
Q-learning can identify an optimal action (that which has the highest value in each state) while in a given state without having a completely defined model of the environment. It is also great at handling problems with stochastic transitions and rewards without requiring tweaking or adaptations.
Here is the mathematical intuition for Q-learning:
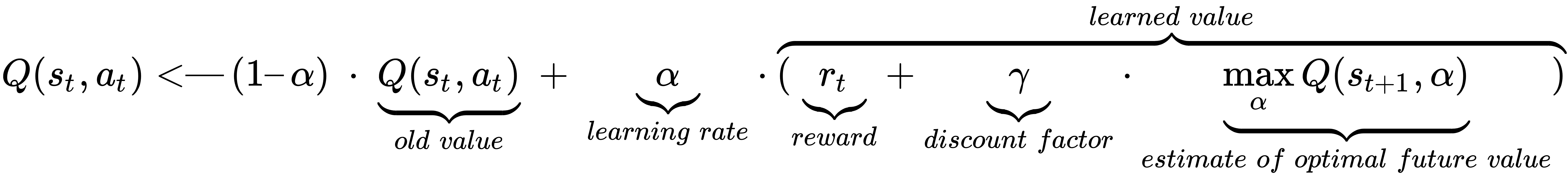
Perhaps it's easier to comprehend if we provide a very high-level abstract example. The agent starts at state 1. It then performs action 1 and gets reward 1. Next, it looks around and sees what the maximum possible reward for an action in state 2 is; it uses that to update the value of action 1. And so on!