
11 Wrap-up: Advanced concepts in streaming systems
In this chapter
- reviewing the more complex topics in streaming systems
- understanding where to go from here
“It’s not whether you get knocked down; it’s whether you get up.”
—Vince Lombardi
You did it! You have reached the end of part two of this book, and we have discussed quite a few topics in more detail. Let’s review them quickly to strengthen your memory.
Is this really the end?
Well, we authors think it’s safe to say this is the end of the book, but you can count on having many more years of learning and experimenting in front of you. As we sit and write this chapter, we’re reflecting on the long journey of learning. What an adventure it has been for us! Hopefully, after reading this book, you feel that you benefited from it—we certainly have.
What you will get from this chapter
There have been many complex topics covered in the second half of the book. We’d like to recap the main points. You may not need to know all of these topics in depth in the beginning of your career, but knowing them will help you establish yourself in the upper echelon of technologists in the field when it comes to real-time systems. After all, learning these topics well is not a trivial task.
Windowed computations
We learned that not all streaming jobs want to handle events one at a time. It can be useful to group events together in some cases, whether that is time- or count-related.

The major window types
Creating or defining a window is entirely up to the developer. We showed three different base window types, using the fraud detection job as an example. Note that time-based windows are used in the diagrams below.
Fixed Windows

Sliding Windows

Session Windows

Joining data in real time
In chapter 8, we covered joining data in real time. In this scenario, we had two different types of events being emitted from the same geographic region. We needed to decide how to join events that are in two different event types and coming at different intervals.

SQL vs. stream joins
Most of us are familiar (enough) with the join clause in SQL. In streaming systems, it is similar but not quite the same. In one typical solution, one incoming stream works like a stream, and the other stream is (or streams are) converted into a temporary in-memory table and used as reference data. The table can be considered to be a materialized view of a stream.
There are two things to remember:
-
Stream join is another type of fan-in.
-
A stream can be materialized into a table continuously or using a window.

Inner joins vs. outer joins
Like the join clause in SQL, there are four types of joins in streaming systems as well. You need to choose the right one for your own use case.

Unexpected things can happen in streaming systems
Building reliable distributed systems is challenging and interesting. In chapter 9, we explored common issues that can occur in streaming systems and cause some instances to lag behind, as well as a widely supported technique for temporary issues: backpressure.

Backpressure: Slow down sources or upstream components
Backpressure is a force opposite to the data flow direction that slows down the event traffic. Two methods we covered for addressing backpressure were stopping the sources and stopping the upstream components.
Stopping the sources

Stopping the upstream components

Another approach to handle lagging instances: Dropping events
In this approach, when an instance is lagging behind, instead of stopping and resuming the processing of the source or the upstream components, the system will just throw away the new events being routed to the instance.
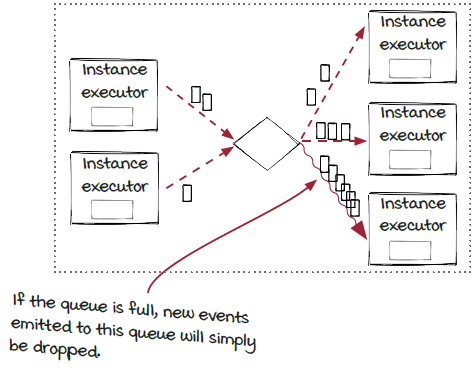
It is certainly reasonable to be cautious when choosing this option, as the events will be lost. However, it may not be as scary as it sounds. The results are not accurate only when backpressure is happening, which should be rare in theory. So, they should still be accurate almost all the time. On the other side, dropping events could be desirable in the cases in which end-to-end latency is more important than accuracy. Don’t forget that dropping events is much more lightweight than pausing and resuming the event processing.
Backpressure can be a symptom when the underlying issue is permanent
We have mentioned a few times that backpressure is a self-protection mechanism for avoiding more serious issues in extreme scenarios. While we hope that the issue that causes some instances to lag behind is temporary and backpressure can handle it automatically, it is possible that the instance won’t recover and the owner’s interventions will be required to take care of the root cause. In these cases, permanent backpressure is a symptom, and developers need to address the root causes.
The instance stops working, so backpressure won’t be relieved
In this case, no events will be consumed from the queue, and the backpressure state will never be relieved at all. This is relatively straightforward to handle: by fixing the instance. Restarting the instance could be an immediate remediation step, but it could be important to figure out the root cause and address it accordingly. Often, the issue leads to bugs that need to be fixed.
The instance can’t catch up, and backpressure will be triggered again: Thrashing
If you see the thrashing, you will likely need to consider why the instance doesn’t process quickly enough. Typically, this kind of issue comes from two causes: the traffic and the components. If the traffic has increased or the pattern has changed, it could be necessary to tune or scale up the system. If the instance runs slower, you will need to figure out the root cause. Note that it is important to take the dependencies into consideration as well. After all, it is important for you, the owner of the systems, to understand the data and the systems and figure out what is causing the backpressure to be triggered.
Stateful components with checkpoints
In chapter 10, we learned how we could stop and start a streaming job without losing data. Stateful components allow for the recreation of a context, so the components resume the processing from the state where it stopped previously. In our specific case, AJ and Miranda needed a way to stop and restart the system usage job on new machines transparently.
A checkpoint, a piece of data that can be used by an instance to restore to a previous state, is the key for persisting and restoring instance states.
-
The
getState()function is called periodically by the instance executor to get the latest state of each instance, and the state object is then sent to the checkpoint manager to create a checkpoint.
-
The
setupInstance()function is called by the instance executor after the instance is created, and the most recent checkpoint is loaded by the checkpoint manager.
Event-based timing
Every instance in a streaming job needs to get its state at the same time, so a job can be restored to a previous time when needed. However, the time here isn’t the clock time. Instead, it needs to be event-based time.

The checkpoint manager is responsible for generating a checkpoint event periodically and emitting it to all the source instances. The event then flows through the whole job to notify each instance that it is time to send the internal state to the checkpoint manager. Note that, unlike the regular data events, which are routed to one instance of a downstream component, the checkpoint event is routed to all the instances of a downstream component.
At the instance level, each event dispatcher connects to multiple upstream instances and multiple downstream instances. The incoming checkpoint events of the event dispatcher may not arrive at the same time, and they need to be synchronized before sending out to the downstream instances.

Stateful vs. stateless components
As a creator or maintainer of streaming jobs, you will need to decide when to use a stateless or a stateful component. This is where you will need to go with your gut instinct or collaborate with a team to make this decision. It is not clear-cut when to use a stateful or stateless component in every scenario, so in times like these, you really become the artist. The following table compares several aspects of stateful and stateless components.
Stateful components are fantastic in terms of adding reliability to a streaming job, but remember to keep things simple at first. As soon as you introduce state into your streaming jobs, the complexity of planning, debugging, diagnosing, and predicting could make them much more cumbersome. Make sure you understand the cost before making each decision.
|
Stateful component |
Stateless component | |
|
Accuracy |
|
|
|
Latency (when errors happen) |
|
|
|
Resource usage |
|
|
|
Maintenance burden |
|
|
|
Throughput |
|
|
|
Code |
|
|
|
Dependency |
|
|
You did it!
Pat yourself on the back; that was a lot of material to cover. You have made it through about 300 pages of how streaming systems work! So, what’s next? Well, you can start working hard to increase your knowledge and experience on the subject. Don’t have a degree? Don’t worry; you don’t need one. With a little dedication you can definitely master streaming systems (and your tech career). We’ve listed a few ideas for you to consider. Again, you don’t necessarily have to work on them in the same order.
Pick an open source project to learn
Try to rebuild the problems you’ve worked through in the book in a real open source streaming framework. See if you can recognize the parts that make up our Streamwork engine in real streaming frameworks. What are instances, instance executors, and event dispatchers called in the frame you picked?
Start a blog, and teach what you learn
The best way to learn something is to teach it. Start to build your own brand, and be ready for some critical reviewers to come your way, too. It is interesting to see people interpret the same concept from many different angles.
Attend meetups and conferences
There are many details and real-world use cases in stream systems and other event processing systems. You can learn a lot from other people’s stories in related meetups and conferences. You can also go further by speaking and holding virtual presentations and discussions as well!
Contribute to open source projects
If there is one thing we can say will work for you most in this list, it’s this one. In our experience, nothing has increased our technology and people skills more than this strategy. Contributing to open source projects exposes you to advanced technologies and allows you to plan, design, and implement features with real-life professionals across the world. Most importantly, we would bet that working on open source projects will fulfill you more than anything you’ve ever been paid for. There is something about contributing to a cause being driven by purpose that will pay more than any paycheck can for years to come.
Don’t quit, ever
Obtaining any extraordinary goal comes with walking through failure over and over. Be okay with failure. It is what will make you better.