The last part of this chapter is an important algorithm that we will use again in the course of this book. It is a very general algorithm used to learn probabilistic models in which variables are hidden; that is, some of the variables are not observed. Models with hidden variables are sometimes called latent variable models. The EM algorithm is a solution to this kind of problem and goes very well with probabilistic graphical models.
Most of the time, when we want to learn the parameters of a model, we write an objective function, such as the likelihood function, and we aim at finding the parameters that maximize this function. Generally speaking, one could simply use a black-box numerical optimizer and just compute the relevant parameters given this function. However, in many cases, this would be intractable and too prone to numerical errors (due to the inherent approximations done by CPUs). Therefore it is generally not a good solution.
We therefore aim at using the specificity of our optimization problem (alongside the assumptions made by a graphical model about the joint probability distribution) to improve our computations and make them fast and reliable.
The EM algorithm is a rather elegant solution to the problem of finding optimal parameters for a graphical model and it can be applied to many types of model.
Latent variables can be used in all models to, for example, introduce a level of simplification, to separate concepts, or to put some hierarchy into the models. For instance, we can observe a certain relationship between a set of variables, but instead of making all those variables dependent we would rather suppose that another hidden variable is simply the source of them and the dependency is done through this higher-level variable.
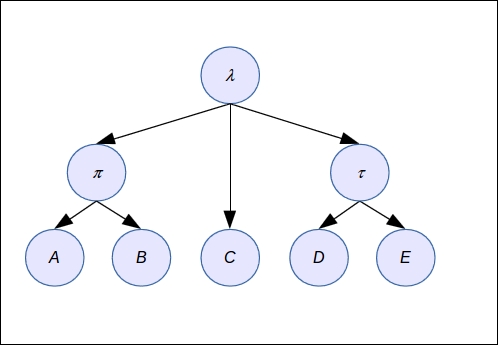
This top-down approach helps to make for simpler models, as in the following figure. This model is rather complex, isn't it ?

But if we add hidden variables (those with a Greek letter in the following figures), then the model becomes utterly simple and presumably tractable and easier to interpret. The problem is that we don't have data to estimate the probability distributions of the hidden variables and this is where we will need to use an EM algorithm.

We can add more levels too to the model and group the variables with different parents, as illustrated in the following example: