
The functional relationship produced by a supervised learning algorithm can be used for inference—that is, to gain insights into how the outcomes are generated—or for prediction—that is, to generate accurate output estimates (represented by 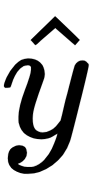 ) for unknown or future inputs (represented by X).
) for unknown or future inputs (represented by X).
For algorithmic trading, inference can be used to estimate the causal or statistical dependence of the returns of an asset on a risk factor, whereas prediction can be used to forecast the risk factor. Combining the two can yield a prediction of the asset price, which in turn can be translated into a trading signal.
Statistical inference is about drawing conclusions from sample data about the parameters of the underlying probability distribution or the population. Potential conclusions include hypothesis tests about the characteristics of the distribution of an individual variable, or the existence or strength of numerical relationships among variables. They also include point or interval estimates of statistical metrics.
Inference depends on the assumptions about the process that generates the data in the first place. We will review these assumptions and the tools that are used for inference with linear models where they are well established. More complex models make fewer assumptions about the structural relationship between input and output, and instead approach the task of function approximation more openly while treating the data-generating process as a black box. These models, including decision trees, ensemble models, and neural networks, are focused on and often outperform when used for prediction tasks. However, random forests have recently gained a framework for inference that we will introduce later.