
During the training phase, we need to correctly predict our training set with our current set of weights; this process consists of evaluating our training set inputs X and comparing with the desired output Y. Some sort of mechanism is needed to quantify (return a scalar number) on how good our current set of weights are in terms of correctly predicting our desired outputs. This mechanism is named the loss function.
The backpropagation algorithm should return the derivative of each parameter with respect to the loss function. This means we find out how changing each parameter will affect the value of the loss function. It is then the job of the optimization algorithm to minimize the loss function, in other words, make the training error smaller as we train.
One important aspect is to choose the right loss function for the job. Some of the most common loss functions and what tasks they are used for are given here:
- Log Loss - Classification tasks (returning a label from a finite set) with only two possible outcomes
- Cross-Entropy Loss - Classification tasks (returning a label from a finite set) with more than two outcomes
- L1 Loss - Regression tasks (returning a real valued number)
- L2 Loss - Regression tasks (returning a real valued number)
- Huber Loss - Regression tasks (returning a real valued number)
We will see different examples of loss functions in action throughout this book.
Another important aspect of loss functions is that they need to be differentiable; otherwise, we cannot use them with backpropagation. This is because backpropagation requires us to be able to take the derivative of our loss function.
In the following diagram, you can observe that the loss function is connected at the end of the neural network (model output) and basically depends on the output of the model and the dataset desired targets.
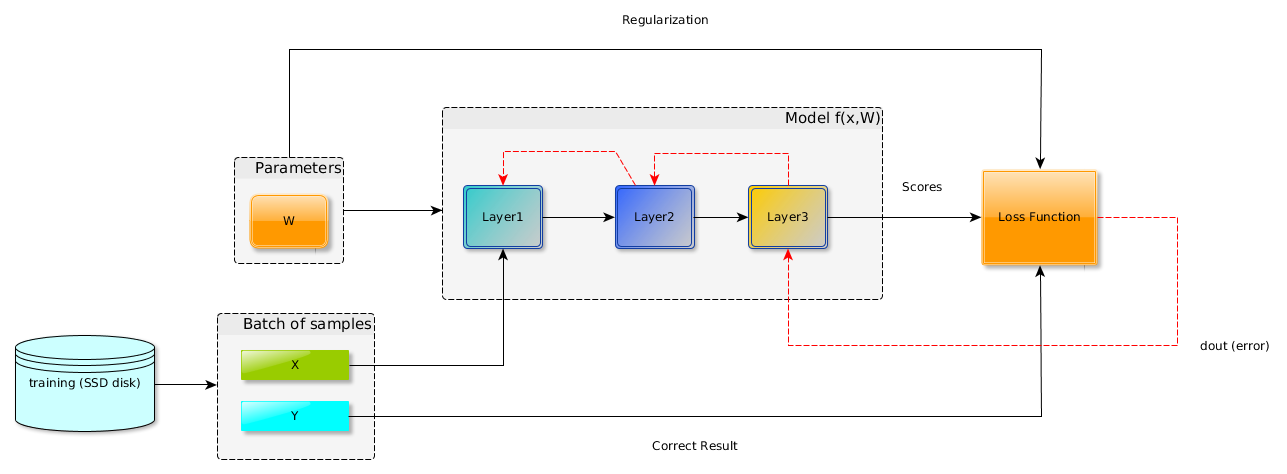
This is also shown in the following line of code in TensorFlow as the loss only needs labels and outputs (called logits here).
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
You probably noticed a third arrow also connected to the loss function. This is related to something named regularization, which will be explored in Chapter 3, Image Classification in TensorFlow; so for now, you can safely ignore it.