

Chapter 3
The SAS Approach to Encodings
There are 10 types of people in this world, those who understand binary and those who do not.
— Anonymous
Encoding in SAS 6
Support for European Locales
Host-to-Host Translation Tables
Transport-Format Translation Tables
Support for Asian Locales
Encoding in SAS 8
Encoding in SAS 9
Encoding of External Files
Encoding of SAS Data Sets
Encoding of RDBMS Tables
Encoding of Output
The SAS/GRAPH Approach to Encoding
SAS Fonts
Transcoding Revisited
How Do We Know Which Encodings Are Compatible with Each Other?
How to Check Character Encodings
Chapter Summary
Encoding in SAS 6
Support for European Locales
In SAS 6 and earlier, SAS was blissfully ignorant of encodings. However, to enable people to transfer their data across platforms, SAS introduced the concept of translate (or translation) tables to convert (transcode) data from one encoding to another.1 Translation tables (trantabs) are (still) mostly used in a European context.
To ensure portability of data and applications for European users, SAS software has basically been providing two data conversion mechanisms:
- Transport-format translation tables that use an intermediate transport format when transporting files from one host to another.
- Host-to-host translation tables that transcode characters directly from the source platform’s encoding to the target platform’s encoding.
These tables usually needed to be customized to accommodate encodings used for languages other than U.S. English. Since translation tables have been widely used and can still be used, the following section describes them in more detail.
Host-to-Host Translation Tables
Each entry contains two tables. The first table is for transcoding on import, and the second table is for transcoding on export. For example, the EBCDIC/ASCII-OEM entry (_00000A0) on z/OS contained an import table for the ASCII-OEM to EBCDIC conversion, and it contained an export table for the EBCDIC to ASCII-OEM conversion.
In SAS 6, host-to-host translation tables were used only with the REMOTE engine to provide access to remote data. In SAS 7 and SAS 8, the UPLOAD and DOWNLOAD procedures also use this method if both the client and server sessions were SAS 7 or 8, and if you were transferring a SAS data set. In SAS 9, these translation tables were superseded by the LOCALE= option; the %lswbatch macro2 could be used to set up the tables for a SAS 8 remote server.
Transport-Format Translation Tables
Translation occurs twice for every transmission. The data is translated from local to transport format, and then the receiving side translates from transport format to local format using the following translation table entries:
- SASXPT controls local-to-transport format translation.
- SASLCL controls transport-to-local format translation.
You can visualize transport format as an 8-bit array in which the 128 code positions in the lower half of the array correspond to ASCII, and the 128 code positions in the upper half of the array were initially unassigned. The default translation tables were meant for ASCII to EBCDIC conversions, where EBCDIC in this context meant code page 1047. The following diagram shows how this ASCII-to-EBCDIC conversion works:
0 1 2 3 4 5 6 7 8 9 A B C D E F
0 00010203372D2E2F1605150B0C0D0E0F
1 101112133C3D322618193F271C1D1E1F
2 405A7F7B5B6C507D4D5D5C4E6B604B61
3 F0F1F2F3F4F5F6F7F8F97A5E4C7E6E6F
4 7CC1C2C3C4C5C6C7C8C9D1D2D3D4D5D6
5 D7D8D9E2E3E4E5E6E7E8E9ADE0BD5F6D
6 79818283848586878889919293949596
7 979899A2A3A4A5A6A7A8A9C04FD0A107
8 20212223242A06172829152B2C090A1B
9 30311A333435360838393A3B04143EE1
A 41424344454647484951525354555657
B 58596263646566676869707172737475
C 767778808A8B8C8D8E8F909A9B9C9D9E
D 9FA0AAABAC4AAEAFB0B1B2B3B4B5B6B7
E B8B9BA4ABC6ABEBFCACBCCCDCECFDADB
F DCDDDEDFEAEBECEDEEEFFAFB6AFDFEFF
Let us have a closer look at some of those hexidecimal codes (marked in bold). The ASCII value 0x20 (a space) is converted to an EBCDIC value 0f 0x40. This is the crossing between the third row (row numbers start at 0) and the first column (column numbers also start at 0). Likewise, ASCII 0x23 (“#”) is converted to EBCDIC 0x7b and ASCII 0x40 (“@”) to EBCDIC 0x7c, and so on. The conversions in the lower half (0x00 to 0x7f) all worked for ASCII to EBCDIC code page 1047. The conversions in the upper half (0x80 to 0xff) were arbitrary, if you will, because they were irrelevant for English and other languages that use only the uppercase and lowercase letters A–Z and some special characters.
The EBCDIC-to-ASCII conversion is the mirror image of the ASCII-to-EBCDIC conversion, as shown in the following diagram:
0 1 2 3 4 5 6 7 8 9 A B C D E F
0 000102039C09867F978D8E0B0C0D0E0F
1 101112139D8A08871819928F1C1D1E1F
2 80818283840A171B8889858B8C050607
3 909116939495960498999A9B14159E1A
4 20A0A1A2A3A4A5A6A7A8D52E3C282B7C
5 26A9AAABACADAEAFB0B121242A293B5E
6 2D2FB2B3B4B5B6B7B8B9E52C255F3E3F
7 BABBBCBDBEBFC0C1C2603A2340273D22
8 C3616263646566676869C4C5C6C7C8C9
9 CA6A6B6C6D6E6F707172CBCCCDCECFD0
A D17E737475767778797AD2D3D45BD6D7
B D8D9DADBDCDDDEDFE0E1E2D5E45DE6E7
C 7B414243444546474849E8E9EAEBECED
D 7D4A4B4C4D4E4F505152EEEFF0F1F2F3
E 5C9F535455565758595AF4F5F6F7F8F9
F 30313233343536373839FAFBE5FDFEFF
Again, the conversion only considered the English character repertoire. So, this was not of much use for people using languages that use accented characters such as ä, é, or ø, not to mention those that use a very different script. In order to cater to those, you had to modify the default mapping of the upper 128 cells to fit the particular encoding that you were using. This was done by modifying the default SASXPT and SASLCL tables. You could do so with the TRANTAB procedure or the TRABASE macro. The TRABASE macro, which builds customized tables for a number of languages and operating systems, used to be part of the SAS sample library. It did not create tables for all possible combinations, but it could easily be adapted for specific needs. Later the NLSSETUP Application (also shipped as part of the SAS sample library) helped users prepare SAS to be used with a language other than English. With its point-and-click interface, it allowed programmers to create both transport-format and host-to-host translation tables for a great number of languages. It was superseded by the Locale Setup Window (LSW)3 in later releases.
Support for Asian Locales
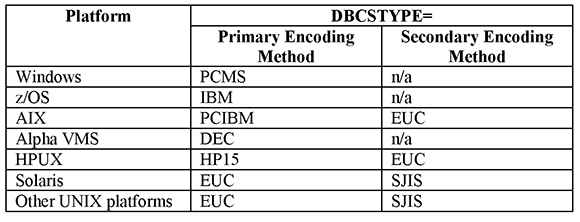
Support for Asian users has been available beginning with SAS 5. In SAS 6, SAS introduced the system options DBCS/NODBCS, DBCSTYPE=, and DBCSLANG= as well as cross-system conversion capabilities with SAS/CONNECT software, and so on.4
The DBCS system option specifies whether SAS recognizes double-byte character sets (DBCS). It is a toggle option whose values are either DBCS or NODBCS. DBCSTYPE specifies the encoding system to use, and DBCSLANG specifies the language to use.
Generally, you need to use all three of these system options together. Here is an example of how they are used in a SAS configuration file:
options dbcs /*turn on DBCS*/
dbcstype=IBM /*specify the IBM mainframe
environment*/
dbcslang=JAPANESE; /*specify the Japanese language */
The following tables list valid values for DBCSLANG and DBCSTYPE.
Table 1: Valid Values for the DBCSLANG= Option
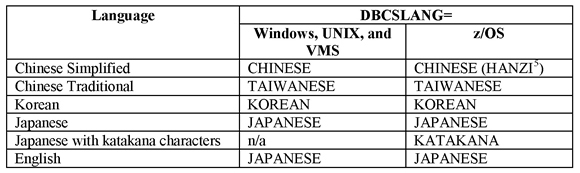
Table 2: Valid Values for the DBCSTYPE= Option
In later versions, the SAS session encoding (see below) could be implicitly specified with the DBCSTYPE= and DBCSLANG= options.
User-defined translation tables can be created with the DBCSTAB procedure. They are used as the 10th slot of the TRANTAB= system option. Here is an example:
OPTIONS TRANTAB=(,,,,,,,,, user_dbcs_table);
Encoding in SAS 8
In SAS 8, SAS introduced the concept of a session encoding. In a nutshell, session encoding is the encoding set for a SAS session by the ENCODING= system option. It also introduced the LOCALE= option that consolidates many features into one simple option. Among other things, the LOCALE= option implicitly sets the ENCODING= and TRANTAB= options. But you can also set the latter two options separately.
The following PROC OPTIONS statement displays the TRANTAB option values for a SAS session on z/OS:
proc options option=trantab; run;
The following figure shows the results for a SAS session on z/OS with a German session encoding.
Figure 1: SAS on z/OS with German Session Encoding

Table eo41wlt1 controls transcoding from open_ed-1141 (the session encoding) to Windows Latin1 (transport format); table wlt1eo41 does the reverse.
The following figure shows the results for a SAS session on z/OS with a Russian session encoding.
Figure 2: SAS on z/OS with Russian Session Encoding

Translation tables have limited use in SAS 8 and 9; but they are still relevant if you transfer external files with the procedures UPLOAD, DOWNLOAD, CPORT, and CIMPORT. As we have learned above, in SAS 6, transport format was basically ASCII and in its upper half undefined. You had to use customized translation tables to make sure that the conversion was going all right. With the introduction of session encoding, this became easier. Transport format was now a Windows encoding, but you still had to make sure that the sending and receiving side used compatible encodings. In other words, it does not make sense to use CPORT on data in a German locale and to use CIMPORT in a Russian one.
Encoding in SAS 9
In SAS 9, SAS applications work with multiple clients, such as Java, Microsoft Office, Web services, and with multiple output formats and delivery options. SAS uses and processes data from a variety of sources: external files (such as text files, spreadsheets, and so on), SAS data sets, and RDBMS tables. Hence, it is important that the encoding is always set appropriately. Encoding is ubiquitous in SAS 9. The good news is that the SAS locale and implicitly the encoding are set during the installation, depending on the OS locale. Most average users, then, should not have to worry about the encoding as long as they are happy with the default values that were set during the installation.
As mentioned, the locale option implicitly sets the encoding option, but you can set the encoding option separately.
Let’s have a look at some examples. By default, LOCALE=fr_FR (or French_France) sets the ENCODING= option to wlatin1 on a Windows PC. However, you can also set the encoding to pcoem850. This latter encoding can also be used with the French language.For an overview of languages and the corresponding encodings see Table 9 below.) You could even set the encoding option to wlatin2. In this case, you will see the following warning in the SAS log:
WARNING: The current session encoding, wlatin2, does not support the locale fr_FR (the POSIX name). However, the LOCALE system option has been set to fr_FR to reflect cultural features.
Beginning with SAS 9.3, DBCSLANG= and DBCSTYPE= are not set explicitly. The only two options the installer sets for a DBCS image are as follows:
-DBCS
-LOCALE
However, LOCALE=ja_JP (or Japanese_Japan) still sets DBCSLANG=JAPANESE and DBCSTYPE=PCMS implicitly in a Windows installation.
The following table gives you an overview of encoding-related options and their use.
Table 3: Encoding-Related Options in SAS


Data can come from a variety of sources, and it can be transformed into a practically unlimited variety of output formats. Here is a typical scenario for gathering and processing data: A company receives name and address source data from several countriesand from that data generates enhanced contact details for direct mail communications using SAS.
Below is an example of such a SAS data set7 with multilingual data viewed from SAS Enterprise Guide. Such data needs to be stored and processed in Unicode. SAS supports Unicode as session encoding in the form of UTF-8. This is the ideal solution for handling multilingual data.8
Figure 3: SAS Data Set with Multilingual Contact Data

Basically, data can be read into a SAS session from three sources:
- external files
- SAS files
- RDBMS tables
In each case, it is important to know about the particular encoding of the source. Let’s take a closer look at how the encoding of source data is determined.
Encoding of External Files
The FILE, FILENAME, and INFILE statements support the ENCODING= option, which enables users to dynamically change the encoding for processing external data.
SAS reads and writes external files using the current session encoding. This means that the system assumes the external file is in the same encoding as the session encoding. For example, if your session encoding is UTF-8 and you are creating a new SAS data set by reading an external file, SAS assumes that the file’s encoding is also UTF-8. If it is not, the data could be written to the new SAS data set incorrectly unless you specify an appropriate ENCODING option. Here is an example:
filename in ‘external-file’ encoding=’Shift-JIS’;
data mylib.contacts;
infile in;
length name $ 30 first $ 30 street $ 60 zip $ 10 city $ 30;
input name first street zip city;
run;
This code makes sure that the data of the external file is transcoded from Shift-JIS to UTF-8.
Likewise, when you write data to an external file, the data is written out in session encoding unless you specify an appropriate ENCODING= option. In the following example, we first create a subset of our contacts data, and then write the output to an external file with an encoding of Shift-JIS:
/* Create a subset with Japanese data from the main table */
proc sql;
create table japan as
select * from mylib.contacts where country_e = ‘Japan’;
quit;
/* Write the output to an external file with an appropriate encoding */
filename out ‘external-file’ encoding=’Shift-JIS’
data _null_;
set WORK.japan;
file out;
put @1 name @31 first @62 street @133 zip @144 city;
run;
When an external file contains a mix of character and binary data, you must use the KCVT function to convert individual fields from the file encoding to the session encoding. See the SAS National Language Support (NLS): Reference Guide for details on using the KCVT function.
Encoding of SAS Data Sets
In SAS 9, data sets have an encoding attribute in the data set header. When SAS reads a data set, it checks the data set header to see if the encoding matches SAS session encoding. When the data set encoding is different from the session encoding, the cross-environment data access (CEDA) facility automatically transcodes character data when it is read and when it is saved. Data sets from earlier releases of SAS do not have an explicit encoding attribute (they have an attribute of “default”), so you must specify the encoding of the incoming data with the ENCODING= data set option or the INENCODING= LIBNAME option. Likewise, you need to specify the encoding of outgoing data either with the ENCODING= data set option or the OUTENCODING= LIBNAME option.
To determine the encoding that was used to create the SAS data set, use the CONTENTS procedure. The following PROC CONTENTS statement displays the encoding value for the SAS data set:
PROC CONTENTS DATA=libref.member;
RUN;
Alternatively, locate the data set using SAS Explorer, right-click on the data set name, and then select View Columns from the menu. Finally, click the Details tab, and drill down to Encoding.
Figure 4: Encoding Attribute

A third method to determine the encoding of a SAS data set is to use the %SYSFUNC macro function. Here is an example:
%LET DSID=%SYSFUNC(open(mylib.contacts,i));
%PUT %SYSFUNC(ATTRC(&DSID, ENCODING)) ;
The same macro function can be used in combination with the GETOPTION function to determine the current session encoding. Here is an example:
%PUT %SYSFUNC(getOption(ENCODING)) ;
Valid values for the ENCODING= option can be found in the SAS National Language Support (NLS): Reference Guide.
The encoding attribute is just a flag; it does not necessarily mean that the data is encoded properly with the specified encoding. For instance, nothing prevents you from creating a transport file in a German session and trying to import this file in a Polish session. As with legacy data, you still need to know what you are doing, so to speak.
When using SAS 9.2 or later for both CPORT and CIMPORT, the encoding is checked and you get a WARNING if the data is not compatible. Here is an example:
The transport file was created in the encoding wlatin1. This session encoding, wlatin2, can read and create transport files in the encoding wlatin2. Data may not be imported correctly.
The encodings of the source and target SAS sessions must be compatible in order for a transport file to be imported successfully. However, if the encodings of the source and target SAS sessions are incompatible, a transport file cannot be successfully imported. For more information on problems with importing transport files, see the section “CIMPORT Problems: Importing Transport Files” in the Base SAS 9.2 Procedures Guide.
Though CEDA does its very best to transcode the data, the result may look undesirable if source and target encoding is incompatible. In this case, you will see a note that says this:
Data file SOURCE.DATA is in a format that is native to another host or the file encoding does not match the session encoding. Cross Environment Data Access will be used, which might require additional CPU resources and might reduce performance.
When transferring data, you need to make sure that client and server are using the same or compatible session encoding. What compatibility means is explained in more detail below.
I’ll leave it to you to decide whether it makes sense to connect from a Japanese SAS session on Windows using Shift-JIS encoding to a Polish SAS session on z/OS using an encoding of open_ed-870. It is possible, but you will see this WARNING message in the SAS log:

You need to make sure that the data that you are trying to transfer does not contain any characters that are not available in the target encoding.
What you cannot do is connect from a SAS Unicode server session (using a session encoding of UTF-8) to a Polish SAS session on z/OS using an encoding of open_ed-870. In this case, you will get this error message:
ERROR: The client session encoding utf-8 is not compatible with the server session encoding open_ed-870.
This is to prevent possible data loss or data corruption. You cannot use Data Transfer Services or Remote Library Services (RLS) in SAS/CONNECT software or the cross-architecture capability of SAS/SHARE software unless both client and server are using an encoding of UTF-8.
Encoding of RDBMS Tables
SAS/ACCESS software enables SAS to share data with Oracle, DB2, and other relational database management systems (RDBMS). SAS can read and write data to an RDBMS in the same manner as reading from or writing to a SAS library.
Transcoding from the database (server) encoding to the client (application session) encoding is usually determined by the OS locale where the client is installed. However, some of the RDBMS clients do not depend on the OS and can be configured differently. This is also true for SAS. The trick, then, is to make sure that the server knows the client’s encoding. In any case, as long as the SAS session encoding is equivalent to the RDBMS client encoding value, there will be no data loss.
Each RDBMS client software application has its own way of being configured with the client application encoding. Client variables ensure that the transcoding from the database encoding to the client’s encoding works correctly. See the following table for illustration.
Table 4: Client Variable Values of Various RDBMS

There are a couple of other attributes that you need to observe: which (character) data type the particular variables have and how variable lengths are defined.
Most database management systems use the following data types to hold textual data: CHAR, VARCHAR, NCHAR, and NVARCHAR. NCHAR and NVARCHAR are used to store Unicode data; CHAR and VARCHAR are used to store non-Unicode character data. In many applications, there is also a need to store large text or binary objects in the database. For these objects, the Large OBject (LOB) data type is available. Specifically, the CLOB9 and BLOB10 data types are available for large character and large binary objects, respectively.
Several engines support options for byte and character conversion and length calculation for a more flexible adjustment of column lengths with the CHAR, NCHAR, VARCHAR, and NVARCHAR data types to match the encoding on both database and client servers. However, different engines have different options, and the same option in another engine may behave differently. Check the documentation for the latest updates and to learn about new features.
Let’s look at how all this works with the specific example of the SAS/ACCESS Interface to Oracle. In Oracle, two character sets11 can be defined for the database (server): The NLS_CHARACTERSET is used for data types such as CHAR and VARCHAR2; the NLS_NCHAR_CHARACTERSET is used for NCHAR and NVARCHAR2 data types.
Both are defined when the database is created and are not intended to be changed afterwards dynamically. NLS_ NCHAR_CHARACTERSET was originally supposed to define an alternate character set, the so called “national character set.” From Oracle version 9i onwards, the NLS_NCHAR_CHARACTERSET can have only two values: UTF8 or AL16UTF16, which are the Unicode character sets in the Oracle database.12 Nevertheless, you can also use the CHAR and VARCHAR2 columns for storing Unicode data in a database that uses AL32UTF8 or UTF8 as NLS_CHARACTERSET.
The NLS_LANG parameter is responsible for setting the locale used by the client application and the database server. NLS_LANG is used to let Oracle know which character set your client application is using so that Oracle can convert from the client’s character set to the database character set, when needed.
NLS_LANG consists of three components, which are specified in the following format, including the punctuation:
NLS_LANG=<Language>_<Territory>.<character set>
For our purposes, we can disregard the first two components and concentrate on the <character set> part of NLS_LANG. For SAS using wlatin1as session encoding, this part of NLS_LANG must be WE8MSWIN1252; for SAS using shift-jis, it should be JA16SJIS to match the SAS session encoding. For details about possible NLS_LANG values, check the respective Oracle documentation.13 NLS_LANG is set as a local environment variable on UNIX platforms. It is set in the Windows registry or in the environment on Windows platforms.
Figure 5: Example of Setting NLS_LANG in the Windows Registry

The “Trouble Shooting SAS/ACCESS Encoding Settings” section of Processing Multilingual Data with the SAS 9.2 Unicode Server illustrates what happens if NLS_LANG uses a wrong value.
BYTE versus CHARACTER Semantics
Calculating column lengths in bytes is called BYTE semantics; measuring the lengths in characters is called CHARACTER semantics. Depending on the data type, most database management systems support either BYTE or CHARACTER semantics. Oracle is the only RDBMS that supports both BYTE and CHARACTER semantics. See the following table for illustration.
Table 5: Data Types and Length Semantics in Several RDBMS


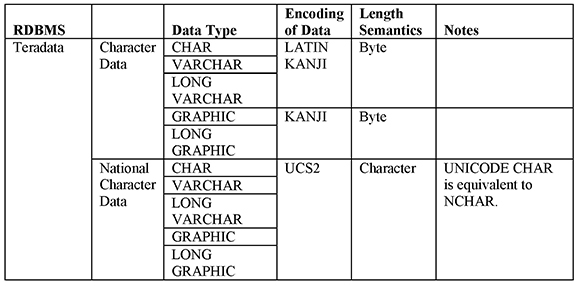
The length semantics determine whether the length of a column is specified in bytes or in characters. For example, a definition of CHAR(3) in CHARACTER semantics means 3 character in length. In BYTE semantics, it means 3 bytes in length. This is not an issue for single-byte encodings where a character is always 1 byte. However, this difference does become an issue with multi-byte encodings where a character is not always equivalent to a byte. Let’s have a look at an example to illustrate this.
Data transfer between SAS and the RDBMS may require data expansion if the encodings in SAS and the RDBMS are different. (If both use the same encoding, there is no character conversion.) For example, the Chinese character for “2D table” in the RDBMS (GBK: ‘表’ [0xB1][0xED]) is converted into the SAS Unicode server (UTF-8) by 3-bytes length (UTF-8: ‘表’ [0xE8][0xA1][0xA8]). On the other hand, the 2-byte length character in SAS using GBK takes 3 bytes of length in the RDBMS with UTF-8.
Figure 6: “2D Table” in GBK and UTF-8 Encoding

Let’s again use the SAS/ACCESS Interface to Oracle as an example to see how this works in practice. As we learned previously, the NLS_LENGTH_SEMANTICS parameter in Oracle determines whether a column of character data type is calculated in bytes or characters. This means a CHAR column with a length of 10 has 10 characters when using character semantics. These 10 characters correspond to 20 bytes in GBK but to 30 bytes in UTF-8. However, SAS always measures the length of its variables in bytes, and in SAS 9.1.3, SAS/ACCESS simply doubled the Oracle variable length to avoid truncation. If a CHAR column with Chinese characters and a length of 10 was transferred to a SAS Unicode server via SAS/ACCESS, SAS 9.1.3 doubled the CHAR (10), which was then10*2=20 bytes in SAS. But it really should have been 10*3=30 bytes. So the last 10 bytes were truncated.
In SAS 9.2, the following LIBNAME options were added to make the variable length more flexible:
- DBCLIENT_MAX_BYTES specifies the maximum number of bytes per character in the database client encoding (which matches SAS encoding). This option is used as the multiplying factor when adjusting the column lengths for CHAR/NCHAR columns for the client encoding. The default is always set to match the maximum bytes per character of the SAS session encoding. This default should be sufficient for most cases, and there should be no need to set this option. For example, with a SAS session encoding of UTF-8, the value is 4.
- DBSERVER_MAX_BYTES specifies the maximum number of bytes per character in the database server encoding. This option is used to derive the number of character values from the lengths for columns created with byte semantics. Use this option to adjust the client lengths of columns created with byte semantics. The default is usually 1, but it might be set to another value if the information is available from the Oracle server.
- ADJUST_BYTE_SEMANTIC_COLUMN_LENGTHS indicates whether the lengths should be adjusted for CHAR/VARCHAR data types. When this option is set to NO, any lengths specified with BYTE semantics on the server are used as on the client side. When this option is set to YES, the lengths are divided with the DBSERVER_MAX_BYTES value and then multiplied with the DBCLIENT_MAX_BYTES value. The default is YES if DBCLIENT_MAX_BYTES is greater than 1; it is NO if DBCLIENT_MAX_BYTES is equal to 1.
- ADJUST_NCHAR_COLUMN_LENGTHS indicates whether the lengths should be adjusted for NCHAR/NVARCHAR data type columns. When set to NO, any lengths specified with NCHAR/NVARCHAR columns are multiplied with the maximum bytes per character value of the database national character set. When this option is set to YES, the lengths are multiplied with the DBCLIENT_MAX_BYTES value.
In SAS 9.3, the following options were added:
- DBSERVER_ENCODING_FIXED specifies whether the database encoding is of a fixed width.
- DBCLIENT_ENCODING_FIXID specifies whether the SAS session encoding is of a fixed width.
The following table shows how these options work together in SAS 9.3. The first table illustrates writing to an Oracle table from SAS.
Table 6: Calculating Variable Lengths When Writing to an Oracle Table

The second table illustrates reading from an Oracle table from SAS.
Table 7: Calculating Variable Lengths When Reading from an Oracle Table

This may still look complicated; a practical example should illustrate the point. Let’s assume we have an Oracle database defined with the following parameters:
NLS_NCHAR_CHARACTERSET UTF8
NLS_LANGUAGE AMERICAN
NLS_TERRITORY AMERICA
NLS_CURRENCY $
NLS_ISO_CURRENCY AMERICA
NLS_NUMERIC_CHARACTERS .,
NLS_CHARACTERSET AL32UTF8
NLS_CALENDAR GREGORIAN
NLS_DATE_FORMAT DD-MON-RR
NLS_DATE_LANGUAGE AMERICAN
NLS_SORT BINARY
NLS_TIME_FORMAT HH.MI.SSXFF AM
NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM
NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR
NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR
NLS_DUAL_CURRENCY $
NLS_COMP BINARY
NLS_LENGTH_SEMANTICS BYTE
NLS_NCHAR_CONV_EXCP FALSE
NLS_RRDBMS_VERSION 11.2.0.1.0
In case 1, we access this database as follows from a SAS session with a session encoding of EUC-CN:
libname lib1 oracle path=nlsbip08 user=scott pw= tiger dbserver_max_bytes=3
dbclient_max_bytes=2 dbclient_encoding_fixed=yes;
Now we insert a character into the database using a DATA step:
data lib1.eucfixed;
string=’表’;
run;
According to our formula: DBLEN = SASLEN / DBCLIENT_MAX_BYTES * DBSERVER_MAX_BYTES. The character is stored in the database with a length of 3 bytes: DBLEN = 2/2 * 3 = 3.
We can check this in SQL*Plus and get the following:

When running PROC CONTENTS, we get the following:

This is because our formula for reading has: SASLEN = DBLEN*DBCLIENT_MAX_BYTES. The character is read in with a length of 6 bytes: SASLEN = 3*2=6.
In case 2, we access the database as follows from a SAS session with a session encoding of EUC-CN:
libname lib2 oracle path=nlsbip08 user=scott pw=tiger dbserver_max_bytes=3
dbclient_max_bytes=2 dbclient_encoding_fixed=no;
Now we insert the same character into the database:
data lib2.eucnotfixed;
string=’表’;
run;
According to our formula: DBLEN = SASLEN * DBSERVER_MAX_BYTES. The character is stored in the database with a length of 6 bytes: DBLEN = 2 * 3 = 6.
We can check this in SQL*Plus and get the following:

When running PROC CONTENTS, we get the following:

This is because our formula for reading (again) has: SASLEN = DBLEN * DBCLIENT_MAX_BYTES. The character is read in with a length of 12 bytes: SASLEN = 6*2=12.
In any case, you need to decide which of these options would serve your purpose best. And, just to re-emphasize, these options are meant for the SAS/ACCESS Interface to Oracle in SAS 9.3. Other SAS/ACCESS products may use different options or use them in a different way. Subsequent versions may be coded differently. Always check the latest documentation for any changes in the actual installation and configuration of SAS/ACCESS products.
Encoding of Output
Generally, session encoding is used by applications that create output or that establish communications with applications whose syntax and protocols are not determined by SAS. However, you can also set the encoding explicitly if you want your output to be created using a different encoding. In the following example, we want to create XML output in wlatin2, whereas our session encoding is UTF-8:
/* Specify a fileref for the XML document and write the output in the wlatin2 encoding */
filename xmlout ‘c: emppolish.xml’;
libname out xml xmlfileref=xmlout xmlencoding=wlatin217;
/* Create a subset with Polish data from the main table */
proc sql;
create table out.polish as
select * from mylib.contacts where country_e = ‘Poland’;
quit;
proc print data=out.polish;
run;
The XML header will then look like this:
<?xml version=”1.0” encoding=”windows-1250” ?>
The SAS/GRAPH Approach to Encoding
SAS/GRAPH software uses a different approach. To compensate for differences between the way that characters are encoded in different operating systems and output devices, the software stores all characters using its own internal encoding scheme,18 which is a set of hexadecimal values that are associated with the supported characters. The following figure shows these internal character encoding (ICE) codes. To view such a table for yourself, run the following code, which uses the Swiss font:
goptions keymap=none;
proc gfont nb name=swiss hex;
run;
quit;
Figure 7: Internal Character Encoding (ICE) Chart

SAS/GRAPH internal encoding bears a strong resemblance to DOS code page 437 but contains more graphical characters.
Key maps (or keymaps) convert your keyboard input into the corresponding SAS/GRAPH internal encoding. Device maps (or devmaps) convert the internal encoding to the codes that are required to produce the corresponding characters on your output device. Key maps and device maps that are supplied by SAS are stored in the catalog SASHELP.FONTS. User-generated key maps and device maps are stored in the catalog GFONT0.FONTS. Key maps are stored with the extension KEYMAP (for example, WLT1.KEYMAP), and device maps are stored with the extension DEVMAP (for example, DEFAULT.DEVMAP).
SAS Fonts
All this applies to software fonts—that is, fonts created and delivered by SAS, or created by users with SAS. Software fonts are the entries in the SASHELP.FONTS catalog. Though software fonts are now largely superseded by TrueType fonts, these fonts might still be used in legacy applications. There are several restrictions. For example, Java and ActiveX devices do not support software fonts, and they are not well suited to create multilingual output.
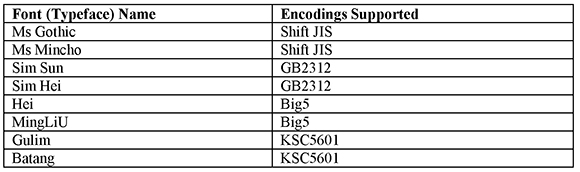
Since SAS 6.10, SAS has supplied two TrueType fonts with Base SAS: SAS Monospace and SAS Monospace Bold. More TrueType fonts were provided with SAS 9. The new SAS fonts were licensed from Monotype Corporation and Ascender Corporation to address problems with display and print quality of text and support of national language characters including Asian locales and WYSIWYG support (see the following table). Beginning with SAS 9.2, all XU printers and a few SAS/GRAPH drivers support TrueType fonts via the FreeType library. Output created with ODS statements and/or SAS Print dialog boxes can be viewed and/or printed across all of the operating systems that SAS software supports. TrueType fonts offer quick rendering, a panorama of portable fonts and, above all, quality output.

Transcoding24 Revisited
Transcoding can occur in the following situations:
- When you move a SAS file from one platform to another and the file’s encoding is different from the current session encoding—for example, from a z/OS operating environment with an EBCDIC-based encoding to a Windows operating environment with an ASCII-based encoding.
- When you share data between two SAS sessions (like in a client/server environment) that use different session encodings.
- When you read or write an external file.
In all these cases, transcoding errors can occur. Data loss or data corruption occurs if the encodings involved are incompatible. The golden rule is: You can successfully transcode only if the sending and the receiving encodings are compatible—that is, if the same character is available on either side.
How Do We Know Which Encodings Are Compatible with Each Other?
Beginning with SAS 9.3, SAS provides two new system options that enable you to verify whether two encodings are compatible and whether an encoding name is valid:
- The ENCODCOMPAT function verifies the transcoding compatibility between two encodings.
- The ENCODISVALID function specifies a valid encoding name.
For example, if your session encoding is wlatin1, the following code will return a ,1 which means the encodings are compatible; transcoding is not needed:
%PUT IsCompat = %SYSFUNC( EncodCompat(cp1252)) ;
The following code will return a 3, which means the character string is a valid alias encoding name:
%PUT IsValid = %SYSFUNC( EncodIsValid(cp1252)) ;
See the latest SAS National Language Support (NLS): Reference Guide for details on using these options.
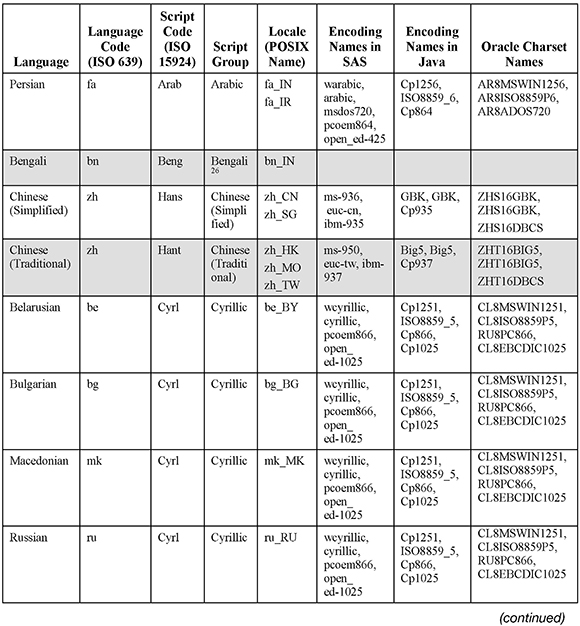
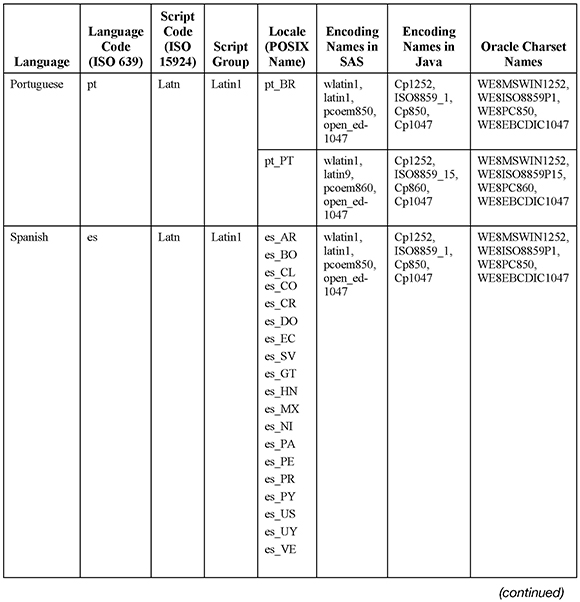
Also, most users might find the following comprehensive table useful. It is meant to give you an overview about which languages share the same encoding and can be used together in SAS. First, we need to re-emphasize that there is no 1:1 correlation between a language and the writing system that it uses. A script may be used for a single language only (e.g., Thai or Telugu), but in most cases a script is used for multiple languages (e.g., Latin or Cyrillic). Certain languages may even use multiple writing systems (e.g., Japanese or Serbian). The same is true for the numerous encoding systems that have been developed to encode the characters of a script. To make things even more complicated, a script can be encoded in several incompatible encodings.
In order to group the languages sensibly, it was necessary to make compromises. In the following table, the column “Encoding Names (in SAS)” lists mainly the primary encodings that are used as session encoding on a particular platform. This means, for example, that languages that logically belong to the group of Western (Latin1) languages may use Latin9 as session encoding if the corresponding countries are members of the European Monetary Union (EMU). Latin1 and Latin9 (and the corresponding ISO standards) are essentially the same; the major difference is the Euro symbol, which replaces the international currency symbol in Latin9 (ISO-8859-15). The same is true for Latin2 (used for Central European languages) and Latin10 (ISO-8859-16), though the latter is not supported in SAS. Vietnamese is grouped as a category of its own,though it also uses the Latin script. However, the Vietnamese alphabet of Latin letters with up to two accents was too large to fit into any of the ISO 8859 standards (Latin1 to Latin10). As mentioned before, Chinese language speakers use two different scripts—simplified and traditional. That is why the table lists them as separate categories. Traditional Chinese characters are used primarily in Taiwan, Hong Kong, and Macau; Simplified Chinese is used in the People’s Republic of China and Singapore. The main Indic scripts are encoded in the Indian Standard Code for Information Interchange (ISCII). Nonetheless, the Indic scripts are listed separately for systematic reasons. ISCII “has not been widely used outside of certain government institutions and has now been rendered largely obsolete by Unicode.”25
In some cases, the script labels may confuse people. For instance, the Arabic writing system is used to represent the Arabic language, along with several others (e.g., Urdu and Persian).
Generally, grouping languages together under the same label does not mean that they are linguistically related. For instance, Finnish and Swedish both use the same script and encoding (i.e., Latin1 (Latin9)), but they are completely unrelated. But closely related languages such as Polish and Russian use different scripts and encodings (Latin2 versus Cyrillic). English is listed (for systematic reasons) as Latin1, but it can be used with any encoding. A number of other languages (for example, German) can also be used with other encodings such as Latin2, Latin3, etc. (see above), but again for systematic reasons that they are listed in one category only. Other caveats are indicated in several notes. The shading of the table is meant to group languages and make the data easier to read.
Table 9: Compatible Languages and Encodings in SAS








How to Check Character Encodings
Quite often you can end up in a situation where you see garbage characters on the screen or in your printed output. In most or all cases, this is due to the fact that either your environment has not been set up correctly, or something went wrong with transcoding.
You do not need to understand binary, but you should be able to check and interpret the hexadecimal values of characters. This will really tell you how a character has been stored in a file, no matter what the display shows you. There are various ways to do so. Some operating systems have mechanisms to display hexadecimal values, or you may want to use a specific editor or make use of specific formats in SAS.
Let’s check some simple test code that uses several of the special characters used in the French language, and see how we can check the hexadecimal values of the special characters:
filename test …;
data _null_;
file test;
put “Test: un élève s’en va à l’école sur son âne”;
run;
For example, as shown in the following figure, on z/OS, you can use the command “hex on” from the primary command field of the ISPF editor to display the hexadecimal values of characters in a file. With the command “hex off,” you turn it off again.
Figure 8: Hexadecimal Display in ISPF Editor

In the previous figure, we can see that the character “é” (Latin Small Letter e with acute) has a hexadecimal value of 0xC0—this corresponds to the value of this character in the EBCDIC code page 1147.
Using another example, od is an octal dumping program for UNIX and UNIX-like systems. It can also dump hexadecimal or decimal data. Using the following command, you can print a record of the test.sas program.
od –x test.sas
Figure 9: od Dumping Program

This may be a bit difficult to read, so let’s concentrate on the underlined lines. They show the text “Test: un élève s’en va à l’école sur son âne”—but with hexadecimal characters. Now, the character é, for instance, has a hexadecimal value of 0xE9—and this corresponds to the value of this character in the ISO-8859-1 (Latin-1) encoding.
In addition, there are many good hexadecimal editors out there,34 some of them being freeware or shareware. Their features vary, but all of them allow you to display every character in a file in hexadecimal notation.
A very convenient way to display a file’s hexadecimal content in SAS is to use the $HEXw. format. The $HEXw. format converts each character into two hexadecimal characters. This works on any operating system that SAS supports. To ensure that SAS writes the full hexadecimal equivalent of your data, make w twice the length of the variable or field that you want to represent. If w is greater than twice the length of the variable that you want to represent, then $HEXw. pads it with blanks (0x20 in ASCII or 0x40 in EBCDIC). In the following code sample, the content of the file test is printed to the LOG both in character and in hexadecimal format.
data _null_;
infile test;
input;
put _infile_ _infile_ $hex90.;
run;
Test: un élève s’en va à l’école sur son âne
546573743A20756E20E96CE87665207327656E20766120E0206C27E9636F6C652073757220736F6E20E26E65
NOTE: 1 record was read from the infile TEST.
The minimum record length was 44.
The maximum record length was 44.
NOTE: DATA statement used (Total process time):
real time 0.00 seconds
cpu time 0.00 seconds
Chapter Summary
Due to the evolutionary nature of SAS software, support for encodings developed gradually. In SAS 6 and earlier, it was the user’s responsibility to store the data correctly in an encoding that was appropriate. But SAS 9 offers a broad variety of encoding-related options, and the average user should not have to worry about the encoding as long as they are happy with the default value that was set during the installation.
Data may come from a variety of sources, and it can be transformed into a practically unlimited variety of output formats. In each case, the encoding needs to be determined to avoid data corruption or data loss.
Transcoding is the process of mapping data from one encoding to another. In order to avoid data loss or data corruption, the encodings involved need to be compatible. You can successfully transcode only if the same characters are available on either side.
You do not need to understand binary, but you should be able to check and interpret the hexadecimal values of characters. This will tell you how a character has really been stored in a file, no matter what the display shows you.
( Endnotes)
1 The following description of data conversion mechanisms in SAS is largely based on SAS Technical Document TS-639, 2007, “Data conversion issues in v6-v8 which is of special interest for customers using languages other than English,” at http://support.sas.com/techsup/technote/ts639.pdf.
2 See SAS Technical Document TS-706, 2007, “How to use the %lswbatch macro,” at http://support.sas.com/techsup/technote/ts706.pdf.
3 The LSW should not be confused with the Locale Setup Manager of SAS 9. Locale Setup Manager is a Java client (available on Windows only) that allows users to change the locale configuration of a SAS Java client (i.e., SAS Management Console, SAS Data Integration Studio, etc.).
4 For a history of SAS System Support for Asian Languages, see Kayano, Shin, and Richardson, Lee, 1993, “SAS System Support for Asian Languages,” in Observations: The Technical Journal for SAS Software Users, 2(2), 4-11.
5 Alias.
6 z/OS only.
7 The sample data set is available for download from the author’s page at http://support.sas.com/publishing/authors/kiefer.html.
8 Much of the information in the following sections is based on the Technical Paper “Processing Multilingual Data with the SAS 9.2 Unicode Server” at http://support.sas.com/resources/papers/92unicodesrvr.pdf.
9 A CLOB (Character Large Object) “is a collection of character data in a database management system, usually stored in a separate location that is referenced in the table itself. Oracle and IBM DB2 provide a construct explicitly named CLOB, and the majority of other database systems support some form of the concept, often labeled as text, memo, or long character fields.” (“Character large object,”2010, July 15, Wikipedia, The Free Encyclopedia. Retrieved 11:09, October 27, 2011, from http://en.wikipedia.org/w/index.php?title=Character_large_object&oldid=373656108.)
10 A BLOB (Binary Large Object) “is a collection of binary data stored as a single entity in a database management system. BLOBs are typically images, audio, or other multimedia objects, though sometimes binary executable code is stored as a BLOB.” (Binary large object. (2011, August 17). In Wikipedia, The Free Encyclopedia. Retrieved 11:10, October 27, 2011, from http://en.wikipedia.org/w/index.php?title=Binary_large_object&oldid=445305789.)
11 Character set is meant as a synonym for encoding in this context.
12 “In releases before Oracle9i, the NCHAR data type supported fixed-width Asian character sets that were designed to provide higher performance. Examples of fixed-width character sets are JA16SJISFIXED and ZHT32EUCFIXED. No Unicode character set was supported as the national character set before Oracle9i.” (Oracle Corporation, 2002, Oracle9i Database Globalization Support Guide, Release 2 (9.2), Part No. A96529-01, p. 5-8.)
13 See also SAS Technical Document TS-691, “SAS encoding values, IANA preferred MIME charset, Java and Oracle encoding names.”
14 ASCII here means any ASCII-based encoding such as Latin1 or Shift-JIS.
15 The CHAR/VARCHAR data type supports only the ISO Latin-9 encoding.
16 The ANSI SQL standard NCHAR/NVARCHAR data type supports Unicode using the UTF-8 encoding.
17 Alternatively, you can use odscharset=”windows-1250” with the LIBNAME statement.
18 Cf. Walker, Douglas, 1988, “Version 6 SAS/GRAPH Software Support for National Characters,” SUGI 13: Proceedings of the Thirteenth Annual SAS Users Group International Conference, Orlando, Florida, March 27-30, 1988, p. 398.
19 A typeface is a set of glyphs with a common design, represented by one or more fonts that differ in weight, orientation, width, size, and spacing. For example, Arial, Arial Bold, Arial Italic, and Arial Bold Italic share the same typeface (Arial), but differ in their orientation and weight.
20 With Han ideographs from CP936 drawn in Simplified Chinese style.
21 With Han ideographs from CP950 drawn in Traditional Chinese style.
22 With Han ideographs from CP932 drawn in Japanese style.
23 With Han ideographs from CP932 drawn in Korean style.
24 See the corresponding chapter, “Transcoding for NLS,” in the SAS 9.2 National Language Support (NLS): Reference Guide.
25 Indian Script Code for Information Interchange, 2011, October 9, in Wikipedia, The Free Encyclopedia. Retrieved 12:13, October 26, 2011, from http://en.wikipedia.org/w/index.php?title=Indian_Script_Code_for_Information_Interchange&oldid=454666490.
26 Used with Latin1 in SAS.
27 The various EBCDIC code pages for Western languages all share the Latin1 character repertoire; nonetheless, they are incompatible with each other. See SAS Technical Document TS-758,2009, “Ensuring Compatibility of Encoding across Different Releases of the SAS System in the z/OS Environment.”
28 Should rather use Latin8.
29 Should rather use Latin6.
30 Could also use Latin3.
31 Latin6 (ISO 8859-10) is not supported in Java. Java supports Latin4 and Latin7, which are not yet supported in SAS. All three encodings are suitable for the Baltic languages as well as for Greenlandic.
32 Used with Latin1 in SAS.
33 Used with Latin1 in SAS.
34 For an overview, see “Comparison of hex editors” in Wikipedia at http://en.wikipedia.org/wiki/Comparison_of_hex_editors.