
4 Tasty testing
- Why we hate testing and how we can love it
- How to make testing more enjoyable
- Avoiding TDD, BDD, and other three-letter acronyms
- Deciding what to test
- Doing less work using tests
- Making tests spark joy
Many software developers would liken testing to writing a book: it’s tedious, nobody likes doing it, and it rarely pays off. Compared to coding, testing is considered a second-class activity, not doing the real work. Testers are subjected to a preconception that they have it too easy.
The reason for the dislike of testing is that we developers see it as disconnected from building software. From a programmer’s perspective, building software is all about writing code, whereas from a manager’s vantage point, it’s all about setting the right course for the team. Similarly, for a tester, it’s all about the quality of the product. We consider testing an external activity because of our perception that it’s not part of software development, and we want to be involved as little as possible.
Testing can be integral to a developer’s work and can help them along the way. It can give you assurances that no other understanding of your code can give you. It can save you time, and you don’t even need to hate yourself for it. Let’s see how.
4.1 Types of tests
Software testing is about increasing confidence in the behavior of software. This is important: tests never guarantee a behavior, but they increase its likelihood quite a lot, as in orders of magnitude. There are many ways to categorize types of testing, but the most important distinction is how we run or implement it because it affects our time economy the most.
4.1.1 Manual testing
Testing can be a manual activity, and it usually is for developers, who test their code by running it and inspecting its behavior. Manual tests have their own types too, like end-to-end testing, which means testing every supported scenario on a software from beginning to end. End-to-end testing’s value is enormous, but it’s time consuming.
Code reviews can be considered a way of testing, albeit a weak one. You can understand what the code does and what it will do when it’s run to a certain extent. You can vaguely see how it fulfills the requirements, but you can’t tell for sure. Tests, based on their types, can provide different levels of assurance about how the code will work. In that sense, a code review can be considered a type of test.
4.1.2 Automated tests
You are a programmer; you have the gift of writing code. That means you can make the computer do things for you, and that includes testing. You can write code that tests your code, so you don’t have to. Programmers usually focus on creating tooling only for the software they’re developing, not on the development process itself, but that’s equally important.
Automated tests can differ vastly in terms of their scope and, more importantly, in how much they increase your confidence in the behavior of the software. The smallest kinds of automated tests are unit tests. They are also the easiest to write because they test only a single unit of code: a public function. It needs to be public because testing is supposed to examine externally visible interfaces rather than the internal details of a class. The definition of a unit can sometimes change in the literature, be it a class or a module or another logical arrangement of those, but I find functions are convenient as the target units.
The problem with unit tests is that even though they let you see if units work okay, they can’t guarantee if they work okay together. Consequently, you have to test whether they get along together too. Those tests are called integration tests. Automated UI tests are usually also integration tests if they run the production code to build the correct user interface.
4.1.3 Living dangerously: Testing in production
I had once bought a poster of a famous meme for one of our developers. It said, “I don’t always test code, but when I do, I do it in production.” I hung it on the wall right behind his monitor so he would always remember not to do that.
DEFINITION In software lingo, the term production means a live environment accessed by actual users where any change affects the actual data. Many developers confuse it with their computer. There is development for that. Development as a name for a runtime environment means code running locally on your machine and not affecting any data that harms production. As a precaution to harming production, there is sometimes a production-like remote environment that is similar to production. It’s sometimes called staging, and it doesn’t affect actual data that is visible to your site’s users.
Testing in production, aka live code, is considered a bad practice; no wonder such a poster exists. The reason is because by the time you find a failure, you might have already lost users or customers. More importantly, when you break production, there is a chance that you might break the workflow of the whole development team. You can easily understand that it has happened by the disappointed looks and raised eyebrows you get if you’re in an open office setting, along with text messages saying, “WTF!!!!???,” Slack notification numbers increasing like KITT’s1 speedometer, or the steam coming out of your boss’s ears.
Like any bad practice, testing in production isn’t always bad. If the scenario you introduce isn’t part of a frequently used, critical code path, you might get away with testing in production. That’s why Facebook had the mantra “Move fast and break things,” because they let the developers assess the impact of the change to the business. They later dropped the slogan after the 2016 US elections, but it still has some substance. If it’s a small break in an infrequently used feature, it might be okay to live with the fallout and fix it as soon as possible.
Even not testing your code can be okay if you think breaking a scenario isn’t something your users would abandon the app for. I managed to run one of the most popular websites in Turkey myself with zero automated tests in its first years, with a lot of errors and a lot of downtime, of course, because, hello: no automated tests!
4.1.4 Choosing the right testing methodology
You need to be aware of certain factors about a given scenario that you are trying to implement or change to decide how you want to test it. Those are mainly risk and cost. It’s similar to what we used to calculate in our minds when our parents assigned us a chore:
-
- How likely is this scenario to break?
- If it breaks, how badly will it impact the business? How much money would you lose, aka, “Would this get me fired if it breaks?”
- If it breaks, how many other scenarios will break along with it? For example, if your mailing feature stops working, many features that depend on it will be broken, too.
- How frequently does the code change? How much do you anticipate it will change in the future? Every change introduces a new risk.
You need to find a sweet spot that costs you the least and poses the least risk. Every risk is an implication of more cost. In time, you will have a map of mental tradeoffs for how much cost a test introduces and how much risk it poses, as figure 4.1 shows.

Figure 4.1 An example of a mental model to assess different testing strategies
Never say “It works on my computer” loudly to someone. That’s for your internal thinking only. There will never be some code that you can describe by saying, “Well, it didn’t work on my computer, but I was weirdly optimistic!” Of course, it works on your computer! Can you imagine deploying something that you cannot even run yourself? You can use it as a mantra while you’re thinking about whether a feature should be tested as long as there is no chain of accountability. If nobody makes you answer for your mistakes, then go for it. That means the (excess) budget of the company you’re working for makes it possible for your bosses to tolerate those mistakes.
If you need to fix your own bugs, though, the “It works on my computer” mentality puts you into a very slow and time-wasting cycle because of the delay between the deployment and the feedback loops. One basic problem with developer productivity is that interruptions cause significant delays. The reason is the zone. I have already discussed how warming up to the code can get your productivity wheels turning. That mental state is sometimes called the zone. You’re in the zone if you’re in that productive state of mind. Similarly, getting interrupted can cause those wheels to stop and take you out of the zone, so you have to warm up again. As figure 4.2 shows, automated tests alleviate this problem by keeping you in the zone until you reach a certain degree of confidence about a feature’s completion. It shows you two different cycles of how expensive “It works on my computer” can be for both the business and the developer. Every time you get out of the zone, you need extra time to reenter it, which sometimes can even be longer than the time required to test your feature manually.

Figure 4.2 The expensive development cycle of “It works on my computer” versus automated tests
You can achieve a quick iteration cycle similar to automated tests with manual tests, but they just take more time. That’s why automated tests are great: they keep you in the zone and cost you the least time. Arguably, writing and running tests can be considered disconnected activities that might push you out of the zone. Still, running unit tests is extremely fast and is supposed to end in seconds. Writing tests is a slightly disconnected activity, but it still makes you think about the code you’ve written. You might even consider it a recap exercise. This chapter is mostly about unit testing in general because it is in the sweet spot of cost versus risk in figure 4.1.
4.2 How to stop worrying and love the tests
Unit testing is about writing test code that tests a single unit of your code, usually a function. You will encounter people who argue about what constitutes a unit. Basically, it doesn’t matter much as long as you can test a given unit in isolation. You can’t test a whole class in a single test anyway. Every test actually tests only a single scenario for a function. Thus, it’s usual to have multiple tests even for a single function.
Test frameworks make writing tests as easy as possible, but they are not necessary. A test suite can simply be a separate program that runs the tests and shows the results. As a matter of fact, that was the only way to test your program before test frameworks became a thing. I’d like to show you a simple piece of code and how unit testing has evolved over time so you can write tests for a given function as easily as possible.
Let’s imagine that you are tasked with changing how the post dates are displayed on a microblogging website called Blabber. The post dates were displayed as a full date, and according to the new social media fashion, it’s more favorable to use acronyms that show a duration since the post was created in seconds, minutes, hours, and so forth. You need to develop a function that gets a DateTimeOffset and converts it into a string that shows the time span in text is expressed as “3h” for three hours, “2m” for two minutes, or “1s” for one second. It should show only the most significant unit. If the post is three hours, two minutes, and one second old, it should only show “3h.”
Listing 4.1 shows such a function. In this listing, we define an extension method to the DateTimeOffset class in .NET, so we can call it wherever we want, like a native method of DateTimeOffset.
We calculate the interval between current time and the post time and check its fields to determine the most significant unit of the interval and return the result based on it.
Listing 4.1 A function that converts a date to a string representation of the interval
public static class DateTimeExtensions {
public static string ToIntervalString(
this DateTimeOffset postTime) { ❶
TimeSpan interval = DateTimeOffset.Now - postTime; ❷
if (interval.TotalHours >= 1.0) { ❸
return $”{(int)interval.TotalHours}h”; ❸
} ❸
if (interval.TotalMinutes >= 1.0) { ❸
return $”{(int)interval.TotalMinutes}m”; ❸
} ❸
if (interval.TotalSeconds >= 1.0) { ❸
return $”{(int)interval.TotalSeconds}s”; ❸
} ❸
return “now”;
}
}❶ This defines an extension method to the DateTimeOffset class.
❸ It’s possible to write this code more briefly or performant, but not when it sacrifices readability.
We have a vague spec about the function, and we can start writing some tests for it. It’d be a good idea to write possible inputs and expected outputs in a table to ensure the function works correctly, as in table 4.1.
Table 4.1 A sample test specification for our conversion function
If DateTimeOffset is a class, we should also be testing for the case when we pass null, but because it’s a struct, it cannot be null. That saved us one test. Normally, you don’t really need to create a table like that, and you can usually manage with a mental model of it, but whenever you’re in doubt, by all means write it down.
Our tests should consist of calls with different DateTimeOffsets and comparisons with different strings. At this point, test reliability becomes a concern because DateTime.Now always changes, and our tests are not guaranteed to run in a specific time. If another test was running or if something slowed the computer down, you can easily fail the test for the output now. That means our tests will be flaky and can fail occasionally.
That indicates a problem with our design. A simple solution would be to make our function deterministic by passing a TimeSpan instead of a DateTimeOffset and calculating the difference in the caller instead. As you can see, writing tests around your code helps you identify design problems too, which is one of the selling points of a test-driven development (TDD) approach. We didn’t use TDD here because we know we can just go ahead and change the function easily, as in the following listing, to receive a TimeSpan directly.
Listing 4.2 Our refined design
public static string ToIntervalString(
this TimeSpan interval) { ❶
if (interval.TotalHours >= 1.0) {
return $"{(int)interval.TotalHours}h";
}
if (interval.TotalMinutes >= 1.0) {
return $"{(int)interval.TotalMinutes}m";
}
if (interval.TotalSeconds >= 1.0) {
return $"{(int)interval.TotalSeconds}s";
}
return "now";
}❶ We receive a TimeSpan instead.
Our test cases didn’t change, but our tests will be much more reliable. More importantly, we decoupled two different tasks, calculating the difference between two dates and converting an interval to a string representation. Deconstructing concerns in code can help you achieve better designs. It can also be a chore to calculate differences, and you can have a separate wrapper function for that.
Now how do we make sure our function works? We can simply push it to production and wait a couple minutes to hear any screams. If not, we’re good to go. By the way, is your résumé up to date? No reason, just asking.
We can write a program that tests the function and see the results. An example program would be like that in listing 4.3. It’s a plain console application that references our project and uses the Debug.Assert method in the System.Diagnostics namespace to make sure it passes. It ensures that the function returns expected values. Because asserts run only in Debug configuration, we also ensure that the code isn’t run in any other configuration at the beginning with a compiler directive.
Listing 4.3 Primitive unit testing
#if !DEBUG ❶ #error asserts will only run in Debug configuration #endif using System; using System.Diagnostics; namespace DateUtilsTests { public class Program { public static void Main(string[] args) { var span = TimeSpan.FromSeconds(3); ❷ Debug.Assert(span.ToIntervalString() == "3s", ❷ "3s case failed"); ❷ span = TimeSpan.FromMinutes(5); ❸ Debug.Assert(span.ToIntervalString() == "5m", ❸ "5m case failed"); ❸ span = TimeSpan.FromHours(7); ❹ Debug.Assert(span.ToIntervalString() == "7h", ❹ "7h case failed"); ❹ span = TimeSpan.FromMilliseconds(1); ❺ Debug.Assert(span.ToIntervalString() == "now", ❺ "now case failed"); ❺ } } }
❶ We need the preprocessor statement to make asserts work.
❺ Test case for less than a second
So why do we need unit test frameworks? Can’t we write all tests like this? We could, but it would take more work. In our example, you’ll note the following:
-
There is no way to detect if any of the tests failed from an external program, such as a build tool. We need special handling around that. Test frameworks and test runners that come with them handle that easily.
-
The first failing test would cause the program to terminate. That will cost us time if we have many more failures. We will have to run tests again and again and thus wasting more time. Test frameworks can run all tests and report the failures all together, like compiler errors.
-
It’s impossible to run certain tests selectively. You might be working on a specific feature and want to debug the function you wrote by debugging the test code. Test frameworks allow you to debug specific tests without having to run the rest.
-
Test frameworks can produce a code-coverage report that helps you identify missing test coverage on your code. That’s not possible by writing ad hoc test code. If you happen to write a coverage analysis tool, you might as well work on creating a test framework.
-
Although those tests don’t depend on each other, they run sequentially, so running the whole test suite takes a long time. Normally, that’s not a problem with a small number of test cases, but in a medium-scale project, you can have thousands of tests that take different amounts of times. You can create threads and run the tests in parallel, but that’s too much work. Test frameworks can do all of that with a simple switch.
-
When an error happens, you only know that there is a problem, but you have no idea about its nature. Strings are mismatched, so, what kind of mismatch is it? Did the function return null? Was there an extra character? Test frameworks can report these details too.
-
Anything other than using .NET-provided
Debug.Assertwill require us writing extra code: a scaffolding, if you will. If you start down that path, using an existing framework is much better. -
You’ll have the opportunity to join never-ending debates about which test framework is better and to feel superior for completely wrong reasons.
Now, let’s try writing the same tests with a test framework, as in listing 4.4. Many test frameworks look alike, with the exception of xUnit, which was supposedly developed by extraterrestrial life-forms visiting Earth, but in principle, it shouldn’t matter which framework you’re using, with the exception of slight changes in the terminology. We’re using NUnit here, but you can use any framework you want. You’ll see how much clearer the code is with a framework. Most of our test code is actually pretty much a text version of our input/output table, as in table 4.1. It’s apparent what we’re testing, and more importantly, although we only have a single test method, we have the capability to run or debug each test individually in the test runner. The technique we used in listing 4.4 with TestCase attributes is called a parameterized test. If you have a specific set of inputs and outputs, you can simply declare them as data and use it in the same function over and over, avoiding the repetition of writing a separate test for each test. Similarly, by combining ExpectedResult values and declaring the function with a return value, you don’t even need to write Asserts explicitly. The framework does it automatically. It’s less work!

Figure 4.3 Test results that you can’t take your eyes off
You can run these tests in a Test Explorer window of Visual Studio: View ® Test Explorer. You can also run a dotnet test from the command prompt, or you can even use a third-party test runner like NCrunch. The test results in Visual Studio’s Test Explorer will look like those in figure 4.3.
Listing 4.4 Test framework magic
using System;
using NUnit.Framework;
namespace DateUtilsTests {
class DateUtilsTest {
[TestCase("00:00:03.000", ExpectedResult = "3s")]
[TestCase("00:05:00.000", ExpectedResult = "5m")]
[TestCase("07:00:00.000", ExpectedResult = "7h")]
[TestCase("00:00:00.001", ExpectedResult = "now")]
public string ToIntervalString_ReturnsExpectedValues(
string timeSpanText) {
var input = TimeSpan.Parse(timeSpanText); ❶
return input.ToIntervalString(); ❷
}
}
}❶ Converting a string to our input type
You can see how a single function is actually broken into four different functions during the test-running phase and how its arguments are displayed along with the test name in figure 4.3. More importantly, you can select a single test, run it, or debug it. And if a test fails, you see a brilliant report that exactly tells what’s wrong with your code. Say you accidentally wrote nov instead of now. The test error would show up like this:
Message:
String lengths are both 3. Strings differ at index 2.
Expected: "now"
But was: "nov"
-------------^Not only do you see that there is an error, but you also see a clear explanation about where it happened.
It’s a no-brainer to use test frameworks, and you will get to love writing tests more when you’re aware of how they save you extra work. They are NASA preflight check lights, “system status nominal” announcements, and they are your little nanobots doing their work for you. Love tests, love test frameworks.
4.3 Don’t use TDD or other acronyms
Unit testing, like every successful religion, has split into factions. Test-driven development (TDD) and behavior-driven development (BDD) are some examples. I’ve come to believe that there are people in the software industry who really love to create new paradigms and standards to be followed without question, and there are people who just love to follow them without question. We love prescriptions and rituals because all we need to do is to follow them without thinking too much. That can cost us a lot of time and make us hate testing.
The idea behind TDD is that writing tests before actual code can guide you to write better code. TDD prescribes that you should write tests for a class first before writing a single line of code of that class, so the code you write constitutes a guideline for how to implement the actual code. You write your tests. It fails to compile. You start writing actual code, and it compiles. Then you run tests, and they fail. Then you fix the bugs in your code to make the tests pass. BDD is also a test-first approach with differences in the naming and layout of tests.
The philosophy behind TDD and BDD isn’t complete rubbish. When you think about how some code should be tested first, it can influence how you think about its design. The problem with TDD isn’t the mentality but the practice, the ritualistic approach: write tests, and because the actual code is still missing, get a compiler error (wow, really, Sherlock?); after writing the code, fix the test failures. I hate errors. They make me feel unsuccessful. Every red squiggly line in the editor, every STOP sign in the Errors list window, and every warning icon is a cognitive load, confusing and distracting me.
When you focus on the test before you write a single line of code, you start thinking more about tests than your own problem domain. You start thinking about better ways to write tests. Your mental space gets allocated to the task of writing tests, the test framework’s syntactic elements, and the organization of tests, rather than the production code itself. That’s not the goal of testing. Tests shouldn’t make you think. Tests should be the easiest piece of code you can write. If that’s not the case, you’re doing it wrong.
Writing tests before writing code triggers the sunk-cost fallacy. Remember how in chapter 3 dependencies made your code more rigid? Surprise! Tests depend on your code too. When you have a full-blown test suite at hand, you become disinclined to change the design of the code because that would mean changing the tests too. It reduces your flexibility when you’re prototyping code. Arguably, tests can give you some ideas about whether the design really works, but only in isolated scenarios. You might later discover that a prototype doesn’t work well with other components and change your design before you write any tests. That could be okay if you spend a lot of time on the drawing board when you’re designing, but that’s not usually the case in the streets. You need the ability to quickly change your design.
You can consider writing tests when you believe you’re mostly done with your prototype and it seems to be working out okay. Yes, tests will make your code harder to change then, but at the same time, they will compensate for that by making you confident in the behavior of your code, letting you make changes more easily. You’ll effectively get faster.
4.4 Write tests for your own good
Yes, writing tests improves the software, but it also improves your living standards. I already discussed how writing tests first can constrain you from changing your code’s design. Writing tests last can make your code more flexible because you can easily make significant changes later, without worrying about breaking the behavior after you forget about the code completely. It frees you. It works as insurance, almost the inverse of the sunk-cost fallacy. The difference in writing tests after is that you are not discouraged in a rapid iteration phase like prototyping. You need to overhaul some code? The first step you need to take is to write tests for it.
Writing tests after you have a good prototype works as a recap exercise for your design. You go over the whole code once again with tests in mind. You can identify certain problems that you didn’t find when you were prototyping your code.
Remember how I pointed out that doing small, trivial fixes in the code can get you warmed up for large coding tasks? Well, writing tests is a great way to do that. Find missing tests and add them. It never hurts to have more tests unless they’re redundant. They don’t have to be related to your upcoming work. You can simply blindly add test coverage, and who knows, you might find bugs while doing so.
Tests can act as a specification or documentation if they’re written in a clear, easy-to-understand way. Code for each test should describe the input and the expected output of a function by how it’s written and how it’s named. Code may not be the best way to describe something, but it’s a thousand times better than having nothing at all.
Do you hate it when your colleagues break your code? Tests are there to help. Tests enforce the contract between the code and the specification that developers can’t break. You won’t have to see comments like this:
// When this code was written,
// only God and I knew what it did.
// Now only God knows. ❶❶ That infamous comment is a derivative joke originally attributed to the author John Paul Friedrich Richter who lived in the 19th century. He didn’t write a single line of code—only comments (https://quoteinvestigator .com/2013/09/24/god-knows/).
Tests assure you that a fixed bug will remain fixed and won’t appear again. Every time you fix a bug, adding a test for it will ensure you won’t have to deal with that bug again, ever. Otherwise, who knows when another change will trigger it again? Tests are critical timesavers when used this way.
Tests improve both the software and the developer. Write tests to be a more efficient developer.
4.5 Deciding what to test
That is not halted which can eternal run,
And with strange eons, even tests may be down.
Writing one test and seeing it pass is only half of the story. It doesn’t mean your function works. Will it fail when the code breaks? Have you covered all the possible scenarios? What should you be testing for? If your tests don’t help you find bugs, they are already failures.
One of my managers had a manual technique to ensure that his team wrote reliable tests: he removed random lines of code from the production code and ran tests again. If your tests passed, that meant you failed.
There are better approaches to identify what cases to test. A specification is a great starting point, but you rarely have those in the streets. It might make sense to create a specification yourself, but even if the only thing you have is code, there are ways to identify what to test.
4.5.1 Respect boundaries
You can call a function that receives a simple integer with four billion different values. Does that mean that you have to test whether your function works for each one of those? No. Instead, you should try to identify which input values cause the code to diverge into a branch or cause values to overflow and then test values around those.
Consider a function that checks whether a birth date is of legal age for the registration page of your online game. It’s trivial for anyone who was born 18 years before (assuming 18 is the legal age for your game): you just subtract the years and check whether it’s at least 18. But what if that person turned 18 last week? Are you going to deprive that person of enjoying your pay-to-win game with mediocre graphics? Of course not.
Let’s define a function IsLegalBirthdate. We use a DateTime class instead of DateTimeOffset to represent a birth date because birth dates don’t have time zones. If you were born on December 21 in Samoa, your birthday is December 21 everywhere in the world, even in American Samoa, which is 24 hours ahead of Samoa despite being only a hundred miles away. I’m sure there is intense discussion there every year about when to have relatives over for Christmas dinner. Time zones are weird.
Anyway, we first calculate the year difference. The only time we need to look at exact dates is for the year of that person’s 18th birthday. If it’s that year, we check the month and the day. Otherwise, we only check whether the person is older than 18. We use a constant to signify legal age instead of writing the number everywhere because writing the number is susceptible to typos, and when your boss comes asking you, “Hey, can you raise the legal age to 21?,” you only have one place to edit it out in this function. You also avoid having to write // legal age next to every 18 in the code to explain it. It suddenly becomes self-explanatory. Every conditional in the function—which encompasses if statements, while loops, switch cases, and so forth—causes only certain input values to exercise the code path inside. That means we can split the range of input values based on the conditionals, depending on the input parameters. In the example in listing 4.5, we don’t need to test for all possible DateTime values between January 1 of the year AD 1 and December 31, 9999, which is about 3.6 million. We only need to test for 7 different inputs.
Listing 4.5 The bouncer’s algorithm
public static bool IsLegalBirthdate(DateTime birthdate) {
const int legalAge = 18;
var now = DateTime.Now;
int age = now.Year - birthdate.Year;
if (age == legalAge) { ❶
return now.Month > birthdate.Month ❶
|| (now.Month == birthdate.Month ❶
&& now.Day > birthdate.Day); ❶
} ❶
return age > legalAge; ❶
}The seven input values are listed in table 4.2.
Table 4.2 Partitioning input values based on conditionals
We suddenly brought down our number of cases from 3.6 million to 7, simply by identifying conditionals. Those conditionals that split the input range are called boundary conditionals because they define the boundaries for input values for possible code paths in the function. Then we can go ahead and write tests for those input values, as shown in listing 4.6. We basically create a clone of our test table in our inputs and convert it to a DateTime and run through our function. We can’t hardcode DateTime values directly into our input/output table because a birth date’s legality changes based on the current time.
We could convert this to a TimeSpan-based function as we did before, but legal age isn’t based on an exact number of days—it’s based on an absolute date-time instead. Table 4.2 is also better because it reflects your mental model more accurately. We use -1 for less than, 1 for greater than, and 0 for equality, and prepare our actual input values using those values as references.
Listing 4.6 Creating our test function from table 4.2
[TestCase(18, 0, -1, ExpectedResult = true)]
[TestCase(18, 0, 0, ExpectedResult = false)]
[TestCase(18, 0, 1, ExpectedResult = false)]
[TestCase(18, -1, 0, ExpectedResult = true)]
[TestCase(18, 1, 0, ExpectedResult = false)]
[TestCase(19, 0, 0, ExpectedResult = true)]
[TestCase(17, 0, 0, ExpectedResult = false)]
public bool IsLegalBirthdate_ReturnsExpectedValues(
int yearDifference, int monthDifference, int dayDifference) {
var now = DateTime.Now;
var input = now.AddYears(-yearDifference) ❶
.AddMonths(monthDifference) ❶
.AddDays(dayDifference); ❶
return DateTimeExtensions.IsLegalBirthdate(input);
}❶ Preparing our actual input here
We did it! We narrowed down the number of possible inputs and identified exactly what to test in our function to create a concrete test plan.
Whenever you need to find out what to test in a function, you’re supposed to start with a specification. In the streets, however, you’ll likely figure out that a specification has never existed or was obsolete a long time ago, so the second-best way would be to start with boundary conditionals. Using parameterized tests also helps us focus on what to test rather than on writing repetitive test code. It’s occasionally inevitable that we have to create a new function for each test, but specifically with data-bound tests like this one, parameterized tests can save you considerable time.
4.5.2 Code coverage
Code coverage is magic, and like magic, it’s mostly stories. Code coverage is measured by injecting every line of your code with callbacks to trace how far the code called by a test executes and which parts it misses. That way, you can find out which part of the code isn’t exercised and therefore is missing tests.
Development environments rarely come with code-coverage measurement tools out of the box. They are either in astronomically priced versions of Visual Studio or other paid third-party tools like NCrunch, dotCover, and NCover. Codecov (https:// codecov.io) is a service that can work with your online repository, and it offers a free plan. Free code-coverage measurement locally in .NET was possible only with the Coverlet library and code-coverage reporting extensions in Visual Studio Code when this book was drafted.
Code-coverage tools tell you which parts of your code ran when you ran your tests. It’s quite handy to see what kind of test coverage you’re missing to exercise all code paths. It’s not the only part of the story, and it’s certainly not the most effective. You can have 100% code coverage and still have missing test cases. I’ll discuss them later in the chapter.
Assume that we comment out the tests that call our IsLegalBirthdate function with a birth date that is exactly 18 years old, as in the following listing.
//[TestCase(18, 0, -1, ExpectedResult = true)] ❶ //[TestCase(18, 0, 0, ExpectedResult = false)] ❶ //[TestCase(18, 0, 1, ExpectedResult = false)] ❶ //[TestCase(18, -1, 0, ExpectedResult = true)] ❶ //[TestCase(18, 1, 0, ExpectedResult = false)] ❶ [TestCase(19, 0, 0, ExpectedResult = true)] [TestCase(17, 0, 0, ExpectedResult = false)] public bool IsLegalBirthdate_ReturnsExpectedValues( int yearDifference, int monthDifference, int dayDifference) { var now = DateTime.Now; var input = now.AddYears(-yearDifference) .AddMonths(monthDifference) .AddDays(dayDifference); return DateTimeExtensions.IsLegalBirthdate(input); }
In this case, a tool like NCrunch, for example, would show the missing coverage, as in figure 4.4. The coverage circle next to the return statement inside the if statement is grayed out because we never call the function with a parameter that matches the condition age == legalAge. That means we’re missing some input values.
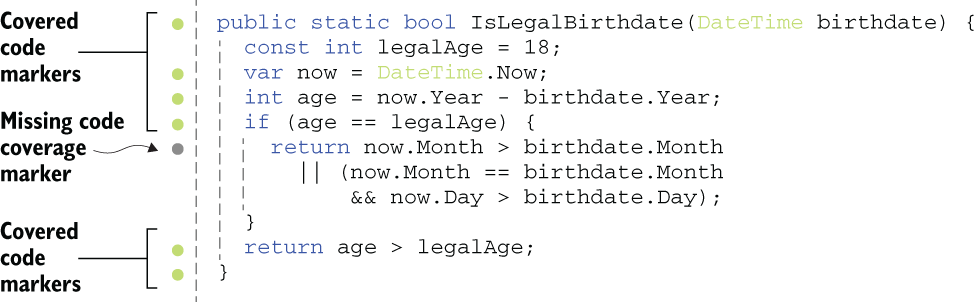
Figure 4.4 Missing code coverage
When you uncomment those commented-out test cases and run tests again, code coverage shows that you have 100% code coverage, as figure 4.5 shows.

Code-coverage tools are a good starting point, but they are not fully effective in showing actual test coverage. You should still have a good understanding of the range of input values and boundary conditionals. One-hundred percent code coverage doesn’t mean 100% test coverage. Consider the following function where you need to return an item from list by index:
public Tag GetTagDetails(byte numberOfItems, int index) {
return GetTrendingTags(numberOfItems)[index];
}Calling that function GetTagDetails(1, 0); would succeed, and we would immediately achieve 100% code coverage. Would we have tested all the possible cases? No. Our input coverage would be nowhere close to that. What if numberOfItems is zero and index is non-zero? What happens if index is negative?
These concerns mean that we shouldn’t be focusing solely on code coverage and trying to fill all the gaps. Instead, we should be conscious about our test coverage by taking all possible inputs into account and being smart about the boundary values. That said, they are not mutually exclusive: you can use both approaches at the same time.
4.6 Don’t write tests
Yes, testing is helpful, but nothing’s better than completely avoiding writing tests. How do you get away without writing tests and still keep your code reliable?
4.6.1 Don’t write code
If a piece of code doesn’t exist, it doesn’t need to be tested. Deleted code has no bugs. Think about this when you’re writing code. Is it worth writing tests for? Maybe you don’t need to write that code at all. For example, can you use an existing package instead of implementing it from scratch? Can you leverage an existing class that does the exact same thing you are trying to implement? For example, you might be tempted to write custom regular expressions for validating URLs when all you need to do is to leverage the System.Uri class.
Third-party code isn’t guaranteed to be perfect or always suitable for your purposes, of course. You might later discover that the code doesn’t work for you, but it’s usually worth taking that risk before trying to write something from scratch. Similarly, the same code base you’re working on might have the code doing the same job implemented by a colleague. Search your code base to see if something’s there.
If nothing works, be ready to implement your own. Don’t be scared of reinventing the wheel. It can be very educational, as I discussed in chapter 3.
4.6.2 Don’t write all the tests
The famous Pareto principle states that 80% of consequences are the results of 20% of the causes. At least, that’s what 80% of the definitions say. It’s more commonly called the 80/20 principle. It’s also applicable in testing. You can get 80% reliability from 20% test coverage if you choose your tests wisely.
Bugs don’t appear homogeneously. Not every code line has the same probability of producing a bug. It’s more likely to find bugs in more commonly used code and code with high churn. You can call those areas of the code where a problem is more likely to happen hot paths.
That’s exactly what I did with my website. It had no tests whatsoever even after it became one of the most popular Turkish websites in the world. Then I had to add tests because too many bugs started to appear with the text markup parser. The markup was custom and it barely resembled Markdown, but I developed it before Markdown was even a vitamin in the oranges Dave Gruber ate. Because parsing logic was complicated and prone to bugs, it became economically infeasible to fix every issue after deploying to production. I developed a test suite for it. That was before the advent of test frameworks, so I had to develop my own. I incrementally added more tests as more bugs appeared because I hated creating the same bugs, and we developed a quite extensive test suite later, which saved us thousands of failing production deployments. Tests just work.
Even just viewing your website’s home page provides a good amount of code coverage because it exercises many shared code paths with other pages. That’s called smoke testing in the streets. It comes from the times when they developed the first prototype of the computer and just tried to turn it on to see if smoke came out of it. If there was no smoke, that was pretty much a good sign. Similarly, having good test coverage for critical, shared components is more important than having 100% code coverage. Don’t spend hours just to add test coverage for a single line in a rudimentary constructor that isn't covered by tests if it won’t make much difference. You already know that code coverage isn’t the whole story.
4.7 Let the compiler test your code
With a strongly typed language, you can leverage the type system to reduce the number of test cases you’ll need. I’ve already discussed how nullable references can help you avoid null checks in the code, which also reduces the need to write tests for null cases. Let’s look at a simple example. In the previous section, we validated that the person who wants to register is at least 18 years old. We now need to validate if the chosen username is valid, so we need a function that validates usernames.
4.7.1 Eliminate null checks
Let our rule for a username be lowercase alphanumeric characters, up to eight characters long. A regular expression pattern for such a username would be "^[a-z0-9]{1,8}$". We can write a username class, as in listing 4.8. We define a Username class to represent all usernames in the code. We avoid having to think about where we should validate our input by passing this to any code that requires a username.
To make sure that a username is never invalid, we validate the parameter in the constructor and throw an exception if it’s not in the correct format. Apart from the constructor, the rest of the code is boilerplate to make it work in comparison scenarios. Remember, you can always derive such a class by creating a base StringValue class and writing minimal code for each string-based value class. I wanted to keep implementations duplicate in the book to clarify what the code entails. Notice the use of the nameof operator instead of hardcoded strings for references to parameters. It lets you keep names in sync after renaming. It can also be used for fields and properties and is especially useful for test cases where data is stored in a separate field and you have to refer to it by its name.
Listing 4.8 A username value type implementation
public class Username {
public string Value { get; private set; }
private const string validUsernamePattern = @"^[a-z0-9]{1,8}$";
public Username(string username) {
if (username is null) { ❶
throw new ArgumentNullException(nameof(username));
}
if (!Regex.IsMatch(username, validUsernamePattern)) { ❶
throw new ArgumentException(nameof(username),
"Invalid username");
}
this.Value = username;
}
public override string ToString() => base.ToString(); ❷
public override int GetHashCode() => Value.GetHashCode(); ❷
public override bool Equals(object obj) { ❷
return obj is Username other && other.Value == Value; ❷
} ❷
public static implicit operator string(Username username) { ❷
return username.Value; ❷
} ❷
public static bool operator==(Username a, Username b) { ❷
return a.Value == b.Value; ❷
} ❷
public static bool operator !=(Username a, Username b) { ❷
return !(a == b); ❷
} ❷
} ❶ We validate the username here, once and for all.
❷ Our usual boilerplate to make a class comparable
Testing the constructor of Username would require us to create three different test methods, as shown in listing 4.9: one for nullability because a different exception type is raised; one for non-null but invalid inputs; and finally, one for the valid inputs, because we need to make sure that it also recognizes valid inputs as valid.
Listing 4.9 Tests for the Username class
class UsernameTest {
[Test]
public void ctor_nullUsername_ThrowsArgumentNullException() {
Assert.Throws<ArgumentNullException>(
() => new Username(null));
}
[TestCase("")]
[TestCase("Upper")]
[TestCase("toolongusername")]
[TestCase("root!!")]
[TestCase("a b")]
public void ctor_invalidUsername_ThrowsArgumentException(string username) {
Assert.Throws<ArgumentException>(
() => new Username(username));
}
[TestCase("a")]
[TestCase("1")]
[TestCase("hunter2")]
[TestCase("12345678")]
[TestCase("abcdefgh")]
public void ctor_validUsername_DoesNotThrow(string username) {
Assert.DoesNotThrow(() => new Username(username));
}
}Had we enabled nullable references for the project Username class was in, we wouldn’t need to write tests for the null case at all. The only exception would be when we’re writing a public API, which may not run against a nullable-references-aware code. In that case, we’d still need to check against nulls.
Similarly, declaring Username a struct when suitable would make it a value type, which would also remove the requirement for a null check. Using correct types and correct structures for types will help us reduce the number of tests. The compiler will ensure the correctness of our code instead.
Using specific types for our purposes reduces the need for tests. When your registration function receives a Username instead of a string, you don’t need to check whether the registration function validates its arguments. Similarly, when your function receives a URL argument as a Uri class, you don’t need to check whether your function processes the URL correctly anymore.
4.7.2 Eliminate range checks
You can use unsigned integer types to reduce the range of possible invalid input values. You can see unsigned versions of primitive integer types in table 4.3. There you can see the varieties of data types with their possible ranges that might be more suitable for your code. It’s also important that you keep in mind whether the type is directly compatible with int because it’s the go-to type of .NET for integers. You probably have already seen these types, but you might not have considered that they can save you having to write extra test cases. For example, if your function needs only positive values, then why bother with int and checking for negative values and throwing exceptions? Just receive uint instead.
Table 4.3 Alternative integer types with different value ranges
When you use an unsigned type, trying to pass a negative constant value to your function will cause a compiler error. Passing a variable with a negative value is possible only with explicit type casting, which makes you think about whether the value you have is really suitable for that function at the call site. It’s not the function’s responsibility to validate for negative arguments anymore. Assume that a function needs to return trending tags in your microblogging website up to only a specified number of tags. It receives a number of items to retrieve rows of posts, as in listing 4.10.
Also in listing 4.10, a GetTrendingTags function returns items by taking the number of items into account. Notice that the input value is a byte instead of int because we don’t have any use case more than 255 items in the trending tag list. That actually immediately eliminates the cases where an input value can be negative or too large. We don’t even need to validate the input anymore. This results in one fewer test case and a much better range of input values, which reduces the area for bugs immediately.
Listing 4.10 Receiving posts only belonging to a certain page
using System;
using System.Collections.Generic;
using System.Linq;
namespace Posts {
public class Tag {
public Guid Id { get; set; }
public string Title { get; set; }
}
public class PostService {
public const int MaxPageSize = 100;
private readonly IPostRepository db;
public PostService(IPostRepository db) {
this.db = db;
}
public IList<Tag> GetTrendingTags(byte numberOfItems) { ❶
return db.GetTrendingTagTable()
.Take(numberOfItems) ❷
.ToList();
}
}
}❶ We chose byte instead of int.
❷ A byte or a ushort can be passed as safely as int too.
Two things are happening here. First, we chose a smaller data type for our use case. We don’t intend to support billions of rows in a trending tag box. We don’t even know what that would look like. We have narrowed down our input space. Second, we chose byte, an unsigned type, which cannot be negative. That way, we avoided a possible test case and a potential problem that might cause an exception. LINQ’s Take function doesn’t throw an exception with a List, but it can when it gets translated to a query for a database like Microsoft SQL Server. By changing the type, we avoid those cases, and we don’t need to write tests for them.
Note that .NET uses int as the de facto standard type for many operations like indexing and counting. Opting for a different type might require you to cast and convert values into ints if you happen to interact with standard .NET components. You need to make sure that you’re not digging yourself into a hole by being pedantic. Your quality of life and the enjoyment you get from writing code are more important than a certain one-off case you’re trying to avoid. For example, if you need more than 255 items in the future, you’ll have to replace all references to bytes with shorts or ints, which can be time consuming. You need to make sure that you are saving yourself from writing tests for a worthy cause. You might even find writing additional tests more favorable in many cases than dealing with different types. In the end, it’s only your comfort and your time that matter, despite how powerful it is to use types for hinting at valid value ranges.
4.7.3 Eliminate valid value checks
There are times we use values to signify an operation in a function. A common example is the fopen function in the C programming language. It takes a second string parameter that symbolizes the open mode, which can mean open for reading, open for appending, open for writing, and so forth.
Decades after C, the .NET team has made a better decision and created separate functions for each case. You have separate File.Create, File.OpenRead, and File.OpenWrite methods, avoiding the need for an extra parameter and for parsing that parameter. It’s impossible to pass along the wrong parameter. It’s impossible for functions to have bugs in parameter parsing because there is no parameter.
It’s common to use such values to signify a type of operation. You should consider separating them into distinct functions instead, which can both convey the intent better and reduce your test surface.
One common technique in C# is to use Boolean parameters to change the logic of the running function. An example is to have a sorting option in the trending tags retrieval function, as in listing 4.11. Assume that we need trending tags in our tag management page, too, and that it’s better to show them sorted by title there. In contradiction with the laws of thermodynamics, developers tend to constantly lose entropy. They always try to make the change with the least entropy without thinking about how much of a burden it will be in the future. The first instinct of a developer can be to add a Boolean parameter and be done with it.
Listing 4.11 Boolean parameters
public IList<Tag> GetTrendingTags(byte numberOfItems,
bool sortByTitle) { ❶
var query = db.GetTrendingTagTable();
if (sortByTitle) { ❷
query = query.OrderBy(p => p.Title);
}
return query.Take(numberOfItems).ToList();
}❷ Newly introduced conditional
The problem is that if we keep adding Booleans like this, it can get really complicated because of the combinations of the function parameters. Let’s say another feature required trending tags from yesterday. We add that in with other parameters in the next listing. Now, our function needs to support combinations of sortByTitle and yesterdaysTags too.
Listing 4.12 More Boolean parameters
public IList<Tag> GetTrendingTags(byte numberOfItems,
bool sortByTitle, bool yesterdaysTags) { ❶
var query = yesterdaysTags ❷
? db.GetTrendingTagTable() ❷
: db.GetYesterdaysTrendingTagTable(); ❷
if (sortByTitle) { ❷
query = query.OrderBy(p => p.Title);
}
return query.Take(numberOfItems).ToList();
}There is an ongoing trend here. Our function’s complexity increases with every Boolean parameter. Although we have three different use cases, we have four flavors of the function. With every added Boolean parameter, we are creating fictional versions of the function that no one will use, although someone might someday and then get into a bind. A better approach is to have a separate function for each client, as shown next.
Listing 4.13 Separate functions
public IList<Tag> GetTrendingTags(byte numberOfItems) { ❶
return db.GetTrendingTagTable()
.Take(numberOfItems)
.ToList();
}
public IList<Tag> GetTrendingTagsByTitle( ❶
byte numberOfItems) {
return db.GetTrendingTagTable()
.OrderBy(p => p.Title)
.Take(numberOfItems)
.ToList();
}
public IList<Tag> GetYesterdaysTrendingTags(byte numberOfItems) { ❶
return db.GetYesterdaysTrendingTagTable()
.Take(numberOfItems)
.ToList();
}❶ We separate functionality by function names instead of parameters
You now have one less test case. You get much better readability and slightly increased performance as a free bonus. The gains are minuscule, of course, and unnoticeable for a single function, but at points where the code needs to scale, they can make a difference without you even knowing it. The savings will increase exponentially when you avoid trying to pass state in parameters and leverage functions as much as possible. You might still be irked by repetitive code, which can easily be refactored into common functions, as in the next listing.
Listing 4.14 Separate functions with common logic refactored out
private IList<Tag> toListTrimmed(byte numberOfItems, ❶ IQueryable<Tag> query) { ❶ return query.Take(numberOfItems).ToList(); ❶ } ❶ public IList<Tag> GetTrendingTags(byte numberOfItems) { return toListTrimmed(numberOfItems, db.GetTrendingTagTable()); } public IList<Tag> GetTrendingTagsByTitle(byte numberOfItems) { return toListTrimmed(numberOfItems, db.GetTrendingTagTable() .OrderBy(p => p.Title)); } public IList<Tag> GetYesterdaysTrendingTags(byte numberOfItems) { return toListTrimmed(numberOfItems, db.GetYesterdaysTrendingTagTable()); }
Our savings are not impressive here, but such refactors can make greater differences in other cases. The important takeaway is to use refactoring to avoid code repetition and combinatorial hell.
The same technique can be used with enum parameters that are used to dictate a certain operation to a function. Use separate functions, and you can even use function composition, instead of passing along a shopping list of parameters.
4.8 Naming tests
There is a lot in a name. That’s why it’s important to have good coding conventions in both production and test code, although they shouldn’t necessarily overlap. Tests with good coverage can serve as specifications if they’re named correctly. From the name of a test, you should be able to tell
I’m kidding about the last one, of course. Remember? You already green-lit that code in the code review. You have no right to blame someone else anymore. At best, you can share the blame. I commonly use an "A_B_C" format to name tests, which is quite different than what you’re used to naming your regular functions. We used a simpler naming scheme in previous examples because we were able to use the TestCase attribute to describe the initial state of the test. I use an additional ReturnsExpectedValues, but you can simply suffix the function name with Test. It’s better if you don’t use the function name alone because that might confuse you when it appears in code completion lists. Similarly, if the function doesn’t take any input or doesn’t depend on any initial state, you can skip the part describing that. The purpose here is to allow you to spend less time dealing with tests, not to put you through a military drill about naming rules.
Say your boss asked you to write a new validation rule for a registration form to make sure registration code returns failure if the user hasn’t accepted the policy terms. A name for such a test would be Register_LicenseNotAccepted_ShouldReturnFailure, as in figure 4.6.

Figure 4.6 Components of a test name
That’s not the only possible naming convention. Some people prefer creating inner classes for each function to be tested and name tests with only state and expected behavior, but I find that unnecessarily cumbersome. It’s important that you pick the convention that works best for you.
Summary
-
It’s possible to overcome the disdain for writing tests by not writing many of them in the first place.
-
Test-driven development and similar paradigms can make you hate writing tests even more. Seek to write tests that spark joy.
-
The effort to write tests can be significantly shortened by test frameworks, especially with parameterized, data-driven tests.
-
The number of test cases can be reduced significantly by properly analyzing the boundary values of a function input.
-
Proper use of types can let you avoid writing many unnecessary tests.
-
Tests don’t just ensure the quality of the code. They can also help you improve your own development skills and throughput.
-
Testing in production can be acceptable as long as your résumé is up to date.
1. KITT, standing for Knight Industries Two Thousand, is a self-driving car equipped with voice recognition. It was depicted in the 1980s sci-fi TV series Knight Rider. It’s normal that you don’t understand this reference since anybody who did is probably dead, with the possible exception of David Hasselhoff. That guy is immortal.