
Chapter 5. Advanced Collections and Collectors
There’s a lot more to the collections library changes than I covered in Chapter 3. It’s time to cover some of the more advanced collections
changes, including the new Collector abstraction. I’ll also introduce method
references, which are a way of using existing code in lambda expressions with
little to no ceremony. They pay huge dividends when it comes to writing
Collection-heavy code. More advanced topics within the collections library
will also be covered, such as element ordering within streams and other useful API
changes.
Method References
A common idiom you may have noticed is the creation of a lambda expression that calls a method on its parameter. If we want a lambda expression that gets the name of an artist, we would write the following:
artist->artist.getName()
This is such a common idiom that there’s actually an abbreviated syntax for this that lets you reuse an existing method, called a method reference. If we were to write the previous lambda expression using a method reference, it would look like this:
Artist::getName
The standard form is Classname::methodName. Remember that even though it’s a
method, you don’t need to use brackets because you’re not actually calling the
method. You’re providing the equivalent of a lambda expression that can be
called in order to call the method. You can use method references in the same
places as lambda expressions.
You can also call constructors using the same abbreviated syntax.
If you were to use a lambda expression to create an Artist, you might write:
(name,nationality)->newArtist(name,nationality)
We can also write this using method references:
Artist::new
This code is not only shorter but also a lot easier to read. Artist::new
immediately tells you that you’re creating a new Artist without your having to scan
the whole line of code. Another thing to notice here is that method references
automatically support multiple parameters, as long as you have the right
functional interface.
It’s also possible to create arrays using this method. Here is how you would
create a String array:
String[]::new
We’ll be using method references from this point onward where appropriate, so you’ll be seeing a lot more examples very soon. When we were first exploring the Java 8 changes, a friend of mine said that method references “feel like cheating.” What he meant was that, having looked at how we can use lambda expressions to pass code around as if it were data, it felt like cheating to be able to reference a method directly.
It’s OK—it’s not cheating! You have to bear in mind that every time you write a
lambda expression that looks like x -> foo(x), it’s really doing the same thing
as just the method foo on its own. All method references do is provide a
simpler syntax that takes advantage of this fact.
Element Ordering
One topic I haven’t discussed so far that pertains to collections is how
elements are ordered in streams. You might be familiar with the concept that
some types of Collection, such as List, have a defined order, and collections
like HashSet don’t. The situation with ordering becomes a little more
complex with Stream operations.
A Stream intuitively presents an order because each element is operated upon,
or encountered, in turn. We call this the encounter order. How the
encounter order is defined depends on both the source of the data and the
operations performed on the Stream.
When you create a Stream from a collection with a defined order, the Stream
has a defined encounter order. As a consequence, Example 5-1 will always
pass.
List<Integer>numbers=asList(1,2,3,4);List<Integer>sameOrder=numbers.stream().collect(toList());assertEquals(numbers,sameOrder);
If there’s no defined order to begin, the Stream produced by that
source doesn’t have a defined order. A HashSet is an example of a collection
without a defined ordering, and because of that Example 5-2 isn’t
guaranteed to pass.
Set<Integer>numbers=newHashSet<>(asList(4,3,2,1));List<Integer>sameOrder=numbers.stream().collect(toList());// This may not passassertEquals(asList(4,3,2,1),sameOrder);
The purpose of streams isn’t just to convert from one collection to another; it’s to be able to provide a common set of operations over data. These operations may create an encounter order where there wasn’t one to begin with. Consider the code presented in Example 5-3.
Set<Integer>numbers=newHashSet<>(asList(4,3,2,1));List<Integer>sameOrder=numbers.stream().sorted().collect(toList());assertEquals(asList(1,2,3,4),sameOrder);
The encounter order is propagated across intermediate operations if it exists;
for example, if we try to map values and there’s a defined encounter order, then
that encounter order will be preserved. If there’s no encounter order on
the input Stream, there’s no encounter order on the output Stream.
Consider the two snippets of code in Example 5-4. We can only make
the weaker hasItem assertions on the HashSet example because the lack
of a defined encounter order from HashSet continues through the map.
List<Integer>numbers=asList(1,2,3,4);List<Integer>stillOrdered=numbers.stream().map(x->x+1).collect(toList());// Reliable encounter orderingassertEquals(asList(2,3,4,5),stillOrdered);Set<Integer>unordered=newHashSet<>(numbers);List<Integer>stillUnordered=unordered.stream().map(x->x+1).collect(toList());// Can't assume encounter orderingassertThat(stillUnordered,hasItem(2));assertThat(stillUnordered,hasItem(3));assertThat(stillUnordered,hasItem(4));assertThat(stillUnordered,hasItem(5));
Some operations are more expensive on ordered streams. This problem can be solved
by eliminating ordering. To do so, call the stream’s unordered
method. Most operations, however, such as filter, map, and reduce, can operate very
efficiently on ordered streams.
This can cause unexpected behavior, for example, forEach provides no guarantees as to encounter order if you’re using parallel streams. (This will be discussed in more detail in Chapter 6.) If you require an ordering guarantee in these situations, then forEachOrdered is your friend!
Enter the Collector
Earlier, we used the collect(toList()) idiom in order to produce lists out of
streams. Obviously, a List is a very natural value to want to produce from a
Stream, but it’s not the only value that you might want to compute. Perhaps you
want to generate a Map or a Set. Maybe you think it’s worth having a domain
class that abstracts the concept you want?
You’ve already learned that you can tell just from the signature of a Stream
method whether it’s an eagerly evaluated terminal operation that can be used to
produce a value. A reduce operation can be very suitable for this purpose.
Sometimes you want to go further than reduce allows, though.
Enter the collector, a general-purpose construct for producing complex
values from streams. These can be used with any Stream by passing
them into the collect method.
The standard library provides a bunch of useful collectors out of the box, so
let’s look at those first. In the code examples throughout this chapter
the collectors are statically imported from the java.util.stream.Collectors
class.
Into Other Collections
Some collectors just build up other collections. You’ve already seen the toList
collector, which produces java.util.List instances. There’s also a toSet
collector and a toCollection collector, which produce instances of Set and
Collection. I’ve talked a lot so far about chaining Stream operations, but
there are still times when you’ll want to produce a Collection as a final value—for
example:
- When passing your collection to existing code that is written to use collections
- When creating a final value at the end of a chain of collections
- When writing test case asserts that operate on a concrete collection
Normally when we create a collection, we specify the concrete type of the collection by calling the appropriate constructor:
List<Artist>artists=newArrayList<>();
But when you’re calling toList or toSet, you don’t get to specify the concrete
implementation of the List or Set. Under the hood, the streams library is picking
an appropriate implementation for you. Later in this book I’ll talk about how you
can use the streams library to perform data parallel operations; collecting the
results of parallel operations can require a different type of Set to be produced
than if there were no requirement for thread safety.
It might be the case that you wish to collect your values into a Collection of
a specific type if you require that type later. For example, perhaps you want
to use a TreeSet instead of allowing the framework to determine what type of
Set implementation you get. You can do that using the toCollection collector,
which takes a function to build the collection as its argument (see Example 5-5).
To Values
It’s also possible to collect into a single value using a collector. There are
maxBy and minBy collectors that let you obtain a single value according to
some ordering. Example 5-6 shows how to find the band with the most
members. It defines a lambda expression that can map an artist to the number
of members. This is then used to define a comparator that is passed into the
maxBy collector.
publicOptional<Artist>biggestGroup(Stream<Artist>artists){Function<Artist,Long>getCount=artist->artist.getMembers().count();returnartists.collect(maxBy(comparing(getCount)));}
There’s also a minBy, which does what it says on the tin.
There are also collectors that implement common numerical operations. Let’s take a look at these by writing a collector to find the average number of tracks on an album, as in Example 5-7.
publicdoubleaverageNumberOfTracks(List<Album>albums){returnalbums.stream().collect(averagingInt(album->album.getTrackList().size()));}
As usual, we kick off our pipeline with the stream method and collect
the results. We then call the averagingInt method, which takes a lambda
expression in order to convert each element in the Stream into an int
before averaging the values. There are also overloaded operations for the
double and long types, which let you convert your element into these type
of values.
Back in Primitives, we talked about how the primitive specialized
variants of streams, such as IntStream, had additional functionality for
numerical operations. In fact, there are also a group of collectors that offer
similar functionality, in the vein of averagingInt. You can add up the values
using summingInt and friends. SummaryStatistics is collectible using summarizingInt and its combinations.
Partitioning the Data
Another common operation that you might want to do with a Stream is
partition it into two collections of values. For example, if you’ve got a
Stream of artists, then you might wish to get all the artists who are solo
artists—that is, who have no fellow band members—and all the artists who are bands. One
approach to doing this is to perform two different filters, one looking for
solo artists and the other for bands.
This approach has a couple of downsides, though. First, you’ll need two streams in order to perform these two stream operations. Second, if you’ve got a long sequence of operations leading up to your filters, these will need to be performed twice over each stream. This also doesn’t result in clean code.
Consequently, there is a collector, partitioningBy, that takes a stream and partitions its
contents into two groups (see Figure 5-1). It uses a Predicate to determine whether an element
should be part of the true group or the false group and returns a Map from
Boolean to a List of values. So, the Predicate returns true for all
the values in the true List and false for the other List.
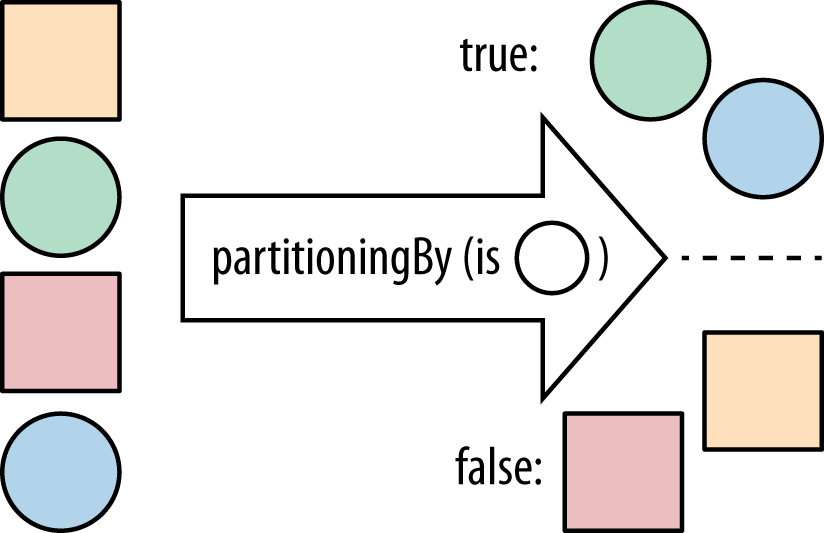
We can use these features to split out bands (artists with more than one member) from solo artists. In this case, our partitioning function tells us whether the artist is a solo act. Example 5-8 provides an implementation.
publicMap<Boolean,List<Artist>>bandsAndSolo(Stream<Artist>artists){returnartists.collect(partitioningBy(artist->artist.isSolo()));}
We can also write this using method references, as demonstrated in Example 5-9.
Grouping the Data
There’s a natural way to generalize partitioning through altering the grouping
operation. It’s more general in the sense that instead of splitting up your
data into true and false groups, you can use whatever values you want.
Perhaps some code has given you a Stream of albums and you want to group them
by the name of their main musician. You might write some code like Example 5-10.
publicMap<Artist,List<Album>>albumsByArtist(Stream<Album>albums){returnalbums.collect(groupingBy(album->album.getMainMusician()));}
As with the other examples, we’re calling collect on the Stream and passing
in a Collector. Our groupingBy collector (Figure 5-2) takes a classifier function in
order to partition the data, just like the partitioningBy collector took a
Predicate to split it up into true and false values. Our classifier is a
Function—the same type that we use for the common map operation.
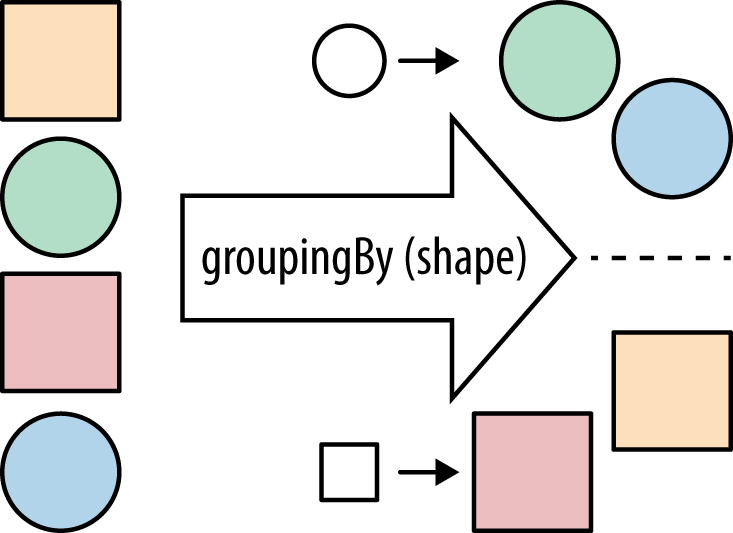
Strings
A very common reason for collecting streams of data is to generate strings at the
end. Let’s suppose that we want to put together a formatted list of
names of the artists involved in an album. So, for example, if our input album
is Let It Be, then we’re expecting our output to look like "[George Harrison,
John Lennon, Paul McCartney, Ringo Starr, The Beatles]".
If we were to implement this before Java 8, we might have come up with
something like Example 5-11. Here, we use a StringBuilder to
accumulate the values, iterating over the list. At each step, we pull out the
names of the artists and add them to the StringBuilder.
StringBuilderbuilder=newStringBuilder("[");for(Artistartist:artists){if(builder.length()>1)builder.append(", ");Stringname=artist.getName();builder.append(name);}builder.append("]");Stringresult=builder.toString();
Of course, this isn’t particularly great code. It’s pretty hard to see what it’s doing without walking through it step by step. With Java 8 we can write Example 5-12, which makes our intent much clearer using streams and collectors.
Stringresult=artists.stream().map(Artist::getName).collect(Collectors.joining(", ","[","]"));
Here, we use a map to extract the artists’ names and then collect the Stream
using Collectors.joining. This method is a convenience for building up
strings from streams. It lets us provide a delimiter (which goes between
elements), a prefix for our result, and a suffix for the result.
Composing Collectors
Although the collectors we’ve seen so far are quite powerful, they become significantly more so when composed with other collectors.
Previously we grouped albums by their main artist; now let’s consider the problem of counting the number of albums for each artist. A simple approach would be to apply the previous grouping and then count the values. You can see how that works out in Example 5-13.
Map<Artist,List<Album>>albumsByArtist=albums.collect(groupingBy(album->album.getMainMusician()));Map<Artist,Integer>numberOfAlbums=newHashMap<>();for(Entry<Artist,List<Album>>entry:albumsByArtist.entrySet()){numberOfAlbums.put(entry.getKey(),entry.getValue().size());}
Hmm, it might have sounded like a simple approach, but it got a bit messy. This code is also imperative and doesn’t automatically parallelize.
What we want here is actually another collector that tells groupingBy that
instead of building up a List of albums for each artist, it should just count them.
Conveniently, this is already in the core library and is called counting. So,
we can rewrite the example into Example 5-14.
publicMap<Artist,Long>numberOfAlbums(Stream<Album>albums){returnalbums.collect(groupingBy(album->album.getMainMusician(),counting()));}
This form of groupingBy divides elements into buckets. Each bucket gets associated with the key provided by the classifier function: getMainMusician. The groupingBy operation then uses the downstream collector to collect each bucket and makes a map of the results.
Let’s consider another example, in which instead of building up a grouping of
albums, we just want their names. Again, one approach is to take our original
collector and then fix up the resulting values in the Map. Example 5-15
shows how we might do that.
publicMap<Artist,List<String>>nameOfAlbumsDumb(Stream<Album>albums){Map<Artist,List<Album>>albumsByArtist=albums.collect(groupingBy(album->album.getMainMusician()));Map<Artist,List<String>>nameOfAlbums=newHashMap<>();for(Entry<Artist,List<Album>>entry:albumsByArtist.entrySet()){nameOfAlbums.put(entry.getKey(),entry.getValue().stream().map(Album::getName).collect(toList()));}returnnameOfAlbums;}
Again, we can produce nicer, faster, and easier-to-parallelize code using another collector. We already know that we can group our albums by the main artist using the groupingBy collector, but that would output a Map<Artist, List<Album>>. Instead of associating a list of albums with each Artist, we want to associate a list of strings, each of which is the name of an album.
In this case, what we’re really trying to do is perform a map operation on
the list from the Artist to the album name. We can’t just use the map method
on streams because this list is created by the groupingBy collector. We
need a way of telling the groupingBy collector to map its list values
as it’s building up the result.
Each collector is a recipe for building a final value. What we really want is a
recipe to give to our recipe—another collector. Thankfully, the boffins at
Oracle have thought of this use case and provided a collector called mapping.
The mapping collector allows you to perform a map-like operation over your
collector’s container. You also need to tell your mapping collector what
collection it needs to store the results in, which you can do with the toList
collector. It’s turtles, I mean collectors, all the way down!
Just like map, this takes an implementation of Function. If we refactor
our code to use a second collector, we end up with Example 5-16.
publicMap<Artist,List<String>>nameOfAlbums(Stream<Album>albums){returnalbums.collect(groupingBy(Album::getMainMusician,mapping(Album::getName,toList())));}
In both of these cases, we’ve used a second collector in order to collect a subpart of the final result. These collectors are called downstream collectors. In the same way that a collector is a recipe for building a final value, a downstream collector is a recipe for building a part of that value, which is then used by the main collector. The way you can compose collectors like this makes them an even more powerful component in the streams library.
The primitive specialized functions, such as averagingInt or summarizingLong, are actually duplicate functionality over calling the method on the specialized stream themselves. The real motivation for them to exist is to be used as downstream collectors.
Refactoring and Custom Collectors
Although the built-in Java collectors are good building blocks for common operations around streams, the collector framework is very generic. There is nothing special or magic about the ones that ship with the JDK, and you can build your own collectors very simply. That’s what we’ll look at now.
You may recall when we looked at strings that we could write our example in Java 7, albeit inelegantly. Let’s take this example and slowly refactor it into a proper String-joining collector. There’s no need for you to use this code—the JDK provides a perfectly good joining collector—but it is quite an instructive example both of how custom collectors work and of how to refactor legacy code into Java 8.
Example 5-17 is a reminder of our Java 7 String-joining example.
StringBuilderbuilder=newStringBuilder("[");for(Artistartist:artists){if(builder.length()>1)builder.append(", ");Stringname=artist.getName();builder.append(name);}builder.append("]");Stringresult=builder.toString();
It’s pretty obvious that we can use the map operation to transform
the Stream of artists into a Stream of String names. Example 5-18
is a refactoring of this code to use streams and map.
StringBuilderbuilder=newStringBuilder("[");artists.stream().map(Artist::getName).forEach(name->{if(builder.length()>1)builder.append(", ");builder.append(name);});builder.append("]");Stringresult=builder.toString();
This has made things a bit clearer in the sense that the mapping to names shows
us what has been built up a bit more quickly. Unfortunately, there’s still this
very large forEach block that doesn’t fit into our goal of writing code that
is easy to understand by composing high-level operations.
Let’s put aside our goal of building a custom collector for a moment and just
think in terms of the existing operations that we have on streams. The
operation that most closely matches what we’re doing in terms of building up a
String is the reduce operation. Refactoring Example 5-18 to use that
results in Example 5-19.
StringBuilderreduced=artists.stream().map(Artist::getName).reduce(newStringBuilder(),(builder,name)->{if(builder.length()>0)builder.append(", ");builder.append(name);returnbuilder;},(left,right)->left.append(right));reduced.insert(0,"[");reduced.append("]");Stringresult=reduced.toString();
I had hoped that last refactor would help us make the code clearer. Unfortunately, it seems to be just as bad as before. Still, let’s see what’s going on. The stream and map calls are the same as in the previous example. Our reduce operation builds up the artist names, combined with ", " delimiters. We start with an empty StringBuilder—the identity of the reduce. Our next lambda expression combines a name with a builder. The third argument to reduce takes two StringBuilder instances and combines them. Our final step is to add the prefix at the beginning and the suffix at the end.
For our next refactoring attempt, let’s try and stick with reduction but hide the mess—I mean, abstract away the details—behind a class that we’ll call a StringCombiner. Implementing this results in Example 5-20.
StringCombinercombined=artists.stream().map(Artist::getName).reduce(newStringCombiner(", ","[","]"),StringCombiner::add,StringCombiner::merge);Stringresult=combined.toString();
Even though this looks quite different from the previous code example, it’s actually doing the exact same thing under the hood. We’re using reduce in order to combine names and delimiters into a StringBuilder. This time, though, the logic of adding elements is being delegated to the StringCombiner.add method and the logic of combining two different combiners is delegated to StringCombiner.merge. Let’s take a look at these methods now, beginning with the add method in Example 5-21.
publicStringCombineradd(Stringelement){if(areAtStart()){builder.append(prefix);}else{builder.append(delim);}builder.append(element);returnthis;}
add is implemented by delegating operations to an underlying StringBuilder instance. If we’re at the start of the combining operations, then we append our prefix; otherwise, we append the string that fits between our elements (the delimiter). We follow this up by appending the element. We return the StringCombiner object because this is the value that we’re pushing through our reduce operation. The merging code, provided in Example 5-22, delegates to appending operations on the StringBuilder.
publicStringCombinermerge(StringCombinerother){builder.append(other.builder);returnthis;}
We’re nearly done with the reduce phase of refactoring, but there’s one small step remaining. We’re going to inline the toString to the end of the method call chain so that our entire sequence is method-chained. This is simply a matter of lining up the reduce code so that it’s ready to be converted into the Collector API (see Example 5-23).
Stringresult=artists.stream().map(Artist::getName).reduce(newStringCombiner(", ","[","]"),StringCombiner::add,StringCombiner::merge).toString();
At this stage, we have some code that looks vaguely sane, but it’s quite hard to
reuse this same combining operation in different parts of our code base. So
we’re going to refactor our reduce operation into a Collector, which
we can use anywhere in our application. I’ve called our Collector
the StringCollector. Let’s refactor our code to use it in Example 5-24.
Stringresult=artists.stream().map(Artist::getName).collect(newStringCollector(", ","[","]"));
Now that we’re delegating the whole of the String-joining behavior to a
custom collector, our application code doesn’t need to understand anything
about the internals of StringCollector. It’s just another Collector
like any in the core framework.
We begin by implementing the Collector interface (Example 5-25). Collector is generic, so we need to determine a few types to interact with:
-
The type of the element that we’ll be collecting, a
String -
Our accumulator type,
StringCombiner, which you’ve already seen -
The result type, also a
String
publicclassStringCollectorimplementsCollector<String,StringCombiner,String>{
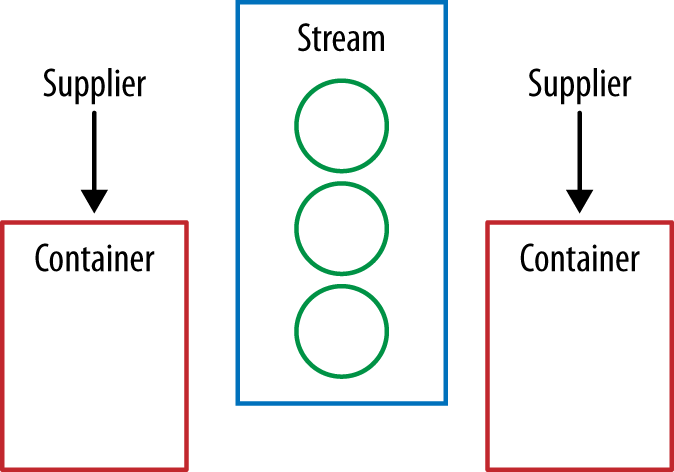
A Collector is composed of four different components. First we have a supplier, which is a factory for making our container—in this case, a StringCombiner. The analogue to this is the first argument provided to the reduce operation, which was the initial value of the reduce (see Example 5-26).
publicSupplier<StringCombiner>supplier(){return()->newStringCombiner(delim,prefix,suffix);}
Let’s step through this in diagram form while we’re walking through the
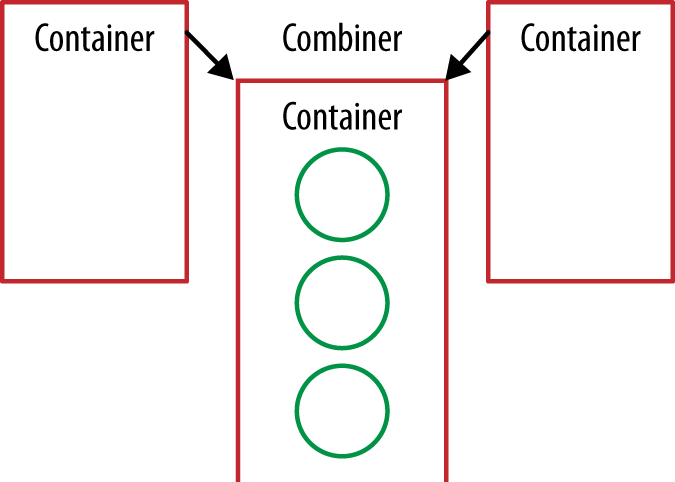
code so that we can see how things fit together. Because collectors can be
collected in parallel, we will show a collecting operation where two container
objects (e.g., StringCombiners) are used in parallel.
Each of the four components of our Collector are functions, so we’ll
represent them as arrows. The values in our Stream are circles, and the final
value we’re producing will be an oval. At the start of the collect operation
our supplier is used to create new container objects (see Figure 5-3).
Our collector’s accumulator performs the same job as the second argument to
reduce. It takes the current element and the result of the preceding
operation and returns a new value. We’ve already implemented this logic in the
add method of our StringCombiner, so we just refer to that (see Example 5-27).
publicBiConsumer<StringCombiner,String>accumulator(){returnStringCombiner::add;}
Our accumulator is used to fold the stream’s values into the container objects (Figure 5-4).
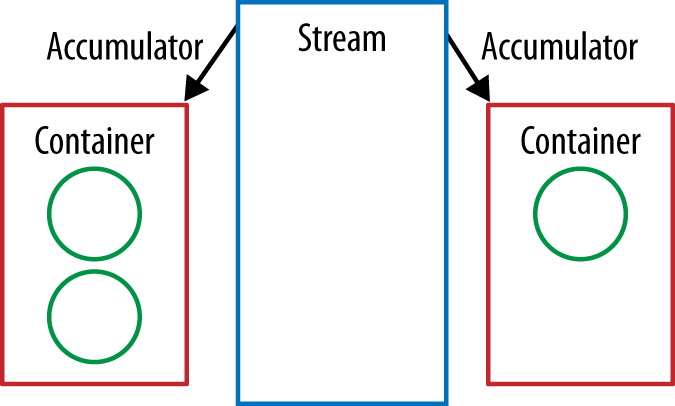
The combine method is an analogue of the third method of our reduce
operation. If we have two containers, then we need to be able to merge them
together. Again, we’ve already implemented this in a previous refactor step,
so we just use the StringCombiner.merge method (Example 5-28).
publicBinaryOperator<StringCombiner>combiner(){returnStringCombiner::merge;}
During the collect operation, our container objects are pairwise merged using the defined combiner until we have only one container at the end (Figure 5-5).
You might remember that the last step in our refactoring process, before we got
to collectors, was to put the toString method inline at the end of the
method chain. This converted our StringCombiner into the String that we
really wanted (Figure 5-6).
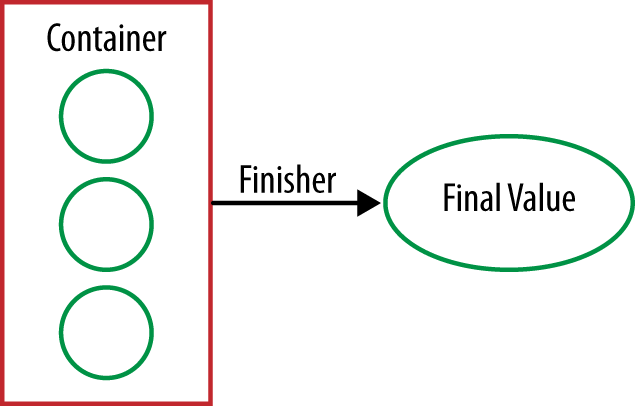
Our collector’s finisher method performs the same purpose. We’ve already
folded our mutable container over a Stream of values, but it’s not quite the
final value that we want. The finisher gets called here, once, in order to
make that conversion. This is especially useful if we want to create an
immutable final value, such as a String, but our container is mutable.
In order to implement the finisher for this operation, we just delegate to the
toString method that we’ve already written (Example 5-29).
publicFunction<StringCombiner,String>finisher(){returnStringCombiner::toString;}
We create our final value from the one remaining container.
There’s one aspect of collectors that I haven’t described so far: characteristics. A characteristic is a Set of objects that describes the Collector, allowing the framework to perform certain optimizations. It’s defined through a characteristics method.
At this juncture, it’s worth reminding ourselves that this code has been written as an educational exercise and differs a little bit from the internal implementation of the joining collector. You may also be thinking that the StringCombiner class is looking quite useful. Don’t worry—you don’t need to write that either! Java 8 contains a java.util.StringJoiner class that performs a similar role and has a similar API.
The main goals of going through this exercise are not only to show how custom collectors work, but also to allow you to write your own collector. This is especially useful if you have a domain class that you want to build up from an operation on a collection and none of the standard collectors will build it for you.
In the case of our StringCollector, the container that we were using to collect values was different from the final value that we were trying to create (a String). This is especially common if you’re trying to collect immutable values rather than mutable ones, because otherwise each step of the collection operation would have to create a new value.
It’s entirely possible for the final value that you’re collecting to be the
same as the container you’ve been folding your values into all along. In fact,
this is what happens when the final value that you’re collecting is a
Collection, such as with the toList collector.
In this case, your finisher method needs to do nothing to its container object. More formally, we can say that the finisher method is the identity function: it returns the value passed as an argument. If this is the case, then your Collector will exhibit the IDENTITY_FINISH characteristic and should declare it using the characteristics method.
Reduction as a Collector
As you’ve just seen, custom collectors aren’t that hard to write, but if you’re thinking about writing one in order to collect into a domain class it is worth examining the alternatives. The most obvious is to build one or more collection objects and then pass them into the constructor of your domain class. This is really simple and suitable if your domain class is a composite containing different collections.
Of course, if your domain class isn’t just a composite and needs to perform some calculation based on the existing data, then that isn’t a suitable route. Even in this situation, though, you don’t necessarily need to build up a custom collector. You can use the reducing collector, which gives us a generic implementation of the reduction operation over streams. Example 5-30 shows how we might write our String-processing example using the reducing collector.
Stringresult=artists.stream().map(Artist::getName).collect(Collectors.reducing(newStringCombiner(", ","[","]"),name->newStringCombiner(", ","[","]").add(name),StringCombiner::merge)).toString();
This is very similar to the reduce-based implementation I covered in
Example 5-20, which is what you might expect given the name. The key
difference is the second argument to Collectors.reducing; we are creating a
dedicated StringCombiner for each element in the stream. If you are shocked
or disgusted at this, you should be! This is highly inefficient and one of the
reasons why I chose to write a custom collector.
Collection Niceties
The introduction of lambda expressions has also enabled other collection
methods to be introduced. Let’s have a look at some useful changes that have
been made to Map.
A common requirement when building up a Map is to compute a value
for a given key. A classic example of this is when implementing a
cache. The traditional idiom is to try and retrieve a value from
the Map and then create it, if it’s not already there.
If we defined our cache as Map<String, Artist> artistCache and were wanting to look up artists using an expensive database operation, we might write something like Example 5-31.
publicArtistgetArtist(Stringname){Artistartist=artistCache.get(name);if(artist==null){artist=readArtistFromDB(name);artistCache.put(name,artist);}returnartist;}
Java 8 introduces a new computeIfAbsent method that takes a lambda to
compute the new value if it doesn’t already exist. So, we can rewrite
the previous block of code into Example 5-32.
publicArtistgetArtist(Stringname){returnartistCache.computeIfAbsent(name,this::readArtistFromDB);}
You may want variants of this code that don’t perform computation only if the value is absent; the new compute and computeIfPresent methods on the Map interface are useful for these cases.
At some point in your career, you might have tried to iterate over a Map. Historically, the approach was to use the values method to get a Set of entries and then iterate over them. This tended to result in fairly hard-to-read code. Example 5-33 shows an approach from earlier in the chapter of creating a new Map counting the number of albums associated with each artist.
Map<Artist,Integer>countOfAlbums=newHashMap<>();for(Map.Entry<Artist,List<Album>>entry:albumsByArtist.entrySet()){Artistartist=entry.getKey();List<Album>albums=entry.getValue();countOfAlbums.put(artist,albums.size());}
Thankfully, a new forEach method has been introduced that takes a BiConsumer (two values enter, nothing leaves) and produces easier-to-read code through internal iteration, which I introduced in From External Iteration to Internal Iteration. An equivalent code sample is shown in Example 5-34.
Key Points
-
Method references are a lightweight syntax for referring to methods and look like this:
ClassName::methodName. -
Collectors let us compute the final values of streams and are the mutable analogue of the
reducemethod. - Java 8 provides out-of-the-box support for collecting into many collection types and the ability to build custom collectors.
Exercises
Method references. Take a look back at the examples in Chapter 3 and try rewriting the following using method references:
-
The
mapto uppercase -
The implementation of
countusingreduce -
The
flatMapapproach to concatenating lists
-
The
Collectors.
Find the artist with the longest name. You should implement this using a
Collectorand thereducehigher-order function from Chapter 3. Then compare the differences in your implementation: which was easier to write and which was easier to read? The following example should return"Stuart Sutcliffe":Stream<String>names=Stream.of("John Lennon","Paul McCartney","George Harrison","Ringo Starr","Pete Best","Stuart Sutcliffe");Given a
Streamwhere each element is a word, count the number of times each word appears. So, if you were given the following input, you would return aMapof[John → 3, Paul → 2, George → 1]:Stream<String>names=Stream.of("John","Paul","George","John","Paul","John");-
Implement
Collectors.groupingByas a custom collector. You don’t need to provide a downstream collector, so just implementing the simplest variant is fine. If you look at the JDK source code, you’re cheating! Hint: you might want to start withpublic class GroupingBy<T, K> implements Collector<T, Map<K, List<T>>, Map<K, List<T>>>. This is an advanced exercise, so you might want to attempt it last.
Map enhancements.
Efficiently calculate a Fibonacci sequence using just the
computeIfAbsentmethod on aMap. By “efficiently,” I mean that you don’t repeatedly recalculate the Fibonacci sequence of smaller numbers.