVariableForBarCpp -- the
// net effect is the same.
static U32 gInternalVariable;
// This function is distinct from foo.cpp’s
// version -- no error. It acts as if we had named it
// internalFunctionForBarCpp().
static void internalFunction()
{
// …
}
// ERROR -- multiply defined symbol!
void externalFunction()
{
// …
}
Technically speaking, declarations don’t have a linkage property at all, because they do not allocate any storage in the executable image; therefore, there is no question as to whether or not the linker should be permitted to cross-reference that storage. A declaration is merely a reference to an entity defined elsewhere. However, it is sometimes convenient to speak about declarations as having internal linkage, because a declaration only applies to the translation unit in which it appears. If we allow ourselves to loosen our terminology in this manner, then declarations always have internal linkage—there is no way to cross-reference a single declaration in multiple .cpp files. (If we put a declaration in a header file, then multiple .cpp files can “see” that declaration, but they are in effect each getting a distinct copy of the declaration, and each copy has internal linkage within that translation unit.)
This leads us to the real reason why inline function definitions are permitted in header files: it is because inline functions have internal linkage by default, just as if they had been declared static. If multiple .cpp files #include a header containing an inline function definition, each translation unit gets a private copy of that function’s body, and no “multiply defined symbol” errors are generated. The linker sees each copy as a distinct entity.
3.3.5 Memory Layout of a C/C++ Program
A program written in C or C++ stores its data in a number of different places in memory. In order to understand how storage is allocated and how the various types of C/C++ variables work, we need to understand the memory layout of a C/C++ program.
3.3.5.1 Executable Image
When a C/C++ program is built, the linker creates an executable file. Most UNIX-like operating systems, including many game consoles, employ a popular executable file format called the executable and linking format (ELF). Executable files on those systems therefore have a .elf extension. The Windows executable format is similar to the ELF format; executables under Windows have a .exe extension. Whatever its format, the executable file always contains a partial image of the program as it will exist in memory when it runs. I say a “partial” image because the program generally allocates memory at runtime in addition to the memory laid out in its executable image.
The executable image is divided into contiguous blocks called segments or sections. Every operating system lays things out a little differently, and the layout may also differ slightly from executable to executable on the same operating system. But the image is usually comprised of at least the following four segments:
main() or WinMain()).const float kPi = 3.141592f;) and all global object instances that have been declared with the const keyword (e.g., const Foo gReadOnlyFoo;) reside in this segment. Note that integer constants (e.g., const int kMaxMonsters = 255;) are often used as manifest constants by the compiler, meaning that they are inserted directly into the machine code wherever they are used. Such constants occupy storage in the text segment, but they are not present in the read-only data segment.Global variables (variables defined at file scope outside any function or class declaration) are stored in either the data or BSS segments, depending on whether or not they have been initialized. The following global will be stored in the data segment, because it has been initialized:
foo.cpp F32 gInitializedGlobal = −2.0f;
and the following global will be allocated and initialized to zero by the operating system, based on the specifications given in the BSS segment, because it has not been initialized by the programmer:
foo.cpp F32 gUninitializedGlobal;
We’ve seen that the static keyword can be used to give a global variable or function definition internal linkage, meaning that it will be “hidden” from other translation units. The static keyword can also be used to declare a global variable within a function. A function-static variable is lexically scoped to the function in which it is declared (i.e., the variable’s name can only be “seen” inside the function). It is initialized the first time the function is called (rather than before main() is called, as with file-scope statics). But in terms of memory layout in the executable image, a function-static variable acts identically to a file-static global variable—it is stored in either the data or BSS segment based on whether or not it has been initialized.
void readHitchhikersGuide(U32 book)
{
static U32 sBooksInTheTrilogy =5; // data segment
static U32 sBooksRead; // BSS segment
// …
}
3.3.5.2 Program Stack
When an executable program is loaded into memory and run, the operating system reserves an area of memory for the program stack. Whenever a function is called, a contiguous area of stack memory is pushed onto the stack—we call this block of memory a stack frame. If function a() calls another function b(), a new stack frame for b() is pushed on top of a()’s frame. When b() returns, its stack frame is popped, and execution continues wherever a() left off.
A stack frame stores three kinds of data:
Pushing and popping stack frames is usually implemented by adjusting the value of a single register in the CPU, known as the stack pointer. Figure 3.10 illustrates what happens when the functions shown below are executed.
void c()
{
U32 localC1;
// …
}
F32 b()
{
F32 localB1;
I32 localB2;
// …
c();
// …
return localB1;
}

void a()
{
U32 aLocalsA1[5];
// …
F32 localA2 = b();
// …
}
When a function containing automatic variables returns, its stack frame is abandoned and all automatic variables in the function should be treated as if they no longer exist. Technically, the memory occupied by those variables is still there in the abandoned stack frame—but that memory will very likely be overwritten as soon as another function is called. A common error involves returning the address of a local variable, like this:
U32* getMeaningOfLife()
{
U32 anInteger = 42;
return &anInteger;
}
You might get away with this if you use the returned pointer immediately and don’t call anyother functions in the interim. But more often than not, this kind of code will crash—sometimes in ways that can be difficult to debug.
3.3.5.3 Dynamic Allocation Heap
Thus far, we’ve seen that a program’s data can be stored as global or static variables or as local variables. The globals and statics are allocated within the executable image, as defined by the data and BSS segments of the executable file. The locals are allocated on the program stack. Both of these kinds of storage are statically defined, meaning that the size and layout of the memory is known when the program is compiled and linked. However, a program’s memory requirements are often not fully known at compile time. A program usually needs to allocate additional memory dynamically.
To allow for dynamic allocation, the operating system maintains a block of memory for each running process from which memory can be allocated by calling malloc() (or an OS-specific function like HeapAlloc() under Windows) and later returned for reuse by the process at some future time by calling free() (or an OS-specific function like HeapFree()). This memory block is known as heap memory, or the free store. When we allocate memory dynamically, we sometimes say that this memory resides on the heap.
In C++, the global new and delete operators are used to allocate and free memory to and from the free store. Be wary, however—individual classes may overload these operators to allocate memory in custom ways, and even the global new and delete operators can be overloaded, so you cannot simply assume that new is always allocating from the global heap.
We will discuss dynamic memory allocation in more depth in Chapter 7. For additional information, see http://en.wikipedia.org/wiki/Dynamic_memory_allocation.
3.3.6 Member Variables
C structs and C++ classes allow variables to be grouped into logical units. It’s important to remember that a class or struct declaration allocates no memory. It is merely a description of the layout of the data—a cookie cutter which can be used to stamp out instances of that struct or class later on. For example:
struct Foo // struct declaration
{
U32 mUnsignedValue;
F32 mFloatValue;
bool mBooleanValue;
};
Once a struct or class has been declared, it can be allocated (defined) in any of the ways that a primitive data type can be allocated; for example,
void someFunction()
{
Foo localFoo;
// …
}
Foo gFoo;
static Foo sFoo;
void someFunction()
{
static Foo sLocalFoo;
// …
}
Foo* gpFoo = nullptr; // global pointer to a Foo
void someFunction()
{
// allocate a Foo instance from the heap
gpFoo = new Foo;
// …
// allocate another Foo, assign to local pointer
Foo* pAnotherFoo = new Foo;
// …
// allocate a POINTER to a Foo from the heap
Foo** ppFoo = new Foo*;
(*ppFoo) = pAnotherFoo;
}
3.3.6.1 Class-Static Members
As we’ve seen, the static keyword has many different meanings depending on context:
static means “restrict the visibility of this variable or function so it can only be seen inside this .cpp file.”static means “this variable is a global, not an automatic, but it can only be seen inside this function.”struct or class declaration, static means “this variable is not a regular member variable, but instead acts just like a global.”Notice that when static is used inside a class declaration, it does not control the visibility of the variable (as it does when used at file scope)—rather, it differentiates between regular per-instance member variables and per-class variables that act like globals. The visibility of a class-static variable is determined by the use of public:, protected: or private: keywords in the class declaration. Class-static variables are automatically included within the namespace of the class or struct in which they are declared. So the name of the class or struct must be used to disambiguate the variable whenever it is used outside that class or struct (e.g., Foo::sVarName).
Like an extern declaration for a regular global variable, the declaration of a class-static variable within a class allocates no memory. The memory for the class-static variable must be defined in a .cpp file. For example:
foo.h
class Foo
{
public:
static F32 sClassStatic; // allocates no
// memory!
};
foo.cpp
F32 Foo::sClassStatic = -1.0f; // define memory and
// initialize
3.3.7 Object Layout in Memory

It’s useful to be able to visualize the memory layout of your classes and structs. This is usually pretty straightforward—we can simply draw a box for the struct or class, with horizontal lines separating data members. An example of such a diagram for the struct Foo listed below is shown in Figure 3.11.
struct Foo
{
U32 mUnsignedValue;
F32 mFloatValue;
I32 mSignedValue;
};

The sizes of the data members are important and should be represented in your diagrams. This is easily done by using the width of each data member to indicate its size in bits—i.e., a 32-bit integer should be roughly four times the width of an eight-bit integer (see Figure 3.12).
struct Bar
{
U32 mUnsignedValue;
F32 mFloatValue;
bool mBooleanValue; // diagram assumes this is 8 bits
};
3.3.7.1 Alignment and Packing
As we start to think more carefully about the layout of our structs and classes in memory, we may start to wonder what happens when small data members are interspersed with larger members. For example:
struct InefficientPacking
{
U32 mU1; // 32 bits
F32 mF2; // 32 bits
U8 mB3; // 8 bits
I32 mI4; // 32 bits
bool mB5; // 8 bits
char* mP6; // 32 bits
};

You might imagine that the compiler simply packs the data members into memory as tightly as it can. However, this is not usually the case. Instead, the compiler will typically leave “holes” in the layout, as depicted in Figure 3.13. (Some compilers can be requested not to leave these holes by using a preprocessor directive like #pragma pack, or via command-line options; but the default behavior is to space out the members as shown in Figure 3.13.)
Why does the compiler leave these “holes”? The reason lies in the fact that every data type has a natural alignment, which must be respected in order to permit the CPU to read and write memory effectively. The alignment of a data object refers to whether its address in memory is a multiple of its size (which is generally a power of two):
Alignment is important because many modern processors can actually only read and write properly aligned blocks of data. For example, if a program requests that a 32-bit (4-byte) integer be read from address 0x6A341174, the memory controller will load the data happily because the address is 4-byte aligned (in this case, its least significant nibble is 0x4). However, if a request is made to load a 32-bit integer from address 0x6A341173, the memory controller now has to read two 4-byte blocks: the one at 0x6A341170 and the one at 0x6A341174. It must then mask and shift the two parts of the 32-bit integer and logically OR them together into the destination register on the CPU. This is shown in Figure 3.14.

Some microprocessors don’t even go this far. If you request a read or write of unaligned data, you might just get garbage. Or your program might just crash altogether! (The PlayStation 2 is a notable example of this kind of intolerance for unaligned data.)
Different data types have different alignment requirements. A good rule of thumb is that a data type should be aligned to a boundary equal to the width of the data type in bytes. For example, 32-bit values generally have a 4-byte alignment requirement, 16-bit values should be 2-byte aligned, and 8-bit values can be stored at any address (1-byte aligned). On CPUs that support SIMD vector math, the vector registers each contain four 32-bit floats, for a total of 128 bits or 16 bytes. And as you would guess, a four-float SIMD vector typically has a 16-byte alignment requirement.

This brings us back to those “holes” in the layout of structInefficient Packing shown in Figure 3.13. When smaller data types like 8-bit bools are interspersed with larger types like 32-bit integers or floats in a structure or class, the compiler introduces padding (holes) in order to ensure that everything is properly aligned. It’s a good idea to think about alignment and packing when declaring your data structures. By simply rearranging the members of struct InefficientPacking from the example above, we can eliminate some of the wasted padding space, as shown below and in Figure 3.15:
struct MoreEfficientPacking
{
U32 mU1; // 32 bits (4-byte aligned)
F32 mF2; // 32 bits (4-byte aligned)
I32 mI4; // 32 bits (4-byte aligned)
char* mP6; // 32 bits (4-byte aligned)
U8 mB3; // 8 bits (1-byte aligned)
bool mB5; // 8 bits (1-byte aligned)
};
You’ll notice in Figure 3.15 that the size of the structure as a whole is now 20 bytes, not 18 bytes as we might expect, because it has been padded by two bytes at the end. This padding is added by the compiler to ensure proper alignment of the structure in an array context. That is, if an array of these structs is defined and the first element of the array is aligned, then the padding at the end guarantees that all subsequent elements will also be aligned properly.
The alignment of a structure as a whole is equal to the largest alignment requirement among its members. In the example above, the largest member alignment is 4-byte, so the structure as a whole should be 4-byte aligned. I usually like to add explicit padding to the end of my structs to make the wasted space visible and explicit, like this:
struct BestPacking
{
U32 mU1; // 32 bits (4-byte aligned)
F32 mF2; // 32 bits (4-byte aligned) I32 mI4; // 32 bits (4-byte aligned)
char* mP6; // 32 bits (4-byte aligned)
U8 mB3; // 8 bits (1-byte aligned) bool mB5; // 8 bits (1-byte aligned)
U8 _pad[2]; // explicit padding
};
3.3.7.2 Memory Layout of C++ Classes
Two things make C++ classes a little different from C structures in terms of memory layout: inheritance and virtual functions.

When class B inherits from class A, B’s data members simply appear immediately after A’s in memory, as shown in Figure 3.16. Each new derived class simply tacks its data members on at the end, although alignment requirements may introduce padding between the classes. (Multiple inheritance does some whacky things, like including multiple copies of a single base class in the memory layout of a derived class. We won’t cover the details here, because game programmers usually prefer to avoid multiple inheritance altogether anyway.)
If a class contains or inherits one or more virtual functions, then four additional bytes (or eight bytes if the target hardware uses 64-bit addresses) are added to the class layout, typically at the very beginning of the class’ layout. These four or eight bytes are collectively called the virtual table pointer or vpointer, because they contain a pointer to a data structure known as the virtual function table or vtable. The vtable for a particular class contains pointers to all the virtual functions that it declares or inherits. Each concrete class has its own virtual table, and every instance of that class has a pointer to it, stored in its vpointer.
The virtual function table is at the heart of polymorphism, because it allows code to be written that is ignorant of the specific concrete classes it is dealing with. Returning to the ubiquitous example of a Shape base class with derived classes for Circle, Rectangle and Triangle, let’s imagine that Shape defines a virtual function called Draw(). The derived classes all override this function, providing distinct implementations named Circle::Draw(), Rectangle::Draw() and Triangle::Draw(). The virtual table for any class derived from Shape will contain an entry for the Draw() function, but that entry will point to different function implementations, depending on the concrete class. Circle’s vtable will contain a pointer to Circle::Draw(), while Rectangle’s virtual table will point to Rectangle::Draw(), and Triangle’s vtable will point to Triangle::Draw(). Given an arbitrary pointer to a Shape (Shape* pShape), the code can simply dereference the vtable pointer, look up the Draw() function’s entry in the vtable, and call it. The result will be to call Circle::Draw() when pShape points to an instance of Circle, Rectangle::Draw() when pShape points to a Rectangle, and Triangle::Draw() when pShape points to a Triangle.
These ideas are illustrated by the following code excerpt. Notice that the base class Shape defines two virtual functions, SetId() and Draw(), the latter of which is declared to be pure virtual. (This means that Shape provides no default implementation of the Draw() function, and derived classes must override it if they want to be instantiable.) Class Circle derives from Shape, adds some data members and functions to manage its center and radius, and overrides the Draw() function; this is depicted in Figure 3.17. Class Triangle also derives from Shape. It adds an array of Vector3 objects to store its three vertices and adds some functions to get and set the individual vertices. Class Triangle overrides Draw() as we’d expect, and for illustrative purposes it also overrides SetId(). The memory image generated by the Triangle class is shown in Figure 3.18.

pShape1 points to an instance of class Circle.class Shape
{
public:
virtual void SetId(int id) {m_id = id;}
int GetId() const {return m_id;}
virtual void Draw() = 0; // pure virtual -- no impl.
private:
int m_id;
};
class Circle : public Shape
{
public:
void SetCenter(const Vector3& c) {m_center=c;}
Vector3 GetCenter() const {return m_center;}
void SetRadius(float r) {m_radius = r;}
float GetRadius() const {return m_radius;}
virtual void Draw()
{
// code to draw a circle
}
private:
Vector3 m_center;
float m_radius;
};
class Triangle : public Shape
{
public:
void SetVertex(int i, const Vector3& v);
Vector3 GetVertex(int i) const {return m_vtx[i];}
virtual void Draw()
{
// code to draw a triangle
}
virtual void SetId(int id)
{
// call base class’ implementation
Shape::SetId(id);
// do additional work specific to Triangles…
}
private:
Vector3 m_vtx[3];
};
// -------------------------
void main(int, char**)
{
Shape* pShape1 = new Circle;
Shape* pShape2 = new Triangle;
pShape1->Draw();
pShape2->Draw();
// …
}
3.4 Computer Hardware Fundamentals
Programming in a high-level language like C++, C# or Python is an efficient way to build software. But the higher-level your language is, the more it shields you from the underlying details of the hardware on which your code runs. To become a truly proficient programmer, it’s important to understand the architecture of your target hardware. This knowledge can help you to optimize your code. It’s also crucial for concurrent programming—and all programmers must understand concurrency if they hope to take full advantage of the ever-increasing degree of parallelism in modern computing hardware.

pShape2 points to an instance of class Triangle.3.4.1 Learning from the Simpler Computers of Yesteryear
In the following pages, we’ll discuss the design of a simple, generic CPU, rather than diving into the specifics of any one particular processor. However, some readers may find it helpful to ground our somewhat theoretical discussion by reading about the specifics of a real CPU. I myself learned how computers work when I was a teenager, by programming my Apple II computer and the Commodore 64. Both of these machines had a simple CPU known as the 6502, which was designed and manufactured by MOS Technology Inc. I also learned some of what I know by reading about and working with the common ancestor to Intel’s entire x86 line of CPUs, the 8086 (and its cousin the 8088). Both of these processors are great for learning purposes due to their simplicity. This is especially true of the 6502, which is the simplest CPU I’ve ever worked with. Once you understand how a 6502 and/or an 8086 works, modern CPUs will be a lot easier to understand.
To that end, here are a few great resources on the details of 6502 and 8086 architecture and programming:

3.4.2 Anatomy of a Computer
The simplest computer consists of a central processing unit (CPU) and a bank of memory, connected to one another on a circuit board called the motherboard via one or more buses, and connected to external peripheral devices by means of a set of I/O ports and/or expansion slots. This basic design is referred to as the von Neumann architecture because it was first described in 1945 by the mathematician and physicist John von Neumann and his colleagues while working on the classified ENIAC project. A simple serial computer architecture is illustrated in Figure 3.19.
3.4.3 CPU
The CPU is the “brains” of the computer. It consists of the following components:

All of these components are driven by a periodic square wave signal known as the clock. The frequency of the clock determines the rate at which the CPU performs operations such as executing instructions or performing arithmetic. The typical components of a serial CPU are shown in Figure 3.20.
3.4.3.1 ALU
The ALU performs unary and binary arithmetic operations such as negation, addition, subtraction, multiplication and division, and also performs logical operations such as AND, OR, exclusive OR (abbreviated XOR or EOR), bitwise complement and bit shifting. In some CPU designs, the ALU is physically split into an arithmetic unit (AU) and a logic unit (LU).
An ALU typically performs integer operations only. Floating-point calculations require very different circuitry, and are usually performed by a physically separate floating-point unit (FPU). Early CPUs like the Intel 8088/8086 had no on-chip FPU; if floating-point math support was desired, these CPUs had to be augmented with a separate FPU co-processor chip such as the Intel 8087. In later CPU designs, an FPU was typically included on the main CPU die.
3.4.3.2 VPU
A vector processing unit (VPU) acts a bit like a combination ALU/FPU, in that it can typically perform both integer and floating-point arithmetic. What differentiates a VPU is its ability to apply arithmetic operators to vectors of input data—each of which typically consists of between two and 16 floatingpoint values or up to 64 integer values of various widths—rather than to scalar inputs. Vector processing is also known as single instruction multiple data or SIMD, because a single arithmetic operator (e.g, multiplication) is applied to multiple pairs of inputs simultaneously. See Section 4.10 for more details.
Today’s CPUs don’t actually contain an FPU per se. Instead, all floatingpoint calculations, even those involving scalar float values, are performed by the VPU. Eliminating the FPU reduces the transistor count on the CPU die, allowing those transistors to be used to implement larger caches, more-complex out-of-order execution logic, and so on. And as we’ll see in Section 4.10.6, optimizing compilers will typically convert math performed on float variables into vectorized code that uses the VPU anyway.
3.4.3.3 Registers
In order to maximize performance, an ALU or FPU can usually only perform calculations on data that exists in special high-speed memory cells called registers. Registers are typically physically separate from the computer’s main memory, located on-chip and in close proximity to the components that access them. They’re usually implemented using fast, high-cost multi-ported static RAM or SRAM. (See Section 3.4.5 for more information about memory technologies.) A bank of registers within a CPU is called a register file.
Because registers aren’t part of main memory,1 they typically don’t have addresses but they do have names. These could be as simple as R0, R1, R2 etc., although early CPUs tended to use letters or short mnemonics as register names. For example, the Intel 8088/8086 had four 16-bit general-purpose registers named AX, BX, CX and DX. The 6502 by MOS Technology, Inc. performed all of its arithmetic operations using a register known as the accumulator2 (A), and used two auxillary registers called X and Y for other operations such as indexing into an array.
Some of the registers in a CPU are designed to be used for general calculations. They’re appropriately named general-purpose registers (GPR). Every CPU also contains a number of special-purpose registers (SPR). These include:
Instruction Pointer
The instruction pointer (IP) contains the address of the currently-executing instruction in a machine language program (more on machine language in Section 3.4.7.2).
Stack Pointer
In Section 3.3.5.2 we saw how a program’s call stack serves both as the primary mechanism by which functions call one another, and as the means by which memory is allocated for local variables. The stack pointer (SP) contains the address of the top of the program’s call stack. The stack can grow up or down in terms of memory addresses, but for the purpose of this discussion let’s assume it grows downward. In this case, a data item may be pushed onto the stack by subtracting the size of the item from the value of the stack pointer, and then writing the item at the new address pointed to by SP. Likewise, an item can be popped off the stack by reading it from the address pointed to by SP, and then adding its size to SP.
Base Pointer
The base pointer (BP) contains the base address of the current function’s stack frame on the call stack. Many of a function’s local variables are allocated within its stack frame, although the optimizer may assign others exclusively to a register for the duration of the function. Stack-allocated variables occupy a range of memory addresses at a unique offset from the base pointer. Such a variable can be located in memory by simply subtracting its unique offset from the address stored in BP (assuming the stack grows down).
Status Register
A special register known as the status register, condition code register or flags register contains bits that reflect the results of the most-recent ALU operation. For instance, if the result of a subtraction is zero, the zero bit (typically named “Z”) is set within the status register, otherwise the bit is cleared. Likewise, if an add operation resulted in an overflow, meaning that a binary 1 must be “carried” to the next word of a multi-word addition, the carry bit (often named “C”) is set, otherwise it is cleared.
The flags in the status register can be used to control program flow via conditional branching, or they can be used to perform subsequent calculations, such as adding the carry bit to the next word in a multi-word addition.
Register Formats
It’s important to understand that the FPU and VPU typically operate on their own private sets of registers, rather than making use of the ALU’s generalpurpose integer registers. One reason for this is speed—the closer the registers are to the compute unit that uses them, the less time is needed to access the data they contain. Another reason is that the FPU’s and VPU’s registers are typically wider than the ALU’s GPRs.
For example, a 32-bit CPU has GPRs that are 32 bits wide each, but an FPU might operate on 64-bit double-precision floats, or even 80-bit “extended” double-precision values, meaning that its registers have to be 64 or 80 bits wide, respectively. Likewise, each register used by a VPU needs to contain a vector of input data, meaning that these registers must be much wider than a typical GPR. For example, Intel’s SSE2 (streaming SIMD extensions) vector processor can be configured to perform calculations on vectors containing either four single-precision (32-bit) floating-point values each, or two double-precision (64-bit) values each. Hence SSE2 vector registers are each 128 bits wide.
The physical separation of registers between ALU and FPU is one reason why conversions between int and float were very expensive, back in the days when FPUs were commonplace. Not only did the bit pattern of each value have to be converted back and forth between its two’s complement integer format and its IEEE 754 floating-point representation, but the data also had to be transferred physically between the general-purpose integer registers and the FPU’s registers. However, today’s CPUs no longer contain an FPU per se—all floating-point math is typically performed by a vector processing unit. A VPU can handle both integer and floating-point math, and conversions between the two are much less expensive, even when moving data from an integer GPU into a vector register or vice-versa. That said, it’s still a good idea to avoid converting data between int and float formats where possible, because even a low-cost conversion is still more expensive than no conversion.
3.4.3.4 Control Unit
If the CPU is the “brains” of the computer, then the control unit (CU) is the “brains” of the CPU. Its job is to manage the flow of data within the CPU, and to orchestrate the operation of all of the CPU’s other components.
The CU runs a program by reading a stream of machine language instructions, decoding each instruction by breaking it into its opcode and operands, and then issuing work requests and/or routing data to the ALU, FPU, VPU, the registers and/or the memory controller as dictated by the current instruction’s opcode. In pipelined and superscalar CPUs, the CU also conains complex circuitry to handle branch prediction and the scheduling of instructions for out-of-order execution. We’ll look at the operation of the CU in more detail in Section 3.4.7.
3.4.4 Clock
Every digital electronic circuit is essentially a state machine. In order for it to change states, the circuit must be driven to do so by a digital signal. Such a signal might be provided by changing the voltage on a line in the circuit from 0 volts to 3.3 volts, or vice-versa.
State changes within a CPU are typically driven by a periodic square wave signal known as the system clock. Each rising or falling edge of this signal is known as a clock cycle, and the CPU can perform at least one primitive operation on every cycle. To a CPU, time therefore appears to be quantized.3
The rate at which a CPU can perform its operations is governed by the frequency of the system clock. Clock speeds have increased significantly over the past few decades. Early CPUs developed in the 1970s, like the MOS Technology’s 6502 and Intel’s 8086/8088 CPUs, had clocks that ran in the 1–2 MHz range (millions of cycles per second). Today’s CPUs, like the Intel Core i7, are typically clocked in the 2–4 GHz range (billions of cycles per second).
It’s important to realize that one CPU instruction doesn’t necessarily take one clock cycle to execute. Not all instructions are created equal—some instructions are very simple, while others are more complex. Some instructions are implemented under the hood as a combination of simpler micro-operations (µ-ops) and therefore take many more cycles to execute than their simpler counterparts.
Also, while early CPUs could truly execute some instructions in a single clock cycle, today’s pipelined CPUs break even the simplest instruction down into multiple stages. Each stage in a pipelined CPU takes one clock cycle to execute, meaning that a CPU with an N-stage pipeline has a minimum instruction latency of N clock cycles. A simple pipelined CPU can retire instructions at a rate of one instruction per clock cycle, because a new instruction is fed into the pipeline each clock tick. But if you were to trace one particular instruction through the pipeline, it would take N cycles to move from start to finish through the pipeline. We’ll discuss pipelined CPUs in more depth in Section 4.2.
3.4.4.1 Clock Speed versus Processing Power
The “processing power” of a CPU or computer can be defined in various ways. One common measure is the throughput of the machine—the number of operations it can perform during a given interval of time. Throughput is expressed either in units of millions of instructions per second (MIPS) or floating-point operations per second (FLOPS).
Because instructions or floating-point operations don’t generally complete in exactly one cycle, and because different instructions take differing numbers of cycles to run, the MIPS or FLOPS metrics of a CPU are just averages. As such, you cannot simply look at the clock frequency of a CPU and determine its processing power in MIPS or FLOPS. For example, a serial CPU running at 3 GHz, in which one floating-point multiply takes six cycles to complete on average, could theoretically achieve 0.5 GFLOPS. But many factors including pipelining, superscalar designs, vector processing, multicore CPUs and other forms of parallelism conspire to obfuscate the relationship between clock speed and processing power. Thus the only way to determine the true processing power of a CPU or computer is to measure it—typically by running standardized benchmarks.
3.4.5 Memory
The memory in a computer acts like a bank of mailboxes at the post office, with each box or “cell” typically containing a single byte of data (an eight-bit value).4 Each one-byte memory cell is identified by its address—a simple numbering scheme ranging from 0 to N − 1, where N is the size of addressable memory in bytes.
Memory comes in two basic flavors:
ROM modules retain their data even when power is not applied to them. Some types of ROM can be programmed only once. Others, known as electronically erasable programmable ROM or EEPROM, can be reprogrammed over and over again. (Flash drives are one example of EEPROM memory.)
RAM can be further divided into static RAM (SRAM) and dynamic RAM (DRAM). Both static and dynamic RAM retain their data as long as power is applied to them. But unlike static RAM, dynamic RAM also needs to be “refreshed” periodically (by reading the data and then re-writing it) in order to prevent its contents from disappearing. This is because DRAM memory cells are built from MOS capacitors that gradually lose their charge, and reading such memory cells is destructive to the data they contain.
RAM can also be categorized by various other design characteristics, such as:
3.4.6 Buses
Data is transferred between the CPU and memory over connections known as buses. A bus is just a bundle of parallel digital “wires” called lines, each of which can represent a single bit of data. When the line carries a voltage signal6 it represents a binary one, and when the line has no voltage applied 0 volts) it represents a binary zero. A bundle of n single-bit lines arranged in parallel can transmit an n-bit number (i.e., any number in the range 0 through 2n − 1).
A typical computer contains two buses: An address bus and a data bus. The CPU loads data from a memory cell into one of its registers by supplying an address to the memory controller via the address bus. The memory controller responds by presenting the bits of the data item stored in the cell(s) in question onto the data bus, where it can be “seen” by the CPU. Likewise, the CPU writes a data item to memory by broadcasting the destination address over the address bus and placing the bit pattern of the data item to write onto the data bus. The memory controller responds by writing the given data into the corresponding memory cell(s). We should note that the address and data buses are sometimes implemented as two physically separate sets of wires, and sometimes as a single set of wires which are multiplexed between address and data bus functions during different phases of the memory access cycle.
3.4.6.1 Bus Widths
The width of the address bus, measured in bits, controls the range of possible addresses that can be accessed by the CPU (i.e., the size of addressable memory in the machine). For example, a computer with a 16-bit address bus can access at most 64 KiB of memory, using addresses in the range 0x0000 through 0xFFFF. A computer with a 32-bit address bus can access a 4 GiB memory, using addresses in the range 0x00000000 through 0xFFFFFFFF. And a machine with a 64-bit address bus can access a staggering 16 EiB (exbibytes) of memory. That’s 264 = 16 × 10246 ≈ 1.8 × 1019 bytes!
The width of the data bus determines how much data can be transferred between CPU registers and memory at a time. (The data bus is typically the same width as the general-purpose registers in the CPU, although this isn’t always the case.) An 8-bit data bus means that data can be transferred one byte at a time—loading a 16-bit value from memory would require two separate memory cycles, one to fetch the least-significant byte and one to fetch the most-significant byte. At the other end of the spectrum, a 64-bit data bus can transfer data between memory and a 64-bit register as a single memory operation.
It’s possible to access data items that are narrower than the width of a machine’s data bus, but it’s typically more costly than accessing items whose widths match that of the data bus. For example, when reading a 16-bit value on a 64-bit machine, a full 64 bits worth of data must still be read from memory. The desired 16-bit field then has to be masked off and possibly shifted into place within the destination register. This is one reason why the C language does not define an int to be a specific number of bits wide—it was purposefully defined to match the “natural” size of a word on the target machine, in an attempt to make source code more portable. (Ironically this policy has actually resulted in source code often being less portable due to implicit assumptions about the width of an int.)
3.4.6.2 Words
The term “word” is often used to describe a multi-byte value. However, the number of bytes comprising a word is not universally defined. It depends to some degree on context.
Sometimes the term “word” refers to the smallest multi-byte value, namely 16 bits or two bytes. In that context, a double word would be 32 bits (four bytes) and a quad word would be 64 bits (eight bytes). This is the way the term “word” is used in the Windows API.
On the other hand, the term “word” is also used to refer to the “natural” size of data items on a particular machine. For example, a machine with 32-bit registers and a 32-bit data bus operates most naturally with 32-bit (four byte) values, and programmers and hardware folks will sometimes say that such a machine as a word size of 32 bits. The takeaway here is to be aware of context whenever you hear the term “word” being used to refer to the size of a data item.
3.4.6.3 n-Bit Computers
You may have encountered the term “n-bit computer.” This usually means a machine with an n-bit data bus and/or registers. But the term is a bit ambiguous, because it might also refer to a computer whose address bus is n bits wide. Also, on some CPUs the data bus and register widths don’t match. For example, the 8088 had 16-bit registers and a 16-bit address bus, but it only had an 8-bit data bus. Hence it acted like a 16-bit machine internally, but its 8-bit data bus caused it to behave like an 8-bit machine in terms of memory accesses. Again, be aware of context when talking about an n-bit machine.
3.4.7 Machine and Assembly Language
As far as the CPU is concerned, a “program” is nothing more than a sequential stream of relatively simple instructions. Each instruction tells the control unit (CU), and ultimately the other components within the CPU such as the memory controller, ALU, FPU or VPU, to perform an operation. An instruction might move data around within the computer or within the CPU itself, or it might transform that data in some manner (e.g., by performing an arithmetic or logical operation on the data). Normally the instructions in a program are executed sequentially, although some instructions can alter this sequential flow of control by “jumping” to a new spot within the program’s overall instruction stream.
3.4.7.1 Instruction Set Architecture (ISA)
CPU designs vary widely from one manufacturer to the next. The set of all instructions supported by a given CPU, along with various other details of the CPU’s design like its addressing modes and the in-memory instruction format, is called its instruction set architecture or ISA. (This is not to be confused with a programming language’s application binary interface or ABI, which defines higher-level protocols like calling conventions.) We won’t attempt to cover the details of any one CPU’s ISA here, but the following categories of instruction types are common to pretty much every ISA:
We can’t possibly list all instruction types here, but if you’re curious you can always read through the ISA documentation of a real processor like the Intel x86 (which is available at http://intel.ly/2woVFQ8).
3.4.7.2 Machine Language
Computers can only deal with numbers. As such, each instruction in a program’s instruction stream must be encoded numerically. When a program is encoded in this way, we say it is written in machine language, or ML for short. Of course, machine language isn’t a single language—it’s really a multitude of languages, one for each distinct CPU/ISA.
Every machine language instruction is comprised of three basic parts:

Operands come in many flavors. Some instructions might take the names (encoded as numeric ids) of one or more registers as operands. Others might expect a literal value as an operand (e.g., “load the value 5 into register R2,” or “jump to address 0x0102ED5C”). The way in which an instruction’s operands are interpreted and used by the CPU is known as the instruction’s addressing mode. We’ll discuss addressing modes in more detail in Section 3.4.7.4.
The opcode and operands (if any) of an ML instruction are packed into a contiguous sequence of bits called an instruction word. A hypothetical CPU might encode its instructions as shown in Figure 3.21 with perhaps the first byte containing the opcode, addressing mode and various options flags, followed by some number of bytes for the operands. Each ISA defines the width of an instruction word (i.e., the number of bits occupied by each instruction) differently. In some ISAs, all instructions occupy a fixed number of bits; this is typical of reduced instruction set computers (RISC). In other ISAs, different types of instructions may be encoded into differently-sized instruction words; this is common in complex instruction set computers (CISC).
Instruction words can be as small as four bits in some microcontrollers, or they may be many bytes in size. Instruction words are often multiples of 32 or 64 bits, because this matches the width of the CPU’s registers and/or data bus. In very long instruction word (VLIW) CPU designs, parallelism is achieved by allowing multiple operations to be encoded into a single very wide instruction word, for the purpose of executing them in parallel. Instructions in a VLIW ISA can therefore be upwards of hundreds of bytes in width.
For a concrete example of machine language instruction encoding on the Intel x86 ISA, see http://aturing.umcs.maine.edu/∼meadow/courses/cos335/Asm07-MachineLanguage.pdf.
3.4.7.3 Assembly Language
Writing a program directly in machine language is tedious and error-prone. To make life easier for programmers, a simple text-based version of machine language was developed called assembly language. In assembly language, each instruction within a given CPU’s ISA is given a mnemonic—a short English word or abbreviation that is much easier to remember than corresponding numeric opcode. Instruction operands can be specified conveniently as well: Registers can be referred to by name (e.g., R0 or EAX), and memory addresses can be written in hex, or assigned symbolic names much like the global variables of higher-level languages. Locations in the assembly program can be tagged with human-readable labels, and jump/branch instructions refer to these labels rather than to raw memory addresses.
An assembly language program consists of a sequence of instructions, each comprised of a mnemonic and zero or more operands, listed in a text file with one instruction per line. A tool known as an assembler reads the program source file and converts it into the numeric ML representation understood by the CPU. For example, an assembly language program that implements the following snippet of C code:
if (a > b) return a + b; else return 0;
could be implemented by an assembly language program that looks something like this:
; if (a > b) cmp eax, ebx ; compare the values jle ReturnZero ; jump if less than or equal ; return a + b; add eax, ebx ; add & store result in EAX ret ; (EAX is the return value) ReturnZero: ; else return 0; xor eax, eax; set EAX to zero ret ; (EAX is the return value)
Let’s breakthis down. The cmp instruction compares the values inregisters EAX and EBX (which we’re assuming contain the values a and b from the C snippet). Next, the jle instruction branches to the label ReturnZero, but it does so if and only if the value in EAX is less than or equal to EBX. Otherwise it falls through.
If EAX is greater than EBX (a > b), we fall through to the add instruction, which calculates a + b and stores the result back into EAX, which we’re assuming serves as the return value. We issue a ret instruction, and control is returned to the calling function.
If EAX is less than or equal to EBX (a <= b), the branch is taken and we continue execution immediately after the label ReturnZero. Here, we use a little trick to set EAX to zero by XORing it with itself. Then we issue a ret instruction to return that zero to the caller.
For more details on Intel assembly language programming, see http://www.cs.virginia.edu/∼evans/cs216/guides/x86.html.
3.4.7.4 Addressing Modes
A seemingly simple instruction like “move” (which transfers data between registers and memory) has many different variants. Are we moving a value from one register to another? Are we loading a literal value like 5 into a register? Are we loading a value from memory into a register? Or are we storing a value in a register out to memory? All of these variants are called addressing modes. We won’t go over all the possible addressing modes here, but the following list should give you a good feel for the kinds of addressing modes you will encounter on a real CPU:
3.4.7.5 Further Reading on Assembly Language
In the preceding sections, we’ve had just a tiny taste of assembly language. For an easy-to-digest description of x86 assembly programming, see http://flint.cs.yale.edu/cs421/papers/x86-asm/asm.html. For more on calling conventions and ABIs, see https://en.wikibooks.org/wiki/X86_Disassembly/Functions_and_Stack_Frames.
3.5 Memory Architectures
In a simple von Neumann computer architecture, memory is treated as a single homogeneous block, all of which is equally accessible to the CPU. In reality, a computer’s memory is almost never architected in such a simplistic manner. For one thing, the CPU’s registers are a form of memory, but registers are typically referenced by name in an assembly language program, rather than being addressed like ordinary ROM or RAM. Moreover, even “regular” memory is typically segregated into blocks with different characteristics and different purposes. This segregation is done for a variety of reasons, including cost management and optimization of overall system performance. In this section, we’ll investigate some of the memory architectures commonly found in today’s personal computers and gaming consoles, and explore some of the key reasons why they are architected the way they are.
3.5.1 Memory Mapping
An n-bit address bus gives the CPU access to a theoretical address space that is 2n bytes in size. An individual memory device (ROM or RAM) is always addressed as a contiguous block of memory cells. So a computer’s address space is typically divided into various contiguous segments. One or more of these segments correspond to ROM memory modules, and others correspond to RAM modules. For example on the Apple II, the 16-bit addresses in the range 0xC100 through 0xFFFF were assigned to ROM chips (containing the computer’s firmware), while the addresses from 0x0000 through 0xBFFF were assigned to RAM. Whenever a physical memory device is assigned to a range of addresses in a computer’s address space, we say that the address range has been mapped to the memory device.
Of course a computer may not have as much memory installed as could be theoretically addressed by its address bus. A 64-bit address bus can access 16 EiB of memory, so we’d be unlikely to ever fully populate such an address space! (At 160 TiB, even HP’s prototype supercomputer called “The Machine” isn’t anywhere close to that amount of physical memory.) Therefore, it’s commonplace for some segments of a computer’s address space to remain unassigned.
3.5.1.1 Memory-Mapped I/O
Address ranges needn’t all map to memory devices—an address range might also be mapped to other peripheral devices, such as a joypad or a network interace card (NIC). This approach is called memory-mapped I/O because the CPU can perform I/O operations on a peripheral device by reading or writing to addresses, just as if they were oridinary RAM. Under the hood, special circuitry detects that the CPU is reading from or writing to a range of addresses that have been mapped to a non-memory device, and converts the read or write request into an I/O operation directed at the device in question. As a concrete example, the Apple II mapped I/O devices into the address range 0xC000 through 0xC0FF, allowing programs to do things like control bank-switched RAM, read and control voltages on the pins of a game controller socket on the motherboard, and perform other I/O operations by merely reading from and writing to the addresses in this range.
Alternatively, a CPU might communicate with non-memory devices via special registers known as ports. In this case, whenever the CPU requests that data be read from or written to a port register, the hardware converts the request into an I/O operation on the target device. This approach is called port-mapped I/O. In the Arduino line of microcontrollers, port-mapped I/O gives a program direct control over the digital inputs and outputs at some of the pins of the chip.
3.5.1.2 Video RAM
Raster-based display devices typically read a hard-wired range of physical memory addresses in order to determine the brightness/color of each pixel on the screen. Likewise, early charcter-based displays would determine which character glyph to display at each location on the screen by reading ASCII codes from a block of memory. A range of memory addresses assigned for use by a video controller is known as video RAM (VRAM).
In early computers like the Apple II and early IBM PCs, video RAM used to correspond to memory chips on the motherboard, and memory addresses in VRAM could be read from and written to by the CPU in exactly the same way as any other memory location. This is also the case on game consoles like the PlayStation 4 and the Xbox One, where both the CPU and GPU share access to a single, large block of unified memory.
In personal computers, the GPU often lives on a separate circuit board, plugged into an expansion slot on the motherboard. Video RAM is typically located on the video card so that the GPU can access it as quickly as possible. A bus protocol such as PCI, AGP or PCI Express (PCIe) is used to transfer data back and forth between “main RAM” and VRAM, via the expansion slot’s bus. This physical separation between main RAM and VRAM can be a significant performance bottleneck, and is one of the primary contributors to the complexity of rendering engines and graphics APIs like OpenGL and DirectX 11.
3.5.1.3 Case Study: The Apple II Memory Map
To illustrate the concepts of memory mapping, let’s look at a simple real-world example. The Apple II had a 16-bit address bus, meaning that its address space was only 64 KiB in size. This address space was mapped to ROM, RAM, memory-mapped I/O devices and video RAM regions as follows:
0xC100 - 0xFFFF ROM (Firmware) 0xC000 - 0xC0FF Memory-Mapped I/O 0x6000 - 0xBFFF General-purpose RAM 0x4000 - 0x5FFF High-res video RAM (page 2) 0x2000 - 0x3FFF High-res video RAM (page 1) 0x0C00 - 0x1FFF General-purpose RAM 0x0800 - 0x0BFF Text/lo-res video RAM (page 2) 0x0400 - 0x07FF Text/lo-res video RAM (page 1) 0x0200 - 0x03FF General-purpose and reserved RAM 0x0100 - 0x01FF Program stack 0x0000 - 0x00FF Zero page (mostly reserved for DOS)
We should note that the addresses in the Apple II memory map corresponded directly to memory chips on the motherboard. In today’s operating systems, programs work in terms of virtual addresses rather than physical addresses. We’ll explore virtual memory in the next section.
3.5.2 Virtual Memory
Most modern CPUs and operating systems support a memory remapping feature known as a virtual memory system. In these systems, the memory addresses used by a program don’t map directly to the memory modules installed in the computer. Instead, whenever a program reads from or writes to an address, that address is first remapped by the CPU via a look-up table that’s maintained by the OS. The remapped address might end up referring to an actual cell in memory (with a totally different numerical address). It might also end up referring to a block of data on-disk. Or it might turn out not to be mapped to any physical storage at all. In a virtual memory system, the addresses used by programs are called virtual addresses, and the bit patterns that are actually transmitted over the address bus by the memory controller in order to access a RAM or ROM module are called physical addresses.
Virtual memory is a powerful concept. It allows programs to make use of more memory than is actually installed in the computer, because data can overflow from physical RAM onto disk. Virtual memory also improves the stability and security of the operating system, because each program has its own private “view” of memory and is prevented from stomping on memory blocks that are owned by other programs or the operating system itself. We’ll talk more about how the operating system manages the virtual memory spaces of running programs in Section 4.4.5.
3.5.2.1 Virtual Memory Pages
To understand how this remapping takes place, we need to imagine that the entire addressable memory space (that’s 2n byte-sized cells if the address bus is n bits wide) is conceptually divided into equally-sized contiguous chunks known as pages. Page sizes differ from OS to OS, but are always a power of two—a typical page size is 4 KiB or 8 KiB. Assuming a 4 KiB page size, a 32-bit address space would be divided up into 1,048,576 distinct pages, numbered from 0x0 to 0xFFFFF, as shown in Table 3.2.
From Address |
To Address |
Page Index |
0x00000000 |
0x00000FFF |
Page 0x0 |
0x00001000 |
0x00001FFF |
Page 0x1 |
0x00002000 |
0x00002FFF |
Page 0x2 |
… |
||
0x7FFF2000 |
0x7FFF2FFF |
Page 0x7FFF2 |
0x7FFF3000 |
0x7FFF3FFF |
Page 0x7FFF3 |
… |
||
0xFFFFE000 |
0xFFFFEFFF |
Page 0xFFFFE |
0xFFFFF000 |
0xFFFFFFFF |
Page 0xFFFFF |
Table 3.2. Division of a 32-bit address space into 4 KiB pages.
The mapping between virtual addresses and physical addresses is always done at the granularity of pages. One hypothetical mapping between virtual and physical addresses is illustrated in Figure 3.22.
3.5.2.2 Virtual to Physical Address Translation
Whenever the CPU detects a memory read or write operation, the address is split into two parts: the page index and an offset within that page (measured in bytes). For a page size of 4 KiB, the offset is just the lower 12 bits of the address, and the page index is the upper 20 bits, masked off and shifted to the right by 12 bits. For example, the virtual address 0x1A7C6310 corresponds to an offset of 0x310 and a page index of 0x1A7C6.
The page index is then looked up by the CPU’s memory management unit (MMU) in a page table that maps virtual page indices to physical ones. (The page table is stored in RAM and is managed by the operating system.) If the page in question happens to be mapped to a physical memory page, the virtual page index is translated into the corresponding physical page index, the bits of this physical page index are shifted to the left as appropriate and ORed together with the bits of the original page offset, and voila! We have a physical address. So to continue our example, if virtual page 0x1A7C6 happens to map to physical page 0x73BB9, then the translated physical address would end up being 0x73BB9310. This is the address that would actually be transmitted over the address bus. Figure 3.23 illustrates the operation of the MMU.
If the page table indicates that a page is not mapped to physical RAM (either because it was never allocated, or because that page has since been swapped out to a disk file), the MMU raises an interrupt, which tells the operating system that the memory request can’t be fulfilled. This is called a page fault. (See Section 4.4.2 for more on interrupts.)
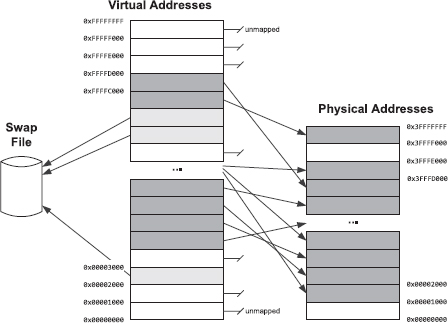
3.5.2.3 Handling Page Faults
For accesses to unallocated pages, the OS normally responds to a page fault by crashing the program and generating a core dump. For accesses to pages that have been swapped out to disk, the OS temporarily suspends the currently-running program, reads the page from the swap file into a physical page of RAM, and then translates the virtual address to a physical address as usual. Finally it returns control back to the suspended program. From the point of view of the program, this operation is entirely seamless—it never “knows” whether a page was already in memory or had to be swapped in from disk.
Normally pages are swapped out to disk only when the load on the memory system is high, and physical pages are in short supply. The OS tries to swap out only the least-frequently-used pages of memory to avoid programs continually “thrashing” between memory-based and disk-based pages.

3.5.2.4 The Translation Lookaside Buffer (TLB)
Because page sizes tend to be small relative to the total size of addressable memory (typically 4 KiB or 8 KiB), the page table can become very large. Looking up physical addresses in the page table would be time-consuming if the entire table had to be scanned for every memory access a program makes.
To speed up access, a caching mechanism is used, based on the assumption that an average program will tend to reuse addresses within a relatively small number of pages, rather than read and write randomly across the entire address range. A small table known as the translation lookaside buffer (TLB) is maintained within the MMU on the CPU die, in which the virtual-to-physical address mappings of the most recently-used addresses are cached. Because this buffer is located in close proximity to the MMU, accessing it is very fast.
The TLB acts a lot like a general-purpose memory cache hierarchy, except that it is only used for caching page table entries. See Section 3.5.4 for a discussion of how cache hierarchies work.
3.5.2.5 Further Reading on Virtual Memory
See https://www.cs.umd.edu/class/sum2003/cmsc311/Notes/Memory/virtual.html and https://gabrieletolomei.wordpress.com/miscellanea/operating-systems/virtual-memory-paging-and-swapping for two good discussions of virtual memory implementation details.
This paper by Ulrich Drepper entitled, “What Every Programmer Should Know About Memory” is also a must-read for all programmers: https://www.akkadia.org/drepper/cpumemory.pdf.
3.5.3 Memory Architectures for Latency Reduction
The speed with which data can be accessed from a memory device is an important characteristic. We often speak of memory access latency, which is defined as the length of time between the moment the CPU requests data from the memory system and the moment that that data is actually received by the CPU. Memory access latency is primarily dependent on three factors:
The access latency of static RAM (SRAM) is generally much lower than that of dynamic RAM (DRAM). SRAM achieves its lower latency by utilizing a more complex design which requires more transistors per bit of memory than does DRAM. This in turn makes SRAM more expensive than DRAM, both in terms of financial cost per bit, and in terms of the amount of real estate per bit that it consumes on the die.
The simplest memory cell has a single port, meaing only one read or write operation can be performed by it at any given time. Multi-ported RAM allows multiple read and/or write operations to be performed simultaneously, thereby reducing the latency caused by contention when multiple cores, or multiple components within a single core, attempt to access a bank of memory simultaneously. As you’d expect, a multi-ported RAM requires more transistors per bit than a single-ported design, and hence it costs more and uses more real estate on the die than a single-ported memory.
The physical distance between the CPU and a bank of RAM also plays a role in determining the access latency of that memory. This is because electronic signals travel at a finite speed within the computer. In theory, electronic signals are comprised of electromagnetic waves, and hence travel at close7 to the speed of light. Additional latencies are introduced by the various switching and logic circuits that a memory access signal encounters on its journey through the system. As such, the closer a memory cell is to the CPU core that uses it, the lower its access latency tends to be.
3.5.3.1 The Memory Gap
In the early days of computing, memory access latency and instruction execution latency were on roughly equal footing. For example, on the Intel 8086, register-based instructions could execute in two to four cycles, and a main memory access also took roughly four cycles. However, over the past few decades both raw clock speeds and the effective instruction throughput of CPUs have been improving at a much faster rate than memory access speeds. Today, the access latency of main memory is extremely high relative to the latency of executing a single instruction: Whereas a register-based instruction still takes between one and 10 cycles to complete on an Intel Core i7, an access to main RAM can take on the order of 500 cycles to complete! This ever-increasing discrepancy between CPU speeds and memory access latencies is often called the memory gap. Figure 3.24 illustrates the trend of an ever-increasing memory gap over time.
Programmers and hardware designers have together developed a wide range of techniques to work around the problems caused by high memory access latency. These techniques usually focus on one or more of the following:
In this section, we’ll have a closer look at memory architectures for average latency reduction. We’ll discuss the other two techniques (latency “hiding” and the minimization of memory accesses via judicious data layout) while investigating parallel hardware design and concurrent programming techniques in Chapter 4.
3.5.3.2 Register Files
A CPU’s register file is perhaps the most extreme example of a memory architecture designed to minimize access latency. Registers are typically implemented using multi-ported static RAM (SRAM), usually with dedicated ports for read and write operations, allowing these operations to occur in parallel rather than serially. What’s more, the register file is typically located immediately adjacent to the circuitry for the ALU that uses it. Furthermore, registers are accessed pretty much directly by the ALU, whereas accesses to main RAM typically have to pass through the virtual address translation system, the memory cache hierarchy and cache coherence protocol (see Section 3.5.4), the address and data buses, and possibly also through crossbar switching logic. These facts explain why registers can be accessed so quickly, and also why the cost of register RAM is relatively high as compared to general-purpose RAM. This higher cost is justified because registers are by far the most frequently-used memory in any computer, and because the total size of the register file is very small when compared to the size of main RAM.

3.5.4 Memory Cache Hierarchies
A memory cache hierarchy is one of the primary mechanisms for mitigating the impacts of high memory access latencies in today’s personal computers and game consoles. In a cache hierarchy, a small but fast bank of RAM called the level 1 (L1) cache is placed very near to the CPU core (on the same die). Its access latency is almost as low as the CPU’s register file, because it is so close to the CPU core. Some systems provide a larger but somewhat slower level 2 (L2) cache, located further away from the core (usually also on-chip, and often shared between two or more cores on a multicore CPU). Some machines even have larger but more-distant L3 or L4 caches. These caches work in concert to automatically retain copies of the most frequently-used data, so that accesses to the very large but very slow bank of main RAM located on the system motherboard are kept to a minimum.
A caching system improves memory access performance by keeping local copies in the cache of those chunks of data that are most frequently accessed by the program. If the data requested by the CPU is already in the cache, it can be provided to the CPU very quickly—on the order of tens of cycles. This is called a cache hit. If the data is not already present in the cache, it must be fetched into the cache from main RAM. This is called a cache miss. Reading data from main RAM can take hundreds of cycles, so the cost of a cache miss is very high indeed.
3.5.4.1 Cache Lines
Memory caching takes advantage of the fact that memory access patterns in real software tend to exhibit two kinds of locality of reference:
To take advantage of locality of reference, memory caching systems move data into the cache in contiguous blocks called cache lines rather than caching data items individually.
For example, let’s say the program is accessing the data members of an instance of a class or struct. When the first member is read, it might take hundreds of cycles for the memory controller to reach out into main RAM to retrieve the data. However, the cache controller doesn’t just read that one member—it actually reads a larger contiguous block of RAM into the cache. That way, subsequent reads of the other data members of the instance will likely result in low-cost cache hits.
3.5.4.2 Mapping Cache Lines to Main RAM Addresses
There is a simple one-to-many correspondence between memory addresses in the cache and memory addresses in main RAM. We can think of the address space of the cache as being “mapped” onto the main RAM address space in a repeating pattern, starting at address 0 in main RAM and continuing on up until all main RAM addresses have been “covered” by the cache.
As a concrete example, let’s say that our cache is 32 KiB in size, and that cache lines are 128 bytes each. The cache can therefore hold 256 cache lines (256 × 128 = 32,768 B = 32 KiB). Let’s further assume that main RAM is 256 MiB in size. So main RAM is 8192 times as big as the cache, because (256 × 1024)/32 = 8192. That means we need to overlay the address space of the cache onto the main RAM address space 8192 times in order to cover all possible physical memory locations. Or put another way, a single line in the cache maps to 8192 distinct line-sized chunks of main RAM.
Given any address in main RAM, we can find its address in the cache by taking the main RAM address modulo the size of the cache. So for a 32 KiB cache and 256 MiB of main RAM, the cache addresses 0x0000 through 0x7FFF (that’s 32 KiB) map to main RAM addresses 0x0000 through 0x7FFF. But this range of cache addresses also maps to main RAM addresses 0x8000 through 0xFFFF, 0x10000 through 0x17FFF, 0x18000 through 0x1FFFF and so on, all the way up to the last main RAM block at addresses 0xFFF8000 through 0xFFFFFFF. Figure 3.25 illustrates the mapping between main RAM and cache RAM.
3.5.4.3 Addressing the Cache
Let’s consider what happens when the CPU reads a single byte from memory. The address of the desired byte in main RAM is first converted into an address within the cache. The cache controller then checks whether or not the cache line containing that byte already exists in the cache. If it does, it’s a cache hit, and the byte is read from the cache rather than from main RAM. If it doesn’t, it’s a cache miss, and the line-sized chunk of data is read from main RAM and loaded into the cache so that subsequent reads of nearby addresses will be fast.

The cache can only deal with memory addresses that are aligned to a multiple of the cache line size (see Section 3.3.7.1 for a discussion of memory alignment). Put another way, the cache can really only be addressed in units of lines, not bytes. Hence we need to convert our byte’s address into a cache line index.
Consider a cache that is 2M bytes in total size, containing lines that are 2n in size. The n least-significant bits of the main RAM address represent the offset of the byte within the cache line. We strip off these n least-significant bits to convert from units of bytes to units of lines (i.e., we divide the address by the cache line size, which is 2n). Finally we split the resulting address into two pieces: The (M − n) least-significant bits become the cache line index, and all the remaining bits tell us from which cache-sized block in main RAM the cache line came from. The block index is known as the tag.
In the case of a cache miss, the cache controller loads a line-sized chunk of data from main RAM into the corresponding line within the cache. The cache also maintains a small table of tags, one for each cache line. This allows the caching system to keep track of from which main RAM block each line in the cache came. This is necessary because of the many-to-one relationship between memory addresses in the cache and memory addresses in main RAM. Figure 3.26 illustrates how the cache associates a tag with each active line within it.
Returning to our example of reading a byte from main RAM, the complete sequence of events is as follows: The CPU issues a read operation. The main RAM address is converted into an offset, line index and tag. The corresponding tag in the cache is checked, using the line index to find it. If the tag in the cache matches the requested tag, it’s a cache hit. In this case, the line index is used to retrieve the line-sized chunk of data from the cache, and the offset is used to locate the desired byte within the line. If the tags do not match, it’s a cache miss. In this case, the appropriate line-sized chunk of main RAM is read into the cache, and the corresponding tag is stored in the cache’s tag table. Subsequent reads of nearby addresses (those that reside within the same cache line) will therefore result in much faster cache hits.
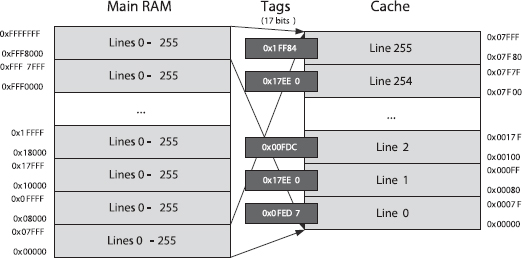
3.5.4.4 Set Associativity and Replacement Policy
The simple mapping between cache lines and main RAM addresses described above is known as a direct-mapped cache. It means that each address in main RAM maps to only one line in the cache. Using our 32 KiB cache with 128-byte lines as an example, the main RAM address 0x203 maps to cache line 4 (because 0x203 is 515, and [515/128] = 4). However, in our example there are 8192 unique cache-line-sized blocks of main RAM that all map to cache line 4. Specifically, cache line 4 corresponds to main RAM addresses 0x200 through 0x27F, but also to addresses 0x8200 through 0x827F, and 0x10200 through 0x1027f, and 8189 other cache-line-sized address ranges as well.
When a cache miss occurs, the CPU must load the corresponding cache line from main memory into the cache. If the line in the cache contains no valid data, we simply copy the data into it and we’re done. But if the line already contains data (from a different main memory block), we must overwrite it. This is known as evicting the cache line.

The problem with a direct-mapped cache is that it can result in pathological cases. For example, two unrelated main memory blocks might keep evicting one another in a ping-pong fashion. We can obtain better average performance if each main memory address can map to two or more distinct lines in the cache. In a 2-way set associative cache, each main RAM address maps to two cache lines. This is illustrated in Figure 3.27. Obviously a 4-way set associative cache performs even better than a 2-way, and an 8-way or 16-way cache can outperform a 4-way cache and so on.
Once we have more than one “cache way,” the cache controller is faced with a dilemma: When a cache miss occurs, which of the “ways” should we evict and which ones should we allow to stay resident in the cache? The answer to this question differs between CPU designs, and is known as the CPU’s replacement policy. One popular policy is not most-recently used (NMRU). In this scheme, the most-recently used “way” is kept track of, and eviction always affects the “way” or “ways” that are not the most-recently used one. Other policies include first in first out (FIFO), which is the only option in a direct-mapped cache, least-recently used (LRU), least-frequently used (LFU), and pseudorandom. For more on cache replacement policies, see https://ece752.ece.wisc.edu/lect11-cache-replacement.pdf.
3.5.4.5 Multilevel Caches
The hit rate is a measure of how often a program hits the cache, as opposed to incurring the large cost of a cache miss. The higher the hit rate, the better the program will perform (all other things being equal). There is a fundamental trade-off between cache latency and hit rate. The larger the cache, the higher the hit rate—but larger caches cannot be located as close to the CPU, so they tend to be slower than smaller ones.
Most game consoles employ at least two levels of cache. The CPU first tries to find the data it’s looking for in the level 1 (L1) cache. This cache is small but has a very low access latency. If the data isn’t there, it tries the larger but higher-latency level 2 (L2) cache. Only if the data cannot be found in the L2 cache do we incur the full cost of a main memory access. Because the latency of main RAM can be so high relative to the CPU’s clock rate, some PCs even include level 3 (L3) and level 4 (L4) caches.
3.5.4.6 Instruction Cache and Data Cache
When writing high-performance code for a game engine or for any other performance-critical system, it is important to realize that both data and code are cached. The instruction cache (I-cache, often denoted I$) is used to preload executable machine code before it runs, while the data cache (D-cache, or D$) is used to speed up read and write operations performed by that machine code. In a level 1 (L1) cache, the two caches are always physically distinct, because it is undesirable for an instruction read to cause valid data to be bumped out of the cache or vice versa. So when optimizing our code, we must consider both D-cache and I-cache performance (although as we’ll see, optimizing one tends to have a positive effect on the other). Higher-level caches (L2, L3, L4) typically do not make this distinction between code and data, because their larger size tends to mitigate the problems of code evicting data or data evicting code.
3.5.4.7 Write Policy
We haven’t talked yet about what happens when the CPU writes data to RAM. How the cache controller handles writes is known as its write policy. The simplest kind of cache is called a write-through cache; in this relatively simple cache design, all writes to the cache are mirrored to main RAM immediately. In a write-back (or copy-back) cache design, data is first written into the cache and the cache line is only flushed out to main RAM under certain circumstances, such as when a dirty cache line needs to be evicted in order to read in a new cache line from main RAM, or when the program explicitly requests a flush to occur.
3.5.4.8 Cache Coherency: MESI, MOESI and MESIF
When multiple CPU cores share a single main memory store, things get more complicated. It’s typical for each core to have its own L1 cache, but multiple cores might share an L2 cache, as well as sharing main RAM. See Figure 3.28 for an illustration of a two-level cache architecture with two CPU cores sharing one main memory store and an L2 cache.

In the presence of multiple cores, it’s important for the system to maintain cache coherency. This amounts to making sure that the data in the caches belonging to multiple cores match one another and the contents of main RAM. Coherency doesn’t have to be maintained at every moment—all that matters is that the running program can never tell that the contents of the caches are out of sync.
The three most common cache coherency protocols are known as MESI (modified, exclusive, shared, invalid), MOESI (modified, owned, exclusive, shared, invalid) and MESIF (modified, exclusive, shared, invalid and forward). We’ll discuss the MESI protocol in more depth when we talk about multicore computing architectures in Section 4.9.4.2.
3.5.4.9 Avoiding Cache Misses
Obviously cache misses cannot be totally avoided, since data has to move to and from main RAM eventually. The trick to writing high performance software in the presence of a memory cache hierarchy is to arrange your data in RAM, and design your data manipulation algorithms, in such a way that the minimum number of cache misses occur.
The best way to avoid D-cache misses is to organize your data in contiguous blocks that are as small as possible and then access them sequentially. When the data is contiguous (i.e., you don’t “jump around” in memory a lot), a single cache miss will load the maximum amount of relevant data in one go. When the data is small, it is more likely to fit into a single cache line (or at least a minimum number of cache lines). And when you access your data sequentially, you avoid evicting and reloading cache lines multiple times.
Avoiding I-cache misses follows the same basic principle as avoiding D-cache misses. However, the implementation requires a different approach. The easiest thing to do is to keep your high-performance loops as small as possible in terms of code size, and avoid calling functions within your innermost loops. If you do opt to call functions, try to keep their code size small too. This helps to ensure that the entire body of the loop, including all called functions, will remain in the I-cache the entire time the loop is running.
Use inline functions judiciously. Inlining a small function can be a big performance boost. However, too much inlining bloats the size of the code, which can cause a performance-critical section of code to no longer fit within the cache.
3.5.5 Nonuniform Memory Access (NUMA)
When designing a multiprocessor game console or personal computer, system architects must choose between two fundamentally different memory architectures: uniform memory access (UMA) and nonuniform memory access (NUMA).
In a UMA design, the computer contains a single large bank of main RAM which is visible to all CPU cores in the system. The physical address space looks the same to each core, and each can read from and write to all memory locations in main RAM. A UMA architecture typically makes use of a cache hierarchy to mitigate memory access latency issues.
One problem with a UMA architecture is that the cores often contend for access to main RAM and any shared caches. For example, the PS4 contains eight cores arranged into two clusters. Each core has its own private L1 cache, but each cluster of four cores shares a single L2 cache, and all cores share main RAM. As such, the cores often contend with one another for access to the L2 cache and main RAM.
One way to address core contention problems is to employ a non-uniform memory access (NUMA) design. In a NUMA system, each core is provided with a relatively small bank of high-speed dedicated RAM called a local store. Like an L1 cache, a local store is typically located on the same die as the core itself, and is only accessible by that core. But unlike an L1 cache, access to the local store is explicit. A local store might be mapped to part of a core’s address space, with main RAM mapped to a different range of addresses. Alternatively, certain cores might only be able to see the physical addresses within its local store, and might rely on a direct memory access controller (DMAC) to transfer data between the local store and main RAM.

3.5.5.1 SPU Local Stores on the PS3
The PlayStation 3 is a classic example of a NUMA architecture. The PS3 contains a single main CPU known as the Power processing unit (PPU), eight8 coprocessors known as synergistic processing units (SPUs), and an NVIDIA RSX graphics processing unit (GPU). The PPU has exclusive access to 256 MiB of main system RAM (with an L1 and L2 cache), the GPU has exclusive access to 256 MiB of video RAM (VRAM), and each SPU has its own private 256 KiB local store.
The physical address spaces of main RAM, video RAM and the SPUs’ local stores are all totally isolated from one another. This means that, for example, the PPU cannot directly address memory in VRAM or in any of the SPUs’ local stores, and any given SPU cannot directly address main RAM, video RAM, or any of the other SPUs’ local stores, only its own local store. The memory architecture of the PS3 is illustrated in Figure 3.29.
3.5.5.2 PS2 Scratchpad (SPR)
Looking even farther back to the PlayStation 2, we can learn about another memory architecture that was designed to improve overall system performance. The main CPU on the PS2, called the emotion engine (EE), has a special 16 KiB area of memory called the scratchpad (abbreviated SPR), in addition to a 16 KiB L1 instruction cache (I-cache) and an 8 KiB L1 data cache (D-cache). The PS2 also contains two vector coprocessors known as VU0 and VU1, each with their own L11- and D-caches, and a GPU known as the graphics synthesizer (GS) connected to a 4 MiB bank of video RAM. The PS2’s memory architecture is illustrated in Figure 3.30.

The scratchpad is located on the CPU die, and therefore enjoys the same low latency as L1 cache memory. But unlike the L1 cache, the scratchpad is memory-mapped so that it appears to the programmer to be a range of regular main RAM addresses. The scratchpad on the PS2 is itself uncached, meaning that reads and writes from and to it are direct; they bypass the EE’s L1 cache entirely.
The scratchpad’s main benefit isn’t actually its low access latency—it’s the fact that the CPU can access scratchpad memory without making use of the system buses. As such, reads and writes from and to the scratchpad can happen while the system’s address and data bus are being used for other purposes. For example, a game might set up a chain of DMA requests to transfer data between main RAM and the two vector processing units (VUs) in the PS2. While these DMAs are being processed by the DMAC, and/or while the VUs are busy performing calculations (both of which would make heavy use of the system buses), the EE can be performing calculations on data that resides within the scratchpad, without interfering with the DMAs or the operation of the VUs. Moving data into and out of the scratchpad can be done via regular memory move instructions (or memcpy() in C/C++), but this task can also be accomplished via DMA requests. The PS2’s scratchpad therefore gives the programmer a lot of flexibility and power in order to maximize a game engine’s data throughput.
_______________
1 Some early computers did use main RAM to implement registers. For example, the 32 registers in the IBM 7030 Stretch (IBM’s first transistor-based supercomputer) were “overlaid” on the first 32 addresses in main RAM. In some early ALU designs, one of its inputs would come from a register while the other came from main RAM. These designs were practical because back then, RAM access latencies were low relative to the overall performance of the CPU.
2 The term “accumulator” arose because early ALUs used to work one bit at a time, and would therefore accumulate the answer by masking and shifting the individual bits into the result register.
3 Contrast this to an analog electronic circuit, where time is treated as continuous. For example, an old-school signal generator can produce a true sine wave that smoothly varies between, say, −5 volts and 5 volts over time.
4 Actually, early computers often accessed memory in units of “words” that were larger than 8 bits. For example, the IBM 701 (produced in 1952) addressed memory in units of 36-bit words, and the PDP-1 (made in 1959) could access up to 4096 18-bit memory words. Eight-bit bytes were popularized by the Intel 8008 in 1972. Seven bits are required to encode both lower- and uppercase English letters. By extending this to eight bits, a wide range of special characters could also be supported.
5 Random-access memory was so named because earlier memory technologies used delay loops to store data, meaning that it could only be read in the order it was written. RAM technology improved on this situation by permitting data to be accessed at random, i.e., in any order.
6 Early transistor-transistor logic (TTL) devices operated at a supply voltage of 5 volts, so a 5-volt signal would represent a binary 1. Most of today’s digital electronic devices utilize complementary metal oxide semiconductor logic (CMOS) which can operate at a lower supply voltage, typically between 1.2 and 3.3 volts.
7 The speed that an electronic signal travels within a transmission medium such as copper wire or optical fiber is always somewhat lower than the speed of light in a vaccuum. Each interconnect material has its own characteristic velocity factor (VF) ranging from less than 50% to 99% the speed of light in a vaccuum.
8 Only six of the SPUs are available for use by game applications—one SPU is reserved for use by the operating system, and one is entirely off-limits to account for inevitable flaws in the fabrication process.