
Chapter 2
Examining Novell Cluster Services Architecture
In the first chapter of this book, Novell Cluster Services (NCS) was introduced from a high-level overview perspective. Before the next chapters of this book talk about the design of a clustered network and the installation and configuration of Novell Cluster Services, this chapter will discuss what’s happening at the background of your Novell cluster. In this chapter you will learn how the different components of an NCS network work together to provide high availability. You will learn about the modules that are used in a cluster, as well as the working of some important background processes. In the second part of this chapter, you will learn how heartbeats, epoch numbers, and the Split Brain Detector (SPD) work together to provide high availability.
Novell Cluster Services is present in two different parts of your network. First, you will find cluster-related eDirectory objects. These objects communicate with binaries and libraries that are present on the server. Sometimes they read configuration files to retrieve information, and other times this information is present in the eDirectory object itself as an attribute. In this section we will present an overview of all the important modules and their related eDirectory objects.
At the highest level, each cluster has a cluster container object in eDirectory. Within the cluster container object, cluster nodes, resources, and templates are created.
This object is used for storage of all important configuration parameters of the cluster. All of these parameters are clusterwide settings that need to be set only once. The most important of these parameters are included in the following list. Consult Chapter 6, “Cluster Management,” for more details about these parameters:
![]() Quorum Trigger: This parameter specifies the number of nodes that must be active in the cluster before any cluster resources can be started. This number is also referred to as the quorum membership.
Quorum Trigger: This parameter specifies the number of nodes that must be active in the cluster before any cluster resources can be started. This number is also referred to as the quorum membership.
![]() Heartbeat Settings: In a clustered environment, nodes need to communicate with each other. Without this communication, it would be impossible to find out whether a node has left the cluster. This communication takes place by means of the heartbeat protocol: By default, all servers send a heartbeat packet once a second. If within a period of eight seconds a node has not been heard from, it will be cast out of the cluster.
Heartbeat Settings: In a clustered environment, nodes need to communicate with each other. Without this communication, it would be impossible to find out whether a node has left the cluster. This communication takes place by means of the heartbeat protocol: By default, all servers send a heartbeat packet once a second. If within a period of eight seconds a node has not been heard from, it will be cast out of the cluster.
![]() Cluster Management Port: This is an automatically assigned port address, used for management of the cluster.
Cluster Management Port: This is an automatically assigned port address, used for management of the cluster.
Every physical servers that is a member of the cluster is present in eDirectory as a cluster node object, which is shown in Figure 2.1. This eDirectory object stores the node number and its IP address. This object is also used by eDirectory to create an alias to the NetWare Core Protocol (NCP) server object it represents.
All applications in the cluster are represented by cluster resource objects. These cluster resource objects contain all important information about the resource as an eDirectory property. The most important properties of the cluster resource are listed here:
![]() Load scripts: These determine how the resource will be loaded. These load scripts are written as bash shell scripts. All resources do have a cluster resource load script.
Load scripts: These determine how the resource will be loaded. These load scripts are written as bash shell scripts. All resources do have a cluster resource load script.
![]() Unload scripts: In the unload script, the cluster resource is terminated properly. In the cluster resource load script, it is particularly important that other modules on which the resource depends are unloaded properly as well. Load scripts as well as unload scripts are discussed in Chapter 5, “Creating Cluster Resources.”
Unload scripts: In the unload script, the cluster resource is terminated properly. In the cluster resource load script, it is particularly important that other modules on which the resource depends are unloaded properly as well. Load scripts as well as unload scripts are discussed in Chapter 5, “Creating Cluster Resources.”
![]() Failover and failback modes: These modes determine what should happen when a node in the cluster on which the resource is currently active fails. The most important choice that has to be made here is that these can happen manually or automatically. More information on the failover and failback modes is found in Chapter 5.
Failover and failback modes: These modes determine what should happen when a node in the cluster on which the resource is currently active fails. The most important choice that has to be made here is that these can happen manually or automatically. More information on the failover and failback modes is found in Chapter 5.
It can be rather difficult to create a cluster resource object all by yourself. To make creation of cluster resources easier for the administrator, some cluster template objects exist. These templates contain all important properties for some often-used cluster resources.
Tip
After installing the latest support pack on your servers, new cluster resource templates that are provided with the support pack are not installed automatically. From a Linux box, use the /opt/novell/ncs/bin/ncs-configd.py -install_templates command to install them. You will want to do this if you’re upgrading from NetWare to Linux; otherwise, you don’t get the new Linux-specific cluster resource templates.
In a NetWare environment, a shared disk that is used by Novell Cluster Services must contain Novell Storage Services (NSS) volumes. These volumes can be either cluster enabled or regular. Both of these volume types can fail over to another server when a node failure occurs. In a Linux environment, NSS is not the only file system that can be used. Traditional Linux file systems such as Reiser and ext3 can be used as well.
If an NSS cluster-enabled volume object is used, three eDirectory objects are created:
![]() Cluster Volume: This is the “normal” volume object, used to represent the cluster-enabled volume.
Cluster Volume: This is the “normal” volume object, used to represent the cluster-enabled volume.
![]() Cluster Volume Resource: This object is similar to the resource objects used for clustered applications. It maintains the load script and unload script, as well as other cluster-related properties of the volume.
Cluster Volume Resource: This object is similar to the resource objects used for clustered applications. It maintains the load script and unload script, as well as other cluster-related properties of the volume.
![]() Cluster Virtual Server: This is a virtual server object that hosts the clustered volume. This object is needed because a clustered volume is not bound to a physical server. Instead, the virtual server acts as a proxy to bind the cluster volume to a real server. The advantage of this solution is that the cluster volume will not go down if some node in the cluster goes down.
Cluster Virtual Server: This is a virtual server object that hosts the clustered volume. This object is needed because a clustered volume is not bound to a physical server. Instead, the virtual server acts as a proxy to bind the cluster volume to a real server. The advantage of this solution is that the cluster volume will not go down if some node in the cluster goes down.
A cluster-enabled shared volume is not needed in all scenarios. If an NCP client reconnect to a volume is not needed and if no fixed server name is needed either, you can do without cluster-enabled shared disk volumes. When a node failure occurs with a volume that is not cluster-enabled, the cluster resource manager module will simply mount the volume on some other node and execute the associated load script.
There is a relation between the objects in eDirectory and files that are kept locally on cluster nodes. The eDirectory information is cached in files in /etc/opt/novell/ncs (see Figure 2.2). In this directory, the load and unload scripts of all resources in the cluster are stored. You can locate these as the files with the .load and the .unload extensions. This directory also contains all eDirectory attributes as .xml and .conf files. For example, the protocol properties that are set at the cluster container level are stored in the gipc.conf file. As an administrator, you should not edit these files by hand. The nds-configd is a user-space Lightweight Directory Access Protocol (LDAP) client that is responsible for synchronizing data between eDirectory and the local files. Apart from the information that is in /etc/opt/novell/ncs, another important part of the cluster status and configuration information can be found in /_admin/Novell/Cluster. For example, the current state of the nodes in the cluster is saved here.
The Novell Cluster Services software consists of different functional parts. In this section we will discuss how these parts interact with each other. An overview of these parts is provided in Figure 2.3.
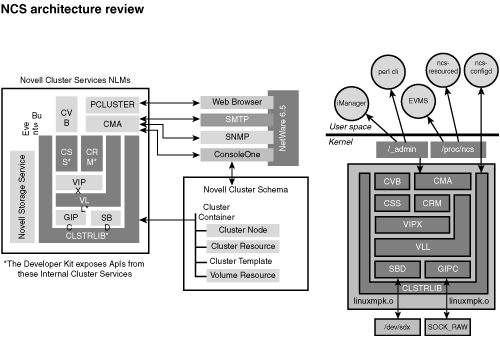
The first thing to notice from Figure 2.3 is that there is no real difference between the modules on NetWare and the modules on Linux. First, there is the cluster configuration library CLSTRLIB. This library provides the interface between Novell Cluster Services and eDirectory. It is the responsibility of the cluster configuration library running on the master node in the cluster to access all cluster-related configuration from eDirectory. The master node stores this information in its memory so that it is available for all other modules used by the cluster software. The master node is also responsible for transmitting this information to all other nodes in the cluster. As changes occur to the cluster configuration in eDirectory, CLSTRLIB accesses the changes, updates the information in its memory, and then transmits it to the other cluster nodes.
The Group Interprocess Protocol (GIPC) tracks changes in cluster membership. It is responsible for handling events related to cluster membership, such as nodes joining the cluster and leaving the cluster. To do so, GIPC runs a set of helper protocols:
![]() Panning: Filters messages to the current epoch.
Panning: Filters messages to the current epoch.
![]() Heartbeat: Responsible for generating heartbeat messages (see the next section in this chapter). The heartbeat information is layered over IP protocol 224 and can be monitored with the Ethereal packet decoder.
Heartbeat: Responsible for generating heartbeat messages (see the next section in this chapter). The heartbeat information is layered over IP protocol 224 and can be monitored with the Ethereal packet decoder.
![]() Sequencer: Responsible for sequencing of multicast and membership changes. This protocol is responsible for notifying all nodes in the cluster about changes in the cluster membership.
Sequencer: Responsible for sequencing of multicast and membership changes. This protocol is responsible for notifying all nodes in the cluster about changes in the cluster membership.
![]() Membership: Maintains information about nodes that currently are a member of the cluster. Its main purpose is to reach an agreement between all nodes on the current cluster membership view.
Membership: Maintains information about nodes that currently are a member of the cluster. Its main purpose is to reach an agreement between all nodes on the current cluster membership view.
![]() Censustaker: Generates reports about unstable membership by monitoring heartbeat packages. This module will report when a node joins or leaves the cluster. This report is considered unstable until accepted by all other nodes in the cluster.
Censustaker: Generates reports about unstable membership by monitoring heartbeat packages. This module will report when a node joins or leaves the cluster. This report is considered unstable until accepted by all other nodes in the cluster.
![]() Group Anchor: Communicates group membership information to the upper modules in the cluster protocol stack.
Group Anchor: Communicates group membership information to the upper modules in the cluster protocol stack.
If a network connection between nodes in a cluster fails, a split brain scenario can occur if clusters use shared disk systems. Each side of the cluster could assume that nodes at the other side have failed and then try to take over the resources from the other nodes. This may cause data corruption. Novell Cluster Services uses a Split Brain Detector to prevent such situations. The SBD relies on a connection from all nodes in the cluster to a shared disk subsystem that works over a dedicated channel. On the shared storage device, a partition is created where all nodes record their view of the current state of the cluster. When changes in the cluster membership occur, these changes can be notified by means of this SBD partition. The following section of this chapter provides more details about the workings of the SBD.
The Cluster Resource Manager (CRM) is responsible for running resources on the correct nodes when changes in the cluster membership occur. This is the responsibility of the CRM on the master node, which receives an alert every time a node joins or leaves the cluster. The master node in the cluster tracks the state of all resources in the cluster and distributes that information to all other nodes in the cluster. If the master fails, the CRM running on another node in the cluster will take over this responsibility. The CRM monitors the following possible states of resources in the cluster:
![]() Unassigned: The preferred nodes of the resource are not currently members of the cluster.
Unassigned: The preferred nodes of the resource are not currently members of the cluster.
![]() Offline: The resource is not active. This is the state you need to enter to be able to modify the properties of the resource.
Offline: The resource is not active. This is the state you need to enter to be able to modify the properties of the resource.
![]() Loading: The resource is currently being loaded.
Loading: The resource is currently being loaded.
![]() Unloading: The resource is currently being unloaded.
Unloading: The resource is currently being unloaded.
![]() Comatose: The resource could not process the complete load script before a timeout occurred.
Comatose: The resource could not process the complete load script before a timeout occurred.
![]() Running: The resource is currently active.
Running: The resource is currently active.
![]() Alert: The resource requires manual intervention.
Alert: The resource requires manual intervention.
![]() NDS Sync: The resource is waiting to synchronize with its eDirectory properties.
NDS Sync: The resource is waiting to synchronize with its eDirectory properties.
![]() Quorum wait: Currently there are not enough nodes in the cluster. The resource is waiting for the other nodes as defined in the quorum to become active.
Quorum wait: Currently there are not enough nodes in the cluster. The resource is waiting for the other nodes as defined in the quorum to become active.
The Virtual Interface Architecture Link Layer (VLL) sits between modules in the cluster. It interfaces with the GIPC, SBD, and CRM modules. If the GIPC stops receiving information from another node in the cluster, it notifies the VLL. This module then contacts the SBD, which determines whether the node is really dead and then informs the CRM of its decision.
The Cluster Volume Broker monitors NSS file system information for the cluster. If a change occurs, it will ensure that the change in the NSS file system is replicated to all other nodes in the cluster.
The Cluster System Services (CSS) module provides an application programming interface (API) that cluster-aware applications can use to enable distributed shared memory and distributed shared locking. Distributed shared memory is a technique that allows cluster-aware applications running across multiple servers to share access to the same data, as if the data were present on the same physical RAM chips. Distributed locking ensures that if one thread on one node gets a lock, another thread on another node can’t get the same lock.
The Cluster Services Management Agent (CMA) acts as a proxy for the management applications. Several applications are available:
![]() ConsoleOne: The legacy management application for NetWare environments. It cannot be used to manage NCS 1.8. It is, however, still needed to manage some applications in an NCS 1.8 environment. GroupWise is an example of such an application.
ConsoleOne: The legacy management application for NetWare environments. It cannot be used to manage NCS 1.8. It is, however, still needed to manage some applications in an NCS 1.8 environment. GroupWise is an example of such an application.
![]() The Perl command-line interface (CLI): On Linux, some Perl utilities are available from the command line. These utilities are used from user space and interact with the data in the
The Perl command-line interface (CLI): On Linux, some Perl utilities are available from the command line. These utilities are used from user space and interact with the data in the /_admin directory to modify and get information from the cluster.
![]() iManager: The iManager management utility interacts with
iManager: The iManager management utility interacts with /_admin and CMA to modify cluster parameters.
The CMA interacts with the CRM to determine current information about the cluster and control the current state of cluster resources. It also performs SNMP management capabilities and Simple Mail Transfer Protocol (SMTP) alerting. To do its work, on Linux a kernel module exports all relevant management files to /_admin/Novell/Cluster. On NetWare the _ADMIN directory is used for the same purpose.
One of the most important things that has to be arranged in a cluster is how the cluster will detect when a node fails. Novell Cluster Services uses heartbeats on the LAN and a Split Brain Detector on the shared storage device to do this. A heartbeat is a small package periodically sent over the LAN (and not over the storage network) by all nodes in the cluster. The master node sends a multicast to all slaves, and the slave nodes send unicast packets directly to the master node. The multicast packet will be picked up by all nodes listening to that particular multicast address. To avoid sending too much network traffic, the master node will reply with a unicast, which is a packet sent to that particular node directly. Related to the heartbeat, there is the tolerance rate, by default set to eight seconds. If a node fails to send heartbeat packages within the period defined as the tolerance rate, it will be removed from the cluster. This happens by crashing the other node; on NetWare the node that has failed to send a heartbeat package will be abended. We describe later in the text how this mechanism works.
A technique that is narrowly related to that is the epoch number that is written over the SAN to the Split Brain Detector partition. This is a small section on the shared storage device. When writing its epoch number, a node first compares the epoch numbers it wants to write to the other epoch numbers on the network. Each time a node joins or leaves the cluster, the epoch number is increased by one. A difference in epoch number may indicate that a critical situation has arisen and may result in casting of a node from the cluster. In the following discussion you will learn how a failed node is removed from the cluster via this mechanism.
Tip
The size of the Split Brain Detector partition cannot be specified when installing the cluster. It will, however, always be big enough to accommodate a 32-node cluster. Each of the nodes needs 512 bytes to communicate necessary status information to the other nodes. Because, however, a partition always needs to be one disk cylinder, a partition of about 8MB will be created. The remainder of this 8MB is used for the persistent cluster event logs. After the partition has been filled, the cluster will begin to reuse the oldest log entries.
Several steps are taken when a slave node fails. These steps are described here:
1. Each node in the cluster sends a heartbeat over the LAN. By default, this happens every second.
2. At half-time of the preconfigured tolerance rate (which is 8 seconds by default), each node writes its epoch number to the Split Brain Detector on the shared storage device. Under normal circumstances the epoch numbers of all nodes in the cluster will be the same.
3. The master node monitors the heartbeat packets and epoch numbers of all nodes in the cluster.
4. If a slave node fails to send a heartbeat package within the period defined as the tolerance rate, the master node and the other slave nodes create a new cluster membership view. This new cluster membership view does not include the failing node.
5. All nodes in the new cluster membership view update their epoch numbers by one and write this modification to the Split Brain Detector. At that moment, there are two cluster membership views: one with the node that failed to send heartbeats within the tolerance rate, and one with the other nodes. This situation is called a split brain.
6. Novell Cluster Services now needs to determine what cluster membership view wins. It does so by voting between the two cluster membership views. There are three possibilities:
![]() The cluster membership view that has the most nodes wins.
The cluster membership view that has the most nodes wins.
![]() If there are equal nodes on both sides, the side with the view that contains the master node wins.
If there are equal nodes on both sides, the side with the view that contains the master node wins.
![]() In a two-node cluster, the node that still has network connectivity wins.
In a two-node cluster, the node that still has network connectivity wins.
7. Based on the results of the vote, a special token is written by the winning nodes to the Split Brain Detector; this is the so-called poison pill. The losing node reads the poison pill and as a result crashes itself with an abend or kernel panic. Terminating the losing node is necessary because it ensures that the losing node cannot corrupt the new cluster.
8. The new cluster migrates all resources previously associated with the failing node and thus guarantees uninterrupted services for end users.
The preceding scenario describes what should happen if a slave node fails. The situation is different when the master node fails because in this case a new master must be assigned as well. The following procedure describes what will happen. It should be noted that the process is more or less the same as what happens when a node that is not the master fails:
1. After failure of the master node, a new cluster membership view is created. This new cluster membership view includes only the slave nodes. The master node maintains the old cluster membership view.
2. The nodes in the new cluster membership view update their epoch number by one.
3. Novell Cluster Services votes based on the new information.
4. The cluster with all the remaining slave nodes wins the vote.
5. The nodes in the winning cluster write a poison pill to the Split Brain Detector.
6. The slave nodes vote who will be the new master. This voting mechanism is more or less random.
7. The failed master node reads the special token and terminates itself.
8. All resources assigned to the failed node are migrated to other nodes in the cluster.
In this chapter, we provided a short overview of the architecture and working of the Novell Cluster Services software. This overview should make it easier for you to analyze what exactly is happening if anything goes wrong. In the next chapter you will read about the design of a cluster based on Novell Cluster Services.