
As we saw, a simple perceptron is a single layer neural unit which is a linear classifier. It is a neuron capable of producing only two output patterns, which can be synthesized in active or inactive. Its decision rule is implemented by a threshold behavior: if the sum of the activation patterns of the individual neurons that make up the input layer, weighted for their weights, exceeds a certain threshold, then the output neuron will adopt the output pattern active. Conversely, the output neuron will remain in the inactive state.
As mentioned, the output is the sum of weights*inputs and a function applied on top of it; output is +1 (y>0) or -1(y<=0), as shown in the following figure:
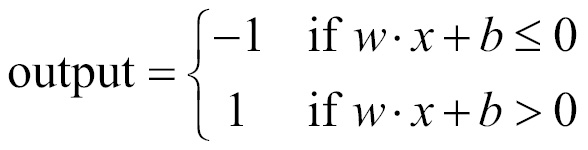
We can see the linear interaction here; the output y is linearly dependent on the inputs.
As with most neural network models, it is possible to realize a learning function based on the modification of synaptic connective weights, even in perceptors. At the beginning of the training phase, weights w of perceptron synaptic connections assume completely random values. For training, we have a number of examples with its relative, correct, classification. The network is presented in turn, the different cases to be classified and the network processes each time its response (greater than the threshold or less than the threshold). If the classification is correct (network output is the same as expected), the training algorithm does not make any changes. On the contrary, if the classification is incorrect, the algorithm changes the synaptic weights in an attempt to improve the classification performance of the network.
The single perceptron is an online learner. The weight updates happen through the following steps:
- Get x and output label y.
- Update w for f(x).
- If f(x)=y, mark as completed; else, fix it
- Now adjust score based on error:
f(x)= sign(sum of weights*inputs), the errors are possible
if y=+1 and f(x)=-1, w*x is too small, make it bigger
if y=-1 and f(x)=+1, w*x is too large make it smaller
- Apply the following rules:
make w=w-x if f(f)=+1 and y=-1
make w=w+x if f(f)=-1 and y=+1
w=w if f(x)=y
Or simply, w=w+yx if f(x)!=y
- Repeat steps 3 to 5, until f(x) = y.
The perceptron is guaranteed to satisfy all our data, but only for a binary classifier with a single neuron. In step 5, we brought a term called learning rate. This helps our model converge. In step 5, w is written as: w=w+αyx if f(x) != y, where α is the learning rate chosen.
The bias is also updated as b=b+ αy if f(x) != y. The b is actually our w0.
If the Boolean function is a linear threshold function (that is, if it is linearly separable), then the local perceptron rule can find a set of weights capable of achieving it in a finite number of steps.
This theorem, known as the perceptron theorem, is also applicable in the case of the global rule, which modifies the vector of synaptic weights w, not at a single input vector, but depending on the behavior of the perceptron on the whole set of input vectors.
We just mentioned the linearly separable function, but what is meant by this term? We will understand it in the following section.