
10
Discovering Inheritance Techniques
BUILDING CLASSES WITH INHERITANCE
In Chapter 5, you learned that an “is-a” relationship recognizes the pattern that real-world objects tend to exist in hierarchies. In programming, that pattern becomes relevant when you need to write a class that builds on, or slightly changes, another class. One way to accomplish this aim is to copy code from one class and paste it into the other. By changing the relevant parts or amending the code, you can achieve the goal of creating a new class that is slightly different from the original. This approach, however, leaves an OOP programmer feeling sullen and highly annoyed for the following reasons:
- A bug fix to the original class will not be reflected in the new class because the two classes contain completely separate code.
- The compiler does not know about any relationship between the two classes, so they are not polymorphic (see Chapter 5)—they are not just different variations on the same thing.
- This approach does not build a true is-a relationship. The new class is very similar to the original because it shares code, not because it really is the same type of object.
- The original code might not be obtainable. It may exist only in a precompiled binary format, so copying and pasting the code might be impossible.
Not surprisingly, C++ provides built-in support for defining a true is-a relationship. The characteristics of C++ is-a relationships are described in the following section.
Extending Classes
When you write a class definition in C++, you can tell the compiler that your class is inheriting from, deriving from, or extending an existing class. By doing so, your class automatically contains the data members and methods of the original class, which is called the parent class or base class or superclass. Extending an existing class gives your class (which is now called a derived class or a subclass) the ability to describe only the ways in which it is different from the parent class.
To extend a class in C++, you specify the class you are extending when you write the class definition. To show the syntax for inheritance, two classes are used, called Base and Derived. Don’t worry—more interesting examples are coming later. To begin, consider the following definition for the Base class:
class Base{public:void someMethod();protected:int mProtectedInt;private:int mPrivateInt;};
If you want to build a new class, called Derived, which inherits from Base, you tell the compiler that Derived derives from Base with the following syntax:
class Derived : public Base{public:void someOtherMethod();};
Derived is a full-fledged class that just happens to share the characteristics of the Base class. Don’t worry about the word public for now—its meaning is explained later in this chapter. Figure 10-1 shows the simple relationship between Derived and Base. You can declare objects of type Derived just like any other object. You could even define a third class that inherits from Derived, forming a chain of classes, as shown in Figure 10-2.


Derived doesn’t have to be the only derived class of Base. Additional classes can also inherit from Base, effectively becoming siblings to Derived, as shown in Figure 10-3.

A Client’s View of Inheritance
To a client, or another part of your code, an object of type Derived is also an object of type Base because Derived inherits from Base. This means that all the public methods and data members of Base and all the public methods and data members of Derived are available.
Code that uses the derived class does not need to know which class in your inheritance chain has defined a method in order to call it. For example, the following code calls two methods of a Derived object even though one of the methods is defined by the Base class:
Derived myDerived;myDerived.someMethod();myDerived.someOtherMethod();
It is important to understand that inheritance works in only one direction. The Derived class has a very clearly defined relationship to the Base class, but the Base class, as written, doesn’t know anything about the Derived class. That means that objects of type Base do not support public methods and data members of Derived because Base is not a Derived.
The following code does not compile because the Base class does not contain a public method called someOtherMethod():
Base myBase;myBase.someOtherMethod(); // Error! Base doesn't have a someOtherMethod().
A pointer or reference to an object can refer to an object of the declared class or any of its derived classes. This tricky subject is explained in detail later in this chapter. The concept to understand now is that a pointer to a Base can actually be pointing to a Derived object. The same is true for a reference. The client can still access only the methods and data members that exist in Base, but through this mechanism, any code that operates on a Base can also operate on a Derived.
For example, the following code compiles and works just fine, even though it initially appears that there is a type mismatch:
Base* base = new Derived(); // Create Derived, store it in Base pointer.
However, you cannot call methods from the Derived class through the Base pointer. The following does not work:
base->someOtherMethod();
This is flagged as an error by the compiler because, although the object is of type Derived and therefore does have someOtherMethod() defined, the compiler can only think of it as type Base, which does not have someOtherMethod() defined.
A Derived Class’s View of Inheritance
To the derived class, nothing much has changed in terms of how it is written or how it behaves. You can still define methods and data members on a derived class just as you would on a regular class. The previous definition of Derived declares a method called someOtherMethod(). Thus, the Derived class augments the Base class by adding an additional method.
A derived class can access public and protected methods and data members declared in its base class as though they were its own, because technically, they are. For example, the implementation of someOtherMethod() on Derived could make use of the data member mProtectedInt, which is declared as part of Base. The following code shows this. Accessing a base class data member or method is no different than if the data member or method were declared as part of the derived class.
void Derived::someOtherMethod(){cout << "I can access base class data member mProtectedInt." << endl;cout << "Its value is " << mProtectedInt << endl;}
When access specifiers (public, private, and protected) were introduced in Chapter 8, the difference between private and protected may have been confusing. Now that you understand derived classes, the difference should be clear. If a class declares methods or data members as protected, derived classes have access to them. If they are declared as private, derived classes do not have access. The following implementation of someOtherMethod() does not compile because the derived class attempts to access a private data member from the base class.
void Derived::someOtherMethod(){cout << "I can access base class data member mProtectedInt." << endl;cout << "Its value is " << mProtectedInt << endl;cout << "The value of mPrivateInt is " << mPrivateInt << endl;// Error!}
The private access specifier gives you control over how a potential derived class could interact with your class. I recommend that you make all your data members private by default. You can provide public getters and setters if you want to allow anyone to access those data members, and you can provide protected getters and setters if you want only derived classes to access them. The reason to make data members private by default is that this provides the highest level of encapsulation. This means that you can change how you represent your data while keeping the public and protected interfaces unchanged. Without giving direct access to data members, you can also easily add checks on the input data in your public and protected setters. Methods should also be private by default. Only make those methods public that are designed to be public, and make methods protected if you want only derived classes to have access to them.
Preventing Inheritance
C++ allows you to mark a class as final, which means trying to inherit from it will result in a compilation error. A class can be marked as final with the final keyword right behind the name of the class. For example, the following Base class is marked as final:
class Base final{// Omitted for brevity};
If a class tries to inherit from this Base class, the compiler will complain because Base is marked as final.
class Derived : public Base{// Omitted for brevity};
Overriding Methods
The main reasons to inherit from a class are to add or replace functionality. The definition of Derived adds functionality to its parent class by providing an additional method, someOtherMethod(). The other method, someMethod(), is inherited from Base and behaves in the derived class exactly as it does in the base class. In many cases, you will want to modify the behavior of a class by replacing, or overriding, a method.
How I Learned to Stop Worrying and Make Everything virtual
There is one small twist to overriding methods in C++ and it has to do with the keyword virtual. Only methods that are declared as virtual in the base class can be overridden properly by derived classes. The keyword goes at the beginning of a method declaration as shown in the modified version of Base that follows:
class Base{public:virtual void someMethod();protected:int mProtectedInt;private:int mPrivateInt;};
The virtual keyword has a few subtleties. A good rule of thumb is to just make all of your methods virtual. That way, you won’t have to worry about whether or not overriding the method will work. The only drawback is a very tiny performance hit. The subtleties of the virtual keyword are covered in the section “The Truth about virtual.”
The same holds for the Derived class. Its methods should also be marked virtual:
class Derived : public Base{public:virtual void someOtherMethod();};
Syntax for Overriding a Method
To override a method, you redeclare it in the derived class definition exactly as it was declared in the base class, and you add the override keyword. In the derived class’s implementation file, you provide the new definition.
For example, the Base class contains a method called someMethod(). The definition of someMethod() is provided in Base.cpp and is shown here:
void Base::someMethod(){cout << "This is Base's version of someMethod()." << endl;}
Note that you do not repeat the virtual keyword in front of the method definition.
If you want to provide a new definition for someMethod() in the Derived class, you must first add it to the class definition for Derived, as follows:
class Derived : public Base{public:virtual void someMethod() override;// Overrides Base's someMethod()virtual void someOtherMethod();};
Adding the override keyword is not mandatory, but it is highly recommended, and discussed in more detail in the section after looking at the client’s view of overridden methods. The new definition of someMethod() is specified along with the rest of Derived’s methods in Derived.cpp.
void Derived::someMethod(){cout << "This is Derived's version of someMethod()." << endl;}
Once a method or destructor is marked as virtual, it is virtual for all derived classes even if the virtual keyword is removed from derived classes. For example, in the following Derived class, someMethod() is still virtual and can still be overridden by classes inheriting from Derived, because it was marked as virtual in the Base class.
class Derived : public Base{public:void someMethod() override;// Overrides Base's someMethod()};
A Client’s View of Overridden Methods
With the preceding changes, other code still calls someMethod() the same way it did before. Just as before, the method could be called on an object of class Base or an object of class Derived. Now, however, the behavior of someMethod() varies based on the class of the object.
For example, the following code works just as it did before, calling Base’s version of someMethod():
Base myBase;myBase.someMethod(); // Calls Base's version of someMethod().
The output of this code is as follows:
This is Base's version of someMethod().
If the code declares an object of class Derived, the other version is automatically called:
Derived myDerived;myDerived.someMethod(); // Calls Derived's version of someMethod()
The output this time is as follows:
This is Derived's version of someMethod().
Everything else about objects of class Derived remains the same. Other methods that might have been inherited from Base still have the definition provided by Base unless they are explicitly overridden in Derived.
As you learned earlier, a pointer or reference can refer to an object of a class or any of its derived classes. The object itself “knows” the class of which it is actually a member, so the appropriate method is called as long as it was declared virtual. For example, if you have a Base reference that refers to an object that is really a Derived, calling someMethod() actually calls the derived class’s version, as shown next. This aspect of overriding does not work properly if you omit the virtual keyword in the base class.
Derived myDerived;Base& ref = myDerived;ref.someMethod(); // Calls Derived's version of someMethod()
Remember that even though a base class reference or pointer knows that it is actually a derived class, you cannot access derived class methods or members that are not defined in the base class. The following code does not compile because a Base reference does not have a method called someOtherMethod():
Derived myDerived;Base& ref = myDerived;myDerived.someOtherMethod(); // This is fine.ref.someOtherMethod(); // Error
The derived class knowledge characteristic is not true for non-pointer or non-reference objects. You can cast or assign a Derived to a Base because a Derived is a Base. However, the object loses any knowledge of the derived class at that point.
Derived myDerived;Base assignedObject = myDerived; // Assigns a Derived to a Base.assignedObject.someMethod(); // Calls Base's version of someMethod()
One way to remember this seemingly strange behavior is to imagine what the objects look like in memory. Picture a Base object as a box taking up a certain amount of memory. A Derived object is a box that is slightly bigger because it has everything a Base has plus a bit more. When you have a reference or pointer to a Derived, the box doesn’t change—you just have a new way of accessing it. However, when you cast a Derived into a Base, you are throwing out all the “uniqueness” of the Derived class to fit it into a smaller box.
The override Keyword
Sometimes, it is possible to accidentally create a new virtual method instead of overriding a method from the base class. Take the following Base and Derived classes where Derived is properly overriding someMethod(), but is not using the override keyword:
class Base{public:virtual void someMethod(double d);};class Derived : public Base{public:virtual void someMethod(double d);};
You can call someMethod() through a reference as follows:
Derived myDerived;Base& ref = myDerived;ref.someMethod(1.1); // Calls Derived's version of someMethod()
This correctly calls the overridden someMethod() from the Derived class. Now, suppose you accidentally use an integer parameter instead of a double while overriding someMethod(), as follows:
class Derived : public Base{public:virtual void someMethod(int i);};
This code does not override someMethod() from Base, but instead creates a new virtual method. If you try to call someMethod() through a reference as in the following code, someMethod() of Base is called instead of the one from Derived!
Derived myDerived;Base& ref = myDerived;ref.someMethod(1.1); // Calls Base's version of someMethod()
This type of problem can happen when you start to modify the Base class but forget to update all derived classes. For example, maybe your first version of the Base class has a method called someMethod() accepting an integer. You then write the Derived class overriding this someMethod() accepting an integer. Later you decide that someMethod() in Base needs a double instead of an integer, so you update someMethod() in the Base class. It might happen that at that time, you forget to update the someMethod() methods in derived classes to also accept a double instead of an integer. By forgetting this, you are now actually creating a new virtual method instead of properly overriding the method.
You can prevent this situation by using the override keyword as follows:
class Derived : public Base{public:virtual void someMethod(int i) override;};
This definition of Derived generates a compilation error, because with the override keyword you are saying that someMethod() is supposed to be overriding a method from a base class, but in the Base class there is no someMethod() accepting an integer, only one accepting a double.
The problem of accidentally creating a new method instead of properly overriding one can also happen when you rename a method in the base class, and forget to rename the overriding methods in derived classes.
The Truth about virtual
If a method is not virtual, you can still attempt to override it, but it will be wrong in subtle ways.
Hiding Instead of Overriding
The following code shows a base class and a derived class, each with a single method. The derived class is attempting to override the method in the base class, but it is not declared to be virtual in the base class:
class Base{public:void go() { cout << "go() called on Base" << endl; }};class Derived : public Base{public:void go() { cout << "go() called on Derived" << endl; }};
Attempting to call go() on a Derived object initially appears to work:
Derived myDerived;myDerived.go();
The output of this call is, as expected, “go() called on Derived”. However, because the method is not virtual, it is not actually overridden. Rather, the Derived class creates a new method, also called go(), that is completely unrelated to the Base class’s method called go(). To prove this, simply call the method in the context of a Base pointer or reference:
Derived myDerived;Base& ref = myDerived;ref.go();
You would expect the output to be “go() called on Derived”, but in fact, the output is “go() called on Base”. This is because the ref variable is a Base reference and because the virtual keyword was omitted. When the go() method is called, it simply executes Base’s go() method. Because it is not virtual, there is no need to consider whether a derived class has overridden it.
How virtual Is Implemented
To understand how method hiding is avoided, you need to know a bit more about what the virtual keyword actually does. When a class is compiled in C++, a binary object is created that contains all methods for the class. In the non-virtual case, the code to transfer control to the appropriate method is hard-coded directly where the method is called based on the compile-time type. This is called static binding, also known as early binding.
If the method is declared virtual, the correct implementation is called through the use of a special area of memory called the vtable, or “virtual table.” Each class that has one or more virtual methods, has a vtable, and every object of such a class contains a pointer to said vtable. This vtable contains pointers to the implementations of the virtual methods. In this way, when a method is called on an object, the pointer is followed into the vtable and the appropriate version of the method is executed based on the actual type of the object at run time. This is called dynamic binding, also known as late binding.
To better understand how vtables make overriding of methods possible, take the following Base and Derived classes as an example:
class Base{public:virtual void func1() {}virtual void func2() {}void nonVirtualFunc() {}};class Derived : public Base{public:virtual void func2() override {}void nonVirtualFunc() {}};
For this example, assume that you have the following two instances:
Base myBase;Derived myDerived;
Figure 10-4 shows a high-level view of how the vtables for both instances look. The myBase object contains a pointer to its vtable. This vtable has two entries, one for func1() and one for func2(). Those entries point to the implementations of Base::func1() and Base::func2().

myDerived also contains a pointer to its vtable, which also has two entries, one for func1() and one for func2(). Its func1() entry points to Base::func1() because Derived does not override func1(). On the other hand, its func2() entry points to Derived::func2().
Note that both vtables do not contain any entry for the nonVirtualFunc() method because that method is not virtual.
The Justification for virtual
Because you are advised to make all methods virtual, you might be wondering why the virtual keyword even exists. Can’t the compiler automatically make all methods virtual? The answer is yes, it could. Many people think that the language should just make everything virtual. The Java language effectively does this.
The argument against making everything virtual, and the reason that the keyword was created in the first place, has to do with the overhead of the vtable. To call a virtual method, the program needs to perform an extra operation by dereferencing the pointer to the appropriate code to execute. This is a miniscule performance hit in most cases, but the designers of C++ thought that it was better, at least at the time, to let the programmer decide if the performance hit was necessary. If the method was never going to be overridden, there was no need to make it virtual and take the performance hit. However, with today’s CPUs, the performance hit is measured in fractions of a nanosecond and this will keep getting smaller with future CPUs. In most applications, you will not have a measurable performance difference between using virtual methods and avoiding them, so you should still follow the advice of making all methods, especially destructors, virtual.
Still, in certain cases, the performance overhead might be too costly, and you may need to have an option to avoid the hit. For example, suppose you have a Point class that has a virtual method. If you have another data structure that stores millions or even billions of Points, calling a virtual method on each point creates a significant overhead. In that case, it’s probably wise to avoid any virtual methods in your Point class.
There is also a tiny hit to memory usage for each object. In addition to the implementation of the method, each object also needs a pointer for its vtable, which takes up a tiny amount of space. This is not an issue in the majority of cases. However, sometimes it does matter. Take again the Point class and the container storing billions of Points. In that case, the additional required memory becomes significant.
The Need for virtual Destructors
Even programmers who don’t adopt the guideline of making all methods virtual still adhere to the rule when it comes to destructors. This is because making your destructors non-virtual can easily result in situations in which memory is not freed by object destruction. Only for a class that is marked as final you could make its destructor non-virtual.
For example, if a derived class uses memory that is dynamically allocated in the constructor and deleted in the destructor, it will never be freed if the destructor is never called. Similarly, if your derived class has members that are automatically deleted when an instance of the class is destroyed, such as std::unique_ptrs, then those members will not get deleted either if the destructor is never called.
As the following code shows, it is easy to “trick” the compiler into skipping the call to the destructor if it is non-virtual:
class Base{public:Base() {}~Base() {}};class Derived : public Base{public:Derived(){mString = new char[30];cout << "mString allocated" << endl;}~Derived(){delete[] mString;cout << "mString deallocated" << endl;}private:char* mString;};int main(){Base* ptr = new Derived(); // mString is allocated here.delete ptr; // ~Base is called, but not ~Derived because the destructor// is not virtual!return 0;}
As you can see from the output, the destructor of the Derived object is never called:
mString allocated
Actually, the behavior of the delete call in the preceding code is undefined by the standard. A C++ compiler could do whatever it wants in such undefined situations. However, most compilers simply call the destructor of the base class, and not the destructor of the derived class.
Note that since C++11, the generation of a copy constructor and copy assignment operator is deprecated if the class has a user-declared destructor, as mentioned in Chapter 8. If you still need a compiler-generated copy constructor or copy assignment operator in such cases, you can explicitly default them. This is not done in the examples in this chapter in the interest of keeping them concise and to the point.
Preventing Overriding
C++ allows you to mark a method as final, which means that the method cannot be overridden in a derived class. Trying to override a final method results in a compilation error. Take the following Base class:
class Base{public:virtual ~Base() = default;virtual void someMethod() final;};
Trying to override someMethod(), as in the following Derived class, results in a compilation error because someMethod() is marked as final in the Base class:
class Derived : public Base{public:virtual void someMethod() override; // Error};
INHERITANCE FOR REUSE
Now that you are familiar with the basic syntax for inheritance, it’s time to explore one of the main reasons that inheritance is an important feature of the C++ language. Inheritance is a vehicle that allows you to leverage existing code. This section presents an example of inheritance for the purpose of code reuse.
The WeatherPrediction Class
Imagine that you are given the task of writing a program to issue simple weather predictions, working with both Fahrenheit and Celsius. Weather predictions may be a little bit out of your area of expertise as a programmer, so you obtain a third-party class library that was written to make weather predictions based on the current temperature and the current distance between Jupiter and Mars (hey, it’s plausible). This third-party package is distributed as a compiled library to protect the intellectual property of the prediction algorithms, but you do get to see the class definition. The WeatherPrediction class definition is as follows:
// Predicts the weather using proven new-age techniques given the current// temperature and the distance from Jupiter to Mars. If these values are// not provided, a guess is still given but it's only 99% accurate.class WeatherPrediction{public:// Virtual destructorvirtual ~WeatherPrediction();// Sets the current temperature in Fahrenheitvirtual void setCurrentTempFahrenheit(int temp);// Sets the current distance between Jupiter and Marsvirtual void setPositionOfJupiter(int distanceFromMars);// Gets the prediction for tomorrow's temperaturevirtual int getTomorrowTempFahrenheit() const;// Gets the probability of rain tomorrow. 1 means// definite rain. 0 means no chance of rain.virtual double getChanceOfRain() const;// Displays the result to the user in this format:// Result: x.xx chance. Temp. xxvirtual void showResult() const;// Returns a string representation of the temperaturevirtual std::string getTemperature() const;private:int mCurrentTempFahrenheit;int mDistanceFromMars;};
Note that this class marks all methods as virtual, because the class presumes that its methods might be overridden in a derived class.
This class solves most of the problems for your program. However, as is usually the case, it’s not exactly right for your needs. First, all the temperatures are given in Fahrenheit. Your program needs to operate in Celsius as well. Also, the showResult() method might not display the result in a way you require.
Adding Functionality in a Derived Class
When you learned about inheritance in Chapter 5, adding functionality was the first technique described. Fundamentally, your program needs something just like the WeatherPrediction class but with a few extra bells and whistles. Sounds like a good case for inheritance to reuse code. To begin, define a new class, MyWeatherPrediction, that inherits from WeatherPrediction.
#include "WeatherPrediction.h"class MyWeatherPrediction : public WeatherPrediction{};
The preceding class definition compiles just fine. The MyWeatherPrediction class can already be used in place of WeatherPrediction. It provides exactly the same functionality, but nothing new yet. For the first modification, you might want to add knowledge of the Celsius scale to the class. There is a bit of a quandary here because you don’t know what the class is doing internally. If all of the internal calculations are made using Fahrenheit, how do you add support for Celsius? One way is to use the derived class to act as a go-between, interfacing between the user, who can use either scale, and the base class, which only understands Fahrenheit.
The first step in supporting Celsius is to add new methods that allow clients to set the current temperature in Celsius instead of Fahrenheit and to get tomorrow’s prediction in Celsius instead of Fahrenheit. You also need private helper methods that convert between Celsius and Fahrenheit in both directions. These methods can be static because they are the same for all instances of the class.
#include "WeatherPrediction.h"class MyWeatherPrediction : public WeatherPrediction{public:virtual void setCurrentTempCelsius(int temp);virtual int getTomorrowTempCelsius() const;private:static int convertCelsiusToFahrenheit(int celsius);static int convertFahrenheitToCelsius(int fahrenheit);};
The new methods follow the same naming convention as the parent class. Remember that from the point of view of other code, a MyWeatherPrediction object has all of the functionality defined in both MyWeatherPrediction and WeatherPrediction. Adopting the parent class’s naming convention presents a consistent interface.
The implementation of the Celsius/Fahrenheit conversion methods is left as an exercise for the reader—and a fun one at that! The other two methods are more interesting. To set the current temperature in Celsius, you need to convert the temperature first and then present it to the parent class in units that it understands.
void MyWeatherPrediction::setCurrentTempCelsius(int temp){int fahrenheitTemp = convertCelsiusToFahrenheit(temp);setCurrentTempFahrenheit(fahrenheitTemp);}
As you can see, once the temperature is converted, the method calls the existing functionality from the base class. Similarly, the implementation of getTomorrowTempCelsius() uses the parent’s existing functionality to get the temperature in Fahrenheit, but converts the result before returning it.
int MyWeatherPrediction::getTomorrowTempCelsius() const{int fahrenheitTemp = getTomorrowTempFahrenheit();return convertFahrenheitToCelsius(fahrenheitTemp);}
The two new methods effectively reuse the parent class because they “wrap” the existing functionality in a way that provides a new interface for using it.
You can also add new functionality completely unrelated to existing functionality of the parent class. For example, you could add a method that retrieves alternative forecasts from the Internet or a method that suggests an activity based on the predicted weather.
Replacing Functionality in a Derived Class
The other major technique for inheritance is replacing existing functionality. The showResult() method in the WeatherPrediction class is in dire need of a facelift. MyWeatherPrediction can override this method to replace the behavior with its own implementation.
The new class definition for MyWeatherPrediction is as follows:
class MyWeatherPrediction : public WeatherPrediction{public:virtual void setCurrentTempCelsius(int temp);virtual int getTomorrowTempCelsius() const;virtual void showResult() const override;private:static int convertCelsiusToFahrenheit(int celsius);static int convertFahrenheitToCelsius(int fahrenheit);};
Here is a possible new user-friendly implementation:
void MyWeatherPrediction::showResult() const{cout << "Tomorrow's temperature will be " <<getTomorrowTempCelsius() << " degrees Celsius (" <<getTomorrowTempFahrenheit() << " degrees Fahrenheit)" << endl;cout << "Chance of rain is " << (getChanceOfRain() * 100) << " percent"<< endl;if (getChanceOfRain() > 0.5) {cout << "Bring an umbrella!" << endl;}}
To clients using this class, it’s as if the old version of showResult() never existed. As long as the object is a MyWeatherPrediction object, the new version is called.
As a result of these changes, MyWeatherPrediction has emerged as a new class with new functionality tailored to a more specific purpose. Yet, it did not require much code because it leveraged its base class’s existing functionality.
RESPECT YOUR PARENTS
When you write a derived class, you need to be aware of the interaction between parent classes and child classes. Issues such as order of creation, constructor chaining, and casting are all potential sources of bugs.
Parent Constructors
Objects don’t spring to life all at once; they must be constructed along with their parents and any objects that are contained within them. C++ defines the creation order as follows:
- If the class has a base class, the default constructor of the base class is executed, unless there is a call to a base class constructor in the ctor-initializer, in which case that constructor is called instead of the default constructor.
- Non-
staticdata members of the class are constructed in the order in which they are declared. - The body of the class’s constructor is executed.
These rules can apply recursively. If the class has a grandparent, the grandparent is initialized before the parent, and so on. The following code shows this creation order. As a reminder, I generally advise against implementing methods directly in a class definition, as is done in the code that follows. In the interest of readable and concise examples, I have broken my own rule. The proper execution of this code outputs 123.
class Something{public:Something() { cout << "2"; }};class Base{public:Base() { cout << "1"; }};class Derived : public Base{public:Derived() { cout << "3"; }private:Something mDataMember;};int main(){Derived myDerived;return 0;}
When the myDerived object is created, the constructor for Base is called first, outputting the string "1". Next, mDataMember is initialized, calling the Something constructor, which outputs the string "2". Finally, the Derived constructor is called, which outputs "3".
Note that the Base constructor was called automatically. C++ automatically calls the default constructor for the parent class if one exists. If no default constructor exists in the parent class, or if one does exist but you want to use an alternate constructor, you can chain the constructor just as when initializing data members in the constructor initializer. For example, the following code shows a version of Base that lacks a default constructor. The associated version of Derived must explicitly tell the compiler how to call the Base constructor or the code will not compile.
class Base{public:Base(int i);};class Derived : public Base{public:Derived();};Derived::Derived() : Base(7){// Do Derived's other initialization here.}
The Derived constructor passes a fixed value (7) to the Base constructor. Derived could also pass a variable if its constructor required an argument:
Derived::Derived(int i) : Base(i) {}
Passing constructor arguments from the derived class to the base class is perfectly fine and quite normal. Passing data members, however, will not work. The code will compile, but remember that data members are not initialized until after the base class is constructed. If you pass a data member as an argument to the parent constructor, it will be uninitialized.
Parent Destructors
Because destructors cannot take arguments, the language can always automatically call the destructor for parent classes. The order of destruction is conveniently the reverse of the order of construction:
- The body of the class’s destructor is called.
- Any data members of the class are destroyed in the reverse order of their construction.
- The parent class, if any, is destructed.
Again, these rules apply recursively. The lowest member of the chain is always destructed first. The following code adds destructors to the previous example. The destructors are all declared virtual! If executed, this code outputs "123321".
class Something{public:Something() { cout << "2"; }virtual ~Something() { cout << "2"; }};class Base{public:Base() { cout << "1"; }virtual ~Base() { cout << "1"; }};class Derived : public Base{public:Derived() { cout << "3"; }virtual ~Derived() { cout << "3"; }private:Something mDataMember;};
If the preceding destructors were not declared virtual, the code would continue to work fine. However, if code ever called delete on a base class pointer that was really pointing to a derived class, the destruction chain would begin in the wrong place. For example, if you remove the virtual keyword from all destructors in the previous code, then a problem arises when a Derived object is accessed as a pointer to a Base and deleted, as shown here:
Base* ptr = new Derived();delete ptr;
The output of this code is a shockingly terse "1231". When the ptr variable is deleted, only the Base destructor is called because the destructor was not declared virtual. As a result, the Derived destructor is not called and the destructors for its data members are not called!
Technically, you could fix the preceding problem by marking only the Base destructor virtual. The “virtualness” is automatically used by any children. However, I advocate explicitly making all destructors virtual so that you never have to worry about it.
Referring to Parent Names
When you override a method in a derived class, you are effectively replacing the original as far as other code is concerned. However, that parent version of the method still exists and you may want to make use of it. For example, an overridden method would like to keep doing what the base class implementation does, plus something else. Take a look at the getTemperature() method in the WeatherPrediction class that returns a string representation of the current temperature:
class WeatherPrediction{public:virtual std::string getTemperature() const;// Omitted for brevity};
You can override this method in the MyWeatherPrediction class as follows:
class MyWeatherPrediction : public WeatherPrediction{public:virtual std::string getTemperature() const override;// Omitted for brevity};
Suppose the derived class wants to add °F to the string by first calling the base class getTemperature() method and then adding °F to the string. You might write this as follows:
string MyWeatherPrediction::getTemperature() const{// Note: u00B0 is the ISO/IEC 10646 representation of the degree symbol.return getTemperature() + "u00B0F"; // BUG}
However, this does not work because, under the rules of name resolution for C++, it first resolves against the local scope, then the class scope, and as a consequence ends up calling MyWeatherPrediction::getTemperature(). This results in an infinite recursion until you run out of stack space (some compilers detect this error and report it at compile time).
To make this work, you need to use the scope resolution operator as follows:
string MyWeatherPrediction::getTemperature() const{// Note: u00B0 is the ISO/IEC 10646 representation of the degree symbol.return WeatherPrediction::getTemperature() + "u00B0F";}
Calling the parent version of the current method is a commonly used pattern in C++. If you have a chain of derived classes, each might want to perform the operation already defined by the base class but add their own additional functionality as well.
As another example, imagine a class hierarchy of book types. A diagram showing such a hierarchy is shown in Figure 10-5.

Because each lower class in the hierarchy further specifies the type of book, a method that gets the description of a book really needs to take all levels of the hierarchy into consideration. This can be accomplished by chaining to the parent method. The following code illustrates this pattern:
class Book{public:virtual ~Book() = default;virtual string getDescription() const { return "Book"; }virtual int getHeight() const { return 120; }};class Paperback : public Book{public:virtual string getDescription() const override {return "Paperback " + Book::getDescription();}};class Romance : public Paperback{public:virtual string getDescription() const override {return "Romance " + Paperback::getDescription();}virtual int getHeight() const override {return Paperback::getHeight() / 2; }};class Technical : public Book{public:virtual string getDescription() const override {return "Technical " + Book::getDescription();}};int main(){Romance novel;Book book;cout << novel.getDescription() << endl; // Outputs "Romance Paperback Book"cout << book.getDescription() << endl; // Outputs "Book"cout << novel.getHeight() << endl; // Outputs "60"cout << book.getHeight() << endl; // Outputs "120"return 0;}
The Book base class has two virtual methods: getDescription() and getHeight(). All derived classes override getDescription(), but only the Romance class overrides getHeight() by calling getHeight() on its parent class (Paperback) and dividing the result by two. Paperback does not override getHeight(), but C++ walks up the class hierarchy to find a class that implements getHeight(). In this example, Paperback::getHeight() resolves to Book::getHeight().
Casting Up and Down
As you have already seen, an object can be cast or assigned to its parent class. If the cast or assignment is performed on a plain old object, this results in slicing:
Base myBase = myDerived; // Slicing!
Slicing occurs in situations like this because the end result is a Base object, and Base objects lack the additional functionality defined in the Derived class. However, slicing does not occur if a derived class is assigned to a pointer or reference to its base class:
Base& myBase = myDerived; // No slicing!
This is generally the correct way to refer to a derived class in terms of its base class, also called upcasting. This is why it’s always a good idea to make your methods and functions take references to classes instead of directly using objects of those classes. By using references, derived classes can be passed in without slicing.
Casting from a base class to one of its derived classes, also called downcasting, is often frowned upon by professional C++ programmers because there is no guarantee that the object really belongs to that derived class, and because downcasting is a sign of bad design. For example, consider the following code:
void presumptuous(Base* base){Derived* myDerived = static_cast<Derived*>(base);// Proceed to access Derived methods on myDerived.}
If the author of presumptuous() also writes code that calls presumptuous(), everything will probably be okay because the author knows that the function expects the argument to be of type Derived*. However, if other programmers call presumptuous(), they might pass in a Base*. There are no compile-time checks that can be done to enforce the type of the argument, and the function blindly assumes that base is actually a pointer to a Derived.
Downcasting is sometimes necessary, and you can use it effectively in controlled circumstances. However, if you are going to downcast, you should use a dynamic_cast(), which uses the object’s built-in knowledge of its type to refuse a cast that doesn’t make sense. This built-in knowledge typically resides in the vtable, which means that dynamic_cast() works only for objects with a vtable, that is, objects with at least one virtual member. If a dynamic_cast() fails on a pointer, the pointer’s value will be nullptr instead of pointing to nonsensical data. If a dynamic_cast() fails on an object reference, an std::bad_cast exception will be thrown. Chapter 11 discusses the different options for casting in more detail.
The previous example could have been written as follows:
void lessPresumptuous(Base* base){Derived* myDerived = dynamic_cast<Derived*>(base);if (myDerived != nullptr) {// Proceed to access Derived methods on myDerived.}}
The use of downcasting is often a sign of a bad design. You should rethink and modify your design so that downcasting can be avoided. For example, the lessPresumptuous() function only really works with Derived objects, so instead of accepting a Base pointer, it should simply accept a Derived pointer. This eliminates the need for any downcasting. If the function should work with different derived classes, all inheriting from Base, then look for a solution that uses polymorphism, which is discussed next.
INHERITANCE FOR POLYMORPHISM
Now that you understand the relationship between a derived class and its parent, you can use inheritance in its most powerful scenario—polymorphism. Chapter 5 discusses how polymorphism allows you to use objects with a common parent class interchangeably, and to use objects in place of their parents.
Return of the Spreadsheet
Chapters 8 and 9 use a spreadsheet program as an example of an application that lends itself to an object-oriented design. A SpreadsheetCell represents a single element of data. Up to now, that element always stored a single double value. A simplified class definition for SpreadsheetCell follows. Note that a cell can be set either as a double or a string, but it is always stored as a double. The current value of the cell, however, is always returned as a string for this example.
class SpreadsheetCell{public:virtual void set(double inDouble);virtual void set(std::string_view inString);virtual std::string getString() const;private:static std::string doubleToString(double inValue);static double stringToDouble(std::string_view inString);double mValue;};
In a real spreadsheet application, cells can store different things. A cell could store a double, but it might just as well store a piece of text. There could also be a need for additional types of cells, such as a formula cell, or a date cell. How can you support this?
Designing the Polymorphic Spreadsheet Cell
The SpreadsheetCell class is screaming out for a hierarchical makeover. A reasonable approach would be to narrow the scope of the SpreadsheetCell to cover only strings, perhaps renaming it StringSpreadsheetCell in the process. To handle doubles, a second class, DoubleSpreadsheetCell, would inherit from the StringSpreadsheetCell and provide functionality specific to its own format. Figure 10-6 illustrates such a design. This approach models inheritance for reuse because the DoubleSpreadsheetCell would only be deriving from StringSpreadsheetCell to make use of some of its built-in functionality.

If you were to implement the design shown in Figure 10-6, you might discover that the derived class would override most, if not all, of the functionality of the base class. Because doubles are treated differently from strings in almost all cases, the relationship may not be quite as it was originally understood. Yet, there clearly is a relationship between a cell containing strings and a cell containing doubles. Rather than using the model in Figure 10-6, which implies that somehow a DoubleSpreadsheetCell “is-a” StringSpreadsheetCell, a better design would make these classes peers with a common parent, SpreadsheetCell. Such a design is shown in Figure 10-7.
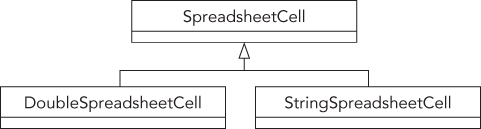
The design in Figure 10-7 shows a polymorphic approach to the SpreadsheetCell hierarchy. Because DoubleSpreadsheetCell and StringSpreadsheetCell both inherit from a common parent, SpreadsheetCell, they are interchangeable in the view of other code. In practical terms, that means the following:
- Both derived classes support the same interface (set of methods) defined by the base class.
- Code that makes use of
SpreadsheetCellobjects can call any method in the interface without even knowing whether the cell is aDoubleSpreadsheetCellor aStringSpreadsheetCell. - Through the magic of
virtualmethods, the appropriate instance of every method in the interface is called depending on the class of the object. - Other data structures, such as the
Spreadsheetclass described in Chapter 9, can contain a collection of multi-typed cells by referring to the parent type.
The SpreadsheetCell Base Class
Because all spreadsheet cells are deriving from the SpreadsheetCell base class, it is probably a good idea to write that class first. When designing a base class, you need to consider how the derived classes relate to each other. From this information, you can derive the commonality that will go inside the parent class. For example, string cells and double cells are similar in that they both contain a single piece of data. Because the data is coming from the user and will be displayed back to the user, the value is set as a string and retrieved as a string. These behaviors are the shared functionality that will make up the base class.
A First Attempt
The SpreadsheetCell base class is responsible for defining the behaviors that all SpreadsheetCell-derived classes will support. In this example, all cells need to be able to set their value as a string. All cells also need to be able to return their current value as a string. The base class definition declares these methods, as well as an explicitly defaulted virtual destructor, but note that it has no data members:
class SpreadsheetCell{public:virtual ~SpreadsheetCell() = default;virtual void set(std::string_view inString);virtual std::string getString() const;};
When you start writing the .cpp file for this class, you very quickly run into a problem. Considering that the base class of the spreadsheet cell contains neither a double nor a string data member, how can you implement it? More generally, how do you write a parent class that declares the behaviors that are supported by derived classes without actually defining the implementation of those behaviors?
One possible approach is to implement “do nothing” functionality for those behaviors. For example, calling the set() method on the SpreadsheetCell base class will have no effect because the base class has nothing to set. This approach still doesn’t feel right, however. Ideally, there should never be an object that is an instance of the base class. Calling set() should always have an effect because it should always be called on either a DoubleSpreadsheetCell or a StringSpreadsheetCell. A good solution enforces this constraint.
Pure Virtual Methods and Abstract Base Classes
Pure virtual methods are methods that are explicitly undefined in the class definition. By making a method pure virtual, you are telling the compiler that no definition for the method exists in the current class. A class with at least one pure virtual method is said to be an abstract class because no other code will be able to instantiate it. The compiler enforces the fact that if a class contains one or more pure virtual methods, it can never be used to construct an object of that type.
There is a special syntax for designating a pure virtual method. The method declaration is followed by =0. No implementation needs to be written.
class SpreadsheetCell{public:virtual ~SpreadsheetCell() = default;virtual void set(std::string_view inString) = 0;virtual std::string getString() const = 0;};
Now that the base class is an abstract class, it is impossible to create a SpreadsheetCell object. The following code does not compile, and returns an error such as “error C2259: ‘SpreadsheetCell’: cannot instantiate abstract class”:
SpreadsheetCell cell; // Error! Attempts creating abstract class instance
However, once the StringSpreadsheetCell class has been implemented, the following code will compile fine because it instantiates a derived class of the abstract base class:
std::unique_ptr<SpreadsheetCell> cell(new StringSpreadsheetCell());
Note that you don’t need a SpreadsheetCell.cpp source file, because there is nothing to implement. Most methods are pure virtual, and the destructor is explicitly defaulted in the class definition.
The Individual Derived Classes
Writing the StringSpreadsheetCell and DoubleSpreadsheetCell classes is just a matter of implementing the functionality that is defined in the parent. Because you want clients to be able to instantiate and work with string cells and double cells, the cells can’t be abstract—they must implement all of the pure virtual methods inherited from their parent. If a derived class does not implement all pure virtual methods from the base class, then the derived class is abstract as well, and clients will not be able to instantiate objects of the derived class.
StringSpreadsheetCell Class Definition
The first step in writing the class definition of StringSpreadsheetCell is to inherit from SpreadsheetCell.
Next, the inherited pure virtual methods are overridden, this time without being set to zero.
Finally, the string cell adds a private data member, mValue, which stores the actual cell data. This data member is an std::optional, which is defined since C++17 in the <optional> header file. The optional type is a class template, so you have to specify the actual type that you need between angled brackets, as in optional<string>. Class templates are discussed in detail in Chapter 12. By using an optional, it is possible to distinguish whether a value for a cell has been set or not. The optional type is discussed in detail in Chapter 20, but its basic use is rather easy, as the next section shows.
class StringSpreadsheetCell : public SpreadsheetCell{public:virtual void set(std::string_view inString) override;virtual std::string getString() const override;private:std::optional<std::string> mValue;};
StringSpreadsheetCell Implementation
The source file for StringSpreadsheetCell contains the implementation of the methods. The set() method is straightforward because the internal representation is already a string. The getString() method has to keep into account that mValue is of type optional, and that it might not have a value. When mValue doesn’t have a value, getString() should return the empty string. This is made easy with the value_or() method of std::optional. By using mValue.value_or(""), the real value is returned if mValue contains an actual value, otherwise the empty string is returned.
void StringSpreadsheetCell::set(string_view inString){mValue = inString;}string StringSpreadsheetCell::getString() const{return mValue.value_or("");}
DoubleSpreadsheetCell Class Definition and Implementation
The double version follows a similar pattern, but with different logic. In addition to the set() method from the base class that takes a string_view, it also provides a new set() method that allows a client to set the value with a double. Two new private
static methods are used to convert between a string and a double, and vice versa. As in StringSpreadsheetCell, it has a data member called mValue, this time of type optional<double>.
class DoubleSpreadsheetCell : public SpreadsheetCell{public:virtual void set(double inDouble);virtual void set(std::string_view inString) override;virtual std::string getString() const override;private:static std::string doubleToString(double inValue);static double stringToDouble(std::string_view inValue);std::optional<double> mValue;};
The set() method that takes a double is straightforward. The string_view version uses the private static method stringToDouble(). The getString() method returns the stored double value as a string, or returns an empty string if no value has been stored. It uses the has_value() method of std::optional to query whether the optional has an actual value or not. If it has a value, the value() method is used to get it.
void DoubleSpreadsheetCell::set(double inDouble){mValue = inDouble;}void DoubleSpreadsheetCell::set(string_view inString){mValue = stringToDouble(inString);}string DoubleSpreadsheetCell::getString() const{return (mValue.has_value() ? doubleToString(mValue.value()) : "");}
You may already see one major advantage of implementing spreadsheet cells in a hierarchy—the code is much simpler. Each object can be self-centered and only deal with its own functionality.
Note that the implementations of doubleToString() and stringToDouble() are omitted because they are the same as in Chapter 8.
Leveraging Polymorphism
Now that the SpreadsheetCell hierarchy is polymorphic, client code can take advantage of the many benefits that polymorphism has to offer. The following test program explores many of these features.
To demonstrate polymorphism, the test program declares a vector of three SpreadsheetCell pointers. Remember that because SpreadsheetCell is an abstract class, you can’t create objects of that type. However, you can still have a pointer or reference to a SpreadsheetCell because it would actually be pointing to one of the derived classes. This vector, because it is a vector of the parent type SpreadsheetCell, allows you to store a heterogeneous mixture of the two derived classes. This means that elements of the vector could be either a StringSpreadsheetCell or a DoubleSpreadsheetCell.
vector<unique_ptr<SpreadsheetCell>> cellArray;
The first two elements of the vector are set to point to a new StringSpreadsheetCell, while the third is a new DoubleSpreadsheetCell.
cellArray.push_back(make_unique<StringSpreadsheetCell>());cellArray.push_back(make_unique<StringSpreadsheetCell>());cellArray.push_back(make_unique<DoubleSpreadsheetCell>());
Now that the vector contains multi-typed data, any of the methods declared by the base class can be applied to the objects in the vector. The code just uses SpreadsheetCell pointers—the compiler has no idea at compile time what types the objects actually are. However, because they are inheriting from SpreadsheetCell, they must support the methods of SpreadsheetCell:
cellArray[0]->set("hello");cellArray[1]->set("10");cellArray[2]->set("18");
When the getString() method is called, each object properly returns a string representation of their value. The important, and somewhat amazing, thing to realize is that the different objects do this in different ways. A StringSpreadsheetCell returns its stored value, or an empty string. A DoubleSpreadsheetCell first performs a conversion if it contains a value, otherwise it returns an empty string. As the programmer, you don’t need to know how the object does it—you just need to know that because the object is a SpreadsheetCell, it can perform this behavior.
cout << "Vector values are [" << cellArray[0]->getString() << "," <<cellArray[1]->getString() << "," <<cellArray[2]->getString() << "]" <<endl;
Future Considerations
The new implementation of the SpreadsheetCell hierarchy is certainly an improvement from an object-oriented design point of view. Yet, it would probably not suffice as an actual class hierarchy for a real-world spreadsheet program for several reasons.
First, despite the improved design, one feature is still missing: the ability to convert from one cell type to another. By dividing them into two classes, the cell objects become more loosely integrated. To provide the ability to convert from a DoubleSpreadsheetCell to a StringSpreadsheetCell, you could add a converting constructor, also known as a typed constructor. It has a similar appearance as a copy constructor, but instead of a reference to an object of the same class, it takes a reference to an object of a sibling class. Note also that you now have to declare a default constructor, which can be explicitly defaulted, because the compiler stops generating one as soon as you declare any constructor yourself:
class StringSpreadsheetCell : public SpreadsheetCell{public:StringSpreadsheetCell() = default;StringSpreadsheetCell(const DoubleSpreadsheetCell& inDoubleCell);// Omitted for brevity};
This converting constructor can be implemented as follows:
StringSpreadsheetCell::StringSpreadsheetCell(const DoubleSpreadsheetCell& inDoubleCell){mValue = inDoubleCell.getString();}
With a converting constructor, you can easily create a StringSpreadsheetCell given a DoubleSpreadsheetCell. Don’t confuse this with casting pointers or references, however. Casting from one sibling pointer or reference to another does not work, unless you overload the cast operator as described in Chapter 15.
Second, the question of how to implement overloaded operators for cells is an interesting one, and there are several possible solutions. One approach is to implement a version of each operator for every combination of cells. With only two derived classes, this is manageable. There would be an operator+ function to add two double cells, to add two string cells, and to add a double cell to a string cell. Another approach is to decide on a common representation. The preceding implementation already standardizes on a string as a common representation of sorts. A single operator+ function could cover all the cases by taking advantage of this common representation. One possible implementation, which assumes that the result of adding two cells is always a string cell, is as follows:
StringSpreadsheetCell operator+(const StringSpreadsheetCell& lhs,const StringSpreadsheetCell& rhs){StringSpreadsheetCell newCell;newCell.set(lhs.getString() + rhs.getString());return newCell;}
As long as the compiler has a way to turn a particular cell into a StringSpreadsheetCell, the operator will work. Given the previous example of having a StringSpreadsheetCell constructor that takes a DoubleSpreadsheetCell as an argument, the compiler will automatically perform the conversion if it is the only way to get the operator+ to work. That means the following code works, even though operator+ was explicitly written to work on StringSpreadsheetCells:
DoubleSpreadsheetCell myDbl;myDbl.set(8.4);StringSpreadsheetCell result = myDbl + myDbl;
Of course, the result of this addition doesn’t really add the numbers together. It converts the double cells into string cells and concatenates the strings, resulting in a StringSpreadsheetCell with a value of 8.4000008.400000.
If you are still feeling a little unsure about polymorphism, start with the code for this example and try things out. The main() function in the preceding example is a great starting point for experimental code that simply exercises various aspects of the class.
MULTIPLE INHERITANCE
As you read in Chapter 5, multiple inheritance is often perceived as a complicated and unnecessary part of object-oriented programming. I’ll leave the decision of whether or not it is useful up to you and your coworkers. This section explains the mechanics of multiple inheritance in C++.
Inheriting from Multiple Classes
Defining a class to have multiple parent classes is very simple from a syntactic point of view. All you need to do is list the base classes individually when declaring the class name.
class Baz : public Foo, public Bar{// Etc.};
By listing multiple parents, the Baz object has the following characteristics:
- A
Bazobject supports thepublicmethods, and contains the data members of bothFooandBar. - The methods of the
Bazclass have access toprotecteddata and methods in bothFooandBar. - A
Bazobject can be upcast to either aFooor aBar. - Creating a new
Bazobject automatically calls theFooandBardefault constructors, in the order that the classes are listed in the class definition. - Deleting a
Bazobject automatically calls the destructors for theFooandBarclasses, in the reverse order that the classes are listed in the class definition.
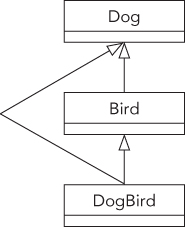
The following example shows a class, DogBird, that has two parent classes—a Dog class and a Bird class, as shown in Figure 10-8. The fact that a dog-bird is a ridiculous example should not be viewed as a statement that multiple inheritance itself is ridiculous. Honestly, I leave that judgment up to you.

class Dog{public:virtual void bark() { cout << "Woof!" << endl; }};class Bird{public:virtual void chirp() { cout << "Chirp!" << endl; }};class DogBird : public Dog, public Bird{};
Using objects of classes with multiple parents is no different from using objects without multiple parents. In fact, the client code doesn’t even have to know that the class has two parents. All that really matters are the properties and behaviors supported by the class. In this case, a DogBird object supports all of the public methods of Dog and Bird.
DogBird myConfusedAnimal;myConfusedAnimal.bark();myConfusedAnimal.chirp();
The output of this program is as follows:
Woof!Chirp!
Naming Collisions and Ambiguous Base Classes
It’s not difficult to construct a scenario where multiple inheritance would seem to break down. The following examples show some of the edge cases that must be considered.
Name Ambiguity
What if the Dog class and the Bird class both had a method called eat()? Because Dog and Bird are not related in any way, one version of the method does not override the other—they both continue to exist in the DogBird-derived class.
As long as client code never attempts to call the eat() method, that is not a problem. The DogBird class compiles correctly despite having two versions of eat(). However, if client code attempts to call the eat() method on a DogBird, the compiler gives an error indicating that the call to eat() is ambiguous. The compiler does not know which version to call. The following code provokes this ambiguity error:
class Dog{public:virtual void bark() { cout << "Woof!" << endl; }virtual void eat() { cout << "The dog ate." << endl; }};class Bird{public:virtual void chirp() { cout << "Chirp!" << endl; }virtual void eat() { cout << "The bird ate." << endl; }};class DogBird : public Dog, public Bird{};int main(){DogBird myConfusedAnimal;myConfusedAnimal.eat();// Error! Ambiguous call to method eat()return 0;}
The solution to the ambiguity is to either explicitly upcast the object using a dynamic_cast(), essentially hiding the undesired version of the method from the compiler, or to use a disambiguation syntax. For example, the following code shows two ways to invoke the Dog version of eat():
dynamic_cast<Dog&>(myConfusedAnimal).eat(); // Calls Dog::eat()myConfusedAnimal.Dog::eat(); // Calls Dog::eat()
Methods of the derived class itself can also explicitly disambiguate between different methods of the same name by using the same syntax used to access parent methods, that is, the :: scope resolution operator. For example, the DogBird class could prevent ambiguity errors in other code by defining its own eat() method. Inside this method, it would determine which parent version to call:
class DogBird : public Dog, public Bird{public:void eat() override;};void DogBird::eat(){Dog::eat(); // Explicitly call Dog's version of eat()}
Yet another way to prevent the ambiguity error is to use a using statement to explicitly state which version of eat() should be inherited in DogBird. This is done in the following DogBird definition:
class DogBird : public Dog, public Bird{public:using Dog::eat; // Explicitly inherit Dog's version of eat()};
Ambiguous Base Classes
Another way to provoke ambiguity is to inherit from the same class twice. For example, if the Bird class inherits from Dog for some reason, the code for DogBird does not compile because Dog becomes an ambiguous base class:
class Dog {};class Bird : public Dog {};class DogBird : public Bird, public Dog {}; // Error!
Most occurrences of ambiguous base classes are either contrived “what-if” examples, as in the preceding one, or arise from untidy class hierarchies. Figure 10-9 shows a class diagram for the preceding example, indicating the ambiguity.
Ambiguity can also occur with data members. If Dog and Bird both had a data member with the same name, an ambiguity error would occur when client code attempted to access that member.
A more likely scenario is that multiple parents themselves have common parents. For example, perhaps both Bird and Dog are inheriting from an Animal class, as shown in Figure 10-10.

This type of class hierarchy is permitted in C++, though name ambiguity can still occur. For example, if the Animal class has a public method called sleep(), that method cannot be called on a DogBird object because the compiler does not know whether to call the version inherited by Dog or by Bird.
The best way to use these “diamond-shaped” class hierarchies is to make the topmost class an abstract base class with all methods declared as pure virtual. Because the class only declares methods without providing definitions, there are no methods in the base class to call and thus there are no ambiguities at that level.
The following example implements a diamond-shaped class hierarchy in which the Animal abstract base class has a pure virtual eat() method that must be defined by each derived class. The DogBird class still needs to be explicit about which parent’s eat() method it uses, but any ambiguity is caused by Dog and Bird having the same method, not because they inherit from the same class.
class Animal{public:virtual void eat() = 0;};class Dog : public Animal{public:virtual void bark() { cout << "Woof!" << endl; }virtual void eat() override { cout << "The dog ate." << endl; }};class Bird : public Animal{public:virtual void chirp() { cout << "Chirp!" << endl; }virtual void eat() override { cout << "The bird ate." << endl; }};class DogBird : public Dog, public Bird{public:using Dog::eat;};
A more refined mechanism for dealing with the top class in a diamond-shaped hierarchy, virtual base classes, is explained at the end of this chapter.
Uses for Multiple Inheritance
At this point, you’re probably wondering why programmers would want to tackle multiple inheritance in their code. The most straightforward use case for multiple inheritance is to define a class of objects that is-a something and also is-a something else. As was said in Chapter 5, any real-world objects you find that follow this pattern are unlikely to translate well into code.
One of the most compelling and simple uses of multiple inheritance is for the implementation of mixin classes. Mixin classes are explained in Chapter 5.
Another reason that people sometimes use multiple inheritance is to model a component-based class. Chapter 5 gives the example of an airplane simulator. The Airplane class has an engine, a fuselage, controls, and other components. While the typical implementation of an Airplane class would make each of these components a separate data member, you could use multiple inheritance. The airplane class would inherit from engine, fuselage, and controls, in effect getting the behaviors and properties of all of its components. I recommend you to stay away from this type of code because it confuses a clear has-a relationship with inheritance, which should be used for is-a relationships. The recommended solution is to have an Airplane class that contains data members of type Engine, Fuselage, and Controls.
INTERESTING AND OBSCURE INHERITANCE ISSUES
Extending a class opens up a variety of issues. What characteristics of the class can and cannot be changed? What is non-public inheritance? What are virtual base classes? These questions, and more, are answered in the following sections.
Changing the Overridden Method’s Characteristics
For the most part, the reason you override a method is to change its implementation. Sometimes, however, you may want to change other characteristics of the method.
Changing the Method Return Type
A good rule of thumb is to override a method with the exact method declaration, or method prototype, that the base class uses. The implementation can change, but the prototype stays the same.
That does not have to be the case, however. In C++, an overriding method can change the return type as long as the original return type is a pointer or reference to a class, and the new return type is a pointer or reference to a descendent class. Such types are called covariant return types. This feature sometimes comes in handy when the base class and derived class work with objects in a parallel hierarchy—that is, another group of classes that is tangential, but related, to the first class hierarchy.
For example, consider a hypothetical cherry orchard simulator. You might have two hierarchies of classes that model different real-world objects but are obviously related. The first is the Cherry chain. The base class, Cherry, has a derived class called BingCherry. Similarly, there is another chain of classes with a base class called CherryTree and a derived class called BingCherryTree. Figure 10-11 shows the two class chains.

Now assume that the CherryTree class has a virtual method called pick() that retrieves a single cherry from the tree:
Cherry* CherryTree::pick(){return new Cherry();}
In the BingCherryTree-derived class, you may want to override this method. Perhaps bing cherries need to be polished when they are picked (bear with me on this one). Because a BingCherry is a Cherry, you could leave the method prototype as is and override the method as in the following example. The BingCherry pointer is automatically cast to a Cherry pointer. Note that this implementation uses a unique_ptr to make sure no memory is leaked when polish() throws an exception.
Cherry* BingCherryTree::pick(){auto theCherry = std::make_unique<BingCherry>();theCherry->polish();return theCherry.release();}
This implementation is perfectly fine and is probably the way that I would write it. However, because you know that the BingCherryTree will always return BingCherry objects, you could indicate this fact to potential users of this class by changing the return type, as shown here:
BingCherry* BingCherryTree::pick(){auto theCherry = std::make_unique<BingCherry>();theCherry->polish();return theCherry.release();}
Here is how you can use the BingCherryTree::pick() method:
BingCherryTree theTree;std::unique_ptr<Cherry> theCherry(theTree.pick());theCherry->printType();
A good way to figure out whether you can change the return type of an overridden method is to consider whether existing code would still work; this is called the Liskov substitution principle (LSP). In the preceding example, changing the return type was fine because any code that assumed that the pick() method would always return a Cherry* would still compile and work correctly. Because a BingCherry is a Cherry, any methods that were called on the result of CherryTree’s version of pick() could still be called on the result of BingCherryTree’s version of pick().
You could not, for example, change the return type to something completely unrelated, such as void*. The following code does not compile:
void* BingCherryTree::pick()// Error!{auto theCherry = std::make_unique<BingCherry>();theCherry->polish();return theCherry.release();}
This generates a compilation error, something like this:
'BingCherryTree::pick': overriding virtual function return type differs and is not covariant from 'CherryTree::pick'.
As mentioned before, this example is using raw pointers instead of smart pointers. It does not work for example when using std::unique_ptr as return type. Suppose the CherryTree::pick() method returns a unique_ptr<Cherry> as follows:
std::unique_ptr<Cherry> CherryTree::pick(){return std::make_unique<Cherry>();}
Now, you cannot change the return type for the BingCherryTree::pick() method to unique_ptr<BingCherry>. That is, the following does not compile:
class BingCherryTree : public CherryTree{public:virtual std::unique_ptr<BingCherry> pick() override;};
The reason is that std::unique_ptr is a class template. Class templates are discussed in detail in Chapter 12. Two instantiations of the unique_ptr class template are created, unique_ptr<Cherry> and unique_ptr<BingCherry>. Both these instantiations are completely different types and are in no way related to each other. You cannot change the return type of an overridden method to return a completely different type.
Changing the Method Parameters
If you use the name of a virtual method from the parent class in the definition of a derived class, but it uses different parameters than the method with that name uses in the parent class, it is not overriding the method of the parent class—it is creating a new method. Returning to the Base and Derived example from earlier in this chapter, you could attempt to override someMethod() in Derived with a new argument list as follows:
class Base{public:virtual void someMethod();};class Derived : public Base{public:virtual void someMethod(int i);// Compiles, but doesn't overridevirtual void someOtherMethod();};
The implementation of this method could be as follows:
void Derived::someMethod(int i){cout << "This is Derived's version of someMethod with argument " << i<< "." << endl;}
The preceding class definition compiles, but you have not overridden someMethod(). Because the arguments are different, you have created a new method that exists only in Derived. If you want a method called someMethod() that takes an int, and you want it to work only on objects of class Derived, the preceding code is correct.
The C++ standard says that the original method is now hidden as far as Derived is concerned. The following sample code does not compile because there is no longer a no-argument version of someMethod().
Derived myDerived;myDerived.someMethod(); // Error! Won't compile because original// method is hidden.
If your intention is to override someMethod() from Base, then you should use the override keyword as recommended before. The compiler then gives an error if you make a mistake in overriding the method.
There is a somewhat obscure technique you can use to have your cake and eat it too. That is, you can use this technique to effectively “override” a method in the derived class with a new prototype but continue to inherit the base class version. This technique uses the using keyword to explicitly include the base class definition of the method within the derived class, as follows:
class Base{public:virtual void someMethod();};class Derived : public Base{public:using Base::someMethod;// Explicitly "inherits" the Base versionvirtual void someMethod(int i);// Adds a new version of someMethodvirtual void someOtherMethod();};
Inherited Constructors
In the previous section, you saw the use of the using keyword to explicitly include the base class definition of a method within a derived class. This works perfectly fine for normal class methods, but it also works for constructors, allowing you to inherit constructors from your base classes. Take a look at the following definition for the Base and Derived classes:
class Base{public:virtual ~Base() = default;Base() = default;Base(std::string_view str);};class Derived : public Base{public:Derived(int i);};
You can construct a Base object only with the provided Base constructors, either the default constructor or the constructor with a string_view parameter. On the other hand, constructing a Derived object can happen only with the provided Derived constructor, which requires a single integer as argument. You cannot construct Derived objects using the constructor accepting a string_view defined in the Base class. Here is an example:
Base base("Hello"); // OK, calls string_view Base ctorDerived derived1(1); // OK, calls integer Derived ctorDerived derived2("Hello"); // Error, Derived does not inherit string_view ctor
If you would like the ability to construct Derived objects using the string_view-based Base constructor, you can explicitly inherit the Base constructors in the Derived class as follows:
class Derived : public Base{public:using Base::Base;Derived(int i);};
The using statement inherits all constructors from the parent class except the default constructor, so now you can construct Derived objects in the following two ways:
Derived derived1(1); // OK, calls integer Derived ctorDerived derived2("Hello"); // OK, calls inherited string_view Base ctor
The Derived class can define a constructor with the same parameter list as one of the inherited constructors in the Base class. In this case, as with any override, the constructor of the Derived class takes precedence over the inherited constructor. In the following example, the Derived class inherits all constructors, except the default constructor, from the Base class with the using statement. However, because the Derived class defines its own constructor with a single parameter of type float, the inherited constructor from the Base class with a single parameter of type float is overridden.
class Base{public:virtual ~Base() = default;Base() = default;Base(std::string_view str);Base(float f);};class Derived : public Base{public:using Base::Base;Derived(float f); // Overrides inherited float Base ctor};
With this definition, objects of Derived can be created as follows:
Derived derived1("Hello"); // OK, calls inherited string_view Base ctorDerived derived2(1.23f); // OK, calls float Derived ctor
A few restrictions apply to inheriting constructors from a base class with the using clause. When you inherit a constructor from a base class, you inherit all of them, except the default constructor. It is not possible to inherit only a subset of the constructors of a base class. A second restriction is related to multiple inheritance. It’s not possible to inherit constructors from one of the base classes if another base class has a constructor with the same parameter list, because this leads to ambiguity. To resolve this, the Derived class needs to explicitly define the conflicting constructors. For example, the following Derived class tries to inherit all constructors from both Base1 and Base2, which results in a compilation error due to ambiguity of the float-based constructors.
class Base1{public:virtual ~Base1() = default;Base1() = default;Base1(float f);};class Base2{public:virtual ~Base2() = default;Base2() = default;Base2(std::string_view str);Base2(float f);};class Derived : public Base1, public Base2{public:using Base1::Base1;using Base2::Base2;Derived(char c);};
The first using clause in Derived inherits all constructors from Base1. This means that Derived gets the following constructor:
Derived(float f); // Inherited from Base1
With the second using clause in Derived, you are trying to inherit all constructors from Base2. However, this causes a compilation error because this means that Derived gets a second Derived(float f) constructor. The problem is solved by explicitly declaring conflicting constructors in the Derived class as follows:
class Derived : public Base1, public Base2{public:using Base1::Base1;using Base2::Base2;Derived(char c);Derived(float f);};
The Derived class now explicitly declares a constructor with a single parameter of type float, solving the ambiguity. If you want, this explicitly declared constructor in the Derived class accepting a float parameter can still forward the call to both the Base1 and Base2 constructors in its ctor-initializer as follows:
Derived::Derived(float f) : Base1(f), Base2(f) {}
When using inherited constructors, make sure that all member variables are properly initialized. For example, take the following new definitions for Base and Derived. This example does not properly initialize the mInt data member in all cases, which is a serious error.
class Base{public:virtual ~Base() = default;Base(std::string_view str) : mStr(str) {}private:std::string mStr;};class Derived : public Base{public:using Base::Base;Derived(int i) : Base(""), mInt(i) {}private:int mInt;};
You can create a Derived object as follows:
Derived s1(2);
This calls the Derived(int i) constructor, which initializes the mInt data member of the Derived class and calls the Base constructor with an empty string to initialize the mStr data member.
Because the Base constructor is inherited in the Derived class, you can also construct a Derived object as follows:
Derived s2("Hello World");
This calls the inherited Base constructor in the Derived class. However, this inherited Base constructor only initializes mStr of the Base class, and does not initialize mInt of the Derived class, leaving it in an uninitialized state. This is not recommended!
The solution in this case is to use in-class member initializers, which are discussed in Chapter 8. The following code uses an in-class member initializer to initialize mInt to 0. The Derived(int i) constructor can still change this and initialize mInt to the constructor parameter i.
class Derived : public Base{public:using Base::Base;Derived(int i) : Base(""), mInt(i) {}private:int mInt = 0;};
Special Cases in Overriding Methods
Several special cases require attention when overriding a method. This section outlines the cases that you are likely to encounter.
The Base Class Method Is static
In C++, you cannot override a static method. For the most part, that’s all you need to know. There are, however, a few corollaries that you need to understand.
First of all, a method cannot be both static and virtual. This is the first clue that attempting to override a static method will not do what you intend it to do. If you have a static method in your derived class with the same name as a static method in your base class, you actually have two separate methods.
The following code shows two classes that both happen to have static methods called beStatic(). These two methods are in no way related.
class BaseStatic{public:static void beStatic() {cout << "BaseStatic being static." << endl; }};class DerivedStatic : public BaseStatic{public:static void beStatic() {cout << "DerivedStatic keepin' it static." << endl; }};
Because a static method belongs to its class, calling the identically named methods on the two different classes calls their respective methods:
BaseStatic::beStatic();DerivedStatic::beStatic();
This outputs the following:
BaseStatic being static.DerivedStatic keepin' it static.
Everything makes perfect sense as long as the methods are accessed by their class name. The behavior is less clear when objects are involved. In C++, you can call a static method using an object, but because the method is static, it has no this pointer and no access to the object itself, so it is equivalent to calling it by classname::method(). Referring to the previous example classes, you can write code as follows, but the results may be surprising.
DerivedStatic myDerivedStatic;BaseStatic& ref = myDerivedStatic;myDerivedStatic.beStatic();ref.beStatic();
The first call to beStatic() obviously calls the DerivedStatic version because it is explicitly called on an object declared as a DerivedStatic. The second call might not work as you expect. The object is a BaseStatic reference, but it refers to a DerivedStatic object. In this case, BaseStatic’s version of beStatic() is called. The reason is that C++ doesn’t care what the object actually is when calling a static method. It only cares about the compile-time type. In this case, the type is a reference to a BaseStatic.
The output of the previous example is as follows:
DerivedStatic keepin' it static.BaseStatic being static.
The Base Class Method Is Overloaded
When you override a method by specifying a name and a set of parameters, the compiler implicitly hides all other instances of the name in the base class. The idea is that if you have overridden one method of a given name, you might have intended to override all the methods of that name, but simply forgot, and therefore this should be treated as an error. It makes sense if you think about it—why would you want to change some versions of a method and not others? Consider the following Derived class, which overrides a method without overriding its associated overloaded siblings:
class Base{public:virtual ~Base() = default;virtual void overload() { cout << "Base's overload()" << endl; }virtual void overload(int i) {cout << "Base's overload(int i)" << endl; }};class Derived : public Base{public:virtual void overload() override {cout << "Derived's overload()" << endl; }};
If you attempt to call the version of overload() that takes an int parameter on a Derived object, your code will not compile because it was not explicitly overridden.
Derived myDerived;myDerived.overload(2); // Error! No matching method for overload(int).
It is possible, however, to access this version of the method from a Derived object. All you need is a pointer or a reference to a Base object:
Derived myDerived;Base& ref = myDerived;ref.overload(7);
The hiding of unimplemented overloaded methods is only skin deep in C++. Objects that are explicitly declared as instances of the derived class do not make the methods available, but a simple cast to the base class brings them right back.
The using keyword can be employed to save you the trouble of overloading all the versions when you really only want to change one. In the following code, the Derived class definition uses one version of overload() from Base and explicitly overloads the other:
class Base{public:virtual ~Base() = default;virtual void overload() { cout << "Base's overload()" << endl; }virtual void overload(int i) {cout << "Base's overload(int i)" << endl; }};class Derived : public Base{public:using Base::overload;virtual void overload() override {cout << "Derived's overload()" << endl; }};
The using clause has certain risks. Suppose a third overload() method is added to Base, which should have been overridden in Derived. This will now not be detected as an error, because, due to the using clause, the designer of the Derived class has explicitly said, “I am willing to accept all other overloads of this method from the parent class.”
The Base Class Method Is private or protected
There’s absolutely nothing wrong with overriding a private or protected method. Remember that the access specifier for a method determines who is able to call the method. Just because a derived class can’t call its parent’s private methods doesn’t mean it can’t override them. In fact, overriding a private or protected method is a common pattern in C++. It allows derived classes to define their own “uniqueness” that is referenced in the base class. Note that, for example, Java and C# only allow overriding public and protected methods, not private methods.
For example, the following class is part of a car simulator that estimates the number of miles the car can travel based on its gas mileage and the amount of fuel left:
class MilesEstimator{public:virtual ~MilesEstimator() = default;virtual int getMilesLeft() const;virtual void setGallonsLeft(int gallons);virtual int getGallonsLeft() const;private:int mGallonsLeft;virtual int getMilesPerGallon() const;};
The implementations of the methods are as follows:
int MilesEstimator::getMilesLeft() const{return getMilesPerGallon() * getGallonsLeft();}void MilesEstimator::setGallonsLeft(int gallons){mGallonsLeft = gallons;}int MilesEstimator::getGallonsLeft() const{return mGallonsLeft;}int MilesEstimator::getMilesPerGallon() const{return 20;}
The getMilesLeft() method performs a calculation based on the results of two of its own methods. The following code uses the MilesEstimator to calculate how many miles can be traveled with two gallons of gas:
MilesEstimator myMilesEstimator;myMilesEstimator.setGallonsLeft(2);cout << "Normal estimator can go " << myMilesEstimator.getMilesLeft()<< " more miles." << endl;
The output of this code is as follows:
Normal estimator can go 40 more miles.
To make the simulator more interesting, you may want to introduce different types of vehicles, perhaps a more efficient car. The existing MilesEstimator assumes that all cars get 20 miles per gallon, but this value is returned from a separate method specifically so that a derived class can override it. Such a derived class is shown here:
class EfficientCarMilesEstimator : public MilesEstimator{private:virtual int getMilesPerGallon() const override;};
The implementation is as follows:
int EfficientCarMilesEstimator::getMilesPerGallon() const{return 35;}
By overriding this one private method, the new class completely changes the behavior of existing, unmodified, public methods. The getMilesLeft() method in the base class automatically calls the overridden version of the private
getMilesPerGallon() method. An example using the new class is shown here:
EfficientCarMilesEstimator myEstimator;myEstimator.setGallonsLeft(2);cout << "Efficient estimator can go " << myEstimator.getMilesLeft()<< " more miles." << endl;
This time, the output reflects the overridden functionality:
Efficient estimator can go 70 more miles.
The Base Class Method Has Default Arguments
Derived classes and base classes can each have different default arguments, but the arguments that are used depend on the declared type of the variable, not the underlying object. Following is a simple example of a derived class that provides a different default argument in an overridden method:
class Base{public:virtual ~Base() = default;virtual void go(int i = 2) {cout << "Base's go with i=" << i << endl; }};class Derived : public Base{public:virtual void go(int i = 7) override {cout << "Derived's go with i=" << i << endl; }};
If go() is called on a Derived object, Derived’s version of go() is executed with the default argument of 7. If go() is called on a Base object, Base’s version of go() is called with the default argument of 2. However (and this is the weird part), if go() is called on a Base pointer or Base reference that really points to a Derived object, Derived’s version of go() is called but with Base’s default argument of 2. This behavior is shown in the following example:
Base myBase;Derived myDerived;Base& myBaseReferenceToDerived = myDerived;myBase.go();myDerived.go();myBaseReferenceToDerived.go();
The output of this code is as follows:
Base's go with i=2Derived's go with i=7Derived's go with i=2
The reason for this behavior is that C++ uses the compile-time type of the expression to bind default arguments, not the run-time type. Default arguments are not “inherited” in C++. If the Derived class in this example failed to provide a default argument as its parent did, it would be overloading the go() method with a new non-zero-argument version.
The Base Class Method Has a Different Access Level
There are two ways you may want to change the access level of a method: you could try to make it more restrictive or less restrictive. Neither case makes much sense in C++, but there are a few legitimate reasons for attempting to do so.
To enforce tighter restrictions on a method (or on a data member for that matter), there are two approaches you can take. One way is to change the access specifier for the entire base class. This approach is described later in this chapter. The other approach is simply to redefine the access in the derived class, as illustrated in the Shy class that follows:
class Gregarious{public:virtual void talk() {cout << "Gregarious says hi!" << endl; }};class Shy : public Gregarious{protected:virtual void talk() override {cout << "Shy reluctantly says hello." << endl; }};
The protected version of talk() in the Shy class properly overrides the Gregarious::talk() method. Any client code that attempts to call talk() on a Shy object gets a compilation error:
Shy myShy;myShy.talk(); // Error! Attempt to access protected method.
However, the method is not fully protected. One only has to obtain a Gregarious reference or pointer to access the method that you thought was protected:
Shy myShy;Gregarious& ref = myShy;ref.talk();
The output of this code is as follows:
Shy reluctantly says hello.
This proves that making the method protected in the derived class actually overrode the method (because the derived class version is correctly called), but it also proves that the protected access can’t be fully enforced if the base class makes it public.
It is much easier (and makes more sense) to lessen access restrictions in derived classes. The simplest way is to provide a public method that calls a protected method from the base class, as shown here:
class Secret{protected:virtual void dontTell() { cout << "I'll never tell." << endl; }};class Blabber : public Secret{public:virtual void tell() { dontTell(); }};
A client calling the public tell() method of a Blabber object effectively accesses the protected method of the Secret class. Of course, this doesn’t really change the access level of dontTell(), it just provides a public way of accessing it.
You can also override dontTell() explicitly in Blabber and give it new behavior with public access. This makes a lot more sense than reducing the level of access because it is entirely clear what happens with a reference or pointer to the base class. For example, suppose that Blabber actually makes the dontTell() method public:
class Blabber : public Secret{public:virtual void dontTell() override { cout << "I'll tell all!" << endl; }};
Now you can call dontTell() on a Blabber object:
myBlabber.dontTell(); // Outputs "I'll tell all!"
If you don’t want to change the implementation of the overridden method, but only change the access level, then you can use a using clause. For example:
class Blabber : public Secret{public:using Secret::dontTell;};
This also allows you to call dontTell() on a Blabber object, but this time the output will be “I’ll never tell.”:
myBlabber.dontTell(); // Outputs "I'll never tell."
In both previous cases, however, the protected method in the base class stays protected because any attempts to call Secret’s dontTell() method through a Secret pointer or reference will not compile.
Blabber myBlabber;Secret& ref = myBlabber;Secret* ptr = &myBlabber;ref.dontTell(); // Error! Attempt to access protected method.ptr->dontTell(); // Error! Attempt to access protected method.
Copy Constructors and Assignment Operators in Derived Classes
Chapter 9 says that providing a copy constructor and assignment operator is considered a good programming practice when you have dynamically allocated memory in a class. When defining a derived class, you need to be careful about copy constructors and operator=.
If your derived class does not have any special data (pointers, usually) that require a nondefault copy constructor or operator=, you don’t need to have one, regardless of whether or not the base class has one. If your derived class omits the copy constructor or operator=, a default copy constructor or operator= will be provided for the data members specified in the derived class, and the base class copy constructor or operator= will be used for the data members specified in the base class.
On the other hand, if you do specify a copy constructor in the derived class, you need to explicitly chain to the parent copy constructor, as shown in the following code. If you do not do this, the default constructor (not the copy constructor!) will be used for the parent portion of the object.
class Base{public:virtual ~Base() = default;Base() = default;Base(const Base& src);};Base::Base(const Base& src){}class Derived : public Base{public:Derived() = default;Derived(const Derived& src);};Derived::Derived(const Derived& src) : Base(src){}
Similarly, if the derived class overrides operator=, it is almost always necessary to call the parent’s version of operator= as well. The only case where you wouldn’t do this would be if there was some bizarre reason why you only wanted part of the object assigned when an assignment took place. The following code shows how to call the parent’s assignment operator from the derived class:
Derived& Derived::operator=(const Derived& rhs){if (&rhs == this) {return *this;}Base::operator=(rhs); // Calls parent's operator=.// Do necessary assignments for derived class.return *this;}
Run-Time Type Facilities
Relative to other object-oriented languages, C++ is very compile-time oriented. As you learned earlier, overriding methods works because of a level of indirection between a method and its implementation, not because the object has built-in knowledge of its own class.
There are, however, features in C++ that provide a run-time view of an object. These features are commonly grouped together under a feature set called run-time type information, or RTTI. RTTI provides a number of useful features for working with information about an object’s class membership. One such feature is dynamic_cast(), which allows you to safely convert between types within an object-oriented hierarchy; this was discussed earlier in this chapter. Using dynamic_cast() on a class without a vtable, that is, without any virtual methods, causes a compilation error.
A second RTTI feature is the typeid operator, which lets you query an object at run time to find out its type. For the most part, you shouldn’t ever need to use typeid because any code that is conditionally run based on the type of the object would be better handled with virtual methods.
The following code uses typeid to print a message based on the type of the object:
#include <typeinfo>class Animal { public: virtual ~Animal() = default; };class Dog : public Animal {};class Bird : public Animal {};void speak(const Animal& animal){if (typeid(animal) == typeid(Dog)) {cout << "Woof!" << endl;} else if (typeid(animal) == typeid(Bird)) {cout << "Chirp!" << endl;}}
Whenever you see code like this, you should immediately consider reimplementing the functionality as a virtual method. In this case, a better implementation would be to declare a virtual method called speak() in the Animal class. Dog would override the method to print "Woof!" and Bird would override the method to print "Chirp!". This approach better fits object-oriented programming, where functionality related to objects is given to those objects.
One of the primary values of the typeid operator is for logging and debugging purposes. The following code makes use of typeid for logging. The logObject() function takes a “loggable” object as a parameter. The design is such that any object that can be logged inherits from the Loggable class and supports a method called getLogMessage().
class Loggable{public:virtual ~Loggable() = default;virtual std::string getLogMessage() const = 0;};class Foo : public Loggable{public:std::string getLogMessage() const override;};std::string Foo::getLogMessage() const{return "Hello logger.";}void logObject(const Loggable& loggableObject){cout << typeid(loggableObject).name() << ": ";cout << loggableObject.getLogMessage() << endl;}
The logObject() function first writes the name of the object’s class to the output stream, followed by its log message. This way, when you read the log later, you can see which object was responsible for every written line. Here is the output generated by Microsoft Visual C++ 2017 when the logObject() function is called with an instance of Foo:
class Foo: Hello logger.
As you can see, the name returned by the typeid operator is “class Foo”. However, this name depends on your compiler. For example, if you compile the same code with GCC, the output is as follows:
3Foo: Hello logger.
Non-public Inheritance
In all previous examples, parent classes were always listed using the public keyword. You may be wondering if a parent can be private or protected. In fact, it can, though neither is as common as public. If you don’t specify any access specifier for the parent, then it is private inheritance for a class, and public inheritance for a struct.
Declaring the relationship with the parent to be protected means that all public methods and data members from the base class become protected in the context of the derived class. Similarly, specifying private inheritance means that all public and protected methods and data members of the base class become private in the derived class.
There are a handful of reasons why you might want to uniformly degrade the access level of the parent in this way, but most reasons imply flaws in the design of the hierarchy. Some programmers abuse this language feature, often in combination with multiple inheritance, to implement “components” of a class. Instead of making an Airplane class that contains an engine data member and a fuselage data member, they make an Airplane class that is a protected engine and a protected fuselage. In this way, the Airplane doesn’t look like an engine or a fuselage to client code (because everything is protected), but it is able to use all of that functionality internally.
Virtual Base Classes
Earlier in this chapter, you learned about ambiguous base classes, a situation that arises when multiple parents each have a parent in common, as shown again in Figure 10-12. The solution that I recommended was to make sure that the shared parent doesn’t have any functionality of its own. That way, its methods can never be called and there is no ambiguity problem.

C++ has another mechanism, called virtual base classes, for addressing this problem if you do want the shared parent to have its own functionality. If the shared parent is a virtual base class, there will not be any ambiguity. The following code adds a sleep() method to the Animal base class and modifies the Dog and Bird classes to inherit from Animal as a virtual base class. Without the virtual keyword, a call to sleep() on a DogBird object would be ambiguous and would generate a compiler error because DogBird would have two subobjects of class Animal, one coming from Dog and one coming from Bird. However, when Animal is inherited virtually, DogBird has only one subobject of class Animal, so there will be no ambiguity with calling sleep().
class Animal{public:virtual void eat() = 0;virtual void sleep() { cout << "zzzzz...." << endl; }};class Dog : public virtual Animal{public:virtual void bark() { cout << "Woof!" << endl; }virtual void eat() override { cout << "The dog ate." << endl; }};class Bird : public virtual Animal{public:virtual void chirp() { cout << "Chirp!" << endl; }virtual void eat() override { cout << "The bird ate." << endl; }};class DogBird : public Dog, public Bird{public:virtual void eat() override { Dog::eat(); }};int main(){DogBird myConfusedAnimal;myConfusedAnimal.sleep(); // Not ambiguous because of virtual base classreturn 0;}
SUMMARY
This chapter covered numerous details about inheritance. You learned about its many applications, including code reuse and polymorphism. You also learned about its many abuses, including poorly designed multiple-inheritance schemes. Along the way, you uncovered some cases that require special attention.
Inheritance is a powerful language feature that takes some time to get used to. After you have worked with the examples in this chapter and experimented on your own, I hope that inheritance will become your tool of choice for object-oriented design.