

Chapter 4
Troubleshooting Encoding Problems and FAQ
Entia non sunt multiplicanda praeter necessitate.
(Entities are not to be multiplied beyond necessity.)
—William of Occam
General Remarks
SAS Encoding and Locale-Related System Options
Operating System-Specific Options
Windows
UNIX
X Window System
z/OS
The Next Steps
How to Handle Specific Issues
Transcoding Problems
Multilingual Data Handling
Garbage Characters in Output or Display
Problems with RDBMS Access
Chapter Summary
General Remarks
Always try to reduce a problem to its core. Cut out unnecessary clutter and try to reproduce the issue with a small, self-contained sample. In many cases, encoding problems can be reproduced in Base SAS.
How can we diagnose encoding problems? In order to understand what went wrong, I suggest that you follow the data on input, transfer, processing, and output. One of the first things to do is to check the session encoding of each SAS session involved. Use the following code:
proc options option=encoding; run;
This code yields the current session encoding in the log:
1 proc options option=encoding; run;
SAS (r) Proprietary Software Release 9.2 TS2M3
ENCODING=WCYRILLIC
Specifies default encoding for processing
external data.
NOTE: PROCEDURE OPTIONS used (Total process time):
real time 0.01 seconds
cpu time 0.01 seconds
SAS Encoding and Locale-Related System Options
A more comprehensive way to list the encoding and other language-related features of SAS is to submit the following code:
proc options group=languagecontrol; run;
In the same session as above, this code yields the following:
2 proc options group=languagecontrol; run;
SAS (r) Proprietary Software Release 9.2 TS2M3
DATESTYLE=DMY Identify sequence of month, day and year when ANYDATE informat data is ambiguous
DFLANG=RUSSIAN Language for EURDF date/time formats and informats
NOLOCALELANGCHG Do not change the language of SAS message text in ODS output when the LOCALE option is specified
PAPERSIZE=LETTER Size of paper to print on
RSASIOTRANSERROR Display a transcoding error when illegal data values for a remote application
TRANTAB=(lat1lat1,lat1lat1,wcyr_ucs,wcyr_lcs,wcyr_ccl,,,)
Names of translate tables
NODBCS Do not process double byte character sets
DBCSLANG=NONE Specifies the double-byte character set (DBCS) language to use
DBCSTYPE=NONE Specifies a double-byte character set (DBCS) encoding method
ENCODING=WCYRILLIC
Specifies default encoding for processing external data.
LOCALE=RUSSIAN_RUSSIA
Specifies the current locale for the SAS session.
NONLSCOMPATMODE Uses the user specified encoding to process character data
NOTE: PROCEDURE OPTIONS used (Total process time):
real time 0.00 seconds
cpu time 0.00 seconds
The primary option here is the LOCALE= option.1 LOCALE= specifies the locale of the SAS session. When specified at SAS session start up, it also automatically sets the session encoding. Usually, a locale has a default encoding that is used for a particular operating system. For example, on a Windows PC, the wlatin1 encoding is the default encoding for the Spanish_Spain locale; on a UNIX box, it is latin9; and on z/OS, it is open_ed-1145.
You can specify the LOCALE= system option in a configuration file, at SAS invocation, in an OPTIONS statement, or in the SAS System Options window. In addition, values for the following system options are set based on the LOCALE= value: DFLANG=2, TRANTAB=, DATESTYLE=, and PAPERSIZE=. For most customers, the encoding will be implicitly set with the LOCALE= system option as well. However, you can specify the ENCODING= system option3 explicitly in a configuration file or at SAS invocation. Note that changing the LOCALE= option after SAS session start up does not affect the value of the ENCODING= or TRANTAB= options.
Here is how the LOCALE=, ENCODING=, and DBCS options interact:
- If a value is not specified for ENCODING= (that is, the installation default is set), then specifying a value for LOCALE= sets the encoding based on the LOCALE= value.
- If a value is specified for ENCODING=, that value sets the session encoding and overrides the one set by LOCALE=.
- The ENCODING= option implicitly sets the TRANTAB= option as well.
- If the value specified for LOCALE= is not compatible with the value specified for ENCODING=, a warning message appears. Here is an example:
WARNING: The current session encoding, wlatin1, does not support the locale ru_RU (the POSIX name). However, the LOCALE system option has been set to ru_RU to reflect cultural features.
- Beginning with SAS 9.3, the LOCALE= option or the ENCODING= option also determine the values of the DBCSLANG= and DBCSTYPE= system options.4 Nevertheless, you can still set these options explicitly.
Operating System-Specific Options
You may also need to check the operating system’s locale and encoding. Typically, they should be synchronized with the SAS locale and encoding and the encoding of your data.
Windows
The Windows operating systems (since Windows NT 3.15) distinguish between Unicode programs and non-Unicode programs. Though SAS supports Unicode (with the SAS Unicode server), it is a non-Unicode application. By default, the language (locale) used by the operating system is considered to be the Unicode language. If a language used by the operating system does not match the language (locale) of your application, some characters in the interface of the application might not display correctly. To fix the problem, you need to change the Windows system locale to match the one used by your application (SAS, for instance). The system locale is used for all conversions to and from Unicode for non-Unicode applications.
In the Windows operating systems, a locale can be changed using the Regional and Language options available in the Control Panel. How this is done varies slightly among the different versions. The following example shows how to check and change the language with the Windows 2003 server.
When the Regional and Language Options dialog box appears, you should see three tabs: Regional Options, Languages, and Advanced.
- On the Regional Options tab, select an appropriate language listed under Standards and formats. This sets the user locale. It determines how programs display dates, times, currency, and so on. It does not affect the rendering of characters of the user interface. So this is optional only.
- On the Advanced tab, select the same language as specified for the user locale in the previous step. This sets the system locale. This setting enables programs that do not support Unicode to display menus and dialog boxes in their native language by installing the necessary code pages and fonts. This is mandatory, and I cannot stress this strongly enough: If you change only the user locale, it does not impact the way non-Unicode characters are rendered!
- Click OK or Apply.
The following figures show what the dialog boxes looks like if you choose Polish as the Windows system language.
Figure 1: Regional and Language Options—Regional Options Tab

Figure 2: Regional and Language Options—Advanced Tab

You will be prompted to insert the Windows CD-ROM or point to a network location where the files are located.
After the files are installed, you must restart your computer.
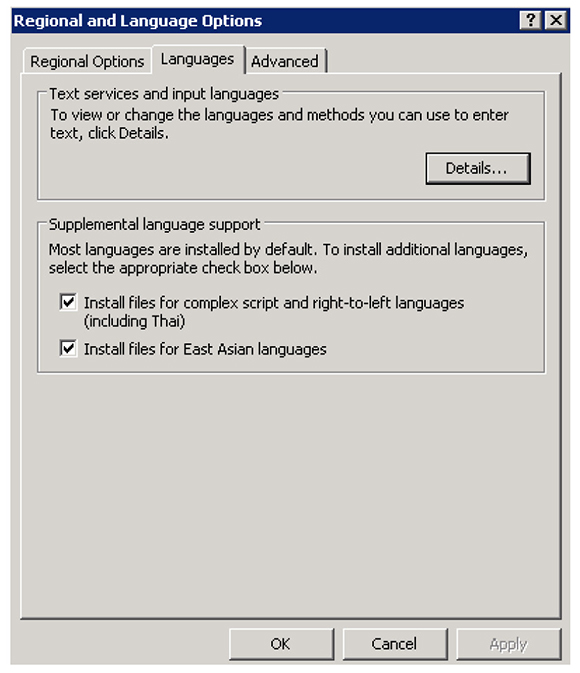
If the desired language does not appear in the drop-down lists, perform the following steps:
- Select the Languages tab.
- Select the check box for one or both of the following options:
- Install files for complex script and right-to-left languages (including Thai)
- Install files for East Asian languages
The complex script and right-to-left languages include Arabic, Armenian, Georgian, Hebrew, the Indic languages, Thai, and Vietnamese; the East Asian languages include Chinese, Japanese, and Korean. The files for most other languages are automatically installed on your computer by Windows.
Figure 3: Regional and Language Options—Languages Tab
If you have set the system locale to Polish (as shown above) the default encoding of a non-Unicode application has to be Windows code page 1250 (wlatin2 in SAS). The operating system then converts between Unicode and the system locale encoding, Windows code page 1250 in this case. If the Windows code page does not match the encoding of your application, the conversion between Unicode and the system code page will fail.
The following figure shows what a pop-up menu in SAS Explorer looks if you are running Polish SAS with a Western system locale (Windows code page 1252).
Figure 4: SAS Pop-up Menu in a Nonmatching OS Locale

Polish characters are then mapped to random Windows 1252 characters.
UNIX
Unlike Windows, UNIX separates the operating system from the windowing system.6 The UNIX windowing system, called X Window, manages the system’s graphical user interface. I will come back to this in more detail later.
The encoding used on a UNIX system depends on the setting of the locale environment variables. Setting the locale is similar on most UNIX systems. Here I use HP-UX as an example to demonstrate how to check and change your system locale on UNIX.
The executable locale shows your current locale and its subcategories:
$ locale
LANG=
LC_CTYPE=”C”
LC_COLLATE=”C”
LC_MONETARY=”C”
LC_NUMERIC=”C”
LC_TIME=”C”
LC_MESSAGES=”C”
LC_ALL=
“C” is usually the default; it is the same as not setting a category at all.
The locale command with the parameter -a displays all the locales currently installed on the machine:
$ locale –a
C
POSIX
C.iso88591
C.utf8
univ.utf8
ar_DZ.arabic8
…
…
…
da_DK.iso885915@euro
de_DE.iso885915@euro
en_GB.iso885915@euro
es_ES.iso885915@euro
fi_FI.iso885915@euro
fr_CA.iso885915
fr_FR.iso885915@euro
is_IS.iso885915@euro
it_IT.iso885915@euro
nl_NL.iso885915@euro
no_NO.iso885915@euro
pt_PT.iso885915@euro
sv_SE.iso885915@euro
zh_CN.hp15CN
zh_TW.eucTW
The locale command with the parameter -m writes the names of available code sets:7
$ locale –m
SJIS.cm
arabic8.cm
ascii.cm
big5.cm
ccdc.cm
eucJP.cm
eucKR.cm
eucTW.cm
greek8.cm
hebrew8.cm
hp15CN.cm
iso88591.cm
iso88592.cm
iso88595.cm
iso88596.cm
iso88597.cm
iso88598.cm
iso88599.cm
kana8.cm
roman8.cm
tis620.cm
turkish8.cm
utf8.cm
iso885915.cm
There are a number of environment variables to control the locale and various subcategories:
- LANG determines the native language, local custom, and coded character set.
- LC_CTYPE determines character-handling functions.
- LC_COLLATE determines character collation.
- LC_MONETARY determines monetary-related numeric formatting.
- LC_NUMERIC determines numeric formatting.
- LC_TIME determines date and time formatting.
- LC_MESSAGES determines the language in which messages should be written.
LC_ALL determines the values for all locale categories. It has precedence over any of the other LC_* environment variables and the LANG environment variable.
A value for a locale category usually has this form:
[language[_territory][.codeset][@modifier]]
For example, LANG could be defined as follows:
$ LANG=fr_FR.iso885915@euro
If you set a category, you to need to export it. For Bourne-like shells, use this:
$ LANG=<value>
$ export LANG
For csh-like shells, use this:
$ setenv LANG=<value>
X Window System
The X Window System (usually called X11, based on its current major version, or simply X) is a software system and network protocol that enables graphical user interfaces (GUIs) for computers on a network. X uses a client/server model. The X server runs on the user’s workstation and provides its services to the X clients. An X client is the application program that uses the input and output services provided by the X server. Wikipedia describes the process in this way: “The server accepts requests for graphical output … and sends back user input (from keyboard, mouse, or touchscreen).”8 If there are several computers on a network, you can run an X server that, in turn, serves X applications from all the other computers in the network.
X provides only the basic framework for building GUI environments; hence, several interfaces exist. Motif is an industry standard graphical user interface, which is used on many hardware and software platforms. Motif is also the base for the Common Desktop Environment (CDE). CDE was originally developed by SunSoft, Hewlett-Packard, IBM, and Novell, and provides a single, standard graphical desktop for all platforms that support the X Window System. There are also several implementations of the X Window System for Microsoft Windows operating systems, such as Xming or Exceed. SAS features an X Window System interface that is based on Motif. This interface uses the window manager on your system to manage the windows on your display. Any window manager that is compliant with the Inter-Client Communication Conventions Manual (ICCCM) can be used with the Motif interface to SAS 9.
X clients usually have characteristics that can be customized; these characteristics or properties are known as X resources. Because SAS functions as an X Windows client, many aspects of the appearance and behavior of the SAS windowing environment are controlled by X resources. For example, X resources can be used to define a font, a background color, or a window size. In our context, definilocang a font that matches the application’s locale is of particular importance. I will come back to this in more detail later. If you need more information about X Window System clients and X resources, see the documentation provided by your vendor.
How and Where Does SAS Load X Resources?
SAS follows the normal X Windows Resource Manager protocol for loading X resources. The methods of customizing the X resource definitions for a client are listed in order of precedence (from highest priority to lowest priority):
- If you do not want to specify resources in a resource file, you can specify session-specific resources by using the
-xrmoption on the command line for each invocation of SAS. For example, the following command specifies a DMS font:
sas -xrm ‘SAS.DMSFont: -adobe-courier-medium-o-normal--24-240-75-75-m-150-iso8859-1’
You must specify the -xrm option for each resource.
- Add resource definitions to a file in your home directory (often this is called .Xdefaults). Merge this file into the X server’s resource database with the following:
xrdb -merge .Xdefaults
Note that if you alter your resource definition file while SAS is running, the changes will not take effect until you quit and rerun SAS.
- Create a subdirectory for storing resource definitions. This subdirectory is usually named “app-defaults.” Create a file called “SAS” in this subdirectory. Your resource definitions can be included in this file. Set the XUSERFILESEARCHPATH environment variable to the pathname of this subdirectory, or have the environment variable XAPPLRESDIR point to the location of this subdirectory. The XAPPLRESDIR and XUSERFILESEARCHPATH environment variables use a slightly different syntax to specify the location of your resource definitions. The location specified by the XUSERFILESEARCH environment variable takes precedence over the location specified by the XAPPLRESDIR variable.
For more information, see the SAS 9.2 Companion for UNIX Environments or the UNIX X main page.
When and How Do You Need to Customize X Resources?
SAS functions correctly without any modifications to the X resources. However, you might want to change the default behavior or appearance of the interface. In our context, it is particularly important to use appropriate fonts that are needed to display the text in the encoding of your locale.
A Side Note to Fonts on UNIX
The xlsfonts command lists the fonts that are available from the X server. The command supports wildcarding in font names; for example, xlsfonts -fn ‘-*iso8859-2*’ will list all the fonts that support the ISO 88959-2 encoding:
-adobe-courier-bold-o-normal--0-0-75-75-m-0-iso8859-2
-adobe-courier-bold-o-normal--10-100-75-75-m-60-iso8859-2
-adobe-courier-bold-o-normal--12-120-75-75-m-70-iso8859-2
-adobe-courier-bold-o-normal--14-140-75-75-m-90-iso8859-2
-adobe-courier-bold-o-normal--18-180-75-75-m-110-iso8859-2
-adobe-courier-bold-o-normal--24-240-75-75-m-150-iso8859-2
-adobe-courier-bold-o-normal--8-80-75-75-m-50-iso8859-2
-adobe-courier-bold-r-normal--0-0-75-75-m-0-iso8859-2
-adobe-courier-bold-r-normal--10-100-75-75-m-60-iso8859-2
-adobe-courier-bold-r-normal--12-120-75-75-m-70-iso8859-2
-adobe-courier-bold-r-normal--14-140-75-75-m-90-iso8859-2
-adobe-courier-bold-r-normal--18-180-75-75-m-110-iso8859-2
….
….
-misc-fixed-medium-r-normal--9-90-75-75-c-60-iso8859-2
-misc-fixed-medium-r-semicondensed--0-0-75-75-c-0-iso8859-2
-misc-fixed-medium-r-semicondensed--12-110-75-75-c-60-iso8859-2
-misc-fixed-medium-r-semicondensed--13-120-75-75-c-60-iso8859-2
-schumacher-clean-medium-r-normal--0-0-75-75-c-0-iso8859-2
-schumacher-clean-medium-r-normal--12-120-75-75-c-60-iso8859-2
Font names follow a standard called X Logical Font Description (XLFD). It consists of 14 parts that are separated by a hyphen:
- Foundry
- Typeface family
- Weight
- Slant
- Width
- Style
- Pixel size
- Point size
- Horizontal resolution
- Vertical resolution
- Spacing
- Average width
- Charset registry
- Charset
If a field is missing, it is replaced by an additional hyphen. Wildcards, such as asterisks (*) can be used for fields that you need not care about. Let’s take a closer look at an example:
-adobe-courier-bold-o-normal--10-100-75-75-m-60-iso8859-2
In this case, the company that created the font was Adobe. The font belongs to the Courier family of fonts; the letters are of bold thickness, oblique slant; the width is normal; and the style is not defined. This is why we see an additional hyphen (what we would have here is things like serif, sans-serif, informal, decorated, and so on). Pixel size is 10, point size is 100; the horizontal and vertical resolution in dots per inch in X and Y direction is 75. It is a monospaced or non-proportional font; this means that it is a font whose characters each occupy the same amount of horizontal space. Its average width is 60. And last but not least, we have the primary and the secondary indicator of the encoding, which is ISO8859-2 (Latin2) in this case.
Using the Right Resources
The following figure shows what Polish SAS looks like with default X resources.
Figure 5: Polish SAS with Western Settings

The following figures shows what Polish SAS looks like with customized resources applied using one of the methods described previously.
Figure 6: Polish SAS with Correct Settings

For Asian languages, SAS provides X resources in template files. They are located in the directory <SASROOT>/X11/resource_files. For the Japanese locale, SAS provides the following X resource template files:
./Resource_CDE.ja - for the CDE environment
./Resource_LNX.ja - for Linux
./Resource_Sun.ja - for Solaris
./Resource_DEC.ja - for Tru64 UNIX
./Resource_HP.ja - for HP-UX
./Resource_IBM.ja - for AIX
./Resource_ReflX.ja - for ReflectionX users
This is what the Resource_CDE.ja file looks like:
! - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
! Resource_CDE.ja
!
! Default font and keyboard defns for CDE for the OSF/Motif interface
! to the SAS System, Release 9.0.
! Note: This resource is used for Japanese locale only
! HP11.x users has to change the charset name for JISX0208
! JISX0208.1983-0 --> JISX0208.1990-0
!
! - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
SAS.*font: -dt-interface system-medium-r-normal-*-14-*-*-*-*-*-jisx0201.1976-0
SAS.*DBfont: -dt-interface system-medium-r-normal-*-14-*-*-*-*-*-jisx0208.1983-0
SAS.systemFont: -dt-interface system-medium-r-normal-*-14-*-*-*-p-*-iso8859-1
SAS.systemDbFont: -dt-interface system-medium-r-normal-*-14-*-*-*-*-*-jisx0208.1983-0
SAS.DMSFont: -dt-interface system-medium-r-normal-*-14-*-*-*-*-*-jisx0201.1976-0
SAS.DMSDBFont: -dt-interface system-medium-r-normal-*-14-*-*-*-*-*-jisx0208.1983-0
SAS.DMSboldFont: -dt-interface system-medium-r-normal-*-14-*-*-*-*-*-jisx0201.1976-0
SAS.DMSDBboldFont: -dt-interface system-medium-r-normal-*-14-*-*-*-*-*-jisx0208.1983-0
SAS.keyboardTranslations: #override
Ctrl<Key>space: sas-begin-conversion()
<Key>Henkan_Mode: sas-begin-conversion()
SAS.fontCharset: jisx0201.1976-0
SAS.fontDBCharset: jisx0208.1983-0
SAS.DMSDBboldFont: -Misc-Fixed-Medium-R-Normal--14-130-75-75-C-140-JISX0208.1983-0
SAS.keyboardTranslations: #override
Ctrl<Key>space: sas-begin-conversion()
<Key>Meta_L: sas-begin-conversion()
<Key>Meta_R: sas-toggle-katakana()
SAS.fontCharset: JISX0201.1976-0
SAS.fontDBCharset: JISX0208.1983-0
To apply the X resources in these template files, copy the appropriate template to one of the following locations, renaming it SAS (in all uppercase):
/usr/lib/X11/app-defaults (on most UNIX systems)
/usr/openwin/lib/X11/app-defaults (on Solaris)
$HOME (your home directory)
For example, on a Solaris system, you would use the following COPY command:
$ cp !SASROOT/X11/resource_files/Resource_CDE.ja /usr/openwin/lib/X11/app-defaults/SAS
In summary, to configure your operating system for your preferred locale, you need to do two things:
- Change your system locale and customize X resources—if necessary. This can be done from the command line or more elegantly using the internationalization features of Motif. The following example shows how to change the system locale with the Solaris Common Desktop Environment from the Options menu on the login screen.
Figure 7: Choose Language from the Options Menu on the Login Screen

After going back, you will see the login window in Japanese, as shown in the following figure.
Figure 8: Solaris Login Screen in Japanese

After you log in, your Common Desktop Environment should reflect the language that you selected, which in this case is Japanese.
Figure 9: Solaris CDE in Japanese

Apply the appropriate X resources as explained previously, and then invoke a Japanese SAS session.
Figure 10: Solaris CDE with Japanese SAS

z/OS
Compared to the remarks about the Windows and UNIX operating systems, the remarks about z/OS will be quite short. This is not because z/OS is less important, but because an end user does not have many possibilities to influence the encoding on z/OS. Typically, encoding is achieved by using a SAS image compiled for a particular EBDCIC code page and by configuring the terminal emulator appropriately.
The OS just sends a data stream to the display. It is then up to the display control unit or emulator to determine how to display characters.
Usually, terminal emulator software sets the Coded Character Set Identifier (CCSID) of the terminal. ISPF (an interactive utility for listing and editing data sets) stores the code page and character set of the terminal in the ZTERMCID system variable. It is set for an ISPF start up and can be queried via ISPF 7.3. Terminal emulator software normally should also take care of transcoding data from the host to the workstation. For more information, check the manual of your terminal emulator software or the ISPF Dialog Developer’s Guide.
Facilities such as Job Control Language (JCL) and ISPF use the IBM Standard Character Set9 for z/OS data set names. This means that you can use uppercase and lowercase unaccented Latin letters (that is, A through Z and a through z), the “national characters”10 @, $, and #, the underscore character _, the digits 0 through 9, and the following special characters: + - , = * ( ) ‘ / &. The national characters (@, #, and $) are expected to reside at the code points of the Standard Character Set (0x7c, 0x7b, and 0x5b).
When using these facilities, customers using an encoding other than EBCDIC 1047 (or EBCDIC 037)11 for their terminal or terminal emulation must specify characters that correspond in their encoding to the valid code points. For example, to process the data set USER01.MY$.SASLIB (where the $ corresponds to 0x5B in 1047), a Finnish user must specify Å (which corresponds to 0x5B in EBCDIC 1143).
Beginning with SAS 9.3, z/OS operating-system names (resource names) are processed “as is” without being converted to a different encoding. In previous releases for a number of locales, a session encoding variant character was mapped to the compiler encoding value (where compiler encoding is understood to be the same as the IBM Standard Character Set; for example, 0x63 was mapped to 0x7B).
The Next Steps
If the OS and SAS encoding are OK, you may need to check the encoding of your output. For instance, you can check whether the HTML or XML header has a correct encoding META tag. Was there any chance for data truncation? Have the appropriate fonts for the particular locales been installed? Last but not least, you may want to check the hexadecimal values of characters as explained in the previous chapter.
The following section lists questions and answers—typical problems and how they can be solved. I hope that users will benefit most from this section when having to troubleshoot their own problems.
How to Handle Specific Issues
The following are real-life examples, categorized into four areas: transcoding problems, multilingual issues, garbage output or display, and problems with RDBMS access. Of course, some of the examples fall into multiple categories.
Transcoding Problems
Transcoding problems in SAS are usually indicated by error messages or warnings. However, the reasons may not always be obvious. At times, some detective work is necessary to get to the source of a problem, or there may be multiple problems.
Question: Why do I see the following error message when I try to access a file from German Enterprise Guide on a UNIX server?
ERROR: File libref.member cannot be updated because its encoding does not match the session encoding or the file is in a format...
Answer: In SAS 9.2 and later, locale and encoding depend on the language of the client application. If the client locale is German, the server locale is also set to German. This may have consequences for the encoding that is set implicitly. In the case of a German locale, the corresponding encoding for UNIX is Latin9. This may not match the locale and/or encoding that was set during the installation. If the locale of the installation was set to English, any data sets created get an encoding attribute of Latin1. Latin9 and Latin1 are very similar, but not identical. (See the remarks that follow.)
To fix this:
- Modify the config file by explicitly setting ENCODING=LATIN9.
- Fix the data set headers so that all files have LATIN9 in their header (as explained previously in this chapter).
Question: Why do I get a warning when I run a SAS server in a UNIX environment and try to import a text file from Windows even though both are using Latin1?
WARNING: A character that could not be transcoded was encountered.
Answer: The encodings used on Windows (WLATIN1, also known as CP1252) and UNIX (LATIN1, also known as ISO-8859-1) are very similar but not identical. For an overview of their differences, see the Wikipedia article “Western Latin character sets (computing): Comparison Table” at http://en.wikipedia.org/wiki/Western_Latin_character_sets_%28computing%29#Comparison_table. The Euro symbol as well as special quotation marks used in Microsoft Word or Microsoft Excel might be potential sources of this transcoding error.
To avoid this problem, you can either change the offending character to something that is available in both encodings (if possible), or you can run the server session with the same encoding as the Windows client. For instance, you can run a UNIX server (in a Western European environment) with a WLATIN1 encoding instead of LATIN1.
Question: How is it possible that we are not able to import characters from a SAS 8 SBCS Latin1 session into a SAS 9 Unicode server session? UTF-8 is supposed to be able to render everything.
Answer: There are a couple of things to note here:
- SAS 9 data sets have an ENCODING attribute. When the data set encoding is different from the session encoding, the cross-environment data access (CEDA) facility automatically transcodes character data when it is read and when it is saved. Data sets from earlier releases (as in this case) do not have an encoding attribute, so you must specify the encoding of the incoming data with the ENCODING= DATA step option or the INENCODING= LIBNAME option.
- You need to increase variable lengths to prevent truncation during transcoding of the data to UTF-8. This is also the case with latin1 characters since some of those require more than one byte in UTF-8. Just use the CVP (character variable padding) engine to expand character variable lengths so that the character data does not truncate.
- Use the NOCLONE option with PROC COPY to change the data representation and encoding to that of your target host. Here is an example:
libname in cvp ‘/tmp’ inencoding=latin1; proc copy indd=in outdd=work noclone; run;
Question: A SAS script on a UNIX server is trying to update or write to SAS data sets on a Windows server. The error message that we get is as follows:
ERROR: File <libref.member> cannot be updated because its encoding does not match the session encoding or the file is in a format native to another host, such as WINDOWS_32.
What can we do?
Answer: To prevent loss or corruption of data, you cannot update a data set that has an encoding different from the encoding of your current SAS session. To update any SAS data set, your session must be running in the same encoding as the data set being updated. If the data is in Windows format, you cannot update it from SAS running on UNIX. The CEDA access engine is read-only. If the data does not need to be updated from SAS on Windows, you can store a UNIX formatted data set on the Windows system. It can be updated by SAS on UNIX, and read from SAS on Windows. There is no method that would enable you to maintain a single copy of the data and update it from both operating systems.
Question: We keep getting the following error when using the METADATA_SETASSN function in an rsubmit from a UNIX platform:
ERROR: Some code points did not transcode.
Answer: Usually, this error occurs when the source and target encoding are not (fully) compatible. You need to identify the offending characters, and you have to remove or replace them. In this case, the encodings involved were ISO-8859-5 (on the UNIX side) and CP1251 on Windows. The text string that caused the error (see the following figure) “«Мега»-пользователь” contained the LEFT-POINTING DOUBLE ANGLE QUOTATION MARK (U+00AB in Unicode notation) and the RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK (U+00BB in Unicode notation). They exist in the Cyrillic as well as the Latin-1 Windows encodings (CP1251 and CP1251), and they also exist in the Latin-1 UNIX encoding (ISO-8859-1). But they do not exist in the Cyrillic UNIX encoding (ISO-8859-5). This is why you got the problem in the first place when using rsubmit. When going from Russian (Cyrillic) to English (Latin1), you do not get this problem because the characters in question do exist in the Windows and UNIX encodings. You can either use characters that do exist in both encodings (e.g., the ASCII QUOTATION MARK , U+0022), or run the HP-UX SAS session with an encoding of wcyrillic (instead of the default cyrillic).
Figure 11: Text String Causing a Transcoding Error in SAS Management Console

You may see the same error in SAS Data Integration Studio. This is almost always the result of having user-written code with special characters. For example, code that is copied from a Word file and pasted into either an external file or a metadata code window usually causes this to occur when generating code for the job. In this case, you need to inspect all of the places in the job where user-written code can be supplied.
In the following example, the Note contains a special character that was copied from a Word document (in this case, the right arrow character from the Wingdings font: → ).
Figure 12: Quick Note with Arrow Character

As shown in the following figure, the use of this special character causes a transcoding error because the character in question does not exist in the Windows Latin1 encoding.
Figure 13: Transcoding Error in SAS Data Integration Studio
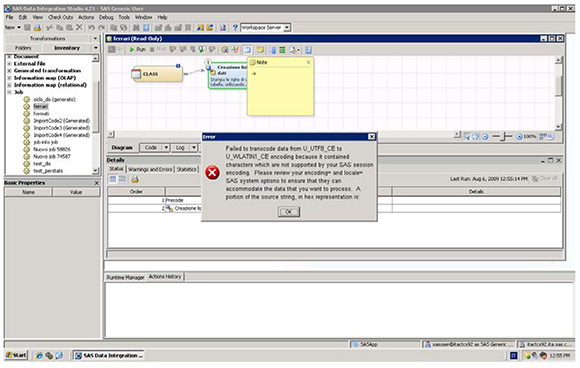
You need to either remove the offending character or run SAS with a session encoding that supports this character (UTF-8 in this case).
This problem can also occur for customers using DBCS (Asian language) SAS, because during the development of SAS Data Integration Studio processes, a user can mistakenly create broken DBCS characters, such as you see in the simple code below. Here variable y has a length of 3 and is assigned 2 DBCS characters. (The encoding is Shift-JIS, and each kanji character needs two bytes.) As mentioned in Chapter 3, SAS always measures the length of its character variables in bytes. Therefore, variable y is not big enough to hold the second DBCS character, so the character is broken.
data _null_;
x=”漢字”;
length y $3;
y=x;
put x= @10 x=$hex.;
put y= @10 y=$hex.; /* broken character at end */
run;
Figure 14: Broken DBCS Character

Question: I have a SAS 9 data set that I am trying to read. It has Japanese characters, and I keep getting the following error:
ERROR: Some character data was lost during transcoding in the dataset SUZUKI.AE.
ERROR: File YAMAHA.AE.DATA has not been saved because copy could not be completed.
Answer: First, you need to check the encoding of the data with one of the methods described previously. In this case, you may find out that it is in Shift-JIS encoding. To successfully read and process the data, you need to run a Japanese (DBCS) SAS session.
If you need to read Microsoft Excel spreadsheets, for instance, you have to set your Windows Regional Options to Japanese as explained previously.
Alternatively, you can read the spread sheets in a Unicode SAS session (English with DBCS and Unicode Support), but the Windows Regional Options should still be Japanese. When doing so, you may need to increase some or all character variables because UTF-8 needs more space for Japanese characters.
You may also see this transcoding error if the number of bytes for a character in a source encoding is smaller than that in a target encoding. For example, when transcoding from Windows Latin2 (CP1250) to UTF-8, the original variable lengths (in bytes) of the wlatin2 characters might not be sufficient to hold the values. In this situation, you can request that the Character Variable Padding (CVP) engine expand character variable lengths so that character data truncation does not occur.
The following examples show you how to import SAS 9 or SAS 8 data. In either case, you need to use the CVP engine to expand character variable lengths.
/*************************************************************/
/* SAS 9 data example */
/* */
/*************************************************************/
libname myfiles ‘SAS data-library’;
libname expand cvp ‘SAS data-library’;
data myfiles.utf8;12
set expand.wlatin2;
run;
Omitting the CVP engine results in the following transcoding error:
ERROR: Some character data was lost during transcoding in the dataset EXPAND.WLATIN2.
NOTE: The data step has been abnormally terminated.
NOTE: The SAS System stopped processing this step because of errors.
This action avoids the risk of data corruption or data loss.
/*************************************************************/
/* SAS 8 data example */
/* */
/*************************************************************/
libname myfiles ‘SAS data-library’;
libname expand cvp ‘SAS data-library’
data myfiles.utf8;
set expand.wlatin2 (encoding=wlatin2);
run;
The only difference in the SAS 8 and SAS 9 code example is that the SAS 8 data set needs the ENCODING= option, and the SAS 9 data set does not. Leaving out the CVP engine in the SAS 8 example would result in the same transcoding error above. Note: Omitting the ENCODING= option does not provoke an error message, but the output data might be corrupted.
The CVP engine does not adjust formats or informats automatically. If you have attached formats to your data variables, you might still run into truncation issues. In this case, you need to adjust these formats manually. The macro code13 that follows enables you to estimate the lengths of character variables (and format widths) when migrating data from a legacy encoding to UTF-8.
%macro
utf8_estimate(dsn,vars=_character_,maxvarlen=200,maxvars=20,out=);
data _utf8_est_ ;
set &dsn end=eof ;
array _c_ $ &vars ;
retain _maxvlen_1-_maxvlen_&maxvars ;
array _mv_ _maxvlen_1-_maxvlen_&maxvars ;
length temp $ &maxvarlen ;
length _vname_ $ 40 ;
do i = 1 to dim(_c_);
temp = put(_c_[i], $utf8x&maxvarlen..) ;
utf8len = length( temp ) ;
_mv_[i] = max(_mv_[i], utf8len ) ;
end ;
if eof then do ;
%if %length(&out) > 0 %then %do ;
call execute(“data &out(encoding=utf8) ;”);
%end ;
do i = 1 to dim(_c_) ;
_vname_ = vname(_c_[i]) ;
_vlen_ = vlength(_c_[i]) ;
_vlenopt_ = _mv_[i] ;
_vlenmax_ = max(_mv_[i], _vlen_) ;
if _vlenopt_ > _vlen_ then _vconv_ = ’Y’ ;
else _vconv_ = ’N’ ;
output ;
%if %length(&out) > 0 %then %do ;
if _vconv_ = ’Y’ then do ;
call execute (’length ’ || _vname_ || ’$’ || put(_vlenopt_,best12.) || ’;’ ) ;
end;
%end ;
end;
%if %length(&out) > 0 %then %do ;
call execute(”set &dsn ; ”);
call execute(”run; ”);
%end ;
end ;
label _vname_ = ’Variable Name’
_vlen_ = ’Current Variable Length’
_vlenopt_ = ’Estimated Variable Length’
_vlenmax_ = ’Required Variable Length’
_vconv_ = ’Conversion Required?’ ;
keep _vname_ _vlen_ _vlenopt_ _vlenmax_ _vconv_ ;
run;
%if %length(&out) = 0 %then %do ;
proc print data=_utf8_est_ label ;
run;
%end ;
%mend ;
The expected input is the data set you want to investigate; the input data set should be in the current SAS session encoding. The output data set needs to be specified after the out= macro keyword; the data is converted to UTF-8 after estimating the required character variable lengths. The macro code also creates a temporary data set _utf8_est_ with information about “Current Variable Length,” “Estimated Variable Length,” and “Required Variable Length”), and if there was a “Conversion Required.” If an adjustment was necessary, the current, estimated, or required lengths differ (if not they were the same).
Let’s have a look at an example. Imagine you have a data set similar to SASHELP.CLASS, but with data in Russian.
Table 1: Cyrillic SASHELP.CLASS

The following table shows a printing of the temporary data set _utf8_est_ :
Table 2: Output of %utf8_estimate Macro

This means that the lengths for the variables names, sexl and group, were increased (in the case of sexl, the length was doubled). The picture might be different with Western European data, and, again, different with data from Asian languages.
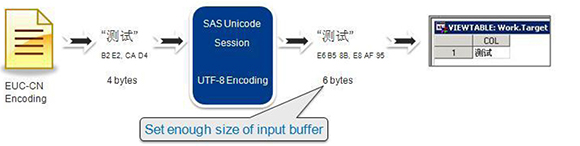
Another method is to calculate the size of the input buffer manually according to the bytes in the SAS session encoding and specify options with a large enough length setting when reading data. When you read data from an external file with fixed record length, you should allocate the space for the SAS variable length, which is called inner buffer size. For example, you may have a file encoded in EUC-CN with two Chinese characters (see Figure 15). The two Chinese characters take 4 bytes in the file. If you read the file in a SAS Unicode environment with UTF-8 encoding, the column length of the resulting table should be set to at least 6; otherwise, data truncation will occur. Typically, one Chinese character takes 3 bytes in UTF-8 encoding.
data target(encoding=’utf-8’);
Infile ‘c: dbcstext.txt’ encoding=’euc-cn’;
Input COL $ 6; /* the column length of result table should be set at least to 6 */
run;
Figure 15: Specifying Enough Space When Reading Data from an External File
Question: I cannot open a file that has a special character in its name on my Linux server. For example, if I try opening the file called “frédérique.txt,” I keep getting the following error message:
ERROR: Invalid open mode.
NOTE: The SAS System stopped processing this step because of errors.
A file with the same name could be opened without problems on a Windows machine. What is wrong here?
Answer: Generally speaking, UNIX has no defined encoding for filenames; hence, a filename is in the encoding that was set when it was created. So, if the OS locale was set to en_US.UTF-8, the filename’s encoding would be UTF-8. If you try to read this file into a Latin1 session, there will be no match. You need to either open the file in a session with a session encoding of UTF-8, or change the encoding of the filename accordingly. For example, convmv is a utility for converting filenames in directory trees from one encoding to another. For details, see the Linux convmv man page.
Multilingual Data Handling
Multilingual data, that is, data coming from a variety of regions, should be stored and processed in Unicode. For more details, see the SAS Technical Paper “Processing Multilingual Data with the SAS 9.2 Unicode Server” and the SAS Global Forum paper “New Language Features in SAS 9.2 for the Global Enterprise.” It may not always be necessary to use Unicode. You need to evaluate the pros (such as one single repository for all possible locales, or a seamless handling of data across all platforms) and cons (such as increased storage space, or special functions needed for data manipulation). You may come to the conclusion that a legacy encoding (see the section about compatible encodings in Chapter 3) would suffice for processing your data.
Question: A user in the U.S. works for a company headquartered in Japan, and keeps getting files created in Japan. What is the best way to exchange the data and avoid transcoding errors?
Answer: The short answer is “it depends.” There are several ways to handle this.
- The U.S. user can convert all the data to the Japanese encoding.
- Both the Japanese and the U.S. users can convert their data to UTF-8. This is especially the case if they have English and Japanese data in the near term. But if they expect to import data from other regions in the future, converting to Unicode is the better option.
- Another idea would be to suggest that the files created in Japan for sharing with the U.S. be created with ENCODING=ASCIIANY. That is, the files being shared with the U.S. colleagues either have no Japanese characters, or the U.S. customer would not be looking at the fields with Japanese characters. They could declare the incoming data as ASCIIANY. Here is an example:
libname t ‘c: emp’;
data test;
set t.japanese (encoding=asciiany);
run;
- They can use TRANSCODE=no to suppress transcoding. The TRANSCODE=NO attribute is a way to flag fields as binary, so they are not accidentally transcoded. Here is an example:
libname t ‘c: emp’;
data test;
attrib name transcode=no
first transcode=no
street transcode=no
city transcode=no
country transcode=no;
set t.japanese;
run;
Question: How can I store multilingual data in EBCDIC without risking data loss?
Answer: EBCDIC with its huge variety of code pages is not well suited for handling multilingual data. Even Western European languages use several incompatible code pages. However, here is a trick that enables you to do this. Let’s imagine that you stored address data from Western Europe in a multilingual customer database such as the one shown in the following table:
Table 3: Multilingual Address Data in EBCDIC Encodings

In addition to names and address data with national characters, we stored the corresponding variables with non-variant characters as well as the encoding of the particular observation.
The data displays correctly only if the emulator is set according to the language. In other words, Spanish data displays correctly only if the emulator is set to code page 1145; Danish data displays correctly if it is set to 1142, and so on.
The following figure shows an example for Spanish.
Figure 16: Display of National Characters in EBCDIC

We can see that only the name Gómez displays properly, whereas the others look inaccurate.
Now, the trick is that if the current encoding does not support display of the national characters of a particular observation, we can use English names that contain only non-variant characters. We can create subsets of the data with something like the following program:
libname x ‘SAS-data-library’;
DATA test;
SET x.multienc;
if (UPCASE(getoption(‘encoding’))) = (UPCASE(encod)) then
do;
name=name;
first=first;
street=street;
city=city;
country=country;
end;
else
do;
name=name_e;
first=first_e;
street=street_e;
city=city_e;
country=country_e;
end;
run;
SAS 8 data sets do not have an ENCODING attribute, so you can easily store data without having it tagged with a particular encoding.
To reproduce this behavior in SAS 9, you need to tag the data with an encoding attribute of EBCDICANY:
DATA test;
SET x.multienc (encoding=EBCDICANY);
if (UPCASE(getoption(‘encoding’))) = (UPCASE(encod)) then
do;
…
…
The following figure shows what the output of PROC PRINT looks like.
Figure 17: Output of PROC PRINT on z/OS

Depending on the emulation in use, national characters may still be distorted. However, the English variables (using non-variant characters only) are always fine.
To summarize: ANY, ASCIIANY, and EBCDICANY are special encoding options that enable users to store mixed encodings in the same data set. Only advanced users who know what they are doing should try this.
- EBCDICANY enables you to create a data set that contains multiple EBCDIC encodings.
- ASCIIANY enables you to create a data set that contains multiple ASCII-based encodings.
- ANY specifies that no transcoding is required, even between EBCDIC and ASCII encodings.
You may need to override default transcoding behavior for several reasons:
- You may want to create a data set that will contain mixed encodings and never have its character data transcoded on input or output by using ENCODING=ANY.
- You may want to create a data set that will contain mixed ASCII encodings and never have its character data transcoded as long as it is accessed from any ASCII-based session encoding by using ENCODING=ASCIIANY. (Note that only the 7-bit ASCII characters will appear correctly in all ASCII-based session encodings.) If the data set is accessed from an EBCDIC-based session encoding, transcoding will occur, and characters not supported by the EBCDIC-based session encoding will be lost.
- You may want to create a data set that will contain mixed EBCDIC encodings and never have its character data transcoded as long as it is accessed from any EBCDIC-based session encoding by using ENCODING=EBCDICANY. (Note that only the invariant EBCDIC characters will appear correctly in all EBCDIC-based session encodings.) If the data set is accessed from an ASCII-based session encoding, transcoding will occur, and characters not supported by the ASCII-based session encoding will be lost.
- You may wish to read a data set with mixed encodings (ANY, EBCDICANY, ASCIIANY, or an old data set with no set encoding) and have character data transcoded to the session encoding, presuming a particular encoding on the file. In this case, you can specify ENCODING=‘encoding name’ as an input data set option to override the mixed encoding that is set on the data set.
- You may wish to read a data set with a specific encoding set on the file without transcoding the character data to session encoding. In this case, you can specify ENCODING=ANY as an input or update a data set option to override the specific encoding that is set on the data set.
- In rare cases, you may believe that the encoding attribute has been set incorrectly. In this case, you can correct the encoding attribute of the SAS data set, as shown in the following example:
proc datasets library=work;
modify employees/correctencoding=wlatin1;
quit;
To re-emphasize: The correctencoding= option in the MODIFY statement in PROC DATASETS does not transcode the variables in the file; it changes only the encoding attribute of that file. If you need to correct the encoding attributes of an entire library, you can use the following macro:
%macro correctencoding(path= );
%local i n;
libname <your library> “&path” ;
options nofmterr;
data _null_;
set sashelp.vtable(where=(libname=’<your library>’ and memtype=’DATA’));
call symput(‘table’!!left(put(_n_,2.)),memname);
call symput(‘n’,left(put(_n_,2.)));
run;
%do i=1 %to &n;
proc datasets nolist library=<your library>;
modify &&table&i /correctencoding=wlatin1;
run;
quit;
%end;
%mend;
The PATH= parameter for the macro %correctencoding should be the path for the location (directory) where you have stored the SAS data sets whose file attributes need to be modified.
In any of the preceding cases, it is the user’s responsibility to know how to make sense of the data.
Garbage Characters in Output or Display
The term garbage characters means that text in output or display has been corrupted so that the text does not make sense. In Japanese, this phenomenon is called mojibake. Mojibake is usually seen when a document is tagged with an incorrect encoding attribute, or when it is moved to an operating system with a different default encoding.14
Question: I execute a stored process in a portal that exports SAS tables to Microsoft Excel. Instead of Cyrillic characters, I see garbage characters in the output though I am using an appropriate session encoding. What is going wrong here?
Answer: This is not related to STP servlet or stored processes. The problem can be reproduced in Base SAS by submitting the following code:
libname test ‘c: emp’;
filename _webout ‘c: emp est.htm’;
%let _ODSDEST = tagsets.MSOffice2K;
%STPBEGIN;
title “ТРАФИК”;
proc report data=test.otest nowindows; run; quit;
%STPEND;
The following figure shows what the output looks like.
Figure 18: Garbled HTML Output

Answer: To fix this, you need to make a simple change to the code by specifying the character set via the _ODSOPTIONS reserved macro variable:
%let _ODSDEST = tagsets.MSOffice2K;
%let _ODSOPTIONS=%str(charset=’windows-1251’);
%STPBEGIN;
title “ТРАФИК”;
proc report data=test.otest nowindows; run; quit;
%STPEND;
Then the output will look much better:
Figure 19: Correct HTML Output

The CHARSET= option specifies the character set to be generated in the META declaration for the output. Here is an example:
<META http-equiv=Content-Type content=”text/html; charset=windows-1251”>
Official character sets for use on the Internet are registered by IANA (Internet Assigned Numbers Authority). IANA is the central registry for various Internet protocol parameters, such as port, protocol and enterprise numbers, and options, codes, and types. For a complete list of character-set values, visit the IANA character set registry at http://www.iana.org/assignments/character-sets. Please note that character set is used like an encoding value in this context. However, character set is the term that is used to identify an encoding that is suitable for use on the Internet.
Question: We publish an HTML file with Hungarian text to a channel in a package, but with a MIME15 type of “application/vnd.ms-excel” supplied in INSERT_FILE (). This is because we want the published file to be opened by Microsoft Excel when it is accessed. When you browse the file, Hungarian characters look like garbage. For example, instead of “Beszállító azonosítója,” we get “BeszállĂ-tĂł azonosĂ-tĂłja.”
Figure 20: The Original HTML File Opened in a Web Browser
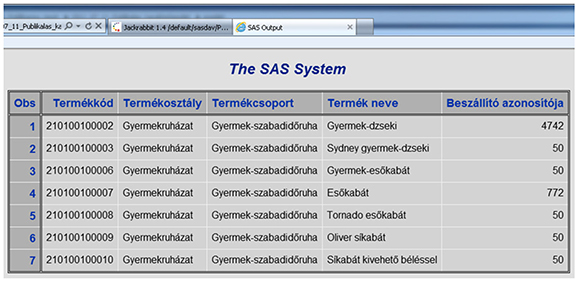
The following figure shows what the published file looks like.
Figure 21: The Published .xls File

Answer: All text files published to our WebDAV16 server are interpreted as UTF-8 since UTF-8 is common to all hosts. However, the charset META tag in the file’s header is still set to windows-1250, which corresponds to the session encoding of wlatin2. This means that wlatin2 characters are interpreted as UTF-8. In order to avoid this, you need to set the type parameter to “BINARY” as is shown in the following code snippet:
data _null_;
length
rc 8
pkg_id
8
pkg_descr $20
nameValue $80
properties $80
abstract $80
dtvalue
8
;
properties=”abstract,expiration_datetime”;
abstract=”Tesztpublikáció”;
dtvalue=datetime();
...
call INSERT_FILE(
pkg_id,
“filename:C: ech_suppMKB2011_11_03_Publikacios_teszt2011_07_11_Publikalas_karakterkeszleteredeti encoding_demo.htm”,
“BINARY”,
“application/vnd.ms-excel”,
“Beillesztés”,
“”,
rc
);
...
...
...
run;
Alternatively, you can use CALL INSERT_HTML with the encoding property set to “windows-1250” to use wlatin2 as HTML encoding. In either case, the published output will then look correct. For details, see the SAS Integration Technologies: Developer’s Guide.
Figure 22: The Published .xls File after Correcting the Code

Question: I am using the Japanese version of SAS. Some parts of the GUI still show garbage characters. What is wrong?
Figure 23: Japanese SAS with Some Garbage Characters

Answer: This is because your Windows system locale is not Japanese. You need to set your system locale to Japanese as explained previously. Then the whole GUI will display correctly.
Figure 24: Japanese SAS Displaying OK

Problems with RDBMS Access
The main problems that you might come across when retrieving data from or storing them into an RDBMS from SAS are character truncations or characters stored incorrectly in the database. In the latter case, you might see replacement characters—usually question marks, inverted question marks, or the Unicode replacement character � (U+FFFD).
When you access data in an RDBMS from a SAS session, it is critical that the RDBMS client software that is used to access the RDBMS server knows what the SAS session encoding is.
Question: When I try to import a DBF file with Hebrew characters, the output does not look right.
Figure 25: Garbled DBF Display

Answer: DBF files are in a file format that dBASE creates. dBASE is a relational database management system for PC systems. DBF files can be created using a variety of PC software programs, such as Microsoft Excel. Often DBF files have been saved in an OEM encoding. To transcode from the file encoding to the SAS session encoding, you need to use the DBENCODING= option as shown in the following sample.
PROC IMPORT OUT= WORK.TEST
DATAFILE= “C:TEMPcodes.dbf”
RDBMS=DBF REPLACE ;
GETDELETED=NO;
DBENCODING=pcoem862;
RUN;
Figure 26: Correct DBF Display

Question: I am opening Oracle data in SAS Enterprise Guide (using SAS/ACCESS Interface to Oracle). As shown in the following example, when I view a table in the data grid, some or all of the special characters are displaying as questions marks. What is wrong?
Figure 27: Question Marks When Reading Data from Oracle

Answer: There are a couple of things that you need to check: the character set of the Oracle database, the Oracle NLS_LANG parameter, and the locale and/or encoding of your SAS session. In this case, the database character set was UTF8, but the NLS_LANG character set was US7ASCII. If not set otherwise, the NLS_LANG value is AMERICAN_AMERICA.US7ASCII by default. NLS_LANG does not necessarily have to be the same as the database character set. However, it does have to be the same as the client character set (encoding). In this case, the SAS server is running with a session encoding of UTF-8. Hence, NLS_LANG has to be set to AMERICAN_AMERICA.UTF8 to match the client encoding.
The NLS_LANG FAQ at http://www.oracle.com/technetwork/database/globalization/nls-lang-099431.html from the Oracle Technology Network provides a good overview of how the NLS_LANG parameter works.
The situation is similar for any other relational database management system. To re-emphasize: You need to make sure that the server knows the client’s encoding. However, each RDBMS client software application has its own way of being configured with the client application encoding. So you need to check the respective software documentation. Table 4 in Chapter 3 provides an overview of client variables for the most frequently used database management systems.
Question: I am using SQL*Loader from SAS 9.2 on an HP-UX 64 Itanium to an Oracle Database 11g running on Windows Server 2003. The loader fails when a character field contains French characters. The database is set to AL32UTF8. I set NLS_LANG on both machines to NLS_LANG=FRENCH_CANADA.WE8MSWIN1252. I am still getting the following error. What seems to be the problem?
ORA-12899: value too large for column BILL_NMADR2 (actual: 26, maximum: 25).
Answer: You need to check all the database parameters, NLS_LENGTH_SEMANTICS in particular. You can do so from SAS with something like the following code:
proc sql;
connect to oracle (user=scott pw=tiger path=nlsbip08);
select * from connection to oracle
(select * from NLS_DATABASE_PARAMETERS);
quit;
If NLS_LENGTH_SEMANTICS was set to BYTE (as per default), a column with a length of 25 bytes may not be sufficient to hold 25 characters. This means two things:
- Changing NLS_LENGTH_SEMANTICS to CHAR via ALTER SYSTEM. This needs a restart to take effect and will affect newly created column definitions so that VARCHAR2(25) means VARCHAR2(25 CHAR) not VARCHAR2(25 BYTE.
- Changing existing column definitions via ALTER TABLE tabname MODIFY colname VARCHAR2(25 CHAR), and so on.
I hope that these few representative examples will suffice both to illustrate problem-solving strategies that are applicable to different types of situations, and to stimulate readers to think for themselves and to tackle specific problems on their own.
Chapter Summary
Always try to reduce a problem to its core. Cut out unnecessary clutter and try to reproduce the issue with a small, self-contained sample. In many cases encoding problems can be reproduced in Base SAS.
How can you diagnose encoding problems? In order to understand what might go wrong, I suggest that you follow the data on input, transfer, processing, and output. One of the first things to do is to check the session encoding of each SAS session involved.
You may also need to check the operating system’s locale and encoding. Typically, they should be synchronized with the SAS locale and encoding and the encoding of your data.
When you troubleshoot encoding problems, the reasons for the problem may not always be obvious. At times, some detective work is necessary to get to the source of a problem or there may be multiple problems.
( Endnotes)
1 See the corresponding chapter “Locale for NLS” in the SAS 9.2 National Language Support (NLS): Reference Guide.
2 The use of the DFLANG= option has been extended. It was introduced to support the EURDF* formats and informats. If it is set to DFLANG=LOCALE, it supports the NL* date/datetime formats and informats.
3 See also the corresponding chapter “Encoding for NLS” in the SAS 9.2 National Language Support (NLS): Reference Guide.
4 If a DBCS encoding and/or a CJK locale is set and the DBCS extensions are not available, SAS will not start.
5 “Microsoft Windows NT 3.1 was the first major operating system to support Unicode, and since then Microsoft Windows NT 4, Microsoft Windows 2000, and Microsoft Windows XP have extended this support, with Unicode being their native encoding.” See “Globalization Step-by-Step” at http://msdn.microsoft.com/en-us/goglobal/bb688113.
6 Haralambous, 2007, p. 221.
7 Code set is used as a synonym of encoding here.
8 X Window System. 2011, October 21, in Wikipedia, The Free Encyclopedia. Retrieved 12:18, October 26, 2011, from http://en.wikipedia.org/w/index.php?title=X_Window_System&oldid=456665230.
9 See Chapter 2.
10 On IBM mainframes, the characters $, #, and @ are called national characters because they can be replaced by other characters such as £ or ¥ for use outside the United States. Source: http://www.allbusiness.com/glossaries/national-characters/4951651-1.html#axzz214IB23JN. For the general definition of “national character,” see the “Glossary” in this book.
11 The major differences in these code pages are the square bracket characters. See Chapter 2.
12 Be careful. If a data set already exists, SAS uses the encoding stored in the original data set!
13 The code is available for download from the author’s page at http://support.sas.com/publishing/authors/kiefer.html.
14 Mojibake, 2011, October 31, in Wikipedia, The Free Encyclopedia. Retrieved 08:56, November 8, 2011, from http://en.wikipedia.org/w/index.php?title=Mojibake&oldid=458244359.
15 MIME = Multipurpose Internet Mail Extensions is an Internet standard that extends the format of e-mail to support, among other things, non-text attachments such as Microsoft Excel files.
16 WebDAV = Web-based Distributed Authoring and Versioning is a set of methods based on the Hypertext Transfer Protocol (HTTP) that facilitates collaboration among users in editing and managing documents and files stored on World Wide Web servers. WebDAV was defined in RFC 4918 by a working group of the Internet Engineering Task Force (IETF). (WebDAV, 2011, October 31, in Wikipedia, The Free Encyclopedia. Retrieved 12:20, November 8, 2011, from http://en.wikipedia.org/w/index.php?title=WebDAV&oldid=458270725.)