
Iris Recognition on Mobile Devices Using Near-Infrared Images
Haiqing Li; Qi Zhang; Zhenan Sun Center for Research on Intelligent Perception and Computing, Institute of Automation, Chinese Academy of Sciences, Beijing, PR China
Abstract
Iris recognition provides a promising solution to enhance the security of private data on mobile devices. This chapter first analyzes the problems of iris recognition on mobile devices and then introduces our attempts to solve these problems by super-resolution, feature learning and multimodal biometrics fusion. Two super-resolution methods, which are based on convolutional neural networks (CNNs) and random forests, respectively, are compared experimentally. A pairwise CNNs model is proposed to automatically learn the correlation features between two iris images. Experimental results show that the learned features are highly complementary to local features, e.g., ordinal measures. Finally, we discuss the fusion of iris, periocular, and facial information which is a natural and effective way to improve the overall performance.
Keywords
Iris recognition; Mobile devices; Near-infrared light; Super-resolution; Convolutional neural networks; Multimodal biometrics
5.1 Introduction
With the wide use of smartphones and tablets, large amounts of private data such as chat logs and photos are stored on mobile devices. The security of private data has become a growing concern. While traditional passwords and personal identification numbers (PINs) are easy to crack by guessing or by dictionary attacks, biometrics provides encouraging personal recognition solutions with benefits of its high universality and distinctiveness. At present, fingerprint and face recognition are available on many mobile devices. However, fingerprints left on screens can be replicated for spoof attacks and the accuracy of face recognition is unsatisfactory for high-level security requirements. Iris texture is difficult to be replicated and highly discriminative. More and more mobile phones, such as Fujitsu's Arrows NX F-04G, Microsoft's Lumia 950, and Samsung Galaxy Note 7, have been equipped with iris recognition to enhance the security.
The foremost challenge in iris recognition on mobile devices is image capture. The melanin pigment in irises will absorb a large amount of visible wavelength (VW) light. Hence, VW light can reveal plentiful texture information for light-colored irises but only little texture information for dark irises. The absorption is weak for wavelengths longer than 700 nm, which makes near-infrared (NIR) light suitable for both light-colored and darkly pigmented iris imaging. Furthermore, optical filters which pass NIR wavelengths and block VW wavelengths can be utilized to avoid specular reflections of ambient light on the cornea, as shown in Fig. 5.1. In order to ensure the quality of iris images, it is necessary to mount additional NIR illuminators and cameras on the front panel of mobile devices.

Currently, the quality of iris images on mobile devices is inferior to that on specialized iris imaging devices due to the space, power, and heat dissipation limitations. The comparison of iris images obtained by a mobile device and IrisGuard AD100 is shown in Fig. 5.2. We can see that the iris radius in the left image is much smaller than iris radius in the right image. The sensor noise on the left image is clearly visible, and impairs the sharpness and contrast of iris texture. Both the camera sensor size and focal length are small on mobile devices. Therefore, the iris radiuses are often less than 80 pixels, which do not satisfy the requirement described in the international standard ISO/IEC 29794-6.2015 [1]. Moreover, iris radiuses decrease rapidly as the stand-off distances increase. As shown in Fig. 5.3, the diameter of the iris decreases from 200 pixels to 135 pixels as the stand-off distance increases only 10 cm. The usage scenarios of mobile devices are usually less constrained, various stand-off distances and environments will introduce a large number of low quality images with low resolution, out-of-focus blur, motion blur, off-axis, or specular reflections.


The accuracy of iris recognition on mobile devices will drop dramatically if low quality iris images are not processed appropriately. This chapter is intended to investigate how to improve the accuracy by elaborately designed preprocessing, feature extraction, and multimodal biometrics fusion algorithms. We will briefly introduce some classic methods, and will focus more attention on the new progress brought by convolutional neural networks (CNNs) [2].
5.2 Preprocessing
Iris images acquired by mobile devices usually contain not only periocular regions but also partial face regions. As shown in Fig. 5.4, the major task for image preprocessing is to detect eye regions and then isolate the valid iris regions from the background. Cho et al. [3,4] are among the first researchers to investigate the iris segmentation algorithms specifically for mobile phones. The intensity characteristics of iris images are exploited to design real-time rule-based algorithms. In addition, floating point operations which are time-consuming on ARM CPU are removed to reduce the processing time.

Although rule-based iris detection and segmentation methods are fast, they cannot deal with low quality iris images. Since the computational capability of mobile devices has been improved greatly, more complex preprocessing algorithms can be utilized. For example, periocular regions are first localized by Adaboost eye detectors [5]. Then, the inner and outer iris boundaries and eyelids are localized by integro-differential operators [6] or Hough transforms [7]. Thirdly, horizontal rank filtering and histogram filtering can be successively used for eyelash and shadow removal [8]. Finally, the isolated iris texture is unfolded to a rectangle image by the homogeneous rubber sheet model [6].
To solve the problem of low resolution iris images acquired by mobile devices, a straightforward idea is to increase the resolution of iris images. Super-resolution (SR) is widely used to increase image resolution. It usually takes one or more low resolution (LR) images as input and maps them to a high resolution (HR) output image. Single image super-resolution (SISR) is a popular research topic nowadays. SR in many computer vision tasks only focuses on visual effect [9], while SR in biometrics mainly aims at improving the recognition rate [10]. After SR, higher resolution iris images or enhanced feature codes are fed into the traditional recognition procedure. In this way, the recognition accuracy is expected to be improved.
We evaluated two pixel level SISR methods which were proposed recently. The first one is Super-Resolution Convolutional Neural Networks (SRCNN) [11]. It learns the nonlinear mapping function between LR images and HR images. The convolutional neural networks (CNNs) have a lightweight structure that only has three convolutional layers, as shown in Fig. 5.5. The loss function is computed as the mean squared error between the reconstructed images and the corresponding ground-truth HR images. It takes three days to train a SRCNN model using 91 images on a GTX 770 GPU. The second method is Super-Resolution Forests (SRF) [12]. Random forests have merits of being highly nonlinear, and are usually extremely fast during both the training and evaluation phases. SRF build on linear prediction models in leaf nodes. During tree growing, a novel regularized objective function is adopted that operates on both output and input domains. SRF can be trained within minutes on a single CPU core, which is very efficient. The SR models for iris recognition are trained by HR images acquired by IrisGuard and the corresponding downsampled LR images. At the testing stage, we input one normalized LR iris image into the trained model and the corresponding HR iris image is output.

Two mobile iris databases are used to evaluate the effectiveness of the above two SISR methods in improving the recognition rate. The first database is the CASIA-Iris-Mobile-V1.0 that includes 2800 iris images from 70 Asians. The second database is CASIA-Iris-Mobile-V2.0 that contains 12,000 iris images from 200 Asians. After super-resolution of LR normalized images, we extract Ordinal Measures (OMs) [16] features from HR images for recognition. Receiver operating characteristic (ROC) curves on the first and second databases are shown in Fig. 5.6 and Fig. 5.7, respectively.


Experiments on these two databases get similar conclusions: (i) the SRCNN and SRF methods get comparable recognition results. SRCNN takes about 3 s on a single normalized image with size of ![]() while the SRF takes only about 0.3 s on the same image. The SRF is much faster; (ii) SISR has limited effectiveness in improving the recognition accuracy. The limitations are as follows: pixel level SISR is not directly related to recognition and may introduce artifacts; the SR model is trained with synthesized LR images that are very different from real-world LR images. We need to focus attention on how to access more information, e.g., by adopting multi-frame SR that can use complementary information from different frames.
while the SRF takes only about 0.3 s on the same image. The SRF is much faster; (ii) SISR has limited effectiveness in improving the recognition accuracy. The limitations are as follows: pixel level SISR is not directly related to recognition and may introduce artifacts; the SR model is trained with synthesized LR images that are very different from real-world LR images. We need to focus attention on how to access more information, e.g., by adopting multi-frame SR that can use complementary information from different frames.
In order to directly boost the recognition accuracy, SR can be applied at the feature and code level. Nguyen et al. [13] propose a novel feature-domain SR approach using 2D Gabor wavelets. The SR output (a super-resolved feature vector) is directly employed for recognition. Liu et al. [14] propose a code-level scheme for heterogeneous matching of LR and HR iris images. They use an adapted Markov network to establish the statistical relationship between a number of binary codes of LR iris images and a binary code corresponding to the latent HR iris image. Besides, the co-occurrence relationship between neighboring bits of HR iris code is also modeled through this Markov network. Therefore, an enhanced iris feature code from the probe set of LR iris image sequences can be obtained. Both of the above SR methods can achieve improved performance compared to pixel level SR.
5.3 Feature Analysis
Iris feature analysis in constrained environments is well developed after more than 20 years of research. Local features, such as Gabor filters [6], multi-channel spatial filters [15], ordinal measures (OMs) [16], can describe the most discriminative texture information. Fig. 5.8 shows Gabor filters of five scales and eight directions. Fig. 5.9 shows various ordinal filters that differ in distance, scale, orientation, lobe numbers, location, and shape.


On the other hand, some researchers use correlation filters to directly measure correlative information between two iris images. Wildes et al. [17] implement the four-level Laplacian pyramid and the goodness of matching is determined by the normalized correlation between two registered iris images. Kumar and co-workers [18] apply advanced correlation filters and achieve good results. However, little work focuses on exploring complementarity of local and correlative features. Zhang et al. [19] apply perturbation-enhanced feature correlation filters on Gabor filtered iris images to encode both local and global features and acquire encouraging results.
Iris recognition on mobile devices is an emerging application. How to transfer traditional high performance iris feature analysis [20] to mobile applications is challenging. At present, there are a number of works in the literature about iris recognition on mobile devices. Most current work about mobile iris authentication is based on the visible spectrum [21]. Barra et al. [22] present a comprehensive approach to iris authentication/recognition on mobile devices based on spatial histograms. Raja et al. [23] propose a feature extraction method based on deep sparse filtering to obtain robust iris features for unconstrained mobile applications. However, Asians have dark-colored irises which show clear texture information only under NIR light. Jeong et al. [24] propose a method of extracting the iris code based on Adaptive Gabor Filter in which the Gabor filter's parameters depend on the amount of blurring and sunlight in captured image. Park et al. [25] present an iris localization method for mobile phones based on corneal specular reflections, and then extract iris features using Gabor filters.
Compared with these hand-crafted filters, the deep learning method can learn filters automatically and has recently shown an explosive popularity, especially CNNs which have been successfully applied in face recognition and achieved outstanding results outperforming most traditional methods. Liu et al. [26] use CNNs in heterogeneous iris verification and achieve better results compared with traditional methods. They use a pairwise CNNs model, as shown in Fig. 5.10. The input of this model is a pair of iris images. It can exploit a large number of training samples from a small database. For example, a database contains 200 classes for training and each class has 30 images. Then there are ![]() intra-input pairs. The model is composed of nine layers including one pairwise filter layer, one convolutional layer, two pooling layers, two normalization layers, two local layers, and one full connection layer. This model can directly measure the similarities of local regions between the input pairs of iris images. It outputs two predictions, 0 is the intra-class pair and 1 is the inter-class pair.
intra-input pairs. The model is composed of nine layers including one pairwise filter layer, one convolutional layer, two pooling layers, two normalization layers, two local layers, and one full connection layer. This model can directly measure the similarities of local regions between the input pairs of iris images. It outputs two predictions, 0 is the intra-class pair and 1 is the inter-class pair.

We fuse ordinal measures features and deep learning features for iris recognition on mobile devices to explore whether these two kinds of features are complementary [27]. Experiments are conducted on 12,000 iris images from 200 Asians. Three score level fusion methods are adopted: the sum, max, and min rules. The equal error rate (EER), false rejection rate (FRR) when the false acceptance rate (FAR) is ![]() , and discriminating index (DI) are used to measure the performance. DI can measure the comprehensive performance of the classifier [6] and can be calculated as:
, and discriminating index (DI) are used to measure the performance. DI can measure the comprehensive performance of the classifier [6] and can be calculated as:

where ![]() and
and ![]() are the mean value of intra-class and inter-class distribution, respectively.
are the mean value of intra-class and inter-class distribution, respectively. ![]() and
and ![]() are the variance of intra-class and inter-class distribution, respectively. The higher of the DI value, the greater the difference of intra- and inter-distributions. The EER, FRR, and DI values of three fusion methods are listed in Table 5.1. The ROC curves are shown in Fig. 5.11.
are the variance of intra-class and inter-class distribution, respectively. The higher of the DI value, the greater the difference of intra- and inter-distributions. The EER, FRR, and DI values of three fusion methods are listed in Table 5.1. The ROC curves are shown in Fig. 5.11.
Table 5.1
The EER, FRR and DI values of three fusion methods
| Method | EER | FRR@FAR = 10−4 | DI |
| OMs | 1.20% | 9.13% | 4.56 |
| CNNs | 0.80% | 7.16% | 5.67 |
| Sum rule | 0.48% | 3.37% | 6.64 |
| Max rule | 0.74% | 6.97% | 5.37 |
| Min rule | 0.80% | 7.61% | 6.34 |
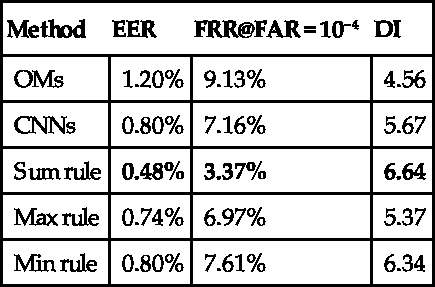

We can see that the fusion method based on the sum rule clearly improves the recognition rate. The results demonstrate that these two kinds of features are highly complementary. The major reason is that OMs can acquire local details of an iris image, while the pairwise CNNs model can measure the correlation of input iris pairs directly. OMs qualitatively encode iris texture to binary codes, which may lose some detailed information. While pairwise features learned by CNNs measure the correlation between two irises starting from the very beginning of the image level, which can retain more detailed information.
5.4 Multimodal Biometrics
The iris images captured on mobile devices also contain periocular regions or even the facial regions. It is promising to develop a multibiometric solution for more accurate, secure and easy-to-use identity recognition on mobile devices. De Marsico et al. [21] implement an embedded biometrics application by fusing face and iris modalities at the score level. Santos et al. [28] focus on biometric recognition in mobile devices using iris and periocular information as the main traits. Raja et al. [23] present a multimodal biometric system using face, periocular and iris biometric for authentication.
We have fused face and iris biometrics on mobile devices using NIR images [29]. Face images are aligned according to eye centers and then represented by histograms of Gabor ordinal measures (GOM). Iris images are cropped from face images and represented by ordinal measures (OMs). Finally, the similarity scores produced by face and iris features are combined at the score level by the sum rule. Experiments are conducted using 2800 iris images of 70 Asians. ROC curves of iris and face fusion are shown in Fig. 5.12. We can draw conclusion that fusion of face and iris biometrics can improve the recognition accuracy significantly.

Research of periocular recognition started to gain popularity after the studies of Park et al. [30]. The periocular region refers to the skin around the eye area, which can show rich skin texture details and strong eye structure information even under visible light. The periocular region can be obtained easily with little cooperation and can be captured with iris simultaneously. It achieves a trade-off between the whole face (which can be occluded at close distances) and the iris texture (which do not have enough resolution at long distances) [31]. Therefore, it is very suitable to fuse iris and periocular region to boost the performance.
The normalization of periocular region mainly depends on the iris. By iris detection, we can get the outer boundary of iris that can be expressed by a circle with the radius (R) and center (![]() ). We define the size of normalized periocular region as (
). We define the size of normalized periocular region as (![]() ) and the radius of iris as
) and the radius of iris as ![]() . Then the relationship between the normalized periocular image
. Then the relationship between the normalized periocular image ![]() and the raw image
and the raw image ![]() is as follows:
is as follows:
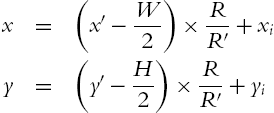
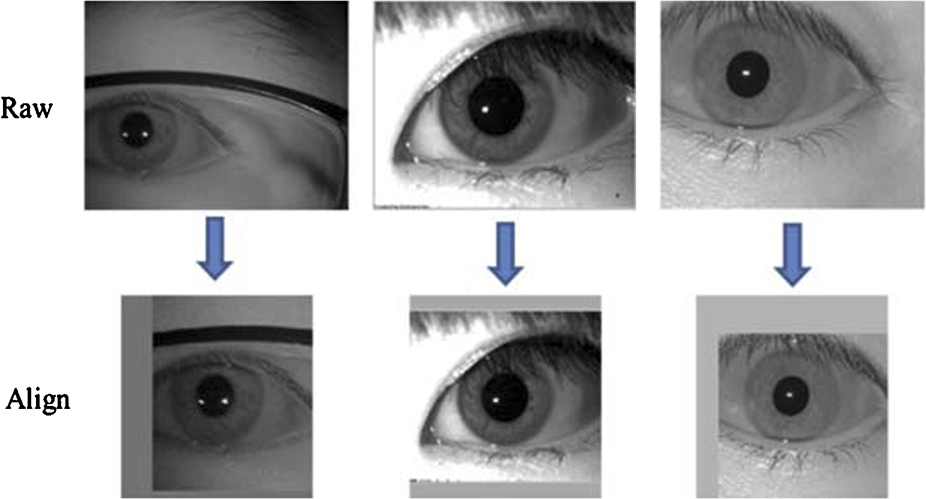
Through the above mapping, the normalized periocular image is obtained by interpolation. The flow chart is shown in Fig. 5.13. Example images of aligned periocular region are shown in Fig. 5.14. The scale and certain translation changes can be overcome by normalization.

Feature analysis for periocular recognition can be classified into two approaches [31]: (i) global approaches extract properties of an entire region of interest, such as texture, color, or shape features; (ii) local approaches detect a sparse set of characteristic points with features describing the neighborhood around characteristic points only. The most widely used methods include Local Binary Patterns (LBP), Histogram of Oriented Gradients (HOG), and Scale Invariant Feature Transform (SIFT). With the popularity and effectiveness of deep learning methods, we can also use deep learning methods to learn robust periocular features automatically.
The periocular region possesses complementary identity information with iris, which will improve the accuracy of a single modality after fusion. Fusion of iris and periocular region can be performed at the feature level and score level [32]. Effective and efficient fusion methods will greatly promote the application of biometrics on mobile devices.
5.5 Conclusions
Iris recognition is a promising technology for identity authentication on mobile devices. However, its space, power and heat dissipation limitations introduce many new challenges, such as low resolution, large iris radius variations, low contrast, and noises. We have tried to improve the performance of iris recognition on mobile devices from different perspectives. At the image level, we employed two pixel level single image super-resolution methods. Although direct super-resolution enhances the visual effect, it has limited effectiveness in improving the recognition accuracy. At the feature level, we fused ordinal measures features and deep learning features to fully exploit their complementary information. Much better recognition results have been achieved. In addition, we discussed a multimodal recognition method which fuses iris, facial, and periocular information. Experimental results have shown that multimodal fusion improves the overall accuracy substantially.
In our future work, we will adopt multi-frame super-resolution methods to integrate richer information. The super-resolution method will be applied at both the feature and code level to boost the recognition accuracy directly. In order to satisfy the speed requirements in practical applications, more efficient iris preprocessing and feature extraction methods will be designed. Besides, sophisticated multimodal fusion methods, such as the weighted fusion and feature level fusion, will be designed to improve the accuracy further.