
Chapter 5. Graphs in the Real World
In this chapter we look at some of the common real-world use cases for graph databases and identify the reasons why organizations choose to use a graph database rather than a relational or other NOSQL store. The bulk of the chapter comprises three in-depth use cases, with details of the relevant data models and queries. Each of these examples has been drawn from a real-world production system; the names, however, have been changed, and the technical details simplified where necessary to highlight key design points and hide any accidental complexity.
Why Organizations Choose Graph Databases
Throughout this book, we’ve sung the praises of the graph data model, its power and flexibility, and its innate expressiveness. When it comes to applying a graph database to a real-world problem, with real-world technical and business constraints, organizations choose graph databases for the following reasons:
- “Minutes to milliseconds” performance
-
Query performance and responsiveness are at the top of many organizations’ concerns with regard to their data platforms. Online transactional systems, large web applications in particular, must respond to end users in milliseconds if they are to be successful. In the relational world, as an application’s dataset size grows, join pains begin to manifest themselves, and performance deteriorates. Using index-free adjacency, a graph database turns complex joins into fast graph traversals, thereby maintaining millisecond performance irrespective of the overall size of the dataset.
- Drastically accelerated development cycles
-
The graph data model reduces the impedance mismatch that has plagued software development for decades, thereby reducing the development overhead of translating back and forth between an object model and a tabular relational model. More importantly, the graph model reduces the impedance mismatch between the technical and business domains. Subject matter experts, architects, and developers can talk about and picture the core domain using a shared model that is then incorporated into the application itself.
- Extreme business responsiveness
-
Successful applications rarely stay still. Changes in business conditions, user behaviors, and technical and operational infrastructures drive new requirements. In the past, this has required organizations to undertake careful and lengthy data migrations that involve modifying schemas, transforming data, and maintaining redundant data to serve old and new features. The schema-free nature of a graph database coupled with the ability to simultaneously relate data elements in lots of different ways allows a graph database solution to evolve as the business evolves, reducing risk and time-to-market.
- Enterprise ready
-
When employed in a business-critical application, a data technology must be robust, scalable, and more often than not, transactional. Although some graph databases are fairly new and not yet fully mature, there are graph databases on the market that provide all the -ilities—ACID (Atomic, Consistent, Isolated, Durable) transactionality, high-availability, horizontal read scalability, and storage of billions of entities—needed by large enterprises today, as well as the previously discussed performance and flexibility characteristics. This has been an important factor leading to the adoption of graph databases by organizations, not merely in modest offline or departmental capacities, but in ways that can truly change the business.
Common Use Cases
In this section we describe some of the most common graph database use cases, identifying how the graph model and the specific characteristics of the graph database can be applied to generate competitive insight and significant business value.
Social
We are only just beginning to discover the power of social data. In their book Connected, social scientists Nicholas Christakis and James Fowler show how we can predict a person’s behavior by understanding who he is connected to.1
Social applications allow organizations to gain competitive and operational advantage by leveraging information about the connections between people. By combining discrete information about individuals and their relationships, organizations are able to to facilitate collaboration, manage information, and predict behavior.
As Facebook’s use of the term social graph implies, graph data models and graph databases are a natural fit for this overtly relationship-centered domain. Social networks help us identify the direct and indirect relationships between people, groups, and the things with which they interact, allowing users to rate, review, and discover each other and the things they care about. By understanding who interacts with whom, how people are connected, and what representatives within a group are likely to do or choose based on the aggregate behavior of the group, we generate tremendous insight into the unseen forces that influence individual behaviors. We discuss predictive modeling and its role in social network analysis in more detail in “Graph Theory and Predictive Modeling”.
Social relations may be either explicit or implicit. Explicit relations occur wherever social subjects volunteer a direct link—by liking someone on Facebook, for example, or indicating someone is a current or former colleague, as happens on LinkedIn. Implicit relations emerge out of other relationships that indirectly connect two or more subjects by way of an intermediary. We can relate subjects based on their opinions, likes, purchases, and even the products of their day-to-day work. Such indirect relationships lend themselves to being applied in multiple suggestive and inferential ways. We can say that A is likely to know, like, or otherwise connect to B based on some common intermediaries. In so doing, we move from social network analysis into the realm of recommendation engines.
Recommendations
Effective recommendations are a prime example of generating end-user value through the application of an inferential or suggestive capability. Whereas line-of-business applications typically apply deductive and precise algorithms—calculating payroll, applying tax, and so on—to generate end-user value, recommendation algorithms are inductive and suggestive, identifying people, products, or services an individual or group is likely to have some interest in.
Recommendation algorithms establish relationships between people and things: other people, products, services, media content—whatever is relevant to the domain in which the recommendation is employed. Relationships are established based on users’ behaviors as they purchase, produce, consume, rate, or review the resources in question. The recommendation engine can then identify resources of interest to a particular individual or group, or individuals and groups likely to have some interest in a particular resource. With the first approach, identifying resources of interest to a specific user, the behavior of the user in question—her purchasing behavior, expressed preferences, and attitudes as expressed in ratings and reviews—are correlated with those of other users in order to identify similar users and thereafter the things with which they are connected. The second approach, identifying users and groups for a particular resource, focuses on the characteristics of the resource in question. The engine then identifies similar resources, and the users associated with those resources.
As in the social use case, making an effective recommendation depends on understanding the connections between things, as well as the quality and strength of those connections—all of which are best expressed as a property graph. Queries are primarily graph local, in that they start with one or more identifiable subjects, whether people or resources, and thereafter discover surrounding portions of the graph.
Taken together, social networks and recommendation engines provide key differentiating capabilities in the areas of retail, recruitment, sentiment analysis, search, and knowledge management. Graphs are a good fit for the densely connected data structures germane to each of these areas. Storing and querying this data using a graph database allows an application to surface end-user real-time results that reflect recent changes to the data, rather than precalculated, stale results.
Geo
Geospatial is the original graph use case. Euler solved the Seven Bridges of Königsberg problem by positing a mathematical theorem that later came to form the basis of graph theory. Geospatial applications of graph databases range from calculating routes between locations in an abstract network such as a road or rail network, airspace network, or logistical network (as illustrated by the logistics example later in this chapter) to spatial operations such as find all points of interest in a bounded area, find the center of a region, and calculate the intersection between two or more regions.
Geospatial operations depend upon specific data structures, ranging from simple weighted and directed relationships, through to spatial indexes, such as R-Trees, which represent multidimensional properties using tree data structures. As indexes, these data structures naturally take the form of a graph, typically hierarchical in form, and as such they are a good fit for a graph database. Because of the schema-free nature of graph databases, geospatial data can reside in the database alongside other kinds of data—social network data, for example—allowing for complex multidimensional querying across several domains.2
Geospatial applications of graph databases are particularly relevant in the areas of telecommunications, logistics, travel, timetabling, and route planning.
Master Data Management
Master data is data that is critical to the operation of a business, but which itself is nontransactional. Master data includes data concerning users, customers, products, suppliers, departments, geographies, sites, cost centers, and business units. In large organizations, this data is often held in many different places, with lots of overlap and redundancy, in several different formats, and with varying degrees of quality and means of access. Master Data Management (MDM) is the practice of identifying, cleaning, storing, and, most importantly, governing this data. Its key concerns include managing change over time as organizational structures change, businesses merge, and business rules change; incorporating new sources of data; supplementing existing data with externally sourced data; addressing the needs of reporting, compliance, and business intelligence consumers; and versioning data as its values and schemas change.
Graph databases don’t necessarily provide a full MDM solution. They are, however, ideally applied to the modeling, storing, and querying of hierarchies, master data metadata, and master data models. Such models include type definitions, constraints, relationships between entities, and the mappings between the model and the underlying source systems. A graph database’s structured yet schema-free data model provides for ad hoc, variable, and exceptional structures—schema anomalies that commonly arise when there are multiple redundant data sources—while at the same time allowing for the rapid evolution of the master data model in line with changing business needs.
Network and Data Center Management
In Chapter 3 we looked at a simple data center domain model, showing how the physical and virtual assets inside a data center can be easily modeled with a graph. Communications networks are graph structures. Graph databases are, therefore, a great fit for modeling, storing, and querying this kind of domain data. The distinction between network management of a large communications network versus data center management is largely a matter of which side of the firewall you’re working. For all intents and purposes, these two things are one and the same.
A graph representation of a network enables us to catalog assets, visualize how they are deployed, and identify the dependencies between them. The graph’s connected structure, together with a query language like Cypher, enable us to conduct sophisticated impact analyses, answering questions such as:
-
Which parts of the network—which applications, services, virtual machines, physical machines, data centers, routers, switches, and fiber—do important customers depend on? (Top-down analysis)
-
Conversely, which applications and services, and ultimately, customers, in the network will be affected if a particular network element—a router or switch, for example—fails? (Bottom-up analysis)
-
Is there redundancy throughout the network for the most important customers?
Graph database solutions complement existing network management and analysis tools. As with master data management, they can be used to bring together data from disparate inventory systems, providing a single view of the network and its consumers, from the smallest network element all the way to application and services and the customers who use them. A graph database representation of the network can also be used to enrich operational intelligence based on event correlations. Whenever an event correlation engine (a Complex Event Processor, for example) infers a complex event from a stream of low-level network events, it can assess the impact of that event using the graph model, and thereafter trigger any necessary compensating or mitigating actions.
Today, graph databases are being successfully employed in the areas of telecommunications, network management and analysis, cloud platform management, data center and IT asset management, and network impact analysis, where they are reducing impact analysis and problem resolution times from days and hours down to minutes and seconds. Performance, flexibility in the face of changing network schemas, and fit for the domain are all important factors here.
Authorization and Access Control (Communications)
Authorization and access control solutions store information about parties (e.g., administrators, organizational units, end-users) and resources (e.g., files, shares, network devices, products, services, agreements), together with the rules governing access to those resources. They then apply these rules to determine who can access or manipulate a resource. Access control has traditionally been implemented either using directory services or by building a custom solution inside an application’s backend. Hierarchical directory structures, however, cannot cope with the nonhierarchical organizational and resource dependency structures that characterize multiparty distributed supply chains. Hand-rolled solutions, particularly those developed on a relational database, suffer join pain as the dataset size grows, becoming slow and unresponsive, and ultimately delivering a poor end-user experience.
A graph database can store complex, densely connected access control structures spanning billions of parties and resources. Its structured yet schema-free data model supports both hierarchical and nonhierarchical structures, while its extensible property model allows for capturing rich metadata regarding every element in the system. With a query engine that can traverse millions of relationships per second, access lookups over large, complex structures execute in milliseconds.
As with network management and analysis, a graph database access control solution allows for both top-down and bottom-up queries:
-
Which resources—company structures, products, services, agreements, and end users—can a particular administrator manage? (Top-down)
-
Which resource can an end user access?
-
Given a particular resource, who can modify its access settings? (Bottom-up)
Graph database access control and authorization solutions are particularly applicable in the areas of content management, federated authorization services, social networking preferences, and software as a service (SaaS) offerings, where they realize minutes to milliseconds increases in performance over their hand-rolled, relational predecessors.
Real-World Examples
In this section we describe three example use cases in detail: social and recommendations, authorization and access control, and logistics. Each use case is drawn from one or more production applications of a graph database (specifically in these cases, Neo4j). Company names, context, data models, and queries have been tweaked to eliminate accidental complexity and to highlight important design and implementation choices.
Social Recommendations (Professional Social Network)
Talent.net is a social recommendations application that enables users to discover their own professional network, and identify other users with particular skill sets. Users work for companies, work on projects, and have one or more interests or skills. Based on this information, Talent.net can describe a user’s professional network by identifying other subscribers who share his or her interests. Searches can be restricted to the user’s current company, or extended to encompass the entire subscriber base. Talent.net can also identify individuals with specific skills who are directly or indirectly connected to the current user. Such searches are useful when looking for a subject matter expert for a current engagement.
Talent.net shows how a powerful inferential capability can be developed using a graph database. Although many line-of-business applications are deductive and precise—calculating tax or salary, or balancing debits and credits, for example—a new seam of end-user value opens up when we apply inductive algorithms to our data. This is what Talent.net does. Based on people’s interests and skills, and their work history, the application can suggest likely candidates to include in one’s professional network. These results are not precise in the way a payroll calculation must be precise, but they are undoubtedly useful nonetheless.
Talent.net infers connections between people. Contrast this with LinkedIn, where users explicitly declare they know or have worked with someone. This is not to say that LinkedIn is a precise social networking capability, because it too applies inductive algorithms to generate further insight. But with Talent.net even the primary tie, (A)-[:KNOWS]->(B), is inferred, rather than volunteered.
The first version of Talent.net depends on users having supplied information regarding their interests, skills, and work history so that it can infer their professional social relations. But with the core inferential capabilities in place, the platform is set to generate even greater insight for less end-user effort. Skills and interests, for example, can be inferred from the processes and products a person’s day-to-day work activities. Whether writing code, writing a document, or exchanging emails, a user must interact with a backend system. By intercepting these interactions, Talent.net can capture data that indicates what skills a person has, and what activities they engage in. Other sources of data that help contextualize a user include group memberships and meetup lists. Although the use case presented here does not cover these higher-order inferential features, their implementation requires mostly application integration and partnership agreements rather than any significant change to the graph or the algorithms used.
Talent.net data model
To help describe the Talent.net data model, we’ve created a small sample graph, as shown in Figure 5-1, which we’ll use throughout this section to illustrate the Cypher queries behind the main Talent.net use cases.
The sample graph shown here has just two companies, each with several employees. An employee is connected to his employer by a WORKS_FOR relationship. Each employee is INTERESTED_IN one or more topics, and has WORKED_ON one or more projects. Occasionally, employees from different companies work on the same project.
This structure addresses two important use cases:
-
Given a user, infer social relations—that is, identify their professional social network—based on shared interests and skills.
-
Given a user, recommend someone that they have worked with, or who has worked with people they have worked with, who has a particular skill.
The first use case helps build communities around shared interests. The second helps identify people to fill specific project roles.
Inferring social relations
Talent.net’s graph allows it to infer a user’s professional social network by finding people who share that user’s interests. The strength of the recommendation depends on the number of shared interests. If Sarah is interested in Java, graphs, and REST, Ben in graphs and REST, and Charlie in graphs, cars, and medicine, then there is a likely tie between Sarah and Ben based on their mutual interest in graphs and REST, and another tie between Sarah and Charlie based on their mutual interest in graphs, with the tie between Sarah and Ben stronger than the one between Sarah and Charlie (two shared interests versus one).
Figure 5-2 shows the pattern representing colleagues who share a user’s interests. The subject node refers to the subject of the query (in the preceding example, this is Sarah). This node can be looked up in an index. The remaining nodes will be discovered once the pattern is anchored to the subject node and then flexed around the graph.
The Cypher to implement this query is shown here:
MATCH(subject:User {name:{name}})MATCH(subject)-[:WORKS_FOR]->(company:Company)<-[:WORKS_FOR]-(person:User),(subject)-[:INTERESTED_IN]->(interest)<-[:INTERESTED_IN]-(person:User)RETURNperson.nameASname,count(interest)ASscore,collect(interest.name)ASinterestsORDER BYscoreDESC

Figure 5-2. Pattern to find colleagues who share a user’s interests
The query works as follows:
-
The first
MATCHfinds the subject (here, Sarah) in the nodes labeledUserand assigns the result to thesubjectidentifier. -
The second
MATCHthen matches thisUserwith people who work for the same company, and who share one or more of their interests. If the subject of the query is Sarah, who works for Acme, then in the case of Ben,MATCHwill match twice: Ben works for Acme, and is interested in graphs (first match), and REST (second match). In the case of Charlie, it will match once: Charlie works for Acme, and is interested in graphs. -
RETURNcreates a projection of the matched data. For each matched colleague, we extract their name, count the number of interests they have in common with the subject of the query (aliasing this result asscore), and, usingcollect, create a comma-separated list of these mutual interests. Where a person has multiple matches, as does Ben in our example,countandcollectaggregate their matches into a single row in the returned results. (In fact, bothcountandcollectcan perform this aggregating function independently of one another.) -
Finally, we order the results based on each colleague’s
score, highest first.
Running this query against our sample graph, with Sarah as the subject, yields the following results:
+---------------------------------------+ | name | score | interests | +---------------------------------------+ | "Ben" | 2 | ["Graphs","REST"] | | "Charlie" | 1 | ["Graphs"] | +---------------------------------------+ 2 rows
Figure 5-3 shows the portion of the graph that was matched to generate these results.

Figure 5-3. Colleagues who share Sarah’s interests
Notice that this query only finds people who work for the same company as Sarah. If we want to extend the search to find people who work for other companies, we need to modify the query slightly:
MATCH(subject:User {name:{name}})MATCH(subject)-[:INTERESTED_IN]->(interest:Topic)<-[:INTERESTED_IN]-(person:User),(person)-[:WORKS_FOR]->(company:Company)RETURNperson.nameASname,company.nameAScompany,count(interest)ASscore,collect(interest.name)ASinterestsORDER BYscoreDESC
The changes are as follows:
-
In the
MATCHclause, we no longer require matched persons to work for the same company as the subject of the query. (We do, however, still capture the company with which a matched person is associated, because we want to return this information in the results.) -
In the
RETURNclause we now include the company details for each matched person.
Running this query against our sample data returns the following results:
+---------------------------------------------------------------+ | name | company | score | interests | +---------------------------------------------------------------+ | "Arnold" | "Startup, Ltd" | 3 | ["Java","Graphs","REST"] | | "Ben" | "Acme, Inc" | 2 | ["Graphs","REST"] | | "Gordon" | "Startup, Ltd" | 1 | ["Graphs"] | | "Charlie" | "Acme, Inc" | 1 | ["Graphs"] | +---------------------------------------------------------------+ 4 rows
Figure 5-4 shows the portion of the graph that was matched to generate these results.
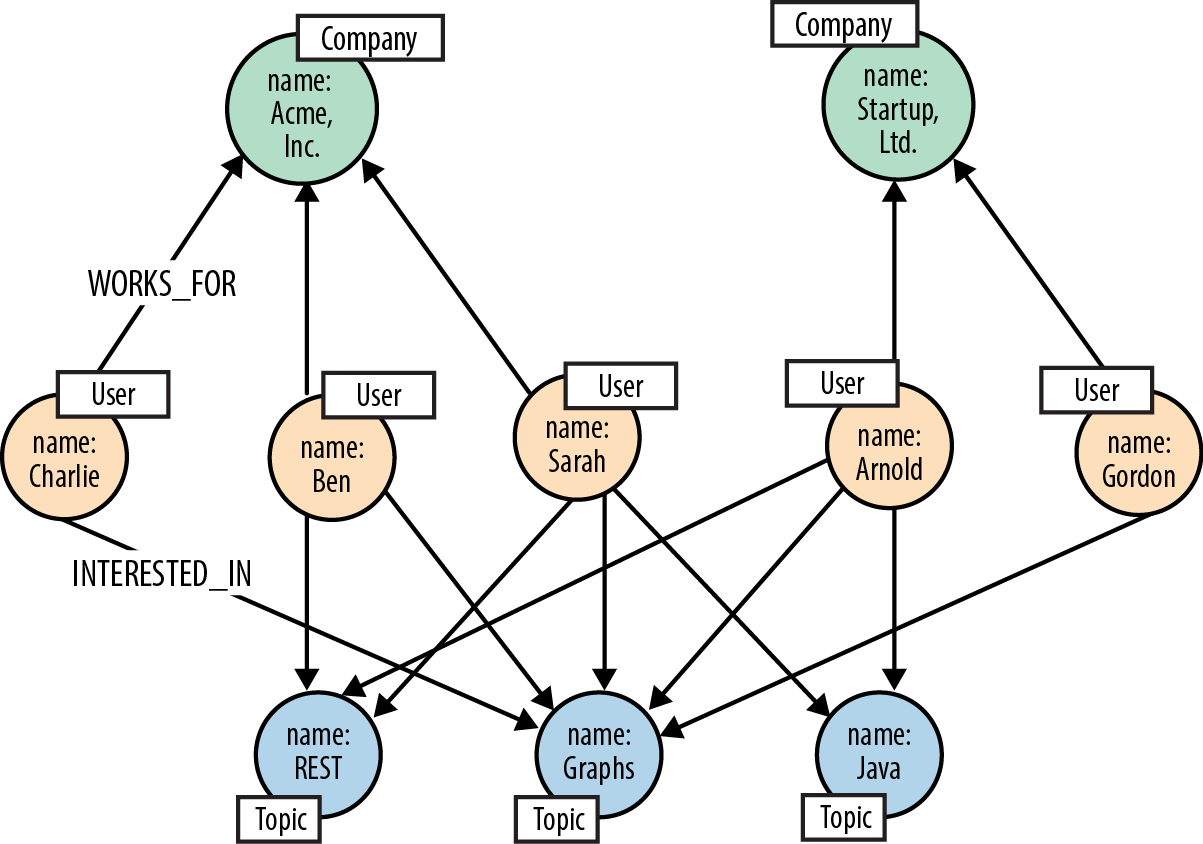
Figure 5-4. People who share Sarah’s interests
Although Ben and Charlie still feature in the results, it turns out that Arnold, who works for Startup, Ltd., has most in common with Sarah: three topics compared to Ben’s two and Charlie’s one.
Finding colleagues with particular interests
In the second Talent.net use case, we turn from inferring social relations based on shared interests to finding individuals who have a particular skillset, and who have either worked with the person who is the subject of the query, or worked with people who have worked with the subject. By applying the graph in this manner we can find individuals to staff project roles based on their social ties to people we trust—or at least with whom we have worked.
The social ties in question arise from individuals having worked on the same project. Contrast this with the previous use case, where the social ties were inferred based on shared interests. If people have worked on the same project, we infer a social tie. The projects, then, form intermediate nodes that bind two or more people together. In other words, a project is an instance of collaboration that has brought several people into contact with one another. Anyone we discover in this fashion is a candidate for including in our results—as long as they possess the interests or skills we are looking for.
Here’s a Cypher query that finds colleagues, and colleagues-of-colleagues, who have one or more particular interests:
MATCH(subject:User {name:{name}})MATCHp=(subject)-[:WORKED_ON]->(:Project)-[:WORKED_ON*0..2]-(:Project)<-[:WORKED_ON]-(person:User)-[:INTERESTED_IN]->(interest:Topic)WHEREperson<>subjectANDinterest.nameIN{interests}WITHperson, interest,min(length(p))aspathLengthORDER BYinterest.nameRETURNperson.nameASname,count(interest)ASscore,collect(interest.name)ASinterests,((pathLength - 1)/2)ASdistanceORDER BYscoreDESCLIMIT{resultLimit}
This is quite a complex query. Let’s break it down little and look at each part in more detail:
-
The first
MATCHfinds the subject of the query in the nodes labeledUserand assigns the result to thesubjectidentifier. -
The second
MATCHfinds people who are connected to thesubjectby way of having worked on the same project, or having worked on the same project as people who have worked with thesubject. For each person we match, we capture his interests. This match is then further refined by theWHEREclause, which excludes nodes that match the subject of the query, and ensures that we only match people who are interested in the things we care about. For each successful match, we assign the entire path of the match—that is, the path that extends from the subject of the query all the way through the matched person to his interest—to the identifierp. We’ll look at thisMATCHclause in more detail shortly. -
WITHpipes the results to theRETURNclause, filtering out redundant paths as it does so. Redundant paths are present in the results at this point because colleagues and colleagues-of-colleagues are often reachable through different paths, some longer than others. We want to filter these longer paths out. That’s exactly what theWITHclause does. TheWITHclause emits triples comprising a person, an interest, and the length of the path from the subject of the query through the person to his interest. Given that any particular person/interest combination may appear more than once in the results, but with different path lengths, we want to aggregate these multiple lines by collapsing them to a triple containing only the shortest path, which we do usingmin(length(p)) as pathLength. -
RETURNcreates a projection of the data, performing more aggregation as it does so. The data piped by theWITHclause toRETURNcontains one entry per person per interest. If a person matches two of the supplied interests, there will be two separate data entries. We aggregate these entries usingcountandcollect:countto create an overall score for a person,collectto create a comma-separated list of matched interests for that person. As part of the results, we also calculate how far the matched person is from the subject of the query. We do this by taking thepathLengthfor that person, subtracting one (for theINTERESTED_INrelationship at the end of the path), and then dividing by two (because the person is separated from the subject by pairs ofWORKED_ONrelationships). Finally, we order the results based onscore, highestscorefirst, and limit them according to aresultLimitparameter supplied by the query’s client.
The second MATCH clause in the preceding query uses a variable-length path, [:WORKED_ON*0..2], as part of a larger pattern to match people who have worked directly with the subject of the query, as well as people who have worked on the same project as people who have worked with the subject. Because each person is separated from the subject of the query by one or two pairs of WORKED_ON relationships, Talent.net could have written this portion of the query as MATCH p=(subject)-[:WORKED_ON*2..4]-(person)-[:INTERESTED_IN]->(interest), with a variable-length path of between two and four WORKED_ON relationships. However, long variable-length paths can be relatively inefficient. When writing such queries, it is advisable to restrict variable-length paths to as narrow a scope as possible. To increase the performance of the query, Talent.net uses a fixed-length outgoing WORKED_ON relationship that extends from the subject to her first project, and another fixed-length WORKED_ON relationship that connects the matched person to a project, with a smaller variable-length path in between.
Running this query against our sample graph, and again taking Sarah as the subject of the query, if we look for colleagues and colleagues-of-colleagues who have interests in Java, travel, or medicine, we get the following results:
+--------------------------------------------------+ | name | score | interests | distance | +--------------------------------------------------+ | "Arnold" | 2 | ["Java","Travel"] | 2 | | "Charlie" | 1 | ["Medicine"] | 1 | +--------------------------------------------------+ 2 rows
Note that the results are ordered by score, not distance. Arnold has two out of the three interests, and therefore scores higher than Charlie, who only has one, even though he is at two removes from Sarah, whereas Charlie has worked directly with Sarah.
Figure 5-5 shows the portion of the graph that was traversed and matched to generate these results.

Figure 5-5. Finding people with particular interests
Let’s take a moment to understand how this query executes in more detail. Figure 5-6 shows three stages in the execution of the query. (For visual clarity we’ve removed labels and emphasized the important property values.) The first stage shows each of the paths as they are matched by the MATCH and WHERE clauses. As we can see, there is one redundant path: Charlie is matched directly, through Next Gen Platform, but also indirectly, by way of Quantum Leap and Emily. The second stage represents the filtering that takes place in the WITH clause. Here we emit triples comprising the matched person, the matched interest, and the length of the shortest path from the subject through the matched person to her interest. The third stage represents the RETURN clause, wherein we aggregate the results on behalf of each matched person, and calculate her score and distance from the subject.

Figure 5-6. Query pipeline
Adding WORKED_WITH relationships
The query for finding colleagues and colleagues-of-colleagues with particular interests is the one most frequently executed on Talent.net’s site, and the success of the site depends in large part on its performance. The query uses pairs of WORKED_ON relationships (for example, ('Sarah')-[:WORKED_ON]->('Next Gen Platform')<-[:WORKED_ON]-('Charlie')) to infer that users have worked with one another. Although reasonably performant, this is nonetheless inefficient, because it requires traversing two explicit relationships to infer the presence of a single implicit relationship.
To eliminate this inefficiency, Talent.net decided to precompute a new kind of relationship, WORKED_WITH, thereby enriching the graph with shortcuts for these performance-critical access patterns. As we discussed in “Iterative and Incremental Development”, it’s quite common to optimize graph access by adding a direct relationship between two nodes that would otherwise be connected only by way of intermediaries.
In terms of the Talent.net domain, WORKED_WITH is a bidirectional relationship. In the graph, however, it is implemented using a unidirectional relationship. Although a relationship’s direction can often add useful semantics to its definition, in this instance the direction is meaningless. This isn’t a significant issue, so long as queries that operate with WORKED_WITH relationships ignore the relationship direction.
Note
Graph databases support traversal of relationships in either direction at the same low cost, so the decision as to whether to include a reciprocal relationship should be driven from the domain. For example, PREVIOUS and NEXT may not both be necessary in a linked list, but in a social network that represents sentiment, it is important to be explicit about who loves whom, and not assume reciprocity.
Calculating a user’s WORKED_WITH relationships and adding them to the graph isn’t difficult, nor is it particularly expensive in terms of resource consumption. It can, however, add milliseconds to any end-user interactions that update a user’s profile with new project information, so Talent.net has decided to perform this operation asynchronously to end-user activities. Whenever a user changes his project history, Talent.net adds a job to a queue. This job recalculates the user’s WORKED_WITH relationships. A single writer thread polls this queue and executes the jobs using the following Cypher statement:
MATCH(subject:User {name:{name}})MATCH(subject)-[:WORKED_ON]->()<-[:WORKED_ON]-(person:User)WHERENOT((subject)-[:WORKED_WITH]-(person))WITH DISTINCTsubject, personCREATE UNIQUE(subject)-[:WORKED_WITH]-(person)RETURNsubject.nameASstartName, person.nameASendName
Figure 5-7 shows what our sample graph looks like once it has been enriched with WORKED_WITH relationships.
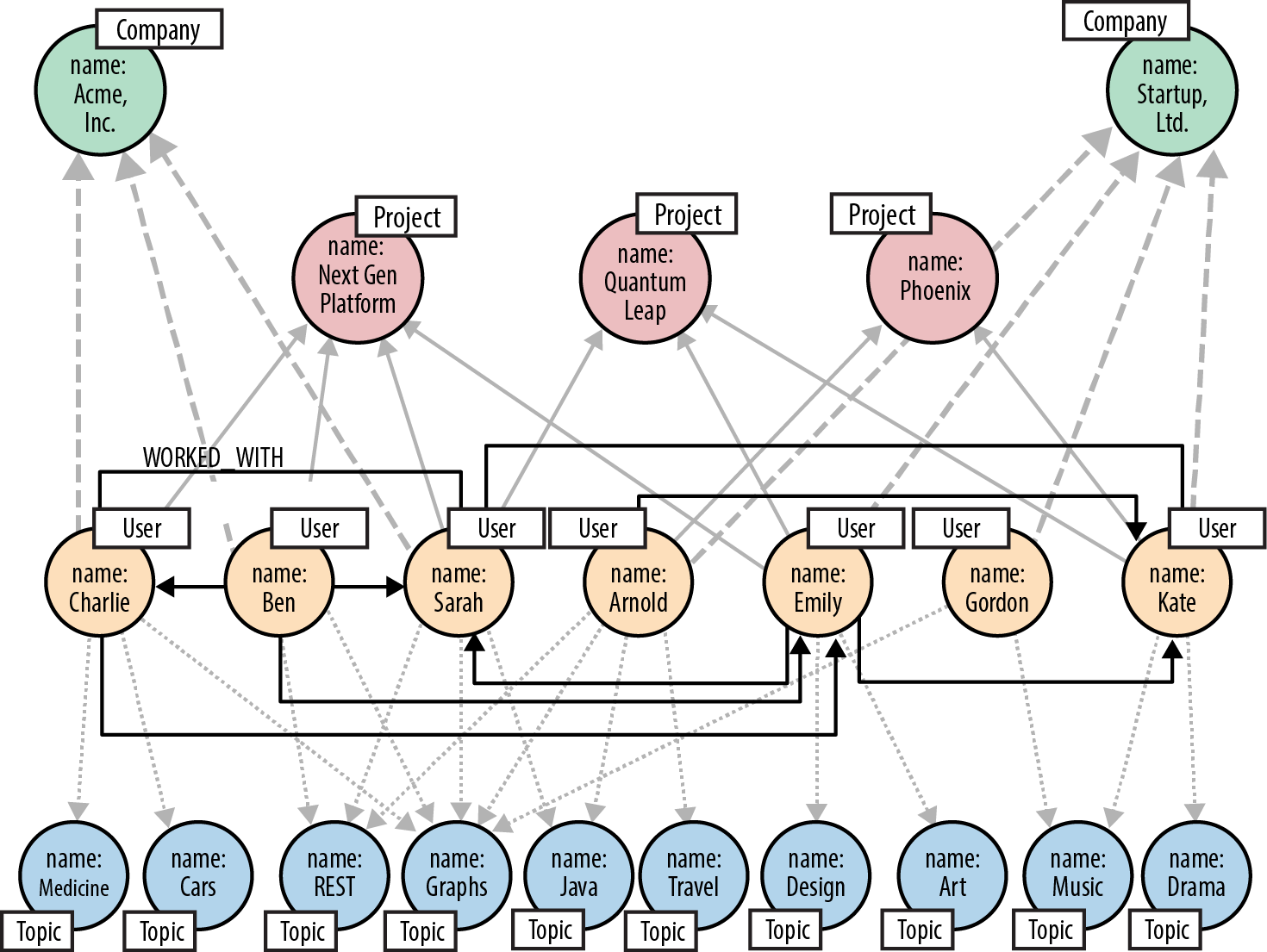
Figure 5-7. Talent.net graph enriched with WORKED_WITH relationships
Using the enriched graph, Talent.net now finds colleagues and colleagues-of-colleagues with particular interests using a slightly simpler version of the query we looked at earlier:
MATCH(subject:User {name:{name}})MATCHp=(subject)-[:WORKED_WITH*0..1]-(:Person)-[:WORKED_WITH]-(person:User)-[:INTERESTED_IN]->(interest:Topic)WHEREperson<>subjectANDinterest.nameIN{interests}WITHperson, interest,min(length(p))aspathLengthRETURNperson.nameASname,count(interest)ASscore,collect(interest.name)ASinterests,(pathLength - 1)ASdistanceORDER BYscoreDESCLIMIT{resultLimit}
Authorization and Access Control
TeleGraph Communications is an international communications services company. Millions of domestic and business users subscribe to its products and services. For several years, it has offered its largest business customers the ability to self-service their accounts. Using a browser-based application, administrators within each of these customer organizations can add and remove services on behalf of their employees. To ensure that users and administrators see and change only those parts of the organization and the products and services they are entitled to manage, the application employs a complex access control system, which assigns privileges to many millions of users across tens of millions of product and service instances.
TeleGraph has decided to replace the existing access control system with a graph database solution. There are two drivers here: performance and business responsiveness.
Performance issues have dogged TeleGraph’s self-service application for several years. The original system is based on a relational database, which uses recursive joins to model complex organizational structures and product hierarchies, and stored procedures to implement the access control business logic. Because of the join-intensive nature of the data model, many of the most important queries are unacceptably slow. For large companies, generating a view of the things an administrator can manage takes many minutes. This creates a very poor user experience, and hampers the revenue-generating opportunities presented by the self-service offering.
TeleGraph has ambitious plans to move into new regions and markets, effectively increasing its customer base by an order of magnitude. But the performance issues that affect the original application suggest it is no longer fit for today’s needs, never mind tomorrow’s. A graph database solution, in contrast, offers the performance, scalability, and adaptiveness necessary for dealing with a rapidly changing market.
TeleGraph data model
Figure 5-8 shows a sample of the TeleGraph data model. (For clarity, labels are presented at the top of each set of nodes once only, rather than being attached to every node. In the real data, all nodes have at least one label.)
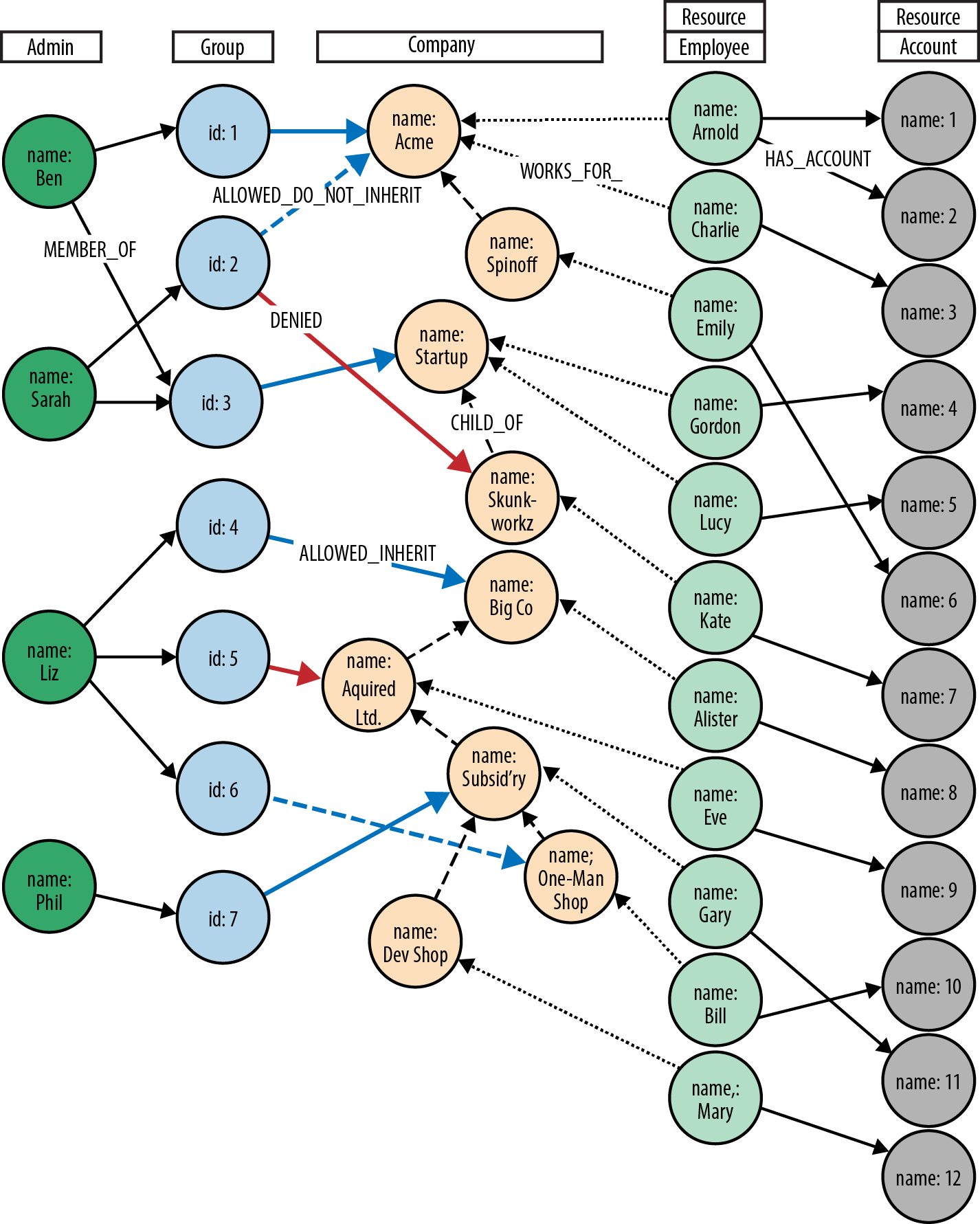
Figure 5-8. Access control graph
This model comprises two hierarchies. In the first hierarchy, administrators within each customer organization are assigned to groups. These groups are then accorded various permissions against that organization’s organizational structure:
-
ALLOWED_INHERITconnects an administrator group to an organizational unit, thereby allowing administrators within that group to manage the organizational unit. This permission is inherited by children of the parent organizational unit. We see an example of inherited permissions in the TeleGraph example data model in the relationships betweenGroup 1andAcme, and the child ofAcme,Spinoff.Group 1is connected toAcmeusing anALLOWED_INHERITrelationship.Ben, as a member ofGroup 1, can manage employees both ofAcmeandSpinoffthanks to thisALLOWED_INHERITrelationship. -
ALLOWED_DO_NOT_INHERITconnects an administrator group to an organizational unit in a way that allows administrators within that group to manage the organizational unit, but not any of its children.Sarah, as a member ofGroup 2, can administerAcme, but not its childSpinoff, becauseGroup 2is connected toAcmeby anALLOWED_DO_NOT_INHERITrelationship, not anALLOWED_INHERITrelationship. -
DENIEDforbids administrators from accessing an organizational unit. This permission is inherited by children of the parent organizational unit. In the TeleGraph diagram, this is best illustrated byLizand her permissions with respect toBig Co,Acquired Ltd,Subsidiary, andOne-Map Shop. As a result of her membership ofGroup 4and itsALLOWED_INHERITpermission onBig Co,Lizcan manageBig Co. But despite this being an inheritable relationship,Lizcannot manageAcquired LtdorSubsidiarybecauseGroup 5, of whichLizis a member, isDENIEDaccess toAcquired Ltdand its children (which includesSubsidiary).Lizcan, however, manageOne-Map Shop, thanks to anALLOWED_DO_NOT_INHERITpermission granted toGroup 6, the last group to whichLizbelongs.
DENIED takes precedence over ALLOWED_INHERIT, but is subordinate to ALLOWED_DO_NOT_INHERIT. Therefore, if an administrator is connected to a company by way of ALLOWED_DO_NOT_INHERIT and DENIED, ALLOWED_DO_NOT_INHERIT prevails.
Finding all accessible resources for an administrator
The TeleGraph application uses many different Cypher queries. We’ll look at just a few of them here.
First up is the ability to find all the resources an administrator can access. Whenever an onsite administrator logs in to the system, he is presented with a list of all the employees and employee accounts he can administer. This list is generated based on the results returned from the following query:
MATCH(admin:Admin {name:{adminName}})MATCHpaths=(admin)-[:MEMBER_OF]->(:Group)-[:ALLOWED_INHERIT]->(:Company)<-[:CHILD_OF*0..3]-(company:Company)<-[:WORKS_FOR]-(employee:Employee)-[:HAS_ACCOUNT]->(account:Account)WHERENOT((admin)-[:MEMBER_OF]->(:Group)-[:DENIED]->(:Company)<-[:CHILD_OF*0..3]-(company))RETURNemployee.nameASemployee, account.nameASaccountUNIONMATCH(admin:Admin {name:{adminName}})MATCHpaths=(admin)-[:MEMBER_OF]->(:Group)-[:ALLOWED_DO_NOT_INHERIT]->(:Company)<-[:WORKS_FOR]-(employee:Employee)-[:HAS_ACCOUNT]->(account:Account)RETURNemployee.nameASemployee, account.nameASaccount
Like all the other queries we’ll be looking at in this section, this query comprises two separate queries joined by a UNION operator. The query before the UNION operator handles ALLOWED_INHERIT relationships qualified by any DENIED relationships. The query following the UNION operator handles any ALLOWED_DO_NOT_INHERIT permissions. This pattern, ALLOWED_INHERIT minus DENIED, followed by ALLOWED_DO_NOT_INHERIT, is repeated in all of the access control example queries that we’ll be looking at.
The first query here, the one before the UNION operator, can be broken down as follows:
-
The first
MATCHselects the logged-in administrator from the nodes labeledAdministrator, and binds the result to theadminidentifier. -
MATCHmatches all the groups to which this administrator belongs, and from these groups, all the parent companies connected by way of anALLOWED_INHERITrelationship. TheMATCHthen uses a variable-length path ([:CHILD_OF*0..3]) to discover children of these parent companies, and thereafter the employees and accounts associated with all matched companies (whether parent company or child). At this point, the query has matched all companies, employees, and accounts accessible by way ofALLOWED_INHERITrelationships. -
WHEREeliminates matches whosecompany, or parent companies, are connected by way of aDENIEDrelationship to the administrator’s groups. ThisWHEREclause is invoked for each match. If there is aDENIEDrelationship anywhere between theadminnode and thecompanynode bound by the match, that match is eliminated. -
RETURNcreates a projection of the matched data in the form of a list of employee names and accounts.
The second query here, following the UNION operator, is a little simpler:
-
The first
MATCHselects the logged-in administrator from the nodes labeledAdministrator, and binds the result to theadminidentifier. -
The second
MATCHsimply matches companies (plus employees and accounts) that are directly connected to an administrator’s groups by way of anALLOWED_DO_NOT_INHERITrelationship.
The UNION operator joins the results of these two queries together, eliminating any duplicates. Note that the RETURN clause in each query must contain the same projection of the results. In other words, the column names in the two result sets must match.
Figure 5-9 shows how this query matches all accessible resources for Sarah in the sample TeleGraph graph. Note that, because of the DENIED relationship from Group 2 to Skunkworkz, Sarah cannot administer Kate and Account 7.
Note
Cypher supports both UNION and UNION ALL operators. UNION eliminates duplicate results from the final result set, whereas UNION ALL includes any duplicates.

Figure 5-9. Finding all accessible resources for a user
Determining whether an administrator has access to a resource
The query we’ve just looked at returned a list of employees and accounts an administrator can manage. In a web application, each of these resources (employee, account) is accessible through its own URI. Given a friendly URI (e.g., http://TeleGraph/accounts/5436), what’s to stop someone from hacking a URI and gaining illegal access to an account?
What’s needed is a query that will determine whether an administrator has access to a specific resource. This is that query:
MATCH(admin:Admin {name:{adminName}}),(company:Company)-[:WORKS_FOR|HAS_ACCOUNT*1..2]-(resource:Resource {name:{resourceName}})MATCHp=(admin)-[:MEMBER_OF]->(:Group)-[:ALLOWED_INHERIT]->(:Company)<-[:CHILD_OF*0..3]-(company)WHERENOT((admin)-[:MEMBER_OF]->(:Group)-[:DENIED]->(:Company)<-[:CHILD_OF*0..3]-(company))RETURNcount(p)ASaccessCountUNIONMATCH(admin:Admin {name:{adminName}}),(company:Company)-[:WORKS_FOR|HAS_ACCOUNT*1..2]-(resource:Resource {name:{resourceName}})MATCHp=(admin)-[:MEMBER_OF]->()-[:ALLOWED_DO_NOT_INHERIT]->(company)RETURNcount(p)ASaccessCount
This query works by determining whether an administrator has access to the company to which an employee or an account belongs. Given an employee or account, we need to determine the company with which this resource is associated, and then work out whether the administrator has access to that company.
How do we identify the company to which an employee or account belongs? By labelling both as Resource (as well as either Company or Account). An employee is connected to a company resource by a WORKS_FOR relationship. An account is associated with a company by way of an employee. HAS_ACCOUNT connects the employee to the account. WORKS_FOR then connects this employee to the company. In other words, an employee is one hop away from a company, whereas an account is two hops away from a company.
With that bit of insight, we can see that this resource authorization check is similar to the query for finding all companies, employees, and accounts—only with several small differences:
-
The first
MATCHfindz the company to which an employee or account belongs. It uses Cypher’s OR operator,|, to match bothWORKS_FORandHAS_ACCOUNTrelationships at depth one or two. -
The
WHEREclause in the query before theUNIONoperator eliminates matches where thecompanyin question is connected to one of the administrator’s groups by way of aDENIEDrelationship. -
The
RETURNclauses for the queries before and after theUNIONoperator return a count of the number of matches. For an administrator to have access to a resource, one or both of theseaccessCountvalues must be greater than 0.
Because the UNION operator eliminates duplicate results, the overall result set for this query can contain either one or two values. The client-side algorithm for determining whether an administrator has access to a resource can be expressed easily in Java:
privatebooleanisAuthorized(Resultresult){Iterator<Long>accessCountIterator=result.columnAs("accessCount");while(accessCountIterator.hasNext()){if(accessCountIterator.next()>0L){returntrue;}}returnfalse;}
Finding administrators for an account
The previous two queries represent “top-down” views of the graph. The last TeleGraph query we’ll discuss here provides a “bottom-up” view of the data. Given a resource—an employee or account—who can manage it? Here’s the query:
MATCH(resource:Resource {name:{resourceName}})MATCHp=(resource)-[:WORKS_FOR|HAS_ACCOUNT*1..2]-(company:Company)-[:CHILD_OF*0..3]->()<-[:ALLOWED_INHERIT]-()<-[:MEMBER_OF]-(admin:Admin)WHERENOT((admin)-[:MEMBER_OF]->(:Group)-[:DENIED]->(:Company)<-[:CHILD_OF*0..3]-(company))RETURNadmin.nameASadminUNIONMATCH(resource:Resource {name:{resourceName}})MATCHp=(resource)-[:WORKS_FOR|HAS_ACCOUNT*1..2]-(company:Company)<-[:ALLOWED_DO_NOT_INHERIT]-(:Group)<-[:MEMBER_OF]-(admin:Admin)RETURNadmin.nameASadmin
As before, the query consists of two independent queries joined by a UNION operator. Of particular note are the following clauses:
-
The first
MATCHclause uses aResourcelabel, which allows it to identify both employees and accounts. -
The second
MATCHclauses contain a variable-length path expression that uses the|operator to specify a path that is one or two relationships deep, and whose relationship types compriseWORKS_FORorHAS_ACCOUNT. This expression accommodates the fact that the subject of the query may be either an employee or an account.
Figure 5-10 shows the portions of the graph matched by the query when asked to find the administrators for Account 10.
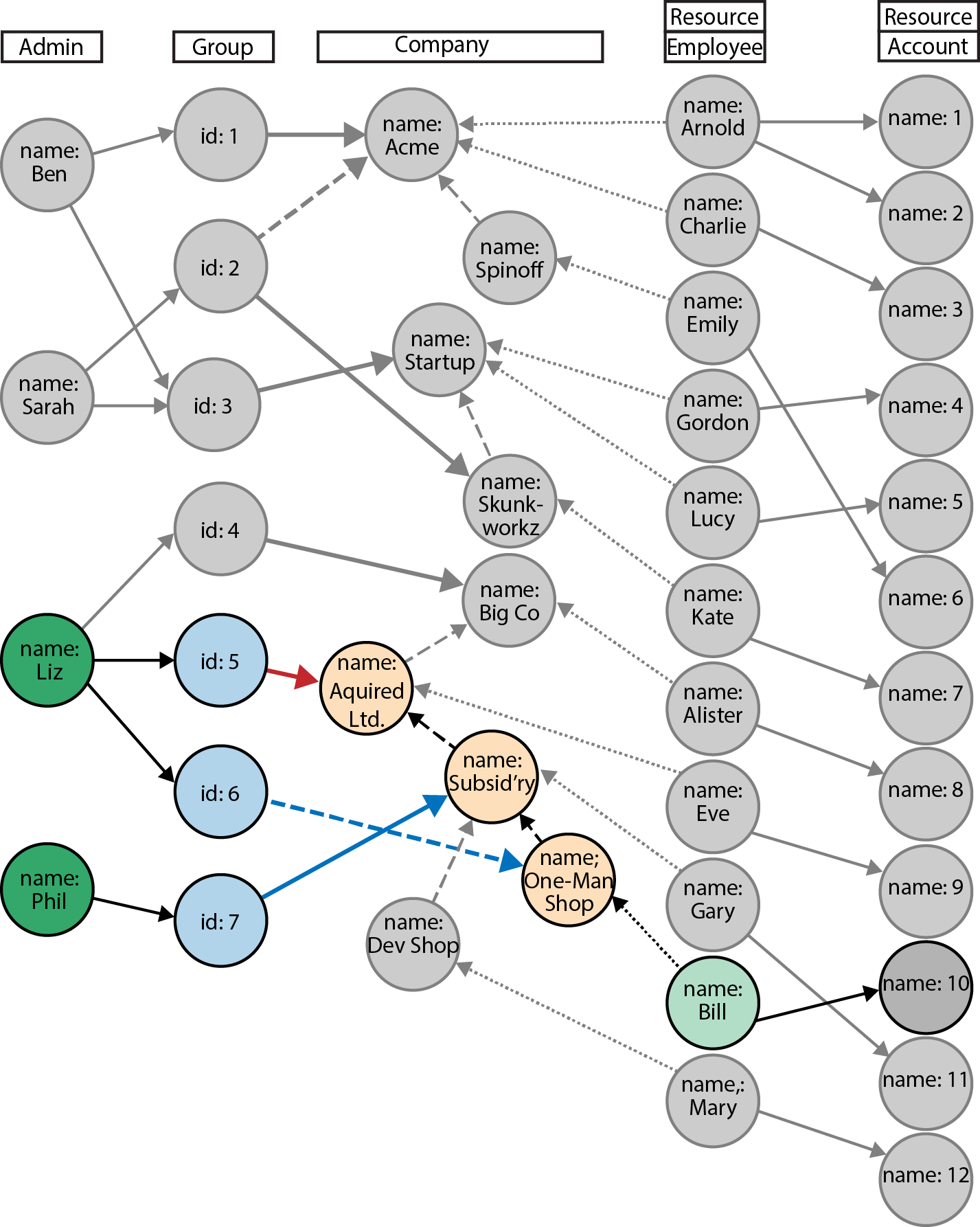
Figure 5-10. Finding an administrator for a specific account
Geospatial and Logistics
Global Post is a global courier whose domestic operation delivers millions of parcels to more than 30 million addresses each day. In recent years, as a result of the rise in online shopping, the number of parcels has increased significantly. Amazon and eBay deliveries now account for more than half of the parcels routed and delivered by Global Post each day.
With parcel volumes continuing to grow, and facing strong competition from other courier services, Global Post has begun a large change program to upgrade all aspects of its parcel network, including buildings, equipment, systems, and processes.
One of the most important and time-critical components in the parcel network is the route calculation engine. Between one and three thousand parcels enter the network each second. As parcels enter the network they are mechanically sorted according to their destination. To maintain a steady flow during this process, the engine must calculate a parcel’s route before it reaches a point where the sorting equipment has to make a choice, which happens only seconds after the parcel has entered the network—hence the strict time requirements on the engine.
Not only must the engine route parcels in milliseconds, but it must do so according to the routes scheduled for a particular period. Parcel routes change throughout the year, with more trucks, delivery people, and collections over the Christmas period than during the summer, for example. The engine must, therefore, apply its calculations using only those routes that are available for a particular period.
On top of accommodating different routes and levels of parcel traffic, the new parcel network must also allow for significant change and evolution. The platform that Global Post develops today will form the business-critical basis of its operations for the next 10 years or more. During that time, the company anticipates large portions of the network—including equipment, premises, and transport routes—will change to match changes in the business environment. The data model underlying the route calculation engine must, therefore, allow for rapid and significant schema evolution.
Global Post data model
Figure 5-11 shows a simple example of the Global Post parcel network. The network comprises parcel centers, which are connected to delivery bases, each of which covers several delivery areas. These delivery areas, in turn, are subdivided into delivery segments covering many delivery units. There are around 25 national parcel centers and roughly 2 million delivery units (corresponding to postal or zip codes).
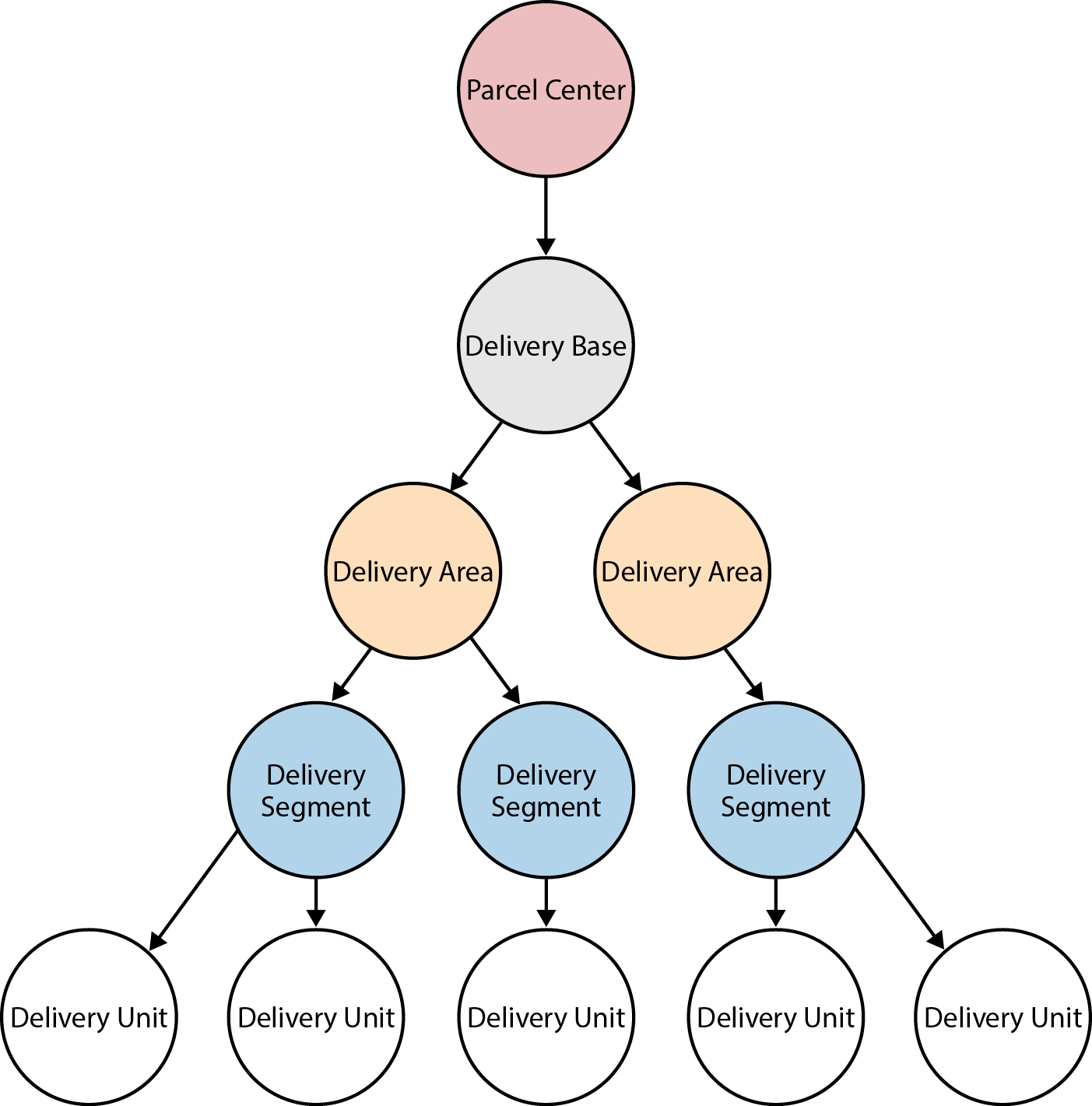
Figure 5-11. Elements in the Global Post network
Over time, the delivery routes change. Figures 5-12, 5-13, and 5-14 show three distinct delivery periods. For any given period, there is at most one route between a delivery base and any particular delivery area or segment. In contrast, there are multiple routes between delivery bases and parcel centers throughout the year. For any given point in time, therefore, the lower portions of the graph (the individual subgraphs below each delivery base) comprise simple tree structures, whereas the upper portions of the graph, made up of delivery bases and parcel centers, are more interconnected.
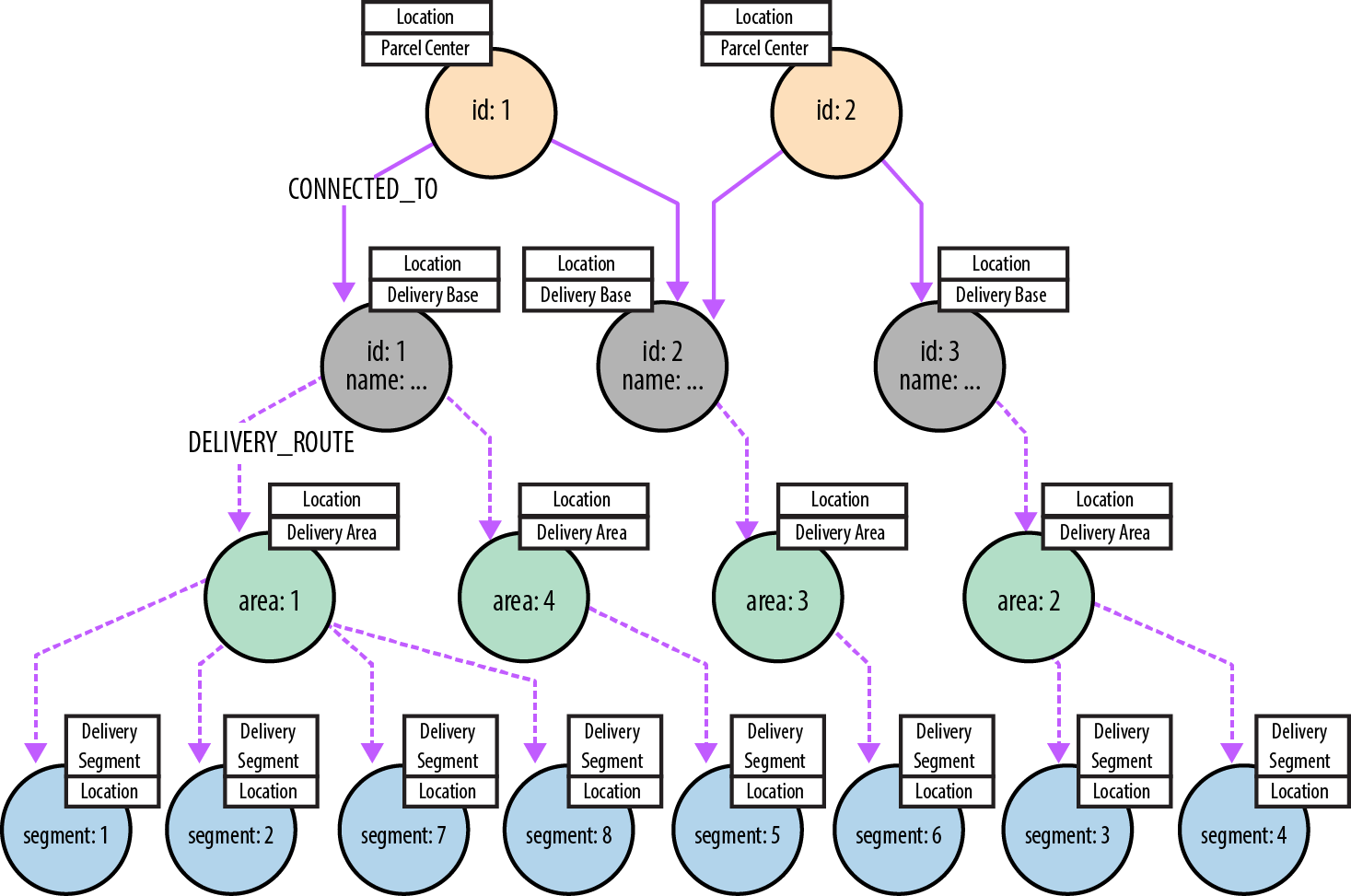
Figure 5-12. Structure of the delivery network for Period 1

Figure 5-13. Structure of the delivery network for Period 2

Figure 5-14. Structure of the delivery network for Period 3
Notice that delivery units are not included in the production data. This is because each delivery unit is always associated with the same delivery segments, irrespective of the period. Because of this invariant, it is possible to index each delivery segment by its many delivery units. To calculate the route to a particular delivery unit, the system need only actually calculate the route to its associated delivery segment, the name of which can be recovered from the index using the delivery unit as a key. This optimization helps both reduce the size of the production graph, and reduce the number of traversals needed to calculate a route.
The production database contains the details of all the different delivery periods. As shown in Figure 5-15, the presence of so many period-specific relationships makes for a densely connected graph.
In the production data, nodes are connected by multiple relationships, each of which is timestamped with a start_date and end_date property. Relationships are of two types: CONNECTED_TO, which connects parcel centers and delivery bases, and DELIVERY_ROUTE, which connects delivery bases to delivery areas, and delivery areas to delivery segments. These two different types of relationships effectively partition the graph into its upper and lower parts, a strategy that provides for very efficient traversals. Figure 5-16 shows three of the timestamped CONNECTED_TO relationships connecting a parcel center to a delivery base.

Figure 5-15. Sample of the Global Post network
Route calculation
As described in the previous section, the CONNECTED_TO and DELIVERY_ROUTE relationships partition the graph into upper and lower parts, with the upper parts made up of complexly connected parcel centers and delivery centers, the lower parts of delivery bases, delivery areas, and delivery segments organized—for any given period—in simple tree structures.
Route calculations involve finding the cheapest route between two locations in the lower portions of the graph. The starting location is typically a delivery segment or delivery area, whereas the end location is always a delivery segment. A delivery segment, as we discussed earlier, is effectively a key for a delivery unit. Irrespective of the start and end locations, the calculated route must go via at least one parcel center in the upper part of the graph.
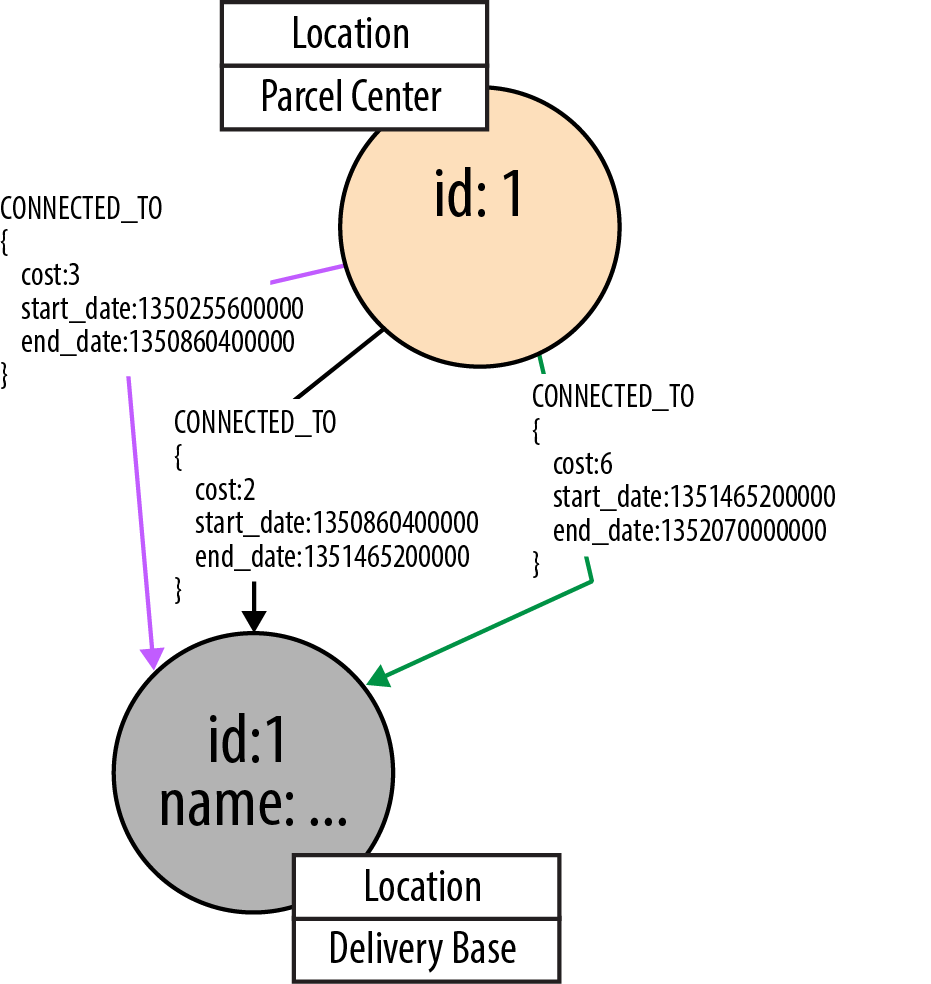
Figure 5-16. Timestamp properties on relationships
In terms of traversing the graph, a calculation can be split into three legs. Legs one and two, shown in Figure 5-17, work their way upward from the start and end locations, respectively, with each terminating at a delivery center. Because there is at most one route between any two elements in the lower portion of the graph for any given delivery period, traversing from one element to the next is simply a matter of finding an incoming DELIVERY ROUTE relationship whose interval timestamps encompass the current delivery period. By following these relationships, the traversals for legs one and two navigate a pair of tree structures rooted at two different delivery centers. These two delivery centers then form the start and end locations for the third leg, which crosses the upper portion of the graph.

Figure 5-17. Shortest path to delivery bases from start and end points
As with legs one and two, the traversal for leg three, as shown in Figure 5-18, looks for relationships—this time, CONNECTED_TO relationships—whose timestamps encompass the current delivery period. Even with this time filtering in place, however, there are, for any given period, potentially several routes between any two delivery centers in the upper portion of the graph. The third leg traversal must, therefore, sum the cost of each route, and select the cheapest, making this a shortest weighted path calculation.
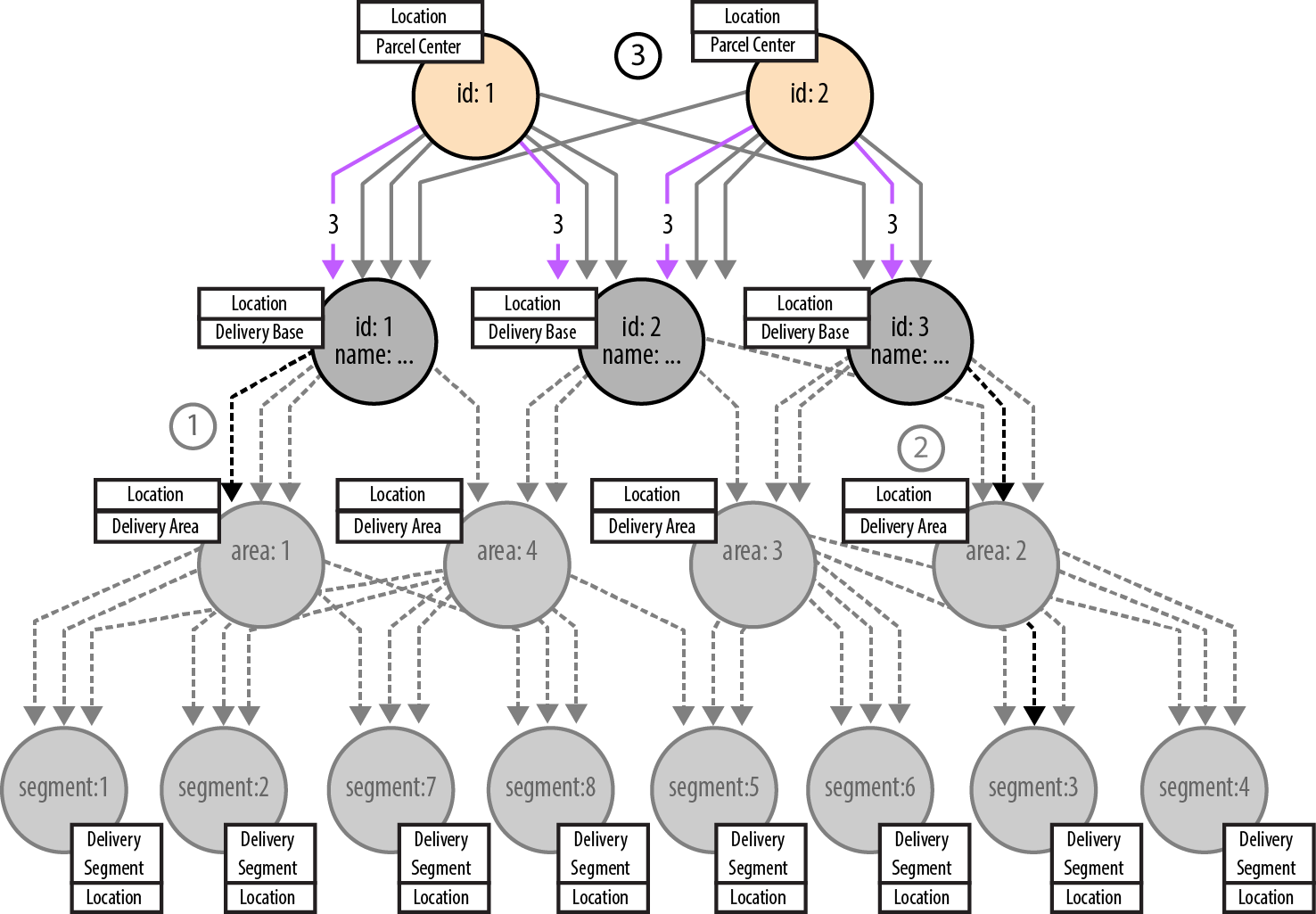
Figure 5-18. Shortest path between delivery bases
To complete the calculation, we need then simply to add the paths for legs one, three, and two, which gives the full path from the start to the end location.
Finding the shortest delivery route using Cypher
The Cypher query to implement the parcel route calculation engine is as follows:
MATCH(s:Location {name:{startLocation}}),(e:Location {name:{endLocation}})MATCHupLeg = (s)<-[:DELIVERY_ROUTE*1..2]-(db1)WHEREall(rinrelationships(upLeg)WHEREr.start_date <={intervalStart}ANDr.end_date >={intervalEnd})WITHe, upLeg, db1MATCHdownLeg = (db2)-[:DELIVERY_ROUTE*1..2]->(e)WHEREall(rinrelationships(downLeg)WHEREr.start_date <={intervalStart}ANDr.end_date >={intervalEnd})WITHdb1, db2, upLeg, downLegMATCHtopRoute = (db1)<-[:CONNECTED_TO]-()-[:CONNECTED_TO*1..3]-(db2)WHEREall(rinrelationships(topRoute)WHEREr.start_date <={intervalStart}ANDr.end_date >={intervalEnd})WITHupLeg, downLeg, topRoute,reduce(weight=0, rinrelationships(topRoute) | weight+r.cost)ASscoreORDER BYscoreASCLIMIT1RETURN(nodes(upLeg) +tail(nodes(topRoute)) +tail(nodes(downLeg)))ASn
At first glance, this query appears quite complex. It is, however, made up of four simpler queries joined together with WITH clauses. We’ll look at each of these subqueries in turn.
Here’s the first subquery:
MATCH(s:Location {name:{startLocation}}),(e:Location {name:{endLocation}})MATCHupLeg = (s)<-[:DELIVERY_ROUTE*1..2]-(db1)WHEREall(rinrelationships(upLeg)WHEREr.start_date <={intervalStart}ANDr.end_date >={intervalEnd})
This query calculates the first leg of the overall route. It can be broken down as follows:
-
The first
MATCHfinds the start and end locations in the subset of nodes labeledLocation, binding them to thesandeidentifiers, respectively. -
The second
MATCHfinds the route from the start location,s, to a delivery base using a directed, variable-lengthDELIVERY_ROUTEpath. This path is then bound to the identifierupLeg. Because delivery bases are always the root nodes ofDELIVERY_ROUTEtrees, and therefore have no incomingDELIVERY_ROUTErelationships, we can be confident that thedb1node at the end of this variable-length path represents a delivery base and not some other parcel network element. -
WHEREapplies additional constraints to the pathupLeg, ensuring that we only matchDELIVERY_ROUTErelationships whosestart_dateandend_dateproperties encompass the supplied delivery period.
The second subquery calculates the second leg of the route, which comprises the path from the end location up to the delivery base whose DELIVERY_ROUTE tree includes that end location as a leaf node. This query is very similar to the first:
WITHe, upLeg, db1MATCHdownLeg = (db2)-[:DELIVERY_ROUTE*1..2]->(e)WHEREall(rinrelationships(downLeg)WHEREr.start_date <={intervalStart}ANDr.end_date >={intervalEnd})
The WITH clause here chains the first subquery to the second, piping the end location and the first leg’s path and delivery base to the second subquery. The second subquery uses only the end location, e, in its MATCH clause; the rest is provided so that it can be piped to subsequent queries.
The third subquery identifies all candidate paths for the third leg of the route—that is, the route between delivery bases db1 and db2—as follows:
WITHdb1, db2, upLeg, downLegMATCHtopRoute = (db1)<-[:CONNECTED_TO]-()-[:CONNECTED_TO*1..3]-(db2)WHEREall(rinrelationships(topRoute)WHEREr.start_date <={intervalStart}ANDr.end_date >={intervalEnd})
This subquery is broken down as follows:
-
WITHchains this subquery to the previous one, piping delivery basesdb1anddb2together with the paths identified in legs one and two to the current query. -
MATCHidentifies all paths between the first and second leg delivery bases, to a maximum depth of four, and binds them to thetopRouteidentifier. -
WHEREconstrains thetopRoutepaths to those whosestart_dateandend_dateproperties encompass the supplied delivery period.
The fourth and final subquery selects the shortest path for leg three, and then calculates the overall route:
WITHupLeg, downLeg, topRoute,reduce(weight=0, rinrelationships(topRoute) | weight+r.cost)ASscoreORDER BYscoreASCLIMIT1RETURN(nodes(upLeg) +tail(nodes(topRoute)) +tail(nodes(downLeg)))ASn
This subquery works as follows:
-
WITHpipes one or more triples, comprisingupLeg,downLeg, andtopRoutepaths, to the current query. There will be one triple for each of the paths matched by the third subquery, with each path being bound totopRoutein successive triples (the paths bound toupLeganddownLegwill stay the same, because the first and second subqueries matched only one path each). Each triple is accompanied by ascorefor the path bound totopRoutefor that triple. This score is calculated using Cypher’sreducefunction, which for each triple sums thecostproperties on the relationships in the path currently bound totopRoute. The triples are then ordered by thisscore, lowest first, and then limited to the first triple in the sorted list. -
RETURNsums the nodes in the pathsupLeg,topRoute, anddownLegto produce the final results. Thetailfunction drops the first node in each of the pathstopRouteanddownLeg, because that node will already be present in the preceding path.
Implementing route calculation with the Traversal Framework
The time-critical nature of the route calculation imposes strict demands on the route calculation engine. As long as the individual query latencies are low enough, it’s always possible to scale horizontally for increased throughput. The Cypher-based solution is fast, but with many thousands of parcels entering the network each second, every millisecond impacts the cluster footprint. For this reason, Global Post adopted an alternative approach: calculating routes using Neo4j’s Traversal Framework.
A traversal-based implementation of the route calculation engine must solve two problems: finding the shortest paths, and filtering the paths based on time period. We’ll look at how we filter paths based on time period first.
Traversals should only follow relationships that are valid for the specified delivery period. In other words, as the traversal progresses through the graph, it should be presented with only those relationships whose periods of validity, as defined by their start_date and end_date properties, contain the specified delivery period.
We implement this relationship filtering using a PathExpander. Given a path from a traversal’s start node to the node where it is currently positioned, a PathExpander’s expand() method returns the relationships that can be used to traverse further. This method is called by the Traversal Framework each time the framework advances another node into the graph. If needed, the client can supply some initial state, called the branch state, to the traversal. The expand() method can use (and even change) the supplied branch state in the course of deciding which relationships to return. The route calculator’s ValidPathExpander implementation uses this branch state to supply the delivery period to the expander.
Here’s the code for the ValidPathExpander:
privatestaticclassValidPathExpanderimplementsPathExpander<Interval>{privatefinalRelationshipTyperelationshipType;privatefinalDirectiondirection;privateValidPathExpander(RelationshipTyperelationshipType,Directiondirection){this.relationshipType=relationshipType;this.direction=direction;}@OverridepublicIterable<Relationship>expand(Pathpath,BranchState<Interval>deliveryInterval){List<Relationship>results=newArrayList<Relationship>();for(Relationshipr:path.endNode().getRelationships(relationshipType,direction)){IntervalrelationshipInterval=newInterval((Long)r.getProperty("start_date"),(Long)r.getProperty("end_date"));if(relationshipInterval.contains(deliveryInterval.getState())){results.add(r);}}returnresults;}}
The ValidPathExpander’s constructor takes two arguments: a relationshipType and a direction. This allows the expander to be reused for different types of relationships. In the case of the Global Post graph, the expander will be used to filter both CONNECTED_TO and DELIVERY_ROUTE relationships.
The expander’s expand() method takes as parameters the path that extends from the traversal’s start node to the node on which the traversal is currently positioned, and the deliveryInterval branch state as supplied by the client. Each time it is called, expand() iterates the relevant relationships on the current node (the current node is given by path.endNode()). For each relationship, the method then compares the relationship’s interval with the supplied delivery interval. If the relationship’s interval contains the delivery interval, the relationship is added to the results.
Having looked at the ValidPathExpander, we can now turn to the ParcelRouteCalculator itself. This class encapsulates all the logic necessary to calculate a route between the point where a parcel enters the network and the final delivery destination. It employs a similar strategy to the Cypher query we’ve already looked at. That is, it works its way up the graph from both the start node and the end node in two separate traversals, until it finds a delivery base for each leg. It then performs a shortest weighted path search that joins these two delivery bases.
Here’s the beginning of the ParcelRouteCalculator class:
publicclassParcelRouteCalculator{privatestaticfinalPathExpander<Interval>DELIVERY_ROUTE_EXPANDER=newValidPathExpander(withName("DELIVERY_ROUTE"),Direction.INCOMING);privatestaticfinalPathExpander<Interval>CONNECTED_TO_EXPANDER=newValidPathExpander(withName("CONNECTED_TO"),Direction.BOTH);privatestaticfinalTraversalDescriptionDELIVERY_BASE_FINDER=Traversal.description().depthFirst().evaluator(newEvaluator(){privatefinalRelationshipTypeDELIVERY_ROUTE=withName("DELIVERY_ROUTE");@OverridepublicEvaluationevaluate(Pathpath){if(isDeliveryBase(path)){returnEvaluation.INCLUDE_AND_PRUNE;}returnEvaluation.EXCLUDE_AND_CONTINUE;}privatebooleanisDeliveryBase(Pathpath){return!path.endNode().hasRelationship(DELIVERY_ROUTE,Direction.INCOMING);}});privatestaticfinalCostEvaluator<Double>COST_EVALUATOR=CommonEvaluators.doubleCostEvaluator("cost");publicstaticfinalLabelLOCATION=DynamicLabel.label("Location");privateGraphDatabaseServicedb;publicParcelRouteCalculator(GraphDatabaseServicedb){this.db=db;}...}
Here we define two expanders—one for DELIVERY_ROUTE relationships, another for CONNECTED_TO relationships—and the traversal that will find the two legs of our route. This traversal terminates whenever it encounters a node with no incoming DELIVERY_ROUTE relationships. Because each delivery base is at the root of a delivery route tree, we can infer that a node without any incoming DELIVERY_ROUTE relationships represents a delivery base in our graph.
Each route calculation engine maintains a single instance of this route calculator. This instance is capable of servicing multiple requests. For each route to be calculated, the client calls the calculator’s calculateRoute() method, passing in the names of the start and end points, and the interval for which the route is to be calculated:
publicIterable<Node>calculateRoute(Stringstart,Stringend,Intervalinterval){try(Transactiontx=db.beginTx()){TraversalDescriptiondeliveryBaseFinder=createDeliveryBaseFinder(interval);PathupLeg=findRouteToDeliveryBase(start,deliveryBaseFinder);PathdownLeg=findRouteToDeliveryBase(end,deliveryBaseFinder);PathtopRoute=findRouteBetweenDeliveryBases(upLeg.endNode(),downLeg.endNode(),interval);Set<Node>routes=combineRoutes(upLeg,downLeg,topRoute);tx.success();returnroutes;}}
calculateRoute() first obtains a deliveryBaseFinder for the specified interval, which it then uses to find the routes for the two legs. Next, it finds the route between the delivery bases at the top of each leg, these being the last nodes in each leg’s path. Finally, it combines these routes to generate the final results.
The createDeliveryBaseFinder() helper method creates a traversal description configured with the supplied interval:
privateTraversalDescriptioncreateDeliveryBaseFinder(Intervalinterval){returnDELIVERY_BASE_FINDER.expand(DELIVERY_ROUTE_EXPANDER,newInitialBranchState.State<>(interval,interval));}
This traversal description is built by expanding the ParcelRouteCalculator’s static DELIVERY_BASE_FINDER traversal description using the DELIVERY_ROUTE_EXPANDER. The branch state for the expander is initialized at this point with the interval supplied by the client. This enables us to use the same base traversal description instance (DELIVERY_BASE_FINDER) for multiple requests. This base description is expanded and parameterized for each request.
Properly configured with an interval, the traversal description is then supplied to findRouteToDeliveryBase(), which looks up a starting node in the location index, and then executes the traversal:
privatePathfindRouteToDeliveryBase(StringstartPosition,TraversalDescriptiondeliveryBaseFinder){NodestartNode=IteratorUtil.single(db.findNodesByLabelAndProperty(LOCATION,"name",startPosition));returndeliveryBaseFinder.traverse(startNode).iterator().next();}
That’s the two legs taken care of. The last part of the calculation requires us to find the shortest path between the delivery bases at the top of each of the legs. calculateRoute() takes the last node from each leg’s path, and supplies these two nodes together with the client-supplied interval to findRouteBetweenDeliveryBases(). Here’s the implementation of findRouteBetweenDeliveryBases():
privatePathfindRouteBetweenDeliveryBases(NodedeliveryBase1,NodedeliveryBase2,Intervalinterval){PathFinder<WeightedPath>routeBetweenDeliveryBasesFinder=GraphAlgoFactory.dijkstra(CONNECTED_TO_EXPANDER,newInitialBranchState.State<>(interval,interval),COST_EVALUATOR);returnrouteBetweenDeliveryBasesFinder.findSinglePath(deliveryBase1,deliveryBase2);}
Rather than use a traversal description to find the shortest route between two nodes, this method uses a shortest weighted path algorithm from Neo4j’s graph algorithm library—in this instance, we’re using the Dijkstra algorithm (see “Path-Finding with Dijkstra’s Algorithm” for more details on the Dijkstra algorithm). This algorithm is configured with ParcelRouteCalculator’s static CONNECTED_TO_EXPANDER, which in turn is initialized with the client-supplied branch state interval. The algorithm is also configured with a cost evaluator (another static member), which simply identifies the property on a relationship representing that relationship’s weight or cost. A call to findSinglePath on the Dijkstra path finder returns the shortest path between the two delivery bases.
That’s the hard work done. All that remains is to join these routes to form the final results. This is relatively straightforward, the only wrinkle being that the down leg’s path must be reversed before being added to the results (the leg was calculated from final destination upward, whereas it should appear in the results delivery base downward):
privateSet<Node>combineRoutes(PathupLeg,PathdownLeg,PathtopRoute){LinkedHashSet<Node>results=newLinkedHashSet<>();results.addAll(IteratorUtil.asCollection(upLeg.nodes()));results.addAll(IteratorUtil.asCollection(topRoute.nodes()));results.addAll(IteratorUtil.asCollection(downLeg.reverseNodes()));returnresults;}
Summary
In this chapter, we’ve looked at some common real-world use cases for graph databases, and described in detail three case studies that show how graph databases have been used to build a social network, implement access control, and manage complex logistics calculations.
In the next chapter, we dive deeper into the internals of a graph database. In the concluding chapter, we look at some analytical techniques and algorithms for processing graph data.
1 See Nicholas Christakis and James Fowler, Connected: The Amazing Power of Social Networks and How They Shape Our Lives (HarperPress, 2011).
2 Neo4j Spatial is an open source library of utilities that implement spatial indexes and expose Neo4j data to geotools.
Figure 5-1. Sample of the Talent.net social network