
Chapter 21. Matrix Multiplication with OpenCL
Matrix multiplication is commonly used to demonstrate program optimization in high-performance computing. In its most basic form, matrix multiplication is a toy program consisting of a single multiply-accumulate statement buried inside a triply nested loop. Unlike most toy programs, however, matrix multiplication has a more serious side. First, this operation is the single most important building block for dense linear algebra computations. Second, if you work at it hard enough, matrix multiplication can run near the peak performance of most modern processors. Therefore, it presents many opportunities for performance optimization, and making it fast has practical value.
In this discussion, we will start with a simple matrix multiplication function for a CPU. We will convert the code into OpenCL. And then we will explore a series of code transformations that take advantage of the OpenCL memory model to optimize the program. Along the way, we will report performance results for the multiplication of square matrices of order 1000. All the results in this chapter were generated on an Intel Core Duo CPU (T8300) running at 2.4GHz and a GeForce 8600M GT GPU from NVIDIA. The OpenCL release used in the benchmarks was provided by Apple as part of the Snow Leopard release of OS X.
The Basic Matrix Multiplication Algorithm
A dense matrix is a rectangular array of numbers. It is called “dense” because the numbers are almost always non-zero; hence there is no reason to keep track of zeros to reduce storage or accelerate computations. Throughout this discussion, we will consider three matrices: A (N by P), B (P by M), and C (N by M). Multiplication of A times B with the result added into C is mathematically defined as
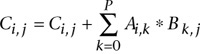
0 ≤ i ≤ N
0 ≤ j ≤ M
Matrix multiplication, as shown in Figure 21.1 for the (i, j)th element of C, consists of a dot product of the ith row of A with the jth column of B. A program to carry out this computation is shown in Listing 21.1. It consists of a double nested loop to run over the elements of the C matrix. Inside is an additional loop to compute the appropriate dot product.
Figure 21.1 A matrix multiplication operation to compute a single element of the product matrix, C. This corresponds to summing into each element Ci,j the dot product from the ith row of A with the jth column of B.
In the listing we represent the matrices as one-dimension arrays with explicit index algebra to map the pair of indices onto a single index. This is a common technique when dealing with multidimension arrays. The program using GCC with default compiler settings ran at 167 MFLOPS.
Listing 21.1 A C Function Implementing Sequential Matrix Multiplication
void seq_mat_mul(
int Mdim, int Ndim, int Pdim, // matrix dimensions
float *A, float *B, float *C) // C = C + A * B
{
int i, j, k;
float tmp;
for (i=0; i<Ndim; i++){
for (j=0; j<Mdim; j++){
tmp = 0.0;
for(k=0;k<Pdim;k++){
// C[i][j]+=A[i][k]* B[k][j];
tmp += *(A+(i*Ndim+k)) * *(B+(k*Pdim+j));
}
*(C+(i*Ndim+j)) = tmp;
}
}
}
A Direct Translation into OpenCL
The matrix multiplication program from Listing 21.1 can be directly converted into an OpenCL kernel. The result is shown in Listing 21.2. Each work-item is assigned an element of the product matrix to compute. The outer two loops over i and j are deleted and replaced with calls to a function to find the global ID for the work-item in each of the two dimensions. Care is taken to make sure the resulting work-item IDs fit within the C matrix, at which point the dot product is carried out to compute the matrix product for element i, j of the C matrix. Note that all three matrices are left in global memory. The resulting performance on the GPU was 511 MFLOPS, and the identical code on the CPU was 744 MFLOPS.
Listing 21.2 A kernel to compute the matrix product of A and B summing the result into a third matrix, C. Each work-item is responsible for a single element of the C matrix. The matrices are stored in global memory.
const char *C_elem_KernelSource = "
"
"__kernel mmul(
"
" const int Mdim,
"
" const int Ndim,
"
" const int Pdim,
"
" __global float* A,
"
" __global float* B,
"
" __global float* C)
"
"{
"
" int k;
"
" int i = get_global_id(0);
"
" int j = get_global_id(1);
"
" float tmp;
"
" if( (i < Ndim) && (j <Mdim))
"
" {
"
" tmp = 0.0;
"
" for(k=0;k<Pdim;k++)
"
" tmp += A[i*Ndim+k] * B[k*Pdim+j];
"
" C[i*Ndim+j] = tmp;
"
" }
"
"}
"
"
";
The host code for the OpenCL matrix multiplication program is provided in Listing 21.3. The first available platform and a device are selected. While the host code from the listing shows a CPU device, this same host program can be used with a GPU by replacing the constant CL_DEVICE_TYPE_CPU in the call to clGetDeviceIDs() with CL_DEVICE_TYPE_GPU. A command-queue is established with profiling enabled through the CL_QUEUE_PROFILING_ENABLE property followed by the definition of the matrices on the host. In this program, two basic matrix manipulation functions are used to initialize the matrices and then later test the results. Because the contents of these functions are simple and not illustrative of the concepts discussed in this chapter, these functions are not included in this listing.
The memory objects are set up by calls to clCreateBuffer(). The program is then constructed from a string literal (the one in Listing 21.2). Throughout this listing, the error testing has been deleted in order to save space. An exception is made, however, for the case of building a program because it is important to understand how to display the output from the OpenCL compiler using a call to clGetProgramBuildInfo().
The kernel and the kernel arguments are then set up, after which the buffers associated with the matrices are submitted to the command-queue. The command-queue is in-order, so it is safe to assume that the memory objects are present in the global memory when the kernel is enqueued. The global dimensions for a two-dimension NDRange are set, while in this case the local dimensions are not set (i.e., they are set to NULL). This was done so that the OpenCL implementation could choose the local dimensions, thereby adjusting to the needs of the CPU or the GPU compute device without programmer intervention.
The host waits for the kernel to complete, at which point timing data is extracted from the enqueue kernel event with calls to clGetEventProfilingInfo(), once with CL_PROFILING_COMMAND_START and then again with CL_PROFILING_COMMAND_END. The memory object associated with the C matrix is then copied onto the host and the results tested. The host program finishes by cleaning up the environment and releasing various OpenCL objects.
Listing 21.3 The Host Program for the Matrix Multiplication Program
#ifdef APPLE
#include <OpenCL/opencl.h>
#else
#include "CL/cl.h"
#endif
#define ORDER 1000
int main(int argc, char **argv)
{
float *A; // A matrix
float *B; // B matrix
float *C; // C matrix (C = A*B)
int Mdim, Ndim, Pdim; // A[N][P], B[P][M], C[N][M]
int err; // error code from OpenCL
int szA, szB, szC; // number of matrix elements
size_t global[DIM]; // global domain size
size_t local[DIM]; // local domain size
cl_device_id device_id; // compute device id
cl_context context; // compute context
cl_command_queue commands; // compute command queue
cl_program program; // compute program
cl_kernel kernel; // compute kernel
cl_uint nd; // Number of dims in NDRange
cl_mem a_in; // Memory object for A matrix
cl_mem b_in; // Memory object for B matrix
cl_mem c_out; // Memory Object for C matrix
int i;
Ndim = ORDER; Pdim = ORDER; Mdim = ORDER;
//-------------------------------------------------------------------
// Set up the OpenCL platform using whichever platform is "first"
//-------------------------------------------------------------------
cl_uint numPlatforms;
cl_platform_id firstPlatformId;
err = clGetPlatformIDs(1, &firstPlatformId, &numPlatforms);
err = clGetDeviceIDs(firstPlatformId, CL_DEVICE_TYPE_CPU, 1,
&device_id, NULL);
cl_context_properties properties [] =
{
CL_CONTEXT_PLATFORM, (cl_context_properties)firstPlatformId,0
};
context = clCreateContext(properties, 1, &device_id, NULL, NULL,
&err);
commands = clCreateCommandQueue(context, device_id,
CL_QUEUE_PROFILING_ENABLE, &err);
// Set up matrices
szA = Ndim*Pdim; szB = Pdim*Mdim; szC = Ndim*Mdim;
A = (float *)malloc(szA*sizeof(float));
B = (float *)malloc(szB*sizeof(float));
C = (float *)malloc(szC*sizeof(float));
initmat(Mdim, Ndim, Pdim, A, B, C); // function to set matrices
// to known values.
//-------------------------------------------------------------------
// Set up the buffers, initialize matrices, and write them
// into global memory
//-------------------------------------------------------------------
a_in = clCreateBuffer(context, CL_MEM_READ_ONLY,
sizeof(float) * szA, NULL, NULL);
b_in = clCreateBuffer(context, CL_MEM_READ_ONLY,
sizeof(float) * szB, NULL, NULL);
c_out = clCreateBuffer(context, CL_MEM_WRITE_ONLY,
sizeof(float) * szC, NULL, NULL);
// Create the compute program from the source buffer
*program = clCreateProgramWithSource(context, 1,
(const char **) & C_elem_KernelSource, NULL, &err);
// Build the program
err = clBuildProgram(*program, 0, NULL, NULL, NULL, NULL);
if (err != CL_SUCCESS)
{
size_t len;
char buffer[2048];
printf("Error: Failed to build program executable!
");
clGetProgramBuildInfo(*program, device_id,
CL_PROGRAM_BUILD_LOG,
sizeof(buffer), buffer, &len);
printf("%s
", buffer);
return FAILURE;
}
// Create the compute kernel from the program
*kernel = clCreateKernel(*program, "mmul", &err);
// Set the arguments to our compute kernel
err = 0;
err = clSetKernelArg(*kernel, 0, sizeof(int), &Mdim);
err |= clSetKernelArg(*kernel, 1, sizeof(int), &Ndim);
err |= clSetKernelArg(*kernel, 2, sizeof(int), &Pdim);
err |= clSetKernelArg(*kernel, 3, sizeof(cl_mem), &a_in);
err |= clSetKernelArg(*kernel, 4, sizeof(cl_mem), &b_in);
err |= clSetKernelArg(*kernel, 5, sizeof(cl_mem), &c_out);
// Write the A and B matrices into compute device memory
err = clEnqueueWriteBuffer(commands, a_in, CL_TRUE, 0,
sizeof(float) * szA, A, 0, NULL, NULL);
err = clEnqueueWriteBuffer(commands, b_in, CL_TRUE, 0,
sizeof(float) * szB, B, 0, NULL, NULL);
cl_event prof_event;
// Execute the kernel over the entire range of C matrix elements
global[0] =(size_t) Ndim; global[1] =(size_t) Mdim; *ndim = 2;
err = clEnqueueNDRangeKernel(commands, kernel, nd, NULL,
global, NULL, 0, NULL, &prof_event);
// Wait for the commands to complete before reading back results
clFinish(commands);
cl_ulong ev_start_time=(cl_ulong)0;
cl_ulong ev_end_time=(cl_ulong)0;
size_t ret_size;
err = clGetEventProfilingInfo(prof_event,
CL_PROFILING_COMMAND_START,
sizeof(cl_ulong),
&ev_start_time,
NULL);
err = clGetEventProfilingInfo(prof_event,
CL_PROFILING_COMMAND_END,
sizeof(cl_ulong),
&ev_end_time,
NULL);
// Read back the results from the compute device
err = clEnqueueReadBuffer( commands, c_out, CL_TRUE, 0,
sizeof(float) * szC, C, 0, NULL, NULL );
run_time = ev_end_time - ev_start_time;
results(Mdim, Ndim, Pdim, C, run_time);
clReleaseProgram(program);
clReleaseKernel(kernel);
clReleaseMemObject(a_in);
clReleaseMemObject(b_in);
clReleaseMemObject(c_out);
clReleaseCommandQueue(commands);
clReleaseContext(context);
}
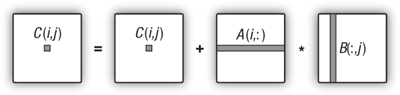
Increasing the Amount of Work per Kernel
In parallel programming, it is important to manage a computation to minimize parallel overhead. With order-1000 matrices, one work-item per matrix element results in a million work-items. This seems a bit excessive, so in the next version of the program, each work-item will compute a row of the matrix. The modifications required to support this change are illustrated in Figure 21.2. An entire row of the C matrix is computed using one row from the A matrix repeatedly while sweeping through the columns of the B matrix. The NDRange is changed from a 2D range set to match the dimensions of the C matrix to a 1D range set to the number of rows in the C matrix. At this point we switch our focus to the GPU, which in this case (as shown by a call to clGetDeviceInfo() with CL_DEVICE_MAX_COMPUTE_UNITS) has four compute units. Hence we set the work-group size to 250 and create four work-groups to cover the full size of the problem.
Figure 21.2 Matrix multiplication where each work-item computes an entire row of the C matrix. This requires a change from a 2D NDRange of size 1000×1000 to a 1D NDRange of size 1000. We set the work-group size to 250, resulting in four work-groups (one for each compute unit in our GPU).
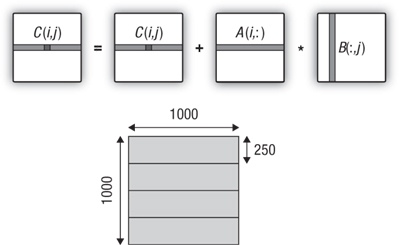
The kernel and changes to the host program required for this case are shown in Listing 21.4. The kernel is similar to the previous version except the code now includes a loop over the j index so the kernel marches across a row of C for each work-item. Note that as before the computation works with the memory objects directly from global memory. The resulting performance on the GPU is 258 MFLOPS, which is a considerable drop from our value of 511 MFLOPS. In a real project (as opposed to this simple example) different work-group sizes would be tried to improve performance and better align with the properties of the GPU. In this case, however, we will settle for 258 MFLOPS and proceed with further optimizations.
Listing 21.4 Each work-item updates a full row of C. The kernel code is shown as well as changes to the host code from the base host program in Listing 21.3. The only change required in the host code was to the dimensions of the NDRange.
const char *C_row_KernelSource = "
"
"__kernel mmul(
"
" const int Mdim,
"
" const int Ndim,
"
" const int Pdim,
"
" __global float* A,
"
" __global float* B,
"
" __global float* C)
"
"{
"
" int k,j;
"
" int i = get_global_id(0);
"
" float tmp;
"
" if( (i < Ndim) )
"
" {
"
" for(j=0;j<Mdim;j++){
"
" tmp = 0.0;
"
" for(k=0;k<Pdim;k++)
"
" tmp += A[i*Ndim+k] * B[k*Pdim+j];
"
" C[i*Ndim+j] = tmp;
"
" }
"
" }
"
"}
"
"
";
//------------------------------------------------------------------
// Host code changes . . . change to a 1D NDRange and set local
// work-group size
//------------------------------------------------------------------
global[0] = (size_t) Ndim;
local[0] = (size_t) 250;
*ndim = 1;
err = clEnqueueNDRangeKernel(commands, kernel, nd, NULL, global,
local, 0, NULL, NULL);
The core of matrix multiplication is a multiply-accumulate computation. Most processors have sufficient bandwidth into the ALU to keep this computation running near peak performance, but only if the data movement costs can be hidden. Hence, the essence of optimizing matrix multiplication is to minimize data movement. Our matrix multiplication kernels up to this point have left all three matrices in global memory. This means the computation streams rows and columns through the memory hierarchy (global to private) repeatedly for each dot product.
We can reduce this memory traffic by recognizing that each work-item reuses the same row of A for each row of C that is updated. This is shown in Figure 21.3.
Figure 21.3 Matrix multiplication where each work-item computes an entire row of the C matrix. The same row of A is used for elements in the row of C so memory movement overhead can be dramatically reduced by copying a row of A into private memory.
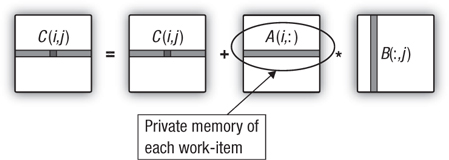
This version of the matrix multiplication program uses the same host code as the prior case. Even the kernel code is only slightly changed. In Listing 21.5, a float array of size 1000 is defined. Because this occurs inside the kernel, the memory is allocated in the private memory of the processing element that will run the kernel. Then, prior to computing the dot products for the elements of the C matrix, the required row of the A matrix is copied from global memory into private memory. The use of private memory for the row of A had a dramatic impact on performance, from our prior result of 258 MFLOPS to 873 MFLOPS.
Listing 21.5 Each work-item manages the update to a full row of C, but before doing so the relevant row of the A matrix is copied into private memory from global memory.
const char *C_row_priv_KernelSource = "
"
"__kernel void mmul(
"
" const int Mdim,
"
" const int Ndim,
"
" const int Pdim,
"
" __global float* A,
"
" __global float* B,
"
" __global float* C)
"
"{
"
" int k,j;
"
" int i = get_global_id(0);
"
" float Awrk[1000];
"
" float tmp;
"
" if( (i < Ndim) )
"
" {
"
" for(k=0;k<Pdim;k++)
"
" Awrk[k] = A[i*Ndim+k];
"
"
"
" for(j=0;j<Mdim;j++){
"
" tmp = 0.0;
"
" for(k=0;k<Pdim;k++)
"
" tmp += Awrk[k] * B[k*Pdim+j];
"
" C[i*Ndim+j] = tmp;
"
" }
"
" }
"
"}
"
"
";
Optimizing Memory Movement: Local Memory
A careful consideration of the dot products in the matrix multiplication shows that while each work-item reuses its own unique row of A, all the work-items in a group repeatedly stream the same columns of B through the compute device in the course of updating a row of C. This is shown in Figure 21.4. We can reduce the overhead of moving data from global memory if the work-items comprising a work-group copy the columns of the matrix B into local memory before they start updating their rows of C.
Figure 21.4 Matrix multiplication where each work-item computes an entire row of the C matrix. Memory traffic to global memory is minimized by copying a row of A into each work-item’s private memory and copying rows of B into local memory for each work-group.
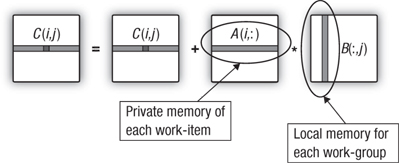
To support this optimization, changes were needed in both the kernel and the host program. These changes are shown in Listing 21.6. The key change was to set up the local memory for each kernel. This is needed because dynamic memory allocation within a kernel is not supported in OpenCL. Hence, a memory object of the appropriate size had to be allocated on the host and then passed as an argument to the kernel. This is done by an extra call to clSetKernelArg(). Then inside the kernel, the work-items copy a column of B into local memory. This is done in parallel using a cyclic distribution of the loop iterations. Before any work-item can proceed, all the copying must complete. Hence, the loop that carries out the copies is followed by a barrier(CLK_LOCAL_MEM_FENCE); with the memory fence selected to ensure that each work-item in the group sees a consistent state for the local memory. Following the barrier, the kernel code is essentially the same as in the previous case. This modification had a dramatic impact on performance, taking the matrix multiplication from 873 MFLOPS to 2472 MFLOPS.
Listing 21.6 Each work-item manages the update to a full row of C. Private memory is used for the row of A and local memory (Bwrk) is used by all work-items in a work-group to hold a column of B. The host code is the same as before other than the addition of a new argument for the B-column local memory.
const char *C_row_priv_bloc_KernelSource = "
"
"__kernel void mmul(
"
" const int Mdim,
"
" const int Ndim,
"
" const int Pdim,
"
" __global float* A,
"
" __global float* B,
"
" __global float* C,
"
" __local float* Bwrk)
"
"{
"
" int k,j;
"
" int i = get_global_id(0);
"
" int iloc = get_local_id(0);
"
" int nloc = get_local_size(0);
"
" float Awrk[1000];
"
" float tmp;
"
" if( (i < Ndim) )
"
" {
"
" for(k=0;k<Pdim;k++)
"
" Awrk[k] = A[i*Ndim+k];
"
"
"
" for(j=0;j<Mdim;j++){
"
" for(k=iloc;k<Pdim;k=k+nloc)
"
" Bwrk[k] = B[k*Pdim+j];
"
" barrier(CLK_LOCAL_MEM_FENCE);
"
" tmp = 0.0;
"
" for(k=0;k<Pdim;k++)
"
" tmp += Awrk[k] * Bwrk[k];
"
" C[i*Ndim+j] = tmp;
"
" }
"
" }
"
"}
"
"
";
//------------------------------------------------------------------
// Host code modifications . . Added one more argument (6) to the
// list of args for the kernel. Note that an OpenCL memory object
// is not provided since this is to be used in local memory.
//------------------------------------------------------------------
err = 0;
err = clSetKernelArg(*kernel, 0, sizeof(int), &Mdim);
err |= clSetKernelArg(*kernel, 1, sizeof(int), &Ndim);
err |= clSetKernelArg(*kernel, 2, sizeof(int), &Pdim);
err != clSetKernelArg(*kernel, 3, sizeof(cl_mem), &a_in);
err |= clSetKernelArg(*kernel, 4, sizeof(cl_mem), &b_in);
err |= clSetKernelArg(*kernel, 5, sizeof(cl_mem), &c_out);
err |= clSetKernelArg(*kernel, 6, sizeof(float)*Pdim, NULL);
Performance Results and Optimizing the Original CPU Code
Performance results from this example are summarized in Table 21.1. Directly translating the program into OpenCL for the CPU resulted in a significant performance improvement. Most of this chapter, however, focused on the GPU. In particular, these results show the impact of optimizing how data is mapped onto global, private, and local memory.
Table 21.1 Matrix Multiplication (Order-1000 Matrices) Results Reported as MFLOPS and as Speedup Relative to the Unoptimized Sequential C Program (i.e., the Speedups Are “Unfair”)
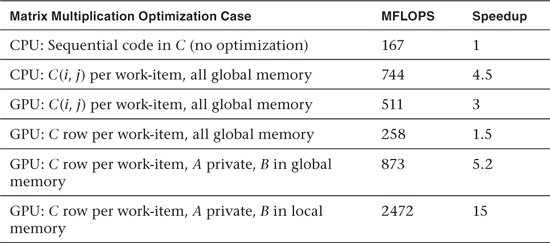
There is an impressive 15-fold speedup for the optimized GPU code versus the CPU code. This speedup value, however, is misleading. Considerable effort was expended to optimize the code on the GPU, but no effort whatsoever was expended to optimize the sequential code on the CPU. This situation, inflating speedups by comparing to an unoptimized sequential code, happens all too often and has led to unrealistic expectations of the benefits of moving from a CPU to a GPU.
Consider the functions in Listing 21.7. These simple optimizations permute the order of the three nested loops. This serves to change the memory access patterns and hence reuse of data from the cache as the contents of the three matrices are streamed through the CPU. Following common practice in the linear algebra literature, we call the dot product algorithm ijk and the two permutations ikj and kij. We also changed the data type from single to double and used the O3 compiler switch to GCC. Performance in MFLOPS varied considerably with 272, 1130, and 481 for the kjk, ikj, and kij, respectively. Note that this is the most trivial of optimizations and many additional optimization are well known (cache blocking, TLB blocking, SSE). Still, with these optimizations, our more honest sequential CPU reference point becomes 1130 MFLOPS, which reduces the OpenCLGPU maximum speedup to a more realistic value of 2.2.
Listing 21.7 Different Versions of the Matrix Multiplication Functions Showing the Permutations of the Loop Orderings
void mat_mul_ijk(int Mdim, int Ndim, int Pdim, double *A,
double *B, double *C)
{
int i, j, k;
for (i=0; i<Ndim; i++){
for (j=0; j<Mdim; j++){
for(k=0;k<Pdim;k++){
/* C(i,j) = sum(over k) A(i,k) * B(k,j) */
C[i*Ndim+j] += A[i*Ndim+k] * B[k*Pdim+j];
}
}
}
}
void mat_mul_ikj(int Mdim, int Ndim, int Pdim, double *A,
double *B, double *C)
{
int i, j, k;
for (i=0; i<Ndim; i++){
for(k=0;k<Pdim;k++){
for (j=0; j<Mdim; j++){
/* C[i][j] += sum(over k) A[i][k] * B[k][j] */
C[i*Ndim+j] += A[i*Ndim+k] * B[k*Pdim+j];
}
}
}
}
void mat_mul_kij(int Mdim, int Ndim, int Pdim, double *A,
double *B, double *C)
{
int i, j, k;
for(k=0;k<Pdim;k++){
for (i=0; i<Ndim; i++){
for (j=0; j<Mdim; j++){
/* C[i][j] += sum(over k) A[i][k] * B[k][j] */
C[i*Ndim+j] += A[i*Ndim+k] * B[k*Pdim+j];
}
}
}
}