
10 Stateful computation
In this chapter
- an introduction to stateful and stateless components
- how stateful components work
- related techniques
“Have you tried turning it off and on again?”
—The IT Crowd
We talked about state in chapter 5. In most computer programs, it is an important concept. For example, the progress in a game, the current content in a text editor, the rows in a spreadsheet, and the opened pages in a web browser are all states of the programs. When a program is closed and opened again, we would like to recover to the desired state. In streaming systems, handling states correctly is very important. In this chapter, we are going to discuss in more detail how states are used and managed in streaming systems.
The migration of the streaming jobs
System maintenance is part of our day-to-day work with distributed systems. A few examples are: releasing a new build with bug fixes and new features, upgrading software or hardware to make the systems more secure or efficient, and handling software and hardware failures to keep the systems running.
AJ and Sid have decided to migrate the streaming jobs to new and more efficient hardware to reduce cost and improve reliability. This is a major maintenance task, and it is important to proceed carefully.

Stateful components in the system usage job
Stateful components are very useful for the components that have internal data. We talked about them briefly in chapter 5 in the context of the system usage job. It is time take a closer look now and see how they really work internally.
We have discussed stateful components briefly in previous chapters. They are needed at a few places in our streaming job.
In order to resume the processing after a streaming job is restarted, each instance of a component needs to persist its key internal data, the state, to external storage beforehand as a checkpoint. After an instance is restarted, the data can be loaded back into memory and used to set up the instance before resuming the process.
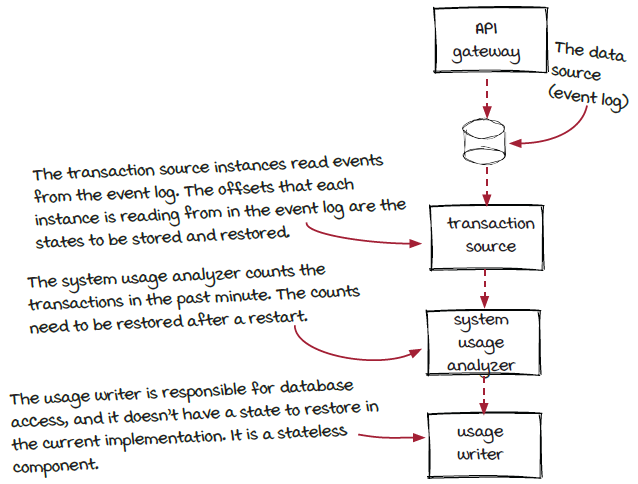
The data to persist varies from component to component. In the system usage job:
-
The transaction source needs to track the processing offsets. The offsets denote the positions that the transaction source component is reading from the data source (the event log).
-
The transaction counts are critical for the system usage analyzer and need to be persisted.
-
The usage writer doesn’t have any data to save and restore.
Therefore, the first two components need to be implemented as stateful components, and the last one is a stateless component.
Revisit: State
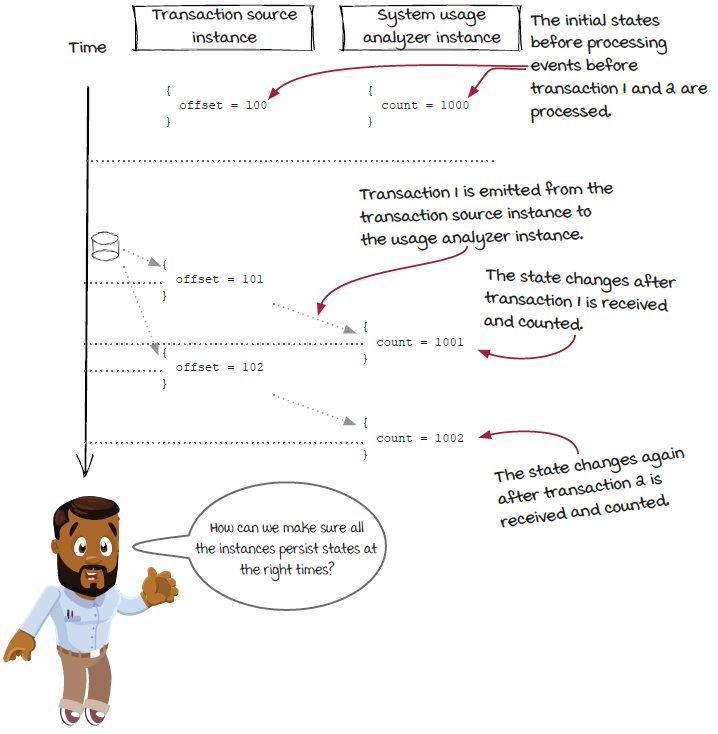
Before going deeper, let’s pause here and revisit a very basic concept: what is a state? As we explained in chapter 5, state is the internal data inside each instance that changes when events are processed. For example, the state of the transaction source component is where each instance is loading from the data source (aka the offset). The offset moves forward after new events are loaded. Let’s look at the state changes of a transaction source instance before and after two transactions are processed.

The states in different components
Things become interesting when we look at states in different components together. In chapter 7 about windowed computation, we said that the processing time of an event is different for different instances because the event flows from one instance to another. Similarly, for the same event, in different instances, the state changes happen at different times. Let’s look at the state changes of a transaction source instance and a system usage analyzer instance together before and after two transactions are processed.
State data vs. temporary data
So far, the definition of state is straightforward: the internal data inside an instance that changes when events are processed. Well, the definition is true, but some state data could be temporary and doesn’t need to be recovered when an instance is restored. Typically, temporary data is not included in the state of an instance.
For example, caching is a popular technique to improve performance and/or efficiency. Caching is the process of a component sitting in front of an expensive or slow calculation (e.g., a complex function or a request to a remote system) and storing the results, so the calculation doesn’t need to be executed repetitively. Normally, caches are not considered to be instance state data, although they could change when events are processed. After all, an instance should still work correctly with a brand new cache after being restarted. The database connection in each usage writer instance is also temporary data, since the connection will be set up again from scratch after the instance is restarted.
Another example is the transaction source component in the fraud detection job. Internally, each instance has an offset of the last transaction event it has loaded from the data source. However, like we have discussed in chapter 5, because latency is critical for this job, it is more desirable to skip to the latest transaction instead of restoring to the previous offset when an instance is restarted. The offset is temporary in this job, and it should not be considered to be state data. Therefore, the component is a stateless component instead of a stateful one.

In conclusion, instance state includes only the key data, so the instance can be rolled back to a previous point and continue working from there correctly. Temporary data is typically not considered to be state data in stream systems.
Stateful vs. stateless components: The code
The transaction source component exists in both the system usage job and the fraud detection job, and it works in a similar way. The only difference is that it is stateful in the system usage job and stateless in the fraud detection job. Let’s put their code together to look at the changes in the stateful component:
-
The
setupInstance()function has an extrastateparameter. -
There is a new
getState()function.
class TransactionSource extends StatefulSource {
EventLog transactions = new EventLog();
int offset = 0;
......
public void setupInstance(int instance, State state) {
SourceState mstate = (SourceState)state;
if (mstate != null) {
offset = mstate.offset; ❶
transactions.seek(offset);
}
}
public void getEvents(Event event, EventCollector eventCollector) {
Transaction transaction = transactions.pull();
eventCollector.add(new TransactionEvent(transaction));
offset++; ❷
system.out.println("Reading from offset %d", offset);
}
public State getState() {
SourceState state = new SourceState();
State.offset = offset;
return new state; ❸
}
}
class TransactionSource extends Source { ❹
EventLog transactions = new EventLog();
int offset = 0;
......
public void setupInstance(int instance) {
offset = transactions.seek(LATEST);
}
public void getEvents(Event event, EventCollector eventCollector) {
Transaction transaction = transactions.pull();
eventCollector.add(new TransactionEvent(transaction));
offset++;
system.out.println("Reading from offset %d", offset);
}
}❶ The stateful version in the system usage job
❷ The data in the state object is used to set up the instance.
❸ The state object of the instance contains the current data offset in the event log.
❹ The stateless version in the fraud detection job
The stateful source and operator in the system usage job
In chapter 5, we have read the code of the TransactionSource and the SystemUsageAnalyzer classes. Now, let’s put them together and compare. Overall, the state handling is very similar between stateful sources and operators.
class TransactionSource extends StatefulSource {
MessageQueue queue;
int offset = 0;
......
public void setupInstance(int instance, State state) {
SourceState mstate = (SourceState)state;
if (mstate != null) {
offset = mstate.offset; ❶
log.seek(offset);
}
}
public void getEvents(Event event, EventCollector eventCollector) {
Transaction transaction = log.pull();
eventCollector.add(new TransactionEvent(transaction));
offset++; ❷
}
public State getState() {
SourceState state = new SourceState();
State.offset = offset;
return new state; ❸
}
}
class SystemUsageAnalyzer extends StatefulOperator {
int transactionCount;
public void setupInstance(int instance, State state) {
AnalyzerState mstate = (AnalyzerState)state;
transactionCount = state.count; ❹
}
public void apply(Event event, EventCollector eventCollector) {
transactionCount++; ❺
eventCollector.add(transactionCount);
}
public State getState() {
AnalyzerState state = new AnalyzerState();
State.count = transactionCount; ❻
return state;
}
}❶ The data in the state object is used to set up the instance.
❷ The offset value changes when a new event is pulled from the event log and emitted to the downstream components.
❸ The state object of the instance contains the current data offset in the event log.
❹ When an instance is constructed, a state object is used to initialize the instance.
❺ The count variable changes when events are processed.
❻ A new state object is created to store instance data periodically.
States and checkpoints
Compared to stateless components we have seen before, two functions are added in stateful components and need to be implemented by developers:
-
The
getState()function, which translates the instance data to a state object. -
The
setupInstance()function, which uses a state object to reconstruct an instance.
Now, let’s look at what really happens behind the scenes to connect the dots. This information could be useful for you to build efficient and reliable jobs and investigate when issues happen.
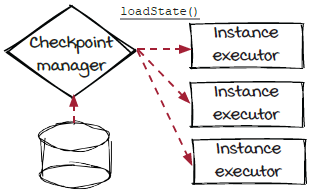
In chapter 5, we defined checkpoint as “a piece of data that can be used by an instance to restore to a previous state.” The streaming engine, more specifically, the instance executor and the checkpoint manager (remember the single responsibility principle?), is responsible for calling the two functions in the following two cases, respectively:
-
The
getState()function is called periodically by the instance executor to get the latest state of each instance, and the state object is then sent to the checkpoint manager to create a checkpoint.

-
The
setupInstance()function is called by the instance executor after the instance is created, and the most recent checkpoint is loaded by the checkpoint manager.

Checkpoint creation: Timing is hard
The instance executors are responsible for calling the instances’ getState() function to get the current states and then sending them to the checkpoint manager to be saved in the checkpoint. An open question is how the instance executors know the right time to trigger the process.
An intuitive answer might be triggering by clock time. All instance executors trigger the function at exactly the same time. A snapshot of the whole system can be taken just like when we put a computer into hibernation mode in which everything in memory is dumped to disk, and the data is reloaded back into memory when the computer is woken up.
However, in streaming systems this technique doesn’t work. When a checkpoint creation is started, some events have been processed by some components but not processed by the downstream components yet. If a checkpoint is created this way and used to reconstruct instances, the states of different instances would be out of sync, and the results will be incorrect afterwards.

For example, in a working streaming job, each event is processed by an instance of the source component (the transaction source in the system usage job), and then sent to the right instance of the downstream component (the system usage analyzer in the system usage job). The process repeats until there is no downstream component left. Therefore, each event is processed at a different time in different components, and at the same time, different components are working on different events.
To avoid the out-of-sync issue and keep the results correct, instead of dumping states at the same clock time, the key is for all the instances to dump their states at the same event-based time: right after the same transaction is processed.
Event-based timing
For checkpointing in streaming systems, time is measured by event id instead of clock time. For example, in the system usage job, the transaction source would be at the time of transaction #1001 when transaction #1001 has just been processed by it and emitted out. The system usage analyzer would be at the time of after transaction #1000 at the same moment and reaches the time of transaction #1001 after transaction #1001 is received, processed, and emitted out. The diagram below shows the clock time and the event-based time in the same place. To keep things simple, we are assuming that each component has only one instance. The multiple instance case will be covered later when we discuss the implementation.

With this event-based timing, all instances can dump their states at the same time to create a valid checkpoint.
Creating checkpoints with checkpoint events
So how is event-based timing implemented in streaming frameworks? Like events, the timing is built in a streaming context we have been talking about throughout this book. Sound interesting?
Event-based timing sounds straightforward overall, but there is a problem: typically, there are multiple instances created for each component, and each event is processed by one of them. How are the instances synchronized with each other? Here, we would like to introduce a new type of events, control events, which have a different routing strategy than the data events.
So far, all our streaming jobs have been processing data events, such as vehicle events and credit card transactions. Control events don’t contain data to process. Instead, they contain data for all modules in a streaming job to communicate with each other. In the checkpoint case, we need a checkpoint event with the responsibility of notifying all the instances in a streaming job that it is time to create a checkpoint. There could be other types of control events, but the checkpoint event is the only one in this book.
Periodically, the checkpoint manager in the job issues a checkpoint event with a unique id and emits it to the source component, or more accurately, the instance executors of the instances of the source component. The instance executors then insert the checkpoint event into the stream of regular data events, and the journey of the checkpoint event starts.

Note that the instances of the source component that contain user logic don’t know the existence of the checkpoint event. All they know is that the getState() function is invoked by the instance executor to extract the current states.
A checkpoint event is handled by instance executors
Each instance executor repeats the same process:
-
Invoking the
getState()function and sending the state to the checkpoint manager -
Inserting the checkpoint event into its outgoing stream
If you look at the diagram below closely, you will find that each checkpoint event also contains a checkpoint id. The checkpoint id can be considered an event-based time. When an instance executor sends the state object to the checkpoint manager, the id is included, so the checkpoint manager knows that the instance is in this state at this time. The id is included in the checkpoint object, as well, for the same purpose.

A checkpoint event flowing through a job
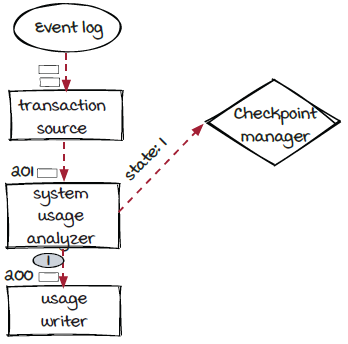
After the checkpoint event is inserted into the event stream by the source instance executors, it is going to flow through the job and visit the instance executors of all the operators in the job. The two diagrams below show that the checkpoint event with id 1 is processed by the transaction source and the system usage analyzer components one after the other.
The last component, usage writer, doesn’t have a state, so it notifies the checkpoint manager that the event has been processed without a state object. The checkpoint manager then knows that the checkpoint event has visited all the components in the job, and the checkpoint is finally completed and can be persisted to storage.

Overall, the checkpoint event flows through the job similarly to a regular event but not in exactly the same way. Let’s look one level deeper.
Creating checkpoints with checkpoint events at the instance level
The checkpoint event flows from component to component. State objects are sent to the checkpoint manager one by one by the instance executors when the checkpoint event is received. As a result, all the states are created between the same two events (200 and 201) for every single component in the example shown here.
One thing we shouldn’t forget is that there could be multiple instances for each component. We learned in chapter 4 that each event is routed to a specific instance based on a grouping strategy. The checkpoint event is routed quite differently; let’s take a look. (Note that this page and the next might be a little too detailed for some readers. If you have this feeling, please feel free to skip them and jump to the checkpoint loading topic.)

The simple answer is that all the instances need to receive the checkpoint event to trigger the getState() call correctly. In our Streamwork framework, the event dispatcher is responsible for synchronizing and dispatching the checkpoint event. Let’s start with the dispatching first (since it is simpler) and talk about the synchronizing in the next page.

When an event dispatcher receives a checkpoint event from the upstream component, it will emit one copy of the event to each instance of the downstream component. For comparison, for a data event, typically only one instance of the downstream component will receive it.
Checkpoint event synchronization
While the checkpoint event dispatching is fairly straightforward, the synchronization part is a little trickier. Checkpoint event synchronization is the process for the event dispatcher to receive the incoming checkpoint events. Each event dispatcher receives events from multiple instances (in fact, it could also receive events from instances of multiple components), so one checkpoint event is expected from each upstream instance executor. These checkpoint events rarely arrive at the same time like in the example in the diagram shown here. So what should it do in this case?
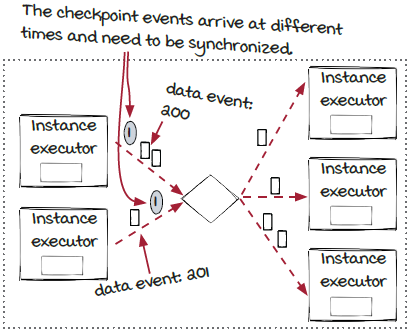
If we look at the diagram above and take the event-based timing into consideration, the time that the checkpoint event #1 represents is between data events #200 and #201. A checkpoint event is received by all the instance executors, so it is possible that the checkpoint event is processed by one instance earlier than the others like in the diagram above. In this case, after receiving the first checkpoint event, the event dispatcher will block the event stream that the checkpoint event came from, until the checkpoint event is received from all the other incoming connections. In other words, the checkpoint event is treated like a barrier, or a blocker. In the example above, the checkpoint event arrives from the bottom connection first. The event dispatcher will block the process of data event #201 and keep processing events (the data events #200 and the one before it) from the upper incoming connection until the checkpoint event is received.
After the checkpoint event #1 is received from both connections, since there are no other incoming connections to wait for, the event dispatcher emits the checkpoint event to all the downstream instance executors and starts consuming data events. As a result, data event #200 is dispatched before checkpoint event #1 and data event #201 by the event dispatcher.

Checkpoint loading and backward compatibility
Now that we have discussed how checkpoints are created, let’s take a look at how checkpoints are loaded and used. Unlike the creation process, which happens repetitively, checkpoint loading happens only once in each life cycle of a stream job: at the start time.
When a streaming job is started (e.g., something has happened, like an instance has just crashed, and the job needs to be restarted on the same machines; the job instances moved to different machines like the migration AJ and Sid are working on), each instance executor requests the state data for the corresponding instance from the checkpoint manager. The checkpoint manager in turn accesses the checkpoint storage, looks for the latest checkpoint, and returns the data to the instance executors. Each instance executor then uses the received state data to set up the instance. After all the instances are constructed successfully, the stream job starts processing events.

The whole process is fairly straightforward, but there is a catch: backward compatibility. The checkpoint was created in the previous run of the job, and the state data in the checkpoint is used to construct the new instances. If the job is simply restarted (manually or automatically), there shouldn’t be any problem, as the logic of the instances is the same as before. However, if the logic of the existing stateful components has changed, it is important for developers to make sure that the new implementation works with the old checkpoints, so the instances’ states can be restored correctly. If this requirement is not met, the job might start from a bad state, or it might stop working.
Some streaming frameworks manage the checkpoints between deployments as a special type of checkpoints: savepoints. These savepoints are similar to regular checkpoints, but they are triggered manually, and developers have more control. This can be a factor to consider when developers choose streaming frameworks for their systems.
Checkpoint storage
The last topic related to checkpoints is storage. Checkpoints are typically created periodically with a monotonically increasing checkpoint id, and this engine-managed process continues until the streaming job is stopped.

When instances are restarted, only the most recent checkpoint is used to initialize them. In theory, we can keep only one checkpoint for a stream job and update it in place when a new one is created.
However, life is full of ups and downs. For example, the checkpoint creation can fail if some instances are lost and the checkpoint is not completed, or the checkpoint data can be corrupted because of disk failures and can’t be loaded. In order to make the streaming systems more reliable, typically the most recent N checkpoints are kept in the storage and the older checkpoints can be dropped and the N is typically configurable. In case the most recent checkpoint is not usable, the checkpoint manager will fall back to the second latest checkpoint and try to use it to restore the streaming job. The fall back can happen again if needed until a good one is loaded successfully.

Stateful vs. stateless components
We have read enough about the details of stateful components and checkpoints. It is time to take a break, look at the bigger picture, and think about the pros and cons of stateful components. After all, stateful components are not free. The real question is: should I use stateful components or not?
The fact is that only you, the developer, have the final answer. Different systems have different requirements. Even though some systems have similar functionality, they may run totally differently because the incoming event traffic has different patterns, such as the throughput, data size, cardinality, and so on. We hope that the brief comparison below can be helpful for you to make better decisions and build better systems. In the rest of this chapter, we are going to talk about two practical techniques to support some useful features of stateful components with stateless components.
|
Stateful component |
Stateless component | |
|
Accuracy |
|
|
|
Latency (when errors happen) |
|
|
|
Resource usage |
|
|
|
Maintenance burden |
|
|
|
Throughput |
|
|
|
Code |
|
|
|
Dependency |
|
|
We use stateful components only when they are necessary. We do this to keep the job as simple as possible to reduce the burden of maintenance.
Manually managed instance states
From the comparison, it is clear that accuracy is the advantage of stateful components. When something happens, and some instances need to be restarted, streaming engines help to manage and rollback the instance states. In addition to the burden, the engine-managed states also have some limitations. One obvious limitation is that the checkpoint shouldn’t be created too frequently because the extra burden would be higher, and the system would become less efficient. Furthermore, it could be more desirable for some components to have different intervals, which is not feasible with engine-managed states. Therefore, sometimes, it is a valid option to consider is managing instance states manually. Let’s use the system usage job as an example to study how it works.

The diagram below shows the system usage job with a state storage hooked up. Different instances store their states in the storage independently. Like we discussed earlier, absolute time won’t really work because different instances are working on different events. And since we are managing states manually, now we don’t have the checkpoint events to provide event-based timing. What should we do to synchronize different instances?
The key is to have something in common that can be used by all components and instances to sync up with each other. One solution is to use transaction id. For example, transaction source instances store offsets, and system usage analyzer instances store transaction ids and current counts in the storage every minute. When the job is restarted, transaction source instances load the offset from storage, and then they go back a little (a number of events or a few minutes back) and restart from there. The system usage analyzer instances load the most recent transaction ids and counts from the storage. Afterwards, the analyzer instances can skip the incoming events until the transaction ids in the states are found and then the regular counting can be resumed. In this solution, transaction source and system usage analyzers can manage their instance states in different ways because the two components are not tightly coupled by the checkpoint ids anymore. As a result, the overhead could be lower, and we also get more flexibility, which could be important for some real-world use cases.

Lambda architecture
Another popular and interesting technique is called lambda architecture. The name sounds fancy, but take it easy; it is not that complicated.
To understand this technique, we will need to recall a concept from chapter 1 about the comparison of batch and stream processing systems. While streaming processing systems can generate results in real time, batch processing systems are normally more failure tolerant because if things go wrong, it is easy to drop all the temporary data and reprocess the event batch from the beginning. In consequence, the final results are accurate because each event is calculated exactly once toward the final results. Also, because batch processing systems can be more efficient to process a huge number of events, in some cases more complicated calculations that are hard to do in real time can be applied.
The idea of lambda architecture is rather simple: running a streaming job and a batch job in parallel on the same event data. In this architecture, the streaming job is responsible for generating the real-time results that are mostly accurate but provides no guarantee when bad things happen; the batch job, on the other hand, is responsible for generating accurate results with higher latency.

With lambda architecture, there will be two systems to build and maintain, and the presentation of the two sets of results can be more complicated. However, the accuracy requirement of the streaming job can be much less strict, and the streaming job can focus on what it is designed for and good at: processing events in real time.
Summary
In this chapter, we revisited the instance state and took a closer look. Then, we dived into more details of how instance states and checkpoints are managed in streaming jobs, including:
-
Checkpoint creation via checkpoint events
-
Checkpoint loading and the backward compatibility issue
-
Checkpoint storage
After briefly comparing stateful and stateless components, we also learned two popular techniques that can be used to archive some benefits of stateful components without the burdens:
-
Manually managed instance states
-
Lambda architecture
Exercises
-
If the system usage job is converted into a stateless job, what are the pros and cons? Can you improve it by manually managing the instance states? And what would happen if a hardware failure occurred and the instances were restarted on different machines?
-
The fraud detection job is optimized for real-time processing because of the latency requirement. What are the tradeoffs, and how can it be improved with lambda architecture?