


System scalability, availability, backup, and recovery
This chapter describes high availability, scalability, performance, backup, and recovery options and strategies for IBM Production Imaging Edition, specifically IBM Datacap Taskmaster Capture (Taskmaster).
This chapter includes the following sections:
12.1 System scalability, performance, and availability
Building an enterprise solution across multiple locations, with large user numbers and a high volume of document throughput, requires a system that can scale horizontally and vertically. This system must also be able to withstand node failure.
Production Imaging Edition is made up of two key components: Taskmaster to scan and capture images and IBM FileNet P8, which is the central repository to store these images. Both Taskmaster and FileNet P8 have several options to design a scalable and available system. This chapter concentrates on scaling the Taskmaster component of Production Imaging Edition.
For information about scaling the FileNet P8 component, see the IBM Redbooks publication IBM FileNet P8 Platform and Architecture, SG24-7667, which explains the approaches and methods of scaling, performance tuning, and availability.
12.1.1 Typical Datacap installation
A typical Taskmaster implementation for a small scale project consists of the following servers:
•The Taskmaster Server, which is the central service that provides user authentication, workflow and queuing
•A Rulerunner Server that runs tasks that do not require human interaction such as Optical Character Recognition (OCR), Intelligent Character Recognition (ICR), and export to repository.
Figure 12-1 shows a simple Taskmaster architecture.

Figure 12-1 Simple Taskmaster architecture
Although it is possible to run all Taskmaster components on the same physical machine, perform this task only for the smallest production capture systems and for development configurations. Performance is limited because Rulerunner tasks are typically processor-intensive and can interfere with Taskmaster Server response times.
12.1.2 Scaling Rulerunner vertically (scale up)
Taskmaster can be scaled vertically, which you can achieve in the following ways to handle the volume of documents that you want to process:
•Increase the hardware specification of the Rulerunner server so that processes can run faster. To realize this goal, you can perform such tasks as upgrading processors, increasing memory, and obtaining a faster network connection.
•Increase the number of available Rulerunner threads to allow multiple tasks to process concurrently and use multicore processors more efficiently. For more information about this process, see 12.2, “Rulerunner” on page 402.
|
Multithread licensing: At the time of publication, an additional license, called the Rulerunner Enterprise license, is required to use multithreading in Rulerunner. Contact your IBM marketing representative for more details.
|
There is a limit to which you can scale the hardware configuration of a single server. The limit can be a physical limit. For example, you cannot get faster components. You can also reach a point at which the benefits of upgrading hardware are less, such as in terms of cost versus performance, than the purchasing of a new separate machine.
Rulerunner is a 32-bit application and, therefore, is restricted to 2–4 GB of addressable memory. However, Rulerunner creates separate processes for OCR and other intensive tasks, which allows for usage of additional memory if the operating system is 64 bit.
Vertical scalability relies on adding processing power to a physical machine. Configuring a system with just one Rulerunner server implies a single point of failure for background processes.
12.1.3 Scaling Rulerunner horizontally (scale out)
Taskmaster can be scaled horizontally by increasing the number of Rulerunner servers used to handle a high volume of documents.
In an installation of this type, you have a centralized Taskmaster Server and a defined number of Rulerunner servers for unattended processing of ingested documents. Depending on your license, you can configure these servers to run a single thread or multiple threads. For more information, see 12.2, “Rulerunner” on page 402.
Figure 12-2 shows a typical horizontal configuration, with a centralized Taskmaster Server and two single-threaded Rulerunner servers that share the load of document processing.

Figure 12-2 Typical horizontal configuration
Each Rulerunner server uses the first-in first-out (FIFO) algorithm to poll the Taskmaster Server for the oldest batch of documents pending for a set of defined background tasks. Then the Rulerunner server processes each batch in turn.
Rulerunner can be configured to poll for specific tasks in given projects. To scale effectively, tasks must be shared intelligently across the available Rulerunner servers. For most purposes, as a best practice, configure all Rulerunner servers to run all background tasks to ensure that any work is processed by the first available Rulerunner as soon as possible. If a Rulerunner server fails, the remaining Rulerunner servers continue to process all tasks. Alternatively, you might want to assign specific subsets of work to a subset of Rulerunner servers. This method helps primarily to control the amount of processing power assigned to specific parts of the workflow. For example, it ensures that priority is given to certain tasks, even if older work is available for other tasks.
The scale-out approach has one disadvantage. That is, as you increase the number of single-threaded Rulerunner servers, you increase the number of physical or virtual machines that require management and administration.
A trade-off between performance, cost, and resiliency must be determined on a case-by-case basis.
For more information about the process of assigning tasks to Rulerunner servers, see 12.3.2, “Installing a single Rulerunner server” on page 412.
12.1.4 Scaling Rulerunner horizontally and vertically
Taskmaster can be scaled horizontally and vertically to achieve the advantages of both methods:
1. Scale up by upgrading the hardware specification of the Rulerunner servers to maximize single-server throughput to maximized hardware usage on the server.
2. Scale out by adding additional Rulerunner servers, with each server running a single threaded Rulerunner.
3. Increase the number of processing threads that are available to each Rulerunner by upgrading to the Rulerunner Enterprise license.
Figure 12-3 illustrates a horizontally and vertically scaled Taskmaster implementation. It details the usage of single- and multi-threaded Rulerunner servers. It also shows usage of a separate database server, file share, and dedicated fingerprint service. More information about these components is provided later in this chapter.

Figure 12-3 Horizontally and vertically scaled Taskmaster configuration
With this approach, you have the advantages is that you remove single points of failure for processing tasks and maximize the performance of available hardware.
For a walkthrough of a Rulerunner configuration, see 12.3, “Configuring Rulerunner” on page 409.
12.1.5 Taskmaster Server scaling and redundancy
As explained in the previous sections, you can scale Rulerunner horizontally and vertically. You can achieve this scaling by increasing the number of Rulerunner servers, increasing the hardware specification, and increasing the number of processing threads by the addition of a Rulerunner Enterprise license. This approach is suitable for task processing, such as OCR or validation. However, all the batches that are being processed are managed by the Taskmaster Server.
The Taskmaster Server is the central Windows service. It provides user authentication, workflow, and queuing (and file services for Taskmaster Web). Without this core component, no tasks can be managed and updated in the system.
Typically the load on a Taskmaster Server is low. Processor and I/O-intensive processes, such as OCR and export, are run on the Rulerunner servers. The main function of Taskmaster Server in this scenario is to access the Taskmaster queuing database (the Engine database) to select batches for processing and update statistics. Roughly six database transactions are performed for each batch. As a result, moderate loads can be easily supported with a single Taskmaster Server. The load must be quite high to require use of an additional server.
This rule comes with exceptions. For example, when using Taskmaster Web to permit the use of web clients, an increased load is placed on the server to transfer batch files to and from the web server. For more information, see 12.1.7, “Taskmaster Web scaling and redundancy” on page 397.
Also, using the RV2 Report Viewer tool increases the load on Taskmaster Server to transfer data from the database to the web server and RV2. If large data sets are transferred, this added load can be significant and might necessitate scale out of Taskmaster Servers.
If the hardware limitation of the Taskmaster Server is reached, in the first instance, the server hardware can be upgraded to meet the demand. If the server hardware does not meet the requirements, additional Taskmaster Servers can be installed. Rulerunner servers and Taskmaster Web can be configured to access the additional Taskmaster Server.
Active-active configuration
Figure 12-4 shows two or more Taskmaster Servers that are configured as companion servers.

Figure 12-4 Active-active Taskmaster Server
The Rulerunner servers (single-threaded or multithreaded) can poll either or both Taskmaster Servers separately, looking for tasks to process.
As of this writing (for Taskmaster v8.0.1), all batch creation tasks must be configured or operated so that they can access a single Taskmaster Server. Conflicts between multiple Taskmaster Servers creating new batches can result in skipped batch IDs and delays in batch creation on some servers.
If one or more Taskmaster Servers fail, the clients connect to the remaining Taskmaster Servers. However, each Rulerunner server must be configured first to achieve this connection. For more information, see 12.4.1, “Adding a failover Taskmaster Server” on page 434, and 12.4.2, “Load sharing between Taskmaster Servers” on page 439.
The Taskmaster Servers use the same database servers and Universal Naming Convention (UNC) path so that the same project can be shared across multiple Taskmaster Servers.
Active-passive configuration
In an active-passive configuration, a single Taskmaster Server is configured as the primary server. A second Taskmaster Server is configured on a secondary server with the same parameters as the primary server, meaning the same IP address and server name.
If the primary Taskmaster Server fails, the secondary server is started manually. Because its configuration is identical to the failed server, it begins to process in the same manner as the primary server. All clients and Rulerunner servers connect as though they are the primary server.
|
Automatic starting option for the secondary server: The secondary server can also be started automatically by using Microsoft Cluster Services. Although this method has not been tested by IBM, customers are using this configuration successfully.
|
Batch abandonment and rollback
In the active-active and active-passive configurations, if a Taskmaster Server fails, any tasks that are processed by clients connected to that server are abandoned in the running state. The secondary server resets such batches before reprocessing.
Batch reset, also known as rollback, can be performed manually or through a scheduled NENU utility. In certain cases, you must restore the former state of the batch for proper reprocessing. This topic is beyond the scope of this book and is not covered here.
12.1.6 Scaling both Taskmaster Server and Rulerunner
Figure 12-5 shows a possible configuration of Taskmaster Servers and Rulerunner servers.

Figure 12-5 Taskmaster and Rulerunner configuration
The two Taskmaster Servers are connected to a single database server. With this connection, both servers can serve out tasks and batches from the same application, and each server updates the batch status to a common database. If one server fails, the other server still has access to the database and batch status.
Rulerunner (single-threaded or multithreaded) has been configured to poll one specific Taskmaster Server considerably more than the other (primary higher priority server). However, it occasionally polls the secondary Taskmaster Server (secondary lower priority server). The fact that Rulerunner knows about both Taskmaster Servers means that, if one fails (the primary high priority server in this example), it starts using its secondary lower priority Taskmaster Server. It drops its priority and polls the secondary Taskmaster Server for all allocated tasks it has configured to process.
12.1.7 Taskmaster Web scaling and redundancy
Taskmaster Web relies on the use of Internet Information Services (IIS) for Windows Server to serve out a web-based user interface for administration, scanning, and data verification tasks. Because the IIS might reside outside of a firewall, for security purposes, all file and database requests are routed through the Taskmaster Server. This routing ensures that all such requests are run securely within the firewall. It also places a greater load on Taskmaster Server than a thick client.
Taskmaster Web response times depend on Taskmaster Server performance. When many users run tasks with large amounts of I/O, such as image upload and database lookup, implementations, including Taskmaster Web, must pay attention to the specification and configuration of Taskmaster machines to ensure adequate performance.
Rules, such as validation and document integrity, that are triggered during Verify tasks are also run on the IIS under Taskmaster Web. Heavy use of validation or other rules also increases the load on the IIS.
If the number of concurrent users who are using Taskmaster Web exceeds the capability of IIS, add another separate IIS that points to the Taskmaster Servers.
If the throughput generated by Taskmaster Web is too great for a single Taskmaster Server, you can add additional, separate Taskmaster Servers in an active-active configuration. For more information, see 12.1.5, “Taskmaster Server scaling and redundancy” on page 393.
Typical capacity range from 50 to 100 users for each instance of IIS.
Figure 12-6 shows a Taskmaster Web configuration that uses multiple Taskmaster Web Servers and multiple Taskmaster Servers.

Figure 12-6 Multiple Taskmaster Web Servers with multiple Taskmaster Servers
The load of web-based thin clients is balanced among the Taskmaster Web Servers to which they connect. Each Taskmaster Web Server can be connected to a primary and secondary Taskmaster Server. This connection allows load balancing between the Taskmaster Servers and adds an element of failover if a Taskmaster Server fails.
12.1.8 Scaling and redundancy for thick clients
Thick clients connect to the Taskmaster Server to authenticate, start batches, verify pages, perform administration, or invoke several other tasks that are not automated.
A thick client connects to the primary Taskmaster Server as defined in the .app file of the application to which it is trying to connect. If this Taskmaster Server fails, the client connection drops.
To reinitiate a connection, the client must be restarted. Upon restarting the client again, it first tries to connect to the primary Taskmaster Server. If this server is still down, the client then attempts to connect to a secondary Taskmaster Server (if configured).
It is also possible to define which Taskmaster Server a client connects to as a primary server. This approach can help to scale out with additional thick clients beyond the capacity of a single Taskmaster Server.
Figure 12-7 shows the configuration of Taskmaster thick clients connecting to a primary Taskmaster Server (Taskmaster Server A). It also shows the redundancy to connect to a secondary Taskmaster Server (Taskmaster Server B).

Figure 12-7 Taskmaster thick clients connecting to multiple Taskmaster Servers
12.1.9 Load balancing of tasks
Load balancing of unattended or background tasks is done in a simple way. Each Rulerunner thread polls the Taskmaster Server that is requesting a list of batches that are pending for any one of the tasks configured. If a batch is available, the first thread to request it gets the work.
Taskmaster processes batches according to their priority level (1–10, with 1 being the highest priority) and then by age (FIFO). Batch priority can be assigned manually or by rules at any point in the workflow.
All Rulerunner servers poll at regularly defined intervals.
Rulerunner has a facility to place a polling priority on each task. The task polling priority is separate from the priority assigned to the batch. The polling priority for a task defines the number of times that a thread polls for the task. For more information, see “Mixed queuing mode” on page 406.
12.1.10 Scaling databases
Taskmaster comes with Microsoft Access as its standard shipped database format. The two main databases are the Taskmaster Engine database and the Taskmaster Administrator database. The Taskmaster Administrator database holds the user credentials for users of the system. The Taskmaster Engine database maintains the status of each batch in the system.
For production implementations, use enterprise-level databases that are currently supported by Datacap. Reserve use of the Microsoft Access database for demonstration, low workloads, or simple testing environments.
To provide optimum performance and scalability, databases must be on a separate dedicated server primarily used for this purpose. For small production systems, the database can share a server with Taskmaster Server or Rulerunner.
Scaling of enterprise-level databases is documented. Because it is beyond the scope of this IBM Redbooks publication, the topic is not addressed in this book.
12.1.11 Network share drive
When Taskmaster captures and processes documents, it stores them in a shared file system. This file system must be read/write accessible across the network by all Taskmaster and Rulerunner servers.
Because batches contain multiple image files, the network bandwidth required for moving these files can get high. Therefore, sufficient bandwidth must be available between the client and the network share drive. The file system must also be mounted on a system that is capable of fast input and output.
A common configuration is to have a Taskmaster Server fail over with a storage area network (SAN) drive that is connected to both.
Small scale implementations suffice on a desktop or on a small server system. For larger scale systems, with high throughput requirements, use a fully dedicated high-speed disk subsystem. Batches of documents can be archived to back up media after they complete the workflow. Archiving can be achieved by using the NENU utility.
12.1.12 Scaling across geographies
Scanning of files and storing them in a remote network shared drive can present performance issues if the network is relatively slow. Therefore, where possible, store the files on a local network share. Figure 12-8 shows a possible distributed, thick client implementation of IBM Production Imaging Edition.

Figure 12-8 Multiple geographies
All the scanned files and batch data are held on a network share drive on the same local area network (LAN) as the users, along with localized Taskmaster Server, Rulerunner servers, and database servers. Only when images and data are ready for committal, they are sent over the wide area network (WAN) to FileNet P8.
|
Important: The application project files must be identical in both geographies to ensure that both systems work as intended. For more information about these files, which are the datacap.xml and <application>.app files, see 12.3.2, “Installing a single Rulerunner server” on page 412.
|
The separation of having two Taskmaster Servers also allows each geography to operate independently of the other, offering a greater degree of resilience if a Taskmaster Server fails.
Alternative configuration for your reference
|
DISCLAIMER: This alternative option is for your reference only. IBM has not tested nor provides support for this type of configuration. We provide this description strictly for your information.
|
Another alternative configuration to scale your system across geographies is to run a centralized Taskmaster Server, database server, and file share. However, network bandwidth issues might become apparent when trying to send large quantities of scanned and verification data over the network in remote or low network bandwidth locations.
To overcome this network bandwidth issue, consider using localized network file shares to store batch data. This approach removes the need to repeatedly move files across potentially low-bandwidth network connections. Instead only move them at the point of committal (if required). This way, you can use a centralized Taskmaster Server to manage all batches and localize clients and Rulerunner servers to process the data. Use separate datacap.xml files to implement this configuration.
12.2 Rulerunner
Rulerunner can be used in a single-thread and multithread configuration. Such configurations require attention to load balance, race condition, and more as explained in this section.
12.2.1 Single-threaded Rulerunner
With a Production Imaging Edition license, you can run Rulerunner with a single thread for each Rulerunner server, physical machine, or VMWare. By using a single thread, processing of Taskmaster tasks is done in serial, with one process being run at any one time on each Rulerunner server.
Figure 12-9 on page 403 shows the process of a single thread within Rulerunner and how it interacts with the Taskmaster Server, batch folder, Engine database, and Administrator database. This process is repeated each time a task is run by a Rulerunner thread.

Figure 12-9 Process of a single thread within Rulerunner
The disadvantage of using a single thread is that you do not use the full potential of the hardware that you have available. For example, if you have a quad-core processor capable of running 6 or more threads, you only gain one-sixteenth of the potential throughput of the server.
12.2.2 Multithread Rulerunner
|
Multithread licensing: At the time of publication, an additional license, called the Rulerunner Enterprise license, is required for use of multithreading in Rulerunner. See your IBM marketing representative for more information.
|
Modern day systems that have multiple processor cores allow for multithreading. To scale up and use this additional processing power, use of multiple threads is advantageous. With a Rulerunner Enterprise license (not currently included with Production Imaging Edition), you can use more than one thread for each physical machine or VMWare.
Rulerunner can manage up to 32 threads. However, an optimal number needs to be determined depending on specific requirements, such as the type of task you are running. If you set the number of threads too high, the system might use up resources, and performance will degrade.
The ratio of threads to processor cores can be a ratio of 1:1, 4:1, or greater. Processing speed and throughput vary depending on the task and must be determined experimentally to ensure optimum performance.
Typically one thread processes a task faster than when four threads process the same task. For example, a Rulerunner server configured to run with only one thread might process a page in 4 seconds. If you now create four threads and process the same task on each one, it might take 5 seconds to process a page for each thread.
If you look at this processing over a minute, in a single-threaded mode, the system processes approximately 15 pages. In a multithreaded mode, the system processes approximately 48 pages. This correlation is not a direct 1:1 relationship. In this example, 15 pages multiplied by 4 equals 60 (15 X 4 = 60), but only 48 pages are processed for the multithread mode with 4 threads. The overall throughput is still higher than a single-thread mode, and you have not increased the footprint of your server room.
Rulerunner is a 32-bit application that can directly access 2–4 GB of memory, depending on the operating system and configuration. However, certain rules create a child process, called DCOProcessor.exe, to perform operations such as OCR, barcode reading, and fingerprint creation. Each process runs in its own 32-bit address space. When running under a 64-bit version of the Windows operating system, memory up to 6 GB can be used by the creation processes.
When Rulerunner creates an external process, it monitors the process to detect if any issues occur. A timeout can be configured, after which it considers the external process to be hung. Rulerunner can also be configured to stop its own service if any task stops. A background service detects if Rulerunner stops or hangs and then attempts to restart it. Logging can also be switched on to aid in troubleshooting any issues that might arise.
Figure 12-10 shows a single-threaded Rulerunner server running tasks A, B, C, and D in order on a quad-core server, not using the additional processing capability of those cores. The order the tasks that are run is repeated in a constant loop.

Figure 12-10 Rulerunner threads
The four-threaded configuration shows different tasks being run simultaneously. Some threads are dedicated to a single task, such as task C in the example. Some threads share the load by running different tasks, similar to the single threaded configuration. The multithread configuration uses the multiple cores that are available on the machine.
The nine-threaded configuration shows different tasks being run simultaneously. Some threads are dedicated to a single task. The configuration also shows that the number of threads is not restricted to the number of processor cores of the server. The number of threads must be optimized depending on the tasks that are being processed.
For a walkthrough of a basic Rulerunner configuration, see 12.3, “Configuring Rulerunner” on page 409. That same section explains how to achieve single threading and multithreading.
12.2.3 Load balancing Rulerunner
Rulerunner can be configured to run in both sequential queuing mode and mixed queuing mode. Choosing the right option is important to scale your system effectively.
Sequential queuing mode
In sequential queuing mode, when all priorities are equal, the order in which the tasks are processed is defined by the order in which they are configured in Rulerunner Manager. The query that is sent to Taskmaster Server consists of only one job for each task pair.
If tasks are given different priorities in Rulerunner Manager, Rulerunner performs the higher priority task on multiple batches before advancing to perform the next task. For example, Thread 1 has Task A with a priority of 8 and Task B with a priority of 2. Priority is calculated based on the lowest common denominator. Therefore, the ratio of 8:2 is simplified to 4:1.
Because Task A is displayed in the thread before Task B, Task A goes first. The thread polls for work from the Taskmaster Server and processes the highest priority, with the oldest available Task A batch available that is pending. It polls four times. Because Task B is displayed next, the thread now polls Taskmaster Server for the highest priority, with the oldest available Task B batch pending. It polls one time.
Mixed queuing mode
In mixed queuing mode, the task priority that is set in Rulerunner is ignored. Taskmaster Server returns the highest priority batches in FIFO order from all of the available job and task pairs in the thread. The first batch in this list is processed.
Mixed queuing mode is not appropriate if Batch Creation tasks, such as VScan, are configured with any other tasks.
In mixed queuing mode, Taskmaster always selects the next batch. The position of the tasks in the thread is unimportant.
For an example, see 12.3.4, “Configuring priorities and queuing” on page 425.
12.2.4 Race conditions
When defining which tasks to run on a specific Rulerunner Server or thread, consider the fact that certain actions use the same resources. For example, a task such as VScan polls a defined directory for available files to consume and then creates a batch. If the same task is running in a separate thread or separate Rulerunner Server attempts to run this task, it might encounter issues. Files that are supposed to be consumed in serial order might be broken into separate batches, corrupting the scanning order.
Similarly, a task might require access to a specific file. The first task places a lock on this file until it completes. Other tasks that also require this file therefore must wait until the lock releases before they can continue. This process impacts the performance of subsequent threads that are each waiting for the lock on the file to be released.
When using multiple servers to implement a solution, separate the tasks that might share local resources or that are not thread safe onto different physical machines or virtual machines where possible. This approach helps to avoid any conflicts that might result in an incorrect operation. Also consider how each task or action works, and then test accordingly to minimize any multiprocessing issues.
|
Important: Consider and test thread safety and multiprocessing when writing custom actions.
|
12.2.5 Running multithreading in VMware
Rulerunner is supported for use on VMWare. Compared to running it natively, running on VMware results in a drop in performance. Therefore, to achieve optimal performance, while running multiple processes, install Rulerunner onto a native Windows operating system without the virtual machine.
12.2.6 Fingerprint Service
|
Additional license: At the time of publication, an additional license is required for use of the Fingerprint Service. See your IBM marketing representative for more information.
|
As explained in previous chapters, Taskmaster uses fingerprinting technology to identify documents as they enter the system. In large-scale Taskmaster implementations, where large numbers of fingerprints (typically over 1000 fingerprints) are required for document identification, use the Fingerprint Service.
The Fingerprint Service overcomes the time-consuming process of loading the fingerprints of the application each time a batch is run. The solution involves reading all the fingerprints into the system memory cache of the Fingerprint Server when the first fingerprint match is requested. To further optimize this process, only the identification portion of the fingerprint is loaded into memory. The fingerprints remain in system memory for the life of the Fingerprint Service process.
When the Fingerprint Service is requested for the first time, it loads all .cco fingerprint files that are defined in the Fingerprint database. The greater the number is of Fingerprints to read into memory, the longer the service takes to start, which can be from a few seconds to a few minutes.
During the startup process, if another Rulerunner workstation tries to call the Fingerprint Service, the second request pauses until the Fingerprint Service completes loading all fingerprints.
If new fingerprints are created on demand by using the Click ‘N Key capability and Intellocate functionality, the new fingerprint is loaded into the service. Similarly, if an image that is recognized returns a fingerprint match from the Fingerprint Service that no longer exists in the Fingerprint database, the image is removed from the Fingerprint Service memory. Then the image is re-queried for another fingerprint match. This method negates the potentially lengthy process of reloading the Fingerprint Service when additions or deletions occur.
To use the Fingerprint Service in a project, you use the SetFingerprintWebServiceURL and SetApplicationID actions in the Autodoc Global action library and point them to the server URL that is running the service. For more information, see 12.3.5, “Installing Fingerprint Service” on page 428.
A tool is available to test the Fingerprint Service so that you can add and search for fingerprints and unload the fingerprints of a project if needed.
12.3 Configuring Rulerunner
This section outlines a basic configuration of Rulerunner. It uses the Auto_Claim project developed for the case study in this Redbooks publication. However, this section does not use the same servers.
This section shows a possible setup in a test environment. For further information about setting up in production, see the installation guide that comes with your software.
The servers ECMDEMO1 and ALPHA are used for this installation. ECMDEMO1 is the central server on which all Production Imaging Edition components are installed (Taskmaster and FileNet P8). ALPHA is initially clean and has an additional Rulerunner and an additional Taskmaster Server installed during the following process.
First you see how to configure Rulerunner on a single server where all Datacap components have been installed. Then configuration is done on a separate machine to show how to scale the system both horizontally and vertically.
As mentioned earlier in this chapter, the single server approach is only for demonstration or testing environments.
12.3.1 The Datacap.xml and <project>.app files
To configure the application to run in Rulerunner, use the Taskmaster Application Manager. This application provides a user interface so that you can change Taskmaster applications defined in the datacap.xml file.
The datacap.xml file contains the centralized Taskmaster Application Service settings that are used by all Taskmaster components in your system. For Rulerunner to run, it requires the location of the datacap.xml file by using a file path (the UNC path for separate server installations):
C:datacapdatacap.xml
\ECMDEMO1datacapdatacap.xml
Example 12-1 shows a possible configuration of the datacap.xml file pointing to various projects on different servers. For Rulerunner to process tasks for a given application, it must be able to gain access the datacap.xml file and to the file shares for the applications defined in this file.
Example 12-1 The datacap.xml file
<datacap ver="8.0">
<app name="Auto_Claim" ref="\ECMDEMO1DatacapAuto_Claim"/>
<app name="Flex" ref="\DEMO2DatacapFlex"/>
<app name="1040ez" ref="\SDEMO2Datacap1040ez"/>
</datacap>
To function, the Taskmaster components must know the location of the datacap.xml file. If you use a single server installation, the location is already set at installation time to the C:datacapdatacap.xml directory.
After the application is reached, Taskmaster Application Manager can query the .app file in the project folder as follows and as used in this example:
C:DatacapAuto_ClaimAuto_Claim.app
\ECMDEMO1DatacapAuto_ClaimAuto_Claim.app
The .app file holds all the project paths, connection strings, and other settings that are used by applications to reference the batch folder. Although you can manually alter the .app file, use the Taskmaster Application Manager instead. Using Taskmaster Application Manager ensures that XML tags are not omitted and that connections strings for databases are correctly encrypted.
Example 12-2 The auto_claim.app file
<app name="Auto_Claim" ver="83" modder="Administrator.ECMDEMO1.ECM" dt="07/08/11.826 10:08:02.826 " src_ver="53">
<k name="tmservers">
<k name="tms" ip="ECMDEMO1" port="2402" retry="3"/>
</k>
<k name="runtime" v="batches"/>
<k name="tmengine"[encoded].DJj6P7G2gg7Y0BhK7zD52[/encoded]"/>
<k name="tmadmin" cs="[encoded].DJj6P7GkgFiZ37g5pr5E[/encoded]"/>
<k name="dco_Auto_Claim">
<k name="setupdco" v="Auto_Claim.xml"/>
<k name="rules" v="rules"/>
<k name="imagefix" v="imagefix.ini"/>
<k name="UseFPXML" v="False"/>
<k name="fingerprintconn" cs="[encoded].DJb6OzGkY15Y[/encoded]"/>
<k name="lookupdb" cs="[encoded].DJj6OzGkYVCUTBSe[/encoded]"/>
<k name="vscanimagedir" v="\ecmdemo1DatacapAuto_Claimimage"/>
<k name="exportdb" cs="[encoded].[/encoded]"/>
</k>
<k name="fingerprint" v="fingerprint"/>
<k name="export" v="export"/>
<k name="tasks">
<k name="VScan" profile="VScan"/>
<k name="PageID" profile="PageID"/>
<k name="Rulerunner" profile="Rulerunner"/>
<k name="Export" profile="Export"/>
</k>
</app>
By use of the datacap.xml and <application>.app files, the location and settings of all projects can be obtained. Use of these files and smart parameters to remove all hardcoded paths and connection strings simplifies promotion from development to production.
Figure 12-11 on page 412 shows the relationship between the datacap.xml file, the .app files for Auto_Claim and 1040ez, and the subsequent Taskmaster Servers, file servers, and database servers that are used.
The datacap.xml file holds the list of applications and where they reside. The program accessing the datacap.xml file can use this location. Then it can open the .app file to extract the information it needs about the application, such as a database connection string, Taskmaster Servers to use, batch directory location, and so on.

Figure 12-11 The datacap.xml and .app file relationship
12.3.2 Installing a single Rulerunner server
When we carried out the installation of Taskmaster on the single server ECMDEMO1 machine, all Taskmaster components were installed.
On ECMDEMO1, when you open the service console in Windows, you can see the two Rulerunner services as shown in Figure 12-12.

Figure 12-12 Rulerunner services on single server installation
In the single server implementation, these services are running under Local System. You are not required to start these services through this console.
|
Tips:
•You can start these services through the Windows command console.
•It is hardly useful to start or stop Rulerunner directly. Therefore, always start or stop the control service by using the sc /start and sc /stop commands as in the following example:
sc \servername stop "Datacap Quattro Control Service"
|
To install a single Rulerunner server, complete these steps:
1. Selecting Start → All Programs → Datacap → Taskmaster Client → Taskmaster Application Manager.
The left area of the Taskmaster Application Manager window shows all projects that are currently available on the system. Clicking each project changes the user interface to reflect the locations of key directories, files, and connections.
2. In the Taskmaster Application Manager window (Figure 12-13), click Auto_Claim to see all the connections strings, file paths, and other settings associated with the project.

Figure 12-13 Taskmaster Application Manager
3. Click the Taskmaster tab (Figure 12-14) to see the server IP and port number. This number is currently set to the localhost IP address of 127.0.0.1, which is acceptable for local installations. Later, when you use a remote server, be sure to change this IP address.

Figure 12-14 Taskmaster Server IP address
4. Create task profiles to run the tasks in the project:
a. To find the tasks, in the Taskmaster Client, open the Auto_Claim project. Note the names of task as shown on the Workflow tab of Taskmaster Administrator (Figure 12-15). In this example, we must run the following tasks:
VScan Pick up image files from a directory.
PageID Perform page identification.
Rulerunner Run the OCR, Validation Rules, and other tasks.
Export Export to FileNet P8.

Figure 12-15 Taskmaster Client
b. Replicate these profiles in the Taskmaster Application Manager user interface for the Auto_Claim project.
c. Click the Quattro tab (Figure 12-16) to ensure that they are spelled correctly with correct usage of uppercase and lowercase.

Figure 12-16 Task profiles
d. Click the Service tab (Figure 12-17). Notice that the management path of the main applications points to a local copy of the datacap.xml file. This path is acceptable for a single server installation. When you do a separate server installation, change this path to use UNC.

Figure 12-17 Main application management path
e. Close the Task Application Manager window. All changes are saved when you exit the window.
6. Click Connect to connect to the Taskmaster Application Service.

Figure 12-18 Datacap login area
When you are prompted for authentication, to get an encrypted password, complete these steps:
a. Start the Sit Manager tool in the C:DatacapsupportSit directory.
b. In the String to Encrypt field, enter your password, and then click the Encrypt button. The tool generates an encrypted string for the password.
c. Enter this string into the Password field on the Datacap Login tab. Click Connect again for so tha it connects now.
You might be able to use Windows authentication. See the installation documentation for more information.
7. Click the Workflow:Job:Task tab. A complete list of the available applications is displayed.
8. Expand Auto_Claim to see your tms server and databases. You see a graphical view of the available Taskmaster Server and databases.
a. Select each database.
b. Right-click tms and select Connect.
c. Repeat these steps for the databases.
You see the connection status change at the bottom of the window. The available tasks in the tree look similar to the tasks shown in the left pane of Figure 12-19.

Figure 12-19 Workflow, Jobs, Tasks
At this point, you can run Rulerunner in either single-threaded mode or multithreaded mode. Currently an additional license, which is the Rulerunner Enterprise license, is required to allow use of multiple threads. Figure 12-19 shows a single-threaded mod example.
9. Right-click the blank right pane, and add three threads (license permitting). Select and then drag the tasks from Main Job to each thread, which creates three separate threads that run simultaneously (Figure 12-20).

Figure 12-20 Multiple threads
As stated earlier in this chapter, a limit of 32 threads is available. However, as resources are consumed, degradation of performance usually occurs before you reach this limit.
10. Optional: Configure priorities in which the tasks run by using the following options:
– Priority
– Skip Same Batch
– Mixed Queuing
Figure 12-21 shows an example of how this priority is configured.

Figure 12-21 Priority configuration
For more information about priorities, see 12.3.4, “Configuring priorities and queuing” on page 425.
11. Optional: Click the Logging tab (Figure 12-22) to turn on logging. Files generated for each thread being run are created in the C:Datacap mclient directory of the Rulerunner server.

Figure 12-22 Logging in Rulerunner
12. Click Save to save this thread configuration.
13. Disconnect from the Taskmaster Application Service. Click the Datacap Login tab, and then click Disconnect.
The settings that were saved are written to both the system registry and an XML file that by default is in the C:Datacap mclient directory.
14. Optional: Create multiple configuration files with different names and load them manually. On the Workflow.Job.Task tab (Figure 12-23), change the value in the Path to Settings File field.

Figure 12-23 Rulerunner XML file
With these different configurations, you can change the processing order, priority, and so on, quickly to predefined configurations by stopping Rulerunner and pointing it to the subsequent quattro.xml configuration file. These settings are ideal when processing a given task requires priority over others, such as clearing a back log.
15. Ensure that no outstanding tasks remain in the Taskmaster Client Job Monitor.
16. Close the Taskmaster Client.
|
Important: A client that is open on the same machine where Rulerunner is running can cause issues with connections.
|
17. Click the Datacap Quattro tab in Rulerunner Manager and click Start to start Rulerunner.
Rulerunner now starts and begin to run the tasks that are assigned to it. No view is available to indicate that it is working. However, you can go to the project batch folder in the C:DatacapAuto_Claimatches directory and see if file creation or update activity is occurring. Alternatively open the Taskmaster Client, and see the tasks processing in the Job Monitor window. Figure 12-24 shows an example of four threads running PageID.

Figure 12-24 Tasks shown in Taskmaster Client Job Monitor
18. As a rest, run a VScan-based task to consume files from a folder. If this task is set to repeatedly grab these files and not delete them, you see batches begin to be generated in the project batch folder.
If you open Windows Task Manager, you see several Document Hierarchy (DCO) processes running in the list.
You can also check for log files if you turned up the logging levels and defined a specific location for them. The log files are useful for debugging issues that might occur. High levels of logging can affect performance. Therefore, it is advantageous to drop them to a suitable level depending on the environment on which you are running.
12.3.3 Installing an additional Rulerunner server
|
Tip: Before you read this section, read 12.3.2, “Installing a single Rulerunner server” on page 412, to help you understand the terminology used in this section.
|
Running Rulerunner on a separate machine requires additional setup. For our example, we use a build of Windows 2008 R2 64-bit. We show a possible setup in a test environment. For more information about setting up the production environment, see the installation guide that comes with your software.
For the purposes of this procedure, we refer to the new machine as ALPHA and the original machine as ECMDEMO1.
Windows is running in a domain which is a requirement for Rulerunner and all Taskmaster software components. All software on all machines must be in the same domain.
To install an additional Rulerunner server, complete these steps:
1. Enable the domain:
a. Select Start → Control Panel → System → Change Settings.
b. Click the Computer Name tab, and then click Change.
c. Enter the domain name you want to join.
d. After join the domain, reboot Windows.
e. Log back in to ALPHA with the domain Administrator account.
2. Create a domain user to run the Rulerunner service:
a. On the Domain Controller server, which is ECMDEMO1 in this example, select Start → Administrative Tools → Active Directory Users and Computers.
b. Enter an appropriate name for the user.
For this example, we create the user QuattroAdmin. Make this user a member of the Domain Admins group to give appropriate privileges to run Rulerunner. Figure 12-25 shows the setting.

Figure 12-25 Rulerunneradmin group memberships
If you want to try a different approach because security is an issue, see the installation documentation.
3. Allow Rulerunner to access the application files on the Taskmaster Server:
a. Share the C:DatacapAuto_Claim folder with access permitted to Rulerunner admin.
b. To complete the connection, set up a network share on ALPHA to the shared C:DatacapAuto_Claim folder on the ECMDEMO1 machine.
4. Install Rulerunner on ALPHA:
a. Double-click the Datacap install executable. Do not install all components, select only Rulerunner/Rulerunner Enterprise.
b. After the installation is complete, restart ALPHA to make any changes take effect.
5. Open Taskmaster Application Manager on ALPHA.
6. Click the Service tab (Figure 12-26). Then change the Main applications management path value to point to the shared network folder where the datacap.xml file resides, which is \ecmdemo1datacapdatacap.xml. This XML file contains details about the current projects.

Figure 12-26 Service path
The Taskmaster Application Manager user interface is updated with details of the projects. The location of the required files and directories now uses UNC paths as shown in Figure 12-27.

Figure 12-27 Taskmaster Application Manager
7. Close the Taskmaster Application Manager for the changes to take effect.
8. Open the Taskmaster Application Manager on ECMDEMO1. Notice the difference because these settings are not configured using UNC paths (as seen on ALPHA).
9. Click the Taskmaster tab. Change the Taskmaster Server name from the localhost address of 127.0.0.1 to the server name of ECMDEMO1. This setting allows nonlocal machines to connect to the Taskmaster Server.
10. Close Taskmaster Application Manager.
11. Go back to ALPHA, and then open its Taskmaster Application Manager.
On the Taskmaster tab, you now see the server name ECMDEMO1 as opposed to 127.0.0.1.
12. Set the VScan string to a UNC path. This string is not automatically changed like the other variables because you might want to point it to a different file system. See Figure 12-27 on page 423 for an example.
13. Change the user that runs the Rulerunner services to the recently created QuattroAdmin user:
a. Open the service console.
b. Change Log on as user to the full domain user ID ([email protected]), and enter the appropriate password.
c. Start the service from the Services window to ensure that the user name and password work as intended. Do not start the service this way normally.
d. If the user credentials work, ensure that the services are stopped (Figure 12-28).

Figure 12-28 Rulerunner server services running as [email protected]
14. Open the Rulerunner Configuration Console.
15. Log in by using the Taskmaster Service user name and password.
16. When you are prompted about encryption, use the Sit Manager from the C:DatacapSupportsit directory to access the encrypted password string.
17. After the connection is made, click the Workflow:Job:Task tab, and expand the Auto_Claim folder. Then, as in 12.3.2, “Installing a single Rulerunner server” on page 412, drag one of the tasks to the thread. It populates the thread with details of the task.
18. Click Save to commit your changes to the quattro.xml configuration file.
19. Optional: Click the Logging tab, and turn on logging as explained previously.
20. Click the Datacap Login tab to disconnect from Taskmaster Services.
21. Click the Datacap Quattro tab, and then click Start to start the Rulerunner server.
Rulerunner now starts and processes any tasks that are assigned to it. As mentioned previously, a visual indication to show that it is working is not available. Look in the project batch folder in the C:DatacapAuto_Claimatches directory on ECMDEMO1. This folder shows an indication of processing occurring. Alternatively open the Taskmaster Client, and then view the tasks processing in the Job Monitor window.
|
Test: A good test is to run a VScan-based task to consume files from a folder. If VScan is set to repeatedly grab these files and not delete them, you see batches begin to be generated in the project batch folder.
|
If you open Windows Task Manager, you see several DCO processes in the window as shown in Figure 12-29.

Figure 12-29 Three DCOProcessors running on Windows
12.3.4 Configuring priorities and queuing
As mentioned previously in this chapter, you can configure priorities against specific tasks, jobs, and so on. You can configure priorities and queuing, for example, in the Rulerunner Manager as shown in Figure 12-30.
Figure 12-30 Configuring priority and skipsamebatch
If we open the quattro.xml file in the C:Datacap mclient directory, we can see in more detail the parameters that are available for each thread, application, server, database, job, and task (Example 12-3).
Only use this file as a reference. Do not change any of the values in the file. Instead, use the Rulerunner Manager to change the values.
Example 12-3 Quattro.xml file
<thread0 enabled="1">
<app name="Auto_Claim" priority="1">
<server name="local" priority="1">
<dbs admin="tmadmin" engine="tmengine" priority="1" >
<job name="Main Job" priority="1">
<task name="Batch Profiler" skipsamebatch="0" priority="1" />
<task name="VScan" skipsamebatch="0" priority="3" />
</job>
</dbs>
</server>
</app>
<app name="1040ez” priority="2">
<server name="local" priority="1">
<dbs admin="tmadmin" engine="tmengine" priority="1" >
<job name="Demo" priority="1">
<task name="VScan" skipsamebatch="0" priority="1" />
</job>
</dbs>
</server>
</app>
<thread0>
Look at the following important parameters in the XML file:
SkipSameBatch Is used when a task might set the batch back to a pending state. If you use VScan configured to remove images after creating the batch, when VScan runs again, and no images are available, the batch is reset to pending. To prevent running the batch repeatedly, this option introduces a delay. Therefore, if the Batch ID is the same next time it runs VScan, do not do anything for X seconds, effectively stopping a repeated loop until images are available.
Priority Is used to determine the ratio that the current thread needs to spend processing the current node among nodes of the same level. The priority is only applicable when more than one node exists at the same level. For example, more than one application (app) exists under one thread or multiple tasks (task) under one job.
The following queuing modes determine how the priority value is used:
Mixed Priorities that are below database (dbs) level are ignored by Rulerunner. Priorities below the (dbs) level are determined by the Taskmaster Server.
Sequential The combined value of priorities of all levels is used to determine how often each particular job and task pair must be run.
The priorities are used to calculate a ratio. All the priorities are divided on the smallest value and rounded. For example, if we set priorities of 5 and 2, they are divided by a ratio of 3:1.
Thread-time distribution is based on the highest level node first. For example, multiple applications are specified, and the ratio is 1:2. If any priorities are set on the task level, the real ratio is combined with the higher level.
Example 12-3 on page 426 has two applications. thread0 queries batches from the 1040ez application twice more than it queries batches from the Auto_Claim application. The Auto_Claim application also has multiple tasks specified. These tasks depend on the queuing mode used:
•In mixed mode, it queries the Taskmaster Server for the batch with highest priority among pending batches for Main Job/Batch Profiler and Main Job/VScan job and task pairs.
•In sequential mode, each time the thread queries the Taskmaster Server, it first tries grabbing a batch for VScan for three times. Only on the fourth attempt, the Batch Profiler batch is grabbed.
In sequential mode, if you have an unlimited amount of batches for all job and tasks pairs from all applications pending it does the following processing:
1. Runs 1040ez VScan two times.
2. Runs Auto_Claim VScan one time.
3. Runs 1040ez VScan two times.
4. Runs Auto_Claim VScan one time.
5. Runs 1040ez VScan two times.
6. Runs Auto_Claim VScan one time.
7. Runs 1040ez VScan two times.
8. Runs Auto_Claim Batch Profiler one time.
If no batches are pending for any job and task pair, this job and task pair are queued next time according to the following formula:
s = 2^n;
where:
s Delay in seconds.
n Amount of unsuccessful attempts to grab the batch.
The maximum wait time will not exceed 64 seconds.
The sample set of values might look like the following process, where each step is an unsuccessful attempt to grab a batch:
1. Wait for 2 seconds
2. Wait for 4 seconds
3. Wait for 8 seconds
4. Wait for 16 seconds
5. Wait for 32 seconds
6. Wait for 64 seconds
7. Wait for 64 seconds
8. Successfully grabbed batch
9. Wait for 2 seconds
10. Wait for 4 seconds
11. ...
If all job and task pairs have no pending batches, the thread goes to sleep for the time interval specified in the registry (default is 10 seconds).
12.3.5 Installing Fingerprint Service
The Fingerprint Service is a web service that runs on IIS. Its purpose is to aid in reducing fingerprint loading times on large-scale implementations using large numbers of fingerprints. For more information, see 12.2.6, “Fingerprint Service” on page 408.
This section shows a possible setup in a test environment. For further information about setting up in production, see the installation guide that comes with your software.
|
Additional license: At the time of publication, an additional license is required for use of the Fingerprint Service. Consult your IBM marketing representative for more details.
|
To install the Fingerprint Service, complete the following steps in which we use a build of Windows 2008 R2 64-bit.
1. Run the installation of Datacap on the machine on which you want to run the Fingerprint Service. The RulerunnerServer component is required during installation.
2. After the installation is complete, go to the C:DatacapFingerprintService directory. Here, you see the web.config file and other required folders and domain link library (DLL) files.
3. Click Start → Control Panel → Programs and Features.
4. Turn the Windows features on or off.
5. Open the Server Manager and click Server Manager, expand Roles, and click Webserver (IIS). If it is not installed, consult the Microsoft documentation to install it.
6. Right-click Webserver (IIS) and select Add Role Services. Ensure that the following options are selected:
– Add Webserver
– Add Common HTTP features
– Add Application Development (ensuring that ASP.Net and ASP are selected)
Figure 12-31 shows the setup.

Figure 12-31 Role Services for IIS
7. Install the components, and then reboot the server.
8. In Windows 2008 R2, open Server Manager, expand Roles → Web Server → Internet Information Services.
9. In the Connections pane:
a. Expand the tree. Right-click Application Pools, and then select Add Application Pool.
b. For the application pool name, enter FingerprintService. As the framework version, select .NET Framework v2.0.50727.
c. Select Integrated as the managed pipeline. Ensure that Start application pool immediately is selected. Then click OK.
10. In the Connections pane, complete these steps:
a. Expand the tree. Right-click Default Web Site, and select Add Application.
b. For Alias, enter FPService, and then for Application pool, select FingerprintService. Click OK.
c. Click the browse button, and then navigate to the installation directory for the fingerprint service. By default, the directory is c:DatacapFingerprintService for the physical path.
d. Click Connect As, and then select the Specific user radio button.
e. Click Set, and then enter the information for the desired user account. For this installation, we use Administrator. In practice, this account must have read and write permissions to this registry branch and sub keys (HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesEventlog). For the purposes of this book, we use Administrator, although you might want to change it. You might also want to make it part of the domain where the Taskmaster and Rulerunner servers reside.
f. Click OK to close the open dialog boxes.
11. From the connection pane, complete these steps:
a. Click Application Pools, and then select FingerprintService.
b. In the Actions pane, click Advanced Settings, and then set Enable 32-Bit Applications to True.
c. Change Idle Time-out (minutes) to 0. Change Identity to the account that you configured for the fingerprint service application (in this case administrator). Then click OK.
12. Open a web browser and point to the following URL:
http://localhost/FPService/service.asmx?WSDL
If successful, you see a web service WSDL page.
13. To test the Fingerprint Service, complete these steps:
a. Select Start → All Programs → Datacap → Support → Fingerprint Service to open the Try Fingerprint Service.
Figure 12-32 shows the Try Fingerprint Service tool window. With this tool, you can test the service by uploading single .cco images or the contents of the entire directory. Then after they are loaded, you can query it for a match by using a specific .cco file. You can also extract statistics and other information from the service.
b. Ensure that you have the correct server name entered into the URL path, which is http://localhost/FPService/service.asmx?WSDL. You can also enter this path into a browser to view the WSDL.
c. Click First ‘N’ Records, which returns “No Fingerprints loaded” in the right pane.
d. For the Upload Fingerprint field, click the ... button, and then look in the C:DatacapFlexfingerprint directory for a single .cco file. Click Upload Fingerprint.
e. For the Find Fingerprint field, click the ... button, and then look in the C:DatacapFlexfingerprint directory for the same .cco file. Click Find Fingerprint.
You now see that a match has been made.

Figure 12-32 Try Fingerprint Service
You can experiment with loading entire directories of .cco files and matching individual fingerprints, for example.
To use this service in a production environment, use a dedicated server to install and run this service.
12.3.6 Using the Fingerprint Service
To use the Fingerprint service, you specify in the application where the web service resides, which is a simple process that you can easily test.
You need to add the following additional actions to your project:
SetFingerprintWebServiceURL
Tells the application where the web service resides. This action shows that web service is held locally, although it is run in a test environment.
Tells the application where the web service resides. This action shows that web service is held locally, although it is run in a test environment.
SetApplicationID Sets the application ID in the Fingerprint service so that fingerprints can be added and removed only from that application.
Figure 12-33 shows an example of these actions used in a project.

Figure 12-33 Fingerprinting setup used in a project
After you run these actions, you see a log similar to Example 12-4.
Example 12-4 Fingerprint run result
----- FindFingerprint of: c:datacapflexatches20110193.002 m000001.tif -----
Updating SearchArea. Top: 0; Bottom: 0.25
Loading Fingerprints...
Fingerprint Record Count: 5
FP Service flag: True
0 fingerprints already loaded...
Updating CCO Fingerprint Service...
Loading FP Service
FPLoading station 1
Attempting to load Fingerprints
Loaded c:datacapflexfingerprint555.cco
Loaded c:datacapflexfingerprint1301.cco
Loaded c:datacapflexfingerprint1302.cco
Loaded c:datacapflexfingerprint1303.cco
Loaded c:datacapflexfingerprint1304.cco
Cleared the FPLoading flag
Loading time: 0.1875
Matching with the Fingerprint WebService...
strCCOFile: c:datacapflexatches20110193.002 m000001.cco
m_SearchArea: 1
sRetn: 0.96,2,0,0
Confidence: 0.96
Template Index: 2
xOffset: 0
YOffset: 0
The FP Service returned fingerprint: 1301
Fingerprint: 1301; index = 2; Confidence = 0.96
Match existing Fingerprint: 1301; Image: c:datacapflexatches20110193.002 m000001.tif
Fingerprint Matching Time: 0.1719
t:C28 p:48E2878 FindFingerprint returns True
This log shows the fingerprints that are being loaded to the web service and the matching that is occurring.
On larger scale implementations, subsequent runs of this fingerprinting process is faster, negating the need to load all fingerprints for every batch.
After you run the Fingerprint Service for the first time, use the Try Fingerprint Service too, which you can access by selecting Start → All Programs → Datacap → Support → Fingerprint Service.
By using this tool, you can enter the application ID that is used in the application (defined in SetApplicationID) and obtain information about the fingerprints. Figure 12-34 shows an example.

Figure 12-34 Try Fingerprint Service returning fingerprints added by an application
12.4 Adding additional Taskmaster Servers
Similar to how you can add additional Rulerunner servers with relative ease, you can add additional Taskmaster Servers. This section shows how to configure two Taskmaster Servers so that they work in an active-active mode to create additional processing power and add redundancy. This section shows a possible setup in a test environment. For more information about setting up in production, see the installation guide that comes with your software.
12.4.1 Adding a failover Taskmaster Server
This section builds upon the configuration in 12.2.2, “Multithread Rulerunner” on page 404. This configuration consists of a central server, named ECMDEMO1, with all Datacap components on it, and a secondary server, named ALPHA, which currently only has Rulerunner. Both ECMDEMO1 and ALPHA are running in the same domain.
To add a failover Taskmaster Server (in our example ALPHA), complete these steps:
1. Install Taskmaster Server on the second server, ALPHA. Follow the standard Datacap installation procedure. Choose the Taskmaster Server module and the client module (to test the setup).
2. After completing the installation, restart the machine.
3. Enable the domain on ALPHA.
Windows must be running in a domain, which is required for Taskmaster Server and all Taskmasters software components. All software on all machines must be in the same domain.
To enable the domain on ALPHA, complete these steps:
a. Select Start → Control Panel → System → Change Settings.
b. Click the Computer Name tab, and then click Change.
c. Enter the domain name of the failover server that needs to join.
d. After the failover server joins the domain, restart Windows.
e. Log in again with the domain Administrator account.
4. Create a domain user under which to run the Taskmaster Server service:
a. On the Domain Controller server, which is ECMDEMO1 in this example, select Start → Administrative Tools → Active Directory Users and Computers.
b. Enter an appropriate name for the user. For this example, we enter TM Admin as the user. Make this user a member of the Domain Admins group to give appropriate privileges to run Taskmaster Server.
For more information about using a different approach if security is an issue, see the installation documentation.
|
Tip: When trying to connect to the Taskmaster databases later, error messages might result because you did not configure the tmadmin user correctly. The new user might not have the permissions to access the shared directory or databases. Check to ensure that the user has that permission.
|
5. Add the information of the second server, ALPHA, to the first server, ECMDEMO:
a. On the first server, ECMDEMO1, where the datacap.xml file is located, open Taskmaster Application Manager.
b. Select the project, which in this example is Auto_Claim, and then click the Taskmaster tab.
c. From the Taskmaster tab, inform the system where additional Taskmaster Servers are located. Figure 12-35 shows that only one Taskmaster Server is currently configured.

Figure 12-35 One Taskmaster Server configured in Taskmaster Application Manager
d. Click Add new Server, and then enter the server name or the IP address and port number for the second server. For our example, we enter a server name of ALPHA and a port number of 2402.
e. Close the Taskmaster Application Manager to save these changes.
Figure 12-36 shows the two Taskmaster Servers that are configured.

Figure 12-36 Two Taskmaster Servers configured
f. Open the c:DatacapAuto_ClaimAuto_Claim.app file or an .app file that you have been working with. You see two lines of XML code similar to the lines in Example 12-5.
Example 12-5 Original Auto_Claim.app file
<k name="tms" ip="ECMDEMO1" port="2402" retry="3"/>
<k name="tms" ip="ALPHA" port="2402" />
g. Add retry="3" to the second Taskmaster Server entry line to ensure that Rulerunner can connect. Example 12-6 shows the updated line.
Example 12-6 Updated Auto_Claim.app file
<k name="tms" ip="ECMDEMO1" port="2402" retry="3"/>
<k name="tms" ip="ALPHA" port="2402" retry="3"/>
h. Go to the ALPHA server where the second Taskmaster Server is installed, and then open Taskmaster Application Manager.
i. Click the Services tab. Enter the shared drive location of the datacap.xml file if it is not already present. In our example, the location is \ecmdemo1datacapdatacap.xml.
j. Refresh the user interface to show a list of the available projects (as defined in the datacap.xml file).
k. Click the Taskmaster tab. You see the two servers: the primary Taskmaster Server, called ECMDEMO1, and the second server, called ALPHA.
6. Repeat step 5 on page 436 (which was done on ECMDEMO) on any subsequent client machines, additional Taskmaster Servers, and Rulerunner machines. Point them to the datacap.xml file so that they are aware of the additional server (which is ALPHA in this case).
7. Ensure that both Taskmaster Servers are running. Select Start → All Programs → Datacap → Taskmaster Server → Taskmaster Server Client. Then click Start.
8. Test that you have two working Taskmaster Servers:
a. Go to the first server, ECMDEMO1, and select Start → All Programs → Datacap → Taskmaster Client.
b. Select the application you want to log in to. Notice the value of Taskmaster Server(s) shows the two server names. In this example, the names are ECMDEMO1 and ALPHA. Point to two servers (Figure 12-37).

Figure 12-37 Taskmaster Servers available for connection
c. Log in to the server. In this case, we log in to ECMDEMO1. Start a few VScan tasks to prove that it can process and run the tasks.
9. To test a failover server, complete these steps:
a. On ECMDEMO1, select Start → All Programs → Datacap → Datacap Taskmaster Server. Open Taskmaster Server Manager. Stop this service.
b. When you see a message box indicating a broken connection, log out and then log back in to the Taskmaster Client again.
This time the client states that it cannot connect to ECMDEMO1.
c. Click OK, and it connects to the secondary server ALPHA. Notice how the tasks in various states are the same as the previous login on ECMDEMO1. The reason is that both Taskmaster Servers use the same database.
You have now added additional Taskmaster Servers for failover, allowing clients and Rulerunner servers to connect to both Taskmaster Servers.
12.4.2 Load sharing between Taskmaster Servers
By load sharing two or more Taskmaster Servers, you can scale effectively in large-scale environments. To achieve this goal, update the .app application file to allow identification of the server within Rulerunner Manager:
1. Go to the application directory, and then open the application file. In this example, we go to C:DatacapAuto_Claims directory and open the Auto_Claim.app file.
2. Change the XML code to add an extra line for each server as shown in bold text in Example 12-7.
Example 12-7 Updated version of the Auto_Claim.app file
<k name="tms" ip="ECMDEMO1" port="2402" retry="3"/>
<k name="tms" ip="ALPHA" port="2402" retry="3"/>
<k name="tmsecmdemo" ip="ECMDEMO1" port="2402" retry="3"/>
<k name="tmsalpha" ip="ALPHA" port="2402" retry="3"/>
|
tms: The third line in Example 12-7 is not strictly needed. When configuring Rulerunner, the key "tms" refers to the first instance of "tms," for which this line creates another name. You only really need to define synonyms or aliases for the second and subsequent tms servers.
|
You must add uniquely identifiable names for the servers, leaving the original tms servers to allow the clients to connect. In our example, the uniquely identifiable names are tmsecmdemo and tmsalpha.
By adding these names, Rulerunner can also identify each server uniquely. If we use tms as we have done before, Rulerunner connects to the first tms server that it reads from the XML code and cannot differentiate between them. If the first Taskmaster Server fails, it connects to the next tms server. In this example, it is a failover from ECMDEMO1 to ALPHA.
If you want to load balance between two servers because the throughput is high, you must add the ability to assign specific tasks to specific Taskmaster Servers (or groups of Taskmaster Servers). These tasks are uniquely identified by the ‘name=’ tag.
If we open Rulerunner Manager on ALPHA, we see the changes that we have made. It shows the original two tms servers, including the additional tmsecmdemo1 and tmsalpha as shown in Figure 12-38.

Figure 12-38 Two additional servers, tmsecmdemo1 and tmsalpha
|
Important: Both the tms servers and the newly named Taskmaster Servers must be present in the .app file as shown in Figure 12-7 on page 439. If the tms servers are not present, the Taskmaster Client is unable to connect to either Taskmaster Server.
|
We can now choose between which Taskmaster Server we assign our tasks to. Earlier in this chapter (see Figure 12-19 on page 417), we explained how to create a thread and drag tasks across it. Here, we perform this task in a slightly different way so that we can assign tasks to a thread and share the thread between two or more Taskmaster Servers on a given ratio. That is 99% of the jobs go to Taskmaster Server, and 1% go to the other server.
To create a thread and share the thread between two or more Taskmaster Servers, complete these steps:
1. Connect to the tmsecmdemo1 server:
a. In Rulerunner Manager, click the Datacap Login tab. If you need to add credentials, see 12.2.1, “Single-threaded Rulerunner” on page 402.
b. Click Connect. The text at the bottom of the window changes to reflect the connection status.
c. Click the Workflow:Job:task tab. From the list of applications, expand Auto_Claim → Servers.
d. Right-click tmsecmdemo1, which selects all the parents, and then select Connect. The text at the bottom of the window changes to reflect the connection to this Taskmaster Server.
For more details about the server, look in the lower right part of the ID and Settings section (Figure 12-39).

Figure 12-39 Taskmaster Server details in the Rulerunner Manager
2. Connect the tmadmin and tmengine databases as follows:
a. Right-click tmadmin, and then select Connect.
b. Right-click tmengine, and then select Connect.
The text at the bottom of the window reflects the fact that you are connected to the Taskmaster Server, logged into the database, and connected to the Taskmaster Application Service.
3. Create a thread to the right of the main tree:
a. Right-click the white space, and then select Threads → Add Thread.
b. Select the tasks that you want to add to the thread, for example, PageID and Rulerunner.
c. Select the parent node of the application, which is Auto_Claim in this case, as highlighted in Figure 12-40.
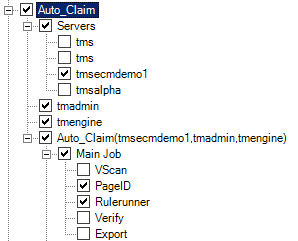
Figure 12-40 Auto_Claim is the parent node
d. Drag this node to the thread that you just created. It populates the thread.
4. Disconnect tmengine, tmadmin, and tmsecmdemo1:
a. Right-click tmengine, and select Disconnect.
b. Repeat step a for tmadmin and tmsecmdemo1.
c. Clear the boxes.
The text at the bottom of the window indicates that you are only connected to the Taskmaster Application Service.
5. Select the second Taskmaster Server, which is tmsalpha in this case. Connect to it along with both the tmadmin and tmengine databases. Select the tasks that you need. Then select the parent node and drag it to the root of the thread (Figure 12-41).
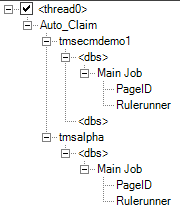
Figure 12-41 Thread setup across two Taskmaster Servers
6. Right-click the <dbs> tag in the center and select Remove.
7. Set priority for the server as needed.
If you click the tmsecmdemo1 node under the thread, and similarly, the tmsalpha node, you can set a priority for them in the lower right pane of the window. In this case, the priority allows you to use one Taskmaster Server more than the other. Setting one server with a higher number means that it will be used more times than the other.
For example, if we set tmsecmdemo1 with a priority of 99, and we can set tmsalpha a priority of 1. Then tmsecmdemo1 will be used 99 times out of 100. If one of these two servers fails, the other server takes on the workload and ignores any defined priorities.
8. Click the Workflow:Job:Task tab, and then clear the Stop on Abort. Stop the service if a task aborts option (Figure 12-42).

Figure 12-42 Clearing the Stop on Abort check box
|
Important: For the failover to work effectively, you must complete this step. Otherwise, all tasks cease to process across all Taskmaster Servers if a Taskmaster Server connection terminates (that is, a Taskmaster Server failure) and stops.
|
9. Set the restart interval for a Rulerunner service.
Rulerunner does not reconnect to a failed Taskmaster Server without restarting. If a Taskmaster Server fails, and then comes back online, restarting the Rulerunner service is required.
You can restart the service manually. Alternatively, you can lower the Restart Interval value on the Advanced Settings tab of the Workflow:Job:Task tab (Figure 12-43). A suitable value must be determined on a case-by-case basis. Restarting a server frequently might reduce throughput of the Rulerunner server.

Figure 12-43 Restart Interval setting
Figure 12-44 shows another possible configuration where a thread has been dedicated to each Taskmaster. The disadvantage of this configuration is that, if the Taskmaster Server fails, the thread becomes inactive until the Taskmaster Server comes back online and the Rulerunner service is restarted.

Figure 12-44 Thread running on separate Taskmaster Servers
For more information about how this process works, see “Sequential queuing mode” on page 406, “Mixed queuing mode” on page 406, and 12.3.4, “Configuring priorities and queuing” on page 425.
10. Save and test the configuration:
a. Click Save to save this configuration.
b. Click the Datacap Login tab, and click Disconnect.
c. Start Rulerunner, and then check if processing is occurring.
d. After the processing is occurring, check whether it works by stopping one of the Taskmaster Servers and checking that the processing still occurs.
12.4.3 Overview of Rulerunner Server and Taskmaster Server
The configuration in Figure 12-45 on page 445 shows complete redundancy if either a Taskmaster or Rulerunner server fails. Similarly, clients can connect to either Taskmaster Server. This configuration is similar to the system created in the previous sections.
The two points of failure in Figure 12-45 on page 445 are the database server and the file share. If you perform appropriate backup on these two areas, you can build a highly resilient document capture system. For information about backup, see 12.5.6, “Backing up the file share” on page 452, and 12.5.3, “Backing up the database server” on page 451.
Figure 12-45 Overall configuration of the Taskmaster and Rulerunner servers
|
Multithread licensing: At the time of publication, an additional license, called the Rulerunner Enterprise license, is required to use multithreading in Rulerunner. See your IBM marketing representative for more information.
|
12.4.4 Scaling a thick client
The previous sections explained failover for both thick and thin clients. This section explains how to scale a thick client. The approach is to use multiple thick clients across multiple Taskmaster Servers.
To balance the load of multiple thick clients across multiple Taskmaster Servers, we must break away from the model defined earlier of the centralized datacap.xml and <application>.app files as follows:
1. For the clients to connect to additional Taskmaster Servers, make a copy of the original datacap.xml and <application>.app files. Place them in a separate shared directory.
2. In Datacap Application Manager on the thick client or Taskmaster Web Server, point the service path to this new copy:
a. Create a user group as part of the domain into which the thick and thin client users can be added.
b. Copy the datacap.xml file from the c:datacap directory to a new location. For this example, we create a folder called c:datacapclient1 and copy it to this new location.
c. Create a copy of the .app file from the application that you want to scale. For this example, we copy the Auto_Claim.app file to a new folder of the same name under c:Datacapclient1.
You now have the following files:
– c:datacapclient1datacap.xml
– c:datacapclient1auto_claimauto_claim.app
If you want to load balance clients in the future, consider making a minimum number of separate configurations during the initial configuration.
|
Additional thick clients: The additional thick clients do not have a one-to-one relationship to the c:datacapclientX configuration folder. This folder can be used by a group of many defined thick clients.
|
Example 12-8 The datacap.xml file
<datacap ver="8.0">
<app name="Auto_Claim" ref="Auto_Claim"></app>
</datacap>
4. Open c:datacapclient1auto_claimauto_claim.app, and then change the XML code to reflect the primary and secondary Taskmaster Servers that you want to use (Example 12-9).
Example 12-9 The auto_claim.app file
<k name="tmservers">
<k name="tms" ip="ECMDEMO1" port="2402" retry="3"/>
<k name="tms" ip="ALPHA" port="2402" retry="3"/>
</k>
5. Share the directory in which this file resides, which is the \ecmdemo1datacapauto_claim directory. The user who is running the thick client or the Taskmaster Web Server must have the appropriate permissions to access the share drive.
6. On the client (thick client or thin web server), open Taskmaster Application Manager.
7. Click the Service tab. For Main applications management path, enter the newly shared directory that contains the datacap.xml file.
The applications populate in the user interface as shown in Figure 12-46.

Figure 12-46 Newly shared directory on the Service tab
If the application does not populate, you can alter the registry. Run the regedit command, and then search for toppath. Alter TopPath to reflect the location of the new datacap.xml file as shown in Figure 12-47.

Figure 12-47 TopPath entry
8. Connect with the client. Point it to the newly defined Taskmaster Servers that you defined, in the order in which you defined the .app file, with only the applications that you defined as available in the datacap.xml file. See Figure 12-48.

Figure 12-48 Selecting the Auto_Claim Datacap application
If the system produces an error message that the application does not specify an administrator database, verify the values on the Taskmaster tab in Taskmaster Application Manager. If they are blank, copy the values from the original .app file in the central server to the new copy .app file. Then, change the values to reflect the proper location of the databases.
Remember that for any changes you make at a later stage to the central .app or dataap.xml file, you must copy them to the additional directories. This way you can ensure that the changes you made to the Taskmaster XML section (see Example 12-9 on page 447) are not effected.
If you need to add additional clients to further scale out, complete these steps:
1. Copy the c:datacapclient1 directory and all its contents to the c:datacapclient2 directory.
2. Modify the .app file in the c:datacapclient1auto_claim directory to reflect the alternate Taskmaster Servers that you want to use.
3. Open Datacap Application Manager on the client that you want to configure, and then point it to the new directory, such as the \ecmdemodatacaclient2datacap.xml directory.
12.4.5 Scaling a Taskmaster Web client
The approach to scale Taskmaster Web entails using multiple Taskmaster Web Servers across multiple Taskmaster Servers. To balance the load of multiple Taskmaster Web Servers across multiple Taskmaster Servers, Taskmaster Web works on the same principles described in 12.4.4, “Scaling a thick client” on page 445. However, rather than on the client machine, it must be carried out on the Taskmaster Webserver.
The web server inherits the Taskmaster Servers that are configured by using the datacap.xml and .app files defined in the Datacap Application Managers on the Services tab.
|
Tip: Similar to the thick client configuration, the additional web servers do not have a one-to-one relationship to a c:datacapclientX configuration folder. The c:datacapclientX configuration folder can be used by a group of many defined web servers.
Place the datacap.xml and .app files on the c: drive of each web server rather than in a shared network location.
|
12.5 Backup and restore
Ensure that a regular backup is made of both the production and development systems. Regular backup ensures that if a failure occurs, you have a recovery point to revert to.
12.5.1 Backing up and restoring Rulerunner machines
Because Rulerunner servers are stateless (process data and push it back to the batch directory and inform the Taskmaster Server of its completion), no data is held on them. Therefore, no data is lost if the server fails. The only information that can potentially be lost is data that is in process at batch execution time.
As a result, backup is made much simpler. The Rulerunner server must be brought down gracefully when no tasks are in process. After the server is brought down, a standard mirror of the whole server can be carried out.
If a failure occurs, the server can be restored to the point at which the mirror is made. Because no processes are running at the time of creation, the system can revert to a clean Rulerunner server status. To successfully revert to a clean Rulerunner server status, downtime for Rulerunner is essential.
After an initial backup is made, subsequent backups are needed only when changes or updates are installed on the Rulerunner server such as fix packs.
12.5.2 Backing up and restoring the Taskmaster Server
The Taskmaster Server is the central Windows service that provides user authentication, workflow, and queuing (and file services for Taskmaster Web). It stores user details and the status of batches in two databases, which are the Administration and Engine databases.
Therefore, you must back up both databases to return to a preferred status. Backing up databases is well documented in many other publications and web sites. The database backup procedure is beyond the scope of this IBM Redbooks publication and, therefore, is not addressed here. Consult your database vendor documentation for further information.
In a critical environment, use a database mirror so that you always have two copies of the database.
Backing up of the Taskmaster Server ensures that you have a snapshot to restore to. You must close the Taskmaster Server gracefully, ensuring that no tasks are currently in progress.
To carry out the shutdown, follow this order:
1. Where possible, close the connected clients.
2. Close any services.
3. Shut down the Taskmaster Server.
After the system shuts down, you can carry out a standard mirror of the whole server.
If a failure occurs, the server can be restored to the point at which the mirror is made. Because no processes are running at the time of mirror creation, the system reverts to a clean Taskmaster Service status. When reverting to a mirror snapshot of the Engine database or the file share that contains document batches, any work processed between the time the mirror was created and the system failure is lost. To successfully back up the system, downtime for the system is essential.
The frequency of backup depends on the specific needs of the client.
12.5.3 Backing up the database server
Taskmaster comes with Microsoft Access as its standard shipped database format. It uses two main databases, the Engine database and the Administrator databases. A Fingerprint database is also available.
Backing up and restoring databases is documented and beyond the scope of this IBM Redbooks publication. Consult with your database vendor documentation for details.
12.5.4 Backing up and restoring the Fingerprint server
The Fingerprint Service, similar to Rulerunner, is stateless. It runs as a service and loads fingerprint details in the Fingerprint database. As a result, backing up is simpler because no fingerprints are stored on its file system.
Bring down the Fingerprint Service gracefully when no tasks are in process. After you bring it down, a standard mirror of the whole server is sufficient.
If a failure occurs, you can restore the server to the point at which the mirror is made. Because no fingerprints are loaded into memory at the time of creation, the system can revert to a clean Fingerprint Server Service. To successfully restore the system, downtime for the system is essential.
The frequency of backup depends on the specific needs of the client.
12.5.5 Backing up and restoring the IIS web server
The IIS web server serves pages to the web for users to scan, verify, and administer the system. When images are scanned, they are held on the IIS web server before they are uploaded. Apart from this process, the server is stateless. It holds no other permanent data.
Bring down the IIS web server gracefully when no tasks are in process. After the server is down, a standard mirror of the whole server is sufficient.
If a failure occurs, you can restore the server to the point at which the mirror is made. The system can revert to a clean IIS web server status. To successfully restore the system, downtime for the system is essential.
The frequency of backup depends on the specific needs of the client.
12.5.6 Backing up the file share
The file share holds all batch data and the Taskmaster application project files (if you store them there). Continuously mirroring this drive ensures that you have a fully current version of the batches. If paired with database mirroring of the Engine database, it also ensures the status of that batch.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.