
Chapter 23: Restructuring SAS Data Sets
The term restructuring, also called transposing, means to take a data set with one observation per subject and convert it to a data set with many observations per subject, or vice versa. Why would you want or need to do this? There are some operations that are most easily performed when all the information per subject (or other unit of analysis) is contained in a single observation. Other operations are more convenient when there are several observations per subject.
Several of the statistical procedures require data to be stored one way or the other, depending on what type of analysis is required.
This chapter demonstrates how to restructure data sets using DATA step approaches and PROC TRANSPOSE.
23.2 Converting a Data Set with One Observation per Subject to a Data Set with Several Observations per Subject: Using a DATA Step
This first example uses a small data set (OnePer) where each subject has from one to three diagnosis codes (Dx1–Dx3). Here is a listing of this data set:
Figure 23.1: Listing of Data Set OnePer

Notice that some subjects have three diagnosis codes, some two, and one (Subject 004) only one. How do you obtain a frequency distribution for diagnosis codes? For example, Subject 001 had code 410 as the third diagnosis and Subject 003 has this same code listed as Dx1. It would be easier to compute frequencies on the diagnosis codes if the data set were structured like this:
Figure 23.2: Listing of Data Set ManyPer

Data set ManyPer has from one to three observations per subject. Here is a program to make this conversion:
Program 23.1: Creating a Data Set with Several Observations per Subject from a Data Set with One Observation per Subject
data Learn.ManyPer;
set Learn.OnePer;
array Dx{3};
do Visit = 1 to 3;
if missing(Dx{Visit}) then delete;
Diagnosis = Dx{Visit};
output;
end;
keep Subj Diagnosis Visit;
run;
Although you don’t have to use arrays to solve this problem, it does make the program more compact. The DX array has three elements: Dx1, Dx2, and Dx3 (remember that if you leave off the variable list, the variable names default to the array name with the digits 1 to n appended to the end).
Let’s take the time to describe in detail how this program works (feel free to skip this section if this program seems intuitively clear to you). The DO loop starts with Visit set equal to 1. The MISSING function tests if the value Dx{1} (equal to Dx1) is missing. For Subject 001, none of the diagnosis codes are missing, so the IF statement is never true for this subject. A new variable, Diagnosis, is set equal to the value of the array element Dx{1}, which is the same as the variable Dx1, which is equal to 450. At this point, the program data vector (PDV) contains the following:
|
Subj |
Dx1 <drop> |
Dx2 <drop> |
Dx3 <drop> |
Visit |
Diagnosis |
|
001 |
450 |
430 |
410 |
1 |
450 |
Because of the KEEP statement, only the variables Subj, Visit, and Diagnosis are written out to data set ManyPer at the bottom of the DO loop.
During the next iteration of the DO loop, Visit is equal to 2, Diagnosis is equal to 430, and these values are written out to the second observation in data set ManyPer. Finally, Visit is set to 3, Diagnosis is set to 410, and the third observation is written to the output data set.
The DATA step has now reached the bottom. Because the end of the file on the OnePer data set has not been reached, a new observation from data set OnePer is brought into the PDV and the process continues. Because the third diagnosis (Dx3) is missing for Subject 002, the MISSING function returns a value of true and the DELETE statement executes. A DELETE statement returns control back to the top of the data set and an observation is not written out to data set ManyPer. (It is also assumed that if there are any missing Dx codes, they come after the nonmissing codes.)
Note: If you replaced DELETE with CONTINUE, this program would work even if the missing Dx codes were stored in any of the Dx variables. See Chapter 8 for a description of the CONTINUE statement.
23.3 Converting a Data Set with Several Observations per Subject to a Data Set with One Observation per Subject: Using a DATA Step
What if you want to go the other way, creating a data set with one observation per subject from one with several observations per subject? This process is a bit more complicated, and you need to take a few special precautions.
As an example, suppose you started with data set ManyPer and wanted to create a data set that looked like OnePer. Here is one way to do it:
Program 23.2: Creating a Data Set with One Observation per Subject from a Data Set with Several Observations per Subject
proc sort data=Learn.ManyPer out=ManyPer;
by Subj Visit;
run;
data OnePer;
set ManyPer;
by Subj Visit;
array Dx{3};
retain Dx1-Dx3;
if first.Subj then call missing(of Dx1-Dx3);
Dx{Visit} = Diagnosis;
if last.Subj then output;
keep Subj Dx1-Dx3;
run;
You first sort the input data set by Subj. (The original data set was already in Subj order, but the sort was included to make the program more general and, although not needed for this example, it was also sorted by visit date.) Next, you set up an array to hold the three Dx values and retain these three variables. You need to retain these three variables because they do not come from a SAS data set and are, by default, set equal to a missing value for each iteration of the DATA step. The RETAIN statement prevents this from happening.
Next, when you start processing the first visit for each subject, you set the three values of Dx to missing. If you don’t do this, a subject with fewer than three visits may wind up with a diagnosis from the previous subject. The CALL MISSING routine can set any number of numeric and/or character values to missing at one time. As with many of the SAS functions and CALL routines, if you use a variable list in the form Var1–Varn, you need to precede the variable list with the keyword OF.
If you need to review First. and Last. variables, please refer to a discussion of these variables in the next chapter.
Next, you assign the value of Diagnosis to the appropriate Dx variable (Dx1 if Visit=1, Dx2 if Visit=2, and Dx3 if Visit=3).
Finally, if you are processing the last visit for a patient, you output a single observation keeping the variables Subj and Dx1–Dx3.
A listing of data set OnePer is identical to the one shown earlier in this chapter.
23.4 Converting a Data Set with One Observation per Subject to a Data Set with Several Observations per Subject: Using PROC TRANSPOSE
PROC TRANSPOSE can also be used to restructure SAS data sets. Sometimes, PROC TRANSPOSE provides a quick and simple solution—sometimes the PROC TRANSPOSE solution can be quite complicated. In general, a DATA step solution gives you more control over the restructuring process. As you will see in this first PROC TRANSPOSE example, you need to add some data set options (see Program 23.4) to achieve the same results as the original DATA step solution.
The following program attempts to solve the same problem as in Section 23.2. You start out with a program that restructures the OnePer data set, but it does not completely solve the problem. Here is the code:
Program 23.3: Using PROC TRANSPOSE to Convert a Data Set with One Observation per Subject into a Data Set with Several Observations per Subject (First Attempt)
***Note: data set already in Subject order;
proc transpose data=Learn.OnePer
out=ManyPer;
by Subj;
var Dx1-Dx3;
run;
PROC TRANSPOSE takes an input data set and outputs a data set where the original rows become columns and the original columns become rows. This program includes a BY SUBJECT statement that performs the operation for each value of Subject. The result is the data set listed next.
Figure 23.3: Listing of ManyPer (Transpose Method)

This is almost what you want. All that is needed is to rename the variable COL1 to Diagnosis, eliminate the _NAME_ variable, and remove the observations with missing Dx values. All these goals are accomplished by using some data set options in the output data set, as follows:
Program 23.4: Using PROC TRANSPOSE to Convert a Data Set with One Observation per Subject into a Data Set with Several Observations per Subject
proc transpose data=Learn.OnePer
out=t_ManyPer(rename=(col1=Diagnosis)
drop=_Name_
where=(Diagnosis is not null));
by Subj;
var Dx1-Dx3;
run;
The RENAME= option renames COL1 to Diagnosis, while the DROP= option eliminates the _NAME_ variable from the data set. Finally, a WHERE= data set option removes observations where Diagnosis is missing. The result is identical to the output from Program 23.1.
23.5 Converting a Data Set with Several Observations per Subject to a Data Set with One Observation per Subject: Using PROC TRANSPOSE
The last example in this chapter shows how to convert a data set with several observations per subject into a data set with one observation per subject using PROC TRANSPOSE.
Program 23.5: Using PROC TRANSPOSE to Convert a SAS Data Set with Several Observations per Subject into One with One Observation per Subject
proc transpose data=Learn.ManyPer prefix=Dx
out=OnePer(drop=_NAME_);
by Subj;
id Visit;
var Diagnosis;
run;
The PREFIX= option to the procedure and an ID statement create an output data set identical to the one produced by Program 23.2.
Figure 23.4: Listing of OnePer (Transpose Method)

The PREFIX= option combines the prefix value (Dx) with the values of Visit (1, 2, and 3) to create the three variables Dx1, Dx2, and Dx3. PROC TRANSPOSE knew to use the values of Visit to create these variable names because it was identified as an ID variable in the procedure.
Solutions to odd-numbered problems are located at the back of this book. Solutions to all problems are available to professors. If you are a professor, visit the book’s companion website at support.sas.com/cody for information about how to obtain the solutions to all problems.
1. A listing of data set Wide, containing the variables Subj, X1–X5, and Y1–Y5, is shown here:

Using a DATA step, create a temporary SAS data set (Long) using data set Wide as input. This data set should contain Subj, Time, X, and Y, with five observations per subject. A partial listing of data set Long looks like this:
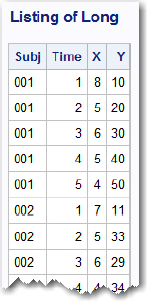
2. Using the SAS data set Narrow (shown here), create a new, temporary SAS data set (Stretch) where the five scores for each subject are contained in a single observation, with the variable names S1–S5. S1 is the Score at Time 1, S2 is the Score at Time 2, etc. Do this using a DATA step.

Data set Stretch should look like this:

3. Repeat Problem 1 using PROC TRANSPOSE. Do this only for the variables X1–X5. Your resulting data set should look like this:

4. Repeat Problem 2 using PROC TRANSPOSE.