
Earlier, we took care of the initialization of our weights to make the job of gradient descent optimizers easier. However, the benefits are only seen during the early stages of training and do not guarantee improvements in the latter stages. That is where we turn to another great invention called the batch norm layer. The effect produced by using the batch norm layer in a CNN model is more or less the same as the input normalization that we saw in Chapter 2, Deep Learning and Convolutional Neural Networks; the only difference now is that this will happen at the output of all the convolution and fully connected layers in your model.
The batch norm layer will usually be attached to the end of every fully connected or convolution layer, but before the activation functions, where it will normalize the layer outputs, as it is shown in the following illustration. It does this by taking a layers output (a batch of activations) and subtracting the batch mean and dividing by the batch standard deviation, so the layer outputs have zero-mean and unit standard deviation. Be aware that the placement of batchnorm before or after activation functions is a hotly debated topic, but both should work.

After this normalization, the batch norm layer also has two learnable parameters that will scale and shift the normalized activations to whatever the model thinks is best to help it learn. The whole process helps training by eliminating vanishing gradient problems. This, in turn, allows a model to use higher learning rates while training, so it converges in less iterations.
During training, a running average of mean and standard deviation values are recorded. These values are then used at test time rather than calculating batch statistics.
Some advantages of the batch norm layer are as follows:
- Improves gradient flow, allowing more deep networks to be trained (fixing the vanishing gradient issue)
- Allows higher learning rates, making the training faster
- Reduces the dependency on good weight initialization (simpler random initialization)
- Gives some sort of regularization effect to your model
- Makes it possible to use saturating nonlinearities such as sigmoid
For the more mathematical reader, a slightly more formal definition can be found in the batch norm paper “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”, which is a really well-written paper that is easy to understand and explains the concept in much more detail. If we assume that we have a simple neural network with only fully connected layers, then as we saw in Chapter 1, Setup and Introduction to TensorFlow, an activation at each layer will be of the  form.
form.
Let’s assume that  is a nonlinearity, such as sigmoid or ReLU, then batch normalization
is a nonlinearity, such as sigmoid or ReLU, then batch normalization  is applied to each unit directly before the nonlinearity as such:
is applied to each unit directly before the nonlinearity as such:

Here, the bias can be ignored, as it will be canceled by mean subtraction. If our batch size is  then the normalized activation
then the normalized activation 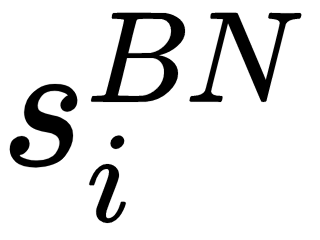 is calculated as follows:
is calculated as follows:




where,  and
and  are learnable parameters that will scale and shift your normalized activations. These parameters are there for the network to decide whether the normalization is needed or not, and how much. This is true, because if we set
are learnable parameters that will scale and shift your normalized activations. These parameters are there for the network to decide whether the normalization is needed or not, and how much. This is true, because if we set  and
and  , then
, then  .
.
Finally, here's an example of how to use the batch norm layer in the classification example code that we started in this chapter. In this case, we have put a batchnorm layer after a convolutional layer and before the activation function:
conv3 = tf.layers.conv2d(inputs=pool2, filters=32, kernel_size=[5, 5],padding="same", activation=None)
conv3_bn = tf.layers.batch_normalization(inputs=conv3, axis=-1, momentum=0.9, epsilon=0.001, center=True,scale=True, training=self.__is_training, name='conv3_bn')
conv3_bn_relu = tf.nn.relu(conv3_bn)
pool3 = tf.layers.max_pooling2d(inputs=conv3_bn_relu, pool_size=[2, 2], strides=2)