
Hadoop scales horizontally as the data grows. Hadoop runs on commodity hardware, so it is cost-effective. Intensive data applications are enabled by scalable, distributed processing frameworks that allow organizations to analyze petabytes of data on large commodity clusters. Hadoop is the first open source implementation of map-reduce. Hadoop relies on a distributed framework for storage called HDFS (Hadoop Distributed File System). Hadoop runs map-reduce tasks in batch jobs. Hadoop requires persisting the data to disk at each map, shuffle, and reduce process step. The overhead and the latency of such batch jobs adversely impact the performance.
Spark is a fast, distributed general analytics computing engine for large-scale data processing. The major breakthrough from Hadoop is that Spark allows data sharing between processing steps through in-memory processing of data pipelines.
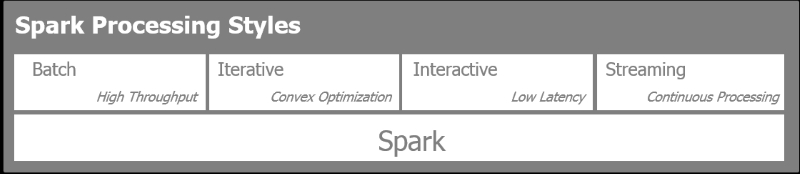
Spark is unique in that it allows four different styles of data analysis and processing. Spark can be used in:
- Batch: This mode is used for manipulating large datasets, typically performing large map-reduce jobs
- Streaming: This mode is used to process incoming information in near real time
- Iterative: This mode is for machine learning algorithms such as a gradient descent where the data is accessed repetitively in order to reach convergence
- Interactive: This mode is used for data exploration as large chunks of data are in memory and due to the very quick response time of Spark
The following figure highlights the preceding four processing styles:
Spark operates in three modes: one single mode, standalone on a single machine and two distributed modes on a cluster of machines—on Yarn, the Hadoop distributed resource manager, or on Mesos, the open source cluster manager developed at Berkeley concurrently with Spark:

Spark offers a polyglot interface in Scala, Java, Python, and R.
Spark comes with batteries included, with some powerful libraries:
- SparkSQL: This provides the SQL-like ability to interrogate structured data and interactively explore large datasets
- SparkMLLIB: This provides major algorithms and a pipeline framework for machine learning
- Spark Streaming: This is for near real-time analysis of data using micro batches and sliding widows on incoming streams of data
- Spark GraphX: This is for graph processing and computation on complex connected entities and relationships
Spark is written in Scala. The whole Spark ecosystem naturally leverages the JVM environment and capitalizes on HDFS natively. Hadoop HDFS is one of the many data stores supported by Spark. Spark is agnostic and from the beginning interacted with multiple data sources, types, and formats.
PySpark is not a transcribed version of Spark on a Java-enabled dialect of Python such as Jython. PySpark provides integrated API bindings around Spark and enables full usage of the Python ecosystem within all the nodes of the cluster with the pickle Python serialization and, more importantly, supplies access to the rich ecosystem of Python's machine learning libraries such as Scikit-Learn or data processing such as Pandas.
When we initialize a Spark program, the first thing a Spark program must do is to create a SparkContext object. It tells Spark how to access the cluster. The Python program creates a PySparkContext. Py4J is the gateway that binds the Python program to the Spark JVM SparkContext. The JVM SparkContextserializes the application codes and the closures and sends them to the cluster for execution. The cluster manager allocates resources and schedules, and ships the closures to the Spark workers in the cluster who activate Python virtual machines as required. In each machine, the Spark Worker is managed by an executor that controls computation, storage, and cache.
Here's an example of how the Spark driver manages both the PySpark context and the Spark context with its local filesystems and its interactions with the Spark worker through the cluster manager:

Spark applications consist of a driver program that runs the user's main function, creates distributed datasets on the cluster, and executes various parallel operations (transformations and actions) on those datasets.
Spark applications are run as an independent set of processes, coordinated by a SparkContext in a driver program.
The SparkContext will be allocated system resources (machines, memory, CPU) from the Cluster manager.
The SparkContext manages executors who manage workers in the cluster. The driver program has Spark jobs that need to run. The jobs are split into tasks submitted to the executor for completion. The executor takes care of computation, storage, and caching in each machine.
The key building block in Spark is the RDD (Resilient Distributed Dataset). A dataset is a collection of elements. Distributed means the dataset can be on any node in the cluster. Resilient means that the dataset could get lost or partially lost without major harm to the computation in progress as Spark will re-compute from the data lineage in memory, also known as the DAG (short for Directed Acyclic Graph) of operations. Basically, Spark will snapshot in memory a state of the RDD in the cache. If one of the computing machines crashes during operation, Spark rebuilds the RDDs from the cached RDD and the DAG of operations. RDDs recover from node failure.
There are two types of operation on RDDs:
- Transformations: A transformation takes an existing RDD and leads to a pointer of a new transformed RDD. An RDD is immutable. Once created, it cannot be changed. Each transformation creates a new RDD. Transformations are lazily evaluated. Transformations are executed only when an action occurs. In the case of failure, the data lineage of transformations rebuilds the RDD.
- Actions: An action on an RDD triggers a Spark job and yields a value. An action operation causes Spark to execute the (lazy) transformation operations that are required to compute the RDD returned by the action. The action results in a DAG of operations. The DAG is compiled into stages where each stage is executed as a series of tasks. A task is a fundamental unit of work.
Here's some useful information on RDDs:
- RDDs are created from a data source such as an HDFS file or a DB query. There are three ways to create an RDD:
- Reading from a datastore
- Transforming an existing RDD
- Using an in-memory collection
- RDDs are transformed with functions such as
maporfilter, which yield new RDDs. - An action such as first, take, collect, or count on an RDD will deliver the results into the Spark driver. The Spark driver is the client through which the user interacts with the Spark cluster.
The following diagram illustrates the RDD transformation and action:
