
![]()
User-Defined Functions
Each new version of SQL Server features improvements to T-SQL that make development easier. SQL Server 2000 introduced (among other things) the concept of user-defined functions (UDFs). Like functions in other programming languages, T-SQL UDFs provide a convenient way for developers to define routines that accept parameters, perform actions based on those parameters, and return data to the caller. T-SQL functions come in three flavors: inline table-valued functions (TVFs), multistatement TVFs, and scalar functions. SQL Server 2014 also supports the ability to create CLR integration UDFs, which are discussed in Chapter 15.
Basically, a scalar UDF is a function that accepts zero or more parameters and returns a single scalar value as the result. You’re probably already familiar with scalar functions in mathematics, and with T-SQL’s built-in scalar functions (such as ABS and SUBSTRING). The CREATE FUNCTION statement allows you to create custom scalar functions that behave like the built-in scalar functions.
To demonstrate scalar UDFs, let’s a trip back in time to high school geometry class. In accordance with the rules passed down from Euclid, this UDF accepts a circle’s radius and returns the area of the circle using the formula area = π × r2. Listing 4-1 demonstrates this simple scalar UDF.
Listing 4-1. Simple Scalar UDF
CREATE FUNCTION dbo.CalculateCircleArea (@Radius float =1.0)
RETURNS float
WITH RETURNS NULL ON NULL INPUT
AS
BEGIN
RETURN PI() * POWER(@Radius, 2);
END;
The first line of the CREATE FUNCTION statement defines the schema and name of the function using a standard SQL Server two-part name (dbo.CalculateCircleArea) and a single required parameter, the radius of the circle (@Radius). The @Radius parameter is defined as a T-SQL float type. The parameter is assigned a default value of 1.0 by the = 1.0 after the parameter declaration:
CREATE FUNCTION dbo.CalculateCircleArea (@Radius float =1.0)
The next line contains the RETURNS keyword, which specifies the data type of the result that will be returned by the UDF. In this instance, the RETURNS keyword indicates that the UDF will return a float result:
RETURNS float
The third line contains additional options following the WITH keyword. The example uses the RETURNS NULL ON NULL INPUT function option for a performance improvement. The RETURNS NULL ON NULL INPUT option is a performance-enhancing option that automatically returns NULL if any of the parameters passed in are NULL. The performance enhancement occurs because SQL Server won’t execute the body of the function if a NULL is passed in and this option is specified:
WITH RETURNS NULL ON NULL INPUT
The AS keyword indicates the start of the function body which must be enclosed in the T-SQL BEGIN and END keywords. The sample function in Listing 4-1 is very simple, consisting of a single RETURN statement that immediately returns the value of the circle area calculation. The RETURN statement must be the last statement before the END keyword in every scalar UDF:
RETURN PI() * POWER(@radius, 2);
You can test this simple UDF with a few SELECT statements like the following. The results are shown in Figure 4-1:
SELECT dbo.CalculateCircleArea(10);
SELECT dbo.CalculateCircleArea(NULL);
SELECT dbo.CalculateCircleArea(2.5);

Figure 4-1. The results of the sample circle area calculations
UDF PARAMETERS
UDF parameters operate similarly to, but slightly differently from, stored procedure (SP) parameters. It’s important to be aware of the differences. For instance, if you create a UDF that accepts no parameters, you still need to include empty parentheses after the function name—both when creating and when invoking the function. Some built-in functions, like the PI() function used in Listing 4-1, which represents the value of the constant π (3.14159265358979), don’t take parameters. Notice that when the function is called in the UDF, it’s still called with empty parentheses.
When SPs are assigned default values, you can simply leave the parameter off your parameter list completely when calling the procedure. This isn’t an option with UDFs. To use a UDF default value, you must use the DEFAULT keyword when calling the UDF. To use the default value for the @radius parameter of the example dbo.CalculateCircleArea UDF, you call the UDF like this:
SELECT dbo.CalculateCircleArea (DEFAULT);
Finally, SPs have no equivalent to the RETURNS NULL ON NULL INPUT option. You can simulate this functionality to some extent by checking your parameters for NULL immediately on entering the SP, though. SPs are discussed in greater detail in Chapter 5.
UDFs provide several creation-time options that allow you to improve performance and security, including the following:
- The ENCRYPTION option can be used to store your UDF in the database in obfuscated format. Note that this isn’t true encryption, but rather an easily circumvented obfuscation of your code. See the “UDF ‘Encryption’” sidebar for more information.
- The SCHEMABINDING option indicates that your UDF will be bound to database objects referenced in the body of the function. With SCHEMABINDING turned on, attempts to change or drop referenced tables and other database objects result in an error. This helps to prevent inadvertent changes to tables and other database objects that can break your UDF. Additionally, the SQL Server Database Engine team has published information indicating that SCHEMABINDING can improve the performance of UDFs, even if they don’t reference other database objects (http://blogs.msdn.com/b/sqlprogrammability/archive/2006/05/12/596424.aspx).
- The CALLED ON NULL INPUT option is the opposite of RETURNS NULL ON NULL INPUT. When CALLED ON NULL INPUT is specified, SQL Server executes the body of the function even if one or more parameters are NULL. CALLED ON NULL INPUT is a default option for all scalar-valued functions.
- The EXECUTE AS option manages caller security on UDFs. You can specify that the UDF be executed as any of the following:
- CALLER indicates that the UDF should run under the security context of the user calling the function. This is the default.
- SELF indicates that the UDF should run under the security context of the user who created (or altered) the function.
- OWNER indicates that the UDF should run under the security context of the owner of the UDF (or the owner of the schema containing the UDF).
- Finally, you can specify that the UDF should run under the security context of a specific user by specifying a username.
UDF “ENCRYPTION”
Using the ENCRYPTION option on UDFs performs a simple obfuscation of your code. It actually does little more than “keep honest people honest,” and in reality it tends to be more trouble than it’s worth. Many developers and DBAs have spent precious time scouring the Internet for tools to decrypt their database objects because they were convinced the scripts in their source control database were out of sync with the production database. Keep in mind that those same decryption tools are available to anyone with an Internet connection and a browser. If you write commercial database scripts or perform database consulting services, your best (and really only) protection against curious DBAs and developers reverse-engineering and modifying your code is a well-written contract. Keep this in mind when deciding whether to “encrypt” your database objects.
Recursion in Scalar User-Defined Functions
Now that you’ve learned the basics, let’s hang out in math class for a few more minutes to talk about recursion. Like most procedural programming languages that allow function definitions, T-SQL allows recursion in UDFs. There’s hardly a better way to demonstrate recursion than the most basic recursive algorithm around: the factorial function.
For those who put factorials out of their minds immediately after graduation, here’s a brief rundown of what they are. A factorial is the product of all natural (or counting) numbers less than or equal to n, where n > 0. Factorials are represented in mathematics with the bang notation: n!. As an example, 5! = 1 × 2 × 3 × 4 × 5 = 120. The simple scalar dbo.CalculateFactorial UDF in Listing 4-2 calculates a factorial recursively for an integer parameter passed into it.
Listing 4-2. Recursive Scalar UDF
CREATE FUNCTION dbo.CalculateFactorial (@n int = 1)
RETURNS decimal(38, 0)
WITH RETURNS NULL ON NULL INPUT
AS
BEGIN
RETURN
(CASE
WHEN @n <= 0 THEN NULL
WHEN @n > 1 THEN CAST(@n AS float) * dbo.CalculateFactorial (@n - 1)
WHEN @n = 1 THEN 1
END);
END;
The first few lines are similar to Listing 4-1. The function accepts a single int parameter and returns a scalar decimal value. The RETURNS NULL ON NULL INPUT option returns NULL immediately if NULL is passed in:
CREATE FUNCTION dbo.CalculateFactorial (@n int = 1)
RETURNS decimal(38, 0)
WITH RETURNS NULL ON NULL INPUT
You return a decimal result in this example because of the limitations of the int and bigint types. Specifically, the int type overflows at 13! and bigint bombs out at 21!. In order to put the UDF through its paces, you have to allow it to return results up to 32!, as discussed later in this section. As in Listing 4-1, the body of this UDF is a single RETURN statement, this time with a searched CASE expression:
RETURN (CASE
WHEN @n <= 0 THEN NULL
WHEN @n > 1 THEN CAST(@n AS float) * dbo.CalculateFactorial (@n - 1)
WHEN @n = 1 THEN 1 END);
The CASE expression checks the value of the UDF parameter, @n. If @n is 0 or negative, dbo.CalculateFactorial returns NULL because the result is undefined. If @n is greater than 1, dbo.CalculateFactorial returns @n * dbo.CalculateFactorial(@n - 1), the recursive part of the UDF. This ensures that the UDF will continue calling itself recursively, multiplying the current value of @n by (@n-1)!.
Finally, when @n reaches 1, the UDF returns 1. This is the part of dbo.CalculateFactorial that stops the recursion. Without the check for @n = 1, you could theoretically end up in an infinite recursive loop. In practice, however, SQL Server saves you from yourself by limiting you to a maximum of 32 levels of recursion. Demonstrating the 32-level limit on recursion is why it was important for the UDF to return results up to 32!. Following are some examples of dbo.CalculateFactorial calls with various parameters, and their results:
SELECT dbo.CalculateFactorial(NULL); -- Returns NULL
SELECT dbo.CalculateFactorial(-1); -- Returns NULL
SELECT dbo.CalculateFactorial(0); -- Returns NULL
SELECT dbo.CalculateFactorial(5); -- Returns 120
SELECT dbo.CalculateFactorial(32); -- Returns 263130836933693520000000000000000000
As you can see, the dbo.CalculateFactorial function easily handles the 32 levels of recursion required to calculate 32!. If you try to go beyond that limit, you get an error message. Executing the following code, which attempts 33 levels of recursion, doesn’t work:
SELECT dbo.CalculateFactorial(33);
This causes SQL Server to grumble loudly with an error message similar to the following:
Msg 217, Level 16, State 1, Line 1
Maximum stored procedure, function, trigger, or view nesting level exceeded (limit 32).
MORE THAN ONE WAY TO SKIN A CAT
The 32-level recursion limit is a hard limit; that is, you can’t programmatically change it through server or database settings. This really isn’t as bad a limitation as you might think. Very rarely do you actually need to recursively call a UDF more than 32 times, and doing so could result in a severe performance penalty. There’s generally more than one way to get the job done. You can work around the 32-level recursion limitation in the dbo.CalculateFactorial function by rewriting it with a WHILE loop or using a recursive common table expression (CTE), as shown here:
CREATE FUNCTION dbo.CalculateFactorial (@n int = 1)
RETURNS float
WITH RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @result float;
SET @result = NULL;
IF @n > 0
BEGIN
SET @result = 1.0;
WITH Numbers (num)
AS (
SELECT 1
UNION ALL
SELECT num + 1
FROM Numbers
WHERE num < @n
)
SELECT @result = @result * num
FROM Numbers;
END;
RETURN @result;
END;
This rewrite of the dbo.CalculateFactorial function averts the recursive function call limit by eliminating the recursive function calls. Instead, it pushes the recursion back into the body of the function through the use of a recursive common table expression (CTE). By default, SQL Server allows up to 100 levels of recursion in a CTE (you can override this with the MAXRECURSION option), greatly expanding your factorial calculation power. With this function, you can easily find out that 33! is 8.68331761881189E+36, or even that 100! is 9.33262154439441E+157. The important idea to take away from this discussion is that although recursive function calls have hard limits on them, you can often work around those limitations using other T-SQL functionality.
Also keep in mind that although you used factorial calculation as a simple example of recursion, this method is considered naive, and there are several more-efficient methods of calculating factorials.
Procedural Code in User-Defined Functions
So far, you’ve seen simple functions that demonstrate the basic points of scalar UDFs. But in all likelihood, unless you’re implementing business logic for a swimming pool installation company, you aren’t likely to need to spend much time calculating the area of a circle in T-SQL.
A common problem that you have a much greater chance of running into is name-based searching. T-SQL offers tools for exact matching, partial matching, and even limited pattern matching via the LIKE predicate. T-SQL even offers built-in phonetic matching (sound-alike matching) through the built-in SOUNDEX function.
Heavy-duty approximate matching usually requires a more advanced tool, like a better phonetic matching algorithm. Let’s use one of these algorithms, the New York State Identification and Intelligence System (NYSIIS) algorithm, to demonstrate procedural code in UDFs.
THE SOUNDEX ALGORITHM
The NYSIIS algorithm is an improvement on the Soundex phonetic encoding algorithm, itself nearly 90 years old. The NYSIIS algorithm converts groups of one, two, or three alphabetic characters (known as n-grams) in names to a phonetic (“sounds like”) approximation. This makes it easier to search for names that have similar pronunciations but different spellings, such as Smythe and Smith. As mentioned in this section, SQL Server provides a built-in SOUNDEX function, but Soundex provides very poor accuracy and usually results in many false hits. NYSIIS and other modern algorithms provide much better results than Soundex.
To demonstrate procedural code in UDFs, you can implement a UDF that phonetically encodes names using NYSIIS encoding rules. The rules for NYSIIS phonetic encoding are relatively simple, with the majority of the rules requiring simple n-gram substitutions. The following is a complete list of NYSIIS encoding rules:
- Remove all non-alphabetic characters from the name.
- The first characters of the name are encoded according to the n-gram substitutions shown in the Start of Name table in Figure 4-2. In Figure 4-2, the n-grams shown to the left of the arrows are replaced with the n-grams to the right of the arrows during the encoding process.

Figure 4-2. NYSIIS phonetic encoding rules / character substitutions
- The last characters of the name are encoded according to the n-gram substitutions shown in the End of Name table in Figure 4-2.
- The first character of the encoded value is set to the first character of the name.
- After the first and last n-grams are encoded, all remaining characters in the name are encoded according to the n-gram substitutions shown in the Middle of Name table in Figure 4-2.
- All side-by-side duplicate characters in the encoded name are reduced to a single character. This means that AA is reduced to A and SS is reduced to S.
- If the last character of the encoded name is S, it’s removed.
- If the last characters of the encoded name are AY, they’re replaced with Y.
- If the last character of the encoded name is A, it’s removed.
- The result is truncated to a maximum length of six characters.
You could use some fairly large CASE expressions to implement these rules, but let’s go with a more flexible option: using a replacement table. This table will contain the majority of the replacement rules in three columns, as described here:
- Location: This column tells the UDF whether the rule should be applied to the start, end, or middle of the name.
- NGram: This column is the n-gram, or sequence of characters, that will be encoded. These n-grams correspond to the left side of the arrows in Figure 4-2.
- Replacement: This column represents the replacement value for the corresponding n-gram on the same row. These character sequences correspond to the right side of the arrows in Figure 4-2.
Listing 4-3 is a CREATE TABLE statement that builds the NYSIIS phonetic encoding replacement rules table.
Listing 4-3. Creating the NYSIIS Replacement Rules Table
-- Create the NYSIIS replacement rules table
CREATE TABLE dbo.NYSIIS_Replacements
(Location nvarchar(10) NOT NULL,
NGram nvarchar(10) NOT NULL,
Replacement nvarchar(10) NOT NULL,
PRIMARY KEY (Location, NGram));
Listing 4-4 is a single INSERT statement that uses row constructors to populate all the NYSIIS replacement rules, as shown in Figure 4-2.
Listing 4-4. INSERT Statement to Populate the NYSIIS Replacement Rules Table
INSERT INTO NYSIIS_Replacements (Location, NGram, Replacement)
VALUES(N'End', N'DT', N'DD'),
(N'End', N'EE', N'YY'),
(N'End', N'lE', N'YY'),
(N'End', N'ND', N'DD'),
(N'End', N'NT', N'DD'),
(N'End', N'RD', N'DD'),
(N'End', N'RT', N'DD'),
(N'Mid', N'A', N'A'),
(N'Mid', N'E', N'A'),
(N'Mid', N'T', N'A'),
(N'Mid', N'K', N'C'),
(N'Mid', N'M', N'N'),
(N'Mid', N'O', N'A'),
(N'Mid', N'Q', N'G'),
(N'Mid', N'U', N'A'),
(N'Mid', N'Z', N'S'),
(N'Mid', N'AW', N'AA'),
(N'Mid', N'EV', N'AF'),
(N'Mid', N'EW', N'AA'),
(N'Mid', N'lW', N'AA'),
(N'Mid', N'KN', N'NN'),
(N'Mid', N'OW', N'AA'),
(N'Mid', N'PH', N'FF'),
(N'Mid', N'UW', N'AA'),
(N'Mid', N'SCH', N'SSS'),
(N'Start', N'K', N'C'),
(N'Start', N'KN', N'NN'),
(N'Start', N'PF', N'FF'),
(N'Start', N'PH', N'FF'),
(N'Start', N'MAC', N'MCC'),
(N'Start', N'SCH', N'SSS'),
GO
Listing 4-5 is the UDF that encodes a string using NYSIIS. This UDF demonstrates the complexity of the control-of-flow logic that can be implemented in a scalar UDF.
Listing 4-5. Function to Encode Strings Using NYSIIS
CREATE FUNCTION dbo.EncodeNYSIIS
(
@String nvarchar(100)
)
RETURNS nvarchar(6)
WITH RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @Result nvarchar(100);
SET @Result = UPPER(@String);
-- Step 1: Remove All Nonalphabetic Characters
WITH Numbers (Num)
AS
(
SELECT 1
UNION ALL
SELECT Num + 1
FROM Numbers
WHERE Num < LEN(@Result)
)
SELECT @Result = STUFF
(
@Result,
Num,
1,
CASE WHEN SUBSTRING(@Result, Num, 1) >= N'A'
AND SUBSTRING(@Result, Num, 1) <= N'Z'
THEN SUBSTRING(@Result, Num, 1)
ELSE N'.'
END )
FROM Numbers;
SET @Result = REPLACE(@Result, N'.', N''),
-- Step 2: Replace the Start N-gram
SELECT TOP (1) @Result = STUFF
(
@Result,
1,
LEN(NGram),
Replacement
)
FROM dbo.NYSIIS_Replacements
WHERE Location = N'Start'
AND SUBSTRING(@Result, 1, LEN(NGram)) = NGram
ORDER BY LEN(NGram) DESC;
-- Step 3: Replace the End N-gram
SELECT TOP (1) @Result = STUFF
(
@Result,
LEN(@Result) - LEN(NGram) + 1,
LEN(NGram),
Replacement
)
FROM dbo.NYSIIS_Replacements
WHERE Location = N'End'
AND SUBSTRING(@Result, LEN(@Result) - LEN(NGram) + 1, LEN(NGram)) = NGram
ORDER BY LEN(NGram) DESC;
-- Step 4: Save the First Letter of the Name
DECLARE @FirstLetter nchar(1);
SET @FirstLetter = SUBSTRING(@Result, 1, 1);
-- Step 5: Replace All Middle N-grams
DECLARE @Replacement nvarchar(10);
DECLARE @i int;
SET @i = 1;
WHILE @i <= LEN(@Result)
BEGIN
SET @Replacement = NULL;
-- Grab the middle-of-name replacement n-gram
SELECT TOP (1) @Replacement = Replacement
FROM dbo.NYSIIS_Replacements
WHERE Location = N'Mid'
AND SUBSTRING(@Result, @i, LEN(NGram)) = NGram
ORDER BY LEN(NGram) DESC;
SET @Replacement = COALESCE(@Replacement, SUBSTRING(@Result, @i, 1));
-- If we found a replacement, apply it
SET @Result = STUFF(@Result, @i, LEN(@Replacement), @Replacement)
-- Move on to the next n-gram
SET @i = @i + COALESCE(LEN(@Replacement), 1);
END;
-- Replace the first character with the first letter we saved at the start
SET @Result = STUFF(@Result, 1, 1, @FirstLetter);
-- Here we apply our special rules for the 'H' character. Special handling for 'W'
-- characters is taken care of in the replacement rules table
WITH Numbers (Num)
AS
(
SELECT 2 -- Don't bother with the first character
UNION ALL
SELECT Num + 1
FROM Numbers
WHERE Num < LEN(@Result)
)
SELECT @Result = STUFF
(
@Result,
Num,
1,
CASE SUBSTRING(@Result, Num, 1)
WHEN N'H' THEN
CASE WHEN SUBSTRING(@Result, Num + 1, 1)
NOT IN (N'A', N'E', N'I', N'O', N'U')
OR SUBSTRING(@Result, Num - 1, 1)
NOT IN (N'A', N'E', N'I', N'O', N'U')
THEN SUBSTRING(@Result, Num - 1, 1)
ELSE N'H'
END
ELSE SUBSTRING(@Result, Num, 1)
END
)
FROM Numbers;
-- Step 6: Reduce All Side-by-side Duplicate Characters
-- First replace the first letter of any sequence of two side-by-side
-- duplicate letters with a period
WITH Numbers (Num)
AS
(
SELECT 1
UNION ALL
SELECT Num + 1
FROM Numbers
WHERE Num < LEN(@Result)
)
SELECT @Result = STUFF
(
@Result,
Num,
1,
CASE SUBSTRING(@Result, Num, 1)
WHEN SUBSTRING(@Result, Num + 1, 1) THEN N'.'
ELSE SUBSTRING(@Result, Num, 1)
END
)
FROM Numbers;
-- Next replace all periods '.' with an empty string ''
SET @Result = REPLACE(@Result, N'.', N''),
-- Step 7: Remove Trailing 'S' Characters
WHILE RIGHT(@Result, 1) = N'S' AND LEN(@Result) > 1
SET @Result = STUFF(@Result, LEN(@Result), 1, N''),
-- Step 8: Remove Trailing 'A' Characters
WHILE RIGHT(@Result, 1) = N'A' AND LEN(@Result) > 1
SET @Result = STUFF(@Result, LEN(@Result), 1, N''),
-- Step 9: Replace Trailing 'AY' Characters with 'Y'
IF RIGHT(@Result, 2) = 'AY'
SET @Result = STUFF(@Result, LEN(@Result) - 1, 1, N''),
-- Step 10: Truncate Result to 6 Characters
RETURN COALESCE(SUBSTRING(@Result, 1, 6), ''),
END;
GO
The NYSIISReplacements table rules reflect most of the NYSIIS rules described by Robert L. Taft in his famous paper “Name Search Techniques.”1 The start and end n-grams are replaced, and then the remaining n-gram rules are applied in a WHILE loop. The special rules for the letter H are applied, side-by-side duplicates are removed, special handling of certain trailing characters is performed, and the first six characters of the result are returned.
NUMBERS TABLES
This example uses recursive CTEs to dynamically generate virtual numbers tables in a couple of places. A numbers table is simply a table of numbers counting up to a specified maximum. The following recursive CTE generates a small numbers table (the numbers 1 through 100):
WITH Numbers (Num)
AS
(
SELECT 1
UNION ALL
SELECT Num + 1
FROM Numbers
WHERE Num < 100
)
SELECT Num FROM Numbers;
Listing 4-5 used the number of characters in the name to limit the recursion of the CTEs. This speeds up the UDF overall. You can get even more performance gains by creating a permanent numbers table in your database with a clustered index/primary key on it, instead of using CTEs. A numbers table is always handy to have around, doesn’t cost you very much to build or maintain, doesn’t take up much storage space, and is extremely useful for converting loops and cursors to set-based code. A numbers table is by far one of the handiest and simplest tools you can add to your T-SQL toolkit.
As an example, you can use the query in Listing 4-6 to phonetically encode the last names of all contacts in the AdventureWorks database using NYSIIS. Partial results are shown in Figure 4-3.
Listing 4-6. Using NYSIIS to Phonetically Encode All AdventureWorks Contacts
SELECT LastName,
dbo.EncodeNYSIIS(LastName) AS NYSIIS
FROM Person.Person
GROUP BY LastName;

Figure 4-3. Partial results of NYSIIS encoding AdventureWorks contacts
Using the dbo.EncodeNYSIIS UDF is relatively simple. Listing 4-7 is a simple example of using the new UDF in the WHERE clause to retrieve all AdventureWorks contacts whose last name is phonetically similar to the name Liu. The results are shown in Figure 4-4.
Listing 4-7. Retrieving All Contact Phonetic Matches for Liu
SELECT
BusinessEntityID,
LastName,
FirstName,
MiddleName,
dbo.EncodeNYSIIS(LastName) AS NYSIIS
FROM Person.Person
WHERE dbo.EncodeNYSIIS(LastName) = dbo.EncodeNYSIIS(N' Liu'),

Figure 4-4. Partial listing of AdventureWorks contacts with names phonetically similar to Liu
The example in Listing 4-7 is the naive method of using a UDF. The query engine must apply the UDF to every single row of the source table. In this case, the dbo.EncodeNYSIIS function is applied to the nearly 20,000 last names in the Person.Contact table, resulting in an inefficient query plan and excessive I/O. A more efficient method is to perform the NYSIIS encodings ahead of time—to pre-encode the names. The pre-encoding method is demonstrated in Listing 4-8.
Listing 4-8. Pre-encoding AdventureWorks Contact Names with NYSIIS
CREATE TABLE Person.ContactNYSIIS
(
BusinessEntityID int NOT NULL,
NYSIIS nvarchar(6) NOT NULL,
PRIMARY KEY(NYSIIS, BusinessEntityID)
);
GO
INSERT INTO Person.ContactNYSIIS
(
BusinessEntityID,
NYSIIS
)
SELECT
BusinessEntityID,
dbo.EncodeNYSIIS(LastName)
FROM Person.Person;
GO
Once you have pre-encoded the data, queries are much more efficient. The query shown in Listing 4-9 uses the table created in Listing 4-8 to return the same results as Listing 4-7—just much more efficiently, because this version doesn’t need to encode every row of data for comparison in the WHERE clause at query time.
Listing 4-9. Efficient NYSIIS Query Using Pre-encoded Data
SELECT
cn.BusinessEntityID,
c.LastName,
c.FirstName,
c.MiddleName,
cn.NYSIIS
FROM Person.ContactNYSIIS cn
INNER JOIN Person.Person c
ON cn.BusinessEntityID = c.BusinessEntityID
WHERE cn.NYSIIS = dbo.EncodeNYSIIS(N'Liu'),
To keep the efficiency of the dbo.EncodeNYSIIS UDF-based searches optimized, I highly recommend pre-encoding your search data. This is especially true in production environments where performance is critical. NYSIIS (and phonetic matching in general) is an extremely useful tool for approximate name-based searches in a variety of applications, such as customer service, business reporting, and law enforcement.
Multistatement Table-Valued Functions
Multistatement TVFs are similar in style to scalar UDFs, but instead of returning a single scalar value, they return their result as a table data type. The declaration is very similar to that of a scalar UDF, with a few important differences:
- The return type following the RETURNS keyword is actually a table variable declaration, with its structure declared immediately following the table variable name.
- The RETURNS NULL ON NULL INPUT and CALLED ON NULL INPUT function options aren’t valid in a multistatement TVF definition.
- The RETURN statement in the body of the multistatement TVF has no values or variables following it.
Inside the body of the multistatement TVF, you can use the SQL Data Manipulation Language (DML) statements INSERT, UPDATE, MERGE, and DELETE to create and manipulate the return results in the table variable that will be returned as the result.
For the example of a multistatement TVF, let’s create another business application function: a product pull list for AdventureWorks. This TVF matches the AdventureWorks sales orders stored in the Sales.SalesOrderDetail table against the product inventory in the Production.ProductInventory table. It effectively creates a list for AdventureWorks employees, telling them exactly which inventory bin to go to when they need to fill an order. Some business rules need to be defined before you write this multistatement TVF:
- In some cases, the number of ordered items may be more than are available in one bin. In that case, the pull list will instruct the employee to grab the product from multiple bins.
- Any partial fills from a bin will be reported on the list.
- Any substitution work (for example, substituting a different-colored item of the same model) will be handled by a separate business process and won’t be allowed on this list.
- No zero fills (ordered items for which there is no matching product in inventory) will be reported back on the list.
For purposes of this example, let’s say there are three customers: Jill, Mike, and Dave. Each of these three customers places an order for exactly five of item number 783, the black Mountain-200 42-inch mountain bike. Let’s also say that AdventureWorks has six of this particular inventory item in bin 1, shelf A, location 7, and another three of this particular item in bin 2, shelf B, location 10. Your business rules will create a pull list like the following:
- Jill’s order: Pull five of item 783 from bin 1, shelf A, location 7; mark the order as a complete fill.
- Mike’s order: Pull one of item 783 from bin 1, shelf A, location 7; mark the order as a partial fill.
- Mike’s order: Pull three of item 783 from bin 2, shelf B, location 10; mark the order as a partial fill.
In this example, there are only 9 of the ordered items in inventory, but 15 total items have been ordered (3 customers multiplied by 5 items each). Because of this, Dave’s order is zero-filled—no items are pulled from inventory to fill his order. Figure 4-5 is designed to help you visualize the sample inventory/order fill scenario.

Figure 4-5. Filling orders from inventory
Because the inventory is out of item 783 at this point (there were nine items in inventory and all nine were used to fill Jill’s and Mike’s orders), Dave’s order is not even listed on the pull list report. This function doesn’t concern itself with product substitutions—for example, completing Mike’s and Dave’s orders with a comparable product such as item ID number 780 (the silver Mountain-200 42-inch mountain bike), if there happens to be some in stock. The business rule for substitutions states that a separate process handles this aspect of order fulfillment.
Many developers may see this problem as an opportunity to flex their cursor-based coding muscles. If you look at the problem from a procedural point of view, it essentially calls for performing nested loops through AdventureWorks’ customer orders and inventory to match them up. However, this code doesn’t require procedural code, and the task can be completed in a set-based fashion using a numbers table, as described in the previous section. A numbers table with numbers from 0 to 30,000 is adequate for this task; the code to create it is shown in Listing 4-10.
Listing 4-10. Creating a Numbers Table
USE [AdventureWorks2014]
GO
IF EXISTS (SELECT * FROM sys.objects
WHERE object_id = OBJECT_ID(N'[dbo].[Numbers]')
AND type in (N'U'))
DROP TABLE [dbo].[Numbers];
-- Create a numbers table to allow the product pull list to be
-- created using set-based logic
CREATE TABLE dbo.Numbers (Num int NOT NULL PRIMARY KEY);
GO
-- Fill the numbers table with numbers from 0 to 30,000
WITH NumCTE (Num)
AS
(
SELECT 0
UNION ALL
SELECT Num + 1
FROM NumCTE
WHERE Num < 30000
)
INSERT INTO dbo.Numbers (Num) SELECT Num FROM NumCTE
OPTION (MAXRECURSION 0);
GO
So, with a better understanding of order-fulfillment logic and business rules, Listing 4-11 creates a multistatement TVF to return the product pull list according to the rules provided. As mentioned, this multistatement TVF uses set-based logic (no cursors or loops) to retrieve the product pull list.
LOOK MA, NO CURSORS!
Many programming problems in business present a procedural loop-based solution on first glance. This applies to problems that you must solve in T-SQL as well. If you look at business problems with a set-based mindset, you often find a set-based solution. In the product pull list example, the loop-based process of comparing every row of inventory to the order-detail rows is immediately apparent.
However, if you think of the inventory items and order-detail items as two sets, then the problem becomes a set-based problem. In this case, the solution is a variation of the classic computer science/mathematics bin-packing problem. In the bin-packing problem, you’re given a set of bins (in this case, orders) in which to place a finite set of items (inventory items in this example). The natural bounds provided are the number of each item in inventory and the number of each item on each order-detail line.
By solving this as a set-based problem in T-SQL, you allow SQL Server to optimize the performance of your code based on the most current information available. As mentioned in Chapter 3, when you use cursors and loops, you take away SQL Server’s performance-optimization options, and you assume the responsibility for performance optimization. You can use set-based logic instead of cursors and loops to solve this particular problem. In reality, solving this problem with a set-based solution took only about 30 minutes of my time. A cursor or loop-based solution would have taken just as long or longer, and it wouldn’t have been nearly as efficient.
Listing 4-11. Creating a Product Pull List
CREATE FUNCTION dbo.GetProductPullList()
RETURNS @result table
(
SalesOrderID int NOT NULL,
ProductID int NOT NULL,
LocationID smallint NOT NULL,
Shelf nvarchar(10) NOT NULL,
Bin tinyint NOT NULL,
QuantityInBin smallint NOT NULL,
QuantityOnOrder smallint NOT NULL,
QuantityToPull smallint NOT NULL,
PartialFillFlag nchar(1) NOT NULL,
PRIMARY KEY (SalesOrderID, ProductID, LocationID, Shelf, Bin)
)
AS
BEGIN
INSERT INTO @result
(
SalesOrderID,
ProductID,
LocationID,
Shelf,
Bin,
QuantityInBin,
QuantityOnOrder,
QuantityToPull,
PartialFillFlag
)
SELECT
Order_Details.SalesOrderID,
Order_Details.ProductID,
Inventory_Details.LocationID,
Inventory_Details.Shelf,
Inventory_Details.Bin,
Inventory_Details.Quantity,
Order_Details.OrderQty,
COUNT(*) AS PullQty,
CASE WHEN COUNT(*) < Order_Details.OrderQty
THEN N'Y'
ELSE N'N'
END AS PartialFillFlag
FROM
(
SELECT ROW_NUMBER() OVER
(
PARTITION BY p.ProductID
ORDER BY p.ProductID,
p.LocationID,
p.Shelf,
p.Bin
) AS Num,
p.ProductID,
p.LocationID,
p.Shelf,
p.Bin,
p.Quantity
FROM Production.ProductInventory p
INNER JOIN dbo.Numbers n
ON n.Num BETWEEN 1 AND Quantity
) Inventory_Details
INNER JOIN
(
SELECT ROW_NUMBER() OVER
(
PARTITION BY o.ProductID
ORDER BY o.ProductID,
o.SalesOrderID
) AS Num,
o.ProductID,
o.SalesOrderID,
o.OrderQty
FROM Sales.SalesOrderDetail o
INNER JOIN dbo.Numbers n
ON n.Num BETWEEN 1 AND o.OrderQty
) Order_Details
ON Inventory_Details.ProductID = Order_Details.ProductID
AND Inventory_Details.Num = Order_Details.Num
GROUP BY
Order_Details.SalesOrderID,
Order_Details.ProductID,
Inventory_Details.LocationID,
Inventory_Details.Shelf,
Inventory_Details.Bin,
Inventory_Details.Quantity,
Order_Details.OrderQty;
RETURN;
END;
GO
Retrieving the product pull list involves a simple SELECT query like the following. Partial results are shown in Figure 4-6:
SELECT
SalesOrderID,
ProductID,
LocationID,
Shelf,
Bin,
QuantityInBin,
QuantityOnOrder,
QuantityToPull,
PartialFillFlag
FROM dbo.GetProductPullList();
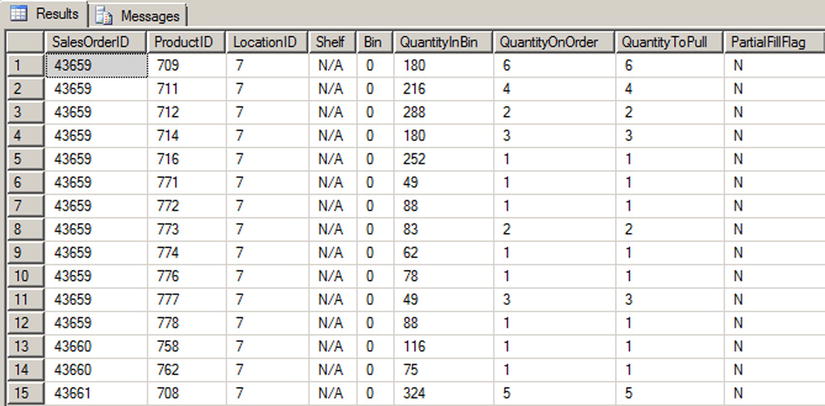
Figure 4-6. AdventureWorks product pull list (partial)
One interesting aspect of the multistatement TVF is the CREATE FUNCTION keyword and its RETURNS clause, which define the name of the procedure, parameters passed in (if any), and the resulting set table structure:
CREATE FUNCTION dbo.GetProductPullList()
RETURNS @result table
(
SalesOrderIlD int NOT NULL,
ProductID int NOT NULL,
LocationID smallint NOT NULL,
Shelf nvarchar(10) NOT NULL,
Bin tinyint NOT NULL,
QuantityInBin smallint NOT NULL,
QuantityOnOrder smallint NOT NULL,
QuantityToPull smallint NOT NULL,
PartialFillFlag nchar(1) NOT NULL,
PRIMARY KEY (SalesOrderID, ProductID, LocationID, Shelf, Bin)
)
Notice that you define a primary key on the table result. This also serves as the clustered index for the result set. Due to limitations in table variables, you can’t explicitly specify other indexes on the result set.
The body of the function begins with the INSERT INTO and SELECT clauses that follow:
INSERT INTO @result
(
SalesOrderID,
ProductID,
LocationID,
Shelf,
Bin,
QuantitylnBin,
QuantityOnOrder,
QuantityToPull,
PartialFillFlag
)
SELECT
Order_Details.SalesOrderID,
Order_Details.ProductID,
Inventory_Details.LocationID,
Inventory_Details.Shelf,
Inventory_Details.Bin,
Inventory_Details.Quantity,
Order_Details.OrderQty,
COUNT(*) AS PullQty,
CASE WHEN C0UNT(*) < Order_Details.OrderQty
THEN N'Y'
ELSE N'N'
END AS PartialFillFlag
These clauses establish population of the @result table variable. The most important point to notice here is that the return results of this multistatement TVF are created by manipulating the contents of the @result table variable. When the function ends, the @result table variable is returned to the caller. Some other important facts about this portion of the multistatement TVF are that the COUNT(*) AS PullQty aggregate function returns the total number of each item to pull from a given bin to fill a specific order-detail row, and the CASE expression returns Y when an order-detail item is partially filled from a single bin and N when an order-detail item is completely filled from a single bin.
The source for the SELECT query is composed of two subqueries joined together. The first subquery, aliased as InventoryDetails, is shown next. This subquery returns a single row for every item in inventory with information identifying the precise location where the inventory item can be found:
(
SELECT ROW_NUMBER() OVER
(
PARTITION BY p.ProductID
ORDER BY p.ProductID,
p.LocationID,
p.Shelf,
p.Bin
) AS Num,
p.ProductID,
p.LocationID,
p.Shelf,
p.Bin,
p.Quantity
FROM Production.ProductInventory p
INNER JOIN dbo.Numbers n
ON n.Num BETWEEN 1 AND Quantity
) Inventory_Details
Consider the previous example with the customers Jill, Mike, and Dave. If there are nine black Mountain-200 42-inch mountain bikes in inventory, this query returns nine rows, one for each instance of the item in inventory, and each with a unique row number counting from 1.
The InventoryDetails subquery is inner-joined to a second subquery, identified as Order_Details:
(
SELECT ROW_NUMBER() OVER
(
PARTITION BY o.ProductID
ORDER BY o.ProductID,
o.SalesOrderID
) AS Num,
o.ProductID,
o.SalesOrderID,
o.OrderQty
FROM Sales.SalesOrderDetail o
INNER JOIN dbo.Numbers n
ON n.Num BETWEEN 1 AND o.OrderQty
) Order_Details
This subquery breaks up quantities of items in all order details into individual rows. Again, in the example of Jill, Mike, and Dave, this query breaks each of the order details into five rows, one for each item of each order detail. The rows are assigned unique numbers for each product. So in the example, the rows for each black Mountain-200 42-inch mountain bike that the three customers ordered are numbered individually from 1 to 15.
The rows of both subqueries are joined based on their ProductID numbers and the unique row numbers assigned to each row of each subquery. This effectively assigns one item from inventory to fill exactly one item in each order. Figure 4-7 is a visualization of the process described here, where the inventory items and order-detail items are split into separate rows and the two rowsets are joined together.

Figure 4-7. Splitting and joining individual inventory and order-detail items
The SELECT statement also requires a GROUP BY to aggregate the total number of items to be pulled from each bin to fill each order detail, as opposed to returning the raw inventory-to-order detail items on a one-to-one basis:
GROUP BY
Order_Details.SalesOrderID,
Order_Details.ProductID,
Inventory_Details.LocationID,
Inventory_Details.Shelf,
Inventory_Details.Bin,
Inventory_Details.Quantity,
Order_Details.OrderQty;
Finally, the RETURN statement returns the @result table back to the caller as the multistatement TVF result. Notice that the RETURN statement in a multistatement TVF isn’t followed by an expression or variable as it is in a scalar UDF:
RETURN;
The table returned by a TVF can be used just like a table in a WHERE clause or a JOIN clause of an SQL SELECT query. Listing 4-12 is a sample query that joins the example TVF to the Production.Product table to get the product names and colors for each product listed in the pull list. Figure 4-8 shows the output of the product pull list joined to the Production.Product table.
Listing 4-12. Retrieving a Product Pull List with Product Names
SELECT
p.Name AS ProductName,
p.ProductNumber,
p.Color,
ppl.SalesOrderID,
ppl.ProductID,
ppl.LocationID,
ppl.Shelf,
ppl.Bin,
ppl.QuantityInBin,
ppl.QuantityOnOrder,
ppl.QuantityToPull,
ppl.PartialFillFlag
FROM Production.Product p
INNER JOIN dbo.GetProductPullList() ppl
ON p.ProductID = ppl.ProductID;

Figure 4-8. Joining the product pull list to the Production.Product table
Inline Table-Valued Functions
If scalar UDFs and multistatement TVFs aren’t enough to get you excited about T-SQL’s UDF capabilities, here comes a third form of UDF: the inline TVF. Inline TVFs are similar to multistatement TVFs in that they return a tabular rowset result.
However, whereas a multistatement TVF can contain multiple SQL statements and control-of-flow statements in the function body, the inline function consists of only a single SELECT query. The inline TVF is literally “inlined” by SQL Server (expanded by the query optimizer as part of the SELECT statement that contains it), much like a view. In fact, because of this behavior, inline TVFs are sometimes referred to as parameterized views.
The inline TVF declaration must simply state that the result is a table via the RETURNS clause. The body of the inline TVF consists of an SQL query after a RETURN statement. Because the inline TVF returns the result of a single SELECT query, you don’t need to bother with declaring a table variable or defining the return-table structure. The structure of the result is implied by the SELECT query that makes up the body of the function.
The sample inline TVF performs a function commonly implemented by developers in T-SQL using control-of-flow statements. Many times, a developer determines that a function or SP requires that a large or variable number of parameters be passed in to accomplish a particular goal. The ideal situation would be to pass an array as a parameter. T-SQL doesn’t provide an array data type per se, but you can split a comma-delimited list of strings into a table to simulate an array. This gives you the flexibility of an array that you can use in SQL joins.
![]() Tip SQL Server 2012 forward allows table-valued parameters, which are covered in Chapter 5 in the discussion of SPs. Because table-valued parameters have special requirements, they may not be optimal in all situations.
Tip SQL Server 2012 forward allows table-valued parameters, which are covered in Chapter 5 in the discussion of SPs. Because table-valued parameters have special requirements, they may not be optimal in all situations.
Although you could do this using a multistatement TVF and control-of-flow statement such as a WHILE loop, you get better performance if you let SQL Server do the heavy lifting with a set-based solution. The sample function accepts a comma-delimited varchar(max) string and returns a table with two columns, Num and Element, which are described here:
- The Num column contains a unique number for each element of the array, counting from 1 to the number of elements in the comma-delimited string.
- The Element column contains the substrings extracted from the comma-delimited list.
Listing 4-13 is the full code listing for the comma-separated string-splitting function. This function accepts a single parameter, which is a comma-delimited string like Ronnie,Bobbie,Ricky,Mike. The output is a table-like rowset with each comma-delimited item returned on its own row. To avoid looping and procedural constructs (which aren’t allowed in an inline TVF), you use the same Numbers table created previously in Listing 4-10.
Listing 4-13. Comma-Separated String-Splitting Function
CREATE FUNCTION dbo.GetCommaSplit (@String nvarchar(max))
RETURNS table
AS
RETURN
(
WITH Splitter (Num, String)
AS
(
SELECT Num, SUBSTRING(@String,
Num,
CASE CHARINDEX(N',', @String, Num)
WHEN 0 THEN LEN(@String) - Num + 1
ELSE CHARINDEX(N',', @String, Num) - Num
END
) AS String
FROM dbo.Numbers
WHERE Num <= LEN(@String)
AND (SUBSTRING(@String, Num - 1, 1) = N',' OR Num = 0)
)
SELECT
ROW_NUMBER() OVER (ORDER BY Num) AS Num,
RTRIM(LTRIM(String)) AS Element
FROM Splitter
WHERE String <> ''
);
GO
The inline TVF name and parameters are defined at the beginning of the CREATE FUNCTION statement. The RETURNS table clause specifies that the function returns a table. Notice that the structure of the table isn’t defined as it is with a multistatement TVF:
CREATE FUNCTION dbo.GetCommaSplit (@String varchar(max)) RETURNS table
The body of the inline TVF consists of a single RETURN statement followed by a SELECT query. This example uses a CTE called Splitter to perform the actual splitting of the comma-delimited list. The query of the CTE returns each substring from the comma-delimited list. CASE expressions are required to handle two special cases, as follows:
- The first item in the list, because it isn’t preceded by a comma
- The last item in the list, because it isn’t followed by a comma
WITH Splitter (Num, String)
AS
(
SELECT Num, SUBSTRING(@String,
Num,
CASE CHARINDEX(N',', @String, Num)
WHEN 0 THEN LEN(@String) - Num + 1
ELSE CHARINDEX(N',', @String, Num) - Num
END
) AS String
FROM dbo.Numbers
WHERE Num <= LEN(@String)
AND (SUBSTRING(@String, Num - 1, l) = N',' OR Num = 0)
)
Finally, the query selects each ROWNUMBER and Element from the CTE as the result to return to the caller. Extra space characters are stripped from the beginning and end of each string returned, and empty strings are ignored:
SELECT
ROW_NUMBER() OVER (ORDER BY Num) AS Num,
LTRIM(RTRIM(String)) AS Element
FROM Splitter
WHERE String <> ''
You can use this inline TVF to split up the Jackson family, as shown in Listing 4-14. The results are shown in Figure 4-9.

Figure 4-9. Splitting up the Jacksons
Listing 4-14. Splitting Up the Jacksons
SELECT Num, Element
FROM dbo.GetCommaSplit ('Michael,Tito,Jermaine,Marlon,Rebbie,Jackie,Janet,La Toya,Randy'),
You can use this technique to pull descriptions for a specific set of AdventureWorks products. A usage like this is good for front-end web page displays or business reports where end users can select multiple items for which they want data returned. Listing 4-15 retrieves product information for a comma-delimited list of AdventureWorks product numbers. The results are shown in Figure 4-10.
Listing 4-15. Using the FnCommaSplit Function
SELECT n.Num,
p.Name,
p.ProductNumber,
p.Color,
p.Size,
p.SizeUnitMeasureCode,
p.StandardCost,
p.ListPrice
FROM Production.Product p
INNER JOIN dbo.GetCommaSplit('FR-R38R-52,FR-M94S-52,FR-M94B-44,BK-M68B-38') n
ON p.ProductNumber = n.Element;

Figure 4-10. Using a comma-delimited list to retrieve product information
Restrictions on User-Defined Functions
T-SQL imposes some restrictions on UDFs. This section discusses these restrictions and some of the reasoning behind them.
Nondeterministic Functions
T-SQL prohibits the use of nondeterministic functions in UDFs. A deterministic function is one that returns the same value every time when passed a given set of parameters (or no parameters). A nondeterministic function can return different results with the same set of parameters passed to it. An example of a deterministic function is ABS, the mathematical absolute value function. Every time and no matter how many times you call ABS(-10), the result is always 10. This is the basic idea behind determinism.
On the flip side, there are functions that don’t return the same value despite the fact that you pass in the same parameters, or no parameters. Built-in functions such as RAND (without a seed value) and NEWID are nondeterministic because they return a different result every time they’re called. One hack that people sometimes use to try to circumvent this restriction is creating a view that invokes the nondeterministic function and selecting from that view inside their UDFs. Although this may work to some extent, it isn’t recommended: it could fail to produce the desired results or cause a significant performance hit, because SQL can’t cache or effectively index the results of nondeterministic functions. Also, if you create a computed column that tries to reference your UDF, the nondeterministic functions you’re trying to access via your view can produce unpredictable results. If you need to use nondeterministic functions in your application logic, SPs are probably the better alternative. Chapter 5 discusses SPs.
NONDETERMINISTIC FUNCTIONS IN A UDF
In previous versions of SQL, there were several restrictions on the use of nondeterministic system functions in UDFs. In SQL Server 2012, these restrictions were somewhat relaxed. You can use the nondeterministic system functions listed in the following table in your UDFs. One thing these system functions have in common is that they don’t cause side effects or change the database state when you use them:
|
@@CONNECTIONS |
@@PACK_RECEIVED |
@@TOTAL_WRITE |
|
@@CPU_BUSY |
@@PACK_SENT |
CURRENT_TIMESTAMP |
|
@@DBTS |
@@PACKET_ERRORS |
GET_TRANSMISSION_STATUS |
|
@@IDLE |
@@TIMETICKS |
GETDATE |
|
@@IO_BUSY |
@@TOTAL_ERRORS |
GETUTCDATE |
|
@@MAX_CONNECTIONS |
@@TOTAL_READ |
If you want to build an index on a view or computed column that uses a UDF, your UDF has to be deterministic. The requirements to make a UDF deterministic include the following:
- The UDF must be declared using the WITH SCHEMABINDING option. When a UDF is schema-bound, no changes are allowed to any tables or objects on which it’s dependent without dropping the UDF first.
- Any functions you refer to in your UDF must also be deterministic. This means if you use a nondeterministic system function—such as GETDATE—in your UDF, it’s marked nondeterministic.
- You can’t invoke extended stored procedures (XPs) in the function. This shouldn’t be a problem, because XPs are deprecated and will be removed from future versions of SQL Server.
If your UDF meets all these criteria, you can check to see if SQL Server has marked it deterministic via the OBJECTPROPERTY function, with a query like the following:
SELECT OBJECTPROPERTY (OBDECT_ID('dbo.GetCommaSplit'), 'IsDeterministic'),
The OBJECTPROPERTY function returns 0 if your UDF is nondeterministic and 1 if it’s deterministic.
State of the Database
One of the restrictions on UDFs is that they aren’t allowed to change the state of the database or cause other side effects. This prohibition on side effects in UDFs means you can’t even execute PRINT statements from within a UDF. It also means that although you can query database tables and resources, you can’t execute INSERT, UPDATE, MERGE, or DELETE statements against database tables. Some other restrictions include the following:
- You can’t create temporary tables within a UDF. You can, however, create and modify table variables in the body of a UDF.
- You can’t execute CREATE, ALTER, or DROP on database tables from within a UDF.
- Dynamic SQL isn’t allowed within a UDF, although XPs and SQLCLR functions can be called.
- A TVF can return only a single table/result set. If you need to return more than one table/result set, you may be better served by an SP.
MORE ON SIDE EFFECTS
Although XPs and SQL CLR functions can be called from a UDF, Microsoft warns against depending on results returned by XPs and SQL CLR functions that cause side effects. If your XP or SQL CLR function modifies tables, alters the database schema, accesses the file system, changes system settings, or utilizes non-deterministic resources external to the database, you may get unpredictable results from your UDF. If you need to change database state or rely on side effects in your server-side code, consider using an SQL CLR function or a regular SP instead of a UDF.
The prohibition on UDF side effects extends to the SQL Server display and error systems. This means you can’t use the T-SQL PRINT or RAISERROR statement in a UDF. The PRINT and RAISERROR statements are useful in debugging stored procedures and T-SQL code batches but are unavailable for use in UDFs. One workaround that I often use is to temporarily move the body of the UDF code to an SP while testing. This gives you the ability to use PRINT and RAISERROR while testing and debugging code in development environments.
Variables and table variables created in UDFs have a well-defined scope and can’t be accessed outside of the UDF. Even if you have a recursive UDF, you can’t access the variables and table variables that were previously declared and assigned values by the calling function. If you need values that were generated by a UDF, you must pass them in as parameters to another UDF call or return them to the caller in the UDF result.
Summary
This chapter discussed the three types of T-SQL UDFs and provided working examples of the different types. Scalar UDFs are analogous to mathematical functions that accept zero or more parameters and return a single scalar value for a result. You can use the standard SQL statements, as well as control-of-flow statements, in a scalar UDF. Multistatement TVFs allow control-of-flow statements as well but return a table-style result set to the caller. You can use the result set returned by a multistatement TVF in WHERE and JOIN clauses. Finally, inline TVFs also return table-style result sets to the caller; however, the body consists of a single SELECT query, much like an SQL view. In fact, inline TVFs are sometimes referred to as parameterized views.
The type of UDF that you need to accomplish a given task depends on the problem you’re trying to solve. For instance, if you need to calculate a single scalar value, a scalar UDF will do the job. On the other hand, if you need to perform complex calculations or manipulations and return a table, a multistatement TVF might be the correct choice.
You also learned about recursion in UDFs, including the 32-level recursion limit. Although 32 levels of recursion is the hard limit, for all practical purposes you should rarely—if ever—hit this limit. If you do need recursion beyond 32 levels, you can replace recursive function calls with CTEs and other T-SQL constructs.
Finally, the chapter talked about determinism and side effects in UDFs. Specifically, your UDFs should not cause side effects, and specific criteria must be met in order for SQL Server to mark your UDFs as deterministic. Determinism is an important aspect of UDFs if you plan to use them in indexed views or computed columns.
The next chapter looks at SPs—another tool that allows procedural T-SQL code to be consolidated into server-side units.
EXERCISES
- [Fill in the blank] SQL Server supports three types of T-SQL UDFs: _______, ________, and _________.
- [True/False] The RETURNS NULL ON NULL INPUT option is a performance-enhancing option available for use with scalar UDFs.
- [True/False] The ENCRYPTION option provides a secure option that prevents anyone from reverse-engineering your source code.
- [Choose all that apply] You aren’t allowed to do which of the following in a multistatement TVF?
- Execute a PRINT statement
- Call RAISERROR to generate an exception
- Declare a table variable
- Create a temporary table
- The algebraic formula for converting Fahrenheit measurements to the Celsius scale is: C=(F – 32.0) × (5/9), where F is the measurement in degrees Fahrenheit and C is the measurement in degrees Celsius.
Write a deterministic scalar UDF that converts a measurement in degrees Fahrenheit to degrees Celsius. The UDF should accept a single float parameter and return a float result. You can use the OBJECTPROPERTY function to ensure that the UDF is deterministic.
_______________
1Robert L. Taft, “Name Search Techniques,” Special Report (Albany, NY: Bureau of Systems Development, 1970).