
Based on the performance of the test data, we can create a confusion matrix. This matrix contains four different parameters: true positive, true negative, false positive, and false negative. Consider the following confusion matrix:
|
Predicted: Positive |
Predicted: Negative |
|
|
Actual: Positive |
True Positive (TP) |
False Negative (FN) |
|
Actual: Negative |
False Positive (FP) |
True Negative (TN) |
This matrix shows four distinct parameters:
- True positives: The model predicts TRUE when the actual value is TRUE.
- True negatives: The model predicts FALSE when the actual value is FALSE.
- False-positives: The model predicts TRUE when the actual value is FALSE. This is also referred to as a Type I Error.
- False-negatives: The model predicts FALSE when the actual value is TRUE. This is also referred to as a Type II Error.
Once we know about the confusion matrix, we can compute several accuracies of the model, including precision, negative predicate value, sensitivity, specificity, and accuracy. Let's take a look at each of them, one by one, and learn how they can be computed.
The precision is the ratio of true positive and the sum of a true positive and false positive. The formula is as follows:

The formula for the Negative Predictive Value (NPV) is as follows:
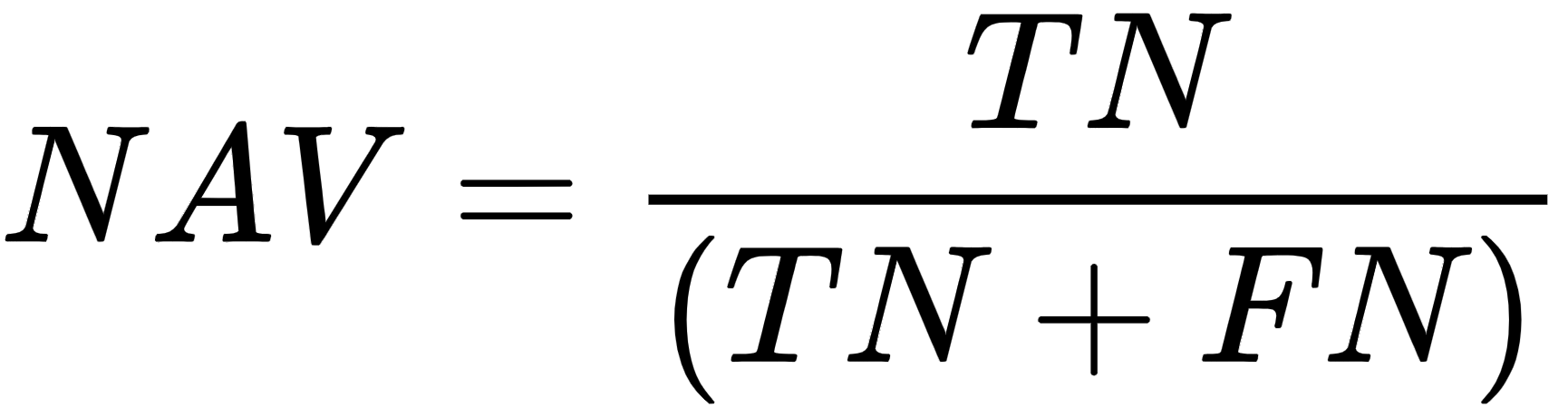
Similarity, the formula for sensitivity is as follows:
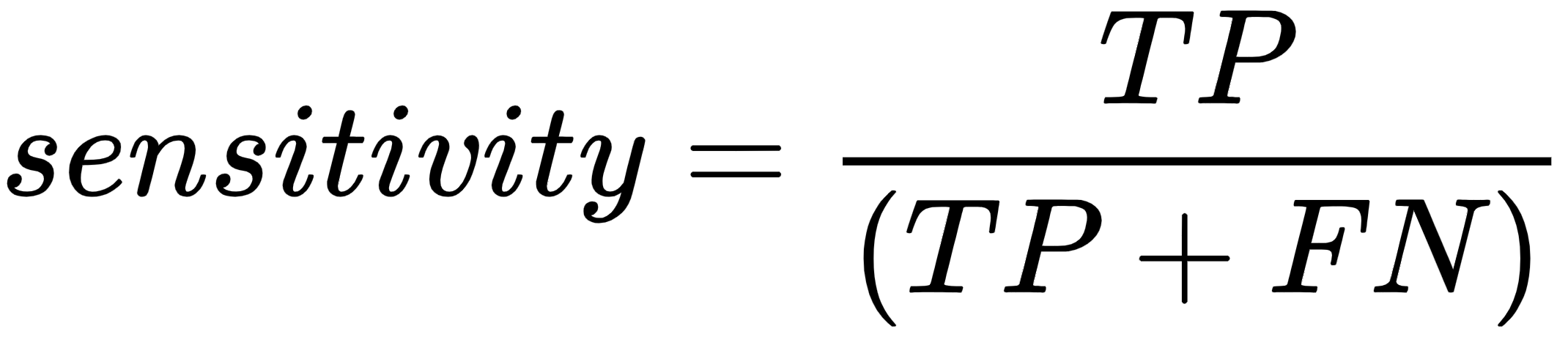
The formula for specificity is as follows:

Finally, the accuracy of the model is given by the formula as:

Let's take a look at an example. Consider we built a supervised classification algorithm that looks at the picture of a window and classifies it as dirty or not dirty. The final confusion matrix is as follows:
|
Predicted: Dirty |
Predicted: Not dirty |
|
|
Actual: Dirty |
TP = 90 |
FN = 40 |
|
Actual: Not dirty |
FP = 10 |
TN = 60 |
Now, let's compute the accuracy measures for this case:
- Precision = TP / (TP + FP) = 90 /(90 + 10) = 90%. This means 90% of the pictures that were classified as dirty were actually dirty.
- Sensitivity = TP / (TP + FN) = 90/(90 + 40) = 69.23%. This means 69.23% of the dirty windows were correctly classified and excluded from all non-dirty windows.
- Specificity = TN / (TN + FP) = 60 / (10 + 60) = 85.71%. This means that 85.71% of the non-dirty windows were accurately classified and excluded from the dirty windows.
- Accuracy = (TP + TN)/(TP + TN + FP + FN) = 75%. This means 75% of the samples were correctly classified.
Another commonly used accuracy model that you will encounter is the F1 Score. It is given by the following equation:

As we can see, the F1 score is a weighted average of the recall and precision. There are too many accuracy measures, right? This can be intimidating at the beginning, but you will get used to it over time.